图解RocketMQ运行原理:Producer、Broker、Consumer全流程深度剖析
本文通过 18 张原理图,从 Producer、Broker、Consumer 三大核心模块出发,图文并茂地拆解 RocketMQ 消息写入、主从同步、消息消费、Raft 协议的完整运行机制。适合有一定分布式基础的 Java 开发者深入阅读。
前言
当我们谈到可靠的、高吞吐量的分布式消息队列,RocketMQ 必将是绕不开的话题。作为阿里巴巴开源的高性能消息中间件,RocketMQ 已在电商、物流、支付等各类核心场景中得到广泛应用,以其出众的吞吐性能和高可靠性赢得了大量企业和开发者的信赖。
本文将深入剖析 RocketMQ 的运行原理,依次探讨:
- Producer:如何选择 Broker 并写入消息(含三种刷盘策略对比)
- Broker:如何通过主从同步保障数据可靠性(Push/Pull 模式详解)
- Consumer:如何高效消费消息并处理失败重试
- Raft 协议:如何支撑过半写入与 Leader 选举
一、RocketMQ 运行原理
1.1 整体架构概览
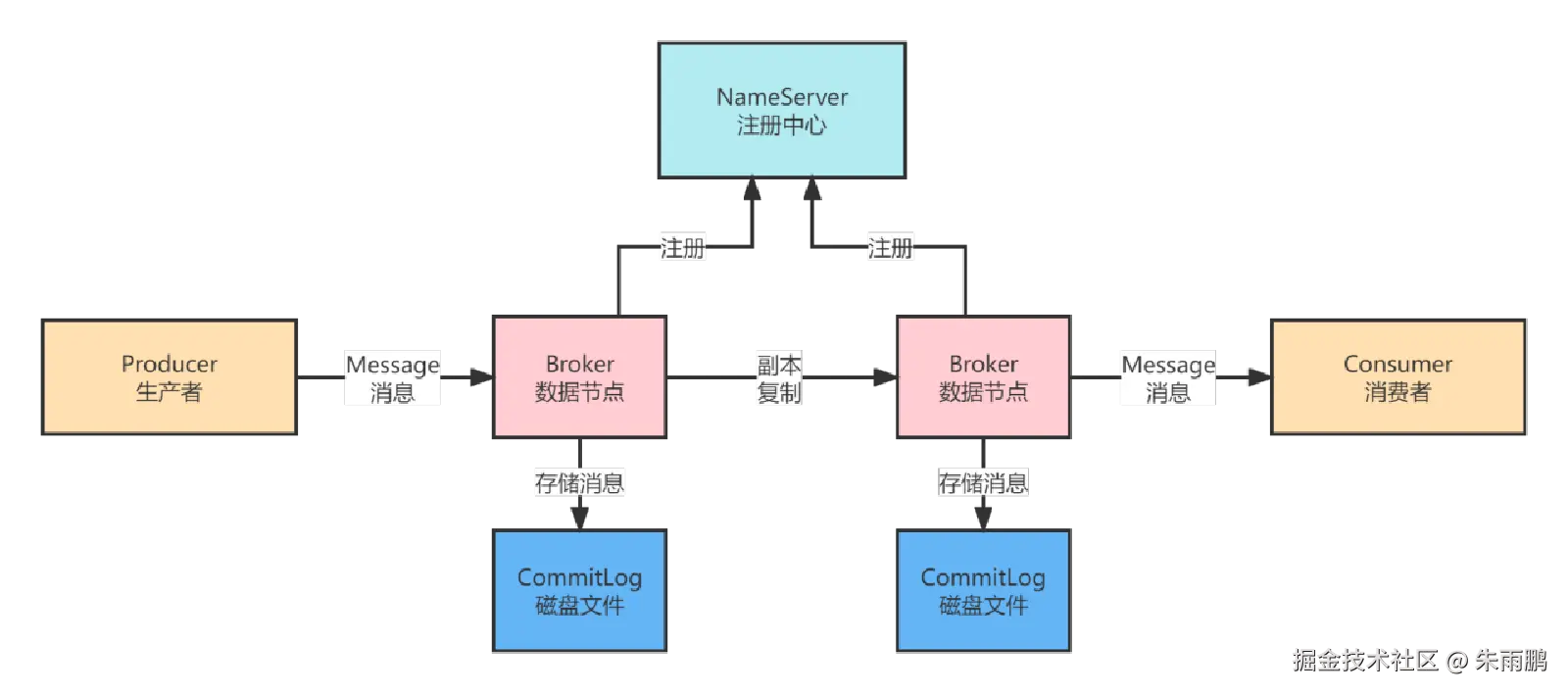
图1:RocketMQ 整体运行流程图
上图是 RocketMQ 运行的整体架构。在深入各模块之前,先了解其四大核心组件:
| 组件 | 角色 | 核心职责 |
|---|---|---|
| NameServer | 注册中心 | 管理 Broker 节点信息,维护 Topic 路由表 |
| Broker | 消息存储核心 | 接收、存储、转发消息,分为主节点(Master)和从节点(Slave) |
| Producer | 消息生产者 | 创建消息并发送到 Broker 主节点 |
| Consumer | 消息消费者 | 从 Broker 拉取消息并交由业务处理 |
整体运行流程:
- Broker 启动后,根据配置向 NameServer 注册,此后每 30 秒发送一次心跳
- NameServer 管理 Broker 集群信息及 Topic 路由信息(哪个 Topic 的哪些 Queue 在哪个 Broker 上)
- Producer 从 NameServer 获取路由信息,通过负载均衡算法选择 Broker,将消息写入主节点
- 消息在 Broker 主节点持久化到 CommitLog,并同步到从节点,保障数据可靠性
- Consumer 从 Broker 拉取消息,完成消费后提交消费进度
1.2 Producer 如何选择 Broker
Producer 写入消息前需要先选择 Broker 节点,具体是如何实现的?
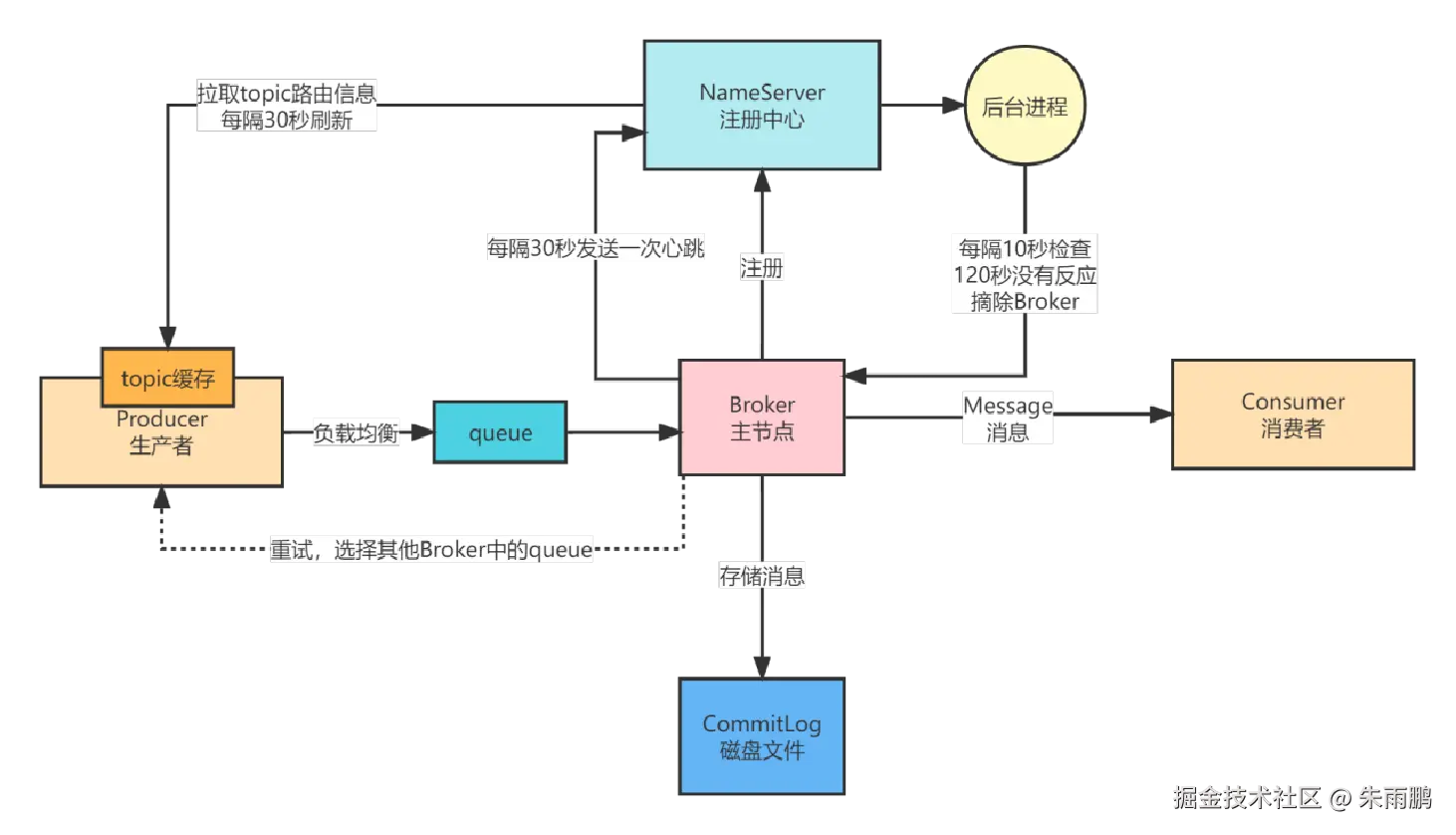
图2:Producer 选择 Broker 流程图
NameServer 心跳检测机制:
- Broker 启动后自动注册到 NameServer,此后每隔 30 秒发送一次心跳
- NameServer 每隔 10 秒检查各 Broker 节点是否在线
- 若某 Broker 120 秒内未发送心跳,NameServer 判定其宕机,将其从路由表中移除
Producer 负载均衡选择 Broker 流程:
Producer 在发送消息前,先从 NameServer 拉取目标 Topic 路由信息 (包含该 Topic 各 Queue 的信息及所在 Broker),缓存到本地后,通过负载均衡算法选择目标 Queue 及其对应的 Broker 节点进行写入。
Broker 故障时的故障退避机制:
:::warning 故障退避机制 若某 Broker 在写入时突然宕机,RocketMQ 的故障处理策略如下:
- 写入失败后立即重试,从可用 Broker 列表中重新选择
- 采用故障退避策略:在一段时间内停止向故障 Broker 发送数据,避免持续失败
- Broker 故障不会立即被感知:只有 NameServer 将其移除、Producer 刷新本地缓存后,才会真正感知该 Broker 不可用 :::
1.3 Producer 写入消息 --- 默认异步刷盘
选定 Broker 后,消息是如何写入并持久化的?
