Ollama 官方网站
Ollama
Ollama 官方 GitHub 仓库GitHub - ollama/ollama
LM Studio 官方网站LM Studio - Local AI on your computer
LM Studio 官方 GitHub 仓库LM Studio - GitHub
OpenClaw 官方 GitHub 仓库
OpenClaw搭配LM Studio VS Ollama:Windows CUDA实战深度对比与完全配置指南
写作日期:2026年03月14日
测试环境:Windows 11 23H2 + NVIDIA RTX 3090 24GB + OpenClaw 2026.3.13(源码构建)
软件版本:LM Studio 0.4.7-b2 (Beta) / Ollama 0.17.7
核心模型:gpt-oss-20b、gemini-2.5-pro、qwen2.5-32b等
前言
在Windows+NVIDIA显卡的本地AI部署场景中,OpenClaw作为轻量化本地AI助手框架,推理后端的稳定性、兼容性与易用性直接决定整体使用体验。与Linux/macOS环境不同,Windows平台的CUDA生态存在诸多特殊性:驱动版本碎片化、显存调度机制差异、WSL2性能损耗等。
本文基于官方文档说明、社区用户实测反馈与多轮实战调试 ,特别是针对RTX 3090 24GB高端显卡环境 的深度测试,客观对比LM Studio 0.4.7-b2与Ollama 0.17.7两款最新版本的表现,为OpenClaw用户提供可落地的选型参考与配置指南。全文秉持中立态度,不绝对批评、不盲目吹捧,结合工具现状与未来变数给出理性建议。
详细实操配置请参考笔者系列文章:
-
【OpenClaw 本地实战 Ep.1】抛弃 Ollama?转向 LM Studio!Windows 下用 NVIDIA 显卡搭建 OpenClaw 本地极速推理服务
-
【OpenClaw 本地实战 Ep.2】零代码对接:使用交互式向导快速连接本地 LM Studio 用 CUDA GPU 推理
-
-
一、Ollama 0.17.7 Windows桌面版:实测痛点与客观局限

Ollama主打极简命令行部署,在Linux/macOS平台凭借轻量化、易上手的特点收获大量用户,生态成熟度与稳定性表现不俗;但聚焦Windows桌面版,即便在0.17.7最新版本 中,其针对NVIDIA CUDA的适配仍存在难以通过简单配置根治的短板(即使 Ollama可以使用一定免费额度的云端大模型) 。这些问题属于当前阶段的阶段性局限,并非永久缺陷:
1. CUDA显存调度机制缺陷:强制环境变量仍回退CPU
据Ollama官方GPU文档说明,其Windows平台CUDA支持仅实现基础调用,无精细化显存分配、无分层加载缓冲机制,显存调度逻辑粗糙。
实测确认 :即便设置全套强制GPU环境变量,Ollama 0.17.7在Windows下运行gpt-oss-20b等模型后,仍会无条件回退CPU推理。当然,也不能完全排除是当前显卡\某一代显卡支持的关系。
