一,机器学习基本步骤
- 建模(找函数):Function with Unknown Parameters
- 定义损失函数(Loss Function):Define Loss from Training Data
- 优化(Optimization)
整个过程如下:拿到训练数据(Training Data)后,拟定一个模型函数
,找到一个合适的损失函数
,然后利用梯度下降找到
。之后将得到的模型
放到测试数据(Testing Data)
得到预测的结果
。
二,模型优化思路
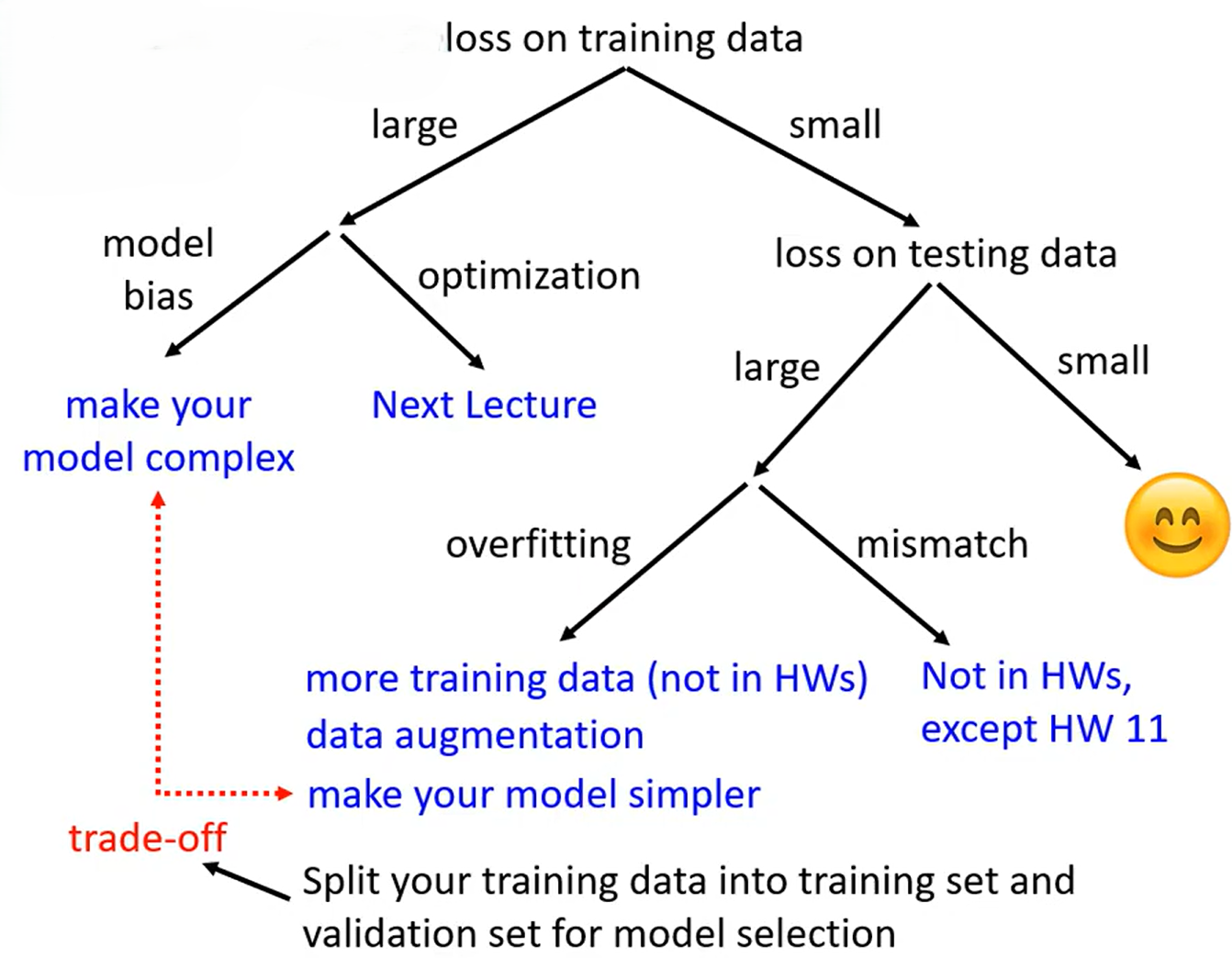
如果你对模型得到的测试集结果不满的话。先检查模型在训练数据上的损失**(loss on training data)** 。如果损失很大**(large)**,显然此模型在训练资料上没有学好,可能的原因有两个:
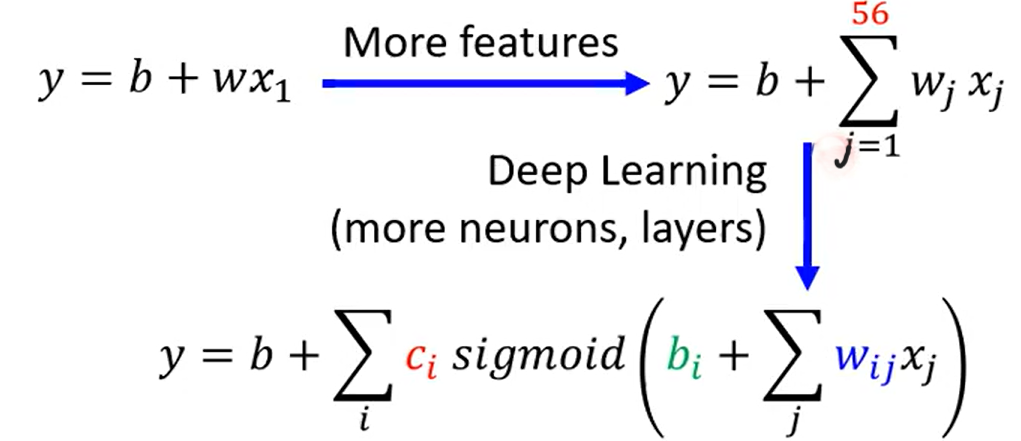
- 模型偏差**(model bias)** :模型太简单。对于你定义的模型,每组参数都可以得到一个单独的function,所有的function集合在一起组成一个function set,但是你的模型太简单,在这个function set找到的最优function
