十三 堆
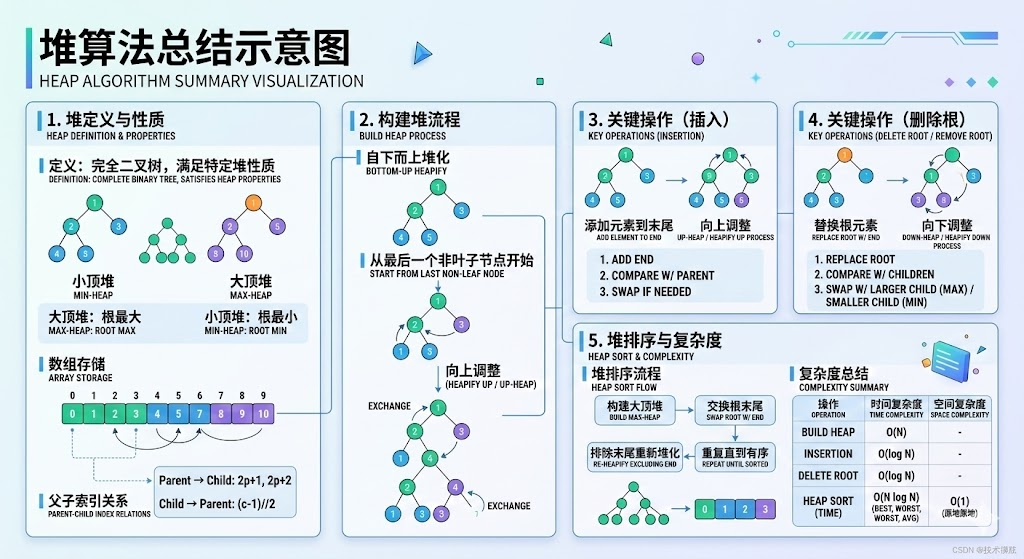
堆知识点
了解大根堆、小根堆,能手写堆排序、快速排序
堆和堆排序
如果要写的话要自己写建堆和维护堆的操作
「堆排序(Heap sort)」是一种基于「堆结构」实现的高效排序算法。在介绍堆排序之前,我们先来了解什么是堆结构
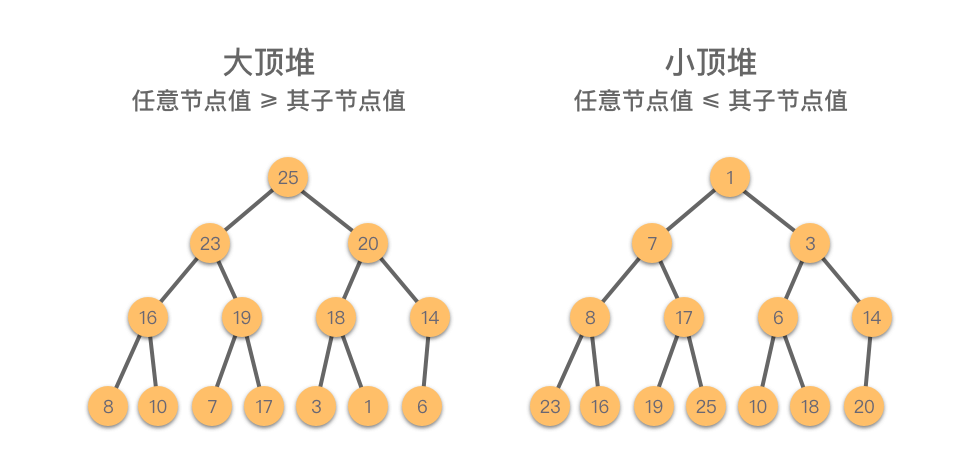
堆(Heap):一种特殊的完全二叉树,具有以下性质之一:
- 大顶堆(Max Heap):任意节点值 ≥ 其子节点值
- 小顶堆(Min Heap):任意节点值 ≤ 其子节点值
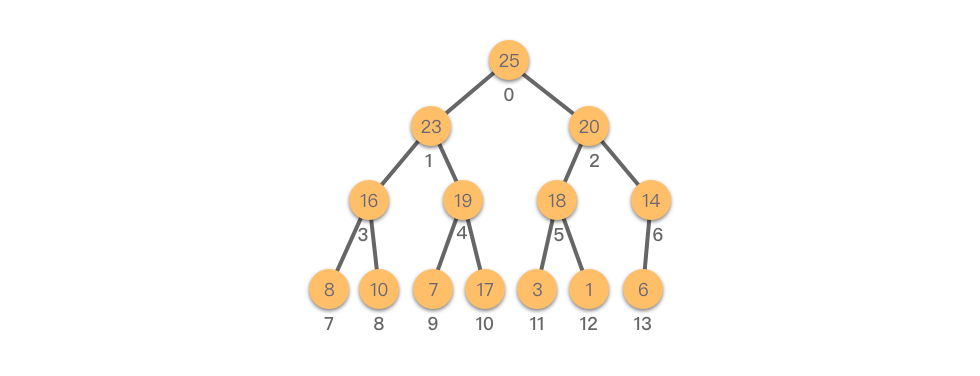
堆的逻辑结构是一棵完全二叉树,如下图所示:
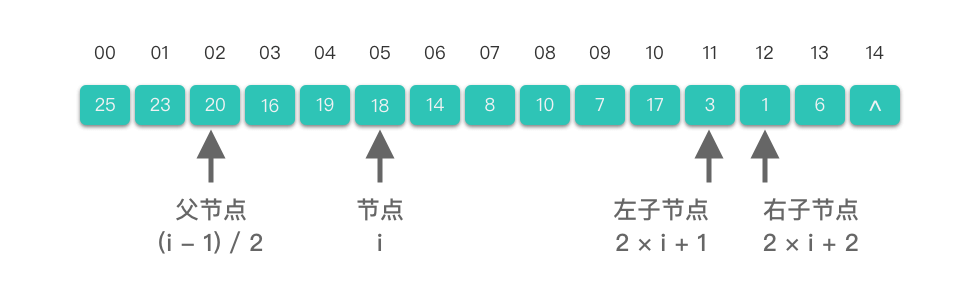
在实际编程中,堆通常采用数组进行存储。使用数组表示堆时,节点与数组索引之间的对应关系如下:
- 如果某节点的下标为 ii ,则其左孩子的下标为 2×i+12×i +1,右孩子的下标为 2×i+22×i+2;
- 如果某节点的下标为 ii ,则其父节点的下标为 ⌊i−12⌋⌊2i−1⌋。
如下图所示,顺序存储结构(数组)可以高效地表示堆:
堆排序:
我们要明确就是我们是用数组表示堆的,都是在数组上做交换维护堆的结构!!!
堆排序分为两个主要阶段:
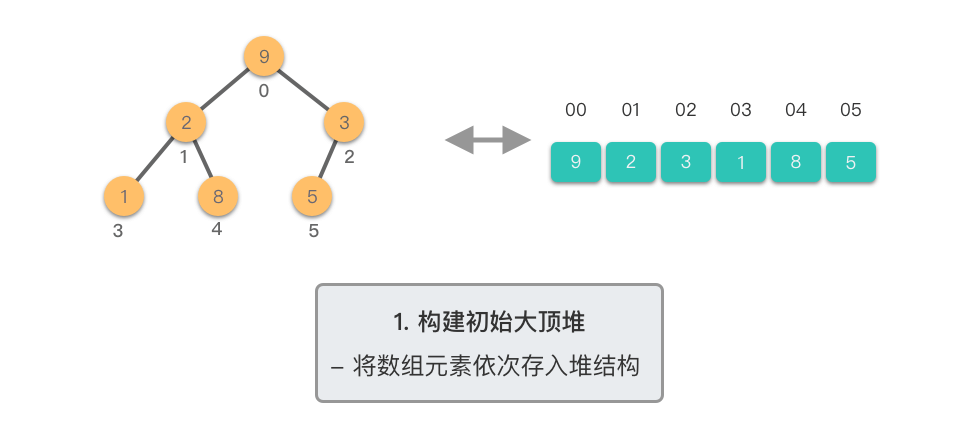
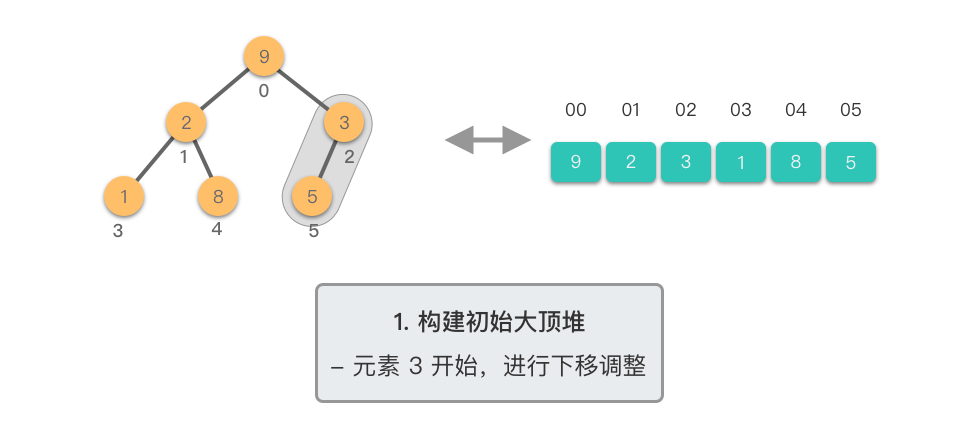
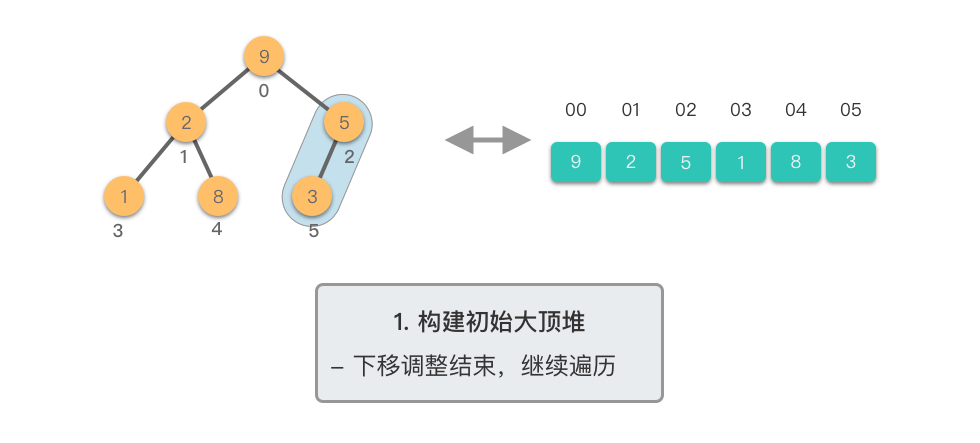
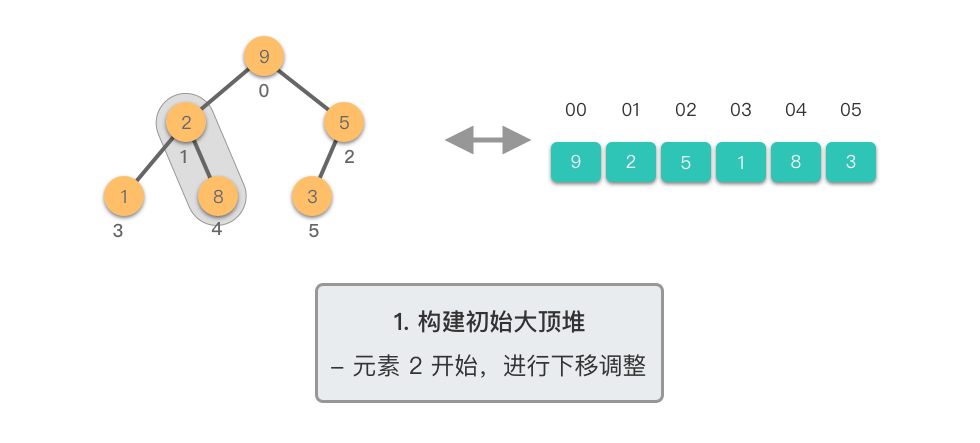
第一阶段:构建初始大顶堆
- 将原始数组视为完全二叉树
- 从最后一个非叶子节点开始,自底向上进行下移调整
- 将数组转换为大顶堆
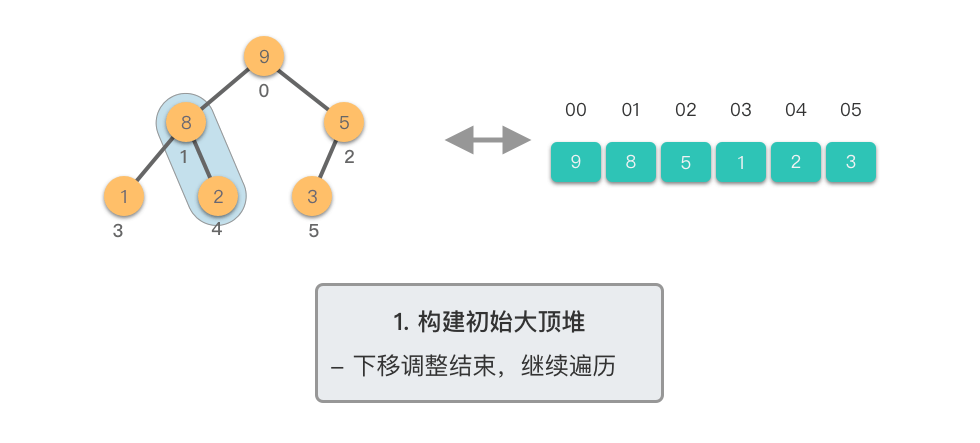
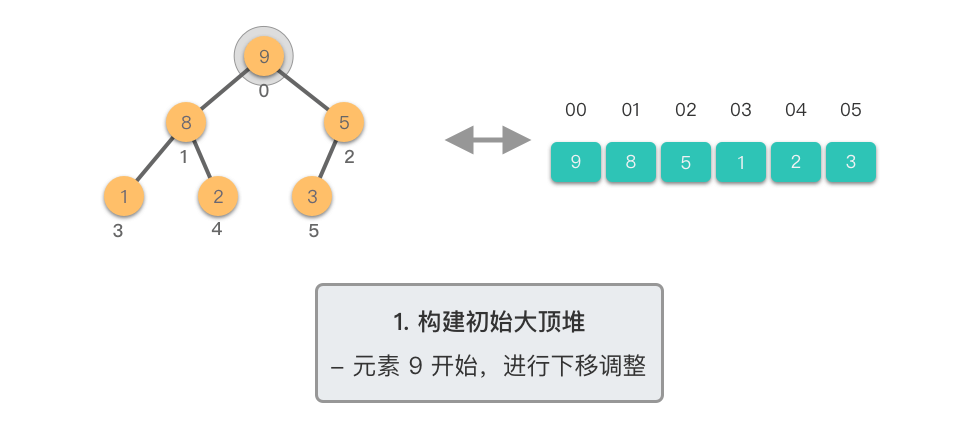
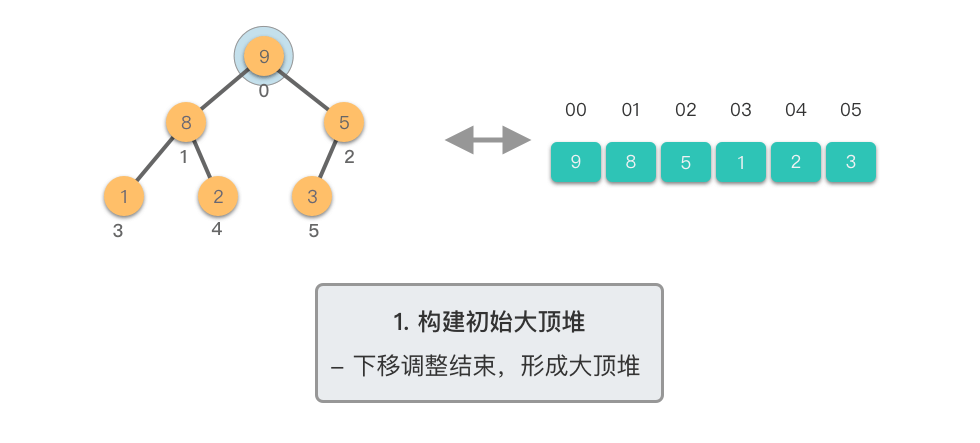
第二阶段:重复提取最大值
- 交换堆顶元素与当前末尾元素
- 堆长度减 11,末尾元素已排好序
- 对新的堆顶元素进行下移调整,恢复堆的性质
- 重复步骤 1∼31∼3,直到堆的大小为 11
java
/*
* 3.堆排序,当下沉和交换操作写好了,堆排序就很简单了,就是建堆,然后交换+调整
* */
public void heapSort(int[] nums) {
int n = nums.length;
