目录
[2.5.安装boost profile库](#2.5.安装boost profile库)
一.ODB
当你使用 C++ 开发一个需要存储数据的应用程序时,你通常会选择 MySQL 这样的关系数据库来持久化数据。但是,直接操作 MySQL 意味着你需要在 C++ 代码中编写大量的 SQL 语句,比如 INSERT、SELECT、UPDATE、DELETE,并且还要处理结果集、数据类型转换等细节。这不仅繁琐,而且容易出错,因为 SQL 字符串在编译时无法检查语法和类型。
ODB 就是用来解决这个问题的。它是一个中间层,让你能够用更自然的方式来操作数据库,而不必直接与 SQL 打交道。下面我会详细解释 ODB 是如何充当这个桥梁的。
ODB 的角色:C++ 对象与 MySQL 表之间的翻译官
ODB 是一个 对象关系映射(ORM) 框架。它的核心思想是:你只需要关注 C++ 中的对象,而 ODB 负责将这些对象自动映射到 MySQL 的表中,并把你对对象的操作翻译成对应的 SQL 语句发送给 MySQL。
具体来说,ODB 做了以下几件事:
-
把 C++ 类映射成 MySQL 表
你在 C++ 中定义一个类,例如"人"类,包含姓名、年龄等属性。ODB 允许你通过一些简单的标记(比如注释或
#pragma指令)告诉它这个类需要持久化。然后 ODB 会在 MySQL 中自动创建一张对应的表,表的列对应类的成员变量。 -
把 C++ 对象映射成表中的行
当你在程序中创建一个"人"对象(比如名叫张三,年龄 30),ODB 可以把这个对象保存到 MySQL 中,成为表里的一行数据。反过来,当你从数据库查询时,ODB 会把查到的每一行数据重新构造成一个 C++ 对象,让你可以直接使用。
-
把对对象的操作翻译成 SQL 语句
你在代码中执行的操作,比如"保存这个对象"、"更新那个对象"、"删除 id 为 5 的对象"、"查询所有年龄大于 25 的人",ODB 都会在背后生成相应的 SQL 语句(
INSERT、UPDATE、DELETE、SELECT)并发送给 MySQL 执行。你完全不需要手写这些 SQL。
工作流程:从定义类到操作数据库
第一步:定义持久化类
你写一个普通的 C++ 类,并用 ODB 能理解的方式标记出哪些属性需要存到数据库、哪个是主键等。例如,你可能会这样描述"人"类:
-
类名:
Person -
属性:名字、年龄
-
主键:一个自动增长的 ID
你只需要在类里加上一些特殊标记,其余代码和普通 C++ 类一样。
第二步:让 ODB 编译器生成辅助代码
写完类定义后,你运行一个叫 odb 的命令行工具,告诉它"请根据这个类生成与 MySQL 交互所需的代码"。这个工具会分析你的类,并生成一组新的 C++ 文件(比如 person-odb.hxx 和 person-odb.cxx)。这些文件里包含了所有让 ODB 知道如何把 Person 对象存到 MySQL 的代码,比如如何构造 SQL 语句、如何把对象的数据填到 SQL 里、如何把查询结果转回对象等。
第三步:在你的程序中使用 ODB API
在你的主程序里,你包含上一步生成的头文件,然后就可以通过 ODB 提供的简单函数来操作数据库了。大致步骤是:
-
建立连接:告诉 ODB 你要连接哪个 MySQL 数据库(地址、用户名、密码、数据库名)。
-
开启事务:为了保证数据一致性,你通常会开启一个事务(一组操作要么全部成功,要么全部失败)。
-
保存对象 :比如你创建了一个
Person对象张三,只需要调用一个类似db.persist(张三)的函数,ODB 就会生成INSERT语句把张三的数据插入 MySQL。 -
查询对象 :如果你想找出所有年龄大于 25 的人,你可以构造一个查询条件,比如
年龄 > 25,然后调用查询函数。ODB 会生成SELECT语句,执行后把结果集中的每一行转换成Person对象,并返回给你一个包含这些对象的列表。 -
更新对象 :如果你修改了某个对象的属性,比如把张三的年龄改为 31,调用
db.update(张三),ODB 会生成UPDATE语句更新数据库。 -
删除对象 :如果你想从数据库中删除张三,调用
db.erase(张三)或根据 ID 删除,ODB 会生成DELETE语句。 -
提交事务:如果所有操作成功,提交事务,更改永久生效。
在整个过程中,你操作的都是 C++ 对象和简单的函数调用,完全看不到任何 SQL 语句。
第四步:编译和运行
最后,你需要编译你的程序,并链接 ODB 的运行时库和 MySQL 的客户端库。编译后得到的可执行文件运行时,就会通过 ODB 与 MySQL 交互。
二.安装ODB
这里我可以先告诉大家,这里安装过程长达3小时。(我的服务器是2核8G内存的)
2.1.build2安装
因为build2安装时,有可能会版本更新,从16变成17,或从17变18,因此注意, 先从build2官网查看安装步骤...
安装步骤:https://build2.org/install.xhtml#unix
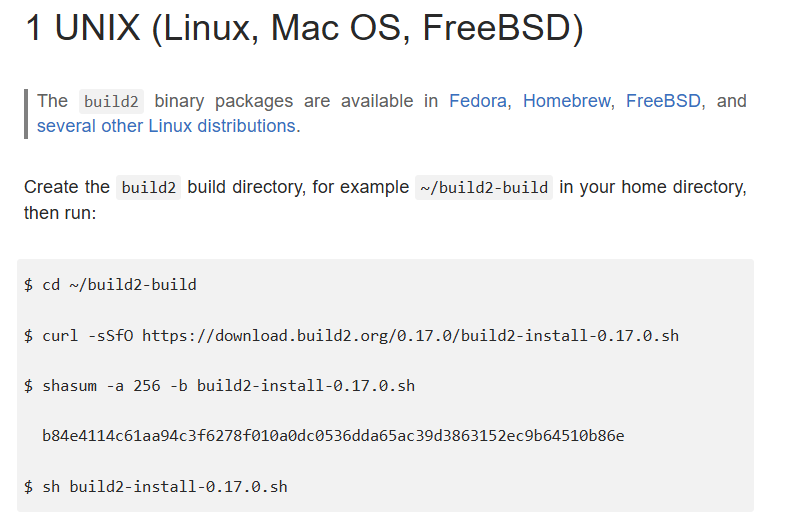
这个安装时间是比较长的。40分钟左右(注意这中间还需要我们输入一个y表示确认)
安装成功的界面如下:
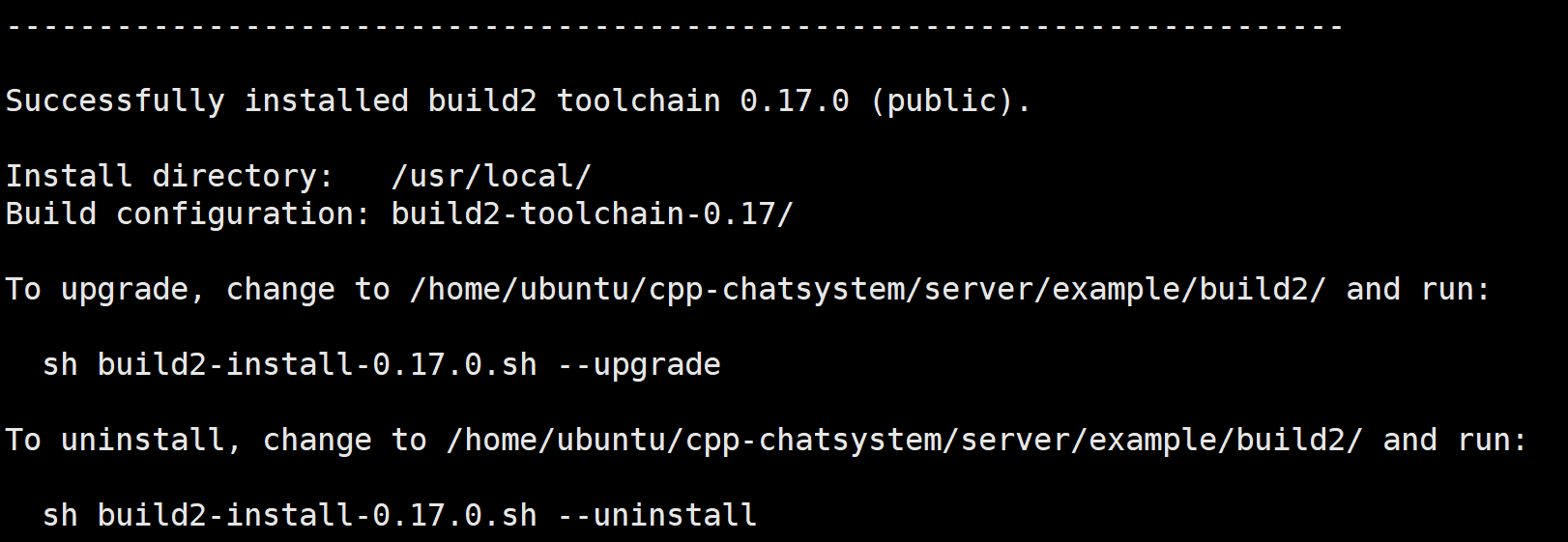
安装中如果因为网络问题,超时失败,解决:将超时时间设置的更长一些
sh build2-install-0.17.0.sh --timeout 1800
在安装过程中,我们可能会遇到下面这种编译错误:
g++ -print-search-dirs 命令输出的库搜索路径中包含了一个相对路径 ./x86_64-linux-gnu/11/。build2 期望所有路径都是绝对路径,遇到以 ./ 开头的相对路径就会认为无效并报错。
libraries: 部分有 ./x86_64-linux-gnu/11/ 和 ./x86_64-linux-gnu/,最前面是一个点,这个会报错,然后我们去查看一下我们的环境变量
bash
ubuntu@10-13-52-255:~/cpp-chatsystem/server/example/build2$ env | grep -E 'LIBRARY_PATH|COMPILER_PATH|C_INCLUDE_PATH|CPLUS_INCLUDE_PATH'
CPLUS_INCLUDE_PATH=:/usr/local/protobuf/include/
LIBRARY_PATH=:/usr/local/protobuf/lib/
LD_LIBRARY_PATH=:/usr/local/protobuf/lib/
C_INCLUDE_PATH=:/usr/local/protobuf/include/如果你需要保留这些路径(例如为了其他项目编译),可以去掉前导冒号,使其成为正常的绝对路径:
bash
export CPLUS_INCLUDE_PATH=/usr/local/protobuf/include
export LIBRARY_PATH=/usr/local/protobuf/lib
export C_INCLUDE_PATH=/usr/local/protobuf/include
export LD_LIBRARY_PATH=/usr/local/protobuf/lib然后重新执行命令。
2.2.安装odb-compiler
首先查看我们的g++版本
bash
g++ -v
可以看到我们的g++的大版本是11.