只是这个简单模型中的最优。所以需要优化模型,使模型更复杂(make your model complex),包含的function更多,function set更大。
具体如何使模型更复杂在之前的回归、分类任务中我们已经介绍
- 优化问题**(optimization)** :梯度更新时遇到局部最小值或者鞍点问题。
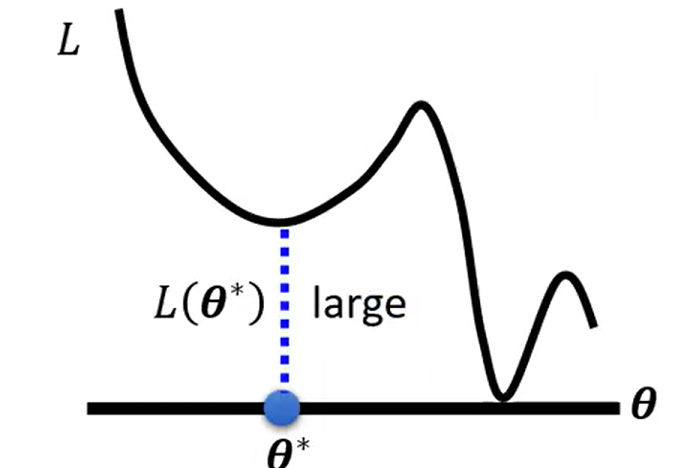
到底该如何判断是model bias还是optimization的问题导致模型在训练集上loss过大,给出以下方法:
- 比较不同的模型来判断当前模型是否足够复杂:具体过程举例如下。看第一张图,56层模型与20层模型相比在测试集上的损失更大,可能是因为过拟合的问题。但是有了第二张图之后发现在训练集上56层模型比20层模型损失依然更大,但是如果是过拟合问题,56层模型相比20层模型更复杂,弹性更大,应该比20层模型在训练集上的损失更小。排除过拟合问题,也不是model bias模型过于简单的问题,所以最后就剩下optimiazation的问题,56层模型的优化做得不是很好,可能遇到的局部最小值或者是鞍点问题。
