使用 Swift 微调 Llama-3.2-3B 打造知乎风格问答机器人
实验记录:从数据清洗到模型微调的完整流程与踩坑指南
https://swift.readthedocs.io/zh-cn/latest/Megatron-SWIFT/LoRA-Training.html
一、实验目标
训练一个具有知乎答主风格的问答机器人,能够:
- 以真实人类的语气回答问题
- 展现丰富的情感(开心、幸福、愤怒、伤心、阴阳怪气等)
- 保持知乎高赞回答的逻辑性和可读性
二、实验环境
| 项目 | 配置 |
|---|---|
| 硬件 | Mac 笔记本 (Apple Silicon) |
| 加速 | MPS (Metal Performance Shaders) |
| 微调框架 | ms-swift |
| 微调方法 | LoRA |
| 基座模型 | Llama-3.2-3B-Instruct |
三、数据准备
3.1 数据来源
使用 ModelScope 上的 Zhihu-KOL 数据集,包含知乎高质量问答内容。
python
from modelscope.msdatasets import MsDataset
ds = MsDataset.load('OmniData/Zhihu-KOL', cache_dir='../data', split='train')
print(f"原始数据量: {len(ds)}") # 约 100 万条原始数据格式:
json
{
"INSTRUCTION": "怎么说服男朋友买烤箱?",
"RESPONSE": "emmmmm,首先想说的是...",
"METADATA": "{\"upvotes\": \"赞同 15\", ...}",
"SOURCE": "Zhihu"
}3.2 数据清洗
使用 Data-Juicer 进行数据清洗,配置文件 zhihu-bot.yaml:
yaml
project_name: 'zhihu-process'
dataset_path: '../data/zhihu.jsonl'
np: 16
text_keys: 'response'
export_path: '../data/zhihu_refine.jsonl'
process:
# 1. 过滤低点赞数据
- specified_numeric_field_filter:
field_key: 'upvotes'
min_value: 500
# 2. 文本长度过滤
- text_length_filter:
min_len: 100
max_len: 2000
# 3. 清洗处理
- clean_email_mapper:
- clean_html_mapper:
- clean_ip_mapper:
- clean_links_mapper:
- clean_copyright_mapper:
# 4. 语言和质量过滤
- language_id_score_filter:
lang: zh
min_score: 0.9
- alphanumeric_filter:
tokenization: false
min_ratio: 0.72
- flagged_words_filter:
lang: zh
max_ratio: 0.0005
- perplexity_filter:
lang: zh
max_ppl: 4000
# 5. 去重
- document_simhash_deduplicator:
tokenization: character
window_size: 5
num_blocks: 10
hamming_distance: 6
# 6. 选取 Top 50000 高赞数据
- topk_specified_field_selector:
field_key: 'upvotes'
topk: 50000
reverse: True3.3 数据质量分析
清洗后数据统计:
| 指标 | 数值 | 说明 |
|---|---|---|
| 数据量 | 50,000 条 | 从 100 万条中筛选 |
| 语言 | 98.5% 中文 | 主要为中文内容 |
