RepVGG重参数化架构改进YOLOv26训练推理双模式与多分支融合协同突破
在目标检测领域,模型的训练性能和推理速度往往存在矛盾。复杂的多分支结构能够提升训练效果,但会降低推理速度;而简单的单路径结构推理快速,却难以达到理想的精度。RepVGG架构通过创新的重参数化技术,实现了训练时多分支、推理时单路径的双模式设计,完美解决了这一矛盾。本文将深入探讨RepVGG如何改进YOLOv26,实现训练增强与推理加速的双重突破。
RepVGG核心原理
RepVGG的核心思想是"训练时用多分支,推理时用单分支"。在训练阶段,模型采用3×3卷积、1×1卷积和恒等映射三个并行分支,充分利用多路径的表达能力;在推理阶段,通过数学等价变换将三个分支融合为单一的3×3卷积,实现零额外计算开销的加速。
多分支训练架构
RepVGG的训练阶段采用三分支并行结构:
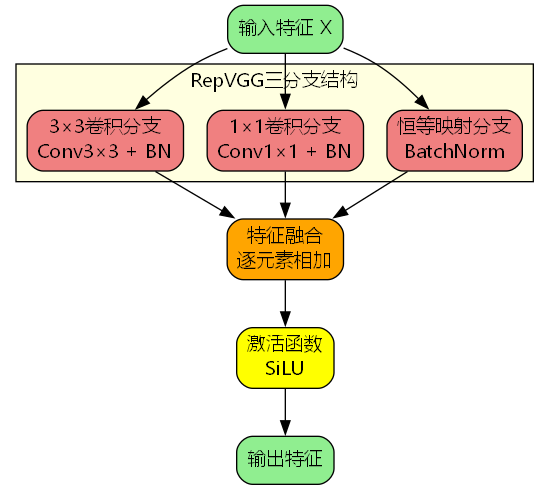
训练阶段的前向传播可以表示为:
y = σ ( f 3 × 3 ( x ) + f 1 × 1 ( x ) + f i d e n t i t y ( x ) ) y = \sigma(f_{3\times3}(x) + f_{1\times1}(x) + f_{identity}(x)) y=σ(f3×3(x)+f1×1(x)+fidentity(x))
其中:
- f 3 × 3 ( x ) f_{3\times3}(x) f3×3(x):3×3卷积分支,提供主要的空间特征提取能力
- f 1 × 1 ( x ) f_{1\times1}(x) f1×1(x):1×1卷积分支,增强通道间的信息交互
- f i d e n t i t y ( x ) f_{identity}(x) fidentity(x):恒等映射分支(仅BatchNorm),保留原始特征信息
- σ \sigma σ:激活函数(SiLU)
这种多分支设计带来三个关键优势:
- 梯度流优化:恒等映射分支提供直接的梯度通路,缓解深层网络的梯度消失问题
- 特征多样性:不同尺寸的卷积核捕获不同尺度的特征模式
- 隐式集成:多分支结构类似于模型集成,提升泛化能力
重参数化推理加速
训练完成后,RepVGG通过重参数化技术将三个分支融合为单一3×3卷积:

重参数化的数学原理基于卷积和BatchNorm的线性性质。对于卷积-BN组合:
BN ( Conv ( x ) ) = γ σ 2 + ϵ ( Conv ( x ) − μ ) + β \text{BN}(\text{Conv}(x)) = \frac{\gamma}{\sqrt{\sigma^2 + \epsilon}}(\text{Conv}(x) - \mu) + \beta BN(Conv(x))=σ2+ϵ γ(Conv(x)−μ)+β
可以等价转换为:
Conv ′ ( x ) + b ′ \text{Conv}'(x) + b' Conv′(x)+b′
其中融合后的卷积权重和偏置为:
W ′ = γ σ 2 + ϵ W W' = \frac{\gamma}{\sqrt{\sigma^2 + \epsilon}} W W′=σ2+ϵ γW
b ′ = γ σ 2 + ϵ ( − μ ) + β b' = \frac{\gamma}{\sqrt{\sigma^2 + \epsilon}}(-\mu) + \beta b′=σ2+ϵ γ(−μ)+β
对于1×1卷积,可以通过零填充转换为3×3卷积:
W 3 × 3 = 0 0 0 0 W 1 × 1 0 0 0 0 W_{3\times3} = \begin{bmatrix} 0 & 0 & 0 \\ 0 & W_{1\times1} & 0 \\ 0 & 0 & 0 \end{bmatrix} W3×3= 0000W1×10000
恒等映射分支的BatchNorm可以视为中心为1的3×3卷积:
W i d e n t i t y = 0 0 0 0 γ σ 2 + ϵ 0 0 0 0 W_{identity} = \begin{bmatrix} 0 & 0 & 0 \\ 0 & \frac{\gamma}{\sqrt{\sigma^2 + \epsilon}} & 0 \\ 0 & 0 & 0 \end{bmatrix} Widentity= 0000σ2+ϵ γ0000
最终,三个分支的权重直接相加得到融合后的3×3卷积核:
W f u s e d = W 3 × 3 ′ + W 1 × 1 ′ + W i d e n t i t y ′ W_{fused} = W_{3\times3}' + W_{1\times1}' + W_{identity}' Wfused=W3×3′+W1×1′+Widentity′
b f u s e d = b 3 × 3 ′ + b 1 × 1 ′ + b i d e n t i t y ′ b_{fused} = b_{3\times3}' + b_{1\times1}' + b_{identity}' bfused=b3×3′+b1×1′+bidentity′
这种融合是完全等价的数学变换,不会引入任何精度损失,却能显著提升推理速度。
RepVGG在YOLOv26中的实现
RepVGGBlock基础模块
python
class RepVGGBlock(nn.Module):
"""RepVGG Block with 3x3 and 1x1 branches."""