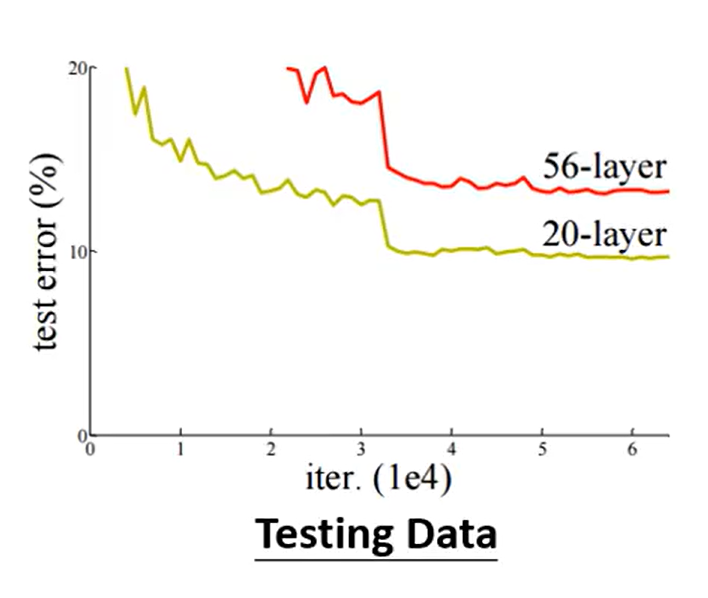
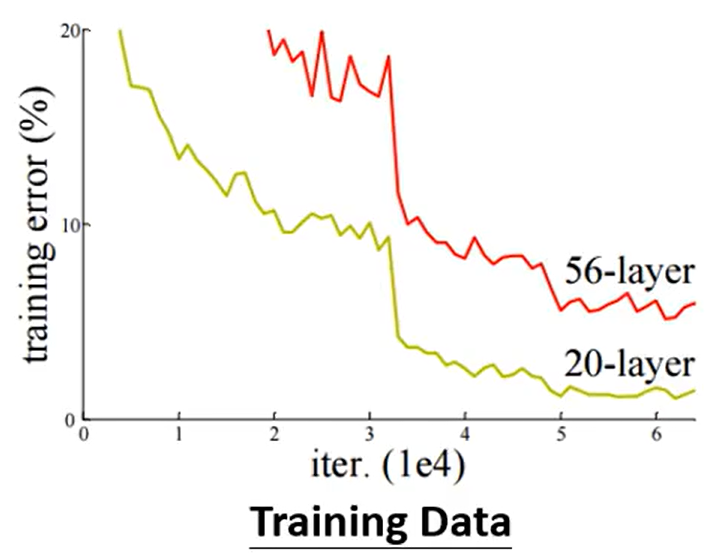
这就给了我们启示:在遇到没有做过的问题时,可以从更浅的深度学习模型或者是线性模型等这些容易做optimization的模型开始做起。然后再进行更深更复杂模型的训练测试,如果更深更复杂的模型没有更简单模型在训练集上的损失小,就可以确定模型遇到了优化问题。
对于如何解决optimization的方法,将在下一节说明**(Next Lecture)**。
如果你对模型得到的测试集结果不满的话。并且检查得到模型在训练数据上的损失够小(small ),那接下来就要看损失(loss)在测试集上的大小(loss on testing data)。如果测试集上的损失也小,这是我们想要的,是一个比较好的模型。如果测试集上的损失不够小,可能的原因有两个:
- 过拟合(Overfitting ):在训练集上的损失小而在测试集上的损失大。一般是训练数据太少或者模型过于复杂(弹性大)导致。