| 平均困惑度 | 2390 | 偏高,但可接受 |
| 点赞范围 | 500 ~ 634,000 | 高质量回答 |
关于困惑度偏高的分析:
- 困惑度 2000+ 在基础模型上计算是正常的
- 最大值 170 万是异常值,已通过
max_ppl: 4000过滤 - 知乎回答风格口语化、有网络用语,困惑度偏高符合预期
3.4 最终数据格式
转换为 Swift 支持的格式:
json
{"query": "语文考试可以写负能量作文吗?", "response": "我真的是服你们这群崽子...", "upvotes": 434000}
{"query": "有哪些知识,你知道后你的世界马上就不一样了?", "response": "1.原则上可以,就是不可以...", "upvotes": 399000}四、模型微调
4.1 Swift 微调命令(Mac MPS 版本)
bash
swift sft \
--train_type lora \
--model /path/to/Llama-3.2-3B-Instruct \
--dataset ../data/zhihu_train.jsonl#3000 \
--system "你是一个真实的人类。回答用户的问题,并在聊天回复中展现你的情绪,包括开心,幸福,愤怒,伤心,阴阳怪气等" \
--split_dataset_ratio 0.01 \
--output_dir ../output \
--target_modules all-linear \
--lora_rank 4 \
--torch_dtype fp16 \
--device_map mps \
--seed 42 \
--learning_rate 1e-4 \
--warmup_ratio 0.05 \
--max_length 512 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--num_train_epochs 1 \
--gradient_accumulation_steps 16 \
--gradient_checkpointing true \
--save_total_limit 2 \
--eval_steps 200 \
--save_steps 2004.2 关键参数说明
| 参数 | 值 | 说明 |
|---|---|---|
--train_type |
lora | 使用 LoRA 微调,参数高效 |
--target_modules |
all-linear | 作用于所有线性层 |
--lora_rank |
4 | LoRA 秩,越小参数越少 |
--torch_dtype |
fp16 | MPS 不支持 bf16 |
--device_map |
mps | 使用 Apple Silicon GPU |
--per_device_train_batch_size |
1 | Mac 内存有限,设为 1 |
--gradient_accumulation_steps |
16 | 梯度累积补偿小 batch |
--gradient_checkpointing |
true | 用时间换内存 |
--max_length |
512 | 限制序列长度,节省内存 |
4.3 实验具体数据
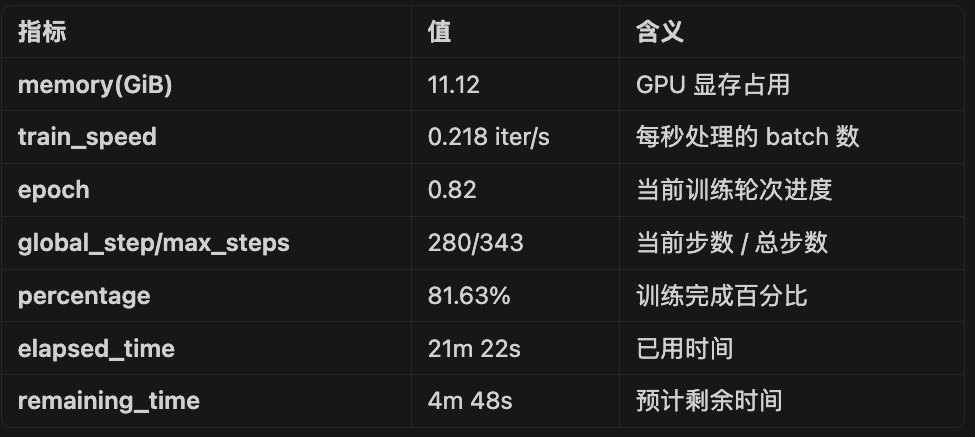
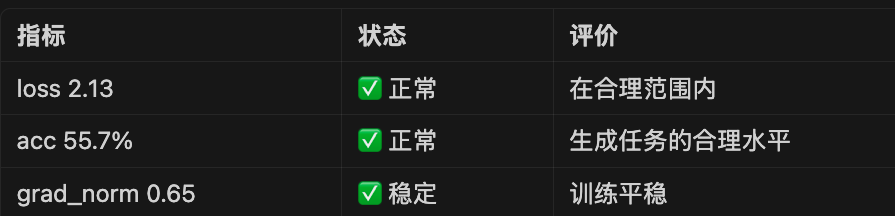
{'loss': 2.13094215, 'acc': 0.55739484, 'grad_norm': 0.6459673, 'learning_rate': 8.99e-06, 'memory(GiB)': 11.12, 'train_speed(iter/s)': 0.218063, 'epoch': 0.82, 'global_step/max_steps': '280/343', 'percentage': '81.63%', 'elapsed_time': '21m 22s', 'remaining_time': '4m 48s'}
