
Introduction to Generative AI 2024 Spring
文章目录
- [1、第16講:可以加速所有語言模型生成速度的神奇外掛 --- Speculative Decoding(24.05.17)](#1、第16講:可以加速所有語言模型生成速度的神奇外掛 — Speculative Decoding(24.05.17))
- [2、Speculative Decoding](#2、Speculative Decoding)
-
- [🍔 用生活例子理解](#🍔 用生活例子理解)
- [⚡ 为什么能加速?](#⚡ 为什么能加速?)
- [🔥 autoregressive 不是一次只能出一个 token 吗?](#🔥 autoregressive 不是一次只能出一个 token 吗?)
- [🔧 实际中怎么用?](#🔧 实际中怎么用?)
- [🎯 怎么判断"预言家(小模型)靠不靠谱"?](#🎯 怎么判断“预言家(小模型)靠不靠谱”?)
- [🎯 什么时候效果最好?](#🎯 什么时候效果最好?)
- [⚙️ 工程里的关键优化点](#⚙️ 工程里的关键优化点)
- [🚀 GPU 上真实执行时间线(工程版)](#🚀 GPU 上真实执行时间线(工程版))
- [🧠 核心总结(超简单版)](#🧠 核心总结(超简单版))
- 3、举个例子
-
- [1. 实际中如何应用(工作流)](#1. 实际中如何应用(工作流))
- [2. 加速的原理:从 AR 变回并行](#2. 加速的原理:从 AR 变回并行)
- [3. 如何确定预言家(小模型)是否可靠?](#3. 如何确定预言家(小模型)是否可靠?)
