文章目录
- 一、前言
- 二、RAG
-
- [1. RAG 概念](#1. RAG 概念)
- [2. RAG Stages](#2. RAG Stages)
-
- [2.1 Indexing 索引](#2.1 Indexing 索引)
- [2.2 Retrieval 检索](#2.2 Retrieval 检索)
- [3. RAG 分类](#3. RAG 分类)
- [三、Easy RAG](#三、Easy RAG)
- [四、RAG 核心 API](#四、RAG 核心 API)
-
- [1. Document](#1. Document)
-
- [1.1 Document](#1.1 Document)
- [1.2 Metadata](#1.2 Metadata)
- [1.3 Document Loader](#1.3 Document Loader)
- [1.4 Document Parser](#1.4 Document Parser)
- [1.5 Document Transformer](#1.5 Document Transformer)
- [1.6 Graph Transformer](#1.6 Graph Transformer)
- [1.7 Text Segment](#1.7 Text Segment)
- [1.8 Document Splitter](#1.8 Document Splitter)
- [1.9 Text Segment Transformer](#1.9 Text Segment Transformer)
- [2. 向量嵌入](#2. 向量嵌入)
-
- [2.1 Embedding](#2.1 Embedding)
- [2.2 Embedding Model](#2.2 Embedding Model)
- [2.3 Embedding Store](#2.3 Embedding Store)
- [2.4 Embedding Store Ingestor](#2.4 Embedding Store Ingestor)
- [五、Naive RAG](#五、Naive RAG)
- [六、Advanced RAG](#六、Advanced RAG)
-
- [1. Retrieval Augmentor](#1. Retrieval Augmentor)
- [2. Query & Query Transformer](#2. Query & Query Transformer)
-
- [2.1 Query](#2.1 Query)
- [2.2 Query Transformer](#2.2 Query Transformer)
- [3. Content & Content Retriever](#3. Content & Content Retriever)
-
- [3.1 Content](#3.1 Content)
- [3.2 Content Retriever](#3.2 Content Retriever)
-
- [3.2.1 Embedding Store Content Retriever](#3.2.1 Embedding Store Content Retriever)
- [3.2.2 Web Search Content Retriever](#3.2.2 Web Search Content Retriever)
- [3.2.3 SQL Database Content Retriever](#3.2.3 SQL Database Content Retriever)
- [3.2.4 Azure AI Search Content Retriever](#3.2.4 Azure AI Search Content Retriever)
- [3.2.5 Neo4j Content Retriever](#3.2.5 Neo4j Content Retriever)
- [3.2.6 Elasticsearch Content Retriever](#3.2.6 Elasticsearch Content Retriever)
- [4. Query Router](#4. Query Router)
- [5. Content Aggregator](#5. Content Aggregator)
- [6. Content Injector](#6. Content Injector)
-
- [6.1 DefaultContentInjector](#6.1 DefaultContentInjector)
- [7. Parallelization](#7. Parallelization)
- [8. Accessing Sources](#8. Accessing Sources)
- 六、简单示例
- 七、参考内容
一、前言
本系列内容来源于 LangChain4J 官网,内容稍作改删,仅做个人笔记使用。
本系列使用 LangChain4J 版本:
xml
<dependencyManagement>
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-bom</artifactId>
<version>1.8.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>本系列完整代码地址 :langchain4j-hwl
大模型本身只 "记得" 训练过的数据,不知道你私有的、最新的、专业领域的数据。想让它理解专属数据,常用三条路:
- RAG:不改动模型,只在回答时实时去查你的文档,把相关内容塞给模型再回答。
- 微调 :用你的数据再训练一遍模型,让模型 "学到" 这些知识。
- RAG + 微调:两种一起用,效果通常更好。
二、RAG
RAG 即 Retrieval-Augmented Generation,检索增强生成。
1. RAG 概念
LLM 的知识局限于训练数据,无法直接使用实时 / 私有 / 领域数据,且易产生 幻觉(虚构信息)。
RAG 的核心思路是 先检索、再生成:在向 LLM 发送用户查询(提示词)前,先从用户自有数据中筛选出与查询相关的信息片段,将这些片段 "附加" 到提示词中;LLM 基于这些真实相关的信息生成回复,既能利用私有 / 实时数据,又能大幅降低幻觉概率。
检索是 RAG 的关键环节,目的是精准找到与用户查询匹配的信息,主流方法分三类:
- 全文(关键词)搜索 :核心原理是 用 TF-IDF(词频 - 逆文档频率)、BM25 等技术,匹配查询中的关键词与文档中的关键词。逻辑简单、速度快,依赖 "关键词匹配",适合对文本结构清晰、关键词明确的场景
- 向量(语义)搜索 :用嵌入模型将文本转为数字向量,通过 "余弦相似度" 等计算查询与文档的语义匹配度。不依赖关键词,能捕捉深层语义(如 "如何付款" 与 "支付方式有哪些" 的关联),精度更高
- 混合式搜索 :核心原理是 结合全文搜索与向量搜索的优势(如先用关键词缩小范围,再用语义精准匹配)。兼顾速度与精度,解决单一方法的局限性(如关键词搜索的语义盲区、向量搜索的效率问题)
官方提到:当前重点介绍向量搜索,全文与混合搜索暂仅支持 Azure AI 搜索集成,未来计划扩展更多工具支持。
2. RAG Stages
RAG 的流程中分为两个阶段:Indexing (索引)和 retrieval(检索)。
- Indexing 阶段:提前 "加工" 原始文档,把无序的文档转化为结构化、可快速搜索的格式(尤其向量格式),解决 "怎么存才能快" 的问题;
- retrieval阶段:实时响应用户查询,从已加工的 "知识库" 中精准找到相关内容,注入 LLM prompt,解决 "怎么取才能准" 的问题。
LangChain4j为这两个阶段都提供了工具支持。
2.1 Indexing 索引
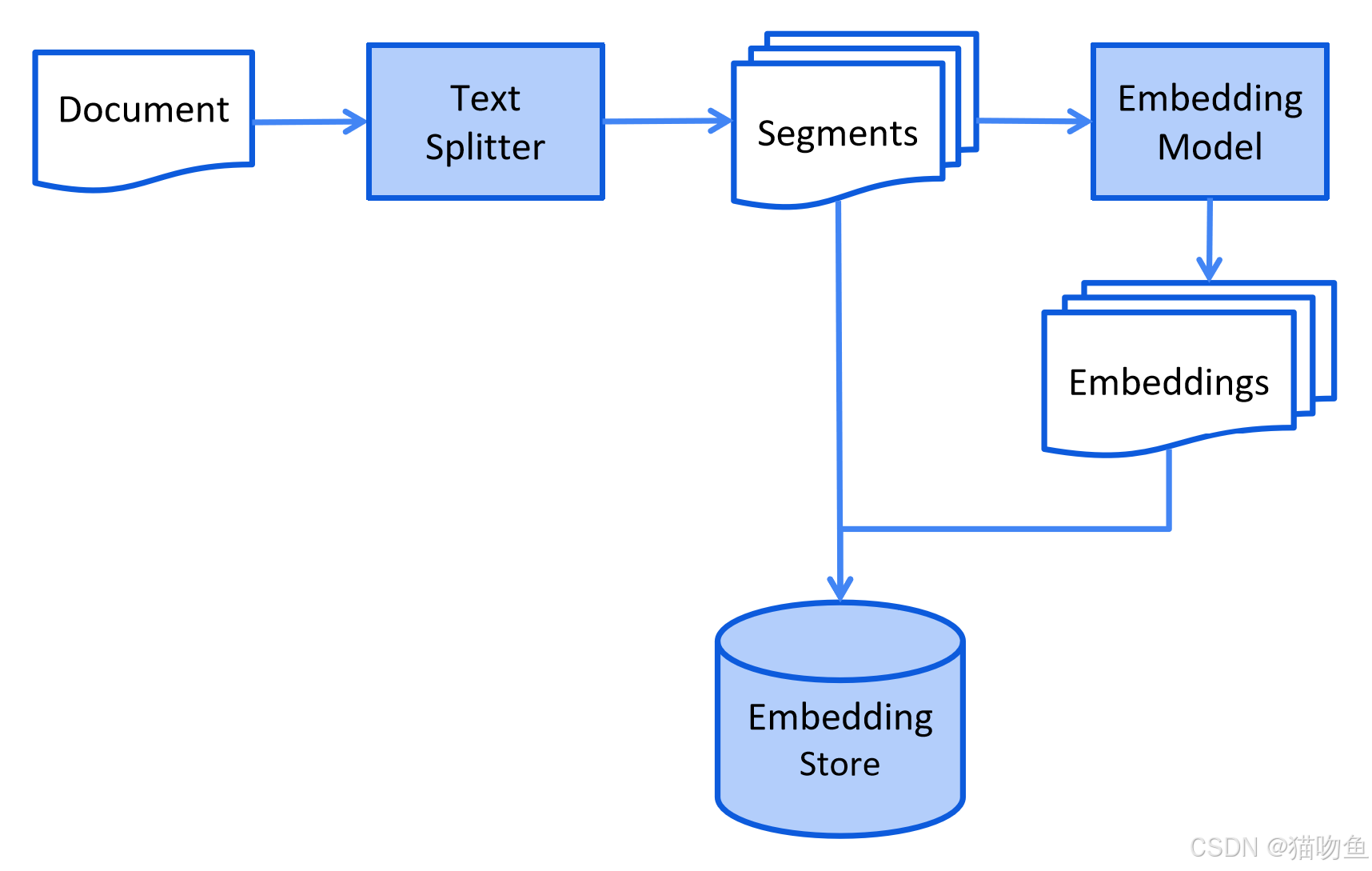
在索引阶段,文档会经过预处理,以便在检索阶段实现高效搜索。这一过程会因所使用的信息检索方法而有所不同。对于向量搜索,这通常包括清理文档、用额外数据和元数据丰富文档、将文档分割成更小的片段(也称为分块)、对这些片段进行嵌入处理,最后将它们存储在嵌入存储(也称为向量数据库)中。
索引阶段通常在离线状态下进行,这意味着它不需要终端用户等待其完成。例如,这可以通过一个定时任务来实现,该任务在周末每周对公司内部文档重新索引一次。负责索引的代码也可以是一个单独的应用程序,仅处理索引任务。
然而,在某些场景下,终端用户可能希望上传他们的自定义文档,以便大语言模型能够访问这些文档。在这种情况下,索引操作应在线进行,并且是主应用程序的一部分。
以下是索引阶段的简化示意图:
2.2 Retrieval 检索
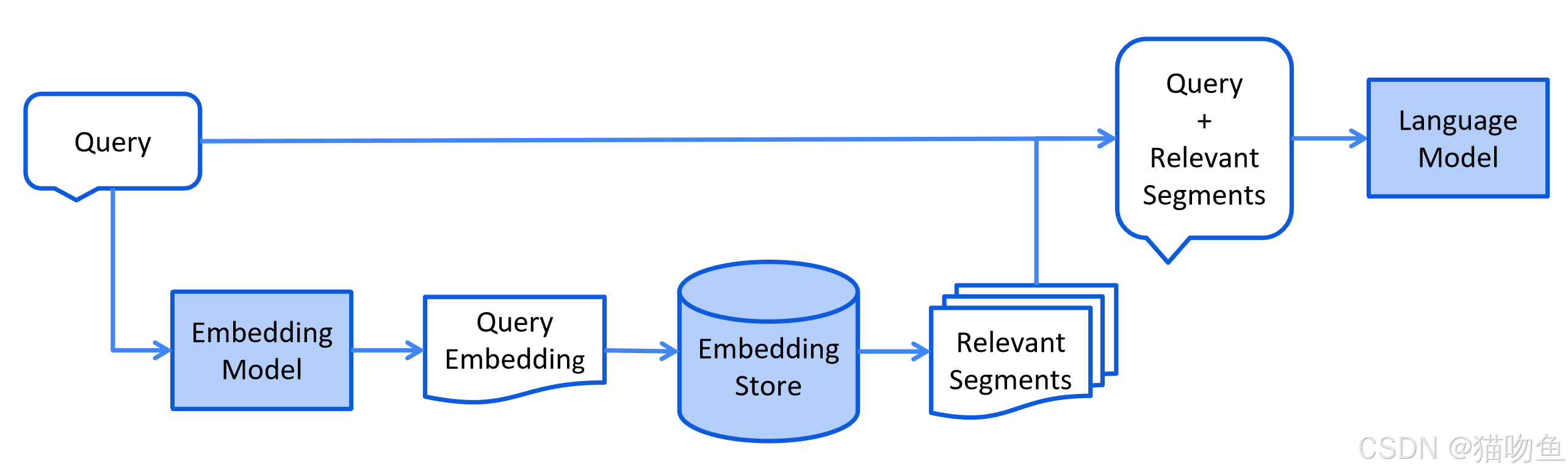
检索阶段通常发生在在线状态下,当用户提交一个需要使用索引文档来回答的问题时。
这一过程会因所使用的信息检索方法而有所不同。对于向量搜索,这通常包括对用户的查询(问题)进行嵌入处理,并在嵌入存储中执行相似性搜索。然后,相关片段(原始文档的部分内容)会被注入到提示词中,并发送给 LLM 。
以下是检索阶段的简化示意图:
3. RAG 分类
LangChain4j提供三种类型的RAG:
-
Easy RAG:开箱即用,零门槛体验 RAG。
- 定位:给新手 / 快速做 Demo 用的全自动黑盒
- 特点
- 不用管嵌入模型、向量库、文档切分、解析
- 只需要指定文档路径,框架自动完成全套 RAG 流程
- 内置默认模型、默认切分、默认内存向量库
- 优点:5 分钟跑通 RAG,极快验证想法
- 缺点:几乎不能定制,效果一般
- 适合:学习、原型验证、内部小工具
-
Naive RAG:使用向量搜索的检索增强生成基础实现,是最简可定制版,真正意义上的入门 RAG。
- 特点
- 需要你手动指定:嵌入模型、向量库、检索器
- 流程:文档切分 → 向量化 → 存入向量库 → 查询检索 → 注入 prompt
- 只做最基础的向量检索,没有额外优化
- 优点:结构清晰、可简单调参、足够应对简单场景
- 缺点:不支持查询改写、多路检索、重排等高级能力
- 适合:简单知识库、内部问答、对效果要求不高的场景
- 特点
-
Advanced RAG:一个模块化的检索增强生成框架,支持查询转换、多源检索和重排序等额外步骤,是面向真实业务的完整 RAG 框架。
- 特点
- 全链路模块化:查询转换、路由、多检索源、内容聚合、重排序、并行检索
- 支持:
- 查询压缩 / 扩展 / 改写
- 多路检索(向量 + 全文 + 网络 + 数据库)
- 结果重排
- 元数据过滤、权限控制
- 可高度定制每一步
- 优点:效果最好、最稳定、幻觉更低、召回更准
- 适合:线上服务、企业知识库、客服机器人等生产环境
- 特点
下面我们来介绍这三种 RAG 的使用。
三、Easy RAG
LangChain4j 的 Easy RAG 是一个 开箱即用、零门槛 的 RAG 封装,帮你自动搞定底层所有复杂步骤,Easy RAG 屏蔽了底层复杂度,用户不用懂词嵌入(embedding)、不用选向量数据库、也不需要挑选嵌入模型等,只需要给文档就能直接用。
下面我们给出一个简单示例:
-
项目引入 easy-rag 依赖
xml<dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-easy-rag</artifactId> </dependency> -
定义 EasyRagAssistant
javapublic interface EasyRagAssistant { String chat(String userMessage); } -
EasyRagAssistant 注入容器
java@Bean public EasyRagAssistant easyRagAssistant(ChatModel chatModel, ChatMemoryProvider chatMemoryProvider) { // 加载 static/knowledge 目录下的文件 (可以通过 PathMatcher 对读取的文件做进一步过滤), // 我这里随便创建了两个文件,内容是 张三的老婆是李四;李四其实是个男的 // 加载目录下的两个文件。 List<Document> documents = ClassPathDocumentLoader.loadDocuments("static/knowledge"); // 构建一个内存中的向量数据库(EmbeddingStore),用于存储文档的向量表示。 InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>(); EmbeddingStoreIngestor.ingest(documents, embeddingStore); // 构建 EasyRagAssistant return AiServices.builder(EasyRagAssistant.class) .chatModel(chatModel) .chatMemoryProvider(chatMemoryProvider) // 核心作用是从预处理好的数据源(如向量数据库 / 嵌入存储)中,根据用户查询提取出最相关的内容片段,为后续 LLM 生成准确回答提供 "事实依据",避免模型依赖过时或错误的内置知识。 .contentRetriever(EmbeddingStoreContentRetriever.from(embeddingStore)) .build(); } -
询问大模型,得到如下回复。
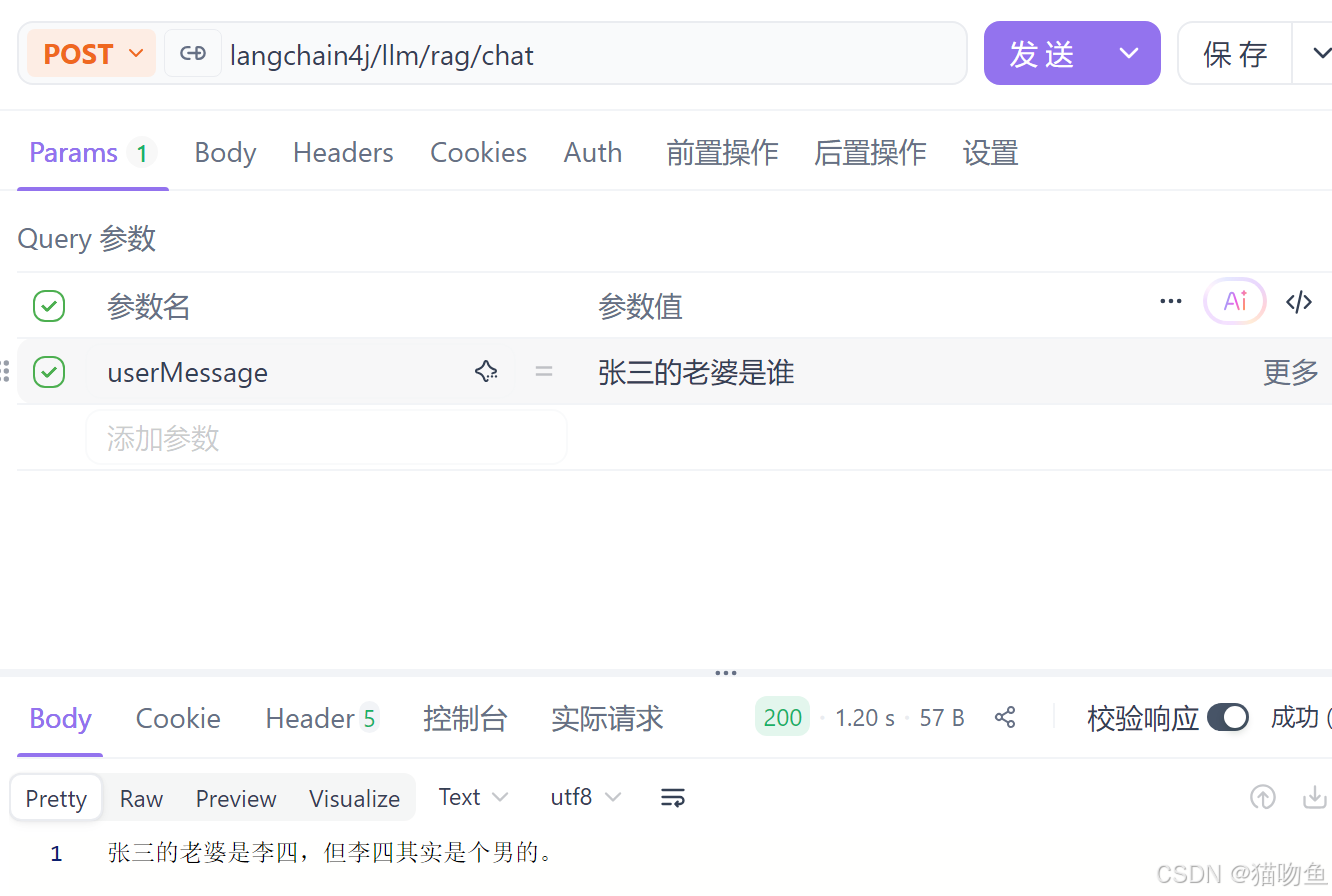
可以看到,通过 RAG LLM 可以获悉本地知识库的内容加以理解并给出正确答复。
四、RAG 核心 API
LangChain4j提供了丰富的API集合,能够轻松构建自定义的RAG管道,详情查阅 官网,本部分进行了部分删改。
1. Document
1.1 Document
Document是 LangChain4j 中用来封装完整文档的核心类,它就像一个 "文档容器":
- 现阶段只能装纯文本内容(比如 PDF 里的文字、网页里的文本);
- 未来会扩展支持图片、表格这类非文本内容,适配更多类型的文档。
Document 的核心方法如下:
| 方法 | 作用 | 通俗举例 |
|---|---|---|
Document.text() |
获取文档里的纯文本内容 | 比如加载了一个 PDF,调用这个方法就能拿到 PDF 里所有文字 |
