文章目录
-
- 前言
- 阶段一:对话(Promot、Context、Memory)
- [阶段二:简单智能体(Agent、RAG、Function Calling、MCP)](#阶段二:简单智能体(Agent、RAG、Function Calling、MCP))
- 阶段三:流程化智能体(LangChain、workflow、Skill、subAgent)
- QA
-
- [1. SKILL 是否可以替代 MCP?](#1. SKILL 是否可以替代 MCP?)
- [2. 都有哪些方法可以实现工作流?](#2. 都有哪些方法可以实现工作流?)
- 一些思考
前言
最近这段时间思考了 AI 的真正落地场景,研究了这两年 AI 应用的历程,可以归纳成三个阶段。
第一个阶段是对话阶段 ,以 chatgpt、文心一言为代表的,以交互式对话的方式进行 AI 落地。
第二个阶段是初级智能体阶段,在对话的基础上附加本地知识的检索和简单的工具调用,让 AI 实现更多形式的任务。
第三个阶段是高级智能体阶段 ,这个阶段的代表性 AI 落地产品是 OpenClaw,将智能体部署到本地或云端,开放更多的命令和接口,赋予智能体更多的权限。另外附加 SKILL 这样的自定义技能,让 AI 在机器上大展拳脚。
接下来我们依次看一下各个阶段都有什么样的新技术,各种技术如何以软件工程的方式组合在一起。
阶段一:对话(Promot、Context、Memory)
原始的 LLM 对话中,大语言模型只能进行一问一答的形式,不能追问。这里的提问被叫做 Promot。

一个提问Promot 中可能包括背景信息和最终的指示,于是把背景信息的部分单独取名叫做 上下文 Context。

现在我们想要对 LLM 进行追问,于是我们就将之前的对话历史全部都塞进 Context 上下文信息中,然后再给出我们的问题,将两者拼接到一起构成 Promot 交给 LLM。这样通过伪装多人对话的方式就实现了追问。
将上面这种特殊的上下文信息叫做 Memory,意思是大模型的记忆。

这些 Memory 可以再次调用大模型进行总结,对内容进行总结摘要,从而对记忆进行压缩,减少上下文的长度。

阶段二:简单智能体(Agent、RAG、Function Calling、MCP)
接下来又遇到了一个问题,LLM 只能进行 token 级别的词语拼接,只能生成文字,无法调用别的工具,比如上网查询。如果我们想要 LLM 来根据最新的信息回答问题,这就无法实现。
