Rust:迭代器
在 Rust 中,迭代器(Iterator)是支撑整个函数式编程风格的核心概念之一。
用循环来遍历数据的时候,需要有个变量来记录每次迭代在数据集合中的位置。在不少编程语言里,出现了一种更规范化的方式,能在迭代过程中返回集合里的各个元素。这种规范化的方式被称作迭代器模式,它能让数据操作变得简单不少。
事实上,在Rust中使用的for ... in ... 循环本质就是迭代器,在每一轮循环体中你可以得到下一个元素,而不关心其内部是如何实现遍历的,这就是迭代器。
几乎所有集合都实现了 Iterator 或能被转化为迭代器。与闭包类似,它也是一种抽象逻辑的工具,背后依赖的是 Trait 的统一行为。
Iterator Trait
所有迭代器都实现了Iterator这个Trait。Iterator 的定义如下:
rust
pub trait Iterator {
/// The type of the elements being iterated over.
#[rustc_diagnostic_item = "IteratorItem"]
#[stable(feature = "rust1", since = "1.0.0")]
type Item;
#[lang = "next"]
#[stable(feature = "rust1", since = "1.0.0")]
fn next(&mut self) -> Option<Self::Item>;
// 其它方法
}这个 Trait 非常关键:
type Item表示每次迭代返回的元素类型next()是迭代器最核心的方法,每次调用会返回一个Option<Item>,若有元素则返回Some(item),否则返回None表示结束
与闭包类似,一个迭代器对象在创建时并不会立即执行,而是仅仅保存了"如何产生下一个值的逻辑",直到你真正去调用 next() 它才会运行。
Iterator 本身还定义了许多衍生方法,比如 map、filter、fold 等等。它们都建立在 next() 之上,只要实现 next() 即可自动获得各种函数式的高级功能。
来看个例子:
rust
fn main() {
let v = vec![10, 20, 30];
let mut iter = v.iter();
println!("{:?}", iter.next()); // Some(&10)
println!("{:?}", iter.next()); // Some(&20)
println!("{:?}", iter.next()); // Some(&30)
println!("{:?}", iter.next()); // None
}以上代码中,v.iter()返回的是一个结构体Iter<'_, T>。它的定义如下:
rust
pub struct Iter<'a, T: 'a> {
ptr: NonNull<T>,
end_or_len: *const T,
_marker: PhantomData<&'a T>,
}这个结构体实现了Iterator,因此可以调用next方法,进行迭代器访问。
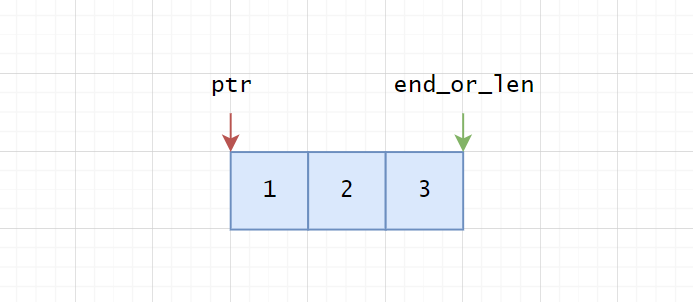
ptr是迭代器当前指向位置的指针,而end_or_len是指向整个数组尾部的指针。每次调用next方法时,ptr都会往后移动一个元素的位置,并且返回Some(&T)。直到ptr == end_or_len,也就是两个指针指向相同地址的时候,说明已经遍历完毕了,就会返回None。
而_marker用于表示Iter逻辑上持有一个T的借用,实际上是*const T的原生指针,这可以保证它的一些型变关系以及借用检查。
从这里也可以看出来,iter()方法拿到的是Iter<'_, T>迭代器,而这种迭代器的所有权是不可变借用,也就是说它迭代器内部拿到了集合元素的不可变借用,当迭代完毕,集合可以正常访问。
如果你注意到的话,你会发现之前的案例中,手动调用迭代器的next()之前,这个迭代器被声明为了mut。这是因为迭代器在调用next()后,内部的ptr需要修改指向下一个元素,因此手动调用next()时,迭代器必须被声明为mut,否则迭代器无法指向下一个元素,更不能遍历集合了。
另外的,这里指向末尾的指针叫做end_or_len,顾名思义它有两种可能,即可能表示指向尾部的指针,也可能是数组长度。
这是因为数组内部有可能存储零大小类型,那么ptr指针和end指针就指向了同一个地址,这就导致迭代器无法通过指针进行判断是否遍历完毕,此时它就表达len的含义,表示当前还有几个元素在数组中。
比如说对于数组[(), (), ()],它存了三个零大小类型,此时end_or_len = 3表示有三个元素,而不是指向一个具体的地址。
IntoIterator Trait
迭代器的本质,就是实现了Iterator的类型,如果想要迭代某个集合的元素,就必须把它转化为迭代器才能使用。
看到以下代码:
rust
let v1 = vec![10, 20, 30];
let v2 = vec![40, 50, 60];
for i in v1.iter() {
println!("v1 item: {}", i);
}
for i in v2 {
println!("v2 item: {}", i);
}以上代码可以正常运行。对于v1来说,for循环可以拿到v1.iter(),也就是Iter<'_, T>迭代器,从而进行遍历。但是为什么可以直接for i in v2?v2是一个集合数组,可不是一个迭代器!