for (int i = n/2-1; i >= 0; i--) {
// 1.从第一个非叶子节点开始建堆,也就上使用下沉操作
heapify(nums, n, i);
}
// 2.开始从后往前交换+调整
for (int i = n-1; i >= 0; i--) {
swap(nums, 0, i);
heapify(nums, i, 0); // 从上到下调整堆,单位也改变了
}
}
/*
* 维持大顶堆特性的下沉操作,在nums中边界为n,操作索引为i,依次就操作一个节点
* */
private void heapify(int[] nums, int n, int i) {
// 1.找子节点有没有更大的,有更大的就交换
int largeIndex = i;
int left = 2 * i + 1, right = 2 * i + 2;
// 2.左右不超出边界的情况下找堆中最大元素
if (left < n && nums[left] > nums[largeIndex]) {
largeIndex = left;
}
if (right < n && nums[right] > nums[largeIndex]) {
largeIndex = right;
}
// 3.如果结构不是大根堆,进行交换,并且递归向下检查
if (largeIndex != i) {
swap(nums, i, largeIndex);
heapify(nums, n, largeIndex);
}
}
/*
* i,j两位位置交换操作。
* */
private void swap(int[] arr, int i, int j) {
int t = arr[i];
arr[i] = arr[j];
arr[j] = t;
}快速排序和快速选择
快速排序(Quick Sort)基本思想:
采用分治策略,选择一个基准元素,将数组分为两部分:小于基准的元素放在左侧,大于基准的元素放在右侧 。然后递归地对左右两部分进行排序,最终得到有序数组
快排
java
public void quickSort(int[] nums, int l, int r) {
if (l >= r) {
// 递归停止条件
return;
}
int n = nums.length;
int left = l, right = r;
int pivot = nums[left + (right - left) / 2];
while (left < right) {
while (nums[left] < pivot) {
left++;
}
while (nums[right] > pivot) {
right--;
}
if (left <= right) {