而上网查询可以轻松使用 python 代码实现。
因此我们需要一段程序,这段程序可以根据执行预设的接口来进行工具调用,拿到想要的信息作为 Context,再由 LLM 生成回答返回给用户。
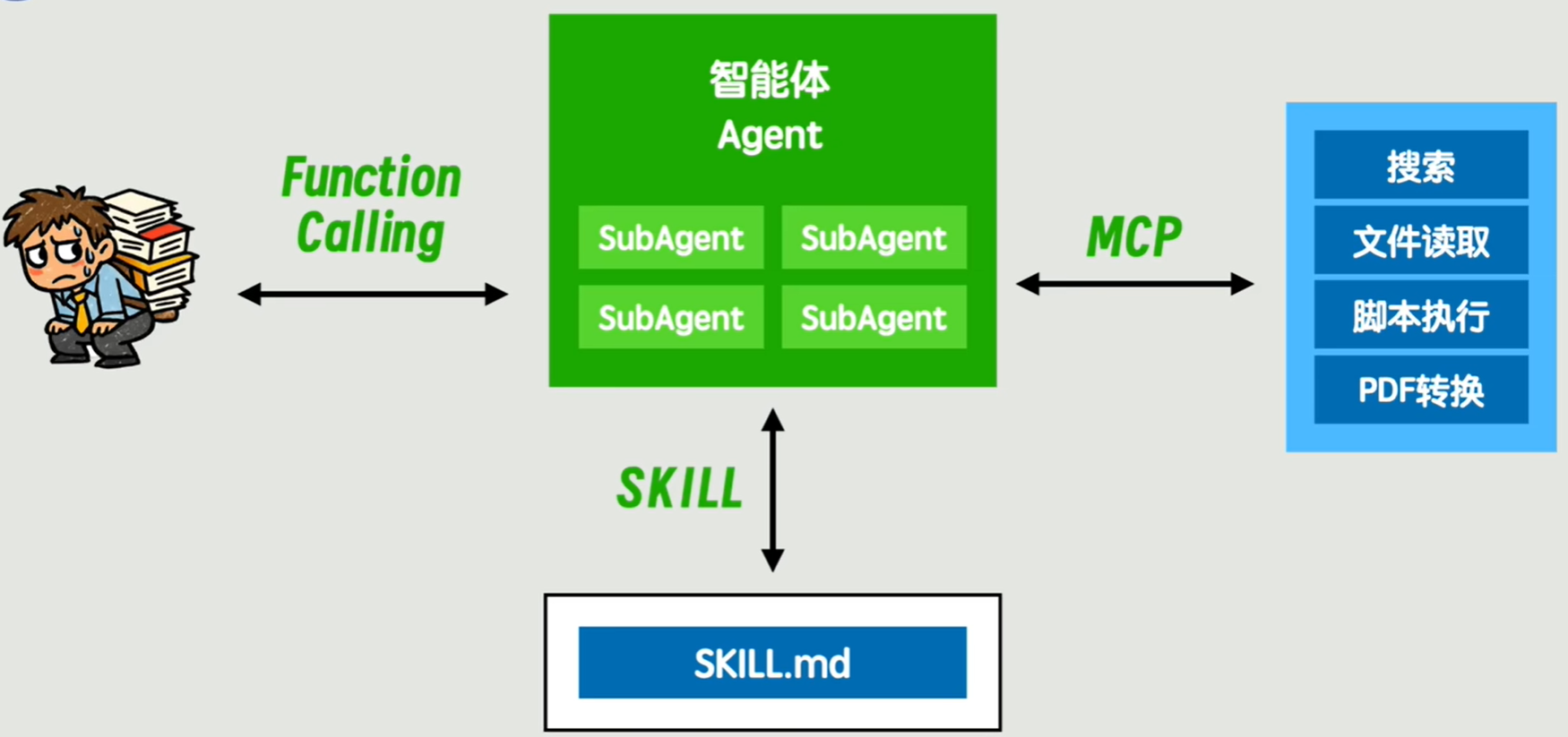
这段程序看似就拥有了更高级别的智能,被称为智能体 Agent。用户只需要跟智能体对话就可以完成可以工具调用获取跟多信息的智能对话。
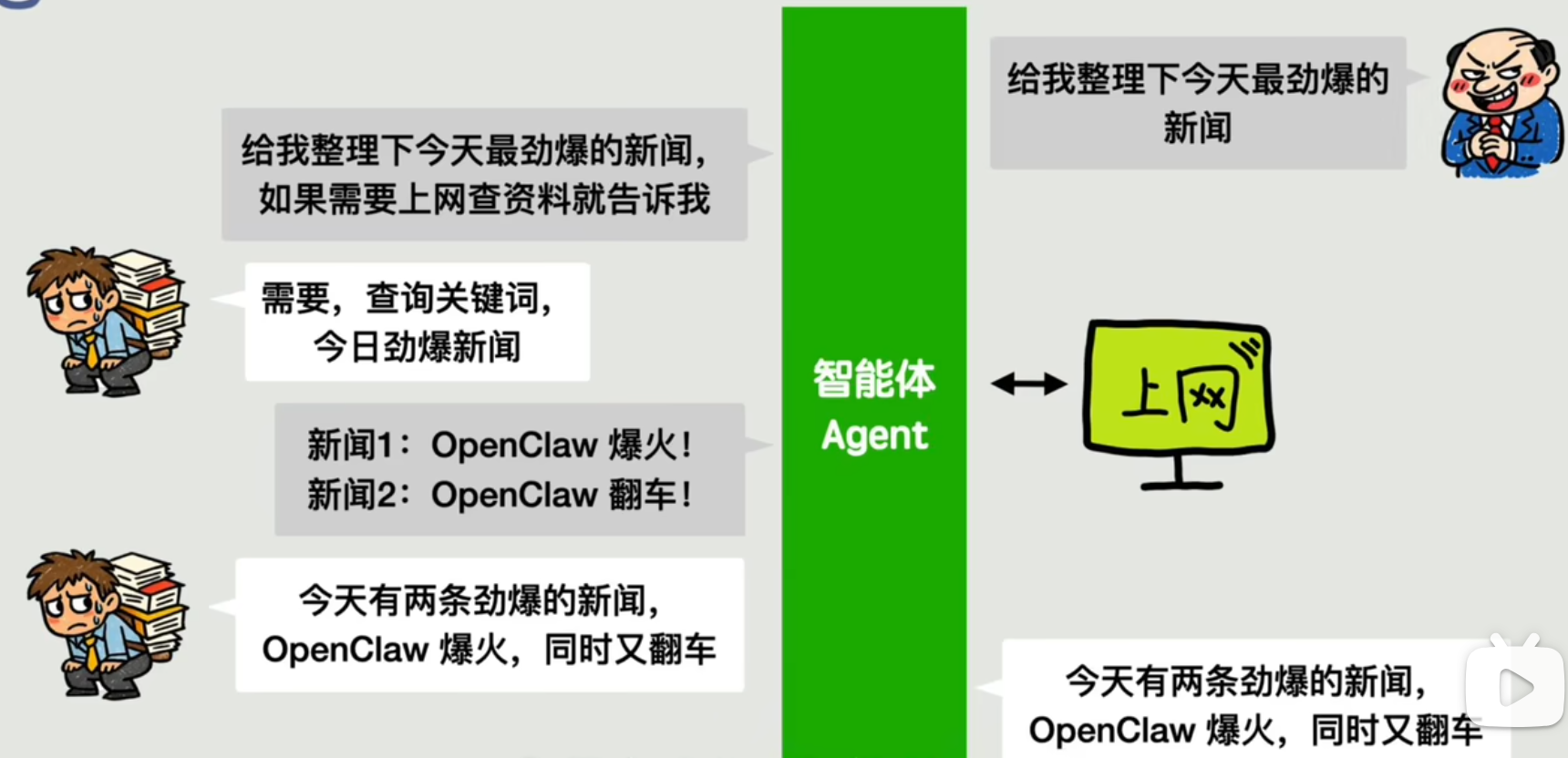
此时的 Agent 既然可以上网,也可以检索本地的文档,同样将和用户提问的 Promot 相关的检索结果作为 Context 交给 LLM,以增强 LLM 生成更加可靠和本地化的回答。这一个过程称为 RAG(Retrieval-Augmented Generation,检索增强生成)。
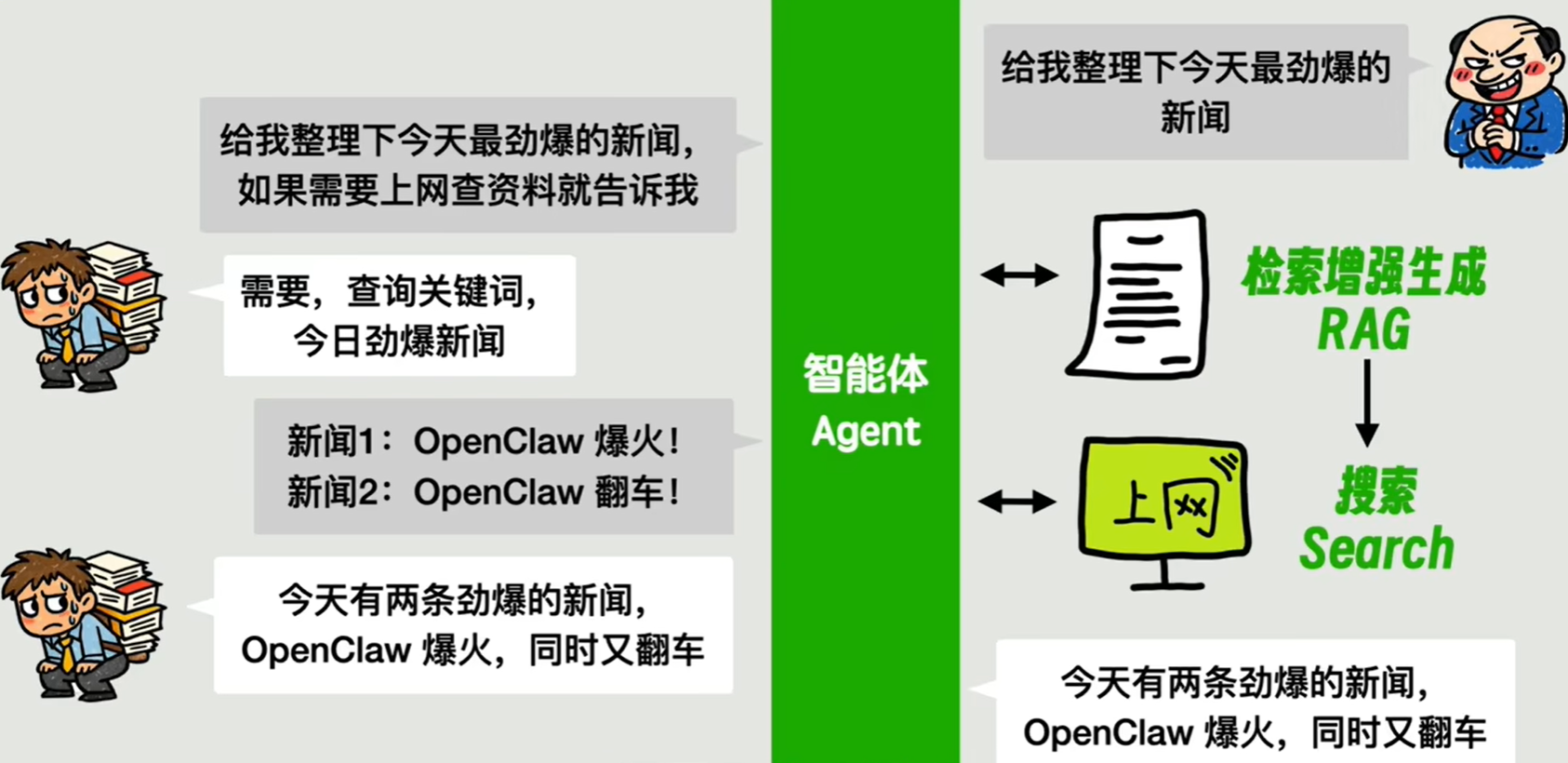
接着又有了一个问题,智能体 Agent 如何知道 LLM 想要调用什么样的工具呢?