Document.metadata() |
获取文档的元数据(Metadata) | 元数据是文档的 "附加信息",比如文件名、创建时间、来源路径等,这个方法能拿到这些信息 |
Document.toTextSegment() |
把整个 Document 转换成 TextSegment | TextSegment 是 "文本片段"(比如文档里的一个段落),这个方法相当于把完整文档拆成一个大的文本片段,方便后续嵌入(Embedding)处理 |
Document.from(String, Metadata) |
用 "文本内容 + 元数据" 创建 Document | 比如:Document.from("这是PDF里的文字", Metadata.from(Map.of("文件名", "教程.pdf"))) |
Document.from(String) |
只用文本内容创建 Document(元数据为空) | 比如:Document.from("这是网页里的文字"),此时调用metadata()会返回空的元数据 |
1.2 Metadata
Metadata 是 LangChain4j 中为每个 Document 附加的结构化辅助信息,本质是一个键值对映射表:
- 键(Key):固定为字符串类型(比如 "file_name"、"owner"、"update_time");
- 值(Value):支持常见基础类型(字符串、整数、浮点数、UUID 等),能灵活存储各类属性。
简单类比:如果把 Document 看作一本实体书,Metadata 就是这本书的 "藏书标签"------ 记录书名、作者、入库时间、所属书架等信息,不影响书的内容,但能方便管理和查找。
Metadata 的价值主要体现在以下几个方面:
- 在向 LLM 的提示词中包含Document内容时,也可以包含元数据条目,为 LLM 提供更多可供参考的信息。例如,提供Document的名称和来源有助于提高 LLM 对内容的理解。
- 在搜索要包含在提示词中的相关内容时,可以通过Metadata条目进行筛选。例如,你可以将语义搜索范围缩小到仅属于特定所有者的Document。
- 当Document的来源更新时(例如,文档的特定页面),人们可以通过其元数据条目(例如"id""来源"等)轻松找到相应的Document,并在EmbeddingStore中对其进行更新,以保持同步。
LangChain4j中Metadata本质是为文档元数据(如来源、更新时间、所有者等)提供标准化的"增删改查、转换、复制、合并"操作能力,确保元数据在RAG(检索增强生成)流程中可灵活管理和使用,其核心方法如下:
| 方法 | 作用 | 通俗举例 |
|---|---|---|
Metadata.from(Map) |
构建 Metadata 对象 | 把普通的 Map(键值对)转换成 Metadata 实例,相当于 "初始化" |
Metadata.put(key, value) |
添加单个元数据 | 给 Metadata 加一条信息,比如 put("file_name", "产品手册.pdf"),支持字符串、整数等多种类型的值 |
Metadata.putAll(Map) |
批量添加元数据 | 一次性把一个 Map 里的所有键值对都加到 Metadata 里,比多次调用 put 更高效 |
Metadata.getString/getInteger(key) |
获取指定类型的值 | 根据键读取值,并自动转换成你需要的类型(比如存的是数字 123,用 getInteger 就能直接拿到 int 类型) |
Metadata.containsKey(key) |
检查键是否存在 | 确认 Metadata 里有没有某个键,避免取值时出现空值问题 |
Metadata.remove(key) |
删除指定元数据 | 根据键删掉某一条元数据,比如删掉过时的 "version" 字段 |
Metadata.copy() |
复制 Metadata | 生成一个和原对象内容完全一样的新 Metadata,修改新对象不会影响原对象 |
Metadata.toMap() |
转换为普通 Map | 把 Metadata 转回普通的 Map,方便和其他只支持 Map 的代码兼容 |
Metadata.merge(Metadata) |
合并两个 Metadata | 把另一个 Metadata 里的所有键值对合并到当前对象中(如果有重复键,通常会覆盖原有的值) |
1.3 Document Loader
Document Loader 即文档加载器,其作用是便捷加载不同来源数据并转换为Document对象 的工具类,核心目的是替代手动从String构建Document的繁琐操作,直接从各类数据源一键加载,是 RAG 流程中「数据接入」环节的核心组件。
LangChain4j 提供了多种 Document Loader,如 FileSystemDocumentLoader 、ClassPathDocumentLoader 、UrlDocumentLoader 、AmazonS3DocumentLoader 、AzureBlobStorageDocumentLoader等,基于这些 Document Loader,我们可以从本地、网络或其他场景加载 Document 。
需要注意,使用其中一些 Document Loader 时需要引入特定的包,具体如下:
| 类名 | 所属模块 | 核心功能 | 适用场景 |
|---|---|---|---|
FileSystemDocumentLoader |
langchain4j(核心模块) |
从本地文件系统加载文档(如本地文件夹、单个文件) | 加载本地 PDF、TXT、MD 等文件 |
ClassPathDocumentLoader |
langchain4j(核心模块) |
从 Java 项目的类路径(resources 目录)加载文档 | 加载项目内置的配置文件、模板文档 |
UrlDocumentLoader |
langchain4j(核心模块) |
从网络 URL 加载文档(如网页、在线文件链接) | 爬取简单网页文本、加载在线文档 |
AmazonS3DocumentLoader |
langchain4j-document-loader-amazon-s3 |
从 AWS S3 存储桶加载文档 | 读取云存储 S3 中的文件 |
AzureBlobStorageDocumentLoader |
langchain4j-document-loader-azure-storage-blob |
从 Azure Blob 存储加载文档 | 读取 Azure 云存储的 Blob 文件 |
GitHubDocumentLoader |
langchain4j-document-loader-github |
从 GitHub 仓库加载文档(如仓库内的 MD、代码文件) | 读取 GitHub 上的文档/代码内容 |
GoogleCloudStorageDocumentLoader |
langchain4j-document-loader-google-cloud-storage |
从谷歌云存储(GCS)加载文档 | 读取 GCS 中的文件 |
SeleniumDocumentLoader |
langchain4j-document-loader-selenium |
基于 Selenium 加载动态渲染的网页(如 JS 渲染的页面) | 爬取需要浏览器渲染的复杂网页 |
PlaywrightDocumentLoader |
langchain4j-document-loader-playwright |
基于 Playwright 加载动态网页(比 Selenium 更轻量) | 高效爬取动态网页,支持多浏览器 |
TencentCosDocumentLoader |
langchain4j-document-loader-tencent-cos |
从腾讯云 COS 存储加载文档 | 读取腾讯云对象存储中的文件 |
1.4 Document Parser
Document可以表示各种格式的文件,例如PDF、DOC、TXT等。为了解析这些格式,LangChain4j 库中包含了一个DocumentParser接口以及多个实现, 如下:
- TextDocumentParser(langchain4j 模块):解析 TXT、HTML、MD 等纯文本格式;
- ApachePdfBoxDocumentParser(langchain4j-document-parser-apache-pdfbox 模块):解析 PDF 文件;
- ApachePoiDocumentParser(langchain4j-document-parser-apache-poi 模块):解析 DOC、DOCX 等微软办公格式;
- ApacheTikaDocumentParser(langchain4j-document-parser-apache-tika 模块):自动检测并解析几乎所有现有文件格式, 默认实现。
- MarkdownDocumentParser(langchain4j-document-parser-markdown 模块):解析 Markdown 格式;
- YamlDocumentParser(langchain4j-document-parser-yaml 模块):解析 YAML 格式。
我们可以通过显式指定解析器也可以使用默认解析器,如下:
- 显式指定解析器:加载文件时手动传入对应解析器(如示例中加载 TXT 用 TextDocumentParser),适合明确文件格式的场景;
- 隐式使用默认解析器:不指定解析器时,优先通过 SPI 加载 ApacheTikaDocumentParser(或 easy-rag 中的解析器),无可用解析器时降级为 TextDocumentParser,简化开发。
如下是官网的加载示例:
java
// Load a single document
Document document = FileSystemDocumentLoader.loadDocument("/home/langchain4j/file.txt", new TextDocumentParser());
// Load all documents from a directory
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j", new TextDocumentParser());
// Load all *.txt documents from a directory
PathMatcher pathMatcher = FileSystems.getDefault().getPathMatcher("glob:*.txt");
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j", pathMatcher, new TextDocumentParser());
// Load all documents from a directory and its subdirectories
List<Document> documents = FileSystemDocumentLoader.loadDocumentsRecursively("/home/langchain4j", new TextDocumentParser());1.5 Document Transformer
DocumentTransformer 是 LangChain4j 中用于对加载后的Document对象进行预处理的核心接口,本质是在文档进入 RAG 的索引 / 检索流程前,对文档内容和元数据做定制化处理,目的是提升后续检索的准确性和效率。
DocumentTransformer 的实现可以执行多种文档转换,例如:
- Cleaning 清洗:这包括从Document文本中去除不必要的噪音,这样可以节省标记并减少干扰。
- Filtering 过滤:将特定的Document完全排除在搜索之外。
- Enriching 丰富:可以向Document添加额外信息,以潜在地优化搜索结果。
- Summarizing 总结:Document可以被总结,其简短摘要可以存储在Metadata中,以便日后包含在每个TextSegment(我们将在下文介绍)中,从而可能改进搜索效果。
在此阶段,还可以添加、修改或删除Metadata条目。
HtmlToTextDocumentTransformer(依赖langchain4j-document-transformer-jsoup模块)是官方提供的唯一默认实现,专门用于从原始 HTML 文档中提取纯文本内容和关键元数据(比如标题、作者),剥离 HTML 标签等无关内容。在更加个性化的场景下,更推荐自定义实现 DocumentTransformer 。
1.6 Graph Transformer
GraphTransformer 是 LangChain4j 中一个接口,核心作用是把 无结构的文本文档(Document) 转换成结构化的语义图(GraphDocument)。
简单理解:它就像一个 "文本转图谱" 的转换器,能从杂乱的文字里,自动识别出 "谁 / 什么(节点)"、"彼此是什么关系(边)",最终形成机器可理解的知识图谱结构。
GraphTransformer 会将原始文档转换为 GraphDocument。其中包括三部分:
- 节点(GraphNode) :代表文本中的实体或概念。(比如人名、地名、职位等,示例中 "Barack Obama" 是 Person 类型节点,"Hawaii" 是 Location 类型节点);
- 关系(GraphEdge) :用于表示这些实体之间的连接方式。(比如 "was born in""served as",描述 "谁做了什么 / 属于什么");
- 源文档: 保留原始的 Document,方便追溯数据来源
GraphTransformer 到目前为止还是实验性的功能,因此功能可能并不稳定。
LangChain4j 提供的默认实现是 LLMGraphTransformer,它依赖LLM(如 OpenAI)+ 提示工程,而非硬编码规则,能智能识别文本中的实体和关系,不需要你手动定义 "什么是 Person、什么是 Location",LLM 会自动通过语义分析完成提取,示例如下:
- 引入依赖 :
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-llm-graph-transformer</artifactId>