bash
sudo apt-get install gcc-11-plugin-dev # 注意这个gcc后面的11是根据我们的g++版本来设定的
mkdir odb-build && cd odb-build # 注意需要在上面那个build2目录里面执行这个命令
bpkg create -d odb-gcc-N cc \
config.cxx=g++ \
config.cc.coptions=-O3 \
config.bin.rpath=/usr/lib \
config.install.root=/usr/ \
config.install.sudo=sudo
cd odb-gcc-N
bpkg build odb@https://pkg.cppget.org/1/beta # 这里安装花了30分钟
bpkg test odb
bpkg install odb
odb --version整个流程下来40分钟左右


如果在执行odb --version时报错了,找不到odb,那就在执行下边的命令
bashsudo echo 'export PATH=${PATH}:/usr/local/bin' >> ~/.bashrc export PATH=${PATH}:/usr/local/bin odb --version
2.3.安装ODB运行时库
bash
cd .. # 回到我们上面的odb-build目录里面
bpkg create -d libodb-gcc-N cc config.cxx=g++ config.cc.coptions=-O3 config.install.root=/usr/ config.install.sudo=sudo
cd libodb-gcc-N
bpkg add https://pkg.cppget.org/1/beta
bpkg fetch # 等待40分钟
bpkg build libodb
bpkg build libodb-mysql # 等待20分钟2.4.安装mysql和客户端开发包
我们先安装一下
bash
sudo apt install -y mysql-server &&\
sudo apt install -y libmysqlclient-dev配置mysql,我们需要去mysql的配置文件里面配置一些信息
sudo vim /etc/my.cnf 或者 /etc/mysql/my.cnf 有哪个修改哪个就行。
像我的这个版本就是/etc/mysql/my.cnf
bash
sudo vim /etc/mysql/my.cnf在文件末尾添加下面这些内容
bash
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
character-set-server=utf8
bind-address = 0.0.0.0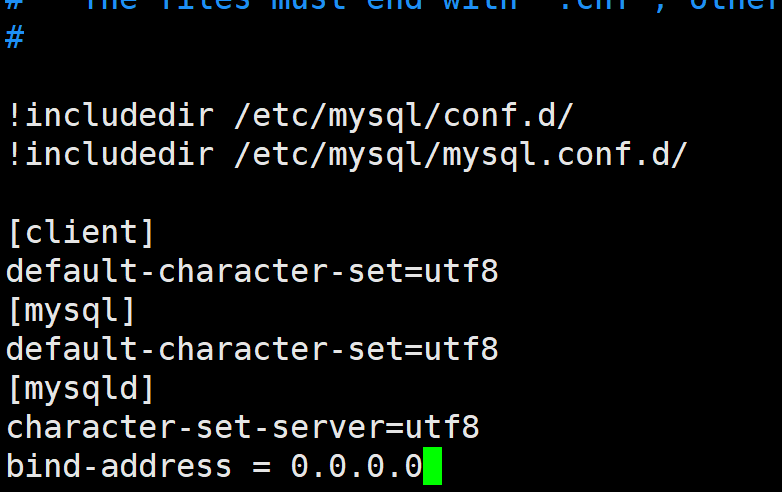
修改root用户密码
bash
sudo cat /etc/mysql/debian.cnf这里存放的是root用户的默认密码,我们需要修改一下
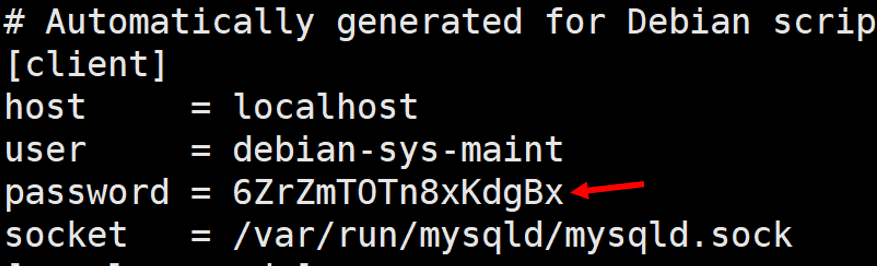
然后我们执行下面这个命令
bash
sudo mysql -u debian-sys-maint -p这里输入上边第6行看到的密码
登陆进去
接下来我们就执行下面这些SQL语句
bash
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '123456';
FLUSH PRIVILEGES;
重启mysql,并设置开机启动
bash
sudo systemctl restart mysql
sudo systemctl enable mysql接下来我们执行下面这个命令
bash
mysql -u root -p输入密码
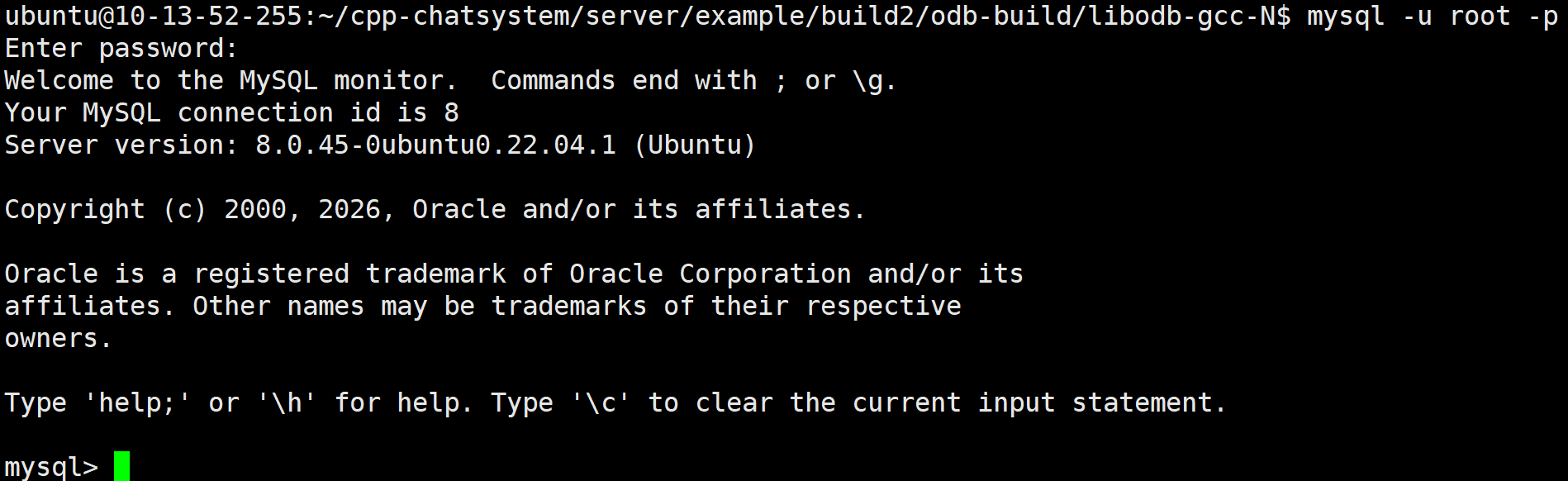
登陆进来了,说明我们成功了。
现在我们去看看我们的配置有没有生效,生效了,说明我们配置的也没有问题
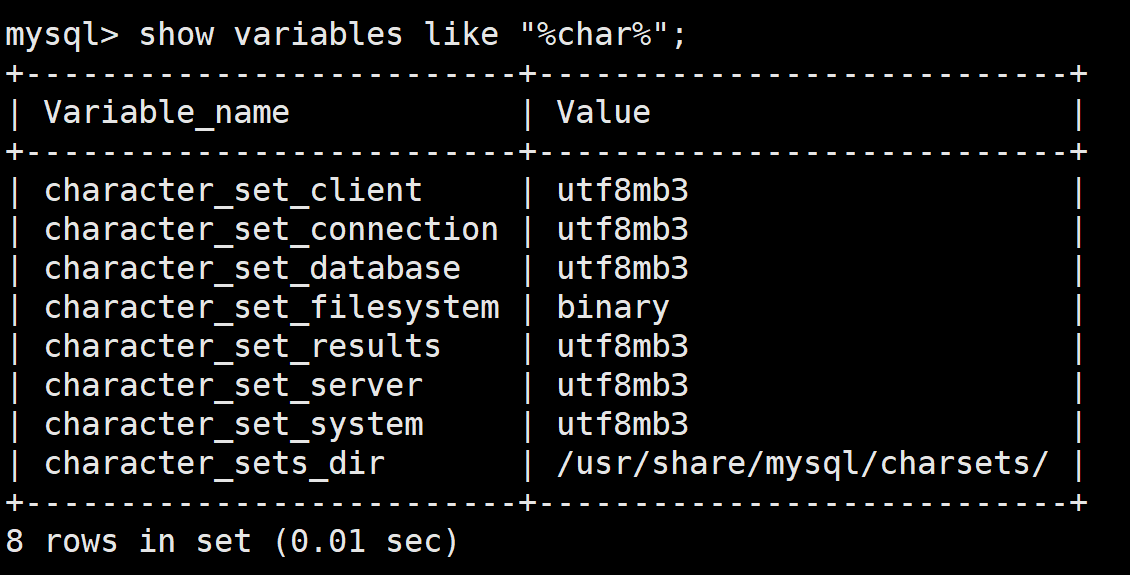
2.5.安装boost profile库
首先我们需要位于odb-build/libodb-gcc-N目录里面执行下面这个
bash
bpkg build libodb-boost2.6.总体打包安装
首先我们需要位于odb-build/libodb-gcc-N目录里面执行下面这个
bash
bpkg install --all --recursive然后我们去
bash
ls /usr/include/odb/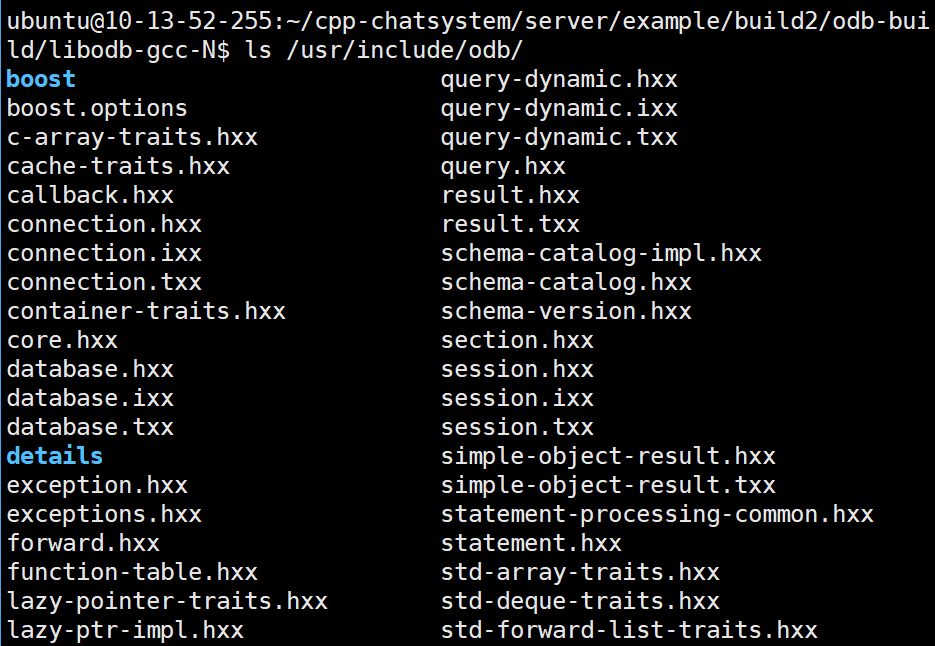
至此,我们整个的ODB就算是安装完毕了
如果说你想做其他操作,其实可以使用下面这个代码
总体卸载(目前不需要)
bashbpkg uninstall --all --recursive总体升级(目前不需要)
bashbpkg fetch bpkg status bpkg uninstall --all --recursive bpkg build --upgrade --recursive bpkg install --all --recursive
三.ODB的简单介绍
3.1.预编译指令介绍
那么在下面的练习中,我们都会把他们放到一个test.hxx文件里面
cpp
#pragma once
#include <string>
#include <cstddef>
#include <boost/date_time/posix_time/posix_time.hpp>
#include <odb/nullable.hxx>
#include <odb/core.hxx>
加上我们的测试代码然后我们去编译这个hxx文件
cpp
odb -d mysql --std c++11 --generate-query --generate-schema --profile boost/date-time test.hxx然后就会生成一个test.sql文件,我们去里面看看
3.1.1.语法讲解
ODB 是一个将 C++ 对象映射到关系数据库的库,它通过特殊的预处理器指令(**以 #pragma db 开头)**来告诉 ODB 编译器(一个专门的工具)如何把 C++ 类、成员变量等映射成数据库中的表、列、约束等元素。这些指令写在 C++ 代码里,但并不是标准 C++ 的一部分,而是 ODB 特有的扩展。
下面这些命令都是符合这种样式的
cpp
#pragma db 属性
- #pragma db object
- 作用:声明一个 C++ 类是一个"数据库对象" ,意思是**这个类将会对应数据库中的一张表。**当你用 ODB 处理这个类时,它会自动生成创建表的 SQL 语句,并提供持久化操作(增删改查)的代码。
- 它告诉 ODB:"这个 C++ 类是一个需要存入数据库的对象。" 没有这个指令,ODB 根本不会把这个类当作数据库相关的类来处理。你可以把它看作是一个"开关",打开了这个类的持久化功能。
- 类比:你告诉 ODB:"这个类我要存到数据库里,请帮我准备好对应的表。"
cpp
#pragma db object
class Person
{
// ... 成员变量
};
// 告诉 ODB:Person 类需要持久化,自动生成对应的表(默认表名 "Person")
- #pragma db table("table_name")
- 作用:**指定这个类映射到数据库中的哪张表。**括号里写的是表名。如果不写这个指令,ODB 会默认使用类的名字作为表名。
- 它告诉 ODB:"如果这个类要映射到数据库,请使用我指定的表名。" 它是一个可选的配置项,用来覆盖默认的表名(默认是类名)。如果没有这个指令,ODB 会直接用类名作为表名。
- 类比:你可以自定义表的名字,比如把 class Person 映射到表 people,而不是默认的 Person 表。
cpp
#pragma db object table("people") // 同时使用 object 和 table
class Person
{
// ... 成员变量
};
// Person 类映射到数据库表 "people",而不是默认的 "Person"
- #pragma db id
- 作用:**标记类中的一个成员变量作为数据库表的主键。**主键是表中唯一标识每一行的字段,通常不能重复且不能为空。
- ODB 要求每个持久化类必须有一个成员被标记为 ID(主键),除非你明确告诉 ODB 这个类不需要 ID。这样 ODB 才能生成正确的数据库表结构和查询代码。
- 类比:就像每个人的身份证号,能唯一确定一个人。这个变量会被当作主键列。
cpp
#pragma db object
class Person
{
public:
#pragma db id
unsigned long id_; // id_ 是主键列
std::string name_;
};生成的test.sql文件内容如下
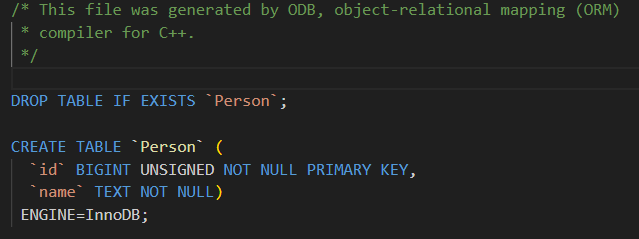
可以看到我们的成员变量名是id_,但是列名就把id_后面的_给自动去掉了。
可以看到这个表名默认使用了Person。这个表名就是我们的类名。
如果我们换一个类名来看看
cpp
#pragma db object
class A
{
public:
#pragma db id
unsigned long id_; // id_ 是主键列
std::string name_;
};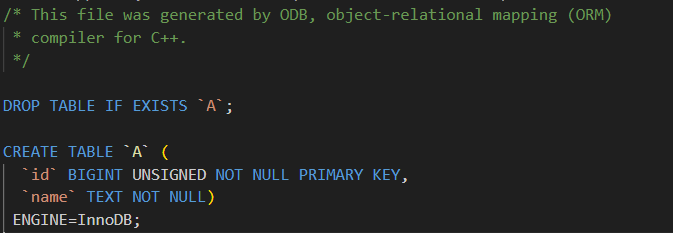
这个表名就是我们的类名。
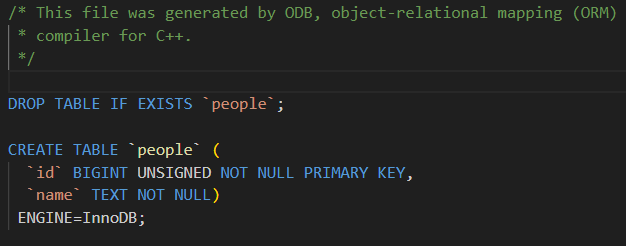
当然我们也可以明确指出表名是啥
cpp
#pragma db object table("people") // 同时使用 object 和 table
class Person
{
public:
#pragma db id
unsigned long id_; // id_ 是主键列
std::string name_;
};可以看到这个表名就换成了我们指定的person
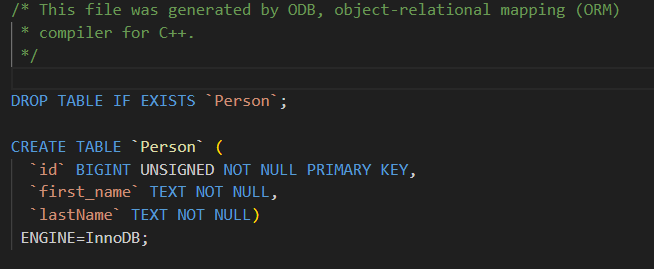
- #pragma db column("列名")
- 作用:指定成员变量映射到数据库表中的哪一列。括号里写的是列名。如果不写,默认使用成员变量的名字作为列名。
- 类比:你可以给列起一个不同于变量名的名字,例如变量叫 firstName,但你想让它在数据库中叫 first_name。
cpp
#pragma db object
class Person
{
public:
#pragma db id
unsigned long id_;
#pragma db column("first_name") // 将 firstName_ 映射到列 "first_name"
std::string firstName_;
std::string lastName_; // 默认列名 "lastName_"
};
- #pragma db view
- 作用:**声明一个类是一个"数据库视图"。**视图是基于 SQL 查询的虚拟表,它不存储数据,而是从其他表查询数据。使用 view 的类可以映射到复杂的查询结果,而不是一张物理表。
- 类比:就像在数据库里创建一个视图,方便你以特定方式查看数据。这个类对应的是一个查询结果集。
cpp
#pragma db view object(Person) // 基于 Person 表的视图
class PersonNames
{
public:
std::string first_name_; // 对应 Person 表的 first_name 列
std::string last_name_;
};
// PersonNames 类对应一个查询视图,例如 "SELECT first_name, last_name FROM Person"注意:这里的这个Person表的编写代码一定要先写出来。
我们看一个例子
cpp
// person.hxx
#ifndef PERSON_HXX
#define PERSON_HXX
#include <string>
#include <odb/core.hxx> // ODB 核心宏定义,使 #pragma 对 C++ 编译器无影响
// 持久化类:对应数据库中的 person 表
#pragma db object