int temp = nums[left];
nums[left] = nums[right];
nums[right] = temp;
left++;
right--;
}
}
quickSort(nums, l, right);
quickSort(nums, left, r);
}快速选择:
java
public int quickSelect(int[] nums, int l, int r, int k) {
// 1. 递归终止条件:区间只剩一个数,那它必然就是我们要找的第 k 小(索引为 k)的数
if (l == r) return nums[l];
// 2. 选取基准值 (Pivot)
// 注意:在 LeetCode 215 等题目中,建议使用 nums[l + (r - l) / 2]
// 防止在处理近乎有序的数组时,时间复杂度退化为 O(n^2)
int x = nums[l];
// 3. 初始化双指针
// 为什么是 l-1 和 r+1?因为下面的 do-while 循环是"先移动再判断"
// 这样初始化能保证第一次执行时,i 从 l 开始,j 从 r 开始
int i = l - 1, j = r + 1;
// 4. 分区过程 (Partition)
while (i < j) {
// do-while 保证了即使 nums[i] == x,指针也会移动,从而避免死循环
do i++; while (nums[i] < x); // 找到左边第一个 >= x 的数
do j--; while (nums[j] > x); // 找到右边第一个 <= x 的数
// 如果指针没相遇,交换这两个数
// 交换后,i 处的值 <= x,j 处的值 >= x,满足分区定义
if (i < j) swap(nums, i, j);
}
/* * 5. 核心边界:此时指针关系必为 j <= i (通常是 j = i 或 j = i - 1)
* 此时数组被划分为两个区间:
* [l, j] 区间:所有元素均 <= x
* [j+1, r] 区间:所有元素均 >= x
* * 注意:x 并不一定在 j 这个位置上,但 j 是一道严格的"分水岭"
*/
// 6. 二选一递归 (Selection)
// 我们要找的目标索引是 k
if (k <= j) {
// 如果 k 在左半部分索引范围内,只需要去左边找
// 必须包含 j,因为 [l, j] 是完整的左区间
return quickSelect(nums, l, j, k);
} else {
// 如果 k 在右半部分,去 [j + 1, r] 找
return quickSelect(nums, j + 1, r, k);
}