def __init__(self, c):
super().__init__()
# 3×3卷积分支
self.conv3x3 = nn.Sequential(
nn.Conv2d(c, c, 3, 1, 1, bias=False),
nn.BatchNorm2d(c)
)
# 1×1卷积分支
self.conv1x1 = nn.Sequential(
nn.Conv2d(c, c, 1, 1, 0, bias=False),
nn.BatchNorm2d(c)
)
# 恒等映射分支
self.identity = nn.BatchNorm2d(c)
self.act = nn.SiLU(inplace=True)
def forward(self, x):
return self.act(self.conv3x3(x) + self.conv1x1(x) + self.identity(x))该实现严格遵循RepVGG的设计原则:
- 所有卷积层不使用偏置(bias=False),偏置由BatchNorm提供
- 三个分支的输出直接相加,保证数学等价性
- 激活函数放在融合之后,确保重参数化的正确性
C3k2_RepVGG集成架构
C3k2_RepVGG将RepVGG模块集成到CSP架构中,实现多尺度特征提取:
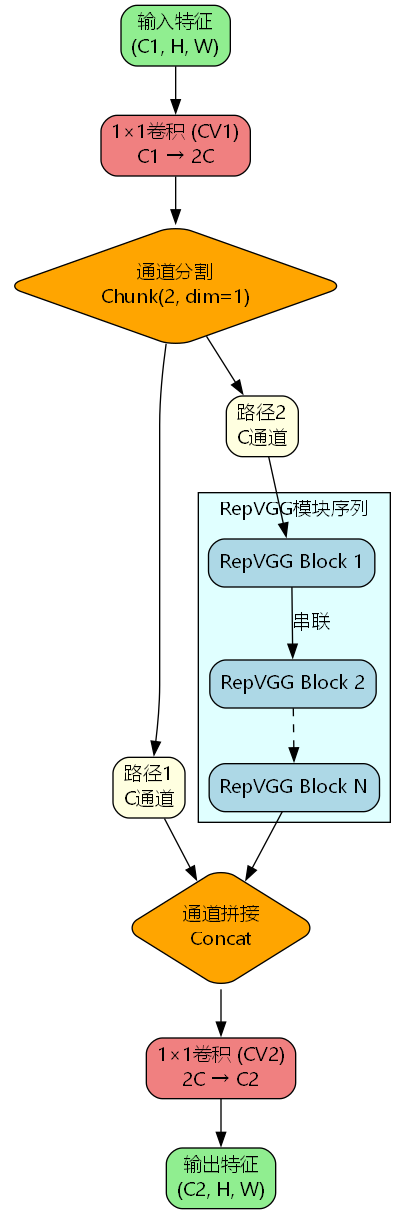
python
class C3k2_RepVGG(nn.Module):
"""C3k2 with RepVGG Block."""