可以通过数据增强(Data augmentation)增强训练数据;
训练数据有限时可以给模型增加限制(constrained model),不让它有太大的弹性,具体做法是通过减少神经元或者共用模型参数来减少模型参数(比如CNN给了模型比较大的限制让它在影像处理中占据优势)。
除此之外,还有Early stopping、Regularization、Dropout等方法,在后续课程会介绍。
尽管可以通过给模型限制来减小过拟合问题,但是也不能给太多的限制,限制太多又容易导致model bias问题

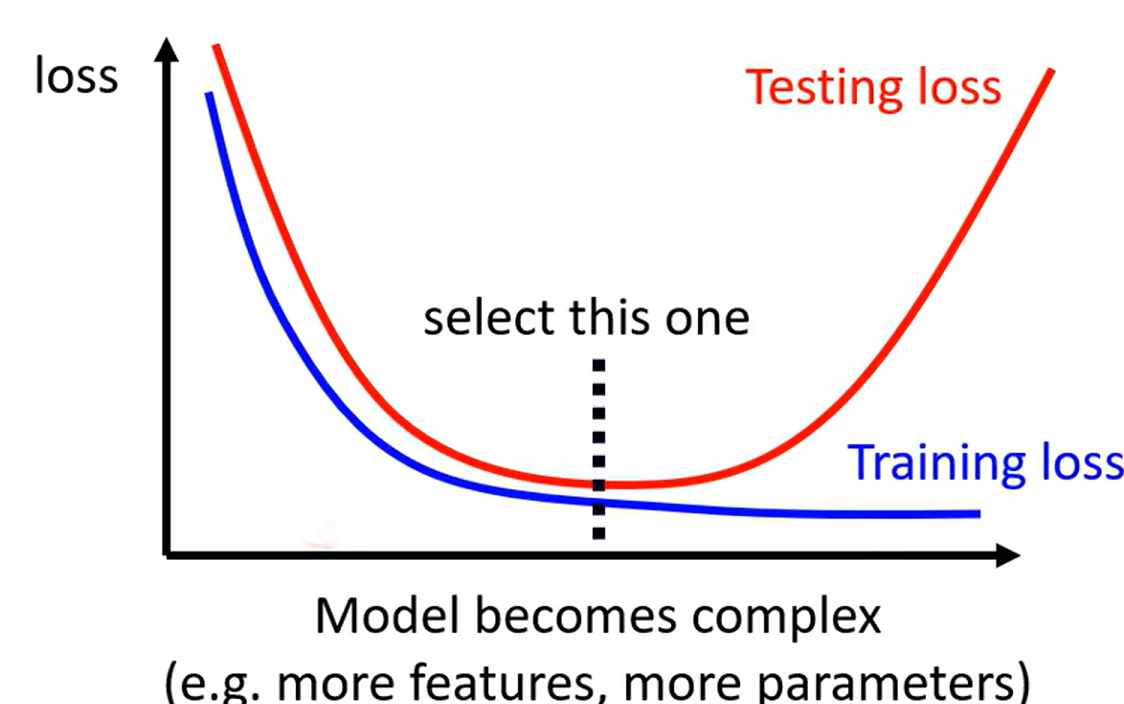
在选择模型复杂度(弹性)时我们可以选择一个不是很复杂也不是很简单的模型(如上图黑色曲线所示位置),这个模型的Testing loss最小。
如何选择这个最低Testing loss的模型呢?
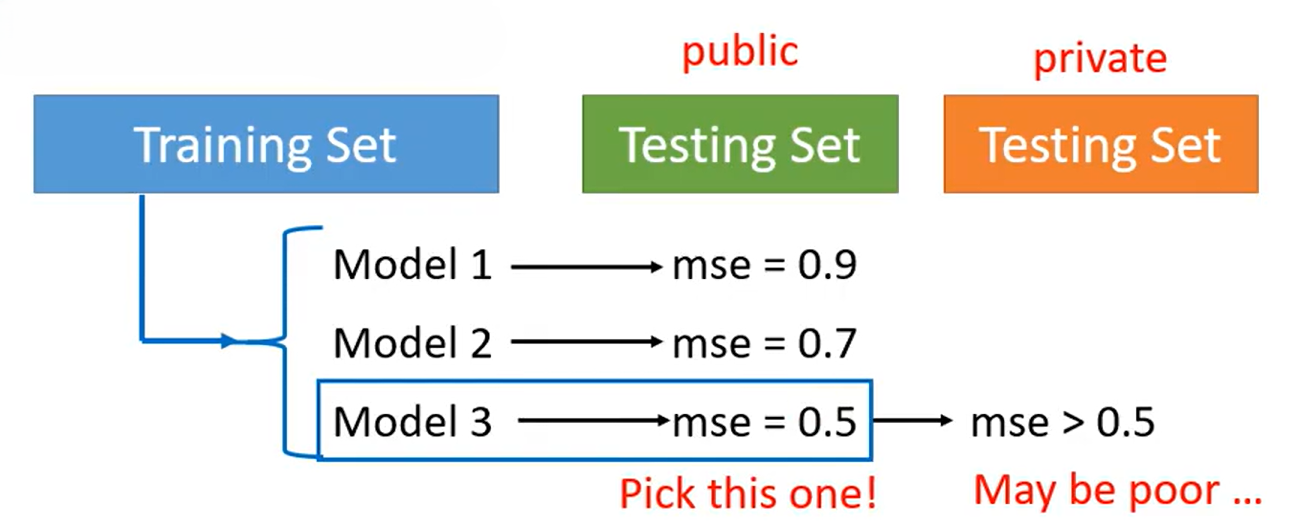