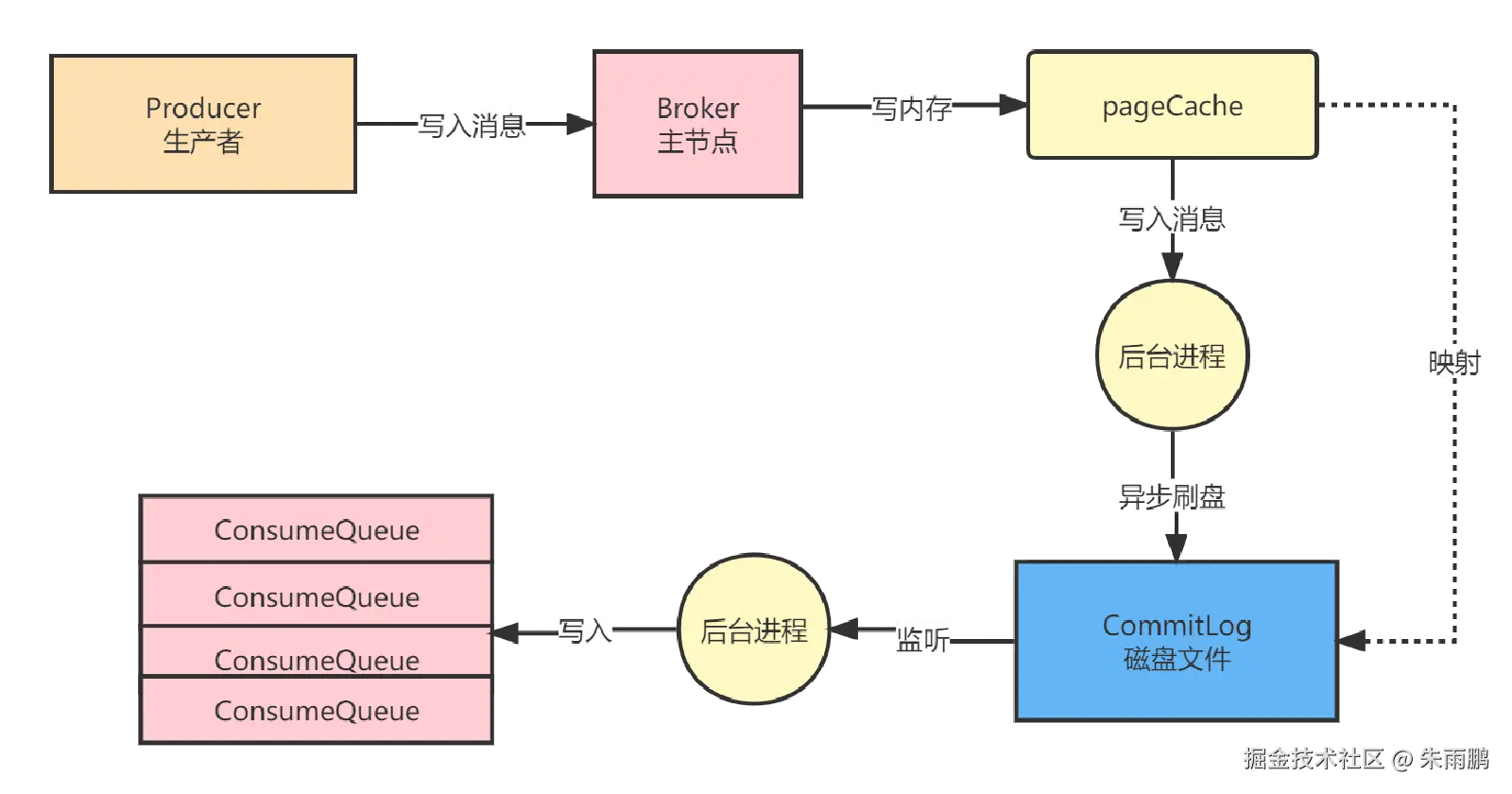
图3:Producer 写入消息 --- 默认异步刷盘模式
默认写入流程(异步刷盘):
- Producer 将消息写入操作系统管理的 PageCache ,写入成功即返回(不等待落盘)
- 后台线程异步 将 PageCache 中的消息刷入磁盘文件 CommitLog
- 另一个专门线程将 CommitLog 中消息的物理偏移量 索引写入 ConsumeQueue
- Consumer 消费时,先查 ConsumeQueue 获取 offset,再到 CommitLog 读取实际消息内容
高并发下的隐患:
异步刷盘性能极高,但当写入与读取请求量极大时,读写都集中在 PageCache,可能触发 Broker busy 异常。
1.4 Producer 写入消息 --- 开启 transientStorePool 机制
Broker busy 怎么解决?RocketMQ 提供了 transientStorePool 机制。
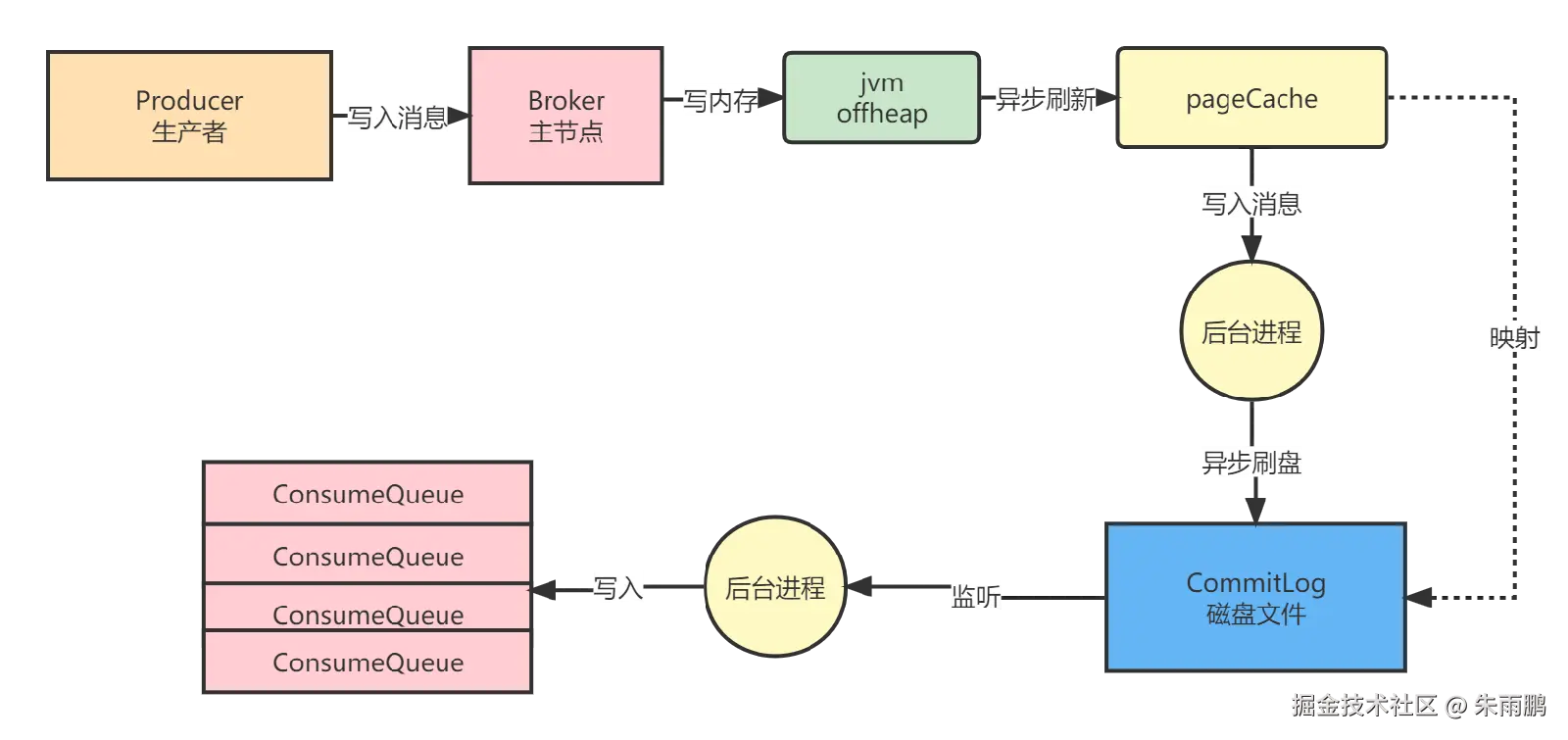
图4:开启 transientStorePool --- 读写分离提升并发性能
核心思路:读写分离
写请求 → JVM offheap 堆外内存 →(异步)→ PageCache →(异步)→ CommitLog(磁盘)
读请求 → PageCache(独立,不受写请求干扰)开启 transientStorePool 后:
- 写请求 直接写入 JVM 管理的 offheap 堆外内存(不经过 PageCache),显著降低写入压力
- 读请求 仍从 PageCache 读取,实现读写分离,大幅提升并发吞吐量
:::warning 数据安全风险 消息写入 offheap 堆外内存后,若 JVM 进程重启或宕机 ,尚未异步刷入 PageCache 的消息将永久丢失。而默认写 PageCache 的方式,JVM 重启后 PageCache 中的数据仍在(由 OS 管理),只有整台服务器宕机才可能丢失。 :::
适用场景: 高并发写入、且业务可容忍极少量数据丢失的场景(如日志收集、埋点上报等)。
1.5 Producer 写入消息 --- 同步写入 CommitLog
若要做到数据不丢失,需要开启同步刷盘。
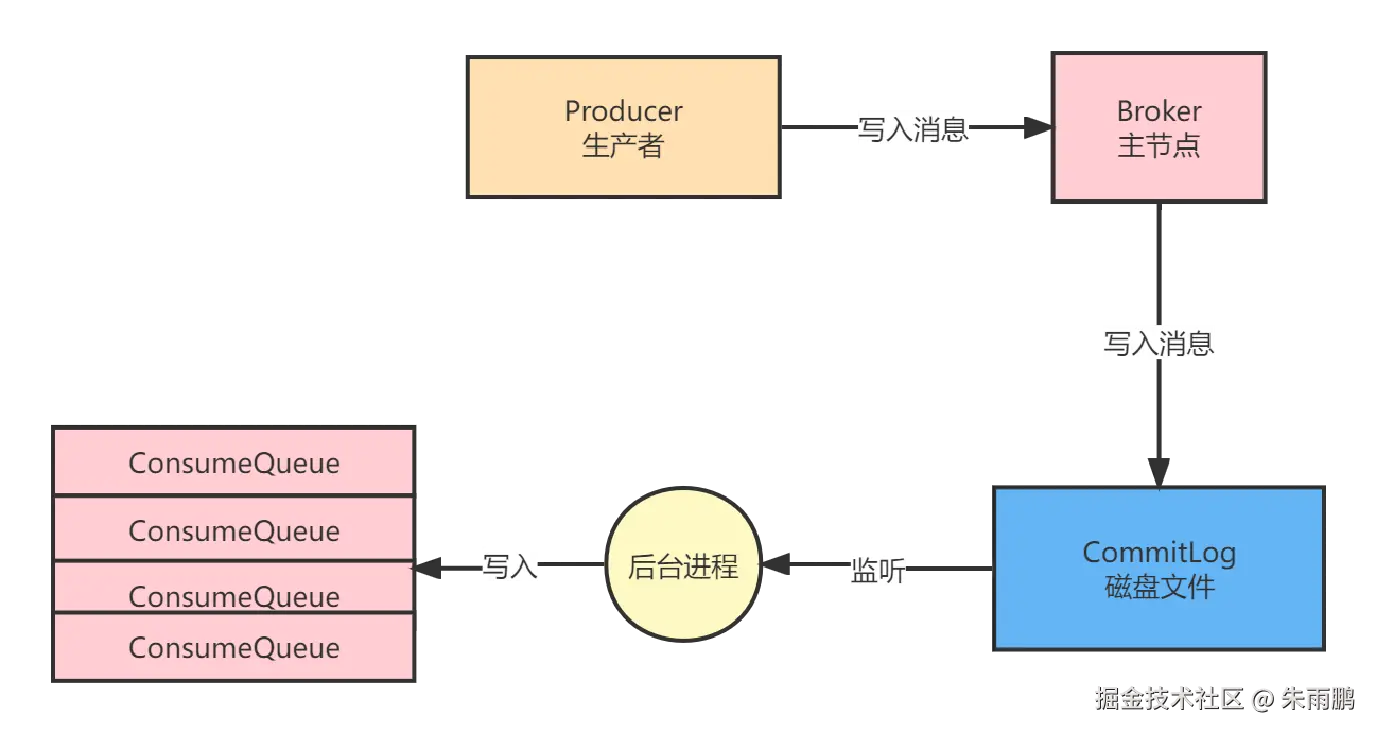
图5:同步写入 CommitLog --- 数据安全最高保障
同步刷盘特点:
- 消息写入后,等待数据落盘到 CommitLog 才返回成功,保证每条消息都已持久化
