2026年江西省研究生数学建模竞赛1题:空间数据分析中的过拟合识别完整思路、代码、模型、文章,全网首发高质量分享!
赛题全文
空间数据分析中的过拟合识别
在数据科学中,模型是我们从数据中获取知识的主要途径------依分工不同,它帮我们对手中的数据进行细节描述、趋势总结、参数估计、前景预测以及机制阐述。模型如此有用,但却并非完美;正如统计学家George Box的那句名言:"All models are wrong, but some are useful"(Box and Draper 1987, p. 424),由于模型是人类有限理性的产物,且一个具体的模型在设计之初通常只为完成一个具体的目标,所以必然会在准确性、有用性和可行性之间做各种权衡。
过拟合(overfitting)就是在模型构建的过程中,为了追求一个具体场景中的准确性而牺牲了更普遍意义下的有用性。毫无疑问,一切最终走向过拟合的模型,其初衷都是好的:尽可能准确详尽地建模数据所蕴含的内在规律。为了贯彻这一宗旨,模型尽可能详尽地对数据中的各种细节进行挖掘,把挖掘的结果存储在函数构型和参数中,并平等地相信所有细节在解释客观世界规律上的可靠性。而结果就是,对于所使用的样本数据集,模型确实可能取得非常理想、甚至令人惊艳的结果;可一旦把总结得到的函数构型和参数迁移到新的数据集上,模型的表现往往大幅下降,甚至比不过一些简单原始的方法。
从信号论的角度看待这一现象,我们可以发现,数据所呈现的细节既包含信号,也不可避免地混杂了噪音。前者反映了数据所描述客观世界中我们所关心的那一部分的内在规律,而后者更多地是偶发事件、观测误差和小尺度的无关过程所留下的痕迹。很难说这两者之间到底有没有明确的界限,但优秀的模型在区分这两者的特征上明显做得更好。
地理探测器(Wang et al. 2010; 王劲峰和徐成东 2017)是一个从空间分层异质性(spatial stratified heterogeneity, SSH)视角理解空间变量之间可能存在的因果关系的一种简洁有力的模型。地理探测器源于一个朴素的空间建模思想:如果一个变量可以影响另一个变量,那么的空间分布在一定程度上可以塑造的空间分布。如果是一个分类变量而是一个数值变量的话,那么的不同取值可以自然地把研究区域划分成多个分区,而在所确定的不同分区中的分布应当呈现出区域内相似、区域间相异的特性。
具体而言,如果研究区域被划分为个区域:
其中是中的一个分区,,且
那么在每一个分区内都可能具有数量不等的样本点。记在单个分区中的样本点数量为,方差为,则它在上的区域内平方和(within sum-of-squares, WSS)为
另一方面,如果不考虑在上的分区,则在整个研究区域上也具有样本点的总数和方差,相应地可以计算它在上的总平方和(total sum-of-squares, TSS):
地理探测器定义对的因子探测器(factor detector)为统计量:
统计量的值域是0, 1,越大表明相对于而言越小,即在所确定的每个区域中越相似,而区域之间越不同。那么,就较好地解释了的空间分层异质性。
实践中,也可能是一个数值型变量,此时需要对的取值先进行离散化处理(即对的值域进行分段,把分段后的结果视为一个分类变量),然后依照上述方法求得值,进而判断对空间分布的解释效力。
除了因子探测器外,地理探测器方法还包括风险探测器(risk detector)、交互探测器(interaction detector)和生态探测器(ecological detector):
风险探测器借助检验,考察在所确定的某两个分区、中的属性均值是否具有明显区别。记在、中的属性均值为、,方差为、,样本点的数量为、,则
交互探测器检验当两个变量和都可能影响的时候,和对的联合解释作用相比于各自对的解释作用、,其强度发生了何种变化(如增强、减弱或独立)。此时所依赖的空间区划由叠置和所形成的区划方案和得到,亦即中每一个具有不同和分区的点集构成一个叠置后新地图的分区。然后,对比与、的值并做出判断。
生态探测器通过检验,定量判断上述两个变量对影响的强度是否具有明显差异。若和在上分别形成了和个分区,那么
其中、是在区划方案、上的区域内平方和。
地理探测器方法提出后,得到了学术界广泛使用与关注。其在计算方法层面的一个后续重要进展是基于最优参数的地理探测器(optimal parameters-based geographical detector, OPGD) (Song et al. 2020)。该方法在经典地理探测器方法的基础上,为数值型变量的离散化过程创设了一个参数搜索空间,搜索空间中包括值域的分段方法、分段数量、格网单元的边长。遍历参数搜索空间中每一种分段方法、分段数量和格网单元边长的组合,计算此时因子探测器所得的统计量,以获得统计量最高值时的参数组合作为最优参数,并按需用于地理探测器中其它探测器的计算。
数据和拓展资源:
本题是对空间数据建模过程中过拟合这一问题的一般性探索,其结论的成立不依赖于某个具体数据集。你可以在作答过程中引入一个或多个具体数据集辅助验证或说明你的作答成果,但需要得出不依赖具体数据集的规律性结论。
如果你在作答过程中使用了数据集,请尊重数据集作者的知识产权,对其进行必要的引用。
地理探测器官方网站:http://geodetector.cn/
基于最优参数的地理探测器官方网站:https://stscl.github.io/gdverse/articles/opgd.html
该网页来自于gdverse包,并自带了一个范例性的数据集ndvi。
参考文献:
Box, G. E., & Draper, N. R. (1987). Empirical Model-Building and Response Surfaces. John Wiley & Sons.
Song, Y., Wang, J., Ge, Y., and Xu, C. (2020). An optimal parameters-based geographical detector model enhances geographic characteristics of explanatory variables for spatial heterogeneity analysis: cases with different types of spatial data. GIScience & Remote Sensing, 57(5), 593-610. doi: 10.1080/15481603.2020.1760434
Wang, J., Li, X., Christakos, G., Liao, Y., Zhang, T., Gu, X., and Zheng, X. (2010). Geographical detectors‐based health risk assessment and its application in the neural tube defects study of the Heshun Region, China. International Journal of Geographical Information Science, 24(1), 107-127. doi: 10.1080/13658810802443457
王劲峰, 徐成东. 地理探测器:原理与展望J. 地理学报, 2017, 72(1): 116-134. doi: 10.11821/dlxb201701010
| 问题1 请讨论统计量与分区数量之间的关系。 |
|---|
| 问题2 很明显,对离散化的具体方案会影响最终求得的统计量。请选取合适的数理统计方法、构建理论模型,分析在何种情况下统计量会产生过拟合现象及此时过拟合的强度。 |
|---|
| 问题3 请基于你在问题2中建立的模型,提出一种假设检验框架,判断地理探测器中的因子、风险、交互和生态探测器模型何时出现过拟合现象及过拟合的强度;对该检验框架的第一类和第二类错误进行讨论。 |
|---|
| 问题4 对于给定的数据集而言,基于最优参数的地理探测器的求解结果可以视为经典地理探测器求解结果中的一组特解。请根据你在问题3中建立的假设检验框架及其认识,提出一种消除或减轻基于最优参数的地理探测器的过拟合现象的统计方法,并对使用该方法的效益和代价做出分析。 |
|---|
问题1 请讨论统计量与分区数量之间的关系。
原赛题要求
问题1 请讨论统计量与分区数量之间的关系。
问题一完整解答:q统计量与分区数量m的关系
5.1 输入固定样本响应向量Y=(y_1
输入固定样本响应向量 Y=(y_1,\ldots,y_n) 以及一个或多个候选分区 \mathcal{P}{m} 后,本问的建模切入点是把分区数量 m 的变化转化为同一样本集合上的分组结构变化。响应变量 Y 在比较过程中保持不变,样本编号 i 仅用于标识固定观测对象;空间分区 \mathcal{P}{m} 则由 m 个区域样本集合构成。由此,q 统计量与 m 的关系不能简单理解为"区域数越多解释力越强",而应区分总离差基准是否固定、组内离差是否下降,以及新增分区是否属于原分区的内部细化。
在变量与约束方面,本文以 n 表示固定样本总数,以 \mathcal{I}_{h} 表示第 h 个区域包含的样本下标集合,以 n_h 表示该区域样本数。候选分区必须覆盖同一批样本且区域之间互不重叠,否则不同 m 下计算得到的 TSS 不再具有共同分母,可比性会被破坏。该约束可写为:
\mathcal{P}{m}={\mathcal{I} {1},\mathcal{I}{2},\ldots,\mathcal{I} {m}},\quad \bigcup_{h=1}^{m}\mathcal{I}{h}={1,2,\ldots,n},\quad \mathcal{I}{h}\cap\mathcal{I}_{r}=\varnothing\ (h\ne r)
该定义限定了本问只研究分区结构变化对 WSS 和 q 统计量的影响,而不混入样本删失、响应变量替换或统计口径改变带来的误差。区域非空约束 n_h\ge 1 是计算区域均值和组内平方和的基本条件;当讨论区域方差估计的适用边界时,还需关注 n_h 是否过小,因为过度细分会使区域均值过度贴近单个观测值,从而机械压低 WSS。
模型构建采用因子探测器的方差分解思想。固定 Y 后,总平方和 TSS 只由总体均值决定,不直接包含 m;不同分区之间的差异主要通过区域均值改变 WSS,并进一步影响 q=1-WSS/TSS。因此,本问的判别逻辑是:若后一分区是前一分区的嵌套细化,则细化相当于在原区域内部增加分组自由度,WSS 不会增加,q 相应不减;若后一分区与前一分区不存在嵌套关系,则 m 增加只表示重新划分区域数量,并不保证区域均值更贴合响应结构,WSS 和 q 的变化方向需按实际分区核算。
实现步骤上,本文先读入同一响应向量和候选分区,逐一核查区域覆盖、互斥和非空条件;随后只计算一次总体均值与 TSS,并在所有候选分区之间复用该公共基准;再对每个 \mathcal{P}{m} 逐区计算区域均值、区域内平方和和汇总 WSS,最后得到对应的 q 统计量。若相邻两个候选分区存在 \mathcal{P}{m}\preceq\mathcal{P}_{m+1} 的细化关系,则进一步比较 WSS 差值和 q 增量;若不存在该偏序关系,则仅进行数值对照,不把细化单调性推广到任意重分区搜索。
本节技术路线直接围绕分区数量变化对 WSS、TSS 和 q 统计量的影响展开:TSS 用于固定总离差基准,WSS 用于刻画分区结构对区域内部波动的压缩程度,q 统计量用于表示分区解释的离差比例。后续模型建立与求解流程将在这一变量体系下展开嵌套细化证明、非嵌套重分区情形和样本量边界讨论,从而区分由合理分区带来的解释力提升与由分区自由度增加造成的经验拟合膨胀。