<version>1.7.1-beta14</version>
</dependency>- 示例Demo如下:
java
public static void main(String[] args) {
OpenAiChatModel chatModel = OpenAiChatModel.builder()
.baseUrl("http://langchain4j.dev/demo/openai/v1")
.apiKey("demo")
.modelName("gpt-4o-mini")
.build();
String examples = """
示例1:文本='张三是李四的父亲,李四和王五是同事'
→ 节点:Person(张三)、Person(李四)、Person(王五)
→ 关系:FATHER(张三→李四)、COLLEAGUE(李四→王五)
""";
LLMGraphTransformer graphTransformer = LLMGraphTransformer.builder()
.model(chatModel)
// 约束输出图谱中仅包含指定类型的节点,防止无关节点混入。
// - 传 List.of("Person", "Company") → 仅提取 "人物 / 公司" 类型节点;
// - 传 null/空 → 允许所有节点类型(如文本中出现的 "地点""事件" 都提取)。
.allowedNodes(List.of("Person"))
// 约束输出图谱中仅包含指定类型的关系,过滤无关关系。
// - 传 List.of("FATHER", "COLLEAGUE") → 仅提取 "父子 / 同事" 关系;
// - 传 null/空 → 允许所有关系类型(如 "朋友""上级" 都提取)。
.allowedRelationships(null)
// 对默认提示词补充说明,避免重写整个 prompt。
// - 传 "提取时忽略所有无关的地点信息" → 仅追加该指令,不改变原有 prompt 核心逻辑。
.additionalInstructions("提取时忽略所有无关的地点信息")
// 提供 "文本→图谱" 的示例,让 LLM 更精准理解提取规则
// - 传 "示例1:文本='张三是李四的父亲' → 节点:Person(张三)、Person(李四);关系:FATHER(张三→李四)"
.examples(examples)
// LLM 生成结果不符合要求(如格式错误)时,自动重试的次数。
.maxAttempts(1)
.build();
String demoText = """
马十三是一家律所的合伙人,他的徒弟是律师冯十四。冯十四的丈夫陈十五是某国企的财务总监,陈十五的表姐林十六是马十三的妻子,林十六的弟弟林十七是陈十五的下属(出纳)。林十七的女朋友欧阳十八是冯十四的客户,欧阳十八的父亲欧阳十九曾委托马十三处理过一起经济纠纷,欧阳十九的生意伙伴黄二十是林十六的高中同学,黄二十的儿子黄二一和冯十四的侄子冯十五是同班同学,且黄二一的母亲张二十二是马十三的大学导师。
""";
Document document = Document.document(demoText);
GraphDocument graphDocument =
graphTransformer.transform(document);
// Access nodes and relationships
Set<GraphNode> nodes = graphDocument.nodes();
Set<GraphEdge> relationships = graphDocument.relationships();
nodes.forEach(System.out::println);
relationships.forEach(System.out::println);
}- 该示例实测可能会出现 JSON 转换异常的情况,调试发现是 LLM 返回的结构多带了
json字符,不过整体人物关系数据已经出来了,如下:
java
json
[
{"head": "马十三", "head_type": "Person", "relation": "徒弟", "tail": "冯十四", "tail_type": "Person"},
{"head": "冯十四", "head_type": "Person", "relation": "丈夫", "tail": "陈十五", "tail_type": "Person"},
{"head": "陈十五", "head_type": "Person", "relation": "表姐", "tail": "林十六", "tail_type": "Person"},
{"head": "林十六", "head_type": "Person", "relation": "弟弟", "tail": "林十七", "tail_type": "Person"},
{"head": "林十七", "head_type": "Person", "relation": "女朋友", "tail": "欧阳十八", "tail_type": "Person"},
{"head": "欧阳十八", "head_type": "Person", "relation": "父亲", "tail": "欧阳十九", "tail_type": "Person"},
{"head": "欧阳十九", "head_type": "Person", "relation": "委托", "tail": "马十三", "tail_type": "Person"},
{"head": "欧阳十九", "head_type": "Person", "relation": "生意伙伴", "tail": "黄二十", "tail_type": "Person"},
{"head": "黄二十", "head_type": "Person", "relation": "同学", "tail": "林十六", "tail_type": "Person"},
{"head": "黄二十", "head_type": "Person", "relation": "儿子", "tail": "黄二一", "tail_type": "Person"},
{"head": "冯十四", "head_type": "Person", "relation": "侄子", "tail": "冯十五", "tail_type": "Person"},
{"head": "黄二一", "head_type": "Person", "relation": "母亲", "tail": "张二十二", "tail_type": "Person"},
{"head": "张二十二", "head_type": "Person", "relation": "导师", "tail": "马十三", "tail_type": "Person"}
]1.7 Text Segment
LLM(大语言模型)的使用有诸多限制,直接用完整文档会暴露很多问题,拆分的核心目的就是解决这些痛点:
- 上下文窗口有限:模型能处理的文本长度(token)有上限,完整知识库可能装不下;
- 成本 & 效率问题:prompt 里内容越多,模型处理越慢、消耗的 token 越多(费用越高);
- 准确性问题:无关信息会干扰模型,增加幻觉概率,也难以追溯模型回答的信息来源。
因此一旦 Document 加载完成,就会将他们拆分为更小的片段。LangChain4j 提供了一个 TextSegment 类,该类表示Document的一个片段。
顾名思义,TextSegment只能表示文本信息。
文档拆分的2种主流路径
针对上述问题,文本提出"将知识库拆分为小片段"的核心思路,并对比了两种落地方式的适用场景、优缺点:
| 拆分路径 | 核心逻辑 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 不拆分,文档整体作为"原子单位" | 不拆分,检索时直接取N个最相关的完整文档 | 需保留完整上下文(如法律条文、技术手册) | 无上下文丢失 | 1. 消耗更多token; 2. 文档内无关内容干扰; 3. 向量搜索精度低(完整文档压缩为固定向量易丢失信息) |
| 拆分为小片段(段落/句子) | 按章节、段落等拆分,检索时取N个相关片段 | 多数通用场景(如问答、信息摘要) | 1. 向量搜索精度更高; 2. 减少token消耗 | 可能丢失片段间的关联上下文,需额外技术(如"句子窗口检索")补充 |
TextSegment类的几个核心方法:
TextSegment.text():返回该文本片段的具体文本内容TextSegment.metadata():返回该文本片段关联的元数据(Metadata)TextSegment.from(String, Metadata):根据指定的文本内容和元数据创建一个TextSegment实例TextSegment.from(String):仅根据文本内容创建TextSegment实例,元数据为空
这些方法提供了TextSegment的基本操作能力,包括获取内容、获取元数据以及创建实例,是处理文档分割后片段的基础接口。
1.8 Document Splitter
DocumentSplitter(文档拆分器)是 LangChain4j 中处理长文本的核心组件,目的是把完整的Document(文档)拆分成大小可控的TextSegment(文本片段)------ 这是 RAG 流程中关键的一步,既能适配 LLM 的上下文窗口限制,又能提升向量检索的精准度。
LangChain4j 提供了多种 DocumentSplitter 实现,不同实现对应不同的拆分规则,覆盖从粗到细的拆分需求,如下:
- 按结构拆分:DocumentByParagraphSplitter(按段落,连续 2 个以上换行符分隔)、DocumentByLineSplitter(按行)、DocumentBySentenceSplitter(按句子,依赖 OpenNLP);
- 按字符 / 单词拆分:DocumentByWordSplitter(按单词)、DocumentByCharacterSplitter(按单个字符);
- 自定义规则:DocumentByRegexSplitter(按正则表达式);
- 兜底方案:DocumentSplitters.recursive()(递归拆分)------ 如果用某类拆分器拆出的单元仍超过设定大小,会自动用更细粒度的拆分器继续拆,是最常用的灵活方案。
所有 DocumentSplitter 都遵循 4 步逻辑,保证拆分结果可控:
- 初始化配置:创建拆分器时,指定TextSegment的最大尺寸(字符 / 令牌数),可选配置 "重叠长度"(比如拆分后相邻片段重叠 30 个字符,避免上下文断裂);
- 执行拆分:调用split(单文档)或splitAll(多文档)方法触发拆分;
- 初步拆分:按自身规则把文档拆成基础单元(比如段落、句子、单词);
- 组装 + 兜底处理 :
- 把基础单元拼接成不超过设定大小的TextSegment;
- 若某个基础单元本身就超大小(比如超长段落),会调用 "子拆分器"(更细粒度的拆分器)继续拆;
- 拆分后自动继承原文档的所有元数据,并给每个TextSegment加唯一的index(索引),方便后续追溯。
1.9 Text Segment Transformer
TextSegmentTransformer 与 DocumentTransformer 类似,但它对TextSegment进行转换。
- DocumentTransformer是对完整的文档(Document) 做整体处理(比如清洗整个 PDF 的文本、给整个文档加元数据);
- 而TextSegmentTransformer是对文档拆分后的小片段(TextSegment) 做精细化处理 ------ 因为文档拆分后会变成多个小文本段,需要针对这些小段单独做调整,两者是 "整体" 和 "局部" 的关系。
与 DocumentTransformer 一样,没有万能的解决方案,所以一般建议根据自己独特的数据实现专属的 TextSegmentTransformer 。
2. 向量嵌入
2.1 Embedding
LangChain4j 中的Embedding类是向量嵌入的程序级封装,其核心作用是将文本(如TextSegment文本片段)的语义含义,转化为可被机器计算、存储和检索的数值向量,是实现 RAG 中向量搜索的基础数据类,完全契合向量嵌入 "用数值捕捉数据语义与关联关系" 的本质定义。
LangChain4j 提供了直接操作向量嵌入的核心方法,满足 RAG 流程中索引、检索阶段的向量计算需求,常用方法包括:
-
Embedding.dimension():返回嵌入向量的维度(即向量长度)- 核心作用:返回嵌入向量的"长度"(即向量包含的数值元素个数),用于明确当前嵌入模型生成向量的维度规格。
- 关键意义:不同嵌入模型生成的向量维度不同(例如BGE-small-en-v1.5模型维度为384,OpenAI的text-embedding-3-small维度为1536),维度直接影响向量存储的空间成本和相似度计算的效率。调用此方法可快速确认向量规格,确保后续存储(如向量数据库)和计算的兼容性。
-
CosineSimilarity.between(Embedding, Embedding):计算两个嵌入向量的余弦相似度- 核心作用 :衡量两个嵌入向量在"语义空间"中的相似程度,返回值范围为 -1, 1 (在RAG场景中通常取正值,实际有效范围为0, 1)。
- 值越接近1:两个向量语义越相似(如 "如何使用LangChain4j的Easy RAG" 和 "LangChain4j中Easy RAG的实现步骤" 两句的向量语义就很接近);
- 值越接近0:两个向量语义关联性极低(如 "RAG的索引步骤" 和 "猫咪的喂养方法")。
- 关键意义:这是RAG中"语义检索"的核心逻辑------用户查询先被转为嵌入向量,再通过此方法与向量数据库中存储的文档片段向量计算相似度,筛选出最相关的内容注入LLM,直接决定检索结果的准确性。
- 核心作用 :衡量两个嵌入向量在"语义空间"中的相似程度,返回值范围为 -1, 1 (在RAG场景中通常取正值,实际有效范围为0, 1)。
-
Embedding.normalize():对嵌入向量进行标准化处理(原地修改)- 核心作用:将嵌入向量转换为"单位向量"(即向量的"模长"为1,所有元素的平方和为1),且不改变向量在语义空间中的方向。
