导读
路面病害检测领域长期缺乏统一的大规模基准数据集,各研究使用不同数据源、标注格式和类别定义,导致模型间难以直接比较。
本文来自北达科他州立大学(NDSU)SMART Lab团队,构建了 PaveSync数据集------整合来自 多个国家的52,747张路面图像(论文摘要称7国,但数据表实际涵盖8国),统一标注为 13类病害、135,277个边界框。在此基准上,团队对 YOLOv8至v12、Faster R-CNN和DETR共7款模型进行了全面评测(1,000 epochs,NVIDIA A100)。结果显示,YOLOv8整体最为均衡;车辙(Rutting)最易检测(YOLOv11 mAP@50达0.986);泛油(Bleeding)和 鼓包(Bumps & Sags)最难检测(最佳mAP@50分别仅0.367和0.453)。作者表示数据集将公开发布,但截至目前论文中提供的Google Drive链接尚无实际内容,可能是论文仍处于预印本阶段暂未开放,或数据仍在准备上传中,建议持续关注。
一、路面病害检测为何需要统一基准?
当前路面病害检测面临的数据困境:
- 标注格式不统一:有的用Pascal VOC(XML),有的用COCO(JSON),有的用YOLO(TXT)
- 类别命名不一致:同一种病害在不同数据集中名称不同(如"Alligator" vs "Alligator Cracking")
- 类别ID冲突:相同病害在不同数据集中被分配了不同的类别编号
- 地域覆盖偏窄:多数数据集仅涵盖单一国家,路面材质、气候条件差异导致模型跨域泛化差
这些问题使得不同研究的结果无法直接对比,也限制了模型在真实世界中的适用范围。PaveSync的目标是将多个公开数据源整合为一个统一基准,消除上述障碍。
二、PaveSync数据集:8国、13类、13.5万标注
数据来源与规模
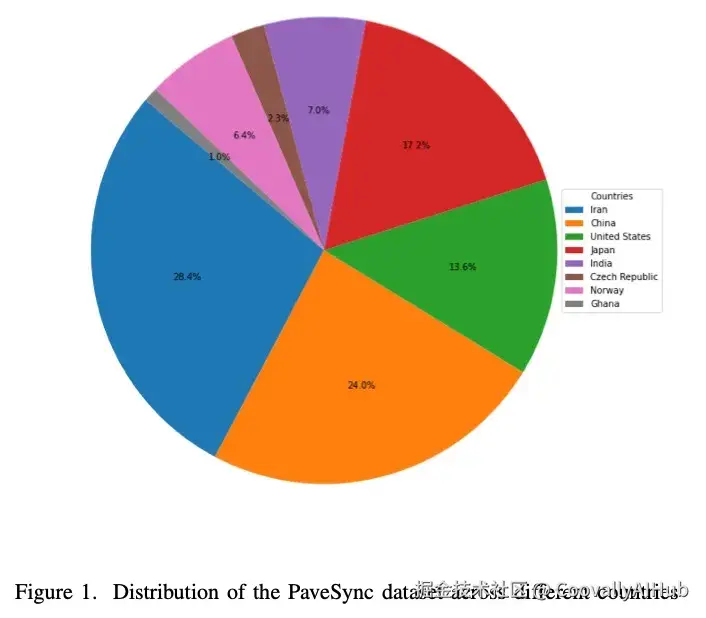
数据集汇集了多个国家的路面图像,涵盖航拍/无人机、车载、地面拍摄等多种采集方式。需要注意的是,论文摘要称数据来自"seven countries",但Table I实际列出了 8个国家(含加纳),以下以Table I数据为准:
| 国家 | 训练集 | 验证集 | 总计 |
|---|---|---|---|
| 伊朗 | 13,485 | 1,498 | 14,983 |
| 中国 | 11,394 | 1,266 | 12,660 |
| 日本 | 8,164 | 907 | 9,071 |
| 美国 | 6,457 | 717 | 7,174 |
| 印度 | 3,323 | 369 | 3,692 |
| 挪威 | 3,038 | 338 | 3,376 |
| 捷克 | 1,092 | 121 | 1,213 |
| 加纳 | 520 | 58 | 578 |
| 总计 | 47,473 | 5,274 | 52,747 |
数据划分为90%训练 / 10%验证,按类别分层抽样。
13类病害分布
| 类别 | 标注数 | 占比 |
|---|---|---|
| Longitudinal Cracking(纵向裂缝) | 33,353 | 24.6% |
| Pothole(坑洞) | 28,638 | 21.2% |
| Alligator Cracking(网状裂缝) | 20,677 | 15.3% |
| Transverse Cracking(横向裂缝) | 19,451 | 14.4% |
| Rutting(车辙) | 17,399 | 12.9% |
| Patching(修补) | 5,121 | 3.8% |
| Repair(维修) | 3,700 | 2.7% |
| Bleeding(泛油) | 1,885 | 1.4% |
| Edge Cracking(边缘裂缝) | 1,714 | 1.3% |
| Shoving(推移) | 1,556 | 1.1% |
| Bumps & Sags(鼓包与沉陷) | 857 | 0.6% |
| Manhole(井盖) | 796 | 0.6% |
| Block Cracking(块状裂缝) | 446 | 0.3% |
| 总计 | 135,277 | --- |
类别间分布极度不平衡:纵向裂缝(33,353标注)是块状裂缝(446标注)的 75倍。
图片来源于原论文
数据统一化流程
- 格式标准化:统一转换为Pascal VOC、COCO和YOLO三种格式
- 类别名称对齐:清理不一致命名和重复标签
- 类别ID统一:重新分配0--12的统一编号
- 低频类去除:样本不足的类别被移除
- 标注验证:分层抽样后逐图叠加标注与原图进行人工校验
- 图像缩放:统一至640×640
- 数据增强:随机裁剪(0.8)、旋转(15°)、水平翻转(50%)、亮度(1.1)、对比度(1.2)、高斯噪声(std 0.01)

图片来源于原论文
三、7模型横评:哪款模型最适合路面病害?