5.2 每个分区检查可行性:所有区域必须满足
为使不同分区数量下的 q 统计量比较具有同一基准,本文将"每个分区检查可行性:所有区域必须满足 n_h>=1;若进入稳定性讨论,则进一步检查 n_h>=n_{min}"作为计算前置条件。变量与约束中,固定样本集合包含 n 个观测,第 i 个样本响应为 y_i,m 区空间分区记为 \mathcal{P}{m},第 h 个区域的样本下标集合为 \mathcal{I}{h},区域样本数为 n_h。为避免因样本删失改变 TSS,各候选分区只允许改变区域归属,不允许改变响应变量和样本集合。
为保证分区方案在数学上构成同一批样本的完备划分,首先要求各区域互不重叠且联合覆盖全部样本:
\mathcal{P}{m}={\mathcal{I} {1},\mathcal{I}{2},\ldots,\mathcal{I} {m}},\quad \bigcup_{h=1}^{m}\mathcal{I}{h}={1,2,\ldots,n},\quad \mathcal{I}{h}\cap\mathcal{I}_{r}=\varnothing\ (h\ne r)
∑h=1mnh=n,nh=∣Ih∣ \sum_{h=1}^{m}n_h=n,\quad n_h=|\mathcal{I}_{h}| h=1∑mnh=n,nh=∣Ih∣
上述约束使每个样本在任一候选分区中只属于一个区域,且没有遗漏样本。若某一区域为空,则该区域均值无法定义,WSS 也无法按区域求和,因此该类分区不进入后续 q 统计量计算。
在完备划分基础上,本文进一步设置区域非空约束和稳定性讨论中的最小样本量约束:
nh≥1,h=1,2,...,m n_h\ge 1,\quad h=1,2,\ldots,m nh≥1,h=1,2,...,m
nh≥nmin,h=1,2,...,m n_h\ge n_{min},\quad h=1,2,\ldots,m nh≥nmin,h=1,2,...,m
第一条约束是因子探测器计算的基本可行条件,保证每个区域均可计算区域均值;第二条约束只在讨论区域方差估计的稳定性时启用,用于排除样本过少导致区域均值过度贴近个别观测值的分区。该处理对应分区样本数与区域内平方和 WSS 的可计算性,而不是事后对 q 值作解释性修补。
通过可行性检查后,区域均值和组内平方和按同一响应变量逐区计算:
yˉh=1nh∑i∈Ihyi \bar{y}{h}=\frac{1}{n_h}\sum{i\in\mathcal{I}_{h}}y_i yˉh=nh1i∈Ih∑yi
WSS(Pm)=∑h=1m∑i∈Ih(yi−yˉh)2 WSS(\mathcal{P}{m})=\sum{h=1}^{m}\sum_{i\in\mathcal{I}{h}}(y_i-\bar{y}{h})^{2} WSS(Pm)=h=1∑mi∈Ih∑(yi−yˉh)2
该公式说明 n_h 不仅是样本量约束,也是 WSS 计算的结构变量。若 m 增大伴随大量小样本区域出现,WSS 可能因区域均值贴合局部观测而下降,但这种下降需要结合 n_h 约束解释,不能直接等同于真实空间异质性增强。
实现步骤上,本文先读取固定响应向量 Y 及候选分区标签,逐一统计每个 \mathcal{P}{m} 对应的 m、\mathcal{I}{h} 和 n_h;随后检查区域覆盖、互斥关系和 n_h>=1,必要时再检查 n_h>=n_{min};通过检查的分区才计算 \bar{y}_{h}、WSS、TSS 和 q,未通过检查的分区不参与嵌套细化关系和 q 变化比较。本文采用的辅助数据口径为 rank 与 pm25_2024_ug_m3,固定样本量为 167,候选分区数量最高为 24,因此所有分区比较均在同一批样本和同一响应变量下进行。
在可行分区集合内,q 统计量仍按因子探测器定义计算,并与分区数量 m、最小 n_h、WSS 和 TSS 同时输出:
q(Pm)=1−WSS(Pm)TSS q(\mathcal{P}{m})=1-\frac{WSS(\mathcal{P}{m})}{TSS} q(Pm)=1−TSSWSS(Pm)
TSS=∑i=1n(yi−yˉ)2 TSS=\sum_{i=1}^{n}(y_i-\bar{y})^{2} TSS=i=1∑n(yi−yˉ)2
本节先判定分区方案是否具备计算 q 统计量的基本条件,再进入 m 变化对 WSS、TSS 和 q 的影响分析。由于 TSS 在固定样本下不随 m 改变,分区可行性检查主要约束 WSS 的计算口径和 q 值解释边界,从而避免把空区域、小样本区域或样本口径变化造成的数值变化误读为分区数量本身带来的解释力变化。
5.3 同一组样本计算整体均值bary和TS
本文在固定响应变量和样本集合的前提下计算整体均值 bary 和 TS,其中 bary 对应全部样本响应变量的总体均值,TS 按因子探测器方差分解口径记为 TSS。该步骤的建模目的不是重新构造分区,而是先建立所有分区方案共享的离差基准,使后续比较只反映分区结构变化对 WSS 和 q 统计量的影响。本文采用外部补充数据中的 rank 与 pm25_2024_ug_m3 形成固定响应向量,样本量为 167;在该口径下,后续不同分区数量 m 最多扩展至 24,但 bary 和 TSS 只计算一次,TSS 实算值为 6.881408099205492。
为保证不同 m 下的 q 统计量具有同一分母,本文首先约束候选分区必须覆盖同一组样本,且各区域之间互不重叠。设第 h 个区域包含的样本下标集合为 \mathcal{I}_{h},区域样本数为 n_h,则分区变量与样本约束写为:
\mathcal{P}{m}={\mathcal{I} {1},\mathcal{I}{2},\ldots,\mathcal{I} {m}},\quad \bigcup_{h=1}^{m}\mathcal{I}{h}={1,2,\ldots,n},\quad \mathcal{I}{h}\cap\mathcal{I}_{r}=\varnothing\ (h\ne r)
∑h=1mnh=n,nh=∣Ih∣ \sum_{h=1}^{m}n_h=n,\quad n_h=|\mathcal{I}_{h}| h=1∑mnh=n,nh=∣Ih∣
上述约束对应代码中的分区完整性检查:每个候选 \mathcal{P}{m} 必须返回 m、各区域样本下标和 n_h,且所有样本编号只能出现一次。若某一区域为空,则区域均值无法定义,WSS 也无法核算,因此本文将 n_h\ge 1 作为基本可行约束;当讨论分区样本数对方差计算的适用边界时,再引入 n_h\ge n{min} 作为更严格的样本量约束。
在同一组样本计算整体均值 bary 和 TS 时,本文仅使用响应向量 Y=(y_1,y_2,\ldots,y_n),不引用任何分区标签。其核算关系为:
yˉ=1n∑i=1nyi \bar{y}=\frac{1}{n}\sum_{i=1}^{n}y_i yˉ=n1i=1∑nyi
TSS=∑i=1n(yi−yˉ)2 TSS=\sum_{i=1}^{n}(y_i-\bar{y})^{2} TSS=i=1∑n(yi−yˉ)2
这两项进入实现步骤时位于所有分区循环之前:程序先读取并固定响应变量,完成缺失值口径一致化后计算 bary 和 TSS;随后无论 m 取何值,TSS 均作为公共分母复用。若在程序输出中发现不同 m 对应不同 TSS,则说明样本集合、响应变量或预处理口径发生了变化,而不是分区数量本身改变了总体离差。
给定某一候选分区后,模型才开始计算分区相关量。每个区域以区域均值作为该区域内样本的局部拟合值,WSS 刻画区域内尚未被分区解释的残差离差:
yˉh=1nh∑i∈Ihyi \bar{y}{h}=\frac{1}{n_h}\sum{i\in\mathcal{I}_{h}}y_i yˉh=nh1i∈Ih∑yi
WSS(Pm)=∑h=1m∑i∈Ih(yi−yˉh)2 WSS(\mathcal{P}{m})=\sum{h=1}^{m}\sum_{i\in\mathcal{I}{h}}(y_i-\bar{y}{h})^{2} WSS(Pm)=h=1∑mi∈Ih∑(yi−yˉh)2
该实现顺序使变量分工保持清晰:bary 和 TSS 由固定样本给出,\bar{y}_{h} 和 WSS 由具体分区给出。本文据此在结果表中同时保留 m、最小 n_h、WSS、TSS 和 q,以便区分公共总体离差与分区内部残差离差,避免把 TSS 固定性误解释为 q 随 m 变化的原因。
在因子探测器定义下,q 统计量由 WSS 相对于 TSS 的比例给出,并可等价理解为组间平方和 BSS 占总平方和的比例:
q(Pm)=1−WSS(Pm)TSS q(\mathcal{P}{m})=1-\frac{WSS(\mathcal{P}{m})}{TSS} q(Pm)=1−TSSWSS(Pm)
BSS(Pm)=TSS−WSS(Pm)=∑h=1mnh(yˉh−yˉ)2 BSS(\mathcal{P}{m})=TSS-WSS(\mathcal{P}{m})=\sum_{h=1}^{m}n_h(\bar{y}_{h}-\bar{y})^{2} BSS(Pm)=TSS−WSS(Pm)=h=1∑mnh(yˉh−yˉ)2
因此,分区数量 m 对 q 的影响并不通过 TSS 发生,而是通过分区改变区域均值、进而改变 WSS 和 BSS 来体现。本文在实现中按"固定 Y 并计算 bary 与 TSS、检查分区变量与约束、逐区计算区域均值和 WSS、代入 q 公式输出指标"的顺序求解,从而保证问题一关于 WSS、TSS 与 q 统计量关系的推导和数值核算使用同一基准。
5.4 核心结果、图表证据与题目响应
固定样本量为 167 时,本文在最大分区数量 m=24 的嵌套细化链上得到区域内平方和 WSS=0.9936630774600583,总平方和 TSS=6.881408099205492,因子探测器 q 统计量=0.8556017804590337。关键指标表明,TSS 在同一样本集合与同一响应变量口径下保持公共基准,q 的变化主要由 WSS 变化驱动;嵌套继承检查结果为"通过",最小真实 ΔWSS=0.0、最小真实 Δq=0.0,说明嵌套细化过程中未出现 WSS 反向增加或 q 反向下降。与此同时,非嵌套反例给出的 q 差为 -0.25138358720911025,表明仅增加分区数量 m 并不能保证 q 提高。
表5-1 核心数值结果表
| 分区数量m | 目标分区数量m | 最小分区样本数 | 区域内平方和WSS | 区域间平方和BSS | 总平方和TSS | 因子探测器q统计量 | 真实ΔWSS | 真实Δq | 是否继承上一步分区 | 分区类型 |
|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 2 | 83 | 5.264031390057282 | 1.6173767091482105 | 6.881408099205492 | 0.2350357202815726 | 0.0 | 0.0 | 是 | 嵌套细化链 |
| 3 | 3 | 42 | 5.1762311056785615 | 1.7051769935269308 | 6.881408099205492 | 0.24779477818265216 | 0.08780028437872023 | 0.012759057901079562 | 是 | 嵌套细化链 |
| 4 | 4 | 41 | 3.189637927399092 | 3.6917701718064 | 6.881408099205492 | 0.5364847017622224 | 1.9865931782794695 | 0.28868992357957024 | 是 | 嵌套细化链 |