- 只有 Broker 的物理存储设备发生故障时,才存在数据丢失风险
- 可配合多副本备份(主从架构)进一步提升数据安全性
:::tip 代价 同步刷盘每次写入都需要等待磁盘 IO 完成,吞吐量会大幅下降,适用于金融、交易等对数据安全要求极高的场景。 :::
三种写入方式横向对比:
| 写入方式 | 性能 | 数据安全性 | 适用场景 |
|---|---|---|---|
| 异步刷盘(默认) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 通用场景,高吞吐 |
| transientStorePool | ⭐⭐⭐⭐⭐ | ⭐⭐ | 极高并发,可容忍少量丢失 |
| 同步刷盘 | ⭐⭐ | ⭐⭐⭐⭐⭐ | 金融交易,强一致要求 |
二、主从同步
为实现高可用,RocketMQ 通常部署多台 Broker,分为主节点(Master)和从节点(Slave),消息写入主节点后需同步到从节点。
2.1 主从同步概述
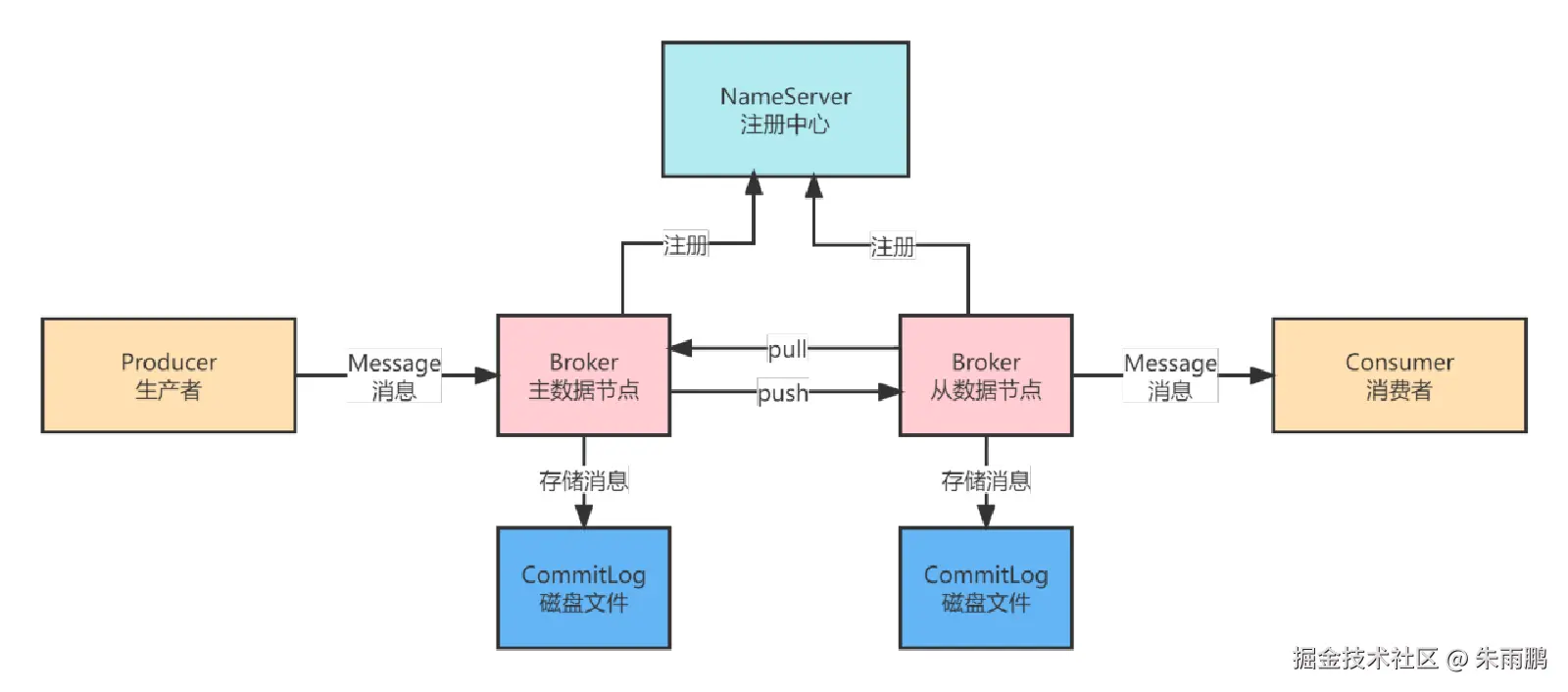
图6:Broker 主从同步整体流程
Broker 主从复制支持 Push 和 Pull 两种模式:
| 模式 | 同步方式 | 特点 |
|---|---|---|
| Push 模式 | 主节点主动推送数据到从节点 | 时延低,性能高 |
| Pull 模式 | 从节点主动拉取主节点数据 | 控制权在从节点,适合数据安全要求高的场景 |
2.2 主从同步 --- Pull 方式详解
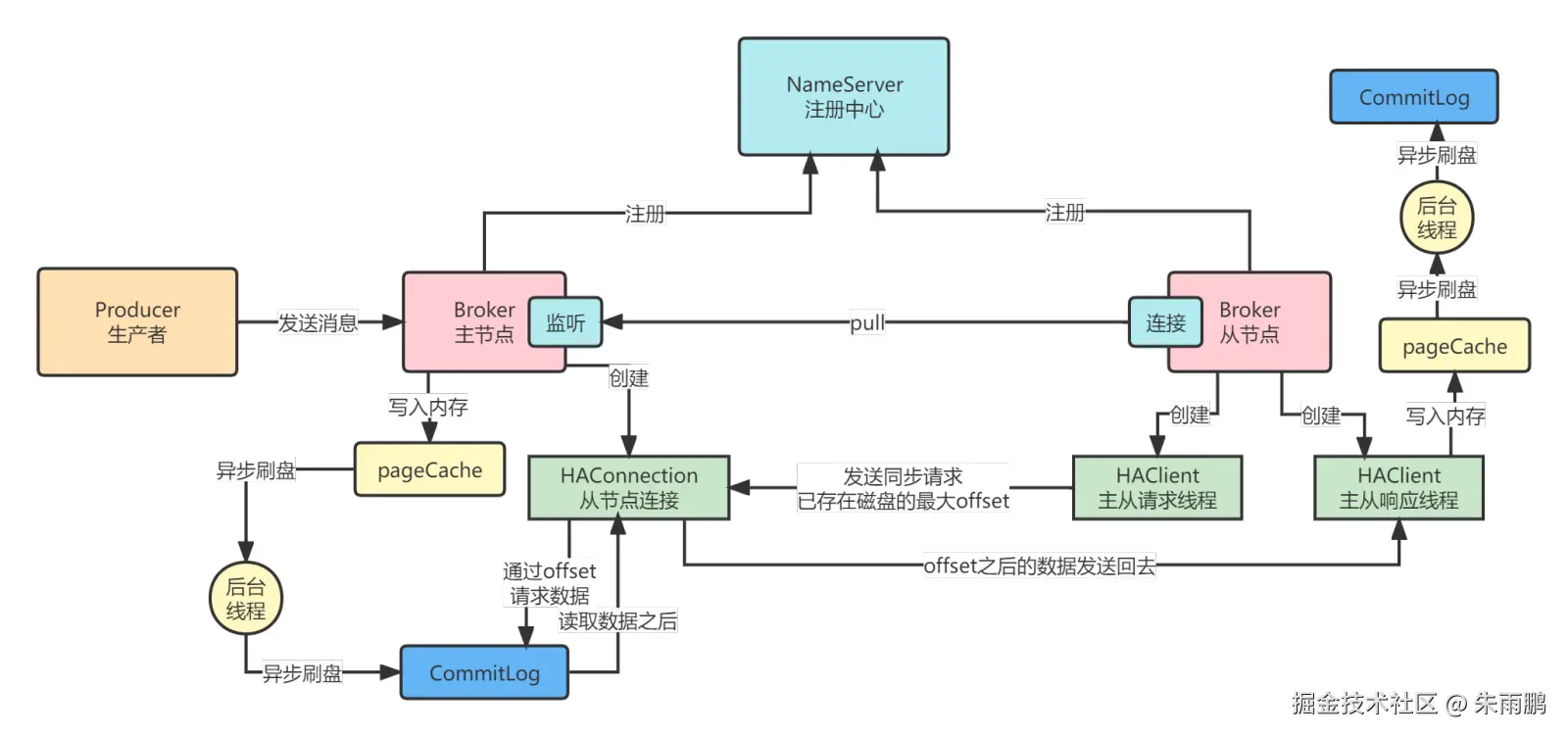
图7:主从同步 Pull 模式详细流程
Pull 模式核心组件与流程:
- 主节点启动 后监听从节点连接,连接建立后初始化
HAConnection组件(每个从节点对应一个专属的 HAConnection) - 从节点创建两个 HAClient 线程:一个负责发出 pull 请求,一个负责处理主节点响应
- HAClient 定期发出 pull 请求,携带本地 CommitLog 的最大物理偏移量(Offset),请求同步该 Offset 之后的所有数据
- 主节点收到请求后,将对应数据发回从节点
- 从节点 HAClient 响应线程将收到的数据写入本地 CommitLog,完成同步
:::warning 风险点 若消息写入主节点 PageCache 后服务器宕机,由于 PageCache 由 OS 管理,未来得及 pull 的数据在切换到从节点时将丢失。 :::
2.3 主从同步 --- 数据零丢失方案(同步写入 + Pull)
如何彻底防止同步过程中的数据丢失?