因为 LLM 的生成结果是自然语言描述,很难用固定的代码脚本进行解析,就很难知道其想要调用什么样的工具。
于是,我们制定了一个约定,让 LLM 按照指定的死板的格式来描述自己的工具调用请求,比如 JSON 格式。这样程序就可以很方便地解析了。
这种 Agent 和大模型之间关于工具调用所约定的对话格式,就叫做 Function Calling。其实就是个约定罢了,就像前端和后端请求时的接口格式约定类似。
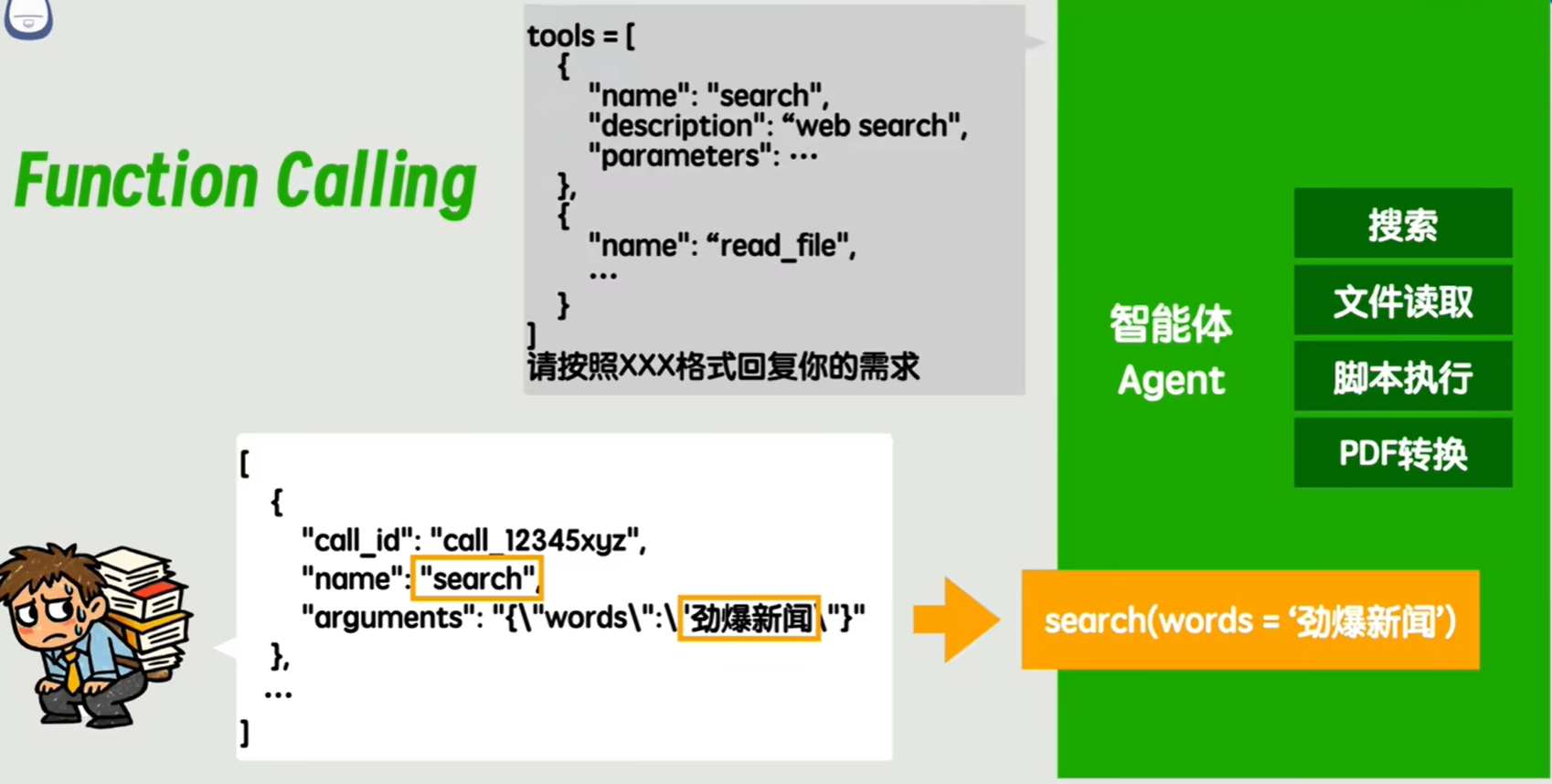
另外还有一点,智能体 Agent 如何发现并调用各种各样的工具呢?
