
目录
[一. 对话历史的持久化存储](#一. 对话历史的持久化存储)
[1. 库表设计](#1. 库表设计)
[二. 对话记忆](#二. 对话记忆)
在上期中我们ai应用生成平台已经实现了基础的网站应用生成能力,但是存在一个问题,就是每次对话都是独立的,AI没有办法及记住之前的交互内容,这样会导致的体验非常不好,如果对于第一次生成的网站不满意,此时就无法基于已经生成的网站进行迭代改进,大大限制了使用性,所以这期我们一起来实现对话记忆功能~
一. 对话历史的持久化存储
在用户发送信息时,需要保存用户信息和AI回复的信息,即使AI回复失败也要记录失败信息,确保对话的完整性,这时候我们就需要将对话信息存入数据库中,记录会话
1. 库表设计
sql
-- 对话历史表
create table chat_history
(
id bigint auto_increment comment 'id' primary key,
message text not null comment '消息',
messageType varchar(32) not null comment 'user/ai',
appId bigint not null comment '应用id',
userId bigint not null comment '创建用户id',
createTime datetime default CURRENT_TIMESTAMP not null comment '创建时间',
updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
isDelete tinyint default 0 not null comment '是否删除',
INDEX idx_appId (appId), -- 提升基于应用的查询性能