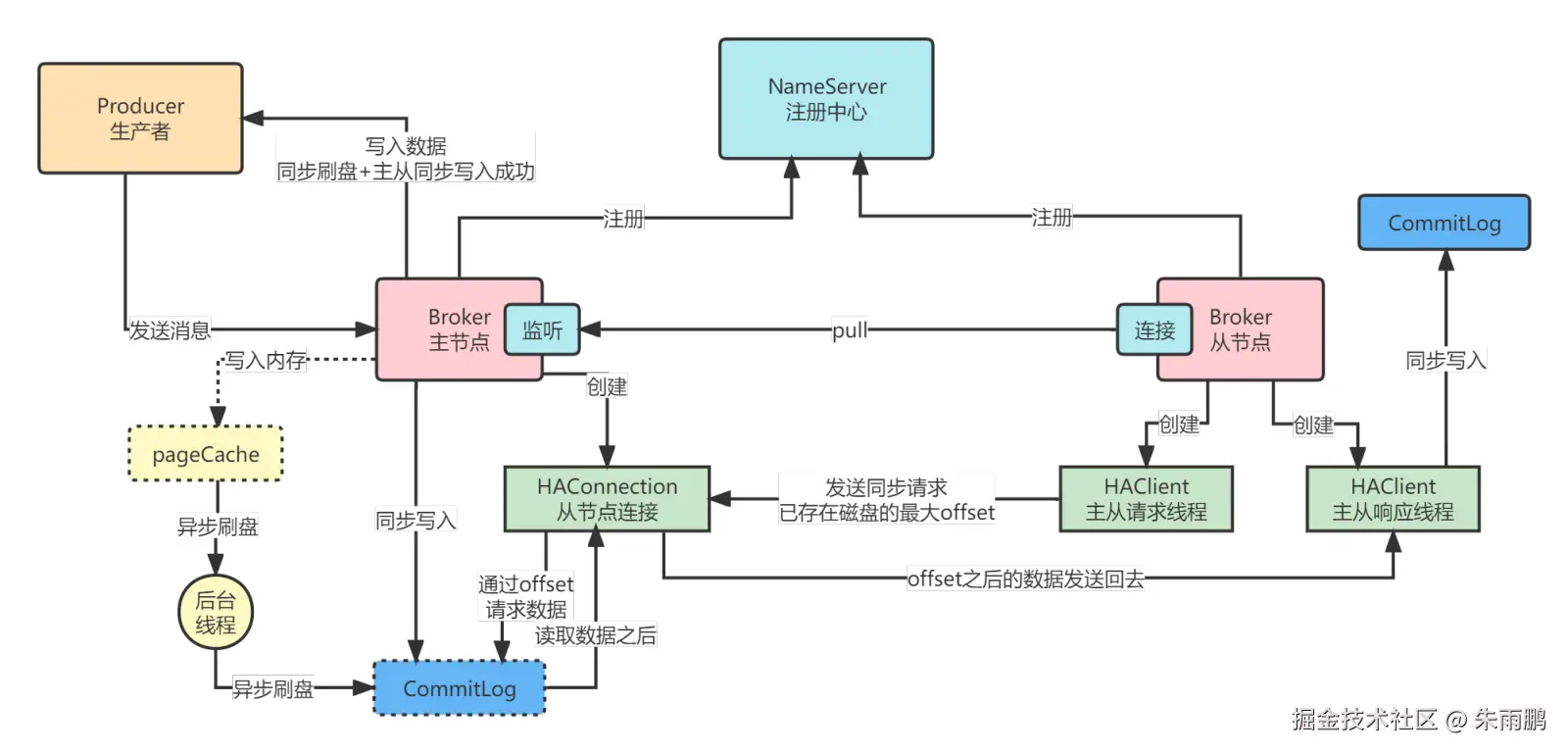
图8:同步写入 + Pull 实现数据零丢失
在金融等高安全场景下,结合同步刷盘 + Pull 模式,完整流程如下:
sql
① 主节点:消息同步写入 CommitLog(1次磁盘IO)
② 等待从节点发来 pull 请求
③ 从节点:查询本地 CommitLog 最大 offset(1次磁盘IO)
④ 从节点 → 主节点:发送 pull 请求(1次网络IO)
⑤ 主节点:读取并对比本地 offset(1次磁盘IO)
⑥ 主节点 → 从节点:发送最新数据(1次网络IO)
⑦ 从节点:写入本地 CommitLog(1次磁盘IO):::tip 总结 同步写入 + Pull 共需 3次磁盘IO + 2次网络IO,可做到数据零丢失,但写入延迟会从几十毫秒拉长到数百毫秒甚至数秒。 :::
2.4 主从同步 --- Push 方式详解
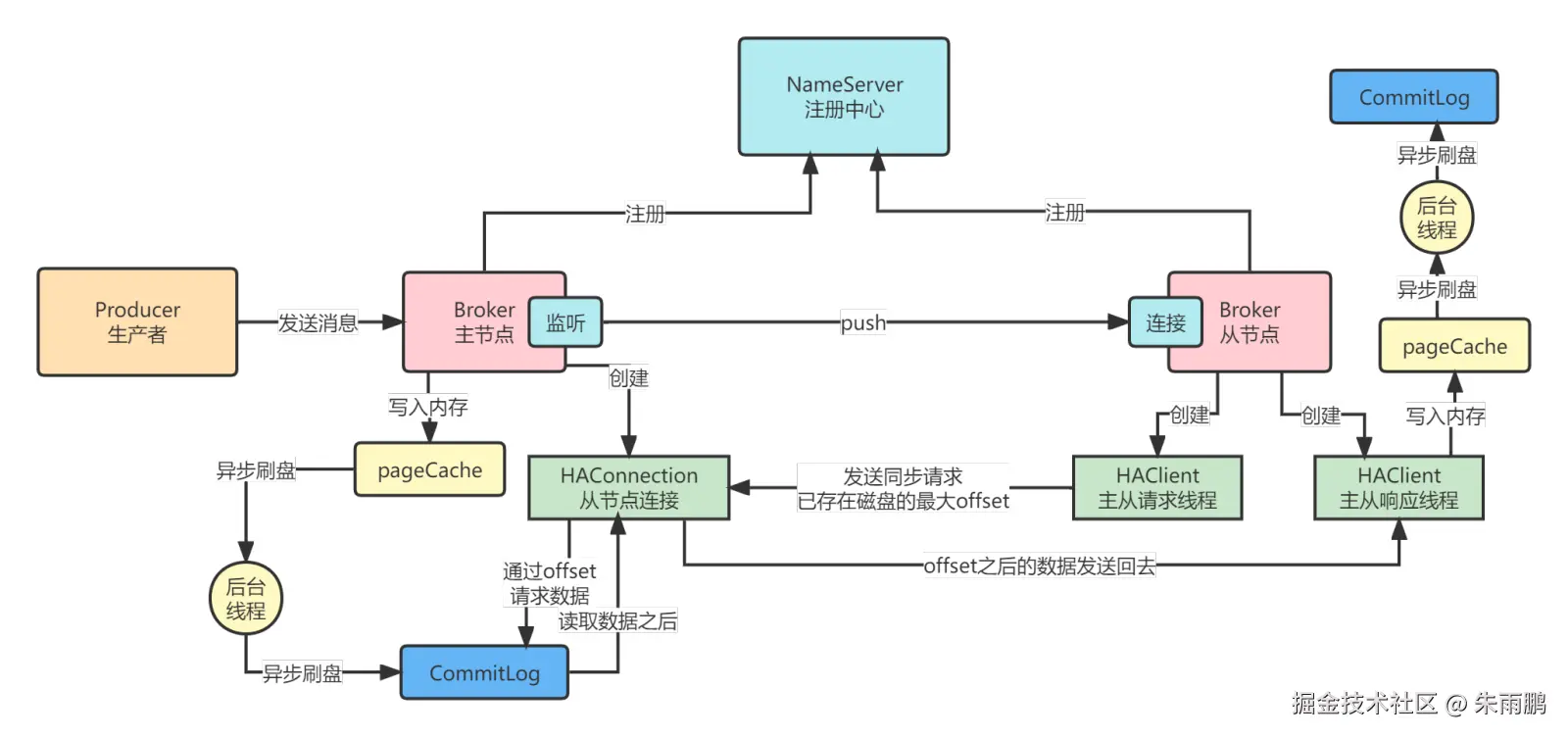
图9:主从同步 Push 模式 --- 高性能异步推送
Push 模式流程:
- 主节点将消息写入 PageCache 后立即返回(异步刷盘)
- 无需等待从节点发起请求,主节点直接 push 数据至从节点
- 从节点收到数据写入 PageCache 后返回,后台线程异步持久化
三种主从同步方案综合对比:
| 方案 | 写入性能 | 数据安全 | 适用场景 |
|---|---|---|---|
| 异步写入 + Push | ⭐⭐⭐⭐⭐ | ⭐⭐ | 高吞吐、容忍少量丢失 |
| 同步写入 + Push | ⭐⭐⭐ | ⭐⭐⭐⭐ | 兼顾性能与安全(推荐) |
| 同步写入 + Pull | ⭐⭐ | ⭐⭐⭐⭐⭐ | 金融核心链路,强一致 |
:::tip 生产推荐 大多数场景下,使用同步写入 + Push 是性能与数据安全性最佳的平衡点。 :::
三、Consumer 消费
3.1 Consumer 如何选择 Queue
每个 Consumer 不是消费所有 Queue 的消息,而是通过分配算法绑定到特定 Queue。
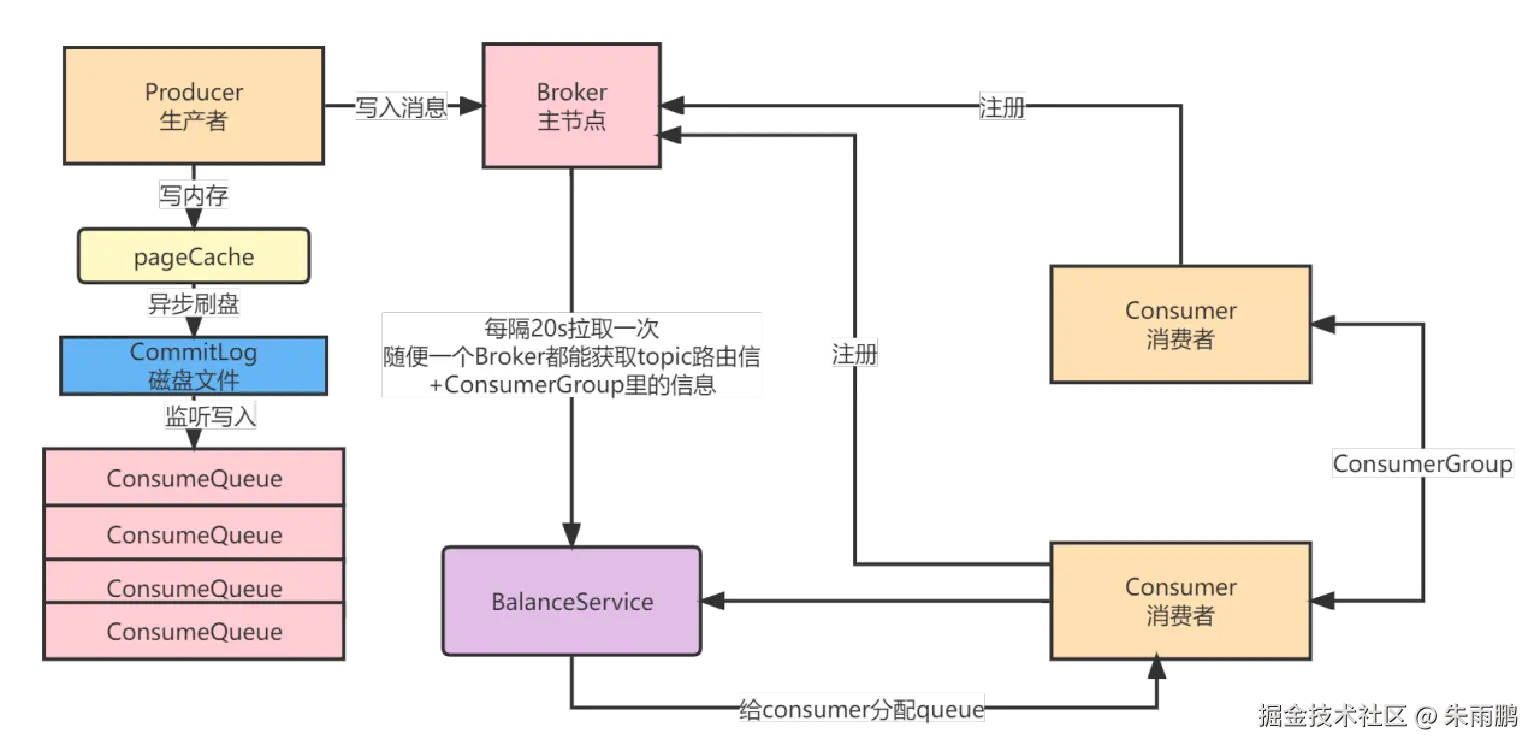
图10:Consumer 通过 BalanceService 进行 Queue 分配
Queue 分配流程:
- Consumer 启动后,将自身信息注册至每个 Broker
- Broker 因此可获取 ConsumerGroup 中所有 Consumer 的信息
- Consumer 内部的 BalanceService 组件每隔 20 秒,从 Broker 拉取 Topic 路由信息和 ConsumerGroup 信息
- BalanceService 基于分配算法,将 Queue 分配给各 Consumer(每个 Queue 同一时刻只分配给一个 Consumer)
常用分配算法:
| 算法 | 描述 | 适用场景 |
|---|---|---|
