一、B+在MySQL索引中的应⽤
⾮叶⼦节点保存索引数据,叶⼦节点保存真实数据,如下图所⽰
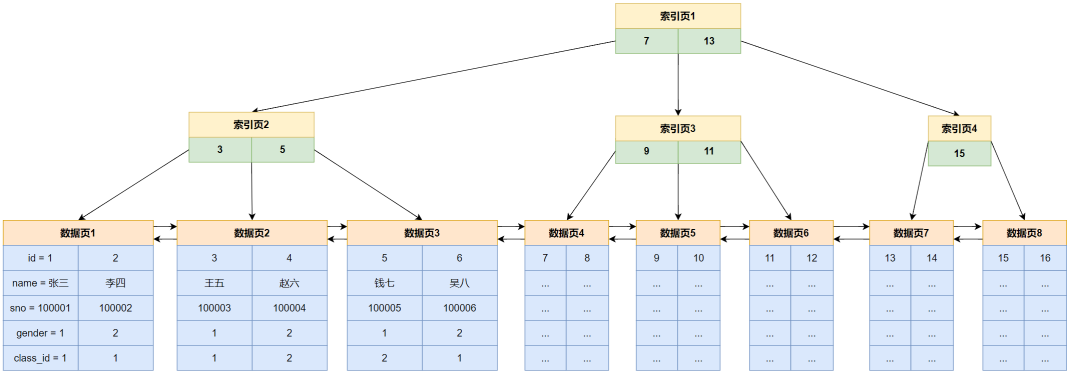
以查找id为5的记录,完整的检索过程如下:
-
⾸先判断B+树的根节点中的索引记录,此时 5 < 7 ,应访问左孩⼦节点,找到索引⻚2
-
在索引⻚2中判断id的⼤⼩,找到与5相等的记录,命中,加载对应的数据⻚
以上的IO过程,加载索引⻚1 --> 加载索引⻚2 --> 加载数据⻚3
1 、计算三层树⾼的B+树可以存放多少条记录
1.假设⼀条⽤⼾数据⼤⼩为1KB,在忽略数据⻚中数据⻚⾃⾝属性空间占⽤的情况下,⼀⻚可以存16条数据
2.索引⻚⼀条数据的⼤⼩为,主键⽤BIGINT类型占8Byte,下⼀⻚地址6Byte,⼀共是14Byte,⼀个索引⻚可以保存 16*1024/14 = 1170 条索引记录
3.如果只有三层树⾼的情况,综合只保存索引的根节点和⼆级节点的索引⻚以及保存真实数据的数据⻚,那么⼀共可以保存 1170*1170*16 = 21,902,400 条记录,也就是说在两千多万条数据的表中,可以通过三次IO就完成数据的检索
二、索引分类
1、主键索引
- 特性:唯一且非空,一张表只能有一个主键索引;
- 本质:InnoDB 中主键索引是聚簇索引(数据和索引存在一起),叶子节点存整行数据;
- 创建示例:
sql
CREATE TABLE user (
id INT NOT NULL,
name VARCHAR(20),
PRIMARY KEY (id) -- 主键索引
);2 、普通索引
- 特性:最基础的索引,无唯一性、非空限制,仅用于提升查询效率;
- 适用场景:普通查询列(如姓名、年龄);
- 创建示例:
sql
-- 给 user 表的 age 列创建普通索引
CREATE INDEX idx_user_age ON user (age);3 、唯⼀索引
- 特性:索引列的值必须唯一,但允许为空(多个 NULL);一张表可以有多个唯一索引;
- 适用场景:保证列的唯一性(如手机号、邮箱);
- 创建示例:
sql
-- 给 user 表的 phone 列创建唯一索引
CREATE UNIQUE INDEX idx_user_phone ON user (phone);4 、全⽂索引
- 定义:专为文本内容的模糊查询设计,能快速匹配文本中的关键词,而非简单的字符匹配。
- 支持引擎:MyISAM(原生支持)、InnoDB(MySQL 5.6+ 支持)。
- 适用场景 :文章内容、商品描述等长文本的模糊搜索(替代
LIKE '%关键词%',效率提升极大)。 - 创建示例:
sql
-- 给 article 表的 content 列创建全文索引
CREATE FULLTEXT INDEX idx_article_content ON article (content);
-- 使用全文索引查询(匹配包含「MySQL」的内容)
SELECT * FROM article WHERE MATCH(content) AGAINST ('MySQL');5 、聚集索引
与主键索引是同义词
如果没有为表定义 PRIMARY KEY, InnoDB使⽤第⼀个 UNIQUE 和 NOT NULL 的列作为聚集索
引。
如果表中没有 PRIMARY KEY 或合适的 UNIQUE 索引,InnoDB会为新插⼊的⾏⽣成⼀个⾏号并
⽤6字节的 ROW_ID 字段记录, ROW_ID 单调递增,并使⽤ ROW_ID 做为索引。
6、 ⾮聚集索引
聚集索引以外的索引称为⾮聚集索引或⼆级索引
⼆级索引中的每条记录都包含该⾏的主键列,以及⼆级索引指定的列。
InnoDB使⽤这个主键值来搜索聚集索引中的⾏,这个过程称为回表查询
7 、索引覆盖
当⼀个select语句使⽤了普通索引且查询列表中的列刚好是创建普通索引时的所有或部分列,这时
就可以直接返回数据,⽽不⽤回表查询,这样的现象称为索引覆盖
三、使⽤索引
1、自动创建
当我们为⼀张表加主键约束(Primary key),外键约束(Foreign Key),唯⼀约束(Unique)时,
MySQL会为对应的的列**⾃动创建⼀个索引**
如果表不指定任何约束时,MySQL会⾃动为每⼀列⽣成⼀个索引并⽤ ROW_ID 进⾏标识
二、手动创建
2.1主键索引
sql
# ⽅式⼀,创建表时创建主键
create table t_test_pk (
id bigint primary key auto_increment,
name varchar(20)
);
# ⽅式⼆,创建表时单独指定主键列
create table t_test_pk1 (
id bigint auto_increment,
name varchar(20),
primary key (id)
);
# ⽅式三,修改表中的列为主键索引
create table t_test_pk2 (
id bigint,
name varchar(20)
);
alter table t_test_pk2 add primary key (id) ;
