一、Update
语法:

核心注意事项
- 必须加 WHERE 子句 :若无 WHERE,会更新全表数据,生产环境慎用!
- 支持同时更新多列,列之间用逗号分隔;
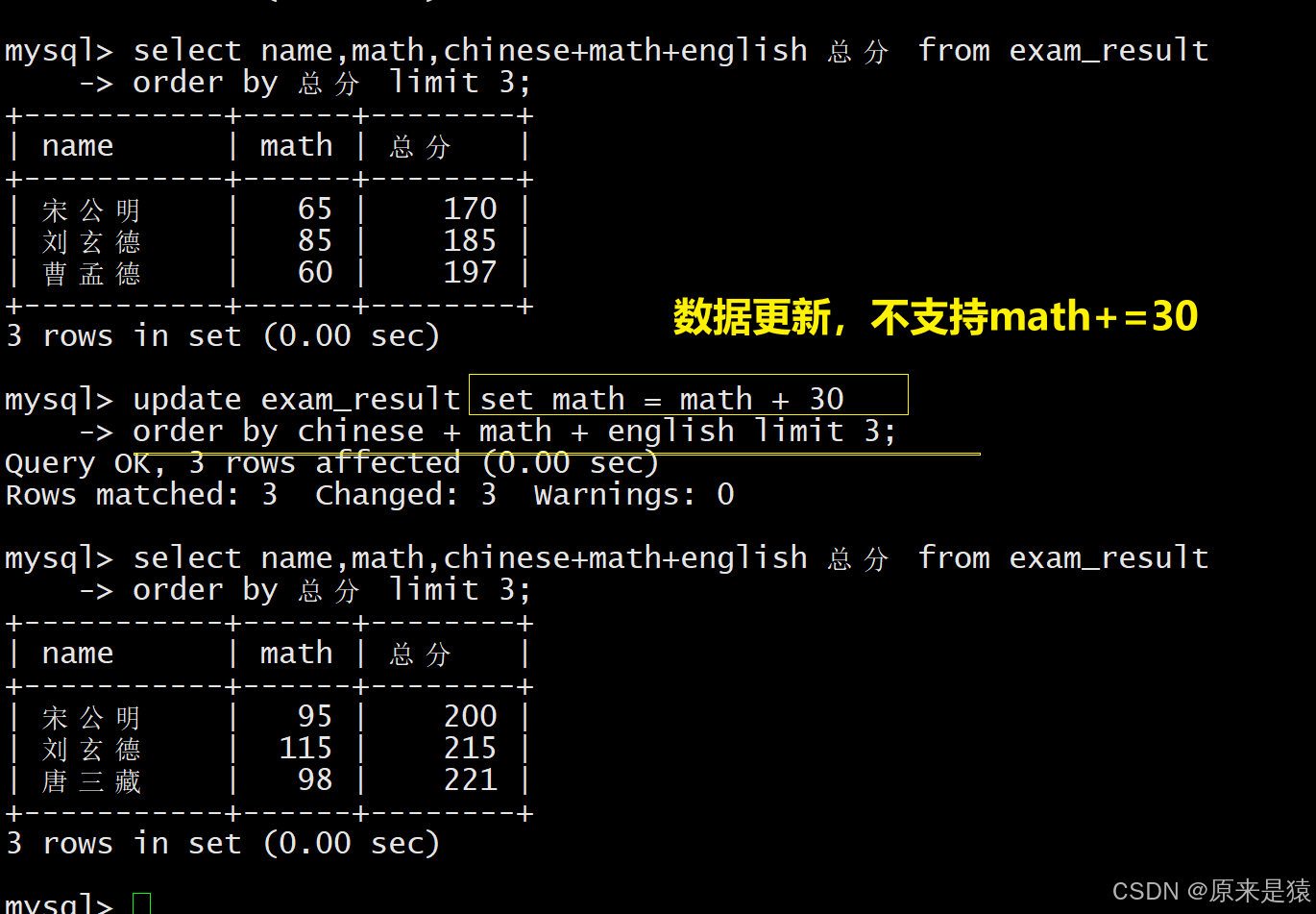
- 支持基于原有值更新(如
math = math + 30),不支持math +=30语法;- 可搭配 ORDER BY、LIMIT 实现精准更新指定条数的数据。
对查询结果进行列值更新
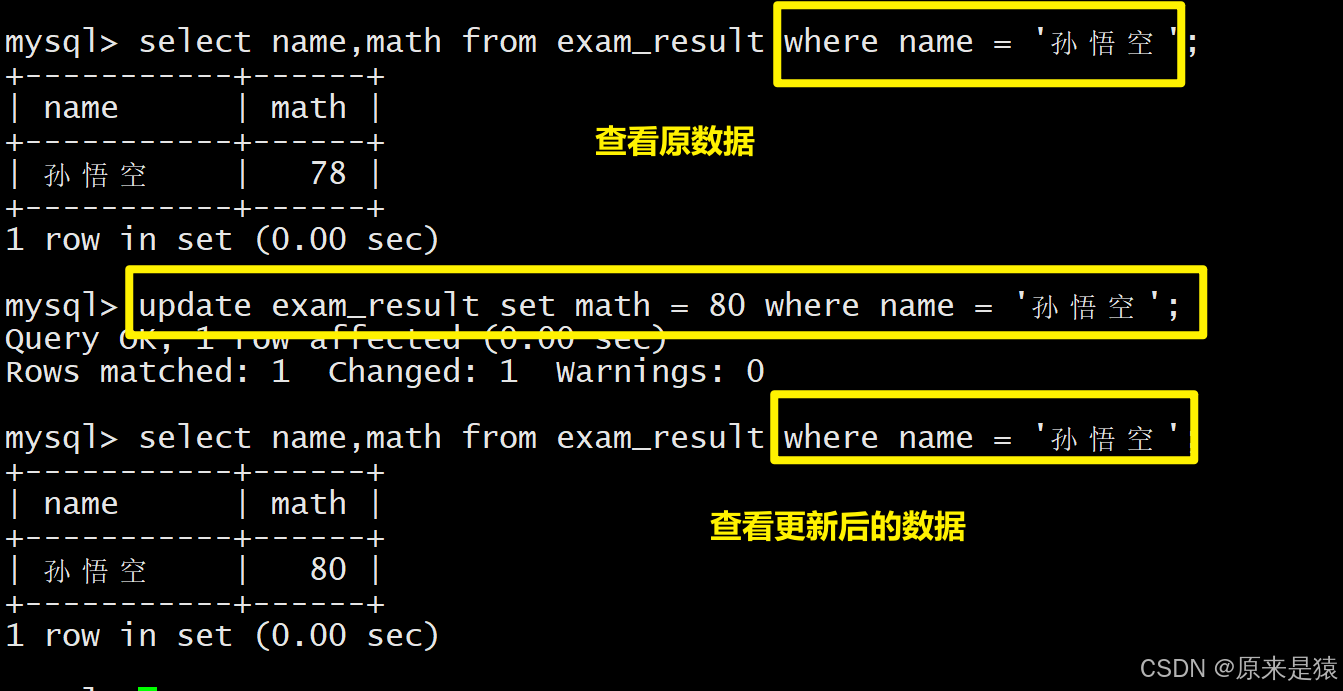