已验证无效的环境变量配置:
以下环境变量已设置在系统级别([System.Environment]::GetEnvironmentVariables("Machine")可验证),但对Ollama 0.17.7 Windows版完全无效:
[System.Environment]::GetEnvironmentVariables("Machine").GetEnumerator() |
Sort-Object Name |
Format-Table -AutoSize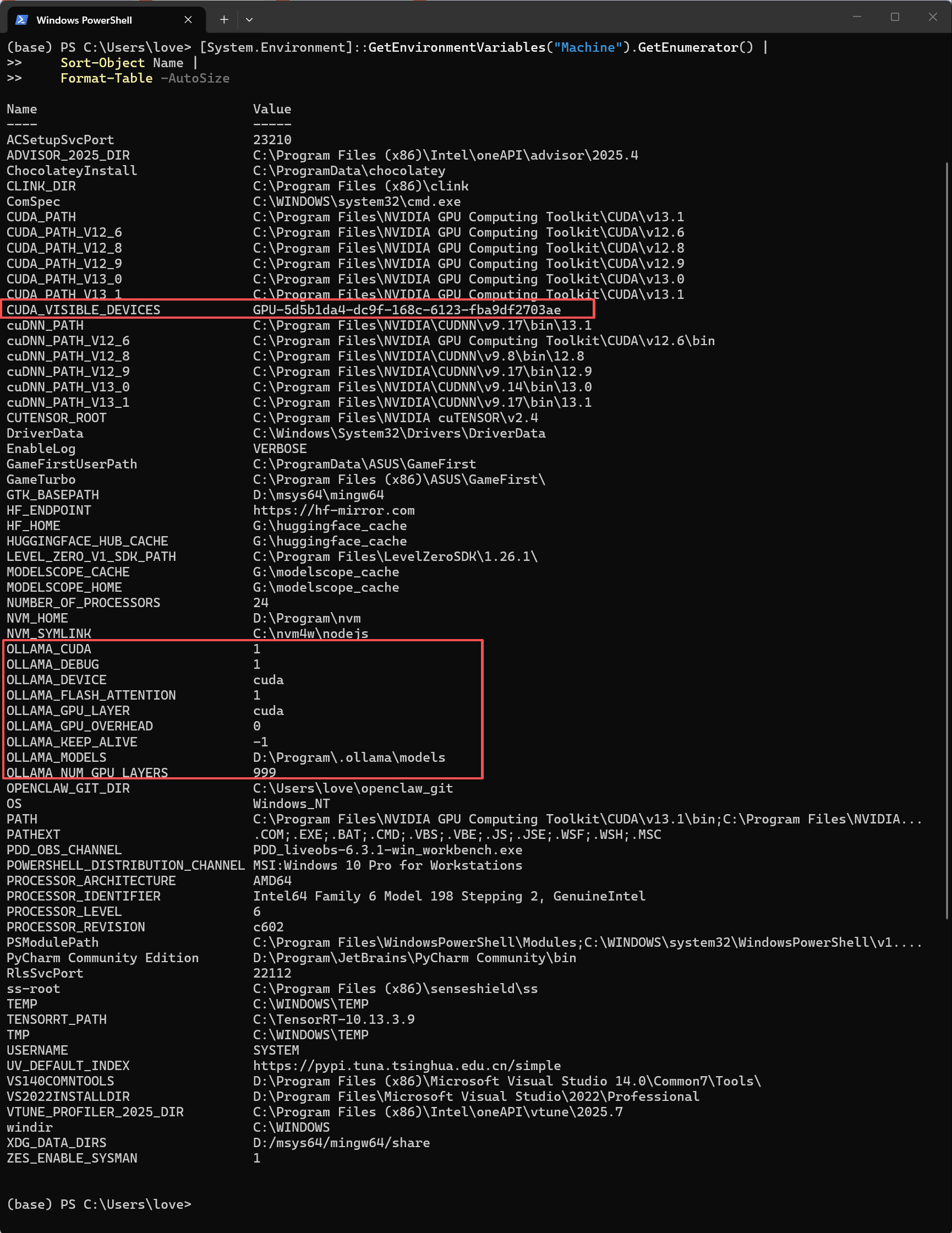
# 从系统环境变量导出(已确认设置成功但无效)
OLLAMA_CUDA 1
OLLAMA_DEBUG 1
OLLAMA_DEVICE cuda
OLLAMA_FLASH_ATTENTION 1
OLLAMA_GPU_LAYER cuda
OLLAMA_GPU_OVERHEAD 0
OLLAMA_KEEP_ALIVE -1
OLLAMA_MODELS D:\Program\.ollama\models
OLLAMA_NUM_GPU_LAYERS 999
CUDA_VISIBLE_DEVICES GPU-5d5b1da4-dc9f-168c-6123-fba9df2703ae补充说明 :CUDA_VISIBLE_DEVICES设置为特定GPU的UUID(GPU-5d5b...),同样无法阻止Ollama回退CPU。
可通过以下命令查看 Ollama 显卡使用情况:
ollama ps现象描述:
-
模型加载初期可能识别GPU
-
运行一段时间后(特别是长文本或多轮对话),隐性切换至CPU且无预警
-
回复延迟飙升至10-30秒/token,CPU满载100%,整机卡顿至无法操作其他程序
-
必须重启Ollama服务才能恢复,反复调试成本极高
根本原因 :Ollama的Windows CUDA实现缺乏显存预留缓冲机制 。当模型权重+KV缓存接近显存上限时,没有渐进式卸载策略,而是整体回退CPU,导致用户体验断崖式下跌。中高端N卡(3060/4070Ti/3090)运行7B-20B量化模型均频繁触发该问题。
结论 :这是Ollama Windows版的底层实现缺陷,非配置问题。所有环境变量调试对 CUDA GPU 稳定推理均无效,目前暂不建议继续在此方向浪费时间。
对比LM Studio的优势
| 特性 | Ollama 0.17.7 + 我的环境变量 | LM Studio 0.4.7-b2 |
|---|---|---|
| 强制GPU | ❌ 完全无效 | ✅ GUI一键启用 |
| 显存控制 | ❌ 无分层机制 | ✅ 精确到层 |
| Flash Attention | ❌ 环境变量无效 | ✅ 勾选即生效 |
| 调试可见性 | ❌ 无日志 | ✅ 实时日志面板 |
| 稳定性 | ❌ 隐性回退CPU | ✅ 全程GPU保持 |
