核心思路是:
先读取一张 模板图片,里面有数字 0~9
把模板中的每个数字单独提取出来,作为标准模板
再读取信用卡图片
用形态学 + 梯度 + 轮廓,把信用卡号的数字区域找出来
把每组数字切分出来
再把每个数字与模板 0~9 逐个匹配
找出最像的那个数字
最后把识别结果画到原图上
代码:
python
from concurrent.futures import thread
import re
from turtle import width
from imutils import contours
import numpy as np
import imutils
import cv2
import os
image_path = r"D:/下载/OpenCV_信用卡数字识别/credit_card_02.png"
template_path = r"D:/下载/OpenCV_信用卡数字识别/ocr_a_reference.png"
print("image exists:", os.path.exists(image_path))
print("template exists:", os.path.exists(template_path))
FIRST_NUMBER = {
"3": "American Express",
"4": "Visa",
"5": "MasterCard",
"6": "Discover Card"
}
def cv_show(name, img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# =========================
# 1. 读取输入图像和模板图像
# =========================
img = cv2.imdecode(np.fromfile(image_path, dtype=np.uint8), cv2.IMREAD_COLOR)
if img is None:
raise FileNotFoundError(f"无法读取输入图像: {image_path}")
cv_show("img", img)
template = cv2.imdecode(np.fromfile(template_path, dtype=np.uint8), cv2.IMREAD_COLOR)
if template is None:
raise FileNotFoundError(f"无法读取模板图像: {template_path}")
cv_show("template", template)
# =========================
# 2. 处理模板图像,提取数字轮廓
# =========================
ref = cv2.cvtColor(template, cv2.COLOR_BGR2GRAY)
cv_show("ref", ref)
# 二值化
ref = cv2.threshold(ref, 10, 255, cv2.THRESH_BINARY_INV)[1]
cv_show("ref_thresh", ref)
# 查找模板数字轮廓
recnts, hierarchy = cv2.findContours(
ref.copy(),
cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE
)
print("模板轮廓个数:", len(recnts))
# 画出模板轮廓
template_copy = template.copy()
cv2.drawContours(template_copy, recnts, -1, (0, 255, 0), 3)
cv_show("img_contours", template_copy)
# 对轮廓从左到右排序
recnts = contours.sort_contours(recnts, method="left-to-right")[0]
digits = {}
# 遍历每个轮廓,提取ROI
for (i, c) in enumerate(recnts):
(x, y, w, h) = cv2.boundingRect(c)
roi = ref[y:y+h, x:x+w]
roi = cv2.resize(roi, (57, 88))
digits[i] = roi
print("digits中模板数字个数:", len(digits))
# =========================
# 3. 创建结构元素
# =========================
rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 3))
sqKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
# =========================
# 4. 重新读取信用卡图像
# =========================
image = cv2.imdecode(np.fromfile(image_path, dtype=np.uint8), cv2.IMREAD_COLOR)
if image is None:
raise FileNotFoundError(f"无法再次读取输入图像: {image_path}")
cv_show("image", image)
image = imutils.resize(image, width=300) # 调整图像大小以适应显示
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv_show("gray", gray)
