学习案例主题:多组数据分析(t检验、单因素方差分析以及多重比较)
学习初衷:①与AI对接很耗时间②自己学会原理,不一定要每个都手敲,但是可以快速定位和优化AI的代码③我们不会因为有了计算器而放弃学数学,学习代码是不是也是这样?
上一篇完成了脚本解释说明、工具调用和数据文件获取及清洗等内容深度学习python代码处理科研测序数据(不想学的话可以直接拿走代码)-上,本篇重点对数据进行多组数据分析。
快速浏览本文结构:
3.1 数据抬头摘要及P值定义
3.2 数据分析(描述统计 → ANOVA → 事后比较)
3.3 数据分析(t检验)
3.4 生成图片文件名描述与绘图准备
3.5 生成柱状图
3.6 生成箱型图
3.7 保存结果及完成提示
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

三、数据统计与分析
3.1 数据抬头摘要及P值定义
print("\n" + "=" * 70)``print("各组统计摘要")``print("=" * 70)``stats_df = df_clean.groupby(group_col)[value_col].agg(['count', 'mean', 'std', 'min', 'max'])``stats_df.columns = ['样本数', '均值', '标准差', '最小值', '最大值']``stats_df['均值'] = stats_df['均值'].round(2)``stats_df['标准差'] = stats_df['标准差'].round(2)``print(stats_df)``# ========== 7. 定义p值星号函数 ==========``def stars(p):`` if p < 0.001:`` return "***"`` elif p < 0.01:`` return "**"`` elif p < 0.05:`` return "*"`` else:`` return "ns"
第1-4行,展示抬头;
第5行:使用清洗后的数据分组计算"'count', 'mean', 'std', 'min', 'max'";
第6行转化为中文;
第7-8行将计算的均值和标准差保留2位小数,别忘了此处有个赋值操作。如下图
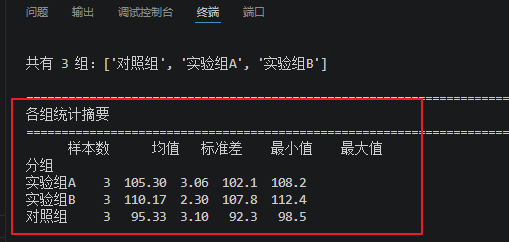
第10-19是P值赋值,按照科学论文中的标准表示法:*** p < 0.001;** p < 0.01;* p < 0.05;ns 或留空 p ≥ 0.05。因为满足要求,return会结束函数,故阈值要从严到宽。
3.2 数据分析(描述统计 → ANOVA → 事后比较)
print("\n" + "=" * 70)``print("单因素方差分析 (ANOVA)")``print("=" * 70)``data_by_group = [df_clean[df_clean[group_col] == g][value_col].values for g in groups]``if len(groups) >= 2:`` f_stat, p_value = f_oneway(*data_by_group)`` print(f"F统计量 = {f_stat:.4f}")`` print(f"p值 = {p_value:.4f}")`` print(f"显著性:{stars(p_value)}")`` `` if p_value < 0.05:`` print("结论:各组之间存在显著差异")`` else:`` print("结论:各组之间无显著差异")`` # 事后检验`` if p_value < 0.05 and len(groups) > 2:`` print("\n" + "=" * 70)`` print("事后检验 (Tukey HSD 多重比较)")`` print("=" * 70)`` tukey = pairwise_tukeyhsd(df_clean[value_col], df_clean[group_col], alpha=0.05)`` print(tukey)
第1-4说明展示,如前,不多解释了。
重点解释第5行:按组别提取数据,转换成列表形式,"\[10, 12, 11, 20, 24, 22, 30, 31, 29]"