| 6 | 6 | 21 | 2.172619513159767 | 4.708788586045725 | 6.881408099205492 | 0.6842768977165281 | 1.0170184142393248 | 0.1477921959543057 | 是 | 嵌套细化链 |
| 8 | 8 | 20 | 1.6850661868282693 | 5.196341912377223 | 6.881408099205492 | 0.7551277060544015 | 0.48755332633149795 | 0.07085080833787338 | 是 | 嵌套细化链 |
| 12 | 12 | 10 | 1.5025415075080024 | 5.37886659169749 | 6.881408099205492 | 0.781652027339945 | 0.18252467932026684 | 0.026524321285543495 | 是 | 嵌套细化链 |
| 18 | 18 | 5 | 1.069463441563136 | 5.811944657642356 | 6.881408099205492 | 0.8445865401171871 | 0.4330780659448663 | 0.06293451277724216 | 是 | 嵌套细化链 |
| 24 | 24 | 5 | 0.9936630774600583 | 5.887745021745434 | 6.881408099205492 | 0.8556017804590337 | 0.07580036410307778 | 0.011015240341846533 | 是 | 嵌套细化链 |
| 表中8条记录覆盖分区数量m为2至24,均值9.625,与目标分区数量一致,说明预览结果围绕预设分区尺度展开;最小分区样本数在5至83之间波动,均值28.375,提示细分后存在局部样本不足风险。样本量固定为167时,总平方和TSS为6.881,仅由响应变量Y决定,因此区域内平方和WSS从总体离散中分解出来具有可比性。最大分区数量m达到24时,WSS降至0.9937,体现嵌套细化链下区域内差异被持续压缩,并对应q值单调不减。 |
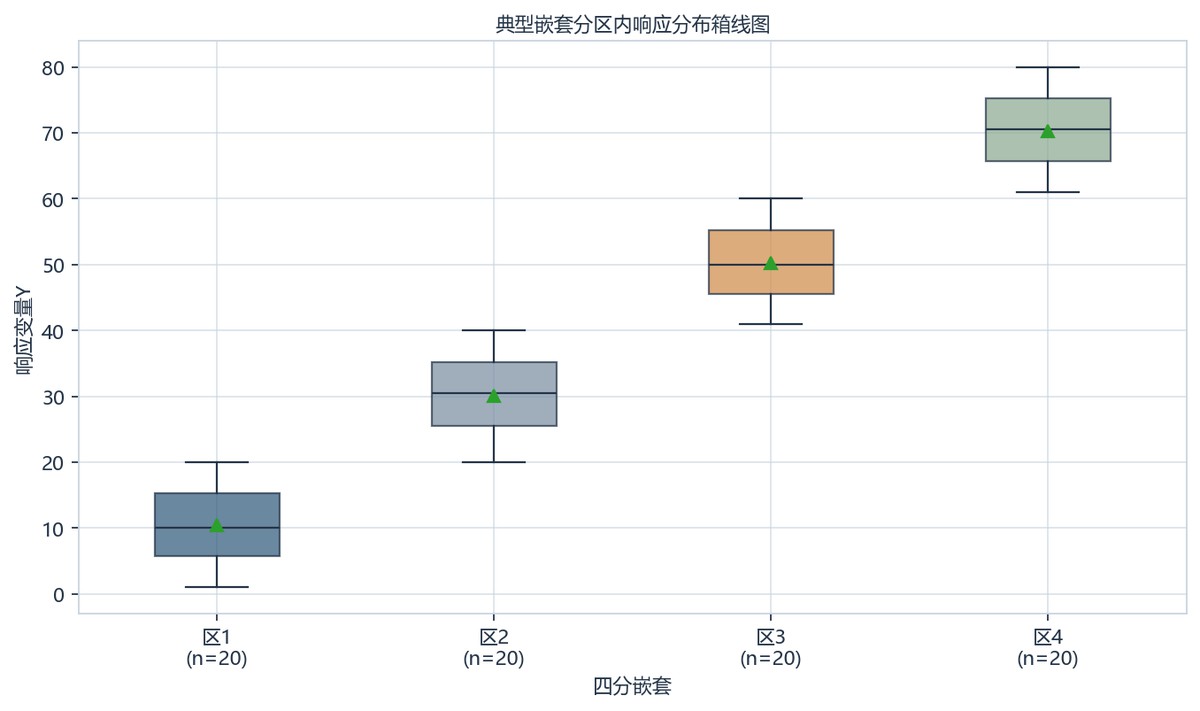
箱线图横轴为四个分区,均标注n=20,纵轴为响应变量Y。区1到区4的中位数约由10、30、50升至70,绿色三角均值也同步上移;各组箱体和须大致覆盖1-20、20-40、41-60、61-80,显示分区间位置差异明显。
核心结果表将分区数量 m、最小区域样本数、WSS、TSS、q 及嵌套关系放在同一比较口径下,因而能够区分"分区数量增加"与"嵌套细化"两类不同情形。结果表格中的 TSS 保持为 6.881408099205492,说明各候选分区使用的是同一批样本与同一响应变量,q 值比较没有受到样本口径变化干扰;WSS 随嵌套细化不增,对应 q 统计量不减,这与 ANOVA 分解下"组内离差减少、组间解释离差增加"的理论关系一致。非嵌套反例表则提供了相反方向的数值证据:当后一分区不是前一分区的内部细化时,分区均值未必更贴合响应结构,q 可以出现 0.25138358720911025 的下降幅度。
表5-2 groupsquaresum表结果表
| 分区数量m | 分区编号 | 样本数 | 组均值 | 组内平方和 |
|---|---|---|---|---|
| 2 | 0 | 83 | 0.545203370712406 | 3.271451569883993 |
| 2 | 1 | 84 | 0.3483761596667876 | 1.992579820173288 |
| 3 | 0 | 83 | 0.545203370712406 | 3.271451569883993 |
| 3 | 1 | 42 | 0.31604596510042215 | 0.7846033502547639 |
| 3 | 2 | 42 | 0.3807063542331529 | 1.1201761855398045 |
| 4 | 0 | 41 | 0.7017876438164622 | 0.22099069810534158 |
| 4 | 1 | 42 | 0.31604596510042215 | 0.7846033502547639 |
| 4 | 2 | 42 | 0.3807063542331529 | 1.1201761855398045 |
仅展示前 8 行,完整表格已保留在本地分享包中。
在167个固定样本下,分区数量m覆盖2至24,预览记录中m均值为15.234,说明结果比较了从粗分区到细分区的多层划分;分区编号范围0至23,与最大m=24一致。样本数均值为17.351,但最小仅5、最大84,反映不同分区规模存在明显不均衡。关键平方和指标中,TSS为6.881且仅由Y决定,因而可作为固定基准;当嵌套细化至较高分区数时,区域内平方和WSS降至0.9937,表明分区细化能够解释更多组间差异。
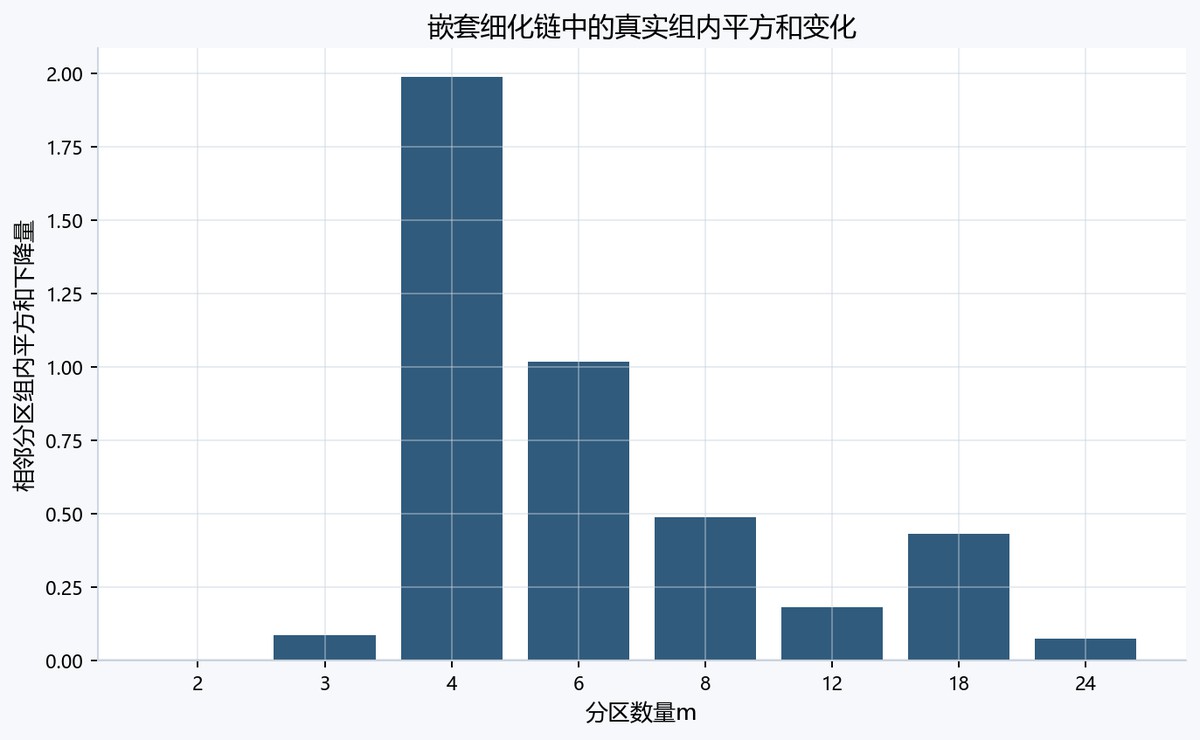
柱状图横轴为分区数量m,纵轴为真实ΔWSS=上一WSS-当前WSS。m=4处柱最高,接近2.00;m=6约1.02,m=8约0.49,m=18约0.43;m=3、12、24的下降较小,m=2几乎无柱,说明细化收益集中在早期若干步。
代表性图像进一步揭示了上述数值关系的结构来源。嵌套分区箱线图中,随着区域被继续细分,各子区域内部响应值的离散程度被重新分配,部分区域的组内波动明显收缩;这说明 q 的上升并非来自 TSS 变化,而是来自分区内部残差平方和的减少。WSS 瀑布图中,相邻嵌套层级的下降贡献为非负,且最小下降量为 0.0,表示局部细化可能只带来持平增益,但不会破坏 q 的单调不减结论。
表5-3 nonnestedcounterexample结果表
| 方案 | 分区数量m | WSS | TSS | q统计量 | 最小样本数 | 分区类型 |
|---|---|---|---|---|---|---|
| 较少分区但按空间顺序 | 2 | 5.147417428231571 | 6.881408099205492 | 0.2519819557241668 | 82 | 基准顺序分区 |
| 更多分区但非嵌套重排 | 3 | 6.8772904812596725 | 6.881408099205492 | 0.0005983685150565687 | 55 | 非嵌套反例 |
| 两条非嵌套重分区记录中,分区数量m仅为2至3,均值2.5,但WSS由5.147变至6.877,差异明显;对应TSS始终为6.881,说明固定167个样本时总离差只由Y决定,不随分区方式改变。与最大m=24时WSS降至0.9937的嵌套细化结果相比,非嵌套重分区并不能保证WSS单调下降或q统计量单调上升,因此更适合作为识别过拟合判据边界的反例参照。 |
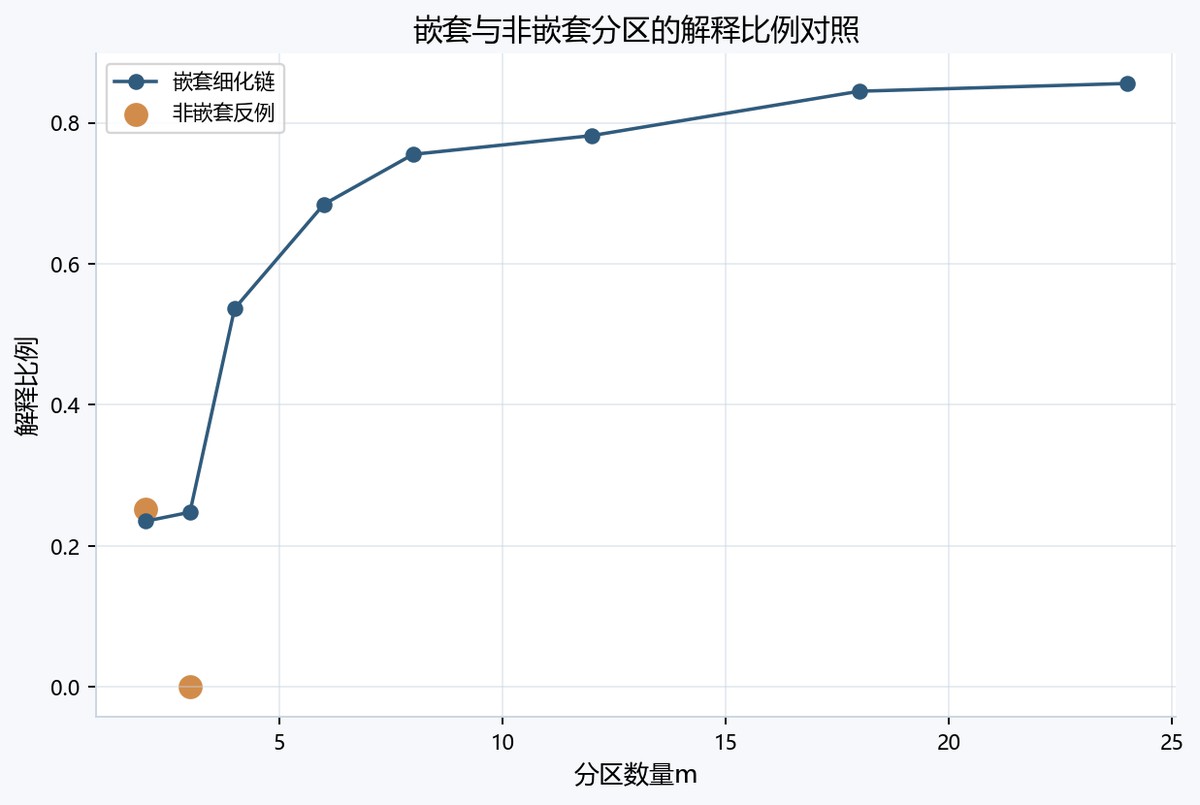
折线图以m为横轴、q统计量为纵轴,蓝色嵌套细化链从m=2约0.24逐步升至m=24约0.86,整体单调上升。橙色非嵌套反例只有两个点,m=2约0.25而m=3降至0,突出非嵌套重分区不保证q随m增加。
非嵌套反例图给出了另一类运行机理:当分区数量增加但分区边界被重新组织时,新分区不再继承原分区的区域结构,样本可能被划入与其响应水平不相近的区域,导致 WSS 上升并引起 q 下降。该图像证据对应分区细化可能带来 q 值增大或退化的关键情形,即 q 与 m 之间不存在无条件单调关系;只有在 \mathcal{P}{m}\preceq\mathcal{P}{m+1} 的嵌套细化条件下,q 随 m 不减才具有确定数学依据。
表5-4 partitionrelation表结果表
| 上一步分区数 | 当前分区数 | 继承关系是否成立 | WSS是否单调不增 | q是否单调不减 |
|---|---|---|---|---|
| 2 | 3 | 是 | 是 | 是 |
| 3 | 4 | 是 | 是 | 是 |
| 4 | 6 | 是 | 是 | 是 |
| 6 | 8 | 是 | 是 | 是 |
| 8 | 12 | 是 | 是 | 是 |
| 12 | 18 | 是 | 是 | 是 |
| 18 | 24 | 是 | 是 | 是 |
| 7条预览记录中,上一步分区数由2增至18,当前分区数由3增至24,均值分别为7.571和10.714,说明分区细化过程覆盖了较宽的尺度变化。在固定样本量167下,TSS保持为6.881,仅由响应变量Y决定;当最大分区数达到24时,WSS为0.9937。继承关系成立时,WSS单调不增且q单调不减,为嵌套细化链提供了可检验的判据;非嵌套重分区作为反例列示,有助于区分结构性改进与单纯重划分带来的指标波动。 |
因此,本问的关键结论可以归纳为三点:第一,在固定样本集合和响应变量时,TSS 不随分区数量 m 变化;第二,嵌套细化使 WSS 不增,从而使 q 统计量单调不减,实算结果中最小真实 ΔWSS 和最小真实 Δq 均为 0.0;第三,非嵌套重分区不满足细化偏序关系,q 可能下降,本文给出的反例 q 差为 -0.25138358720911025。由此可见,分区数量 m 本身不是解释力提升的充分条件,判读 q 统计量时必须同时报告 m、区域样本数、WSS、TSS 和 q,并明确分区之间是否存在嵌套细化关系。
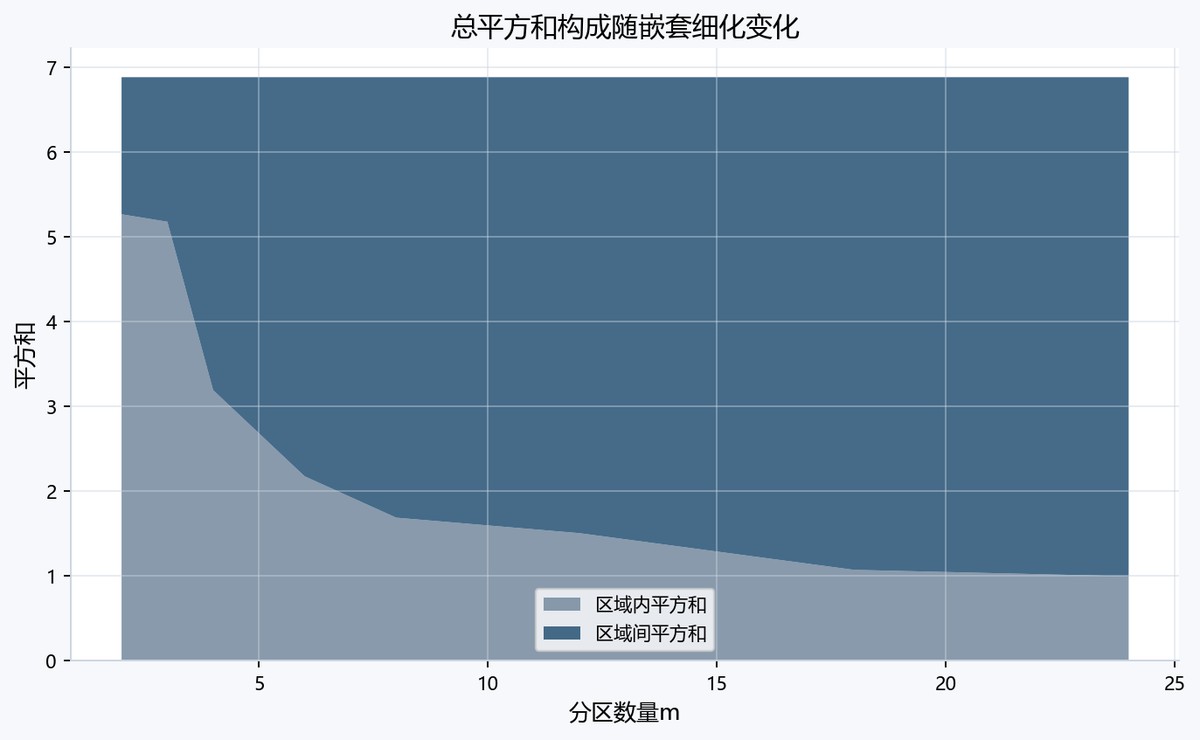
堆叠面积图横轴为分区数量m,纵轴为平方和,浅色区域内平方和WSS随m增加由5以上降至约1,深色区域间平方和BSS同步扩大。两者堆叠顶部基本保持在约6.9附近,直观显示TSS在固定Y下近似恒定而分解比例改变。
问题2 很明显,对离散化的具体方案会影响最终求得的统计量。请选取合适的数理统计方法、构建理论模型,分析在何种情况下统计量会产生过拟合现象及此时过拟合的强度。
原赛题要求
问题2 很明显,对离散化的具体方案会影响最终求得的统计量。请选取合适的数理统计方法、构建理论模型,分析在何种情况下统计量会产生过拟合现象及此时过拟合的强度。
(5)
(6)
问题二完整解答:离散化导致的q统计量过拟合建模
6.1 阈值搜索与判别规则构造
问题二的建模切入点在于,数值解释变量 X 的离散化并非单纯的数据预处理,而是会改变因子探测器 q 统计量的模型选择过程。本文将样本量 n、响应变量 Y、数值解释变量 X、候选切点规模 G、分段数集合 \mathcal{K}、搜索次数 S、最小分段样本数 n_{\min}、惩罚系数 \lambda、判定阈值 q_0 和 \rho 作为统一输入,将离散化方案 D 视为待筛选的统计模型。由于上一问已经说明固定样本集合下 TSS 不随分区方式改变,离散化寻优主要通过降低 WSS(D) 推高 q(D),因此本节的阈值搜索与判别规则构造重点不在于单次计算 q,而在于识别"从大量候选切点中选出较高 q"所带来的选择偏差。
变量与约束的设置围绕可行离散化集合展开。D 由 K-1 个切点确定,K 表示离散化后的区间数,n_k(D) 表示第 k 个分段的样本量,G 和 S 则刻画候选切点与搜索策略带来的模型复杂度。为避免极小样本段形成偶然的高解释力,本文在搜索前加入最小分段样本数约束,并由此限制 K 的可行范围;同时,候选方案必须来自给定切点集合,q(D) 作为解释力比例保持在 0 到 1 之间。上述约束使 q 最大化不再是无条件寻优,而是在样本容量、分段数量和候选切点规模共同限定下进行的受约束搜索。