1.1 将孙悟空同学的数据成绩变更为80分
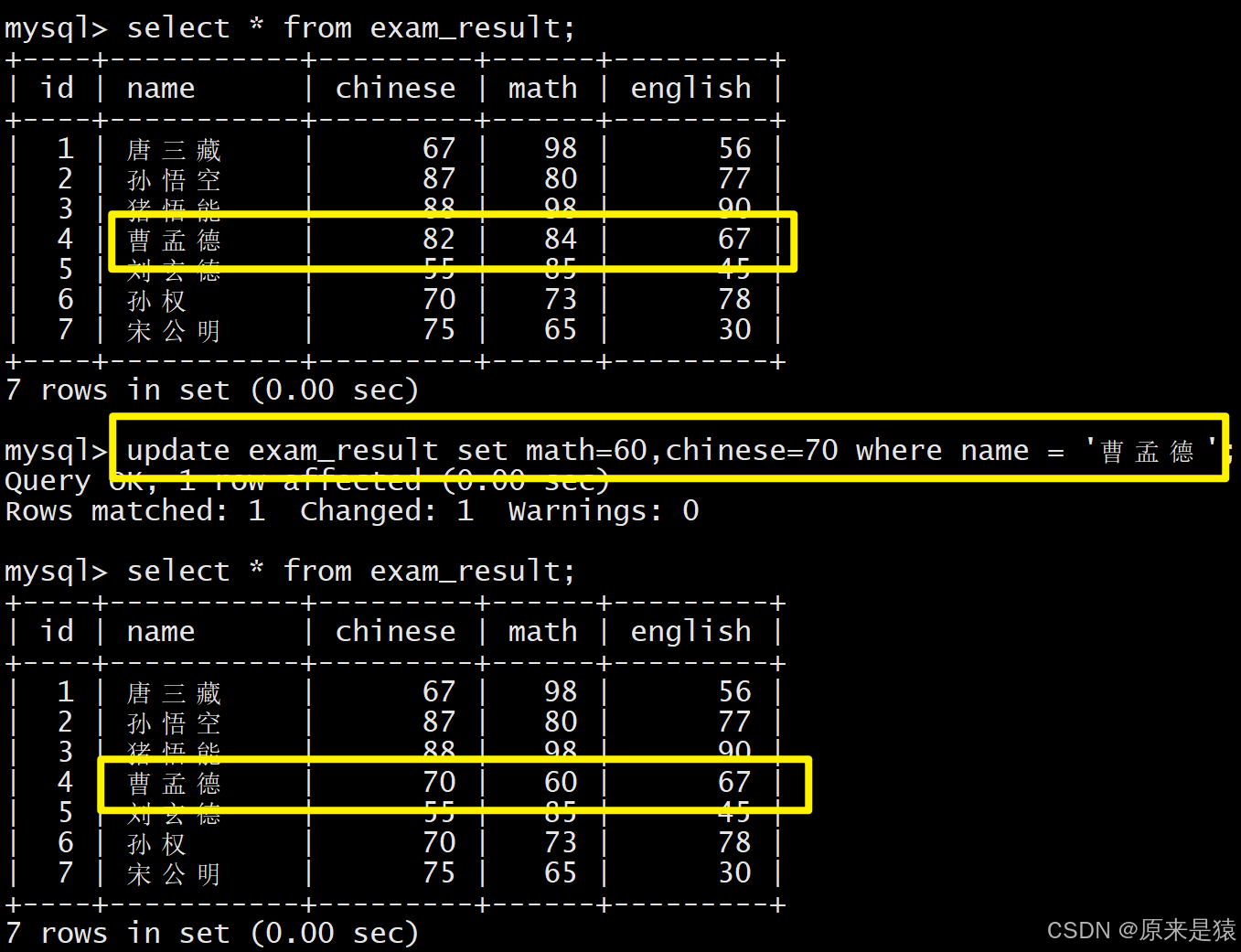
1.2 将曹孟德同学的数学成绩变更为60分,语文成绩变更为70分
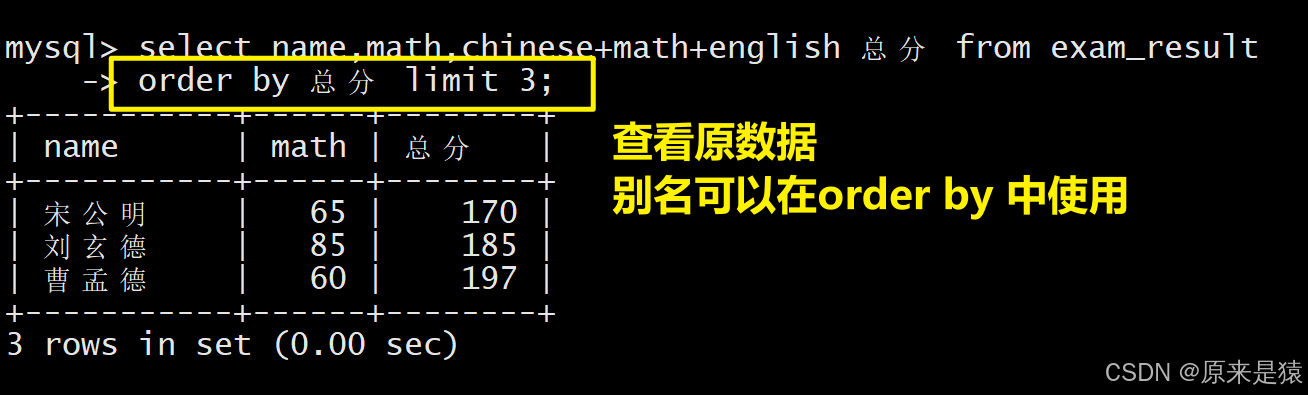
1.3 将总成绩倒数前三的3位同学的数学成绩加上30分
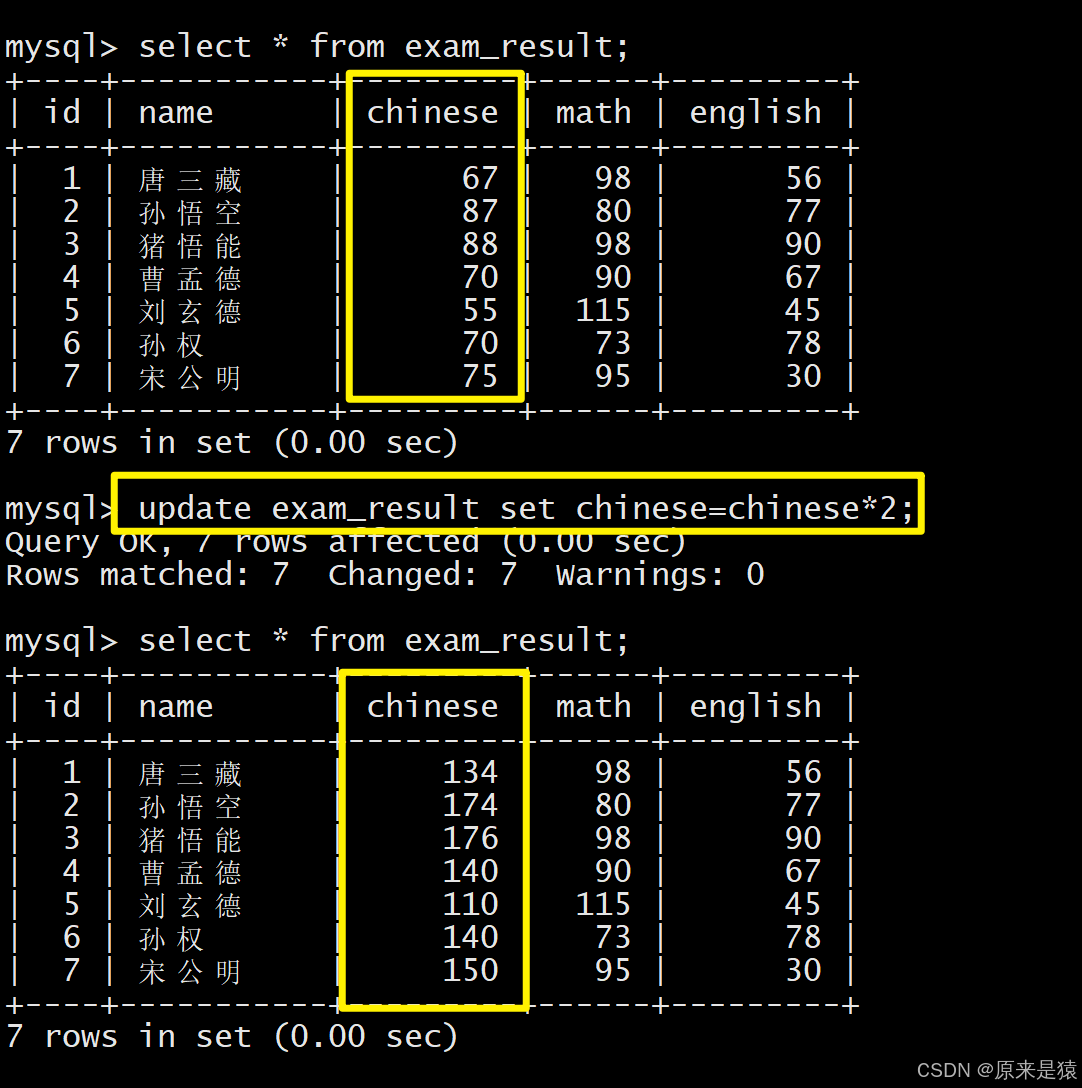
1.4 将所有同学的语文成绩更新为原来的2倍
没有where 子句 ,则更新全表 !!!
