一、为什么需要向量数据库?
在AI时代,大量非结构化数据(文本、图像、音频、视频)通过Embedding模型被转换为高维向量(如一段文字→768维向量、一张图片→512维向量)。当数据量达到百万、十亿甚至千亿级时,传统关系型数据库(MySQL、PostgreSQL)无法高效完成**"找出与这个向量最相似的Top-K个向量"**的近似最近邻搜索(ANN)任务。
向量数据库与传统数据库的本质区别可以用一句话概括:普通数据库的"查"是精确的等值匹配,向量数据库的"查"是找"最相似的那个" 。这一个字的差别,背后是完全不同的存储结构和索引逻辑。
二、Milvus核心概念与架构
2.1 什么是Milvus?
Milvus是由Zilliz开发的开源向量数据库,已捐赠给Linux基金会旗下的LF AI & Data基金会,采用Apache 2.0许可发布。其名称源自鹰科猛禽Milvus,以飞行速度快、视力敏锐、适应性强著称------这也恰好凸显了它作为向量数据库时的优秀性能。Salesforce、PayPal、eBay、NVIDIA、ARM、英特尔、Meta、IBM、阿里巴巴、微软等大量知名企业都是Milvus的使用者和贡献者,这也从侧面说明了它在生产环境中的可靠性。
Milvus 2.6版本引入了多项关键技术升级:Storage Format V2(面向对象存储的列式布局)、BM25全文搜索(Milvus团队基准测试显示比Elasticsearch快400%)、以及FP32到FP16/BF16的自动转换(在2.6.10中发布,可将内存占用减半而无明显召回损失)。
2.2 三种部署模式
Milvus提供了三种部署模式,覆盖从本地原型开发到大规模生产部署的各类场景:
|------------------------|----------|-----------------------------------------------|
| 部署模式 | 适用规模 | 特点 |
| Milvus Lite | 百万级以内向量 | 轻量级Python库,可直接集成到应用中,适合Jupyter Notebook快速原型开发 |
| Milvus Standalone | 约一亿规模 | 单机服务器部署,所有组件打包在一个Docker镜像中,部署简单 |
| Milvus Distributed | 一亿到数百亿规模 | 部署在Kubernetes集群上,云原生架构,计算与存储分离,支持动态扩缩容 |
Milvus Lite适合学习和原型验证,Milvus Standalone适合中小规模生产,Milvus Distributed则是专为大规模部署设计的。同一个pymilvus客户端可对任意部署形态工作,同一套Schema定义可从本地流向生产,同一套索引原语(HNSW、IVF_FLAT、DISKANN、AUTOINDEX、SPARSE_INVERTED_INDEX)全矩阵可用------这种可移植性是很多团队选择Milvus而非锁定在托管API上的关键原因。
2.3 分布式架构设计
Milvus遵循数据平面与控制平面分解的原则,由四个主要层组成,各层在可扩展性和灾难恢复方面相互独立:
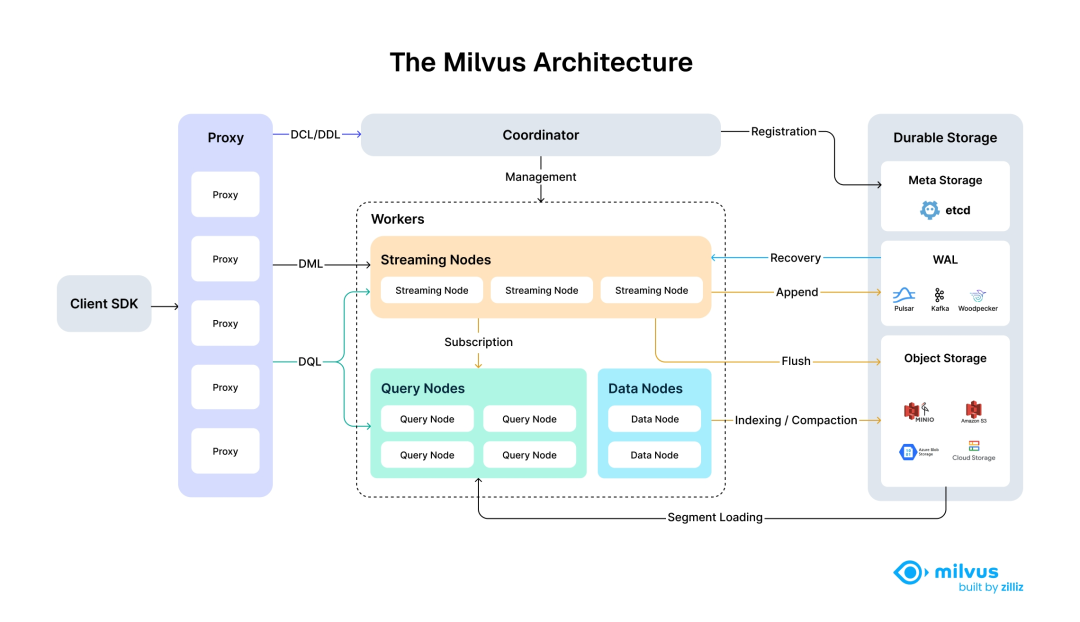
- 第1层:访问层(Access Layer):由一组无状态代理(Proxy)组成,是系统的前端层,负责验证客户端请求并减少返回结果。Proxy本身是无状态的,可使用Nginx、Kubernetes Ingress、NodePort和LVS等负载均衡组件提供统一的服务地址
- 存储层:支持对象存储(如S3、MinIO)持久化数据
- 计算层:流处理分为流节点(Streaming Node)、查询节点(Query Node)和数据节点(Data Node),在满足实时处理要求的同时实现高性能
- 协调层:负责集群管理和元数据维护
这种计算与存储完全分离的共享存储架构,使得计算节点可以横向扩展,同时将啄木鸟(Woodpecker)作为零磁盘WAL层实施,以增强弹性并减少操作开销。
三、Schema设计与数据建模
Schema是Milvus中用于定义数据模型的核心概念,类似于MySQL中建表时定义的字段。
3.1 核心数据模型:Collection、Entity、Field
Milvus的数据模型由三个层级组成:
- Collection(集合):类似于关系型数据库中的"表"。同一个Collection中存放相同Schema定义的Entity,支持增删改查操作
- Entity(实体):Collection中的单条记录,类似数据库中的一行。一个Entity由一组Field组成
- Field(字段):Entity中的单个属性,类似数据库中的列
3.2 两类Field
Milvus中的Field分为两大类:
标量字段(Scalar Field) :用于存储传统数据类型(如整数、字符串、浮点数等),主要用于存储元数据和过滤条件。主要类型包括DataType.VARCHAR(变长字符串)、DataType.INT64(64位整数)、DataType.FLOAT、DataType.BOOL、DataType.ARRAY(数组类型,2.4版本新增)、DataType.JSON(JSON数据,2.4版本新增)等。
