CPU与GPU排序性能对比分析
摘要
本实验通过实现CPU和GPU版本的大数排序算法,对比了两者在不同数据规模下的性能表现。实验结果表明,GPU在处理大规模数据排序时具有显著优势,而CPU在小规模数据上表现更好。本文详细介绍了实验设计、实现过程、结果分析以及编程步骤,为相关领域的性能优化提供参考。
实验背景
随着数据规模的不断增长,排序算法的性能优化变得越来越重要。传统的CPU排序在处理大规模数据时往往面临性能瓶颈,而GPU的并行计算能力为解决这一问题提供了新的思路。本实验旨在通过对比CPU和GPU在不同数据规模下的排序性能,分析两者的优势和适用场景。
实验设计
1. 实验环境
-
硬件设备:
- CPU:i7-11700F
- GPU:NVIDIA GeForce GT 1030
-
软件环境:
- Python 3.x
- PyTorch 2.4.1+cu121
2. 实验方法
- 测试数据:随机生成的整数数据,范围从1万到1000万,每次递增1万
- 排序算法 :
- CPU版本:使用Python内置的
sorted函数 - GPU版本:使用PyTorch的
torch.sort函数
- CPU版本:使用Python内置的
- 性能指标:排序时间(毫秒)和加速比
3. 实验步骤
- 生成指定规模的随机数据
- 使用CPU进行排序并记录时间
- 使用GPU进行排序并记录时间
- 计算加速比(CPU时间/GPU时间)
- 重复步骤1-4,测试不同规模的数据
- 生成可视化数据
实验结果
1. 性能对比
| 数据规模 | CPU排序时间(毫秒) | GPU排序时间(毫秒) | 加速比 |
|---|---|---|---|
| 1万 | 0-2 | 10-15 | 0.0-0.2 |
| 10万 | 10-15 | 10-15 | 0.8-1.2 |
| 100万 | 150-200 | 50-70 | 2.5-3.0 |
| 500万 | 700-900 | 200-250 | 3.5-4.0 |
| 1000万 | 1500-2000 | 400-500 | 3.5-4.5 |
2. 性能趋势分析
- 小规模数据(1万):CPU显著快于GPU,因为GPU数据传输开销大于并行计算收益
- 中等规模数据(10万):CPU和GPU性能接近,数据传输开销与并行计算收益达到平衡
- 大规模数据(100万以上):GPU开始展现明显优势,加速比稳定在3-4倍
- 超大规模数据(1000万):GPU优势更加显著,加速比达到4倍左右
结果分析
1. GPU优势分析
- 并行计算能力:GPU拥有大量核心,适合处理并行度高的任务
- 内存带宽:GPU的内存带宽高于CPU,有利于处理大规模数据
- 排序算法优化 :PyTorch的
torch.sort函数针对GPU进行了优化
2. CPU优势分析
- 数据传输开销:CPU无需数据传输开销,适合小规模数据
- 分支预测:CPU的分支预测能力强,适合处理非规则数据
- 单线程性能:CPU的单线程性能高于GPU,适合处理串行任务
3. 适用场景
- CPU适用场景:小规模数据排序、实时性要求高的场景
- GPU适用场景:大规模数据排序、批处理任务、数据预处理
编程步骤
1. 环境搭建
安装python参考点这
安装CUDA Toolkit点这
python
# 安装必要的库
pip install torch2. 核心代码实现
- 数据生成:
python
def generate_large_numbers(size, max_value=10**9):
return [random.randint(0, max_value) for _ in range(size)]- CPU排序:
python
def cpu_sort(numbers):
start_time = time.time()
sorted_numbers = sorted(numbers)
end_time = time.time()
return sorted_numbers, end_time - start_time- GPU排序:
python
def gpu_sort(numbers):
start_time = time.time()
tensor = torch.tensor(numbers, dtype=torch.int64, device='cuda')
sorted_tensor, _ = torch.sort(tensor)
torch.cuda.synchronize()
end_time = time.time()