}题目1------数组中的第K个最大元素【必考】【562】
给定整数数组
nums和整数k,请返回数组中第k个最大的元素。请注意,你需要找的是数组排序后的第
k个最大的元素,而不是第k个不同的元素。你必须设计并实现时间复杂度为
O(n)的算法解决此问题。所以直接上来排序肯定不行示例 1:
输入: [3,2,1,5,6,4], k = 2 输出: 5示例 2:
输入: [3,2,3,1,2,4,5,5,6], k = 4 输出: 4提示:
1 <= k <= nums.length <= 105-104 <= nums[i] <= 104
思路:优先队列,弹出k-1个
虽然很多考法解法可以通过用例,但是真正的考法是堆排序,手写堆/快速选择
手写堆:
java
public int findKthLargest(int[] nums, int k) {
// 基于堆排序
// 在nums上建堆
int n = nums.length;
buildMaxHeap(nums, n);
// 开始选,因为堆排序本身就是现在将最大的堆顶放在最后,再调整堆,那我们就继续交换调整k-1次
for (int i = n - 1; i > n - k; i--) {
swap(nums, 0, i);
heapify(nums, i, 0);
}
// 返回数组第一个元素
return nums[0];
}
public void buildMaxHeap(int[] nums, int heapSize) {
// 从第一个非叶子节点开始建堆
for (int i = heapSize / 2 - 1; i >= 0; i--) {
heapify(nums, heapSize, i);
}
}
public void heapify(int[] nums, int n, int i) {
/*
* n为数组边界,i为操作索引,在索引i,界限为n上执行大顶堆的交换操作,还要递归
* 还要下沉递归向下检查及进行交换
* */
// 找三个中的最大,并进行交换
int largeIndex = i;
int l = 2 * i+1, r = 2 * i + 2;
if (l < n && nums[largeIndex] < nums[l]) {
largeIndex = l;
}
if (r < n && nums[largeIndex] < nums[r]) {
largeIndex = r;
}
// 没有变化就交换,然后进行递归向下检查
if (largeIndex != i) {
swap(nums, largeIndex, i);
heapify(nums, n, largeIndex);
}
}