| 平均分配 | Queue 数量均分给各 Consumer | 最常用,节点数量均衡 |
| 轮询分配 | 按轮询顺序依次分配 Queue | 需要顺序消费时 |
| 基于机房分配 | 优先将 Queue 分配给同机房 Consumer | 多机房部署,降低跨机房流量 |
3.2 Consumer 拉取消息
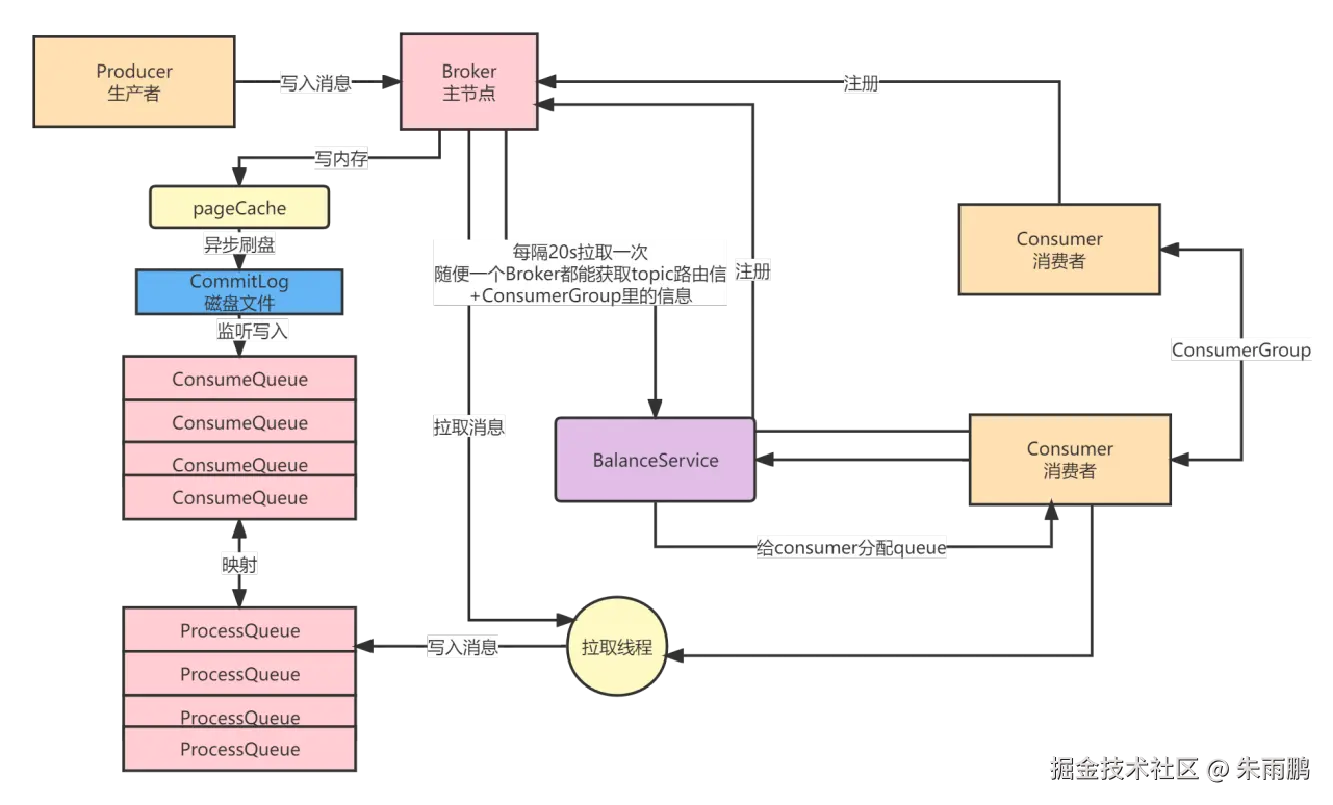
图11:Consumer 拉取消息并写入 ProcessQueue
消息拉取流程:
- Queue 分配完成后,Consumer 启动拉取线程开始拉取消息
- Producer 写入的消息已经历
PageCache → CommitLog → ConsumeQueue的存储流程 - Consumer 读取 ConsumeQueue 中的索引(offset),再到 CommitLog 中读取实际消息
- 拉取到的消息写入内存中的 ProcessQueue(ProcessQueue 是 ConsumeQueue 消息的内存映射),为后续并发处理做准备
3.3 Consumer 消息处理
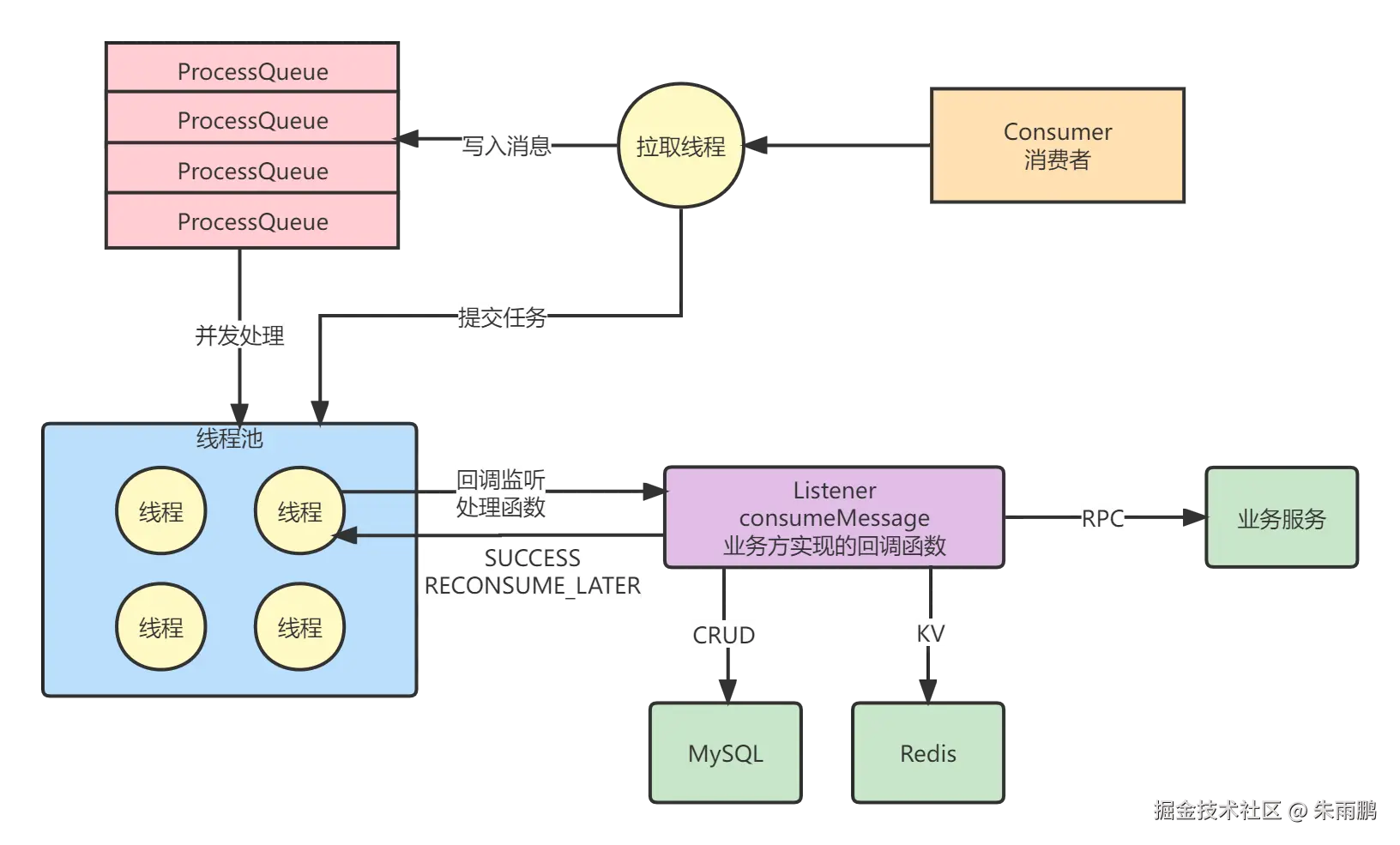
图12:Consumer 启动线程池并发处理消息
消息写入 ProcessQueue 后,Consumer 启动线程池并发处理,回调业务方实现的监听器:
java
// Spring Boot 集成 RocketMQ 消费者示例
@RocketMQMessageListener(topic = "order-topic", consumerGroup = "order-consumer-group")
public class OrderMessageListener implements RocketMQListener<String> {
@Override
public void onMessage(String message) {
// 1. 写入数据库(MySQL 订单状态更新)
orderService.updateStatus(message);
// 2. 更新缓存(Redis)
redisTemplate.opsForValue().set("order:" + message, "processed");
// 3. 调用下游服务(RPC)
notifyService.send(message);
}
}处理结果与后续动作:
| 处理结果 | 返回状态 | 后续动作 |
|---|---|---|
| 业务处理成功 | ConsumeConcurrentlyStatus.CONSUME_SUCCESS |
提交 ACK,更新消费进度 |
| 业务处理失败 | ConsumeConcurrentlyStatus.RECONSUME_LATER |
消息延迟重试,最多重试 16 次 |
3.4 消费成功 --- SUCCESS 处理流程