- 关键意义:余弦相似度的本质是"两个向量夹角的余弦值",当向量经过标准化后,"向量点积"的结果就等同于余弦相似度(无需额外计算模长),能显著简化相似度计算的步骤、提升效率。此方法通过"原地修改"向量(不创建新对象),还能减少内存占用,适合大规模向量处理场景。
2.2 Embedding Model
Embedding Model 即嵌入模型。EmbeddingModel 是 LangChain4j 中定义的一个接口(规范),专门用来表示「文本转向量」的模型。你可以把它理解成一个 "文本编码工具" 的统一操作标准 ------ 不管是用 OpenAI 的嵌入模型、本地的 bge-small 模型,只要实现了这个接口,就能用同样的方式把文字转换成计算机能理解的向量(Embedding)。
EmbeddingModel 接口的核心方法如下:
embed(String):最基础的用法,传入一段普通文本(比如 "如何使用 RAG"),返回这段文本对应的向量。embed(TextSegment):针对 LangChain4j 中封装好的「文本片段」(TextSegment,比如拆分后的文档小片段)做向量转换,会自动带上片段的元数据上下文。embedAll(List<TextSegment>):批量转换多个文本片段,适合处理大量拆分后的文档内容,效率比逐个调用 embed 更高。dimension():返回该模型生成的向量维度(比如 bge-small-en-v1.5 是 384 维,OpenAI text-embedding-3-small 是 1536 维),维度决定了向量的 "信息量" 和存储 / 计算成本。
2.3 Embedding Store
LangChain4j 中提供了 EmbeddingStore 接口表示Embedding的存储库,也称为向量数据库。EmbeddingStore 本质是向量数据库的抽象接口,专门用来存 Embedding(文本转成的数值向量),核心能力是「存向量」+「快速找相似向量」(通过向量空间的距离判断相似度)。
LangChain4j 目前支持的嵌入存储参考 此处。
EmbeddingStore 的存储方式分两种:
- 轻量化存储:只存 Embedding + ID,原始文本(如 TextSegment)存在别处,通过 ID 关联(省空间,但查的时候要额外关联);
- 完整存储:同时存 Embedding + 原始文本(TextSegment),查的时候直接返回,更方便但占用空间多。
下面我们来介绍 EmbeddingStore 中所涉及的一些组件
-
EmbeddingSearchRequest :表示在 EmbeddingStore 中进行搜索的请求,承载了请求的条件信息。包含 4 个关键参数:
queryEmbedding:参考向量(比如用户问题转成的 Embedding),以此为基准找相似向量;maxResults:最多返回多少条结果(默认 3 条);minScore:相似度分数阈值(0-1),只返回分数≥这个值的结果(默认 0,即不筛选);filter:元数据筛选器,只返回 Metadata 符合条件的 TextSegment 结果(比如只找「文档类型 = PDF」的内容)。
-
Filter :在做向量搜索时,可以用 Metadata(元数据) 来过滤结果,比如只搜某个来源、某个作者、某个时间的文档。
Filter 目前支持
等于、不等于、大于、大于等于、小于、小于等于、在列表里、不在列表里、包含这些常见的条件判断 并且可以通过and、or、not组合条件进行组合查询。需要注意的是:
-
EmbeddingSearchResult :
EmbeddingSearchResult是 LangChain4j 中专门用来承载向量搜索结果的封装类,它的核心作用就是把向量数据库(EmbeddingStore)中相似性搜索的结果结构化返回,让开发者能清晰获取匹配到的内容。具体拆解如下:
- 本质定位:它是一个「结果容器」,所有从 EmbeddingStore 中执行相似性搜索(比如余弦相似度匹配)后得到的结果,都会被封装成这个类的实例返回。
- 核心内容 :它的核心属性是
EmbeddingMatch类型的列表(List)。每个EmbeddingMatch又包含三部分关键信息:- 匹配到的
Embedding(向量本身) - 对应的原始文本片段(
TextSegment) - 相似度分数(比如余弦相似度值,越接近1表示匹配度越高)
- 匹配到的
- 使用场景 :在 RAG 的「检索阶段」,当你把用户问题转换成向量、去 EmbeddingStore 搜索相似内容时,最终拿到的就是
EmbeddingSearchResult,你可以从中提取Top N个高相似度的文本片段,注入到LLM的提示词中。
逻辑示例如下:
java// 1. 把用户问题转成向量 Embedding queryEmbedding = embeddingModel.embed("How to use Easy RAG?"); // 2. 去向量库搜索相似内容 EmbeddingSearchResult searchResult = embeddingStore.search(queryEmbedding, 5); // 取Top5 // 3. 从结果中提取匹配的文本片段 List<TextSegment> relevantSegments = searchResult.matches().stream() .map(EmbeddingMatch::embeddedObject) // 获取TextSegment .toList(); -
Embedding Match : EmbeddingMatch 就是向量检索返回的一条 "匹配结果",里面同时装了:
- 匹配到的向量 Embedding
- 相似度 / 相关度分数 score
- 这条数据的唯一 ID
- 原始文本片段 TextSegment
它是 RAG 检索环节里,从向量库查回来的标准结果对象。
2.4 Embedding Store Ingestor
EmbeddingStoreIngestor 是LangChain4j中封装好的文档入库流水线工具 ,本质是一个数据摄入流水线,负责把原始的 Document(文档)处理后存入 EmbeddingStore(向量数据库),是连接 "原始文档" 和 "向量存储" 的桥梁。
-
基础功能(最简配置)
只需要指定
EmbeddingModel(嵌入模型)和EmbeddingStore(向量库),它会自动完成:- 使用嵌入模型把
Document转换成向量(Embedding) - 将 "文档 + 向量" 一起存入向量库
- 所有
ingest()方法都会返回IngestionResult,能查看嵌入过程的令牌消耗(TokenUsage)等关键信息。
如下官方示例:使用嵌入模型将 "文档 + 向量" 一起存入向量库 ,并返回令牌消耗数据
javaEmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder() .embeddingModel(embeddingModel) .embeddingStore(embeddingStore) .build(); ingestor.ingest(document1); ingestor.ingest(document2, document3); IngestionResult ingestionResult = ingestor.ingest(List.of(document4, document5, document6)); - 使用嵌入模型把
-
可选的流水线扩展(核心价值)
它支持在 "嵌入存储" 前对数据做三步可选处理,解决实际场景中的数据优化问题:
DocumentTransformer:预处理原始文档(如清洗、加元数据、格式化)DocumentSplitter:拆分大文档为小的TextSegment,解决大文档向量搜索效果差、提示词token成本高的问题;TextSegmentTransformer:预处理拆分后的文本片段(如补充文档名),提升后续检索的精准度。
如下官方示例:
javaEmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder() // 给每个文档加了`userId`元数据,方便后续按用户过滤; .documentTransformer(document -> { document.metadata().put("userId", "12345"); return document; }) // splitting each Document into TextSegments of 1000 tokens each, with a 200-token overlap // 将大文档拆分:拆成1000令牌/段,重叠200令牌 .documentSplitter(DocumentSplitters.recursive(1000, 200, new OpenAiTokenCountEstimator("gpt-4o-mini"))) // adding a name of the Document to each TextSegment to improve the quality of search // 把文件名加到片段开头,提升语义搜索的准确性。 .textSegmentTransformer(textSegment -> TextSegment.from( textSegment.metadata().getString("file_name") + "\n" + textSegment.text(), textSegment.metadata() )) .embeddingModel(embeddingModel) .embeddingStore(embeddingStore) .build();
五、Naive RAG
上面我们已经介绍过三种 RAG 的分类,可以知道 Naive RAG 是 Easy RAG 的 "功能升级版",相应的,功能升级就代表着复杂度提升,下面我们具体来看。
- Easy RAG 是基于成熟框架或工具链的低代码 / 无代码解决方案,通过封装底层技术细节(如文档解析、向量存储、嵌入模型),大幅简化 RAG 系统的搭建流程。
- Naive RAG 通过手动编写代码实现 RAG 的核心流程,完全控制每个技术环节(从数据预处理到检索逻辑)。
当一个 文档经过加载(如通过FileSystemDocumentLoader)、分割(如DocumentSplitter拆成TextSegment)、嵌入(EmbeddingModel转成向量),最终存储到EmbeddingStore(向量数据库)中后,后续便可以从向量数据库中"检索"相关内容,这是配置RAG的基础。
如下,我们可以通过 AiServices 来配置 Native RAG :
java
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(5)
.minScore(0.75)
.build();
Assistant assistant = AiServices.builder(Assistant.class)
.chatModel(model)
.contentRetriever(contentRetriever)
.build();其中 EmbeddingStoreContentRetriever是LangChain4j中实现"检索"功能的核心类,作用是从EmbeddingStore(向量库)中,根据用户查询的向量,找到最相关的文本片段,是"简单RAG"的核心检索器。
代码中通过builder()模式配置了4个关键参数,每个参数的作用直接影响检索效果:
| 参数名 | 作用说明 |
|---|---|
embeddingStore |
指定检索的"数据源"------即之前存储了文档向量的向量库(如InMemoryEmbeddingStore或第三方向量库) |
embeddingModel |
指定将"用户查询"转成向量的模型------需与文档嵌入时用的模型一致(保证向量空间统一,检索准确) |
maxResults(5) |
限制每次检索返回的"最相关文本片段数量"(此处为5条,避免返回过多无关内容占用LLM上下文) |
minScore(0.75) |
设定相关性分数阈值(范围0-1)------只返回分数≥0.75的结果,过滤低相关性内容,提升回答质量 |
六、Advanced RAG
LangChain4j 中的 Advanced RAG(高级检索增强生成)是对基础 RAG 的模块化扩展,核心是通过多阶段的组件协作解决简单 RAG 中「单一检索、无优化」的问题,提升检索精准度和生成效果。以下是核心组件和流程的通俗解析:
| 组件 | 核心作用 |
|---|---|
| QueryTransformer | 「查询优化器」:把用户原始问题(Query)改写/拆分/优化,比如将模糊问题拆成多个精准子查询,或翻译成适配检索的格式。 |
| QueryRouter | 「查询路由器」:根据查询类型/领域,把不同子查询分发到对应的检索器(比如电商问题路由到商品库检索,售后问题路由到售后文档检索)。 |
| ContentRetriever | 「多源检索器」:每个检索器对应不同数据源(向量库、全文检索库、数据库等),负责针对单个子查询拉取相关内容。 |
| ContentAggregator | 「内容聚合器」:收集所有检索器返回的内容,去重、排序(按相关性),最终生成一份统一的优质内容列表。 |
| ContentInjector | 「内容注入器」:把聚合后的相关内容嵌入到用户原始提问的上下文里,形成包含「问题+参考内容」的完整提示词。 |
这些组件的协同工作过程是「单问题 → 多精准查询 → 多源检索 → 内容整合 → 增强提示」的闭环,具体如下:
-
流程起点:从"用户消息"到"检索查询"
用户输入的自然语言消息(
UserMessage,比如"如何配置LangChain4j的向量存储?")会先被转换为标准化的Query------这一步是为了统一后续检索组件的"输入格式",避免自然语言的模糊性,让检索更精准(比如将口语化表述转化为更贴合数据存储逻辑的查询形式)。 -
流程扩展:Query的"优化与拆分"(QueryTransformer)
QueryTransformer(查询转换器)会对原始Query进行处理,可能输出1个或多个新Query。核心作用是提升检索覆盖度:- 比如用户问"RAG的索引步骤",转换器可能拆分为"RAG索引阶段的文档预处理""RAG索引的向量存储步骤"两个子Query,分别对应不同数据源的信息,避免漏检;