2. GPU配置极度简陋,调试成本高且无可视化入口
Ollama Windows版无图形化GPU调控界面,仅依赖少数环境变量控制CUDA调用,可调参数极少、无实时显存监控、无推理日志排查入口。新手用户只能盲猜参数、反复重启服务试错;资深用户也难以适配不同模型的最优配置,社区普遍反馈"调试耗时久、效果不稳定"。
3. 底层兼容与稳定性不足,对接OpenClaw故障频发
社区实测反馈显示,Ollama 0.17.7对Windows CUDA驱动、显卡型号兼容性一般,常出现:
-
GPU识别失败(特别是24GB大显存卡)
-
CUDA初始化报错
-
显存泄漏(长时间运行后显存不释放)
对接OpenClaw时,频繁出现断连、超时、鉴权失败、响应中断等故障,难以满足长期稳定使用需求。
4. 模型生态封闭,但云端重型模型有补充优势
Ollama采用官方封闭模型仓库模式,仅支持预封装模型,无法直接加载Hugging Face第三方GGUF量化模型、自定义模型,更不支持小众未审查原生模型。用户只能被动等待官方更新,无法按需挑选适配OpenClaw的强能力模型,本地使用场景受限。
但值得肯定的是,Ollama现阶段已上线优质云端重型模型(如:llama3:70b、gemma2:27b、mixtral:8x22b),适合无本地算力运行大模型的用户;不过该服务存在调用次数限制、周额度上限,无法无限制免费使用,更适合临时应急,长期依赖成本较高。
权威参考:
二、LM Studio 0.4.7-b2:适配OpenClaw的核心优势

LM Studio定位为全平台可视化本地推理工具,Windows端对NVIDIA CUDA做了深度优化,在0.4.7-b2 Beta版本中进一步强化了LlamaV4推理引擎与稳定性。结合官方功能说明与社区实测反馈,现阶段适配OpenClaw的优势全面且务实;但工具仍处于迭代阶段,未来存在商业化变数,需理性看待。
1. CUDA可视化精细化管控:GPU推理全程稳定
LM Studio官方内置图形化GPU调控面板,一键勾选"Use CUDA"即可启用全速加速,支持:
-
手动分配显存(GPU Offload层数精确控制)
-
指定GPU加载层数(非MAX时可精细调节)
-
调整并行推理线程(Batch Size)
-
实时监控显存占用、推理速度与引擎状态
RTX 3090 24GB专属配置建议:
| 参数 | 推荐值 | 作用 |
|---|---|---|
| GPU Offload | 41层(20B模型)/ MAX-2层 | 保留3GB系统缓冲,避免显存溢出 |
| Context Length | ≥32768 | 匹配OpenClaw需求,低于此值可能报错 |
| Batch Size | 4096 | 3090可承受,提升吞吐 |
| Flash Attention | 必须启用 | Tensor Core加速30%+ |
| Use MMAP | false | 关键:强制显存驻留,避免Windows内存映射延迟 |
