软件开发流程整体介绍
类比计网,项目开发变成这个样子了。
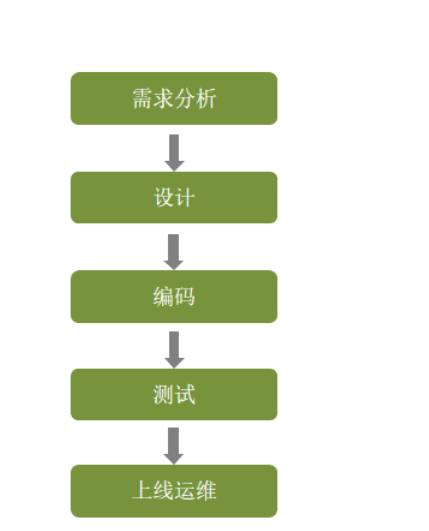
然后软件开发有一个流程
如下图所示
需求分析就是开发之前分析需求并且会有一个文档
然后有两个文档一个是需求规格说明书 一个是产品原型
然后需求规格说明书一般是一个word形式的文档
产品原型是一个静态网页形式展示一个个项目功能
2). 第2阶段: 设计
设计的内容包含 UI设计、数据库设计、接口设计。
这里重点讲一下接口设计

你得设计接口 就是告诉请求路径 也就是这里的path 请求方式post
还有请求参数 和返回的数据
3). 第3阶段: 编码
编写项目代码、并完成单元测试。
项目代码编写:作为软件开发工程师,我们需要对项目的模块功能分析后,进行编码实现。
单元测试:编码实现完毕后,进行单元测试,单元测试通过后再进入到下一阶段。例如:
4). 第4阶段: 测试
在该阶段中主要由测试人员, 对部署在测试环境的项目进行功能测试, 并出具测试报告。比如测试用例就是这个阶段弄的
5). 第5阶段: 上线运维
在项目上线之前, 会由运维人员准备服务器上的软件环境安装、配置, 配置完毕后, 再将我们开发好的项目,部署在服务器上运行。
显然这么多步骤不可能由一个人去做,一个人去做那就是全栈了
1.2 角色分工
在对整个软件开发流程熟悉后, 我们还有必要了解一下在整个软件开发流程中涉及到的岗位角色,以及各个角色的职责分工。
|-----------|----------|-----------------------|
| 岗位/角色 | 对应阶段 | 职责/分工 |
| 项目经理 | 全阶段 | 对整个项目负责,任务分配、把控进度 |
| 产品经理 | 需求分析 | 进行需求调研,输出需求调研文档、产品原型等 |
| UI设计师 | 设计 | 根据产品原型输出界面效果图 |
| 架构师 | 设计 | 项目整体架构设计、技术选型等 |
| 开发工程师 | 编码 | 功能代码实现 |
| 测试工程师 | 测试 | 编写测试用例,输出测试报告 |
| 运维工程师 | 上线运维 | 软件环境搭建、项目上线 |
上述我们讲解的角色分工, 是在一个项目组中比较标准的角色分工, 但是在实际的项目中, 有一些项目组由于人员配置紧张, 可能并没有专门的架构师或测试人员, 这个时候可能需要有项目经理或者程序员兼任。
后端程序员主要负责编码
1.3 软件环境
作为软件开发工程师,在编码的过程中就不可避免地会接触多种软件环境,我们主要来分析在工作中经常遇到的三套环境, 分别是: 开发环境、测试环境、生产环境。 接下来,我们分别介绍一下这三套环境的作用和特点。
1). 开发环境(development)
我们作为软件开发人员,在开发阶段使用的环境,就是开发环境,一般外部用户无法访问。
比如,我们在开发中使用的MySQL数据库和其他的一些常用软件,我们可以安装在本地, 也可以安装在一台专门的服务器中, 这些应用软件仅仅在软件开发过程中使用, 项目测试、上线时,我们不会使用这套环境了,这个环境就是开发环境。
2). 测试环境(testing)
当软件开发工程师,将项目的功能模块开发完毕,并且单元测试通过后,就需要将项目部署到测试服务器上,让测试人员对项目进行测试。那这台测试服务器就是专门给测试人员使用的环境, 也就是测试环境,用于项目测试,一般外部用户无法访问。
3). 生产环境(production)
当项目开发完毕,并且由测试人员测试通过之后,就可以上线项目,将项目部署到线上环境,并正式对外提供服务,这个线上环境也称之为生产环境。
开发环境 测试环境 生产环境
首先,会在开发环境中进行项目开发,往往开发环境大多数都是本地的电脑环境和局域网内的环境,当开发完毕后,然后会把项目部署到测试环境,测试环境一般是一台独立测试服务器的环境,项目测试通过后,最终把项目部署到生产环境,生产环境可以是机房或者云服务器等线上环境。
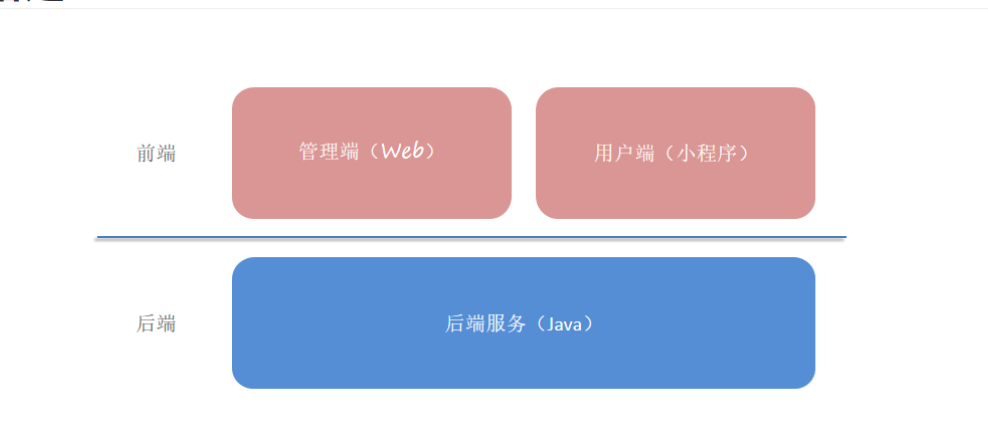
苍穹外卖项目介绍
在开发苍穹外卖这个项目之前,我们需要全方位的来介绍一下当前我们学习的这个项目。接下来,我们将从项目简介、产品原型、技术选型三个方面来介绍苍穹外卖这个项目。
产品原型前面提到了是产品经理,技术选型是架构师决定用什么项目
可以看到下图是产品原型,全都是html 页面,所以可以直观感受到什么是产品原型了
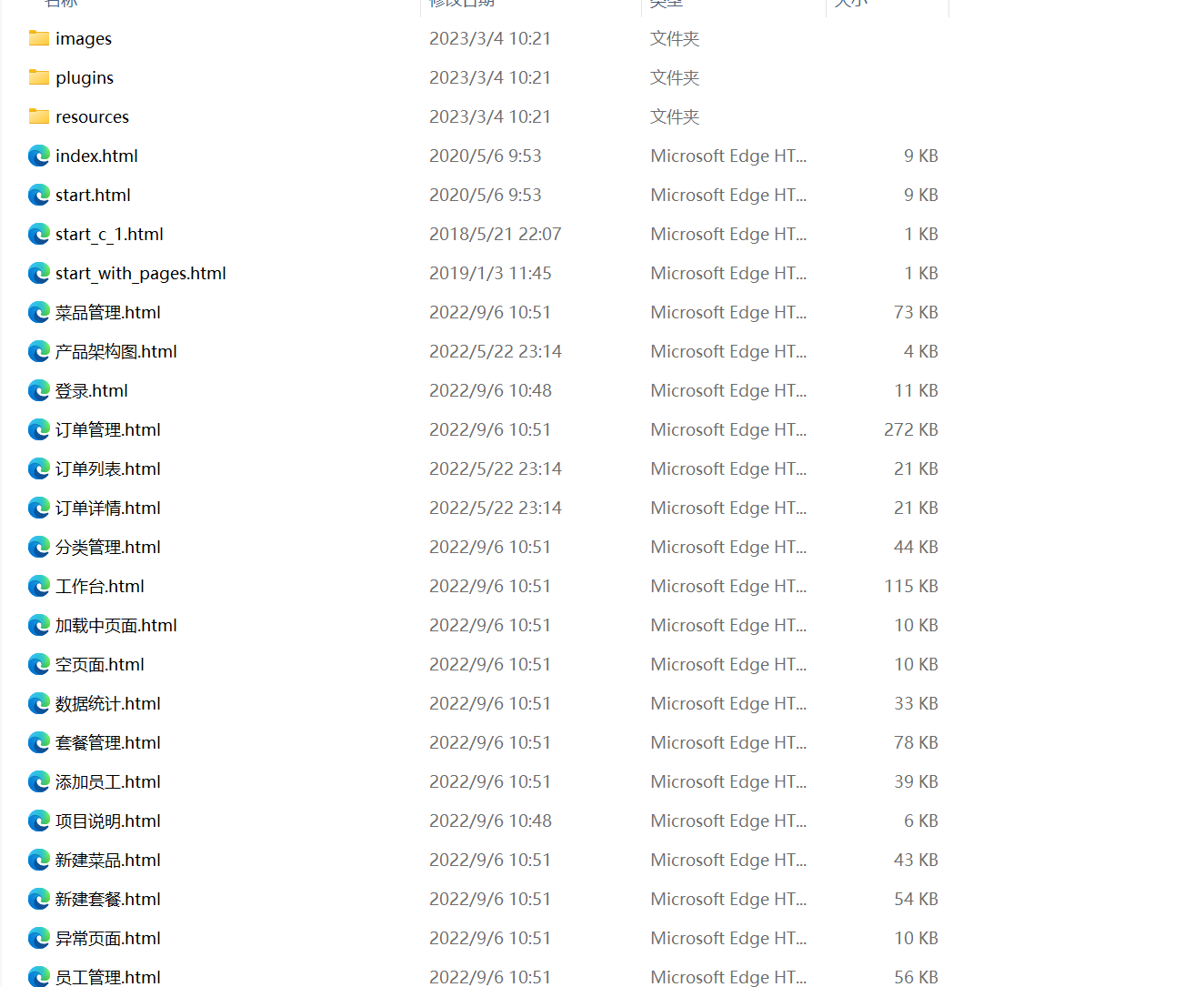
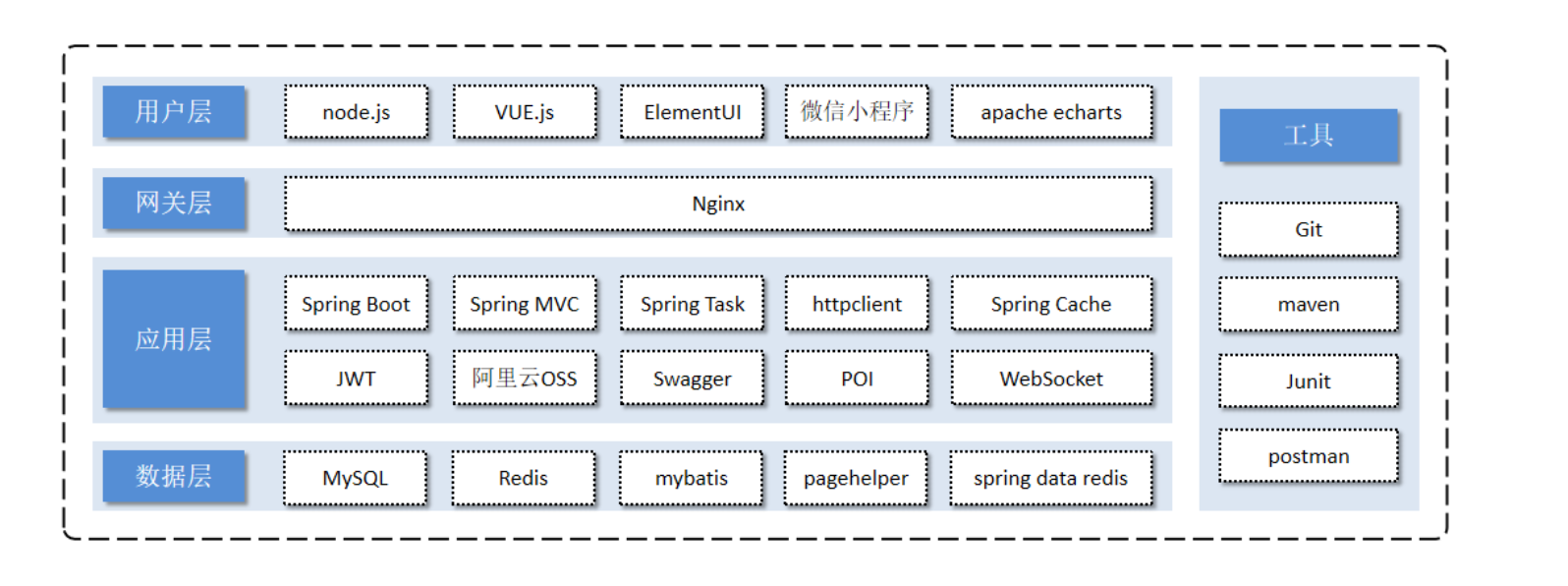
下面就是技术选型

nginx属于服务器,用户层这些基本上都是前端技术
1). 用户层
本项目中在构建系统管理后台的前端页面,我们会用到H5、Vue.js、ElementUI、apache echarts(展示图表)等技术。而在构建移动端应用时,我们会使用到微信小程序。
2). 网关层
Nginx是一个服务器,主要用来作为Http服务器,部署静态资源,访问性能高。在Nginx中还有两个比较重要的作用: 反向代理和负载均衡, 在进行项目部署时,要实现Tomcat的负载均衡,就可以通过Nginx来实现。负载均衡就是让每个tomcat服务器都能平衡的工作起来
反向代理就是先把请求发给nginx,然后他作为一个总主机,再把这个请求发给具体tomcat 这样做会更加安全些.
这里来辨析一下正向代理和反向代理
这两个代理数据流向都是
客户端 (A) -> 代理 (B) -> 服务器 (C)
区别
正向代理
- 代理是谁的人? 是你(客户端) 的人。是你主动配置的(比如你在浏览器或系统里开了 VPN)。
- 谁被隐藏了? 你(客户端) 被隐藏了。房东只认识中介,根本不知道其实是你住进去了。
- 你知道目标是谁吗? 知道。你明确知道你要访问谷歌,是你指挥中介去的。
正向代理总结:代理代表客户端,帮客户端出头。
反向代理
关键点:
- 代理是谁的人? 是 房东(服务器端) 的人。你根本没有配置任何东西,你只是输入了网址,是淘宝自己架设了 Nginx。
- 谁被隐藏了? 具体的房间(真实服务器) 被隐藏了。你只认识前台大厅(Nginx),你根本不知道你最终住的是 301 还是 302,你也联系不到房东。
- 你知道目标是谁吗? 不知道细节 。你以为你访问的是"淘宝",但其实你访问的是"淘宝的前台",具体谁为你服务,你无法决定。
反向代理总结:代理代表服务器,帮服务器挡枪/分流。
一句话总结就是这个代理是用户客户端比如vpn找的,就是正向的,这个代理是服务器那边找的比如nginx这个代理那就是反向代理
3). 应用层
SpringBoot: 快速构建Spring项目, 采用 "约定优于配置" 的思想, 简化Spring项目的配置开发。
SpringMVC:SpringMVC是spring框架的一个模块,springmvc和spring无需通过中间整合层进行整合,可以无缝集成。
Spring Task: 由Spring提供的定时任务框架。
httpclient: 主要实现了对http请求的发送。
Spring Cache: 由Spring提供的数据缓存框架
JWT: 用于对应用程序上的用户进行身份验证的标记。
阿里云OSS: 对象存储服务,在项目中主要存储文件,如图片等。
Swagger: 可以自动的帮助开发人员生成接口文档,并对接口进行测试。
POI: 封装了对Excel表格的常用操作。
WebSocket: 一种通信网络协议,使客户端和服务器之间的数据交换更加简单,用于项目的来单、催单功能实现。
4). 数据层
MySQL: 关系型数据库, 本项目的核心业务数据都会采用MySQL进行存储。
Redis: 基于key-value格式存储的内存数据库, 访问速度快, 经常使用它做缓存。
Mybatis: 本项目持久层将会使用Mybatis开发。
pagehelper: 分页插件。
spring data redis: 简化java代码操作Redis的API。
5). 工具
git: 版本控制工具, 在团队协作中, 使用该工具对项目中的代码进行管理。
maven: 项目构建工具。
junit:单元测试工具,开发人员功能实现完毕后,需要通过junit对功能进行单元测试。
postman: 接口测工具,模拟用户发起的各类HTTP请求,获取对应的响应结果。
前端环境搭建
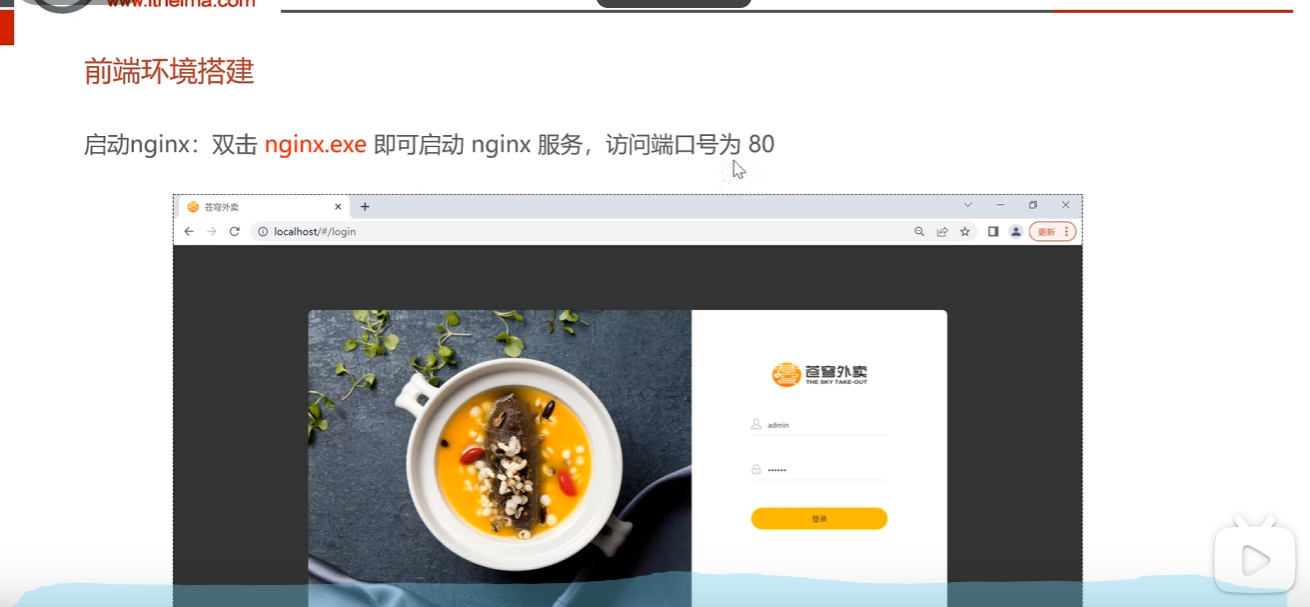
计网学过http服务器端口号默认使用80
然后就是后端环境构建 ,后端环境是通过maven进行分模块构建的
对工程的每个模块作用说明:
|--------|--------------|--------------------------------------------|
| 序号 | 名称 | 说明 |
| 1 | sky-take-out | maven父工程,统一管理依赖版本,聚合其他子模块 |
| 2 | sky-common | 子模块,存放公共类,例如:工具类、常量类、异常类等 |
| 3 | sky-pojo | 子模块,存放实体类、VO、DTO等 |
| 4 | sky-server | 子模块,后端服务,存放配置文件、Controller、Service、Mapper等 |
对项目整体结构了解后,接下来我们详细分析上述的每个子模块:
对一些疑难点的解答
首先了解三大框架
核心对应关系表
|----------|------------------|----------------|----------------------------------------------------------|
| 代码层级 | 英文名称 | 主要归属框架 | 角色职责 |
| 控制层 | Controller | Spring MVC | 接待员 :负责接收用户的 HTTP 请求,解析参数,然后指挥 Service 干活。 |
| 业务层 | Service | Spring | 大脑 :负责核心业务逻辑(比如计算价格、判断权限),它是被 Spring 容器管理的 Bean。 |
| 持久层 | Mapper (DAO) | MyBatis | 档案员 :负责和数据库打交道,执行 SQL 语句(增删改查)。 |
- 然后springboot是负责整合这三大框架的
- maven是负责项目快速构建的工具,如果没有maven得自己一个个去导包,很麻烦
- 上面提到的Dto实际上是pojo,但是是更细分的pojo ,比如你从mapper(dao)里面拿到了数据库一堆数据,你只想让他显示一部分数据,这个时候就要写一个dto,还有pojo就是java类
- 我们经常说到java bean ,spring bean ,bean 其实就是指代的就是对象,也就是你new出来的东西就是对象。
- 而spring 和 java 类本质区别 他是具有带有注释的java类,被spring (框架)进行了统一管理的类。
,然后他的bean也一个对象,不过他不是new出来的,而是可以直接get获取,下图有例子
pojo
首先我们要清楚 Entity、DTO、VO 的本质都是 POJO:
|--------|--------------------------------|----------------------|----------------------|
| 特性 | DTO (Data Transfer Object) | VO (View Object) | Entity (实体类pojo) |
| 方向 | 前端 ->后端 (入参) | 后端 <- 前端 (出参) | 后端 <-> 数据库 |
在 sky-pojo 模块中:
-
看到 DTO ,就要想到:这是前端发给我的数据包。
-
看到 VO ,就要想到:这是我要发给前端的数据包。
-
看到 Entity ,就要想到:这是数据库表的映射。
// 这是一个普通的类定义
public class UserService {
public void work() {
System.out.println("我在干活...");
}
}
public class TestObject {
public static void main(String[] args) {
// 动作:你需要自己动手 new 出来
UserService u1 = new UserService();
UserService u2 = new UserService();// 验证:看看它们是不是同一个? System.out.println(u1 == u2); // 输出:false (不是同一个) // 结论: // 你 new 了两次,内存里就产生了 2 个对象。 // 如果你 new 1000 次,内存里就有 1000 个对象。 // 这就是普通的 Object。 }}
Java
// 1. 给类打上标签,让它成为 Spring 的"编制内人员"
@Component
public class UserService {
public void work() {
System.out.println("我在干活...");
}
}
然后,启动 Spring 容器:Java
public class TestSpringBean {
public static void main(String[] args) {
// 1. 启动 Spring 容器(相当于公司开门了)
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);// 2. 动作:你要用的时候,是问 Spring 容器"要"一个,而不是自己 new UserService b1 = context.getBean(UserService.class); UserService b2 = context.getBean(UserService.class); // 验证:看看它们是不是同一个? System.out.println(b1 == b2); // 输出:true (是同一个!) // 结论: // 无论你要多少次,Spring 永远只给你那唯一的一个对象(单例)。 // 这就是 Bean。 }}
后端环境搭建
git环境搭建
参考前面git-maven-docker这片文档
数据库环境搭建
找到data import 去导入准备好的sql文件
选择下面的self-contained file
说一下这两者区别,foleder是文件夹,如果你想引入的是文件夹那就选folder,如果你想引入的是文件,比如以.sql后缀结尾的文件,那就选self-contained file
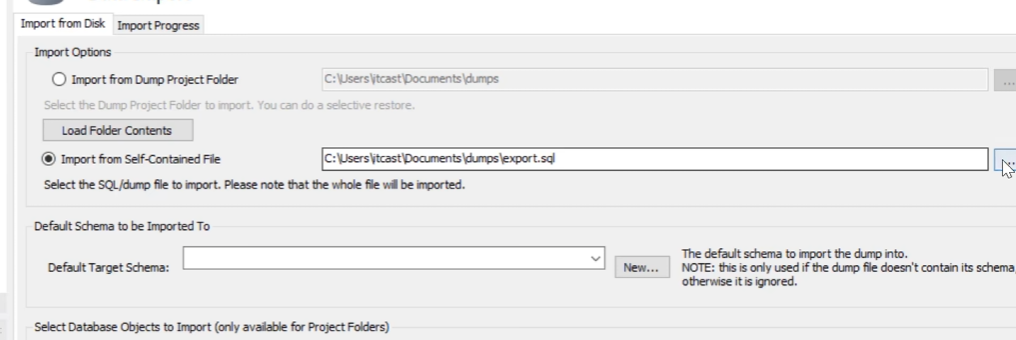
看到上面的图片,如果是一个文件夹,那就选上面这个,如果是.sql文件就选下面这个.
切换标签页
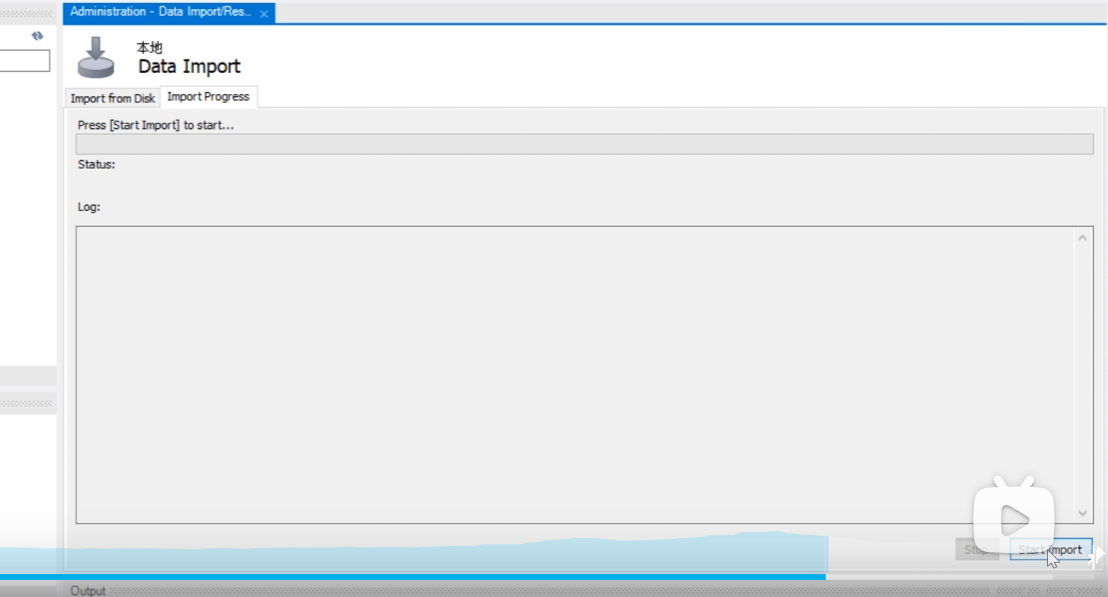
点击start import
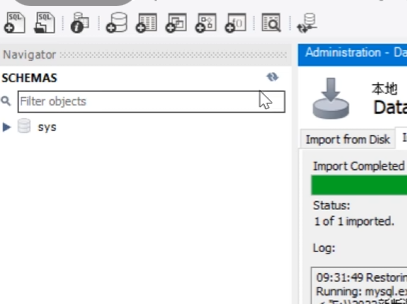
然后点击左侧的刷新按钮
前后端联调
常见问题解决方案
接下来进行前后端联调测试,看看前端和后端是否连通
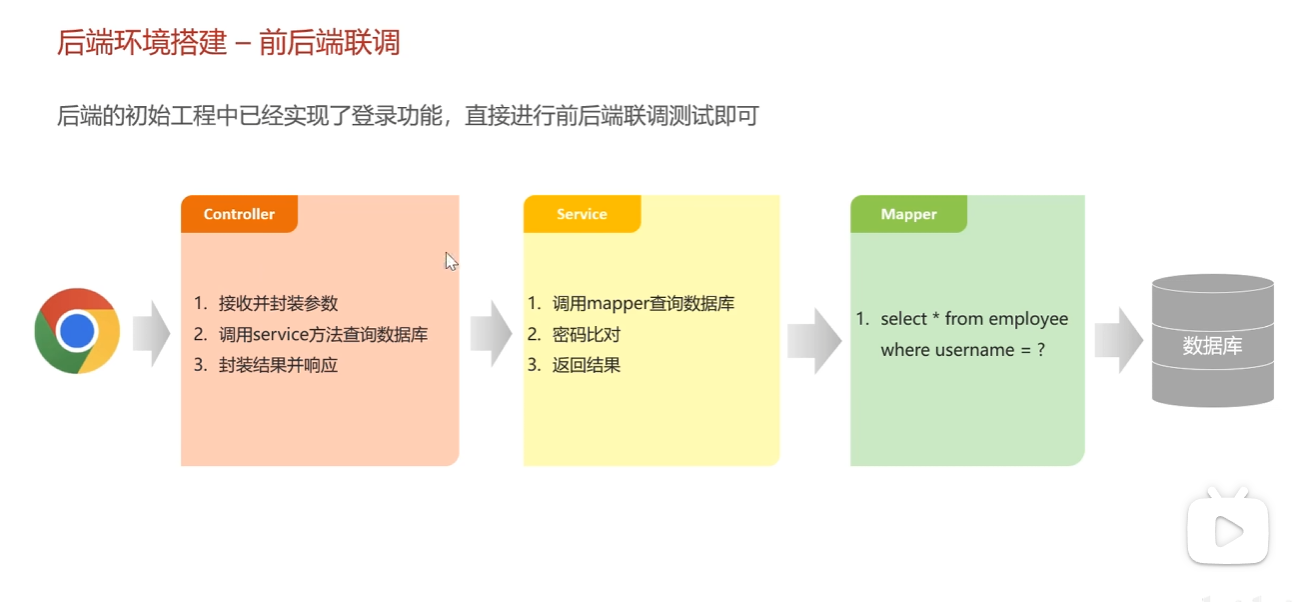
浏览器就是我们前端的某个页面,他会发送请求去请求到我们的controller(spring mvc)
然后是service(spring)最后是mapper(dao)(mybaits)
首先我们在右侧的maven找到 compile 双击一下,先编译再运行
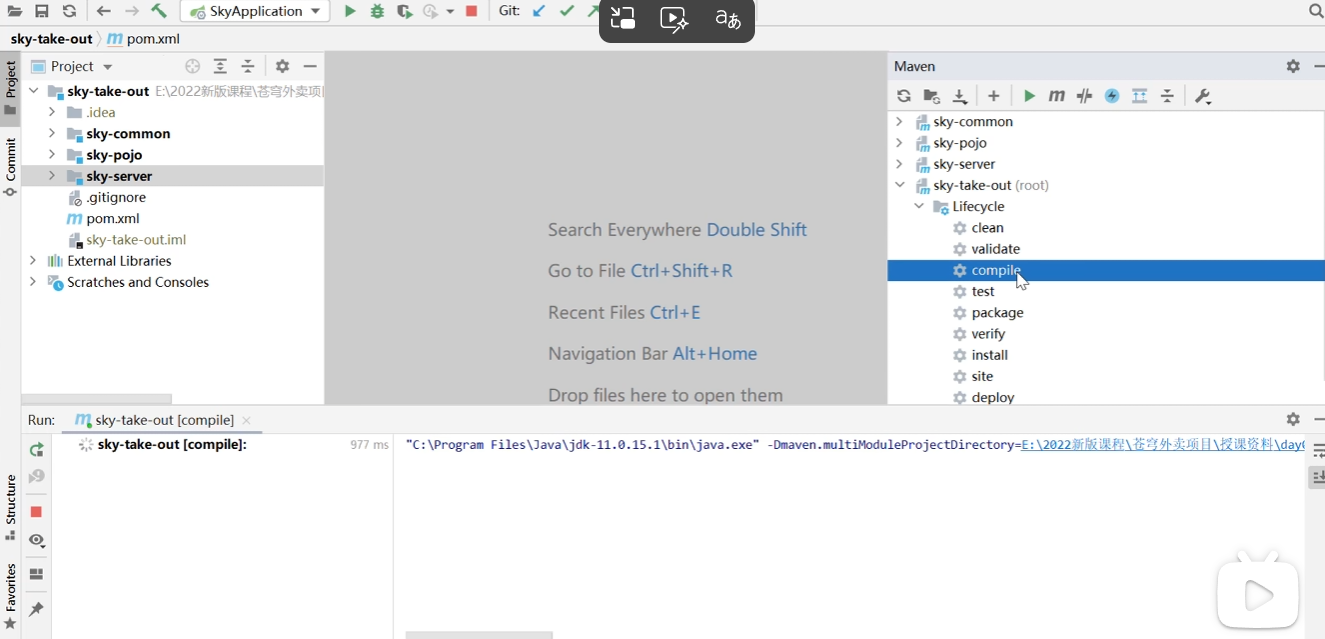
然后找到启动类 skyapplication 最后启动我们的程序就可以了
这个时候你运行可能会报错 lombok 编译时,找不到符号
实际上
并且还要找到
数据库配置文件把这个也给改好
然这里有个混淆的概念容易搞错
这里是连接名 但是jdbc 要的是你数据库的名字
所以才会导致连接不上
解决完这些我们便可以成功登陆了
在这里我用的jdk版本是11 完全没问题
断点调试
接下来我们学习断点调试,这个我之前在c语言很会用,但是在java一直想学,我们来好好学习一下我们先把当前的项目运行关闭

选择那个小虫子 是debug的标志
注意当我们启动过一次之后,就无需再去找到启动类去启动了,可以直接点击上面小虫子启动
接下来我们思考一下,前端发送的请求是如何请求到后端服务的
下面这个图是我们整体的结构框架
对工程的每个模块作用说明:
|--------|--------------|--------------------------------------------|
| 序号 | 名称 | 说明 |
| 1 | sky-take-out | maven父工程,统一管理依赖版本,聚合其他子模块 |
| 2 | sky-common | 子模块,存放公共类,例如:工具类、常量类、异常类等 |
| 3 | sky-pojo | 子模块,存放实体类、VO、DTO等 |
| 4 | sky-server | 子模块,后端服务,存放配置文件、Controller、Service、Mapper等 |
代码细节
然后分析他们的源码发现,他在这里用一个builder构造器,
我们来说一下这个builder,他在这里创建EmployeeLoginVO对象并且给他们赋值是通过这种方式
EmployeeLoginVO employeeLoginVO = EmployeeLoginVO.builder()
.id(employee.getId())
.userName(employee.getUsername())
.name(employee.getName())
.token(token)
.build();实际上
为什么要用 Builder 而不是 new?
如果没有 @Builder,你需要用传统的 set 方法,代码会写成这样:
传统写法(Setter):
Java
EmployeeLoginVO vo = new EmployeeLoginVO();
vo.setId(employee.getId());
vo.setUserName(employee.getUsername());
vo.setName(employee.getName());
vo.setToken(token);
// 这种写法比较散,而且容易漏掉某些属性Builder 写法(链式调用):
Java
EmployeeLoginVO vo = EmployeeLoginVO.builder()
.id(employee.getId()) // 像填表一样,一行一个
.userName(employee.getUsername())
.name(employee.getName())
.token(token)
.build(); // 最后封口打包Builder 的好处:
- 优雅: 代码像流一样连贯,易读性强。
- 清晰: 赋值哪个字段一目了然。
- 防止状态不一致: 特别是当对象属性很多时,
build()方法可以确保对象构建完成才返回。
3. 使用条件
要想用这个功能,必须满足两个条件:
引入依赖: 你的 pom.xml 里必须有 lombok 的依赖(苍穹外卖项目通常在父工程里已经引了)。
-
XML
org.projectlombok lombok -
IDEA 插件: 你的 IntelliJ IDEA 必须安装了 Lombok 插件(新版 IDEA 默认已捆绑,旧版需要去 Plugin 市场搜一下安装),否则编辑器会标红报错,因为它看不见那些生成的代码。
-
加注解: 在你想用的类(通常是 Entity, DTO, VO)头上加上
@Builder。
在这个地方我们第一次感受到了泛型的作用
我们惊奇的发现和我们当时学javaweb时候不同,他这里的result是加<>泛型的,我们之前是直接result没有用泛型的。那他这里用这个有什么用
这里是我们javaweb 方法返回参数的写法

