之前写过HKUDS(港大实验室)介绍。
DeepTutor
官网,HKUDS开源(GitHub,10.5K Star,1.4K Fork)集成文档问答、可视化讲解、智能出题、深度研究于一体的个人学习助手。
核心能力:
- 文档知识问答:多Agent问题求解能力
- 交互式可视化讲解:
- 智能出题与模拟
- 深度研究模式
部署
bash
docker run -d --name deeptutor \
-p 8001:8001 -p 3782:3782 \
-e LLM_MODEL=gpt-4o \
-e LLM_API_KEY=your-api-key \
-e LLM_HOST=https://api.openai.com/v1 \
-e EMBEDDING_MODEL=text-embedding-3-large \
-e EMBEDDING_API_KEY=your-api-key \
-e EMBEDDING_HOST=https://api.openai.com/v1 \
-v $(pwd)/data:/app/data \
-v $(pwd)/config:/app/config:ro \
ghcr.io/hkuds/deeptutor:latest浏览器打开http://localhost:3782开始体验;API文档在http://localhost:8001/docs。
Python示例:
py
import asyncio
from src.agents.solve import MainSolver
from src.agents.question import AgentCoordinator
async def main():
solver = MainSolver(kb_name="ai_textbook")
result = await solver.solve(
question="计算 x=[1,2,3] 和 h=[4,5] 的线性卷积",
mode="auto"
)
print(result['formatted_solution'])
asyncio.run(main())
async def main():
coordinator = AgentCoordinator(
kb_name="ai_textbook",
output_dir="data/user/question"
)
# 从文本需求生成多个题目
result = await coordinator.generate_questions_custom(
requirement_text="生成3道关于向量数据库的中等难度题目",
difficulty="medium",
question_type="choice",
count=3
)
print(f"✅生成{result['completed']}/{result['requested']}道题目")
for q in result['results']:
print(f"- 相关性: {q['validation']['relevance']}")Paper2Slides
GitHub,3.1K Star,418 Fork。
把生成PPT这件事做得更专业一些,基于专业论文生成PPT。
功能
- 通用文档支持:可同时无缝处理PDF、三件套、Markdown等多种文件格式;
- 全面的内容提取:RAG驱动机制确保每个关键见解、数字和数据点都能被精确捕获;
- 来源链接准确性:保持生成内容与原始来源之间的直接可追溯性,消除信息漂移;
- 自定义样式自由:从专业的内置主题中选择,或用自然语言描述您的想法以进行自定义样式设计;
- 闪电般快速的生成:即时预览模式可实现快速实验和实时改进;
- 无缝会话管理:高级检查点系统可保留所有进度,立即暂停、恢复或切换主题而不会丢失任何进度;
- 专业级视觉效果:提供符合出版质量标准的精美、可直接用于演示的幻灯片和海报;
优势:支持多worker并行生成,对长文档非常友好。
提供:
- 命令行工具,包括Docker、Conda部署,适合科研人员
- 网页使用方式,可降低使用门槛,适合学生群体
实战
bash
git clone https://github.com/HKUDS/Paper2Slides.git
cd Paper2Slides
conda create -n paper2slides python=3.12 -y
conda activate paper2slides
pip install -r requirements.txt启动Web界面:./scripts/start.sh,同时启动后端和前端服务,浏览器访问http://localhost:5173,开始体验。