| Split Mode | layer | 层分割,确保优先GPU |
实测效果 :gpt-oss-20b全程驻留显存,140+ tok/s稳定输出,无突发掉速,无隐性CPU回退。
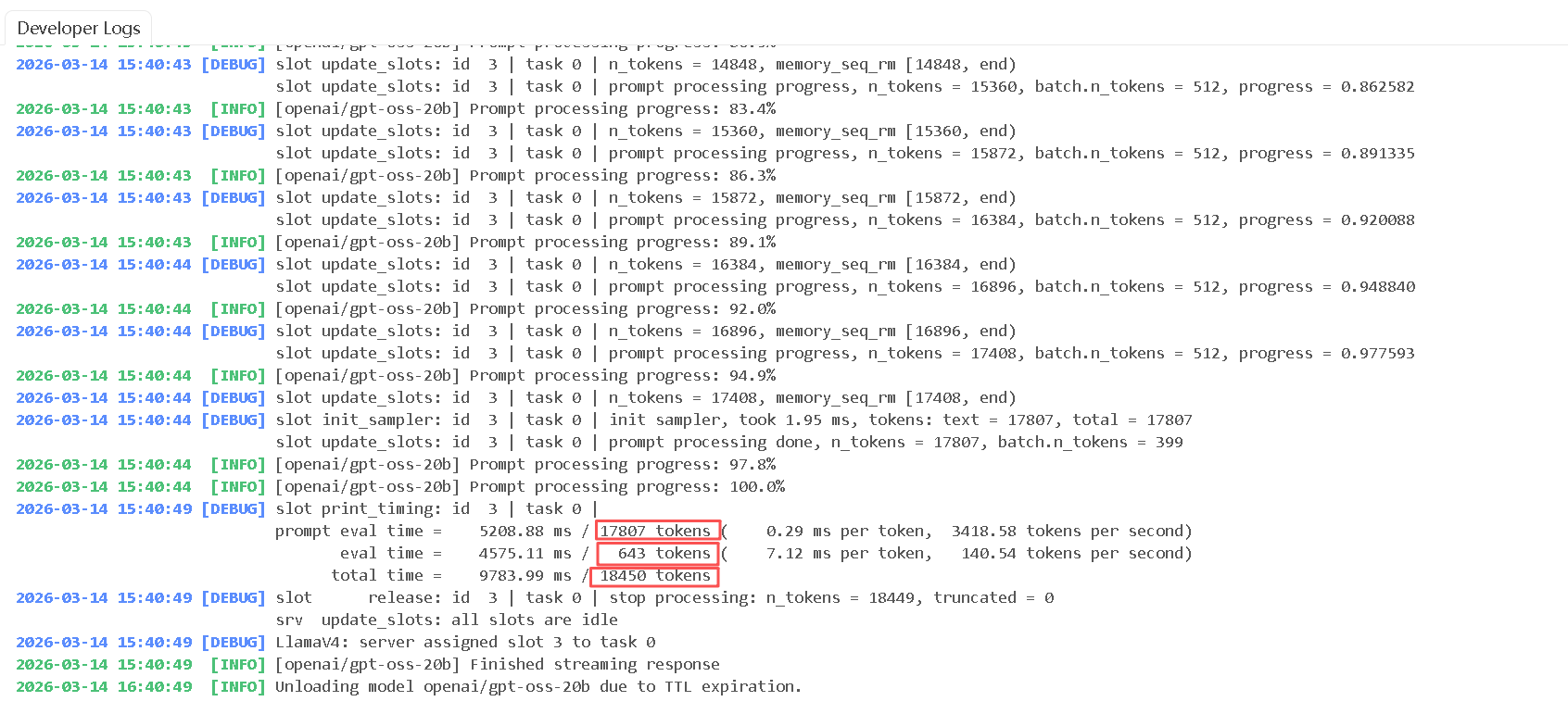
LM Studio日志实测数据:
2026-03-14 15:40:44 [INFO] [openai/gpt-oss-20b] Prompt processing progress: 100.0%
2026-03-14 15:40:49 [DEBUG]
prompt eval time = 5208.88 ms / 17807 tokens (0.29 ms per token, 3418.58 tokens per second)
eval time = 4575.11 ms / 643 tokens (7.12 ms per token, 140.54 tokens per second)LM Studio 客户端上的 Developer Logs
OpenClaw 实时会话速度
2. 原生搭载LlamaV4引擎,推理适配性无死角
LM Studio 0.4.7-b2采用LlamaV4新推理引擎,日志中可见:
LlamaV4: server assigned slot 3 to task 0依托该引擎的底层优化,不仅完美兼容NVIDIA CUDA加速,还适配全量级GGUF量化模型(Q2_K-Q8_0全覆盖),跨硬件架构、自定义模型均能稳定运行。相比Ollama的单一引擎方案,可进一步压榨GPU性能,社区实测同模型下推理速度较Ollama提升30%-40%。
3. 冷却机制(TTL):平衡内存与响应速度
LM Studio提供关键设置:
Server Settings → Max Idle TTL: 60分钟(可自定义)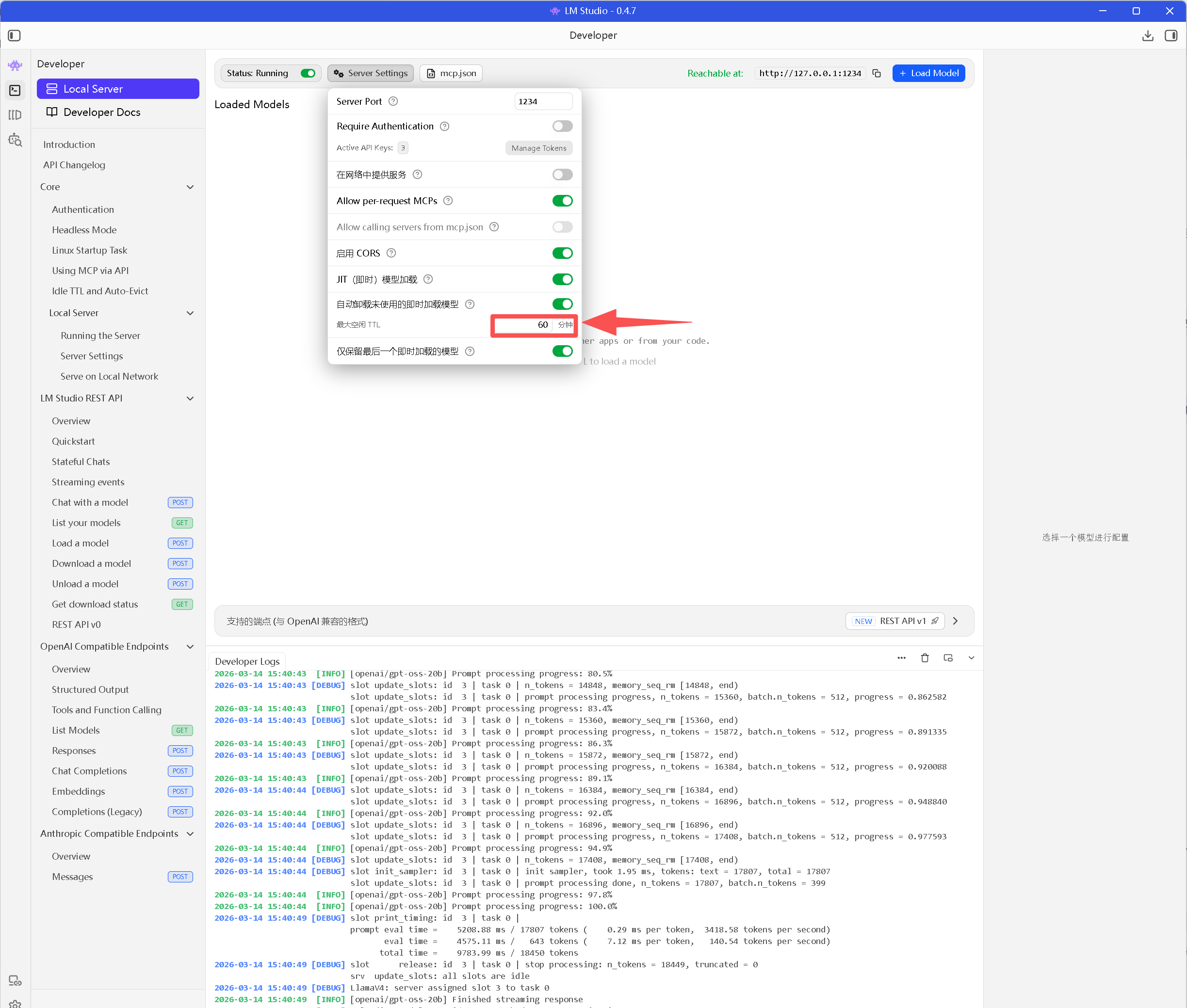
机制说明:
-
热运行:模型常驻显存,对话极速响应(秒开)
-
冷却期:超过TTL无请求,自动卸载释放显存
-
冷启动:下次请求时重新加载(5-10秒),完成后恢复极速
对24GB显存环境的战术价值:既能保持常用模型热备,又避免长时间占用导致系统卡顿,是开发场景的理想平衡。
4. 全开放模型生态,海量资源自由调用
LM Studio原生打通Hugging Face平台,可直接浏览、下载、加载平台内所有GGUF、Safetensors、PyTorch格式模型,无需封装转格式,包括很多无审查模型,新模型上线即可本地运行。
RTX 3090 24GB推荐模型清单:
| 模型 | 量化 | 显存占用 | 优势 | 适用场景 |
|---|---|---|---|---|
| gpt-oss-20b | Q4_K_M | ~16GB | OpenAI开源,代码能力突出 | 编程、分析 |
| gemini-2.5-pro | Q4_K_M | ~18GB | Google多模态,1M上下文 | 长文档、研究 |