我们来到源码发现,用泛型可以使得代码变得更灵活,如果不用这里的data 类型就写死了,那以后要给前端返回的数据(也就是vo)都只能返回规定好的一种类型,但是用了之后这个data的类型就会根据我们传入的泛型<T>里面T的值去动态改变
*/
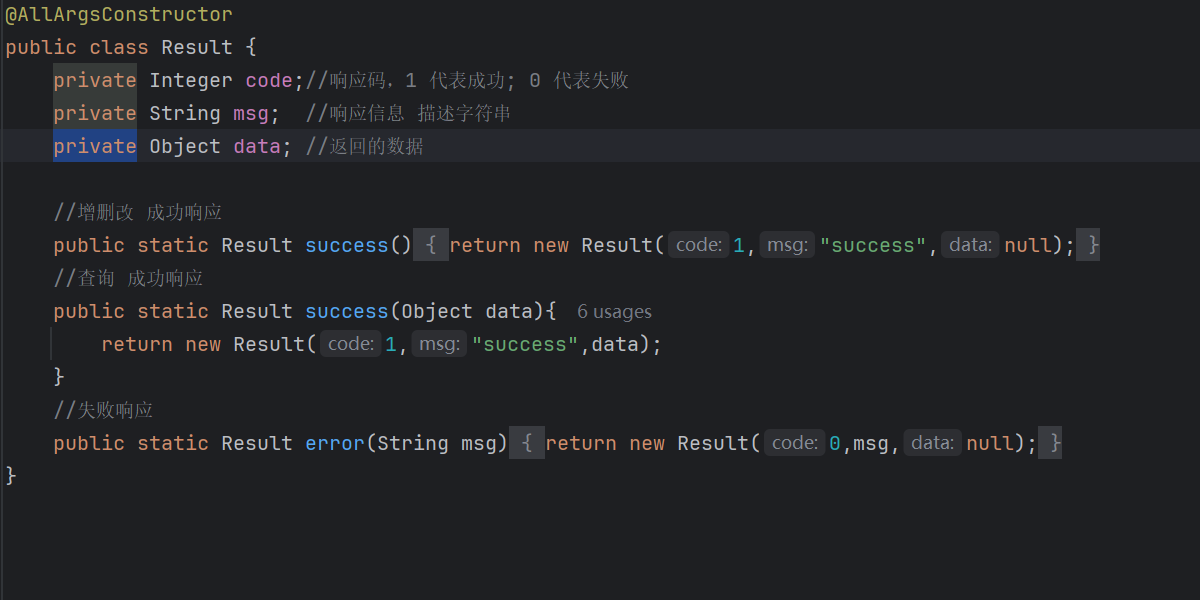
@Data
public class Result<T> implements Serializable {
private Integer code; //编码:1成功,0和其它数字为失败
private String msg; //错误信息
private T data; //数据
public static <T> Result<T> success() {
Result<T> result = new Result<T>();
result.code = 1;
return result;
}
public static <T> Result<T> success(T object) {
Result<T> result = new Result<T>();
result.data = object;
result.code = 1;
return result;
}
public static <T> Result<T> error(String msg) {
Result result = new Result();
result.msg = msg;
result.code = 0;
return result;
}但其实我们javaweb是怎么解决的呢,用的是Object类来解决的
但是使用泛型这种方式更符合企业级开发的规范
然后关于exception,这里要说一下,这个地方是人为的抛出异常,然后这个异常是我们自己定义的异常 ,然后这个异常到时候会被我们的全局异常处理器捕获 (或者try catch 捕获,但是通常我们用全局异常处理器)
我们经常看到我们通常会在方法名后面加一个throw new exception,这个是异常的声明和这里自己主动抛出不一样,主动抛出你会发现是写在方法里面的
这个时候我就要提出一个问题了,声明了异常和不声明异常有什么区别呢?
区别在于:能不能通过编译(能不能运行)
情况 A:你不声明 throws IOException
如果你把代码改成这样:
Java
// ❌ 删掉了 throws IOException
public void readFile() {
System.out.println("开始读取");
throw new IOException("硬盘坏了!"); // 报错!
}结果:
-
你连运行的机会都没有!直接编译都不通过,刚刚亲测如果代码出现可能产生Ioexception的代码,如果不在方法里面声明throw IOException ,编译器会直接爆红,点运行都点不动 ,比如说这样
-
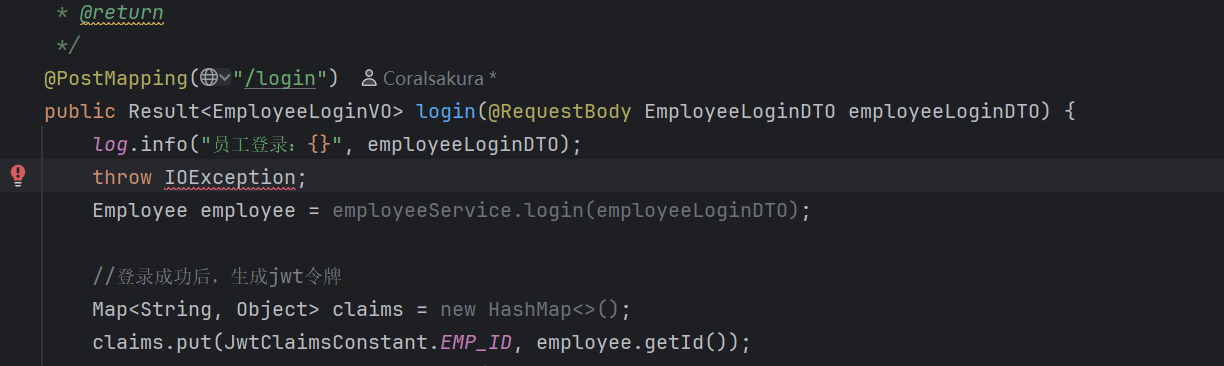
-
IDEA 会直接标红,Java 编译器(javac)会报错:
Unhandled exception: java.io.IOException(未处理的异常)。 -
程序就像被"保安"拦在门口,根本进不去。
情况 B:你声明了 throws IOException
Java
// ✅ 加上了 throws IOException
public void readFile() throws IOException {
System.out.println("开始读取");
throw new IOException("硬盘坏了!");
}结果:
- 编译通过了!
- IDEA 不报错,你可以点击"运行"按钮。
- 程序跑起来了,打印"开始读取",然后在运行过程中炸了(抛出异常并终止)。其实这个炸了指的就是这个异常会一层层往上抛,抛给底层的springframwork代码然后处理
所以这两种都不推荐 ,之后我们会用try catch 和全局异常处理器,这个写了之后就不用再方法后面声明异常了,
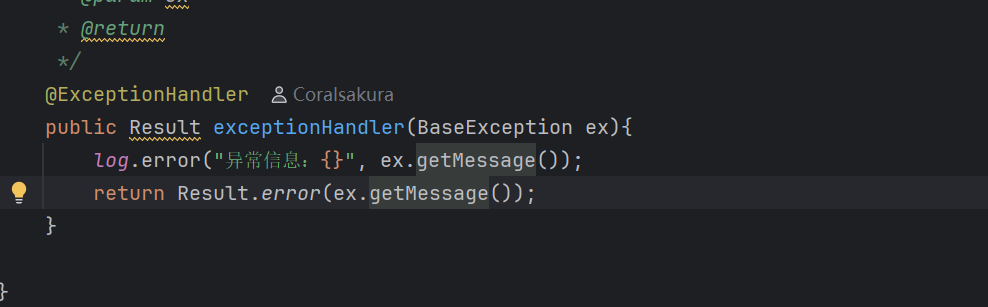
比如这个段代码里面其实我们已经在形参里面声明了可能出现的异常了,然后出现之后就会返回我们自己预设好的数据,而不是前面那种抛给底层的springframwork代码然后处理之后返回的一段乱码
/**
* 员工登录
*
* @param employeeLoginDTO
* @return
*/
public Employee login(EmployeeLoginDTO employeeLoginDTO) {
String username = employeeLoginDTO.getUsername();
String password = employeeLoginDTO.getPassword();
//1、根据用户名查询数据库中的数据
Employee employee = employeeMapper.getByUsername(username);
//2、处理各种异常情况(用户名不存在、密码不对、账号被锁定)
if (employee == null) {
//账号不存在
throw new AccountNotFoundException(MessageConstant.ACCOUNT_NOT_FOUND);
}
//密码比对
if (!password.equals(employee.getPassword())) {
//密码错误
throw new PasswordErrorException(MessageConstant.PASSWORD_ERROR);
}
if (employee.getStatus() == StatusConstant.DISABLE) {
//账号被锁定
throw new AccountLockedException(MessageConstant.ACCOUNT_LOCKED);
}
//3、返回实体对象
return employee;
}之前我们一直有个误区:只要你写了 try-catch**(全局异常处理器之后),你就通常不需要再写** throws****了。
这两者是"二选一"的关系,而不是先后 关系。
我们在这里面是手动抛出了new ExceptionNotfouind类
接下来我们来分析一下这个类
package com.sky.exception;
/**
* 账号不存在异常
*/
public class AccountNotFoundException extends BaseException {
public AccountNotFoundException() {
}
public AccountNotFoundException(String msg) {
super(msg);
}
}这里面有一个关键词super 我们来复习一下super这个关键词的作用
super 在 Java 中确实可以用来调用父类的方法,但它其实有 两副面孔 。你需要根据它后面跟着的是 "圆括号" 还是 "点" 来区分它们。
这两种用法完全不同,千万别混淆:
1. 面孔一: super(参数)****------ 调用父类的【构造器】
这就是你刚才在 AccountNotFoundException****代码里看到的用法。
- 长相:
super(msg)或super()。只有括号,没有点。 - 作用: "爸爸先请" 。在创建一个子类对象(比如
new Son())时,必须先初始化父类(Father)。 - 规则: 这行代码必须写在子类构造方法的 第一行。
代码示例:
Java
// 父类
public class Father {
public Father(String name) {
System.out.println("我是父类,我叫:" + name);
}
}
// 子类
public class Son extends Father {
public Son() {
// 必须第一行调用父类构造器,把名字传给爸爸
super("大头爸爸");
System.out.println("我是子类,我也出生了");
}
}2. 面孔二: super.方法名()****------ 调用父类的【普通方法】
这就是你刚才问的用法。
- 长相:
super.eat()。中间有个点。 - 作用: "借用一下爸爸的技能"。通常用在子类**重写(Override)**了父类的方法,但又想在子类里保留父类原有逻辑的时候。
场景: 假设父类赚钱很难,子类赚钱很容易,但子类想保留父类赚钱的逻辑,再加点自己的。
代码示例:
Java
public class Father {
public void makeMoney() {
System.out.println("辛苦搬砖赚了 100 块");
}
}
public class Son extends Father {
@Override
public void makeMoney() {
// 1. 先调用父类的方法(保留父类的逻辑)
super.makeMoney();
// 2. 再加自己的逻辑
System.out.println("做投资赚了 100 万!");
}
}运行 Son****的 makeMoney****结果:
辛苦搬砖赚了 100 块 做投资赚了 100 万!
全局异常处理器就处理这个异常
@ExceptionHandler
public Result exceptionHandler(BaseException ex){ // ex 就是刚才那个包裹
// 1. ex.getMessage() 就是在读取快递单上的内容
// 因为你在构造方法里用 super(msg) 填了单,所以这里能读到 "账号不存在"
log.error("异常信息:{}", ex.getMessage());
// 2. 把读到的内容放到 Result 里返回给前端
return Result.error(ex.getMessage());
}然后正是因为我调用了super(msg)传入了值进去,我们最后在全局异常处理器 ex.getMessage才能拿到刚刚我们写好的异常消息
其实这个baseexception 是我们刚刚抛出Accountnotfoundexception异常的父类
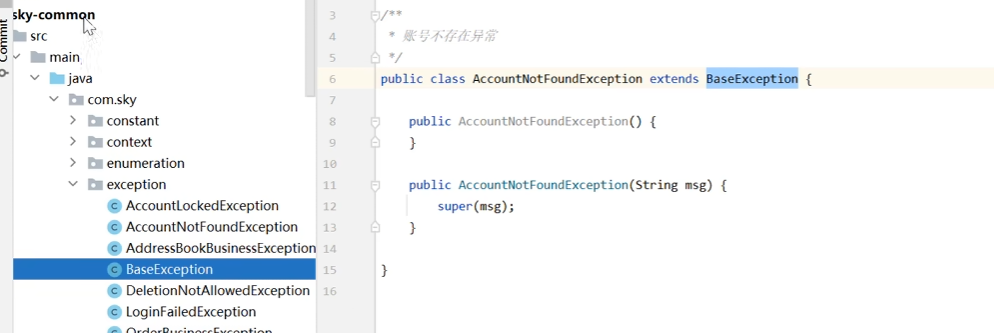
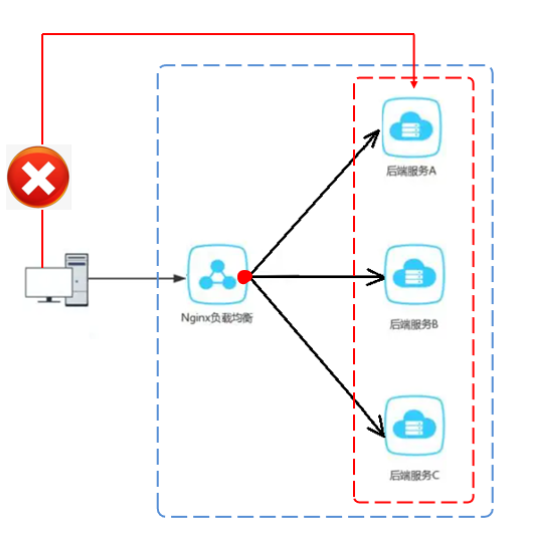
nignx反向代理和负载均衡
对登录功能测试完毕后,接下来,我们思考一个问题:前端发送的请求,是如何请求到后端服务的?
前端请求地址:http://localhost/api/employee/login
后端接口地址:http://localhost:8080/admin/employee/login
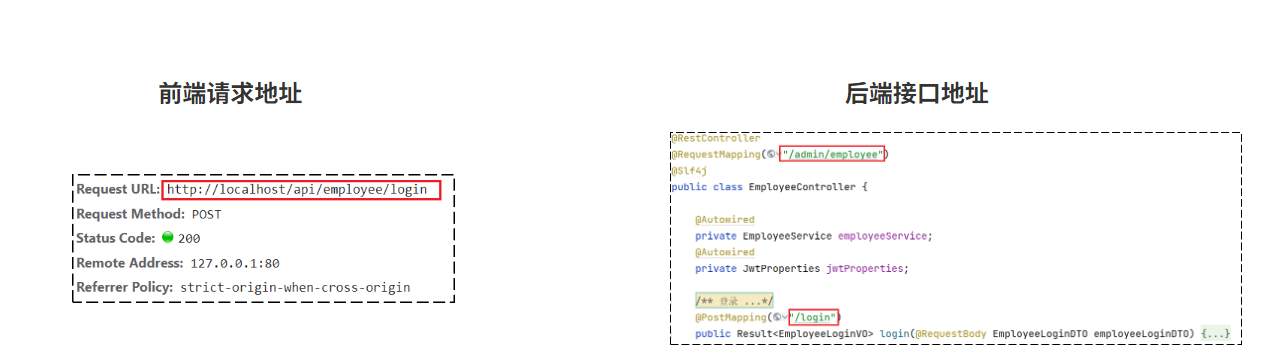
很明显,两个地址不一致,那是如何请求到后端服务的呢?

1). nginx反向代理
nginx 反向代理,就是将前端发送的动态请求由 nginx 转发到后端服务器
那为什么不直接通过浏览器直接请求后台服务端,需要通过nginx反向代理呢?
nginx 反向代理的好处:
- 提高访问速度
因为nginx本身可以进行缓存,如果访问的同一接口,并且做了数据缓存,nginx就直接可把数据返回,不需要真正地访问服务端,从而提高访问速度。
- 进行负载均衡
所谓负载均衡,就是把大量的请求按照我们指定的方式均衡的分配给集群中的每台服务器。
- 保证后端服务安全
因为一般后台服务地址不会暴露,所以使用浏览器不能直接访问,可以把nginx作为请求访问的入口,请求到达nginx后转发到具体的服务中,从而保证后端服务的安全。
说完了nginx反向代理原理之后,我们来谈谈如何配置,需要在nginx.conf文件里面配置
nginx 反向代理的配置方式:
server{
listen 80;
server_name localhost;
location /api/{
proxy_pass http://localhost:8080/admin/; #反向代理
}
}我们发现其实就是把这个api前面的内容替换了,一共其实就做了两件事,第一件就是看端口号是不是自己监听的 ,这里http默认就是80,不用写也是,然后看路径里面有没有location后面的那个路径(api),这里api是我们人为自己取的名字,还可以取别的名字,如果匹配到了就转发
**proxy_pass:**该指令是用来设置代理服务器的地址,可以是主机名称,IP地址加端口号等形式。
如上代码的含义是:监听80端口号, 然后当我们访问 http://localhost:80/api/../..这样的接口的时候,它会通过 location /api/ {} 这样的反向代理到 http://localhost:8080/admin/上来。
接下来,进到nginx-1.20.2\conf,打开nginx配置
# 反向代理,处理管理端发送的请求
location /api/ {
proxy_pass http://localhost:8080/admin/;
#proxy_pass http://webservers/admin/;
}当在访问http://localhost/api/employee/login,nginx接收到请求后转到http://localhost:8080/admin/,故最终的请求地址为http://localhost:8080/admin/employee/login,和后台服务的访问地址一致。
2). nginx 负载均衡
当如果服务以集群的方式进行部署时,那nginx在转发请求到服务器时就需要做相应的负载均衡。其实,负载均衡从本质上来说也是基于反向代理来实现的,最终都是转发请求。
nginx 负载均衡的配置方式:
upstream webservers{
server 192.168.100.128:8080;
server 192.168.100.129:8080;
}
server{
listen 80;
server_name localhost;
location /api/{
proxy_pass http://webservers/admin;#负载均衡
}
}**upstream:**如果代理服务器是一组服务器的话,我们可以使用upstream指令配置后端服务器组。
如上代码的含义是:监听80端口号, 然后当我们访问 http://localhost:80/api/../..这样的接口的时候,它会通过 location /api/ {} 这样的反向代理到 http://webservers/admin,根据webservers名称找到一组服务器,根据设置的负载均衡策略(默认是轮询)转发到具体的服务器。
**注:**upstream后面的名称可自定义,但要上下保持一致。
nginx 负载均衡策略:
|------------|--------------------------------|
| 名称 | 说明 |
| 轮询 | 默认方式,(意思就是请求按循环顺序访问1,2,3服务器) |
| weight | 权重方式,默认为1,权重越高,被分配的客户端请求就越多 |
| ip_hash | 依据ip分配方式,这样每个访客可以固定访问一个后端服务 |
| least_conn | 依据最少连接方式,把请求优先分配给连接数少的后端服务 |
| url_hash | 依据url分配方式,这样相同的url会被分配到同一个后端服务 |
| fair | 依据响应时间方式,响应时间短的服务将会被优先分配 |
具体配置方式:
轮询:
upstream webservers{
server 192.168.100.128:8080;
server 192.168.100.129:8080;
}weight:
upstream webservers{
server 192.168.100.128:8080 weight=90;
server 192.168.100.129:8080 weight=10;
}ip_hash:
upstream webservers{
ip_hash;
server 192.168.100.128:8080;
server 192.168.100.129:8080;
}least_conn:
upstream webservers{
least_conn;
server 192.168.100.128:8080;
server 192.168.100.129:8080;
}url_hash:
upstream webservers{
hash &request_uri;
server 192.168.100.128:8080;
server 192.168.100.129:8080;
}fair:
upstream webservers{
server 192.168.100.128:8080;
server 192.168.100.129:8080;
fair;
}MD5加密方式对明文密码加密
完善登录功能
**问题:**员工表中的密码是明文存储,安全性太低。

解决思路:
- 将密码加密后存储,提高安全性
MD5 是一种老牌的加密摘要算法,能把密码变成乱码存储,但因为容易被破解,现在已经不推荐用于高安全性的场景了。
- 使用MD5加密方式对明文密码加密

注意md5加密的过程是不可逆的,单向的,我们只能123456加密得到一串乱码,而不能通过这段乱码回到123456的状态,所以接下来比对,也是先把前端传过来的先加密,然后再把密文进行比对
实现步骤:
- 修改数据库中明文密码,改为MD5加密后的密文
打开employee表,修改密码

- 修改Java代码,前端提交的密码进行MD5加密后再跟数据库中密码比对
打开EmployeeServiceImpl.java,修改比对密码
/**
* 员工登录
*
* @param employeeLoginDTO
* @return
*/
public Employee login(EmployeeLoginDTO employeeLoginDTO) {
//1、根据用户名查询数据库中的数据
//2、处理各种异常情况(用户名不存在、密码不对、账号被锁定)
//.......
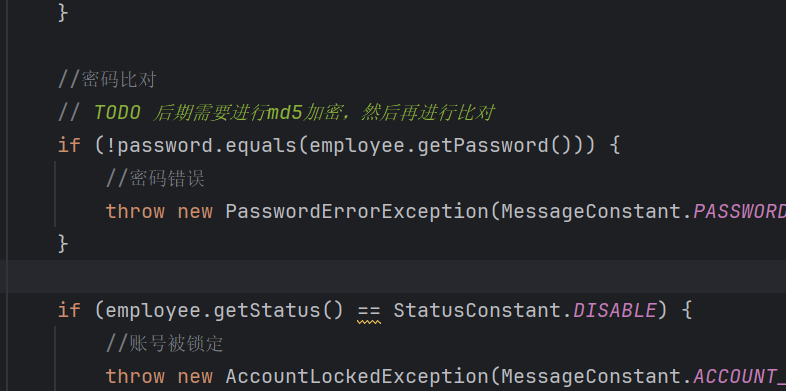
//密码比对
// TODO 后期需要进行md5加密,然后再进行比对
password = DigestUtils.md5DigestAsHex(password.getBytes());
if (!password.equals(employee.getPassword())) {
//密码错误
throw new PasswordErrorException(MessageConstant.PASSWORD_ERROR);
}
//........
//3、返回实体对象
return employee;
}你可以发现我们并没有引入任何依赖,但是最后还是可以直接使用DigestUtils包下的md5DigestAsHex方法,这是因为,这个springframework自带支持这个md5加密
这里面有一个技巧 Todo ,可以在idea左侧三个点点开后找到
比如这里我们以后要进行md5加密,但是现在我们现在先不写,又怕以后忘了就可以在注释里面写TODO记得一定要大写其实就是todolist
点开后就是这个
这里介绍一个idea的快捷键
(通常是 IntelliJ IDEA )提供的一个超级好用的快捷功能。
它的学名叫 Postfix Completion(后缀补全)。
简单来说,它的作用是:
帮你自动生成变量声明,不用你把光标移回到行首去写类型和变量名。
具体效果演示:
当你输入完代码,敲下回车(Enter)后,编辑器会发生如下变化:
操作前(你现在的状态):
Java
// 你在表达式后面加了 .var
DigestUtils.md5DigestAsHex(password.getBytes()).var操作后(按下回车瞬间): 编辑器会自动把光标跳到行首,并补全类型和变量名,变成下面这样:
Java
// 自动生成了前面的 "String s ="
String s = DigestUtils.md5DigestAsHex(password.getBytes());getByte 又是干嘛的
- 你的密码 ( password**)** :是一个字符串(String),比如
"123456"。这是给人看的。 - 加密工具 ( DigestUtils**)** :它要求的输入必须是字节数组 ( byte[]****),不能直接给它字符串。
- **.getBytes()**的作用 :就是把
"123456"拆碎,翻译成计算机底层的数字编码(比如 ASCII 码),变成类似[49, 50, 51, 52, 53, 54]这样的数组。
我们回顾一下
Java 里的整数家族
其实 Java 里存整数的有四兄弟,从小到大分别是:
- byte (1字节) ------ 极小,存原始数据(你的例子就在用它)。
short(2字节) ------ 短整数,稍微大点,现在很少用了。- int (4字节) ------ 最常用,一般算数都用它。
long(8字节) ------ 超大整数,算天文数字或时间戳用。
此外
在 Java 的 String(字符串)这个类里,有 getBytes(),但是没有 getInt()。
这是为什么呢?我们可以用**"拆快递"**来理解:
1. 为什么有 getBytes()****?
因为字符串在计算机底层本来就是由一个个字节(byte)拼起来的。
password.getBytes()就像是把一个乐高玩具拆回成一块块的积木(byte)。- 这是还原它的本质。
2. 为什么没有 getInt()****?
因为字符串不是由整数(int)拼起来的。
- 你不能指着那个乐高玩具说:"把它拆成一个个大西瓜(int)给我。"
- 它里面本来就没有大西瓜,所以拆不出来。
如果你真的想要"整数",该怎么办?
通常有两种情况,看你想要哪种:
情况 A:把文字内容的"数字"拿出来(最常用) 比如你的字符串是 "123456",你想把它变成数学里的数字 123456 用来做加减法。
- 方法: 用"解析"工具。
- 代码:
Integer.parseInt("123456"); - 这叫 Parsing(解析),不叫 Get(获取)。
导入接口文档
接下来,就要进入到项目的业务开发了,而我们的开发方式就是基本当前企业主流的前后端分离开发方式,那么这种方式就要求我们之前需要先将接口定义好,这样前后端人员才能并行开发,所以,这个章节就需要将接口文档导入到管理平台,为我们后面业务开发做好准备。其实,在真实的企业开发中,接口设计过程其实是一个非常漫长的过程,可能需要多次开会讨论调整,甚至在开发的过程中才会发现某些接口定义还需要再调整,这种情况其实是非常常见的,但是由于项目时间原因,所以选择一次性导入所有的接口,在开发业务功能过程当中,也会带着大家一起来分析一下对应的接口是怎么确定下来的,为什么要这样定义,从而培养同学们的接口设计能力。
4.1 前后端分离开发流程
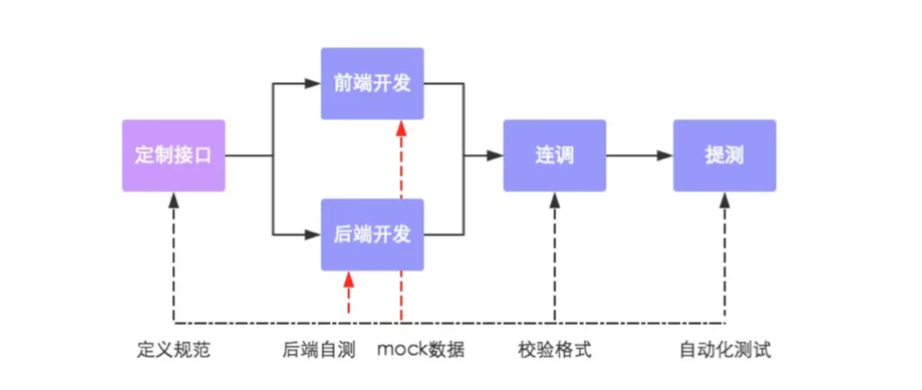
第一步:定义接口,确定接口的路径、请求方式、传入参数、返回参数。
第二步:前端开发人员和后端开发人员并行开发,同时,也可自测。
第三步:前后端人员进行连调测试。
第四步:提交给测试人员进行最终测试。(也就是上面图中的提测)
4.2 操作步骤
将课程资料中提供的项目接口导入YApi。访问地址:http://yapi.smart-xwork.cn/
这个网站现在用不了了,我们用apifox
1). 从资料中找到项目接口文件

2). 导入到YApi平台
在YApi平台创建出两个项目
选择苍穹外卖-管理端接口.json导入
这一步在apifox里面 点击加号,然后选择导入,选择yapi,也可以导入josn数据了
导入成功
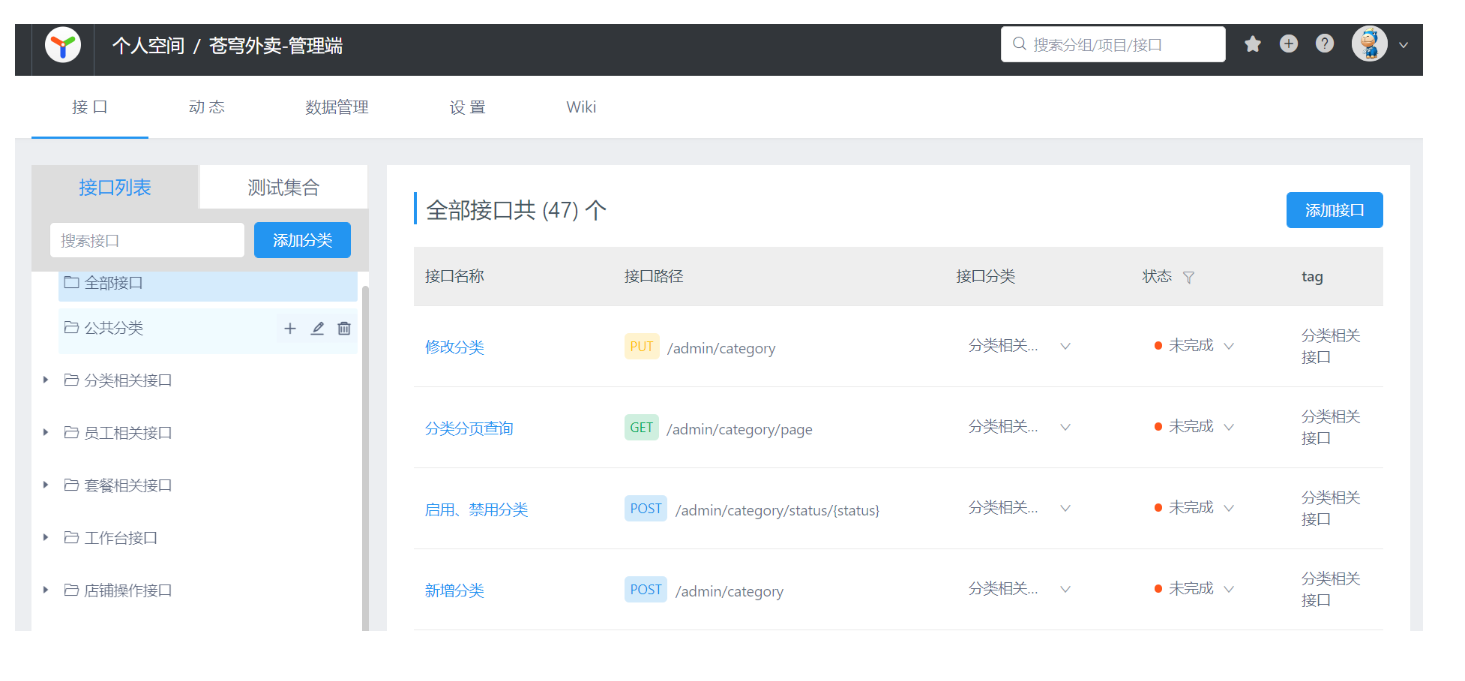
另一个用户端json文件也执行相同操作。
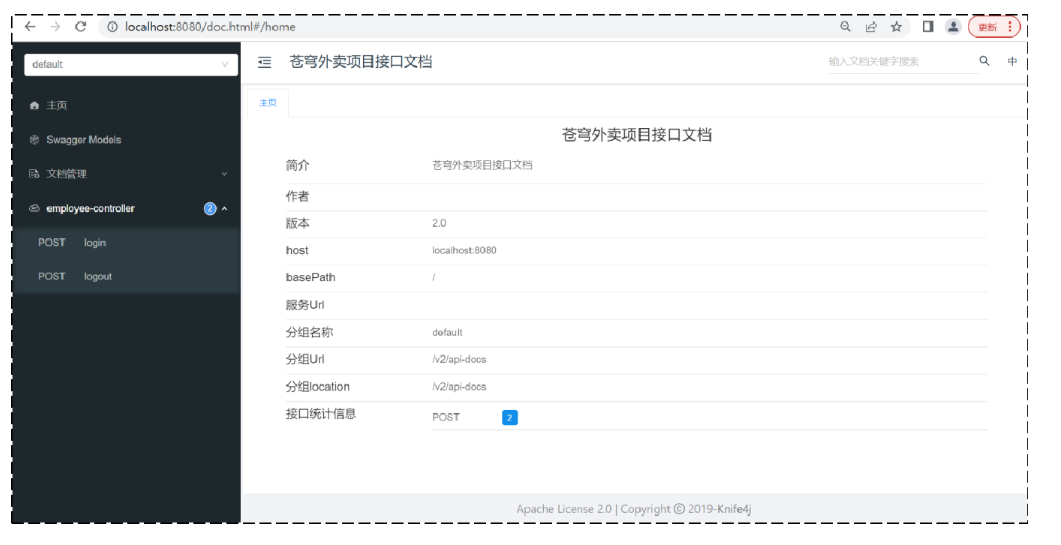
5. Swagger
5.1 介绍
Swagger 是一个规范和完整的框架,用于生成、描述、调用和可视化 RESTful 风格的 Web 服务(https://swagger.io/)。 它的主要作用是:
- 使得前后端分离开发更加方便,有利于团队协作
- 接口的文档在线自动生成,降低后端开发人员编写接口文档的负担
- 功能测试
Spring已经将Swagger纳入自身的标准,建立了Spring-swagger项目,现在叫Springfox。通过在项目中引入Springfox ,即可非常简单快捷的使用Swagger。
knife4j是为Java MVC框架集成Swagger生成Api文档的增强解决方案,前身是swagger-bootstrap-ui,取名kni4j是希望它能像一把匕首一样小巧,轻量,并且功能强悍!
目前,一般都使用knife4j框架。
5.2 使用步骤
- 导入 knife4j 的maven坐标
在pom.xml中添加依赖
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-spring-boot-starter</artifactId>
</dependency>- 在配置类中加入 knife4j 相关配置
WebMvcConfiguration.java
/**
* 通过knife4j生成接口文档
* @return
*/
@Bean
public Docket docket() {
ApiInfo apiInfo = new ApiInfoBuilder()
.title("苍穹外卖项目接口文档")
.version("2.0")
.description("苍穹外卖项目接口文档")
.build();
Docket docket = new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo)
.select()
.apis(RequestHandlerSelectors.basePackage("com.sky.controller"))
.paths(PathSelectors.any())
.build();
return docket;
}这里面最重要的是这一句**.apis(RequestHandlerSelectors.basePackage("com.sky.controller"))**
意思就是去扫描com.sky.controller这个包,然后通过反射机制去解析这里面的类,和这个类里面的方法去生成接口文档
那什么是反射呢?
为什么要用反射?
你的截图中,Knife4j/Swagger 的配置代码里有这样一句: apis(RequestHandlerSelectors.basePackage("com.sky.controller"))
思考一下: Knife4j 是别人写好的库(Jar包),而 EmployeeController 是你后来写的代码。 Knife4j 在被开发出来的时候,你的代码压根还不存在! 它怎么知道你要写一个 login 方法?怎么知道你的方法的返回值是 Result?
答案就是:反射。
答案就是:反射。
- 你给了它一个线索: "com.sky.controller"****(字符串)。
- 程序启动时,Knife4j 启动了"反射雷达"。
- 它扫描这个包下所有的 .class****文件。
- 它利用反射机制,"暴力"拆解你的类:
-
- "哦,这里有个 EmployeeController****类。"
- "它有个 login****方法。"
- "这个方法头上顶着个 **@ApiOperation("员工登录")**的注解。"
- "好,我把'员工登录'这几个字抓取下来,生成到网页文档里。"
这就是截图里那句注释的意思:"通过反射机制去解析这里面的类"。
为什么说它没写死?(高能对比)
假设你在做一个电商系统,现在只支持 支付宝 。
场景 A:不用反射(硬编码 / 写死)
你的代码是这样写的:
Java
// 你的业务代码
public void pay() {
// ❌ 这里写死了!必须用 new 关键字
Alipay payment = new Alipay();
payment.pay();
}后果: 老板突然说:"明天我们要换成 微信支付 ,把支付宝下架。" 你必须:
- 打开 Java 代码文件。
- 把 new Alipay()删掉,改成 **new WechatPay()**。
- 重新编译 整个项目(javac)。
- 重启 服务器。 这就叫"写死",因为你要改源码。
场景 B:使用反射(动态 / 灵活)
你的代码变成了这样:
Step 1: 准备一个外部配置文件 (config.properties) 这个文件就像个记事本,谁都能改,不需要编译。
Properties
# 老板想用哪个,就在这里改字,不用动代码!
pay_class_name=com.sky.pay.WechatPayStep 2: 你的 Java 代码 (永远不用改!)
Java
public void pay() {
// 1. 读取配置文件(读取上面的 config.properties)
String className = readConfig("pay_class_name");
// 2. 此时 className = "com.sky.pay.WechatPay"
// 关键点:这一行代码写完后,哪怕过10年,都不用动!
Class<?> clz = Class.forName(className);
// 3. 反射创建对象
Object payment = clz.newInstance();
// 4. 执行支付
Method method = clz.getMethod("pay");
method.invoke(payment);
}后果: 老板说:"换微信支付!" 你只需要:
- 打开 config.properties****记事本。
- 把 Alipay****改成 WechatPay**。**
- 保存。完事! 甚至不需要重启服务器,程序下次读取文件时,自动就变成了微信支付。
3. 这和 Knife4j/Swagger 有什么关系?
回到你之前的截图: apis(RequestHandlerSelectors.basePackage("com.sky.controller"))
Knife4j 的作者根本不知道你会写一个 EmployeeController**,更不知道你会写** OrderController**。**
如果不通过反射,Knife4j 的源码就得这样写:
Java
// ❌ Knife4j 作者如果不用反射,他得预知未来:
if (用户写了 EmployeeController) {
new EmployeeController()...
}
if (用户写了 OrderController) {
new OrderController()...
}这显然是不可能的。
所以 Knife4j 说: "我不猜了。我给你一个配置项(包名字符串)。程序跑起来的时候,我通过反射去扫描这个包。只要扫描到什么,我就解析什么。"
- 设置静态资源映射,否则接口文档页面无法访问
WebMvcConfiguration.java
/**
* 设置静态资源映射
* @param registry
*/
protected void addResourceHandlers(ResourceHandlerRegistry registry) {
registry.addResourceHandler("/doc.html").addResourceLocations("classpath:/META-INF/resources/");
registry.addResourceHandler("/webjars/**").addResourceLocations("classpath:/META-INF/resources/webjars/");
}如果不配置上面这个 在我们请求 http://localhost:8080/doc.html时候,springmvc并不会认为我们是在请求动态资源,以为我们是在请求controller呢
- 访问测试
接口文档访问路径为 http://ip:port/doc.html ---> http://localhost:8080/doc.html
Swagger 是通过 反射 读取了你代码里的 Spring 注解,从而"自动"帮你生成了基础版文档。 ,其实此时我没有写任何注解,所以他是认识spring里面的这些比如说postmapping rescontroller之类的注解
接口测试:测试登录功能
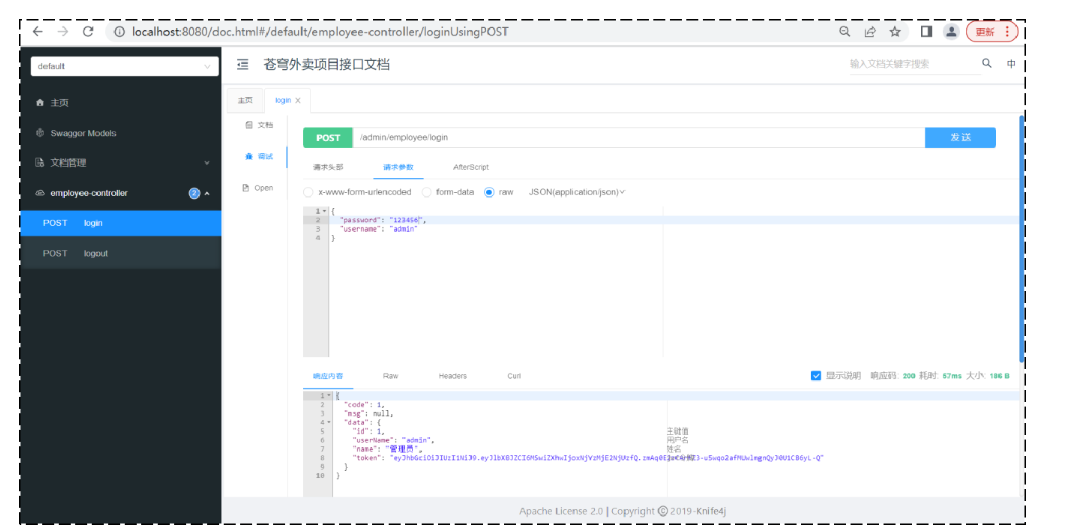
**思考:**通过 Swagger 就可以生成接口文档,那么我们就不需要 Yapi 了?
1、Yapi 是设计阶段使用的工具,管理和维护接口
2、Swagger 在开发阶段使用的框架,帮助后端开发人员做后端的接口测试
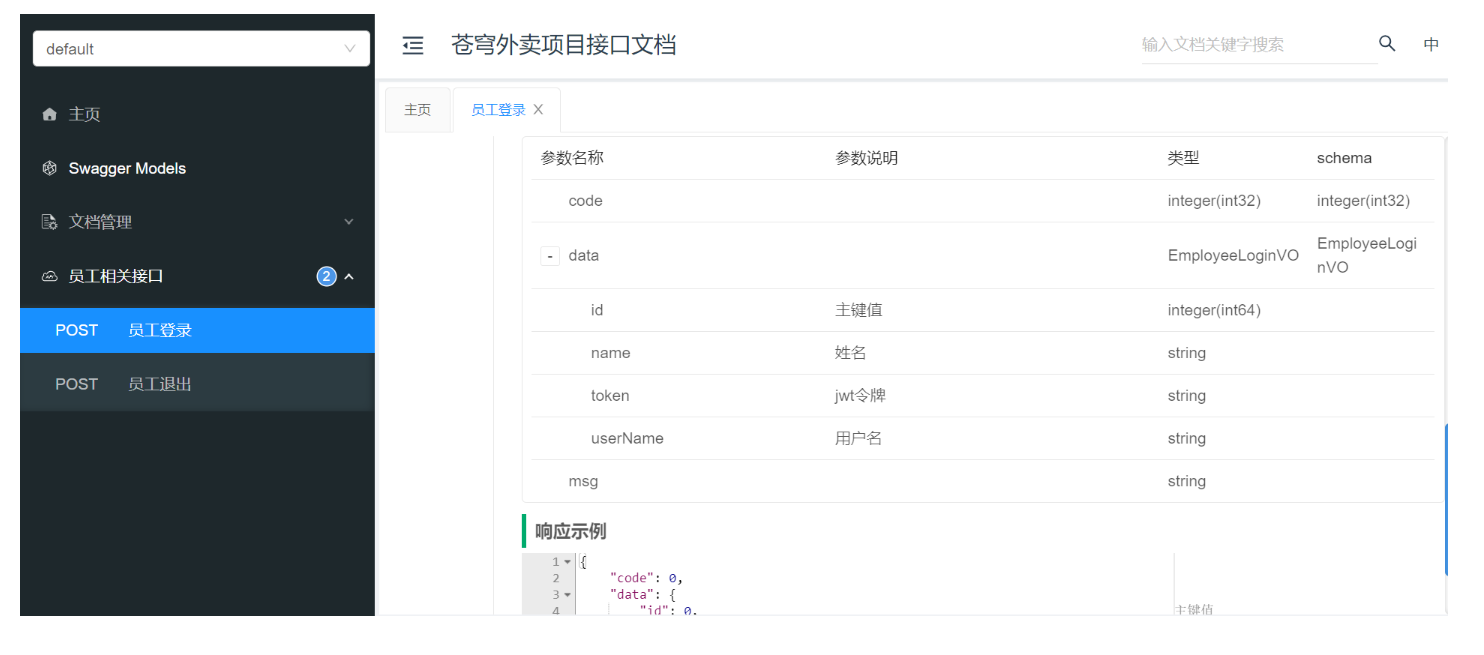
5.3 常用注解
通过注解可以控制生成的接口文档,使接口文档拥有更好的可读性,常用注解如下:
|-------------------|--------------------------------------------------|
| 注解 | 说明 |
| @Api | 用在类上,例如Controller,表示对类的说明 |
| @ApiModel | 用在类上,例如entity、DTO、VO |
| @ApiModelProperty | 用在属性上,描述属性信息 |
| @ApiOperation | 用在方法上,例如Controller的方法,说明方法的用途、作用 (value可以不写) |
接下来,使用上述注解,生成可读性更好的接口文档
在sky-pojo模块中
EmployeeLoginDTO.java
package com.sky.dto;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import java.io.Serializable;
@Data
@ApiModel(description = "员工登录时传递的数据模型")
public class EmployeeLoginDTO implements Serializable {
@ApiModelProperty("用户名")
private String username;
@ApiModelProperty("密码")
private String password;
}EmployeeLoginVo.java
package com.sky.vo;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
@ApiModel(description = "员工登录返回的数据格式")
public class EmployeeLoginVO implements Serializable {
@ApiModelProperty("主键值")
private Long id;
@ApiModelProperty("用户名")
private String userName;
@ApiModelProperty("姓名")
private String name;
@ApiModelProperty("jwt令牌")
private String token;
}在sky-server模块中
EmployeeController.java
package com.sky.controller.admin;
import com.sky.constant.JwtClaimsConstant;
import com.sky.dto.EmployeeLoginDTO;
import com.sky.entity.Employee;
import com.sky.properties.JwtProperties;
import com.sky.result.Result;
import com.sky.service.EmployeeService;
import com.sky.utils.JwtUtil;
import com.sky.vo.EmployeeLoginVO;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;
import java.util.Map;
/**
* 员工管理
*/
@RestController
@RequestMapping("/admin/employee")
@Slf4j
@Api(tags = "员工相关接口")
public class EmployeeController {
@Autowired
private EmployeeService employeeService;
@Autowired
private JwtProperties jwtProperties;
/**
* 登录
*
* @param employeeLoginDTO
* @return
*/
@PostMapping("/login")
@ApiOperation(value = "员工登录")
public Result<EmployeeLoginVO> login(@RequestBody EmployeeLoginDTO employeeLoginDTO) {
//..............
}
/**
* 退出
*
* @return
*/
@PostMapping("/logout")
@ApiOperation("员工退出")
public Result<String> logout() {
return Result.success();
}
}启动服务:访问http://localhost:8080/doc.html
业务功能的开发(员工管理分类管理)
接下来来到业务功能的开发
- 新增员工
- 员工分页查询
- 启用禁用员工账号
- 编辑员工
- 导入分类模块功能代码
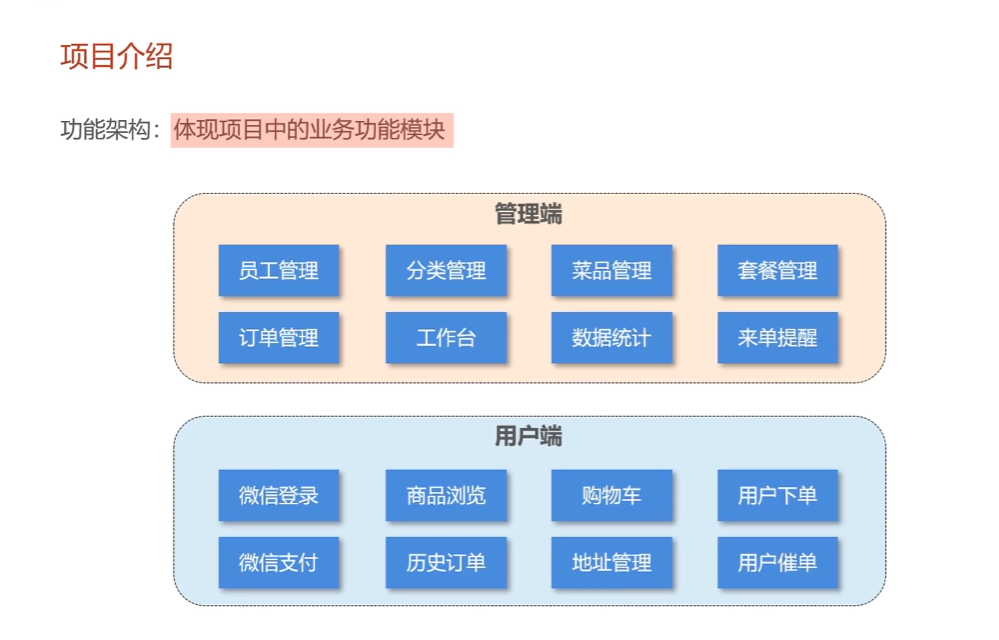
**功能实现:**员工管理、菜品分类管理。
员工管理效果:
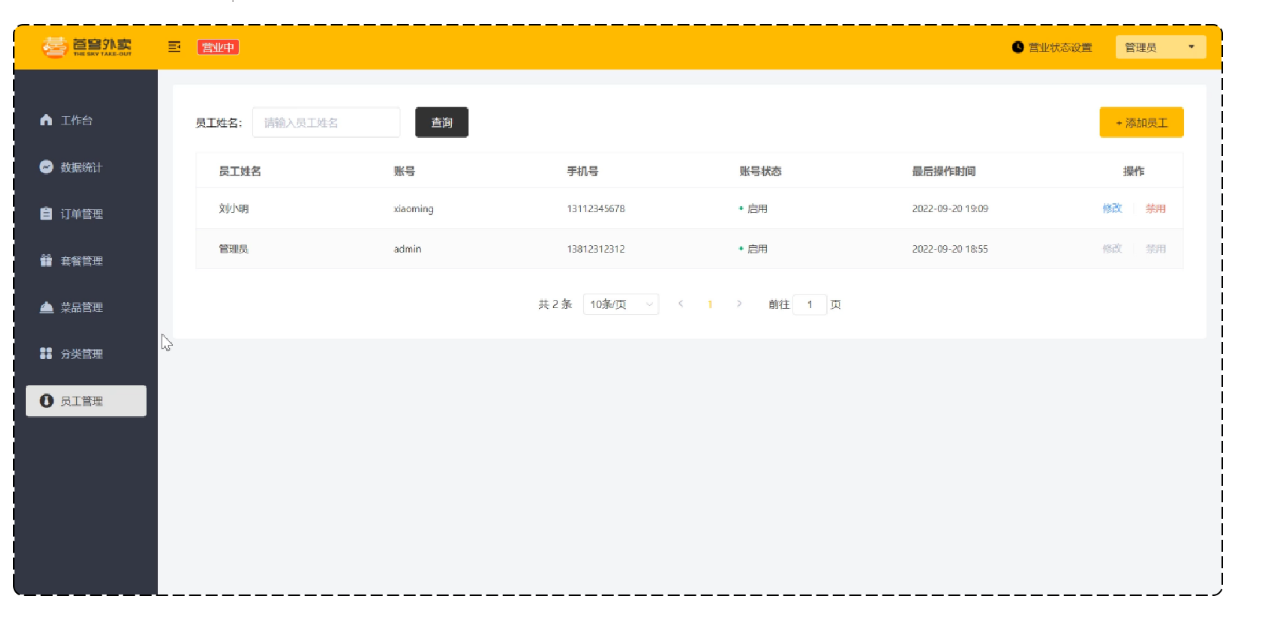
菜品分类管理效果:
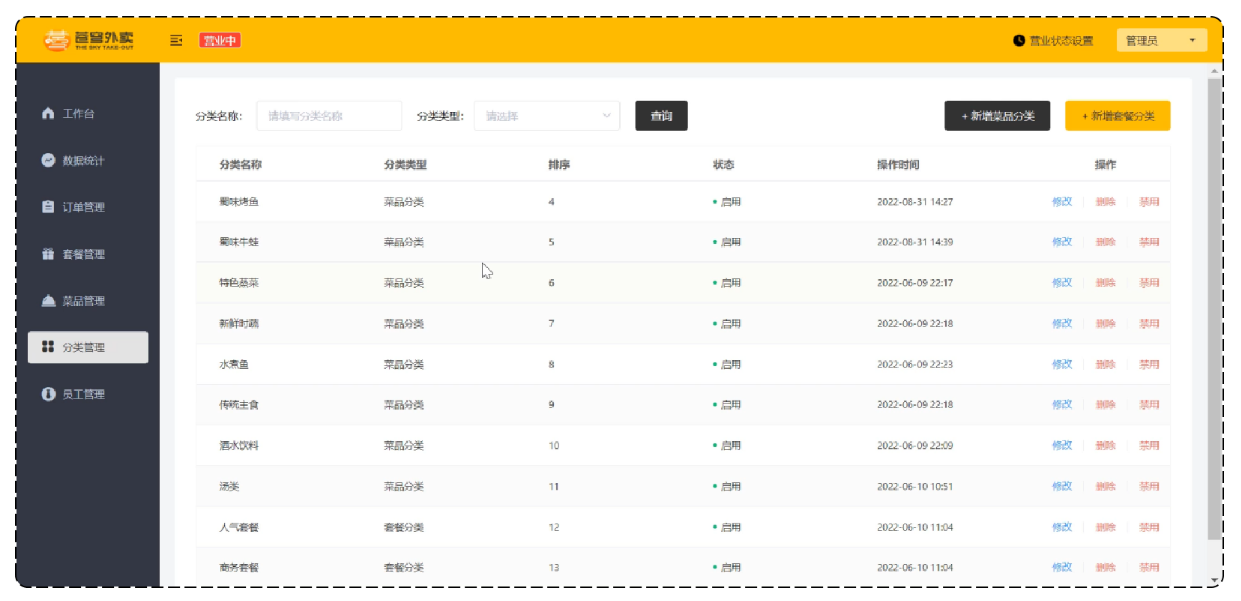
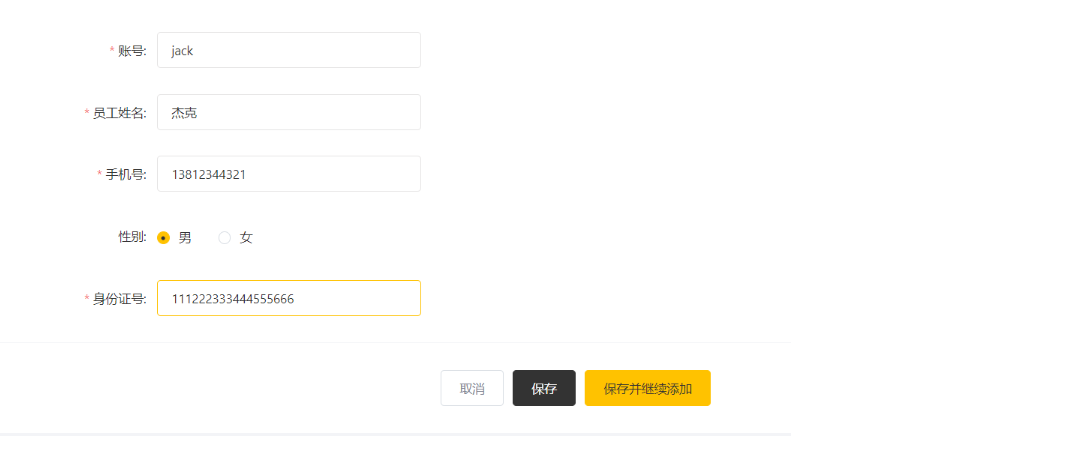
新增员工
1.1 需求分析和设计
1.1.1 产品原型
一般在做需求分析时,往往都是对照着产品原型进行分析,因为产品原型比较直观,便于我们理解业务。
后台系统中可以管理员工信息,通过新增员工来添加后台系统用户。
新增员工原型:
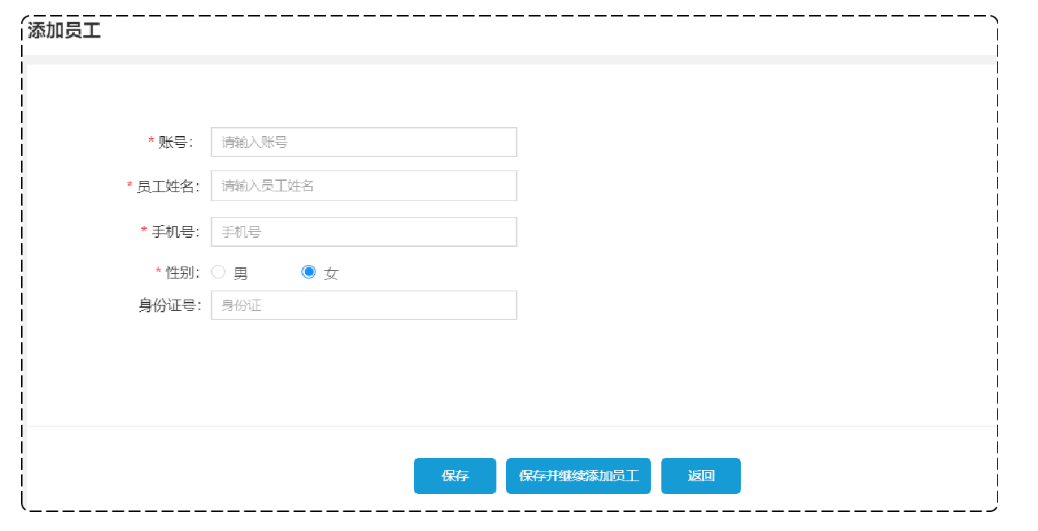
当填写完表单信息, 点击"保存"按钮后, 会提交该表单的数据到服务端, 在服务端中需要接受数据, 然后将数据保存至数据库中。
注意事项:
- 账号必须是唯一的
- 手机号为合法的11位手机号码
- 身份证号为合法的18位身份证号码
- 密码默认为123456
1.1.2 接口设计
找到资料-->项目接口文档-->苍穹外卖-管理端接口.html

