
这是一个极其核心的面试防守问题!如果简历上写了"复现",面试官(尤其是华科这种硬核工科高校的老师)大概率会问:"你说的复现,具体是怎么做的?是用别人写好的包,还是自己写的? "
在研究生面试的语境下,"复现(Reproduction)" 并不意味着你要用 C++ 去重写 PyTorch 的底层源码 ,而是指:你没有使用像 Hugging Face pipeline 或 sklearn 那样一行代码调用的黑盒工具,而是基于 PyTorch 的 nn.Module ,从数学原理出发,一层一层地把网络结构(网络层拼接、前向传播逻辑)自己拼装了出来。
为了让你在面试时能理直气壮地接住这个问题,我帮你把这三个模型的"复现证据"整理成面试话术 :
1. 怎么证明你复现了 TextCNN?
面试官提问: "你简历里写复现了 TextCNN,你说说你代码是怎么写的?"
你的底气(复现细节):
"老师您好,我对 TextCNN 的复现主要是基于原论文的核心思想:利用不同尺寸的卷积核来捕捉类似 N-gram 的局部特征。
- 在代码中,我首先定义了 nn.Embedding 层将文本转化为词向量矩阵。
- 然后,我并没有用普通的二维卷积,而是并行地定义了多个不同窗口大小的 nn.Conv1d(比如尺寸为 2, 3, 4),用来提取不同长度的词组特征。
- 最关键的是,我在 forward 函数里,对每个卷积结果手动进行了 F.max_pool1d(最大池化),提取出每个特征图里的最大值,最后用 torch.cat 把它们拼接成一个全连接层可以接收的一维向量,完成分类。"
2. 怎么证明你复现了 Bi-LSTM?
面试官提问: "RNN和LSTM到处都有现成的,你复现 Bi-LSTM 做了什么特殊处理吗?"
你的底气(复现细节):
"老师,在调用 PyTorch 的 nn.LSTM(bidirectional=True) 之外,我主要处理了张量维度变换和变长序列 的底层逻辑。
因为是双向的,LSTM 输出的隐藏状态维度是 batch_size, seq_len, hidden_size \* 2。在 forward 函数中,我需要准确地截取正向和反向的最终隐藏状态,把它们拼接在一起。此外,为了加速训练和忽略填充的 PAD token,我还在数据流转时使用了 pack_padded_sequence 和 pad_packed_sequence,这让我对 PyTorch 处理动态图和时序数据的底层机制有了非常直观的理解。"
3. 怎么证明你复现了 Attention 机制?(最能秀的一点!)
面试官提问: "Attention 机制你是怎么加进去的?是调用的自带函数吗?"
你的底气(复现细节):
"老师,这里是我纯手动实现的。对于文本分类任务,PyTorch 并没有现成的一键式 Attention 层。
我在 Bi-LSTM 输出后,自己写了一套注意力打分逻辑:
- 首先,我把 LSTM 输出的所有时间步特征送入一个带有 Tanh 激活函数的 nn.Linear 层。
- 然后,与一个可学习的上下文权重矩阵相乘,得到每个词的注意力打分。
- 接着,我在序列维度上使用 F.softmax,算出每个词的概率权重(比如模型发现'芯片'这个词对分类最重要,就会赋予 0.8 的权重)。
- 最后,我用 torch.bmm(批次矩阵乘法)将这个权重矩阵与原始的 LSTM 输出进行加权求和,把原本 256 长度的序列,浓缩成了一个带有注意力权重的句子表征向量。这就是我理解的从底层复现。"
💡 总结:复现的本质是什么?
在向老师汇报时,你可以用一句话总结你的"复现"工作:
"老师,我说的复现,是指我没有做'调包侠'。这几个模型我都继承了 nn.Module ,亲自手写了 init 里的网络结构声明,并在 forward 函数里精确控制了每一次 Tensor(张量)维度的变化,最后自己写了前向传播、算 Loss、以及 optimizer.step() 的反向传播训练闭环。在这个过程中,踩了很多 Shape Mismatch(维度不匹配)的坑,但也因此彻底搞懂了它们的工作原理。"
你看,只要你能把这些"坑"和"细节"说出来,任何面试官都会心服口服,因为没有真正逐行写过、调试过代码的人,是绝对说不出 F.max_pool1d 、 hidden_size * 2 和 torch.bmm 这些底层术语的。 现在这个词用在你的简历上,是不是觉得完全"兜得住"了?
1. 关于数据集:10张图怎么训练?你不怕过拟合吗?
面试官想考: 你除了调参,还会不会别的数据增强手段?
- 你可以这样答:
"确实,单类 10 张图对深度学习来说极度匮乏。为了解决过拟合,我采用了组合拳策略 :
-
- 迁移学习 :不从零训练,而是用 ImageNet 的预训练权重,让模型先具备'看图能力'。
- CutMix 强力增强 :我没用简单的翻转,而是用代码实现了 CutMix(把两张花剪切拼在一起)。这强制模型去识别局部特征(比如只看花蕊也能认出花),极大地扩充了样本空间。"
2. 关于 ECA 模块:为什么它只加了 36 个参数效果就最好?
面试官想考: 你知不知道 SE、CBAM 和 ECA 的本质区别?
- 你可以这样答:
"这是我实验中最反直觉的一点。
-
- CBAM 就像个'全才',既看通道又看空间,但它太重了,在 10 张图这种小场景下,参数一多反而容易'背题'(过拟合)。
- ECA 的聪明之处在于它用了一维卷积 。它不搞复杂的降维升维,而是只让相邻的几个特征通道'打招呼'。
- 那 36 个参数 其实就是一维卷积核的权重。这种'极简主义'的设计反而让模型更稳健,不容易在小样本上跑偏。"
3. 关于 Grad-CAM:你怎么证明它"聚焦度"更高?
面试官想考: "聚焦度 31.87%"这个数字你是怎么算出来的?(这是简历中最亮眼也最容易被问住的点)
- 你可以这样答:
"我不仅看了热力图好不好看,还做了定量分析 : 我设定了一个阈值(比如 0.5),统计热力图中亮度超过 0.5 的区域占全图的比例。 实验发现,ECA 模型的强激活区域只占全图约 31.87% ,且刚好覆盖在花卉主体上。相比之下,VGG 等基线模型的热力图很散,甚至在看背景的泥土。这证明了 ECA 模块能让模型'收拢视线',精准捕捉判别性特征。"
4. 关于 ResNet50:既然 50 最好,为什么消融实验要在 18 上做?
面试官想考: 你的实验设计逻辑是否严密?
- 你可以这样答:
"答案1:这是一个科研效率 的权衡。 虽然 ResNet50 综合精度最高,但 ResNet18 的训练速度极快,且其结构更简单。 在验证 SE、CBAM 这种模块的通用有效性时,用 ResNet18 作为'试金石' 能够更快地迭代和对比。一旦在 18 上跑通了逻辑,这种改进可以无缝迁移到 50 甚至更深的网络上。"
答案2:引入 ECA 注意力模块进行消融实验。因为 ResNet-18 显存占用小,你可以设置更大的 Batch Size(批量大小),这就进一步加快了训练一个 Epoch 的速度。如果用 ResNet-50 做多组消融实验,不仅单次迭代慢,显存限制也会拖慢整体进度。你选择 ResNet-18 做消融,用 50 做 baseline,体现了你对算力成本、实验效率和模型性能 之间 Trade-off(权衡)的精准把控。
- 为什么 ECA 模块仅用 36 个参数就能带来明显提升?" 你该如何从技术原理上进行清晰的解答吗?