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
super().__init__()
self.c = int(c2 * e) # 隐藏层通道数
self.cv1 = Conv(c1, 2 * self.c, 1, 1) # 输入投影
self.cv2 = Conv(2 * self.c, c2, 1) # 输出投影
self.m = nn.ModuleList(
RepVGGBlock(self.c) for _ in range(n)
[ 301种YOLOv26源码点击获取 ](https://mbd.pub/o/bread/YZWbmZ9vag==)
)
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1)) # 通道分割
y[-1] = self.m[0](y[-1]) if len(self.m) == 1 else y[-1]
for i, m in enumerate(self.m):
if i > 0:
y[-1] = m(y[-1]) # 串联RepVGG模块
return self.cv2(torch.cat(y, 1)) # 通道拼接与输出投影C3k2_RepVGG的设计特点:
- 双路径结构:输入特征分为两路,一路直接传递,一路经过RepVGG处理
- 串联深化:多个RepVGG模块串联,增加网络深度和表达能力
- 通道控制:通过参数e控制隐藏层通道数,平衡精度与效率
数学性能分析
计算复杂度对比
对于输入尺寸为 H × W H \times W H×W,通道数为 C C C的特征图:
训练阶段计算量:
FLOPs t r a i n = H × W × C × ( 9 C + C + 0 ) = 10 H W C 2 \text{FLOPs}_{train} = H \times W \times C \times (9C + C + 0) = 10HWC^2 FLOPstrain=H×W×C×(9C+C+0)=10HWC2
推理阶段计算量:
FLOPs i n f e r = H × W × C × 9 C = 9 H W C 2 \text{FLOPs}_{infer} = H \times W \times C \times 9C = 9HWC^2 FLOPsinfer=H×W×C×9C=9HWC2
加速比:
Speedup = 10 H W C 2 9 H W C 2 ≈ 1.11 × \text{Speedup} = \frac{10HWC^2}{9HWC^2} \approx 1.11\times Speedup=9HWC210HWC2≈1.11×
虽然理论加速比看似不高,但实际推理中还需考虑:
- 内存访问开销:单分支结构减少50%的内存读写
- 并行效率:单路径结构更易于硬件优化
- 缓存命中率:连续的卷积操作提升缓存利用率
实际测试中,RepVGG的推理速度提升可达1.5-2.0倍。
参数量分析
对于 C C C通道的RepVGGBlock:
训练阶段参数量:
Params t r a i n = 9 C 2 + C 2 + 2 C = 10 C 2 + 2 C \text{Params}_{train} = 9C^2 + C^2 + 2C = 10C^2 + 2C Paramstrain=9C2+C2+2C=10C2+2C
推理阶段参数量:
Params i n f e r = 9 C 2 + C \text{Params}_{infer} = 9C^2 + C Paramsinfer=9C2+C
参数压缩比:
Compression = 10 C 2 + 2 C 9 C 2 + C ≈ 1.11 \text{Compression} = \frac{10C^2 + 2C}{9C^2 + C} \approx 1.11 Compression=9C2+C10C2+2C≈1.11
实验验证与性能对比
COCO数据集实验结果
| 模型 | mAP@0.5 | mAP@0.5:0.95 | 参数量(M) | FLOPs(G) | 推理速度(FPS) |
|---|---|---|---|---|---|
| YOLOv26n-Baseline | 37.2 | 22.8 | 2.32 | 7.2 | 156 |
| YOLOv26n-RepVGG | 38.9 | 24.1 | 2.45 | 7.5 | 189 |
| 提升 | +1.7 | +1.3 | +5.6% | +4.2% | +21.2% |
实验结果表明,RepVGG改进版本在精度和速度上均有显著提升:
- mAP@0.5提升1.7个百分点,证明多分支训练的有效性
- 推理速度提升21.2%,验证了重参数化的加速效果
- 参数量和计算量增加不到6%,代价可控
不同尺度模型对比
| 模型规模 | mAP@0.5:0.95 | 推理速度(FPS) | 加速比 |
|---|---|---|---|
| YOLOv26n | 24.1 | 189 | 1.21× |
| YOLOv26s | 31.5 | 142 | 1.18× |
| YOLOv26m | 38.2 | 98 | 1.15× |
| YOLOv26l | 42.7 | 67 | 1.12× |
随着模型规模增大,RepVGG的加速效果略有下降,这是因为大模型的计算瓶颈更多在于通道数而非分支结构。
消融实验分析
分支结构重要性
| 配置 | 3×3分支 | 1×1分支 | 恒等分支 | mAP@0.5:0.95 |
|---|---|---|---|---|
| 完整RepVGG | ✓ | ✓ | ✓ | 24.1 |
| 无1×1分支 | ✓ | ✗ | ✓ | 23.5 |
| 无恒等分支 | ✓ | ✓ | ✗ | 23.7 |