想要理解这个问题,就需要了解另外一个Trait,它就是IntoIterator。
IntoIterator 是另一个常与 Iterator 搭配出现的 Trait,它的作用是:让一个类型能够被转换成迭代器。
它的定义如下:
rust
pub trait IntoIterator {
#[stable(feature = "rust1", since = "1.0.0")]
type Item;
#[stable(feature = "rust1", since = "1.0.0")]
type IntoIter: Iterator<Item = Self::Item>;
#[lang = "into_iter"]
#[stable(feature = "rust1", since = "1.0.0")]
fn into_iter(self) -> Self::IntoIter;
}它包含一个into_iter方法,这个方法会返回一个迭代器Self::IntoIter。实现了这个Trait的类型,都可以直接调用into_iter拿到这个类型的迭代器。
而且可以看出来,into_iter()的参数类型为self,这说明调用这个方法会失去所有权,把集合的所有权转移到迭代器内部,这是它与iter()的最大区别。那么它们的返回值自然也有区别,Iter是以不可变借用形式迭代,而Self::IntoIter就是以所有权的形式迭代了。
Vec::IntoIter定义如下:
rust
pub struct IntoIter<
T,
#[unstable(feature = "allocator_api", issue = "32838")] A: Allocator = Global,
> {
pub(super) buf: NonNull<T>,
pub(super) phantom: PhantomData<T>,
pub(super) cap: usize,
pub(super) alloc: ManuallyDrop<A>,
pub(super) ptr: NonNull<T>,
pub(super) end: *const T,
}这个结构体内部,包含了非常多成员,比如buf就是指向整个数组的指针,cap是数组的容量等等,这些都是Vec本身的数据,由于结构体所有权转移,这些数据当然就被转移给了迭代器进行存储。而ptr和end是迭代器遍历的核心,和之前一样,ptr指向当前迭代的元素,而end指向整个数组的尾部。
通过 for item in v { ... } 使用时,其实编译器自动调用 IntoIterator::into_iter(v)方法拿到迭代器。所以能被 for in 使用的必要条件就是实现 IntoIterator。
而Vec实现了这个方法,因此你可以直接向for in传入一个Vec类型,而非它的迭代器。
示例:
rust
for item in v {
println!("{}", item);
}
for item in v.into_iter() {
println!("{}", item);
}以上两段代码是完全等效的,因为在for item in v时,编译器会直接调用v.into_iter()拿到它的迭代器,再进一步遍历。
特别的是,迭代器本身也实现了 IntoIterator!
rust
let v = vec![1, 2, 3];
for n in v.iter() {
println!("{n}");
}对于for in,不论in 后面传入了什么内容,都会固定的去调用它的into_iter()方法,哪怕它本身就是一个迭代器。
为此,所有实现了Iterator的类型,都自动实现了IntoIterator,并且它们直接返回它们自己。
注:此处不会发生所有权变化,比如Iter::into_iter()返回的就是Iter,IntoIter::into_iter()返回的是IntoIter。原本是不可变借用迭代器,返回的就是不可变借用迭代器,原本是所有权迭代器,返回的就是所有权迭代器。
以上代码等效于:
rust
let v = vec![1, 2, 3];
for n in v.iter().into_iter() {
println!("{n}");
}甚至你可以写一点花活:v.iter().into_iter().into_iter().into_iter().into_iter(),这也是合法的,因为每次into_iter()返回的都是Iter迭代器自己,当然可以再调用自己的into_iter()方法了。
迭代器所有权
现在有了不可变借用迭代器Iter、所有权迭代器IntoIter,那么当然也会有一个可变借用迭代器,它就是IterMut,结构体定义如下:
rust
pub struct IterMut<'a, T: 'a> {
ptr: NonNull<T>,
end_or_len: *mut T,
_marker: PhantomData<&'a mut T>,
}IterMut和Iter非常相似,只是内部的所有权变成了&mut T。这个迭代器通过iter_mut()方法获取,每次迭代器的next都会返回Some(&mut T)类型。
到现在为止,我们已经学习了两个Trait以及三种迭代器结构体,用一个图表总结它们:
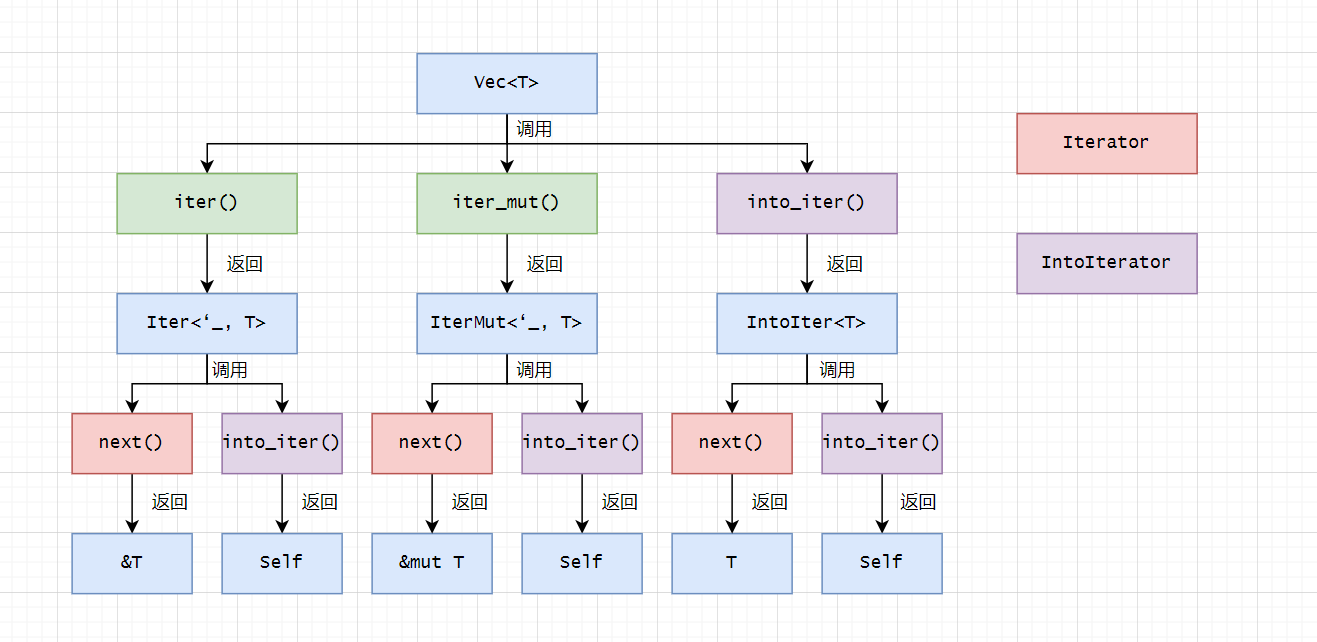
如图所示,紫色的方法是into_iter(),可以调用这个方法说明实现了IntoIterator。而红色的方法是next(),可以调用这个方法说明实现了Iterator。
三种迭代器Iter、IterMut、IntoIter都实现了这两个Trait。into_iter()都返回它们自己,这是为了兼容for in循环的语法糖。而它们调用next()时,返回的类型不同,这是它们在所有权上的差别。
而对于集合类型,在impl Vec<T>中实现了iter()和iter_mut()拿到前两种迭代器。在impl IntoIterator for Vec<T>中实现了into_iter拿到第三种迭代器,也因此集合类型可以直接放在for in循环中。
在实际使用时,如果需要占有原本集合类型的所有权,可以直接在for in中填入集合类型本身,本质是调用了into_iter()。如果只是读取或者修改,不希望所有权被转移,那么就手动调用iter()或者iter_mut()。
另外的,对于一个集合类型,你可能见过多种写法:
rust
let mut v = vec![1, 2, 3, 4, 5];