同样需要约定一套规范,将工具调用的接口格式给统一化。比如 Agent 执行 tools/list 方法可以返回工具列表,执行 toos/call/xxx 方法可以调用具体的 xxx 工具。约定了如何调用,如何传参,如何接收返回值等。
这套约定就叫做 MCP(Model Context Protocol,模型上下文协议)。
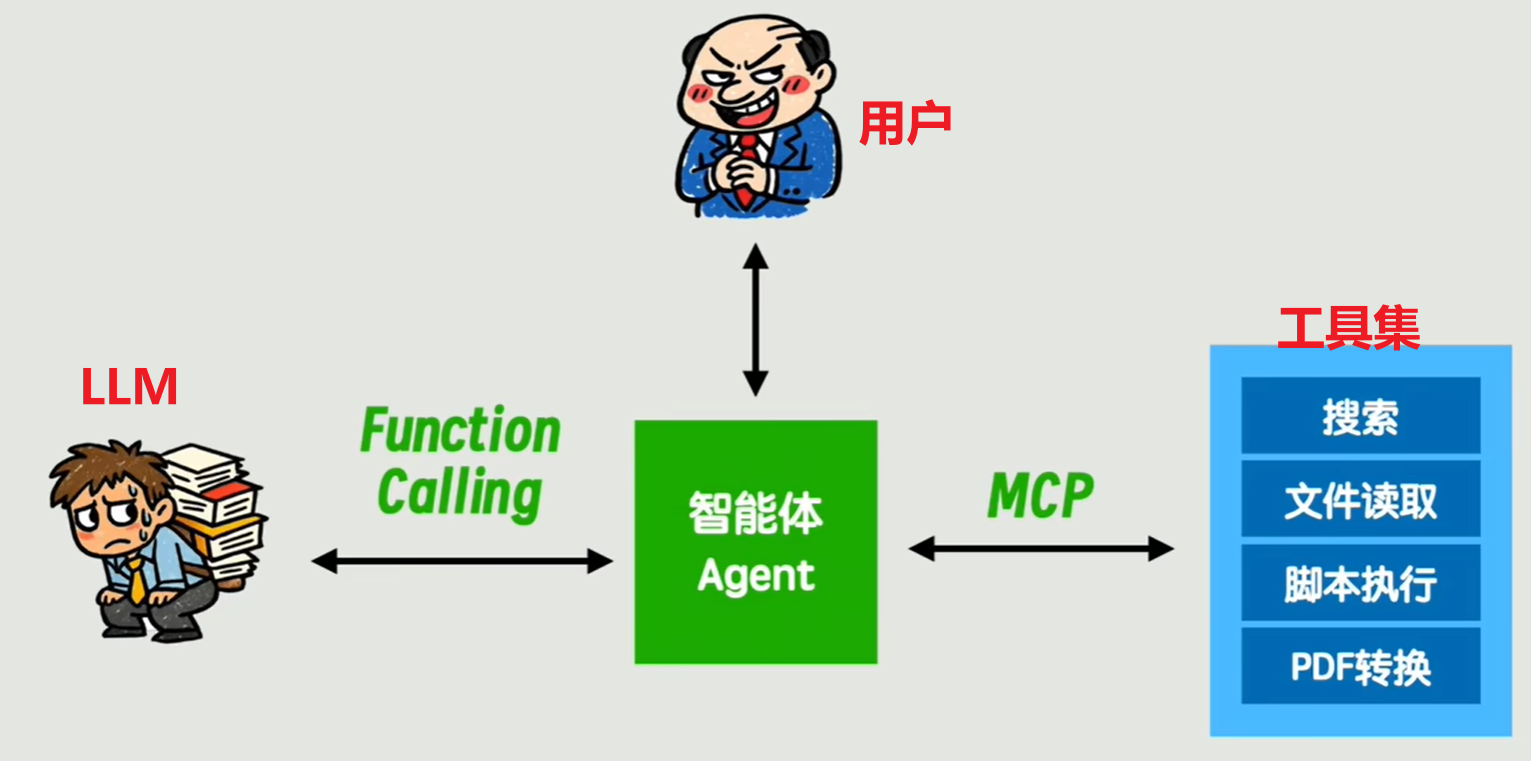
此时,整个对话的流程就变成了:
- 你将提问发送给智能体 Agent。
- 智能体 Agent 把提问与可用的工具名称发给 LLM。
- LLM 分析问题和可用的工具,并以
Function Calling约定的格式返回使用哪一个(或多个)。 - 智能体 Agent 解析出工具,通过
MCP Server执行,工具的执行结果被送回给智能体。 - 智能体结合执行结果构造最终的
prompt,交给 LLM 生成自然语言的回答,返回给你。
阶段三:流程化智能体(LangChain、workflow、Skill、subAgent)
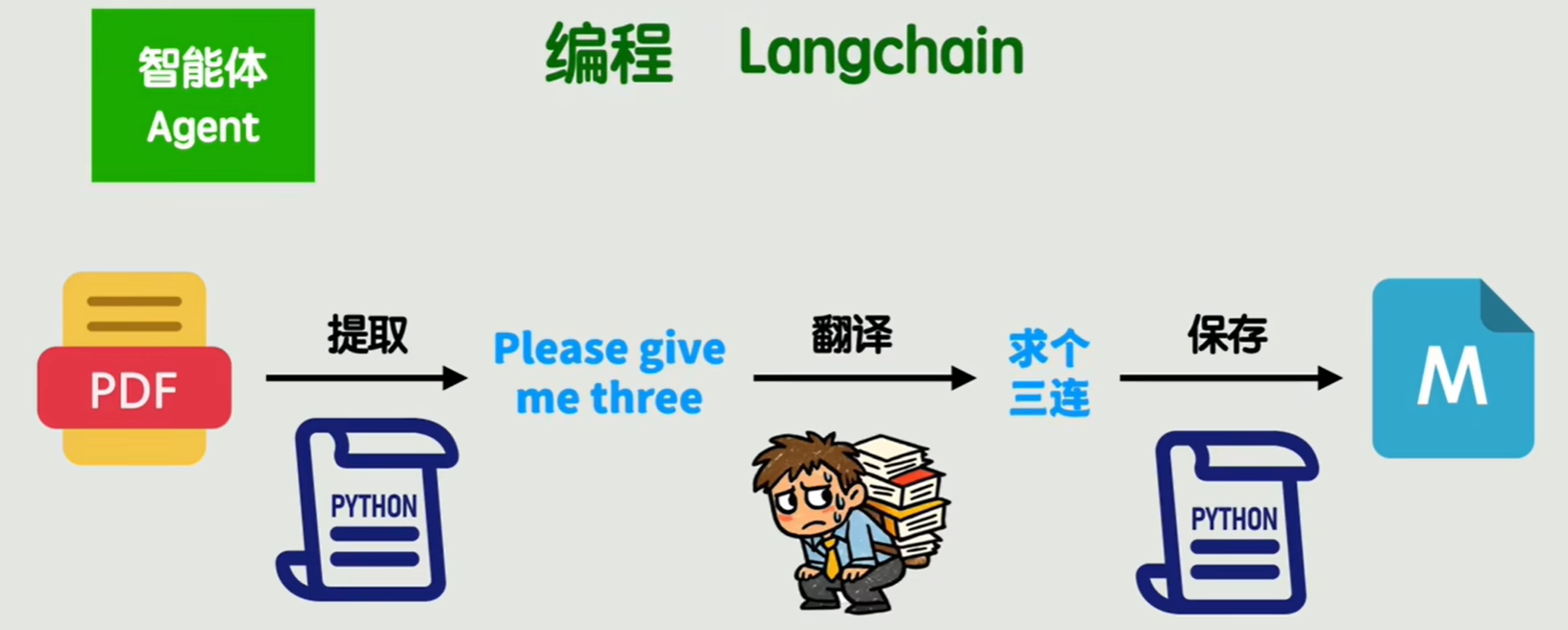
接下来我们有一个需求:从一个英文文件中提取内容,翻译成中文,最后保存成 Markdown 格式。
当然可以直接将这个需求描述发给 LLM,把提取内容和保存的这两个工具也交给 LLM,让它自己策划整体的流程。
