一、什么是文本向量化?
1.1 通俗理解
文本向量化就是把文字(如一句话、一段文章)转换成一串数字(向量)的过程。这串数字就像文字的"数学指纹",能够被计算机理解和计算。
举个生活中的例子:
-
形容一个人:身高175cm、体重70kg、年龄28岁 →
[175, 70, 28](这就是一个三维向量) -
形容"苹果"这个词:可能被转换成
[0.2, -0.5, 0.8, 0.1, ...](高维向量)
1.2 为什么需要向量化?
核心原因 :计算机无法理解文字的"含义",只能处理数字。向量化的目标是将文字的语义关系 映射到数学空间中。
关键特性:语义相近的文字,它们的向量在空间中也相互靠近。
"猫" → [0.2, 0.8, 0.3, ...]
"猫咪" → [0.21, 0.79, 0.31, ...] (距离很近)
"汽车" → [0.9, 0.1, 0.7, ...] (距离较远)1.3 向量化的过程
原始文本
↓
分词处理
↓
【嵌入模型(Embedding Model)】
- OpenAI的text-embedding-ada-002
- 通义千问的text-embedding-v1
- 开源的all-MiniLM-L6-v2
↓
高维向量(如384维、768维、1536维)
↓
[0.12, -0.34, 0.56, 0.78, -0.23, ...]1.4 向量化的核心价值
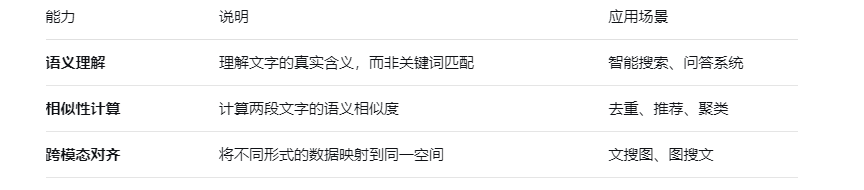
二、向量数据库介绍
2.1 什么是向量数据库?
向量数据库 是专门用于存储、管理和检索向量数据 的数据库系统。它的核心能力是通过高效的索引结构 和相似性计算算法 ,支持大规模向量数据的快速查询与分析。
维度越高,查询精准度也越高,但计算复杂度也会增加。
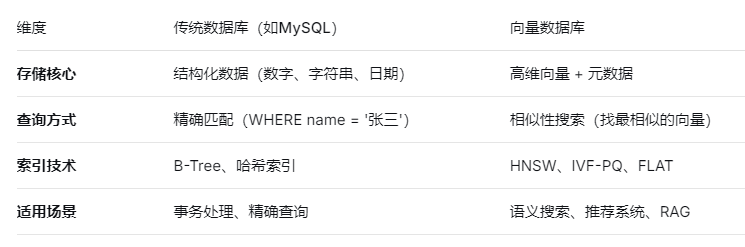
2.2 与传统数据库的对比
2.3 向量数据库的核心能力
-
向量索引:建立高效的数据结构,避免暴力遍历
-
相似性搜索:支持余弦相似度、欧氏距离、内积等距离计算
-
混合检索:同时支持向量相似度搜索和标量字段过滤
-
高性能:亿级数据毫秒级响应
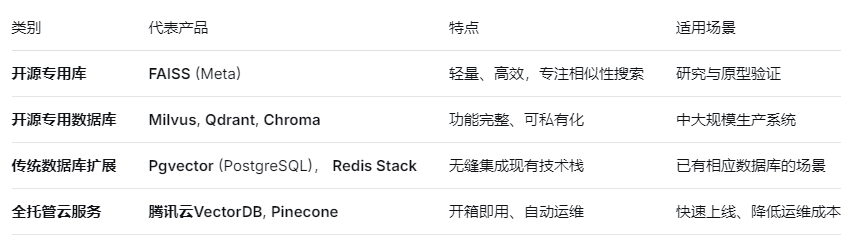
2.4 常见向量数据库分类
2.5 向量数据库的核心算法
2.5.1 相似性度量方法
// 1. 余弦相似度(Cosine Similarity)
相似度 = cos(θ) = (A·B) / (|A|·|B|)
// 值域[-1, 1],越接近1越相似,常用于文本
// 2. 欧氏距离(Euclidean Distance)
距离 = √(∑(Aᵢ - Bᵢ)²)
// 越小越相似
// 3. 内积(Dot Product)
内积 = A·B = ∑Aᵢ·Bᵢ
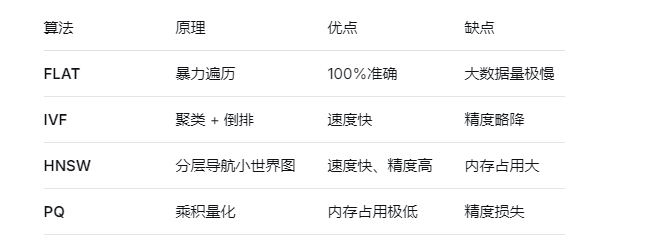
// 越大越相似,常用于评分预测2.5.2 索引算法
2.6 向量数据库的典型应用
-
应用1:语义搜索(RAG的基础)
用户问题:"如何治疗感冒?"
↓ 向量化
[0.2, -0.5, 0.8, ...]
↓ 向量数据库相似性搜索
返回最相似的文档:- "感冒的常见治疗方法..."(相似度0.95)
- "流感预防措施..."(相似度0.82)
- "发烧如何处理..."(相似度0.71)
-
应用2:推荐系统
用户看过《流浪地球》
↓ 向量化
[0.3, 0.7, -0.2, ...]
↓ 向量数据库搜索
推荐相似电影:- 《星际穿越》(相似度0.92)
- 《火星救援》(相似度0.88)
- 《阿凡达》(相似度0.75)
-
应用3:图片搜索
"一张日落海滩的照片"
↓ 文本向量化
[0.1, 0.6, -0.3, ...]
↓ 搜索图片向量库
返回最匹配的图片
2.7 向量数据库在RAG中的位置
用户问题
↓
向量化(Embedding Model)
↓
【向量数据库检索】 ← 知识库文档(已向量化)
↓
返回最相关的N个文档片段
↓
问题 + 检索到的文档 → 大模型(LLM) → 最终答案