二、Delete
删除表中的数据,分为删除指定数据 和删除全表数据。
2.1 删除数据
语法:

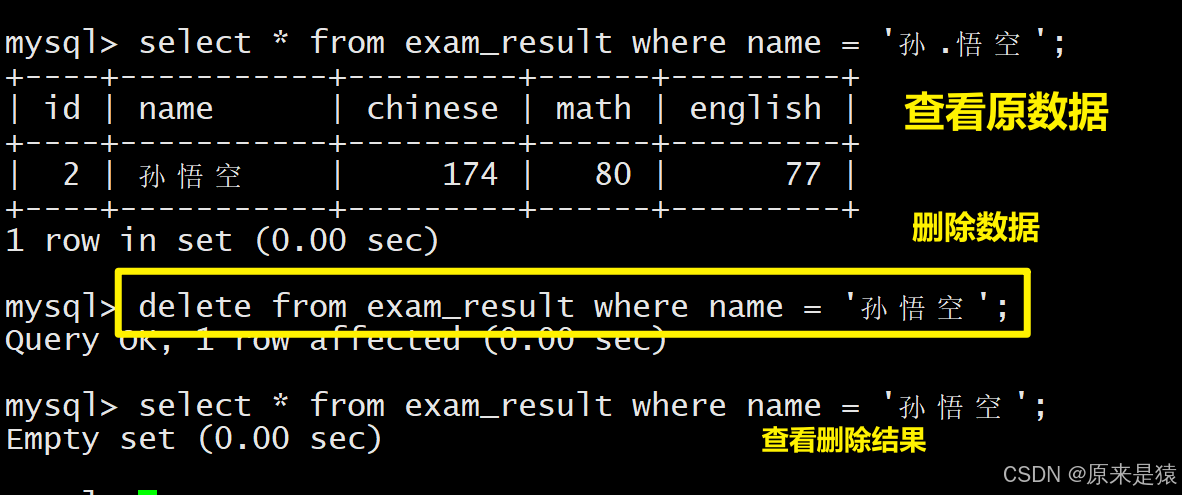
2.1.1 删除孙悟空同学的考试成绩
必须加 WHERE 子句,否则会删除全表数据,示例:
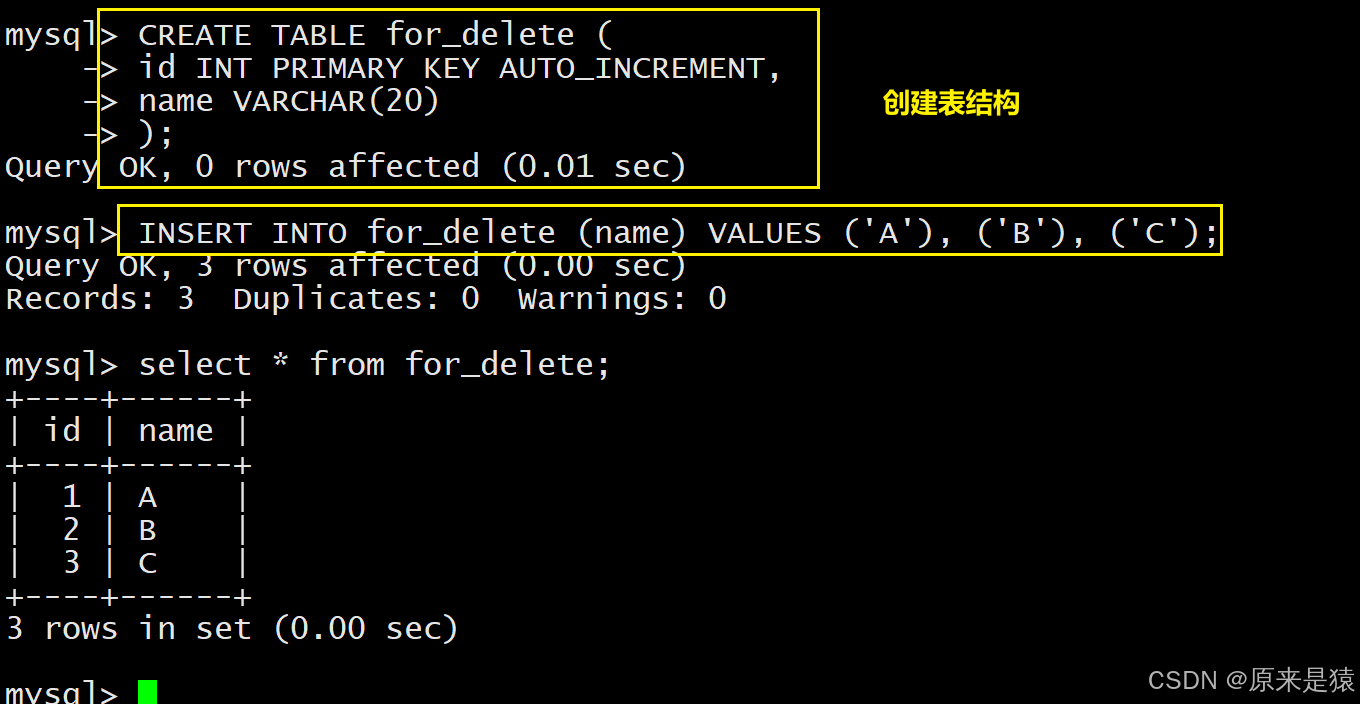
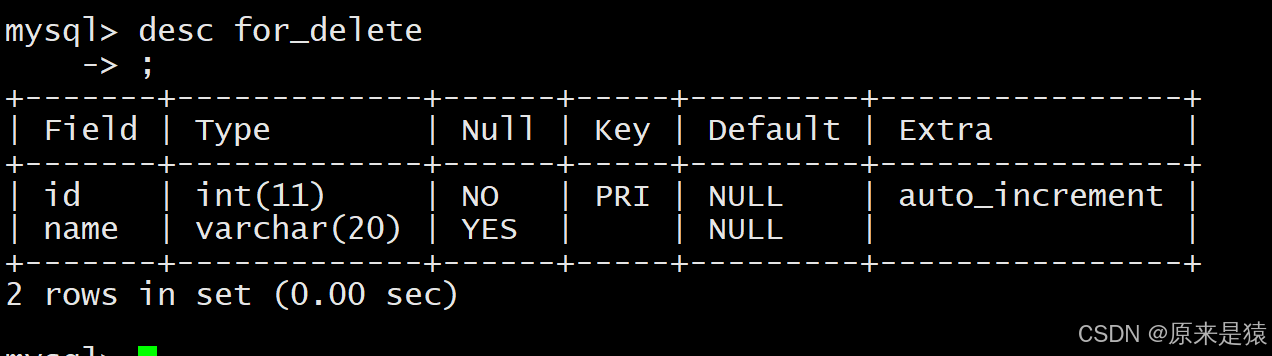
2.1.2 删除整张表的数据
注意:删除整表操作要慎用!
