- 🍨 本文为 🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者: K同学啊
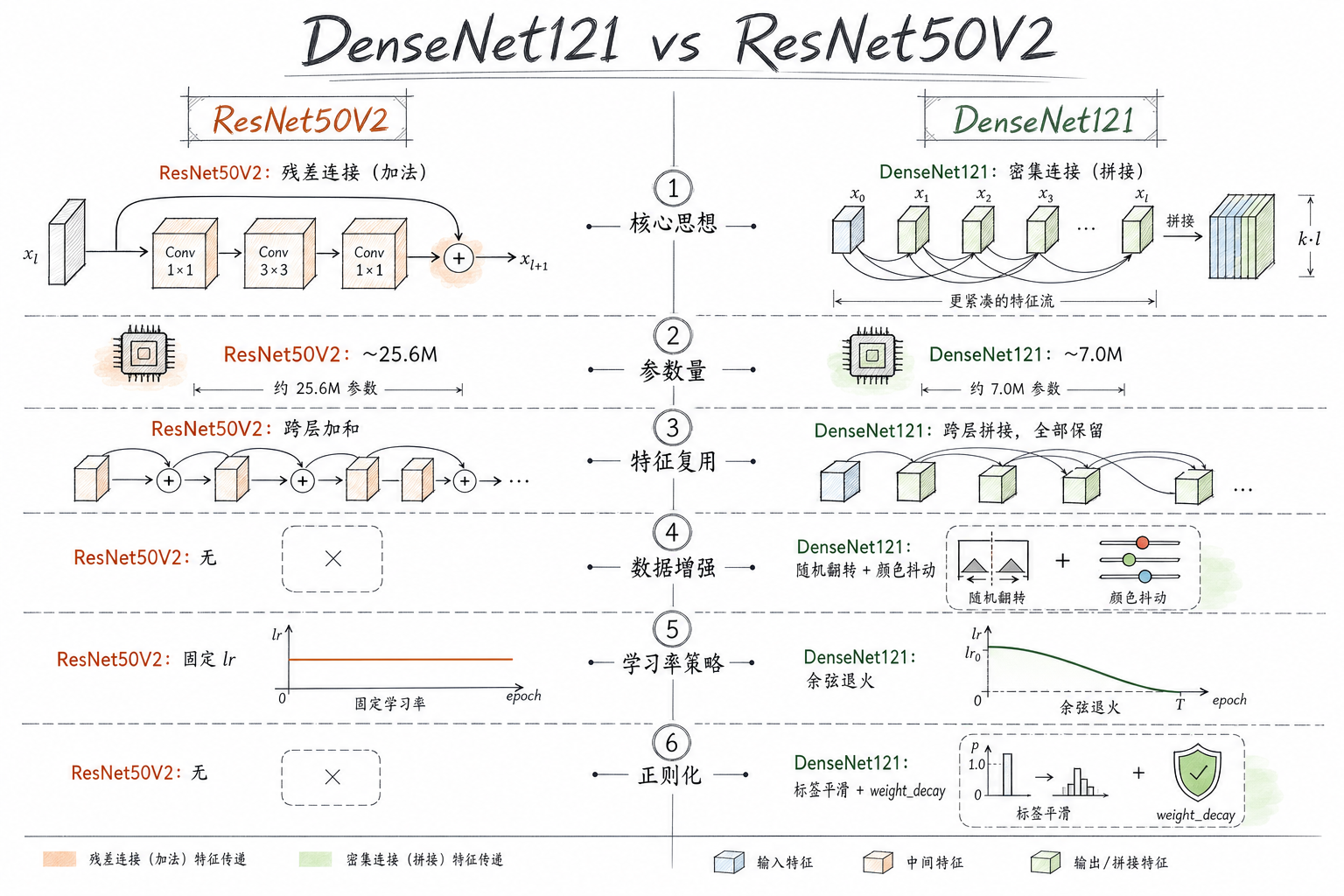
一、前置知识
1、知识总结
相比 ResNet50V2 的优化点:
- DenseNet121:密集连接(Dense Connectivity),每一层的输入包含前面所有层的输出,特征复用更充分
- 数据增强:增加随机水平翻转、颜色抖动,提升泛化能力
- 学习率调度:使用 CosineAnnealing 余弦退火策略,避免学习率突变
- 标签平滑:Label Smoothing 防止过拟合
- 权重初始化:Kaiming 初始化加速收敛
二、代码实现
1、准备工作
1.1.设置GPU
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import os,PIL,pathlib,warnings
warnings.filterwarnings("ignore") #忽略警告信息
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
device(type='cuda')1.2 导入数据(增加数据增强)
data_dir = './data/day01'
# 训练集:增加数据增强
train_transforms = transforms.Compose([
transforms.Resize([224, 224]),
transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转
transforms.ColorJitter(brightness=0.2, # 颜色抖动
contrast=0.2,
saturation=0.1),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 测试集:仅做标准化
test_transforms = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 先用统一 transform 加载全部数据(获取类别信息和总样本数)
total_data = datasets.ImageFolder(data_dir, transform=train_transforms)
total_data
Dataset ImageFolder
Number of datapoints: 1661
Root location: ./data/day01
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=True)
RandomHorizontalFlip(p=0.5)
ColorJitter(brightness=(0.8, 1.2), contrast=(0.8, 1.2), saturation=(0.9, 1.1), hue=None)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
total_data.class_to_idx
{'0Normal': 0, '2Mild': 1, '4Severe': 2}1.3.划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
# 测试集使用无增强的 transform
test_dataset.dataset = datasets.ImageFolder(data_dir, transform=test_transforms)
# 保留训练集的增强
train_dataset.dataset = datasets.ImageFolder(data_dir, transform=train_transforms)
batch_size = 8 # DenseNet 参数效率高,可以适当增大 batch_size
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=0)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
num_workers=0)
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
Shape of X [N, C, H, W]: torch.Size([8, 3, 224, 224])
Shape of y: torch.Size([8]) torch.int642、搭建模型
2.1.搭建DenseNet121模型

DenseNet121 结构:
|-------------|----|------|
| Dense Block | 层数 | 输出通道 |
| Block 1 | 6 | 256 |
| Block 2 | 12 | 512 |
| Block 3 | 24 | 1024 |
| Block 4 | 16 | 1024 |
import torch.nn.functional as F
class _DenseLayer(nn.Module):
"""DenseNet 单层:瓶颈结构 (BN→ReLU→1x1Conv→BN→ReLU→3x3Conv)"""
def __init__(self, in_channels, growth_rate, bn_size=4):
super(_DenseLayer, self).__init__()
self.bn1 = nn.BatchNorm2d(in_channels)
self.relu1 = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(in_channels, bn_size * growth_rate,
kernel_size=1, stride=1, bias=False)
self.bn2 = nn.BatchNorm2d(bn_size * growth_rate)