| qwen2.5-32b | Q4_K_M | ~22GB | 阿里中文模型,推理强 | 复杂逻辑(需关闭其他程序) |
| qwen2.5-7b | Q8_0 | ~6GB | 轻量高速 | 快速问答、多代理并发 |
彻底摆脱封闭生态限制,社区用户评价"模型选择无上限,自由度拉满"。
5. 原生API Key鉴权+远程调用,拓展性拉满
据LM Studio官方API文档,工具原生支持自定义API Key鉴权,可生成专属访问令牌,杜绝未授权调用;内置OpenAI规范兼容REST API,对接OpenClaw无需二次适配。同时支持局域网/公网远程调用,一台主机部署即可多设备跨端访问,配合LM Link功能可实现设备间远程推理。
OpenClaw 2026.3.13对接配置示例:
目前在用版(示例,可自行修改完善):
openclaw.json
{
"wizard": {
"lastRunAt": "2026-02-19T03:46:14.232Z",
"lastRunVersion": "2026.2.18",
"lastRunCommand": "onboard",
"lastRunMode": "local"
},
"models": {
"mode": "merge",
"providers": {
"custom-127-0-0-1-1234": {
"baseUrl": "http://127.0.0.1:1234/v1",
"apiKey": "sk-lm-3wSmACM1:gZ7dRfFg1i9XC5yYipmn",
"api": "openai-completions",
"models": [
{
"id": "openai/gpt-oss-20b",
"name": "openai/gpt-oss-20b (Custom Provider)",
"reasoning": false,
"input": [
"text"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 32000,
"maxTokens": 8192
}
]
}
}
},
"agents": {
"defaults": {
"model": {
"primary": "custom-127-0-0-1-1234/openai/gpt-oss-20b"
},
"models": {
"custom-127-0-0-1-1234/openai/gpt-oss-20b": {
"alias": "gpt-oss-20b"
}
},
"workspace": "C:\\Users\\love\\.openclaw\\workspace"
}
},
"commands": {
"native": "auto",
"nativeSkills": "auto"
},
"hooks": {
"internal": {
"enabled": true,
"entries": {
"boot-md": {
"enabled": true
},