alter table t_test_pk2 modify id bigint auto_increment;2.2唯⼀索引
sql
# ⽅式⼀,创建表时创建唯⼀键
create table t_test_uk (
id bigint primary key auto_increment,
name varchar(20) unique
);
# ⽅式⼆,创建表时单独指定唯⼀列
create table t_test_uk1 (
id bigint primary key auto_increment,
name varchar(20),
unique (name)
);
# ⽅式三,修改表中的列为唯⼀索引
create table t_test_uk2 (
id bigint primary key auto_increment,
name varchar(20)
);
alter table t_test_uk2 add unique (name) ;2.3普通索引
sql
# ⽅式⼀,创建表时指定索引列
create table t_test_index (
id bigint primary key auto_increment,
name varchar(20) unique
sno varchar(10),
index(sno)
);
# ⽅式⼆,修改表中的列为普通索引
create table t_test_index1 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10)
);
alter table t_test_index1 add index (sno) ;
# ⽅式三,单独创建索引并指定索引名
create table t_test_index2 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10)
);
create index index_name on t_test_index2(sno);2.4创建复合索引
创建语法与创建普通索引相同,只不过指定多个列,列与列之间⽤逗号隔开
sql
# ⽅式⼀,创建表时指定索引列
create table t_test_index4 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10),
class_id bigint,
index (sno, class_id)
);
# ⽅式⼆,修改表中的列为复合索引
create table t_test_index5 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10),
class_id bigint
);
alter table t_test_index5 add index (sno, class_id);
# ⽅式三,单独创建索引并指定索引名
create table t_test_index6 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10),
class_id bigint
);
create index index_name on t_test_index6 (sno, class_id);2.5查看索引
sql
# ⽅式⼀:show keys from 表名
mysql> show keys from t_test_index6\G
# ⽅式⼆
show index from t_test_index6;
# ⽅式三,简要信息:desc 表名;
desc t_test_index6;四、删除索引
1、主键索引
sql
# 语法
alter table 表名 drop primary key;
# ⽰例,删除t_test_index6表中的主键
mysql> alter table t_test_index6 drop primary key;
# 如查提⽰由于⾃增列的错误,先删除⾃增属性
mysql> alter table t_test_index6 modify id bigint;
# 重新删除主键
mysql> alter table t_test_index6 drop primary key;
# 查看结果
mysql> show keys from t_test_index6\G2、其他索引
sql
# 语法
alter table 表名 drop index 索引名;
# ⽰例,删除t_test_index6表中名为index_name的索引
mysql> alter table t_test_index6 drop index index_name;
# 查看结果
mysql> show keys from t_test_index6\G五、创建索引的注意事项
1.索引应该创建在⾼频查询的列上
2.索引需要占⽤额外的存储空间
3.对表进⾏插⼊、更新和删除操作时,同时也会修索引,可能会影响性能
4.创建过多或不合理的索引会导致性能下降,需要谨慎选择和规划索引