class person
{
public:
person (const std::string& name, unsigned short age)
: name_(name), age_(age) {}
const std::string& name () const { return name_; }
unsigned short age () const { return age_; }
private:
friend class odb::access;
person () {} // 默认构造(ODB 需要)
#pragma db id auto // 自动生成主键
unsigned long id_;
std::string name_;
unsigned short age_;
};
// 视图类:基于 SQL 查询,统计每个年龄的人数
#pragma db view query("SELECT age, COUNT(*) FROM person GROUP BY age")
struct age_count
{
// 将查询结果中的 age 列映射到 age 成员
#pragma db column("age")
unsigned short age;
// 将查询结果中的 COUNT(*) 列映射到 count 成员
#pragma db column("count(*)")
size_t count;
};
#endif // PERSON_HXX
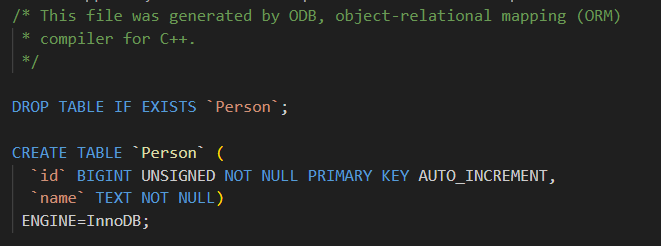
- #pragma db session
- 作用:用于**声明一个全局变量或成员变量是一个"数据库会话"。**会话是 ODB 中管理对象缓存、事务和对象标识的机制,通常一个线程对应一个会话。这个指令一般用在需要手动管理会话的地方。
- 类比:会话就像一次数据库操作的"工作单元",记录你加载和修改的对象,帮你做缓存和一致性检查。
cpp
#pragma db object session // 声明 Person 类支持 session
class Person
{
public:
#pragma db id auto
unsigned long id;
std::string name;
};
- #pragma db query("query")
- 作用:**用于定义自定义的查询函数。**你可以在类中声明一个成员函数,并用这个指令附加一段 SQL 查询语句,ODB 会生成执行该查询的代码。
- 类比:你预先写好一个常用的 SQL 查询,并把它绑定到一个函数上,调用这个函数就能直接执行该查询。
cpp
#pragma db object
class Person
{
public:
#pragma db id
unsigned long id_;
std::string name_;
#pragma db query("SELECT name FROM person WHERE age > 50")
static std::vector<std::string> findSeniors(); // 自定义查询函数
};
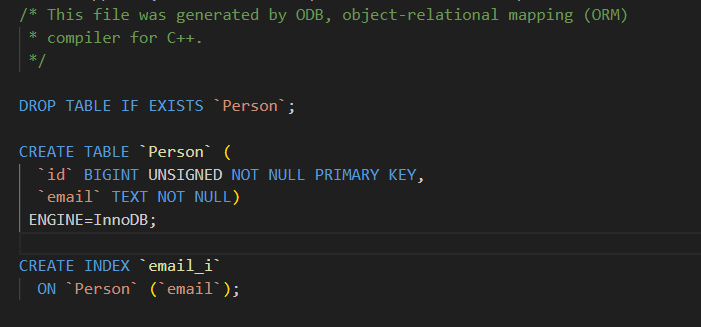
- #pragma db index
- 作用:指定某个成员变量(或几个变量组合)应该**创建数据库索引。**索引可以加快查询速度,括号里是索引的名字。
- 类比:就像给书的目录建一个索引,让你能更快找到内容。这个指令告诉数据库:请给这个列建索引。
cpp
#pragma db object
class Person
{
public:
#pragma db id
unsigned long id_;
#pragma db index //给email列创建索引
std::string email_;
};
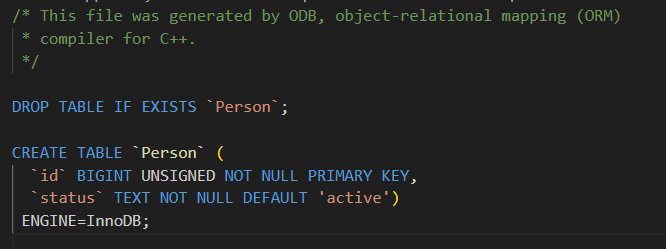
- #pragma db default("默认值")
- 作用:**为成员变量指定一个默认值。**当向数据库插入新记录时,如果没有给这个列赋值,数据库就会使用这里指定的默认值。
- 类比:比如一个 status 变量,默认是 'active',插入新用户时如果不指定状态,数据库自动填上 active。
cpp
#pragma db object
class Person
{
public:
#pragma db id
unsigned long id_;
#pragma db default("active") // 插入时若未指定 status_,则默认 'active'
std::string status_;
};
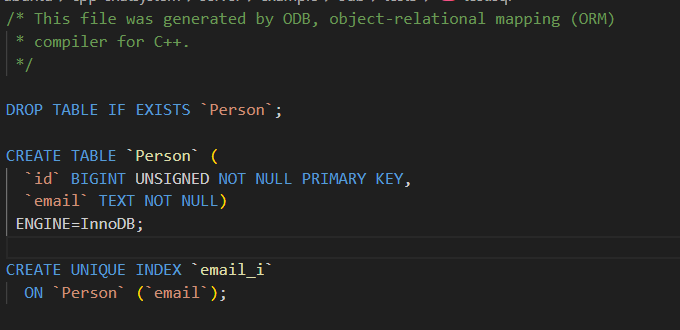
- #pragma db unique
- 作用:**指定成员变量(或一组变量)必须具有唯一性,**即表中不能有两行在该列(或列组合)上拥有相同的值。这相当于数据库中的唯一约束。
- 类比:就像邮箱地址不能重复,这个指令保证你指定的列不会出现重复值。
cpp
#pragma db object
class Person
{
public:
#pragma db id
unsigned long id_;
#pragma db unique // email_ 列的值不能重复
std::string email_;
};
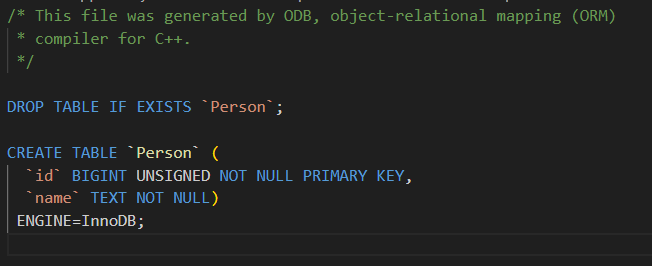
- #pragma db not_null
- 作用:指定**成员变量在数据库中对应的列不允许为空(NULL)。**也就是说,插入或更新记录时,必须给这个列提供一个非空的值。
- 类比:类似 HTML 表单中的必填项,数据库会强制这个字段必须有值。
cpp
#pragma db object
class Person
{
public:
#pragma db id
unsigned long id_;
#pragma db not_null // name_ 列不能为 NULL
std::string name_;
};
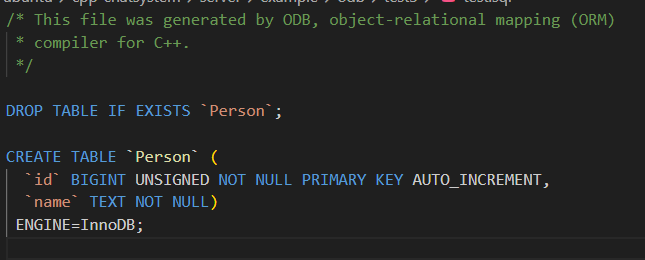
- #pragma db auto
- 作用:**指定成员变量的值在插入时自动生成。**通常用于主键,比如自动递增的整数。当你插入新对象时,不需要手动设置这个值,数据库会自动生成。
- 类比:就像 MySQL 的 AUTO_INCREMENT 属性,每次插入新行,数据库自动给这个列分配一个递增的数字。
cpp
#pragma db object
class Person
{
public:
#pragma db id auto // id_ 自动递增
unsigned long id_;
std::string name_;
};
- #pragma db transient
- 作用:标记一个成员变量不应该被持久化到数据库中。也就是说,这个变量只在程序运行时使用,不会被存入数据库表。
- 类比:就像你在表单里有一个临时计算的字段,不需要存到数据库里,所以 ODB 会忽略它。
cpp
#pragma db object
class Person
{
public:
#pragma db id
unsigned long id_;
std::string name_;
#pragma db transient // temp_ 不会被存入数据库
int temp_; // 仅用于运行时计算
};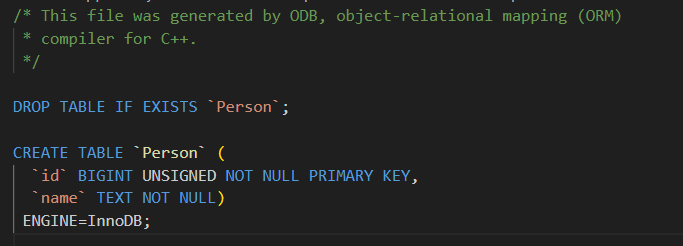
可以看到这个temp就没有在我们的SQL数据表里面
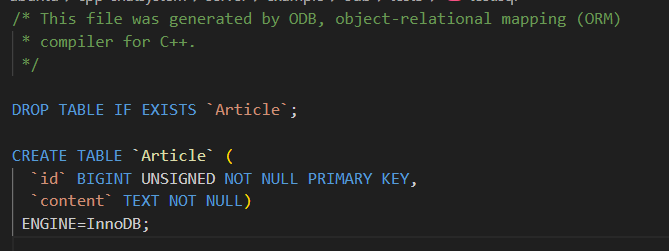
- #pragma db type("类型名称")
- 作用:**指定成员变量在数据库中对应的 SQL 数据类型。**当 ODB 默认的类型映射不符合你的需求时,可以用这个指令手动指定类型,比如 "VARCHAR(255)" 或 "TEXT"。
- 类比:你想让一个 std::string 在数据库中存成 TEXT 而不是默认的 VARCHAR,就可以用这个指令指明。
cpp
#pragma db object
class Article
{
public:
#pragma db id
unsigned long id_;
#pragma db type("TEXT") // 将 content_ 映射为数据库 TEXT 类型
std::string content_;
};
- #pragma db convert("converter")
- 作用:**为成员变量指定一个自定义的类型转换器。**当你的 C++ 类型和数据库类型不能直接映射时,可以写一个转换器类,然后用这个指令告诉 ODB 使用哪个转换器来处理该成员的读写。
- 类比:比如你有一个 C++ 的 Point 类,想存成数据库的两个整数列,就需要一个转换器来拆分和组装。这个指令就是关联转换器的。
cpp
// 假设有一个 Point 类型和对应的转换器 PointConverter
#pragma db object
class Shape
{
public:
#pragma db id
unsigned long id_;
#pragma db convert("PointConverter") // 使用 PointConverter 转换 point_ 成员
Point point_;
};
- #pragma db pool("pool_name")
- 作用:指定用于数据库连接的连接池。连接池是管理数据库连接的一种机制,可以提高性能。这个指令一般用在需要显式指定某个对象使用特定连接池的场景。
- 类比:就像你去银行办事,有不同的窗口(连接池),你可以指定去哪个窗口办理。通常由 ODB 配置管理,不常用。
cpp
#pragma db object pool("write_pool") // 该类的数据库操作使用 write_pool 连接池
class Person
{
public:
#pragma db id
unsigned long id_;
std::string name_;
};
- #pragma db trigger("trigger_name")
- 作用:**指定在插入、更新或删除操作时触发的数据库触发器。**触发器是一种在特定事件发生时自动执行的数据库脚本。这个指令用于将 C++ 对象与数据库中的触发器关联起来。
- 类比:比如你希望每当有新用户插入时,自动记录一条日志,数据库触发器可以做这件事。这个指令就是告诉 ODB,这个对象涉及到的表有这样一个触发器。
cpp
#pragma db object trigger("person_audit") // Person 表的操作会触发 person_audit 触发器
class Person
{
public:
#pragma db id
unsigned long id_;
std::string name_;
};3.1.2.多属性声明
在 ODB 中,你可以在一个 #pragma db 指令后面同时指定多个属性(也称为"限定符"或"指示符"),它们之间用空格隔开。
这种写法被称为"多属性声明",能够让你在一个地方简洁地描述一个类或成员在数据库中的多个映射特性。
语法形式
cpp
#pragma db 属性1 属性2 ... 属性N每个属性可以是:
- 无参数的,如 object、id、auto、transient 等。
- 带参数的,如 table("表名")、column("列名")、type("数据库类型") 等。
这些属性共同作用于紧随其后的声明(类定义、成员变量或函数)。
适用场景
用于类:同时标记该类为持久化对象,并指定表名、视图等。
cpp
#pragma db object table("person")
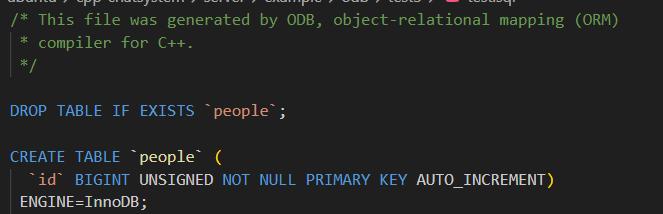
class Person { ... };用于成员变量:同时指定该成员为主键、自动增长、映射到特定列名,并加上约束。
cpp
#pragma db id auto column("person_id") not_null
unsigned long id_;用于成员函数:例如自定义查询函数可以同时指定查询语句和其他属性(较少见,但语法一致)。
常见组合示例
声明 Person 类为持久化对象,并指定其对应的数据库表名为 people(而不是默认的 Person)。
cpp
#pragma db object table("people")
class Person
{
// ...