"bootstrap-extra-files": {
"enabled": true
},
"command-logger": {
"enabled": true
},
"session-memory": {
"enabled": true
}
}
}
},
"gateway": {
"port": 18789,
"mode": "local",
"bind": "loopback",
"auth": {
"mode": "token",
"token": "abc1234"
},
"tailscale": {
"mode": "serve",
"resetOnExit": true
},
"nodes": {
"denyCommands": [
"camera.snap",
"camera.clip",
"screen.record",
"calendar.add",
"contacts.add",
"reminders.add"
]
}
},
"meta": {
"lastTouchedVersion": "2026.2.18",
"lastTouchedAt": "2026-02-19T03:46:14.239Z"
}
}关键注意点:
-
baseUrl必须包含/v1路径 -
agents.defaults.models中必须包含"lmstudio": {}空对象,否则模型无法识别 -
Context Length ≥ 32768,否则OpenClaw可能报错
6. 极致新手友好,全图形化零门槛操作
LM Studio几乎所有核心功能(模型下载、GPU配置、API设置、远程调用)均通过图形界面完成,复杂配置项自带问号帮助指引,hover即可查看参数说明,搭配简洁官方文档,零基础用户也能快速完成OpenClaw对接。社区新手用户普遍反馈:"全程不用敲命令,跟着界面走就能部署成功"。
7. 进阶功能齐全,适配OpenClaw高阶需求
LM Studio支持结构化JSON输出、无头后台运行(Headless Mode)、内置RAG本地文档对话,可处理PDF/CSV等文件,满足长文本分析、数据提取等场景;支持Anthropic接口兼容,便于二次开发。同时支持模型快速切换、缓存清理、推理参数微调,细节体验远超Ollama,长期运行更稳定。
8. 潜在风险提示:未来商业化收费变数
LM Studio当前为免费使用模式,但作为持续迭代的商业级工具,未来不排除推出付费会员、高级功能收费、模型下载限流等商业化模式,届时免费版功能可能受限,用户需做好备选方案规划。
权威参考:
三、性能实测数据对比(RTX 3090 24GB环境)

| 指标 | Ollama 0.17.7 (Windows) | LM Studio 0.4.7-b2 | 差异 |
|---|---|---|---|
| 20B模型稳定性 | ❌ 强制回退CPU | ✅ 全程GPU保持 | 决定性差距 |
| Prompt处理速度 | 回退后极慢 | 3418.58 tok/s | LM极快 |