明确新增员工接口的请求路径、请求方式、请求参数、返回数据。
本项目约定:
- 管理端 发出的请求,统一使用**/admin**作为前缀。
- 用户端 发出的请求,统一使用**/user**作为前缀。
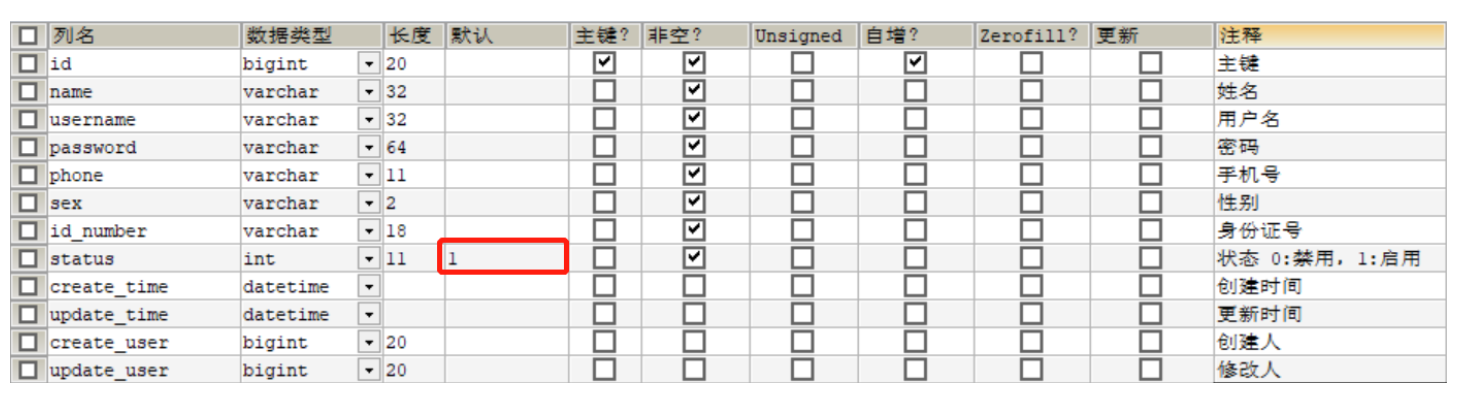
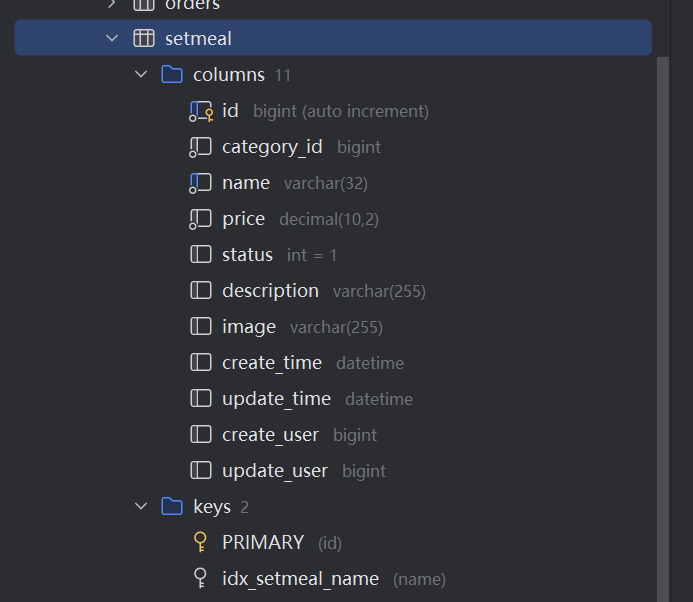
1.1.3 表设计
新增员工,其实就是将我们新增页面录入的员工数据插入到employee表。
employee表结构:
|-------------|-------------|---------|---------|
| 字段名 | 数据类型 | 说明 | 备注 |
| id | bigint | 主键 | 自增 |
| name | varchar(32) | 姓名 | |
| username | varchar(32) | 用户名 | 唯一 |
| password | varchar(64) | 密码 | |
| phone | varchar(11) | 手机号 | |
| sex | varchar(2) | 性别 | |
| id_number | varchar(18) | 身份证号 | |
| status | Int | 账号状态 | 1正常 0锁定 |
| create_time | Datetime | 创建时间 | |
| update_time | datetime | 最后修改时间 | |
| create_user | bigint | 创建人id | |
| update_user | bigint | 最后修改人id | |
其中,employee表中的status字段已经设置了默认值1,表示状态正常。
1.2 代码开发
1.2.1 设计DTO类
根据新增员工接口设计对应的DTO
前端传递参数列表:
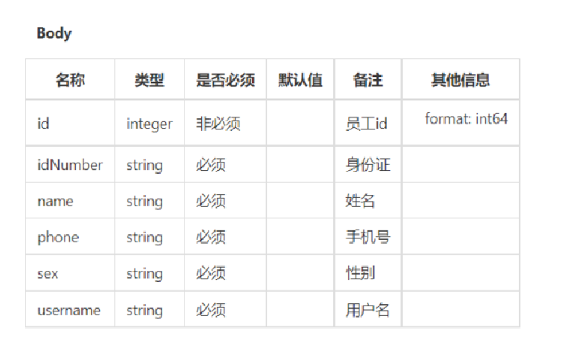
**思考:**是否可以使用对应的实体类来接收呢?

注意: 当前端提交的数据和实体类中对应的属性差别比较大时,建议使用DTO来封装数据
这一句话直接点出了DTO存在的意义,实体类是直接和数据库一一对应的类,他包括了所有属性,但有的时候前端只传过来了一部分数据, 例如pasword这个属性前端就没传过来
由于上述传入参数和实体类有较大差别,所以自定义DTO类。
进入sky-pojo模块,在com.sky.dto包下,已定义EmployeeDTO
package com.sky.dto;
import lombok.Data;
import java.io.Serializable;
@Data
public class EmployeeDTO implements Serializable {
private Long id;
private String username;
private String name;
private String phone;
private String sex;
private String idNumber;
}1.2.2 Controller层
EmployeeController中创建新增员工方法
进入到sky-server模块中,在com.sky.controller.admin包下,在EmployeeController中创建新增员工方法,接收前端提交的参数。
/**
* 新增员工
* @param employeeDTO
* @return
*/
@PostMapping
@ApiOperation("新增员工")
public Result save(@RequestBody EmployeeDTO employeeDTO){
log.info("新增员工:{}",employeeDTO);
employeeService.save(employeeDTO);//该方法后续步骤会定义
return Result.success();
}在这里虽然我们定义的Result<>泛型,但是在这里并没有指定Result泛型的类型,在没有指定的情况下,这个时候默认这个T就是Object
**注:**Result类定义了后端统一返回结果格式。
进入sky-common模块,在com.sky.result包下定义了Result.java
package com.sky.result;
import lombok.Data;
import java.io.Serializable;
/**
* 后端统一返回结果
* @param <T>
*/
@Data
public class Result<T> implements Serializable {
private Integer code; //编码:1成功,0和其它数字为失败
private String msg; //错误信息
private T data; //数据
public static <T> Result<T> success() {
Result<T> result = new Result<T>();
result.code = 1;
return result;
}
public static <T> Result<T> success(T object) {
Result<T> result = new Result<T>();
result.data = object;
result.code = 1;
return result;
}
public static <T> Result<T> error(String msg) {
Result result = new Result();
result.msg = msg;
result.code = 0;
return result;
}
}1.2.3 Service层接口
在EmployeeService接口中声明新增员工方法
进入到sky-server模块中,com.sky.server.EmployeeService
/**
* 新增员工
* @param employeeDTO
*/
void save(EmployeeDTO employeeDTO);1.2.4 Service层实现类
在EmployeeServiceImpl中实现新增员工方法
com.sky.server.impl.EmployeeServiceImpl中创建方法
/**
* 新增员工
*
* @param employeeDTO
*/
public void save(EmployeeDTO employeeDTO) {
Employee employee = new Employee();
//对象属性拷贝
BeanUtils.copyProperties(employeeDTO, employee);
//设置账号的状态,默认正常状态 1表示正常 0表示锁定
employee.setStatus(StatusConstant.ENABLE);
//设置密码,默认密码123456
employee.setPassword(DigestUtils.md5DigestAsHex(PasswordConstant.DEFAULT_PASSWORD.getBytes()));
//设置当前记录的创建时间和修改时间
employee.setCreateTime(LocalDateTime.now());
employee.setUpdateTime(LocalDateTime.now());
//设置当前记录创建人id和修改人id
employee.setCreateUser(10L);//目前写个假数据,后期我们会学一个技术来获取当前登陆的人的id来修改这里
employee.setUpdateUser(10L);
employeeMapper.insert(employee);//后续步骤定义
}这里有一个细节,虽然我们前面使用的是dto来接受前端的数据,但是在mapper层我们还是得用empolyee,也就是实体类,BeanUtils.copyProperties(employeeDTO, employee);
这一段就是拷贝方法,要求 employeeDTO和employee里面的属性得一一对应,一模一样 但是我们发现实体类里面实际的数据会更多,要dto里面的数据会更少,所以我们得手动去设置那些没有被dto里面没有的数据
虽然我也不理解为什么要这样多此一举,但是先跟着去吧
在sky-common模块com.sky.constants包下已定义StatusConstant.java
package com.sky.constant;
/**
* 状态常量,启用或者禁用
*/
public class StatusConstant {
//启用
public static final Integer ENABLE = 1;
//禁用
public static final Integer DISABLE = 0;
}1.2.5 Mapper层
在EmployeeMapper中声明insert方法
com.sky.EmployeeMapper中添加方法
/**
* 插入员工数据
* @param employee
*/
@Insert("insert into employee (name, username, password, phone, sex, id_number, create_time, update_time, create_user, update_user,status) " +
"values " +
"(#{name},#{username},#{password},#{phone},#{sex},#{idNumber},#{createTime},#{updateTime},#{createUser},#{updateUser},#{status})")
void insert(Employee employee);在application.yml中已开启驼峰命名,故id_number和idNumber可对应。
mybatis:
configuration:
#开启驼峰命名
map-underscore-to-camel-case: true1.3 功能测试
代码已经发开发完毕,对新增员工功能进行测试。
功能测试实现方式:
- 通过接口文档测试
- 通前后端联调测试
接下来我们使用上述两种方式分别测试。
1.3.1 接口文档测试
启动服务: 访问http://localhost:8080/doc.html,进入新增员工接口
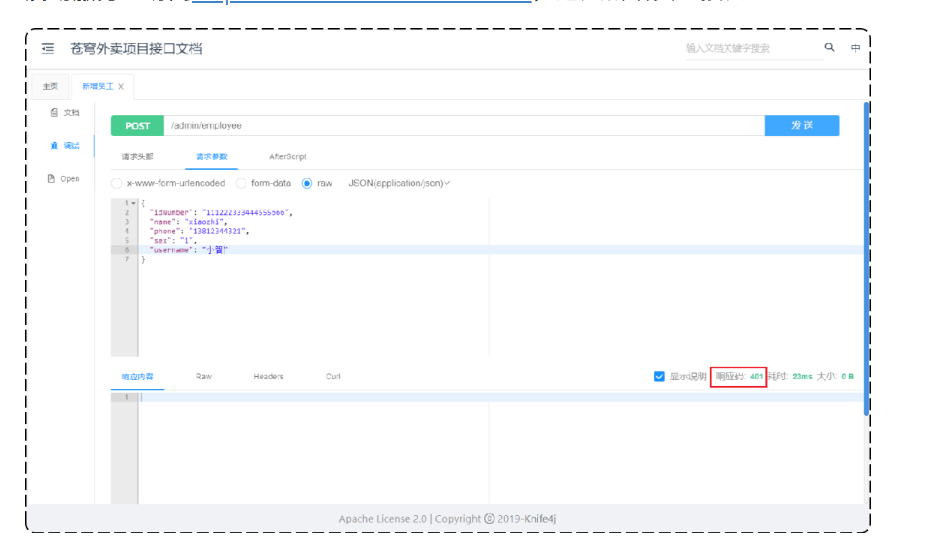
json数据:
{
"idNumber": "111222333444555666",
"name": "xiaozhi",
"phone": "13812344321",
"sex": "1",
"username": "小智"
}响应码:401 报错
**通过断点调试:**进入到JwtTokenAdminInterceptor拦截器
/**
* 校验jwt
*
* @param request
* @param response
* @param handler
* @return
* @throws Exception
*/
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//判断当前拦截到的是Controller的方法还是其他资源
if (!(handler instanceof HandlerMethod)) {
//当前拦截到的不是动态方法,直接放行
return true;
}
//1、从请求头中获取令牌 jwtProperties.getAdminTokenName()获取为token
String token = request.getHeader(jwtProperties.getAdminTokenName());
//2、校验令牌
try {
log.info("jwt校验:{}", token);
Claims claims = JwtUtil.parseJWT(jwtProperties.getAdminSecretKey(), token);
Long empId = Long.valueOf(claims.get(JwtClaimsConstant.EMP_ID).toString());
log.info("当前员工id:", empId);
//3、通过,放行
return true;
} catch (Exception ex) {
//4、不通过,响应401状态码
response.setStatus(401);
return false;
}
}**报错原因:**由于JWT令牌校验失败,导致EmployeeController的save方法没有被调用
**解决方法:**调用员工登录接口获得一个合法的JWT令牌
使用admin用户登录获取令牌
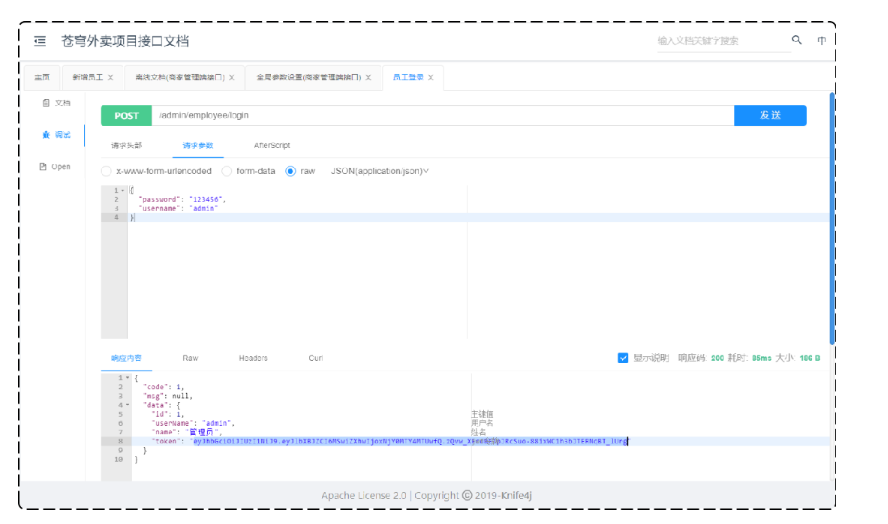
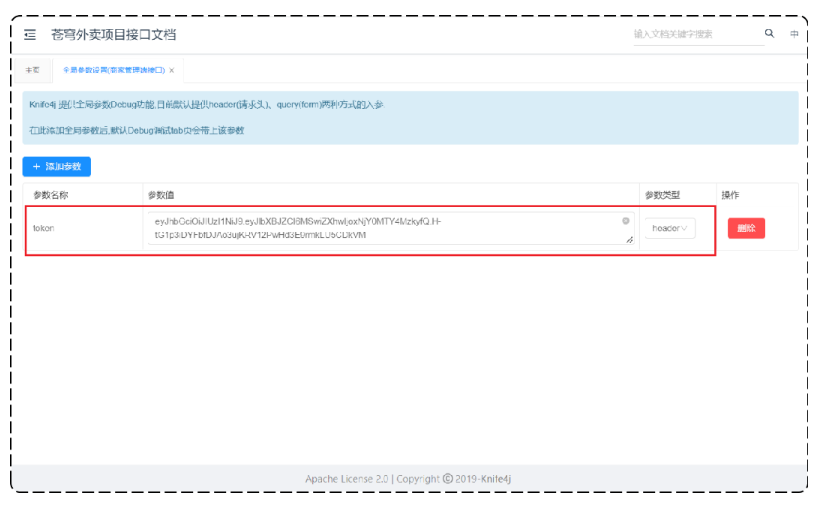
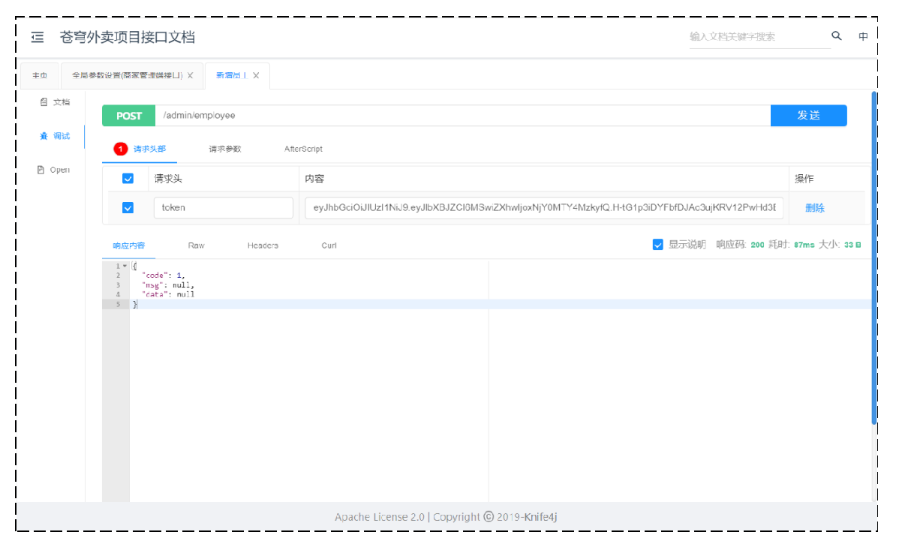
添加令牌:
将合法的JWT令牌添加到全局参数中
文档管理-->全局参数设置-->添加参数
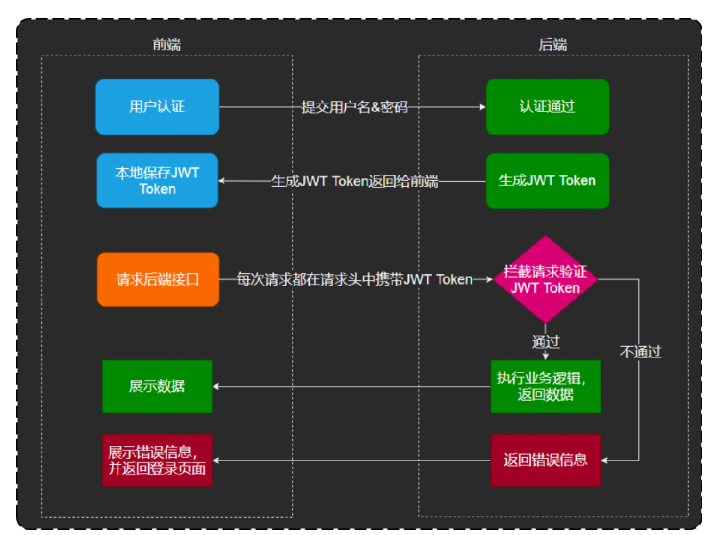
这里有一个小疑惑说一下 这里有三个地方都叫token,其实这几个地方有点区别
1.浏览器把 JWT 存为 token,最直接的原因是前端代码(Vue/React等)写死了要把它存成叫 token 的名字。
2.而前端能够拿到这个值,是因为你返回给前端的 VO(比如 EmployeeLoginVO)里面有一个属性叫 token。
3.至于你 yml 里面配置的 admin-token-name: token,它决定的是后端去读前端传来的请求头,什么请求头(名字叫token的请求)这个地方就用到了yml配置里的token ,正因为,前端代码在vue中给浏览器写死了叫token名字,这次后端才能通过token这个名字再次找到请求头里面的名为token的令牌
然后一开始登陆生成令牌的时候,就是通过下面这种方式传给前端的
这里是前端代码JavaScript示例
// 假设 res 是后端返回的响应体
if (res.code === 1) {
// 1. 从响应体的 data 中取出叫 token 的属性(对应你的 VO)
const jwtString = res.data.token;
// 2. 把它存入浏览器的 LocalStorage 中,并且起名叫 'token'
localStorage.setItem('token', jwtString);
}接口测试:
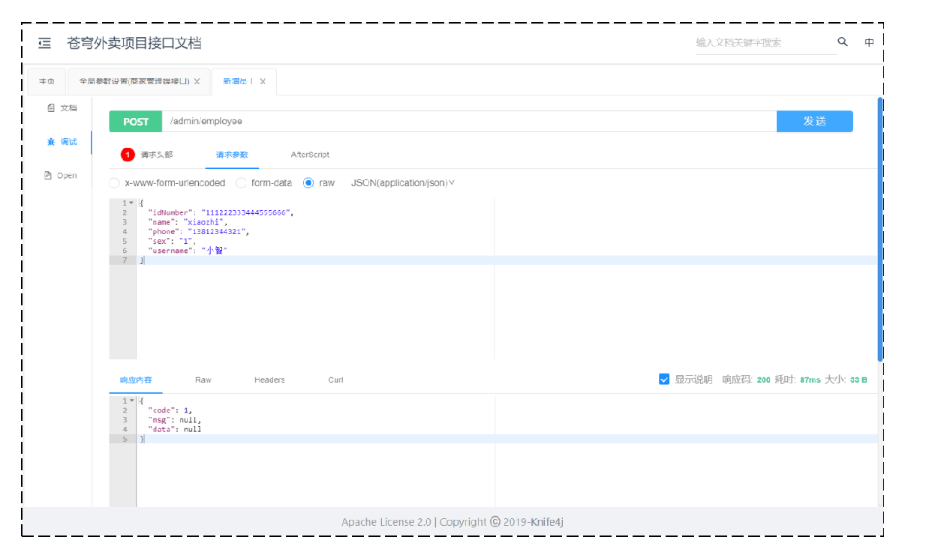
其中,请求头部含有JWT令牌
查看employee表:

测试成功。
1.3.2 前后端联调测试
启动nginx,访问 http://localhost
登录-->员工管理-->添加员工
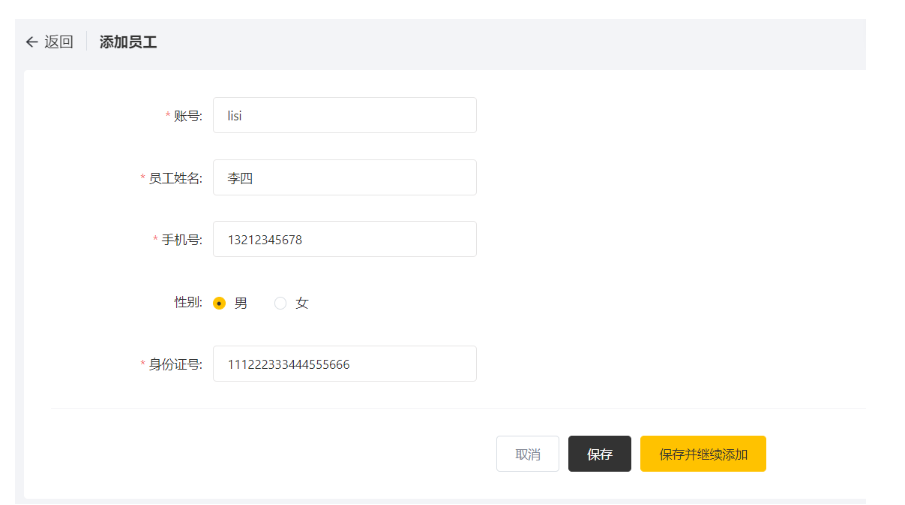
保存后,查看employee表

测试成功。
**注意:**由于开发阶段前端和后端是并行开发的,后端完成某个功能后,此时前端对应的功能可能还没有开发完成,导致无法进行前后端联调测试。所以在开发阶段,后端测试主要以接口文档测试为主。
1.4 代码完善
目前,程序存在的问题主要有两个:
- 录入的用户名已存,抛出的异常后没有处理
- 新增员工时,创建人id和修改人id设置为固定值
接下来,我们对上述两个问题依次进行分析和解决。
1.4.1 问题一
**描述:**录入的用户名已存,抛出的异常后没有处理
分析:
新增username=zhangsan的用户,若employee表中之前已存在。
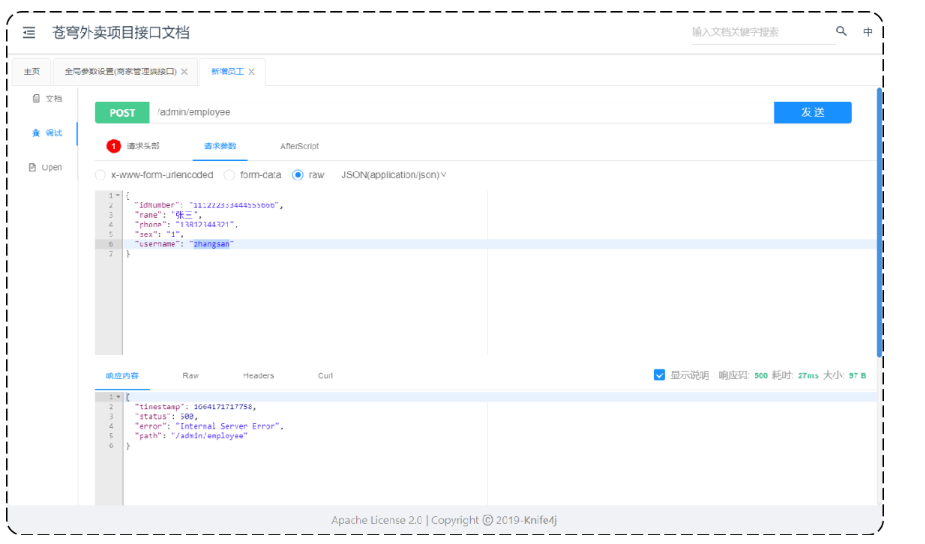
后台报错信息:

查看employee表结构:
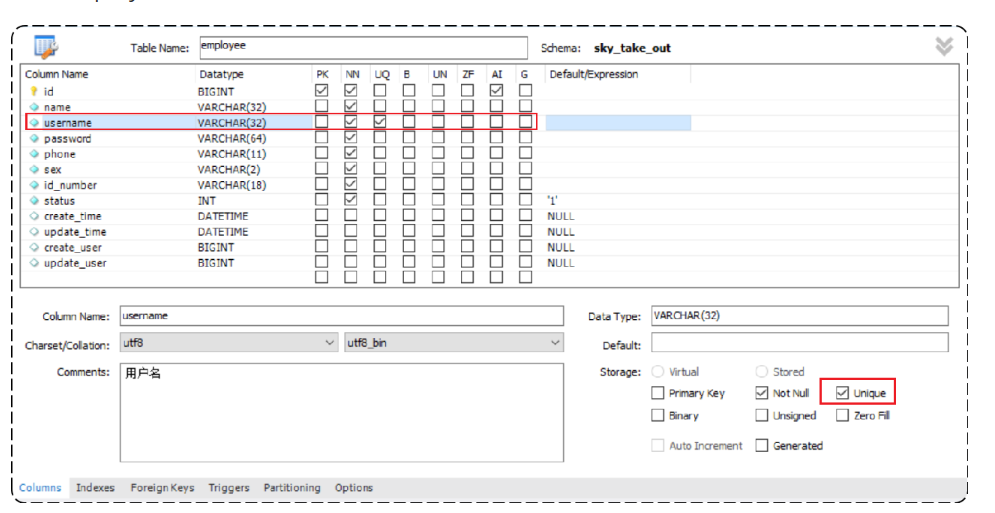
发现,username已经添加了唯一约束,不能重复。
解决:
通过全局异常处理器来处理。
进入到sky-server模块,com.sky.hander包下,GlobalExceptionHandler.java添加方法
这里里面异常类型我们是通过报错信息得到的(SQLIntegrityConstraintViolationException)