};主键 + 自动增长 + 列名重命名
cpp
#pragma db object table("people")
class Person
{
public:
#pragma db id auto column("id")
unsigned long id_;
};
唯一约束 + 索引
cpp
#pragma db object table("people")
class Person
{
public:
#pragma db id auto // 自动生成的主键
unsigned long id_;
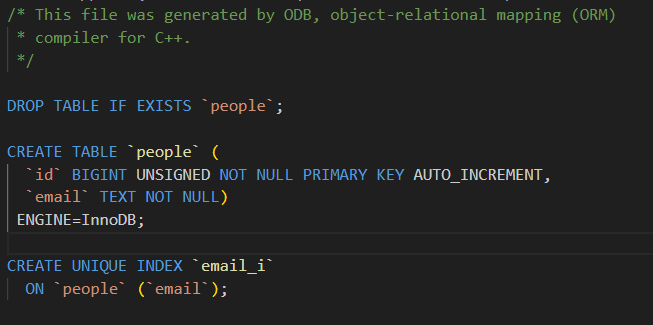
#pragma db unique index
std::string email_;
};
非空 + 默认值
cpp
#pragma db object table("people")
class Person
{
public:
#pragma db id auto // 自动生成的主键
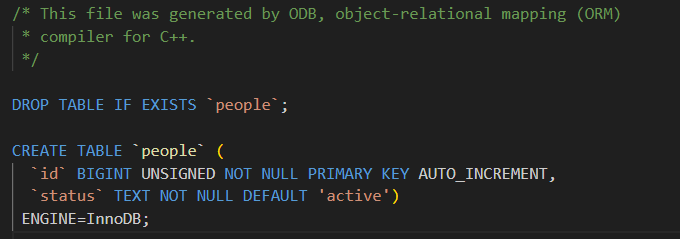
unsigned long id_;
#pragma db not_null default("active")
std::string status_;
};
3.1.3.ODB在使用过程中的一些小细节
1.ODB的访问控制
不知道大家有没有注意到
在使用ODB框架时,我们通常会在头文件(.hxx)中为持久化类添加编译指令,例如 #pragma db object、#pragma db id 等,以指示ODB如何将C++类映射到数据库表。这些指令一般放置在类的 public 部分。
那么,是否可以将这些编译指令放在类的 private 或 protected 部分呢?
其实很简单:加一个友元声明即可
cpp
#pragma db object table("people")
class Person
{
public:
A区域
private:
friend class odb::access; // 让 ODB 生成的代码可以访问私有成员
B区域
protected:
friend class odb::access; // 让 ODB 生成的代码可以访问保护成员
C区域
};通过在类中添加 friend class odb::access;,ODB 生成的代码就可以访问该类的所有成员,无论它们位于 public、protected 还是 private 区域。这是因为 C++ 的 friend 声明是对整个类生效的,它授予 odb::access 类对该类所有成员的访问权限,而不受成员访问限定符的限制。
2.使用小技巧
在 ODB 的使用中,有一个常见且推荐的小细节:
为了在保持良好封装性的同时让 ODB 能够访问类的私有成员,通常
private 部分:
- 将 ODB 的预编译指令 (如 #pragma db id、#pragma db index 等)放在类的 private 部分,紧挨着对应的数据成员。
- 同时,通过**声明 friend class odb::access;,**授予 ODB 生成的代码访问私有成员的特权。
- 此外,将默认构造函数也声明为 private,因为该构造函数仅用于 ODB 内部(例如从数据库加载对象时),不应被普通业务代码直接调用。
public 部分:
- 提供必要的 setter 和 getter 方法,供外部代码以受控的方式访问和修改私有成员变量。
这种设计既遵循了面向对象的封装原则,又能与 ODB 无缝协作,是实践中广泛采用的模式。
补充说明:
- 为什么将默认构造函数私有化? ODB 在实例化对象时需要调用默认构造函数,但通常我们不希望外部代码随意创建未初始化的对象,因此将其设为私有,并通过 odb::access 友元授予 ODB 调用权,从而兼顾安全性与功能性。
- getter/setter 的作用:它们不仅实现了数据隐藏,还允许你在将来修改内部实现时(例如添加校验逻辑或改变存储结构)不影响外部使用接口。
我们这里举一个例子
cpp
#pragma once
#include <odb/core.hxx>
#pragma db object
class User
{
public:
// 公有构造函数:创建新用户时必须提供名字和年龄
User(const std::string& name, unsigned short age)
: name_(name), age_(age)
{
}
// Getter:返回名字的常量引用(只读)
const std::string& name() const { return name_; }
// Getter:返回年龄(只读)
unsigned short age() const { return age_; }
// Setter:修改年龄(可在此添加合法性校验)
void age(unsigned short new_age) { age_ = new_age; }
private:
friend class odb::access; // 授权 ODB 访问私有成员
// 私有默认构造函数(仅 ODB 内部使用)
User() {}
#pragma db id auto
unsigned long id_; // 自动生成的主键
std::string name_; // 名字(无 setter,不可变)
unsigned short age_; // 年龄(提供 getter/setter)
};这个结构非常的完美
使用示例
那么在下面的练习中,我们都会把他们放到一个test.hxx文件里面
cpp
#pragma once
#include <string>
#include <cstddef>
#include <boost/date_time/posix_time/posix_time.hpp>
#include <odb/nullable.hxx>
#include <odb/core.hxx>
加上我们的测试代码然后我们去编译这个hxx文件
cpp
odb -d mysql --std c++11 --generate-query --generate-schema --profile boost/date-time test.hxx然后就会生成一个test.sql文件,我们去里面看看
- 示例1
cpp
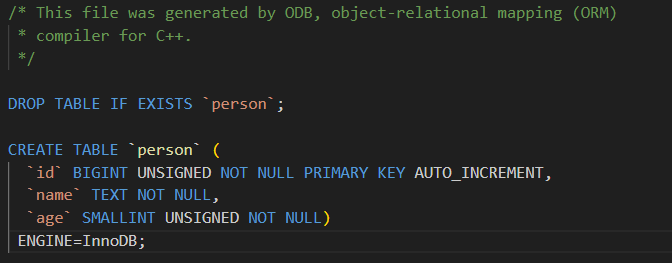
#pragma db object
class person
{
public:
person (const std::string& name, unsigned short age)
: name_ (name), age_ (age)
{
}
const std::string&
name () const { return name_; }
unsigned short
age () const { return age_; }
void
age (unsigned short age) { age_ = age; }
private:
friend class odb::access;
person () {} // 默认构造函数,供 ODB 内部使用
#pragma db id auto
unsigned long id_; // 自动生成主键
std::string name_;
unsigned short age_;
};
- 示例2
cpp
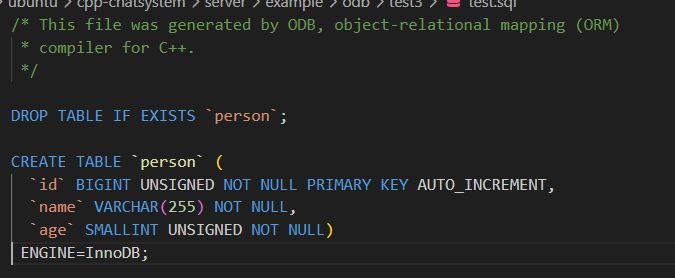
// 声明这是一个持久化类(对应数据库中的一张表)
#pragma db object
class person
{
public:
// 方便使用的构造函数
person (const std::string& name, unsigned short age)
: name_(name), age_(age)
{
}
// 获取 id(由数据库自动生成)
unsigned long long id () const { return id_; }
// 获取姓名
const std::string& name () const { return name_; }
// 设置姓名
void name (const std::string& name) { name_ = name; }
// 获取年龄
unsigned short age () const { return age_; }
// 设置年龄
void age (unsigned short age) { age_ = age; }
private:
// 让 ODB 能够访问私有成员(用于对象加载/保存)
friend class odb::access;
// ODB 需要的默认构造函数(私有化,防止外部直接调用)
person () {}
// 主键,auto 表示由数据库自动生成(如自增字段)
#pragma db id auto
unsigned long long id_;
// 显式指定数据库列类型为 VARCHAR(255)(可选)
#pragma db type("VARCHAR(255)")
std::string name_;
// 年龄(使用默认映射,通常为 SMALLINT 或 INT)
unsigned short age_;
};
- 示例3
cpp
#pragma db object
class user
{
public:
user (const std::string& name,
const std::string& email,
unsigned short age)
: name_(name), email_(email), age_(age)
{
}
// Getter 示例(可选)
unsigned long long id () const { return id_; }
const std::string& name () const { return name_; }
const std::string& email () const { return email_; }
unsigned short age () const { return age_; }
// Setter 示例
void name (const std::string& n) { name_ = n; }
void email (const std::string& e) { email_ = e; }
void age (unsigned short a) { age_ = a; }
private:
friend class odb::access;
user () {} // 默认构造函数(ODB 需要)
// 主键,自动生成
#pragma db id auto
unsigned long long id_;
// 姓名:不能为空
#pragma db not_null
std::string name_;
// 邮箱:不能为空,且唯一
#pragma db not_null unique
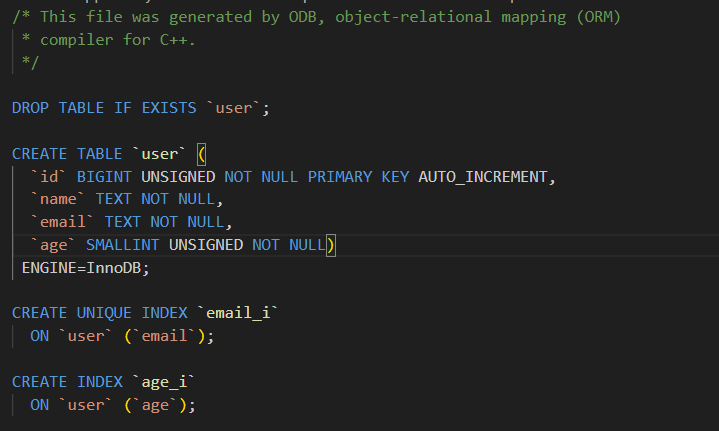
std::string email_;
// 年龄:创建索引(加速按年龄查询),且不能为空
#pragma db not_null index
unsigned short age_;
};
3.2.ODB编译指令讲解
我们在上面学会了预编译指令,我们就能写出这个.hxx文件,那么后续我们还是需要借助这个ODB编译器编译生成对应的C++代码
ODB 是一个用于 C++ 的对象关系映射(ORM)编译器,它读取带有持久化声明的 C++ 头文件,并生成用于数据库存取的代码。使用 ODB 时,最常用的命令行选项如下:
cpp
odb [选项]... 输入文件.hxx- 最常用选项
--database <数据库类型>
-
作用:指定要连接和生成代码的数据库后端。ODB 支持多种主流数据库,通过此选项告知编译器针对哪种数据库生成特定的 SQL 语法和运行时库调用。
可选值:mysql、pgsql(PostgreSQL)、sqlite、oracle 等。根据项目实际使用的数据库选择。
-
例:--database mysql
--generate-query
- 生成数据库查询支持代码(即 query 类和相关函数)。如果需要在代码中使用灵活的条件查询,必须加上此选项。
--generate-schema
-
生成 数据库模式(schema)创建语句。ODB 会根据你的类定义生成 CREATE TABLE 等 SQL 语句,这些语句可以用于初始化数据库表结构。
-
作用:生成数据库模式(schema)的定义语句,通常是 CREATE TABLE、CREATE INDEX 等 SQL 语句。这些语句可以用于创建数据库表结构,以匹配持久化类的定义。
-
输出形式:生成的 SQL 语句可以单独输出到一个 .sql 文件(配合 --schema-format separate),也可以嵌入到生成的 C++ 源文件中。
-
注意:默认情况下这些 SQL 语句是不会嵌入在生成的 C++ 源文件中的,而是会输出为独立的 .sql 文件。
--output-dir <路径>
- 指定生成的源文件(.cxx)和头文件(.hxx)的输出目录。默认输出到当前目录。
--header-suffix <后缀> / --source-suffix <后缀>
- 作用:自定义生成的头文件和源文件的扩展名。默认情况下,ODB 生成的头文件后缀为 .hxx,源文件后缀为 .cxx。通过这两个选项可以改为项目惯用的后缀,例如 .h 和 .cpp。
--include <路径>
- 作用:添加额外的头文件搜索路径,类似于 C++ 编译器的 -I 选项。ODB 在解析输入的头文件时,需要处理其中的 #include "自己写的头文件" 指令,这些路径可以帮助 ODB 找到被引用的头文件。
--include-with-brackets
- 作用:控制生成的代码中,对于 ODB 运行时头文件的包含方式。默认情况下,生成的代码使用双引号 #include "odb/xxx.hxx" 来包含 ODB 运行时头文件。如果启用此选项,则改为尖括号 #include <odb/xxx.hxx>。
--include-prefix <前缀>
- 给生成的 #include 指令中所有用户头文件添加路径前缀。例如 --include-prefix model/ 会生成 #include "model/xxx.hxx"。
--std <标准>
- 指定 C++ 语言标准,如 c++11、c++14、c++17。ODB 会根据此选项生成符合相应标准的代码。
--profile <配置文件>
- 启用特定库的支持配置文件,常用的有 boost(使用 Boost 智能指针、容器等)、qt(使用 Qt 容器、字符串等)。可以多次使用以组合多个配置文件。
--odb-epilogue <文本>
- 在生成的代码末尾插入用户提供的文本,常用于添加自定义宏或声明。
--odb-prologue <文本>
- 在生成的代码开头插入用户提供的文本。
--generate-only
- 只生成代码,不调用 C++ 编译器进行编译。适合在构建脚本中分步处理
3.3.ODB常用的操作接口
事实上呢,ODB提供了一系列操作接口来帮我们去操作这个数据库