for val in &v {
println!("{}", val);
}
for val in &mut v {
println!("{}", val);
}
for val in v {
println!("{}", val);
}在for in 循环的时候,你可以对&v、&mut v、v三种情况进行迭代。
有了之前的只是,就可以解释这三种场景了。既然这三个类型都可以放进for in中,说明&Vec、&mut Vec、Vec一定都实现了IntoIterator。&Vec返回的迭代器Item = &T,&mut Vec返回的迭代器Item = &mut T、Vec返回的迭代器Item = T。其实也就是分别调用了iter()、iter_mut()、into_iter()方法,拿到不同所有权的迭代器。
相比于直接调用方法拿到迭代器再迭代,这种写法更简短。
迭代器适配器
迭代器就像一个工厂,它会遍历集合,源源不断的产出数据。
在现实中,一个工厂未必就会产生直接使用的产品,恰恰相反,工厂往往会产生原料,而这些原料经过不同加工,才会进一步成为出售的产品。
加入现在有一个产生布匹的工厂,它产生布匹后,将布匹交往其它工厂。有的工厂拿布做衣服,有的做被子,也有的做窗帘等等。对于已经产生的布匹,经过不同加工可以得到不同的产品。
迭代器也是如此,对于迭代器产出的数据,可以对其进行二次处理、三次处理甚至更多,最后得到符合要求的数据,这是函数式编程的精髓所在。
而对原有迭代器数据进行二次处理,就是迭代器适配器的任务。
Rust 的函数式风格主要靠迭代器适配器实现。所谓适配器,就是在原迭代器的基础上,返回一个新的迭代器以延迟执行某种操作。
map
Map是最常用的适配器,通过Iterator::map()方法即可得到。调用时需要传入一个闭包,那么迭代器的所有元素返回前,就会先执行这个闭包。
示例:
rust
let v = vec![4, 5, 6];
let iter = v.iter();
let iter_weapper = iter.map(|&x| x * 10);
for item in iter_weapper {
println!("{}", item);
}这段代码中,先通过v.iter()拿到一个迭代器,随后调用迭代器的iter.map()进行包装。适配器传入的闭包为|&x| x * 10,也就是将每个元素乘10后再返回。
要注意的是,当前面的迭代器元素是什么类型,map的闭包就拿到什么类型,这里iter返回的是&i32,因此在闭包参数中需要用&x模式匹配拆掉一层借用。
当通过next()遍历迭代器,就会得到40、50、60,这就是map包装后的效果。
Iterator::map()是Iterator内部的方法,它会返回一个结构体Map,定义如下:
rust
pub struct Map<I, F> {
pub(crate) iter: I,
f: F,
}这个Map只存储两个内容,一个是原始的迭代器iter,另一个是闭包f。
rust
impl<B, I: Iterator, F> Iterator for Map<I, F>
where
F: FnMut(I::Item) -> B,
{
type Item = B;
#[inline]
fn next(&mut self) -> Option<B> {
self.iter.next().map(&mut self.f)
}
// other
}迭代器适配器也实现了Iterator,自然也实现了IntoIterator,因此可以直接被for in 遍历。
在Map调用next()方法时,实际上调用的是self.iter.next()。此时拿到的是一个Option<T>,它的map方法在为Some(val)时,将val传给闭包,并返回闭包的结果,在为None时,直接返回None。
注意区分迭代器的map和Option的map,这是两个不同的方法,只是恰好同名而已,功能也确实是类似的。
其它
通过map了解了迭代器适配器的原理后,再看看其它常用的适配器。
chain:串联两个迭代器
rust
let a = vec!["A", "B"];
let b = vec!["C", "D"];
let iter = a.iter().chain(b.iter());
for item in iter {
println!("{:?}", item);
}输出结果:
text
"A"
"B"
"C"
"D"此处chain要求传入另外一个迭代器,最后迭代器输出时,会把多个迭代器的内容串联起来。
filter:基于条件保留元素
rust
let nums = vec![1, 2, 3, 4, 5, 6];
let iter = nums.iter().filter(|&&x| x % 2 == 0);
for item in iter {
println!("{:?}", item);
}输出结果:
text
2
4
6filter用于过滤元素,传入一个闭包。如果某个元素执行闭包为true则保留,反之则丢弃。
关于这个filter,有一个要注意的地方,它的闭包参数是&&x,这看起来很奇怪。
看一下filter的定义:
rust
fn filter<P>(self, predicate: P) -> Filter<Self, P>
where
Self: Sized,
P: FnMut(&Self::Item) -> bool,
{
Filter::new(self, predicate)
}filter接收的闭包的参数是&Self::Item类型,它是一个借用,这里的Self是指实现了Iterator的类型,也就是iter()的返回值。
而iter()是返回不可变借用的迭代器,因此这里的Self::Item的类型实际上是&i32。相当于filter对&i32进行了再次借用,闭包最后得到&&i32类型。因此要在参数的位置进行模式匹配,把这两层借用脱掉,最后x的类型才是i32。
可以回去对比一下map,它的闭包参数类型是FnMut(Self::Item) -> B,这里没有一层借用,因此用起来就不那么别扭。
flat_map:将多层迭代器扁平化为一层
rust
let words = vec!["Hi", "Yo"];
let iter = words.iter().flat_map(|w| w.chars());
for ch in iter {
println!("{:?}", ch);
}输出结果:
text
'H'
'i'
'Y'