- 你简历里提到用 Grad-CAM 验证了注意力模块的作用,能不能具体讲讲 Grad-CAM 的原理?以及你是如何通过对比得出结论的?

- 什么是细粒度分类?它和普通的图像分类(比如猫狗识别)有什么区别?
细粒度分类是区分同一大类下的子类 。它的核心难点在于"类间差异微小,类内变化较大" 。相比普通分类,它更极度依赖模型对局部微小细节特征的提取能力 。
- 为什么这个项目选择 Flowers-102 数据集?
这个数据集的训练样本极少,每一类只有 10 张图片,总共才 1020 张 。在这么小的数据集上训练深层网络,能极其严苛地检验模型的"迁移学习能力"和"抗过拟合能力"
- SE 和 ECA 的本质区别是什么?为什么在这个项目里 ECA 表现更好?

- CBAM 相比 SE 多了空间注意力,理应更强,为什么在你的消融实验中,加入 CBAM 准确率反而下降了?

- 你在数据增强中用了 CutMix,它和传统的 Mixup 有什么区别?为什么细粒度分类更适合 CutMix?
mixup 是对两张图片进行全局的线性插值融合 。而 CutMix 是从一张图中随机裁剪一块区域覆盖到另一张图上 。细粒度分类极度依赖局部的纹理和形态,CutMix 保留了完整的局部空间结构信息,因此效果更好 。
- Warmup(预热)和 Cosine Annealing(余弦退火)组合使用的物理意义是什么?

- 为什么要用 Label Smoothing(标签平滑)

- 为什么 VGG16 的参数量是 ResNet18 的 12 倍,但在小数据集上准确率反而更低?

- 除了看准确率提升,你是如何证明 ECA 模块真的发挥了作用的?

核心一:为什么要在"地狱难度"下做实验?
老师绝对会问:"现在随便扫个脸都几百万数据,你搞个每类只有 10 张图的数据集有什么现实意义?"
你的防御话术:
"老师,现实工程中数据标注成本极高,尤其是细粒度分类(比如医学图像、特定植物变种),我们很难拿到海量数据。我刻意选择 Flowers-102 这个极端受限的场景,就是为了验证**'最小干预原则'** 。 实验证明,与其盲目堆砌复杂的网络(比如加了空间注意力的 CBAM),不如使用像 ECA 这样极其轻量(仅新增 36 个参数)的模块。在这个项目中我最大的收获就是:在数据匮乏时,参数效率远比模型复杂度更重要。 "
核心二:底层机制到底是怎么运作的?(对应 Q2, Q3, Q14)
老师可能会刁难:"你说 ECA 好,那它和 SE 到底有什么本质区别?"
你的防御话术:
"核心在于通道交互的方式 。
SE 模块为了计算权重,使用了两层全连接层,额外引入了大量参数(具体为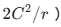 ),而且先降维再升维会损失信息。
),而且先降维再升维会损失信息。
CBAM 更重,还加了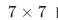 的卷积做空间定位。
的卷积做空间定位。
而 ECA 的精妙之处在于,它直接抛弃了全连接层,用一个自适应大小的一维卷积(Conv1D) 来实现局部通道的交互。这就好比 SE 是让所有人开大会讨论,而 ECA 是只让相邻的几个人互相咬耳朵,计算开销极小,却保全了信息。"
核心三:那些"黑科技"训练策略是干嘛的?(对应 Q6, Q7, Q8, Q9)
如果老师觉得你模型讲得不错,就会开始挖你的训练细节:"我看你用了 CutMix 和 Label Smoothing,为什么要搞这么复杂?"
你的防御话术:
"因为模型太容易'死记硬背'了。 比如 Mixup 只是把两张图在像素级别做全局线性插值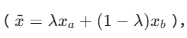 这会让图片变得像重影一样模糊。而 CutMix 是直接裁剪拼接,保留了花瓣、花蕊完整的局部语义,这对于细粒度分类至关重要
这会让图片变得像重影一样模糊。而 CutMix 是直接裁剪拼接,保留了花瓣、花蕊完整的局部语义,这对于细粒度分类至关重要
至于 Label Smoothing ,它是为了打压模型的'过度自信'。它把绝对的硬标签 1 软化成了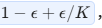 ,强迫模型在学习时不要太绝对,从而留出泛化的空间。"
,强迫模型在学习时不要太绝对,从而留出泛化的空间。"
核心四:你凭什么证明你的改进是有效的?(对应 Q5, Q10, Q12)
老师最后的绝杀:"准确率提升 1% 可能是运气,你怎么证明不是随机波动?"
你的防御话术:
"这就是我引入 Grad-CAM 热力图 的原因。我不能只拿准确率(91.82% )说事。 通过热力图反向传播计算梯度权重,我直观地看到了模型的'视线'。基线模型经常会盯着背景里的叶子或泥土,而加入了 ECA 模块的模型,其高激活区域极其精准地收敛在了花朵本体上(聚焦度达到 31.87% )。这种从视觉层面得到的因果解释,印证了我的准确率提升是真实有效的特征提取能力增强,而不是随机波动。"
Q:为什么选择 Flowers-102 数据集
A:Flowers-102 是经典的细粒度分类基准,训练集极小(每类仅10张),能充分检 验模型的迁移学习和泛化能力
Q:SE 和 ECA 的核心区别是什么