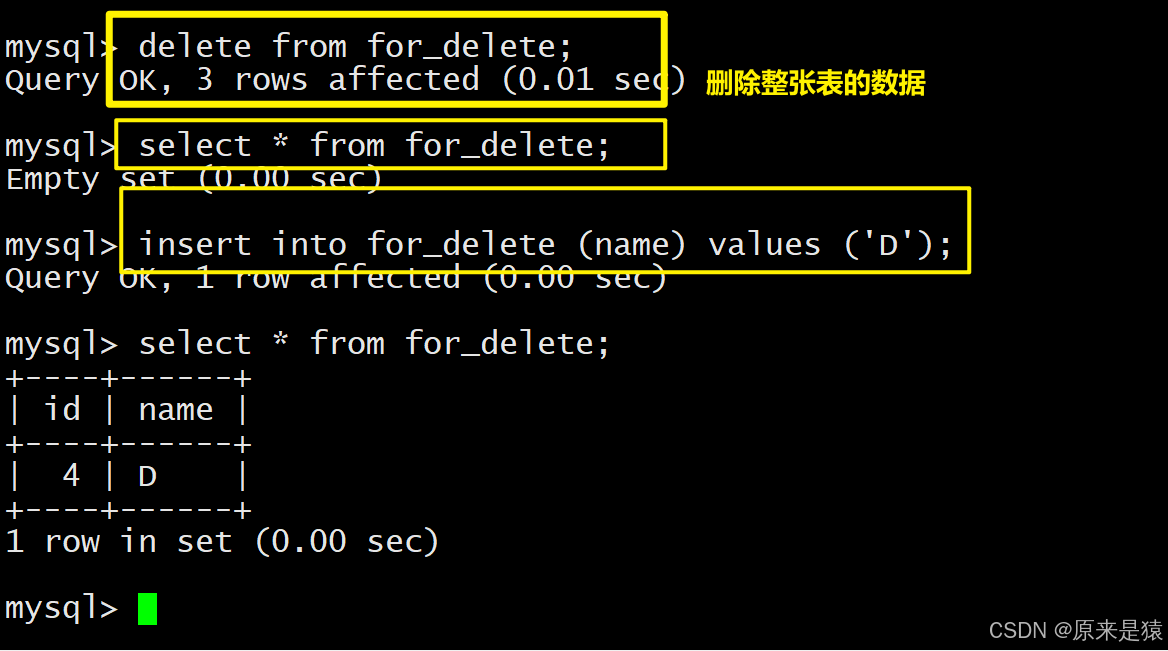
自增序列的计数器并不会置零~
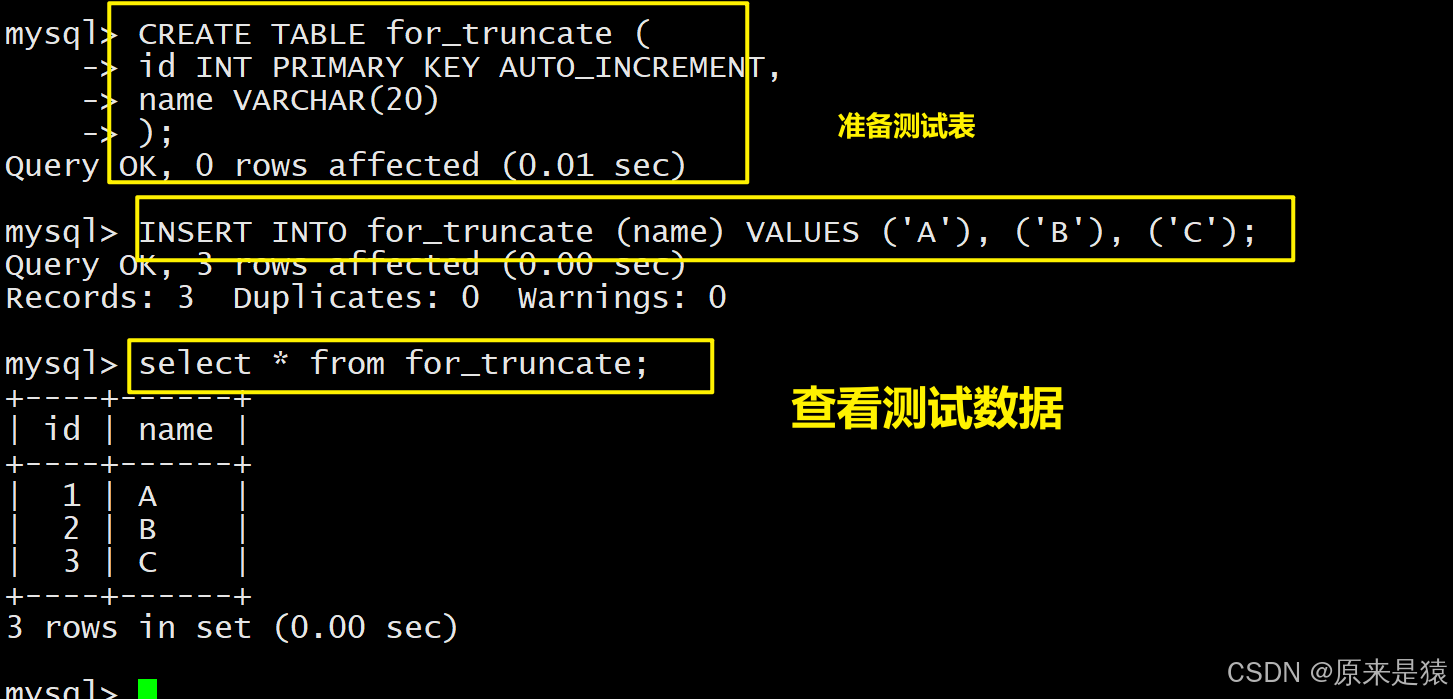
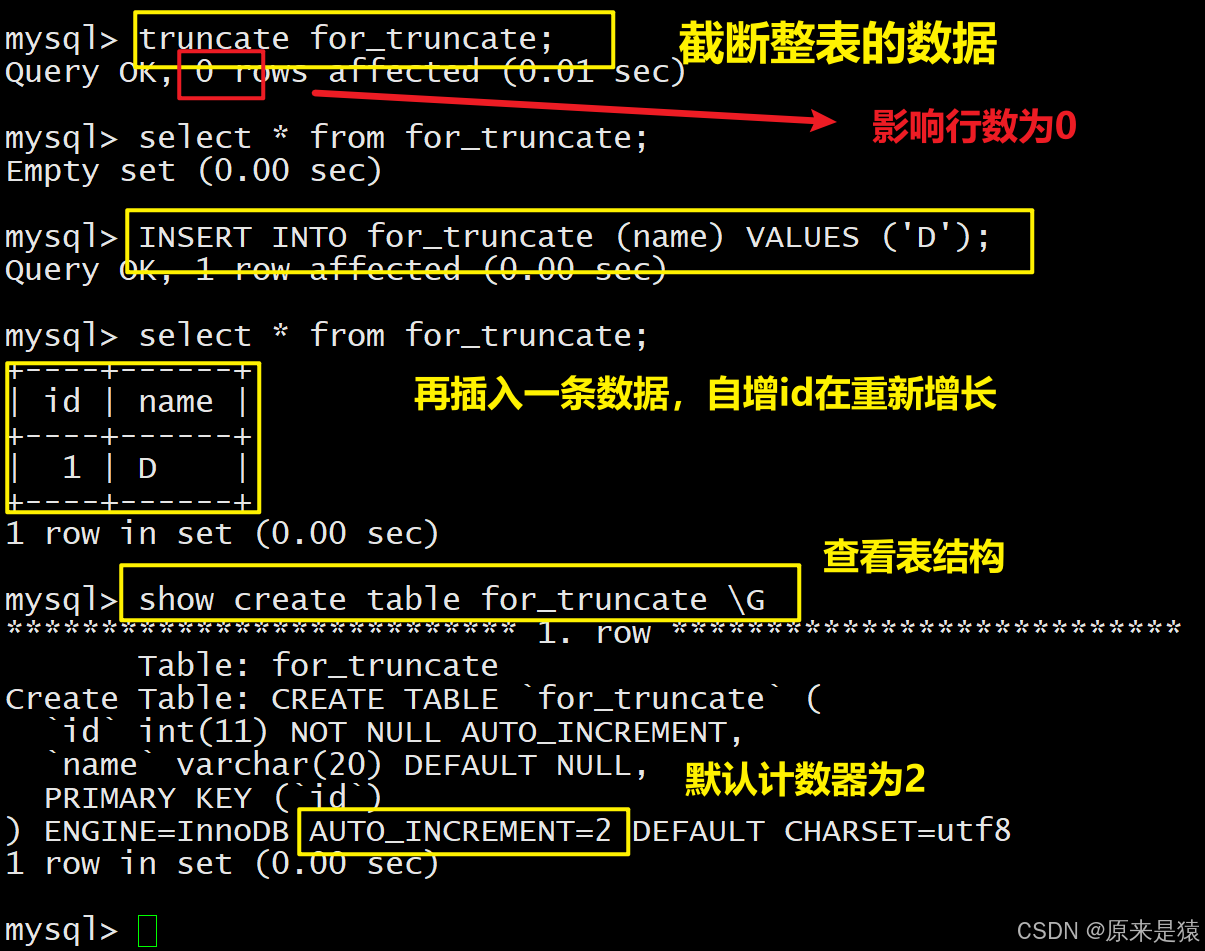
2.2 截断表
语法:

注意:这个操作慎用!!