public void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}快速选择:
设定:
nums = [3, 1, 2, 4, 3],l = 0,r = 4,target_k = 2。
第一轮递归:
quickSelect(nums, 0, 4, 2)
- 选基准 :
x = nums[0] = 3。- 初始化指针 :
i = -1,j = 5。- 分区循环开始:
do i++:i停在0(因为nums[0]=3不小于3)。do j--:j停在4(因为nums[4]=3不大于3)。- 交换 :
i < j(0 < 4),交换nums[0]和nums[4]。
- 数组变为:
[3, 1, 2, 4, 3](虽然还是 3 和 3 互换,但指针移动了)。- 继续循环 :
do i++:i停在3(因为nums[1]=1,nums[2]=2都小于 3,直到nums[3]=4停止)。do j--:j停在2(因为nums[3]=4大于 3,直到nums[2]=2停止)。- 检查条件 :此时
i = 3, j = 2,i < j不再成立,退出while循环。
- 二选一判定:
- 当前
j = 2,我们的目标k = 2。- 满足
k <= j(2 <= 2),所以目标在左半部分。- 下一轮递归 :
quickSelect(nums, 0, 2, 2)。
第二轮递归:
quickSelect(nums, 0, 2, 2)此时数组状态为:
[3, 1, 2 | 4, 3](注意,只有前三个数在我们的处理范围内)。
- 选基准 :
x = nums[0] = 3。- 初始化 :
i = -1,j = 3。- 分区循环开始:
do i++:i停在0(nums[0]=3)。do j--:j绕过nums[2]=2,nums[1]=1,最后停在索引0(因为nums[0]=3不大于 3)。- 检查条件 :
i = 0, j = 0,不满足i < j,退出循环。
- 二选一判定:
- 当前
j = 0,目标k = 2。k <= j(2 <= 0) 不成立,所以目标在右半部分。- 下一轮递归 :
quickSelect(nums, 1, 2, 2)(即j+1到r)。
第三轮递归:
quickSelect(nums, 1, 2, 2)此时处理范围:索引
1到2,即子数组[1, 2]。
- 选基准 :
x = nums[1] = 1。- 分区循环开始:
do i++:i停在1(nums[1]=1)。do j--:j停在1(因为nums[2]=2大于 1,直到nums[1]=1停止)。- 退出循环 :
i=1, j=1。
- 二选一判定:
- 当前
j = 1,目标k = 2。k <= j(2 <= 1) 不成立,去右边。- 下一轮递归 :