我们这里不想直接给你们讲,我们直接看例子来学习
首先,我们在做下面这些示例的时候,我们需要提前在MySQL数据库里面创建好一个数据库TestDB
cpp
CREATE DATABASE IF NOT EXISTS TestDB CHARACTER SET utf8;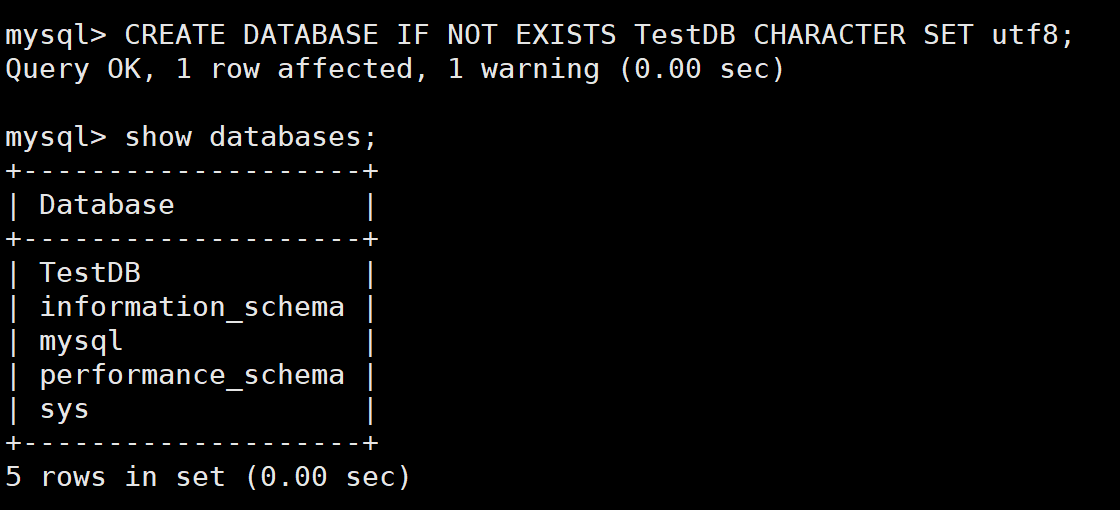
因为我们ODB的代码默认是不会去创建这个数据库的。
3.3.1.示例1------增删查改
下面是一个基于 MySQL 数据库的 ODB 完整代码示例,代码中每一行都加了详细注释。
示例实现了:
- 定义一个简单的 person 持久化类;
- 连接 MySQL 数据库;
- 创建表(如果不存在);
- 插入一条记录;
- 查询所有记录;
- 更新一条记录;
- 删除一条记录。
test.hxx
cpp
#pragma once
#include <string>
#include <odb/core.hxx>
// person.hxx
#pragma db object // 告诉 ODB 这是一个持久化类
class person
{
public:
// 构造函数
person (const std::string& name, int age)
: name_(name), age_(age) {}
// 获取 id(主键)
unsigned long id () const { return id_; }
// 获取姓名
const std::string& name () const { return name_; }
// 获取年龄
int age () const { return age_; }
// 设置年龄(用于更新)
void set_age (int age) { age_ = age; }
private:
// ODB 需要访问私有成员,所以声明为友元
friend class odb::access;
person(){}//默认构造函数,供ODB内部使用
// 主键,自动生成(对应 MySQL 的 AUTO_INCREMENT)
#pragma db id auto
unsigned long id_;
std::string name_;
int age_;
};test.cpp
cpp
// main.cpp
#include <iostream>
#include <memory> // std::shared_ptr
// ODB 核心头文件
#include <odb/database.hxx>
#include <odb/transaction.hxx>
#include <odb/query.hxx>
// MySQL 后端头文件
#include <odb/mysql/database.hxx>
// 由 ODB 编译器生成的包含数据库操作代码的头文件
#include "test-odb.hxx"
int main ()
{
// 使用命名空间简化代码
using namespace odb::core;
// 1. 创建 MySQL 数据库连接对象
// 参数依次为:数据库名、用户名、密码、主机名、端口号
auto db = std::make_shared<odb::mysql::database> (
"root", // 用户名
"123456", // 密码
"TestDB", // 数据库名
"127.0.0.1", // 主机地址
0, // 端口号(0 表示使用默认端口 3306)
nullptr, // Unix socket 文件路径:nullptr 表示使用 TCP/IP 连接(Windows 下忽略)
"utf8" // 客户端字符集
);
// 2. 创建 person 表(如果表不存在)
{
// 开启事务(所有修改操作都必须在事务中)
transaction t (db->begin ());
// 执行 SQL 建表语句
// 注意:这里使用 MySQL 的 CREATE TABLE IF NOT EXISTS,避免重复创建出错
db->execute ("CREATE TABLE IF NOT EXISTS person ("
"id INTEGER PRIMARY KEY AUTO_INCREMENT, "
"name TEXT NOT NULL, "
"age INTEGER NOT NULL)");
// 提交事务
t.commit ();
}
// 3. 插入一条 person 记录
{
// 创建一个 person 对象(id 为 0,由数据库自动生成)
person john ("John Doe", 30);
// 开启事务
transaction t (db->begin ());
// 将对象持久化到数据库(执行 INSERT 语句)
db->persist (john);
// 提交事务
t.commit ();
// 输出插入后的 id(由数据库自动生成并回填到对象中)
std::cout << "Inserted person with id = " << john.id () << std::endl;
}
// 4. 查询所有 person 记录
{
// 定义查询和结果类型别名,简化书写
typedef odb::query<person> query;
typedef odb::result<person> result;
// 开启事务(查询也可以不放在事务中,但放在事务中更规范)
transaction t (db->begin ());
// 执行查询,获取所有 person 对象(不指定条件表示查询全部)
result r (db->query<person> ());
// 遍历结果集
for (const auto& p : r)
{
std::cout << "id: " << p.id ()
<< ", name: " << p.name ()
<< ", age: " << p.age () << std::endl;
}
t.commit ();
}
// 5. 更新一条记录(假设 id 为 1 的记录存在)
{
// 开启事务
transaction t (db->begin ());
// 根据 id 加载 person 对象(如果 id 不存在,程序会崩溃,这里为简化不处理)
std::unique_ptr<person> p (db->load<person> (1));
// 修改年龄
p->set_age (31);
// 将改动更新到数据库(执行 UPDATE 语句)
db->update (*p);
// 提交事务
t.commit ();
std::cout << "Updated person id 1 to age 31" << std::endl;
}
// 6. 删除一条记录(假设 id 为 1 的记录存在)
{
// 开启事务
transaction t (db->begin ());
// 根据 id 删除 person 对象(执行 DELETE 语句)
db->erase<person> (1);
t.commit ();
std::cout << "Deleted person id 1" << std::endl;
}
return 0;
}makefile
cpp
all : test
test-odb.hxx test-odb.ixx test-odb.cxx :
odb -d mysql --std c++11 --generate-query --generate-schema test.hxx
test : test.cpp test-odb.cxx
c++ $^ -o $@ -lodb-mysql -lodb -lodb-boost
.PHONY : clean
clean :
rm test test-odb.hxx test-odb.ixx test-odb.cxx test.sql编译运行一下

我们可以去数据库看看
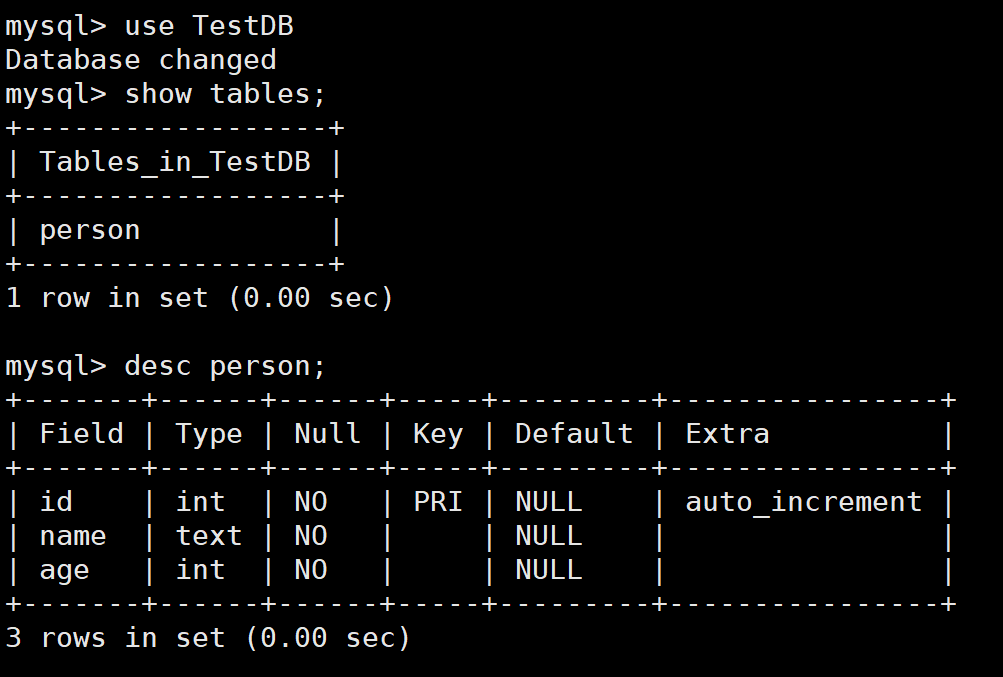

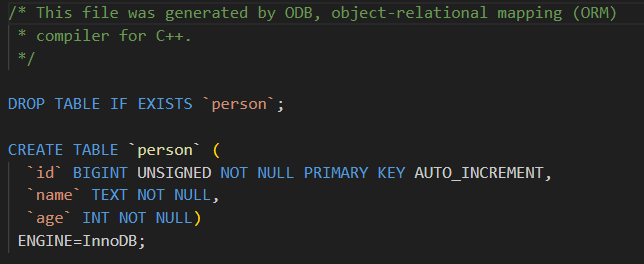
我们仔细看这个表的结构和我们生成的test.sql,是完全一样的。
3.3.2.示例2------查询
--generate-query编译指令的厉害之处
ODB 是一个用于 C++ 的 ORM 系统,它将 C++ 类映射到数据库表,并自动生成持久化代码。ODB 编译器(odb)读取包含持久化类的头文件,并根据命令行选项生成不同的代码文件。
--generate-query 是其中一个常用选项,它的作用是生成与查询相关的代码,包括:
- 每个持久化类的查询列标识符(例如 table::column1、table::column2 等),这些标识符可以在查询表达式中直接使用。
- 为每个持久化类生成查询类型(如 query<person>),它支持在 C++ 中构建类型安全的查询条件。
- 提供一些预定义的查询函数(如 query::id == 123、query::name.like("%john%")),使查询语句的编写更接近自然语言。
生成的这些代码让你能够用纯 C++ 语法构造复杂的 SQL 查询,而无需手写字符串拼接,从而避免语法错误、SQL 注入风险,并享受编译时检查。
它如何让查询变得更简单?
假设我们有一个简单的 C++ 类 person:
cpp
#pragma db object
class person
{
public:
person (const std::string& name, int age) : name_(name), age_(age) {}
const std::string& name () const { return name_; }
int age () const { return age_; }
private:
friend class odb::access;
person () {}
#pragma db id auto
unsigned long id_;
std::string name_;
int age_;
};使用 --generate-query 选项编译这个头文件后,ODB 会生成类似以下的查询支持(简化示意):
cpp
namespace query
{
namespace person
{
// 列标识符
extern const odb::query_column<unsigned long> id;
extern const odb::query_column<std::string> name;
extern const odb::query_column<int> age;
}
}
typedef odb::query< ::person> person_query;现在,你可以在应用程序中用非常直观的方式构建查询:
cpp
// 查询所有年龄大于 18 的人
person_query q (person_query::age > 18);
// 查询名字以 "J" 开头的人
person_query q2 (person_query::name.like ("J%"));
// 组合条件:年龄在 20 到 30 之间且名字不包含 "Smith"
person_query q3 (person_query::age.between (20, 30) &&
person_query::name.not_like ("%Smith%"));然后通过数据库操作(如 db.query<person>(q))执行这些查询,ODB 会将 C++ 表达式转换成对应的 SQL WHERE 子句。整个过程都是类型安全的:如果误把字符串和整数比较,编译时会报错。
示例
首先我们先去数据库里面把这个表删除

test.hxx
cpp
// person.hxx
#ifndef PERSON_HXX
#define PERSON_HXX
#include <odb/core.hxx>
#include <string>
#pragma db object
class Person
{
public:
Person(const std::string& name, int age, const std::string& email = "")
: name_(name), age_(age), email_(email) {}
// 获取成员(仅用于演示)
std::string getName() const { return name_; }
int getAge() const { return age_; }
std::string getEmail() const { return email_; }
private:
friend class odb::access;
Person() {} // ODB 需要的默认构造函数
#pragma db id auto
unsigned long id_; // 自动主键
std::string name_;
int age_;
std::string email_; // 允许为空
};
#endiftest.cpp
cpp
// main.cpp (MySQL 版本)
// 包含输入输出流头文件,用于控制台输出
#include <iostream>
// 包含 ODB 数据库核心头文件,提供 database、transaction 等基础类
#include <odb/database.hxx>
// 包含 ODB 事务管理头文件
#include <odb/transaction.hxx>
// 包含 MySQL 数据库驱动头文件,提供 mysql::database 类
#include <odb/mysql/database.hxx>
// 包含我们定义的持久化类 Person 的头文件
#include "test.hxx"
// 包含 ODB 生成的 Person 持久化支持代码,包括查询类等
#include "test-odb.hxx"
// 主函数入口
int main()
{
// 使用 odb::core 命名空间,简化代码(如 transaction、database 等)
using namespace odb::core;
// 1. 创建 MySQL 数据库连接
// 使用 std::make_unique 创建 odb::mysql::database 对象的独占指针
// 构造函数参数依次为:数据库名、用户名、密码、主机地址
auto db = std::make_shared<odb::mysql::database> (
"root", // 用户名
"123456", // 密码
"TestDB", // 数据库名
"127.0.0.1", // 主机地址
0, // 端口号(0 表示使用默认端口 3306)
nullptr, // Unix socket 文件路径:nullptr 表示使用 TCP/IP 连接(Windows 下忽略)
"utf8" // 客户端字符集
);
// 2. 创建数据库表(如果尚未创建)
{
// 开始一个数据库事务
transaction t(db->begin());
// 执行原生的 SQL 语句创建表 Person