- 只能对整张操作 , 不能像delete 一样针对部分数据操作
- 实际上Mysql不对数据操作 , 所以比delete更快 , 但是truncate在删除数据的时候,并不经过真正的事务,所以无法回归
- 会重置auto_increment项~
| 操作 | 语法 | 特点 | 自增列 | 事务回滚 |
|---|---|---|---|---|
| DELETE | DELETE FROM 表名 | 逐行删除,会记录日志 | 保留原有自增值,新插入从原最大值继续 | 支持(InnoDB) |
| TRUNCATE | TRUNCATE TABLE 表名 | 直接清空表,不记录行日志,速度更快 | 重置自增列为 1,重新开始 | 不支持 |
三、插入查询结果
插入查询结果 和聚合函数,实现数据的批量处理与统计分析。
语法:

经典场景:删除表中的重复数据,只保留一份。
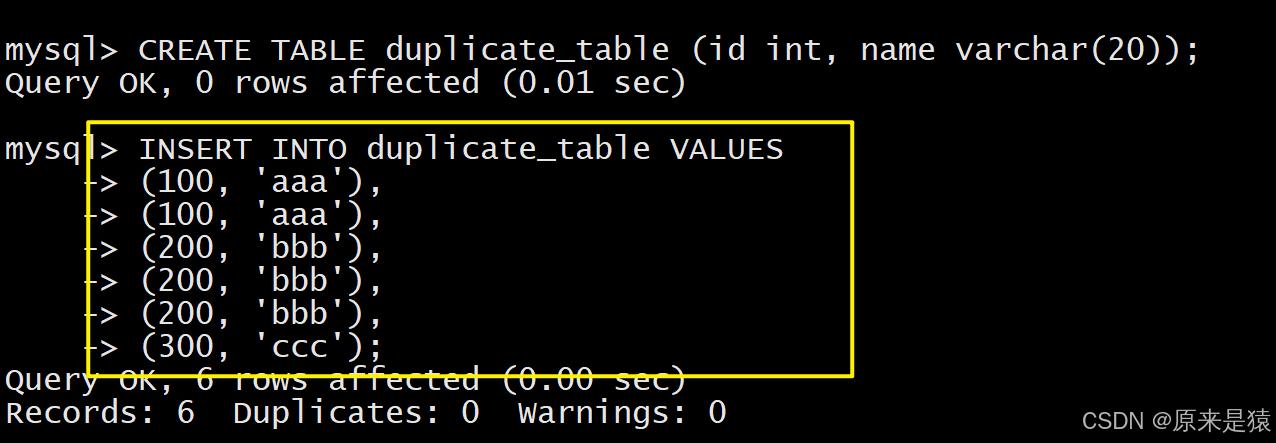

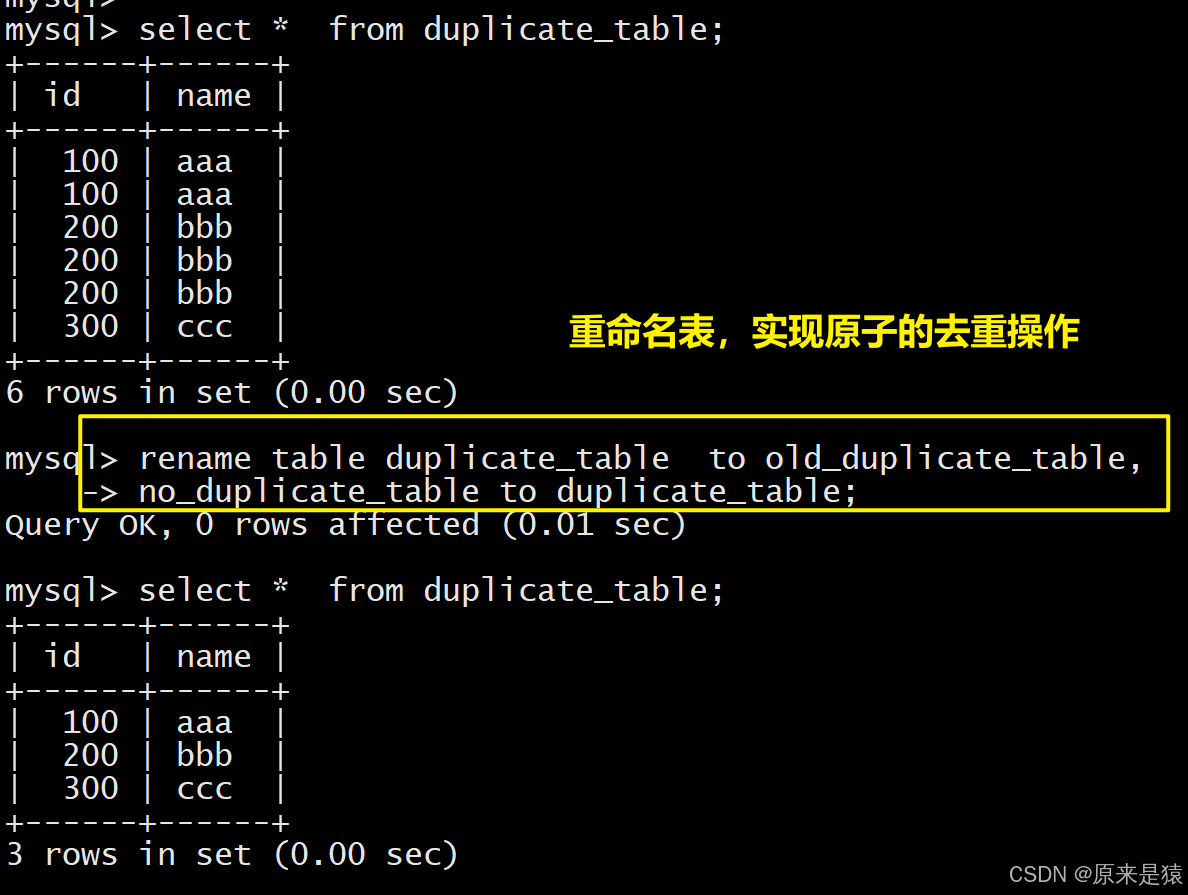
为什么最后是通过rename 方式进行?