向量字段(Vector Field):用于存储高维向量数据,是实现语义检索的核心。目前Milvus支持四种向量类型:
|-------------------------------|-------------------------------------------|
| 向量类型 | 说明 |
| FLOAT_VECTOR(浮点型向量) | 32位浮点数,精度最高,也是最常用的向量类型 |
| FLOAT16_VECTOR(半精度浮点型向量) | 16位浮点数,减少了一半的存储空间和内存占用 |
| BFLOAT16_VECTOR(脑浮点型向量) | 专为深度学习优化的16位浮点表示,2.6版本新增,在保持数值范围的同时降低内存占用 |
| SPARSE_FLOAT_VECTOR(稀疏浮点向量) | 用于稀疏向量表示,适合BM25等全文搜索 |
3.3 定义Schema实战
以下Schema定义了三个标量字段(id、title、text)和一个浮点向量字段:
from pymilvus import MilvusClient, DataType
schema = MilvusClient.create_schema()
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, auto_id=True)
schema.add_field(field_name="title", datatype=DataType.VARCHAR, max_length=512)
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=65535)
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=1024)3.4 关键Schema设计决策
主键字段 :每个Collection中必须指定一个主键字段。主键可以是DataType.INT64(设置auto_id=True时由Milvus自动分配,类似MySQL的自增ID)或DataType.VARCHAR(需要用户自行指定,适合使用文档哈希等唯一标识作为主键)。自动生成的ID起始偏移量为2的46次方,多个Collection之间不会重复。启用主键去重功能可保证相同主键的数据自动更新而非重复插入。
分区键(Partition Key):通过对分区键的值进行哈希分区,将数据均匀分布到不同分区中,实现更高效的数据管理。适合按tenant、日期等字段进行分区,但每个Collection最多只能指定一个分区键。
动态字段开关 :启用enable_dynamic_field=True允许插入Schema中未预先定义的字段,Milvus会自动将这些额外的字段存储为动态字段,适合数据格式不固定的场景。但需要注意动态字段全部按JSON格式存储,查询性能不如预先定义的字段。
一致性级别 :Milvus支持四种一致性级别------Strong(强一致性,查询操作将等待所有数据更新完成后再返回结果,保证读到最新数据)、Bounded(有界一致性,可容忍一定程度的滞后)、Eventually(最终一致性,查询尽可能快地返回,一致性要求最弱)和Session(会话一致性,同一会话内保证读到自己的写入)。通常搜索场景中对实时性要求较高时使用Strong,对吞吐量要求较高的场景可使用Eventually。
3.5 自动方案(快速入门)
如果不想手动定义Schema,还可以使用enable_auto_schema=True开启自动推断Schema:
client.create_collection(
collection_name="quick_setup",
auto_schema_mode=True,
enable_dynamic_field=True,
vector_field_name="vector",
dim=1024
)此时Milvus会自动推断字段类型,所有非向量字段都可作为过滤条件。
四、索引机制深度解析
索引是向量数据库实现高性能检索的核心。不建索引时Milvus会进行暴力搜索(Flat Search),虽然精度高但性能差,数据量一大查询就会很慢。因此,在插入数据后必须创建索引。
4.1 索引类型分类
目前Milvus支持15种索引类型,按内存索引、磁盘索引、GPU索引、稀疏向量索引分类:
4.1.1 内存索引
|-------------|---------|-----------------------|
| 索引类型 | 索引类型 | 适用场景 |
| IVF_FLAT | 基于量化的索引 | 精度较高,适合中等规模数据 |
| IVF_SQ8 | 基于量化的索引 | 精度略降但内存占用减半 |
| IVF_PQ | 基于量化的索引 | 乘积量化,极高压缩率 |
| SCANN | 基于量化的索引 | Google出品,相似加速 |
| HNSW | 基于图的索引 | 速度最快,精度高,内存占用大 |
