1. Transformer 的相关概念
首先复习 Transformer 的相关概念:
https://fairy-study.blog.csdn.net/article/details/154795289
2. Prefill 的概念
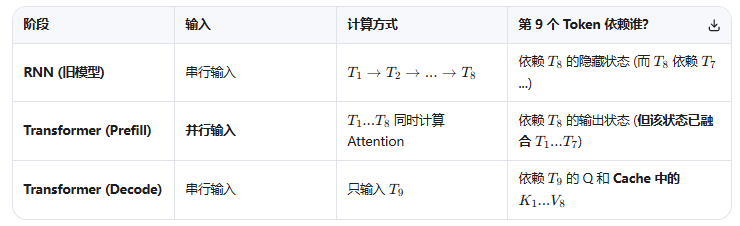
Prefill 的处理目标是对 输入 进行 并行 处理,得到最后一个 Token 的 输出状态,将用于 Decode 阶段。
2.1 Prefill 流程
任务: 处理所有 输入 Token,并计算出 第 1 个输出 Token。
- 输入: "告", "诉", "我", "如", "何", "学", "习", "?" (假设 8 个 Token)
- 并行计算:
GPU一次性把这 8 个 Token 全部送入模型。- 模型计算这 8 个 Token 的
Q、K、V。 - 然后将这 8 个输入 Token 产生的
K、V矩阵存入显存(KV Cache 此时大小 = 8)。
- 生成第一个 Token:
- 模型利用第 8 个 Token("?")的输出状态,计算 第 9 个位置 的概率分布。
Softmax->采样-> 得到 第 1 个输出 Token(比如"要")。
- 结束: Prefill 阶段结束。
- 耗时 :这就是 TTFT (Time To First Token,首字延迟)。
- 用户感知 :屏幕上是空白,直到这一刻,突然跳出第一个字"要"。
KV-Cache 的好处
不用重复生成以往 Token 的 KV 键值对了,直接从 Cache 中提取出来和当前 Token 的 Q 算点积,然后加权求和即可。
3. Prefill 流程的例子
虽然 Prompt 的 Q、K、V 的生成是并行的,但是最后一个 Token(Q) 会和所有 Token(K) 进行计算,然后加权求和(投影到所有 Token 信息量上),得到的向量再给到 FFN 输出然后 Softmax 采样投影到词表上,即为下一个 Token 的生成。
Prefill 和 Decode 的区别如下所示:
3.1 输入层 (Embedding)
用户输入 8 个词,经过 Embedding 后变成了一个巨大的矩阵。
- Shape:
[8, 4096]
3.2 生成 Q, K, V (Linear Projection)
矩阵一次性乘以三个权重矩阵 W q , W k , W v W_q, W_k, W_v Wq,Wk,Wv(形状均为 [4096, 4096])。
- Q Shape:
[8, 4096] - K Shape:
[8, 4096] - V Shape:
[8, 4096]
关键点: 这 8 个位置的向量在此时确实是"各跑各的"。
3.3 计算 Attention (核心聚合步骤)
这是"信息聚合"发生的地方。计算 Q × K T Q \times K^T Q×KT:
- 运算:
[8, 4096] @ [4096, 8] - Attention Score Shape:
[8, 8]
因果掩码 (Causal Mask): 这是一个 8 × 8 8 \times 8 8×8 的下三角矩阵。
- 第一行只有 1 个有效值(只能看自己)。
- 第八行有 8 个有效值(能看前面所有人)。
3.4 加权求和 (V-Aggregation)
用 [8, 8] 的注意力得分去乘以 V 矩阵 [8, 4096]:
- 运算:
[8, 8] @ [8, 4096] - Output Shape:
[8, 4096]
深度剖析: 虽然形状还是
[8, 4096],但此时第 8 行 的那个向量,已经通过矩阵乘法,融合了 V 1 V_1 V1 到 V 8 V_8 V8 的所有信息。它就是你说的"吸干精华"的那个向量。
3.5 存储 KV Cache
此时,模型会将刚才算出的 K 和 V 存入显存。
- KV Cache Shape (每层):
[8, 4096](K 矩阵) 和[8, 4096](V 矩阵)。
3.6 预测首字 (LM Head)
模型并不在乎前 7 个位置的输出,它只切出最后一行:
- Slice:
[1, 4096](这是第 8 个位置的输出状态)。 - LM Head Projection:
[1, 4096] @ [4096, 128000](词表大小)。 - Probabilities Shape:
[1, 128000]。 - 结果: 采样得到第 9 个 Token(第 1 个生成的字)。
3.7 总结:Shape 的变迁表
| 阶段 | 矩阵操作 / 描述 | 输出 Shape | 备注 |
|---|---|---|---|
| Input | Embedding | [8, 4096] |
8个初始向量 |
| QKV Gen | X × W X \times W X×W | Q, K, V 各 [8, 4096] |
并行线性变换 |
| Attention | Q × K T Q \times K^T Q×KT | [8, 8] |
因果关联发生处 |
| Context | S c o r e × V Score \times V Score×V | [8, 4096] |
信息聚合完毕 |
| Cache | 写入显存 | K, V 各 [8, 4096] |
为后续 Decode 存底 |
| Logits | 仅取最后一位映射 | [1, 128000] |
准备吐出第 1 个字 |
问题:既然是并行的话,为什么长输入模型处理仍然很慢?
这个问题其实分为两个问题:
- 并行的话,为什么长输入模型处理仍然很慢?
- 为什么输入越长,消耗的显存就越大?
答案就在才推导的那个 8, 8 的注意力得分矩阵(Attention Score Matrix)里(第三步)。让我们把这个数字放大,看看长文本下发生了什么:
为什么会变慢?& 显存消耗大:
- 计算复杂度 O ( N 2 ) O(N^2) O(N2): 随着序列长度 N N N 的增加,计算量不是线性增长,而是翻倍增长。100k 的输入比 1k 的输入长了 100 倍,但计算量却增加了 10,000 倍。
- 显存压力: 这个 N, N 的矩阵需要临时存储在显存中(即便使用了 FlashAttention 这种优化技术,中间变量的开销依然巨大)。当 N N N 极大时,单张显卡的显存会被这个矩阵直接撑爆。(虽然算完后就会删掉这个 N, N 的矩阵),同时
KV-Cache作为长期资产也会消耗极大的显存
注意:
[N, N]的注意力矩阵算完后就会删除,因为我们只需要获取Prompt最后一个Token对前面Token的注意力权重 (shape为[1, dim]);以此获得下一个Token的预测。
内存带宽瓶颈(Memory Wall)
虽然 GPU 算矩阵乘法很快,但 Prefill 阶段还需要把算出来的每一个 K K K 和 V V V 写入显存(即创建 KV Cache),这对 IO 吞吐量的要求很大(挑战带宽极限)。
- 当 N N N 非常大时,模型需要一次性往显存里写入海量数据。
- 比如一个 128k 长度的 Prefill,在 Llama 3-8B 上产生的 KV Cache 大约有几个 GB。虽然听起来不大,但 GPU 需要在极短的时间内完成大规模并发写入,这会撞上 显存带宽(Bandwidth) 的天花板。
4. Decode 的概念
在 Decode 阶段,模型不再一次性处理所有 Token,而是一次只处理一个 Token,生成之后再将该 Token 作为下一次的输入。这就是所谓的**自回归(Autoregressive)**生成。
4.1 Decode 的核心流程
假设我们在 Prefill 阶段已经输出了第 1 个字"要",现在我们要生成第 2 个字。
- 输入: 只有刚才生成的那个字"要" (Shape:
[1, 4096])。 - 计算: 计算"要"的
Q、K、V。 - KV Cache 复用(核心!) :
- 模型不去重新计算前 8 个 Token 的
K, V,而是直接从显存中读取KV Cache([8, 4096])。 - 将"要"产生的
K_9, V_9拼接到 Cache 后面,更新为[9, 4096]。
- 模型不去重新计算前 8 个 Token 的
- Attention 聚合:
- 仅用"要"的
Q_9与全部K(1-9) 做点积。 - 得到一个长度为 9 的注意力权重向量
[1, 9]。 - 用这个权重去加权求和所有的
V(1-9),得到一个融合了上下文信息的向量[1, 4096]。
- 仅用"要"的
- 输出预测: 经过 FFN 和 LM Head,映射到词表概率,采样得到第 2 个字(比如"学")。
4.2 Prefill vs Decode 的本质差异
| 维度 | Prefill (预填充) | Decode (解码) |
|---|---|---|
| 输入规模 | [N, 4096] (并行全量) |
[1, 4096] (逐个迭代) |
| 计算模式 | 计算密集型 (Compute-Bound) | 访存密集型 (Memory-Bound) |
| GPU 状态 | 核心满载,并行矩阵乘法 | 核心闲置,主要在搬运数据 |
| KV Cache | 从无到有,批量写入 | 逐行追加,读多写少 |
4.3 为什么 Decode 阶段会面临"显存带宽墙"?
这是你前面提到的疑问,在 Decode 阶段表现得尤为明显:
- 算力利用率极低 (MFU 低): 在 Decode 时,为了生成一个词,GPU 需要把模型的所有参数(比如 8B 的参数,约 16GB)从显存搬运到计算单元,就为了做一次加乘。为了蹦一个字,要搬运 16GB 的数据。这导致 GPU 的 Tensor Core 大部分时间都在等数据从显存搬运过来。
- 带宽就是生命线: 如果你有 100 个用户同时在对话,GPU 就需要同时维护 100 份 KV Cache。在 Decode 阶段,GPU 需要在极短时间内读出这 100 份 Cache 并进行计算,如果显存带宽不够,用户的生成速度(Tokens Per Second, TPS)就会直线下降,甚至出现明显的"卡顿"。
没问题,我们抛弃厨房做菜这种比喻,直接进入 GPU 硬件架构与访存的硬核底层逻辑。
要理解为什么 Decode 阶段会卡在"搬运数据"上,必须看透 "算力(FLOPS)"与"显存带宽(Bandwidth)"的物理不对称性。
4.3.1 物理层面的"算力 vs 带宽"陷阱
现代 GPU 的设计目标是处理大规模并行计算,而不是为了处理这种"高频、低计算量"的自回归推理。
- 计算能力 (FLOPS): NVIDIA H100 的 FP16 计算能力高达 2000 TFLOPS (每秒 2000 万亿次运算)。
- 显存带宽 (Bandwidth): H100 的 HBM3 带宽约为 3.3 TB/s (每秒 3.3 万亿字节)。
核心瓶颈公式:
在 Decode 阶段,针对一个 Token 的计算量是极小的,但为了完成这个计算,你必须遍历整个模型权重。
计算强度 (Arithmetic Intensity) = 总计算量 (FLOPs) 总访存量 (Bytes) \text{计算强度 (Arithmetic Intensity)} = \frac{\text{总计算量 (FLOPs)}}{\text{总访存量 (Bytes)}} 计算强度 (Arithmetic Intensity)=总访存量 (Bytes)总计算量 (FLOPs)
当这个强度低于某个阈值(Roofline Model 的临界点)时,GPU 的 Tensor Core 就会因为还没拿到数据而进入"等待(Stall)"状态。这就是你感受到的"算力利用率低"。
4.3.2 为什么 Decode 阶段必须搬运所有权重?
你在处理 Decoder-only Transformer(如 Llama/GPT)时,其结构是固定的:
- 逐层处理: 输入必须经过第 1 层、第 2 层... 直到第 L L L 层。
- 权重不可丢弃: 在计算第 i i i 层的隐藏状态时,必须使用该层对应的 W q , W k , W v W_q, W_k, W_v Wq,Wk,Wv 以及 W f f n W_{ffn} Wffn 矩阵。
- 计算逻辑: 由于这是一个串行过程(这一层的输出是下一层的输入),计算单元(ALU/Tensor Core)在处理第 i i i 层时,第 i i i 层的权重必须已经在计算单元的缓存(SRAM)中。
当处理完第 i i i 层后,这部分权重会被换出,立即搬入第 i + 1 i+1 i+1 层的权重。这种逐层加载模式,意味着无论你生成多少 Token,每一轮 Decode 都要把整个模型参数搬一遍。
4.3.3 KV Cache 的带宽开销
在之前的对话中,我们确定了 N × N N \times N N×N 的 Attention 矩阵在 FlashAttention 下实现了"算完即焚",不需要长期占用带宽。但是,KV Cache 是不同的:
- 读写循环: 每一轮 Decode,GPU 必须:
- 从显存读取
KV_1到KV_{N-1}的历史记录(带宽消耗 O ( N × d ) O(N \times d) O(N×d))。 - 计算当前
KV_N。 - 将更新后的
KV_1到KV_N写回显存(带宽消耗 O ( N × d ) O(N \times d) O(N×d))。
- 随着上下文增长: N N N 越大,每一轮 Decode 必须搬运的 KV 数据就越多。当 N N N 达到 128k 时,每生成一个 Token,你需要从显存中搬运几 GB 的数据,这直接导致了你看到的"TPS 下降"。
4.3.4 为什么会有"卡顿"?
当 100 个用户并发时,我们使用了 Continuous Batching (连续批处理)。
- 调度层: 我们将 100 个用户的请求放在一个 Batch 里,GPU 一次性搬运 16GB 的模型权重。
- 物理层: 由于带宽是有限的,GPU 必须在 100 个请求之间频繁切换以完成计算。如果显存带宽被 100 个用户的 KV Cache 读写填满,计算单元(Tensor Cores)就会因为缺乏下一层的权重数据而空转。
这就是所谓的**"带宽墙 (Memory Wall)"**。
总结
- 算力利用率低是因为计算单元处理一个 Token 所需的运算量(FLOPs)太小,远少于它在相同时间内能完成的上限。
- 带宽瓶颈是因为模型参数量(16GB+)太大,相对于每秒能搬运的极限(3.3 TB/s),它拖慢了处理下一个 Token 的速度。
既然这是硬件架构决定的"物理限制",现在的工程优化手段(如量化 Quantization、Speculative Decoding 投机采样)本质上都是在尝试突破这个限制。你认为通过"压缩数据量(量化)"和"减少搬运次数(投机采样)",哪一种方式对解决你目前关注的瓶颈更有效?