就是单纯的想等一些都就绪了,然后统一放入、更新、生效
四、聚合函数
聚合函数用于对一组数据进行统计计算,返回单个结果,是数据分析的基础,常用聚合函数如下:
| 函数 | 说明 | 注意 |
|---|---|---|
| COUNT(DISTINCT expr) | 统计数据条数 | COUNT (*) 不受 NULL 影响,COUNT (列) 会忽略 NULL |
| SUM(DISTINCT expr) | 统计数据总和 | 非数字类型无意义 |
| AVG(DISTINCT expr) | 统计平均值 | 非数字类型无意义,忽略 NULL |
| MAX(DISTINCT expr) | 统计最大值 | 忽略 NULL |
| MIN(DISTINCT expr) | 统计最小值 | 忽略 NULL |
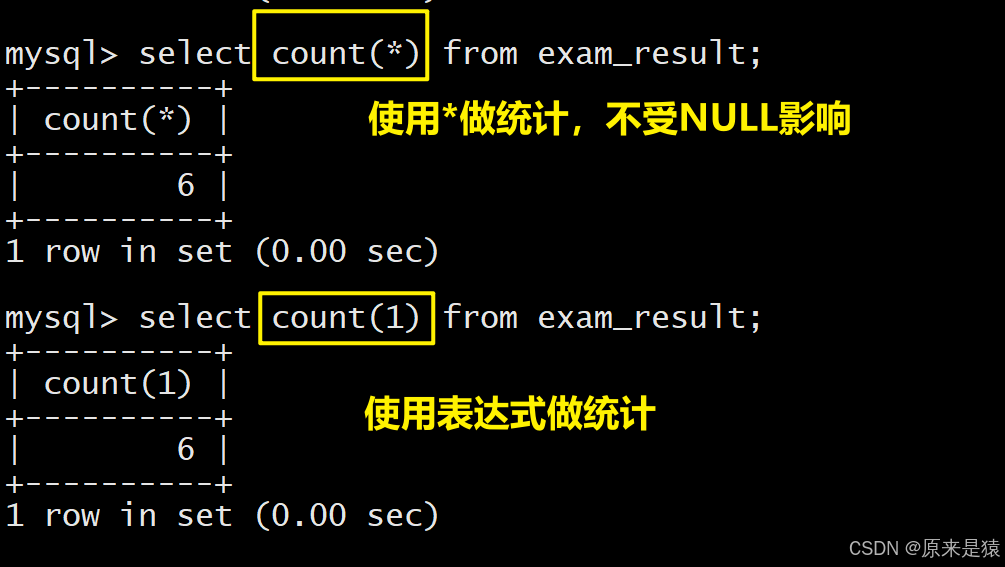
-- 1. 统计学生总数(COUNT(*))
SELECT COUNT(*) FROM students;
-- 2. 统计有QQ号的学生数(COUNT(列)忽略NULL)
SELECT COUNT(qq) FROM students;
-- 3. 统计数学成绩总分、平均分
SELECT SUM(math), AVG(math) FROM exam_result;
-- 4. 统计英语最高分、70分以上的数学最低分
SELECT MAX(english), MIN(math) FROM exam_result WHERE math > 70;
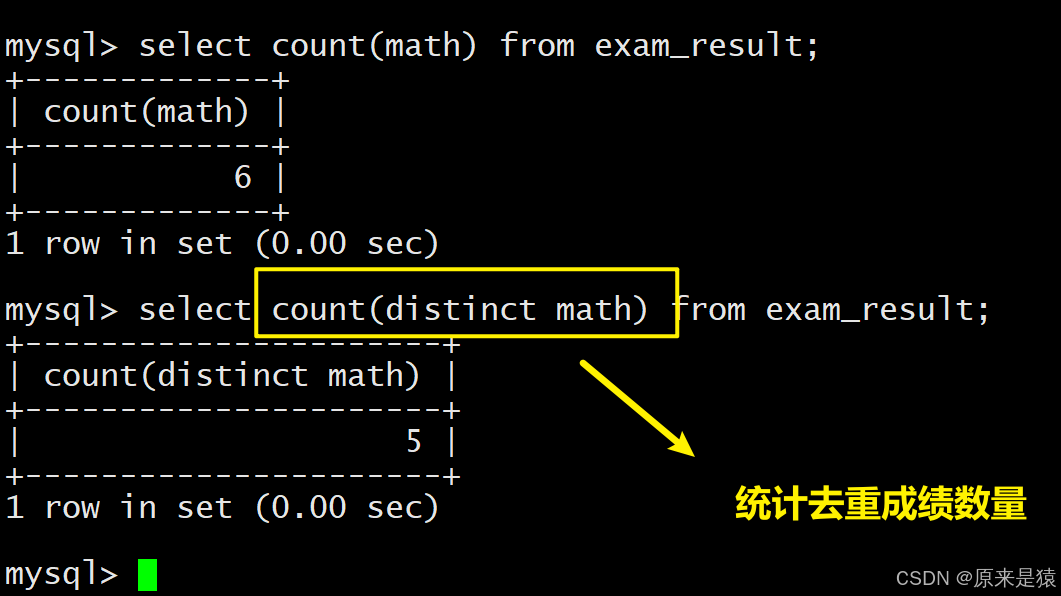
-- 5. 统计去重后的数学成绩个数
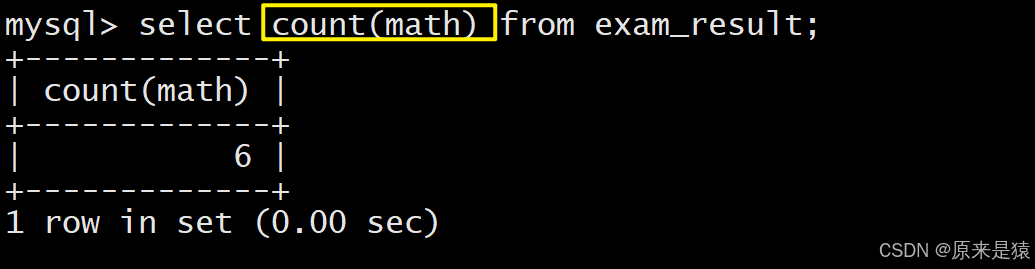
SELECT COUNT(DISTINCT math) FROM exam_result;4.1 统计班级有多少同学