// 注意 MySQL 的语法:AUTO_INCREMENT 必须定义在 PRIMARY KEY 或唯一键上
db->execute("CREATE TABLE IF NOT EXISTS Person ("
"id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY,"
"name TEXT NOT NULL,"
"age INT NOT NULL,"
"email TEXT) ENGINE=InnoDB DEFAULT CHARSET=utf8");
// 提交事务,使建表操作生效
t.commit();
}
// 3. 插入测试数据
{
// 开启一个新事务
transaction t(db->begin());
// 创建六个 Person 对象,包含姓名、年龄和邮箱(部分邮箱为空)
Person p1("张三", 25, "zhangsan@example.com");
Person p2("李四", 30, ""); // 空邮箱
Person p3("王五", 35, "wangwu@example.com");
Person p4("赵六", 40); // 不传递邮箱
Person p5("孙七", 22, "sunqi@example.com");
Person p6("周八", 30, "zhouba@example.com");
// 将每个对象持久化到数据库(插入记录)
db->persist(p1);
db->persist(p2);
db->persist(p3);
db->persist(p4);
db->persist(p5);
db->persist(p6);
// 提交事务,使所有插入操作生效
t.commit();
// 输出提示信息
std::cout << "插入了 6 条人员记录。\n\n";
}
// 4. 查询示例(与 SQLite 版本完全相同)
// 定义查询和结果集的类型别名,方便使用
using query = odb::query<Person>;
using result = odb::result<Person>;
// 示例 1:查询年龄大于 30 的人
{
transaction t(db->begin()); // 开启事务
// 构建查询条件:age > 30
auto cond = query::age > 30;
// 执行查询,返回结果集
result r = db->query<Person>(cond);
// 输出标题
std::cout << "--- 年龄 > 30 的人 ---\n";
// 遍历结果集,输出每个人的信息
for (const auto& person : r) {
std::cout << "姓名: " << person.getName()
<< ", 年龄: " << person.getAge()
<< ", 邮箱: " << person.getEmail() << "\n";
}
std::cout << "\n";
t.commit(); // 提交事务
}
// 示例 2:查询名字以 "张" 开头的人(模糊查询)
{
transaction t(db->begin());
// 使用 like 操作符,'张%' 表示以"张"开头的任意字符串
auto cond = query::name.like("张%");
result r = db->query<Person>(cond);
std::cout << "--- 名字以 '张' 开头的人 ---\n";
for (const auto& person : r) {
std::cout << "姓名: " << person.getName() << "\n";
}
std::cout << "\n";
t.commit();
}
// 示例 3:查询邮箱不为空的人(IS NOT NULL)
{
transaction t(db->begin());
// 使用 is_not_null() 判断字段非空
auto cond = query::email.is_not_null() && (query::email != "");
result r = db->query<Person>(cond);
std::cout << "--- 有邮箱的人 ---\n";
for (const auto& person : r) {
std::cout << "姓名: " << person.getName()
<< ", 邮箱: " << person.getEmail() << "\n";
}
std::cout << "\n";
t.commit();
}
// 示例 4:组合条件:年龄在 25 到 35 之间,并且邮箱不为空
{
transaction t(db->begin());
// 使用 between 指定范围,&& 表示逻辑与
auto cond = (query::age >= 25 && query::age <= 35) && query::email.is_not_null() && (query::email != "");
result r = db->query<Person>(cond);
std::cout << "--- 年龄 25-35 且有邮箱的人 ---\n";
for (const auto& person : r) {
std::cout << "姓名: " << person.getName()
<< ", 年龄: " << person.getAge() << "\n";
}
std::cout << "\n";
t.commit();
}
// 示例 5:排序:按年龄升序,年龄相同按姓名降序
{
transaction t(db->begin());
// 构建一个始终为真的条件(age > 0),用于查询所有记录
auto cond = query::age > 0;
// 通过字符串拼接的方式附加 ORDER BY 子句(通用写法)
result r = db->query<Person>(cond + "ORDER BY age ASC, name DESC");
std::cout << "--- 所有人按年龄升序,姓名降序 ---\n";
for (const auto& person : r) {
std::cout << "姓名: " << person.getName()
<< ", 年龄: " << person.getAge() << "\n";
}
std::cout << "\n";
t.commit();
}
return 0; // 程序正常结束
}makefile
cpp
all : test
test-odb.hxx test-odb.ixx test-odb.cxx :
odb -d mysql --std c++11 --generate-query --generate-schema test.hxx
test : test.cpp test-odb.cxx
c++ $^ -o $@ -lodb-mysql -lodb -lodb-boost
.PHONY : clean
clean :
rm test test-odb.hxx test-odb.ixx test-odb.cxx test.sql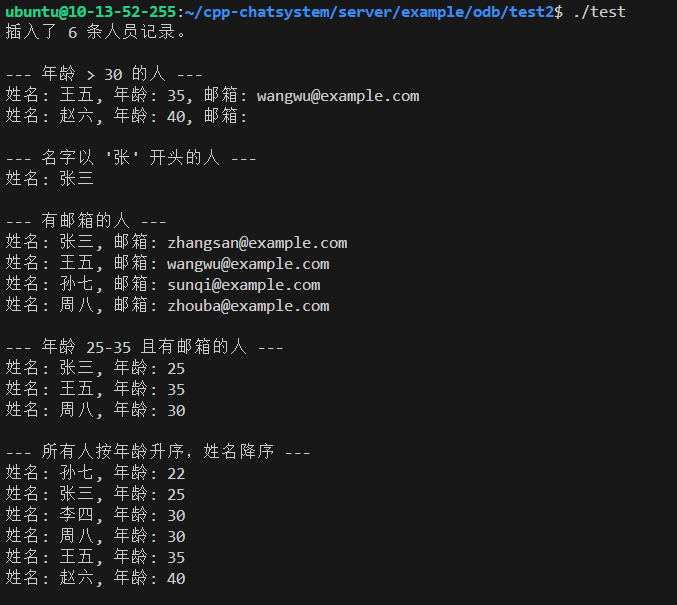
我们去数据库看看
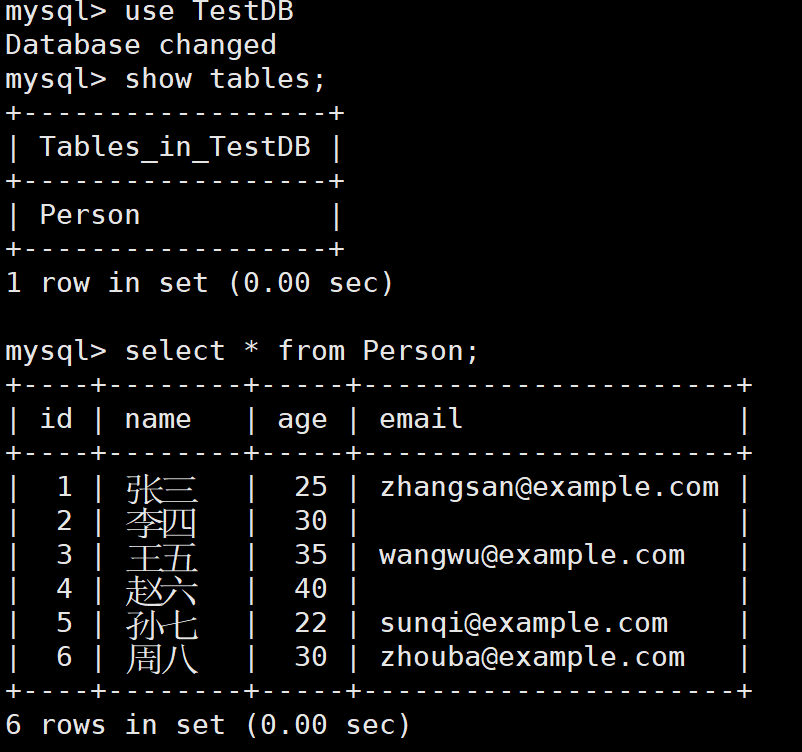
和我们的预期也还算是相符合吧。
3.3.2.示例3------综合示例
person.hxx
cpp
#pragma once
#include <string>
#include <cstddef>
#include <boost/date_time/posix_time/posix_time.hpp>
#include <odb/nullable.hxx>
#include <odb/core.hxx>
// 为 boost::posix_time::ptime 定义简短别名,方便使用
typedef boost::posix_time::ptime ptime;
// 声明 Person 类是一个持久化类,并映射到数据库表 "person"
#pragma db object table("person")
class Person {
public:
// 构造函数:初始化 name、age 和 update 字段
Person(const std::string &name, int age, const ptime &update)
: _name(name), _age(age), _update(update) {}
// age 字段的 setter
void age(int val) { _age = val; }
// age 字段的 getter
int age() { return _age; }
// name 字段的 setter
void name(const std::string& val) { _name = val; }
// name 字段的 getter
std::string name() { return _name; }
// update 字段的 setter(接收 ptime 对象)
void update(const ptime &update) { _update = update; }
// update 字段的 getter,返回格式化的字符串表示(注意:未检查 _update 是否为空)
std::string update() {
return boost::posix_time::to_simple_string(*_update);
}
private:
// 将 odb::access 类声明为 Person 的友元,使 ODB 能够访问私有成员
// 和默认构造函数(如果类具有公共默认构造函数和公共数据成员,
// 则不需要此友元声明)
friend class odb::access;
// ODB 需要的默认构造函数(私有,仅由 ODB 使用)
Person() {}
// _id 是数据库主键,使用 auto 说明符表示由数据库自动生成
#pragma db id auto
unsigned long _id;
// _age 映射到数据库列 "user_age",类型为 int,默认值为 20
#pragma db column("user_age") type("int") default(20)
unsigned short _age;
// _name 添加唯一约束,确保数据库中的 name 值不重复
#pragma db unique type("VARCHAR(255)")
std::string _name;
// _update 映射为数据库 TIMESTAMP 类型,添加索引,并允许为空(nullable)
#pragma db type("TIMESTAMP") index
odb::nullable<boost::posix_time::ptime> _update;
};
// 将 ODB 编译指示组合在一起并放在类定义之后也是可行的。
// 以下是被注释掉的另一种写法,可以将持久化信息与类定义分离:
// #pragma db object(person)
// #pragma db member(person::_name) id
// 完成后,需要使用 odb 编译器生成数据库支持代码。
// 基本命令(MySQL 后端):
// odb -d mysql --generate-query --generate-schema person.hxx
// 如果使用了 Boost 日期时间库,需要添加 --profile boost/date-time 选项:
// odb -d mysql --generate-query --generate-schema --profile boost/date-time person.hxx接下来我们就来编译这个文件
cpp
odb -d mysql --std c++11 --generate-query --generate-schema --profile boost/date-time person.hxx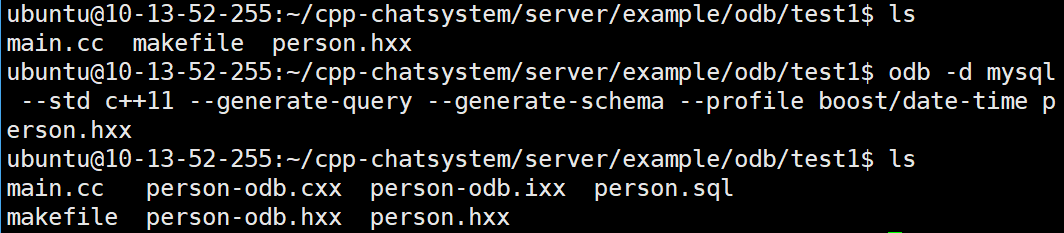
我们可以看看这个person.sql里面是什么
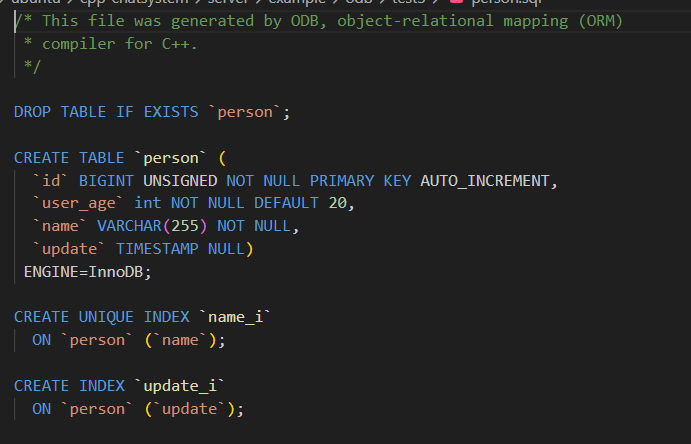
可以看到,就是一个创建表的sql语句,我们可以进行修改一些
注意:ODB 本身不提供专门的创建数据库的函数,所以,我们必须提前建立好我们的数据库。
有了这个person.sql,我们完全可以将这个sql文件导入到我们的mysql里面,这样子就创建好了我们的这个表
cpp
mysql -u root -D TestDB -p < person.sql注意我们这里导入的时候指定了数据库------TestDB
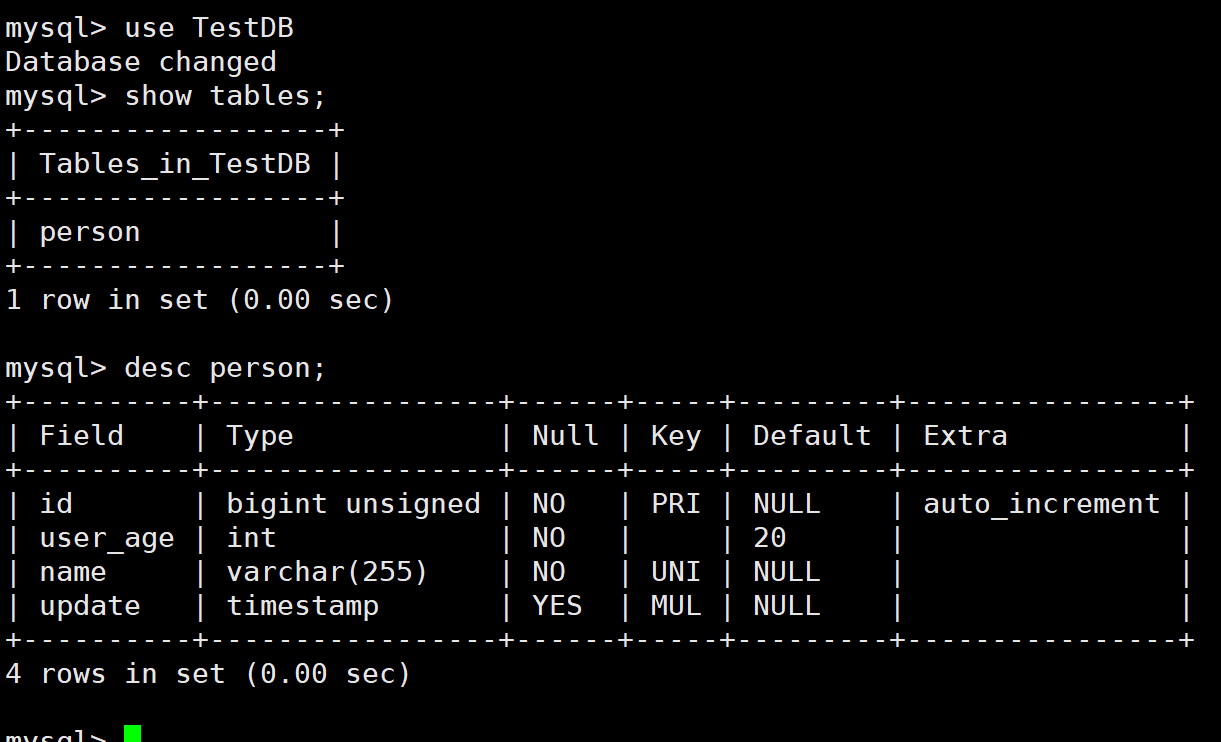
怎么样?是不是和我们预期的相同。就创建好了一个表。
接下来我们写一下我们的测试代码
cpp
#include <string>
#include <memory> // std::shared_ptr
#include <cstdlib> // std::exit
#include <iostream>
// 包含 ODB 核心数据库接口和 MySQL 后端数据库类
#include <odb/database.hxx>
#include <odb/mysql/database.hxx>
// 包含用户定义的持久化类 Person 的头文件(由 ODB 编译器处理)
#include "person.hxx"
// 包含 ODB 生成的数据库支持代码(查询、结果集等)
#include "person-odb.hxx"
int main()
{
// 创建指向 MySQL 数据库的共享指针,连接参数依次为:
// 用户名 "root"、密码 "123456"、数据库名 "TestDB"、主机地址 "127.0.0.1"、
// 端口 0(使用默认端口 3306)、socket 参数 0(不使用 Unix socket)、
// 客户端字符集 "utf8"
std::shared_ptr<odb::core::database> db(
new odb::mysql::database("root", "123456",
"TestDB", "127.0.0.1", 0, nullptr, "utf8"));
// 如果数据库连接创建失败,则直接返回 -1(实际此处 new 不会返回空,但保留检查)
if (!db) { return -1; }
// 获取当前系统时间(本地时间),用于对象的 update 字段
ptime p = boost::posix_time::second_clock::local_time();
// 创建两个 Person 对象:小张(18岁)和小王(19岁),update 时间均为当前时间
Person zhang("小张", 18, p);
Person wang("小王", 19, p);
// 定义查询和结果类型别名,方便使用
typedef odb::query<Person> query;