INDEX idx_createTime (createTime), -- 提升基于时间的查询性能
INDEX idx_appId_createTime (appId, createTime) -- 游标查询核心索引
) comment '对话历史' collate = utf8mb4_unicode_ci;这里的 idx_appId_createTime复合索引是为了提高后续通过游标查询会话历史的效率
- 游标查询
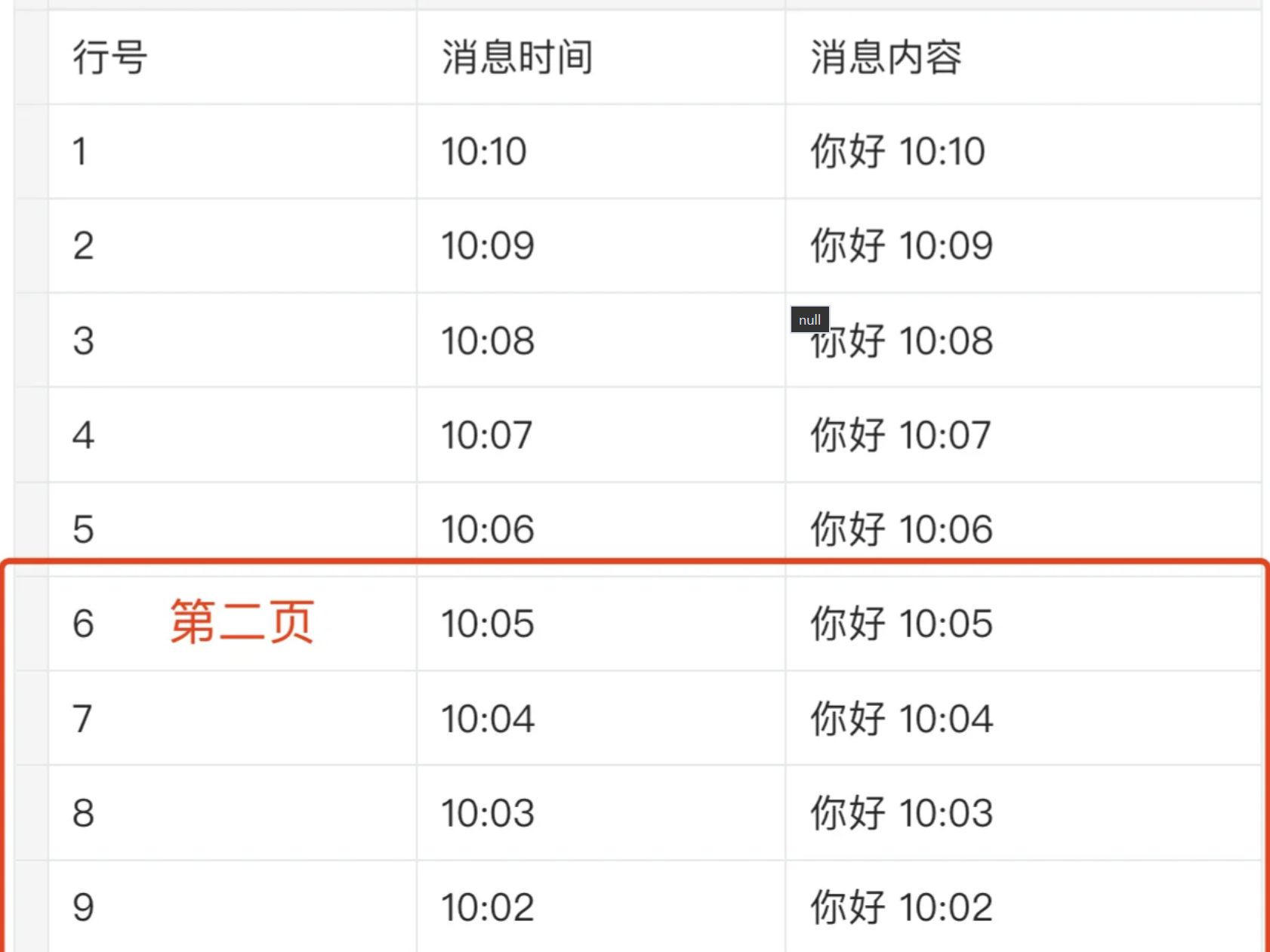
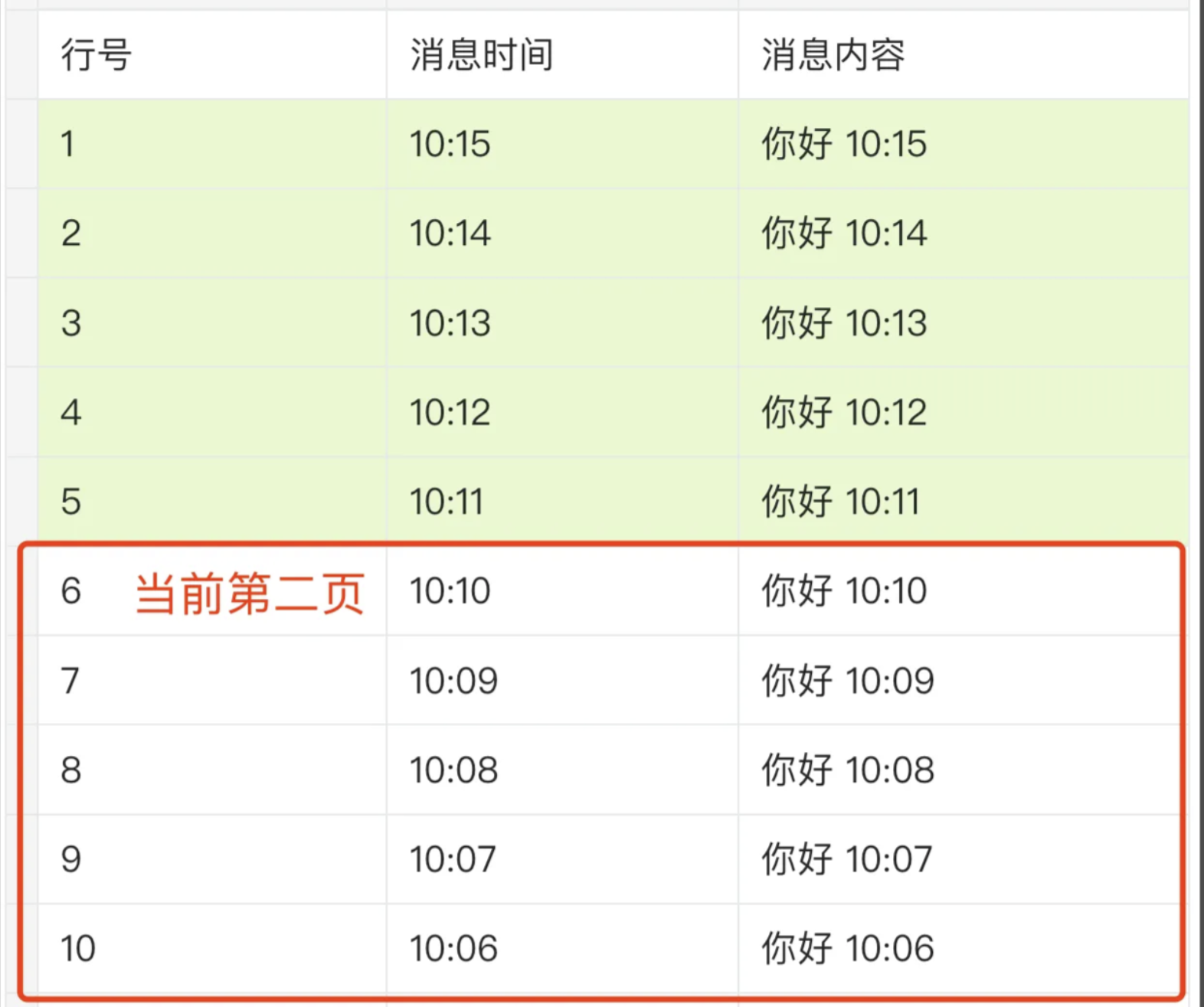
对于对话历史的分页查询,为什么这里不采用传统的分页查询呢,这是因为在传统分页中,数据通常是基于页码或者偏移量进行加载的,但是如果数据在分页过程中发生了变化,比如插入新数据或者删除老数据,那么用户看到的分页数据可能会出现不一致情况