/**
* 处理SQL异常
* @param ex
* @return
*/
@ExceptionHandler
public Result exceptionHandler(SQLIntegrityConstraintViolationException ex){
//Duplicate entry 'zhangsan' for key 'employee.idx_username'
String message = ex.getMessage();
if(message.contains("Duplicate entry")){
String[] split = message.split(" ");
String username = split[2];
String msg = username + MessageConstant.ALREADY_EXISTS;
return Result.error(msg);
}else{
return Result.error(MessageConstant.UNKNOWN_ERROR);
}
}需要注意的是 String\[\] split = message.split(" "); 这里意思是message根据空格来分隔,分隔之后的片段会存入数组里面,然后我们需要取出数组里面的第三个
进入到sky-common模块,在MessageConstant.java添加
public static final String ALREADY_EXISTS = "已存在";
再次,接口测试:
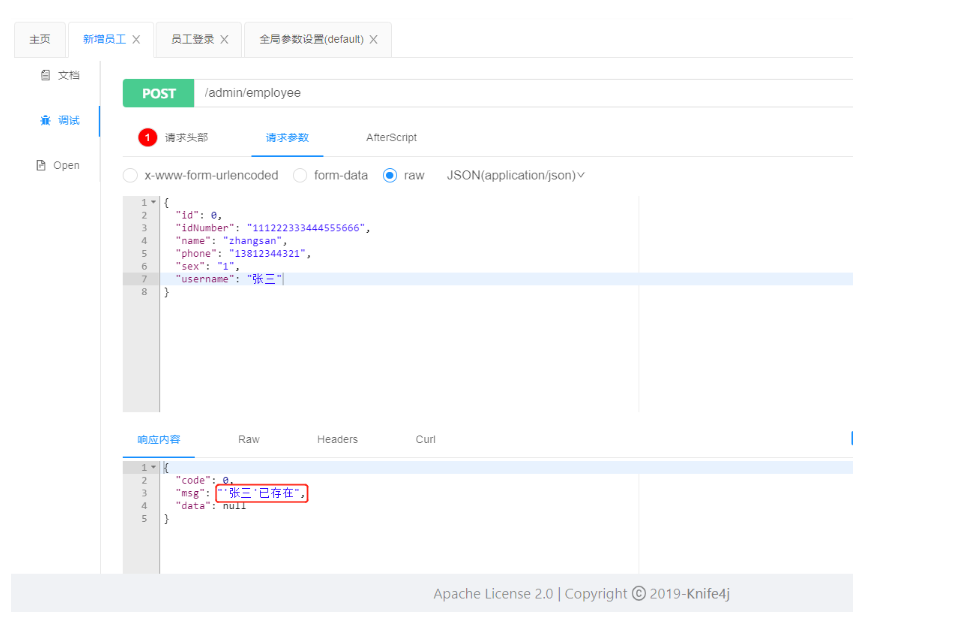
1.4.2 问题二
描述:新增员工时,创建人id和修改人id设置为固定值
分析:
/**
* 新增员工
*
* @param employeeDTO
*/
public void save(EmployeeDTO employeeDTO) {
Employee employee = new Employee();
//................
//////////当前设置的id为固定值10//////////
employee.setCreateUser(10L);
employee.setUpdateUser(10L);
//////////////////////////////////////
//.................................
employeeMapper.insert(employee);//后续步骤定义
}解决:
通过某种方式动态获取当前登录员工的id。
员工登录成功后会生成JWT令牌并响应给前端:
在sky-server模块
package com.sky.controller.admin;
/**
* 员工管理
*/
@RestController
@RequestMapping("/admin/employee")
@Slf4j
@Api(tags = "员工相关接口")
public class EmployeeController {
@Autowired
private EmployeeService employeeService;
@Autowired
private JwtProperties jwtProperties;
/**
* 登录
*
* @param employeeLoginDTO
* @return
*/
@PostMapping("/login")
@ApiOperation(value = "员工登录")
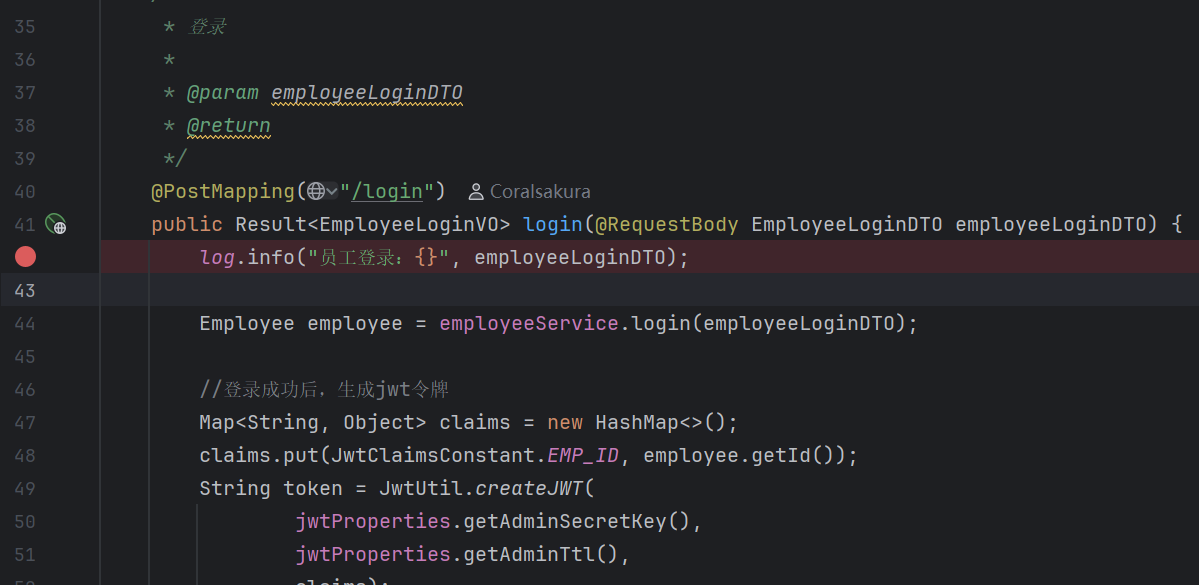
public Result<EmployeeLoginVO> login(@RequestBody EmployeeLoginDTO employeeLoginDTO) {
//.........
//登录成功后,生成jwt令牌
Map<String, Object> claims = new HashMap<>();
claims.put(JwtClaimsConstant.EMP_ID, employee.getId());
String token = JwtUtil.createJWT(
jwtProperties.getAdminSecretKey(),
jwtProperties.getAdminTtl(),
claims);
//............
return Result.success(employeeLoginVO);
}
}后续请求中,前端会携带JWT令牌,通过JWT令牌可以解析出当前登录员工id:
JwtTokenAdminInterceptor.java
package com.sky.interceptor;
/**
* jwt令牌校验的拦截器
*/
@Component
@Slf4j
public class JwtTokenAdminInterceptor implements HandlerInterceptor {
@Autowired
private JwtProperties jwtProperties;
/**
* 校验jwt
*
* @param request
* @param response
* @param handler
* @return
* @throws Exception
*/
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//..............
//1、从请求头中获取令牌
String token = request.getHeader(jwtProperties.getAdminTokenName());
//2、校验令牌
try {
log.info("jwt校验:{}", token);
Claims claims = JwtUtil.parseJWT(jwtProperties.getAdminSecretKey(), token);
Long empId = Long.valueOf(claims.get(JwtClaimsConstant.EMP_ID).toString());
log.info("当前员工id:", empId);
//3、通过,放行
return true;
} catch (Exception ex) {
//4、不通过,响应401状态码
response.setStatus(401);
return false;
}
}
}**思考:**解析出登录员工id后,如何传递给Service的save方法?
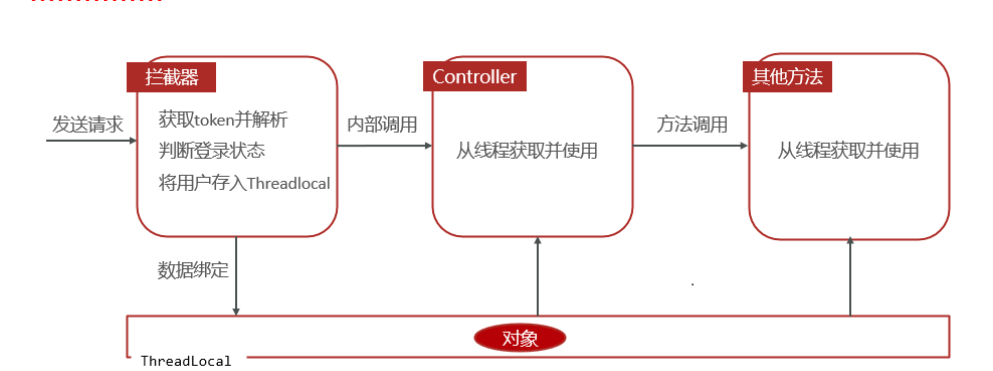
通过ThreadLocal进行传递。
1.4.3 ThreadLocal
介绍:
ThreadLocal 并不是一个Thread,而是Thread的局部变量。ThreadLocal为每个线程提供单独一份存储空间,具有线程隔离的效果,只有在线程内才能获取到对应的值,线程外则不能访问。
常用方法:
- public void set(T value) 设置当前线程的线程局部变量的值
- public T get() 返回当前线程所对应的线程局部变量的值
- public void remove() 移除当前线程的线程局部变量
对ThreadLocal有了一定认识后,接下来继续解决问题二
初始工程中已经封装了 ThreadLocal 操作的工具类:
在sky-common模块
package com.sky.context;
public class BaseContext {
public static ThreadLocal<Long> threadLocal = new ThreadLocal<>();
public static void setCurrentId(Long id) {
threadLocal.set(id);
}
public static Long getCurrentId() {
return threadLocal.get();
}
public static void removeCurrentId() {
threadLocal.remove();
}
}在拦截器中解析出当前登录员工id,并放入线程局部变量中:
在sky-server模块中,拦截器:
package com.sky.interceptor;
/**
* jwt令牌校验的拦截器
*/
@Component
@Slf4j
public class JwtTokenAdminInterceptor implements HandlerInterceptor {
@Autowired
private JwtProperties jwtProperties;
/**
* 校验jwt
*
* @param request
* @param response
* @param handler
* @return
* @throws Exception
*/
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//.............................
//2、校验令牌
try {
//.................
Claims claims = JwtUtil.parseJWT(jwtProperties.getAdminSecretKey(), token);
Long empId = Long.valueOf(claims.get(JwtClaimsConstant.EMP_ID).toString());
log.info("当前员工id:", empId);
/////将用户id存储到ThreadLocal////////
BaseContext.setCurrentId(empId);
////////////////////////////////////
//3、通过,放行
return true;
} catch (Exception ex) {
//......................
}
}
}在Service中获取线程局部变量中的值:
/**
* 新增员工
*
* @param employeeDTO
*/
public void save(EmployeeDTO employeeDTO) {
//.............................
//设置当前记录创建人id和修改人id
employee.setCreateUser(BaseContext.getCurrentId());//目前写个假数据,后期修改
employee.setUpdateUser(BaseContext.getCurrentId());
employeeMapper.insert(employee);
}测试:使用admin(id=1)用户登录后添加一条记录
查看employee表记录
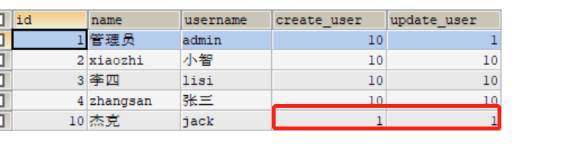
这里就提到了线程的概念了,黑马说在每一次发起请求的过程中,contorller层,service层,和mapper层都在一个线程里面
前端发起的一次完整请求,它所经过的 Controller、Service、Mapper(DAO)层,确实都是由同一个线程自上而下贯穿执行的。 注意每次请求都是一次单独线程,就是下次请求与这次请求线程就不一样了
1. 为什么会在同一个线程里?
这要归功于底层的 Web 服务器(比如 Spring Boot 内置的 Tomcat)。
- 线程池待命: Tomcat 启动时,会在后台准备好一个"线程池"(你可以想象成一个由很多服务员组成的待命小队,默认通常是 200 个线程)。
- 分配线程: 当客户端(前端)发起一个 HTTP 请求到达服务器时,Tomcat 会从线程池里"抓"出一个空闲的线程(比如叫
Thread-1)来接待这个请求。 - 同步执行: 接下来,
Thread-1就开始干活了。它会依次走过:Filter(过滤器) ->Interceptor(拦截器) ->Controller->Service->Mapper-> 数据库。因为代码是同步、顺序执行的 ,在拿到数据库的返回结果之前,Thread-1哪里都不会去,一直"阻塞"在这里处理这个专属的请求。 - 响应与归还: 等数据一路原路返回,最终响应给前端后,
Thread-1的任务结束,它会被"扔"回 Tomcat 的线程池中,等待接待下一次的请求。
2. 都在一个线程里,有什么好处?
教程里特意提到"同一个线程"这个概念,通常是为了引出一个非常重要的 Java 神器:ThreadLocal。
1.5 代码提交
点击提交:
提交过程中,出现提示:
继续push:
推送成功:
然这里学到一个小技巧,在断点调试的过程中,如果想要获取到这个某个值的结果,一般运行到这行之后,再鼠标直接悬停会显示,但是在这里是一个表达式的结果,我们想知道这个值的结果可以选中之后鼠标右键,点击evaluate expression
员工分页查询
需求分析和设计
2.1.1 产品原型
系统中的员工很多的时候,如果在一个页面中全部展示出来会显得比较乱,不便于查看,所以一般的系统中都会以分页的方式来展示列表数据。而在我们的分页查询页面中, 除了分页条件以外,还有一个查询条件 "员工姓名"。
查询员工原型:
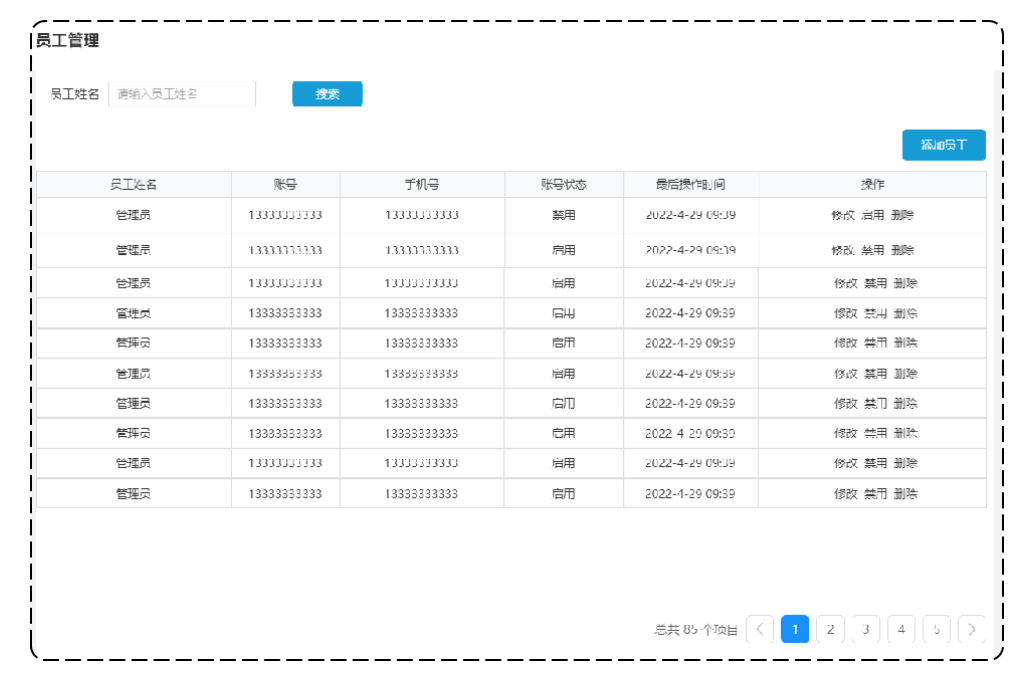
业务规则:
- 根据页码展示员工信息
- 每页展示10条数据
- 分页查询时可以根据需要,输入员工姓名进行查询
2.1.2 接口设计
找到资料-->项目接口文档-->苍穹外卖-管理端接口.html
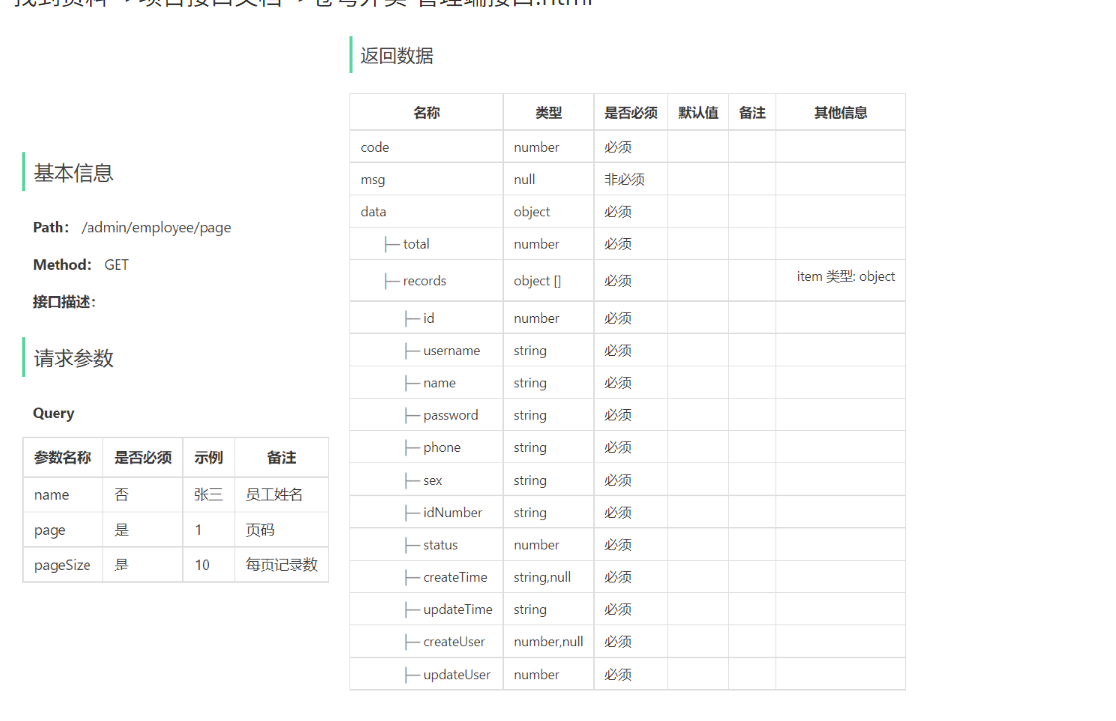
注意事项:
- 请求参数类型为Query,不是json格式提交,在路径后直接拼接。/admin/employee/page?name=zhangsan
- (这里面的Query就是最普通的查询方式直接拼接在路径后面)
- 返回数据中records数组中使用Employee实体类对属性进行封装。
2.2 代码开发
2.2.1 设计DTO类
根据请求参数进行封装,在sky-pojo模块中
package com.sky.dto;
import lombok.Data;
import java.io.Serializable;
@Data
public class EmployeePageQueryDTO implements Serializable {
//员工姓名
private String name;
//页码
private int page;
//每页显示记录数
private int pageSize;
}2.2.2 封装PageResult
后面所有的分页查询,统一都封装为PageResult对象。
在sky-common模块
package com.sky.result;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
import java.util.List;
/**
* 封装分页查询结果
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class PageResult implements Serializable {
private long total; //总记录数
private List records; //当前页数据集合
}我们发现这里 implements Serializable 和后面的实体类都继承了这个类,这个类并没有实际作用,只是相当于给他颁发了一个许可证,这个许可证现在不写没任何问题,但是之后如果没有在redis那里会报错
然后这里的List没有指定任何泛型,那就是object类型
员工信息分页查询后端返回的对象类型为: Result<PageResult>
package com.sky.result;
import lombok.Data;
import java.io.Serializable;
/**
* 后端统一返回结果
* @param <T>
*/
@Data
public class Result<T> implements Serializable {
private Integer code; //编码:1成功,0和其它数字为失败
private String msg; //错误信息
private T data; //数据
public static <T> Result<T> success() {
Result<T> result = new Result<T>();
result.code = 1;
return result;
}
public static <T> Result<T> success(T object) {
Result<T> result = new Result<T>();
result.data = object;
result.code = 1;
return result;
}
public static <T> Result<T> error(String msg) {
Result result = new Result();
result.msg = msg;
result.code = 0;
return result;
}
}2.2.3 Controller层
在sky-server模块中,com.sky.controller.admin.EmployeeController中添加分页查询方法。
/**
* 员工分页查询
* @param employeePageQueryDTO
* @return
*/
@GetMapping("/page")
@ApiOperation("员工分页查询")
public Result<PageResult> page(EmployeePageQueryDTO employeePageQueryDTO){
log.info("员工分页查询,参数为:{}", employeePageQueryDTO);
PageResult pageResult = employeeService.pageQuery(employeePageQueryDTO);//后续定义
return Result.success(pageResult);
}2.2.4 Service层接口
在EmployeeService接口中声明pageQuery方法:
/**
* 分页查询
* @param employeePageQueryDTO
* @return
*/
PageResult pageQuery(EmployeePageQueryDTO employeePageQueryDTO);2.2.5 Service层实现类
在EmployeeServiceImpl中实现pageQuery方法:
/**
* 分页查询
*
* @param employeePageQueryDTO
* @return
*/
public PageResult pageQuery(EmployeePageQueryDTO employeePageQueryDTO) {
// select * from employee limit 0,10
//开始分页查询
PageHelper.startPage(employeePageQueryDTO.getPage(), employeePageQueryDTO.getPageSize());
Page<Employee> page = employeeMapper.pageQuery(employeePageQueryDTO);//后续定义
long total = page.getTotal();
List<Employee> records = page.getResult();
return new PageResult(total, records);
}**注意:**此处使用 mybatis 的分页插件 PageHelper 来简化分页代码的开发。底层基于 mybatis 的拦截器实现。
前面我们也学过,现在当作复习一下,我们底层在数据库层其实是通过limit关键字来进行查询的(比如limit 10,10 就是查询从第11跳开始的后面10条 ),但是这里不能写死,自己用这个关键词实现动态查询会比较繁琐,所以这个插件就是用来动态查询
然后注意这里是最最重要的一点
Page<Employee> page = employeeMapper.pageQuery(employeePageQueryDTO);//后续定义
这里要求我们返回值就是固定的,也就是必须得是Page类型 这个类型是pageHelper提供的,其实底层就是一个list类型 然后泛型就是写我查询之后每一条记录数封装的类型(也就是实体类型employee)
故在pom.xml文中添加依赖(初始工程已添加)
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>${pagehelper}</version>
</dependency>2.2.6 Mapper层
在 EmployeeMapper 中声明 pageQuery 方法:
/**
* 分页查询
* @param employeePageQueryDTO
* @return
*/
Page<Employee> pageQuery(EmployeePageQueryDTO employeePageQueryDTO);在 src/main/resources/mapper/EmployeeMapper.xml 中编写SQL:
<select id="pageQuery" resultType="com.sky.entity.Employee">
select * from employee
<where>
<if test="name != null and name != ''">
and name like concat('%',#{name},'%')
</if>
</where>
order by create_time desc
</select>这里复习一下,之前学javaweb时候,#{name}会预编译成?,而这个问号是不能写到'?'(引号里面的)
第二个这里的and其实是会被这个<where>标签给去掉的
还有一个地方值得关注的是 这里为什么这类型是employee,而不是page类型,比如在集合里面,xml中这种resultType类型必须得是集合单个实体的类型,而不能是整个整体类型(在这里是page)
比如 resultType="com.github.pagehelper.Page",那会发生什么灾难?
我们无需写那种limit那种关键词,在xml文件里面我也只需要写一个根据名字来模糊查询就可以了,之后pagehelper会帮我们实现
MyBatis 会完全傻眼:它只知道你要一个 Page****集合,但它完全不知道集合里面应该装什么对象!因为它在底层运行的时候,Java 的泛型会被擦除,它不知道里面是 Employee****还是 Order**。**
而且在这个地方我们传入employeePageQueryDTO,但是xml文件中and name like concat('%',#{name},'%')中这个#{name}依然能自动找到employeePageQueryDTO里面这个name
2.3 功能测试
可以通过接口文档进行测试,也可以进行前后端联调测试。
接下来使用两种方式分别测试:
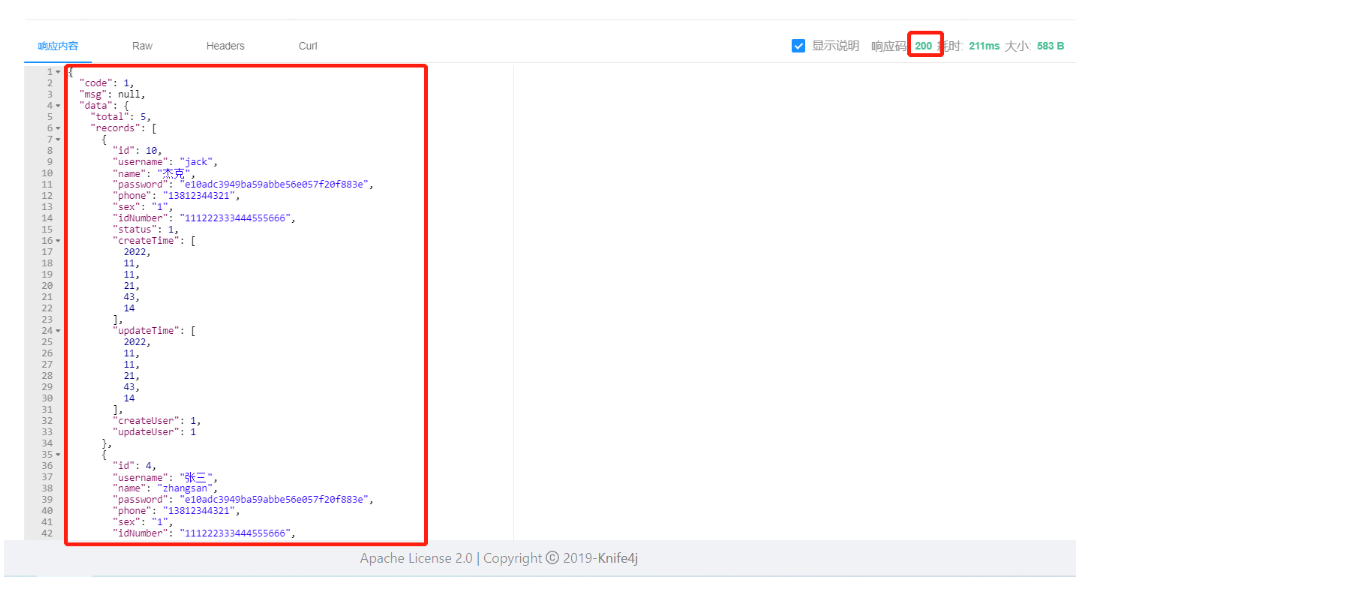
2.3.1 接口文档测试
重启服务: 访问http://localhost:8080/doc.html,进入员工分页查询
响应结果:
2.3.2 前后端联调测试
点击员工管理
输入员工姓名为zhangsan
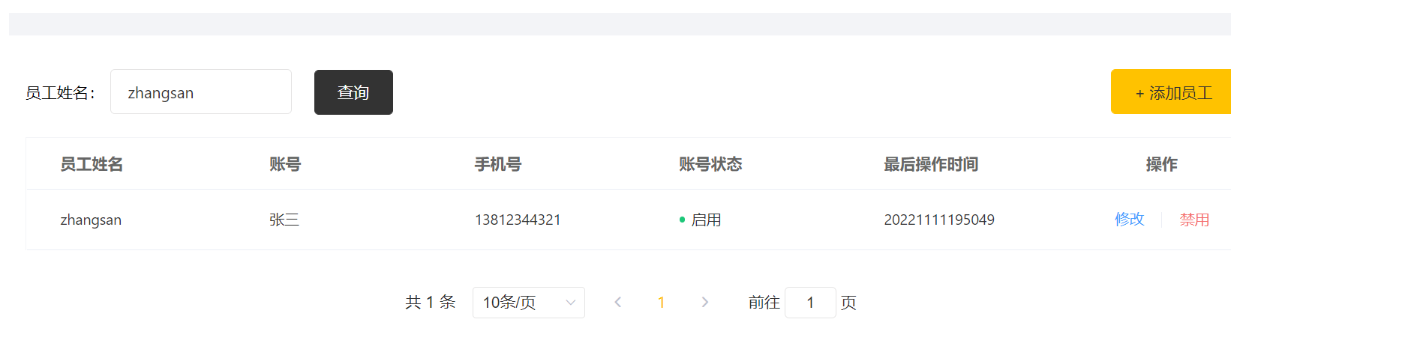
不难发现,最后操作时间格式 不清晰,在代码完善中解决。

2.4 代码完善
**问题描述:**操作时间字段显示有问题。
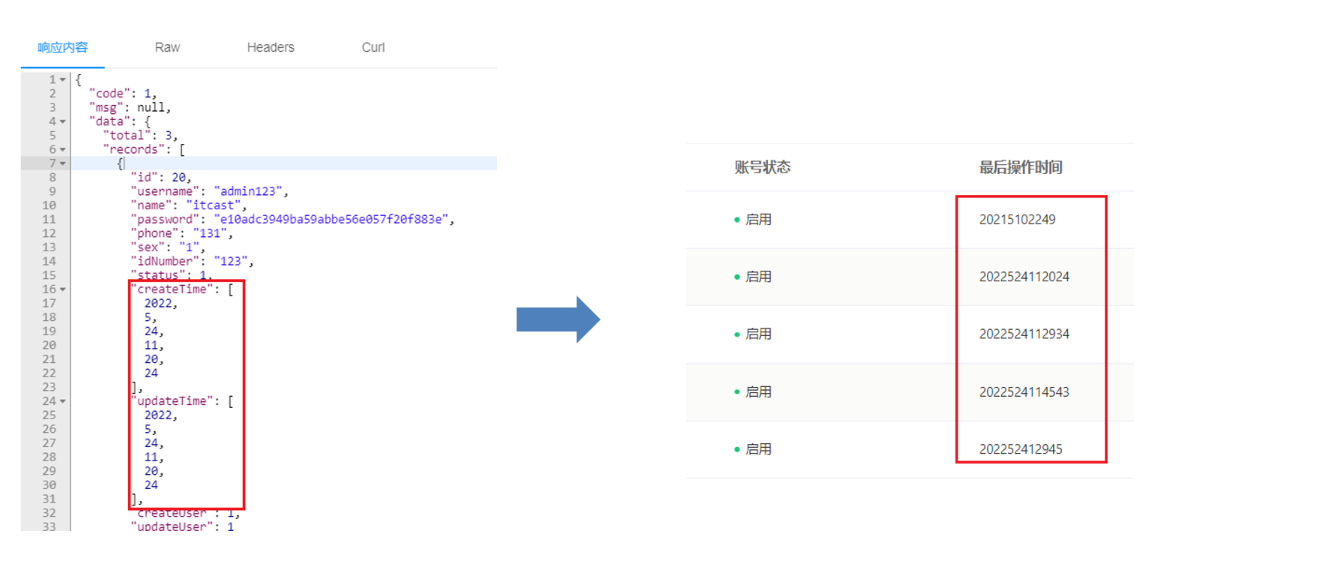
解决方式:
1). 方式一
在属性上加上注解,对日期进行格式化
但这种方式,需要在每个时间属性上都要加上该注解,使用较麻烦,不能全局处理。
2). 方式二(推荐 )
第二种方式其实就扩展springmvc框架的消息转换器 这里的扩展其实就是类与类之间(用extends)
我们只要重写父类里面的一个方法就可以了
第一步:为什么要自己创建"消息转换器(MessageConverter)"?
当你的 Controller 返回一个 Employee****对象时,Spring 需要把它变成 JSON 字符串通过网络发给前端。Spring 内部其实已经自带了转换器,但 自带的转换器有时候不符合我们的特殊要求 。
- 比如:自带的转换器可能把 Java 里的日期时间直接转换成了一长串看不懂的数字时间戳,而不是我们想要的 *"2023-10-24 12:00:00"*格式。
- 为了解决这个问题,我们需要在 extendMessageConverters**(扩展消息转换器)方法中,** 自己造一个懂我们规矩的"翻译官" ,也就是代码里的 MappingJackson2HttpMessageConverter**。**
第二步:为什么要给转换器设置"对象转换器(ObjectMapper)"?
- MessageConverter**(消息转换器)** :相当于翻译部门的一个 岗位 ,它负责对接 Spring 框架,告诉 Spring "交给我来转成 JSON 吧"。
- ObjectMapper**(对象转换器)** :相当于这个岗位上使用的 核心翻译字典/引擎 (由底层 Jackson 框架提供)。
代码 converter.setObjectMapper(...)的意思就是: 你给这个新成立的翻译岗位( converter),发配了一本 你自己编写的、包含特殊规则的翻译字典 ( ObjectMapper**)。这本字典里规定了遇到日期该怎么转、遇到超长数字(Long)该怎么转,从而防止前端接收数据时出现格式错乱或精度丢失。**
在WebMvcConfiguration中扩展SpringMVC的消息转换器,统一对日期类型进行格式处理
/**
* 扩展Spring MVC框架的消息转化器
* @param converters
*/
protected void extendMessageConverters(List<HttpMessageConverter<?>> converters) {
log.info("扩展消息转换器...");
//创建一个消息转换器对象
MappingJackson2HttpMessageConverter converter = new MappingJackson2HttpMessageConverter();
//需要为消息转换器设置一个对象转换器,对象转换器可以将Java对象序列化为json数据
converter.setObjectMapper(new JacksonObjectMapper());
//将自己的消息转化器加入容器中
converters.add(0,converter);
}默认我们自己定义的消息转换器是放在最后一位的
converters.add(0,converter);有两个作用
- 把你自定义的转换器放在第 0 位,就能保证 Spring 优先使用你的规则来转换 JSON,从而覆盖掉系统默认的规则。
2.就是把我们刚刚创建好的消息转换器,加入到容器中
添加后,再次测试
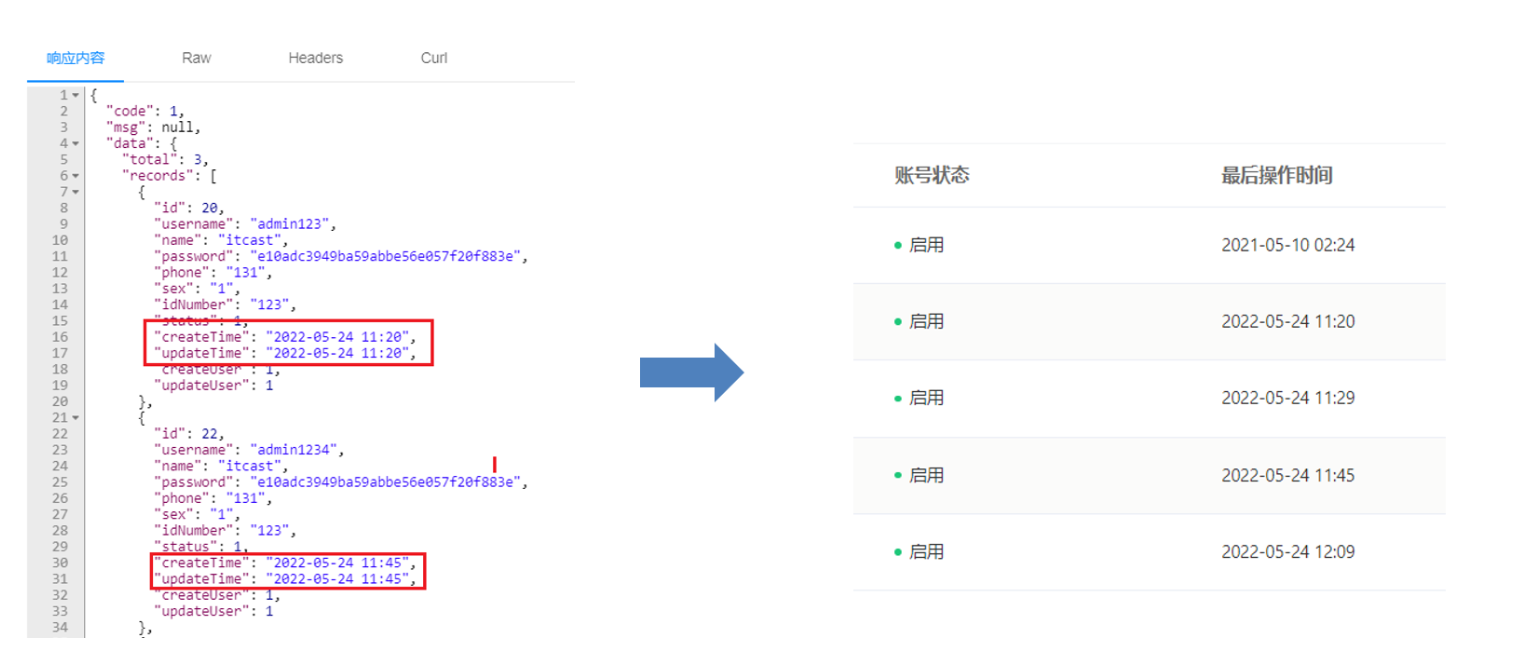
时间格式定义在sky-common模块中JacksonObjectMapper类中写好了
package com.sky.json;
public class JacksonObjectMapper extends ObjectMapper {
//.......
public static final String DEFAULT_DATE_TIME_FORMAT = "yyyy-MM-dd HH:mm";
//.......
}
}2.5 代码提交
后续步骤和新增员工代码提交一致,不再赘述。
这里我们知道序列化就是把java对象到josn
反序列化就是把josn到java对象的过程
这里再补充一个知识
无论是 Jackson(它的核心就是 ObjectMapper)还是阿里巴巴的 Fastjson(我们之前在javaweb课程里面用的就是这个),它们在 Java 世界里干的都是完全一样的一件事:
同工(核心目标):JSON 序列化与反序列化
- 把 Java 里的对象(比如
Employee)变成一串 JSON 字符串发给前端。 - 把前端传过来的一串 JSON 字符串,重新组装成 Java 里的对象。
但是,它们的**"异曲"(实现风格、优缺点、江湖地位)**差别很大,这也是面试时经常会问到的点,我给你简单对比一下:
1. Jackson (Spring Boot 的"原配夫人")
- 江湖地位: 全球 Java 界的标准,Spring Boot 官方默认钦定自带的 JSON 框架。
- 特点: 极其稳定 、功能极其强大、配置非常灵活(所以你才能自定义一个
JacksonObjectMapper去魔改它的时间格式)。 - 缺点: API 稍微有点点繁琐(比如你要先
new ObjectMapper(),然后再调方法)。
2. Fastjson (阿里巴巴的"性能狂人")
- 江湖地位: 在国内非常火,几乎是前几年国内互联网公司的标配。
- 特点: 极致的快! 它的设计初衷就是为了榨干性能。而且它的 API 极其简单粗暴,一行代码搞定:
JSON.toJSONString(对象)。 - 致命弱点(经常被吐槽): 因为为了追求极致的速度,底层用了很多骚操作,导致它前几年频频爆出严重的安全漏洞(反序列化漏洞,黑客能借此直接控制服务器)。虽然现在出了 Fastjson2 解决了很多问题,但很多大厂在选型时依然会对它保持谨慎。
启用禁用员工账号
3.1 需求分析与设计
3.1.1 产品原型
在员工管理列表页面,可以对某个员工账号进行启用或者禁用操作。账号禁用的员工不能登录系统,启用后的员工可以正常登录。如果某个员工账号状态为正常,则按钮显示为 "禁用",如果员工账号状态为已禁用,则按钮显示为"启用"。
启禁用员工原型:
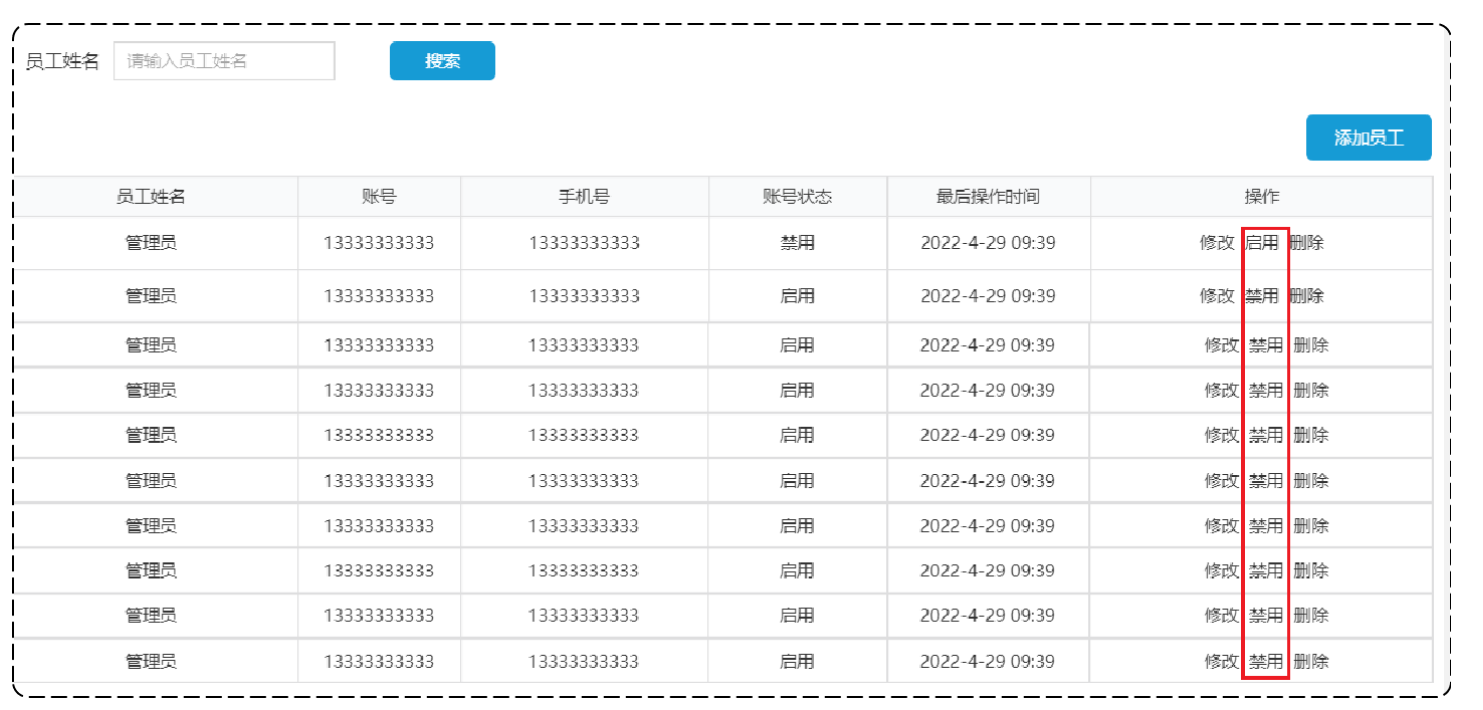
业务规则:
- 可以对状态为"启用" 的员工账号进行"禁用"操作
- 可以对状态为"禁用"的员工账号进行"启用"操作
- 状态为"禁用"的员工账号不能登录系统
3.1.2 接口设计