"data_by_group = df_clean\[df_clean\[group_col == g]value_col.values for g in groups]":g代表组别(比如A、B、C组),筛选出对应A(B、C组)组的所有行(比如A组共有3行数据23,24,25)------筛选行
"data_by_group = df_clean\[df_clean\[group_col == g]value_col.values for g in groups]":提取上述所有行的值------选择列
"data_by_group = df_clean\[df_clean\[group_col == g]value_col.values for g in groups]":将数值转换成数组,如23 24 25-------转成numpy数组
第7行:f_stat:它是方差分析(ANOVA)计算出来的一个数字,用来判断各组均值之间是否存在显著差异。
f_stat = 组与组之间的差异 ÷ 组内部个体的差异。p值:如果各组实际上没有差异,你看到这么大差异的可能性有多大。p值越小,越说明"差异不是偶然"。F代表差异的大小,P代表差异是否可靠。如果F越大,P越小,说明数据之间有差异,且差异显著。
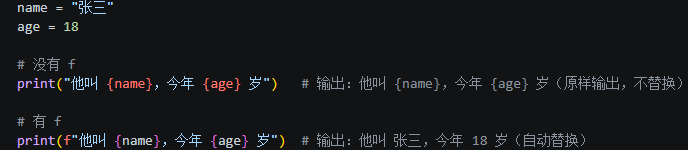
第8行:"F统计量 = {f_stat:.4f}" 4f保留4为小数;f-string:在字符串前面加个 f ,这样字符串里的 {变量名} 就会被自动替换成变量的值。举例说明,如下图
第16行:事后检验<多重比较>,用于找出具体哪些组之间存在显著差异ANOVA:三组之间有差异吗?→ 只能告诉你有差异
Tukey HSD:哪两组之间有差异?→ 具体指出 A和B、A和C、B和C
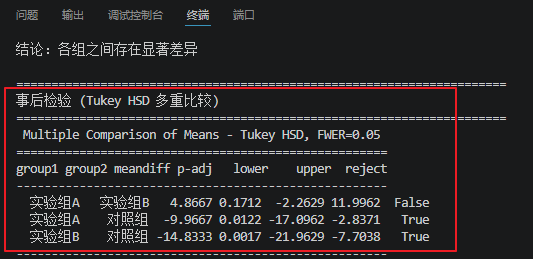
reject(True):有足够证据证明两组有差异,默认有差异。 reject(False):没有足够的证据证明有差异,默认无差异
3.3 数据分析(t检验)
print("\n" + "=" * 70)``print("两组间t检验(各组 vs 对照组)")``print("=" * 70)``control_group = groups[0]``control_data = df_clean[df_clean[group_col] == control_group][value_col]``ttest_results = []``p_values_for_plot = []``for group in groups[1:]:`` group_data = df_clean[df_clean[group_col] == group][value_col]`` t_stat, p_val = ttest_ind(control_data, group_data)`` p_values_for_plot.append(p_val)`` `` pooled_std = np.sqrt((control_data.var() + group_data.var()) / 2)`` cohens_d = (group_data.mean() - control_data.mean()) / pooled_std`` `` ttest_results.append({`` "组别": group,`` "对照组": control_group,`` "均值差": f"{group_data.mean() - control_data.mean():.2f}",`` "t值": f"{t_stat:.3f}",`` "p值": f"{p_val:.4f}",`` "显著性": stars(p_val),`` "Cohen's d": f"{cohens_d:.3f}"`` })``df_ttest = pd.DataFrame(ttest_results)``print(df_ttest.to_string(index=False))
代码注释:相比对照组,每个实验组是否有显著差异,差异有多大。
前4行:结果展示说明。第5-6行:选第一组为对照组,获取对照组数据
第7-8行:保存实验组的统计结果,画p值。