typedef odb::result<Person> result;
// 第一个事务:将两个 Person 对象持久化到数据库
{
// 开始事务
odb::core::transaction t(db->begin());
// 将 zhang 对象插入数据库,返回自动生成的主键 ID
size_t zid = db->persist(zhang);
// 将 wang 对象插入数据库,返回自动生成的主键 ID
size_t wid = db->persist(wang);
// 提交事务,使插入操作生效
t.commit();
}
// 第二个事务:查询所有 Person 对象并输出
{
// 开始事务
odb::core::transaction t(db->begin());
// 执行无条件查询,返回所有 Person 记录的结果集
result r(db->query<Person>());
// 遍历结果集,输出每个人的姓名、年龄和更新时间
for (result::iterator i(r.begin()); i != r.end(); ++i) {
std::cout << "Hello, " << i->name() << " ";
std::cout << i->age() << " " << i->update() << std::endl;
}
// 提交事务(查询操作一般不需要提交,但此处为了完整性仍调用 commit)
t.commit();
}
return 0; // 程序正常结束
}makefile
cpp
all : test
person-odb.hxx person-odb.ixx person-odb.cxx :
odb -d mysql --std c++11 --generate-query --generate-schema --profile boost/date-time person.hxx
test : test.cpp person-odb.cxx
c++ $^ -o $@ -lodb-mysql -lodb -lodb-boost
.PHONY : clean
clean :
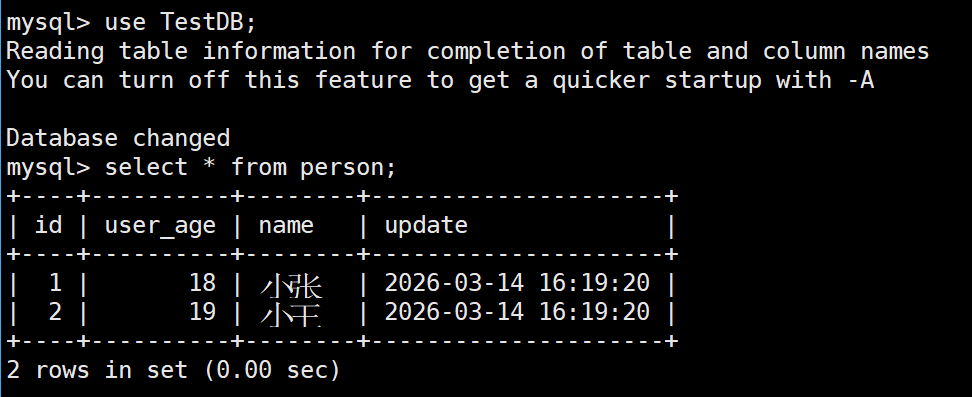
rm test person-odb.hxx person-odb.ixx person-odb.cxx person.sql运行一下

我们去数据库看看,也是跟着更新了
3.3.4.示例4------视图
employee.hxx
cpp
// employee.hxx
#ifndef EMPLOYEE_HXX
#define EMPLOYEE_HXX
#include <string>
#include <odb/core.hxx>
// 持久类 Employee
#pragma db object
class Employee
{
public:
Employee (const std::string& name, int age)
: name_(name), age_(age) {}
unsigned long id() const { return id_; }
const std::string& name() const { return name_; }
int age() const { return age_; }
private:
friend class odb::access;
Employee () {}
#pragma db id auto
unsigned long id_;
std::string name_;
int age_;
};
// 视图类 EmployeeView,基于 Employee 对象,映射 id 和 name 列
#pragma db view object(Employee)
struct EmployeeView
{
#pragma db column(Employee::id_)
unsigned long id;
#pragma db column(Employee::name_)
std::string name;
};
#endif // EMPLOYEE_HXXtest.cpp
cpp
// test.cpp
#include <iostream>
#include <odb/database.hxx>
#include <odb/transaction.hxx>
#include <odb/mysql/database.hxx>
#include <odb/schema-catalog.hxx> // 用于自动建表
#include "employee.hxx"
#include "employee-odb.hxx"
// 程序主入口
int main ()
{
try
{
// 创建MySQL数据库连接对象
// 参数依次为:
// - 用户名:root
// - 密码:123456
// - 数据库名:TestDB(需提前创建)
// - 主机地址:127.0.0.1(本地)
// - 端口号:0(使用默认端口3306)
// - Unix socket:nullptr(使用TCP/IP)
// - 客户端字符集:utf8
auto db = std::make_shared<odb::mysql::database> (
"root", // 用户名
"123456", // 密码
"TestDB", // 数据库名
"127.0.0.1", // 主机地址
0, // 端口号(0表示使用默认端口3306)
nullptr, // Unix socket 文件路径:nullptr表示使用TCP/IP连接
"utf8" // 客户端字符集
);
// 插入三条员工记录
{
// 开始数据库事务
odb::transaction t (db->begin ());
// 创建三个Employee对象(具名对象,避免右值引用问题)
Employee e1 ("John Doe", 30);
Employee e2 ("Jane Smith", 28);
Employee e3 ("Bob Johnson", 35);
// 将对象持久化到数据库(插入记录)
db->persist (e1);
db->persist (e2);
db->persist (e3);
// 提交事务,确认插入操作
t.commit ();
std::cout << "Inserted 3 employees." << std::endl;
}
// 使用视图查询所有员工的id和name
{
// 开始新的事务
odb::transaction t (db->begin ());
// 定义查询和结果类型别名
typedef odb::query<EmployeeView> query;
typedef odb::result<EmployeeView> result;
// 执行无条件查询,获取所有视图记录
result r (db->query<EmployeeView> ());
std::cout << "\nEmployeeView (id, name):" << std::endl;
// 遍历结果集并输出每一行的id和name
for (const auto& v : r)
std::cout << "id: " << v.id << ", name: " << v.name << std::endl;
// 提交事务
t.commit ();
}
// 使用带条件的视图查询(年龄 > 30)
{
// 开始事务
odb::transaction t (db->begin ());
// 定义查询和结果类型别名
typedef odb::query<EmployeeView> query;
typedef odb::result<EmployeeView> result;
// 执行条件查询:筛选age大于30的记录
// 注意:query::age 是视图查询中使用的列名,具体取决于视图定义
result r (db->query<EmployeeView> (query::age > 30));
std::cout << "\nEmployees older than 30 (via view):" << std::endl;
// 遍历并输出符合条件的记录
for (const auto& v : r)
std::cout << "id: " << v.id << ", name: " << v.name << std::endl;
// 提交事务
t.commit ();
}
}
catch (const odb::exception& e)
{
// 捕获ODB异常并输出错误信息
std::cerr << "ODB exception: " << e.what () << std::endl;
return 1;
}
}makefile
bash
# Makefile for ODB MySQL example (no variables)
all: test
# 生成 ODB 支持文件
employee-odb.cxx: employee.hxx
odb -d mysql --generate-query --generate-schema --std c++11 employee.hxx
# 编译主程序
test: test.cpp employee-odb.cxx
g++ -std=c++11 -I. -o test test.cpp employee-odb.cxx -lodb-mysql -lodb -lmysqlclient
# 清理生成的文件
clean:
rm -f employee-odb.cxx employee-odb.hxx employee-odb.ixx test
.PHONY: all clean我们编译一下,就会发现有employee.sql这个文件,我们进去看看
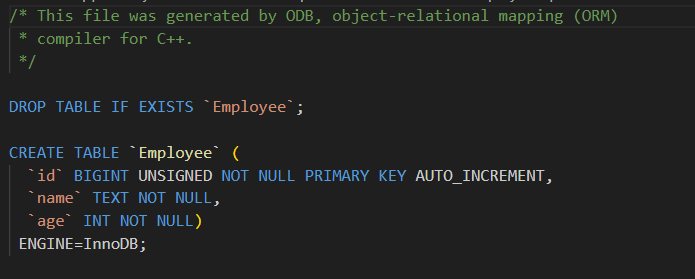
可以看到,就是一个创建表的sql语句
注意:ODB 本身不提供专门的创建数据库的函数,所以,我们必须提前建立好我们的数据库。
有了这个person.sql,我们完全可以将这个sql文件导入到我们的mysql里面,这样子就创建好了我们的这个表
cpp
mysql -u root -D TestDB -p < employee.sql注意我们这里导入的时候指定了数据库------TestDB
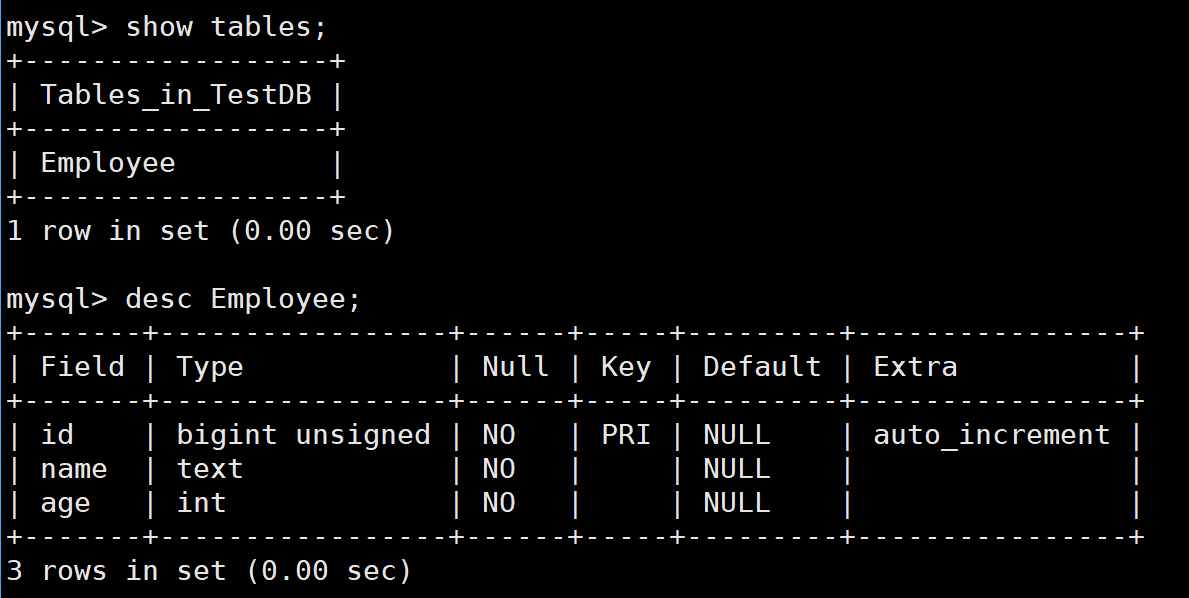
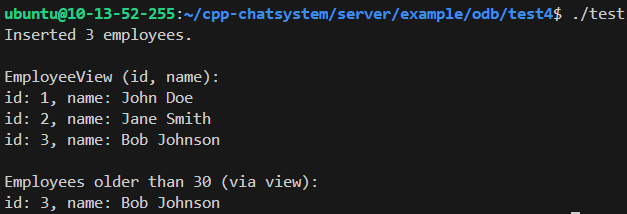
我们去数据库看看
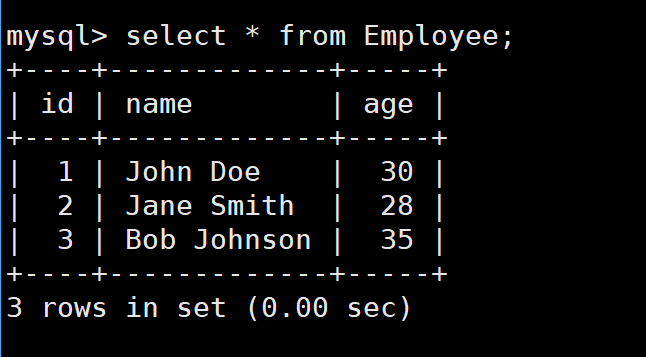
3.3.5.示例5
student.hxx
cpp
#pragma once
#include <string>
#include <cstddef>
#include <boost/date_time/posix_time/posix_time.hpp>
#include <odb/nullable.hxx>
#include <odb/core.hxx>
// 声明一个持久化类 Student,对应数据库中的 student 表
#pragma db object
class Student
{
public:
// 默认构造函数,ODB 在加载对象时需要
Student() {}
// 带参数的构造函数,便于创建学生对象
Student(unsigned long sn, const std::string &name, unsigned short age, unsigned long cid):
_sn(sn), _name(name), _age(age), _classes_id(cid){}
// 设置和获取学号(sn)
void sn(unsigned long num) { _sn = num; }
unsigned long sn() { return _sn; }
// 设置和获取姓名
void name(const std::string &name) { _name = name; }
std::string name() { return _name; }
// 设置和获取年龄,年龄可以为空(nullable)
void age(unsigned short num) { _age = num; }
odb::nullable<unsigned short> age() { return _age; }
// 设置和获取所属班级 ID(外键)
void classes_id(unsigned long cid) { _classes_id = cid; }
unsigned long classes_id() { return _classes_id; }
unsigned long id() const { return _id; }
private:
// 将 odb::access 声明为友元,以便 ODB 能够访问私有成员
friend class odb::access;
// ODB 自动生成主键,自增
#pragma db id auto
unsigned long _id;
// 学号字段,具有唯一性约束
#pragma db unique
unsigned long _sn;
// 姓名字段(字符串)
std::string _name;
// 年龄字段,使用 odb::nullable 包装,表示该字段在数据库中可以为 NULL
odb::nullable<unsigned short> _age;
// 班级 ID 字段,并为其创建数据库索引,提高连接查询效率
#pragma db index
unsigned long _classes_id;
};
// 声明一个持久化类 Classes,对应数据库中的 classes 表
#pragma db object
class Classes
{
public:
// 默认构造函数
Classes() {}
// 带参数的构造函数,创建班级时只需指定名称
Classes(const std::string &name) : _name(name){}
// 设置和获取班级名称
void name(const std::string &name) { _name = name; }
std::string name() { return _name; }
private:
friend class odb::access;
// 自动生成的主键 ID
#pragma db id auto
unsigned long _id;
// 班级名称字段
std::string _name;
};
// 定义一个视图(view),用于查询所有学生信息并显示对应的班级名称
// 该视图连接 Student 和 Classes 两张表,相当于 SQL 的 INNER JOIN
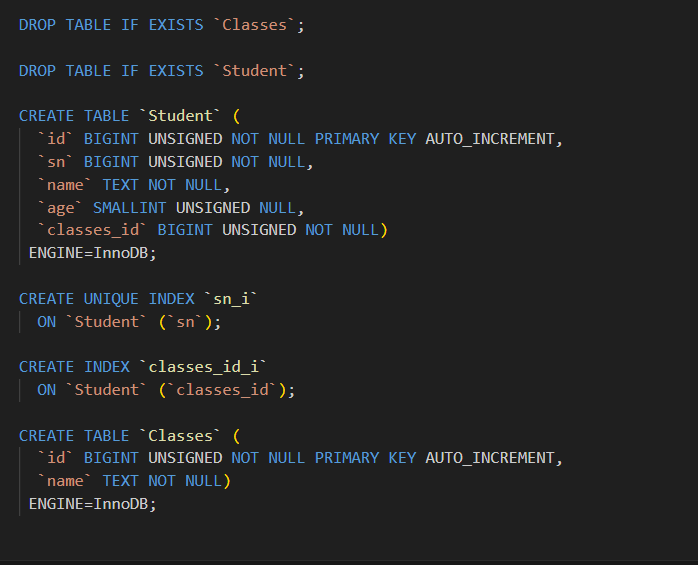
#pragma db view object(Student)\
object(Classes = classes : Student::_classes_id == classes::_id)\
query((?))