1). 路径参数携带状态值。
2). 同时,把id传递过去,明确对哪个用户进行操作。
3). 返回数据code状态是必须,其它是非必须。
3.2 代码开发
3.2.1 Controller层
在sky-server模块中,根据接口设计中的请求参数形式对应的在 EmployeeController 中创建启用禁用员工账号的方法:
/**
* 启用禁用员工账号
* @param status
* @param id
* @return
*/
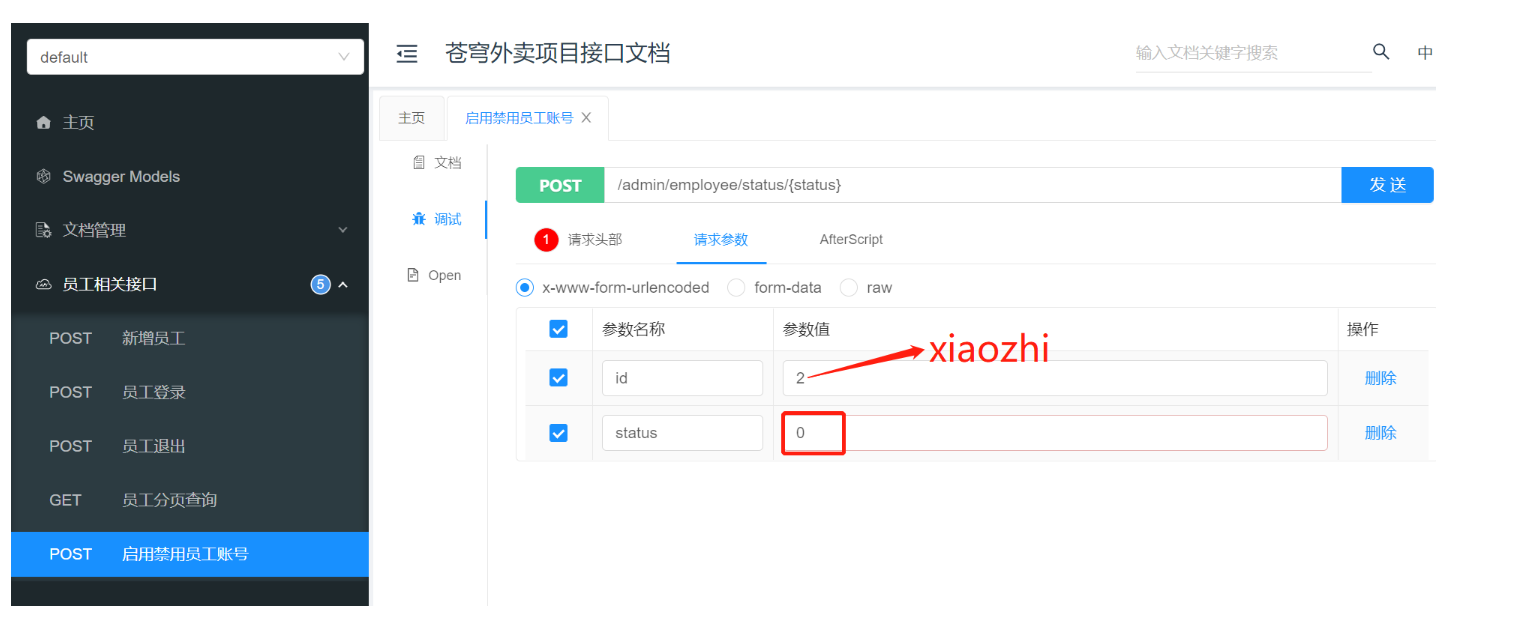
@PostMapping("/status/{status}")
@ApiOperation("启用禁用员工账号")
public Result startOrStop(@PathVariable Integer status,Long id){
log.info("启用禁用员工账号:{},{}",status,id);
employeeService.startOrStop(status,id);//后绪步骤定义
return Result.success();
}3.2.2 Service层接口
在 EmployeeService 接口中声明启用禁用员工账号的业务方法:
/**
* 启用禁用员工账号
* @param status
* @param id
*/
void startOrStop(Integer status, Long id);3.2.3 Service层实现类
在 EmployeeServiceImpl 中实现启用禁用员工账号的业务方法:
/**
* 启用禁用员工账号
*
* @param status
* @param id
*/
public void startOrStop(Integer status, Long id) {
Employee employee = Employee.builder()
.status(status)
.id(id)
.build();
employeeMapper.update(employee);
}3.2.4 Mapper层
在 EmployeeMapper 接口中声明 update 方法:
/**
* 根据主键动态修改属性
* @param employee
*/
void update(Employee employee);在 EmployeeMapper.xml 中编写SQL:
<update id="update" parameterType="Employee">
update employee
<set>
<if test="name != null">name = #{name},</if>
<if test="username != null">username = #{username},</if>
<if test="password != null">password = #{password},</if>
<if test="phone != null">phone = #{phone},</if>
<if test="sex != null">sex = #{sex},</if>
<if test="idNumber != null">id_Number = #{idNumber},</if>
<if test="updateTime != null">update_Time = #{updateTime},</if>
<if test="updateUser != null">update_User = #{updateUser},</if>
<if test="status != null">status = #{status},</if>
</set>
where id = #{id}
</update>需要提一下,在这里<update id="update" parameterType="Employee">不用
写完整的全类名是因为我们底下在yml文件中设置了扫entity底下的包所以不用再写一个类名,只要写别名就行了
写这个是告诉mybaits我们传入的要修改的java对象的类型,但是现在可以省略不写这个了(因为现在更智能了)
1. 什么是"别名"(Alias)?
"别名"通俗来说就是**"小名" 或者 "简称"**。
- 全类名(大名/身份证名): com.sky.entity.Employee**。它包含了完整的包路径,非常长,写起来很麻烦。**
- 别名(小名): Employee**。**
就像你在学校里,官方档案上写的是你的全名和学号,但在班级里老师直接叫你的名字就行了,因为大家都知道在这个班级(包)里,叫这个名字的就是你。
3.3 功能测试
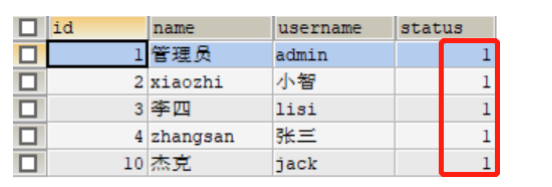
3.3.1 接口文档测试
**测试前,**查询employee表中员工账号状态
开始测试
测试完毕后,再次查询员工账号状态
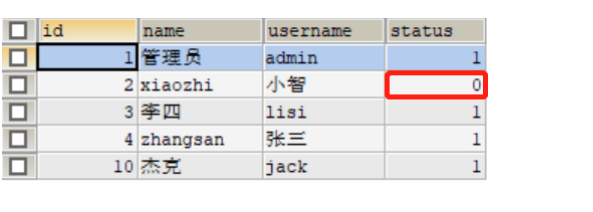
3.3.2 前后端联调测试
测试前:
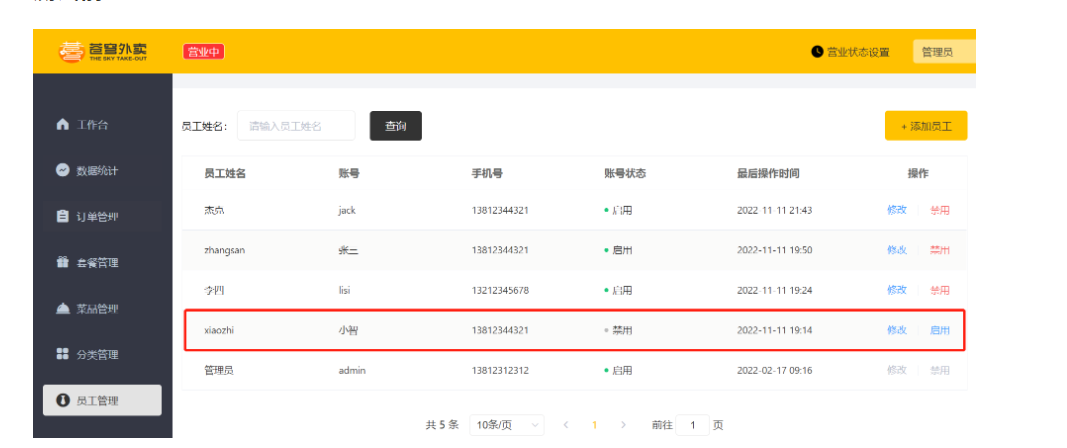
点击启用:
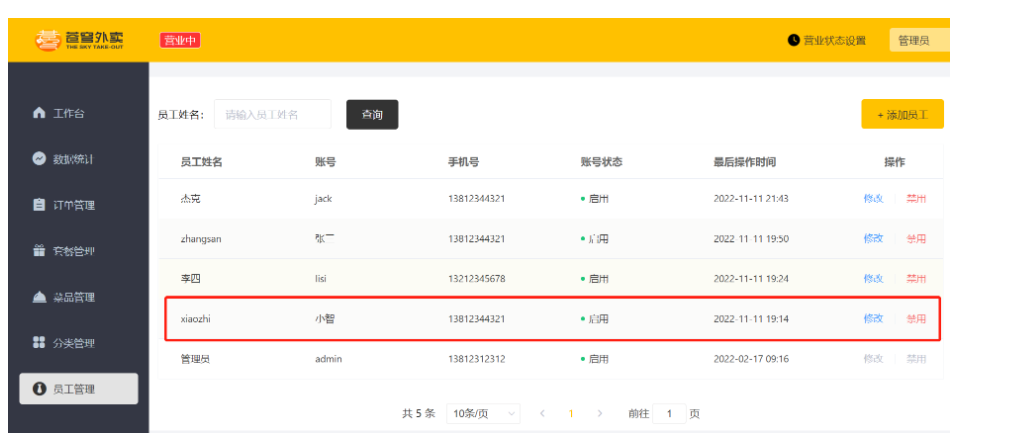
3.4 代码提交
后续步骤和上述功能代码提交一致,不再赘述。
编辑员工
4.1 需求分析与设计
4.1.1 产品原型
在员工管理列表页面点击 "编辑" 按钮,跳转到编辑页面,在编辑页面回显员工信息并进行修改,最后点击 "保存" 按钮完成编辑操作。
员工列表原型:
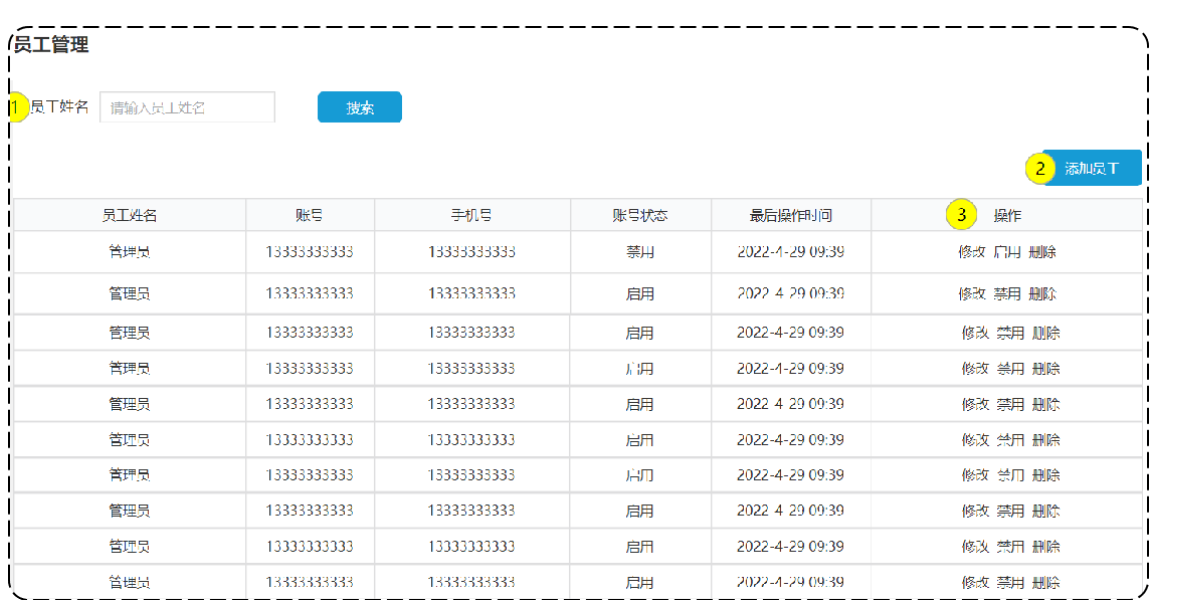
修改页面原型:
注:点击修改时,数据应该正常回显到修改页面。
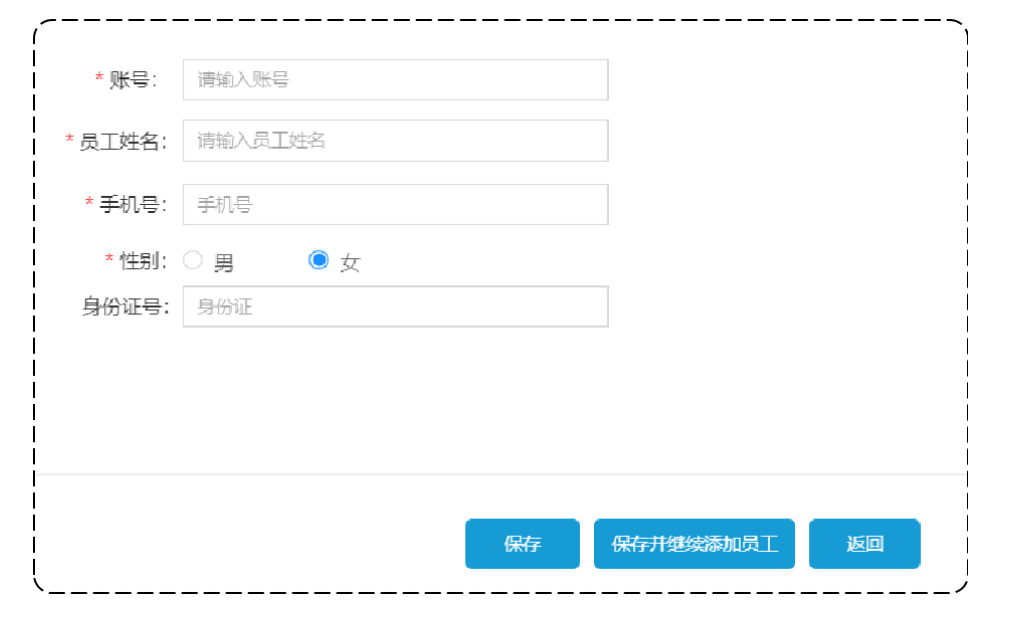
4.1.2 接口设计
根据上述原型图分析,编辑员工功能涉及到两个接口:
- 根据id查询员工信息(这个就是把点开的员工信息回显展示在对话框内,这里用到了路径参数)
- 编辑员工信息
1). 根据id查询员工信息

2). 编辑员工信息

注:因为是修改功能,请求方式可设置为PUT。
4.2 代码开发
4.2.1 回显员工信息功能
1). Controller层
在 EmployeeController 中创建 getById 方法:
/**
* 根据id查询员工信息
* @param id
* @return
*/
@GetMapping("/{id}")
@ApiOperation("根据id查询员工信息")
public Result<Employee> getById(@PathVariable Long id){
Employee employee = employeeService.getById(id);
return Result.success(employee);
}2). Service层接口
在 EmployeeService 接口中声明 getById 方法:
/**
* 根据id查询员工
* @param id
* @return
*/
Employee getById(Long id);3). Service层实现类
在 EmployeeServiceImpl 中实现 getById 方法:
/**
* 根据id查询员工
*
* @param id
* @return
*/
public Employee getById(Long id) {
Employee employee = employeeMapper.getById(id);
employee.setPassword("****");
return employee;
}4). Mapper层
在 EmployeeMapper 接口中声明 getById 方法:
/**
* 根据id查询员工信息
* @param id
* @return
*/
@Select("select * from employee where id = #{id}")
Employee getById(Long id);4.2.2 修改员工信息功能
1). Controller层
在 EmployeeController 中创建 update 方法:
/**
* 编辑员工信息
* @param employeeDTO
* @return
*/
@PutMapping
@ApiOperation("编辑员工信息")
public Result update(@RequestBody EmployeeDTO employeeDTO){
log.info("编辑员工信息:{}", employeeDTO);
employeeService.update(employeeDTO);
return Result.success();
}2). Service层接口
在 EmployeeService 接口中声明 update 方法:
/**
* 编辑员工信息
* @param employeeDTO
*/
void update(EmployeeDTO employeeDTO);3). Service层实现类
在 EmployeeServiceImpl 中实现 update 方法:
/**
* 编辑员工信息
*
* @param employeeDTO
*/
public void update(EmployeeDTO employeeDTO) {
Employee employee = new Employee();
BeanUtils.copyProperties(employeeDTO, employee);
employee.setUpdateTime(LocalDateTime.now());
employee.setUpdateUser(BaseContext.getCurrentId());
employeeMapper.update(employee);
}在实现启用禁用员工账号功能时,已实现employeeMapper.update(employee),在此不需写Mapper层代码。
4.3 功能测试
4.3.1 接口文档测试
分别测试根据id查询员工信息 和编辑员工信息两个接口
1). 根据id查询员工信息
查询employee表中的数据,以id=4的记录为例

开始测试
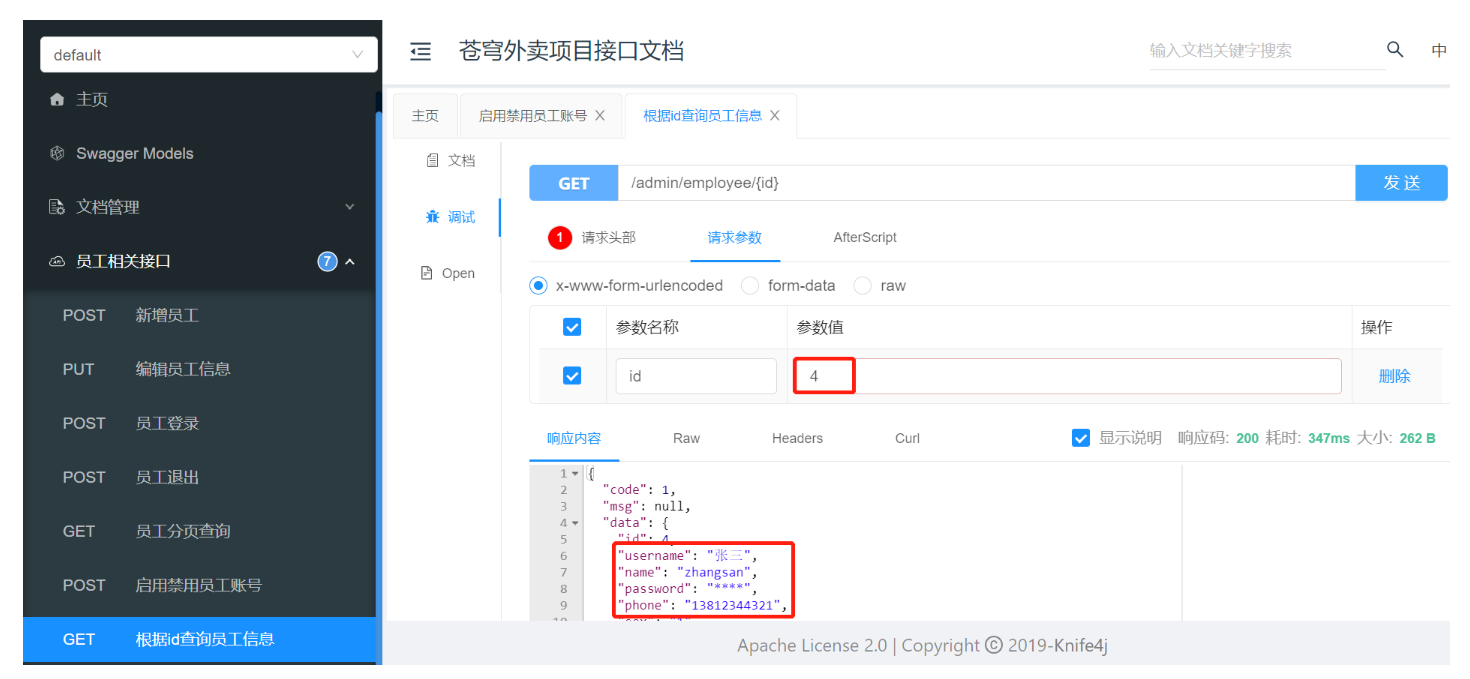
获取到了id=4的相关员工信息
2). 编辑员工信息
修改id=4的员工信息,name 由zhangsan 改为张三丰 ,username 由张三 改为zhangsanfeng。
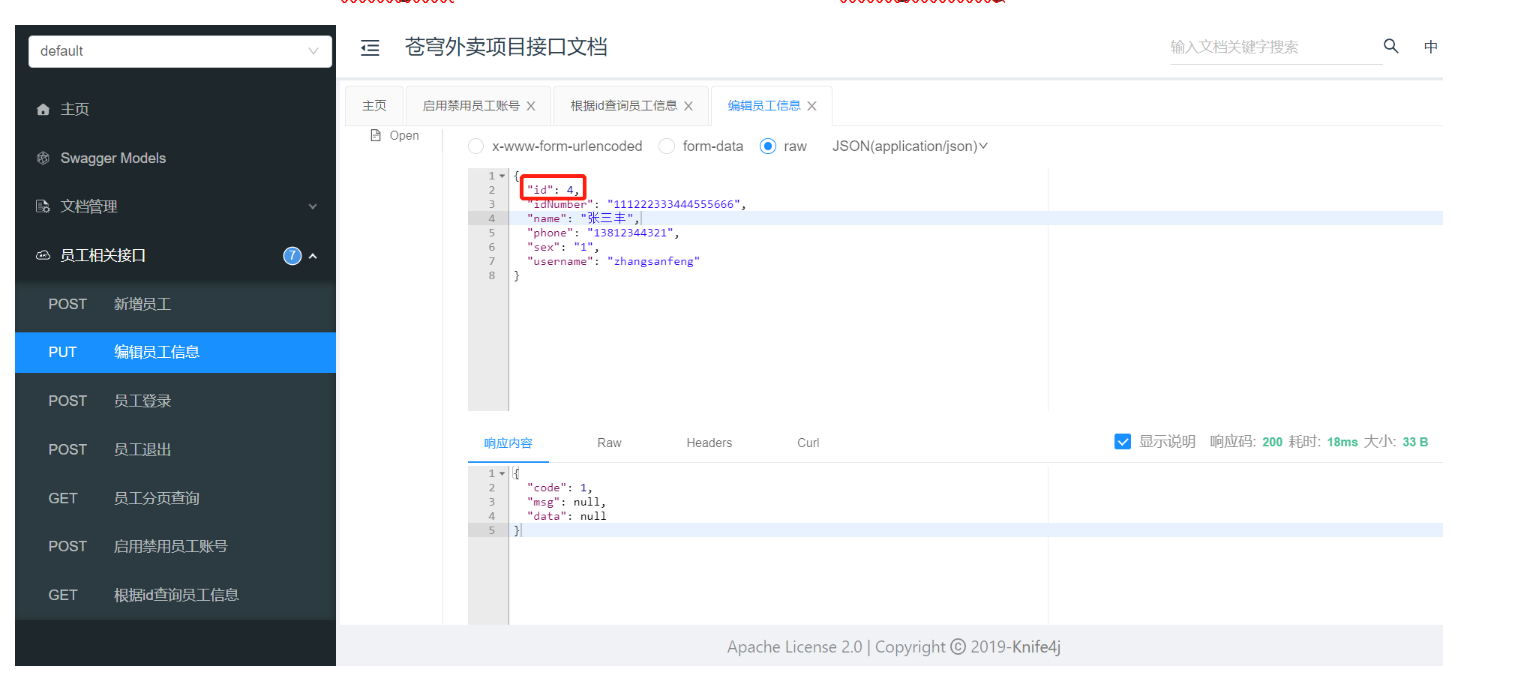
查看employee表数据

4.3.2 前后端联调测试
进入到员工列表查询
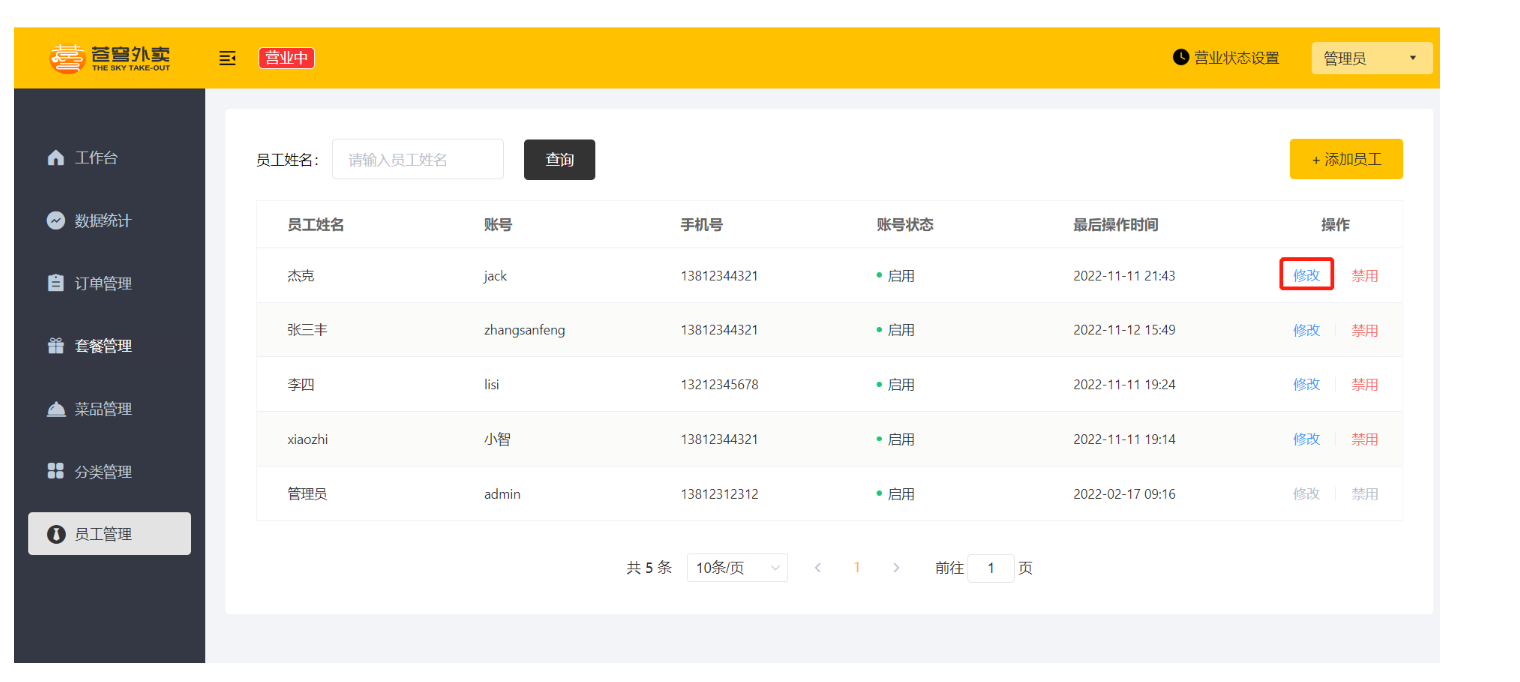
对员工姓名为杰克的员工数据修改,点击修改,数据已回显
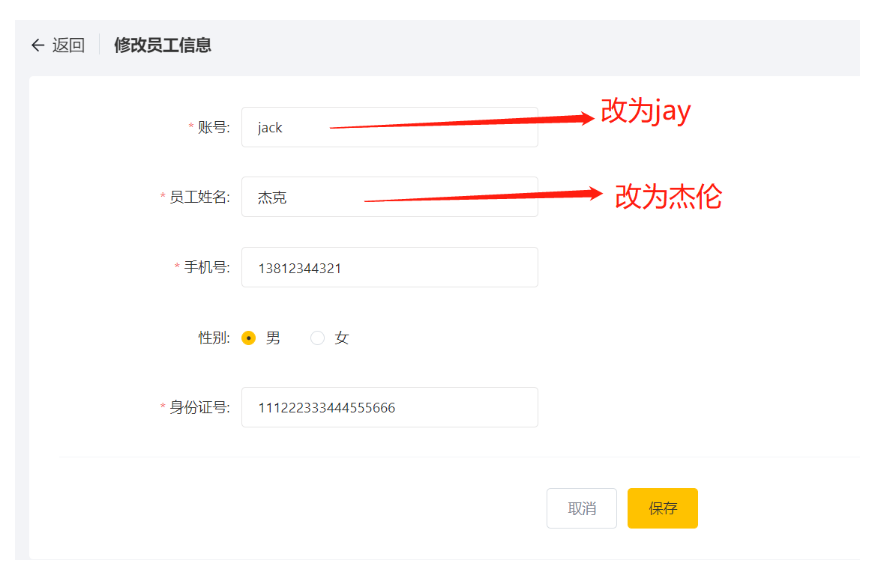
修改后,点击保存
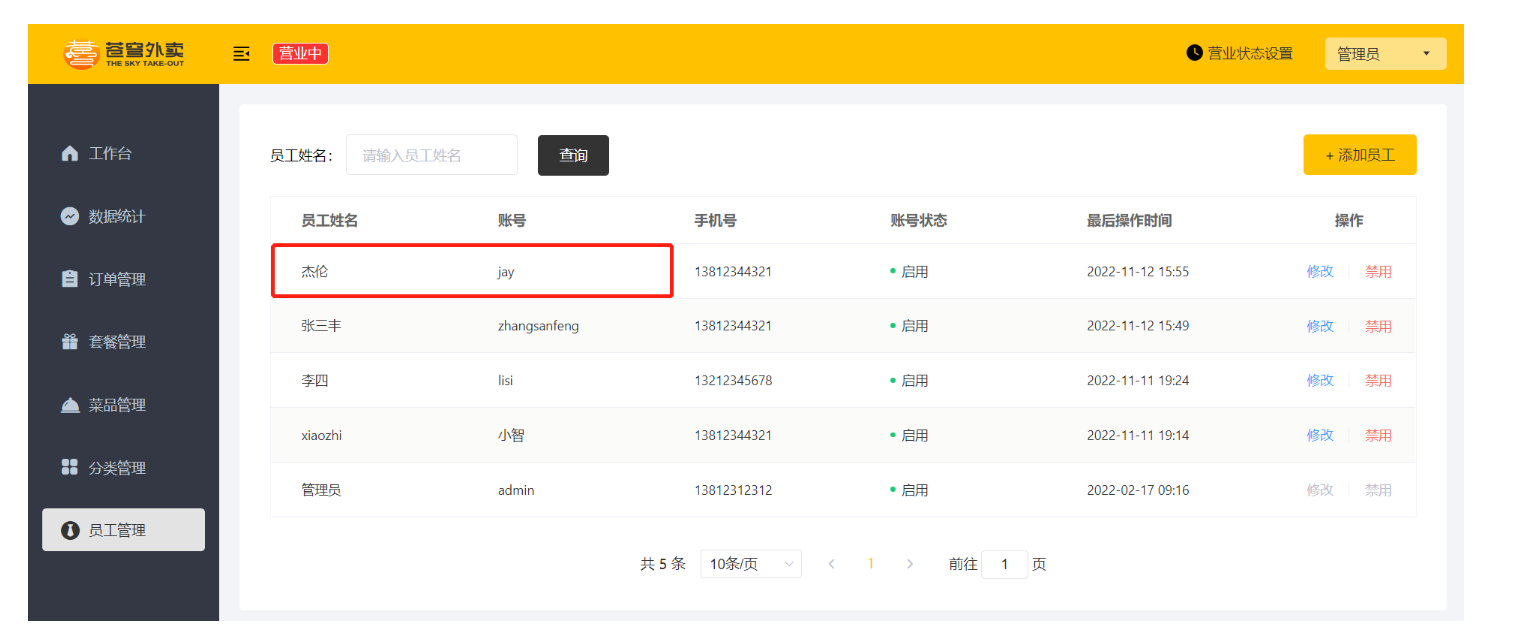
4.4 代码提交
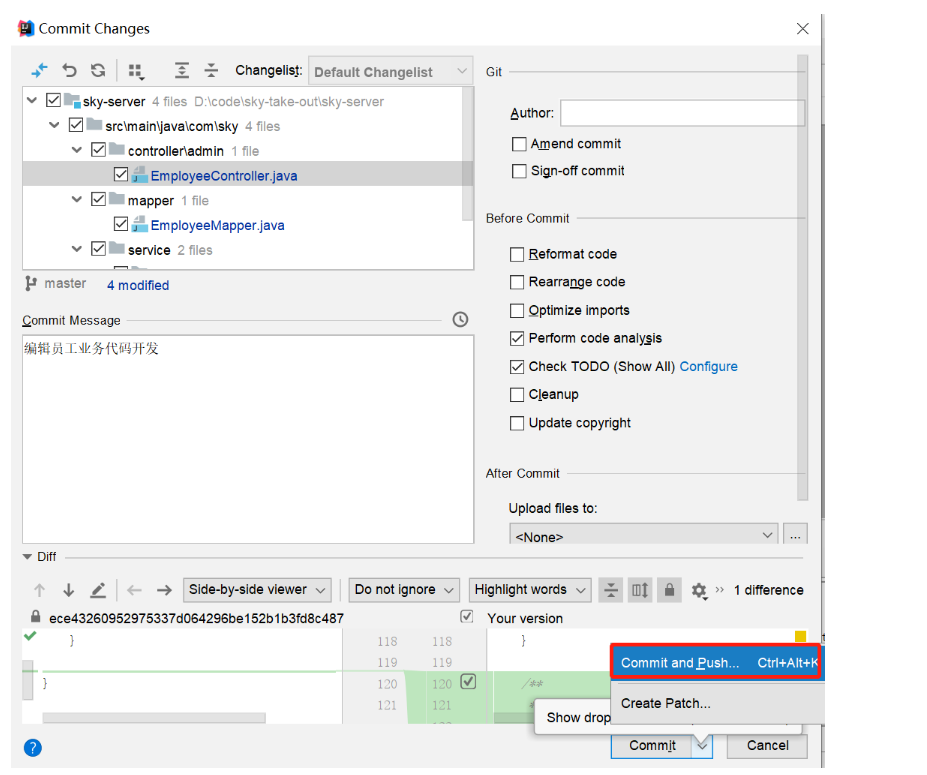
后续步骤和上述功能代码提交一致,不再赘述。
这里还学到一种加注释的方式
在idea编辑器中先输入/** 然后再回车会自动生成一段注释 如图所示
然后把注释填到里面就行了,比如下一段代码是干嘛的之类的
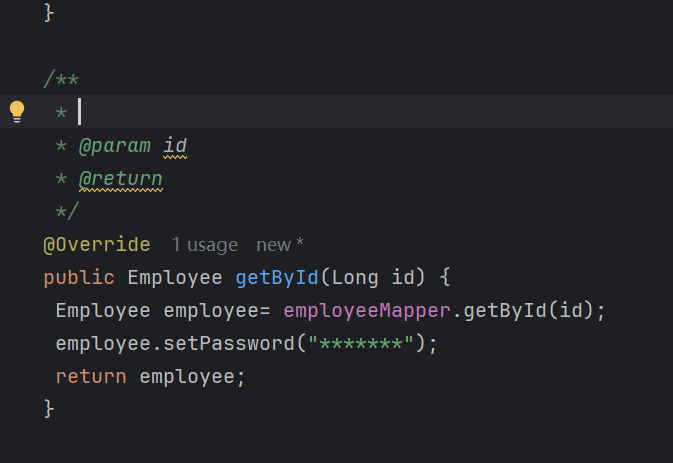
还有浏览器里面response和preview里面都是响应数据,只是reponnse里面的数据没有格式化,而preview里面的数据格式化了
然后这个是控制台清理按钮
导入分类模块功能代码
因为这一块技术和之前员工管理代码里用到的技术非常类似,所以直接提供了现成的代码
5.1 需求分析与设计
5.1.1 产品原型
后台系统中可以管理分类信息,分类包括两种类型,分别是 菜品分类 和 套餐分类 。
也就是如下图所示的功能
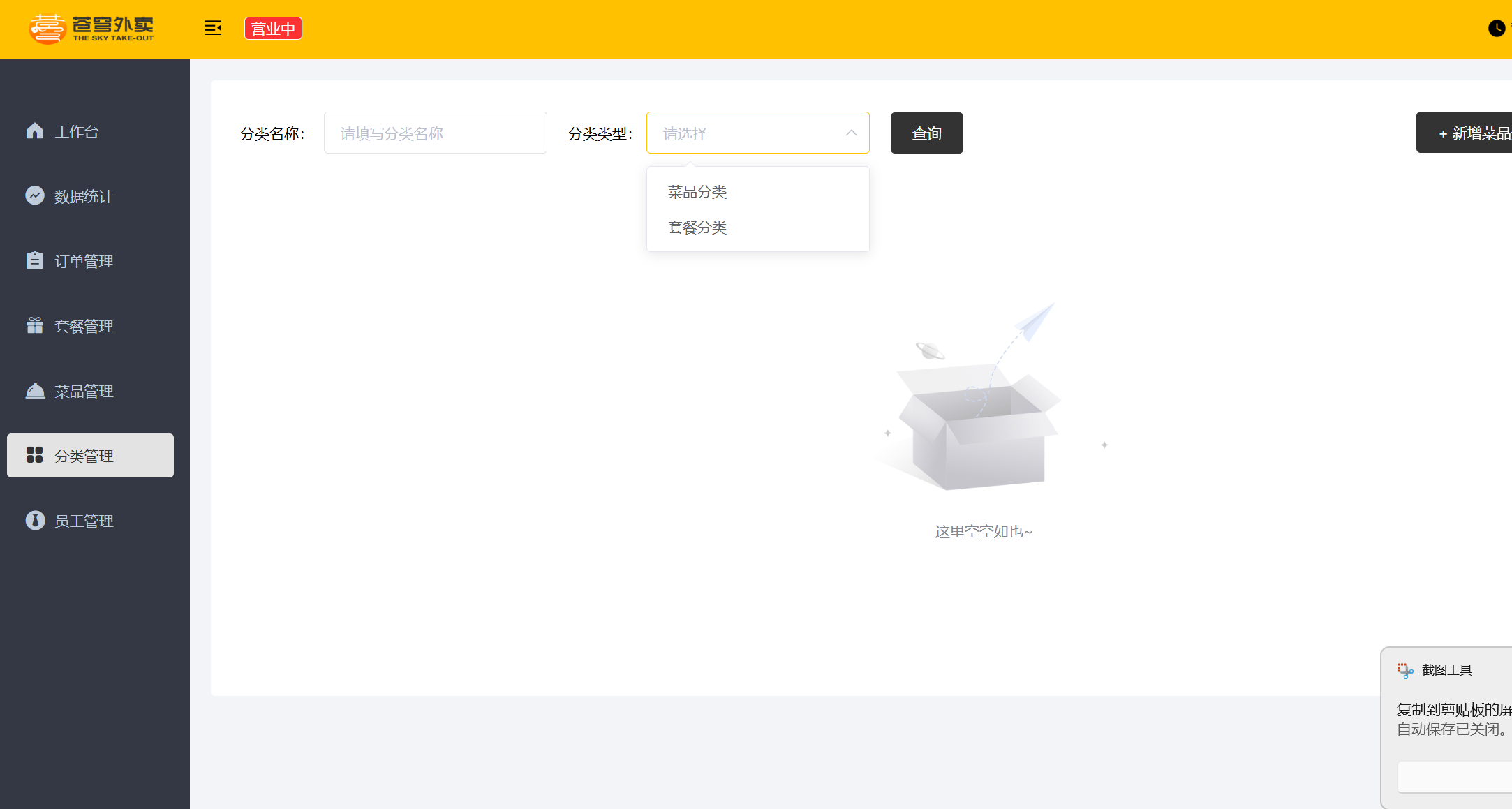
先来分析菜品分类相关功能。
**新增菜品分类:**当我们在后台系统中添加菜品时需要选择一个菜品分类,在移动端也会按照菜品分类来展示对应的菜品。
**菜品分类分页查询:**系统中的分类很多的时候,如果在一个页面中全部展示出来会显得比较乱,不便于查看,所以一般的系统中都会以分页的方式来展示列表数据。
**根据id删除菜品分类:**在分类管理列表页面,可以对某个分类进行删除操作。需要注意的是当分类关联了菜品或者套餐时,此分类不允许删除。
**修改菜品分类:**在分类管理列表页面点击修改按钮,弹出修改窗口,在修改窗口回显分类信息并进行修改,最后点击确定按钮完成修改操作。
**启用禁用菜品分类:**在分类管理列表页面,可以对某个分类进行启用或者禁用操作。
**分类类型查询:**当点击分类类型下拉框时,从数据库中查询所有的菜品分类数据进行展示。
分类管理原型:
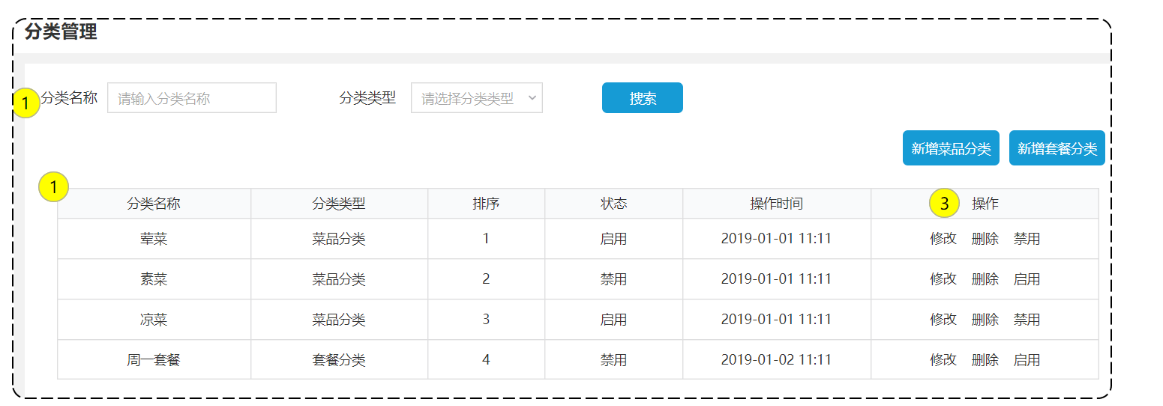
业务规则:
- 分类名称必须是唯一的
- 分类按照类型可以分为菜品分类和套餐分类
- 新添加的分类状态默认为"禁用"
5.1.2 接口设计
根据上述原型图分析,菜品分类模块共涉及6个接口。
- 新增分类
- 分类分页查询
- 根据id删除分类
- 修改分类
- 启用禁用分类
- 根据类型查询分类
接下来,详细地分析每个接口。
找到资料-->项目接口文档-->苍穹外卖-管理端接口.html
1). 新增分类
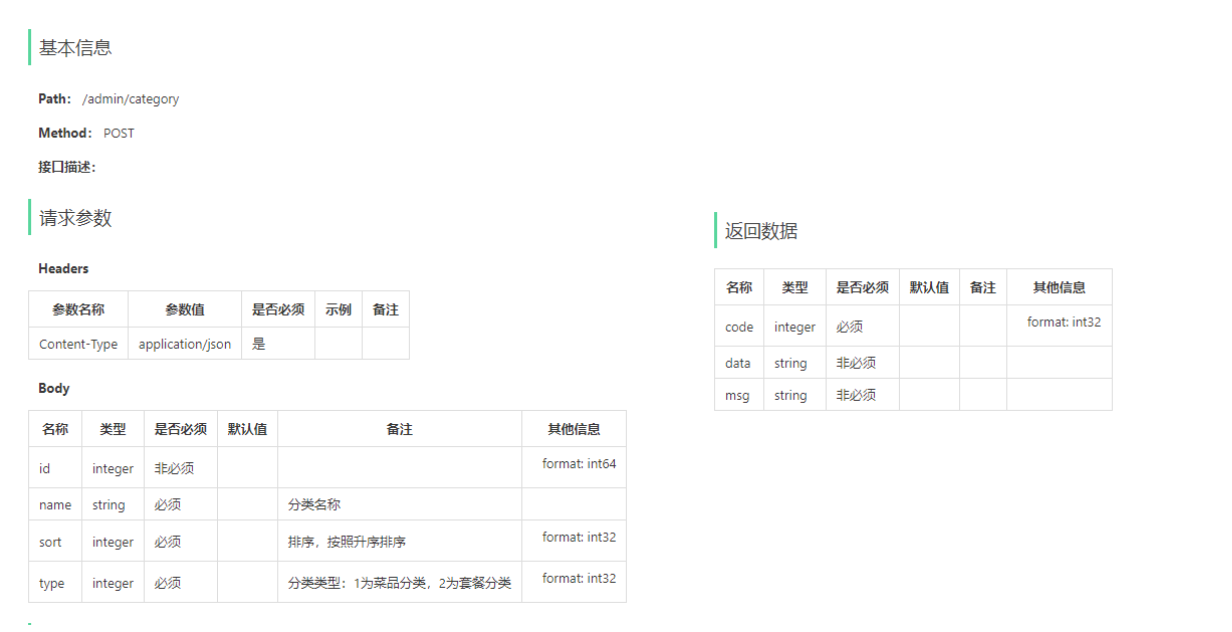
2). 分类分页查询
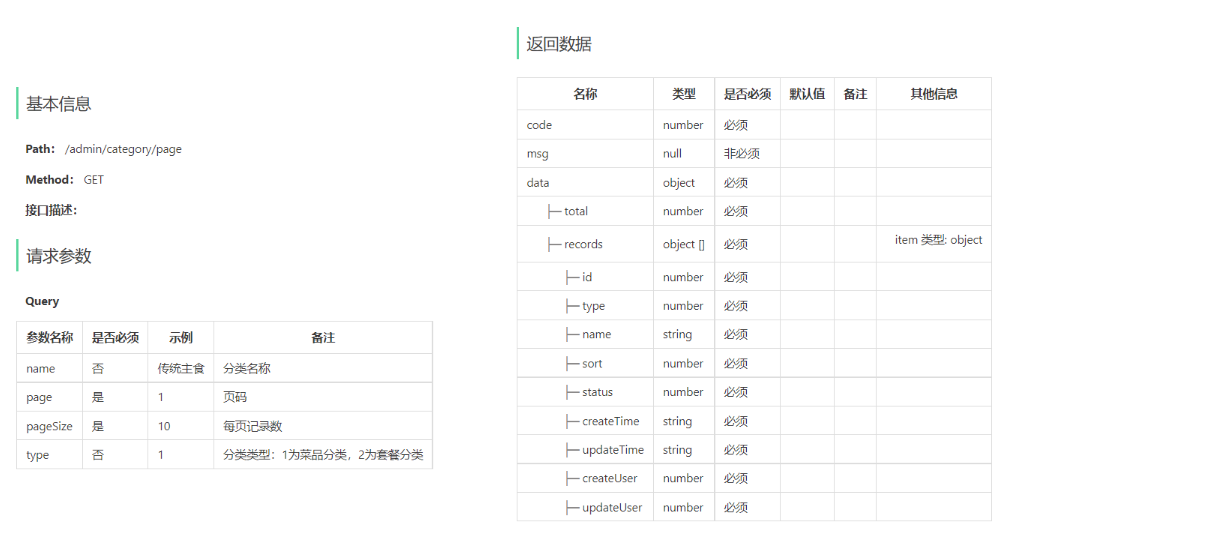
3). 根据id删除分类
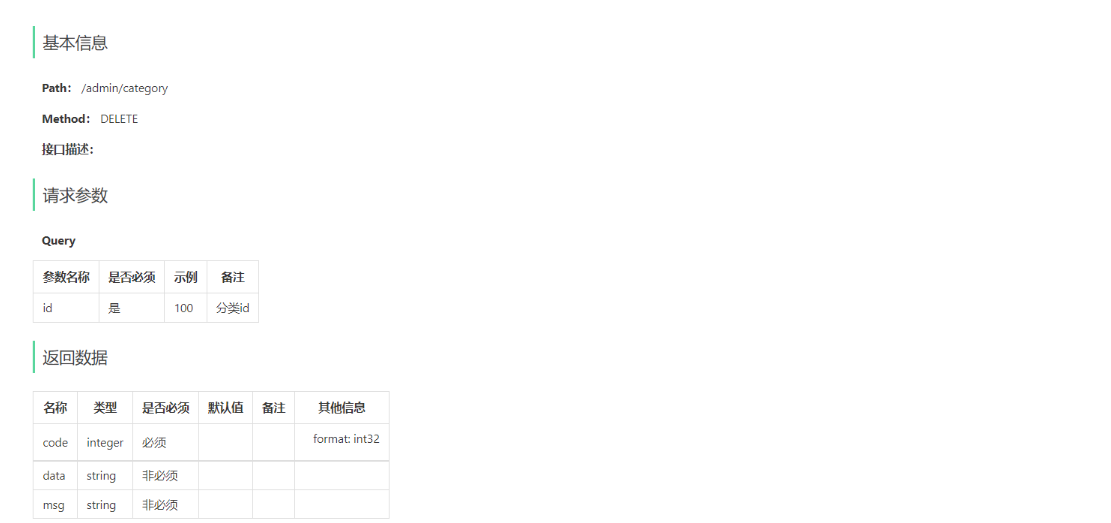
4). 修改分类