比如说:用户会持续收到新的消息,如果按照传统分页查询,第一页已经加载了1-5行的数据,这时候本来要查询第二页的数据6-10行,结果在查询第二页之前,突然又收到了5条信息,数据库的记录就变成了原本的第一页变成了当前的第二页,这样就导致了查询出的第二页数据正好是之前已经查过的第一个数据,造成了数据重复加载
并且,传统的offset分页方式在处理大量对话数据时存在严重性能问题,假设要查询 limit 10000 ,10 这里的数据,数据需要先扫描和跳过前面的10000条数据,才能返回真正需要的10条数据,查询性能非常低,在高并发场景下很容易称为系统瓶颈
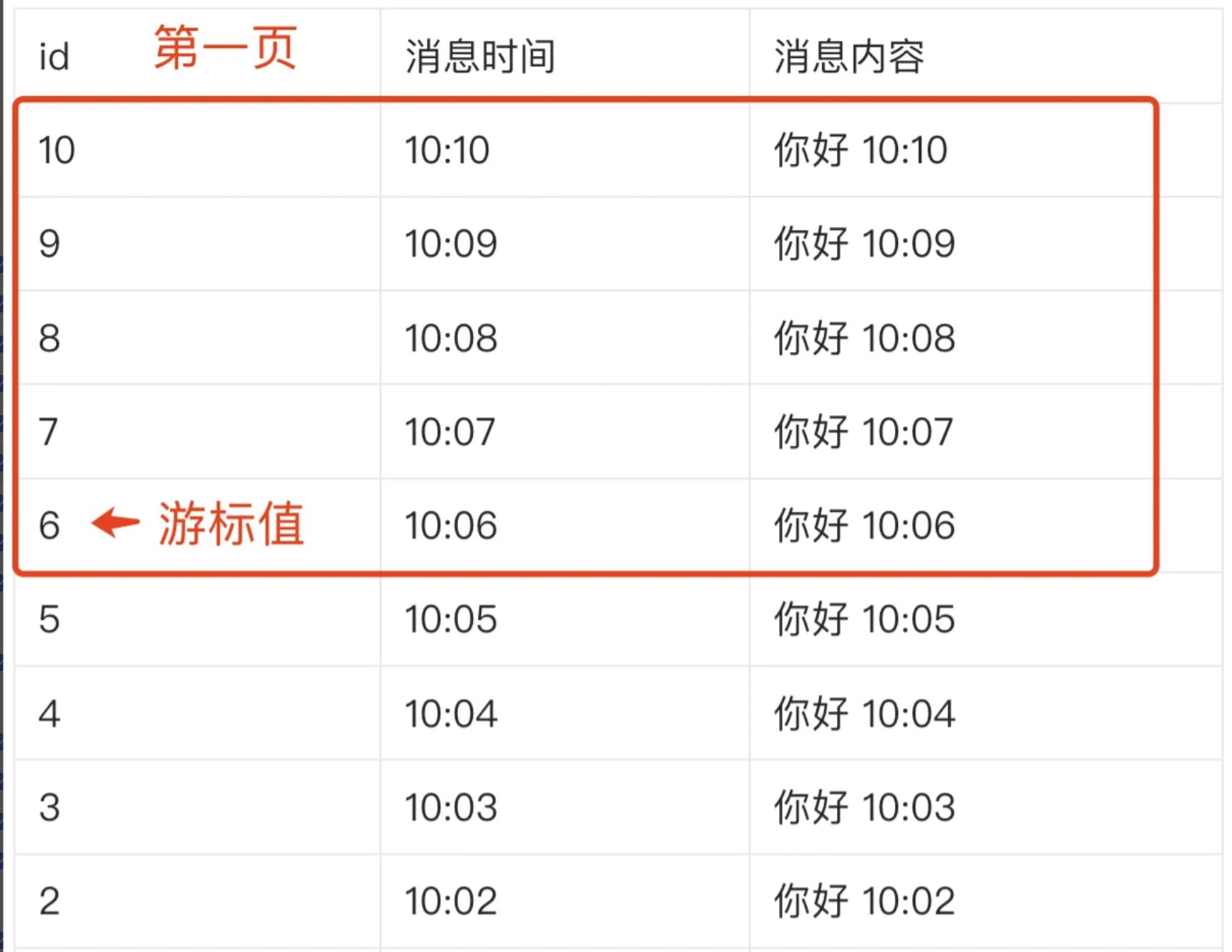
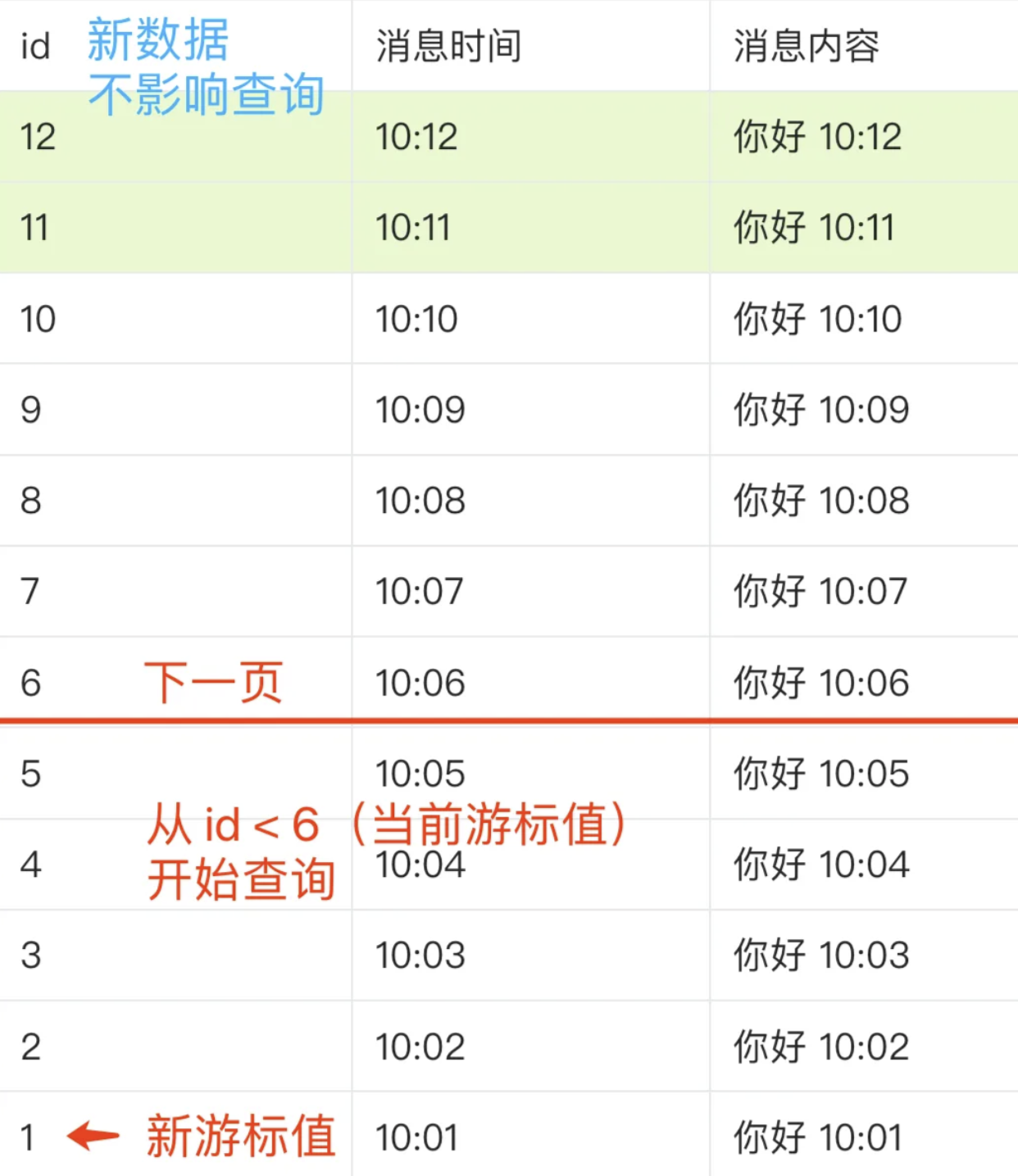
为了解决这两个问题,我们采用游标分页的当时,使用一个游标案例跟踪分页位置,每次请求从上一次请求的游标开始加载数据
通过情况下使用主键、时间戳来作为游标,每次查询完当前界面的数据后,将最后一条数据记录的id作为游标传递给前端,当要加载下一页时,前端携带游标指发起拆线呢,后端操作数据库从id小于当前游标值的数据开始查询,这样查询结果就不会受到新数据影响
然后就可以进行后端开发了,就是一些对话历史的crud,这里就不展示了,相信各位都会~
通过数据库来记录对话记录,前端就可以显示对话历史啦
二. 对话记忆
在大多数情况下,AI生成的网站是没办法一次性满足用户的需求的,所以需要提供网站修改功能,但是目前来说跟AI进行对话,AI是无法记住之前的对话内容的,每次修改实际上都是重新生成完整的网站,而不是在原有的基础上进行修改,这时候用户就不能进行迭代式网站开发,极大限制了平台的实用性,那么为了解决这个问题,就需要给AI增加对话记忆的能力
方案设计
在LangChain4j中不仅提供了对话记忆功能,而且还能结合redis进行持久化记忆,这里为什么不使用内存或者数据库来存储会话记忆呢?