- 也可能优化Query表述(比如补充领域术语),让后续检索更匹配数据存储中的内容。
-
流程分发:Query的"精准路由"(QueryRouter)
QueryRouter(查询路由器)负责将每个Query分配到对应的ContentRetriever(内容检索器)。核心逻辑是"按需匹配数据源":- 假设系统中有多个检索器(比如"文档检索器"对应本地PDF文档、"API检索器"对应外部知识库接口),路由器会根据Query的类型(如"本地配置问题"→文档检索器,"实时数据问题"→API检索器),将Query发送到最适合的检索器,避免无效检索。
-
流程核心:信息的"检索获取"(ContentRetriever)
每个
ContentRetriever会针对分配到的Query,从对应的数据源(如向量数据库、文件系统、API接口)中抓取最相关的Content(内容片段)------比如从本地文档中提取"LangChain4j索引阶段的 chunking 步骤说明",这一步是RAG"外部信息注入"的核心,直接决定后续LLM回答的依据是否准确。 -
流程整合:检索结果的"去重与排序"(ContentAggregator)
由于可能存在多个Query、多个检索器返回的多份Content,
ContentAggregator(内容聚合器)会做两件关键事:- 合并去重:剔除重复或高度相似的Content,避免冗余;
- 排序优化:根据"Content与原始用户需求的相关性"(如向量相似度、关键词匹配度)对Content排序,让最核心的信息排在前面,减少LLM处理负担。
-
流程收尾:信息注入与LLM调用
最终排序后的Content列表会被"注入"回原始的
UserMessage中,形成一份"用户原始问题+精准外部信息"的组合输入,再发送给LLM。此时LLM无需依赖自身有限的训练数据,而是基于注入的外部信息生成回答,既能避免"幻觉",又能覆盖训练数据之外的领域知识(如企业内部文档、最新技术文档等)。
官网上也给了具体的工作流程图,如下:
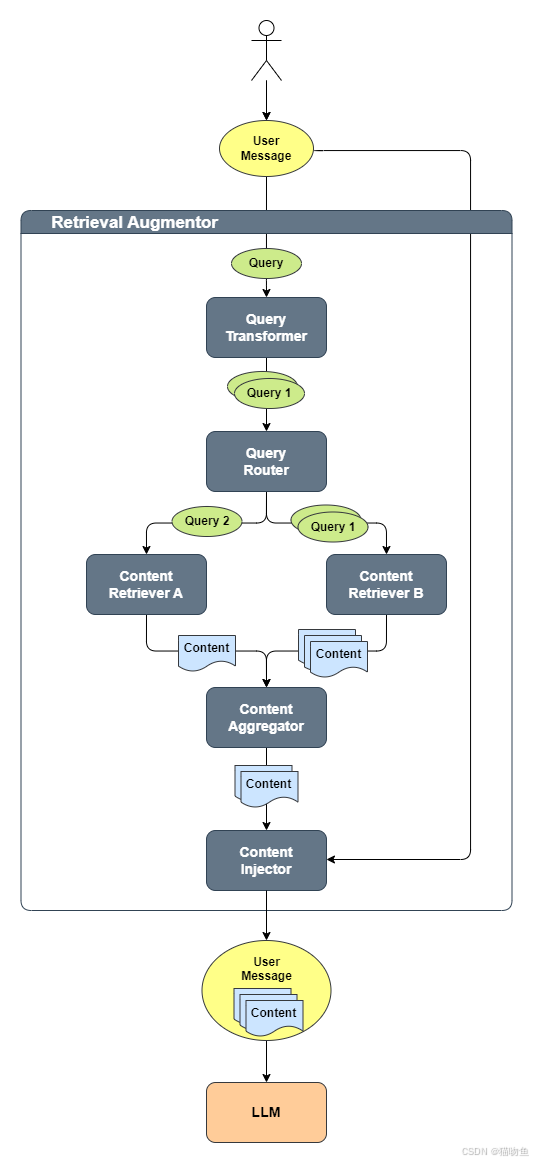
简言之,整个流程的核心目标是:通过"拆分-路由-检索-聚合"的标准化步骤,让LLM"带着精准的外部信息"回答问题,是RAG架构中"检索"与"生成"衔接的关键环节。
伪代码如下:
java
// 用户查询
// -> Query(原始查询内容)
// -> QueryTransformer : 转为更合规的 Query)
// -> QueryRouter : 根据 Query 的内容路由到匹配的 ContentRetriever)
// -> ContentRetriever : 进行内容检索,输出 Content)
// -> contentAggregator : 对输出的 Content 进行排序聚合)
// -> contentInjector : 将最终的 Content 注入到 UserMessage 中一起发给 LLM
DefaultRetrievalAugmentor retrievalAugmentor = DefaultRetrievalAugmentor.builder()
// 指定 查询转换器 :将查询内容转化为更合规的 Query 内容
.queryTransformer()
// 指定 查询路由器 :将用户查询的 Query 分配到对应的 contentRetriever上
.queryRouter()
// 指定 内容检索器 :筛选与 Query 相关的 Content 内容
.contentRetriever()
// 指定 内容整合器 :整合来自不同渠道的已排序 Content 列表
.contentAggregator()
// 指定 内容注入器 :将筛选整合后的 Content 注入到 UserMessage 中
.contentInjector()
// 指定 查询(Query)和检索(ContentRetriever)时的线程处理机制
.executor()
.build();
return AiServices.builder(AdvancedRagAssistant.class)
.chatModel(chatModel)
.chatMemoryProvider(chatMemoryProvider)
.retrievalAugmentor(retrievalAugmentor)
.contentRetriever()
.build();下面我们看每个组件的详细介绍。
1. Retrieval Augmentor
RetrievalAugmentor 是 LangChain4j 中 RAG 管道(检索增强生成流程)的核心入口组件,它的核心职责是:
- 接收用户的 UserMessage(用户提问);
- 从各类数据源(向量库、数据库等)检索与提问相关的 Content(文本片段、文档内容等);
- 将这些相关内容 "注入" 到 ChatMessage 中,让 LLM 能基于这些外部知识回答问题(而非仅依赖自身训练数据)。
简单来说,它就是 "把检索到的知识喂给大模型" 的关键环节,是 RAG 中 "检索 + 增强" 的核心执行者。
在 LangChain4j 中,RetrievalAugmentor 需通过 AiServices.builder() 绑定到具体的 AI 服务(如对话助手 Assistant),代码逻辑如文档所示:
java
Assistant assistant = AiServices.builder(Assistant.class)
// 其他配置(如LLM模型、聊天记忆等)
.retrievalAugmentor(retrievalAugmentor) // 绑定RetrievalAugmentor实例
.build();每次调用该 AI 服务(如 assistant.chat("用户问题"))时,绑定的 RetrievalAugmentor 会自动被触发------先检索与"当前用户消息(UserMessage)"相关的 Content,再将这些内容注入到 UserMessage 中,最后将"增强后的消息"传给 LLM 生成回答。
LangChain4j 提供两种使用方式,适配不同需求:
-
默认实现(DefaultRetrievalAugmentor):
- LangChain4j 提供了的 默认实现,已封装了"查询处理、多源检索、结果聚合"等基础逻辑,降低上手成本,适用于大多数 RAG 用例 开箱即用,无需手动开发,
-
自定义实现:
- 若业务有特殊需求(如自定义检索数据源、复杂的结果过滤规则、多阶段检索逻辑等),可通过实现
RetrievalAugmentor接口,按需定制"检索-增强"流程。
- 若业务有特殊需求(如自定义检索数据源、复杂的结果过滤规则、多阶段检索逻辑等),可通过实现
2. Query & Query Transformer
简单来说 :Query 是带上下文的用户问题,QueryTransformer 负责把它改得更利于检索。
2.1 Query
在RAG(检索增强生成)流程中,Query是用户查询的结构化表示,是连接"用户需求"与"检索系统"的核心载体。它并非简单的用户输入文本,而是包含两部分关键信息:
-
查询文本:用户原始提问内容(如"LangChain4j的Easy RAG如何实现?");
-
查询元数据(Query Metadata) :辅助检索的上下文信息,用于让RAG各组件更精准地理解查询背景、筛选数据。
元数据是
Query的"附加信息库",作用是为RAG流程中的检索、路由等组件提供决策依据,避免因信息缺失导致检索偏差。核心包含4类关键信息:元数据项 作用场景与示例 Metadata.userMessage()存储原始用户消息,确保后续增强(如注入检索内容)时不偏离用户初始需求。 Metadata.chatMemoryId()通过 @MemoryId注解关联用户标识(如用户ID),用于权限控制或数据筛选(例:仅检索该用户有权访问的文档)。Metadata.chatMemory()携带历史对话记录(如之前的提问、AI回复),帮助理解查询的上下文(例:用户后续问"他是谁"时,明确"他"指历史中的"John Doe")。 Metadata.invocationParameters()存储调用AI服务时的自定义参数(如 userId: 12345),支持组件间数据传递(例:从RAG检索组件将用户ID传递给工具调用组件),参数存储在"可变、线程安全的Map"中,确保多组件协同可靠。
2.2 Query Transformer
Query Transformer(查询转换) 是提升检索精度的关键前置步骤 ------ 它能将用户的原始模糊问题((如"他住在哪?"未明确"他"指谁)),转化为更精准、更适配检索的查询语句(如补充语义、拆分多意图、翻译成模型适配语言、纠错等),尤其适合中文场景下的口语化 / 模糊问题处理。
LangChain4j提供3类核心实现:
-
Default Query Transformer(默认转换器)
- 逻辑:无任何修改,直接将原始Query传递给检索组件;
- 适用场景:用户查询本身清晰、无歧义(如"什么是RAG?"),无需额外处理。
-
Compressing Query Transformer(压缩转换器)
- 核心能力 :用LLM将"当前Query + 历史对话"压缩为独立、完整的Query,解决"上下文依赖型查询"的歧义问题;
- 典型示例 :
- 历史对话:用户问"介绍下John Doe",AI回复"John Doe是XX";
- 用户后续查询:"他住在哪?"(原始Query无"John Doe",检索会失效);
- 转换器输出:"John Doe住在哪?"(补充上下文,确保检索精准);
- 适用场景:多轮对话中的后续提问(依赖历史信息的查询)。
-
Expanding Query Transformer(扩展转换器)
- 核心能力 :用LLM将1个原始Query扩展为多个Query(多维度重新表述),扩大检索覆盖范围;
- 逻辑 :LLM会从不同角度改写查询(如同义词替换、句式调整、补充潜在需求),例:
- 原始Query:"LangChain4j如何集成向量存储?";
- 扩展后Query:①"LangChain4j连接向量数据库的步骤?"②"LangChain4j中EmbeddingStore的集成方法?"③"如何在LangChain4j中使用向量存储实现RAG?";
- 适用场景:需要全面检索、避免遗漏相关信息的场景(如复杂问题、多维度需求)。
同样的,用户可以通过实现 QueryTransformer 接口来自定义 QueryTransformer 。
Query及其 Query Transformer 是RAG流程中"提升检索精准度"的关键环节:
Query通过"文本+元数据"结构化用户需求,为后续组件提供完整上下文;- 转换器则针对不同查询缺陷(歧义、范围窄)进行优化,确保检索到的信息"准、全、相关",最终为LLM生成可靠回答奠定基础。
3. Content & Content Retriever
Content 是资料,ContentRetriever 是找资料的工具,不同实现对应不同数据源,一起组成 RAG 的 "检索" 环节。
3.1 Content
Content 是 RAG(检索增强生成)流程中 "检索" 阶段的关键产出 ------ 它特指从文档库中筛选出的、与用户 Query(查询)语义相关的信息片段,是后续注入 LLM(大语言模型) prompt、辅助模型生成精准回答的核心依据。
目前 Content 仅支持文本类型,且具体对应框架中的TextSegment类(即文档拆分后形成的文本片段)。这意味着当前 LangChain4j 的 RAG 能力仅围绕 "文本知识库" 展开,暂不支持非文本类数据的检索与增强。
3.2 Content Retriever
ContentRetriever(内容检索器) 是 RAG(检索增强生成)流程中的 "检索执行者",核心作用是接收用户的Query(查询,如问题、需求文本),并从指定的底层数据源中筛选出与Query相关的Content(内容,如文档片段、数据库记录等),为后续 LLM(大语言模型)生成回答提供 "事实依据"。
它对数据源的兼容性极强,覆盖了 RAG 场景中常见的各类存储 / 检索系统,具体包括:
- 嵌入存储(Embedding Store):如向量数据库(Milvus、Qdrant 等),存储文本的向量表示,通过语义相似度匹配检索;
- 全文搜索引擎:如 Elasticsearch,基于关键词(TF-IDF、BM25 等算法)匹配检索文本;
- 混合检索系统:结合向量语义搜索与全文关键词搜索,平衡 "语义理解" 与 "精准匹配";
- 网络搜索引擎:直接对接外部网络(如 Google、 Bing),获取实时 / 公开的网络信息;
- 知识图谱:从结构化的实体 - 关系网络(如 Neo4j)中检索关联的实体、属性或关系;
- SQL 数据库:从传统关系型数据库(如 MySQL、PostgreSQL)中通过 SQL 查询获取结构化数据;
- 其他:理论上可扩展至任何能提供 "可检索内容" 的系统(如 NoSQL 数据库、本地文件库等)。
检索得到的Content列表会按 "相关性从高到低" 排序------ 即最匹配Query需求的内容排在最前,确保后续注入 LLM 时,模型优先使用最相关的信息,减少冗余计算并提升回答准确性。
在 LangChain4j 中提供了诸多是实现,下面我们具体来看。
3.2.1 Embedding Store Content Retriever
EmbeddingStoreContentRetriever 是 LangChain4j 中实现 Naive RAG 的核心组件,其核心作用是连接"查询嵌入"与"向量存储检索",为 LLM 筛选出与用户查询相关的内容(Content),具体逻辑可拆解为 3 个关键步骤:
-
输入:接收用户查询(Query)
用户发起的原始查询(如"如何用 LangChain4j 实现 Easy RAG")会作为输入,该查询需先转化为可用于"语义匹配"的格式------这一步依赖
EmbeddingModel。 -
核心步骤:查询嵌入(Query Embedding)
借助传入的
EmbeddingModel(如默认的 bge-small-en-v1.5),将用户的文本查询转化为数值向量(Embedding):- 原理:嵌入模型通过语义理解,把文本中的"含义"编码成固定维度的数字向量(如 384 维、768 维),语义越相似的文本,向量在空间中的距离越近。
- 作用:将"文本匹配"转化为"向量相似度计算",解决传统关键词搜索无法理解语义的问题(如"如何实现"与"怎样做"语义相近,向量距离会很小)。