Q:CBAM 相比 SE 增加了什么?
A:CBAM 在通道注意力基础上增加了空间注意力分支,使用7×7卷积学习"关 注图像的哪个位置",实现了"通道选择+空间定位"的双重注意力
Q:为什么注意力模块没有提升性能
:轻量级的ECA和SE能有效提升性能,但参数较重的CBAM在仅1020张训 练集上出现微弱过拟合。核心经验是:小数据集场景下应优先选择参数极少的注意 力方案(如ECA仅+36参数),避免引入过多可学习参数
Q: "这位同学,你在简历最后写到:'定量证实 ECA 模型对花瓣形态等关键细节的聚焦度最高(31.87%)'。我平时看别人的论文,Grad-CAM 热力图都是贴几张好看的红红绿绿的图上去,凭肉眼说'你看我的模型看对了地方'。你是怎么得出 31.87% 这个非常精确的定量数字的?为什么说这个数字证明了'参数效率优于模型复杂度'?"
传统的 Grad-CAM 分析往往只停留在视觉展示层面。为了定量化,我提取了模型输出的热力图矩阵,并设定了一个高响应阈值(例如激活值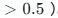 )。我计算了高激活像素点占整张图像的面积比例 ,将其定义为**'聚焦度得分(Focus Score)'** 。31.87% 就是 ECA 模型在测试集上的平均高激活面积占比。
)。我计算了高激活像素点占整张图像的面积比例 ,将其定义为**'聚焦度得分(Focus Score)'** 。31.87% 就是 ECA 模型在测试集上的平均高激活面积占比。
关于为什么能证明结论: 在对比实验中我发现,基线模型以及结构复杂的 CBAM 模型,它们的高激活区域往往是大面积弥散的(比例远大于 30%),甚至覆盖了背景杂草,这说明模型在决策时引入了大量无关的噪声特征(即过拟合表现)。
反观 ECA 模块 ,虽然它仅新增了 36 个一维卷积参数,但它的聚焦度收敛到了最紧凑的 31.87%,且在视觉上极其精准地覆盖了判别性最强的花蕊和花瓣边缘。
这通过严格的因果归因(即模型究竟凭什么做出分类),从视觉和数值双重层面印证了我的核心结论:在极端数据受限的场景下,精简而高效的局部通道交互(参数效率),远比盲目增加感受野和注意力维度的庞大模型(模型复杂度)更具鲁棒性。 "
Q:Grad-CAM 的原理是什么?
:对目标类别得分反向传播到指定卷积层,获取梯度作为各通道的权重,加权求 和特征图后取ReLU,生成与输入同尺寸的热力图,高亮模型判断依据的关键区域。
当模型判断出一张图是'玫瑰花'后,我们通过反向传播,去问最后一个卷积层里的几百个特征通道:'你们谁对玫瑰花这个结论贡献最大?'
贡献越大的通道,它的梯度(也就是权重)就越高。然后,我们把这些通道捕捉到的画面,按照权重大小加权叠加在一起。
最关键的一步是,我们会过一个 ReLU 激活函数,把那些反对'玫瑰花'结论的负面干扰全部过滤掉,只保留正向支持的证据。最后把这张证据图放大盖在原图上,就生成了我们看到的红红绿绿的热力图,红色越深,代表模型看这个地方看得越专注。"
Q:CutMix 和 Mixup 有什么区别