- 使用内存存储有一个问题,首先是重启后会丢失记忆,其次如果每个应用都在内存中维护会话记忆,很容易出现内存溢出问题(我们的内存可是很宝贵的)
- 那么为什么不使用Mysql中,这是因为redis作为内存数据库,在读写对话记忆时,性能更高,并且数据库中的对话历史表包含其他业务字段,不适合直接交给 LangChain4j 的对话记忆组件管理。
加载历史
redis的内存也不是无限的,这时候就要给redis中的key设置过期时间,这就可能导致redis中的会话记忆被删除的情况,这时候就需要将之前在数据库中保存的用户和ai信息取出来,在初始化会话记忆的时候,加载最新的对话记录到redis中,就能确保ai了解交互历史了
对话隔离
每个应用的对话记忆应该是相互隔离的,LangChain4j也提供了对话记忆隔离能力,那么接下来我们就一起来开发吧
开发实现
- 引入依赖
这个依赖会引入 Redis 的 Jedis 客户端,以及与 LangChain4j 的整合组件。
sql
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-redis-spring-boot-starter</artifactId>
<version>1.1.0-beta7</version>
</dependency>- 配置redis
sql
spring:
# redis
data:
redis:
host: localhost
port: 6379
password:
ttl: 3600创建redis对话记忆存储配置类 初始化RedisChatMemoryStore Bean
sql
@Configuration
@ConfigurationProperties(prefix = "spring.data.redis")
@Data
public class RedisChatMemoryStoreConfig {
private String host;
private int port;
private String password;
private long ttl;
@Bean
public RedisChatMemoryStore redisChatMemoryStore() {
return RedisChatMemoryStore.builder()
.host(host)
.port(port)
.password(password)
.ttl(ttl)
.build();
}
}在启动类中排除embedding自动装配
sql
@SpringBootApplication(exclude = {RedisEmbeddingStoreAutoConfiguration.class})- 使用对话记忆
在Langchain4j中有两种实现方式:内存隔离机制和AI Service隔离
1)内存隔离机制
可以给AI服务方法中增加memoryId注解和参数,然后通过chatMemoryProvider为每个appId分配对话记忆
修改AIService方法:
sql
interface AiCodeGeneratorService {
HtmlCodeResult generateHtmlCode(@MemoryId int memoryId, @UserMessage String userMessage);
}在工厂类中创建AI Service时,我们必须通过chatMemoryProvider为每个moemoryId来构造专属的MessgeWindowChatMemory,必须为MessageWindewChatMemory设置id,因为使用的是同一个redis实例,否则redis中存储的key都是default,不能区分不同的对话
java
private final RedisChatMemoryStore redisChatMemoryStore;
@Bean
public AiCodeGeneratorService aiCodeGeneratorService() {
return AiServices.builder(AiCodeGeneratorService.class)
.chatModel(chatModel)
.streamingChatModel(streamingChatModel)
// 根据 id 构建独立的对话记忆
.chatMemoryProvider(memoryId -> MessageWindowChatMemory
.builder()
.id(memoryId)
.chatMemoryStore(redisChatMemoryStore)
.maxMessages(20)
.build())
.build();