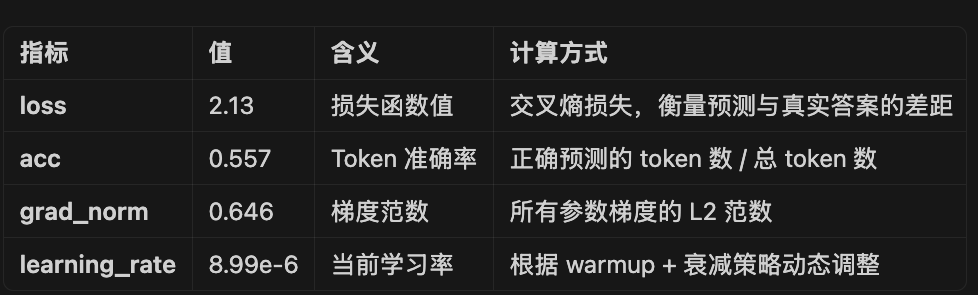
- acc 0.557 (55.7%)
→ 模型能正确预测超过一半的 token
→ 对于生成任务来说是正常水平 - grad_norm 0.646
→ 非常稳定,说明训练平稳
异常情况: - grad_norm 很大 (>10) → 可能梯度爆炸
- grad_norm 接近 0 → 可能梯度消失
五、踩坑记录
5.1 Data-Juicer: topk_specified_field_selector 非常慢
问题 :topk_specified_field_selector 处理 100 万条数据耗时极长。
原因:
- 全局排序无法并行化,必须收集所有数据
- 排序算法复杂度 O(n log n)
解决方案:
- 提高
upvotes阈值预过滤数据 - 分两步处理:先过滤去重,再单独排序
5.2 Swift 新版本参数名变化
问题:旧教程的参数名在新版本中不识别。
参数对照表:
| 旧参数 | 新参数 |
|---|---|
--sft_type |
--train_type |
--model_type + --model_id_or_path |
--model |
--dataset_test_ratio |
--split_dataset_ratio |
--lora_target_modules |
--target_modules |
--dtype |
--torch_dtype |
--batch_size |
--per_device_train_batch_size |
--device |
--device_map |
5.3 target_modules: ALL 不被识别
问题:
ValueError: Target modules {'ALL'} not found in the base model.解决:
- 新版本使用
all-linear而非ALL - 或指定具体模块:
q_proj k_proj v_proj o_proj gate_proj up_proj down_proj
5.4 MPS 不支持 bf16
问题:Mac MPS 后端不支持 bfloat16。
解决:
- 使用
--torch_dtype fp16替代bf16 - 或使用
fp32(更慢但更稳定)
5.5 内置数据集下载失败
问题 :qwen2-pro-zh 等内置数据集无法自动下载。
解决:
- 只使用本地数据集:
--dataset ../data/zhihu_train.jsonl#3000 - 或手动从 ModelScope 下载后本地引用
六、垂直领域微调的核心要点
6.1 数据质量 > 数据数量
垂直领域微调,数据质量是第一要素:
| 维度 | 要求 | 本实验做法 |
|---|---|---|
| 准确性 | 内容正确无误 | 选取高赞回答(经过社区验证) |
| 多样性 | 覆盖领域内不同场景 | 保留多话题、多风格 |
| 一致性 | 风格/格式统一 | 统一转换为 query-response 格式 |
| 代表性 | 体现领域特点 | 保留知乎特有的表达风格 |
经验法则:
- 高质量数据 1 万条 > 低质量数据 10 万条
- 宁缺毋滥,异常数据会严重影响模型效果
6.2 数据混用策略(防止灾难性遗忘)
微调垂直领域时,模型容易"忘记"通用能力。解决方案是混合训练数据:
总训练数据 = 垂直领域数据 + 通用数据推荐混合比例
| 场景 | 垂直数据 : 通用数据 | 说明 |
|---|---|---|
| 轻度定制 | 7 : 3 | 保留大部分通用能力 |
| 中度定制 | 5 : 5 | 平衡垂直和通用 |
| 深度定制 | 8 : 2 | 专注垂直领域,接受通用能力下降 |
本实验的数据混用示例
bash
--dataset ../data/zhihu_train.jsonl#3000 \ # 垂直领域:知乎数据
alpaca-gpt4-data-zh#1500 \ # 通用数据:中文指令
belle-1m#1500 # 通用数据:中文对话通用数据推荐
| 数据集 | 用途 | 来源 |