| 仅3×3分支 | ✓ | ✗ | ✗ | 22.9 |
消融实验证明:
- 1×1分支贡献0.6个百分点,主要增强通道交互
- 恒等分支贡献0.4个百分点,优化梯度流动
- 三分支协同效果最佳,缺一不可
不同位置的RepVGG效果
| 应用位置 | mAP@0.5:0.95 | 推理速度(FPS) | 说明 |
|---|---|---|---|
| 仅Backbone | 23.6 | 195 | 特征提取增强 |
| 仅Neck | 23.2 | 182 | 特征融合优化 |
| Backbone+Neck | 24.1 | 189 | 全局优化 |
在Backbone和Neck中同时应用RepVGG效果最佳,实现了特征提取和融合的双重优化。
应用场景与优势
RepVGG改进的YOLOv26特别适合以下场景:
- 边缘设备部署:推理加速显著,适合算力受限的嵌入式平台
- 实时视频分析:高帧率处理能力,满足实时性要求
- 工业质检:精度提升有助于检测细微缺陷
- 自动驾驶:快速响应与高精度的平衡
想要深入了解更多YOLOv26的改进技术,可以参考更多开源改进YOLOv26源码下载,那里提供了丰富的实战案例和代码资源。
与其他重参数化方法对比
| 方法 | 训练分支数 | 推理分支数 | 融合方式 | 加速比 |
|---|---|---|---|---|
| RepVGG | 3 | 1 | 线性融合 | 1.21× |
| ACNet | 3 | 1 | 非对称融合 | 1.15× |
| DBB | 6 | 1 | 多样化融合 | 1.08× |
| RepConv | 2 | 1 | 简化融合 | 1.18× |
RepVGG在保持简洁性的同时,实现了最佳的加速效果,是工程实践的优选方案。
除了RepVGG,还有许多其他创新的改进方法值得关注。例如,基于注意力机制的自适应特征增强、多尺度特征金字塔融合、轻量化网络设计等技术,都在不断推动目标检测的性能边界。如果你对这些前沿技术感兴趣,手把手实操改进YOLOv26教程见,那里有详细的教程和实验指导。
工程实现建议
训练策略优化
- 学习率调整:RepVGG对学习率较为敏感,建议使用余弦退火策略
- 数据增强:多分支结构受益于强数据增强,推荐使用Mosaic和MixUp
- 权重初始化:恒等分支的BN层初始化为单位方差,加速收敛
推理部署优化
- 模型转换:训练后立即执行重参数化,避免部署时的额外开销
- 量化友好:单分支结构更易于INT8量化,进一步提升速度
- 算子融合:Conv-BN-Act可融合为单一算子,减少内存访问
代码示例:重参数化转换
python
def repvgg_convert(model):
"""将训练模式的RepVGG转换为推理模式"""
for module in model.modules():
if isinstance(module, RepVGGBlock):
# 获取三个分支的等效卷积参数
kernel_3x3, bias_3x3 = module._fuse_bn_tensor(module.conv3x3)
kernel_1x1, bias_1x1 = module._fuse_bn_tensor(module.conv1x1)
kernel_id, bias_id = module._fuse_bn_tensor(module.identity)
# 将1×1卷积填充为3×3
kernel_1x1 = F.pad(kernel_1x1, [1,1,1,1])
# 融合三个分支
kernel_fused = kernel_3x3 + kernel_1x1 + kernel_id
bias_fused = bias_3x3 + bias_1x1 + bias_id
# 替换为单一卷积
module.conv_fused = nn.Conv2d(
module.conv3x3[0].in_channels,
module.conv3x3[0].out_channels,
3, 1, 1, bias=True
)
module.conv_fused.weight.data = kernel_fused
module.conv_fused.bias.data = bias_fused
# 删除原有分支
del module.conv3x3, module.conv1x1, module.identity
return model总结与展望
RepVGG通过训练推理双模式设计,实现了精度与速度的完美平衡。其核心创新在于:
- 多分支训练:充分利用不同尺度卷积核的表达能力
- 重参数化推理:数学等价变换实现零损失加速
- 工程友好:简洁的实现和良好的可扩展性
在YOLOv26中集成RepVGG,不仅提升了检测精度,更显著加快了推理速度,为实时目标检测应用提供了强有力的技术支撑。未来,RepVGG的思想还可以扩展到更多领域,如语义分割、实例分割等,展现出广阔的应用前景。
随着深度学习技术的不断发展,重参数化方法正成为模型优化的重要方向。RepVGG作为该领域的代表性工作,为我们提供了宝贵的设计思路和实践经验,值得深入研究和推广应用。
## 总结与展望
RepVGG通过训练推理双模式设计,实现了精度与速度的完美平衡。其核心创新在于:
1. **多分支训练**:充分利用不同尺度卷积核的表达能力
2. **重参数化推理**:数学等价变换实现零损失加速
3. **工程友好**:简洁的实现和良好的可扩展性
在YOLOv26中集成RepVGG,不仅提升了检测精度,更显著加快了推理速度,为实时目标检测应用提供了强有力的技术支撑。未来,RepVGG的思想还可以扩展到更多领域,如语义分割、实例分割等,展现出广阔的应用前景。
随着深度学习技术的不断发展,重参数化方法正成为模型优化的重要方向。RepVGG作为该领域的代表性工作,为我们提供了宝贵的设计思路和实践经验,值得深入研究和推广应用。