5). 启用禁用分类

6). 根据类型查询分类

5.1.3 表设计
category表结构:
|-------------|-------------|---------|-------------|
| 字段名 | 数据类型 | 说明 | 备注 |
| id | bigint | 主键 | 自增 |
| name | varchar(32) | 分类名称 | 唯一 |
| type | int | 分类类型 | 1菜品分类 2套餐分类 |
| sort | int | 排序字段 | 用于分类数据的排序 |
| status | int | 状态 | 1启用 0禁用 |
| create_time | datetime | 创建时间 | |
| update_time | datetime | 最后修改时间 | |
| create_user | bigint | 创建人id | |
| update_user | bigint | 最后修改人id | |
我们看到这里有bigint,这个其实数据库里面一种数据类型
- 数据库的 int➡️对应 Java 的 int**(或** Integer**)**
- 数据库的 bigint➡️对应 Java 的 long**(或** Long**)**
5.2 代码导入
导入资料中的分类管理模块功能代码即可

可按照mapper-->service-->controller依次导入,这样代码不会显示相应的报错。
这个导入顺序非常重要,为什么导入这个导入顺序,是可以保证每次导入的过程中不会报错,直接先导入controller肯定一片红
还有一个本来只有Category(分类表)字段,但是出现了DishMapper(菜品表)字段,和SetmealMapper(套餐表)字段,这两个字段出现的原因是,因为我们对分类有一个限定,删除不是直接删除的,删除之前需要看这个分类里面有没有与菜品表和套餐表有关联( 需要注意的是当分类关联了菜品或者套餐时,此分类不允许删除 。)
补充一下这个概念在数据库中被称为 外键约束 (Foreign Key Constraint)
但其实上我们去数据库里面查询,发现并没有看到我们定义了所谓的外键,取而代之的是一个普通
category_id,这个是作为普通字段而已
为什么它看起来是个普通字段?
在你目前学习的这个项目(看表结构大概率是"苍穹外卖"或类似实战项目)中,架构上故意放弃了数据库层面的物理外键。
在互联网大厂和现代企业级开发中,大家通常遵循阿里巴巴 Java 开发手册里的规范:【强制】不得使用外键与级联,一切外键概念必须在应用层解决。 不建物理外键的好处是:
- 提升性能:数据库每次写/删数据不用去检查另一张表了,速度更快。
- 防止死锁:高并发下,物理外键很容易引发死锁。
- 方便分库分表:如果以后数据太多,套餐表和分类表被拆分到了两台不同的服务器上,物理外键就直接失效了。
那么,该去哪里查看这个"约束"呢?
既然数据库里没有,那这个"关联了就不让删除"的限制到底写在哪里了呢?
答案是:写在你的 Java 代码里!,你看完全是通过自己来添加约束的,所以现在一般都不咋使用数据库里面的外键了,把这个技术用在了java代码里面
进入到sky-server模块中
5.2.1 Mapper层
DishMapper.java
package com.sky.mapper;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
@Mapper
public interface DishMapper {
/**
* 根据分类id查询菜品数量
* @param categoryId
* @return
*/
@Select("select count(id) from dish where category_id = #{categoryId}")
Integer countByCategoryId(Long categoryId);
}SetmealMapper.java
package com.sky.mapper;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
@Mapper
public interface SetmealMapper {
/**
* 根据分类id查询套餐的数量
* @param id
* @return
*/
@Select("select count(id) from setmeal where category_id = #{categoryId}")
Integer countByCategoryId(Long id);
}CategoryMapper.java
package com.sky.mapper;
import com.github.pagehelper.Page;
import com.sky.dto.CategoryPageQueryDTO;
import com.sky.entity.Category;
import org.apache.ibatis.annotations.Delete;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
@Mapper
public interface CategoryMapper {
/**
* 插入数据
* @param category
*/
@Insert("insert into category(type, name, sort, status, create_time, update_time, create_user, update_user)" +
" VALUES" +
" (#{type}, #{name}, #{sort}, #{status}, #{createTime}, #{updateTime}, #{createUser}, #{updateUser})")
void insert(Category category);
/**
* 分页查询
* @param categoryPageQueryDTO
* @return
*/
Page<Category> pageQuery(CategoryPageQueryDTO categoryPageQueryDTO);
/**
* 根据id删除分类
* @param id
*/
@Delete("delete from category where id = #{id}")
void deleteById(Long id);
/**
* 根据id修改分类
* @param category
*/
void update(Category category);
/**
* 根据类型查询分类
* @param type
* @return
*/
List<Category> list(Integer type);
}CategoryMapper.xml,进入到resources/mapper目录下
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.sky.mapper.CategoryMapper">
<select id="pageQuery" resultType="com.sky.entity.Category">
select * from category
<where>
<if test="name != null and name != ''">
and name like concat('%',#{name},'%')
</if>
<if test="type != null">
and type = #{type}
</if>
</where>
order by sort asc , create_time desc
</select>
<update id="update" parameterType="Category">
update category
<set>
<if test="type != null">
type = #{type},
</if>
<if test="name != null">
name = #{name},
</if>
<if test="sort != null">
sort = #{sort},
</if>
<if test="status != null">
status = #{status},
</if>
<if test="updateTime != null">
update_time = #{updateTime},
</if>
<if test="updateUser != null">
update_user = #{updateUser}
</if>
</set>
where id = #{id}
</update>
<select id="list" resultType="Category">
select * from category
where status = 1
<if test="type != null">
and type = #{type}
</if>
order by sort asc,create_time desc
</select>
</mapper>5.2.2 Service层
CategoryService.java
package com.sky.service;
import com.sky.dto.CategoryDTO;
import com.sky.dto.CategoryPageQueryDTO;
import com.sky.entity.Category;
import com.sky.result.PageResult;
import java.util.List;
public interface CategoryService {
/**
* 新增分类
* @param categoryDTO
*/
void save(CategoryDTO categoryDTO);
/**
* 分页查询
* @param categoryPageQueryDTO
* @return
*/
PageResult pageQuery(CategoryPageQueryDTO categoryPageQueryDTO);
/**
* 根据id删除分类
* @param id
*/
void deleteById(Long id);
/**
* 修改分类
* @param categoryDTO
*/
void update(CategoryDTO categoryDTO);
/**
* 启用、禁用分类
* @param status
* @param id
*/
void startOrStop(Integer status, Long id);
/**
* 根据类型查询分类
* @param type
* @return
*/
List<Category> list(Integer type);
}EmployeeServiceImpl.java
package com.sky.service.impl;
import com.github.pagehelper.Page;
import com.github.pagehelper.PageHelper;
import com.sky.constant.MessageConstant;
import com.sky.constant.PasswordConstant;
import com.sky.constant.StatusConstant;
import com.sky.context.BaseContext;
import com.sky.dto.EmployeeDTO;
import com.sky.dto.EmployeeLoginDTO;
import com.sky.dto.EmployeePageQueryDTO;
import com.sky.entity.Employee;
import com.sky.exception.AccountLockedException;
import com.sky.exception.AccountNotFoundException;
import com.sky.exception.PasswordErrorException;
import com.sky.mapper.EmployeeMapper;
import com.sky.result.PageResult;
import com.sky.service.EmployeeService;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.util.DigestUtils;
import java.time.LocalDateTime;
import java.util.List;
@Service
public class EmployeeServiceImpl implements EmployeeService {
@Autowired
private EmployeeMapper employeeMapper;
/**
* 员工登录
*
* @param employeeLoginDTO
* @return
*/
public Employee login(EmployeeLoginDTO employeeLoginDTO) {
String username = employeeLoginDTO.getUsername();
String password = employeeLoginDTO.getPassword();
//1、根据用户名查询数据库中的数据
Employee employee = employeeMapper.getByUsername(username);
//2、处理各种异常情况(用户名不存在、密码不对、账号被锁定)
if (employee == null) {
//账号不存在
throw new AccountNotFoundException(MessageConstant.ACCOUNT_NOT_FOUND);
}
//密码比对
// TODO 后期需要进行md5加密,然后再进行比对
password = DigestUtils.md5DigestAsHex(password.getBytes());
if (!password.equals(employee.getPassword())) {
//密码错误
throw new PasswordErrorException(MessageConstant.PASSWORD_ERROR);
}
if (employee.getStatus() == StatusConstant.DISABLE) {
//账号被锁定
throw new AccountLockedException(MessageConstant.ACCOUNT_LOCKED);
}
//3、返回实体对象
return employee;
}
/**
* 新增员工
*
* @param employeeDTO
*/
public void save(EmployeeDTO employeeDTO) {
Employee employee = new Employee();
//对象属性拷贝
BeanUtils.copyProperties(employeeDTO, employee);
//设置账号的状态,默认正常状态 1表示正常 0表示锁定
employee.setStatus(StatusConstant.ENABLE);
//设置密码,默认密码123456
employee.setPassword(DigestUtils.md5DigestAsHex(PasswordConstant.DEFAULT_PASSWORD.getBytes()));
//设置当前记录的创建时间和修改时间
employee.setCreateTime(LocalDateTime.now());
employee.setUpdateTime(LocalDateTime.now());
//设置当前记录创建人id和修改人id
employee.setCreateUser(BaseContext.getCurrentId());//目前写个假数据,后期修改
employee.setUpdateUser(BaseContext.getCurrentId());
employeeMapper.insert(employee);
}
/**
* 分页查询
*
* @param employeePageQueryDTO
* @return
*/
public PageResult pageQuery(EmployeePageQueryDTO employeePageQueryDTO) {
// select * from employee limit 0,10
//开始分页查询
PageHelper.startPage(employeePageQueryDTO.getPage(), employeePageQueryDTO.getPageSize());
Page<Employee> page = employeeMapper.pageQuery(employeePageQueryDTO);
long total = page.getTotal();
List<Employee> records = page.getResult();
return new PageResult(total, records);
}
/**
* 启用禁用员工账号
*
* @param status
* @param id
*/
public void startOrStop(Integer status, Long id) {
Employee employee = Employee.builder()
.status(status)
.id(id)
.build();
employeeMapper.update(employee);
}
/**
* 根据id查询员工
*
* @param id
* @return
*/
public Employee getById(Long id) {
Employee employee = employeeMapper.getById(id);
employee.setPassword("****");
return employee;
}
/**
* 编辑员工信息
*
* @param employeeDTO
*/
public void update(EmployeeDTO employeeDTO) {
Employee employee = new Employee();
BeanUtils.copyProperties(employeeDTO, employee);
employee.setUpdateTime(LocalDateTime.now());
employee.setUpdateUser(BaseContext.getCurrentId());
employeeMapper.update(employee);
}
}5.2.3 Controller层
CategoryController.java
package com.sky.controller.admin;
import com.sky.dto.CategoryDTO;
import com.sky.dto.CategoryPageQueryDTO;
import com.sky.entity.Category;
import com.sky.result.PageResult;
import com.sky.result.Result;
import com.sky.service.CategoryService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
/**
* 分类管理
*/
@RestController
@RequestMapping("/admin/category")
@Api(tags = "分类相关接口")
@Slf4j
public class CategoryController {
@Autowired
private CategoryService categoryService;
/**
* 新增分类
* @param categoryDTO
* @return
*/
@PostMapping
@ApiOperation("新增分类")
public Result<String> save(@RequestBody CategoryDTO categoryDTO){
log.info("新增分类:{}", categoryDTO);
categoryService.save(categoryDTO);
return Result.success();
}
/**
* 分类分页查询
* @param categoryPageQueryDTO
* @return
*/
@GetMapping("/page")
@ApiOperation("分类分页查询")
public Result<PageResult> page(CategoryPageQueryDTO categoryPageQueryDTO){
log.info("分页查询:{}", categoryPageQueryDTO);
PageResult pageResult = categoryService.pageQuery(categoryPageQueryDTO);
return Result.success(pageResult);
}
/**
* 删除分类
* @param id
* @return
*/
@DeleteMapping
@ApiOperation("删除分类")
public Result<String> deleteById(Long id){
log.info("删除分类:{}", id);
categoryService.deleteById(id);
return Result.success();
}
/**
* 修改分类
* @param categoryDTO
* @return
*/
@PutMapping
@ApiOperation("修改分类")
public Result<String> update(@RequestBody CategoryDTO categoryDTO){
categoryService.update(categoryDTO);
return Result.success();
}
/**
* 启用、禁用分类
* @param status
* @param id
* @return
*/
@PostMapping("/status/{status}")
@ApiOperation("启用禁用分类")
public Result<String> startOrStop(@PathVariable("status") Integer status, Long id){
categoryService.startOrStop(status,id);
return Result.success();
}
/**
* 根据类型查询分类
* @param type
* @return
*/
@GetMapping("/list")
@ApiOperation("根据类型查询分类")
public Result<List<Category>> list(Integer type){
List<Category> list = categoryService.list(type);
return Result.success(list);
}
}全部导入完毕后,进行编译
5.3 功能测试
重启服务,访问http://localhost:80,进入分类管理
分页查询:
分类类型:
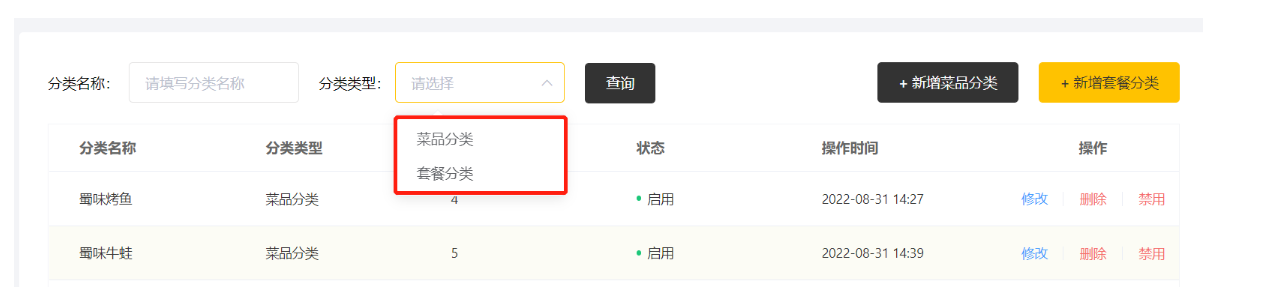
启用禁用:
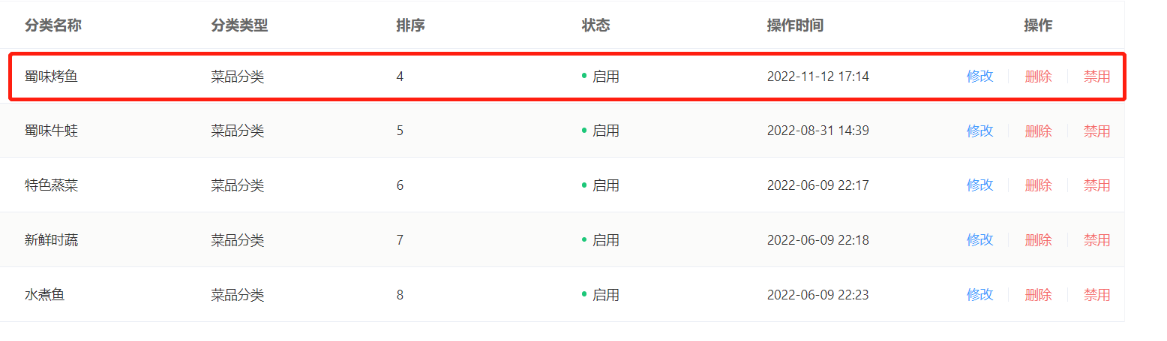
点击禁用
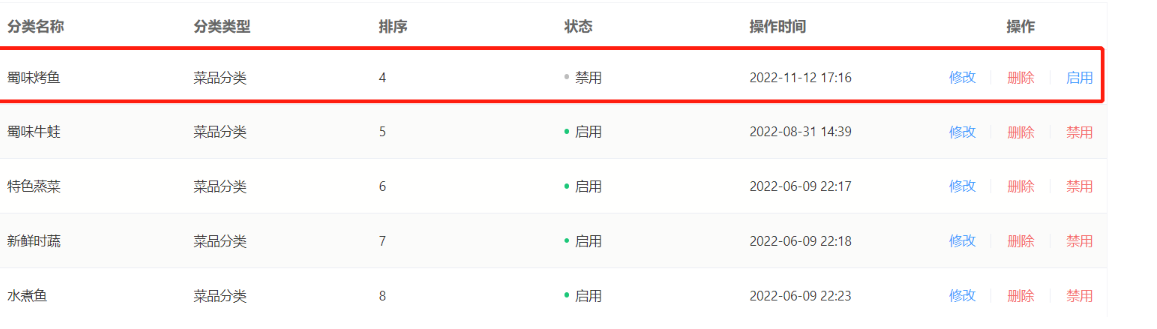
修改:
回显
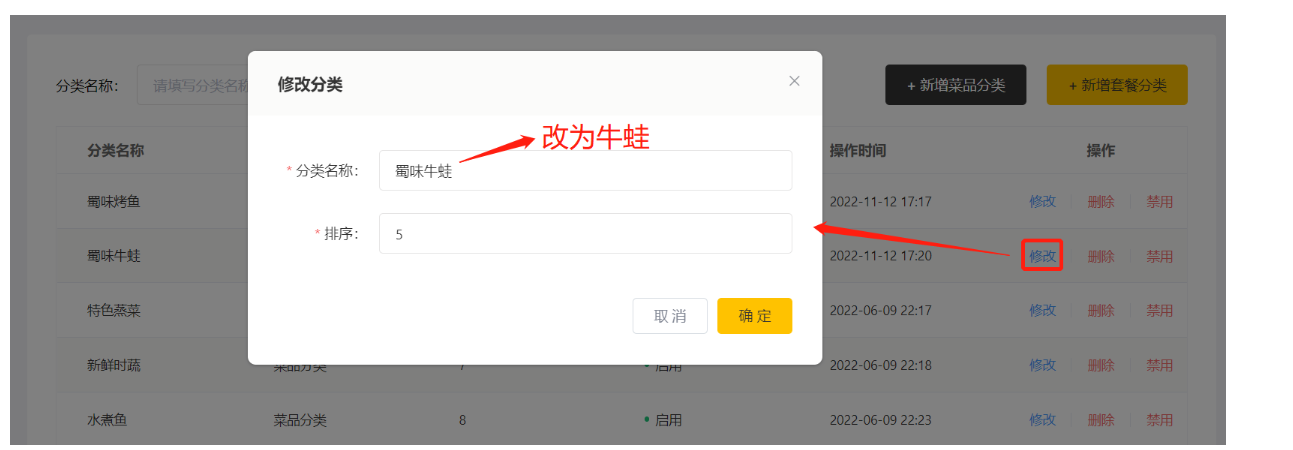
修改后
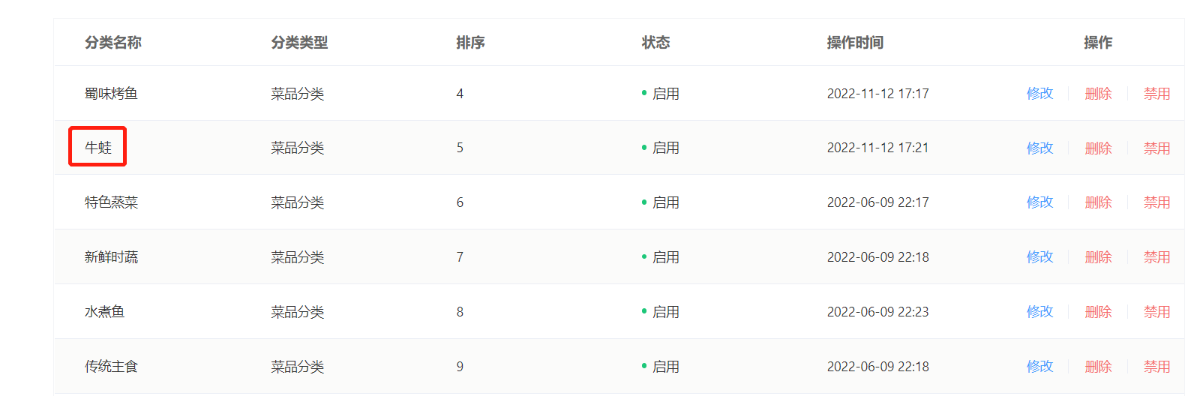
新增:
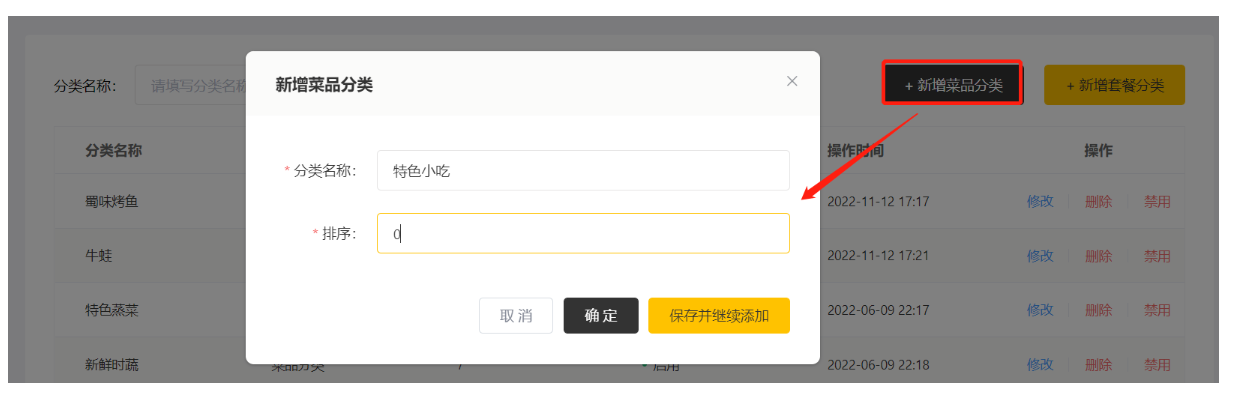
点击确定,查询列表
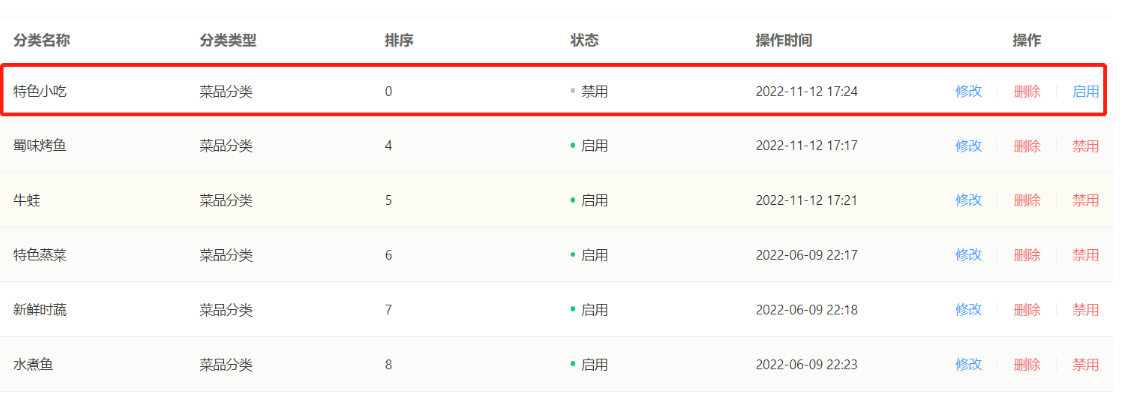
删除:
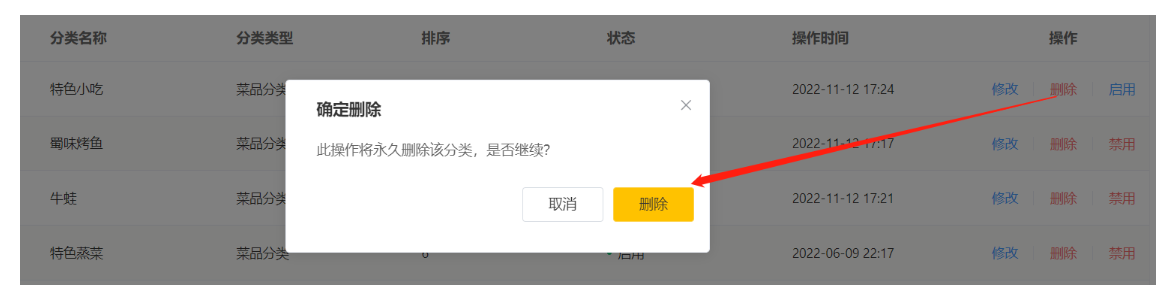
删除后,查询分类列表
删除成功
5.4 代码提交
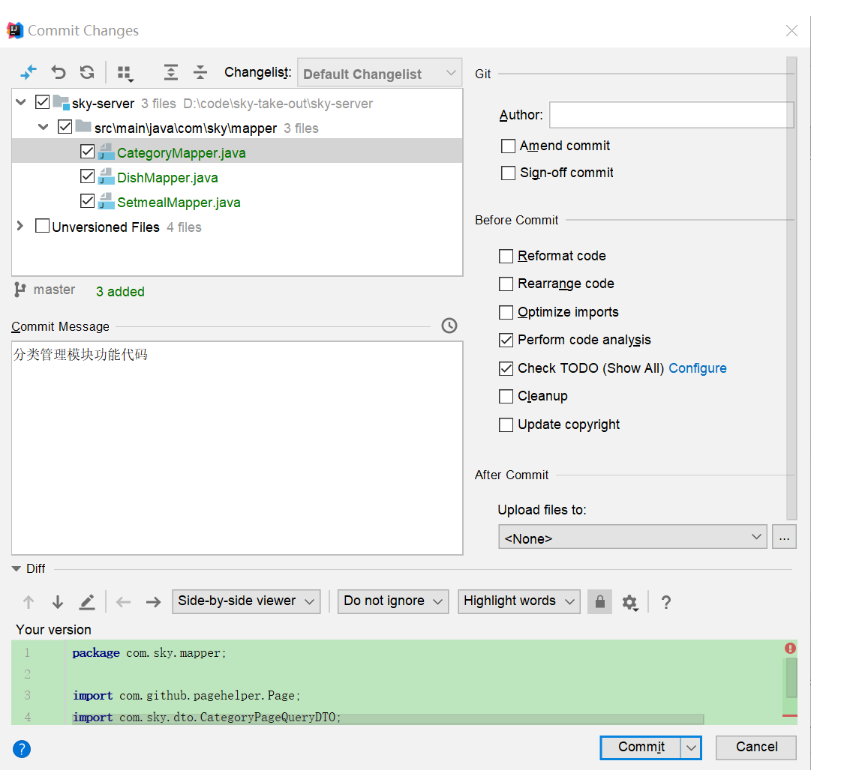
后续步骤和上述功能代码提交一致,不再赘述。
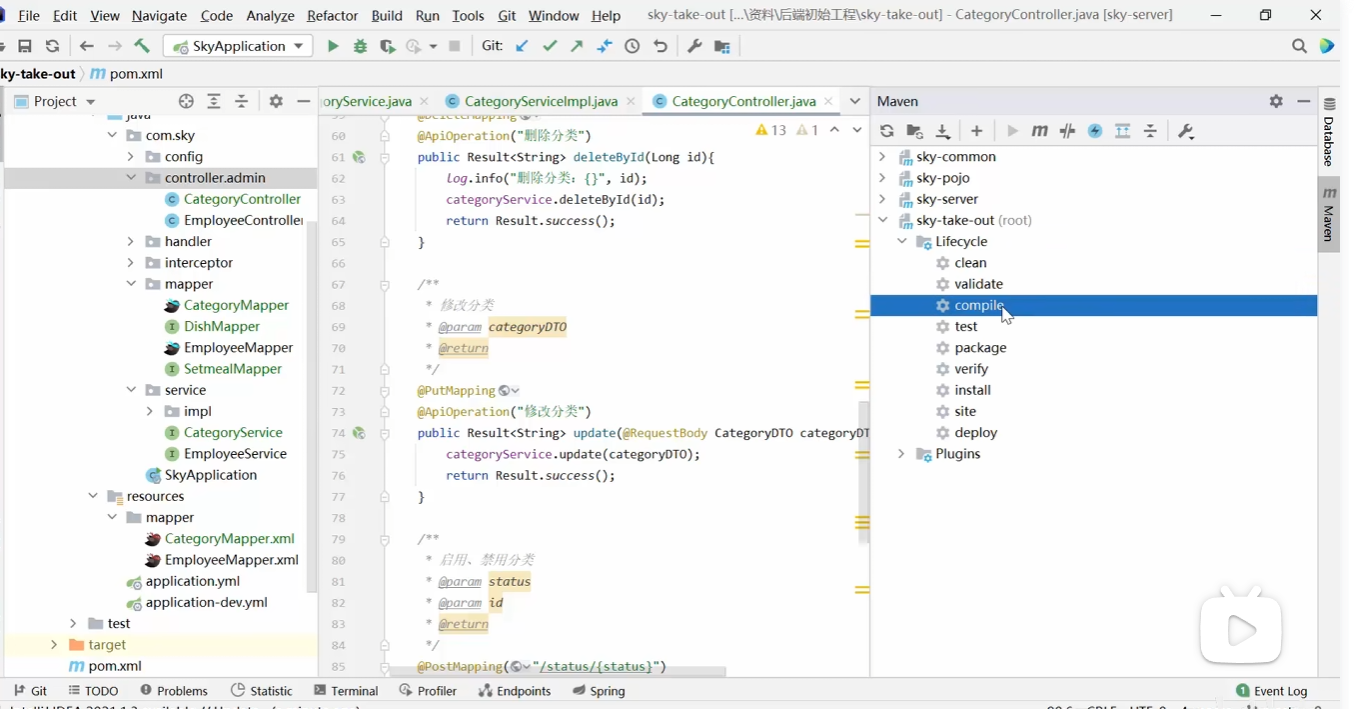
注意拷贝过来的代码不会进行编译,我们最好手动进行一下编译,找到如图所示的地方,点击编译
菜品管理
- 公共字段自动填充
- 新增菜品
- 菜品分页查询
- 删除菜品
- 修改菜品
**功能实现:**菜品管理
菜品管理效果图:
公共字段自动填充
1.1 问题分析
在上一章节我们已经完成了后台系统的员工管理功能 和菜品分类功能 的开发,在新增员工 或者新增菜品分类 时需要设置创建时间、创建人、修改时间、修改人等字段,在编辑员工 或者编辑菜品分类时需要设置修改时间、修改人等字段。这些字段属于公共字段,也就是也就是在我们的系统中很多表中都会有这些字段,如下:
|--------|-------------|--------|----------|
| 序号 | 字段名 | 含义 | 数据类型 |
| 1 | create_time | 创建时间 | datetime |
| 2 | create_user | 创建人id | bigint |
| 3 | update_time | 修改时间 | datetime |
| 4 | update_user | 修改人id | bigint |
而针对于这些字段,我们的赋值方式为:
1). 在新增数据时, 将createTime、updateTime 设置为当前时间, createUser、updateUser设置为当前登录用户ID。
2). 在更新数据时, 将updateTime 设置为当前时间, updateUser设置为当前登录用户ID。
目前,在我们的项目中处理这些字段都是在每一个业务方法中进行赋值操作,如下:
新增员工方法:
/**
* 新增员工
*
* @param employeeDTO
*/
public void save(EmployeeDTO employeeDTO) {
//.......................
//////////////////////////////////////////
//设置当前记录的创建时间和修改时间
employee.setCreateTime(LocalDateTime.now());
employee.setUpdateTime(LocalDateTime.now());
//设置当前记录创建人id和修改人id
employee.setCreateUser(BaseContext.getCurrentId());//目前写个假数据,后期修改
employee.setUpdateUser(BaseContext.getCurrentId());
///////////////////////////////////////////////
employeeMapper.insert(employee);
}别忘了Basecontext里面是ThreadLocal,别不认识了
编辑员工方法:
/**
* 编辑员工信息
*
* @param employeeDTO
*/
public void update(EmployeeDTO employeeDTO) {
//........................................
///////////////////////////////////////////////
employee.setUpdateTime(LocalDateTime.now());
employee.setUpdateUser(BaseContext.getCurrentId());
///////////////////////////////////////////////////
employeeMapper.update(employee);
}新增菜品分类方法:
/**
* 新增分类
* @param categoryDTO
*/
public void save(CategoryDTO categoryDTO) {
//....................................
//////////////////////////////////////////
//设置创建时间、修改时间、创建人、修改人
category.setCreateTime(LocalDateTime.now());
category.setUpdateTime(LocalDateTime.now());
category.setCreateUser(BaseContext.getCurrentId());
category.setUpdateUser(BaseContext.getCurrentId());
///////////////////////////////////////////////////
categoryMapper.insert(category);
}修改菜品分类方法:
/**
* 修改分类
* @param categoryDTO
*/
public void update(CategoryDTO categoryDTO) {
//....................................
//////////////////////////////////////////////
//设置修改时间、修改人
category.setUpdateTime(LocalDateTime.now());
category.setUpdateUser(BaseContext.getCurrentId());
//////////////////////////////////////////////////
categoryMapper.update(category);
}如果都按照上述的操作方式来处理这些公共字段, 需要在每一个业务方法中进行操作, 编码相对冗余、繁琐,那能不能对于这些公共字段在某个地方统一处理,来简化开发呢?
答案是可以的,我们使用AOP切面编程,实现功能增强,来完成公共字段自动填充功能。
AOP切面编程他终于来了 ,切面什么时候用,就是我们需要统一来处理某个东西时候,就会用aop
1.2 实现思路
在实现公共字段自动填充,也就是在插入或者更新的时候为指定字段赋予指定的值,使用它的好处就是可以统一对这些字段进行处理,避免了重复代码。在上述的问题分析中,我们提到有四个公共字段,需要在新增/更新中进行赋值操作, 具体情况如下:
比如我们需要调用mapper层的insert执行操作之前,我们可以使用aop切面来统一的拦截,统一的给这个create_time字段赋值
但其实并不是每一个操作都要对这些字段赋值,比如查询操作就不用,所以我们接下来会使用定义注解,也就是为这个mapper的方法来定义注解,表示当前的我们这个方法需要被拦截,没有加这个注解表示不需要被处理
|--------|-------------|--------|----------|---------------|
| 序号 | 字段名 | 含义 | 数据类型 | 操作类型 |
| 1 | create_time | 创建时间 | datetime | insert |
| 2 | create_user | 创建人id | bigint | insert |
| 3 | update_time | 修改时间 | datetime | insert、update |
| 4 | update_user | 修改人id | bigint | insert、update |
实现步骤:
1). 自定义注解 AutoFill,用于标识需要进行公共字段自动填充的方法
2). 自定义切面类 AutoFillAspect,统一拦截加入了 AutoFill 注解的方法,通过反射为公共字段赋值
3). 在 Mapper 的方法上加入 AutoFill 注解
若要实现上述步骤,需掌握以下知识(之前课程内容都学过)
技术点: 枚举(会标识我们操作的类型,会标识是insert操作还是update操作)、注解、AOP、反射
1.3 代码开发
按照上一小节分析的实现步骤依次实现,共三步。
1.3.1 步骤一
自定义注解 AutoFill
进入到sky-server模块,创建com.sky.annotation包。
在这里会遇到一个问题,我们导入的时候尽量不要选com.sun开头的包,出现这个开头的包表示就是
Java 开发中有一个不成文的铁律:尽量永远不要在你的业务代码里导入以 **com.sun.***开头的包。
-
com.sun.tools.javac.*是 Java 编译器(javac)内部自己使用的底层源码类。package com.sky.annotation;
import com.sky.enumeration.OperationType;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;/**
- 自定义注解,用于标识某个方法需要进行功能字段自动填充处理
*/
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface AutoFill {
//数据库操作类型:UPDATE INSERT
OperationType value();
}
- 自定义注解,用于标识某个方法需要进行功能字段自动填充处理
我们来复习一下啊注解
@ Target 就是说你个注解想放到哪个地方 ,这里写的是METHOD 说明你定义的这个注解只能放到方法前面
然后这个value 你就把当当作成员变量看就行了(其实底层是接口)
OperationType value(); 是啥,之前学javaweb时候我们定义注解啥也没加啊?
在这个地方可以把它完全等同于普通 Java 类里的"成员变量",只是注解的语法规定必须加个括号。
其中OperationType已在sky-common模块中定义
package com.sky.enumeration;
/**
* 数据库操作类型
*/
public enum OperationType {
/**
* 更新操作
*/
UPDATE,
/**
* 插入操作
*/
INSERT
}1.3.2 步骤二
自定义切面 AutoFillAspect
在sky-server模块,创建com.sky.aspect包。
package com.sky.aspect;
/**
* 自定义切面,实现公共字段自动填充处理逻辑
*/
@Aspect
@Component
@Slf4j
public class AutoFillAspect {
/**
* 切入点
*/
@Pointcut("execution(* com.sky.mapper.*.*(..)) && @annotation(com.sky.annotation.AutoFill)")
public void autoFillPointCut(){}
/**
* 前置通知,在通知中进行公共字段的赋值
*/
@Before("autoFillPointCut()")
public void autoFill(JoinPoint joinPoint){
/////////////////////重要////////////////////////////////////
//可先进行调试,是否能进入该方法 提前在mapper方法添加AutoFill注解
log.info("开始进行公共字段自动填充...");
}
}其实我们看到这里切入点表达式
就算去掉 execution( com.sky.mapper..(..))****,仅仅保留* @annotation(com.sky.annotation.AutoFill)****,程序也完全能够照常运行,也能准确拦截到你加了注解的 mapper 方法。 但是处于安全性的考虑我们还是加上了
完善自定义切面 AutoFillAspect 的 autoFill 方法
package com.sky.aspect;
import com.sky.annotation.AutoFill;
import com.sky.constant.AutoFillConstant;
import com.sky.context.BaseContext;
import com.sky.enumeration.OperationType;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.stereotype.Component;
import java.lang.reflect.Method;
import java.time.LocalDateTime;
/**
* 自定义切面,实现公共字段自动填充处理逻辑
*/
@Aspect
@Component
@Slf4j
public class AutoFillAspect {
/**
* 切入点
*/
@Pointcut("execution(* com.sky.mapper.*.*(..)) && @annotation(com.sky.annotation.AutoFill)")
public void autoFillPointCut(){}
/**
* 前置通知,在通知中进行公共字段的赋值
*/
@Before("autoFillPointCut()")
public void autoFill(JoinPoint joinPoint){
log.info("开始进行公共字段自动填充...");
//这里就是通过连接点来获取到参数
//获取到当前被拦截的方法上的数据库操作类型
MethodSignature signature = (MethodSignature) joinPoint.getSignature();//方法签名对象
AutoFill autoFill = signature.getMethod().getAnnotation(AutoFill.class);//获得方法上的注解对象
OperationType operationType = autoFill.value();//获得数据库操作类型
//这个.value()这个里能拿到值貌似涉及到了代理的知识,先学这它怎么用就行了,以后再填这个坑
//获取到当前被拦截的方法的参数--实体对象
Object[] args = joinPoint.getArgs();
if(args == null || args.length == 0){
return;
}
Object entity = args[0];
//准备赋值的数据
LocalDateTime now = LocalDateTime.now();
Long currentId = BaseContext.getCurrentId();
//根据当前不同的操作类型,为对应的属性通过反射来赋值
if(operationType == OperationType.INSERT){
//为4个公共字段赋值
try {
Method setCreateTime = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_CREATE_TIME, LocalDateTime.class);
Method setCreateUser = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_CREATE_USER, Long.class);
Method setUpdateTime = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_TIME, LocalDateTime.class);
Method setUpdateUser = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_USER, Long.class);
//通过反射为对象属性赋值 invoke是执行方法
setCreateTime.invoke(entity,now);
setCreateUser.invoke(entity,currentId);
setUpdateTime.invoke(entity,now);
setUpdateUser.invoke(entity,currentId);
} catch (Exception e) {
e.printStackTrace();
}
}else if(operationType == OperationType.UPDATE){
//为2个公共字段赋值
try {
Method setUpdateTime = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_TIME, LocalDateTime.class);
Method setUpdateUser = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_USER, Long.class);
//通过反射为对象属性赋值
setUpdateTime.invoke(entity,now);
setUpdateUser.invoke(entity,currentId);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}这里还有一个非常非常关键的知识点
在这里我们是通过entity.getClass()获取到的字节码对象,这种方式对应阿伟讲放射里面的第三种
其实 不管你是通过 entity.getClass()还是 **Class.forName("...")来获取 **Class对象和 Method**,只要你在调用** invoke()时传入的 依然是那个 **entity**实例对象 ,最终修改的就是同一个对象。程序的其他地方自然也能读取到最新赋的值。
首先通知类型很多,有前置通知,环绕通知,后置通知,异常通知等
我们这里用的是前置通知@ Before 必须得在insert 执行之前,进行赋值,如果执行之后再赋值就没有意义了
@ Data注解默认是public 的get 和set方法 所以在这里我们无需修改访问权限
这里我来解释一下
最开始我们是要获取原始方法的注解是哪个,用于下面接下来作判断
然后这里的
- **Object[] args = joinPoint.getArgs();**的作用是:获取被拦截方法运行时的 所有传入参数 。
- 取 **args[0]**就是获取被拦截原始方法的 第一个参数 。
而这里的原始方法,如图所示只有一个参数就是我们的Employee 实体类