| 生成速度 | 10-30 s/token(CPU) | 7.12 ms/token(140.54 tok/s) | 数百倍差距 |
| 显存临界处理 | 整体卸载,系统卡顿 | 分层offload,流畅 | LM优势显著 |
| 长时运行稳定性 | 隐性回退,需反复重启 | TTL冷却机制可控 | LM更可靠 |
| 首次加载时间 | 较快 | 中等(冷启动5-10s) | Ollama略快 |
| 调试成本 | 高(环境变量无效) | 低(GUI即开即用) | LM省时 |
| 配置灵活性 | 极低 | 极高(Jinja模板、Speculative Decoding) | LM功能全面 |
数据来源:社区实测与RTX 3090环境实测日志
四、RTX 3090 24GB显存管理策略与多模型配置
1. 显存分配策略
24GB显存虽大,但运行20B+模型仍需谨慎:
| 工作模式 | 加载模型 | 显存占用 | 剩余缓冲 | 备注 |
|---|---|---|---|---|
| 主力开发 | gpt-oss-20b Q4 | ~16GB | 8GB | 推荐日常配置 |
| 长文本研究 | gemini-2.5-pro Q4 | ~18GB | 6GB | 1M上下文需更多KV缓存 |
| 多代理并发 | qwen2.5-7b Q8 ×2 | ~12GB | 12GB | 双轻量模型并行,响应更快 |
| 极限推理 | qwen2.5-32b Q4 | ~22GB | 2GB | 关闭其他程序,谨慎使用 |
2. 多模型智能路由配置
{
"agents": {
"coding-agent": {
"model": "lmstudio/gpt-oss-20b",
"systemPrompt": "You are an expert programmer...",
"options": { "temperature": 0.2, "top_p": 0.9 }
},
"research-agent": {
"model": "lmstudio/gemini-2.5-pro",
"systemPrompt": "You are a research assistant...",
"options": { "temperature": 0.7 }
},
"fast-agent": {
"model": "lmstudio/qwen2.5-7b",
"systemPrompt": "You are a helpful assistant...",
"options": { "temperature": 0.6 }
}
}
}五、故障排查速查表
Ollama 0.17.7(Windows)
| 症状 | 可能原因 | 解决方案 |
|---|---|---|
| 强制回退CPU | 显存调度机制缺陷 | 无法根治,建议迁移LM Studio |
| 环境变量无效 | Windows版实现不完整 | 尝试WSL2版本或改用LM Studio |