| AUTOINDEX | 自动选择 | 自动选择最合适的索引类型,推荐使用 |
| INVERTED | 标量索引 | 对标量字段建立倒排索引,加速标量过滤 |
4.1.2 磁盘索引
|-----------|-----------------------------------------|
| 索引类型 | 适用场景 |
| DISKANN | 磁盘存储索引,十亿级规模适用,内存占用极小,支持MMAP方式直接映射文件到内存 |
| MMAP | 将数据直接映射到磁盘,几乎不占内存 |
4.1.3 GPU索引
Milvus支持的GPU索引包括GPU_BRUTE_FORCE、GPU_IVF_FLAT、GPU_IVF_SQ8、GPU_IVF_PQ、GPU_CAGRA(NVIDIA RAFT库中最先进的基于GPU的图索引)等。当有GPU集群时,可以充分使用GPU资源来加速搜索。
4.1.4 稀疏向量索引
对于稀疏浮点向量,支持SPARSE_INVERTED_INDEX(基于倒排索引的稀疏向量索引)和SPARSE_WAND(基于WAND算法的稀疏向量索引)。
4.2 三种核心索引算法对比
|--------------|-------------------------------------|-------------|------------|-----------|
| 算法 | 原理 | 优点 | 缺点 | 适用场景 |
| IVF_FLAT | 使用K-Means对向量聚类,查询时先找最近的聚类中心,再在聚类内遍历 | 精度较高,内存占用较小 | 搜索速度不如HNSW | 中等规模、精度优先 |
| HNSW | 构建多层可导航小世界图,每层是一个近邻图 | 速度快、精度高 | 内存占用大、构建慢 | 高性能场景 |
| DISKANN | 将索引存储在磁盘上,内存中仅保留导航信息 | 十亿级规模、内存极小 | 速度不如内存索引 | 大规模、低内存 |
4.3 关键索引参数详解
nlist(IVF_FLAT) :聚类中心数量。推荐值为4 × sqrt(n)(n为向量总数)。查询时检索的聚类数量nprobe越大召回率越高但速度越慢。
M(HNSW):每个节点最大邻居数。范围4-64,越大精度越高但内存占用越大。通常设置为16-32。
efConstruction(HNSW) :构建阶段搜索宽度。范围8-512,越大构图质量越高但构建时间越长。构建完成后不受此参数影响,查询阶段的ef参数从Milvus 2.4.11开始动态调整,无需用户手动设置。
segment_file_size(DISKANN):控制每次搜索时读取磁盘文件的体积,用于平衡I/O效率。
4.4 AUTOINDEX:自动选择最优索引
从Milvus 2.5开始,AUTOINDEX已成为创建索引时的默认索引类型。它会自动根据数据集的规模和分布选择最合适的索引算法,相当于把索引优化交给了Milvus。
4.5 索引构建实战代码
# 准备索引参数
index_params = MilvusClient.prepare_index_params()
# 为向量字段添加索引
index_params.add_index(
field_name="vector",
index_type="AUTOINDEX", # 自动选择索引
metric_type="COSINE", # 余弦相似度
)
# 为标量字段添加索引(可选,但推荐)
index_params.add_index(field_name="id", index_type="STL_SORT")
index_params.add_index(field_name="title", index_type="INVERTED")
# 创建索引
client.create_index(collection_name="demo", index_params=index_params)
client.load_collection(collection_name="demo") # 加载到内存4.6 索引选型建议
|-------------|-----------|-----------|
| 场景 | 推荐索引 | 理由 |
| 不确定该用什么索引 | AUTOINDEX | 自动选择最合适方案 |
| 百万级数据,精度要求高 | IVF_FLAT | 精度与速度的平衡 |
| 千万级数据,内存充足 | HNSW | 速度最快 |
| 亿级以上,内存有限 | DISKANN | 内存友好 |
五、相似度度量(Metric Type)
相似度度量决定了Milvus如何判断两个向量之间的"相似程度",直接关系到检索的准确性。Milvus支持七种度量类型,主要分为两类:
5.1 浮点向量度量
|------------------|---------------------------------------|---------------------------------|
| 度量类型 | 说明 | 特点 |
| COSINE(余弦相似度) | 衡量两个向量之间的夹角,值域-1, 1,越大越相似 | 关注方向而非长度,文本语义检索最常用 |