-
核心步骤:从 EmbeddingStore 检索相关内容
基于生成的"查询向量",在
EmbeddingStore(向量数据库,如 InMemoryEmbeddingStore、Milvus 等)中执行相似度搜索:- 搜索逻辑:计算"查询向量"与存储在
EmbeddingStore中的所有"内容向量"(即之前通过EmbeddingStoreIngestor存入的 TextSegment 嵌入结果)的相似度(常用余弦相似度)。 - 结果筛选:根据配置的参数(如
maxResults限制返回数量、minScore过滤低相似度结果),筛选出 Top N 个最相关的TextSegment(即"相关 Content")。
- 搜索逻辑:计算"查询向量"与存储在
-
输出:为 LLM 提供"相关上下文"
检索到的相关 Content 会被注入到 LLM 的 Prompt 中,让 LLM 基于这些"实时、专属"的信息生成回答,避免依赖过时训练数据或产生幻觉。
简言之,EmbeddingStoreContentRetriever 的本质是 语义中介 :一边用 EmbeddingModel 把查询"翻译"成向量,一边在 EmbeddingStore 中找到"向量最像"的内容,最终为 RAG 提供"精准的上下文输入"。
3.2.2 Web Search Content Retriever
WebSearchContentRetriever 是 LangChain4j 中用于从网络获取相关内容(Content) 的组件,其核心逻辑是依托 WebSearchEngine(网页搜索引擎)实现检索能力,本质是将"网络搜索"整合进 RAG(检索增强生成)流程,解决本地/私有数据覆盖不到的"实时性、通用性信息需求"(例如查询最新行业动态、公共知识更新等)。
在 RAG pipeline 中,它补充了传统"基于本地向量库检索"的局限:当用户查询涉及本地数据未包含的信息 (如2025年后的新政策、实时新闻、公开文档更新等)时,WebSearchContentRetriever 会调用配置的 WebSearchEngine 执行网页搜索,抓取相关结果并整理为"可注入 LLM prompt 的 Content",最终让 LLM 基于"本地数据+网络实时数据"生成更准确的回答。
它本身不直接实现搜索功能,而是依赖 WebSearchEngine 接口的具体实现(即 LangChain4j 支持的"网页搜索引擎集成")。用户需通过配置指定使用的搜索引擎(如谷歌搜索、必应搜索、自定义企业级网页检索服务等),组件会通过对应引擎的 API 发起搜索请求、解析返回结果(如提取网页标题、正文片段、来源链接等),并封装为标准化的 Content 格式。
对比 LangChain4j 中基于本地向量库的 EmbeddingStoreContentRetriever,WebSearchContentRetriever 的核心差异在于数据来源:
EmbeddingStoreContentRetriever:从本地预存储的向量数据库(如 PGVector、Milvus 等)中检索;WebSearchContentRetriever:从公开/指定网络资源中实时检索,无需提前存储数据,适合动态、时效性强的场景。
如果要使用该组件,需先引入对应 WebSearchEngine 集成的依赖(如谷歌搜索集成、必应搜索集成等),并配置搜索引擎的 API 密钥(如果需要);
具体支持的
WebSearchEngine列表参见官网给出的链接 :https://docs.langchain4j.dev/category/web-search-engines,有具体使用示例。
官网示例如下:
java
WebSearchEngine googleSearchEngine = GoogleCustomWebSearchEngine.builder()
.apiKey(System.getenv("GOOGLE_API_KEY"))
.csi(System.getenv("GOOGLE_SEARCH_ENGINE_ID"))
.build();
ContentRetriever contentRetriever = WebSearchContentRetriever.builder()
.webSearchEngine(googleSearchEngine)
.maxResults(3)
.build();3.2.3 SQL Database Content Retriever
作为 LangChain4j 中 ContentRetriever 接口的实验性实现,核心作用是从 SQL 数据库中检索与自然语言查询(Query)相关的内容,而非传统的向量数据库或文档库。
需引入
langchain4j-experimental-sql模块("experimental" 表明其功能仍在迭代中,暂不建议直接用于生产环境)。
其核心是通过 "自然语言→SQL→数据库查询→结果返回" 的链路,实现对结构化数据(SQL 数据库)的检索,依赖两个关键组件:
- DataSource:即数据库连接源,用于建立与 SQL 数据库(如 MySQL、PostgreSQL 等)的连接,是获取数据的基础。
- LLM(大语言模型) :负责将用户输入的自然语言 Query(如"查询 2024 年 Q1 销售额超过 100 万的产品")转化为合法、可执行的 SQL 语句,同时可能辅助处理查询结果的格式适配(确保符合
ContentRetriever接口的输出要求)。
适用于需要直接从结构化 SQL 数据库中获取数据来支撑 LLM 回答的场景,例如:
- 企业内部数据查询(如财务数据、用户行为数据):用户用自然语言提问,无需手动写 SQL,即可获取数据库中的精准数据。
- 数据驱动的问答系统:结合 RAG 流程,将 SQL 查询结果作为"相关信息"注入 LLM prompt,提升回答的准确性和数据时效性。
关键注意事项
- 实验性特性:因处于"experimental"阶段,功能稳定性、兼容性(如对复杂 SQL 语法的支持、不同数据库的适配)可能存在限制,使用前需通过 Javadoc 确认当前版本的支持范围。
- 依赖配置 :除引入
langchain4j-experimental-sql模块外,还需配置对应 SQL 数据库的驱动(如mysql-connector-java)及DataSource连接信息(URL、用户名、密码等)。 - LLM 选型影响:SQL 生成的准确性高度依赖所用 LLM 的能力(如对 SQL 语法、表结构的理解),建议选择对结构化查询语言支持较好的模型(如 GPT-4、Claude 等)。
官方提供了示例 Demo,详参 :官方示例
3.2.4 Azure AI Search Content Retriever
AzureAiSearchContentRetriever 是与Azure AI 搜索的集成。它支持全文搜索、向量搜索和混合搜索,以及重新排序。它可以在langchain4j-azure-ai-search模块中找到。
更多信息参考官网
3.2.5 Neo4j Content Retriever
Neo4jContentRetriever 是与 Neo4j 图形数据库的集成。它能将自然语言查询转换为 Neo4j Cypher 查询,并通过在 Neo4j 中运行这些查询来检索相关信息。它可以在 langchain4j-community-neo4j-retriever 模块中找到。
更多信息参考官网
3.2.6 Elasticsearch Content Retriever
ElasticsearchContentRetriever 是与Elasticsearch的集成。它支持全文搜索、向量搜索和混合搜索。可以在langchain4j-elasticsearch模块中找到它。有关更多信息,请参考ElasticsearchContentRetriever的Javadoc。
更多信息参考官网
4. Query Router
QueryRouter(查询路由器)是 LangChain4j 中 Advanced RAG(高级检索增强生成) pipeline 的关键组件,核心职责是根据规则或智能判断,将用户的 Query(查询)精准分配到对应的 ContentRetriever(内容检索器),确保后续能从最相关的数据源中获取信息,提升 RAG 结果的准确性和效率。
可以用来实现工作流中的意图识别路由。
LangChain4j 提供了两种主流的 QueryRouter 实现,适配不同的使用场景,具体差异如下:
| 实现类型 | 核心逻辑 | 适用场景 |
|---|---|---|
| DefaultQueryRouter | 无需复杂判断,直接将 单个 Query 路由到所有已配置的 ContentRetriever。 | 场景简单、数据源数量少,或需要从所有数据源"全面检索"以避免遗漏信息的场景(如小型知识库、单一类型文档集合)。 |
| LanguageModelQueryRouter | 借助 大语言模型(LLM)的语义理解能力,分析 Query 意图后,决定路由到哪些 ContentRetriever。 | 场景复杂、数据源多样(如区分"产品文档""技术手册""用户反馈"等不同数据源),需要根据 Query 语义精准匹配数据源的场景(如企业级多维度知识库)。 |
Query Router 的关键价值在于:
- 降低检索冗余:避免盲目从所有数据源检索(尤其是数据源庞大时),减少无效计算和时间成本;
- 提升检索精准度:通过"按需路由",确保 Query 只进入最相关的 ContentRetriever,减少无关信息干扰;
- 适配复杂场景:支持多数据源、多检索策略的灵活组合(如部分数据源用向量检索,部分用关键词检索),满足多样化 RAG 需求。
5. Content Aggregator
ContentAggregator(内容聚合器)是 LangChain4j 中 Advanced RAG(高级检索增强生成) 流程的关键组件,核心职责是整合来自不同渠道的已排序 Content 列表,最终输出一份统一、优化的内容列表,为后续注入 LLM 提供高质量参考信息。其聚合的来源明确包含两类:
- 多个 Query(查询) :即用户原始查询经
QueryTransformer转换后生成的多个衍生查询,每个查询可能从数据中检索到独立的排序内容列表。 - 多个 ContentRetriever(内容检索器):即不同类型的检索工具(如向量检索器、全文检索器,或连接不同数据源的检索器),每个检索器会返回各自排序的相关内容。
LangChain4j 提供了两种常用的 ContentAggregator 实现,适配不同的优化需求:
-
DefaultContentAggregator(默认内容聚合器)
- 核心逻辑 :采用 两阶段 reciprocal rank fusion(RRF, reciprocal rank fusion, reciprocal 排序融合) 算法。
RRF 的核心思想是:不直接依赖各来源内容的原始评分,而是通过内容在不同列表中的"排名位置" 计算综合得分,从而平衡不同检索渠道的结果(例如避免单一检索器因评分偏差导致优质内容被忽略)。
例如:某条 Content 在列表 A 中排第 2 名,在列表 B 中排第 5 名,RRF 会通过公式(如1/(k + rank),k 为常数)将排名转换为得分后求和,最终确定其在聚合列表中的位置。 - 适用场景:无需额外引入外部模型,追求轻量、高效的基础聚合效果,适合大多数通用 RAG 场景。
- 核心逻辑 :采用 两阶段 reciprocal rank fusion(RRF, reciprocal rank fusion, reciprocal 排序融合) 算法。
-
ReRankingContentAggregator(重排序内容聚合器)
- 核心逻辑 :依赖 ScoringModel(评分模型,如 Cohere 等专门的重排序模型) ,对所有来源的 Content 进行二次评分与排序 。
与 RRF 基于"排名"的间接融合不同,它直接让专业模型分析内容与用户查询的语义相关性,重新计算更精准的得分,从而进一步提升聚合结果的质量(尤其适合原始检索结果噪音较多的场景)。 - 关键依赖 :需集成外部评分模型(支持的模型列表可通过官方链接查询),会额外消耗模型调用资源,但能获得更优的相关性排序。
- 适用场景:对检索精度要求高的场景(如专业领域问答、复杂query理解),愿意承担额外模型成本以提升结果准确性。
- 核心逻辑 :依赖 ScoringModel(评分模型,如 Cohere 等专门的重排序模型) ,对所有来源的 Content 进行二次评分与排序 。
6. Content Injector
ContentInjector(内容注入器) 是 LangChain4j 中 Advanced RAG(高级检索增强生成)流程的关键组件,核心职责是将 ContentAggregator(内容聚合器)筛选、排序后的相关 Content(检索到的文档片段等信息),以特定格式注入到 UserMessage(用户提问)中,最终生成包含"用户问题+相关参考信息"的完整输入,传递给 LLM 用于生成回答。
6.1 DefaultContentInjector
DefaultContentInjector 是 ContentInjector 的默认实现,无需额外配置即可使用,其注入规则固定:
- 位置:将检索到的 Content 附加到 UserMessage 的末尾;
- 前缀 :所有 Content 统一以
Answer using the following information:作为开头,明确告知 LLM"需基于以下信息回答"; - 格式:每个 Content 会默认展示其文本内容(TextSegment.text()),若配置了 Metadata 注入,还会附带指定的 Metadata 键值对(如来源、日期等)。
若上面说的默认格式不满足需求(如调整前缀、改变内容顺序、增加额外说明),可通过以下 3 种方式自定义:
-
覆盖默认 PromptTemplate(最常用)
通过自定义
PromptTemplate(提示模板),灵活控制 UserMessage 与 Content 的组合格式,核心要求是模板中必须包含{``{userMessage}}(用户问题占位符)和{``{contents}}(检索到的 Content 占位符)。示例:将 Content 直接跟在用户问题后,不添加默认前缀(仅保留换行分隔):