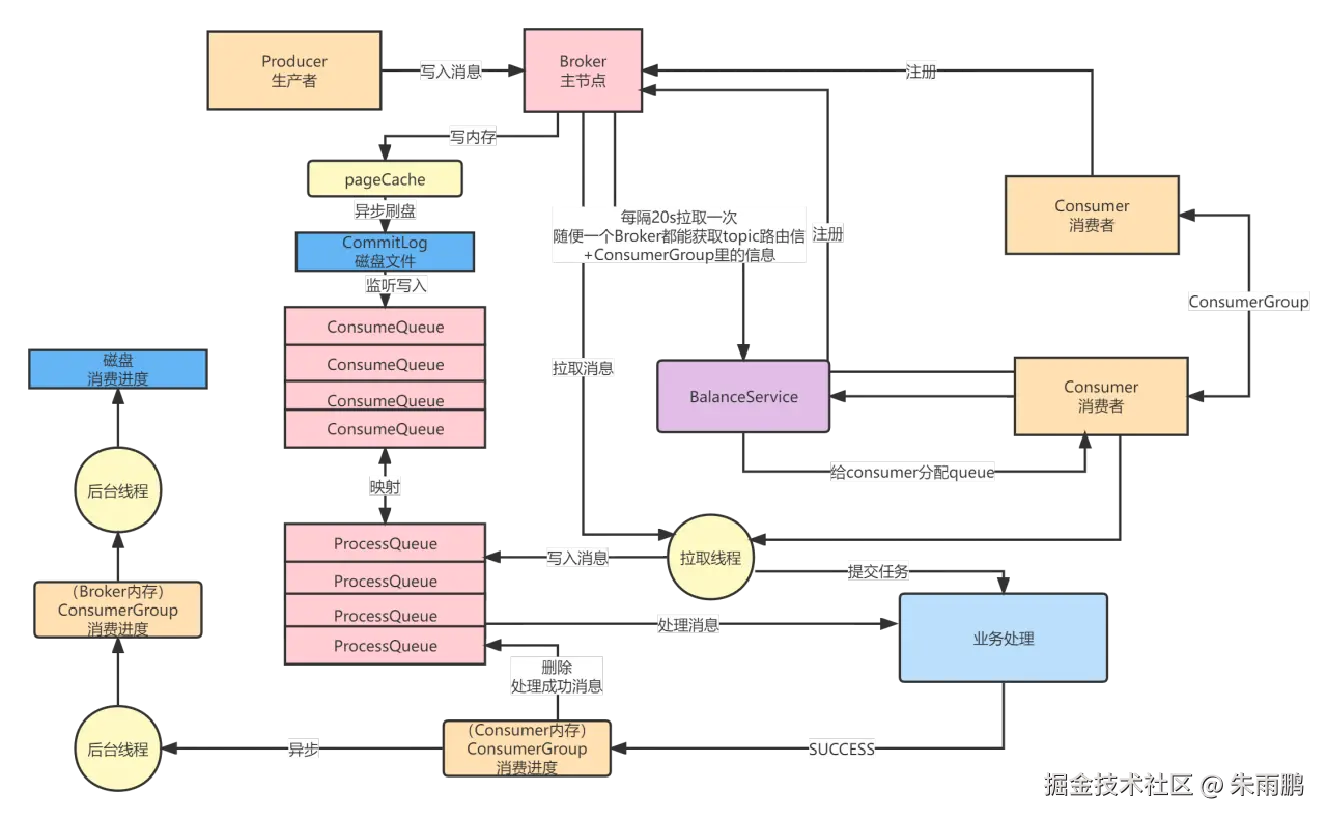
图13:消费成功后的消费进度持久化流程
SUCCESS 后的完整处理链路:
- 消费者返回 SUCCESS 状态
- 从 ProcessQueue 中移除已成功消费的消息
- 在内存中记录消费进度(当前 Queue 消费到哪个 offset)
- 后台线程异步将消费进度上报给 Broker
- Broker 将消费进度持久化到磁盘,保障重启后不丢失
:::tip 消费进度的关键作用 当消费者节点数量发生变化(扩容/缩容)时,BalanceService 会触发 Queue 重新分配。由于消费进度已持久化,新分配到该 Queue 的 Consumer 直接从上次消费的 offset 继续处理,既不会重复消费,也不会漏消费。 :::
3.5 消费失败 --- RECONSUME_LATER 重试机制
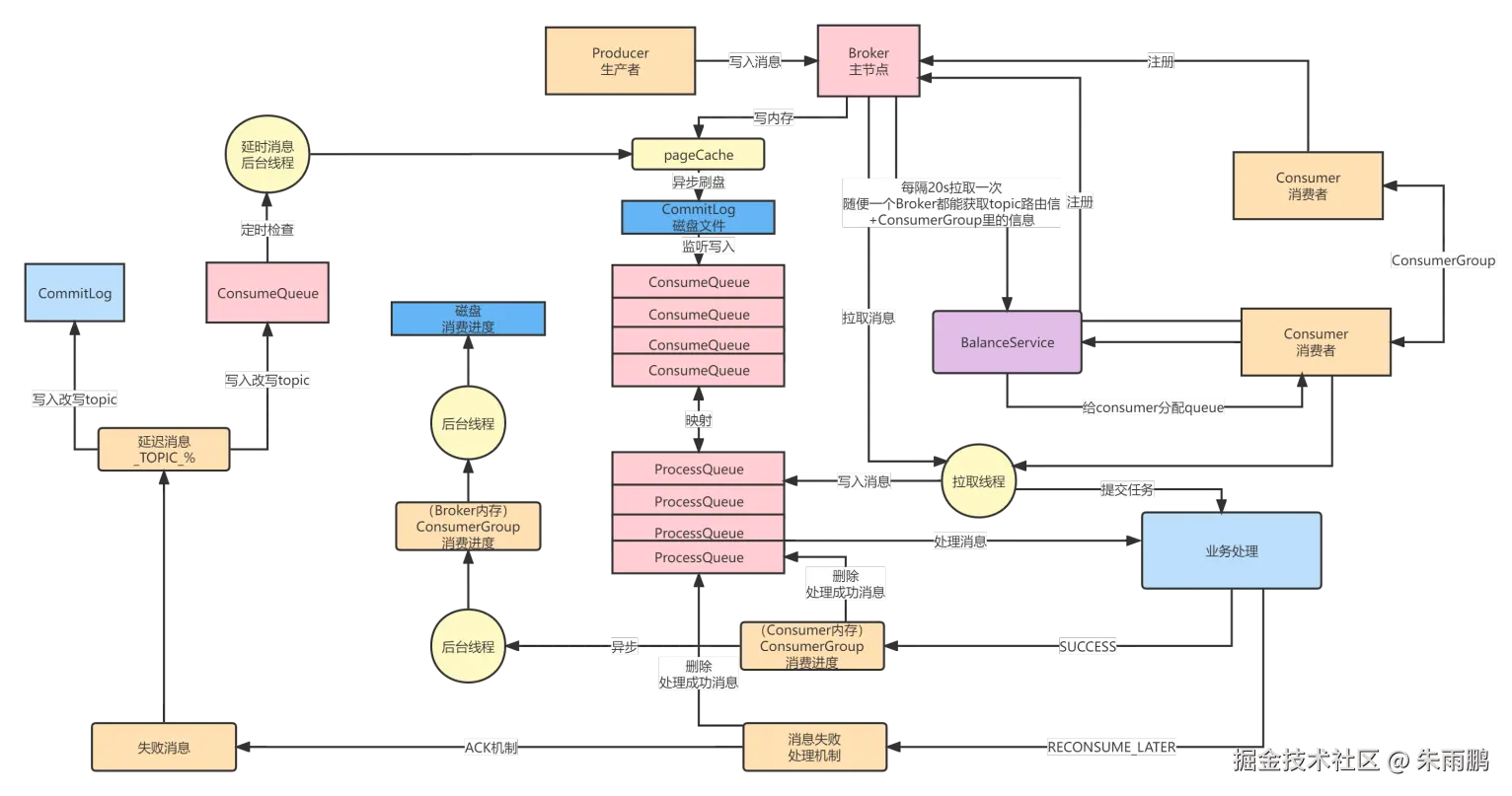
图14:消费失败后的延迟重试机制
RECONSUME_LATER 重试流程:
- Consumer 通过 ACK 机制通知 Broker 该消息消费失败,需要重试
- Broker 将失败消息的 Topic 重写 为重试 Topic(格式:
%RETRY%ConsumerGroup),存入 CommitLog 及 ConsumeQueue - Broker 启动定时任务 ,按指数退避策略 设置重试延迟:
- 10s → 30s → 1min → 2min → 3min → 4min → ... 最多 16 次
- 延迟时间到达后,Broker 将消息 Topic 恢复为原始 Topic,重新投递给 Consumer 消费
:::danger 死信队列 超过最大重试次数(16次)后,消息进入死信队列(Dead Letter Queue,DLQ) ,Topic 为 %DLQ%ConsumerGroup,需要人工介入处理,避免消息永久丢失。 :::
🎯 类比理解: 就像快递投递失败后,快递员不会立刻再次投递,而是将快件暂存,等合适时间重新投递,且每次失败后等待时间会更长。
3.6 Consumer 消费完整流程汇总
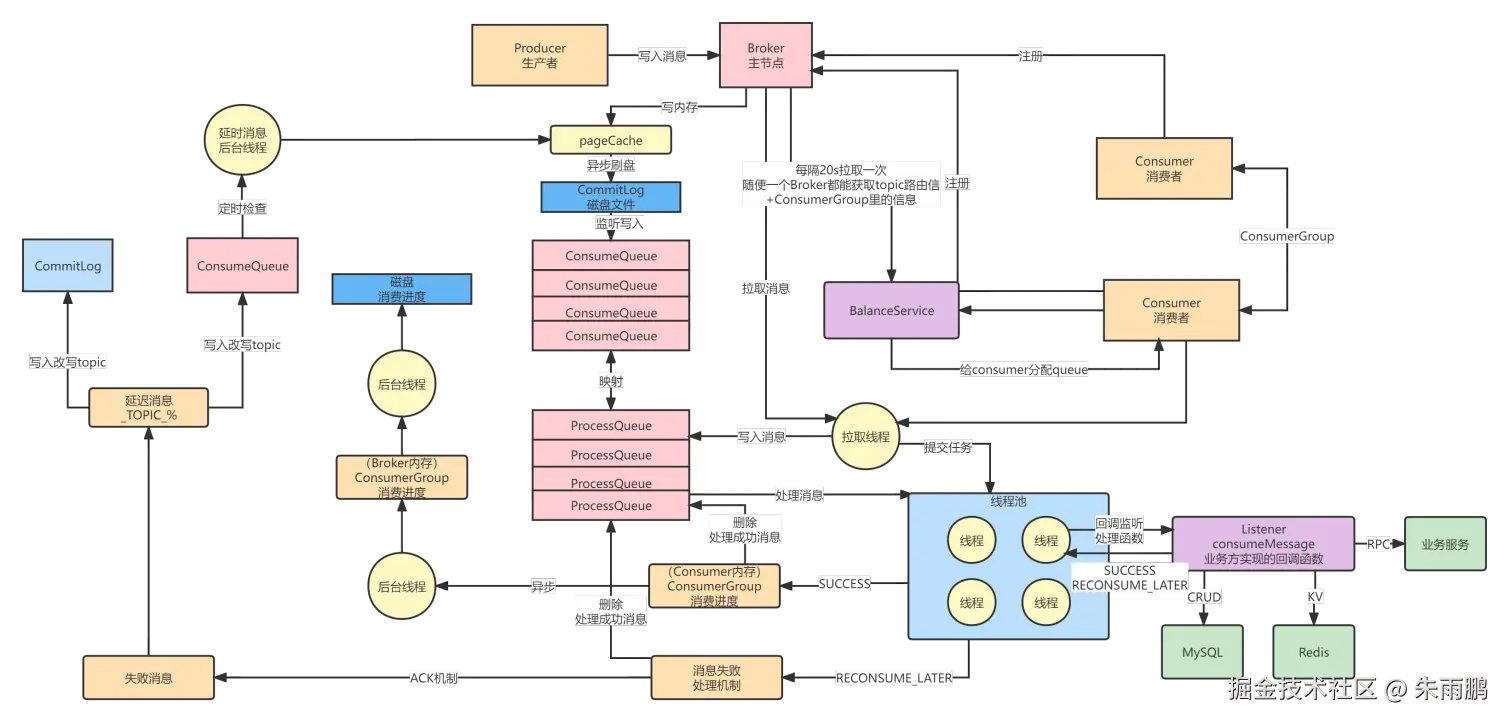
图15:RocketMQ Consumer 消费完整流程图
完整消费链路回顾:
markdown
Consumer 启动
│
├─► 向每个 Broker 注册自身信息
│
├─► BalanceService(每20秒)拉取 Topic 路由 + ConsumerGroup 信息
│ └─► 分配算法:确定当前 Consumer 负责消费哪些 Queue
│
├─► 拉取线程:从 Broker ConsumeQueue 拉取消息 → 写入 ProcessQueue
│
└─► 线程池并发处理 ProcessQueue 中的消息
│
├─► 回调业务监听器(MessageListener.onMessage)