}现在调用AI生成方法时,就需要多传递一个id参数:
java
generateHtmlCode(1, "生成博客网站");
generateHtmlCode(2, "生成电商网站");方式2 AI Service隔离
之前所有应用都使用的同一个AI Service实例,如果想隔离会话记忆,可以给每个应用分配一个AI Service实例,每个AI Service绑定独立的对话记忆,修改AI Service工厂类,提供根据appId获取服务实例的方法:
java
@Configuration
public class AiCodeGeneratorServiceFactory {
@Resource
private ChatModel chatModel;
@Resource
private StreamingChatModel streamingChatModel;
@Resource
private RedisChatMemoryStore redisChatMemoryStore;
/**
* 根据 appId 获取服务
*/
public AiCodeGeneratorService getAiCodeGeneratorService(long appId) {
// 根据 appId 构建独立的对话记忆
MessageWindowChatMemory chatMemory = MessageWindowChatMemory
.builder()
.id(appId)
.chatMemoryStore(redisChatMemoryStore)
.maxMessages(20)
.build();
return AiServices.builder(AiCodeGeneratorService.class)
.chatModel(chatModel)
.streamingChatModel(streamingChatModel)
.chatMemory(chatMemory)
.build();
}
}为了保证和之前代码兼容,默认提供一个AI Service Bean
java
/**
* 默认提供一个 Bean
*/
@Bean
public AiCodeGeneratorService aiCodeGeneratorService() {
return getAiCodeGeneratorService(0L);
}- 本地缓存优化
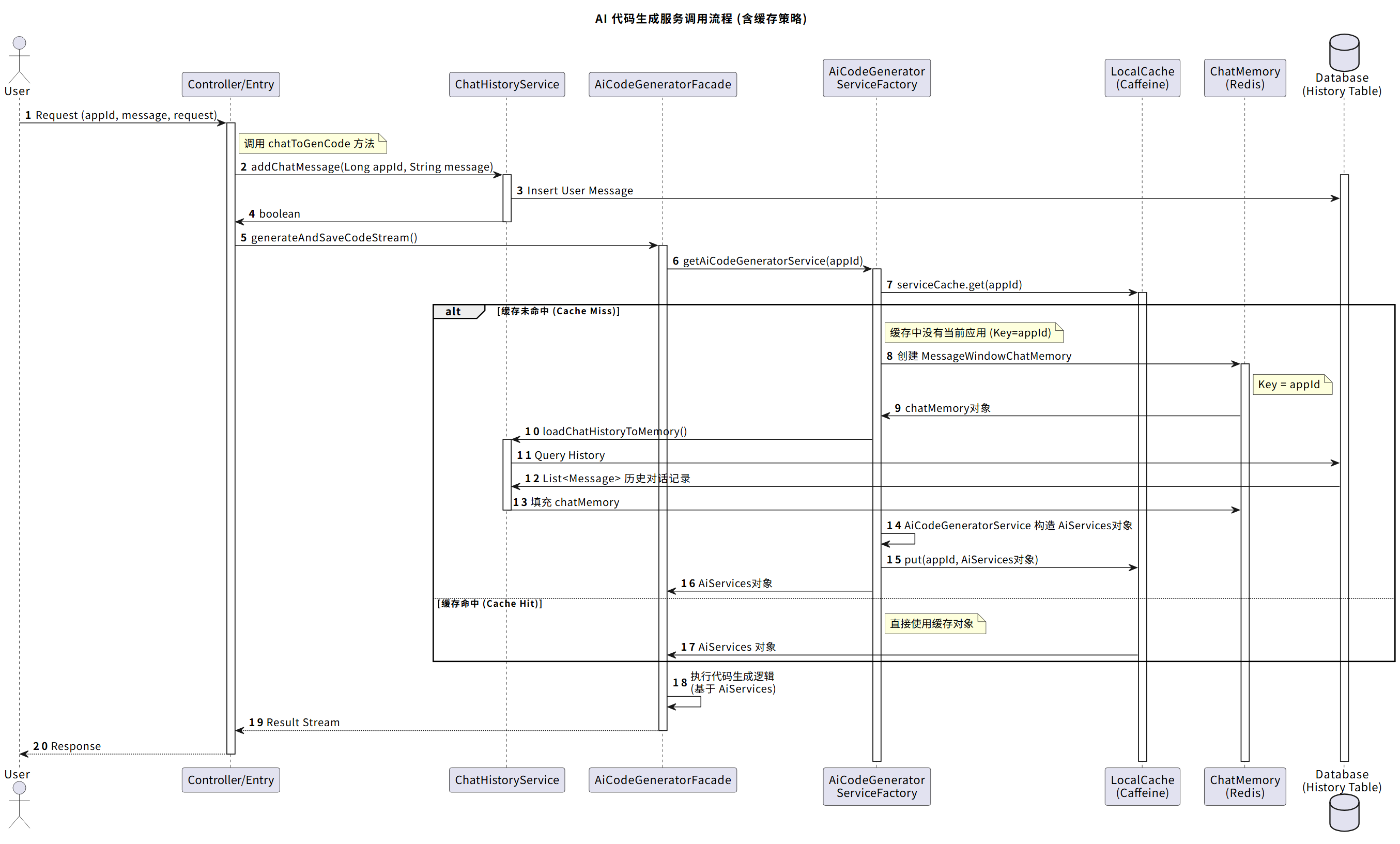
对于方案二,我们可以利用Caffeine本地缓存进一步优化性能,每次构造完AI服务实例后,利用Caffeine缓存来存储AI服务实例,之后相同的appId就能直接获取到AI服务实例,避免重复构造,本地缓存占用的时内存,所以和redis一样需要设置合理的过期时间,防止内存泄漏
java
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>优化工厂类,使用缓存:
java
/**
* AI 服务实例缓存
* 缓存策略:
* - 最大缓存 1000 个实例
* - 写入后 30 分钟过期
* - 访问后 10 分钟过期
*/
private final Cache<Long, AiCodeGeneratorService> serviceCache = Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(Duration.ofMinutes(30))
.expireAfterAccess(Duration.ofMinutes(10))
.removalListener((key, value, cause) -> {
log.debug("AI 服务实例被移除,appId: {}, 原因: {}", key, cause);
})
.build();
/**
* 根据 appId 获取服务(带缓存)
*/
public AiCodeGeneratorService getAiCodeGeneratorService(long appId) {
return serviceCache.get(appId, this::createAiCodeGeneratorService);
}
/**
* 创建新的 AI 服务实例
*/
private AiCodeGeneratorService createAiCodeGeneratorService(long appId) {
log.info("为 appId: {} 创建新的 AI 服务实例", appId);
// 根据 appId 构建独立的对话记忆
MessageWindowChatMemory chatMemory = MessageWindowChatMemory