|---|---|---|
| alpaca-gpt4-data-zh | 中文指令跟随 | ModelScope |
| belle-1m | 中文多轮对话 | ModelScope |
| firefly-train-1.1M | 中文多任务 | HuggingFace |
| moss-sft-data | 通用问答 | ModelScope |
6.3 防止灾难性遗忘的技术手段
除了数据混用,还有以下方法:
方法 1:使用 LoRA 而非全量微调
bash
--train_type lora # LoRA 只更新少量参数
--lora_rank 4 # 较小的 rank 减少对原模型的干扰原理:LoRA 冻结原始权重,只训练低秩适配器,最大程度保留原始能力。
方法 2:降低学习率
bash
--learning_rate 1e-5 # 比通常的 1e-4 更小原理:小学习率减少对原始权重的修改幅度。
方法 3:减少训练轮数
bash
--num_train_epochs 1 # 1-2 轮足够原理:过多轮次会导致过拟合到垂直领域,丢失通用能力。
方法 4:使用 NEFTune(噪声嵌入)
bash
--neftune_noise_alpha 5 # 在嵌入层添加噪声原理:增加训练噪声,提高模型泛化能力。
6.4 数据配比的动态调整
训练过程中可以观察指标来调整配比:
| 现象 | 原因 | 调整方向 |
|---|---|---|
| 垂直领域效果差 | 垂直数据不足 | 增加垂直数据比例 |
| 通用能力明显下降 | 过拟合垂直领域 | 增加通用数据比例 |
| 两者都不理想 | 数据质量问题 | 检查数据清洗流程 |
6.5 评估策略
微调后需要同时评估两方面:
1. 垂直领域评估
- 用垂直领域测试集评估(如知乎问题)
- 人工评估回答风格是否符合预期
2. 通用能力评估
- 用通用 benchmark 测试(如 C-Eval、CMMLU)
- 测试常识问答、数学、代码等基础能力6.6 本实验的数据策略总结
┌─────────────────────────────────────────────────────┐
│ 训练数据组成 │
├─────────────────────────────────────────────────────┤
│ 知乎高赞数据 (3000条) │
│ ├── 高点赞筛选 (upvotes > 500) │
│ ├── 质量过滤 (困惑度、长度、语言) │
│ └── SimHash 去重 │
├─────────────────────────────────────────────────────┤
│ 通用中文数据 (建议添加 1500-3000条) │
│ ├── alpaca-gpt4-data-zh (指令跟随) │
│ └── belle / moss (对话能力) │
└─────────────────────────────────────────────────────┘
↓
LoRA 微调 (rank=4, lr=1e-4)
↓
知乎风格 + 保留通用能力七、Mac 微调的局限性
| 限制 | 影响 | 建议 |
|---|---|---|
| 内存有限 | batch_size 只能设 1 | 使用梯度累积 |
| 不支持 bf16 | 精度略有损失 | 使用 fp16 |
| 速度慢 | 3B 模型训练耗时长 | 用于小规模测试 |
| MPS 不稳定 | 部分算子可能出错 | 设置 PYTORCH_ENABLE_MPS_FALLBACK=1 |
建议:Mac 适合小规模测试(几百~几千条数据),正式训练建议使用云服务器(如 AutoDL A10 GPU)。
八、总结
本实验完成了:
- ✅ 知乎数据集清洗与筛选(100万→5万条高质量数据)
- ✅ 数据格式转换(适配 Swift 框架)
- ✅ 配置 Mac MPS 环境的微调参数
- ✅ 解决 Swift 新版本的兼容性问题
后续计划:
- 在 GPU 服务器上完成完整训练
- 评估微调后模型的回答质量
- 尝试不同的 system prompt 调整风格
- 多轮对话能力增强