│
├─► 返回 SUCCESS
│ ├─► 清理 ProcessQueue 中已消费消息
│ ├─► 内存记录消费进度
│ └─► 异步上报 Broker,持久化消费进度
│
└─► 返回 RECONSUME_LATER
├─► ACK 通知 Broker 消费失败
├─► Broker 重写 Topic 为 %RETRY%Group
└─► 按指数退避延迟后重新投递(最多16次)
└─► 超出次数 → 进入死信队列(DLQ)四、基于 Raft 协议的过半写入机制
在了解完消息消费流程后,我们来看 RocketMQ 如何通过 Raft 协议保证分布式场景下的写入一致性。
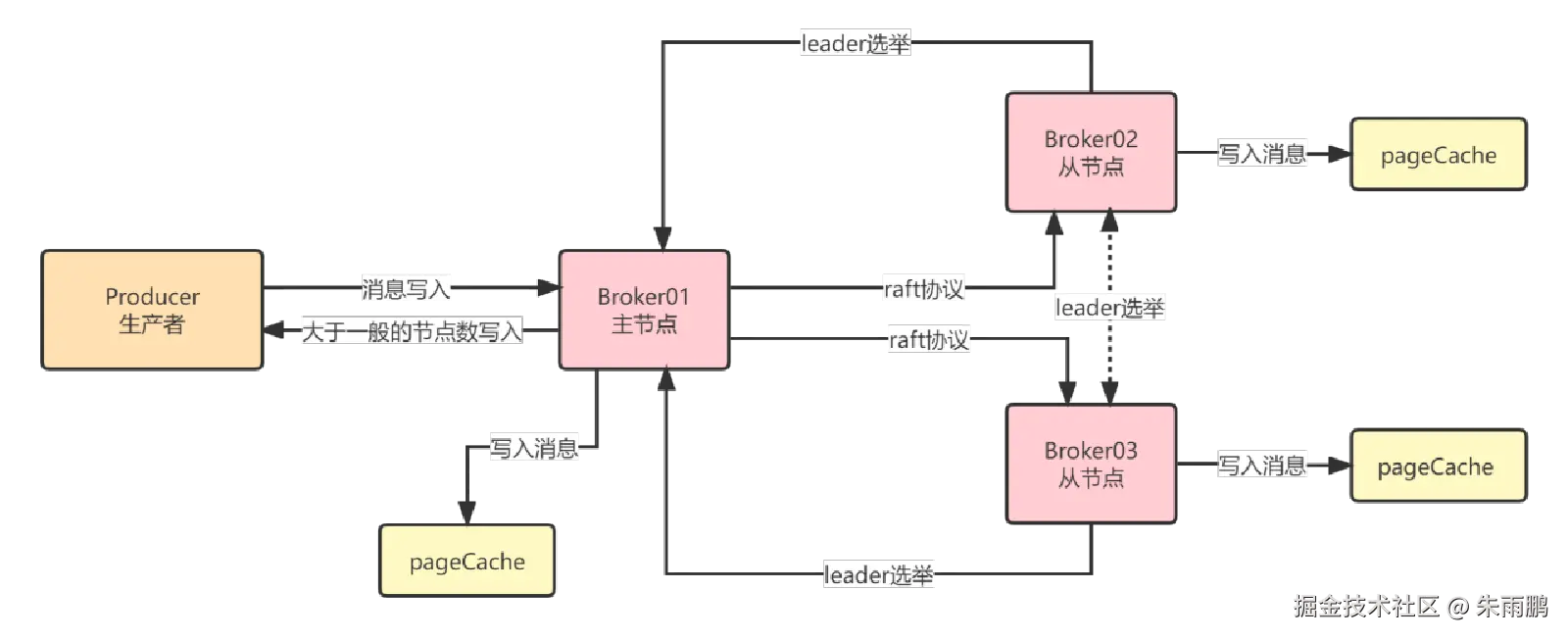
图16:基于 Raft 协议的过半写入机制(三节点示例)
以 Broker01(主)、Broker02(从)、Broker03(从)三节点集群为例:
- Producer 将消息写入 Broker01,成功写入 PageCache 即认为 Broker01 写入完成
- 基于 Raft 协议,Broker01 将消息同步至 Broker02 和 Broker03
- 只要 Broker02 和 Broker03 中任意一个成功写入,整体写入即视为成功
:::tip 过半原则 3个节点中,只需 2个节点(≥ N/2+1 = 2)写入成功,消息即可确认写入。这是 Raft 协议保证多数派一致的核心思想。 :::
Broker01 故障时的降级行为:
若 Broker01 故障,剩余 Broker02 和 Broker03 通过 Leader 选举产生新主节点。此时集群变为 2节点 ,需要 2个节点全部写入成功(2/2,依然满足过半),才视为写入成功,保持系统可用。
五、基于 Raft 协议的 Leader 选举机制
当 Broker 主节点宕机时,集群需要通过 Leader 选举 选出新的主节点,保证消息传输的持续可用。
5.1 三种角色与状态转换
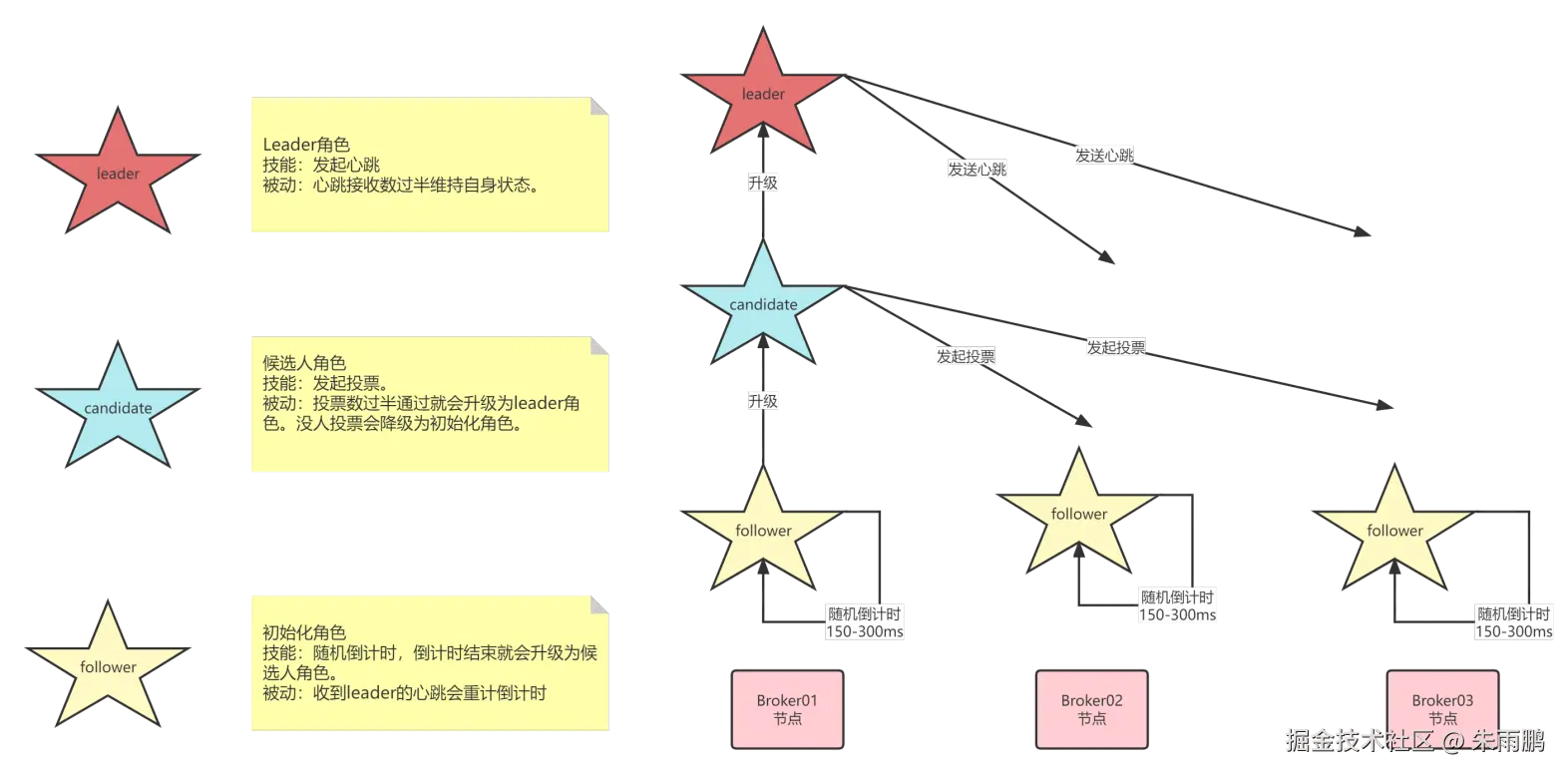
图17:Raft 协议三角色状态机
RocketMQ 中的 Leader 选举基于 Raft 协议,节点分为三种角色:
| 角色 | 初始/触发条件 | 主动行为 | 状态转换规则 |
|---|---|---|---|
| Follower(跟随者) | 节点启动默认状态 | 无,被动响应 | 收到心跳 → 重置倒计时保持 Follower;随机倒计时结束 → 升级为 Candidate |
| Candidate(候选人) | Follower 倒计时超时 | 发起投票,向其他节点请求选票 | 获票数 ≥ N/2+1 → 升级为 Leader;获票不足 → 降级为 Follower |
| Leader(领导者) | Candidate 赢得选举 | 定期发送心跳,阻止其他节点超时 | 正常运行 → 持续发送心跳;网络隔离或宕机 → 触发新一轮选举 |
