目录


🎬 云泽Q :个人主页
🔥 专栏传送入口 : 《C语言》《数据结构》《C++》《Linux》《蓝桥杯系列》
⛺️遇见安然遇见你,不负代码不负卿~
前言
大家好啊,我是云泽Q,欢迎阅读我的文章,一名热爱计算机技术的在校大学生,喜欢在课余时间做一些计算机技术的总结性文章,希望我的文章能为你解答困惑~
一、贪心算法
1.1 哈夫曼编码
1. 树的带权路径长度
从树的根到任意结点的路径长度与该结点上权值的乘积,称为该结点的带权路径长度。树中所有叶结点的带权路径长度之和称为该树的带权路径长度
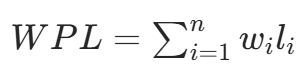
其中,wi 是第 i 个叶结点所带的权值,li 是该叶结点到根结点的路径长度。
2. 哈夫曼树
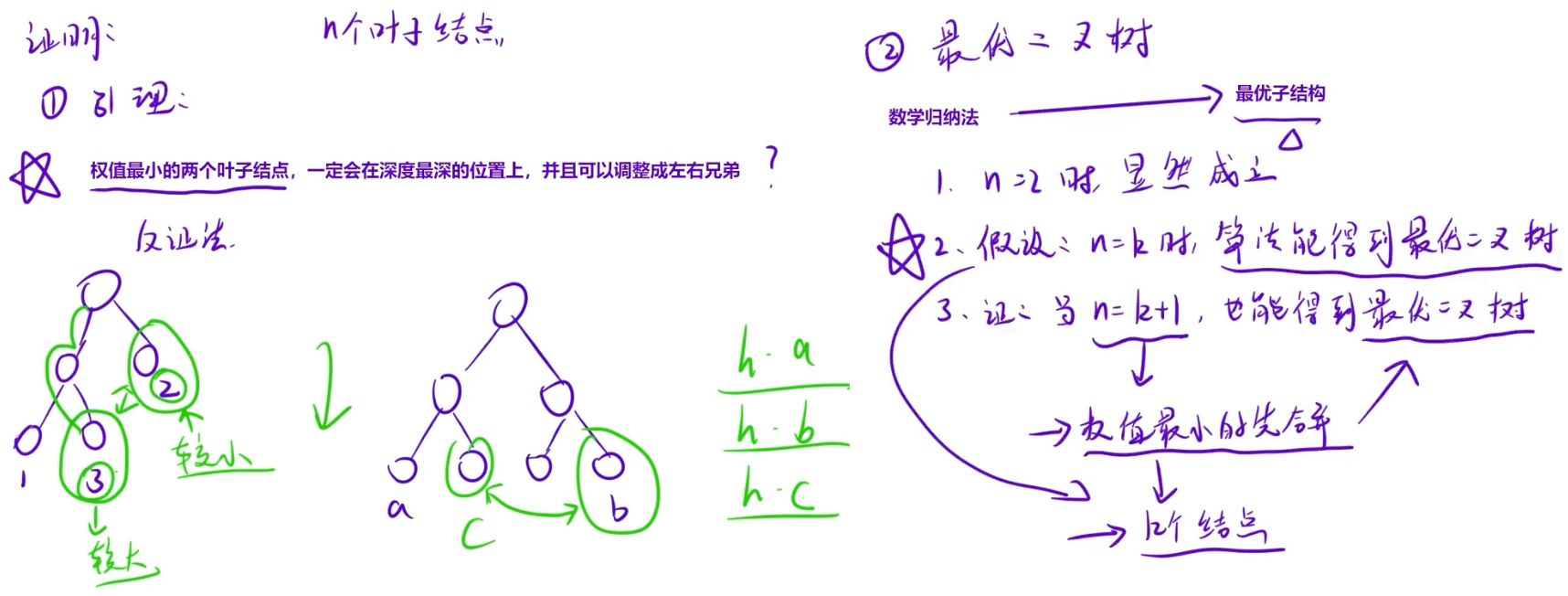
在含有 n 个带权叶结点的二叉树中,其中带权路径长度最小的二叉树称为哈夫曼树,也称最优二叉树。
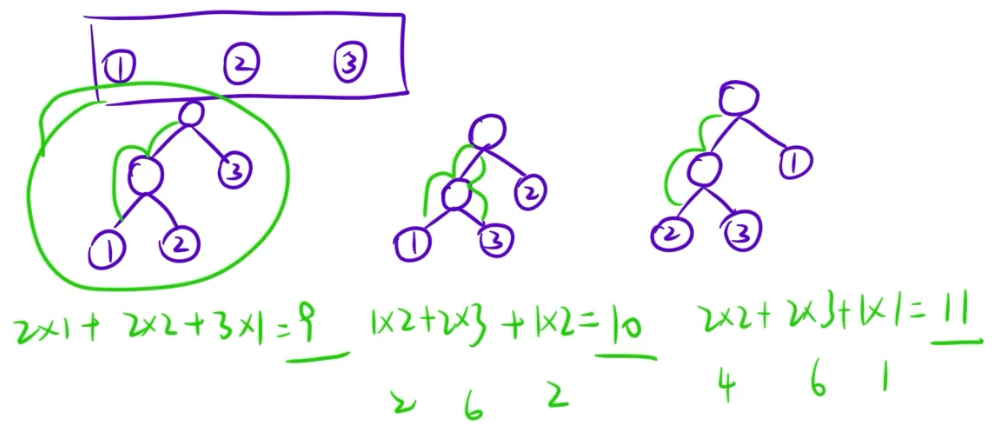
3. 哈夫曼算法
哈夫曼算法是哈夫曼树的构建过程,是根据贪心策略得到的算法。主要流程为:
- 初始化:将所有叶子结点看做一棵棵树,那么刚开始我们有一片森林;
- 贪心:每次选择根结点权值最小的两棵树作为左右子树合并成一棵新的二叉树,这棵新的二叉树根结点的权值为左右子树的权值之和;
- 重复 2 过程,直到森林中所有的树合并成一棵树。