self.relu2 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(bn_size * growth_rate, growth_rate,
kernel_size=3, stride=1, padding=1, bias=False)
def forward(self, x):
out = self.conv1(self.relu1(self.bn1(x)))
out = self.conv2(self.relu2(self.bn2(out)))
return out
class _DenseBlock(nn.ModuleDict):
"""Dense Block:包含多个 DenseLayer,每层输入为前面所有层输出的拼接"""
def __init__(self, num_layers, in_channels, growth_rate, bn_size=4):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(
in_channels=in_channels + i * growth_rate,
growth_rate=growth_rate,
bn_size=bn_size
)
self.add_module('denselayer%d' % (i + 1), layer)
def forward(self, init_features):
x = init_features
for name, layer in self.items():
new_features = layer(x)
x = torch.cat([x, new_features], dim=1)
return x
class _Transition(nn.Sequential):
"""过渡层:BN→ReLU→1x1Conv→AvgPool2d,压缩特征图"""
def __init__(self, in_channels, out_channels):
super(_Transition, self).__init__()
self.bn = nn.BatchNorm2d(in_channels)
self.relu = nn.ReLU(inplace=True)
self.conv = nn.Conv2d(in_channels, out_channels,
kernel_size=1, stride=1, bias=False)
self.pool = nn.AvgPool2d(kernel_size=2, stride=2)
class DenseNet121(nn.Module):
"""DenseNet-121:4个 Dense Block,层数分别为 [6, 12, 24, 16]"""
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16),
num_init_features=64, bn_size=4, num_classes=1000):
super(DenseNet121, self).__init__()
# ===== Stem =====
self.features = nn.Sequential(
nn.Conv2d(3, num_init_features, kernel_size=7, stride=2,
padding=3, bias=False),
nn.BatchNorm2d(num_init_features),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# ===== Dense Blocks + Transitions =====
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(
num_layers=num_layers,
in_channels=num_features,
growth_rate=growth_rate,
bn_size=bn_size
)
self.features.add_module('denseblock%d' % (i + 1), block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1:
num_out = int(num_features * 0.5)
trans = _Transition(in_channels=num_features, out_channels=num_out)
self.features.add_module('transition%d' % (i + 1), trans)
num_features = num_out
# ===== 最后的 BN =====
self.features.add_module('norm5', nn.BatchNorm2d(num_features))
# ===== 分类器 =====
self.classifier = nn.Linear(num_features, num_classes)
# ===== 权重初始化 =====
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = F.relu(features, inplace=True)
out = F.adaptive_avg_pool2d(out, (1, 1))
out = torch.flatten(out, 1)
out = self.classifier(out)
return out
model = DenseNet121(num_classes=3).to(device)
model
DenseNet121(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(denseblock1): _DenseBlock(
(denselayer1): _DenseLayer(
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
...
(denselayer6): _DenseLayer(