所有模型使用统一配置训练:1,000个epoch ,batch size 16,Adam 优化器,学习率0.001+余弦退火,硬件为 NVIDIA A100(24GB显存) ,框架PyTorch 2.0。
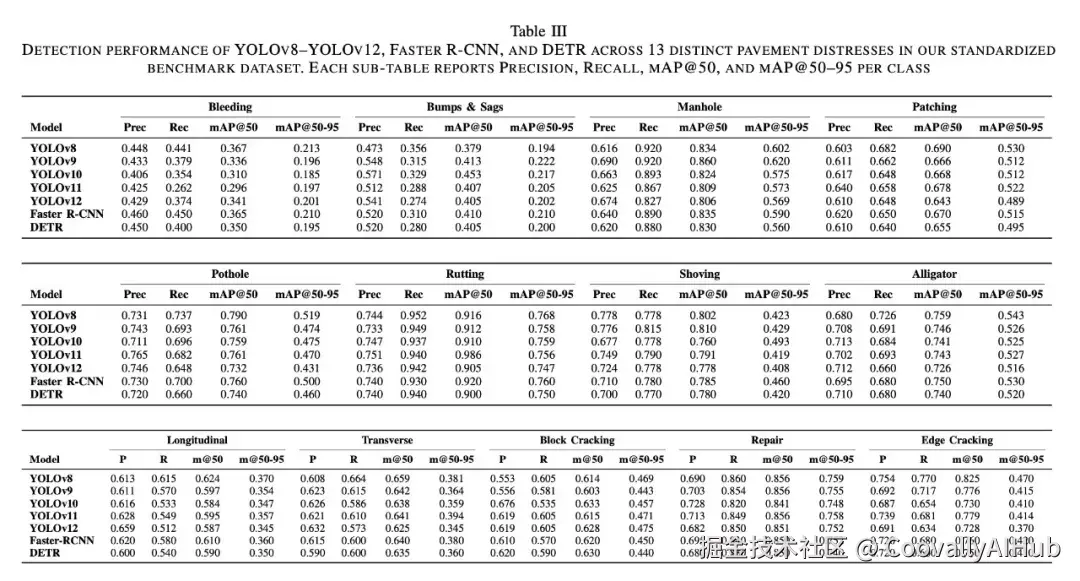
各模型在13类病害上的mAP@50
| 类别 | YOLOv8 | YOLOv9 | YOLOv10 | YOLOv11 | YOLOv12 | F-RCNN | DETR |
|---|---|---|---|---|---|---|---|
| Rutting | 0.916 | 0.912 | 0.910 | 0.986 | 0.905 | 0.920 | 0.900 |
| Repair | 0.856 | 0.856 | 0.841 | 0.856 | 0.851 | 0.850 | 0.850 |
| Manhole | 0.834 | 0.860 | 0.824 | 0.809 | 0.806 | 0.835 | 0.830 |
| Edge Cracking | 0.825 | 0.776 | 0.730 | 0.779 | 0.728 | 0.760 | 0.750 |
| Shoving | 0.802 | 0.810 | 0.760 | 0.791 | 0.778 | 0.785 | 0.780 |
| Pothole | 0.790 | 0.761 | 0.759 | 0.761 | 0.732 | 0.760 | 0.740 |
| Alligator Cracking | 0.759 | 0.746 | 0.741 | 0.743 | 0.726 | 0.750 | 0.740 |
| Patching | 0.690 | 0.666 | 0.668 | 0.678 | 0.643 | 0.670 | 0.655 |
| Transverse Cracking | 0.659 | 0.642 | 0.638 | 0.641 | 0.625 | 0.640 | 0.635 |
| Longitudinal Cracking | 0.624 | 0.597 | 0.584 | 0.595 | 0.587 | 0.610 | 0.590 |
| Block Cracking | 0.614 | 0.603 | 0.633 | 0.615 | 0.628 | 0.620 | 0.630 |
| Bumps & Sags | 0.379 | 0.413 | 0.453 | 0.407 | 0.405 | 0.410 | 0.405 |
| Bleeding | 0.367 | 0.336 | 0.310 | 0.296 | 0.341 | 0.365 | 0.350 |
(加粗为该类别最佳)
关键发现
易检测类别(mAP@50 > 0.80):
- 车辙最易检测:YOLOv11达0.986,所有模型均超0.90。车辙具有规则的纵向带状特征,视觉上较为明确
- 维修 和 井盖次之:形状规则、与周围路面对比度高
难检测类别(mAP@50 < 0.50):
- 泛油最难:最佳仅0.367(YOLOv8)。泛油表现为路面颜色深浅变化,缺乏明确的边界和形状特征
- 鼓包与沉陷次难:最佳仅0.453(YOLOv10)。样本量仅857,且2D图像难以捕捉高度变化
模型层面:
- YOLOv8在13类中的8类取得最优或并列最优的mAP@50,是整体最均衡的选择
- YOLOv12 虽然架构最新,但 未在任何类别上取得单独最优,在低频类别上Recall普遍偏低
表格图像来源于原论文
四、消融实验:模型架构差异如何影响不同病害类型的检测?