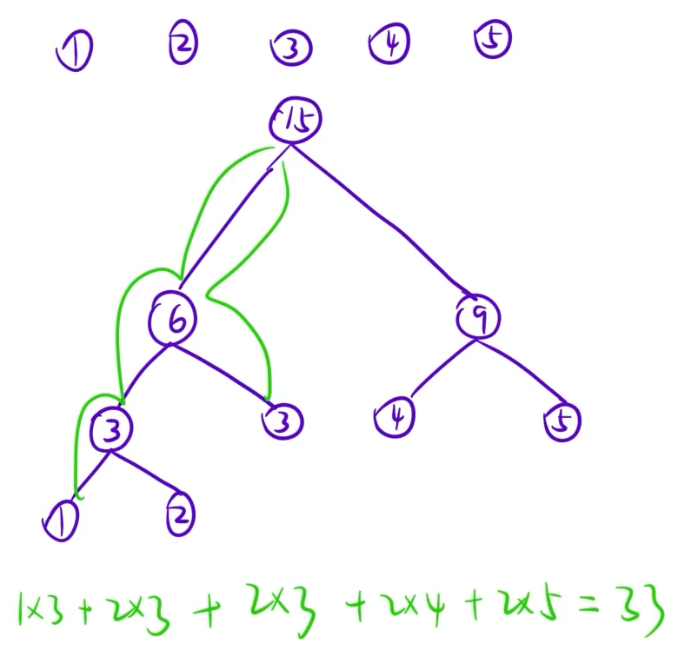
在构建哈夫曼树的合并操作中,就可以计算出带权路径长度:
- 在合并的过程中,每一棵树的根结点的权值其实等于该树所有叶子结点的权值之和;
- 在每次合并的时候,由于多出来两条路径,此时累加上左右子树的根结点权值,相当于计算了一次叶子结点到这两条路径的长度;
- 每次合并都把左右子树的权值累加起来,就是最终的带权路径长度。
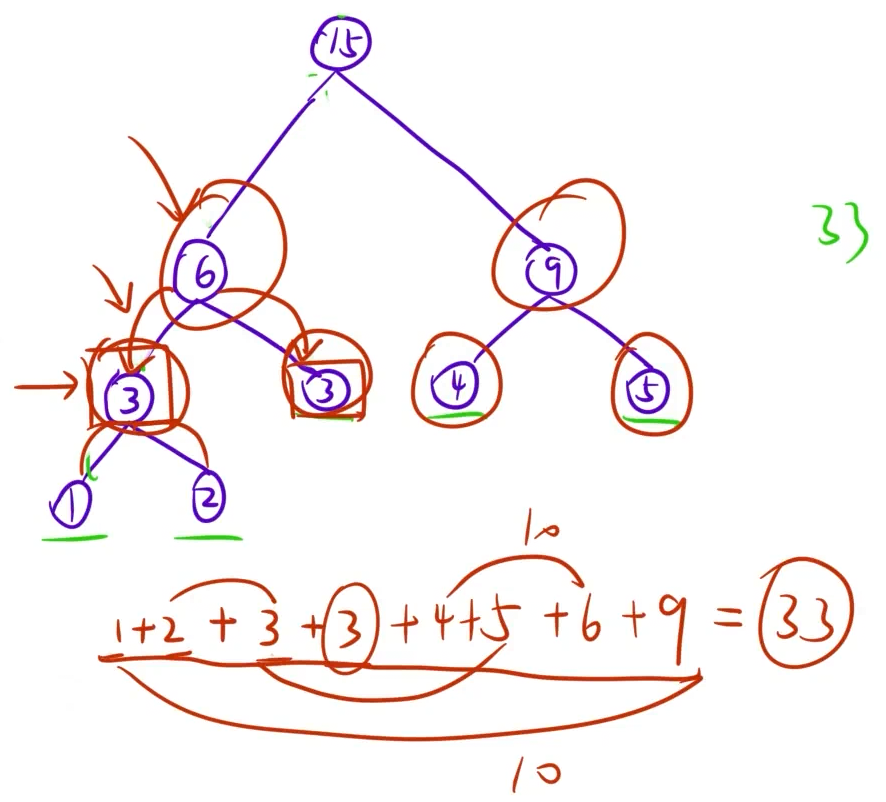
下面是哈夫曼算法能得到最优二叉树的证明,感觉归感觉,学工科还是需要严谨的
4. 哈夫曼编码
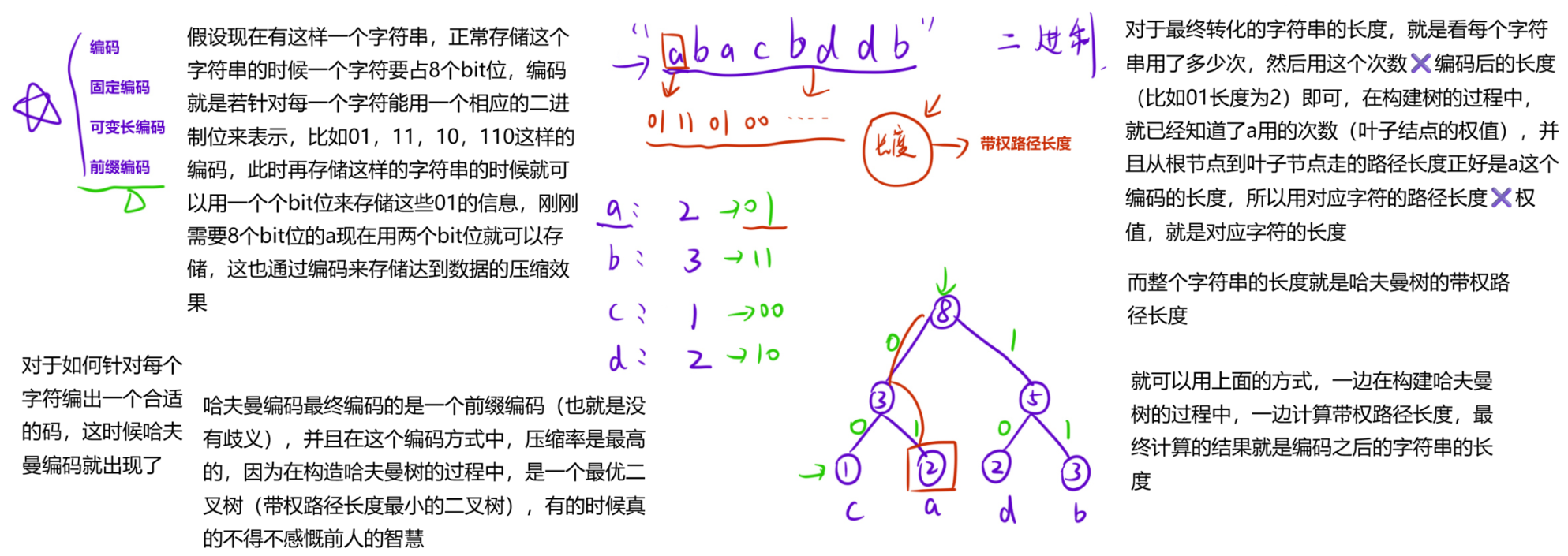
哈夫曼编码是一种被广泛应用而且非常有效的数据压缩编码,其构造步骤如下:
- 统计待编码的序列中,每一个字符出现的次数;
- 将所有的次数当成叶结点,构造哈夫曼树;
- 规定哈夫曼树的左分支为 0,右分支为 1,那么从根结点走到叶子结点的序列,就是该叶子结点对应字符的编码。
1.1.1 哈夫曼编码
cpp
#include<iostream>
#include<vector>
#include<queue>
using namespace std;
typedef long long LL;
priority_queue<LL, vector<LL>, greater<LL>> heap;