| IP(内积/点积) | 两向量逐元素相乘后求和,越大越相似 | 余弦相似度的未归一化版本,适用于某些特定Embedding模型 |
| L2(欧氏距离) | 两向量之间的直线距离,越小越相似 | 直观的空间距离,适合图像检索等场景 |
| HAMMING(汉明距离) | 比较两个二进制向量对应位置不同的位数 | 适用于二进制向量,计算极快 |
| JACCARD(杰卡德距离) | 衡量两个集合之间的相似性 | 适用于集合型数据的相似度计算 |
| TANIMOTO(谷本距离) | 汉明距离的位宽无关版本 | 适用于二进制向量 |
| BM25(全文搜索度量) | 适合基于全文检索和混合搜索的SPARSE_FLOAT_VECTOR度量方式 | 全文搜索,2.6版本新增 |
5.2 选型建议
绝大多数文本语义检索场景使用COSINE,某些特定Embedding模型(如部分OpenAI模型)推荐使用IP。
六、混合搜索:向量语义 + 标量过滤 + 全文搜索
混合搜索是Milvus区别于纯向量数据库的核心能力之一:在一个查询中同时结合向量相似性搜索和标量字段过滤。
6.1 基本混合搜索
results = client.search(
collection_name="demo",
data=[query_vector],
limit=5,
filter='title like "%倚天屠龙记%"', # 标量过滤
output_fields=["title", "text"]
)6.2 高级混合搜索:多向量混合检索
Milvus支持同时使用多个向量字段进行检索,然后通过Reranker策略将结果合并。这是通过ranker参数实现的,支持WeightedRanker(加权合并各向量检索结果)和RRFRanker(倒数排序融合,合并多个检索结果)。
from pymilvus import WeightedRanker, RRFRanker
# 同时检索dense_vector和sparse_vector字段
results = client.search(
collection_name="demo",
data=[query_dense_vector],
anns_fields=["dense_vector", "sparse_vector"],
search_params=[
{"metric_type": "COSINE"},
{"metric_type": "BM25"}
],
ranker=WeightedRanker(0.7, 0.3), # 稠密70% + 稀疏30%
limit=5
)6.3 混合搜索的三个步骤
- 确定搜索参数 :指定需要检索的向量字段名称,按顺序传入对应的
metric_type - 配置Reranker:选择合适的合并策略(加权或RRF)
- 执行搜索 :
search()方法自动完成多向量检索和结果融合
6.4 高级过滤能力
Milvus支持丰富的标量过滤表达式,远超基础的等值匹配:
- 集合表达式 :
filter='product_id in [1,2,3,4]' - 范围匹配 :
filter='5 < product_id < 10' - 字符串匹配 :
filter='product_name like "%手机%"' - 数组匹配 :
filter='product_id not in [1,2,3,4]' - JSON字段过滤 :
filter='product_info["color"] == "red"'
可以利用ARRAY_CONTAINS、JSON_CONTAINS等函数实现数组和JSON字段内的值匹配。
七、实战
在了解所有基础概念之后,来看一个完整的端到端实践案例。以下步骤以金庸武侠小说为原始语料,从零构建一个语义检索系统。
7.1 环境准备
pip install milvus-lite pymilvus langchain-milvus langchain sentence-transformers7.2 读取文档并切块
使用LangChain的TextLoader读取TXT格式的金庸小说文件,然后采用混合策略切块:优先按章节标题("第XX回"、"附录"、"后记"等)做正则切分,再对超过256字符的段落用RecursiveCharacterTextSplitter做二次补充切分,保持语义完整性。
7.3 文本向量化
使用HuggingFace的BGE中文Embedding模型(BAAI/bge-large-zh-v1.5)将每个文本片段转换为1024维向量。
7.4 创建Collection并插入数据
# 定义Schema
schema = MilvusClient.create_schema(auto_id=True, enable_dynamic_field=True)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("text", DataType.VARCHAR, max_length=65535)