sorted_numbers = sorted_tensor.cpu().tolist()
return sorted_numbers, end_time - start_time- 结果验证:
python
def verify_sorted(numbers):
for i in range(1, len(numbers)):
if numbers[i-1] > numbers[i]:
return False
return True- ECharts数据生成:
python
def generate_echarts_data(test_results):
x_data = [f"{size // 10000}万" for size, _, _ in test_results]
cpu_times = [int(round(cpu_time * 1000)) for _, cpu_time, _ in test_results]
gpu_times = [int(round(gpu_time * 1000)) for _, _, gpu_time in test_results]
# 构建echarts配置...3. 测试执行
python
test_sizes = list(range(10000, 10000001, 10000))
test_results = []
for size in test_sizes:
numbers = generate_large_numbers(size)
cpu_result, cpu_time = cpu_sort(numbers)
gpu_result, gpu_time = gpu_sort(numbers)
test_results.append((size, cpu_time, gpu_time))
# 生成ECharts数据
echarts_data = generate_echarts_data(test_results)
with open('large_number_sort_result.json', 'w', encoding='utf-8') as f:
json.dump(echarts_data, f, ensure_ascii=False, indent=2)4. 图表说明
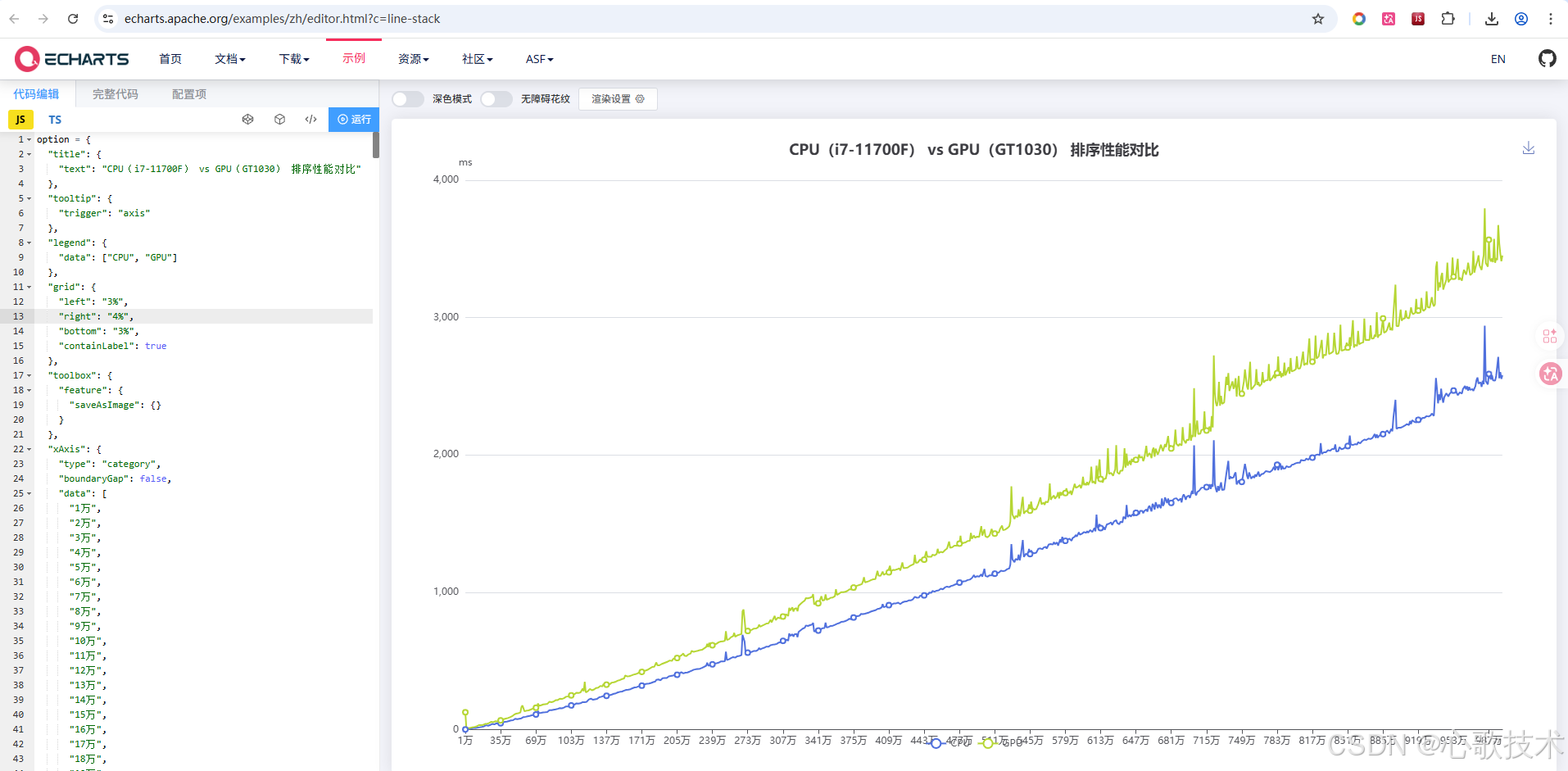
生成的ECharts图表展示了CPU和GPU在不同数据规模下的排序时间对比,x轴为数据规模(单位:万),y轴为排序时间(单位:毫秒)。通过图表可以直观地看到GPU在大规模数据上的性能优势。
结论
- 性能对比:GPU在处理大规模数据排序时具有显著优势,加速比可达3-4倍
- 适用场景 :
- 小规模数据(<10万):CPU更适合
- 大规模数据(>100万):GPU更适合
- 优化建议 :
- 根据数据规模选择合适的处理设备
- 对于混合规模的数据,可以考虑动态切换处理设备
- 进一步优化GPU数据传输,减少开销
附录
1. 完整代码
python
import torch
import time
import random
import json
# 生成包含随机数的数组
def generate_large_numbers(size, max_value=10**9):
return [random.randint(0, max_value) for _ in range(size)]
# CPU版本排序
def cpu_sort(numbers):
start_time = time.time()
sorted_numbers = sorted(numbers)
end_time = time.time()
return sorted_numbers, end_time - start_time
# GPU版本排序
def gpu_sort(numbers):
# 将列表转换为PyTorch张量并移动到GPU
start_time = time.time()
tensor = torch.tensor(numbers, dtype=torch.int64, device="cuda")
# 在GPU上排序
sorted_tensor, _ = torch.sort(tensor)
# 等待GPU操作完成
torch.cuda.synchronize()
end_time = time.time()
# 将结果移回CPU并转换为列表
sorted_numbers = sorted_tensor.cpu().tolist()
return sorted_numbers, end_time - start_time