(bn1): BatchNorm2d(224, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(224, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(transition1): _Transition(
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(pool): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
(denseblock2): _DenseBlock(
(denselayer1): _DenseLayer(
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
...
(denselayer12): _DenseLayer(
(bn1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(480, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(transition2): _Transition(
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(pool): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
(denseblock3): _DenseBlock(
(denselayer1): _DenseLayer(
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
...
(denselayer24): _DenseLayer(
(bn1): BatchNorm2d(992, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(992, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(transition3): _Transition(
(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(pool): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
(denseblock4): _DenseBlock(
(denselayer1): _DenseLayer(
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
...
(denselayer16): _DenseLayer(
(bn1): BatchNorm2d(992, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(992, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(norm5): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(classifier): Linear(in_features=1024, out_features=3, bias=True)
)2.2.查看模型详情
# 统计模型参数量以及其他指标
import torchsummary as summary
summary.summary(model, (3, 224, 224))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
BatchNorm2d-5 [-1, 64, 56, 56] 128
ReLU-6 [-1, 64, 56, 56] 0
Conv2d-7 [-1, 128, 56, 56] 8,192
....
_DenseLayer-425 [-1, 32, 7, 7] 0
_DenseBlock-426 [-1, 1024, 7, 7] 0
BatchNorm2d-427 [-1, 1024, 7, 7] 2,048
Linear-428 [-1, 3] 3,075
================================================================
Total params: 6,956,931
Trainable params: 6,956,931
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 313.52
Params size (MB): 26.54
Estimated Total Size (MB): 340.64
----------------------------------------------------------------3、训练模型
3.1.编写训练函数
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_loss, train_acc = 0, 0
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss3.2.编写测试函数
测试函数和训练函数大致相同,但是由于不进行梯度下降对网络权重进行更新,所以不需要传入优化器
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, test_acc = 0, 0
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss3.3.正式训练
优化策略:
- AdamW 优化器 + 标签平滑(label_smoothing=0.1)
- 余弦退火 学习率调度
-
batch_size=8(DenseNet 参数量少,可增大 batch)
import copy
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3, weight_decay=1e-4)标签平滑:防止过拟合