命令行示例:
bash
python -m paper2slides --input paper.pdf --output slides --length medium
python -m paper2slides --input paper.pdf --output poster --style "minimalist with blue theme" --density medium
python -m paper2slides --input paper.pdf --output slides --fast
python -m paper2slides --input paper.pdf --output slides --parallel 2 # 启用并行生成,默认2个工作进程
python -m paper2slides --list # 列出所有已处理的输出支持的命令行参数:
| 选项 | 描述 | 默认值 |
|---|---|---|
--input,-i |
输入文件(夹)目录 | 必填 |
--output |
输出类型,支持:slidesorposter |
poster |
--content |
内容类型:paperorgeneral |
paper |
--style |
风格:academic,doraemon,orcustom |
doraemon |
--length |
页数长度:short,medium,long |
short |
--density |
Posterdensity:sparse,medium,dense |
medium |
--fast |
快速模式,跳过RAG检索 | false |
--parallel |
是否开启并行生成:--parallel表示使用2个worker,--parallel N表示使用N个worker |
1(sequential without this option) |
--from-stage |
Force restart from stage:rag,summary,plan,generate |
Auto-detect |
--debug |
是否开启调试日志 | false |
ViMax
GitHub,2.5K Star,445 Fork.。
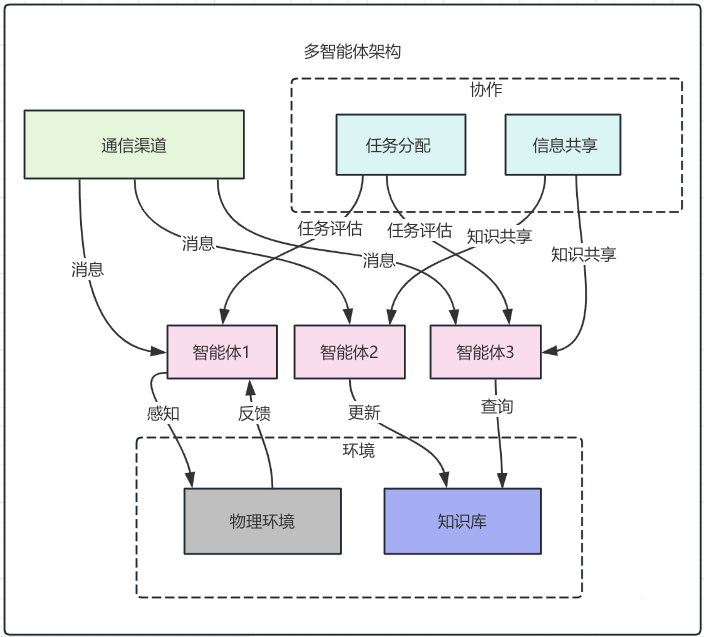
AI视频领域长期存在的"三秒魔咒"(长视频画面崩坏、角色不一致)仍未完全破解,香港大学数据智能实验室开源的ViMax(Agentic Video Generation)框架给出工程化答案,以多智能体协作架构复刻文本到视频的自动化创作逻辑,通过RAG、VLM视觉校验等技术直击长视频核心痛点,支持创意、小说、剧本生成及角色无缝植入四大模式,且开源可定制、支持本地部署。
提出一种区别于"训练更大模型"的工程化解法。不再试图用一个模型解决所有问题,而是构建一个多智能体协作系统。ViMax扮演"制片人"和"导演"的角色,调度LLM负责剧本,调度图像模型负责分镜,调度视频模型负责动态生成,并通过一致性校验机制将它们串联起来。
核心价值在于长程叙事控制,将模糊创意转化为精确的执行指令,并通过代理工作流(Agentic Workflow)解决长视频生成中的一致性难题。
四大核心应用模式:
- 创意到视频(Idea-to-Video):全自动化的叙事构建。自动化程度最高的模式,旨在将"一句话灵感"转化为"完整视频"。用户只需输入一个简单的脑洞,ViMax内置的编剧智能体(Screenwriter Agent)会自动扩写故事线,补充情节冲突;导演智能体会将其转化为分镜脚本,并自动调度图像和视频生成器完成制作。适用于快速原型验证、儿童故事生成或短视频创意测试,屏蔽复杂的提示词工程,让用户专注于创意本身。
- 小说到视频(Novel-to-Video):基于RAG的长文本改编。视频生成模型通常无法处理小说级别的长文本输入(Context Window限制)。系统分析长篇小说,识别关键情节与核心对话,将其转化为标准的分集视频脚本。通过RAG建立视觉资产索引,在生成第50个镜头时,系统能检索第1个镜头中主角的视觉特征,确保角色在长篇幅中不"换脸"。这是小说推文、有声书视觉化改编的杀手级功能。
- 剧本到视频(Script-to-Video):导演级的精准控制。对于专业创作者,允许直接输入行业标准的剧本格式。系统能解析专业剧本标记(如EXT. SCHOOL GYM - DAY)。不仅仅是理解文本,还能根据剧本中的镜头描述(如"特写"、"广角")来指导视频模型的运镜生成。适用于影视预演(Pre-viz)和专业广告分镜制作,创作者可以精确控制每一个镜头的调度。