schema.add_field("source", DataType.VARCHAR, max_length=512)
schema.add_field("vector", DataType.FLOAT_VECTOR, dim=1024)
# 创建Collection
client.create_collection("jin_yong_novels", schema)
# 插入数据
client.insert("jin_yong_novels", entities)
# 创建索引
index_params = MilvusClient.prepare_index_params()
index_params.add_index("vector", index_type="AUTOINDEX", metric_type="COSINE")
client.create_index("jin_yong_novels", index_params)
client.load_collection("jin_yong_novels")7.5 执行语义搜索
query = "张三丰最喜欢的徒弟是谁?"
query_vector = model.encode([query]).tolist()
results = client.search(
collection_name="jin_yong_novels",
data=[query_vector],
limit=3,
output_fields=["text", "source"]
)结果示例:检索到"张三丰见了他这等飘逸灵动的身手,心下惊喜,赞道......"等与"张三丰的徒弟"语义高度相关的内容,即使原文中并没有出现"最喜欢的徒弟"这几个字。
7.6 整合RAG链路
将Milvus作为Retriever集成到LangChain中,实现完整的RAG问答:
from langchain_milvus import Milvus
vector_store = Milvus(
embedding_function=embeddings,
collection_name="jin_yong_novels",
connection_args={"uri": "./milvus_demo.db"}
)
retriever = vector_store.as_retriever(search_kwargs={"k": 3})
qa_chain = RetrievalQA.from_chain_type(
llm=ChatOpenAI(model="gpt-3.5-turbo"),
retriever=retriever
)
answer = qa_chain.invoke("张三丰最喜欢的徒弟是谁?")八、实战:13步构建生产级RAG系统
8.1 环境准备与部署(Step 1-2)
Step 1 :安装核心依赖。需要Python 3.10+,安装pymilvus==2.6.x、sentence-transformers、langchain、langchain-milvus、langchain-openai等包。
Step 2:启动Milvus Standalone。使用Docker Compose启动完整服务(包括etcd、MinIO等依赖组件),或直接使用Milvus Lite进行快速开发。
wget https://github.com/milvus-io/milvus/releases/download/v2.6.16/milvus-standalone-docker-compose.yml -O docker-compose.yml
docker compose up -d8.2 Schema设计与数据建模(Step 3-4)
Schema设计与前面章节一致,但教程强调了版本兼容性问题:pymilvus 2.5客户端在Milvus 2.6服务器上可能在某些边缘情况抛出协议错误,Milvus Lite对哪些索引族可以在进程内工作也有自己的限制。因此务必对齐版本矩阵,确保server与client版本一致。
8.3 文档摄入与Embedding(Step 5-6)
Step 5 :文档加载与切分。使用LangChain加载文档并按chunk切分。教程推荐chunk_size=512、chunk_overlap=64。
Step 6 :生成Embedding。使用sentence-transformers模型将每个chunk转换为向量,然后批量插入Milvus。
8.4 索引创建与查询(Step 7-8)
Step 7 :创建索引并加载Collection。推荐使用AUTOINDEX。
Step 8:执行向量搜索与混合搜索。
# 基本向量搜索
results = client.search(
collection_name="rag_demo",
data=[query_embedding],
limit=5,
output_fields=["text", "source"]
)
# 混合搜索:向量 + 元数据过滤
results = client.search(
collection_name="rag_demo",