quickSelect(nums, 2, 2, 2)。
最终结果
- 调用
quickSelect(nums, 2, 2, 2)。- 触发
if (l == r),直接返回nums[2]。- 此时
nums[2]的值就是 2。
java
public int quickSelect(int[] nums, int l, int r, int k) {
// 1. 递归终止条件:区间只剩一个数,那它必然就是我们要找的第 k 小(索引为 k)的数
if (l == r) return nums[l];
// 2. 选取基准值 (Pivot)
// 注意:在 LeetCode 215 等题目中,建议使用 nums[l + (r - l) / 2]
// 防止在处理近乎有序的数组时,时间复杂度退化为 O(n^2)
int x = nums[l];
// 3. 初始化双指针
// 为什么是 l-1 和 r+1?因为下面的 do-while 循环是"先移动再判断"
// 这样初始化能保证第一次执行时,i 从 l 开始,j 从 r 开始
int i = l - 1, j = r + 1;
// 4. 分区过程 (Partition)
while (i < j) {
// do-while 保证了即使 nums[i] == x,指针也会移动,从而避免死循环
do i++; while (nums[i] < x); // 找到左边第一个 >= x 的数
do j--; while (nums[j] > x); // 找到右边第一个 <= x 的数
// 如果指针没相遇,交换这两个数
// 交换后,i 处的值 <= x,j 处的值 >= x,满足分区定义
if (i < j) swap(nums, i, j);
}
/* * 5. 核心边界:此时指针关系必为 j <= i (通常是 j = i 或 j = i - 1)
* 此时数组被划分为两个区间:
* [l, j] 区间:所有元素均 <= x
* [j+1, r] 区间:所有元素均 >= x
* * 注意:x 并不一定在 j 这个位置上,但 j 是一道严格的"分水岭"
*/
// 6. 二选一递归 (Selection)
// 我们要找的目标索引是 k
if (k <= j) {
// 如果 k 在左半部分索引范围内,只需要去左边找
// 必须包含 j,因为 [l, j] 是完整的左区间
return quickSelect(nums, l, j, k);
} else {
// 如果 k 在右半部分,去 [j + 1, r] 找
return quickSelect(nums, j + 1, r, k);
}
}题目2------前 K 个高频元素【35】
给你一个整数数组