然后你可以会问我们这里都已经获取到实体类了,为什么不直接调用里面set和get方法呢
Object entity = new Employee();
entity.setCreateTime(now); // 报错!如果直接调用上面的代码就等价于,这个是不允许的,因为我们知道当实现多态时候,父类只能调用那些自己已经声明好的方法,Object类里面 发现 Object****只有 toString()****、 **equals()**等基础方法,根本没有 **setCreateTime()**方法。 所以我们得用反射的方式去执行set方法
MethodSignature是Signature的实现类,Signature是一个接口
这里我们还用到了向下转型,首先joinPoint.getSignature(),返回的对象的类型是Signature,我们这里向下转型把他转成了MethodSignature
这里你可能会问
"为什么不直接用 Signature?"
根本原因用一句话就能概括:因为 Signature****这个父接口里,根本就没有 getMethod()这个方法!只有向下转型为 MethodSignature,我们才能解锁获取真实方法对象的"特权"。
下面是是一段话可以更好理解这一过程
要理解这个,你只需要记住 Java 世界里的一句至理名言:在 Java 中,一切皆对象。
我们平时写代码的时候,觉得方法就是一段代码逻辑,比如 public void save() { ... }****,写在类里面,感觉它只是一个"动作"。
但在 Java 虚拟机(JVM)运行的时候,它可不这么认为。JVM 会把这个"动作"也包装成一个实实在在的 对象 。
这个代表着那段代码逻辑的对象,就是 java.lang.reflect.Method****类的实例。这就是我一直强调的**"真实方法"**。
为了让你彻底明白,我们用一个**"通缉令与嫌疑人"**的比喻来对比一下 Signature****和 Method**(真实方法):**
1. joinPoint.getSignature()****= 通缉令(描述信息)
当 AOP 拦截到一个方法执行时,它手里拿到的 Signature**,其实就像是一张** 通缉令 或者 档案表 。
- 上面写着:"这个方法叫 saveEmployee**,属于** EmployeeService****类,参数是个 Employee**。"**
- 它的局限性 :通缉令只是一张纸(字符串和描述信息)。你对着这张纸大喊"运行!",纸是不会理你的;你对着这张纸问"你头上有 @AutoFill****注解吗?",纸也没法回答你。
2. signature.getMethod()****= 嫌疑人本尊(真实方法实体)
当你调用 **getMethod()**的时候,你实际上是对系统说:"别给我看通缉令了,去 JVM 内存里,把叫这个名字的那个**真正的代码执行器(Method 对象)**给我抓过来!"
这个被抓过来的 Method****对象,也就是所谓的"真实方法",拥有着极大的权力:
- 它拥有 **invoke()**技能 :因为它肚子里装着真正的底层字节码指令,所以只要你给它传参数,它就能直接让那段代码跑起来。
- 它拥有 getAnnotation()技能 :因为在 JVM 加载类的时候,是把注解直接贴在这个 **Method**对象身上的。只有找到这个对象本尊,你才能去翻看它身上有没有贴着 @AutoFill****的标签。
总结一下它们的关系
你写在 .java****文件里的一段代码逻辑 ->被 JVM 加载到内存后,变成了一个真正的 Method****对象(真实方法)-> AOP 拦截到了它,为了方便记录,给它生成了一份描述文件叫 Signature**。**
所以,你在代码里做的步骤:
- joinPoint.getSignature()****:AOP 给你一份拦截记录(档案)。
- (MethodSignature)****:你确认这是一份"方法"的档案。
- .getMethod()****:你拿着档案,去 JVM 内存里把 那个真正能执行代码、身上贴着注解的 Method****对象本尊 揪了出来!
有了这个"本尊",你才能提取出它头上的操作类型(INSERT/UPDATE),进而决定给实体类赋什么值。
1.3.3 步骤三
在Mapper接口的方法上加入 AutoFill 注解
以CategoryMapper 为例,分别在新增和修改方法添加@AutoFill()注解,也需要EmployeeMapper做相同操作
package com.sky.mapper;
@Mapper
public interface CategoryMapper {
/**
* 插入数据
* @param category
*/
@Insert("insert into category(type, name, sort, status, create_time, update_time, create_user, update_user)" +
" VALUES" +
" (#{type}, #{name}, #{sort}, #{status}, #{createTime}, #{updateTime}, #{createUser}, #{updateUser})")
@AutoFill(value = OperationType.INSERT)
void insert(Category category);
/**
* 根据id修改分类
* @param category
*/
@AutoFill(value = OperationType.UPDATE)
void update(Category category);
}同时,将业务层为公共字段赋值的代码注释掉。
1). 将员工管理的新增和编辑方法中的公共字段赋值的代码注释。
2). 将菜品分类管理的新增和修改方法中的公共字段赋值的代码注释。
1.4 功能测试
以新增菜品分类为例,进行测试
启动项目和Nginx
查看控制台
通过观察控制台输出的SQL来确定公共字段填充是否完成

查看表
category表中数据

其中create_time,update_time,create_user,update_user字段都已完成自动填充。
由于使用admin(id=1)用户登录进行菜品添加操作,故create_user,update_user都为1.
1.5 代码提交
点击提交:
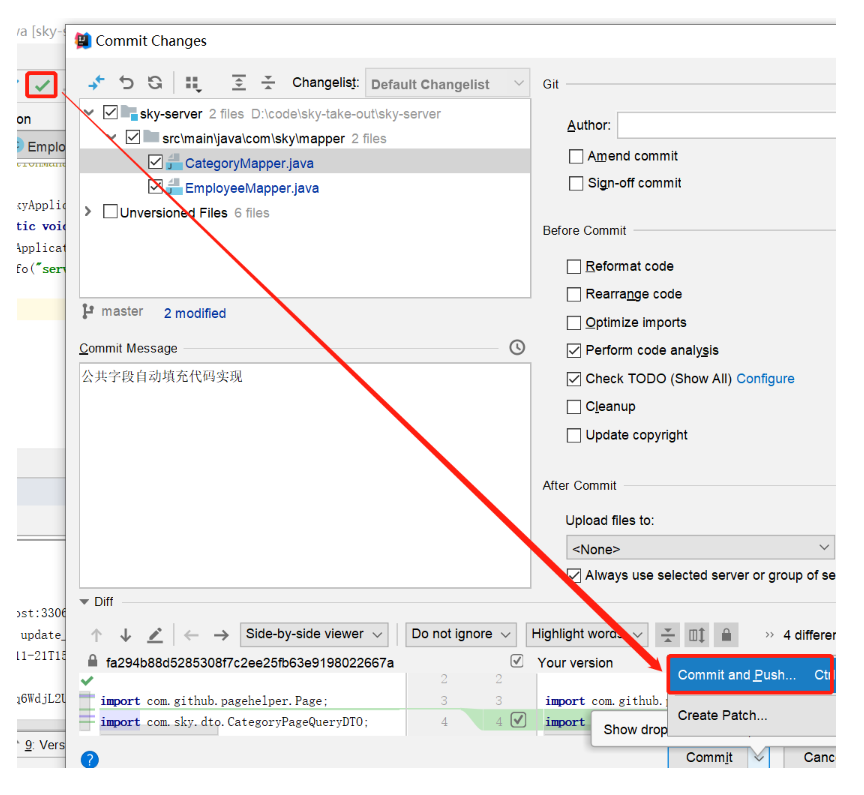
提交过程中,出现提示:
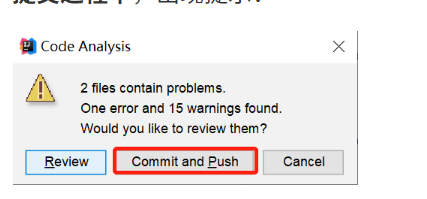
继续push:
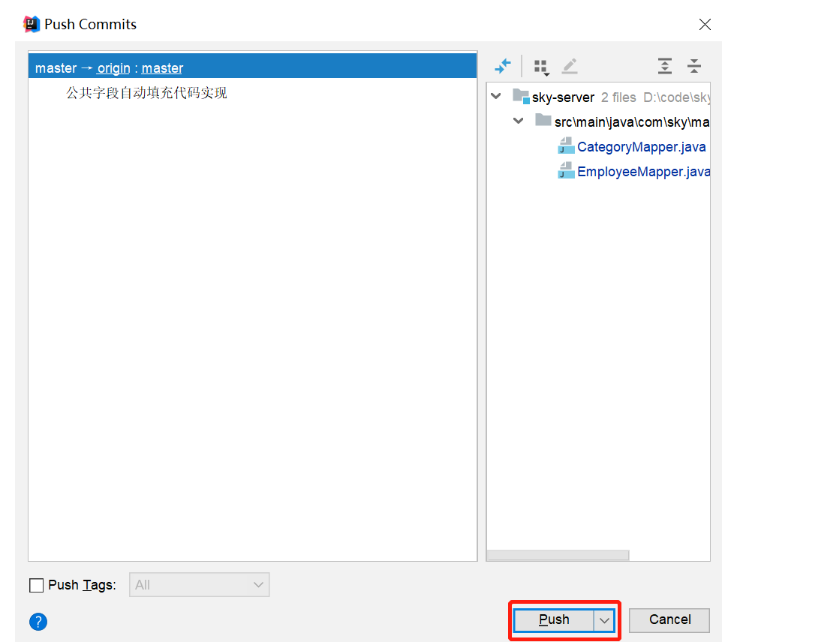
推送成功:
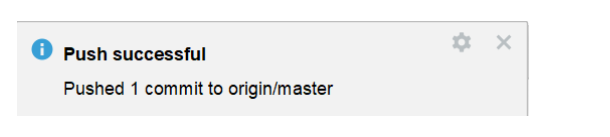
补充快捷键学习 ctrl+ alt +b 查看有哪些实现类
新增菜品
2.1 需求分析与设计
2.1.1 产品原型
后台系统中可以管理菜品信息,通过 新增功能来添加一个新的菜品,在添加菜品时需要选择当前菜品所属的菜品分类,并且需要上传菜品图片。
新增菜品原型:
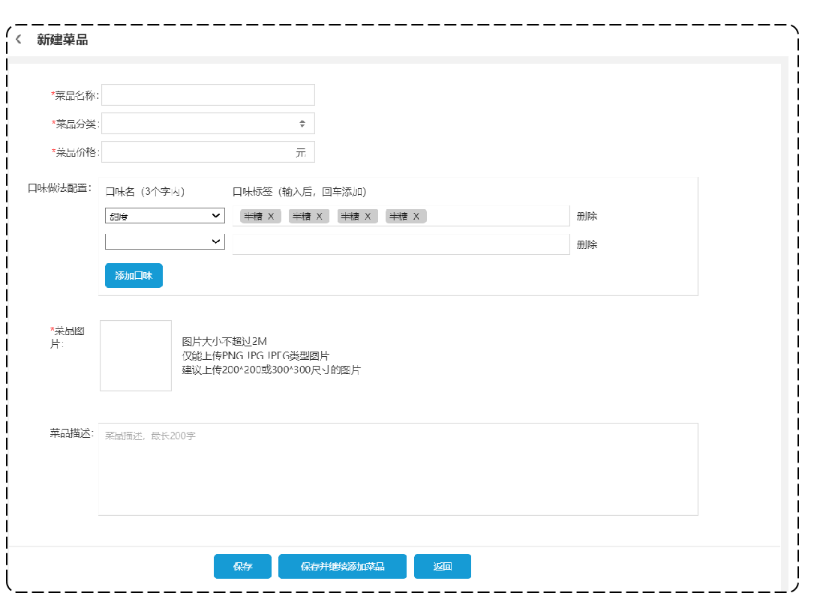
当填写完表单信息, 点击"保存"按钮后, 会提交该表单的数据到服务端, 在服务端中需要接受数据, 然后将数据保存至数据库中。
业务规则:
- 菜品名称必须是唯一的
- 菜品必须属于某个分类下,不能单独存在
- 新增菜品时可以根据情况选择菜品的口味
- 每个菜品必须对应一张图片
2.1.2 接口设计
根据上述原型图先粗略设计接口,共包含3个接口。
接口设计:
- 根据类型查询分类(已完成)
- 文件上传
- 新增菜品
接下来细粒度分析每个接口,明确每个接口的请求方式、请求路径、传入参数和返回值。
1. 根据类型查询分类

2. 文件上传

3. 新增菜品
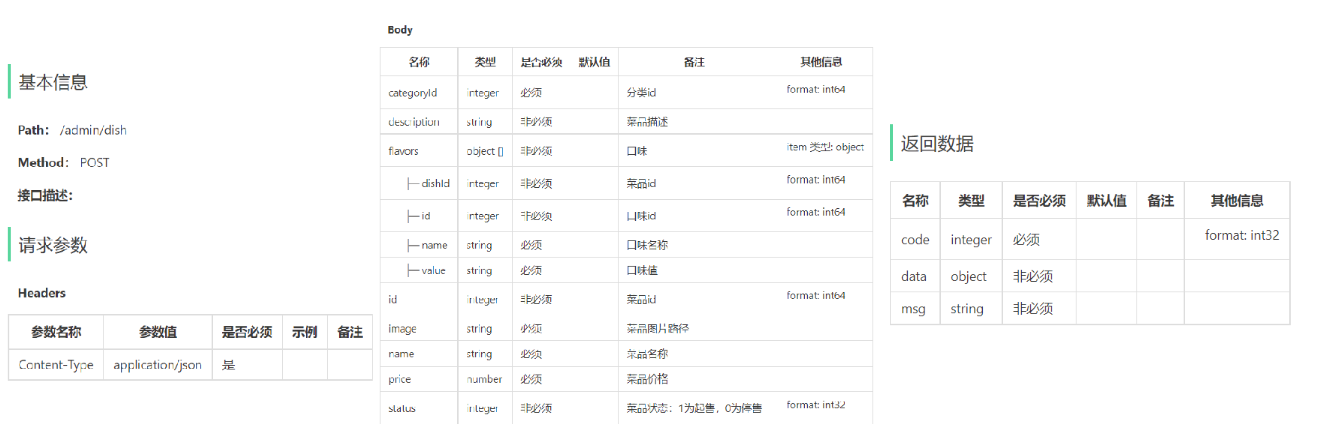
2.1.3 表设计
通过原型图进行分析:
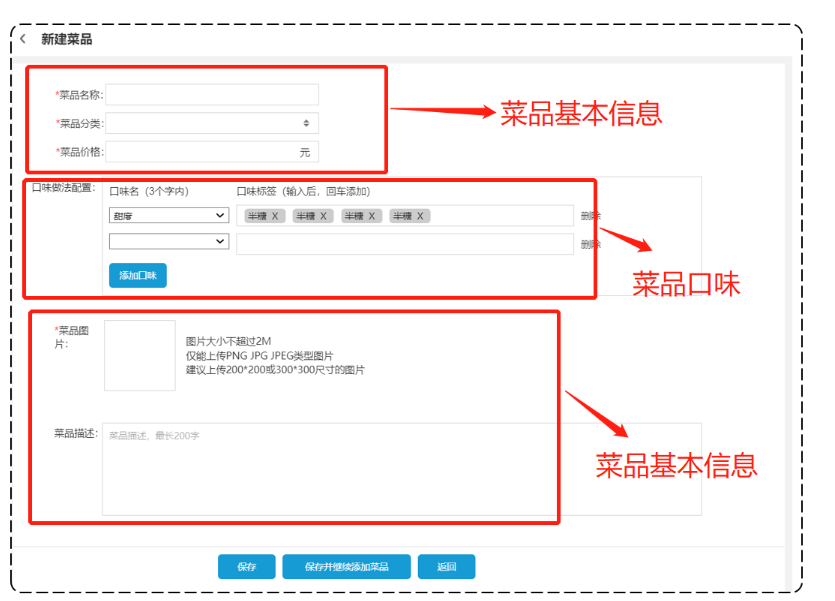
新增菜品,其实就是将新增页面录入的菜品信息插入到dish表,如果添加了口味做法,还需要向dish_flavor表插入数据。所以在新增菜品时,涉及到两个表:
|-------------|--------|
| 表名 | 说明 |
| dish | 菜品表 |
| dish_flavor | 菜品口味表 |
1). 菜品表:dish
|-------------|---------------|---------|---------------------------------------|
| 字段名 | 数据类型 | 说明 | 备注 |
| id | bigint | 主键 | 自增 |
| name | varchar(32) | 菜品名称 | 唯一 |
| category_id | bigint | 分类id | 逻辑外键(就是我前面说的并不是真的有一个外键,而是通过java代码来约束) |
| price | decimal(10,2) | 菜品价格 | |
| image | varchar(255) | 图片路径 | |
| description | varchar(255) | 菜品描述 | |
| status | int | 售卖状态 | 1起售 0停售 |
| create_time | datetime | 创建时间 | |
| update_time | datetime | 最后修改时间 | |
| create_user | bigint | 创建人id | |
| update_user | bigint | 最后修改人id | |
关于外键删除的问题这里有一个口诀
谁拿着别人的ID,谁就是自由的;谁的ID被别人拿着,谁就被绑死了(不能随便删)。 所以在这里面dish表可以随便删,并且里面有逻辑外键(分类表),但是分类表不能随便删,删之前会查询当前分类id下有没有dish表绑定了这个id
2). 菜品口味表:dish_flavor
|---------|--------------|--------|--------|
| 字段名 | 数据类型 | 说明 | 备注 |
| id | bigint | 主键 | 自增 |
| dish_id | bigint | 菜品id | 逻辑外键 |
| name | varchar(32) | 口味名称 | |
| value | varchar(255) | 口味值 | |
2.2 代码开发
文件上传实现
因为在新增菜品时,需要上传菜品对应的图片(文件),包括后绪其它功能也会使用到文件上传,故要实现通用的文件上传接口。
文件上传,是指将本地图片、视频、音频等文件上传到服务器上,可以供其他用户浏览或下载的过程。文件上传在项目中应用非常广泛,我们经常发抖音、发朋友圈都用到了文件上传功能。
实现文件上传服务,需要有存储的支持,那么我们的解决方案将以下几种:
- 直接将图片保存到服务的硬盘(springmvc中的文件上传)
-
- 优点:开发便捷,成本低
- 缺点:扩容困难
- 使用分布式文件系统进行存储
-
- 优点:容易实现扩容
- 缺点:开发复杂度稍大(有成熟的产品可以使用,比如:FastDFS,MinIO)
- 使用第三方的存储服务(例如OSS)
-
- 优点:开发简单,拥有强大功能,免维护
- 缺点:付费
在本项目选用阿里云的OSS服务进行文件存储。(前面课程已学习过阿里云OSS,不再赘述)
实现步骤:
1). 定义OSS相关配置
在sky-server模块
application-dev.yml
sky:
alioss:
endpoint: oss-cn-hangzhou.aliyuncs.com
access-key-id: LTAI5tPeFLzsPPT8gG3LPW64
access-key-secret: U6k1brOZ8gaOIXv3nXbulGTUzy6Pd7
bucket-name: sky-take-out
#你可能会疑惑,这里的sky-take-out为什么采用横线命名,其实很简单黑马创建这个bucket时候,取的名字就是
sky-take-out ,这里并不是所谓的匹配驼峰,前面才是我们注意到yml文件命名方式都采用的是横线命名法,其实采用驼峰命名也行,但是yml用横线命名会更加规范
并且我们发现在我们编写的时候,会弹出提示,这个提示是怎么来的,其实是我们早就编写好了对应的properties的类,他与这个关联起来了
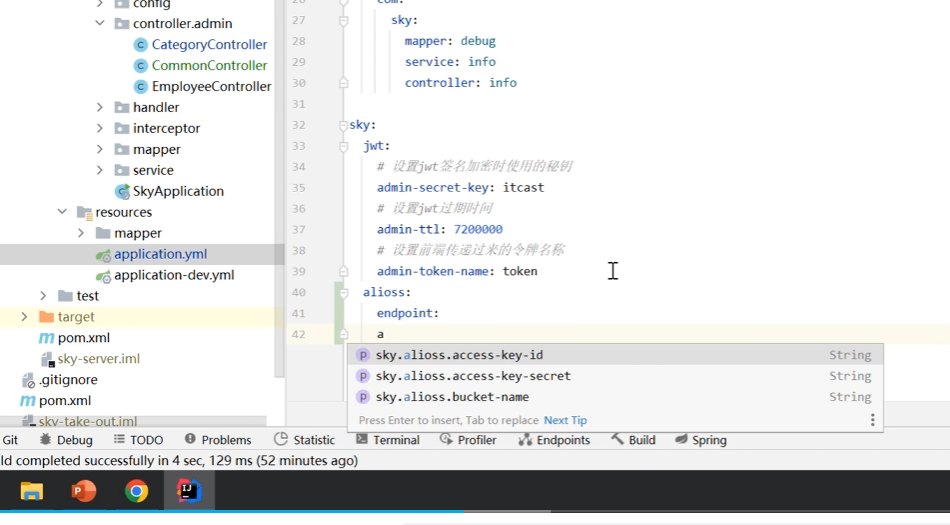
application.yml
spring:
profiles:
active: dev #设置环境 #前面三行在开头,已经写好了
sky:
alioss:
endpoint: ${sky.alioss.endpoint}
access-key-id: ${sky.alioss.access-key-id}
access-key-secret: ${sky.alioss.access-key-secret}
bucket-name: ${sky.alioss.bucket-name}这两个yml文件都在一个包底下,并且都在sky-server模块里面,为什么要写两份,因为这样会更加灵活
采用这种模式,你可以创建 application-dev.yml、application-test.yml、application-prod.yml 三个文件,里面填各自独立的密钥。以后要把项目部署到线上,只需要在 application.yml(这个我们通常称之为主yml配置文件,在这个文件本身是不写配置数据,通过引用方式${}去引用别的配置文件 ) 里把 active: dev(dev表示开发环境配置文件) 改成 active: prod(product缩写表示产品配置文件),就能一键切换所有配置,既安全又高效。
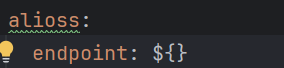
注意根据yml书写规范这里要空格
2). 读取OSS配置
在sky-common模块中,已定义
package com.sky.properties;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
@Component
@ConfigurationProperties(prefix = "sky.alioss")
@Data
public class AliOssProperties {
private String endpoint;
private String accessKeyId;
private String accessKeySecret;
private String bucketName;
}他这个类的作用就是去yml里面的数据给读出来,我们可以看到这里写了@Component,ioc容器其实就已经创建好了一个对象里面包括yml的值
到时候我们会通过底下的那个配置类把会把AliOSS工具类交给IOC容器管理,是通过@ bean注解实现的,也就是我们会定义一个方法,该方法返回的对象会教给ioc容器管理,然后在创建这个对象的时候,
我们就用到了之前我们已经交给ioc容器管理的对象aliOssProperties,然后把值赋给他
其实这个工具类才是真正连接远程oss 的起作用的代码
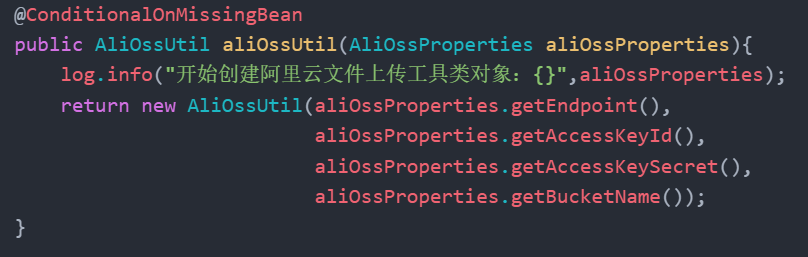
3). 生成OSS工具类对象
在sky-server模块
package com.sky.config;
import com.sky.properties.AliOssProperties;
import com.sky.utils.AliOssUtil;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 配置类,用于创建AliOssUtil对象
*/
@Configuration
@Slf4j
public class OssConfiguration {
@Bean
@ConditionalOnMissingBean//这个就是当没有这个bean的时候再去创建,防止很多个重复的bean
public AliOssUtil aliOssUtil(AliOssProperties aliOssProperties){
log.info("开始创建阿里云文件上传工具类对象:{}",aliOssProperties);
return new AliOssUtil(aliOssProperties.getEndpoint(),
aliOssProperties.getAccessKeyId(),
aliOssProperties.getAccessKeySecret(),
aliOssProperties.getBucketName());
//这里传入参数的顺序是要严格遵守AliOssUtil里面成员变量定义的先后的顺序
}
}其实这种把第三方的类(比如这里的util类)交给ioc容器管理 一般都是通过配置类+@ bean来实现,其实用普通类也可以实现这个过程,但是普通类会出现很多问题,至于为什么现在没必要搞懂原理,记住这样规定就行了
其实我们能够通过方法里面参数直接依赖注入aliOssPoroperties 其实是多亏了@ bean注解
其实@ Service 也可以通过这种方式完成注入,但是条件就是必须得是构造方法里面,但是这个 @ bean注解底下任何的 普通方法里面的参数也会直接注入
还记得之前学过依赖注入有两种方式吗?
第一种是 做法 A:构造器注入(最推荐,和你在配置类里看到的原理一模一样而且在service注解底下必须得声明这个变量 如果是configration就不用)
@Service
public class DishServiceImpl implements DishService {
private final AliOssProperties aliOssProperties;
// 只要类上加了 @Service,写在构造器的参数里,Spring 也会自动把它传进来
public DishServiceImpl(AliOssProperties aliOssProperties) {
this.aliOssProperties = aliOssProperties;
}
}第二种是我们之前经常用的
做法 B:字段注入(使用 @Autowired,很常见但官方现在不太推荐)
@Service
public class DishServiceImpl implements DishService {
@Autowired
private AliOssProperties aliOssProperties; // Spring 会自动把对象赋值给这个变量
}其中,AliOssUtil.java已在sky-common模块中定义
package com.sky.utils;
import com.aliyun.oss.ClientException;
import com.aliyun.oss.OSS;
import com.aliyun.oss.OSSClientBuilder;
import com.aliyun.oss.OSSException;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import java.io.ByteArrayInputStream;
@Data
@AllArgsConstructor
@Slf4j
public class AliOssUtil {
private String endpoint;
private String accessKeyId;
private String accessKeySecret;
private String bucketName;
/**
* 文件上传
*
* @param bytes
* @param objectName
* @return
*/
public String upload(byte[] bytes, String objectName) {
// 创建OSSClient实例。
OSS ossClient = new OSSClientBuilder().build(endpoint, accessKeyId, accessKeySecret);
try {
// 创建PutObject请求。
ossClient.putObject(bucketName, objectName, new ByteArrayInputStream(bytes));
} catch (OSSException oe) {
System.out.println("Caught an OSSException, which means your request made it to OSS, "
+ "but was rejected with an error response for some reason.");
System.out.println("Error Message:" + oe.getErrorMessage());
System.out.println("Error Code:" + oe.getErrorCode());
System.out.println("Request ID:" + oe.getRequestId());
System.out.println("Host ID:" + oe.getHostId());
} catch (ClientException ce) {
System.out.println("Caught an ClientException, which means the client encountered "
+ "a serious internal problem while trying to communicate with OSS, "
+ "such as not being able to access the network.");
System.out.println("Error Message:" + ce.getMessage());
} finally {
if (ossClient != null) {
ossClient.shutdown();
}
}
//文件访问路径规则 https://BucketName.Endpoint/ObjectName
StringBuilder stringBuilder = new StringBuilder("https://");
stringBuilder
.append(bucketName)
.append(".")
.append(endpoint)
.append("/")
.append(objectName);
log.info("文件上传到:{}", stringBuilder.toString());
return stringBuilder.toString();
}
}4). 定义文件上传接口
在sky-server模块中定义接口
package com.sky.controller.admin;
import com.sky.constant.MessageConstant;
import com.sky.result.Result;
import com.sky.utils.AliOssUtil;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
import java.util.UUID;
/**
* 通用接口
*/
@RestController
@RequestMapping("/admin/common")
@Api(tags = "通用接口")
@Slf4j
public class CommonController {
@Autowired
private AliOssUtil aliOssUtil;
/**
* 文件上传
* @param file
* @return
*/
@PostMapping("/upload")
@ApiOperation("文件上传")
public Result<String> upload(MultipartFile file){
log.info("文件上传:{}",file);
try {
//原始文件名
String originalFilename = file.getOriginalFilename();
//截取原始文件名的后缀 dfdfdf.png
String extension = originalFilename.substring(originalFilename.lastIndexOf("."));
//构造新文件名称
String objectName = UUID.randomUUID().toString() + extension;
//文件的请求路径
String filePath = aliOssUtil.upload(file.getBytes(), objectName);
return Result.success(filePath);
} catch (IOException e) {
log.error("文件上传失败:{}", e);
}
return Result.error(MessageConstant.UPLOAD_FAILED);
}
}我们来复习一下
String filePath = aliOssUtil.upload(file.getBytes(), objectName);
第一个参数是要传一个Byte类型数组,我们直接用file.getBytes()来生成,第二参数是要传文件名,如果我们直接传名字可能会重复,但是oss不能存名字相同的两张图片,所以在这里我们使用uuid来生成那种不会重复的文件名。
然后我们来学习一下这句代码的作用
String extension = originalFilename.substring(originalFilename.lastIndexOf("."));
这句代码的作用是从一个完整的文件名中提取出文件的后缀名(扩展名),并且包含点号(.)。
我们可以把这句代码拆解成三个部分来理解:
originalFilename:这是一个字符串变量,通常代表原始的完整文件名,比如 "my_photo.jpg" 或者 "report.2023.pdf"。
lastIndexOf("."):这个方法会找到最后一个点号 . 在字符串中的位置(索引)。
为什么要找最后一个点? 因为有些文件名本身就包含多个点,比如 "backup.tar.gz" 或 "v1.0.txt"。使用 lastIndexOf 可以确保我们锁定的是决定文件类型的最后那个点。
substring(...):这个方法用来截取字符串。它接收了刚才找到的点号位置,然后从这个点号开始,一直截取到字符串的最后。
💡 举个例子
假设 originalFilename 的值是 "document.docx":
originalFilename.lastIndexOf(".") 会找到点号的位置是 8。
originalFilename.substring(8) 会从第8个位置开始向后截取,得到 ".docx"。
最后,这个 ".docx" 就被赋值给了变量 extension。新增菜品实现
1). 设计DTO类
在sky-pojo模块中
package com.sky.dto;
import com.sky.entity.DishFlavor;
import lombok.Data;
import java.io.Serializable;
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.List;
@Data
public class DishDTO implements Serializable {
private Long id;
//菜品名称
private String name;
//菜品分类id
private Long categoryId;
//菜品价格
private BigDecimal price;
//图片
private String image;
//描述信息
private String description;
//0 停售 1 起售
private Integer status;
//口味
private List<DishFlavor> flavors = new ArrayList<>();
}首先我们必须得意识到一个知识,就是成员变量是可以直接给它赋初始值的,之前的没写里面就是null,
这里private List<DishFlavor> flavors = new ArrayList<>();,选择这样写就是处于安全的考虑,防止空指针异常
下面给出解释
❌ 写法一:没有小尾巴(private List<DishFlavor> flavors;)
在 Java 里,如果你只声明了一个对象(List 是一个对象)但不给它赋值,它的默认值就是 null(真空、什么都没有)。
想象一下这个场景:你新建了一个菜品对象 DishDTO,这时候你想往里面加一个新口味:
Java
DishDTO dishDTO = new DishDTO();
// 此时 dishDTO 里的 flavors 是 null
dishDTO.getFlavors().add(new DishFlavor("微辣")); // 💥 轰!程序在这里直接崩溃报错!
为什么崩溃? 因为 flavors 是 null,你不能对一段"真空"调用 .add() 方法。这就好比你试图往一个根本不存在的箱子里放苹果,系统当然会罢工。
✅ 写法二:加上小尾巴(= new ArrayList<>();)
当你写了这句代码,就相当于在创建 DishDTO 这个对象的同时,顺手在里面放了一个真实存在的、但是空空如也的箱子(容量为 0 的集合)。
再来看同样的场景:
Java
DishDTO dishDTO = new DishDTO();
// 此时 dishDTO 里的 flavors 是一个空的 ArrayList,不是 null
dishDTO.getFlavors().add(new DishFlavor("微辣")); // ✨ 完美运行!成功把口味放进了箱子里。
不仅如此,如果你去调用 dishDTO.getFlavors().size(),它会乖乖返回 0,而不会像之前那样报错崩溃。在这里我们遇到了一个新的变量名叫BigDecimal
什么是 BigDecimal**?**
它是 Java ( java.math****包下) 提供的一个类,专门用来处理 极高精度、绝对不会丢失精度 的数字。
❌ 为什么算钱不能用我们熟悉的 double**?**
因为计算机底层是用"二进制"来存储数据的,而有些十进制的小数转换成二进制时是无限循环的。这就导致了 double****和 float****在进行计算时, 极其容易产生精度丢失(算不准) 。
我给你看一个著名的 Java 经典"坑": 假如你有一个菜卖 0.1 元,另一个菜卖 0.2 元,用 double****加起来:
Java
System.out.println(0.1 + 0.2);
// 你以为会输出 0.3
// 但实际控制台输出的是:0.30000000000000004想象一下,如果这是用户的账单,明明该付 0.3 元,系统却让他付 0.30000000000000004 元,或者在算折扣的时候差了一分钱,日积月累下来,公司的财务报表就直接爆炸了。
✅ BigDecimal****是怎么解决的?
BigDecimal****内部有一套非常严谨的算法(你可以把它简单理解为把小数放大了变成整数来算,或者当成字符串来精确处理),它能够保证 0.1 + 0.2****算出来的结果 绝对是精确的 0.3 。
⚠️ 使用 BigDecimal****的两个"硬规定"
既然它是个对象(类),而不是基本数据类型(像 int, double),它的用法就会有点不一样:
- 不能用传统的加减乘除符号 ( + - * /****) 了! 想要计算,必须调用它自带的方法:
-
- 加法: a.add(b)
- 减法: a.subtract(b)
- 乘法: a.multiply(b)
- 除法: a.divide(b)
- 创建它的时候,强烈建议传入字符串! new BigDecimal("0.1")是安全的。如果你写成 **new BigDecimal(0.1)**(传入 double),它依然会把 double 那个不精确的尾巴带进去。
这里有一个知识点的补充
1. 0.1****默认是 double****吗?
是的,完全正确! 在 Java 中,只要你在代码里直接写一个小数(比如 0.1**、** 3.14**),Java 编译器默认就会把它当成** double**(双精度浮点数,占用 64 位空间)** 。
如果你想让它变成单精度的 float**(占用 32 位),你必须在后面加上字母** f**,写成** 0.1f**。**
2. 为什么会输出 0.30000000000000004**?(背后的元凶)**
这其实不是 Java 的错,而是 所有使用 IEEE 754 国际标准来存储浮点数的编程语言(C, C++, Python, JavaScript 等等)共同的痛点 。
你可以用一个我们生活中常见的例子来理解这个现象:
🍰 类比:十进制里的"无限循环"
在我们的十进制世界里,如果你想把 1/3 转换成小数,你会得到 0.3333333...****,这个 3****是无限循环的。如果你在一张纸上写,纸的长度有限,你只能写到某一位就停笔(比如写到 0.33333**)。这就意味着,** 你写在纸上的数字,已经和真实的 1/3 产生了一点点微小的误差。
💻 现实:二进制里的"无限循环"
计算机底层只认识 0****和 1**(二进制)。当我们把十进制的** 0.1****翻译给计算机听,让它存成二进制时,奇妙的事情发生了:
十进制的 0.1****转换成二进制,是一个 无限循环小数 :
0.000110011001100110011...****( 0011****会一直循环下去)
但是, double****类型的内存空间是有限的(只有 64 个坑位/比特位)。计算机没有办法存储无限个数字,所以它只能像我们刚才在纸上写字一样, 在某一位上"一刀切",把后面的数字截断丢掉或者四舍五入。
💥 最终的灾难现场
- 当你在代码里写下 0.1****时,计算机存进去的其实是类似 **0.100000000000000005551115...**这样一个稍微大一丁点儿的近似值。
- 同理, 0.2****存进去的也是一个类似 **0.20000000000000001110223...**的近似值。
- 当你让计算机执行 0.1 + 0.2****时,它是拿这两个 本来就不准的近似值 去相加。
- 误差一叠加,再转换回十进制打印出来,就露馅了,变成了那个带着尾巴的 0.30000000000000004**。**
2). Controller层
进入到sky-server模块
package com.sky.controller.admin;
import com.sky.dto.DishDTO;
import com.sky.dto.DishPageQueryDTO;
import com.sky.entity.Dish;
import com.sky.result.PageResult;
import com.sky.result.Result;
import com.sky.service.DishService;
import com.sky.vo.DishVO;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
import java.util.Set;
/**
* 菜品管理
*/
@RestController
@RequestMapping("/admin/dish")
@Api(tags = "菜品相关接口")
@Slf4j
public class DishController {
@Autowired
private DishService dishService;
/**
* 新增菜品
*
* @param dishDTO
* @return
*/
@PostMapping
@ApiOperation("新增菜品")
public Result save(@RequestBody DishDTO dishDTO) {
log.info("新增菜品:{}", dishDTO);
dishService.saveWithFlavor(dishDTO);//后绪步骤开发
return Result.success();
}
}3). Service层接口
package com.sky.service;
import com.sky.dto.DishDTO;
import com.sky.entity.Dish;
public interface DishService {
/**
* 新增菜品和对应的口味
*
* @param dishDTO
*/
public void saveWithFlavor(DishDTO dishDTO);
}4). Service层实现类
package com.sky.service.impl;
@Service
@Slf4j
public class DishServiceImpl implements DishService {
@Autowired
private DishMapper dishMapper;
@Autowired
private DishFlavorMapper dishFlavorMapper;
/**
* 新增菜品和对应的口味
*
* @param dishDTO
*/
@Transactional
public void saveWithFlavor(DishDTO dishDTO) {
Dish dish = new Dish();
BeanUtils.copyProperties(dishDTO, dish);
//向菜品表插入1条数据
dishMapper.insert(dish);//后绪步骤实现
//获取insert语句生成的主键值
Long dishId = dish.getId();
//让每一条口味记录绑定当前添加菜品的id
List<DishFlavor> flavors = dishDTO.getFlavors();
if (flavors != null && flavors.size() > 0) {
flavors.forEach(dishFlavor -> {
dishFlavor.setDishId(dishId);
});
//向口味表插入n条数据
dishFlavorMapper.insertBatch(flavors);//后绪步骤实现
}
}
}注意: 要想使用@ Transactional注解,我们必须得在启动类上开启注解,如下图所示
关于什么时候用.size() 什么时候用.length()的问题
- 数组 (Array) 用 length (注意:没有括号,它是一个属性)
- 字符串 (String) 用 length() (注意:有括号,它是一个方法)
- 集合 (Collection) 用 size() (注意:有括号,它也是一个方法)
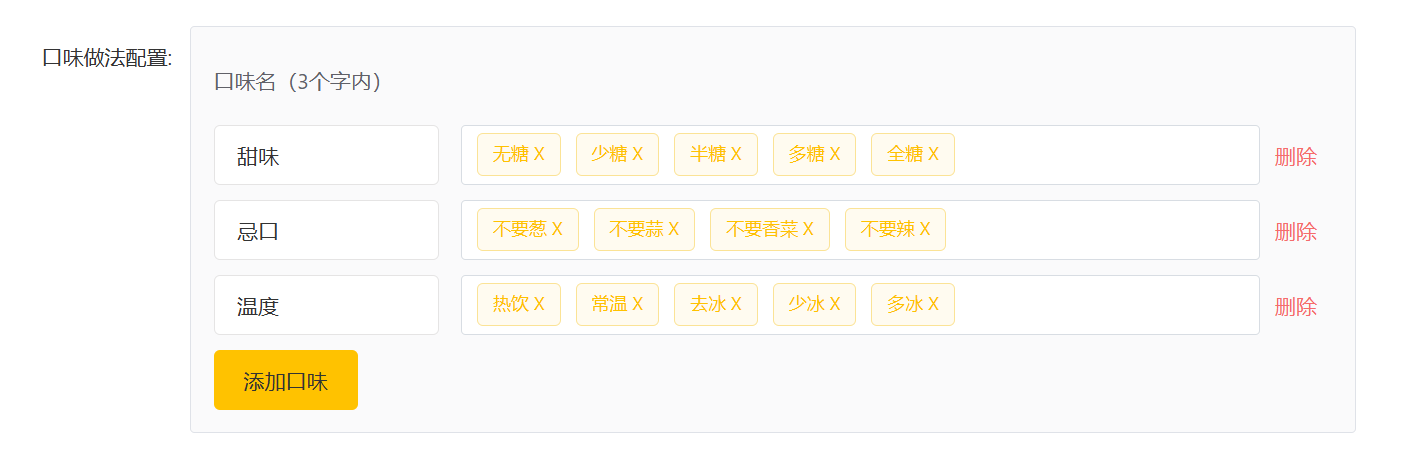
可以看到前端可以一次性直接传递过来三个口味,所以在DishDto里面我们得用集合来定义这个flavors
又碰到foreach我们来好好分析一下这个foreach
我们还原匿名内部类的写法
// 这是使用【匿名内部类】的写法
flavors.forEach(new Consumer<DishFlavor>() {
@Override
public void accept(DishFlavor dishFlavor) {
dishFlavor.setDishId(dishId);
}
});我们知道lambda表达式直接从方法里面的参数dishFlavor开始写起(其实这里的参数类型也可以省略掉了,因为我们调用的是flavors.forEach,这里的这个flavors是一个集合里面存储了的就是这个省略的参数类型DishFlavor,整个过程他自己会去找,所以可以直接省略不写),
5). Mapper层
DishMapper.java中添加
/**
* 插入菜品数据
*
* @param dish
*/
@AutoFill(value = OperationType.INSERT)
void insert(Dish dish);在/resources/mapper中创建DishMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.sky.mapper.DishMapper">
<insert id="insert" useGeneratedKeys="true" keyProperty="id">
insert into dish (name, category_id, price, image, description, create_time, update_time, create_user,update_user, status)
values (#{name}, #{categoryId}, #{price}, #{image}, #{description}, #{createTime}, #{updateTime}, #{createUser}, #{updateUser}, #{status})
</insert>
</mapper>因为我们插入时候并没给dish里面id赋值,是依靠数据库自己的主键自增完成的,所以在这里我们必须得
拿到这个主键值
方法是通过一个叫主键回显的方法
在这里的xml配置里面,有有个地方是值得关注的
我们发现有useGeneratedKeys="true"和 keyProperty="id
<insert id="insert" useGeneratedKeys="true" keyProperty="id">
这两个属性的神奇作用
为了解决上面的痛点,MyBatis 提供了这两个属性搭配使用:主键回显(也叫主键返回)。
- useGeneratedKeys="true": 这是在给 MyBatis 下达指令:"嘿,执行完这条 insert 语句后,请把数据库刚刚自动生成的那个主键值给我拿回来。"
- keyProperty="id": 这是告诉 MyBatis 拿到主键后该放哪:"请把拿回来的那个主键值,塞回到我传进来的 Java 对象的 id****属性里面。"
DishFlavorMapper.java
package com.sky.mapper;
import com.sky.entity.DishFlavor;
import java.util.List;
@Mapper
public interface DishFlavorMapper {
/**
* 批量插入口味数据
* @param flavors
*/
void insertBatch(List<DishFlavor> flavors);
}在/resources/mapper中创建DishFlavorMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.sky.mapper.DishFlavorMapper">
<insert id="insertBatch">
insert into dish_flavor (dish_id, name, value) VALUES
<foreach collection="flavors" item="df" separator=",">
(#{df.dishId},#{df.name},#{df.value})
</foreach>
</insert>
</mapper>2.3 功能测试
进入到菜品管理--->新建菜品
由于没有实现菜品查询功能,所以保存后,暂且在表中查看添加的数据。
dish表:

dish_flavor表:
测试成功。
2.4代码提交
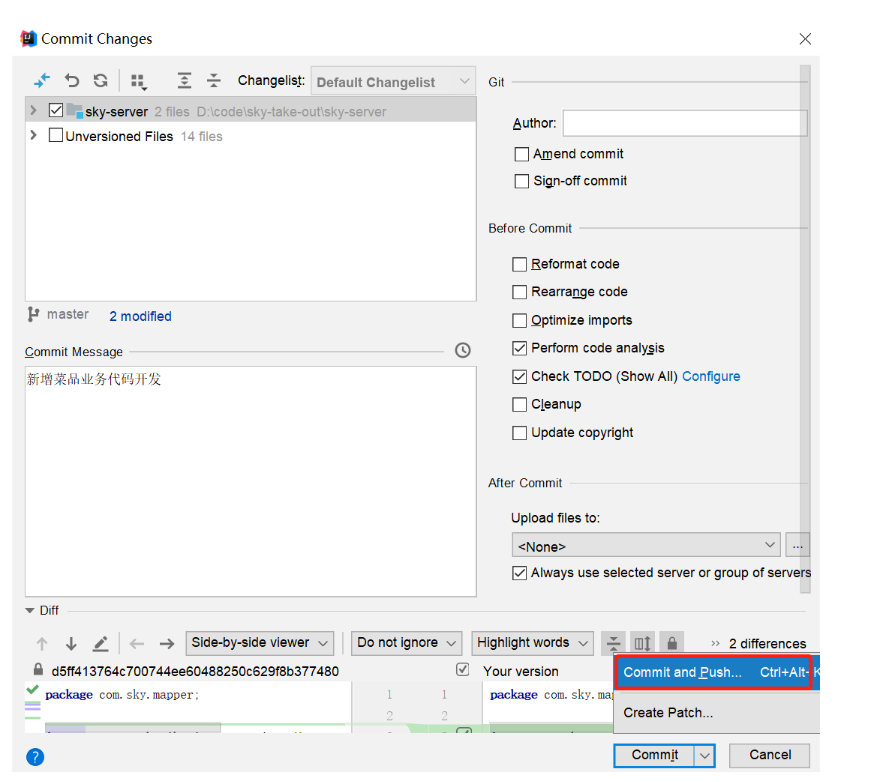
后续步骤和上述功能代码提交一致,不再赘述。
菜品分页查询
需求分析和设计
产品原型
系统中的菜品数据很多的时候,如果在一个页面中全部展示出来会显得比较乱,不便于查看,所以一般的系统中都会以分页的方式来展示列表数据。
菜品分页原型:
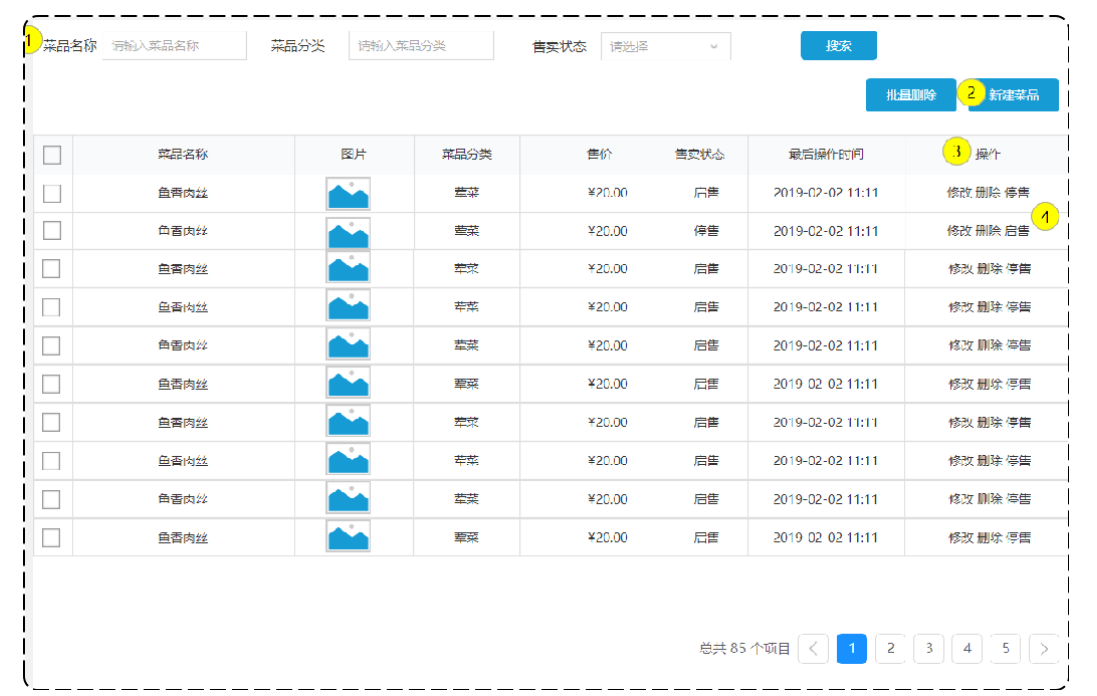
在菜品列表展示时,除了菜品的基本信息(名称、售价、售卖状态、最后操作时间)外,还有两个字段略微特殊,第一个是图片字段 ,我们从数据库查询出来的仅仅是图片的名字,图片要想在表格中回显展示出来,就需要下载这个图片。第二个是菜品分类,这里展示的是分类名称,而不是分类ID,此时我们就需要根据菜品的分类ID,去分类表中查询分类信息,然后在页面展示。
业务规则:
- 根据页码展示菜品信息
- 每页展示10条数据
- 分页查询时可以根据需要输入菜品名称、菜品分类、菜品状态进行查询
3.1.2 接口设计
根据上述原型图,设计出相应的接口。
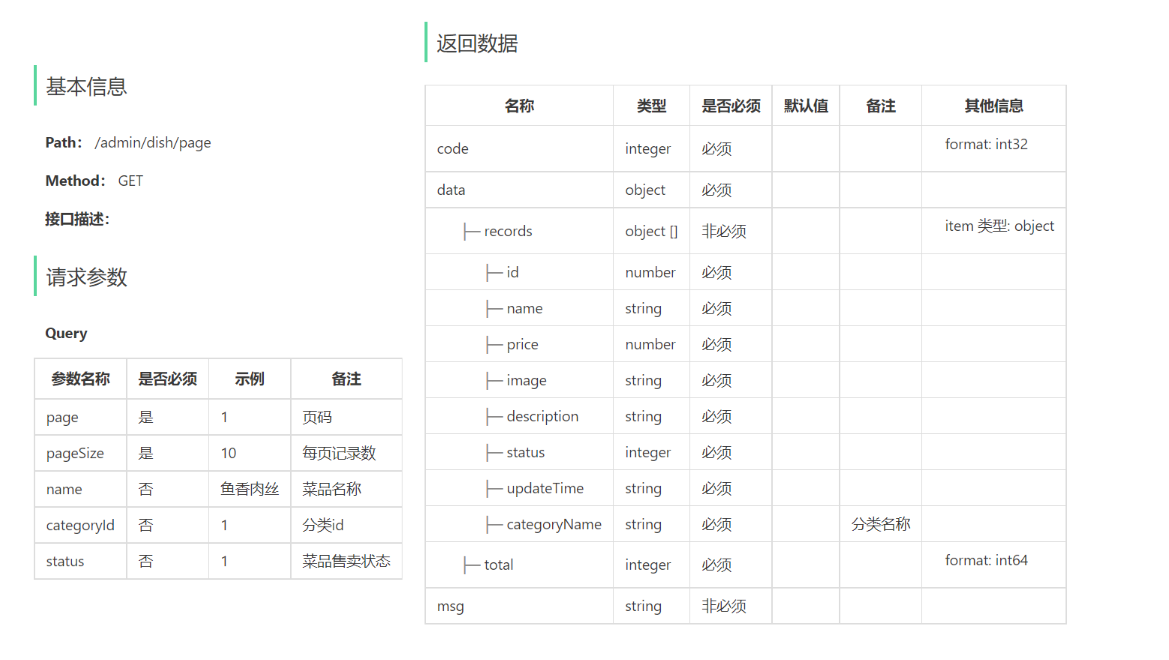
3.2 代码开发
3.2.1 设计DTO类
根据菜品分页查询接口定义设计对应的DTO:
在sky-pojo模块中,已定义
package com.sky.dto;
import lombok.Data;
import java.io.Serializable;
@Data
public class DishPageQueryDTO implements Serializable {
private int page;
private int pageSize;
private String name;
private Integer categoryId; //分类id
private Integer status; //状态 0表示禁用 1表示启用
}3.2.2 设计VO类
根据菜品分页查询接口定义设计对应的VO:
在sky-pojo模块中,已定义
package com.sky.vo;
import com.sky.entity.DishFlavor;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
import java.math.BigDecimal;
import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.List;
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class DishVO implements Serializable {
private Long id;
//菜品名称
private String name;
//菜品分类id
private Long categoryId;
//菜品价格
private BigDecimal price;
//图片
private String image;
//描述信息
private String description;
//0 停售 1 起售
private Integer status;
//更新时间
private LocalDateTime updateTime;
//分类名称
private String categoryName;
//菜品关联的口味
private List<DishFlavor> flavors = new ArrayList<>();
}3.2.3 Controller层
根据接口定义创建DishController的page分页查询方法:
/**
* 菜品分页查询
*
* @param dishPageQueryDTO
* @return
*/
@GetMapping("/page")
@ApiOperation("菜品分页查询")
public Result<PageResult> page(DishPageQueryDTO dishPageQueryDTO) {
log.info("菜品分页查询:{}", dishPageQueryDTO);
PageResult pageResult = dishService.pageQuery(dishPageQueryDTO);//后绪步骤定义
return Result.success(pageResult);
}分页查询一定是返回统一对象PageResult
3.2.4 Service层接口
在 DishService 中扩展分页查询方法:
/**
* 菜品分页查询
*
* @param dishPageQueryDTO
* @return
*/
PageResult pageQuery(DishPageQueryDTO dishPageQueryDTO);3.2.5 Service层实现类
在 DishServiceImpl 中实现分页查询方法:
/**
* 菜品分页查询
*
* @param dishPageQueryDTO
* @return
*/
public PageResult pageQuery(DishPageQueryDTO dishPageQueryDTO) {
PageHelper.startPage(dishPageQueryDTO.getPage(), dishPageQueryDTO.getPageSize());
Page<DishVO> page = dishMapper.pageQuery(dishPageQueryDTO);//后绪步骤实现
return new PageResult(page.getTotal(), page.getResult());
}Mapper层方法执行完之后,返回类型一定是Page <>里面的泛型倒是可以自己指定
3.2.6 Mapper层
在 DishMapper 接口中声明 pageQuery 方法:
vb
`/**
* 菜品分页查询
*
* @param dishPageQueryDTO
* @return
*/
Page<DishVO> pageQuery(DishPageQueryDTO dishPageQueryDTO);`在 DishMapper.xml 中编写SQL:
<select id="pageQuery" resultType="com.sky.vo.DishVO">
select d.* , c.name as categoryName from dish d left outer join category c on d.category_id = c.id
<where>
<if test="name != null">
and d.name like concat('%',#{name},'%')
</if>
<if test="categoryId != null">
and d.category_id = #{categoryId}
</if>
<if test="status != null">
and d.status = #{status}
</if>
</where>
order by d.create_time desc
</select>注意这里看不懂很正常,因为用到了多表查询
我们快速把多表查询学一下 因为代码里面用了 代码里用了 join,
多表查询
这个见Mysql笔记
3.3 功能测试
3.3.1 接口文档测试
启动服务: 访问http://localhost:8080/doc.html,进入菜品分页查询接口
**注意:**使用admin用户登录重新获取token,防止token失效。
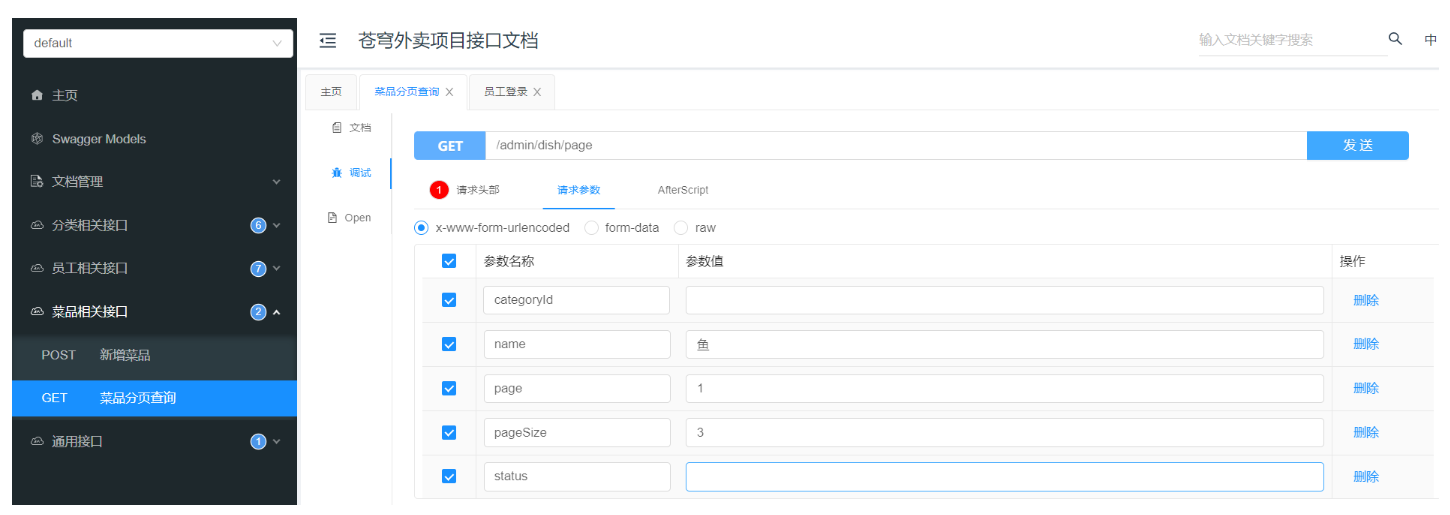
点击发送:
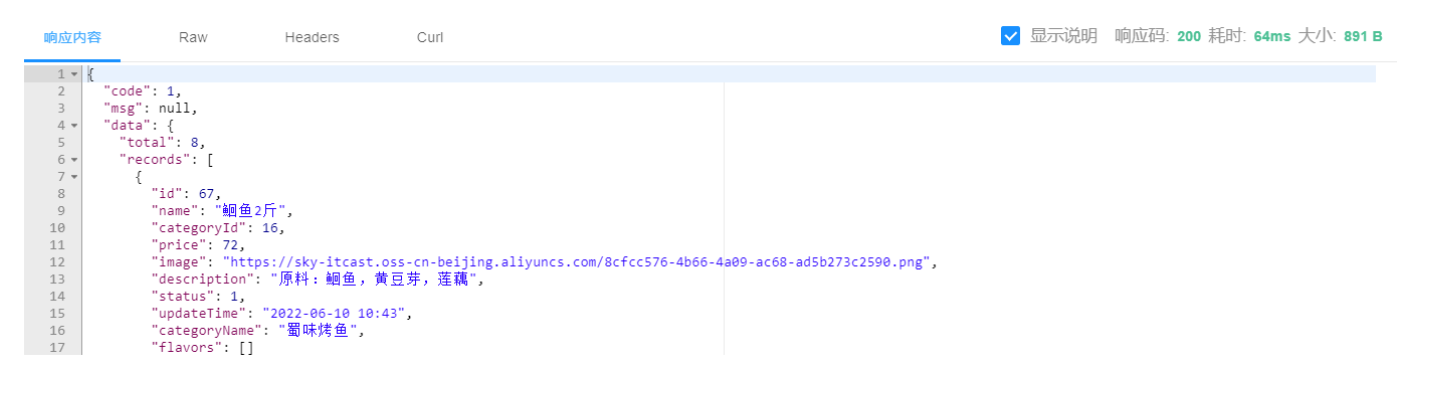
3.3.2 前后端联调测试
启动nginx,访问 http://localhost
点击菜品管理
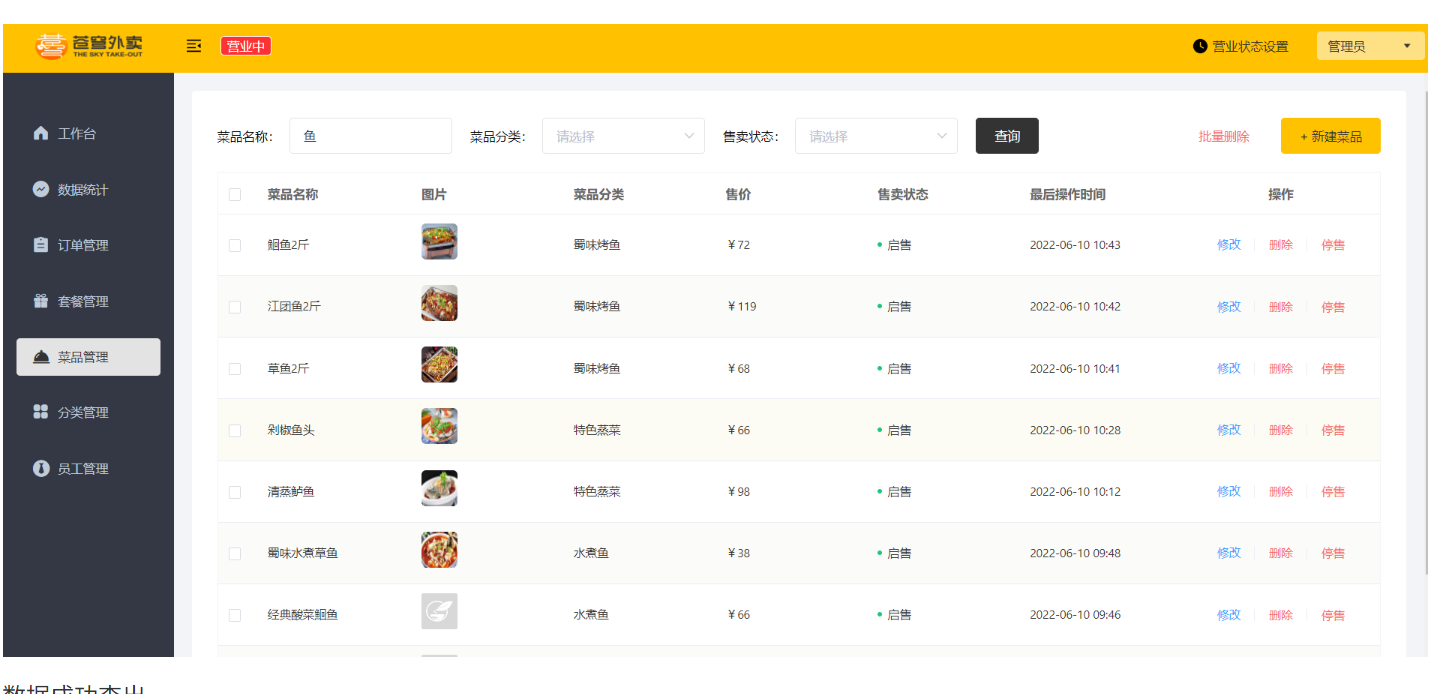
数据成功查出。
删除菜品
4.1 需求分析和设计
4.1.1 产品原型
在菜品列表页面,每个菜品后面对应的操作分别为修改 、删除 、停售,可通过删除功能完成对菜品及相关的数据进行删除。
删除菜品原型:
业务规则:
- 可以一次删除一个菜品,也可以批量删除菜品
- 起售中的菜品不能删除
- 被套餐关联的菜品不能删除
- 删除菜品后,关联的口味数据也需要删除掉
4.1.2 接口设计
根据上述原型图,设计出相应的接口。

**注意:**删除一个菜品和批量删除菜品共用一个接口,故ids可包含多个菜品id,之间用逗号分隔。
4.1.3 表设计
在进行删除菜品操作时,会涉及到以下三张表。
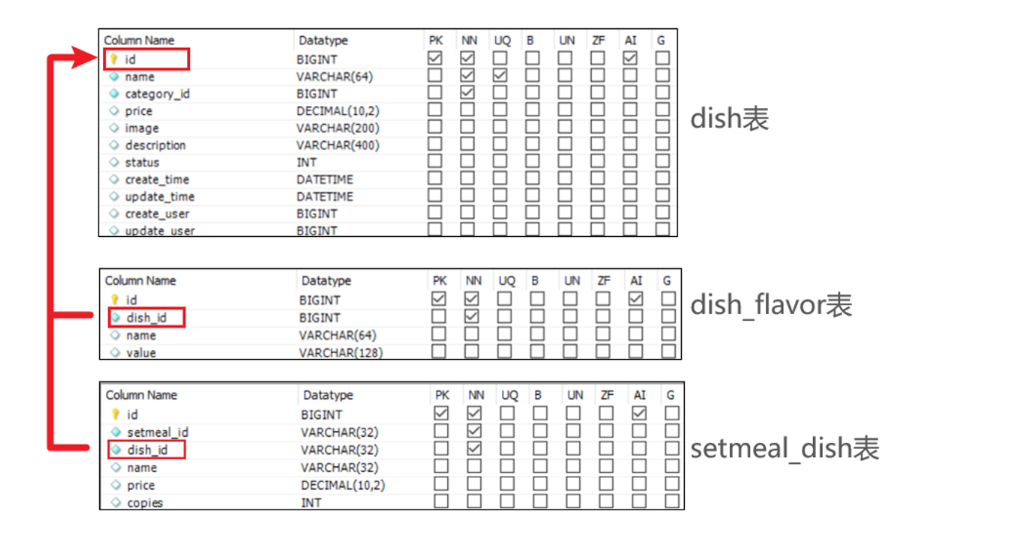
注意事项:
- 在dish表中删除菜品基本数据时,同时,也要把关联在dish_flavor表中的数据一块删除。
- setmeal_dish表为菜品和套餐关联的中间表。
- 若删除的菜品数据关联着某个套餐,此时,删除失败。
- 若要删除套餐关联的菜品数据,先解除两者关联,再对菜品进行删除。
注意事项:
- 在dish表中删除菜品基本数据时,同时,也要把关联在dish_flavor表中的数据一块删除。
- setmeal_dish表为菜品和套餐关联的中间表。
- 若删除的菜品数据关联着某个套餐,此时,删除失败。
- 若要删除套餐关联的菜品数据,先解除两者关联,再对菜品进行删除。
这个接口的开发中,我们可以学到对多张表的删除学习,这是我们之前从未体验过的
4.2 代码开发
4.1.2 Controller层
根据删除菜品的接口定义在DishController中创建方法:
/**
* 菜品批量删除
*
* @param ids
* @return
*/
@DeleteMapping
@ApiOperation("菜品批量删除")
public Result delete(@RequestParam List<Long> ids) {
log.info("菜品批量删除:{}", ids);
dishService.deleteBatch(ids);//后绪步骤实现
return Result.success();
}4.2.2 Service层接口
在DishService接口中声明deleteBatch方法:
/**
* 菜品批量删除
*
* @param ids
*/
void deleteBatch(List<Long> ids);4.2.3 Service层实现类
在DishServiceImpl中实现deleteBatch方法:
@Autowired
private SetmealDishMapper setmealDishMapper;
/**
* 菜品批量删除
*
* @param ids
*/
@Transactional//事务
public void deleteBatch(List<Long> ids) {
//判断当前菜品是否能够删除---是否存在起售中的菜品??
for (Long id : ids) {
Dish dish = dishMapper.getById(id);//后绪步骤实现
if (dish.getStatus() == StatusConstant.ENABLE) {
//当前菜品处于起售中,不能删除
throw new DeletionNotAllowedException(MessageConstant.DISH_ON_SALE);
}
}
//判断当前菜品是否能够删除---是否被套餐关联了??
List<Long> setmealIds = setmealDishMapper.getSetmealIdsByDishIds(ids);
if (setmealIds != null && setmealIds.size() > 0) {
//当前菜品被套餐关联了,不能删除
throw new DeletionNotAllowedException(MessageConstant.DISH_BE_RELATED_BY_SETMEAL);
}
//删除菜品表中的菜品数据
for (Long id : ids) {
dishMapper.deleteById(id);//后绪步骤实现
//删除菜品关联的口味数据
dishFlavorMapper.deleteByDishId(id);//后绪步骤实现
}
}4.2.4 Mapper层
在DishMapper中声明getById方法,并配置SQL:
/**
* 根据主键查询菜品
*
* @param id
* @return
*/
@Select("select * from dish where id = #{id}")
Dish getById(Long id);创建SetmealDishMapper,声明getSetmealIdsByDishIds方法,并在xml文件中编写SQL:
package com.sky.mapper;
import com.sky.entity.SetmealDish;
import org.apache.ibatis.annotations.Delete;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
@Mapper
public interface SetmealDishMapper {
/**
* 根据菜品id查询对应的套餐id
*
* @param dishIds
* @return
*/
//select setmeal_id from setmeal_dish where dish_id in (1,2,3,4)
List<Long> getSetmealIdsByDishIds(List<Long> dishIds);
}SetmealDishMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.sky.mapper.SetmealDishMapper">
<select id="getSetmealIdsByDishIds" resultType="java.lang.Long">
select setmeal_id from setmeal_dish where dish_id in
<foreach collection="dishIds" item="dishId" separator="," open="(" close=")">
#{dishId}
</foreach>
</select>
</mapper>在DishMapper.java中声明deleteById方法并配置SQL:
/**
* 根据主键删除菜品数据
*
* @param id
*/
@Delete("delete from dish where id = #{id}")
void deleteById(Long id);在DishFlavorMapper中声明deleteByDishId方法并配置SQL:
/**
* 根据菜品id删除对应的口味数据
* @param dishId
*/
@Delete("delete from dish_flavor where dish_id = #{dishId}")
void deleteByDishId(Long dishId);4.3 功能测试
既可以通过Swagger接口文档进行测试,也可以通过前后端联调测试,接下来,我们直接使用前后端联调测试。
进入到菜品列表查询页面
对测试菜品进行删除操作
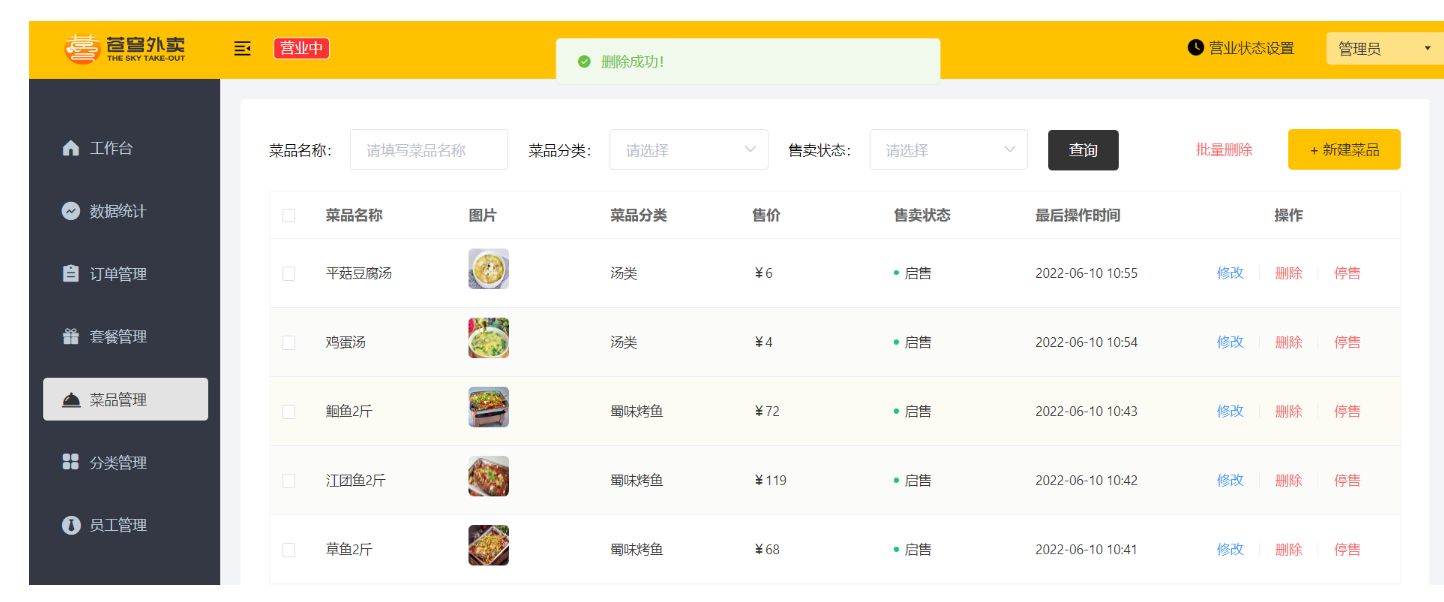
同时,进到dish表和dish_flavor两个表查看测试菜品的相关数据都已被成功删除。
再次,删除状态为启售的菜品
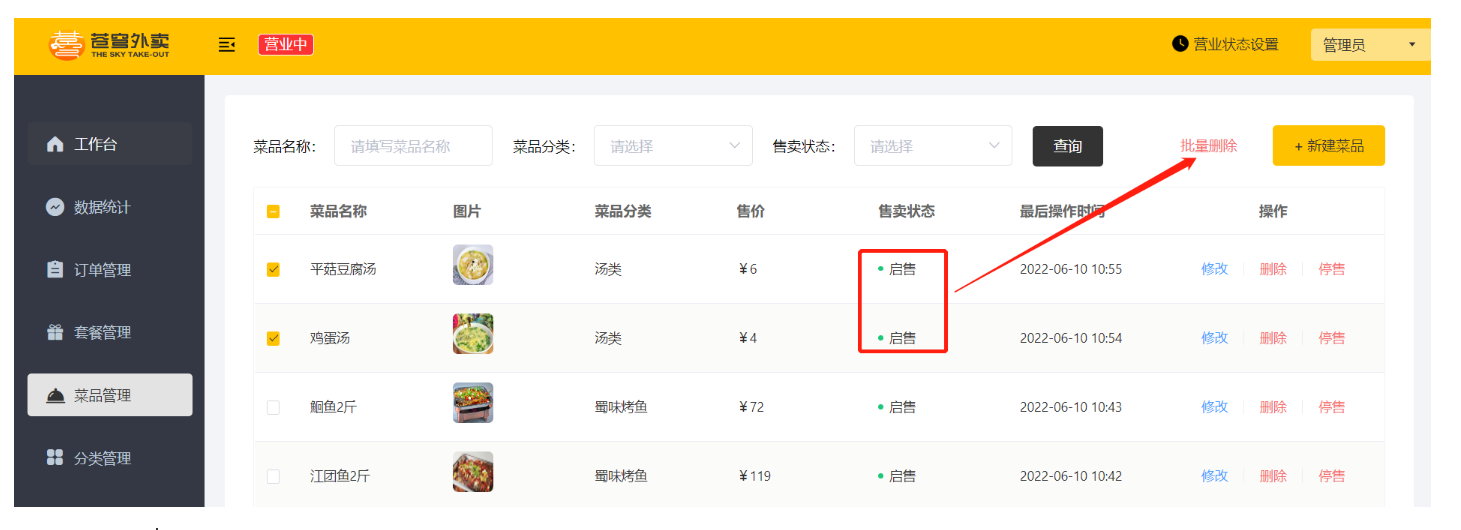
点击批量删除
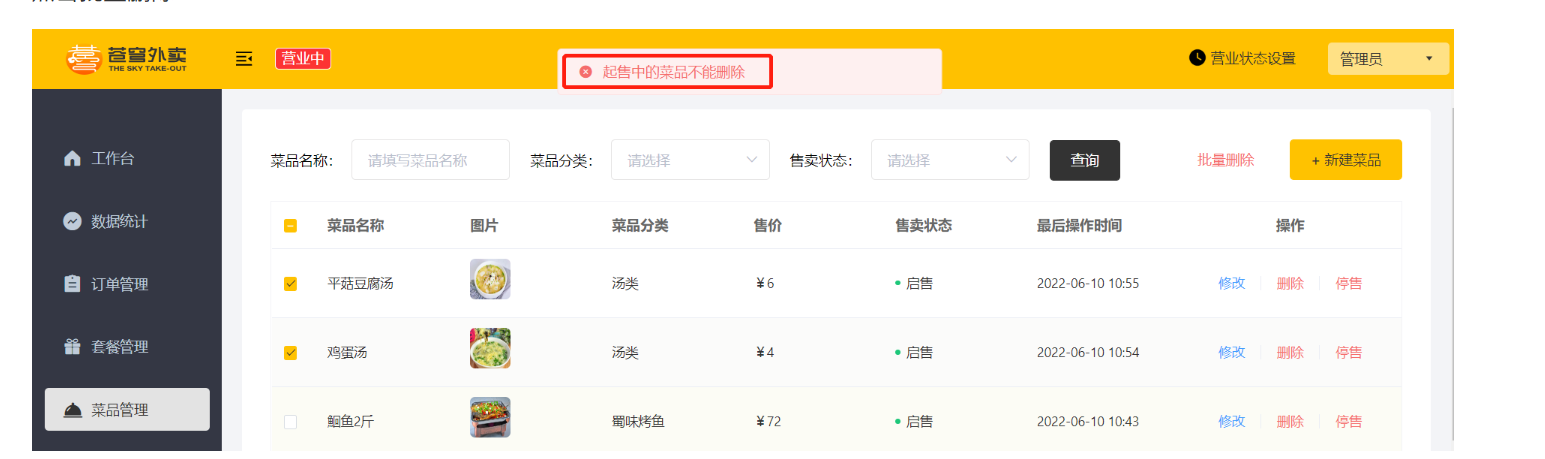
删除失败,因为起售中的菜品不能删除。
4.4 代码提交
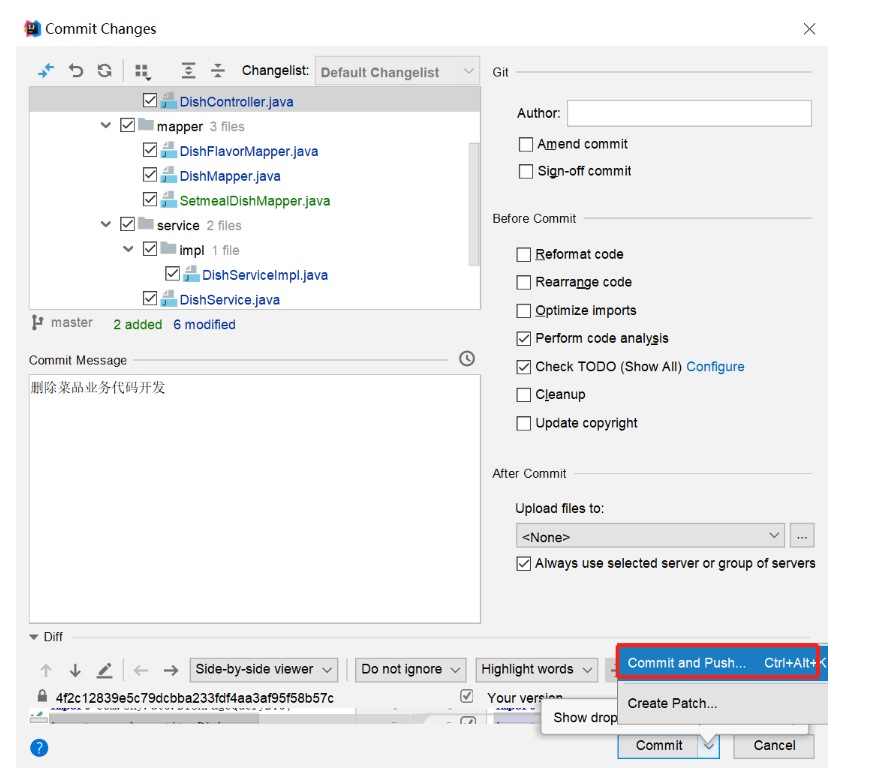
后续步骤和上述功能代码提交一致,不再赘述。