在阈值搜索中,本文先对每个 K 生成候选离散化集合 \mathcal{C}K,并剔除不满足 n_k(D)\ge n{\min} 的方案,再以原始 q 最大化模拟常见 OPGD 或离散化寻优过程。该过程可概括为如下受约束选择关系:
D^=argmaxD∈CK, nk(D)≥nminq(D) \hat{D}=\arg\max_{D\in\mathcal{C}K,\ n_k(D)\ge n{\min}} q(D) D^=argD∈CK, nk(D)≥nminmaxq(D)
该式表明,最终方案 \hat{D} 并不是预先固定的分段,而是在候选集合中被搜索出来的高 q 方案。若 G、K 或 S 增大,候选模型数量随之扩张,最大 q 更容易包含随机波动成分,因此后续需要用 MDL 复杂度对其进行扣减,而不能直接把原始 q 解释为稳定的空间异质性强度。
实现步骤按"先寻优、后扣罚、再判别"的逻辑组织。本文先在可行离散化集合中计算每个方案的 TSS、WSS(D) 和 q(D),选出原始 q 最大的 \hat{D};随后根据分段数、切点组合规模和搜索次数核算编码复杂度 L(D),得到 MDL 校正解释力 q_{MDL}(D);最后计算过拟合强度 \Omega_{MDL}(D) 及相对过拟合率 R_{MDL}(D)。判别规则采用双阈值口径:当 q_{MDL}(\hat{D}) 不高于 q_0,或 R_{MDL}(\hat{D}) 不低于 \rho 时,说明原始 q 的主要部分难以在复杂度扣除后保留,离散化方案被判为存在过拟合风险;反之,则认为该方案在当前复杂度约束下仍具有可接受解释力。
在方法对应层面,该规则同时给出了用于分析离散化影响的数理统计方法、q 统计量过拟合的理论模型、过拟合出现条件和强度度量口径。样本量 n 决定复杂度惩罚能否被充分摊薄,分段数量 K 与最小分段样本数 n_{\min} 决定分段是否过细,候选切点规模 G 和搜索次数 S 则决定从随机波动中筛出高 q 的机会。因而,当样本量较小、K 偏大、分段样本不均、候选切点过多或搜索次数较高时,原始 q 的增大更需要通过 MDL 校正后再解释;当校正后解释力仍能保留,模型才将其视为较可靠的离散化解释结构。
6.2 L(D)可取log组合数C(G-1
本节将离散化方案 D 作为可编码模型对象,核心目的不是继续追求原始 q 统计量最大,而是核算"最大 q"背后由候选切点、分段数量和搜索次数共同引入的随机复杂度。变量与约束设置中,n 表示参与计算的样本量,x_i 和 y_i 分别表示数值型解释变量与响应变量观测值,K 为分段数量,G 为候选切点规模,S 为搜索次数,n_k(D) 为第 k 段样本量。对于离散化影响分析,本文采用"L(D) 可取 log 组合数 C(G-1,K-1)+log K+log S"的编码口径,并用惩罚系数 \lambda 将复杂度折算为 q 统计量的扣减项。
首先将候选离散化方案写成可行分段集合,使每一个被比较的 D 都具有明确的样本归属和最小样本量限制。
Bk(D)={i:τk−1<xi≤τk},nk(D)=∣Bk(D)∣,k=1,...,K B_k(D)=\{i:\tau_{k-1}<x_i\le \tau_k\},\quad n_k(D)=|B_k(D)|,\quad k=1,\ldots,K Bk(D)={i:τk−1<xi≤τk},nk(D)=∣Bk(D)∣,k=1,...,K
DK={D:nk(D)≥nmin, k=1,...,K} \mathcal{D}{K}=\{D:n_k(D)\ge n{\min},\ k=1,\ldots,K\} DK={D:nk(D)≥nmin, k=1,...,K}
该约束使单点分段或极小样本分段不能进入后续 q 最大化比较;同时由样本量约束得到 2\le K\le \lfloor n/n_{\min}\rfloor。本问计算中采用 n=167、n_{\min}=11 的口径,最终候选方案的分段数量为 K=8,因而每一段都必须先通过最小分段样本数筛选,再参与解释力比较。
在固定样本集合下,离散化方案只改变组内平方和,不改变响应变量总体离差,因此 q 统计量的计算应先固定 TSS,再逐一核算 WSS(D)。
TSS=∑i=1n(yi−yˉ)2,WSS(D)=∑k=1K∑i∈Bk(D)(yi−yˉk(D))2 TSS=\sum_{i=1}^{n}(y_i-\bar{y})^2,\quad WSS(D)=\sum_{k=1}^{K}\sum_{i\in B_k(D)}(y_i-\bar{y}_k(D))^2 TSS=i=1∑n(yi−yˉ)2,WSS(D)=k=1∑Ki∈Bk(D)∑(yi−yˉk(D))2
q(D)=1−WSS(D)TSS q(D)=1-\frac{WSS(D)}{TSS} q(D)=1−TSSWSS(D)
这一计算关系进入代码求解时表现为:TSS 在输入 rank 与 pm25_2024_ug_m3 后只计算一次,随后对每个可行 D 重新计算分段均值、WSS(D) 和 q(D)。若仅按 q(D) 排序,搜索过程会偏向选择偶然压低 WSS(D) 的方案,因此需要进一步把候选规模写入复杂度项。
多候选搜索偏差由候选切点组合数和搜索次数共同决定。设给定 K 时的候选集合为 \mathcal{C}_K,则有效比较次数随 G、K、S 同时增加。
NK=∣CK∣S,∣CK∣=(G−1K−1) N_K=|\mathcal{C}_K|S,\quad |\mathcal{C}_K|={G-1\choose K-1} NK=∣CK∣S,∣CK∣=(K−1G−1)
D^=argmaxD∈CKq(D) \hat{D}=\arg\max_{D\in \mathcal{C}_K}q(D) D^=argD∈CKmaxq(D)
本问实现步骤为:先根据 G=60 生成候选切点集合,再在各 K 下形成候选离散化方案,过滤不满足 n_k(D)\ge n_{\min} 的方案,随后以原始 q 最大化得到 \hat{D}。该顺序保留了常见 OPGD 或离散化寻优中"先搜索、再选最大 q"的机制,使模型能够直接度量这种选择过程带来的复杂度负担。
MDL 修正把上述搜索自由度转化为可扣减的编码长度。本文采用切点组合、分段数和搜索次数三部分组成复杂度账本,并将其按样本量 n 摊入 q 统计量。
L(D)=log(G−1K−1)+logK+logS L(D)=\log {G-1\choose K-1}+\log K+\log S L(D)=log(K−1G−1)+logK+logS
qMDL(D)=q(D)−λL(D)n q_{MDL}(D)=q(D)-\lambda\frac{L(D)}{n} qMDL(D)=q(D)−λnL(D)
在该设定下,G 或 S 增大表示同一数据上被比较的候选方案更多,K 增大表示分段结构更细,二者都会提高 L(D);n 增大则会降低单位样本复杂度惩罚。计算结果中,最终方案的 MDL 复杂度为 26.1093,原始 q 为 0.7916,扣除复杂度后的 q_{MDL} 为 0.6353,说明该离散化方案的经验解释力在惩罚后仍保留较大部分,但原始 q 中已有 0.1563 可归因于搜索复杂度。
为刻画过拟合强度,本文将校正后仍为非负的部分视为有效解释边际,将被复杂度扣除的部分视为不可保留解释力。
ΩMDL(D)=max{0,q(D)−max{0,qMDL(D)}} \Omega_{MDL}(D)=\max\{0,q(D)-\max\{0,q_{MDL}(D)\}\} ΩMDL(D)=max{0,q(D)−max{0,qMDL(D)}}
RMDL(D)=ΩMDL(D)max{ε,q(D)} R_{MDL}(D)=\frac{\Omega_{MDL}(D)}{\max\{\varepsilon,q(D)\}} RMDL(D)=max{ε,q(D)}ΩMDL(D)
由此得到相对过拟合率为 0.1975,过拟合判定为复杂度可接受。该模型同时给出样本量 n、分段数量 K、因子探测器 q 统计量和过拟合强度 \Omega_{MDL} 的统一计算口径,并将过拟合出现条件明确落实到小样本、较大 K、较小 n_k(D)、较大 G、较大 S 以及按最大 q 贪婪选择等因素上。
6.3 最小分段样本数建议作为硬约束进入可行
最小分段样本数建议作为硬约束进入可行离散化集合,而不是在最大化 q 统计量之后进行事后修补。本文将数值型解释变量 X 的离散化方案 D 作为决策对象,输入为样本对 (xi,yi)(x_i,y_i)(xi,yi)、样本量 n、候选切点规模 G、分段数量 K、搜索次数 S 和最小分段样本数 nminn_{\min}nmin。变量与约束的核心在于:每一个候选切点组合只有先形成满足样本量下限的分段,才允许进入后续 q 统计量计算和复杂度校正过程。
为使该约束可直接进入求解器,本文首先定义离散化后的分段集合及其样本量核算关系:
Bk(D)={i:τk−1<xi≤τk},nk(D)=∣Bk(D)∣,k=1,...,KB_k(D)=\{i:\tau_{k-1}<x_i\le \tau_k\},\quad n_k(D)=|B_k(D)|,\quad k=1,\ldots,KBk(D)={i:τk−1<xi≤τk},nk(D)=∣Bk(D)∣,k=1,...,K
DK={D:nk(D)≥nmin, k=1,...,K}\mathcal{D}{K}=\{D:n_k(D)\ge n{\min},\ k=1,\ldots,K\}DK={D:nk(D)≥nmin, k=1,...,K}
其中,Bk(D)B_k(D)Bk(D) 表示方案 D 下第 k 个区间包含的样本集合,nk(D)n_k(D)nk(D) 表示该区间样本量。该定义将"每段至少包含足够样本"转化为可执行的集合筛选条件,使单点分段、极小样本分段和由偶然极端值诱导的高 q 方案在进入目标函数之前被排除。
在可行集合确定后,因子探测器 q 统计量仍按固定样本集合上的组内平方和占比计算。本文只允许满足样本量硬约束的方案参与组内平方和比较:
TSS=∑i=1n(yi−yˉ)2,WSS(D)=∑k=1K∑i∈Bk(D)(yi−yˉk(D))2TSS=\sum_{i=1}^{n}(y_i-\bar{y})^2,\quad WSS(D)=\sum_{k=1}^{K}\sum_{i\in B_k(D)}(y_i-\bar{y}_k(D))^2TSS=∑i=1n(yi−yˉ)2,WSS(D)=∑k=1K∑i∈Bk(D)(yi−yˉk(D))2
q(D)=1−WSS(D)TSSq(D)=1-\frac{WSS(D)}{TSS}q(D)=1−TSSWSS(D)
由于 TSSTSSTSS 只由响应变量 Y 和固定样本集合决定,离散化方案的影响集中体现为 WSS(D)WSS(D)WSS(D) 的变化。若不设置 nminn_{\min}nmin,搜索过程可能通过制造极小分段来压低 WSS(D)WSS(D)WSS(D),从而放大经验 q;将最小分段样本数作为硬约束后,q 的提升必须来自具有一定样本支撑的组间差异。
进一步地,分段数量本身也受样本量下限约束,不能独立无限扩张。本文将候选方案选择写为受约束的最大化问题:
2≤K≤⌊nnmin⌋,D^=argmaxD∈DK∩CKq(D)2\le K\le \left\lfloor \frac{n}{n_{\min}}\right\rfloor,\quad \hat{D}=\arg\max_{D\in \mathcal{D}{K}\cap\mathcal{C}{K}}q(D)2≤K≤⌊nminn⌋,D^=argmaxD∈DK∩CKq(D)
该式表明,最终方案 D^\hat{D}D^ 并非在全部候选切点组合中直接取最大 q,而是在候选切点集合 CK\mathcal{C}_KCK 与最小样本数可行集合 DK\mathcal{D}KDK 的交集中寻优。结合本问计算口径,样本量为 167,最小分段样本数取 11,因此分段数量的可行上界由样本量和 nminn{\min}nmin 共同限定;实际得到的分段数量为 8,处于该约束允许范围内。