- 智能客串(Smart Cameo):用户角色的无缝植入。一个极具互动性的功能,解决了"如何让自己进入AI电影"的问题。ViMax采用身份保持(Identity Consistency)技术。用户上传一张照片,系统会在生成过程中将该人物的视觉特征注入到每一个分镜中。与简单的后期换脸不同,这种方式能确保人物在不同光影、角度下与环境的融合更加自然。这适用于个性化视频贺卡、沉浸式互动视频、虚拟形象内容生产。
技术架构与运行原理
ViMax的本质是一个调度框架,而非单一生成模型,理解其架构有助于在部署时进行配置。
- 多智能体协作系统
ViMax模拟一个影视制作团队:中央调度(Central Dispatch)负责资源分配和流程控制;编剧智能体调用LLM(如Gemini)进行文本理解和剧本拆解;视觉智能体调用Image Generator(如Nano Banana)生成分镜首帧;视频智能体调用Video Generator(如Veo)基于首帧生成动态视频。
- 一致性保障机制
为了防止长视频崩坏,引入双重校验:视觉资产索引系统会维护一个Asset Bank,存储已生成的角色和场景图。生成新镜头时,会强制检索相关联的旧镜头作为参考(Reference Image)。VLM校验官在生成关键帧时,系统会并行生成多张备选图,并调用多模态大模型(VLM)像人类导演一样进行打分,剔除构图错误或角色不一致的画面。
对比
在AI视频生成工作流领域,除ViMax,市场上还有Oiioii、Seko、Moki等产品。将从产品形态、控制力及一致性方案三个维度进行客观对比。
| 对比项目 | 产品形态 | 一致性方案 | 可控性 | 部署难度 | 生成质量 | 适用人群 |
|---|---|---|---|---|---|---|
| ViMax | 开源代码框架,不含底模,需自行配置API,侧重架构与调度 | 代码级检索+VLM校验,通过逻辑强制检索历史帧,并用模型自动筛选 | 提供极高(White-box)控制,开发者可修改调度逻辑,更换底层模型(如换成GPT-4) | 高,需懂Python,需配置环境与API Key | 取决于接入的模型,上限由接入的API(如Veo)决定 | 适合开发者、管线工程师,需要搭建私有化、可定制的视频生产流水线 |
| Oiioii | 故事创作工具,侧重文本到视频流的转化体验 | 侧重叙事连贯,侧重于文本层面的剧情衔接 | 提供中等控制,依赖预设模版与参数或文本指令精度 | 低,注册账号或网页/App操作即可 | 流畅,侧重生成速度 | 适合网文/故事作者 |
| Seko | AI视频工具,侧重特定风格流与社区分享 | 采用风格迁移,通过强风格化滤镜掩盖细节瑕疵 | 提供中等控制,依赖预设模版与参数或文本指令精度 | 低,注册账号或网页/App操作即可 | 风格化强,特定风格表现好 | 适合C端娱乐用户 |
| Moki | 网页端SaaS,高度集成的在线工作台,开箱即用 | 使用角色库(Character Bank),用户预设角色,系统在生成时强制约束LoRA/Ref | 提供高(UI-based)控制,提供图形化的分镜调整、重绘功能 | 低,注册账号或网页/App操作即可 | 稳定,平台调优过的模型参数,有底线保证 | 适合产品经理、内容创作者,需要快速产出成品视频 |
分析结论:Moki/Seko/Oiioii是封装好的商业产品,体验好但黑盒化。ViMax是一个技术脚手架。它不提供算力,但提供了逻辑。对于希望拥有"源代码级"控制权,或者希望将最新的模型(如DeepSeek、Flux)整合进视频流的开发者来说,ViMax是不错的选择。
实战
本地部署,指在本地运行智能体调度代码,实际的图像和视频渲染依赖于配置文件中指定的API(默认为Google Gemini/Veo)。
支持Linux和Windows系统,官方推荐使用uv进行包管理,以避免Python依赖冲突。
bash
git clone https://github.com/HKUDS/ViMax.git
cd ViMax
uv syncViMax的运行完全依赖于configs/idea2video.yaml配置文件,需配置聊天模型(大脑,用于剧本生成和逻辑调度)、图像生成器(画师,用于生成分镜首帧)和视频生成器(摄影师,用于生成动态视频)。
yaml
chat_model:
init_args:
model: google/gemini-2.5-flash-lite-preview-09-2025
model_provider: openai
api_key:
base_url: https://openrouter.ai/api/v1