但是这样的每次都让 LLM 自由发挥,不但原本简单的流程变得不稳定,而且非常浪费 token。
完全可以在全局层面通过编程的方式将整个流程固定,先提取内容,再翻译,最后保存。
提取内容和保存直接调用脚本执行,LLM 只会在中间的翻译步骤被沟通。
LangChain 这个编程框架就是为了固定这种流程用的。
同时也出现了 workflow(工作流),通过可视化拖拽来自定义执行流程。
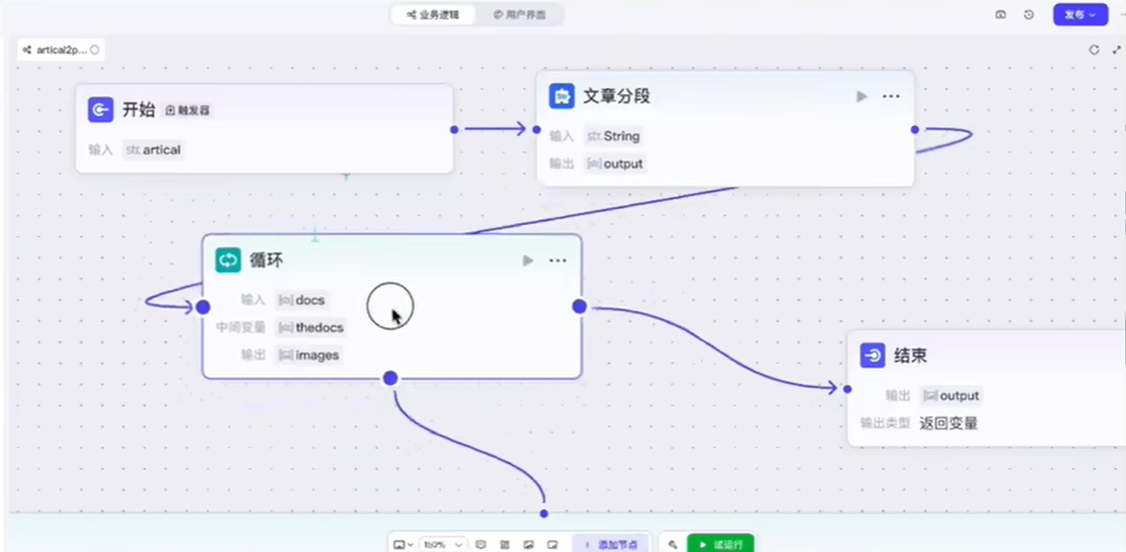
另外,如果文件的类型有多个格式,保存的格式也可以有多种,并且用户以自然语言的形式下发"从一个英文文件中提取内容,翻译成中文,最后保存成好看的页面格式"指令,那么保存的类型不确定,就无法直接执行特定的转换脚本了。上面的 LangChain 和 workflow 也就不管用了。
为了解决这个问题,充分发挥 LLM 的灵活性,可以从 Agent 的层面出发,将不同文件类型的提取文字和保存脚本都放在同一个目录下,再写一个 SKLL.md 文件描述这个目录是在什么任务下使用的,按照什么样的流程执行,可以按需调用合适的脚本。
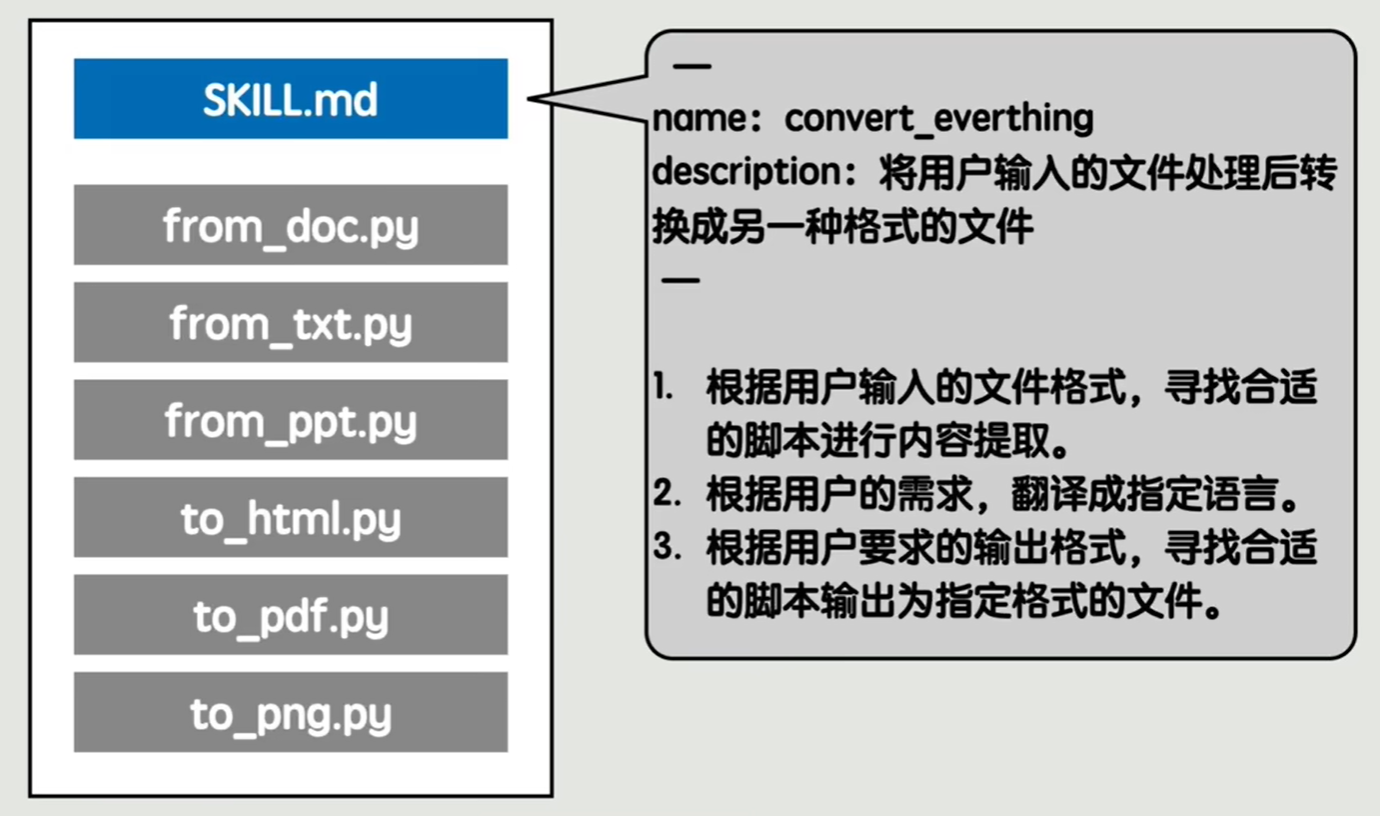
在提示词中先让 LLM 读取 SKLL.md,再完成用户的指令。