如果没有这两行,最终返回的结果是最后一个,相当于,做了统计但是未记录下来,被后来的覆盖了
第9行:遍历,从第二组开始,每个组依次与对照组比较。第10行,命名实验组,且确定实验组的逻辑。第11-12行,做独立样本t检验,存好P值。
第14-15行,差异的实际大小(标准化后的效应量),告诉你"即使p值显著,这个差异到底有没有实际价值"。p值显著 + 大效应量 → 既有统计意义又有实际意义。
第17-26行,将t检验所有结果存在excel表格中。第27行,打印到终端,显现出来。
恭喜你!数据分析已完成,下面是图片生成,就相对比较简单了
3.4 生成图片文件名描述与绘图准备
today = datetime.now().strftime("%Y%m%d")``existing_files = [f for f in os.listdir(output_dir) if f.startswith(today)]``bar_count = len([f for f in existing_files if "柱状图" in f])``box_count = len([f for f in existing_files if "箱线图" in f])``bar_name = f"{today}_柱状图_{bar_count+1}.png"``box_name = f"{today}_箱线图_{box_count+1}.png"``bar_path = os.path.join(output_dir, bar_name)``box_path = os.path.join(output_dir, box_name)``print(f"\n图片将保存为:")``print(f" 柱状图:{bar_name}")``print(f" 箱线图:{box_name}")``# ========== 11. 绘图数据准备 ==========``means = df_clean.groupby(group_col)[value_col].mean()``stds = df_clean.groupby(group_col)[value_col].std()
第1-7获取当前日期+列出输出文件夹今天已存在的所有文件,统计以今天日期的柱状图/箱型图文件数,累加生成以日期20260512_柱状图_1的文件
第8-12行:生成两种图形的保存位置,打印到终端
第14-15行,分组计算平均值和标准差(柱状图的误差线)
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

3.5 生成柱状图
(柱状图需要平均值和标准差)
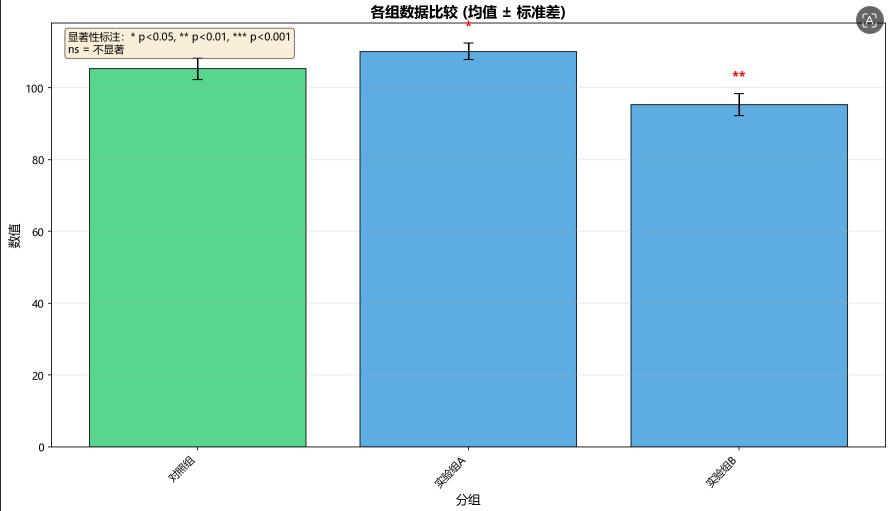
print("\n生成柱状图...")``fig1, ax1 = plt.subplots(figsize=(12, 7))``colors = ['#2ecc71'] + ['#3498db'] * (len(groups)-1)``bars = ax1.bar(range(len(groups)), means, yerr=stds, capsize=5,`` color=colors, alpha=0.8, edgecolor='black', linewidth=1)``ax1.set_xticks(range(len(groups)))``ax1.set_xticklabels(groups, rotation=45, ha='right')``ax1.set_ylabel(value_col, fontsize=12)``ax1.set_xlabel(group_col, fontsize=12)``ax1.set_title('各组数据比较 (均值 ± 标准差)', fontsize=14, fontweight='bold')``ax1.grid(True, alpha=0.3, axis='y')``# 标注显著性``if len(groups) >= 2:`` y_max = (means + stds).max()`` for i, p_val in enumerate(p_values_for_plot):`` star = stars(p_val)`` if star != 