# Rate limits for chat model API calls
# Set to null to disable rate limiting for this service
max_requests_per_minute: 500
max_requests_per_day: 2000
image_generator:
class_path: tools.ImageGeneratorNanobananaGoogleAPI
init_args:
api_key:
max_requests_per_minute: 10
max_requests_per_day: 500
video_generator:
class_path: tools.VideoGeneratorVeoGoogleAPI
init_args:
api_key:
max_requests_per_minute: 2
max_requests_per_day: 10
working_dir: .working_dir/idea2video运行模式
- 创意生成视频(Idea-to-Video)
配置好YAML文件后,编辑项目根目录下的main_idea2video.py脚本,填入创意:
py
# 定义创意
idea = \"""If a cat and a dog are best friends, what would happen when they meet a new cat?"""
# 定义约束条件
user_requirement = \"""For children, do not exceed 3 scenes."""
# 定义风格
style = "Cartoon"执行生成:python main_idea2video.py。程序运行后,会看到控制台输出智能体的思考过程,最终生成的视频将保存在.working_dir/idea2video目录下。
- 剧本生成视频 (Script-to-Video)
如果有具体剧本,配置configs/script2video.yaml,编辑main_script2video.py:
py
script = \"""EXT. SCHOOL GYM - DAYA group of students are practicing basketball in the gym. The gym is large and open, with a basketball hoop at one end and a large crowd of spectators at the other end. John (18, male, tall, athletic) is the star player, and he is practicing his dribble and shot. Jane (17, female, short, athletic) is the assistant coach, and she is helping John with his practice. The other students are watching the practice and cheering for John.John: (dribbling the ball) I'm going to score a basket!Jane: (smiling) Good job, John!John: (shooting the ball) Yes!..."""
user_requirement = \"""Fast-paced with no more than 20 shots."""
style = "Animate Style"`执行生成:python main_script2video.py
ViMax的发布,为AI视频生成提供一个工业化样本。证明在底层模型能力尚未达到完美的今天,通过工程化的手段(Agentic Workflow),依然能构建出可用的长视频生产管线。不仅仅是一个工具,更是一个开源的多模态调度协议。
对于企业和开发者而言,最大价值在于其架构的可复用性。完全可以保留ViMax的调度逻辑,将底层的大脑换成DeepSeek,将画师换成Flux,将摄影师换成CogVideoX,从而搭建一套完全私有化、零API成本的自动化视频工厂。
FastCode
港大开源(GitHub,2K Star,220 Fork)的代码提速推理框架,效率是Cursor和Claude Code的三倍,但使用成本却比他们低50%。
核心:三段式框架:
- 让大模型读懂整个项目代码的骨架
- 根据指令精准定位与当前问题最相关的代码片段
- 成本感知,在有限的上下文窗口里筛选出含金量最高的上下文,交给大模型进行推理和回答,让大模型在面对庞大复杂项目时,依然能找得准、跑得快,还省钱。