LL n;
int main()
{
cin >> n;
for(int i = 1; i <= n; i++)
{
LL x; cin >> x;
//每个字符的出现次数,作为一个独立的叶子节点
heap.push(x);
}
LL ret = 0;
//哈夫曼编码
while(heap.size() > 1)
{
LL x = heap.top(); heap.pop();
LL y = heap.top(); heap.pop();
ret += (x + y);
heap.push(x + y);
}
cout << ret << endl;
return 0;
}补充要点:
priority_queue<LL, vector< LL >, greater< LL >> heap:小根堆(最小优先队列),堆顶永远是当前权值最小的元素,这是哈夫曼贪心算法的核心数据结构,用于高效获取最小的两个节点。
heap.size() > 1的作用:
先搞懂核心逻辑:哈夫曼树的 "合并次数" 和 "节点数" 的关系
哈夫曼树的本质是把多个独立的叶子节点,通过 "两两合并" 最终变成一棵完整的树,核心规则是:
- 初始有 n 个独立的叶子节点(对应堆里的 n 个数);
- 每合并2 个节点 ,会生成1 个新节点 → 每轮合并后,总节点数会 减少 1 个(2 个变 1 个,净减 1);
- 要把 n 个节点合并成1 棵完整的树(只剩 1 个根节点),需要合并 n-1 次。
举个最直观的例子:如果有 3 个节点(1、2、3),需要合并 2 次,最终只剩 1 个根节点;如果有 2 个节点(5、8),需要合并 1 次,最终只剩 1 个根节点;如果只有 1 个节点(比如 n=1),不需要合并,直接结束。
1.1.2 合并果子
这题就没啥好说的了,看完就懂了,都给主播我写爽了,学算法都是这种题就好了
cpp
#include<iostream>
#include<vector>
#include<queue>
using namespace std;
typedef long long LL;
priority_queue<LL, vector<LL>, greater<LL>> heap;
LL n;
int main()
{
cin >> n;
for(int i = 1; i <= n; i++)
{
LL x; cin >> x;
//每个字符的出现次数,作为一个独立的叶子节点
heap.push(x);
}
LL sum = 0;
//哈夫曼编码
while(heap.size() > 1)
{
LL x = heap.top(); heap.pop();
LL y = heap.top(); heap.pop();
sum += (x + y);
heap.push(x + y);
}
cout << sum << endl;
return 0;
}结语