'ns':`` y_position = means.iloc[i+1] + stds.iloc[i+1] + y_max * 0.03`` ax1.text(i+1, y_position, star, ha='center', fontsize=14,`` fontweight='bold', color='red')``# 图例说明``ax1.text(0.02, 0.98, '显著性标注:* p<0.05, ** p<0.01, *** p<0.001\nns = 不显著',`` transform=ax1.transAxes, fontsize=10, verticalalignment='top',`` bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5))``plt.tight_layout()``plt.savefig(bar_path, dpi=150, bbox_inches='tight')``plt.close(fig1)
第4行:在"画纸"ax1上画出一个大小为12,7的图片fig1
第5行:对照组和除对照组以外的组设置颜色(绿、蓝)
第6-7行:bars是存储变量,后续可以修改;bar是柱状图;range是范围,代表所有组(每个组需要平均值,误差线,误差线上横,颜色,透明度,边框色,边框粗细)
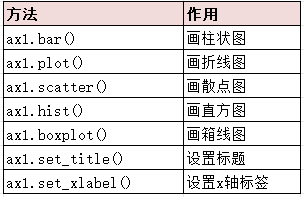
第8-11行:"画纸",遍历组别,画小竖线;给小竖线对应上名字,斜度45℃,右对齐(当标签是斜着的时候,右对齐看起来最整齐);设置y轴和x轴坐标轴标题,字体12号
第12-13行:图标题写"各组数据比较(均值±标准差)",字号14,加粗;加横向网格线(true:打开网格线,透明度:浅,y轴方向画,即画水平线)
第15-20行:显著性在组数≥2才启动;最大组的平均值和误差值的和赋给变量y_max(用作富余量的百分比计算,担心星号碰到柱子);给P值列表标记:第几组+P值。
enumerate类似标签作用,Python内置函数,举例"给班级所有人一人一个号码牌";把p值转化成星号;"!="在编程中是不等于的意思,ns = n ot significant;python一般i从0开始数,所以i+1就是实验组的第一个,iloc定位,pandas的方法,举例"按照号码牌叫人",在y=平均值+误差+y_max*0.3处添加星号。
第21-22行:在"画纸"上画(组数,高度,画星星,水平居中,14号字,粗体,红色)
第23-29行图例(显著性的等级说明)
柱状图如下:
3.6 生成箱型图
(箱型图需要原始数据,计算中位数、四分位数、异常值、最大值和最小值)
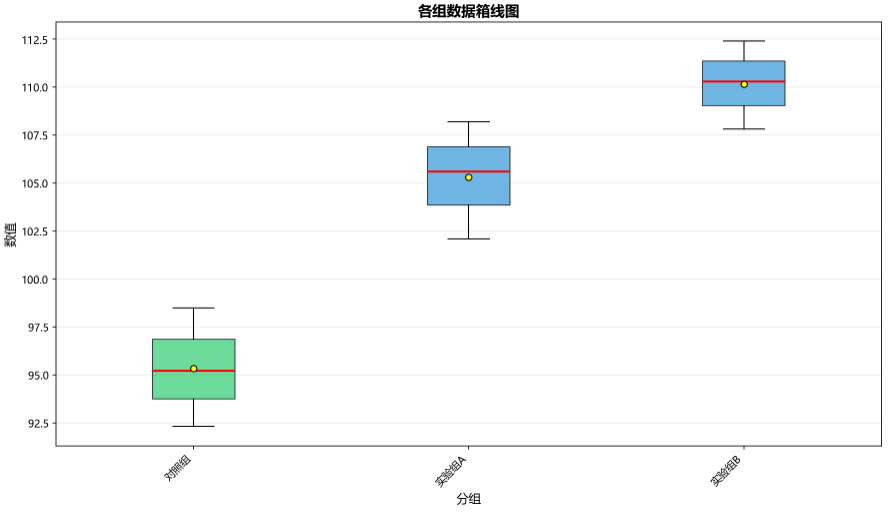
print("生成箱线图...")``fig2, ax2 = plt.subplots(figsize=(12, 7))``box_data = [df_clean[df_clean[group_col] == g][value_col].values for g in groups]``bp = ax2.boxplot(box_data, labels=groups, patch_artist=True, showmeans=True)``for patch, color in zip(bp['boxes'], colors):`` patch.set_facecolor(color)`` patch.set_alpha(0.7)``for median in bp['medians']:`` median.set_color('red')`` median.set_linewidth(2)``for mean in bp['means']:`` mean.set_marker('o')`` mean.set_markerfacecolor('yellow')`` mean.set_markeredgecolor('black')`` mean.set_markersize(6)``ax2.set_xticklabels(groups, rotation=45, ha='right')``ax2.set_ylabel(value_col, fontsize=12)``ax2.set_xlabel(group_col, fontsize=12)``ax2.set_title('各组数据箱线图', fontsize=14, fontweight='bold')``ax2.grid(True, alpha=0.3, axis='y')``plt.tight_layout()``plt.savefig(box_path, dpi=150, bbox_inches='tight')``plt.close(fig2)