loss_fn = nn.CrossEntropyLoss(label_smoothing=0.1)
余弦退火学习率调度
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10, eta_min=1e-6)
epochs = 10
train_loss = []
train_acc = []
test_loss = []
test_acc = []best_acc = 0
for epoch in range(epochs):
model.train() epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer) # 余弦退火更新学习率 scheduler.step() model.eval() epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn) if epoch_test_acc > best_acc: best_acc = epoch_test_acc best_model = copy.deepcopy(model) train_acc.append(epoch_train_acc) train_loss.append(epoch_train_loss) test_acc.append(epoch_test_acc) test_loss.append(epoch_test_loss) lr = optimizer.state_dict()['param_groups'][0]['lr'] template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}') print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss, lr))保存最佳模型
PATH = './model/day03_densenet121_best_model.pth'
os.makedirs(os.path.dirname(PATH), exist_ok=True)
torch.save(best_model.state_dict(), PATH)print('Done')
Epoch: 1, Train_acc:66.2%, Train_loss:0.907, Test_acc:67.0%, Test_loss:0.903, Lr:9.76E-04
Epoch: 2, Train_acc:70.4%, Train_loss:0.838, Test_acc:73.3%, Test_loss:0.841, Lr:9.05E-04
Epoch: 3, Train_acc:73.5%, Train_loss:0.794, Test_acc:75.4%, Test_loss:0.742, Lr:7.94E-04
Epoch: 4, Train_acc:76.3%, Train_loss:0.742, Test_acc:73.3%, Test_loss:0.805, Lr:6.55E-04
Epoch: 5, Train_acc:77.9%, Train_loss:0.704, Test_acc:81.1%, Test_loss:0.664, Lr:5.01E-04
Epoch: 6, Train_acc:81.2%, Train_loss:0.660, Test_acc:76.0%, Test_loss:0.753, Lr:3.46E-04
Epoch: 7, Train_acc:81.2%, Train_loss:0.645, Test_acc:81.7%, Test_loss:0.663, Lr:2.07E-04
Epoch: 8, Train_acc:84.3%, Train_loss:0.609, Test_acc:81.4%, Test_loss:0.668, Lr:9.64E-05
Epoch: 9, Train_acc:83.8%, Train_loss:0.599, Test_acc:85.6%, Test_loss:0.536, Lr:2.54E-05
Epoch:10, Train_acc:84.7%, Train_loss:0.578, Test_acc:86.2%, Test_loss:0.526, Lr:1.00E-06
Done
4、结果可视化
4.1. Loss与Accuracy图
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 100
from datetime import datetime
current_time = datetime.now()
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('DenseNet121 - Training and Validation Accuracy')
plt.xlabel(current_time)
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('DenseNet121 - Training and Validation Loss')
plt.show()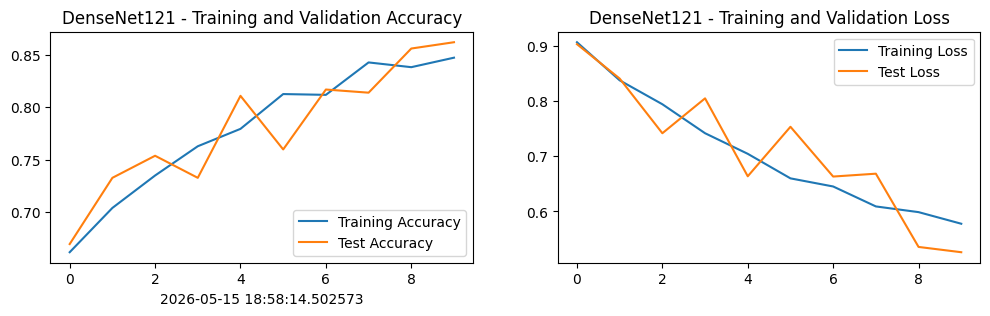
4.2. 模型评估
best_model.load_state_dict(torch.load(PATH, map_location=device, weights_only=True))
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
print(f'DenseNet121 Best Test Accuracy: {epoch_test_acc*100:.1f}%')
print(f'DenseNet121 Best Test Loss: {epoch_test_loss:.4f}')
DenseNet121 Best Test Accuracy: 86.2%
DenseNet121 Best Test Loss: 0.5261