这样,既保证了整个过程不需要让 LLM 消耗过多 token 去思考流程,让流程可控,又保证了一定的灵活性。
SKLL.md 所在的目录就叫做 Skill,即 Agent 的技能。 其实是一个渐进式披露、按需加载的 Promot。
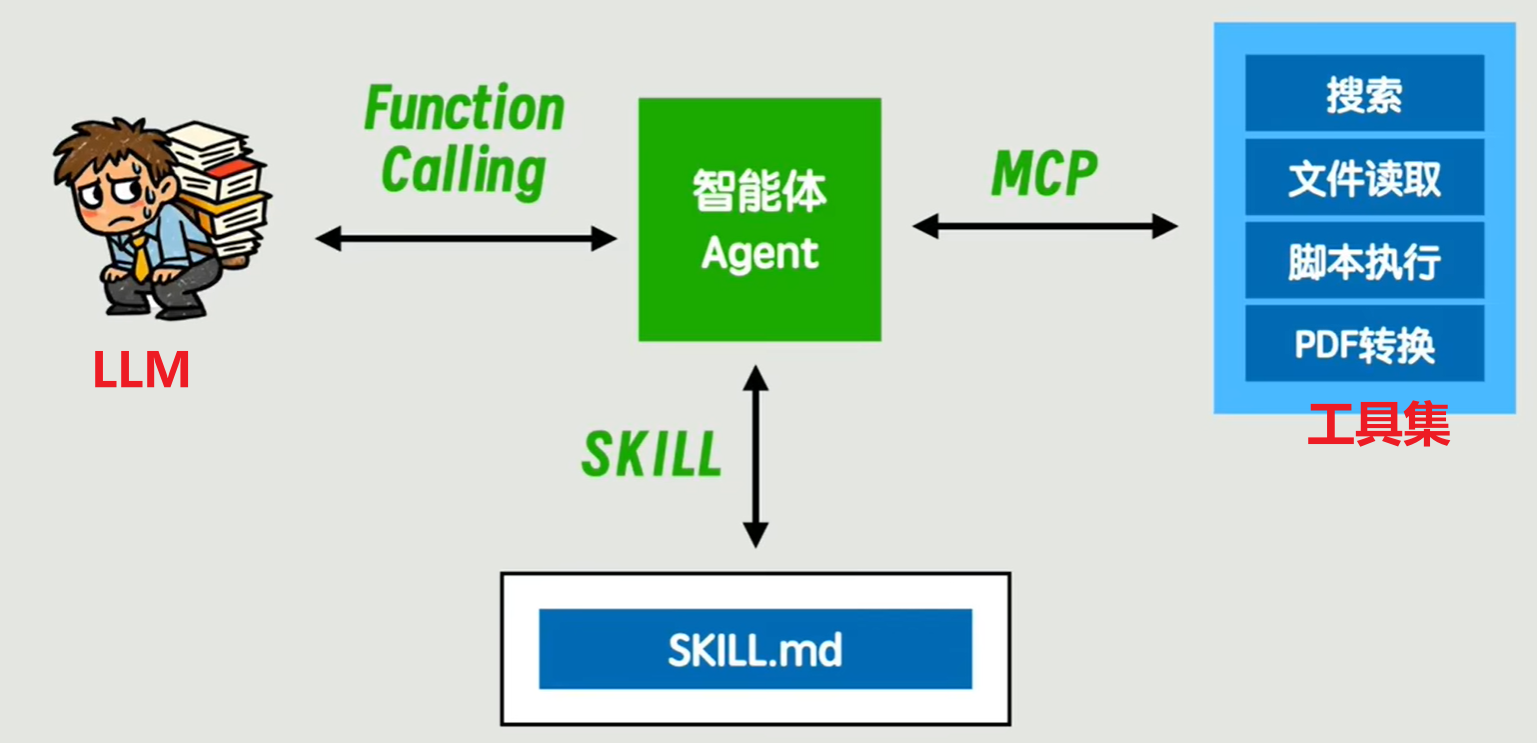
另外又来了一个问题,对于一些复杂任务来说,比如生成一个大项目,那么上下文就会变得非常大,于是可以使用多个 Agent,每个 Agent 负责其中的一部分子任务。这就是subAgent。
本质上是为了做上下文隔离,子 Agent 产生的上下文不会保存在主 Agent 中,每个 Agent 各司其职把自己的任务处理好。
QA
1. SKILL 是否可以替代 MCP?
我觉得是可以的,把 MCP 中可以使用的工具统统放在 SKILL 目录下,只需要在 SILL.md 文件中声明什么情况下可以使用即可。
2. 都有哪些方法可以实现工作流?
可以使用 LangChain(LangGraph)、workflow、SKILL 这三种方式实现相对固定顺序的工作流。
其灵活性也是逐渐提高的:
LangChain(LangGraph)将流程中的每个步骤通过编码的方式写死,整个过程极度固定。虽然特别稳定,但是也失去了一定的柔性,很难包容一些小问题。workflow将程序替换成了低代码的拖拽,通过交互的方式将流程修改变得简单一些。SKILL则是通过说明文档和执行可运行脚本的方式,将由程序控制的流程走向变成了由 Agent 自行控制,存在灵活调整的空间,同时又不至于像直接调用 LLM 那样不可控。
一些思考
其实从上面的各个名词发展的历程来看,所有的新技术新名词都是围绕着如何去自动向提示词中添加上下文信息,去构建一个好的 Promot,从而让回答的结果更加满足要求。
而 Agent 发挥作用的只是在对话流程中能用固定的程序解决、不需要问 LLM 的地方。
将模糊的分流逻辑交给大模型,根据语义识别出用户意图,把确定的分流逻辑由 Agent 交给程序。
归根结底,只要想让 LLM 回答的满意,就必须"把事情说清楚",而"说清楚"的载体就是 Prompt。
整个 Agent 系统不过是将意图、环境状态、工具,转化为 Promot 的 Token 流,交给 LLM。
参考:https://www.bilibili.com/video/BV1ojfDBSEPv/
https://zhuanlan.zhihu.com/p/29001189476
https://blog.csdn.net/a2875254060/article/details/142468037
https://zhuanlan.zhihu.com/p/1919781127339620246
https://zhuanlan.zhihu.com/p/2014273572974130629