2026 年 3 月 10 日,谷歌 DeepMind 正式推出 Gemini Embedding 2。这不仅是常规的迭代,而是 AI 向量技术的一次重大跨越------它是谷歌首个基于 Gemini 架构构建的原生多模态嵌入模型 (Natively Multimodal Embedding Model)。它打破了不同媒介之间的壁垒,将文本、图像、视频、音频和 PDF 文档统一映射到了同一个向量空间中。
【核心突破与技术亮点】
1.真正的"全模态"统一融合与交错输入 (Interleaved Input) 以往的检索通常需要用独立的模型处理不同的数据。Gemini Embedding 2 不仅可以直接原生地"吃"进五大类数据,更强大的是它原生支持"交错输入" 。这意味着你可以在同一次请求中同时传入多种模态(例如:一张图片 + 一段文字描述),模型能够精准捕捉不同媒体类型之间复杂而微妙的关系,提供更深刻的真实世界数据理解。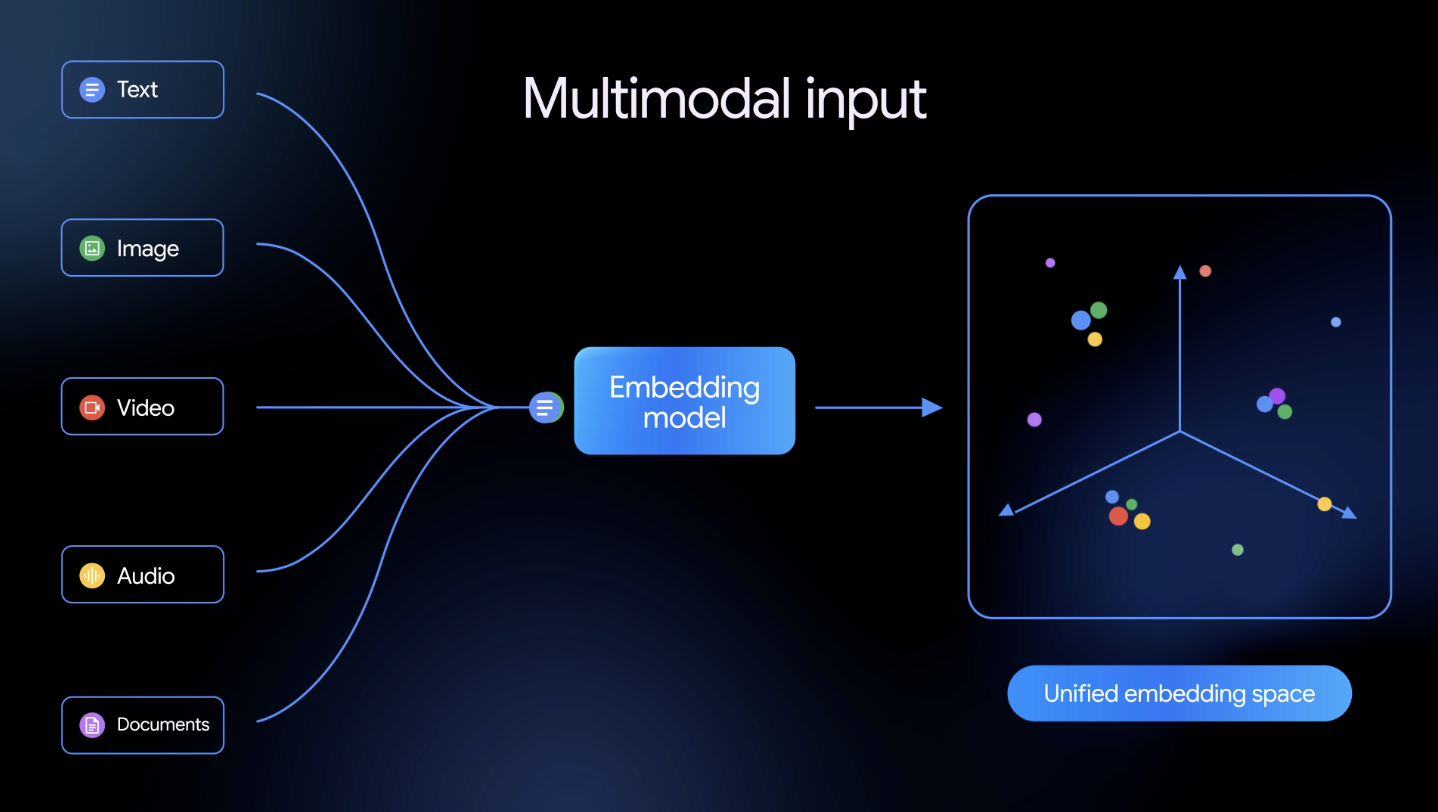
2. 原生语音与文档理解(告别中间转换) 新模型引入了强大的原生语音处理能力,可以直接摄入音频并生成嵌入向量,完全跳过了"语音转文字"的中间环节。同时,它也能直接处理 PDF 文档,大大简化了复杂的数据处理流水线 (Pipelines)。
3. MRL 弹性维度与 3072 维超强输出 模型默认输出高达 3072 维的浮点向量,能够捕捉极其细腻的语义特征。同时,它采用了 Matryoshka 表示学习 (MRL) 技术,允许开发者根据需要在不损失核心精度的前提下灵活缩小维度。官方推荐使用 3072、1536 或 768 维,让企业能在"极致检索精度"与"存储成本"之间自由寻找平衡点。