// object(Classes = classes : Student::_classes_id == classes::_id)
// 表示连接 Classes 表,并将表别名设为 classes,连接条件为 Student 的 _classes_id 等于 Classes 的 _id
// query((?)) 中的 (?) 是一个占位符,允许在使用视图时动态添加 WHERE 条件
struct classes_student
{
// 从 Student 表中选取 _id 列,映射到结果结构体的 id 成员
#pragma db column(Student::_id)
unsigned long id;
// 从 Student 表中选取 _sn 列,映射到 sn
#pragma db column(Student::_sn)
unsigned long sn;
// 从 Student 表中选取 _name 列,映射到 name
#pragma db column(Student::_name)
std::string name;
// 从 Student 表中选取 _age 列,映射到 age(可为空)
#pragma db column(Student::_age)
odb::nullable<unsigned short> age;
// 从 Classes 表中选取 _name 列,映射到 classes_name
#pragma db column(classes::_name)
std::string classes_name;
};
// 定义另一个视图,仅查询学生的姓名
// 该视图使用原始 SQL 查询语句,而不是通过对象关联
#pragma db view query("select name from Student" + (?))
// query("select name from Student" + (?)) 表示视图的基础查询是 "select name from Student"
// 后面的 (?) 同样允许在查询时追加条件(如 WHERE 子句)
struct all_name {
// 结果中只有一个字段:学生的姓名
std::string name;
};
// 说明:
// 使用 ODB 编译器时,需要运行类似以下命令来生成持久化代码:
// odb -d mysql --std c++11 --generate-query --generate-schema --profile boost/date-time student.hxx
// --profile boost/date-time 用于正确处理 boost::posix_time::ptime 类型(虽然本示例未使用 ptime,但包含该头文件)
cpp
#include <iostream>
#include <memory>
#include <odb/database.hxx>
#include <odb/mysql/database.hxx>
#include "student.hxx"
#include "student-odb.hxx"
#include <gflags/gflags.h>
// 定义字符串类型的命令行参数:MySQL服务器地址,默认值为"127.0.0.1"
DEFINE_string(host, "127.0.0.1", "这是Mysql服务器地址");
// 定义整数类型的命令行参数:MySQL服务器端口,默认值为0(使用默认端口3306)
DEFINE_int32(port, 0, "这是Mysql服务器端口");
// 定义字符串类型的命令行参数:默认数据库名称,默认值为"TestDB"
DEFINE_string(db, "TestDB", "数据库默认库名称");
// 定义字符串类型的命令行参数:MySQL用户名,默认值为"root"
DEFINE_string(user, "root", "这是Mysql用户名");
// 定义字符串类型的命令行参数:MySQL密码,默认值为"123456"
DEFINE_string(pswd, "123456", "这是Mysql密码");
// 定义字符串类型的命令行参数:客户端字符集,默认值为"utf8"
DEFINE_string(cset, "utf8", "这是Mysql客户端字符集");
// 定义整数类型的命令行参数:连接池最大连接数,默认值为3
DEFINE_int32(max_pool, 3, "这是Mysql连接池最大连接数量");
int main(int argc, char *argv[])
{
// 解析命令行参数(gflags)
google::ParseCommandLineFlags(&argc, &argv, true);
// 1. 构造MySQL连接池工厂配置对象
// 参数1:最大连接数;参数2:最大空闲时间(0表示不限制)
std::unique_ptr<odb::mysql::connection_pool_factory> cpf(
new odb::mysql::connection_pool_factory(FLAGS_max_pool, 0));
// 2. 构造MySQL数据库操作对象
// 参数依次为:用户名、密码、数据库名、主机地址、端口、套接字(空)、字符集、
// SSL选项(0)、连接池工厂(通过std::move转移所有权)
odb::mysql::database db(
FLAGS_user, FLAGS_pswd, FLAGS_db,
FLAGS_host, FLAGS_port, "", FLAGS_cset,
0, std::move(cpf));
// ==================== 插入班级数据 ====================
try {
// 开始事务
odb::transaction trans(db.begin());
// 创建两个班级对象
Classes c1("一年级一班");
Classes c2("一年级二班");
// 将班级对象持久化到数据库(执行INSERT操作)
db.persist(c1);
db.persist(c2);
// 提交事务,使插入操作生效
trans.commit();
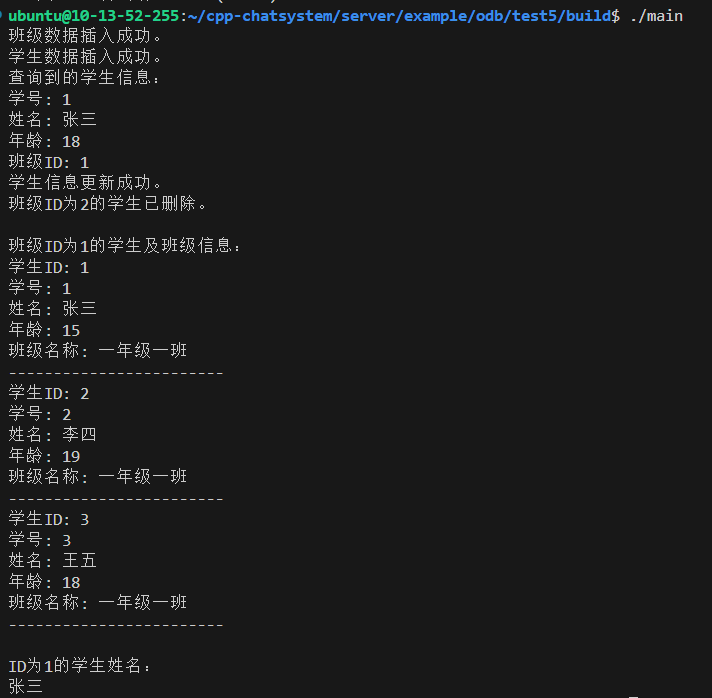
std::cout << "班级数据插入成功。" << std::endl;
} catch (std::exception &e) {
std::cout << "插入班级数据出错:" << e.what() << std::endl;
}
// ==================== 插入学生数据 ====================
try {
// 开始事务
odb::transaction trans(db.begin());
// 创建六个学生对象,分别指定学号、姓名、年龄、班级ID
Student s1(1, "张三", 18, 1);
Student s2(2, "李四", 19, 1);
Student s3(3, "王五", 18, 1);
Student s4(4, "赵六", 15, 2);
Student s5(5, "刘七", 18, 2);
Student s6(6, "孙八", 23, 2);
// 将学生对象持久化到数据库
db.persist(s1);
db.persist(s2);
db.persist(s3);
db.persist(s4);
db.persist(s5);
db.persist(s6);
// 提交事务
trans.commit();
std::cout << "学生数据插入成功。" << std::endl;
} catch (std::exception &e) {
std::cout << "插入学生数据出错:" << e.what() << std::endl;
}
// ==================== 查询姓名为"张三"的学生 ====================
Student stu; // 用于存储查询结果(默认构造)
try {
// 开始事务
odb::transaction trans(db.begin());
// 定义查询类型和结果类型别名,简化代码
typedef odb::query<Student> query;
typedef odb::result<Student> result;
// 执行查询:查找姓名为"张三"的所有学生
result r(db.query<Student>(query::name == "张三"));
// 检查查询结果数量,如果不是1条记录则认为数据异常
if (r.size() != 1) {
std::cout << "查询张三:数据量不对!" << std::endl;
} else {
// 获取结果集中的第一条记录
stu = *r.begin();
// 输出学生信息
std::cout << "查询到的学生信息:" << std::endl;
std::cout << "学号: " << stu.sn() << std::endl;
std::cout << "姓名: " << stu.name() << std::endl;
if (stu.age()) std::cout << "年龄: " << *stu.age() << std::endl;
std::cout << "班级ID: " << stu.classes_id() << std::endl;
}
// 提交事务
trans.commit();
} catch (std::exception &e) {
std::cout << "查询学生数据出错:" << e.what() << std::endl;
}
// ==================== 修改学生年龄并更新 ====================
// 仅当查询到有效学生时才执行更新
if (stu.id() != 0) {
stu.age(15); // 修改年龄为15
try {
// 开始事务
odb::transaction trans(db.begin());
// 执行更新操作(根据对象的主键更新数据库中的对应记录)
db.update(stu);
// 提交事务
trans.commit();
std::cout << "学生信息更新成功。" << std::endl;
} catch (std::exception &e) {
std::cout << "更新学生数据出错:" << e.what() << std::endl;
}
}
// ==================== 删除班级ID为2的所有学生 ====================
try {
// 开始事务
odb::transaction trans(db.begin());
// 定义查询类型别名
typedef odb::query<Student> query;
// 执行批量删除:删除所有classes_id等于2的学生记录
db.erase_query<Student>(query::classes_id == 2);
// 提交事务
trans.commit();
std::cout << "班级ID为2的学生已删除。" << std::endl;
} catch (std::exception &e) {
std::cout << "删除学生数据出错:" << e.what() << std::endl;
}
// ==================== 查询班级ID为1的所有学生及其班级信息 ====================
// 假设存在一个名为 classes_student 的视图结构,联合了学生和班级表
try {
// 开始事务
odb::transaction trans(db.begin());
// 定义视图查询类型和结果类型别名
typedef odb::query<struct classes_student> query;
typedef odb::result<struct classes_student> result;
// 执行查询:查询班级ID为1的学生信息(包含班级名称等)
result r(db.query<struct classes_student>(query::classes::id == 1));
std::cout << "\n班级ID为1的学生及班级信息:" << std::endl;
// 遍历结果集并输出每个字段
for (auto it = r.begin(); it != r.end(); ++it) {
std::cout << "学生ID: " << it->id << std::endl;
std::cout << "学号: " << it->sn << std::endl;
std::cout << "姓名: " << it->name << std::endl;
std::cout << "年龄: " << *it->age << std::endl;
std::cout << "班级名称: " << it->classes_name << std::endl;
std::cout << "------------------------" << std::endl;
}
// 提交事务
trans.commit();
} catch (std::exception &e) {
std::cout << "查询班级学生数据出错:" << e.what() << std::endl;
}
// ==================== 查询ID为1的学生姓名 ====================
// 假设存在一个名为 all_name 的视图结构,只包含学生姓名
try {
// 开始事务
odb::transaction trans(db.begin());
// 定义学生查询类型和视图结果类型别名
typedef odb::query<Student> query;
typedef odb::result<struct all_name> result;
// 执行查询:查询学生ID为1的记录,并映射到all_name视图(只取姓名)
result r(db.query<struct all_name>(query::id == 1));
std::cout << "\nID为1的学生姓名:" << std::endl;
// 遍历结果集,输出每个姓名
for (auto it = r.begin(); it != r.end(); ++it) {
std::cout << it->name << std::endl;
}
// 提交事务
trans.commit();
} catch (std::exception &e) {
std::cout << "查询所有学生姓名数据出错:" << e.what() << std::endl;
}
return 0;
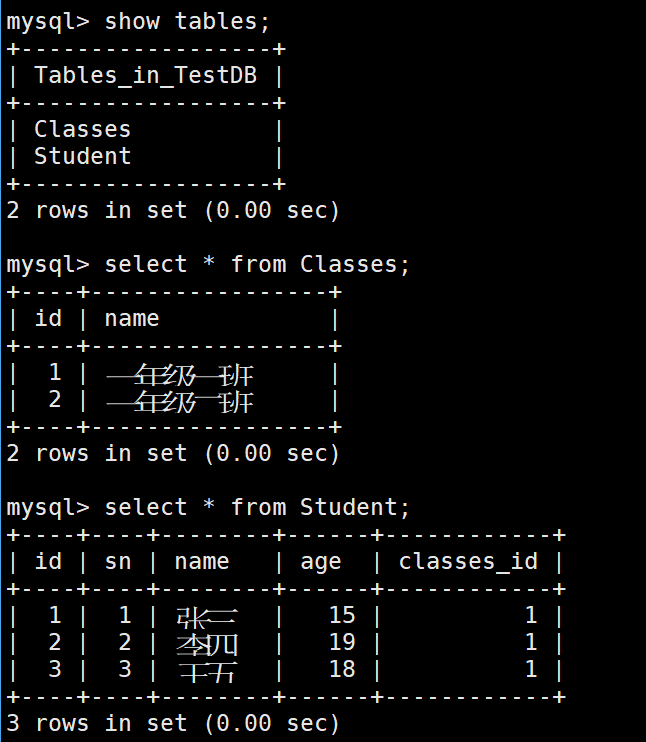
}编译完成之后,就会生成一个student.sql
我们看看
然后我们执行
cpp
mysql -u root -D TestDB -p < student.sql这样子就在数据库里面创建好这个表了
然后我们运行程序
我们去数据库看看