一般直觉的做法是将复杂度不同的训练好的模型直接放到公开测试集(Public Testing Set)上计算损失,损失最低的就是那个最低Testing loss的模型,但是这样做会有问题,举一个极端的例子说明:假如我们有很多模型,这些模型的特点是它们只会记住训练集的数据,不是训练集的数据它们就输出一个随机值,将这些模型放到公开测试集分别计算其损失值,由于都是随机值,所有肯定会有一个损失是最小的,你会认为这个模型是好的但实际上它是随机中的最好,如果把它放到私有测试集(Private Testing Set)它仍然是随机的,得到的结果就很不理想。所以如果你只根据公开测试集去寻找的最优模型,可能在私有数据集上的结果会很差。
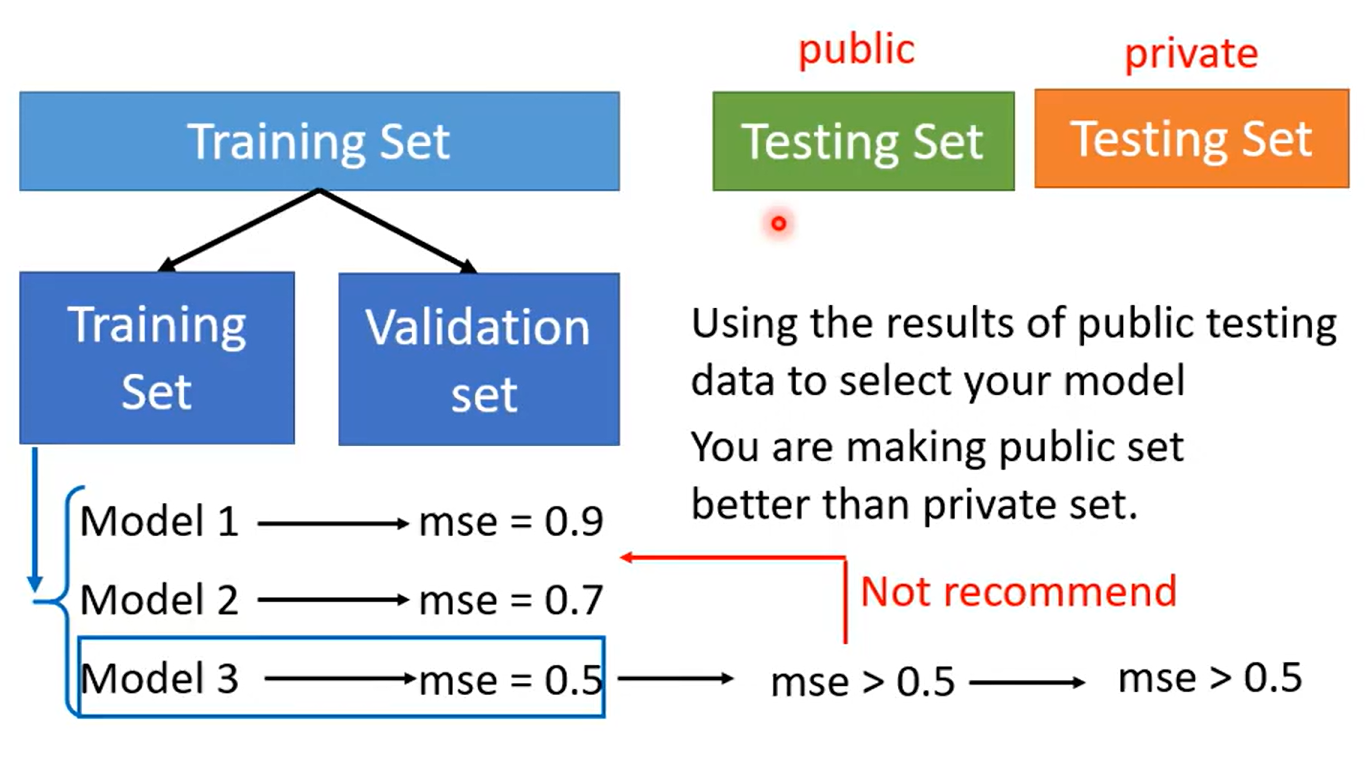
正确的方法应该是交叉验证(Cross Validation),将Training Set分为两部分,一部分用于训练(Training Set),另一部分用于测试(Validation Set) 。先在Training Set上训练出各个模型,然后在Validation Set上找到损失最小的模型,最后将这个你认为最好的模型放到公开测试集上得到损失。(最好不要再通过在公开数据集上得到的损失去调整Model,否则又会出现上面所提到的问题,正确的做法应该是在Training Set和Validation Set上不断调整模型,将公开数据集的结果仅作为参考)。