java// 1. 构建自定义 ContentInjector(使用自定义 PromptTemplate) ContentInjector customInjector = DefaultContentInjector.builder() .promptTemplate(PromptTemplate.from("{{userMessage}}\n{{contents}}")) // 模板:用户问题 + 换行 + Content .build(); // 2. 将自定义 Injector 配置到 RetrievalAugmentor(RAG 流程入口) RetrievalAugmentor retrievalAugmentor = DefaultRetrievalAugmentor.builder() .contentInjector(customInjector) .build(); -
继承 DefaultContentInjector 并重写 format 方法
若需更精细的格式控制(如对不同类型的 Content 应用不同前缀),可继承 DefaultContentInjector,并重写其
format相关方法(如format(UserMessage, List<Content>)),自定义内容拼接逻辑。 -
完全实现自定义 ContentInjector
若默认实现的框架无法满足需求(如注入前需对 Content 做复杂处理,或调整注入位置到用户问题之前),可直接实现
ContentInjector接口,自行定义全套"Content 注入 UserMessage"的逻辑(需实现接口中的inject方法)。
7. Parallelization
DefaultRetrievalAugmentor(并行化)在处理查询和检索时的线程处理机制:
-
单任务场景:当只有一个查询(Query)和一个内容检索器(ContentRetriever)时,查询路由和内容检索会在同一个线程中依次执行,无需并行处理。
-
多任务场景 :当存在多个查询或多个检索器时,会通过
Executor进行并行处理,以提高效率。 -
默认线程池 :默认使用的是经过修改的
Executors.newCachedThreadPool(),其区别(线程空闲存活时间)从默认的60秒调整为1秒,更适合短期任务处理。 -
自定义配置 :允许在创建
DefaultRetrievalAugmentor时通过.executor(executor)方法指定自定义的Executor实例,以满足特定的线程管理需求。
8. Accessing Sources
这段内容核心是讲解在 LangChain4j 中使用 AI 服务时,如何获取用于增强消息的检索来源(Retrieved Contents),分为普通调用和流式传输两种场景,逻辑清晰且操作简洁:
-
普通调用场景:用
Result类包装返回类型当不需要实时流式获取结果,而是等待完整响应时,通过将 AI 服务接口的返回类型从原始类型(如
String)包装为Result<T>类,即可同时获取最终回答和其对应的检索来源。-
步骤解析:
- 定义接口时,将返回值设为
Result<String>(String对应回答的类型,可根据实际调整); - 调用接口后,通过
result.content()获取 LLM 生成的最终回答; - 通过
result.sources()获取用于生成该回答的「检索内容列表」(即 RAG 过程中从向量库等来源查询到的Content数据)。
- 定义接口时,将返回值设为
-
核心价值:解决了「回答溯源」问题,可明确知道 LLM 的回答基于哪些原始检索信息,降低幻觉风险,也便于后续验证或引用来源。
-
-
流式传输场景:用
onRetrieved()监听来源当需要实时流式获取 LLM 的响应(如逐token返回)时,无法通过
Result类直接获取来源,需通过TokenStream的onRetrieved()方法指定一个「来源消费者」(Consumer<List<Content>>)来监听并处理检索来源。-
步骤解析:
- 接口返回类型设为
TokenStream(流式响应类型); - 调用接口后,通过
onRetrieved((sources) -> { ... })定义来源的处理逻辑(如打印来源、存储来源等); - 同时可搭配
onPartialResponse()(处理部分响应)、onCompleteResponse()(处理完整响应)等方法,实现流式场景下的全流程控制。
- 接口返回类型设为
-
核心价值:在不阻断流式响应的前提下,实时获取并处理检索来源,兼顾「流式体验」和「来源可追溯性」。
-
两种方式的核心目标一致------让 RAG 流程中的「检索来源」可被访问 ,区别仅在于适配「普通完整响应」和「流式实时响应」两种使用场景,且都通过 LangChain4j 封装好的 API(Result 类、onRetrieved() 方法)实现,无需额外编写复杂的检索来源提取逻辑,降低了开发成本。
六、简单示例
基于上面介绍的各个组件,我们来实现一个简单的客服系统。
本系列完整代码地址 :langchain4j-hwl
- EmbeddingModel :使用 BgeSmallZhV15QuantizedEmbeddingModel 作为嵌入模型 BgeSmallZhV15QuantizedEmbeddingModel 是 BAAI(智源研究院) 推出的 bge-small-zh-v1.5 中文轻量级嵌入模型的量化版本,主打极小体积、极快推理、中文语义强,专为资源受限场景(边缘 / 移动端 / CPU) 做 RAG、语义检索、向量库而生。
- EmbeddingStore :本例使用 InMemoryEmbeddingStore
- QueryTransformer : 进行 Query 内容补充。
- QueryRouter :进行请求路由。根据用户信息确定用户不同的意图。
- ContentAggregator :对知识库 检索出的内容进行重排序。
- ContentInjector :完成 重排序后的内容注入
本例仅仅是为了使用上述各种组件而使用,有些过度设计
-
pom.xml引入如下 BgeSmallZhV15QuantizedEmbeddingModel 模型。xml<dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-embeddings-bge-small-zh-v15-q</artifactId> </dependency> -
定义 CustomerServiceAssistant,如下:
javapublic interface CustomerServiceAssistant { /** * 智能客服对话入口 * * @param memoryId 会话 ID,用于区分不同用户的对话历史 * @param userMessage 用户输入的消息 * @return 客服回复内容 */ @SystemMessage(""" 你是一名专业的智能客服助手,能够处理以下类型的问题: 1. 产品咨询:基于知识库内容,准确回答产品信息、功能说明、使用方法等问题 2. 订单查询:协助用户了解订单状态、物流信息、退换货流程,需要具体信息时引导用户提供订单号 3. 投诉建议:以真诚、理解的态度处理投诉,给出解决方案;严重投诉告知将在24小时内跟进 4. 通用咨询:友好回答其他问题,必要时引导用户描述具体需求 如果知识库中没有相关信息,请如实告知并建议联系人工客服。 始终保持专业、友好、耐心的服务态度。 """) String chat(@MemoryId String memoryId, @UserMessage String userMessage); } -
定义 CustomerServiceRouter
javapublic interface CustomerServiceRouter { /** * 用户意图分类枚举 * * @see CustomerServiceRouter#classify(String) */ enum UserIntent { /** * 产品/知识咨询:用户询问产品信息、功能说明、使用方法等 */ PRODUCT_INQUIRY, /** * 订单相关:用户询问订单状态、物流、退换货等 */ ORDER_INQUIRY, /** * 投诉建议:用户反馈问题、提出投诉或改进建议 */ COMPLAINT, /** * 通用聊天:闲聊或无法归类的其他问题 */ GENERAL_CHAT } /** * 对用户消息进行意图分类 * * @param userMessage 用户输入的消息 * @return 用户意图分类 */ @SystemMessage(""" 你是一个智能客服意图分类器。 请根据用户的消息,将其归类为以下四种意图之一: - PRODUCT_INQUIRY:用户在询问产品信息、功能说明、使用方法、价格等产品相关问题 - ORDER_INQUIRY:用户在询问订单状态、物流信息、退换货、支付等订单相关问题 - COMPLAINT:用户在投诉、反馈问题或提出改进建议 - GENERAL_CHAT:闲聊或无法归类的其他问题 只返回枚举值,不要返回任何其他内容。 """) UserIntent classify(@UserMessage String userMessage); } -
定义 DashScopeScoringModel 重排序模型
java/** * @author : haowl * @date : 2026/3/9 * @desc : 阿里云 DashScope Rerank API 的 ScoringModel 实现 * 调用 gte-rerank-v2 模型对检索结果进行精排,支持中英文等50+语言 */ @Slf4j @Builder public class DashScopeScoringModel implements ScoringModel { /** * 阿里云 DashScope Rerank API 地址 */ private static final String RERANK_URL = "https://dashscope.aliyuncs.com/api/v1/services/rerank/text-rerank/text-rerank"; /** * 使用的重排序模型名称 * - gte-rerank-v2:支持中英文等50+语言,每次最多500篇文档,单文档最大4000 tokens * - qwen3-rerank:支持100+语言,免费额度100万tokens(激活后90天内有效) */ @Builder.Default private final String modelName = "gte-rerank-v2"; /** * DashScope API Key,从环境变量 aliQwen-api 读取 */ private final String apiKey; /** * 批量对多个文本与查询的相关性打分(核心方法,实现 ScoringModel 唯一抽象方法) * 一次 API 调用返回所有文档的分数,按原始顺序排列 * * @param texts 待评分的文档列表(TextSegment) * @param query 用户查询 * @return 与入参 texts 顺序一一对应的相关性分数列表 */ @Override public Response<List<Double>> scoreAll(List<TextSegment> texts, String query) { // 将 TextSegment 转为字符串列表 List<String> documents = texts.stream() .map(TextSegment::text) .toList(); return scoreAllByStrings(documents, query); } /** * 内部批量打分实现,调用 DashScope Rerank HTTP API * * @param documents 文档文本列表 * @param query 用户查询 * @return 与入参 documents 顺序一一对应的相关性分数列表 */ private Response<List<Double>> scoreAllByStrings(List<String> documents, String query) { // 构建请求体 JSONObject requestBody = JSONUtil.createObj() .set("model", modelName) .set("input", JSONUtil.createObj() .set("query", query) .set("documents", documents)) .set("parameters", JSONUtil.createObj() // 不返回原始文档内容,减少网络传输 .set("return_documents", false)); log.info("调用 DashScope Rerank API:model={}, query={}, documents={}", modelName, query, documents); try (HttpResponse response = HttpRequest.post(RERANK_URL) .header("Authorization", "Bearer " + apiKey) .header("Content-Type", "application/json") .body(requestBody.toString()) .execute()) { if (!response.isOk()) { log.error("DashScope Rerank API 调用失败:status={}, body={}", response.getStatus(), response.body()); throw new RuntimeException("DashScope rerank API failed with status: " + response.getStatus()); } JSONObject responseJson = JSONUtil.parseObj(response.body()); JSONArray results = responseJson.getByPath("output.results", JSONArray.class); // API 返回的 results 按 relevance_score 降序排列,需要按原始 index 还原顺序 Double[] scores = new Double[documents.size()]; for (int i = 0; i < results.size(); i++) { JSONObject result = results.getJSONObject(i); int originalIndex = result.getInt("index"); double relevanceScore = result.getDouble("relevance_score"); scores[originalIndex] = relevanceScore; } // 将结果转为列表,未出现在结果中的文档分数置为 0.0 List<Double> scoreList = new ArrayList<>(documents.size()); for (Double score : scores) { scoreList.add(score != null ? score : 0.0); } log.info("DashScope Rerank API 返回分数:{}", scoreList); return Response.from(scoreList); } catch (RuntimeException e) { throw e; } catch (Exception e) { throw new RuntimeException("DashScope rerank API request failed: " + e.getMessage(), e); } } } -