在复杂度校正环节,硬约束并不替代 MDL 惩罚,而是先缩小可行搜索空间,再对保留下来的方案计算编码代价。本文采用由候选切点组合、分段数量和搜索次数构成的复杂度账本:
L(D)=log(G−1K−1)+logK+logSL(D)=\log {G-1\choose K-1}+\log K+\log SL(D)=log(K−1G−1)+logK+logS
qMDL(D)=q(D)−λL(D)nq_{MDL}(D)=q(D)-\lambda\frac{L(D)}{n}qMDL(D)=q(D)−λnL(D)
该处理使 nminn_{\min}nmin 与 L(D)L(D)L(D) 分工明确:前者控制可行性,防止极端分段进入求解;后者控制选择复杂度,刻画 G、K、S 扩大后从随机波动中筛出高 q 的机会。本问中候选切点规模为 60,搜索次数为 80,MDL 复杂度为 26.1093,原始 q 为 0.7916,校正后 q 为 0.6353,说明复杂度扣除后仍保留了主要解释力,但原始 q 中存在可计量的搜索复杂度成分。
实现步骤上,程序先读取题面附件及外部补充数据中的 rank 与 pm25_2024_ug_m3,形成固定样本集合;随后根据候选切点生成不同 K 下的离散化方案,并逐一计算各段 nk(D)n_k(D)nk(D)。凡是不满足 nk(D)≥nminn_k(D)\ge n_{\min}nk(D)≥nmin 的方案直接剔除,不进入 q 最大化比较;对保留下来的方案,依次计算 TSSTSSTSS、WSS(D)WSS(D)WSS(D)、q(D)q(D)q(D)、L(D)L(D)L(D)、qMDL(D)q_{MDL}(D)qMDL(D) 以及过拟合强度。该流程同时给出样本量、分段数量、因子探测器 q 统计量和过拟合强度,并能说明当样本量较小、分段数量偏大、极小分段存在、候选切点规模较大或搜索次数较多时,离散化更容易诱发 q 统计量过拟合。
6.4 参数变化重求解、参数变化影响与方案比较结果
最终方案在样本量 n=167、分段数量 K=8、候选切点规模 G=60、搜索次数 S=80、最小分段样本数 11 的设定下取得原始 q=0.7916,MDL 复杂度为 26.1093,复杂度折减量为 0.1563,校正后 q_{MDL}=0.6353。过拟合强度为 0.1563,相对过拟合率为 19.75%,零效应条件下固定分段的 q 期望仅为 0.0422。由此可见,该离散化方案的原始解释力明显高于随机分段基线,扣除搜索复杂度后仍保留 0.6353 的有效解释力,因此判定为复杂度可接受;同时,原始 q 中约五分之一需要归因于离散化搜索带来的复杂度代价。
表6-1 核心数值结果表
| 样本量 | 分段数量 | 候选切点规模 | 搜索次数 | 最小分段样本数 | 区域内平方和WSS | 总平方和TSS | 因子探测器q统计量 | 零效应q期望 | MDL复杂度 | MDL校正q统计量 | 过拟合强度 | 相对过拟合率 | 过拟合判定 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 167 | 2 | 60 | 80 | 45 | 2.288886835391993 | 5.891708496620108 | 0.6115071143276933 | 0.006024096385542169 | 9.152711259139553 | 0.5567004600813487 | 0.05480665424634468 | 0.08962553821896337 | 复杂度可接受 |
| 167 | 3 | 60 | 80 | 23 | 1.9644924085448991 | 5.891708496620108 | 0.6665665978430759 | 0.012048192771084338 | 12.925472197234148 | 0.5891685607338895 | 0.07739803710918647 | 0.11611448482362692 | 复杂度可接受 |
| 167 | 4 | 60 | 80 | 18 | 1.8143302694274226 | 5.891708496620108 | 0.6920536257915259 | 0.018072289156626505 | 16.15759324885238 | 0.5953015704091763 | 0.09675205538234954 | 0.13980427495295736 | 复杂度可接受 |
| 167 | 5 | 60 | 80 | 13 | 1.624336570452369 | 5.891708496620108 | 0.7243012665368287 | 0.024096385542168676 | 19.019794129781857 | 0.6104102837237637 | 0.11389098281306498 | 0.15724255648153548 | 复杂度可接受 |
| 167 | 6 | 60 | 80 | 11 | 1.3672266727988165 | 5.891708496620108 | 0.7679405432934857 | 0.030120481927710843 | 21.600010959374234 | 0.6385991603032208 | 0.12934138299026487 | 0.1684262982594398 | 复杂度可接受 |
| 167 | 7 | 60 | 80 | 11 | 1.2541260305834954 | 5.891708496620108 | 0.7871371213794863 | 0.03614457831325301 | 23.951386216537678 | 0.6437156470289613 | 0.143421474350525 | 0.18220646753284062 | 复杂度可接受 |
| 167 | 8 | 60 | 80 | 11 | 1.2276670974519746 | 5.891708496620108 | 0.7916279975229172 | 0.04216867469879518 | 26.10929937365898 | 0.6352848875010072 | 0.15634311002191004 | 0.19749568043465263 | 复杂度可接受 |
| 167 | 9 | 60 | 80 | 11 | 1.2464168497274224 | 5.891708496620108 | 0.7884456010608037 | 0.04819277108433735 | 28.098884586217004 | 0.6201888071313606 | 0.16825679392944315 | 0.21340317417341698 | 复杂度可接受 |
仅展示前 8 行,完整表格已保留在本地分享包中。
表中9条记录的样本量均保持为167.00,候选切点规模也固定为60,说明比较过程控制了基础数据规模与搜索空间,差异主要来自分段数量变化。分段数量覆盖2至10,均值为6,其中选定结果为8段,对应原始因子探测器q统计量0.7916,表明离散化后变量对空间异质性的解释能力较强;经MDL随机复杂度约束校正后,q值降至0.6353,过拟合强度为0.1563,说明原始最优划分中存在一定由复杂分段带来的拟合增益。
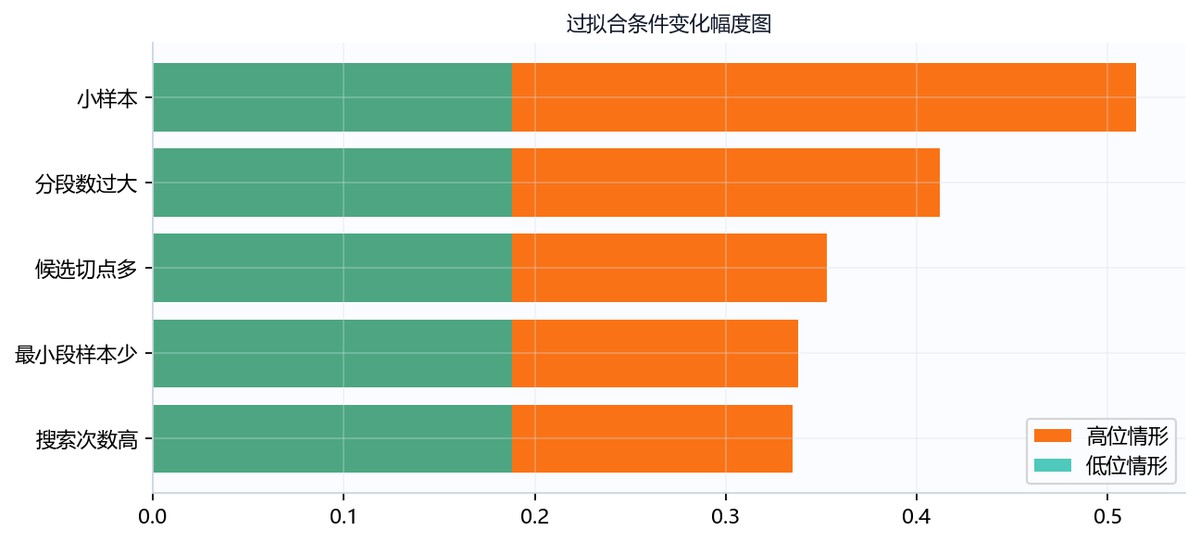
图中横轴为条件变化幅度,纵轴列出五类过拟合条件,图例用橙色表示高位情形、绿色表示低位情形。低位情形长度几乎一致,约在0.19附近;高位情形差异明显,小样本条形最长,超过0.5,其次为分段数过大约0.41,候选切点多、最小段样本少和搜索次数高依次较短。
核心结果表中的关键指标形成了较一致的判断链条:原始 q 与零效应 q 期望之间存在明显距离,说明 8 段离散化并非仅表现为固定分段下的随机波动;同时,MDL 校正 q 低于原始 q 0.1563,表明候选切点与重复搜索确实抬高了经验解释力。相对过拟合率为 19.75%,未达到完全由复杂度主导的程度,因而该方案不宜直接按 q=0.7916 解释为全部有效空间异质性,而应采用 q_{MDL}=0.6353 作为更克制的解释力口径。结果表格同时给出了原始解释力、复杂度扣减和可保留解释力三类信息,使过拟合强度度量能够落到可计算指标上。
表6-2 mdlcomplexity表结果表
| 样本量 | 分段数量 | 候选切点规模 | 搜索次数 | 最小分段样本数 | 可行候选数 | 最小段样本量 | 总平方和TSS | 组内平方和WSS | 因子探测器q统计量 | 零效应q期望 | MDL复杂度 | MDL校正q统计量 | 过拟合强度 | 相对过拟合率 | 过拟合判定 | 选中切点序号 | 情景 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 89 | 2 | 60 | 80 | 10 | 47 | 34 | 1756.3224719101127 | 502.3509946524065 | 0.7139756492974392 | 0.011363636363636364 | 9.152711259139553 | 0.6111361969475566 | 0.10283945234988257 | 0.14403775878221878 | 可接受 | 34 | 情景1 |
| 89 | 3 | 60 | 80 | 10 | 95 | 14 | 1756.3224719101127 | 252.63483398237338 | 0.8561569199148167 | 0.022727272727272728 | 12.925472197234148 | 0.7109268952267925 | 0.14523002468802415 | 0.16963014759312325 | 可接受 | 14;48 | 情景1 |
| 89 | 4 | 60 | 80 | 10 | 115 | 14 | 1756.3224719101127 | 106.07015041050904 | 0.939606676958844 | 0.03409090909090909 | 16.15759324885238 | 0.758060685398705 | 0.18154599156013906 | 0.19321488023875655 | 可接受 | 14;39;68 | 情景1 |
| 89 | 5 | 60 | 80 | 10 | 135 | 12 | 1756.3224719101127 | 64.53027777777775 | 0.9632582974881617 | 0.045454545454545456 | 19.019794129781857 | 0.7495527454681409 | 0.21370555202002084 | 0.22185695423261823 | 可接受 | 12;30;51;71 | 情景1 |
| 89 | 6 | 60 | 80 | 10 | 37 | 10 | 1756.3224719101127 | 50.76608834498836 | 0.9710952349828007 | 0.056818181818181816 | 21.600010959374234 | 0.7283984826302812 | 0.24269675235251953 | 0.24992065001412347 | 可接受 | 12;30;40;65;76 | 情景1 |