'o'flat_map接受一个闭包FnMut(Self::Item) -> U,要求闭包必须返回U: IntoIterator,也就是说返回的类型必须可以转化为迭代器。
随后把所有返回的迭代器,连接成一个迭代器输出。比如在vec中有两个字符串,通过chars()方法可以拿到遍历字符的迭代器。最后flat_map会把返回的所有迭代器连接起来形成一个迭代器。
从结果上看,原本的结构是数组里面存字符串,字符串里面存字符。经过flat_map,直接拿到遍历每层内部字符的迭代器了,也就是把多层结构扁平化为一层。
cloned:将引用元素克隆为值
rust
let names = vec!["Alice", "Bob", "Carol"];
let iter = names.iter().cloned();
for name in iter {
println!("{:?}", name);
}输出结果:
text
"Alice"
"Bob"
"Carol"在这里,iter()拿到的是不可变借用,通过clone()适配后,最后输出的字符串是原字符串的clone。
enumerate:附带元素索引
rust
let fruits = vec!["apple", "banana", "cherry"];
let iter = fruits.iter().enumerate();
for (index, fruit) in iter {
println!("{}: {:?}", index, fruit);
}输出结果:
text
0: "apple"
1: "banana"
2: "cherry"会在原迭代器的基础上,封装每次遍历的下标,以元组的形式返回。这样在遍历数组的时候,就可以拿到数组下标,进行一些下标相关的处理了,是很常用的适配器。
cycle:循环无限遍历
rust
let nums = vec![1, 2, 3];
let iter = nums.iter().cycle();
for item in iter {
println!("{:?}", item);
}输出结果:
text
1
2
3
1
2
3
1
... // 无限循环很多迭代器是有上限的,使用cycle适配后,每当遍历到最后一个元素,再次next()会重新回到第一个元素,形成一个无限遍历。
take:截取前 N 个元素
rust
let nums = vec![1, 2, 3, 4, 5, 6];
let iter = nums.iter().take(3);
for item in iter {
println!("{:?}", item);
}输出结果:
text
1
2
3take 会返回一个新的迭代器,最多取前 N 个元素。
底层其实是一个小计数器,每次 next() 后把剩余个数减一,当数量归零后,直接返回 None。
它常用于"截断"无限迭代器,把无穷流控制成有限输出,特别好搭配刚才的 cycle。
例如:
rust
let nums = vec![1, 2, 3];
let iter = nums.iter().cycle().take(8);
for item in iter {
print!("{} ", item);
}输出结果:
text
1 2 3 1 2 3 1 2 这里 cycle 让迭代器循环成无限流,而 take(8) 限定了只取前 8 个值。
rev:反向遍历
rust
let nums = vec![10, 20, 30, 40];
let iter = nums.iter().rev();
for item in iter {
println!("{:?}", item);
}输出结果:
text
40
30
20
10使用rev适配后,迭代器的遍历方向会反转。
在这里,rev()要求迭代器必须实现了 DoubleEndedIterator 这个Trait,这表示迭代器可以同时从两个方向迭代,它是Iterator的子Trait。
还记得Vec的迭代器长啥样吗?再看一遍:
rust
pub struct Iter<'a, T: 'a> {
ptr: NonNull<T>,
end_or_len: *const T,
_marker: PhantomData<&'a T>,
}它维护了两个指针,ptr和end_or_len。调用Iterator::next()方法,ptr就会往后偏移。但是Vec允许双向迭代,因此Iter实现了DoubleEndedIterator,它内部有一个next_back方法,这个方法会让end_or_len向前偏移,并且返回当前数组尾部的元素,这就是反向遍历。
示例:
rust
let numbers = vec![1, 2, 3, 4, 5, 6];
let mut iter = numbers.iter();
assert_eq!(Some(&1), iter.next());
assert_eq!(Some(&6), iter.next_back());
assert_eq!(Some(&5), iter.next_back());
assert_eq!(Some(&2), iter.next());
assert_eq!(Some(&3), iter.next());
assert_eq!(Some(&4), iter.next());
assert_eq!(None, iter.next());
assert_eq!(None, iter.next_back());这段代码中,同时调用next()和next_back()进行遍历,两者可以同时遍历,逻辑如下:
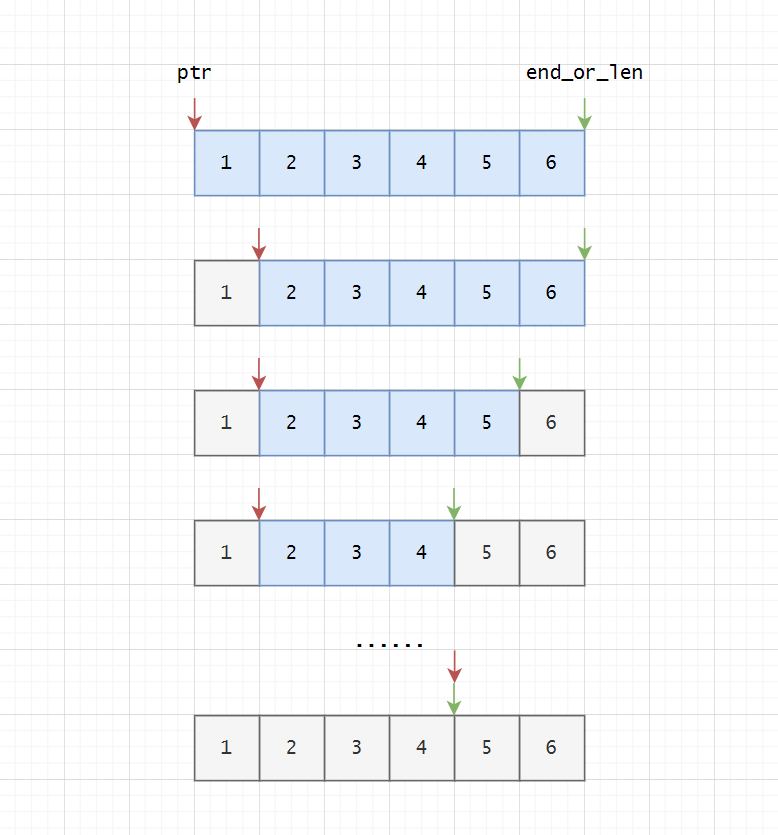
起初ptr和end_or_len分别指向头尾,每次调用next()时ptr向后,调用next_back()时end_or_len向前,直到两个指针相遇,返回None表示迭代完毕。
双向迭代器是指可以同时从两个方向迭代,但是它们不是独立的,而是共享的,并且保证不论用户以何种顺序遍历,最后所有元素只会被消费一次。
而rev()这个包装器,在调用next()时实际调用的是原迭代器的next_back(),因此直接遍历rev()适配后的迭代器,就是反向的。
消费者方法
迭代器是惰性的,与闭包一样,不论是迭代器还是适配器,它们本质就是一个结构体,只要不调用next()方法,就不会产生任何结果。
除了自己手动调用next()和for in,还提供了一系列方法可以直接使用迭代器,将迭代器产生的值处理成预期的结构,本质还是调用next()方法,它们就叫做消费者方法。
常见的消费者方法如下:
| 方法 | 返回类型 | 功能描述 |
|---|---|---|
collect() |
通常是 Vec、HashMap 等集合 |
收集所有元素 |
for_each() |
() |
对每个元素执行操作 |
sum() / product() |
T |
求和 / 求积 |
count() |
usize |
计算元素个数 |
any() / all() |
bool |
满足条件检测 |
fold() |
累加器 | 通用聚合操作 |
接下来详细介绍两个比较重要的collect和fold。
collect
collect将迭代器的所有元素收拢为一个集合类型。
rust
let numbers = vec![1, 2, 3, 4, 5];
// 把迭代结果收集成 Vec
let doubled: Vec<_> = numbers.iter()
.map(|&x| x * 2)
.collect();
println!("{:?}", doubled); // [2, 4, 6, 8, 10]首先通过iter()拿到迭代器,然后使用map()将每个元素乘二,到此为止迭代器都还没有被消费。最后希望所有元素乘二之后的结果,放到一个数组内部,就可以用collect()方法。
这个方法可以返回很多集合类型,这需要在返回值指定类型,比如这里doubled: Vec<_>指定需要一个数组,那么collect返回的就是数组,也可以通过turbofish指定collect::<Vec<_>>()。
collect源码如下:
rust
fn collect<B: FromIterator<Self::Item>>(self) -> B
where
Self: Sized,
{
if cfg!(debug_assertions) {
let hint = self.size_hint();
assert!(hint.1.is_none_or(|high| high >= hint.0), "Malformed size_hint {hint:?}");
}
FromIterator::from_iter(self)
}可以看出,它返回一个B类型,并且约束这个类型必须实现FromIterator。它和之前讲的IntoIterator刚好相反,实现这个Trait意味着可以通过迭代器转换为对应类型,而collect的返回值就是直接把self转为对应类型。
比如刚才代码中,使用Vec类型接收了返回值,那么调用的就是Vec实现的from_iter()方法,基于一个迭代器构造出一个数组。
fold
fold聚合所有元素为一个返回值。
fold接受两个参数,一个初始值,一个闭包。而闭包又接受两个参数,第一个是累计值,第二个是每次迭代得到的元素。
示例:
rust
let numbers = vec![1, 2, 3, 4, 5];
// 把所有元素求和
let sum = numbers.iter().fold(0, |acc, &x| acc + x);
println!("{}", sum); // 输出 15此处,fold指定初始值为0。传入闭包|acc, &x| acc + x,第一个参数acc就是一个迭代期间一直维护的值。acc的初始值就是fold的第一个参数,每次迭代时,acc的值都会更新为闭包的返回值。
比如以上代码就是完成所有元素的累加,一开始acc = 0。第一次迭代,x的值就是第一个元素1,因此acc = acc + x,也就是acc = 1。以此类推,最后acc = 15。
再比如:
rust
let words = vec!["Rust", "is", "fun"];
let sentence = words.iter().fold(String::new(), |mut acc, &word| {
acc.push_str(word);
acc
});
println!("{sentence}"); // "Rustisfun"这段代码完成了字符串拼接,一开始acc = String::new(),也就是一个空字符串。闭包中接受acc,而且是以可变绑定形式。每次迭代把本轮迭代器内部的字符串通过push_str加到acc末尾,最后返回acc。
要注意的是,iter方法的迭代器,返回的是不可变借用,在fold的闭包参数中,需要用&word模式匹配脱掉一层借用,拿到的才是数据本体。否则就要在闭包内部使用*解引用。
范围类型
在for in循环中,经常可以看到使用范围的写法:
rust
for i in 0..5 {
println!("{}", i);
}这个循环表示遍历[0, 5)区间的值,实际上0..5本质是一个范围类型。
Rust 的范围迭代器分为以下几种形式:
| 表达式 | 类型 | 包含关系 | 可迭代 |
|---|---|---|---|
a..b |
Range |
[a, b) |
是 |
a..=b |
RangeInclusive |
[a, b] |
是 |
a.. |
RangeFrom |
[a, ∞) |
是 |
..b |
RangeTo |
[0, b) |
否 |
..=b |
RangeToInclusive |
[0, b] |
否 |
.. |
RangeFull |
整体范围 | 否 |
即便是无限序列,如 (0..),也可以独立存在:
rust
for i in 10.. {
println!("{}", i);
}此时就形成了从10开始的无限循环。
这些范围类型本质也就是一个实现了IntoIterator的结构体,可以当做迭代器使用,直接放到for in里面。
而对于..b和、..和..=b,它们的范围不确定,因此一般只用于切片,而不会用来迭代。
其它进阶方法
peekable
普通迭代器调用 next() 会推进状态,取出一个元素,就再也回不去了。
但有时候我们想提前看看下一个元素该不该取,就需要读取而不真正消费,这时 peekable() 就派上用场了。
peekable()处于Iterator中,方法定义如下:
rust
fn peekable(self) -> Peekable<Self>
where
Self: Sized,
{
Peekable::new(self)
}这个方法很简单,直接使用当前迭代器,返回一个Peekable结构体。
结构体定义如下:
rust
pub struct Peekable<I: Iterator> {
iter: I,
/// Remember a peeked value, even if it was None.