data=[query_embedding],
limit=5,
filter='source == "product_docs" and year > 2023',
output_fields=["text", "source", "year"]
)8.5 LangChain RAG链路集成(Step 9-10)
Step 9:将Milvus集成为LangChain的Retriever。
Step 10:构建完整的RAG QA Chain,将检索到的上下文注入Prompt,由LLM生成最终答案。
8.6 生产加固(Step 11-13)
Step 11 :备份与恢复。Milvus支持通过pymilvus的backup模块进行数据备份,或直接备份MinIO中的对象存储和etcd中的元数据。Milvus 2.6的Storage Format V2进一步优化了对象存储上的数据布局,使备份效率更高。
Step 12:监控。集成Prometheus + Grafana监控Milvus的查询延迟、QPS、内存使用、磁盘占用等关键指标。
Step 13 :连接池与性能调优。使用pymilvus的连接池管理,配置合理的连接数和超时参数,配合search_params中的nprobe(IVF索引)或ef(HNSW索引)参数来平衡精度与性能。
九、与其他向量数据库的对比
9.1 Milvus vs FAISS
FAISS是Meta开源的向量相似性搜索库,提供GPU加速,在学术界和工业界都有广泛使用。它与Milvus的核心区别在于定位:
|------|------------------------|-----------------------------------|
| 维度 | FAISS | Milvus |
| 本质 | 算法库,提供高效的向量索引和搜索实现 | 数据库系统,具备完整的CRUD、持久化、高可用等数据库功能 |
| 存储 | 索引通常驻留在内存中 | 支持磁盘持久化、对象存储等 |
| 分布式 | 不提供原生的分布式支持 | 云原生分布式架构,支持动态扩缩容 |
| 适用场景 | 适合作为其他系统的底层索引引擎 | 适合需要完整数据库能力的场景 |
实际上,Milvus内部也集成了FAISS的索引能力。选择FAISS意味着需要自行处理数据管理、持久化和分布式等问题;选择Milvus则意味着获得开箱即用的数据库体验。
9.2 Milvus的独特优势总结
|---------------|-------------------------------------------------|
| 优势 | 说明 |
| 可扩展性 | 支持十亿级向量毫秒级响应,水平扩展计算与存储分离 |
| 混合查询 | 向量相似性 + 标量过滤 + BM25全文搜索 |
| 多语言SDK | Python、Java、Go、Node.js、RESTful API |
| 与主流AI框架集成 | 兼容LangChain、LlamaIndex、Haystack、PyTorch、OpenAI等 |
| 部署灵活性 | 同一套Schema和客户端从Lite到Standalone到Distributed全覆盖 |
| 开源协议 | Apache 2.0,允许商业使用 |
十、核心要点总结
- 向量数据库的本质:普通数据库做的是"精确匹配",向量数据库做的是"找最相似的"------这一字之差意味着完全不同的存储结构和索引逻辑。
- Milvus的三级部署:从Milvus Lite(百万级,原型开发)到Milvus Standalone(亿级,单机生产)再到Milvus Distributed(数百亿级,云原生K8s集群),同一套Schema和客户端贯穿全部模式。
- Schema是数据管理的核心:理解Collection/Entity/Field的层级模型、标量字段与向量字段的区别、以及分区键、动态字段、一致性级别等关键设计决策,是高效使用Milvus的基础。
- 索引是性能的关键:从AUTOINDEX自动选择到HNSW的高速图搜索,再到DISKANN的十亿级磁盘索引,选对索引类型并设置合理的参数(nlist、M、efConstruction等)直接决定查询性能的上限。
- 混合搜索是Milvus的王牌能力:在一个查询中同时结合向量相似性搜索(COSINE/IP/L2)、标量字段过滤(like/in/range/JSON)和BM25全文搜索,通过WeightedRanker或RRFRanker融合结果。
- 从原型到生产的完整链路:通过金庸小说语义检索这个端到端案例,可以看到从文档加载→切块→Embedding→Schema定义→数据插入→索引创建→语义搜索→LangChain RAG集成的完整工作流。在实际项目中,可以通过这13步从零构建生产级RAG系统。
- 与FAISS的关系:Milvus是数据库,FAISS是算法库。Milvus内部集成了FAISS等索引能力,同时提供了完整的CRUD、持久化、分布式和高可用能力,选择Milvus意味着获得开箱即用的数据库体验。
参考文章:
一文搞懂Milvus:从基本概念到Schema定义、向量搜索全解析