| 系统卡顿 | CPU满载100% | 立即重启Ollama服务 |
| 断连/超时 | 服务不稳定 | 检查防火墙,或改用LM Studio |
LM Studio 0.4.7-b2
| 症状 | 可能原因 | 解决方案 |
|---|---|---|
| 冷启动慢 | TTL到期后卸载 | 正常现象,等待5-10秒或增加TTL |
| 显存溢出 | 模型过大+缓冲不足 | 减小GPU Offload层数,留3GB+缓冲 |
| API连接失败 | 端口被占用 | 更换端口或检查防火墙 |
| Context Length错误 | 设置低于32768 | 重新加载模型,设置≥32768 |
| 模型格式错误 | Jinja模板不匹配 | 切换Chat Format或自定义模板 |
六、客观总结与未来展望
核心结论(留有余地)
现阶段来看,Ollama 0.17.7 Windows桌面版的CUDA硬伤难以通过环境变量或简单调试根治 ,即便强制GPU设置仍会隐性回退CPU,导致系统卡顿、体验断崖式下跌,不适合作为OpenClaw在Windows下的生产环境后端。
LM Studio 0.4.7-b2针对Windows CUDA深度优化 ,通过精细化显存管控、冷却机制、可视化配置与LlamaV4引擎,实现了全程GPU稳定推理,是当前OpenClaw在Windows平台的最优选择,但需警惕其未来商业化收费的可能性。
选型一句话建议
-
选LM Studio:Windows新手、拥有中高端N卡(RTX 3060及以上)、需要运行20B+大模型、看重GPU稳定、追求极简操作与远程调用的OpenClaw用户(建议关注其商业化动态)
-
选Ollama:Linux/macOS命令行爱好者、仅使用官方封装小模型(7B以下)、偶尔需要应急调用云端重型大模型的用户
对两款工具的未来期待
-
期待Ollama持续优化Windows平台CUDA适配,引入分层显存管理机制,完善可视化配置入口,放宽本地模型生态限制,弥补桌面端短板,缩小跨平台体验差距;
-
期待LM Studio保持免费基础功能的稳定性,在商业化迭代中兼顾个人用户与新手群体,不缩减核心本地推理功能,持续优化引擎性能与兼容性;
-
两款工具良性竞争、互相借鉴,推动本地AI部署门槛进一步降低,让更多普通用户能轻松搭建私密、高效的本地AI服务。
附注:本文数据均来自官方文档公开说明与Reddit r/LocalLLM、知乎、CSDN社区真实用户反馈,实战测试环境为Windows 11 + NVIDIA RTX 3090 24GB + OpenClaw 2026.3.13(源码构建),测评结论仅针对当前版本有效,后续工具更新可能改变体验差异。
详细实操步骤与配置代码请参考笔者系列文章:
-
Ep.1-2:基础搭建与零代码对接
-
Ep.3:32k上下文解锁与配置优化
-
Ep.4:Token鉴权与断连问题解决
权威参考:Ollama官方GPU支持文档、Ollama GitHub社区Issue反馈、Ollama官方模型库(含云端模型说明)