peeked: Option<Option<I::Item>>,
}这个结构体的本质也是迭代器适配器,它内部存储了迭代器iter,另外还维护了一个peeked,它内部存储的是迭代器产生的值Item。
peeked是一个缓存,它通过双层Option表示三种状态:
None:当前没有缓存Some(None):迭代器到达结尾了Some(Some(val)):缓存了一个值val
被Peekable包装的迭代器,你可以通过peek()方法拿到下一个元素的不可变借用,预览下一个元素的值而不消费它,也就是迭代器不会推进。
实际上它的行为是这样的:
- 调用
peek()时- 如果
peeked为None,说明没缓存下一个元素,调用iter.next()拿到下一个元素,存入缓存中,返回借用 - 如果
peeked为Some(val),说明已经缓存了下一个元素,或者走到结尾了,直接返回val的借用
- 如果
- 调用
next()时- 如果
peeked为None,说明没缓存下一个元素,调用iter.next()拿到下一个元素,返回结果 - 如果
peeked为Some(val),说明已经缓存了下一个元素,直接返回val,此时peeked变回None状态
- 如果
也就是说,其实Peekable是在内部维护了一个缓存,从而允许我们预览下一个元素。所谓的没有消费下一个元素,其实本质还是消费了下一个元素,只是把消费的元素先存起来,下次调用next()就不再调用迭代器了,而是返回缓存值。而用户用起来的感觉就是可以预览下一个元素,好像没有消费迭代器。
示例:
rust
let mut iter = (1..5).peekable();
println!("peek 1: {:?}", iter.peek()); // Some(&1)
println!("next 1: {:?}", iter.next()); // Some(1)
println!("next 2: {:?}", iter.next()); // Some(2)
println!("peek 3: {:?}", iter.peek()); // Some(&3)
println!("peek 3: {:?}", iter.peek()); // Some(&3)这段代码中,多次调用了peek()方法,但每次调用触发的行为是略有差别的。
第一次先调用peek(),那么会把值进行缓存,随后调用next()触发了缓存,会返回并且清空缓存值。
第二次直接调用next(),由于没有缓存值,所以直接返回迭代器的下一个元素。
第三次进行了两次peek(),第一次会进行缓存。第二次再调用peek,由于已经有缓存值了,所以不会再调用内部迭代器,直接返回缓存值的借用。
inspect
inspect可以在迭代器适配器之间阅读迭代器返回的元素,从而进行调试日志输出。
示例:
rust
let sum: i32 = (1..=5)
.map(|x| x * 2)
.inspect(|x| println!("map 结果: {x}"))
.filter(|x| x % 3 != 0)
.inspect(|x| println!("{x} 符合要求"))
.sum();
println!("Sum = {}", sum);这段代码将返回类型先后进行map、filter,最后sum消费。
如果你想要在每次map和filter执行完毕后,查看得到的结果值,就可以在这些适配器之间插入inspect。
inspect接受一个闭包,它的参数是指向迭代器返回值的不可变借用,你可以读取并且输出这些迭代器的返回值,而且可以插入在任意一层迭代器。
输出结果:
rust
map 结果: 2
2 符合要求
map 结果: 4
4 符合要求
map 结果: 6
map 结果: 8
8 符合要求
map 结果: 10
10 符合要求
Sum = 24这在一些需要调试的场景,比如算法调试,网络流日志的情况下很有用。
by_ref
在使用迭代器时,可能会遇到以下问题:
rust
let mut iter = 0..10;
let first_three: Vec<_> = iter.take(3).collect();
let sum_rest: i32 = iter.map(|x| x * 2).sum(); // iter 已经被 move现在有一个迭代器iter,通过take(3)拿走它的前三个元素并且消费掉。随后我们希望把迭代器的后7个元素乘二后求和。
报错了,因为take()是一个迭代器适配器,它会直接拿走原迭代器的所有权。但是实际上这个take没有用完底层的iter迭代器,它只把底层的迭代器推进到第三个元素,还有七个元素没有遍历。
也就是说,有时候我们不希望迭代器适配器拿走整个迭代器的所有权,而是拿走借用,这样当这个适配器消费掉之后,可能原迭代器还没消费完,还能继续使用。
这就好像某个工厂产出了十块布料,某个厂家制定了一个生产线,把布料制作成窗帘,但是厂家不知道要消耗多少布料,于是决定把十块布料全都预定了。等到厂家正式开工,做完窗帘发现只用了三块布,还有七块布。原本的工厂看到还有七块布,于是决定卖给其它厂家,但是这七块布被窗帘厂家预定了,即使窗帘厂不要这七块布了,你也不能卖给别人,这不就白白浪费了吗?
这就是刚才的代码中遇到的困境,collect()只消费了三个元素。当用户希望把剩下的七个元素给sum()消费时,却被所有权规则阻止了。
为了解决这个问题,可以使用by_ref()方法,方法定义如下:
rust
fn by_ref(&mut self) -> &mut Self
where
Self: Sized,
{
self
}不知道你看完这段代码什么感觉,反正我初看的时候更加一头雾水了,这个函数看起来啥也没干啊!!!
它接受一个&mut self,返回一个&mut self,然后呢?啥也没做,take()就可以不移动迭代器所有权了???