第4行:g就相当于i的角色,都是遍历。
for i in range(拿着号码牌,将号码牌分给组别),for g in groups,直接取组别。
第5行:ax2.boxplot画箱型图;原始数据;每组对应标签;patch_artist和showmeans都是设置动作,True设置为实心可改颜色/显示均值,如果是False,是默认,不能更改或无。
第6-16行:箱子:绿色/蓝色半透明 的盒子;中位数:箱子中间一条粗红线;均值 :盒子里的黄色圆点(带黑边)
修改颜色(colors柱状图有定义和透明度alpha);修改中位数线(红色,加粗到2);修改均值点(设为圆形,默认可能是菱形或三角形,圆形内部填充黄色,边框设置黑色,点大小6像素)
第17-21行:同柱状图,xy轴标签,分组,图标题,加线等。
第22-24行:plt:图;tight:紧凑的,裁掉多余空白部分;layout:合理布局;dpi像素;24行关闭图片。
箱型图如下:
3.7 保存结果及完成提示
print("\n保存分析结果...")``result_file = os.path.join(output_dir, f"{today}_分析结果.xlsx")``with pd.ExcelWriter(result_file, engine='openpyxl') as writer:`` stats_df.to_excel(writer, sheet_name='统计摘要')`` `` if len(groups) >= 2:`` anova_df = pd.DataFrame({`` '指标': ['F统计量', 'p值', '显著性'],`` '数值': [f_stat, p_value, stars(p_value)]`` })`` anova_df.to_excel(writer, sheet_name='方差分析', index=False)`` `` if len(ttest_results) > 0:`` df_ttest.to_excel(writer, sheet_name='t检验_vs对照组', index=False)``# ========== 15. 完成提示 ==========``print("\n" + "=" * 70)``print("分析完成!")``print("=" * 70)``print(f"\n输出文件夹:{output_dir}")``print(f"数据文件:{os.path.basename(file_path)}")``print(f"分析结果:{os.path.basename(result_file)}")``print(f"柱状图:{bar_name}")``print(f"箱线图:{box_name}")``print("\n" + "=" * 70)``# 防止窗口闪退``input("按 Enter 键退出...")
第3行:结果文件设置:路径-命名(如,20260512_分析结果)
第4行:openpyxl:打开;pd的excel编辑器,写;with...as writer:自动打开和关闭(类似ctrl+s自动保存)
第5行:把 stats_df(每组样本量、均值、标准差等)保存到名为 "统计摘要" 的sheet里。
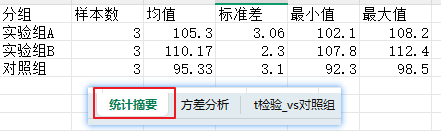
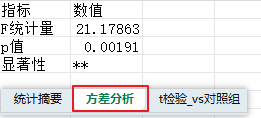
第7-12行:把指标(F、P、显著性)和数值(计算结果)保存到名为"方差分析"的sheet里。
第14-15行:把t检验的结果保存到名为"t检验_vs对照组"的sheet里

第17-25打印展示,如下图:
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可