4. SOTA 性能 Gemini Embedding 2 不仅超越了以往的模型,它还为多模态深度处理设立了新的性能标杆,引入了强大的语音能力,并在文本、图像和视频任务中超越了领先模型。这种可量化的提升以及独特的多模态覆盖范围,恰好满足了开发者在多样化嵌入需求上的期待。
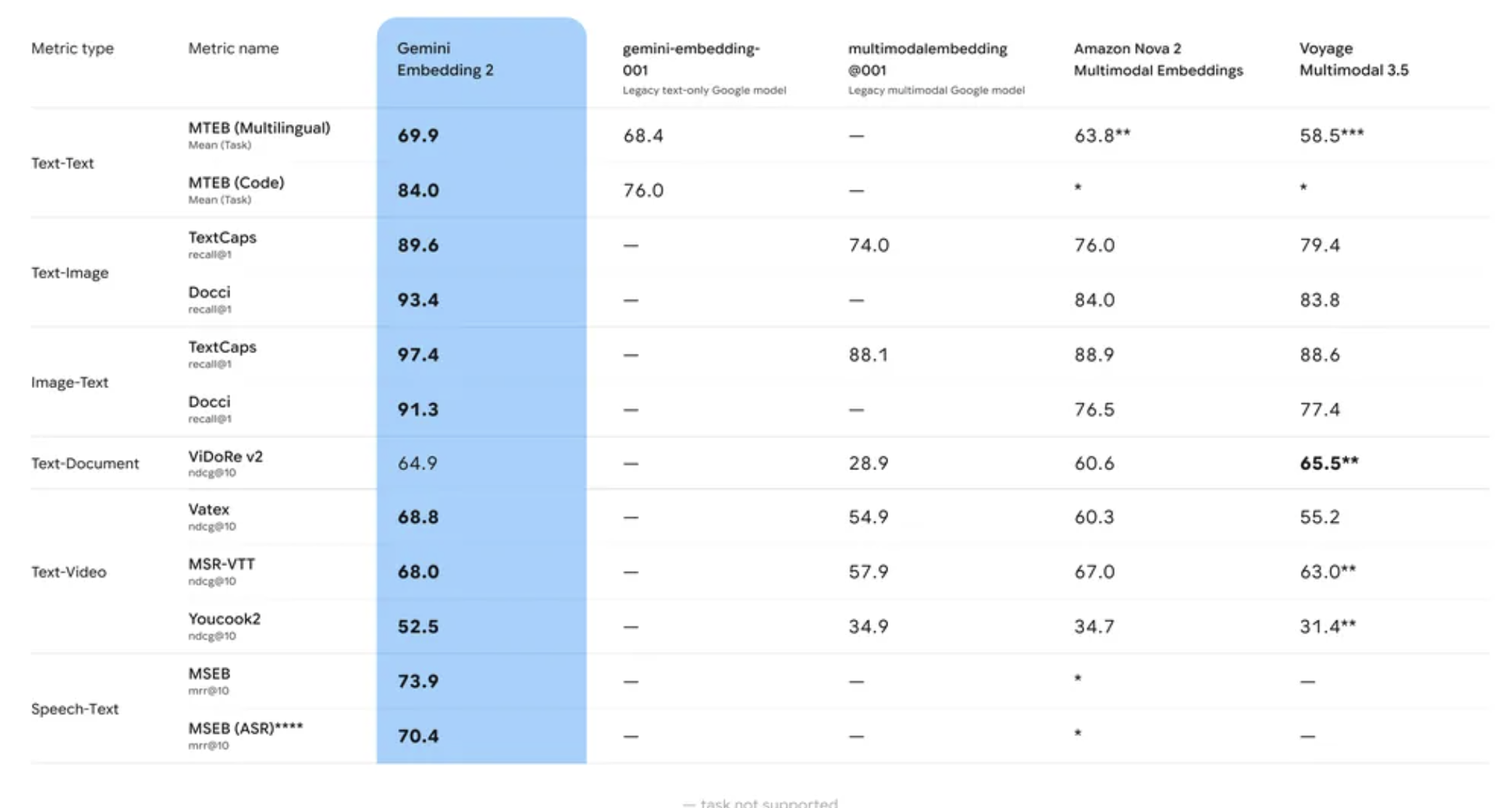
【必看的规格参数】 对于想要立刻上手的技术读者,以下是该预览版模型 (gemini-embedding-2-preview) 的输入限制:
- 文本:最多支持 8,192 tokens。
- 图像:每次请求最多 6 张(支持 PNG、JPEG)。
- 音频:原生支持,无需中间文本转录。
- 视频:无音频视频最长 120 秒;带音频视频最长 80 秒(支持 MP4、MOV/MPEG)。
- 文档:每次最多支持 1 个 PDF 文件,最高 6 页。
【应用场景】
结合全模态特性,它能将传统的 AI 玩法提升到新高度:
检索增强生成 (RAG): 支持图文音视频混合检索,大幅提升大模型生成内容的质量。
跨模态信息检索: 用一段音频或一张截图,直接精准搜索语义最匹配的文档或视频片段。
搜索结果重新排名: 根据多模态语义相关性得分,优先展示最匹配的初始结果。
异常值检测: 比较多模态向量群组,快速揪出海量混合数据中的违规或离群点。
零样本分类: 无需额外训练专门的分类器,自动对多媒体内容进行情感分析或打标。
数据聚类: 将复杂的音视频和报告统一向量化,通过可视化图表洞察业务关联。【如何抢先体验】
目前,Gemini Embedding 2 已经通过 Gemini API 和 Google Cloud 的 Vertex AI 平台进入公开预览阶段 (Public Preview),模型 ID 为 gemini-embedding-2-preview。