4.2 统计班级收集的qq号有多少
4.3 统计本次考试的数学成绩分数个数
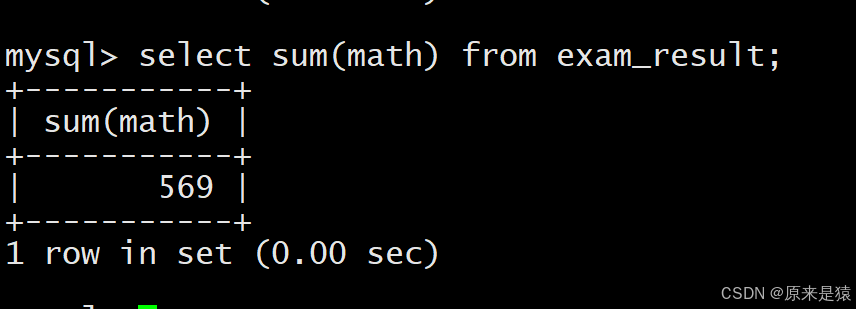
4.4 统计数学成绩总分
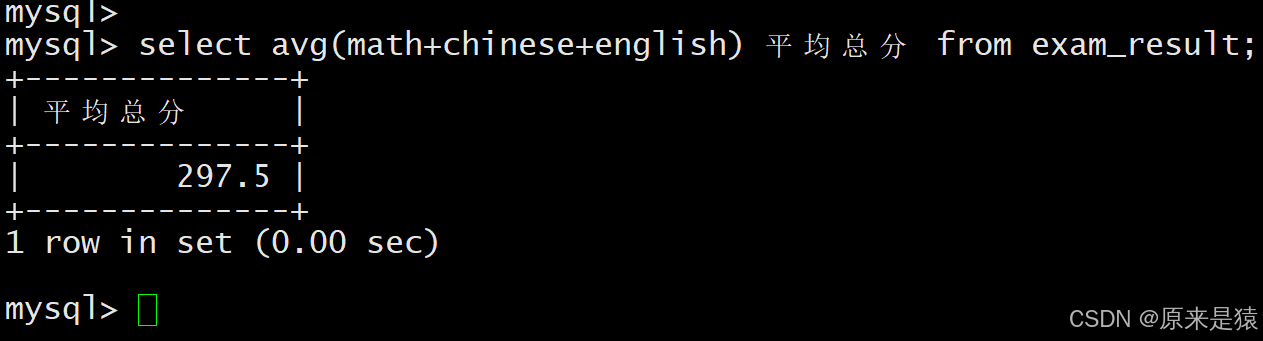
4.5 统计平均总分
4.6 返回英语最高分

4.7 返回>70分以上的数学最低分

五、group by 子句的使用
聚合函数通常与GROUP BY搭配 使用,实现按指定列分组统计,核心语法:

核心规则
- GROUP BY 后可跟多列,按多列组合分组;
- 需对分组结果再筛选时,使用
HAVING(而非 WHERE),HAVING 支持聚合函数 / 别名;- WHERE 筛选原始数据 ,HAVING 筛选分组后的数据。
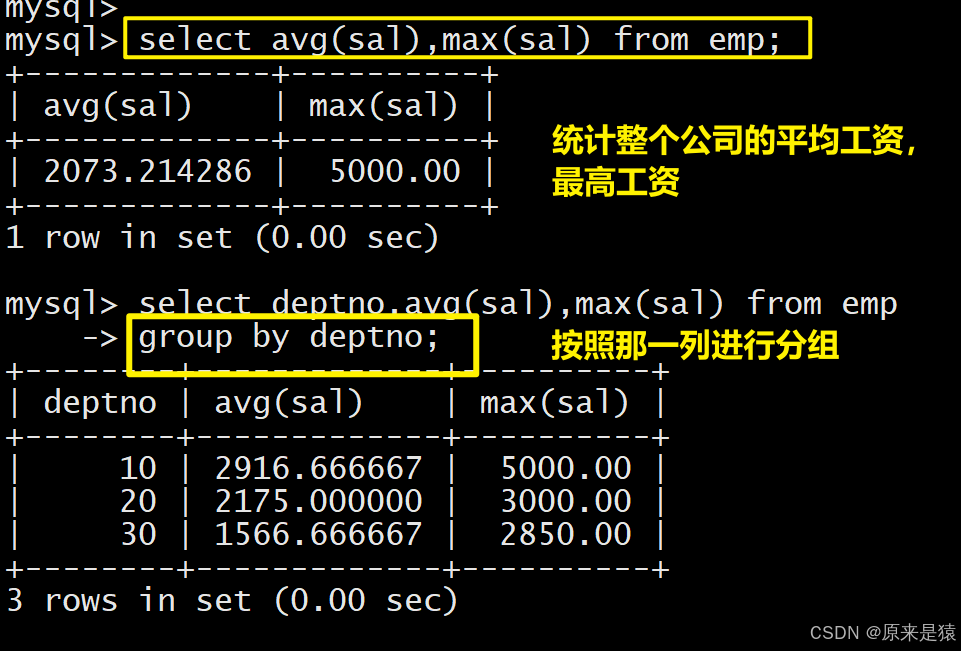
-- 1. 按部门分组,统计每个部门的平均工资、最高工资
SELECT deptno, AVG(sal), MAX(sal) FROM EMP GROUP BY deptno;
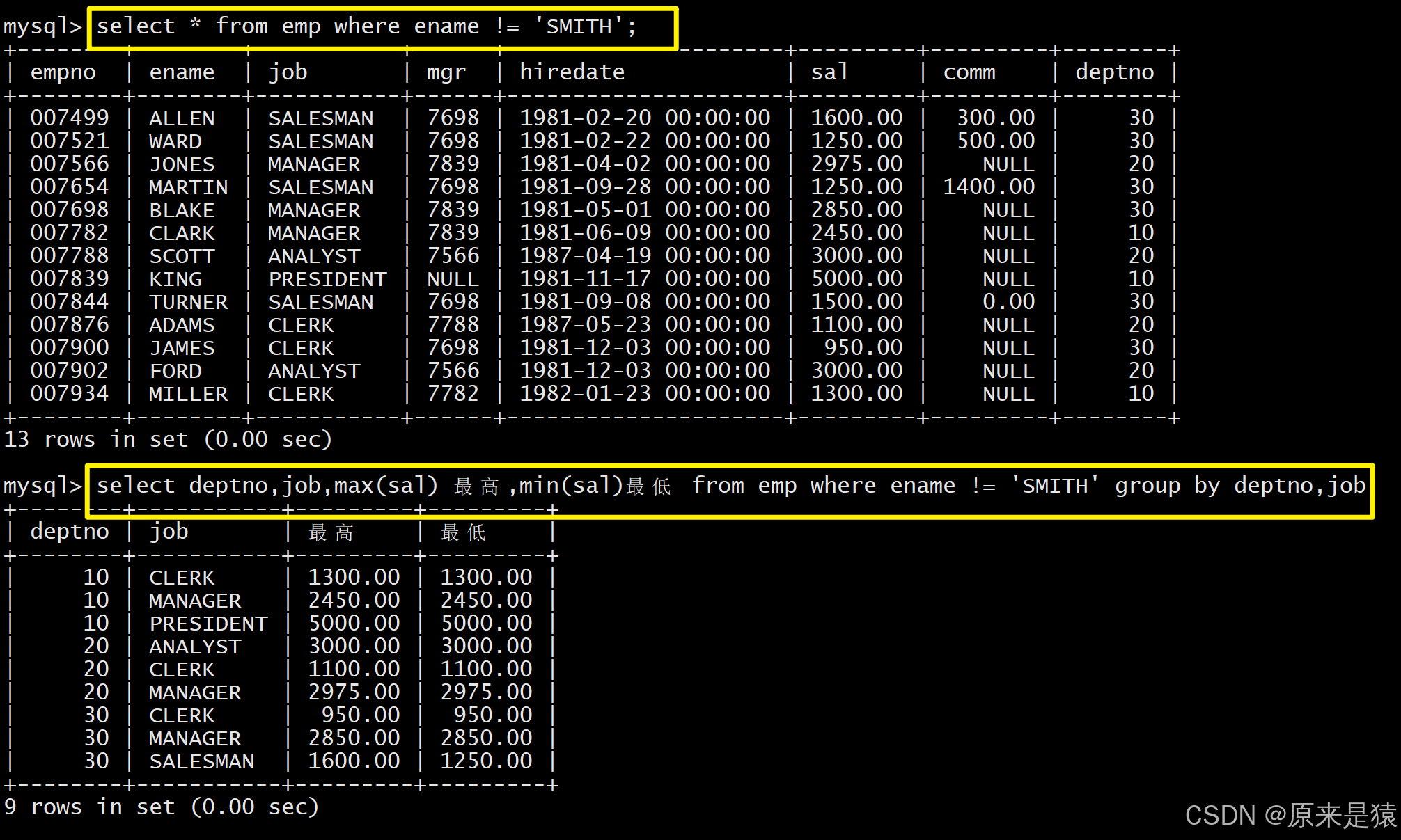
-- 2. 按部门+岗位分组,统计每个部门每个岗位的平均工资、最低工资
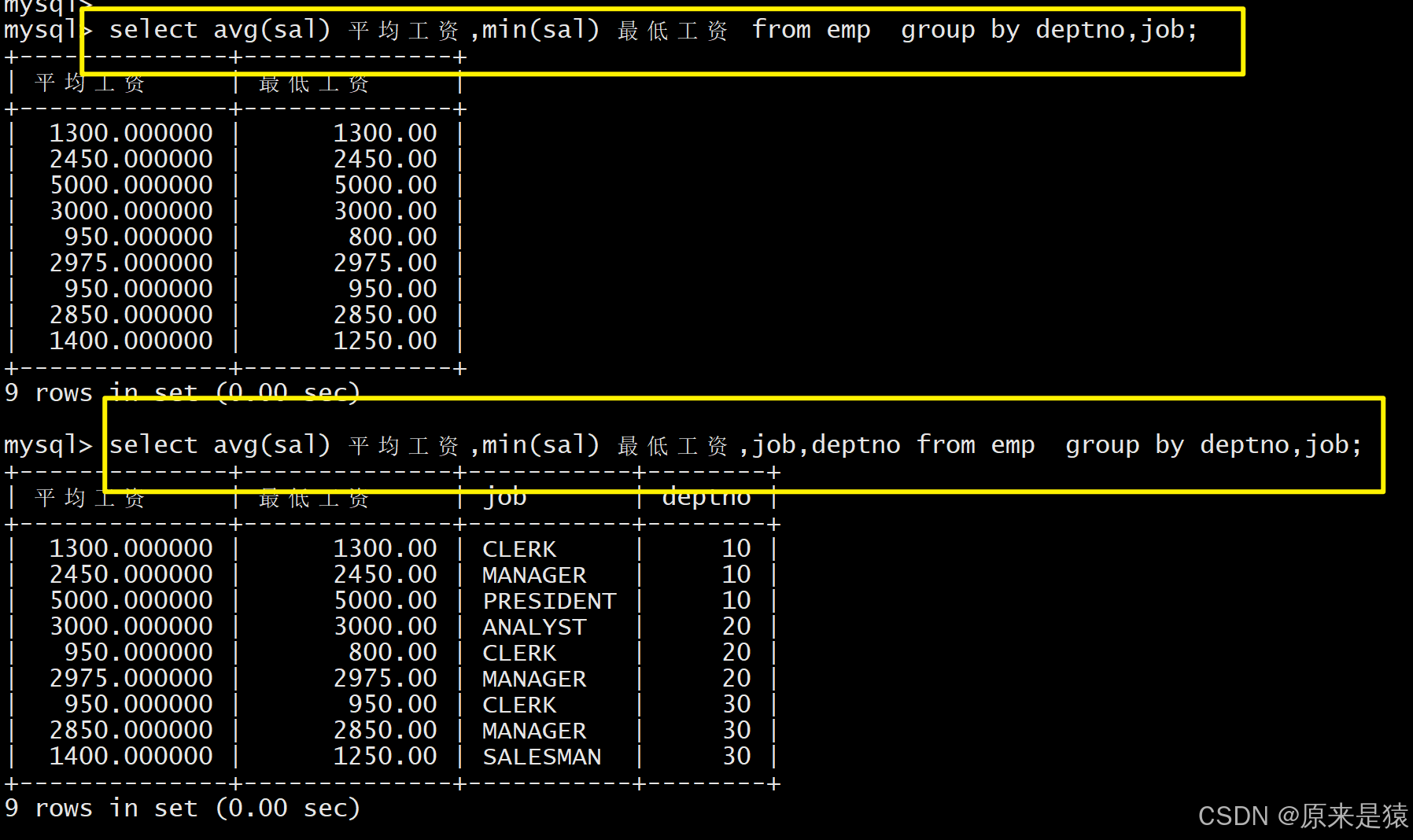
SELECT deptno, job, AVG(sal), MIN(sal) FROM EMP GROUP BY deptno, job;
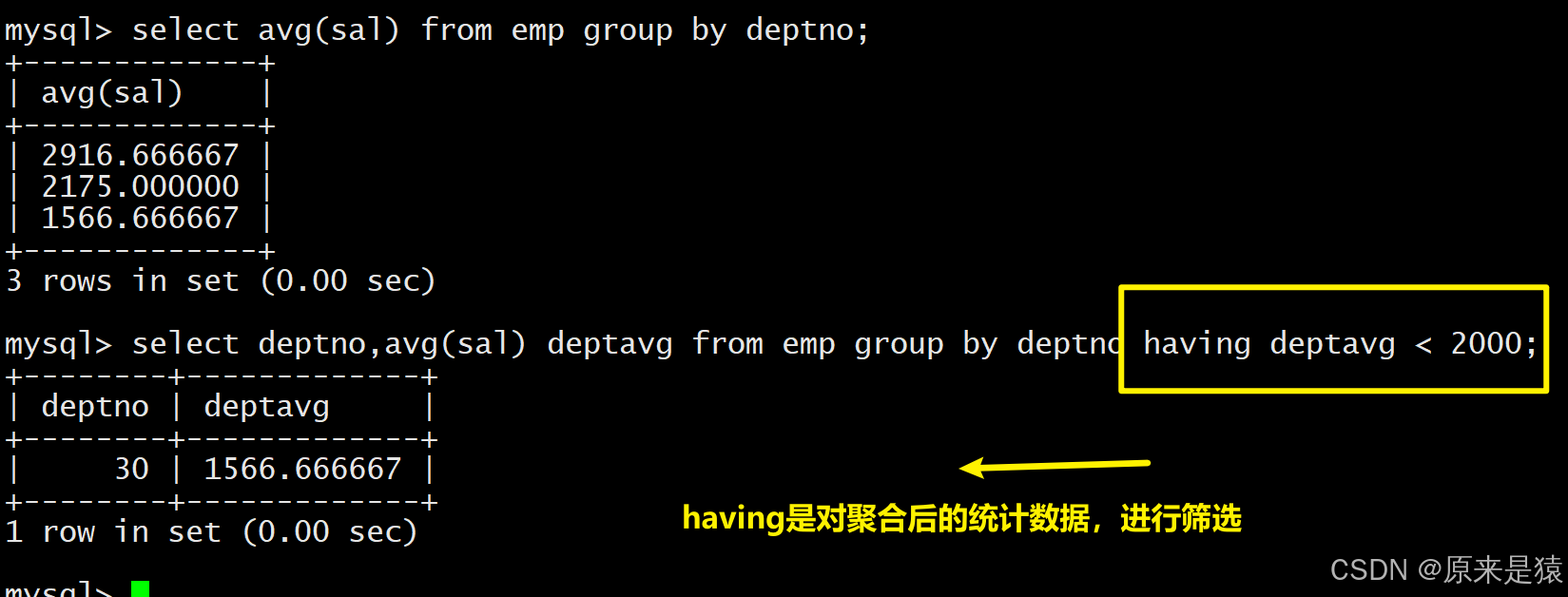
-- 3. 统计平均工资低于2000的部门(HAVING筛选分组结果)
SELECT deptno, AVG(sal) myavg FROM EMP GROUP BY deptno HAVING myavg < 2000;