YOLO系列内部对比
从结果可以提炼出模型架构与病害特征的对应关系:
| 模型 | 架构特点 | 优势类别 | 论文分析 |
|---|---|---|---|
| YOLOv8 | anchor-free + 解耦头 | 坑洞、网状裂缝、边缘裂缝等(8类最优) | 特征提取适合大尺度、易识别的形变 |
| YOLOv9 | GELAN + 可编程梯度 | 井盖(0.860)、推移(0.810) | 即使目标不明显也能保持较高召回 |
| YOLOv10 | NMS-free双分配 | 鼓包(0.453)、块状裂缝(0.633) | 架构优化提升了跨类别的检测一致性 |
| YOLOv11 | C3k2 + 空间注意力 | 车辙(0.986) | 聚焦精细特征定位,对复杂纹理类别有优势 |
| YOLOv12 | FlashAttention + 区域注意力 | 无单独最优类别 | 整体表现稳定,但在不规则类别上召回偏低 |
YOLO vs 两阶段/Transformer
- Faster R-CNN基于区域提议的方法在多类别上提供了均衡表现,泛油检测(0.365)接近YOLOv8(0.367)
- DETR的注意力驱动架构对具有明确形状特征的类别召回较高,但在鼓包等视觉特征不明显的类别上精度偏低
- 整体而言,两阶段和Transformer模型在路面病害检测上与YOLO系列表现接近,未展现系统性优势
精度指标对比(以mAP@50-95计)
在更严格的mAP@50-95指标下,模型间差距更为明显。以几个代表性类别为例:
| 类别 | YOLOv8 | YOLOv9 | YOLOv10 | YOLOv11 | YOLOv12 |
|---|---|---|---|---|---|
| Rutting | 0.768 | 0.758 | 0.759 | 0.756 | 0.747 |
| Manhole | 0.602 | 0.620 | 0.575 | 0.573 | 0.569 |
| Pothole | 0.519 | 0.474 | 0.475 | 0.470 | 0.431 |
| Bleeding | 0.213 | 0.196 | 0.185 | 0.197 | 0.201 |
YOLOv8在Rutting(0.768)和Pothole(0.519)的mAP@50-95上均为YOLO系列最高;YOLOv9在Manhole上以0.620领先。
五、总结与讨论:统一基准的意义与局限
PaveSync 的核心价值在于为路面病害检测提供了一个 可直接回答"该用哪个模型" 的统一基准。基于13.5万标注的评测结果,对实际工程选型有直接参考意义:
| 场景 | 推荐模型 | 理由 |
|---|---|---|
| 一般路面巡检 | YOLOv8 | 13类中8类最优或并列最优 |
| 车辙专项检测 | YOLOv11 | mAP@50达0.986 |
| 稀有病害关注 | YOLOv10 | 鼓包、块状裂缝表现最稳定 |
需要注意的局限:
- 类别不平衡:纵向裂缝(33,353标注)是块状裂缝(446标注)的75倍,低频类别的评测结论需谨慎解读
- 难检测类别瓶颈:泛油和鼓包的mAP@50 < 0.45,现有模型在缺乏明确视觉边界的病害类型上仍有较大提升空间
- 分辨率损失:统一缩放至640×640可能损失了部分细粒度裂缝的空间信息
作者在论文中表示将公开发布数据集,并提供了Google Drive链接,同时提供Pascal VOC、COCO和YOLO三种标注格式。但截至2026年3月,该链接尚无实际内容,数据集可能仍在准备上传中,建议关注后续更新。
论文信息
- 标题: PaveSync: A Unified and Comprehensive Dataset for Pavement Distress Analysis and Classification
- 作者: Blessing Agyei Kyem, Joshua Kofi Asamoah, Anthony Dontoh, Andrews Danyo, Eugene Denteh, Armstrong Aboah
- 机构: 北达科他州立大学土木工程系SMART Lab;孟菲斯大学
- 资助: North Dakota Economic Diversification Research Fund (EDRF)