tophat=cv2.morphologyEx(gray, cv2.MORPH_TOPHAT, rectKernel) #应用顶帽变换,突出显示亮区域
cv_show("tophat", tophat)
cv2.waitKey(0)
cv2.destroyAllWindows()
gradx=cv2.Sobel(tophat,ddepth=cv2.CV_32F,dx=1,dy=0,ksize=-1) #计算图像的x方向梯度
gradx=np.absolute(gradx) #取绝对值
(minVal,maxVal)=np.min(gradx),np.max(gradx)
gradx=(255*(gradx-minVal)/maxVal).astype("uint8") #归一化梯度图像到0-255范围
cv_show("gradx", gradx)
gradx=cv2.morphologyEx(gradx,cv2.MORPH_CLOSE,rectKernel) #把被 Sobel 边缘检测分开的数字边缘连接起来,形成连续的数字区域。
cv_show("gradx_closed", gradx)
thresh=cv2.threshold(gradx,0,255,cv2.THRESH_BINARY|cv2.THRESH_OTSU)[1] #使用 Otsu 的方法对闭合后的梯度图像进行二值化,得到二值图像
cv_show("thresh", thresh)
threshcnts,hierarchy=cv2.findContours(thresh.copy(),cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE) #查找二值图像中的轮廓
print("threshcnts中轮廓个数:", len(threshcnts))
cnts=threshcnts
cur_img=image.copy()
cv2.drawContours(cur_img,cnts,-1,(0,255,0),3)
cv_show("threshcnts", cur_img)
locs=[]
for (i,c) in enumerate(cnts):
(x,y,w,h)=cv2.boundingRect(c)
ar=w/float(h) #计算轮廓的宽高比
if ar>2.5 and ar<4.0: #筛选出宽高比在2.5到4.0之间的轮廓,这些轮廓可能包含信用卡数字
locs.append((x,y,w,h)) #将符合条件的轮廓的位置信息添加到locs列表中
print("locs中符合条件的轮廓个数:", len(locs))
for (i,(gX,gY,gW,gH)) in enumerate(locs):
groupOutput=[] #初始化一个列表,用于存储每个数字的识别结果
group=gray[gY-5:gY+gH+5,gX-5:gX+gW+5] #从灰度图像中提取出包含数字的区域,稍微扩大边界以确保完整捕获数字
cv_show(f"group_{i}", group)
group=cv2.threshold(group,0,255,cv2.THRESH_BINARY|cv2.THRESH_OTSU)[1] #对提取的区域进行二值化处理
cv_show(f"group_thresh_{i}", group)
digitCnts,hierarchy=cv2.findContours(group.copy(),cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE) #查找二值图像中的轮廓,这些轮廓可能对应于单个数字
digitCnts=contours.sort_contours(digitCnts,method="left-to-right")[0] #对找到的轮廓进行排序,按照从左到右的顺序
for c in digitCnts:
(x,y,w,h)=cv2.boundingRect(c) #计算轮廓的边界框,返回x、y坐标以及宽度和高度
roi=group[y:y+h,x:x+w] #提取轮廓区域的图像
roi=cv2.resize(roi,(57,88)) #将轮廓区域的图像调整为固定大小57x88
scores=[] #初始化一个列表,用于存储每个模板数字与当前ROI的匹配分数
for (digit,digitROI) in digits.items():
result=cv2.matchTemplate(roi,digitROI,cv2.TM_CCOEFF) #使用模板匹配方法比较当前ROI与每个模板数字,得到匹配结果
(_,score,_,_) = cv2.minMaxLoc(result) #从匹配结果中提取最大值作为匹配分数
scores.append(score) #将匹配分数添加到scores列表中
groupOutput.append(str(np.argmax(scores))) #找到匹配分数最高的模板数字索引,并将其转换为字符串添加到groupOutput列表中
print("识别结果:", "".join(groupOutput))
cv2.rectangle(image,(gX-5,gY-5),(gX+gW+5,gY+gH+5),(0,255,0),2) #在原始图像上绘制一个矩形框,标记出包含数字的区域
cv2.putText(image,"".join(groupOutput),(gX,gY-15),cv2.FONT_HERSHEY_SIMPLEX,0.65,(0,255,0),2) #在原始图像上添加文本,显示识别出的数字
cv_show("final_result", image)- 程序功能概述
这段代码实现的是典型的信用卡卡号 OCR 识别流程。它并不是基于深度学习模型,而是采用传统计算机视觉方法:先从模板图像中提取 0-9 数字轮廓,构建标准数字模板;再对信用卡图像进行增强、梯度计算、二值化和轮廓筛选,定位出卡号区域;最后把每个数字与模板逐一匹配,得到识别结果。