:Mixup 是对两张图片做全局线性插值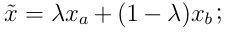 CutMix 是随机裁剪 一块区域替换,保留了更多局部语义信息,在细粒度任务上通常效果更好/
CutMix 是随机裁剪 一块区域替换,保留了更多局部语义信息,在细粒度任务上通常效果更好/
CutMix 数据增强。相比于传统的 Mixup 导致图像重影,CutMix 通过局部的图像裁剪与拼接,强制模型去学习花瓣、花蕊等局部判别性特征。
Q:为什么使用 Cosine Annealing 而不是 StepLR
Cosine Annealing 提供平滑的学习率衰减曲线,避免了StepLR阶梯下降带来的 突变。在训练后期,学习率缓慢趋近零,有助于模型精细收敛到更好的局部最优
Q:Label Smoothing 的作用是什么
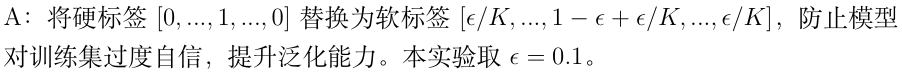
Q:Warmup 策略的意义?
:微调预训练模型时,初始阶段使用较小学习率,避免随机梯度破坏已学到的特 征表示。前3个epoch线性升温到目标学习率,之后再进行正常的Cosine衰减。
q: 本实验的具体数值结果是什么?
A:基线实验中ResNet50最优(TestAcc=93.19%, F1=0.9309);注意力消融中ECA 最优(Test Acc=91.82%),仅增加 36 个参数即超越 Baseline +1.27%;Grad-CAM 分析显示ECA聚焦度最集中(31.87%),注意力与准确率正相关。
Q:如果要提升注意力模块的效果,你会怎么做
:(1)增加训练数据或使用更强的数据增强;(2)延长训练轮数至100+epochs;(3) 对注意力模块单独设置更大的学习率;(4)尝试non-local attention 等更强力的注 意力方案。
Q:为什么 VGG16 参数量是 ResNet18 的 12 倍但准确率更低
VGG16 的参数主要集中在三层全连接层(约123M),这些参数在小数据集上 极易过拟合。ResNet18 通过残差连接实现了更深的有效特征提取,同时参数效率 远高于VGG的全连接架构。
Q:什么是细粒度分类?与普通分类的区别
A:细粒度分类是对同一大类下的子类进行区分(如区分不同种类的花、鸟、车型), 类间差异微小但类内变化较大。相比普通分类(如猫/狗),细粒度分类更依赖局部 细节特征,通常需要更强的特征提取能力。
Q:ResNet 的残差连接为什么有效?
A:残差连接让网络学习残差映射F(x)=H(x)−x而非直接映射H(x),当最优映 射接近恒等映射时,残差更容易学习。同时残差连接提供了梯度直通路径,缓解了 深层网络的梯度消失问题。
Q:这个项目对你最大的收获是什么?
A:最大的收获是理解了「轻量级设计的力量」------ECA仅用36个参数就超越了 拥有87K 额外参数的SE和CBAM。这教会我在实际工程中,参数效率比模型复 杂度更重要,尤其在数据受限场景下,最小干预原则往往能取得最好效果。同时, Grad-CAM 可视化让我直观理解了注意力机制的工作方式,聚焦度与准确率的正相 关关系也验证了注意力机制的理论基础