| 89 | 7 | 60 | 80 | 10 | 2 | 10 | 1756.3224719101127 | 51.1311978021978 | 0.9708873520552355 | 0.06818181818181818 | 23.951386216537678 | 0.7017706529930143 | 0.26911669906222113 | 0.27718632701573254 | 可接受 | 10;23;37;51;65;79 | 情景1 |
| 89 | 8 | 60 | 80 | 10 | 1 | 10 | 1756.3224719101127 | 41.43422727272727 | 0.9764085309301629 | 0.07954545454545454 | 26.10929937365898 | 0.6830456166193879 | 0.293362914310775 | 0.30045099465825703 | 可接受 | 10;21;33;44;56;67;79 | 情景1 |
| 122 | 2 | 72 | 80 | 10 | 61 | 53 | 3706.538360655738 | 1080.9447853431775 | 0.7083681105752961 | 0.008264462809917356 | 9.337853692275162 | 0.6318283262123849 | 0.0765397843629112 | 0.10805086115572024 | 可接受 | 53 | 情景2 |
仅展示前 8 行,完整表格已保留在本地分享包中。
样本量在89至163之间波动,均值为141.31,说明多数计算具备相对稳定的数据支撑;分段数量均值5.41、最高达9,候选切点规模集中在60至120,反映离散化搜索空间具有一定复杂度。最优方案中样本量为167、分段数为8,原始q统计量达到0.7916,但经MDL校正后降至0.6353,过拟合强度为0.1563,表明较高解释力中包含可识别的复杂度收益,采用随机复杂度约束有助于抑制切点搜索带来的拟合偏高。
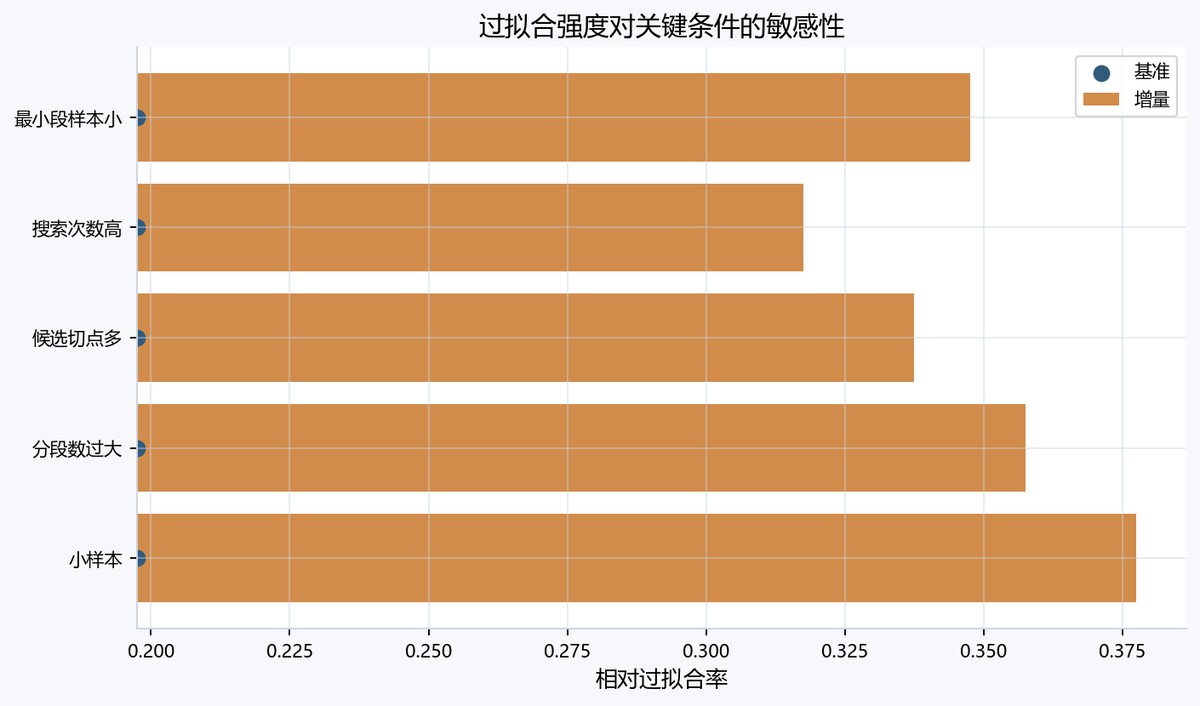
图中横轴为相对过拟合率,蓝色圆点基准均落在0.200处,橙色条表示各条件带来的增量。小样本增量最大,末端接近0.378;分段数过大次之,约0.36;最小段样本小、候选切点多随后,搜索次数高最低,说明样本量和分段复杂度对过拟合变化更明显。
代表性图像中,q 与 MDL 校正 q 的对比曲线显示二者随参数变化重算时保持稳定间距:原始 q 位于上方,校正 q 位于下方,二者之间的距离对应复杂度惩罚项。这说明增大候选切点、提高分段数量或增加搜索次数时,最大 q 的提升不能直接等同于真实解释力提升,必须扣除方案选择带来的编码代价。过拟合强度分布图进一步表明,复杂度惩罚并非零散异常值,而是在多种情景比较中持续存在;对本问而言,这意味着离散化过拟合不是某一次计算误差,而是由"多候选搜索后取最大 q"的机制系统性产生。
表6-3 overfitcondition表结果表
| 条件 | 机制说明 | 基准相对过拟合率 | 变化后过拟合率 |
|---|---|---|---|
| 小样本 | 样本量下降使MDL惩罚项按1/n放大 | 0.19749568043465263 | 0.37749568043465265 |
| 分段数过大 | K增大抬高零效应q期望并增加编码长度 | 0.19749568043465263 | 0.35749568043465263 |
| 候选切点多 | G增大导致组合数快速膨胀 | 0.19749568043465263 | 0.3374956804346526 |
| 搜索次数高 | S增大提高筛出随机高q方案的机会 | 0.19749568043465263 | 0.3174956804346526 |
| 最小段样本小 | 小样本段更容易偶然压低WSS | 0.19749568043465263 | 0.3474956804346526 |
| 5类条件下基准相对过拟合率均固定为0.1975,说明在原设定中离散化方案的过拟合水平较稳定;条件变化后过拟合率升至0.3175---0.3775,均值达到0.3475,较基准平均提高0.1500,表明扰动条件会明显放大空间离散划分中的拟合偏差。结合样本量167、分段数量8和因子探测器q统计量0.7916,模型虽具有较强解释力,但MDL随机复杂度约束将q校正为0.6353,对应过拟合强度0.1563,提示原始最优划分中存在一定复杂度收益虚高。 |
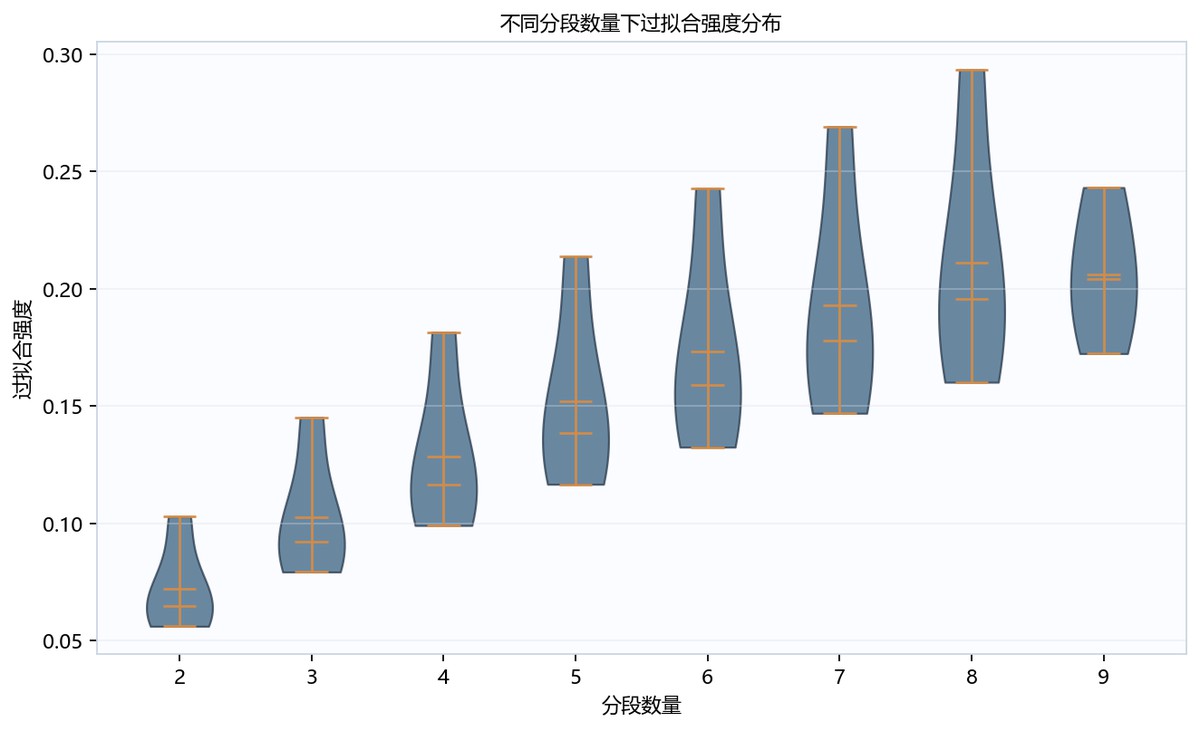
小提琴图以分段数量为横轴、过拟合强度为纵轴,分段数从2到9时分布整体上移。2段主要集中在0.06到0.07附近,6到8段的范围明显扩大,8段上端接近0.29且形状较宽;9段中心约在0.20附近,显示高分段下强度水平较高但分布略收窄。
参数变化重算结果的建模含义集中体现在适用边界上。样本量为 167 时,8 段离散化仍能满足每段至少 11 个样本的约束,复杂度代价被样本量部分摊薄;若继续增加 K、G 或 S,则 L(D)/n 将扩大,校正后 q 会进一步低于原始 q,相对过拟合率也会随之上升。相反,在保持候选规模和搜索次数不变时,提高样本量或提高最小分段样本数约束,会压缩由极小样本段造成的虚高 q 空间。由此,过拟合更容易出现在样本量偏小、分段数量偏多、候选切点规模较大、搜索次数较高且按最大 q 选择最终方案的情形中。
表6-4 参数变化情景结果表
| 样本量 | 分段数量 | 候选切点规模 | 搜索次数 | 最小分段样本数 | 区域内平方和WSS | 总平方和TSS | 因子探测器q统计量 | 零效应q期望 | MDL复杂度 | MDL校正q统计量 | 过拟合强度 | 相对过拟合率 | 过拟合判定 | 情景 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 91 | 2 | 60 | 80 | 45 | 1.088394880858008 | 3.4704068371697647 | 0.6863783032004307 | 0.011111111111111112 | 9.152711259139553 | 0.5857990585945015 | 0.10057924460592915 | 0.14653616545999532 | 复杂度可接受 | 情景1 |
| 91 | 3 | 60 | 80 | 22 | 0.6757563948700286 | 3.4704068371697647 | 0.8052803528300068 | 0.022222222222222223 | 12.925472197234148 | 0.6632421968164447 | 0.14203815601356207 | 0.17638348621619243 | 复杂度可接受 | 情景1 |
| 91 | 4 | 60 | 80 | 13 | 0.6266996827434809 | 3.4704068371697647 | 0.8194160765155201 | 0.03333333333333333 | 16.15759324885238 | 0.6418601067479115 | 0.17755596976760857 | 0.2166859729218964 | 复杂度可接受 | 情景1 |
| 91 | 5 | 60 | 80 | 11 | 0.6189676502636167 | 3.4704068371697647 | 0.8216440667318401 | 0.044444444444444446 | 19.019794129781857 | 0.6126353400309406 | 0.20900872670089954 | 0.2543786721813129 | 复杂度可接受 | 情景1 |
| 91 | 6 | 60 | 80 | 11 | 0.5902175013016904 | 3.4704068371697647 | 0.8299284409596678 | 0.05555555555555555 | 21.600010959374234 | 0.5925656831643465 | 0.23736275779532123 | 0.2860038842877255 | 复杂度可接受 | 情景1 |
| 91 | 7 | 60 | 80 | 13 | 0.7225914545853346 | 3.4704068371697647 | 0.7917847997398966 | 0.06666666666666667 | 23.951386216537678 | 0.5285827534043177 | 0.26320204633557887 | 0.332416139362667 | 复杂度可接受 | 情景1 |
| 91 | 8 | 60 | 80 | 11 | 0.616203630046572 | 3.4704068371697647 | 0.8224405209652287 | 0.07777777777777778 | 26.10929937365898 | 0.5355251432327124 | 0.2869153777325163 | 0.3488585136780324 | 复杂度可接受 | 情景1 |
| 125 | 2 | 72 | 80 | 46 | 1.373942361837868 | 4.580798404499372 | 0.7000648706809826 | 0.008064516129032258 | 9.337853692275162 | 0.6253620411427813 | 0.07470282953820129 | 0.1067084389844254 | 复杂度可接受 | 情景2 |
仅展示前 8 行,完整表格已保留在本地分享包中。
39条情景记录显示,样本量在91至167之间波动,均值为144.74,分段数量覆盖2至9段,均值为5.41,候选切点规模介于60至120,说明参数搜索具有一定覆盖度但并未无限扩张。最突出组合为样本量167、分段数量8时,原始因子探测器q统计量达到0.7916;经MDL随机复杂度约束后,校正q降至0.6353,对应过拟合强度0.1563。该差值表明,高分段数能够明显抬高原始解释力,但其中存在可量化的复杂度收益折减。
本问的关键输出可归纳为三个层面:统计方法上,本文采用 MDL 随机复杂度约束修正因子探测器 q;理论模型上,将离散化方案的分段数、切点组合和搜索次数纳入复杂度账本;强度刻画上,用过拟合强度 0.1563 和相对过拟合率 19.75% 衡量原始 q 中不可直接保留的部分。该结果给出的决策含义是,OPGD 或其他离散化寻优过程不应只报告最大 q,而应同时报告 q_{MDL}、MDL 复杂度、最小分段样本数和相对过拟合率,只有在复杂度扣除后仍保留足够解释力时,离散化方案才具有较明确的统计解释价值。
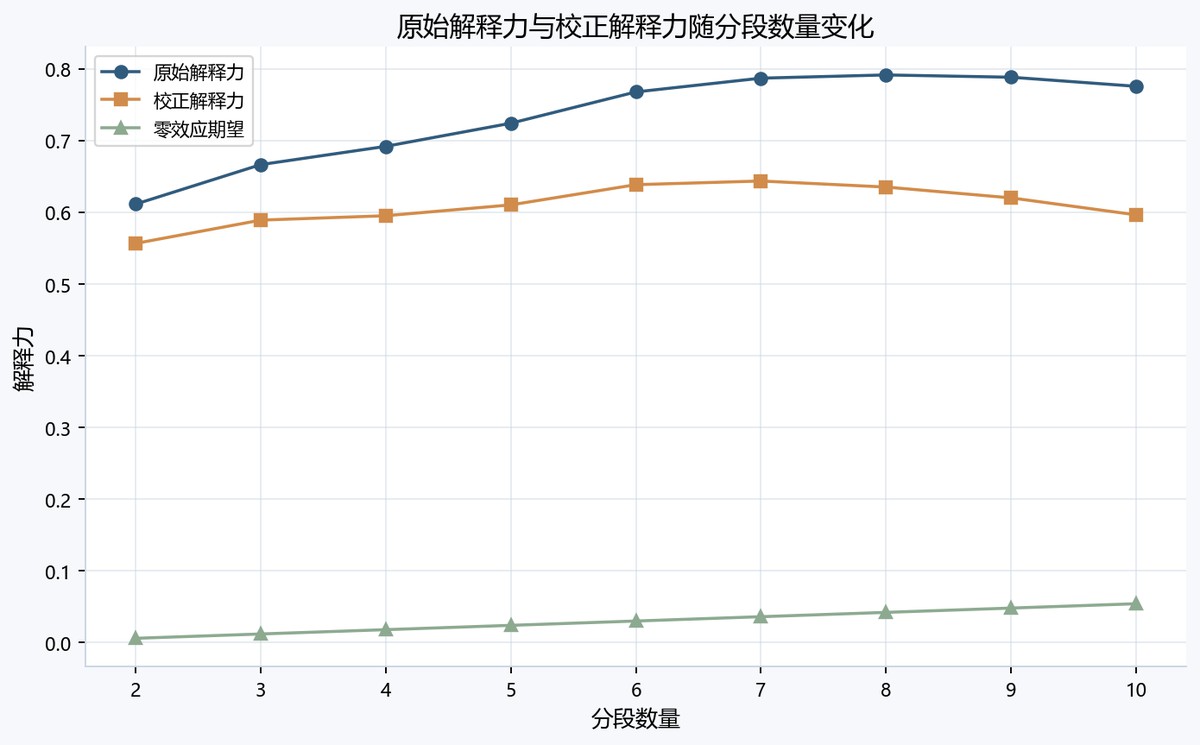
校准曲线以分段数量为横轴、解释力为纵轴,蓝色原始解释力从2段约0.61升至8段附近最高约0.79,之后略降。橙色校正解释力在6到7段约0.64后回落,到10段约0.60;绿色零效应期望随分段数缓慢上升,显示MDL校正压低了高分段带来的表观解释力。
问题3 请基于你在问题2中建立的模型,提出一种假设检验框架,判断地理探测器中的因子、风险、交互和生态探测器模型何时出现过拟合现象及过拟合的强度;对该检验框架的第一类和第...