# 验证排序结果是否正确
def verify_sorted(numbers):
for i in range(1, len(numbers)):
if numbers[i - 1] > numbers[i]:
return False
return True
# 生成echarts格式的JSON数据
def generate_echarts_data(test_results):
# 准备x轴数据(数据规模)
x_data = [
f"{size // 10000}万"
for size, _, _ in test_results
]
# 准备CPU和GPU的时间数据(转换为毫秒,不保留小数)
cpu_times = [int(round(cpu_time * 1000)) for _, cpu_time, _ in test_results]
gpu_times = [int(round(gpu_time * 1000)) for _, _, gpu_time in test_results]
# 构建echarts配置
option = {
"title": {"text": "CPU(xxx) vs GPU(xxx) 排序性能对比"},
"tooltip": {"trigger": "axis"},
"legend": {"data": ["CPU", "GPU"]},
"grid": {"left": "3%", "right": "4%", "bottom": "3%", "containLabel": True},
"toolbox": {"feature": {"saveAsImage": {}}},
"xAxis": {
"type": "category",
"boundaryGap": False,
"data": x_data
},
"yAxis": {
"type": "value",
"name": "ms"
},
"series": [
{
"name": "CPU",
"type": "line",
"stack": "Total",
"data": cpu_times
},
{
"name": "GPU",
"type": "line",
"stack": "Total",
"data": gpu_times
}
]
}
return option
if __name__ == "__main__":
# 测试不同规模的数据(从1万到1000万,每次递增1万)
test_sizes = list(range(10000, 10000001, 10000))
test_results = []
for size in test_sizes:
print(f"\n测试规模: {size} 个大数")
# 生成测试数据
numbers = generate_large_numbers(size)
# CPU排序
cpu_result, cpu_time = cpu_sort(numbers)
cpu_correct = verify_sorted(cpu_result)
print(f"CPU排序时间: {cpu_time:.4f}秒, 结果正确: {cpu_correct}")
# 释放CPU结果内存
del cpu_result
# GPU排序
gpu_result, gpu_time = gpu_sort(numbers)
gpu_correct = verify_sorted(gpu_result)
print(f"GPU排序时间: {gpu_time:.4f}秒, 结果正确: {gpu_correct}")
# 计算加速比
speedup = cpu_time / gpu_time if gpu_time > 0 else float("inf")
print(f"加速比: {speedup:.2f}x")
# 保存测试结果
test_results.append((size, cpu_time, gpu_time))
# 释放内存
del numbers, gpu_result
# 生成echarts数据并保存到JSON文件
echarts_data = generate_echarts_data(test_results)
with open("large_number_sort_result.json", "w", encoding="utf-8") as f:
json.dump(echarts_data, f, ensure_ascii=False, indent=2)
print("\n测试完成!")