这里有一个隐藏的规则:如果类型T实现了Iterator,那么&mut T自动实现Iterator。
take()是一个迭代器适配器,它要拿走迭代器的所有权。但是&mut T本身就是一个迭代器,它拿走的实际上是一个指针的所有权,而指针是值类型,不会移动,本质发生了一次拷贝。
感受一下这里类型的差别:
rust
let mut iter = 0..10;
iter.take(3);
iter.by_ref().take(3);在第一行代码中,take(self)中的self是Range<i32>,第二行代码中take()的self是&mut Range<i32>。
从来没有人说过借用不能作为self吧?这里需要绕一个弯子,理解take()内部的self类型已经发生变化了。
因此适配器最后只会拿走原迭代器的可变借用,当适配器被消费完,原迭代器可以继续使用。
而by_ref()只是强制返回了原本迭代的可变借用,从而改变take()的内部迭代器类型。
既然by_ref()本质只是进行了一次类型转换,那么我们手动转换也是可以的,你就可以写出这样的骚操作:
rust
let mut iter = 1..10;
let first_three: Vec<_> = (&mut iter).take(3).collect();
let sum_rest: i32 = iter.map(|x| x * 2).sum();直接对iter可变借用,然后再调用take(),最后适配器没有移动迭代器的所有权,适配器消费完之后,可以继续使用迭代器。
只是说这样的代码很容易给同事造成困惑,尤其是你的同事可能不知道迭代器的可变借用也自动实现了Iterator,所以还是最好写出by_ref(),哪怕它啥也没干。
迭代器短路
在之前的消费器中,提到了几个不起眼的消费器any、all。
它们的用法很简单:
rust
let arr = [1, 2, 3, 4, 5];
arr.iter().any(|&x| x % 3 == 0);
arr.iter().all(|&x| x <= 2);两个消费器都传入一个闭包,any表示迭代器中任意一个元素符合要求,而all表示迭代器中所有元素都符合要求。
比如第一个any最终返回true,而all返回false。
这些消费器不一定会消费掉所有的迭代器元素,而是会发生短路。
比如说any要求有任意一个元素满足要求,只要检测到某个迭代器元素满足要求,就不会继续迭代了,直接返回结果。而all只要检测到任意一个迭代器元素不符合要求,也会直接返回结果。
可以用刚才学过inspect方法进行检测:
rust
let arr = [1, 2, 3, 4, 5];
arr.iter()
.inspect(|&&x| println!("any 迭代: {}", x))
.any(|&x| x % 3 == 0);
arr.iter()
.inspect(|&&x| println!("all 迭代: {}", x))
.all(|&x| x <= 2);输出结果:
rust
any 迭代: 1
any 迭代: 2
any 迭代: 3
all 迭代: 1
all 迭代: 2
all 迭代: 3可以看到两个消费器都只消费到第三个元素就停止了,因为3是第一个符合any要求的元素,直接返回true,它也是第一个不符合all要求的元素,直接返回false。
理解复杂迭代器工作流
最后谈一谈,经过多层适配器的迭代器到底如何工作的?
虽然经过前面的讲解,你对迭代器的理解已经非常不错了,但是我们还需要从全局上再谈迭代器。
示例:
rust
let mut iter = 1..=6;
let ret: Vec<_> = iter.map(|x| x * 2)
.filter(|&x| x % 2 == 0)
.collect();这个代码很简单,拿到一个迭代器。然后经过两层适配器,最后通过collect()消费掉它。
你可以用你的大脑想象一下,它是如何运作的,如何一个一个把值产出来然后放到数组里面的。
有的人可能会这么想,它是"横向"工作的:
iter首先产生1, 2, 3, 4, 5, 6- 把刚才的元素依次给
map,得到2 4 6 8 10 12 - 再把它们依次给
filter,得到6 12 - 最后把
6, 12放到数组中,得到[6, 12]
如果你这么想,确实可以写出合理的代码,也不会影响你的业务,甚至我推荐你去这样思考。但是迭代器不是这么运作的。
迭代器是"纵向"工作的:
iter产生第一个元素1,把1交给map得到2,把2交给filter不符合要求,丢弃iter产生第一个元素2,把2交给map得到4,把4交给filter不符合要求,丢弃iter产生第一个元素3,把3交给map得到6,把6交给filter符合要求,collect把6插入数组iter产生第一个元素4,把4交给map得到8,把8交给filter不符合要求,丢弃iter产生第一个元素5,把5交给map得到10,把10交给filter不符合要求,丢弃iter产生第一个元素6,把6交给map得到12,把12交给filter符合要求,collect把12插入数组
每两个步骤之间,是一次next()调用。
如图:
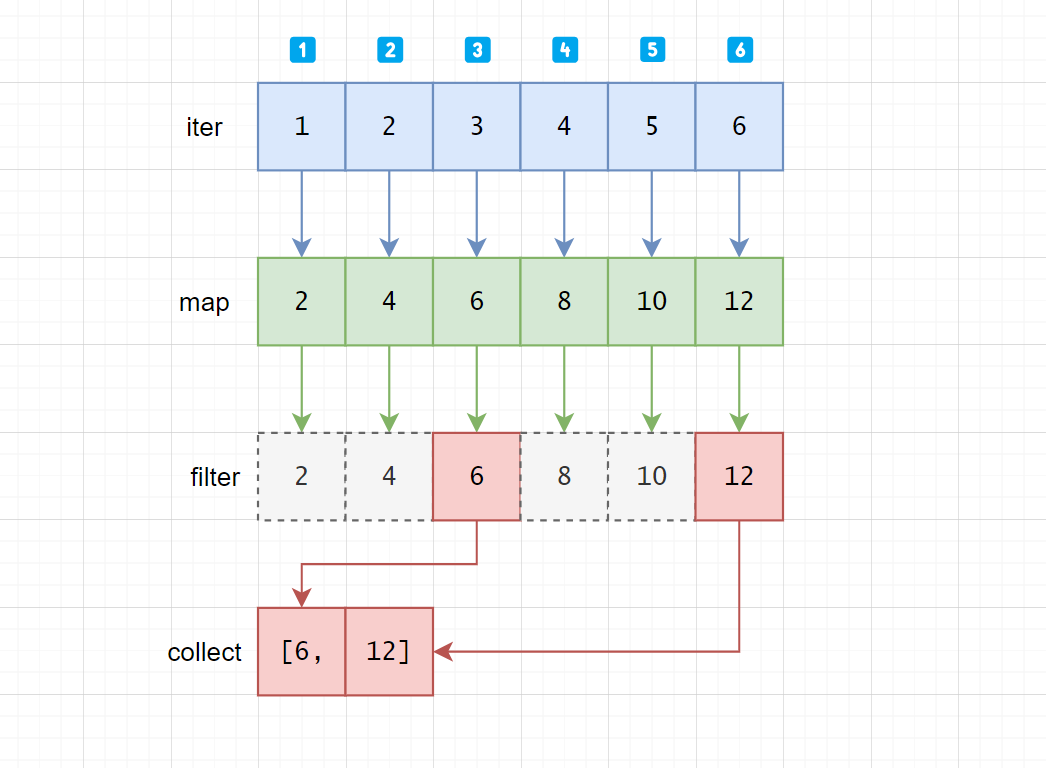
从左到右,是按照一列一列的顺序运行的。当处理完第一个元素,调用next()才会以相同的逻辑处理下一个元素。
博客前文介绍了不少迭代器适配器,并把它们的源码都附带出来了。可以发现迭代器适配器是一层一层嵌套的,比如这里就有三层嵌套,Filter内部嵌套Map,而Map内部嵌套Range<i32>,它们形成以下关系结构:
rust
struct Filter {
iter: Map,
predicate: P,
}
struct Map {
iter: Range<i32>,
f: F,
}在collect消费器中,消费的是最外层Filter迭代器,也就是调用它的next方法。
而Filter::next()会先调用Map::next()方法,拿到值后再进行判断是否保留。
而Map::next由会调用Range<i32>::next()方法拿到本次迭代的值,然后再进行闭包处理。
你会发现,本质上迭代器的适配器模式,就是一层结构体套一层结构体。每层结构体作为外层的迭代器,会被外层调用next()方法,自己又去调用内层的next(),它们被这一个接口串联了起来。
每当想要拿到迭代器的某个元素,就会从最内层的迭代器开始返回,并一层层经过不同适配器的处理,最后得到结果。这是一个"纵向"传递,层层处理的过程。
上层的适配器不一定会消费掉所有底层迭代器的元素,比如刚才的案例:
rust
let mut iter = 0..10;
let first_three: Vec<_> = iter.by_ref().take(3).collect();
let sum_rest: i32 = iter.map(|x| x * 2).sum();同一个底层迭代器iter,前三个元素被collect()消费,后七个元素被map适配后,由sum()消费。
如下图:
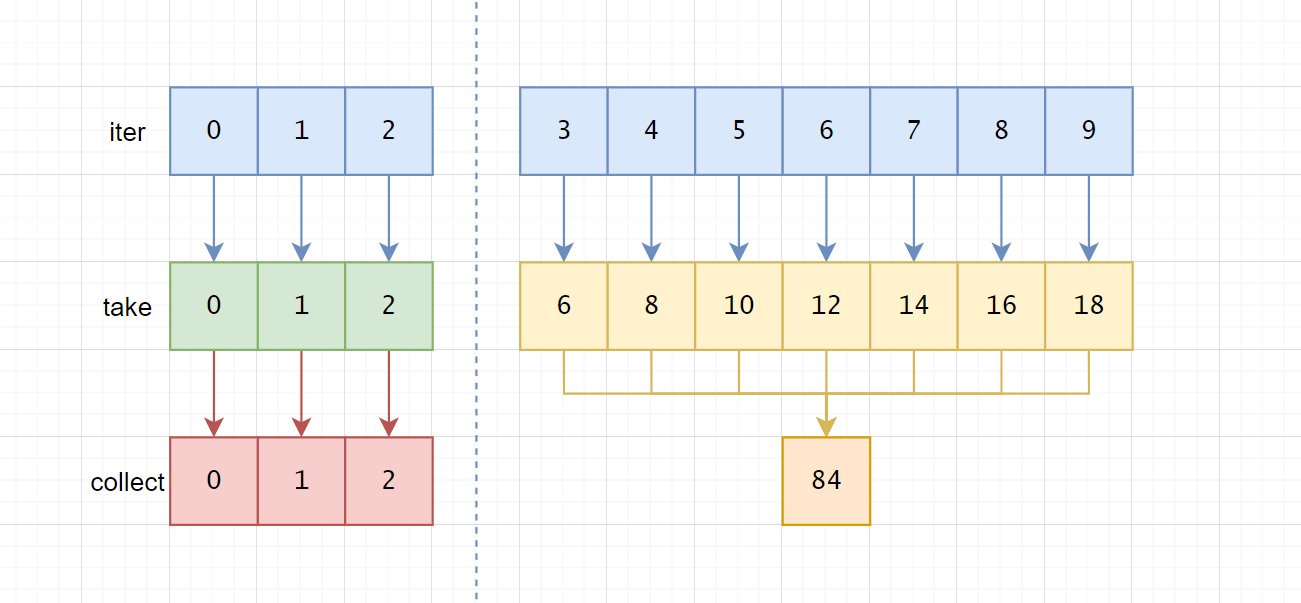
逻辑为:
iter产生第一个元素0,把1交给take得到0,collect把0插入数组iter产生第一个元素1,把1交给take得到1,collect把1插入数组iter产生第一个元素2,把2交给take得到2,collect把2插入数组iter产生第一个元素3,把3交给map得到6,sum累加得到6iter产生第一个元素4,把4交给map得到8,sum累加得到14iter产生第一个元素5,把5交给map得到10,sum累加得到24iter产生第一个元素6,把6交给map得到12,sum累加得到36iter产生第一个元素7,把7交给map得到14,sum累加得到50iter产生第一个元素8,把8交给map得到16,sum累加得到66iter产生第一个元素9,把9交给map得到18,sum累加得到84
从第三个元素开始,底层的iter被别的适配器适配了,想要理解这种一个迭代器不同部分被不同适配器包装,就必须用这种"纵向"的思维去理解。