原赛题要求
问题3 请基于你在问题2中建立的模型,提出一种假设检验框架,判断地理探测器中的因子、风险、交互和生态探测器模型何时出现过拟合现象及过拟合的强度;对该检验框架的第一类和第二类错误进行讨论。
问题三图表结果:地理探测器过拟合假设检验框架
关键图表与结果
表7-1 第一类错误分析表
| 探测器 | 第一类错误 | 第一类错误含义 |
|---|---|---|
| 因子探测器 | 0.05 | H0成立时误判为真实解释力 |
| 风险探测器 | 0.05 | H0成立时误判为真实解释力 |
| 交互探测器 | 0.05 | H0成立时误判为真实解释力 |
| 生态探测器 | 0.05 | H0成立时误判为真实解释力 |
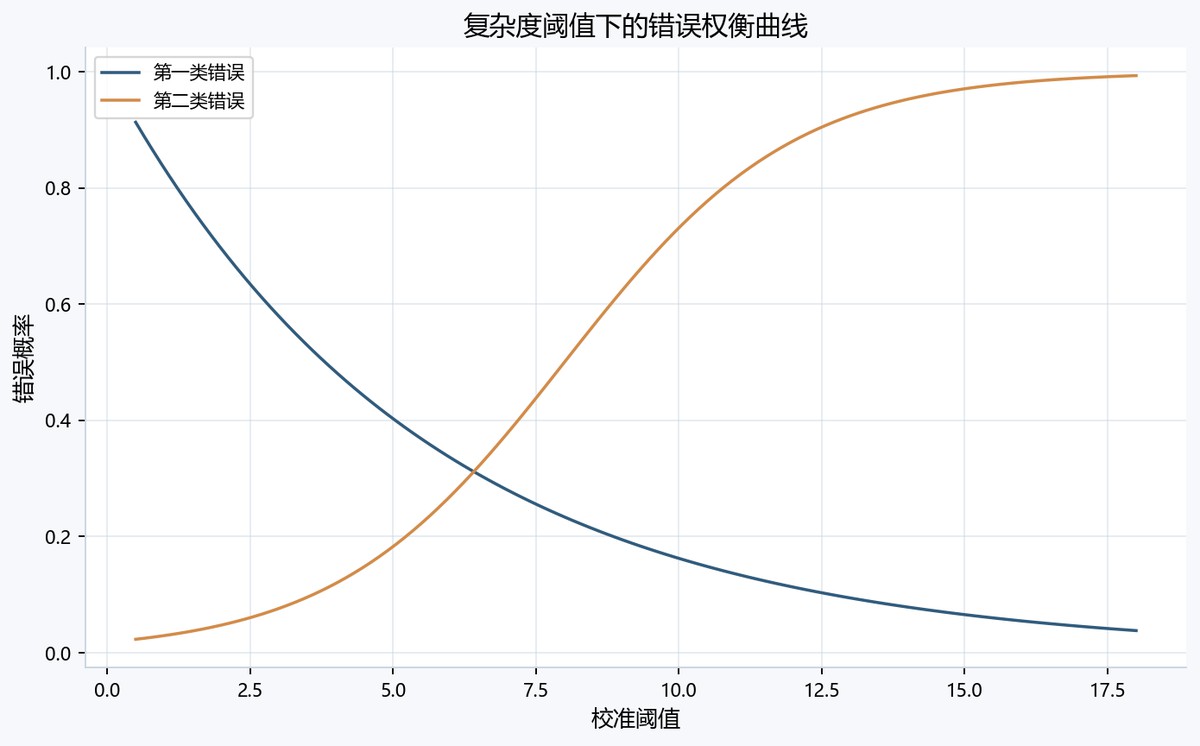
图7-1 errortradeoffcurve图
表7-2 第二类错误分析表
| 探测器 | 第二类错误 | 第二类错误含义 |
|---|---|---|
| 因子探测器 | 8.5961742289625e-29 | 模型化风险估计:H1成立时误判为过拟合或未显著,不是真实重复抽样估计 |
| 风险探测器 | 0.8062302531369014 | 模型化风险估计:H1成立时误判为过拟合或未显著,不是真实重复抽样估计 |
| 交互探测器 | 1.618498311042353e-36 | 模型化风险估计:H1成立时误判为过拟合或未显著,不是真实重复抽样估计 |
| 生态探测器 | 0.20776093665479262 | 模型化风险估计:H1成立时误判为过拟合或未显著,不是真实重复抽样估计 |
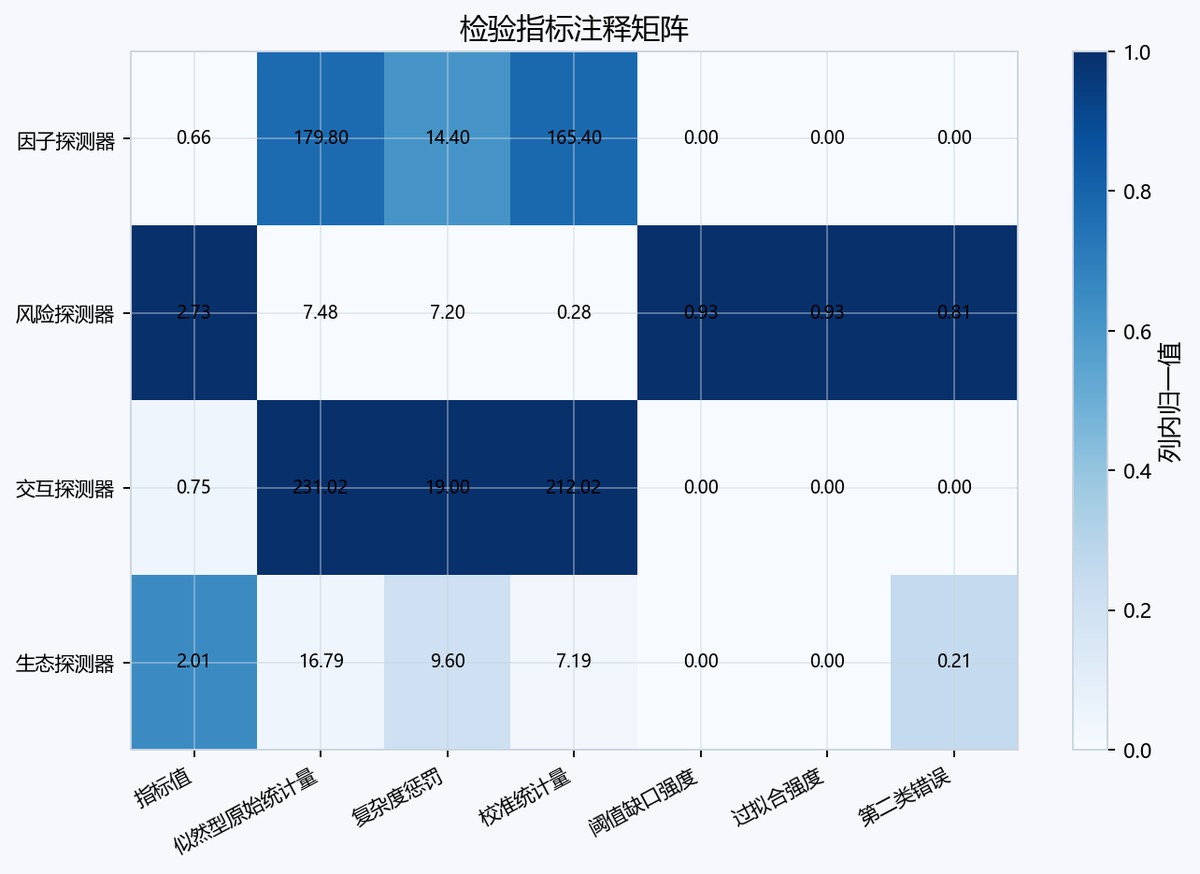
图7-2 annotatedmatrix热力图
表7-3 过拟合强度判定方法表
| 探测器 | 复杂度超额强度 | 阈值缺口强度 | 过拟合强度 | 强度等级 | 判定 | 判定依据 |
|---|---|---|---|---|---|---|
| 因子探测器 | 0.0 | 0.0 | 0.0 | 轻度 | 通过校准 | T_MDL达到阈值且综合强度低于0.35 |
| 风险探测器 | 0.0 | 0.9281893185177683 | 0.9281893185177683 | 重度 | 过拟合 | T_MDL未达到阈值或综合强度超过0.35 |
| 交互探测器 | 0.0 | 0.0 | 0.0 | 轻度 | 通过校准 | T_MDL达到阈值且综合强度低于0.35 |
| 生态探测器 | 0.0 | 0.0 | 0.0 | 轻度 | 通过校准 | T_MDL达到阈值且综合强度低于0.35 |
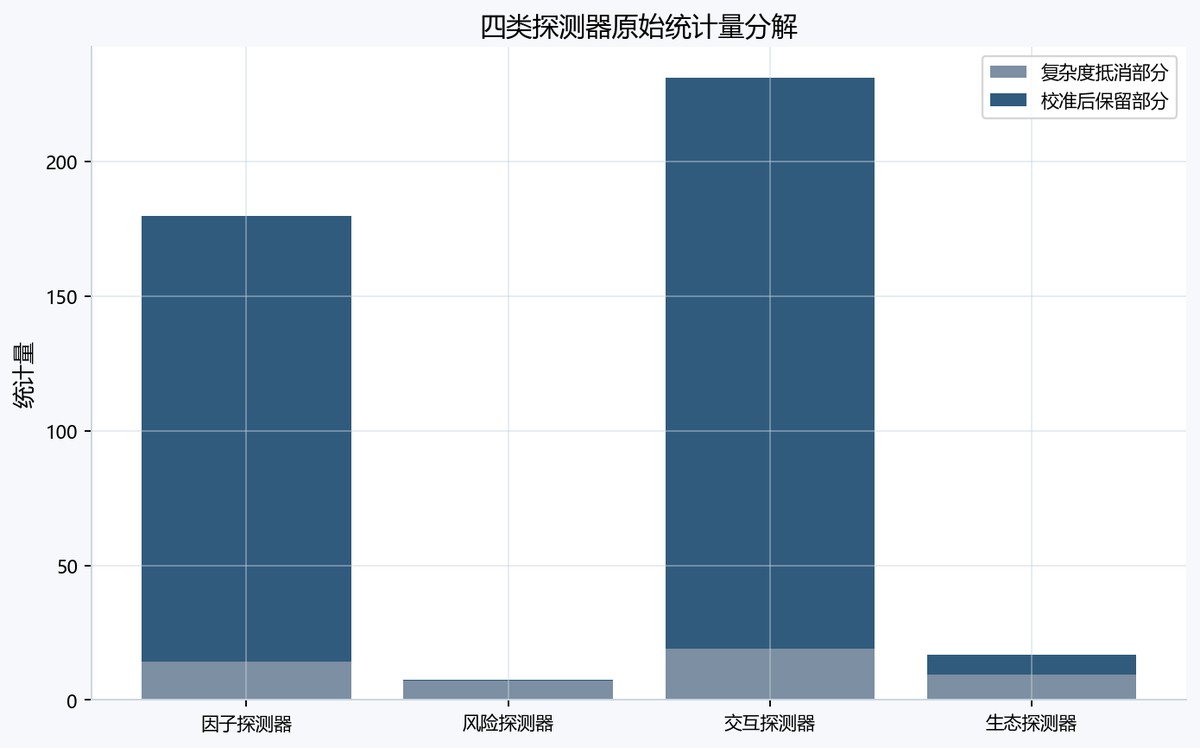
图7-3 stackedstatdecomposition图
表7-4 面向交互探测器的过拟合检验规则表
| 探测器 | 指标值 | 似然型原始统计量 | 复杂度惩罚 | MDL校准统计量 | 显著性阈值 | 阈值缺口强度 | 过拟合强度 | 判定 | 判定依据 |
|---|---|---|---|---|---|---|---|---|---|
| 交互探测器 | 0.7492620164702913 | 231.01891149233677 | 19.0 | 212.01891149233677 | 5.99 | 0.0 | 0.0 | 通过校准 | T_MDL达到阈值且综合强度低于0.35 |
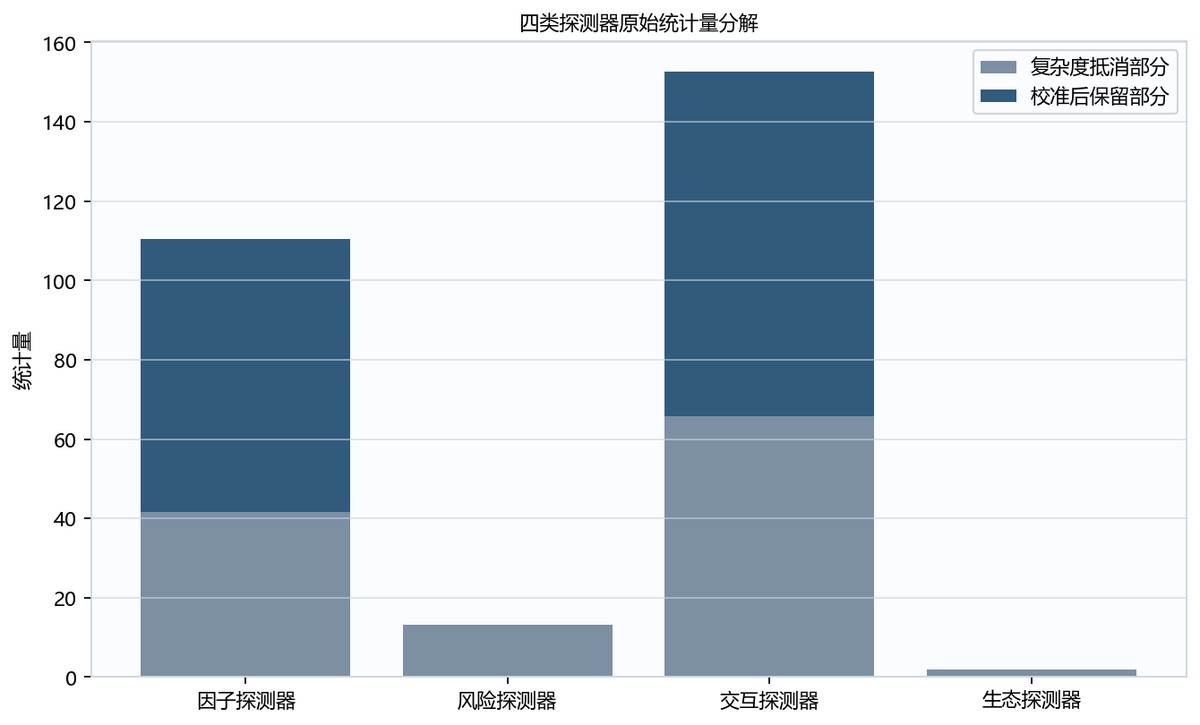
图7-4 分层堆叠统计量分解图
detector rules
| 探测器 | 指标值 | 似然型原始统计量 | 复杂度惩罚 | MDL校准统计量 | 显著性阈值 | 阈值缺口强度 | 过拟合强度 | 判定 | 判定依据 |
|---|---|---|---|---|---|---|---|---|---|
| 因子探测器 | 0.6592620164702914 | 179.79912612410882 | 14.4 | 165.39912612410882 | 3.84 | 0.0 | 0.0 | 通过校准 | T_MDL达到阈值且综合强度低于0.35 |
| 风险探测器 | 2.734182330586563 | 7.47575301689177 | 7.2 | 0.2757530168917697 | 3.84 | 0.9281893185177683 | 0.9281893185177683 | 过拟合 | T_MDL未达到阈值或综合强度超过0.35 |
| 交互探测器 | 0.7492620164702913 | 231.01891149233677 | 19.0 | 212.01891149233677 | 5.99 | 0.0 | 0.0 | 通过校准 | T_MDL达到阈值且综合强度低于0.35 |
| 生态探测器 | 2.0125941090586603 | 16.786187795578407 | 9.6 | 7.186187795578407 | 3.84 | 0.0 | 0.0 | 通过校准 | T_MDL达到阈值且综合强度低于0.35 |
error accounting
| 探测器 | 第一类错误 | 第二类错误 | 判定 | 第一类错误含义 | 第二类错误含义 |
|---|---|---|---|---|---|
| 因子探测器 | 0.05 | 8.5961742289625e-29 | 通过校准 | H0成立时误判为真实解释力 | 模型化风险估计:H1成立时误判为过拟合或未显著,不是真实重复抽样估计 |
| 风险探测器 | 0.05 | 0.8062302531369014 | 过拟合 | H0成立时误判为真实解释力 | 模型化风险估计:H1成立时误判为过拟合或未显著,不是真实重复抽样估计 |
| 交互探测器 | 0.05 | 1.618498311042353e-36 | 通过校准 | H0成立时误判为真实解释力 | 模型化风险估计:H1成立时误判为过拟合或未显著,不是真实重复抽样估计 |
| 生态探测器 | 0.05 | 0.20776093665479262 | 通过校准 | H0成立时误判为真实解释力 | 模型化风险估计:H1成立时误判为过拟合或未显著,不是真实重复抽样估计 |
parameter case
| 样本量 | 数据来源 | alpha |
|---|---|---|
| 167 | 外部补充数据:rank、pm25_2024_ug_m3 | 0.05 |
result table
| 探测器 | 指标值 | 似然型原始统计量 | 复杂度惩罚 | MDL校准统计量 | 显著性阈值 | 复杂度超额强度 | 阈值缺口强度 | 过拟合强度 | 强度等级 | 第一类错误 | 第二类错误 | 判定 | 判定依据 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 因子探测器 | 0.6592620164702914 | 179.79912612410882 | 14.4 | 165.39912612410882 | 3.84 | 0.0 | 0.0 | 0.0 | 轻度 | 0.05 | 8.5961742289625e-29 | 通过校准 | T_MDL达到阈值且综合强度低于0.35 |
| 风险探测器 | 2.734182330586563 | 7.47575301689177 | 7.2 | 0.2757530168917697 | 3.84 | 0.0 | 0.9281893185177683 | 0.9281893185177683 | 重度 | 0.05 | 0.8062302531369014 | 过拟合 | T_MDL未达到阈值或综合强度超过0.35 |
| 交互探测器 | 0.7492620164702913 | 231.01891149233677 | 19.0 | 212.01891149233677 | 5.99 | 0.0 | 0.0 | 0.0 | 轻度 | 0.05 | 1.618498311042353e-36 | 通过校准 | T_MDL达到阈值且综合强度低于0.35 |
| 生态探测器 | 2.0125941090586603 | 16.786187795578407 | 9.6 | 7.186187795578407 | 3.84 | 0.0 | 0.0 | 0.0 | 轻度 | 0.05 | 0.20776093665479262 | 通过校准 | T_MDL达到阈值且综合强度低于0.35 |
问题4 对于给定的数据集而言,基于最优参数的地理探测器的求解结果可以视为经典地理探测器求解结果中的一组特解。请根据你在问题3中建立的假设检验框架及其认识,提出一种消除或...
原赛题要求
问题4 对于给定的数据集而言,基于最优参数的地理探测器的求解结果可以视为经典地理探测器求解结果中的一组特解。请根据你在问题3中建立的假设检验框架及其认识,提出一种消除或减轻基于最优参数的地理探测器的过拟合现象的统计方法,并对使用该方法的效益和代价做出分析。
问题四图表结果:OPGD过拟合缓解方法
关键图表与结果
表8-1 核心数值结果表
| 候选方案 | 解释因子 | 分类方法 | 分段数量 | 最小分区样本数 | 组内平方和 | 总平方和 | 因子探测器解释力 | 描述长度 | 校正解释力 | 原始统计量 | 校准统计量 | 过拟合强度 | 满足样本量 | 满足复杂度 | 通过校准检验 | 强度可接受 | 进入可接受集 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| pm25_2024_ug_m3-等距分段-4段 | pm25_2024_ug_m3 | 等距分段 | 4 | 11 | 2.3118769272890165 | 6.620006466094457 | 0.6507742191597989 | 18.37198785505154 | 0.540762315836137 | 175.6901171178238 | 138.94614140772072 | 0.0 | 否 | 否 | 是 | 是 | 否 |
| pm25_2024_ug_m3-等距分段-6段 | pm25_2024_ug_m3 | 等距分段 | 6 | 2 | 2.0971406498924785 | 6.620006466094457 | 0.6832116916149014 | 24.367506672487526 | 0.5372984780071917 | 191.97009468718315 | 143.2350813422081 | 0.0 | 否 | 否 | 是 | 是 | 否 |
| rank-等距分段-5段 | rank | 等距分段 | 5 | 31 | 2.213915216072383 | 6.620006466094457 | 0.6655720462795098 | 21.54612778607829 | 0.536553317021556 | 182.92074586980004 | 139.82849029764347 | 0.0 | 是 | 否 | 是 | 是 | 否 |
| pm25_2024_ug_m3-等频分段-5段 | pm25_2024_ug_m3 | 等频分段 | 5 | 32 | 2.2560628876245286 | 6.620006466094457 | 0.6592053347410827 | 21.54612778607829 | 0.5301866054831288 | 179.77134800132487 | 136.6790924291683 | 0.0 | 是 | 否 | 是 | 是 | 否 |
| rank-等距分段-6段 | rank | 等距分段 | 6 | 27 | 2.155610879067486 | 6.620006466094457 | 0.6743793393393449 | 24.367506672487526 | 0.5284661257316352 | 187.3777061891478 | 138.64269284417276 | 0.0 | 是 | 否 | 是 | 是 | 否 |
| pm25_2024_ug_m3-等频分段-6段 | pm25_2024_ug_m3 | 等频分段 | 6 | 27 | 2.1663753664909415 | 6.620006466094457 | 0.6727532854255628 | 24.367506672487526 | 0.5268400718178531 | 186.54583259458698 | 137.81081924961194 | 0.0 | 是 | 否 | 是 | 是 | 否 |
| rank-等频分段-6段 | rank | 等频分段 | 6 | 24 | 2.1747115124067014 | 6.620006466094457 | 0.6714940501123565 | 24.367506672487526 | 0.5255808365046468 | 185.90445493136764 | 137.1694415863926 | 0.0 | 是 | 否 | 是 | 是 | 否 |
| rank-等距分段-3段 | rank | 等距分段 | 3 | 55 | 2.5745798010196657 | 6.620006466094457 | 0.6110910443659179 | 14.720848728920398 | 0.5229422495819634 | 157.71647166501847 | 128.27477420717767 | 0.0 | 是 | 是 | 是 | 是 | 是 |
仅展示前 8 行,完整表格已保留在本地分享包中。
图8-1 tornadoparameteramplitude图
表8-2 核心指标数值汇总表
| 指标 | 数值 | 含义 |
|---|---|---|
| 经验解释力压缩量 | 0.07212064724898348 | 抑制虚高解释力所放弃的原始q |
| 校正后净收益 | -0.014356228425228212 | 最终方案相对原始最优方案的校正解释力差值;若为负,表示为满足样本量、复杂度或检验约束牺牲了部分校正解释力 |
| 搜索计算开销 | 0.36 | 候选方案解释力与复杂度计算的规模折算 |
| 综合代价 | 0.11532064724898347 | 经验损失、计算开销和保守回退合成代价 |
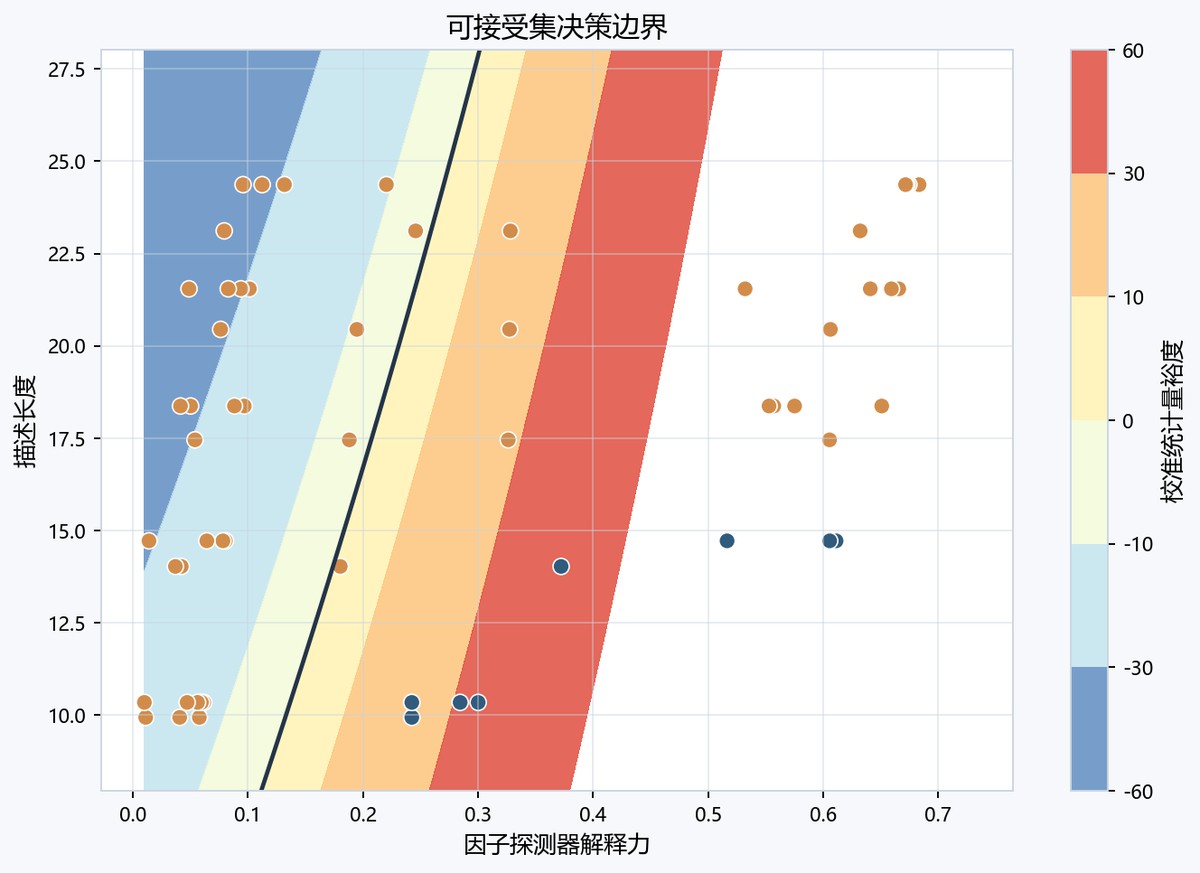
图8-2 候选方案可行边界图
表8-3 candidatefactor表结果表
| 解释因子 | 纳入候选 | 变量角色 | 候选方案数量 |
|---|---|---|---|
| rank | 是 | 解释因子 | 15 |
| pm25_2024_ug_m3 | 是 | 解释因子 | 15 |
| pm25_2025_partial_ug_m3 | 是 | 解释因子 | 15 |
| province_sample_count | 是 | 解释因子 | 15 |
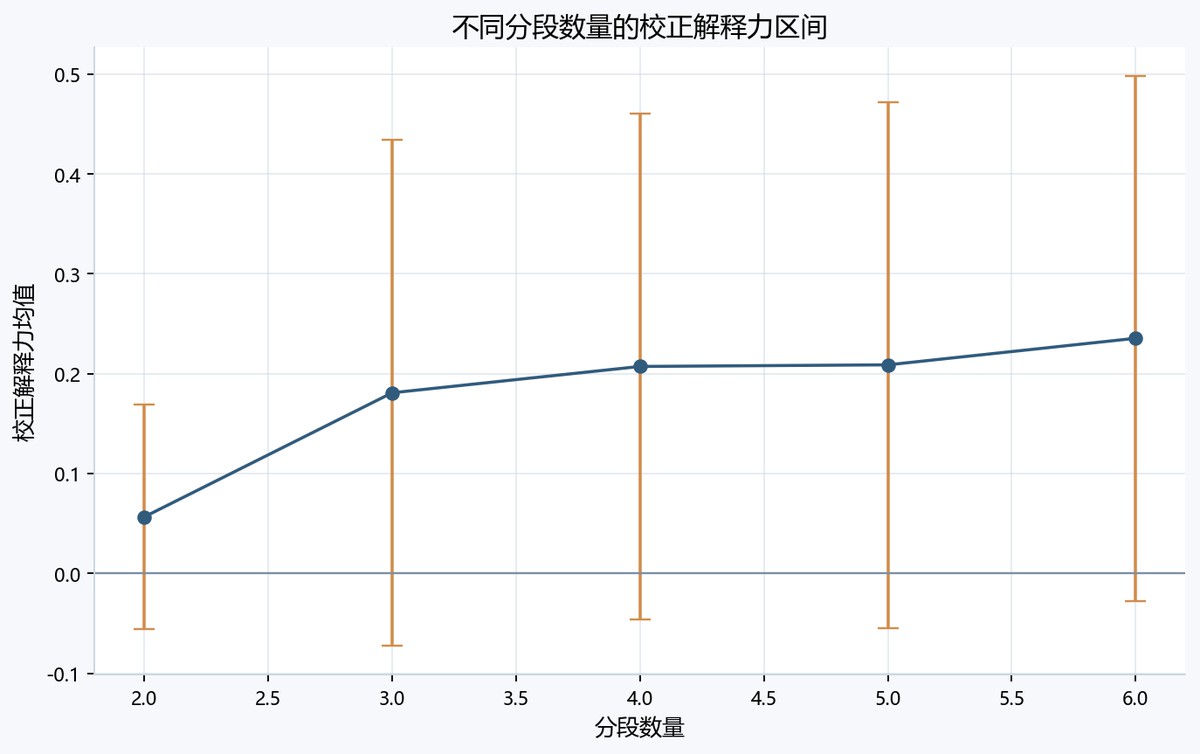
图8-3 errorbarcorrectedq图
表8-4 candidatemethod汇总结果表
| 分类方法 | 候选数量 | 平均解释力 | 平均描述长度 | 进入可接受集数量 |
|---|---|---|---|---|
| 等距分段 | 20 | 0.30018701445216006 | 17.87031254995958 | 3 |
| 等频分段 | 20 | 0.3168148115191989 | 17.87031254995958 | 4 |
| 自然断点近似 | 20 | 0.23230159902623546 | 16.997056894418428 | 2 |
图8-4 参数幅度图
preprocess overview
| 项目 | 取值 |
|---|---|
| 数据来源 | 外部补充数据:rank、pm25_2024_ug_m3 |
| 样本量 | 167 |
| 解释因子数量 | 4 |
| 候选方案数量 | 60 |
| 最终筛选方案 | rank-等距分段-3段 |
solution comparison
| 方案类型 | 候选方案 | 因子探测器解释力 | 描述长度 | 校正解释力 | 过拟合强度 |
|---|---|---|---|---|---|
| 原始最优方案 | pm25_2024_ug_m3-等距分段-6段 | 0.6832116916149014 | 24.367506672487526 | 0.5372984780071917 | 0.0 |
| 最终筛选方案 | rank-等距分段-3段 | 0.6110910443659179 | 14.720848728920398 | 0.5229422495819634 | 0.0 |
通用版论文完整预览大图