- 如何显示每个部门的平均工资和最高工资:

- 显示每个部门的每种岗位的平均工资和最低工资

- 显示平均工资低于2000的部门和它的平均工资
- 先统计各个部门的平均工资【结果先聚合出来】
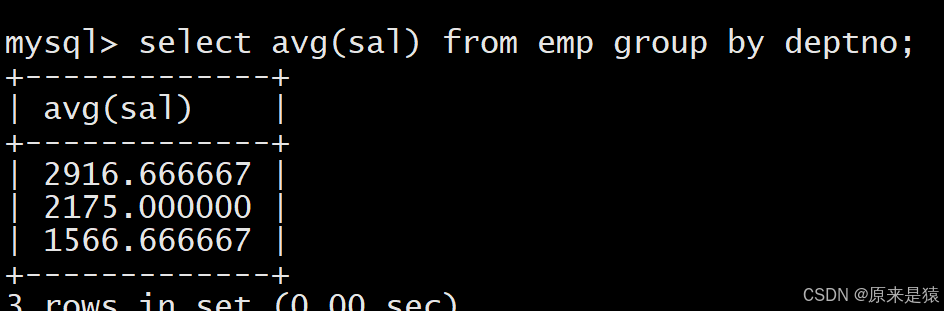
- 对聚合的结果进行判断 【having和group by配合使用,对group by 的结果进行过滤
having经常和group by搭配使用,作用是对分组进行筛选,作用有些像****where。
HAVING 和 WHERE :
| 特性 | WHERE | HAVING |
|---|---|---|
| 筛选时机 | 分组(GROUP BY)之前 | 分组(GROUP BY)之后 |
| 筛选对象 | 原始的、未分组的单行数据 | 分组后的「统计结果」(组级数据) |
| 能否用聚合函数 | ❌ 不可以(操作的是单行数据) | ✅ 可以(操作的是分组统计结果) |
| 适用场景 | 过滤单个符合条件的记录 | 过滤符合条件的分组 |
WHERE 是「分组前」筛选单行数据(不能用聚合函数),HAVING 是「分组后」筛选分组结果(可以用聚合函数);
通俗举例:假设你要统计「每个班级数学平均分超过 80 分的班级」:
- WHERE:先筛选「数学分数 > 0 分的学生」(排除无效数据),这是对单个学生的筛选;
- HAVING:在按班级分组计算平均分后,筛选「平均分 > 80 分的班级」,这是对整个班级的筛选。


- 不要单纯的认为,只有磁盘上表结构导入到mysql , 真实存在的表才叫表,这是不对的
- 中间筛选出来的,包括最终结果,在我看来,全部都是逻辑上的表 !!!
- ''MYSQL一切皆表'',未来只要我们能够处理好单表的CURD,所有sql场景,我们也可以用同一种方式进行~