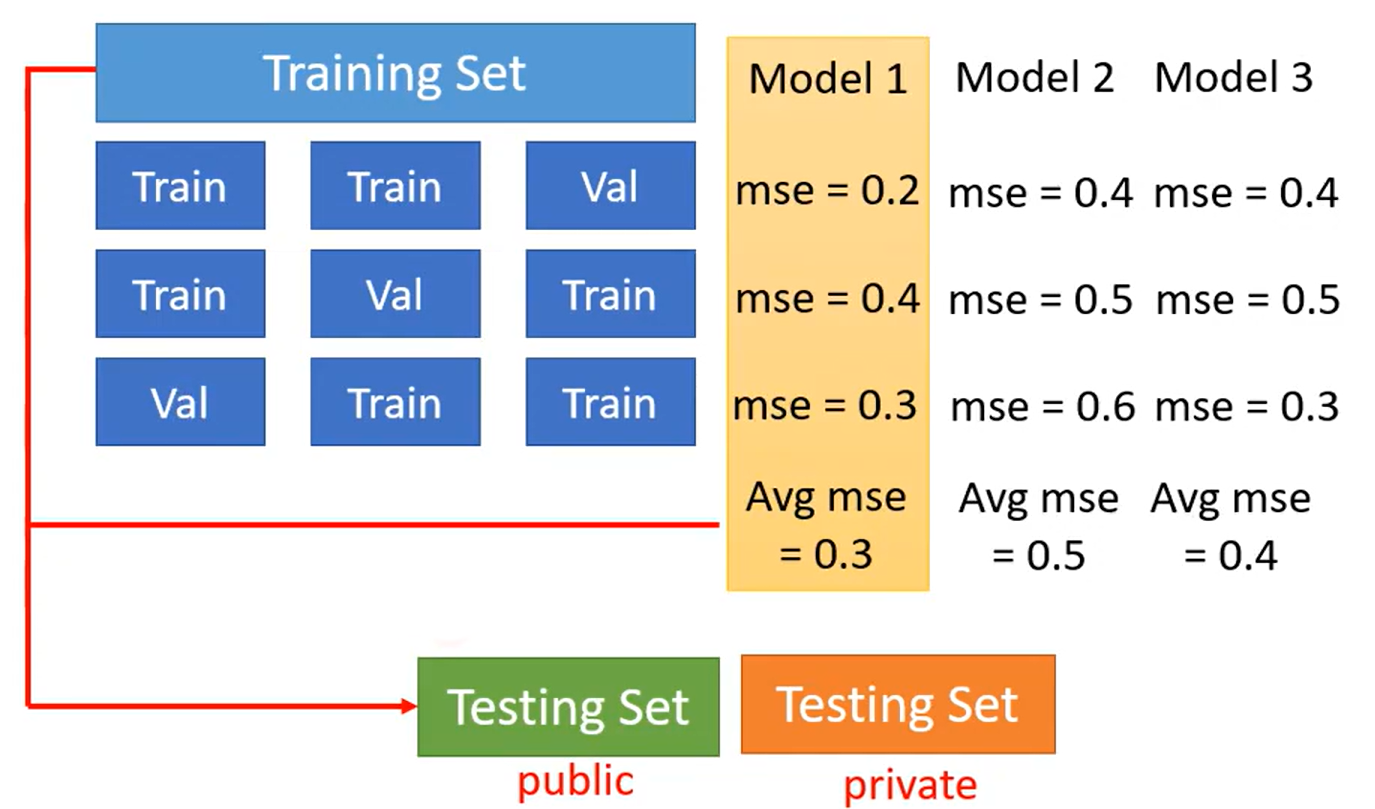
如果你认为你对Training Set和Validation Set的分类不好,可以使用N-fold Cross Validation,具体做法是将Training Set切为N等分(下图为三等分为例),然后将其中的两份作为Training Set,将另一份作为Validation Set(共三种不同的顺序,如下所示)。然后将不同的模型分别在三种不同的顺序下训练分别得到损失值,最后计算平均损失,选择平均损失最小的那个模型用在公开测试集上。
- 分布不匹配 (Mismatch,也成为Distribution Shift(分布漂移)):主要是训练集和数据集两者的数据分布本身不一致的问题。如下图所示就是一个分布不匹配的例子。

再比如训练数据是 2023 年的电商数据,测试数据是 2025 年的,用户消费习惯、商品品类都发生了变化;训练数据是猫的正面照,测试数据是猫的侧面 / 俯视照,特征分布发生了偏移。