整个程序的核心思想可以概括为:模板制作 - 候选区域定位 - 单个数字切分 - 模板匹配识别 - 结果可视化。
-
整体处理流程
-
导入依赖库,设置图像路径与银行卡前缀字典。
-
读取信用卡图像和 OCR 模板图像,解决中文路径读取问题。
-
把模板图像转灰度并二值化,提取模板数字轮廓。
-
按从左到右顺序保存模板中的 0-9 数字 ROI。
-
对信用卡图像做灰度化、顶帽运算、Sobel 梯度增强和闭运算。
-
对增强结果进行二值化并查找候选轮廓,筛选可能的 4 位数字组区域。
-
在每个候选组中再次分割单个数字,并与模板库做 matchTemplate 匹配。
-
输出识别结果,并把识别出的卡号绘制到原图上。
-
关键库与变量说明
名称 作用 说明
cv2 OpenCV 图像处理核心库 完成读取、灰度化、二值化、轮廓检测、形态学处理和模板匹配
imutils.contours 轮廓排序 把模板数字或识别数字按从左到右排序
np.fromfile + cv2.imdecode 读取中文路径图像 避免 cv2.imread 在中文路径下失败
FIRST_NUMBER 银行卡类型映射 根据首位数字映射卡组织,如 Visa、MasterCard
digits 模板数字字典 保存模板图中的每个数字 ROI,供后续匹配
- 代码逐段讲解
4.1 导入库与路径设置
这一部分导入了程序所需的基础库。其中 cv2 是 OpenCV 主库,负责图像处理;imutils 主要用于简化轮廓排序和图像缩放;numpy 用于数组处理;os 用于检查路径是否存在。
image_path 和 template_path 分别对应待识别的信用卡图像和模板图像。随后通过 os.path.exists() 打印路径是否存在,便于提前排查文件路径错误。
from imutils import contours
import numpy as np
import imutils
import cv2
import os
4.2 银行卡首位数字映射
这个字典的作用是根据银行卡号第一位数字判断卡片类型。虽然你当前代码最后没有把该类型打印出来,但它通常会在完整项目中用于展示"识别出的卡号属于哪种银行卡"。例如首位为 4 时,可判定为 Visa。
FIRST_NUMBER = {
"3": "American Express",
"4": "Visa",
"5": "MasterCard",
"6": "Discover Card"
}
4.3 图像显示函数 cv_show
该函数是一个简单封装,用于调试过程中逐步查看中间结果。name 是窗口标题,img 是待显示图像。每调用一次都会暂停,直到按键后关闭窗口。这个函数在学习 OpenCV 流程时非常有用,因为它能帮助观察灰度图、二值图、梯度图和轮廓图是否符合预期。
def cv_show(name, img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
4.4 读取输入图像与模板图像
这里没有直接使用 cv2.imread,而是采用"np.fromfile + cv2.imdecode"的组合。这是因为 Windows 下如果路径中包含中文,cv2.imread 有时会读取失败。使用这种写法可以稳定读取中文路径图像,是本代码非常实用的一点。
img = cv2.imdecode(np.fromfile(image_path, dtype=np.uint8), cv2.IMREAD_COLOR)
template = cv2.imdecode(np.fromfile(template_path, dtype=np.uint8), cv2.IMREAD_COLOR)
4.5 模板图像预处理与轮廓提取
先把模板图像转为灰度图,再进行二值化。这里使用 THRESH_BINARY_INV,意味着原本较亮的数字会被变成白色前景,背景变为黑色,这样更便于后续 findContours 提取外部轮廓。
cv2.RETR_EXTERNAL 表示只保留最外层轮廓;cv2.CHAIN_APPROX_SIMPLE 用于压缩轮廓点,减少冗余。提取出的 recnts 就是模板中的 0 到 9 的轮廓集合。
ref = cv2.cvtColor(template, cv2.COLOR_BGR2GRAY)
ref = cv2.threshold(ref, 10, 255, cv2.THRESH_BINARY_INV)1
recnts, hierarchy = cv2.findContours(ref.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
4.6 模板数字排序与标准化
由于模板图中的数字通常是从左到右排列的,因此先对轮廓排序,再逐个裁剪 ROI。每个数字都被缩放到统一大小 57×88,这样在模板匹配时,待识别数字与模板数字尺寸一致,能够提升匹配稳定性。
digits 字典最终保存的就是"数字索引 -> 标准化模板图像"的映射。
recnts = contours.sort_contours(recnts, method="left-to-right")0
for (i, c) in enumerate(recnts):
(x, y, w, h) = cv2.boundingRect(c)
roi = refy:y+h, x:x+w
roi = cv2.resize(roi, (57, 88))
digitsi = roi
4.7 结构元素的定义
结构元素是形态学操作中的核心参数。这里定义了两个矩形核:
(1) rectKernel=(9,3) 更偏向水平方向,适合把一组横向排列的数字连接起来;
(2) sqKernel=(5,5) 是方形核,通常可用于更均衡的膨胀、腐蚀或闭运算。
在你当前代码中,rectKernel 被实际用于顶帽后的闭运算处理。
rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 3))
sqKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
4.8 信用卡图像预处理
先把图像缩放到固定宽度 300,便于控制后续处理尺度。随后转灰度,减少颜色信息干扰。
顶帽运算 = 原图 - 开运算结果,主要作用是突出比周围背景更亮的区域。在信用卡图像中,卡号通常比周围底纹更亮,因此顶帽操作能强化数字区域。
image = imutils.resize(image, width=300)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
tophat = cv2.morphologyEx(gray, cv2.MORPH_TOPHAT, rectKernel)
4.9 Sobel 梯度与闭运算增强
Sobel 在 x 方向求梯度,目的是强调垂直边缘变化。信用卡数字是一串竖直笔画较多的字符,因此 x 方向梯度很适合增强它们。
之后将梯度值归一化到 0-255,便于显示和阈值分割。再通过闭运算把原本断裂的数字边缘连接起来,从而形成较完整的数字组区域。
gradx = cv2.Sobel(tophat, ddepth=cv2.CV_32F, dx=1, dy=0, ksize=-1)
gradx = np.absolute(gradx)
(minVal, maxVal) = np.min(gradx), np.max(gradx)
gradx = (255 * (gradx - minVal) / maxVal).astype("uint8")
gradx = cv2.morphologyEx(gradx, cv2.MORPH_CLOSE, rectKernel)
4.10 二值化与候选数字组筛选
Otsu 自动阈值法会根据图像灰度分布自动找到较优阈值,把增强后的数字区域分离出来。
随后对二值图像中的轮廓计算外接矩形,并通过宽高比 ar 做筛选。因为银行卡号通常按 4 位一组横向排列,所以一个数字组整体看起来会"宽而不高",其宽高比通常落在一定区间内。这里用 2.5 到 4.0 作为经验阈值,把可能是数字组的区域保存到 locs 中。
thresh = cv2.threshold(gradx, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)1
threshcnts, hierarchy = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in cnts:
(x, y, w, h) = cv2.boundingRect(c)
ar = w / float(h)
if ar > 2.5 and ar < 4.0:
locs.append((x, y, w, h))
4.11 单组数字分割与模板匹配
在每个候选数字组中,先适当向外扩 5 个像素,避免数字边界被裁掉。然后再次二值化和提取轮廓,此时轮廓对象不再是一整组数字,而更接近单个数字。
再次按从左到右排序后,就可以逐个提取数字 ROI,准备与模板库比较。
group = graygY-5:gY+gH+5, gX-5:gX+gW+5
group = cv2.threshold(group, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)1
digitCnts, hierarchy = cv2.findContours(group.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
digitCnts = contours.sort_contours(digitCnts, method="left-to-right")0
4.12 模板匹配识别
cv2.matchTemplate 用于比较当前 ROI 和每一个模板数字的相似度。这里采用 TM_CCOEFF 方法,得分越高表示越相似。
遍历完 10 个模板后,取分数最高的索引作为当前数字识别结果。因为 digits 字典的键就是 0-9 的顺序索引,所以 np.argmax(scores) 可以直接对应到预测数字。
for (digit, digitROI) in digits.items():
result = cv2.matchTemplate(roi, digitROI, cv2.TM_CCOEFF)
(_, score, _, _) = cv2.minMaxLoc(result)
scores.append(score)
groupOutput.append(str(np.argmax(scores)))
4.13 结果绘制与输出
最后一步是在原图上标出识别区域,并把识别出的数字字符串绘制在区域上方。这样既能看到原始信用卡图像,又能直观看到程序检测到的卡号组以及对应的识别结果。
cv2.rectangle(image, (gX-5, gY-5), (gX+gW+5, gY+gH+5), (0,255,0), 2)
cv2.putText(image, "".join(groupOutput), (gX, gY-15), cv2.FONT_HERSHEY_SIMPLEX, 0.65, (0,255,0), 2)
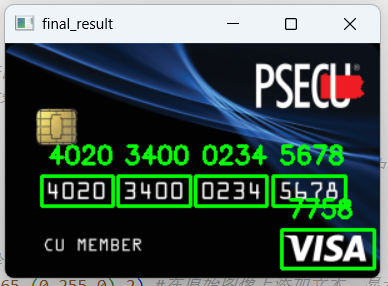
- 程序的识别逻辑总结
模板图像负责提供标准数字外观;信用卡图像经过顶帽、梯度和闭运算后,先定位到"数字组",再进一步切分到"单个数字";最终通过模板匹配完成识别。
这是一种经典的传统视觉 OCR 思路,优势是实现简单、可解释性强、无需训练深度学习模型;不足是对图像质量、光照、旋转、模糊、卡号字体变化较敏感。