.builder()
.id(appId)
.chatMemoryStore(redisChatMemoryStore)
.maxMessages(20)
.build();
return AiServices.builder(AiCodeGeneratorService.class)
.chatModel(chatModel)
.streamingChatModel(streamingChatModel)
.chatMemory(chatMemory)
.build();
}- 历史对话加载
那么在初始化AI Service实例前,我们需要将之前存入数据库中的对话历史导入到记忆中(redis)
在ChatHistoryService中开发加载方法(就是查询数据)
java
@Override
public int loadChatHistoryToMemory(Long appId, MessageWindowChatMemory chatMemory, int maxCount) {
try {
// 直接构造查询条件,起始点为 1 而不是 0,用于排除最新的用户消息
QueryWrapper queryWrapper = QueryWrapper.create()
.eq(ChatHistory::getAppId, appId)
.orderBy(ChatHistory::getCreateTime, false)
.limit(1, maxCount);
List<ChatHistory> historyList = this.list(queryWrapper);
if (CollUtil.isEmpty(historyList)) {
return 0;
}
// 反转列表,确保按时间正序(老的在前,新的在后)
historyList = historyList.reversed();
// 按时间顺序添加到记忆中
int loadedCount = 0;
// 先清理历史缓存,防止重复加载
chatMemory.clear();
for (ChatHistory history : historyList) {
if (ChatHistoryMessageTypeEnum.USER.getValue().equals(history.getMessageType())) {
chatMemory.add(UserMessage.from(history.getMessage()));
loadedCount++;
} else if (ChatHistoryMessageTypeEnum.AI.getValue().equals(history.getMessageType())) {
chatMemory.add(AiMessage.from(history.getMessage()));
loadedCount++;
}
}
log.info("成功为 appId: {} 加载了 {} 条历史对话", appId, loadedCount);
return loadedCount;
} catch (Exception e) {
log.error("加载历史对话失败,appId: {}, error: {}", appId, e.getMessage(), e);
// 加载失败不影响系统运行,只是没有历史上下文
return 0;
}
}然后就可以在初始化 AI Service 的对话记忆时调用了。
java
private AiCodeGeneratorService createAiCodeGeneratorService(long appId) {
log.info("为 appId: {} 创建新的 AI 服务实例", appId);
// 根据 appId 构建独立的对话记忆
MessageWindowChatMemory chatMemory = MessageWindowChatMemory
.builder()
.id(appId)
.chatMemoryStore(redisChatMemoryStore)
.maxMessages(20)
.build();
// 从数据库加载历史对话到记忆中
chatHistoryService.loadChatHistoryToMemory(appId, chatMemory, 20);
return AiServices.builder(AiCodeGeneratorService.class)
.chatModel(chatModel)
.streamingChatModel(streamingChatModel)
.chatMemory(chatMemory)
.build();
}这时候与AI进行对话时就会拥有记忆啦