5.2 选举示例一:顺利选举
场景: Broker01、Broker02、Broker03 三节点同时启动,随机倒计时后 Broker01 最先超时。
过程:
- Broker01 倒计时结束 → 升级为 Candidate,向 Broker02、Broker03 发起投票请求
- Broker02 和 Broker03 将票投给 Broker01(每个节点在一个任期只能投一票)
- Broker01 获得 3 票(含自己),超过半数 → 升级为 Leader
- Broker01 开始向 Broker02、Broker03 发送心跳,两者重置倒计时,保持 Follower 状态
5.3 选举示例二:平票情况
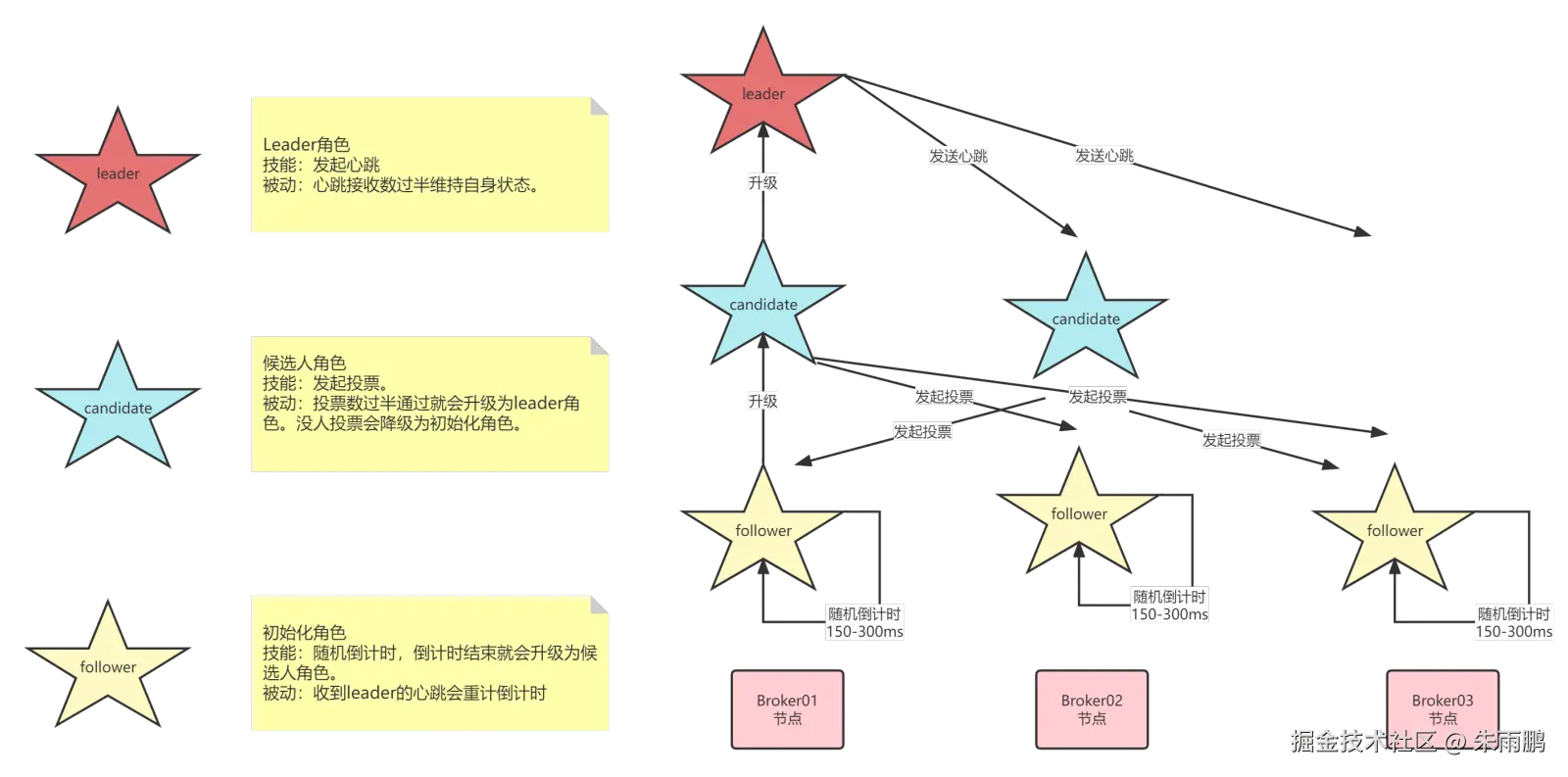
图18:Raft 协议 Leader 选举 --- 平票情况处理
场景: Broker01 和 Broker02 几乎同时倒计时结束,同时发起投票。
过程:
- Broker01 投自己一票,Broker02 投自己一票
- Broker03 投票给 Broker01(先到先得原则)
- Broker01 获得 2 票(含自己),达到过半数 → 升级为 Leader
- Broker02 只有 1 票,未过半 → 降级为 Follower,重新开始随机倒计时,等待下次选举
:::tip Raft 随机超时的妙处 Raft 的随机倒计时设计正是为了解决平票问题:每个节点的超时时间随机,大概率避免多节点同时发起选举;即使偶发平票,也会在下一轮重新选出 Leader,保证最终一致。 :::
六、总结
本文通过 18 张原理图,系统梳理了 RocketMQ 的核心运行机制:
🔵 Producer 消息写入
- Producer 基于 NameServer 路由信息 + 负载均衡算法选择 Broker
- 三种刷盘策略:异步刷盘(高性能) 、transientStorePool(读写分离) 、同步刷盘(强安全)
- 故障退避机制保证 Broker 宕机时的写入可用性
🟢 Broker 主从同步
- Push 模式性能高,Pull 模式控制精细
- 推荐生产环境使用同步刷盘 + Push,兼顾性能与数据安全
- 同步刷盘 + Pull 可实现数据零丢失,但 IO 开销大
🟡 Consumer 消息消费
- BalanceService 每 20 秒进行 Queue 动态分配,支持消费者弹性扩缩容
- 消费失败后最多重试 16 次(指数退避),超限进入死信队列(DLQ)
- 消费进度持久化到 Broker,保证 Queue 重分配后无消息丢失
🔴 Raft 协议
- 过半写入机制保障分布式写入一致性(N/2+1 节点写入即成功)
- Leader 选举机制保障主节点故障后快速恢复,系统持续可用
- 随机超时设计有效规避平票问题
如果这篇文章对你有帮助,欢迎点个 👍 支持一下,你的鼓励是我继续创作的动力!
有任何问题或不同见解,欢迎在评论区交流 💬
参考资料: