我们为什么还要学习统计学习方法?
在如今深度学习(Deep Learning)和大语言模型(LLMs)"大杀四方"的时代,连几行代码就能调用强大的 AI,为什么我们还要回头去啃《统计学习方法》里那些看似"老旧"的传统算法(如 SVM、逻辑斯谛回归、决策树)?
我们学习统计学习方法,是因为它是对人类"认知过程"和"世界运转规律"最严谨的数学抽象。它不仅是一门技术,更是一套底层世界观。
深度学习像是一门极度发达的炼金术------我们把海量数据丢进高温熔炉(GPU),炼出了令人惊叹的智能,但我们往往不知道炉子里到底发生了什么。
而统计学习是化学。它探究的是分子结构的键结规律、反应的质量守恒。学习统计学习方法,不是为了让你去用那些老旧的公式,而是为了让你拥有这套"化学体系"------让你在面对任何绚丽的 AI 魔法时,都能一眼看穿它背后的概率与边界。
总的来说,学习统计学习方法不仅是为了"打地基",更是为了解决工业界中深度学习无法解决的痛点。具体原因可以归结为以下五点:
1. 它是理解一切现代 AI 的"内功心法"
深度学习并不是凭空出现的,它本质上仍然是统计学习的延伸(可以理解为一个极度复杂、非线性的模型)。 今天大模型训练中用到的核心概念------损失函数(Loss Function)、梯度下降(Gradient Descent)、过拟合与正则化、交叉验证------全部脱胎于传统的统计学习。如果不理解这些底层概念,在调参神经网络时就会像"炼丹"一样盲目,遇到模型不收敛或泛化能力差的问题时,根本无从下手排查。
2. 极致的可解释性(Interpretability)
这是传统统计学习最大的护城河。深度学习是一个"黑盒",它也许能给出 99% 准确率的预测,但它无法告诉你为什么。
-
在医疗诊断中,医生不能仅仅因为"AI 说病人有 90% 的概率患癌"就做手术,他们需要知道是哪些指标导致了这个结论。
-
在金融风控(如信贷审批)中,法律合规要求银行必须向客户解释为什么拒绝了他们的贷款申请。 在这些对安全性和合规性要求极高的领域,逻辑斯谛回归或决策树等具备清晰数学解释的统计学习方法,依然是不可替代的绝对主力。
3. 小数据场景的"王者"
深度学习是"数据喂出来的巨兽",需要海量的标注数据才能发挥威力。但在现实的很多商业场景或科学研究中,我们根本拿不到千万级的数据。 如果你手头只有几百或几千条样本,跑深度学习模型几乎肯定会严重过拟合。此时,支持向量机(SVM)、随机森林(Random Forest)或朴素贝叶斯(Naive Bayes)反而能发挥极其稳定的作用,在极小的数据集上榨取最大的价值。
4. 算力与工程成本的极高性价比
训练一个深度神经网络通常需要昂贵的 GPU 算力、复杂的环境配置以及几小时甚至几天的训练时间。 相比之下,训练一个传统的统计学习模型(比如用 Scikit-Learn 跑一个线性回归或 k近邻),在普通的 CPU 笔记本上只需要几毫秒到几秒钟。在对延迟要求极高、或者部署资源极其受限(如边缘计算、物联网设备)的场景下,轻量级的传统模型是唯一的选择。
5. 工业界的"基准线(Baseline)"
在真实的算法工程实践中,面对一个新问题,成熟的工程师永远不会 一上来就套用最复杂的深度神经网络。 标准流程是:先花 10 分钟跑一个最简单的统计学习模型(比如逻辑斯谛回归),建立一个基准线(Baseline)。
-
如果基准模型已经达到了 85% 的准确率,满足了业务需求,那么项目就可以直接上线,节省了巨大的研发成本。
-
如果基准模型表现不佳,这个过程也能帮助工程师快速了解数据的分布特征,然后再有针对性地引入更复杂的模型。
总结来说: 深度学习决定了目前人工智能能达到的上限 ,而统计学习方法决定了你在算法领域的下限。前者教你如何造出马力最大的发动机,后者教你理解机械运转的物理规律。
第一章:统计学习
在《统计学习方法》一书中,李航给出了一个严谨的定义:统计学习(Statistical Learning)是关于计算机基于数据构建概率统计模型,并运用模型对数据进行预测与分析的一门学科。
它在学术界和工业界也常被称为统计机器学习(Statistical Machine Learning)。
如果跳出学术定义,用通俗的话来解释,统计学习就是教计算机如何"从历史经验中总结规律,并利用这些规律来预测未知"。
1. 统计学习的核心运作逻辑
传统的计算机程序是"规则驱动"的(程序员写好 If-Else,计算机照做);而统计学习是"数据驱动"的。它的完整链路通常包含三步:
-
输入数据(Data): 收集大量的、已经被记录下来的事实(即训练集)。比如一万封标记了"正常"或"垃圾"的邮件。数据是统计学习的"燃料"。
-
构建模型(Modeling): 假设数据背后存在某种未知的数学规律(概率分布或函数映射)。计算机运用算法,在海量数据中不断试错、调整参数,最终拟合出一个最符合这批数据的数学模型。这就相当于计算机"学"到了识别垃圾邮件的规律。
-
预测未知(Prediction): 当有一封全新的邮件进入系统时,计算机利用刚才学到的模型,计算出这封信是垃圾邮件的概率。
2. 统计学习的三个显著特点
-
拥抱不确定性(以概率统计为基础): 现实世界充满了噪声和例外,很难用绝对的公式来描述。统计学习不去寻找绝对真理,而是寻找统计学上的最优解。它输出的结果往往是概率(例如"这张图片有 95% 的概率是猫"),这让它对真实世界的容错率非常高。
-
数据决定上限: 既然规律是从数据里提取的,那么数据的质量、规模和代表性,就直接决定了模型最终的聪明程度。"Garbage in, garbage out(垃圾进,垃圾出)"是统计学习的铁律。
-
注重可解释性: 传统的统计学习方法(如决策树、逻辑斯谛回归)往往有着严密的数学理论支撑,当模型给出一个预测时,我们通常可以从数学上解释它为什么会得出这个结论。不过现在的深度学习比较类似于黑盒
3. 它和机器学习、深度学习是什么关系?
-
统计学习 ≈ 机器学习: 在现代语境下,人们口中的"传统机器学习"(如支持向量机 SVM、随机森林、k近邻等)绝大多数都属于统计学习的范畴。两者在很大程度上是同义词。
-
统计学习 vs 深度学习: 深度学习(如神经网络、大语言模型)本质上也是基于数据进行优化的模型,可以看作是统计学习的一个极其复杂、非线性的分支。不过,传统的统计学习更依赖人工提取数据的特征(Feature Engineering),模型相对简单透明;而深度学习模型像一个巨大的"黑盒",它自己学习提取特征,能力更强,但牺牲了可解释性和数学上的优美性。
第二章:统计学习分类
为了避免我们陷入只见树木不见森林的算法细节中,书中从四个不同的维度对统计学习进行了全面的分类。我们逐一拆解:
1. 基本分类(按数据有没有"标准答案"分)
这是最常见、也最重要的分类方式。它是根据输入数据(特别是标签变量 的存在与否)来划分的:
监督学习(Supervised Learning):
特点: 数据集里的每一个样本都有"标准答案"(标签 Y)。比如一张猫的图片,一定附带着"这是一只猫"的标记。形式化表示为 。
比喻: 就像学生做带有标准答案的练习题,做错了老师会立刻纠正(计算损失),直到学会为止。
无监督学习(Unsupervised Learning):
特点: 数据集里只有特征 X,没有任何标签 Y。系统需要自己去发现数据内部的结构和规律。
典型任务: 聚类(把长得像的数据分到一组)、降维(把高维数据压缩到低维)。
比喻: 给你一堆没有书名的书,让你自己想办法把它们分门别类摆到书架上。
半监督学习(Semi-supervised Learning):
特点: 少量数据有标签,海量数据无标签。利用无标签数据来辅助提升有标签数据的学习效果。这是因为现实中"打标签"的成本极高(比如需要医生逐一标注几十万张 X 光片)。
强化学习(Reinforcement Learning):
特点: 没有明确的数据集,而是让一个智能体(Agent)在环境(Environment)中不断试错。做对了给奖励,做错了给惩罚,最终学到一个最优的行动策略(Policy)。
比喻: 就像训练小狗,它坐下了你就给骨头,它乱咬人你就训斥。AlphaGo 下围棋就是典型的强化学习。
2. 按模型分类(按内部构造分)
当确定了我们要解决什么基本问题后,我们选择的"模型"本身可以怎么分类?书中给出了三个对比视角:
概率模型 vs 非概率模型:
-
概率模型: 模型学到的是一个联合概率分布
或条件概率分布
-
非概率模型(确定性模型): 模型学到的是一个严密的函数映射
线性模型 vs 非线性模型:
- 如果模型的决策边界是一个平直的超平面(在二维里是直线,三维里是平面),就是线性模型 (如线性回归)。如果决策边界弯曲了,就是非线性模型(如深度神经网络)。
参数化模型 vs 非参数化模型(极其重要的考点):
-
参数化模型(Parametric): 无论输入数据有多少,模型参数的维度是固定死 的。比如一条直线
-
非参数化模型(Non-parametric): 这是一个极其糟糕的翻译!它不是指"没有参数",而是指"参数的维度不固定,会随着数据量的增大而无限增多"。比如决策树,数据越复杂,树长得越深,参数就越多。
3. 按算法分类(按学习方式分)
这关乎计算机吸收数据的方式:
-
批量学习(Batch Learning): 必须把所有数据一次性全部喂给计算机,算出一个全局最优解。如果明天多了一条新数据,对不起,整个模型必须推倒重新训练一遍。
-
在线学习(Online Learning): 数据像流水一样一个一个地进来,模型每看一个数据,就微微调整一下自己的参数。它非常适合数据源源不断产生的场景(比如股票预测、淘宝的实时商品推荐)。
4. 按技巧分类(按底层的数学思想分)
这是从更高的理论视角来看待机器学习的流派:
-
贝叶斯学习(Bayesian Learning): 它的核心思想是"先验 + 证据 = 后验"。它不仅给出一个单一的最优预测,还会给出这个预测的"置信度"(即我有多大的把握认为它是对的)。
-
核方法(Kernel Method): 这是本世纪初统治学术界的"神技"。当我们遇到在低维空间里根本无法用直线切分的数据(线性不可分)时,核函数(Kernel Trick)可以兵不血刃地将数据映射到无限维的空间中,让它们瞬间变得线性可分。支持向量机(SVM)就是把它发扬光大的代表。
第三章:统计学习方法三要素
这是整本书的核心骨架 ,李航老师在 1.3 节提出了一个极其著名的公式: 方法 = 模型(Model) + 策略(Strategy) + 算法(Algorithm)
这就好比你要去相亲(解决一个具体问题),你需要先确定你想找个什么样的人(模型),然后确定你们俩到底配不配的判断标准(策略),最后决定你用什么手段去追到这个人(算法)。
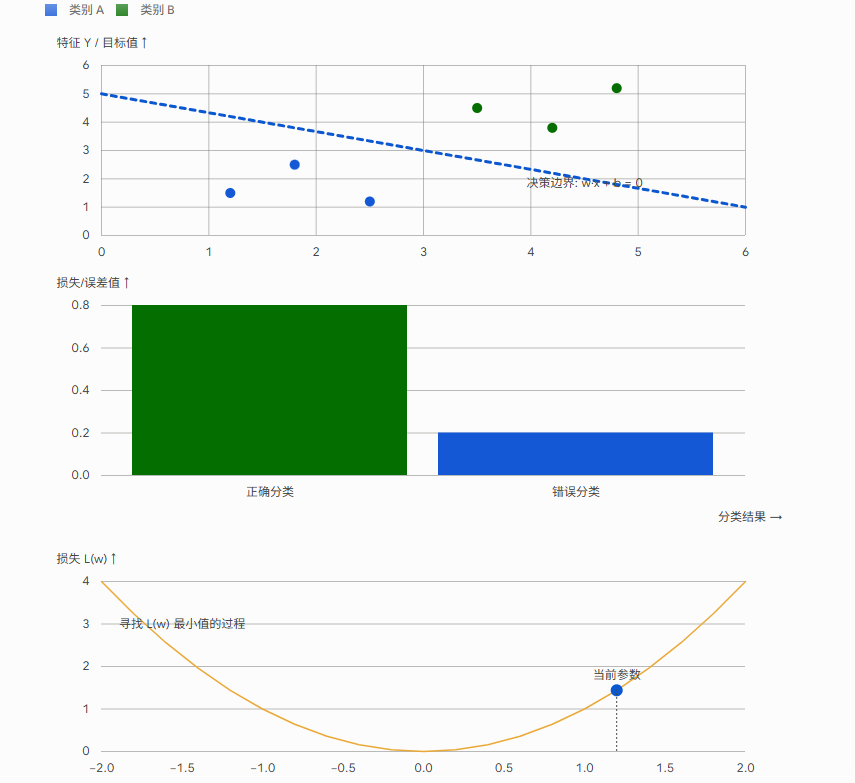
1. 模型(Model):假设空间
"你想找一个什么样的函数来拟合数据?"
我们面对一堆数据时,并不知道它们背后真实的规律究竟是直线、抛物线还是更复杂的曲线。因此,我们要预先给定一个"范围",这个范围在数学上叫作假设空间(Hypothesis Space)。
-
如果我们假设数据背后是线性关系,我们的假设空间就是所有的线性函数(比如
-
模型就是这个空间里等待被确定的那一个具体的函数 。我们最终要学的,其实就是公式里的那些参数(比如
2. 策略(Strategy):评价标准
"在这么多可选的模型中,你怎么定义哪个是'最好'的?"
哪怕你确定了只找"直线",假设空间里也有无数条直线。为了挑出最好的一条,我们需要一套评价标准。这就引出了两个极其关键的概念:
-
损失函数(Loss Function): 用来衡量单次预测有多离谱。比如你预测房价是 100 万,实际是 120 万,那误差就是 20 万。常见的有 0-1 损失、平方损失、绝对损失、对数损失。
-
风险函数(Risk Function): 用来衡量模型在所有可能的数据上的平均损失。我们当然希望风险越小越好。
这里就产生了两个著名的策略:
-
经验风险最小化(ERM): 只要在现有的训练数据上误差最小,就是好模型(容易导致过拟合)。
-
结构风险最小化(SRM): 在经验风险的基础上加上一个惩罚项(正则化),既要求对训练数据拟合得好,又要求模型不能太复杂。
3. 算法(Algorithm):求解方法
"既然有了评价标准,你怎么计算出那个最好的模型?"
在确定了模型和策略后,统计学习问题就彻底变成了一个纯粹的最优化问题(Optimization Problem)。
算法,指的就是我们用什么具体的数学计算手段来找到让损失函数最小的那些参数(比如 w 和 b)。
-
如果最优化问题有显式的解析解,那算法就比较简单(比如线性回归的最小二乘法)。
-
如果解析解算不出来,我们就需要用数值计算的方法去一步步逼近最优解,比如深度学习中最常用的梯度下降法(Gradient Descent),或者牛顿法、拟牛顿法等。
总结起来:
你拿到一个实际问题时,首先构建模型 (圈定你要找的函数范围),然后设定策略 (写出一个包含你要找的参数的损失函数),最后运行算法(用求导或梯度下降把这个损失函数的最小值算出来,得到最终的参数)。
第四章:模型选择与模型评估
在理解了上一节的"三要素"(怎么把模型算出来)之后,紧接着面临的就是一个灵魂拷问:算出来的这个模型,真的好用吗?
这正是 1.4 节"模型评估与模型选择"要解决的问题。如果说 1.3 节教你怎么训练一个模型,那么 1.4 节就是在教你怎么给这个模型"阅卷",并淘汰掉不合格的残次品。
1. 评估标准:训练误差 vs 测试误差
衡量一个模型好不好,书中给出了两个维度的指标:
-
训练误差(Training Error): 模型在训练集 (已经见过的数据)上的平均损失。这反映了模型的拟合能力,就好比学生做"课后练习题"的错误率。
-
测试误差(Test Error): 模型在测试集 (从未见过的新数据)上的平均损失。这反映了模型对未知世界的泛化能力(Generalization Ability),就好比学生在"期末闭卷考试"中的错误率。
书中强调了一个铁律:测试误差(泛化能力)才是评估模型的唯一黄金标准。 毕竟我们训练 AI 是为了预测未来,而不是背诵过去。
2. 核心痛点:过拟合(Overfitting)
既然我们要选最好的模型,那是不是在假设空间里,直接挑那个"训练误差最小"的模型就行了? 绝对不行。 这就引出了机器学习中最臭名昭著的现象------过拟合。
-
本质原因: 模型过于复杂(参数太多、能力太强),为了强行让训练误差降到 0,它把训练数据里的"随机噪声"和"偶然特征"也当成了普遍规律学了进去。
-
通俗比喻: 就像一个学生为了拿满分,不仅死记硬背了所有历史练习题的答案,连某道题旁边沾了一滴墨水都当成了解题规律记了下来。结果一上期末考场遇到新题,彻底抓瞎(训练误差接近 0,但测试误差极大)。
随着模型复杂度逐渐增大:
-
训练误差: 会一直单调下降,因为模型越来越聪明,总能完美拟合见过的数据。
-
测试误差: 呈现出一个明显的 "U 型曲线"。
当模型太简单时,训练和测试误差都很大,这叫欠拟合(Underfitting) ;当模型太复杂时,就陷入了过拟合 。 因此,模型选择(Model Selection)的终极目标,就是在复杂的假设空间中,寻找这个"U型曲线"的最低点------既不太简单,也不太复杂,恰好能捕捉数据真实规律的那个模型。
第五章:正则化与交叉验证
如果在上一节,模型因为"死记硬背"患上了过拟合的绝症,那么李航在第 1.5 节就开出了两剂极其经典的解药:一剂来自数学的内服药(正则化),一剂来自工程实践的外敷药(交叉验证)。
这两者也是机器学习面试中几乎必考的核心知识点。
解药一:正则化(Regularization)------ 数学层面的"断舍离"
正则化的核心哲学是奥卡姆剃刀原理(Occam's Razor) :在所有可能选择的模型中,能够很好地解释已知数据并且十分简单的模型才是最好的。
它是怎么运作的?
上一节我们说,模型为了追求"训练误差最小",会疯狂变复杂。正则化的做法非常霸道:直接在损失函数(评价标准)后面加上一个惩罚项(Penalty)。
其数学公式通常长这样:
-
前面那一堆是经验风险(模型在训练集上犯的错)。
-
后面的 J(f) 就是正则化项/惩罚项(代表模型的复杂程度)。
-
这样一来,模型在训练时就面临一个两难的选择:如果想让前面的训练误差降到 0,就必须变复杂,但一旦变复杂,后面的惩罚项就会变得极大。为了让总得分(结构风险)最小,模型只能被迫"断舍离",舍弃掉那些不必要且复杂的参数。
书中提到了最常用的两种惩罚方式:
-
-
解药二:交叉验证(Cross Validation)------ 工程层面的"模拟考"
如果说正则化是在算法内部做文章,那么交叉验证就是在数据的使用方式上做文章。
评估模型泛化能力最标准的方法是:把数据切分为训练集(平时练习)、验证集(模拟考,用来调参)、测试集(期末考,只看一次) 。 但是,现实中往往数据不够用。如果你切出太多数据去考试,用来训练的数据就变少了,模型根本学不到东西。
交叉验证的本质就是:榨干每一滴数据的价值,让数据既当训练题,又当考试题。

书中总结了三种常见的交叉验证方法:
-
简单交叉验证: 随便把数据切成两半,70% 训练,30% 测试。缺点是如果切分得很偏,结果就不可靠。
-
S折交叉验证(S-fold): 就像上面的组件演示的,把数据均分成 S份。每次拿 1 份当测试,剩下 S-1 份当训练。重复 S 次,最后把 S$次的准确率取个平均值。这是工业界用得最多、最稳妥的评估方式。
-
留一交叉验证(Leave-One-Out): 极其极端的一种做法。假设你有 N 条数据,就把数据切成 N份。每次拿 1 条数据测试,剩下的 N-1 条全部用来训练。由于每次只留一条数据,它的评估结果非常准,但计算量大得惊人(如果是十万条数据,你要训练十万次模型),通常只在数据量极小(比如只有几十条生物医疗数据)时使用。
第六章:泛化能力
在《统计学习方法》的 1.5 节中,除了正则化和交叉验证,另一个核心的纯理论概念是泛化能力(Generalization Ability)及其数学化表述------泛化误差上界(Generalization Error Bound)。
统计学习中最核心的矛盾是:我们想知道模型在未来所有未知数据上的真实错误率(泛化误差),但我们永远只能计算出它在当前有限训练数据上的错误率(训练误差)。
如果一个模型在训练数据上错误率是 5%,我们能说它在未来的真实错误率也是 5% 吗? 绝对不能。
这就产生了一个焦虑:训练错误率和真实错误率之间,到底有多大的差距?这个差距有没有一个物理或者数学上的极限?
这一部分完全建立在概率论与统计学的基础上,用于从数学上证明"为什么模型在训练集上表现好,在测试集上也能有保障"。我们直接从其数学定义和定理推导来进行拆解:
1. 泛化误差的本质定义
泛化能力是指由该方法学习到的模型对未知数据的预测能力。
在数学上,如果学习到的模型是 ,那么这个模型的泛化能力就是用泛化误差(Generalization Error)来衡量的。泛化误差实际上就是模型
的期望风险(Expected Risk):
-
由于联合概率分布
-
我们在训练时唯一能直接计算的是经验风险(Empirical Risk) ,即模型在训练集上的平均误差
因此,统计学习理论的核心任务之一,就是通过已知的经验风险 ,去估计未知的泛化误差
。
2. 泛化误差上界(Generalization Error Bound)
为了建立经验风险和泛化误差之间的数学关系,书中引入了"泛化误差上界"的定理。
其基本逻辑是:泛化误差总是小于或等于"训练误差"加上一个"复杂度的惩罚项"。
即真实的错误率,绝对不会超过"训练错误率"加上一个"极限偏差 "。
只要我们能算出这个极限偏差 是多少,我们对模型在未来的表现就有底了。
用不等式表示为:
其中:
-
-
-
3. 泛化误差上界的数学推导(以有限假设空间为例)
书中为了证明这个结论,以二类分类问题、且假设空间 是有限集合(包含
个函数)为例,利用霍夫丁不等式(Hoeffding Inequality)进行了推导。
最终得出的泛化误差上界公式为:对于任意函数 ,至少以概率
,以下不等式成立:
我们直接对公式右侧的第二项(即复杂度项 \\varepsilon)进行变量分析,这解释了机器学习中的三个绝对客观规律:
-
样本容量 N 的影响:
变量 N 在根号下的分母位置。当样本容量N 增大时,整体项
-
假设空间容量 $(模型复杂度)的影响:
变量 d代表假设空间中函数的个数(可以抽象理解为模型的复杂度),它在根号下的分子位置(
-
置信度
第七章:生成模型与判别模型
在监督学习中,我们的最终目标都是针对给定的输入特征 X,预测出输出标签 Y。但在实现这个目标的数学路径上,存在着两种截然不同的建模思路。
李航在书中将它们划分为生成方法(Generative Approach)和判别方法(Discriminative Approach) 。它们的根本区别在于模型试图去拟合哪一种概率分布。
1. 判别方法 (Discriminative Approach)
数学本质: 直接从数据中学习决策函数 或者条件概率分布
。
-
运算逻辑: 判别模型不关心输入数据 X 本身是如何产生的,也不关心 X 的内部特征分布(即不计算 P(X))。它只专注于寻找一条"决策边界"。给定一个输入 X,模型直接计算出它属于各个类别 Y 的概率 P(Y|X),然后取概率最大的那个类别作为结果。
-
优化目标: 直接最小化分类误差或预测误差。
-
书中的典型算法: k近邻法、感知机、决策树、逻辑斯谛回归模型、最大熵模型、支持向量机(SVM)、提升方法(AdaBoost)。
2. 生成方法 (Generative Approach)
数学本质: 先从数据中学习输入 和输出
的联合概率分布
,然后再利用概率论中的计算公式得出条件概率分布
作为预测模型。
-
运算逻辑: 生成模型需要学习数据生成的最底层机制。在实际计算中,联合概率分布通常被拆解为先验概率
当需要对未知数据进行预测时,生成模型会调用贝叶斯定理(Bayes' Theorem),将学到的联合分布转化为我们需要的分类概率:
-
优化目标: 还原出最符合训练数据真实分布的联合概率密度函数。
-
书中的典型算法: 朴素贝叶斯法(Naive Bayes)、隐马尔可夫模型(HMM)。
我们假设有一个极其简单的二分类问题数据集:
-
输入特征 X: 只有三个离散取值
-
输出标签 Y: 只有两个类别
-
样本总量
数据分布如下表:
| X 取值 | 标签 Y=0 的样本数 | 标签 Y=1 的样本数 | 总计 |
|---|---|---|---|
| A | 30 | 10 | 40 |
| B | 20 | 10 | 30 |
| C | 10 | 20 | 30 |
| 总计 | 60 | 40 | 100 |
现在,我们的目标是:当给定一个全新的未知样本特征 X=A 时,预测它的标签 Y 是 0 还是 1?
我们来看看两种模型在数学上是如何分别处理这个任务的。
1. 判别模型的数学运算路径
判别模型的逻辑极其直接:只计算条件概率 ,其他一概不管。
它直接在给定的特征 发生的前提下,去数据里看类别
的比例:
-
已知特征为 A 的样本总共有 40 个。
-
其中 Y=0 有 30 个,所以:
-
其中 Y=1 有 10 个,所以:
预测结论: 因为 0.75 > 0.25,判别模型直接输出预测结果:Y=0。
它的特点: 判别模型在计算时,直接切断了数据全貌,它根本不关心 X=A、X=B在整体中占多大比例(比如它不在乎 P(X=A) = 0.4 这一全局事实)。它只聚焦于局部的分类边界。
2. 生成模型的数学运算路径
生成模型的逻辑是绕远的:必须先还原出数据的完整联合概率分布 P(X,Y),再通过贝叶斯定理推导预测结果。
它严格按照以下三个数学步骤执行:
第一步:计算先验概率 P(Y)
模型先去学习两种类别的全局基础分布:
第二步:计算条件概率分布 P(X|Y)
模型分别进入 Y=0 和 Y=1的内部,计算在给定了类别的条件下,特征 X 是怎么分布的:
-
在 Y=0 的 60 个样本中:
-
在 Y=1 的 40 个样本中:
第三步:计算联合概率分布 P(X,Y)
根据概率乘法公式 P(X,Y) = P(Y)P(X|Y),模型得到了完整的数据分布密度(这就是生成模型学到的最终产物):
-
-
最终预测:调用贝叶斯定理求解 P(Y|X)
当要求预测 X=A 的标签时,生成模型利用刚才学到的联合概率进行反推计算:
预测结论: 输出结果同样是 Y=0。
从上面的推导中,你能发现生成模型多算了很多东西(比如它算出了 P(Y=0)=0.6 和 P(X=A|Y=0)=0.5)。
这赋予了生成模型一项判别模型绝对做不到的能力------逆向采样生成新数据。
如果我要求模型:"请在计算机里凭空生成一条符合历史规律的新数据。"
-
判别模型做不到: 因为它只有 P(Y|X),如果没有输入 X,它什么也算不出来。
-
生成模型可以做到:
-
它先掷一个偏心骰子,按照 P(Y) 分布(60% 的概率)生成一个标签。假设掷出了 Y=0。
-
然后它再掷第二个偏心骰子,按照 P(X|Y=0) 分布(50% 概率出 A,33% 出 B,17% 出 C)生成一个特征。假设掷出了 X=A。
-
一条全新的数据 (特征A, 标签0) 就这样从数学概率中被"生成"出来了。
-
这就是生成模型(Generative Model)名称的由来。它不仅能做分类任务,更因为它掌握了 P(X,Y) 这个底层分布,所以它能够按照原有数据的分布规律,凭空创造出新的特征矩阵。
大模型之所以强大,正是因为它耗费了庞大的算力,硬生生地去逼近了人类语言底层那个极其复杂的联合概率分布。
第八章:监督学习应用
既然监督学习的本质是学习一个映射关系 或
,那么根据输出变量
的数据类型及其内部结构,书中将监督学习的应用严格划分为三大类基本问题:分类问题 、标注问题 和回归问题。
1. 分类问题 (Classification)
数学定义: 当输出变量 Y 取有限个离散值时,预测问题便成为分类问题。
-
工作逻辑: 学习过程是从训练数据中找出一个决策函数或条件概率分布;预测过程则是给定新的输入 X,计算出它属于哪一个离散的类别 Y。如果是二分类,也就是输出
-
评估指标的数学化: 对于分类问题,书中不再仅仅使用宽泛的"损失函数",而是引入了基于混淆矩阵(Confusion Matrix)的严密评价体系:
-
TP (True Positive): 正类被正确预测为正类。
-
FN (False Negative): 正类被错误预测为负类(漏报)。
-
FP (False Positive): 负类被错误预测为正类(误报)。
-
TN (True Negative): 负类被正确预测为负类。
基于以上四个基础数值,推导出了工业界最常用的两个评价指标:
-
精确率 (Precision):
-
召回率 (Recall):
-
F1 值: 为了综合考量 P和 R,使用的是它们的调和平均数:
-
-
典型算法: k近邻法、感知机、朴素贝叶斯法、决策树、支持向量机等。
2. 标注问题 (Tagging)
数学定义: 输入变量 X 和输出变量 Y都是变量序列。它是分类问题的一个更复杂的推广形式(即结构化预测问题)。
-
工作逻辑: 在分类问题中,输入是一个孤立的向量,输出是一个孤立的标签。但在标注问题中:
输入是一个观察序列:
输出是一个标记序列:
-
数学难点: 序列中的标签
-
典型应用: 自然语言处理(NLP)中的核心底层任务。例如词性标注 (输入一句话的单词序列,输出对应的"名词、动词、形容词"序列)或命名实体识别。
-
典型算法: 隐马尔可夫模型(HMM)、条件随机场(CRF)。
3. 回归问题 (Regression)
数学定义: 输入变量 X 和输出变量 Y 均为连续实数值。
-
工作逻辑: 回归问题的本质是函数拟合。它要求模型在多维空间中找到一条平滑的超曲面,使其能够尽可能紧密地穿过所有的训练数据点。当给定一个新的连续输入 X 时,模型能够输出一个无限精度的实数值 Y。
-
评估指标: 因为输出是连续值,无法像分类问题那样计算"对/错"的个数,所以回归问题最常用的损失函数是平方损失函数(Squared Loss):
优化过程即利用最小二乘法(Least Squares)或梯度下降法,去求解平方损失函数最小值对应的参数。
-
典型应用: 股票价格预测、房屋价格预测、市场趋势定量分析。
-
典型算法: 线性回归、多项式回归、支持向量回归(SVR)。