定义 CustomerServiceLLmConfig 配置类,相关配置类都在其中
java@Slf4j @Configuration public class CustomerServiceLLmConfig { public static final String API_KEY = "Your Api Key"; /** * 初始化嵌入模型(阿里云 text-embedding-v3,支持中文) */ @Bean public EmbeddingModel embeddingModel() { return OpenAiEmbeddingModel.builder() .baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1") .apiKey(API_KEY) .modelName("text-embedding-v3") .build(); } /** * 意图分类路由器:识别用户意图(产品咨询/订单查询/投诉建议/通用聊天) */ @Bean public CustomerServiceRouter customerServiceRouter(ChatModel chatModel) { return AiServices.builder(CustomerServiceRouter.class) .chatModel(chatModel) .build(); } /** * 智能客服 Assistant(统一入口) * <p> * RAG 流水线: * 用户查询 * → QueryTransformer :短查询补充领域关键词,提升检索召回率 * → QueryRouter :根据用户意图路由到对应的 ContentRetriever * - PRODUCT_INQUIRY → 产品知识库检索器(向量相似度检索) * - 其他意图 → 空检索器(由 SystemMessage 提示词驱动) * → ContentRetriever :向量检索,召回候选文档片段 * → ContentAggregator :LLM 打分重排序,精选 top3 注入上下文 * → ContentInjector :将检索内容以结构化格式注入 UserMessage * → LLM */ @Bean public CustomerServiceAssistant customerServiceAssistant( ChatModel chatModel, ChatMemoryProvider chatMemoryProvider, CustomerServiceRouter customerServiceRouter) { ContentRetriever productRetriever = buildProductRetriever(); ContentRetriever emptyRetriever = query -> List.of(); RetrievalAugmentor retrievalAugmentor = DefaultRetrievalAugmentor.builder() // 1. QueryTransformer:短查询补充"产品"关键词,提升向量检索召回率 // CompressingQueryTransformer 可结合对话历史压缩改写,适合多轮对话场景 .queryTransformer(this::buildQueryTransformer) // 2. QueryRouter:根据用户意图路由到对应的 ContentRetriever // - PRODUCT_INQUIRY → 产品知识库检索器 // - 其他意图 → 空检索器(由 SystemMessage 提示词驱动回答) .queryRouter(query -> buildQueryRouter(query, customerServiceRouter, productRetriever, emptyRetriever)) // 3. ContentAggregator:LLM 打分重排序 // 功能验证方案:复用 ChatModel 对每条候选文档打 0~10 分,精选 top3 // 生产环境建议替换为 DashScopeScoringModel(调用 gte-rerank-v2 API,延迟更低) .contentAggregator(buildReRankingAggregator()) // 4. ContentInjector:将检索内容以带序号格式注入 UserMessage .contentInjector(this::buildContentInjector) // 5. Executor:多路检索时可指定线程池并行执行,降低延迟 // .executor(Executors.newFixedThreadPool(4)) .build(); return AiServices.builder(CustomerServiceAssistant.class) .chatModel(chatModel) .chatMemoryProvider(chatMemoryProvider) .retrievalAugmentor(retrievalAugmentor) .build(); } /** * 构建产品知识库检索器 * 加载 static/knowledge2 目录文档作为知识库,拆成500令牌/段,重叠100令牌 * 检索时最多召回5条候选,相似度阈值0.6 */ private ContentRetriever buildProductRetriever() { log.info("智能客服产品知识库加载开始"); EmbeddingModel embeddingModel = new BgeSmallZhV15QuantizedEmbeddingModel(); List<Document> documents = ClassPathDocumentLoader.loadDocuments("static/knowledge2"); InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>(); IngestionResult result = EmbeddingStoreIngestor.builder() .documentSplitter(DocumentSplitters.recursive(500, 100, new OpenAiTokenCountEstimator("gpt-4o-mini"))) .embeddingModel(embeddingModel) .embeddingStore(embeddingStore) .build() .ingest(documents); log.info("智能客服产品知识库加载完成,tokenUsage: {}", result.tokenUsage()); return EmbeddingStoreContentRetriever.builder() .embeddingStore(embeddingStore) .embeddingModel(embeddingModel) .maxResults(5) .minScore(0.6) .build(); } /** * QueryTransformer:对原始查询进行改写 * 若查询过短(少于5个字),补充"产品"关键词辅助向量检索 */ private List<Query> buildQueryTransformer(Query query) { if (query.text().length() < 5) { return List.of(Query.from("产品: " + query.text(), query.metadata())); } return List.of(query); } /** * QueryRouter:根据用户意图决定走哪个 ContentRetriever * PRODUCT_INQUIRY → 产品知识库检索器;其他意图 → 空检索器 */ private Collection<ContentRetriever> buildQueryRouter( Query query, CustomerServiceRouter customerServiceRouter, ContentRetriever productRetriever, ContentRetriever emptyRetriever) { CustomerServiceRouter.UserIntent intent = customerServiceRouter.classify(query.text()); log.info("智能客服意图识别:intent={}, query={}", intent, query.text()); if (intent == CustomerServiceRouter.UserIntent.PRODUCT_INQUIRY) { return List.of(productRetriever); } return List.of(emptyRetriever); } /** * ContentInjector:将检索内容以带序号的格式注入 UserMessage */ private dev.langchain4j.data.message.ChatMessage buildContentInjector( List<dev.langchain4j.rag.content.Content> contents, dev.langchain4j.data.message.ChatMessage userMessage) { if (contents.isEmpty()) { return userMessage; } StringBuilder sb = new StringBuilder(((UserMessage) userMessage).singleText()); sb.append("\n\n请参考以下知识库内容作答:\n"); for (int i = 0; i < contents.size(); i++) { sb.append(i + 1).append(". ").append(contents.get(i).textSegment().text()).append("\n"); } log.info("userMessage={}", sb.toString()); return UserMessage.from(sb.toString()); } /** * 构建重排序聚合器 * <p> * 使用阿里云 DashScope gte-rerank-v2 模型对向量检索结果进行精排: * 1. 向量检索(EmbeddingStoreContentRetriever)先召回 maxResults=5 条候选文档 * 2. ReRankingContentAggregator 调用 Rerank API 对5条候选文档重新打分排序 * 3. 最终只保留分数最高的 3 条注入 UserMessage * <p> * 相比纯向量检索的优势: * - 向量检索基于语义相似度(Bi-Encoder),速度快但精度有限 * - Rerank 模型(Cross-Encoder)对 query 和文档联合编码,精度更高 * - 两阶段组合:召回阶段用向量检索保证速度,精排阶段用 Rerank 保证质量 * <p> * DashScope gte-rerank-v2 模型说明: * - 支持中英文等50+语言,适合本项目中文知识库场景 * - 单次最多500篇文档,单文档最大4000 tokens * - 计费:$0.115 / 1M tokens * - API 文档:https://www.alibabacloud.com/help/en/model-studio/text-rerank-api */ private ContentAggregator buildReRankingAggregator() { DashScopeScoringModel scoringModel = DashScopeScoringModel.builder() .apiKey(API_KEY) // gte-rerank-v2:支持中英文等50+语言 // 可替换为 qwen3-rerank:支持100+语言,有免费额度 .modelName("gte-rerank-v2") .build(); return ReRankingContentAggregator.builder() .scoringModel(scoringModel) // 从向量检索的5条候选中精选3条注入 LLM 上下文 // 减少 token 消耗的同时保证内容质量 .maxResults(3) .build(); } } -
调用 CustomerServiceAssistant#chat 消息可以得到结果:
- 智能便携翻译机 上市时间
- 智能便携翻译机 ProX-9 的上市时间是 2025 年 9 月。如果您有更多关于该产品的信息需求或其他问题,欢迎随时告诉我!
如果观察日志,可以清除看到执行过程中的各种信息。这里就不再赘述。