nums和一个整数k,请你返回其中出现频率前k高的元素。你可以按 任意顺序 返回答案。示例 1:
**输入:**nums = 1,1,1,2,2,3, k = 2
输出:1,2
示例 2:
**输入:**nums = 1, k = 1
输出:1
示例 3:
**输入:**nums = 1,2,1,2,1,2,3,1,3,2, k = 2
输出:1,2
提示:
1 <= nums.length <= 105-104 <= nums[i] <= 104k的取值范围是[1, 数组中不相同的元素的个数]- 题目数据保证答案唯一,换句话说,数组中前
k个高频元素的集合是唯一的**进阶:**你所设计算法的时间复杂度 必须 优于
O(n log n),其中n是数组大小。
思路:用哈希表统计频率,然后返回
java
public int[] topKFrequent(int[] nums, int k) {
if (nums.length == 1) {
return new int[]{nums[0]};
}
int[] ans = new int[k];
Map<Integer, Integer> map = new HashMap<>();
for (int num : nums) {
map.merge(num, 1, Integer::sum);
}
// 再使用优先队列
Queue<Integer> pq = new PriorityQueue<>(Comparator.comparingInt(map::get).reversed());
for (Integer key : map.keySet()) {
pq.add(key);
}
for (int i = 0; i < k; i++) {
ans[i] = pq.poll();
}
return ans;
}题目3------数据流的中位数【34】
中位数是有序整数列表中的中间值。如果列表的大小是偶数,则没有中间值,中位数是两个中间值的平均值。
- 例如
arr = [2,3,4]的中位数是3。- 例如
arr = [2,3]的中位数是(2 + 3) / 2 = 2.5。实现 MedianFinder 类:
MedianFinder()初始化MedianFinder对象。void addNum(int num)将数据流中的整数num添加到数据结构中。double findMedian()返回到目前为止所有元素的中位数。与实际答案相差10-5以内的答案将被接受。示例 1:
输入 ["MedianFinder", "addNum", "addNum", "findMedian", "addNum", "findMedian"] [[], [1], [2], [], [3], []] 输出 [null, null, null, 1.5, null, 2.0] 解释 MedianFinder medianFinder = new MedianFinder(); medianFinder.addNum(1); // arr = [1] medianFinder.addNum(2); // arr = [1, 2] medianFinder.findMedian(); // 返回 1.5 ((1 + 2) / 2) medianFinder.addNum(3); // arr[1, 2, 3] medianFinder.findMedian(); // return 2.0提示:
-105 <= num <= 105- 在调用
findMedian之前,数据结构中至少有一个元素- 最多
5 * 104次调用addNum和findMedian
使用什么数据结构
数据结构:优先队列实现大根堆和小根堆
维护过程:
MedianFinder()初始化MedianFinder对象。void addNum(int num)将数据流中的整数num添加到数据结构中。double findMedian()返回到目前为止所有元素的中位数。与实际答案相差10-5以内的答案将被接受
java
// 大根堆,存储小的一半
private Queue<Integer> maxpq;
// 小根堆,存储大的一半
private Queue<Integer> minpq;
// 元素个数
private int n;
// 初始化
public MedianFinder() {
maxpq = new PriorityQueue<>((a, b) -> b - a);
minpq = new PriorityQueue<>();
n = 0;
}
//添加
public void addNum(int num){
if (maxpq.isEmpty() || num <= maxpq.peek()) {
maxpq.add(num);
} else {
minpq.add(num);
}
n+=1;
// 进行数量调整
if (maxpq.size() > minpq.size() + 1) {
minpq.add(maxpq.poll());
} else if (minpq.size()>maxpq.size()){
maxpq.add(minpq.poll());
}
}
// 返回中位数
public double findMedian(){
if (n % 2 == 0) {
return (maxpq.peek()+minpq.peek())/2.0;
} else {
return (double) maxpq.peek();
}
}