- 4、推测解码验证流程图
-
- [1. 并行采样(Parallel Scoring)](#1. 并行采样(Parallel Scoring))
- [2. 逐位验证(Token Validation)](#2. 逐位验证(Token Validation))
- [3. 截断与修正(Truncation & Correction)](#3. 截断与修正(Truncation & Correction))
- [4. 奖励步(The Bonus Token)](#4. 奖励步(The Bonus Token))
- 5、参考
1、第16講:可以加速所有語言模型生成速度的神奇外掛 --- Speculative Decoding(24.05.17)

觉得现在语言模型还不够快吗?
+Speculative Decoding 后能提升 2~3 倍
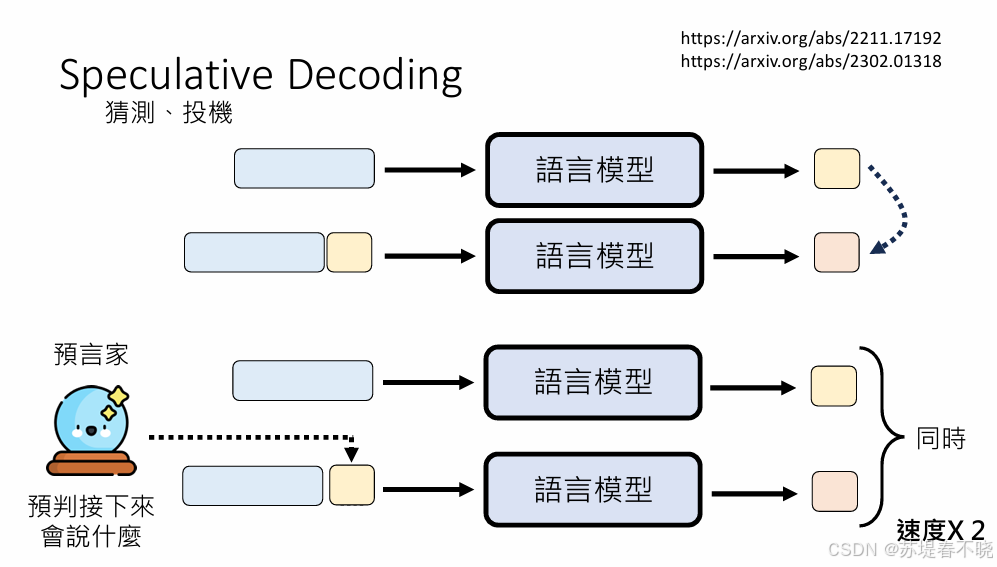
预言家,预判接下来会说什么
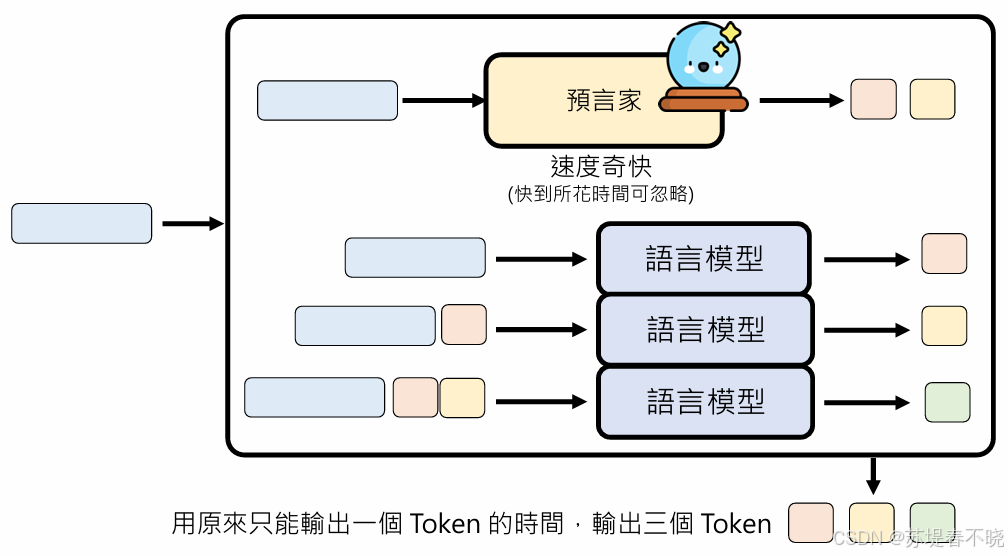
eg:用原来只能输出一个 token 的时间,输出三个 token
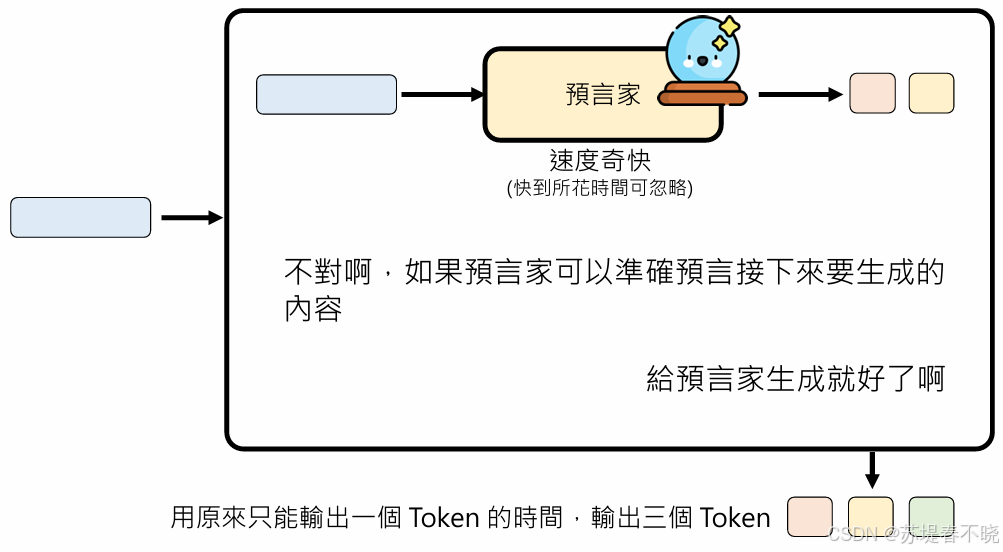
不对啊,如果预言家可以准确预研接下来要生成的内容,给预言家生成就好了啊?
预言家可能会犯错
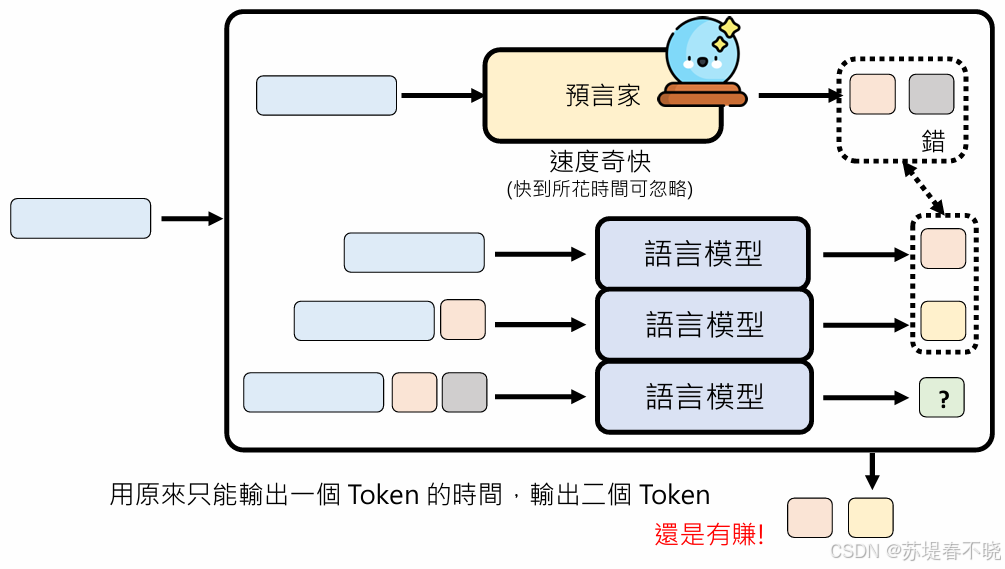
模型真正输出的结果,比对预言家的结果,一致保留,不一致也不亏,因为预言家很快
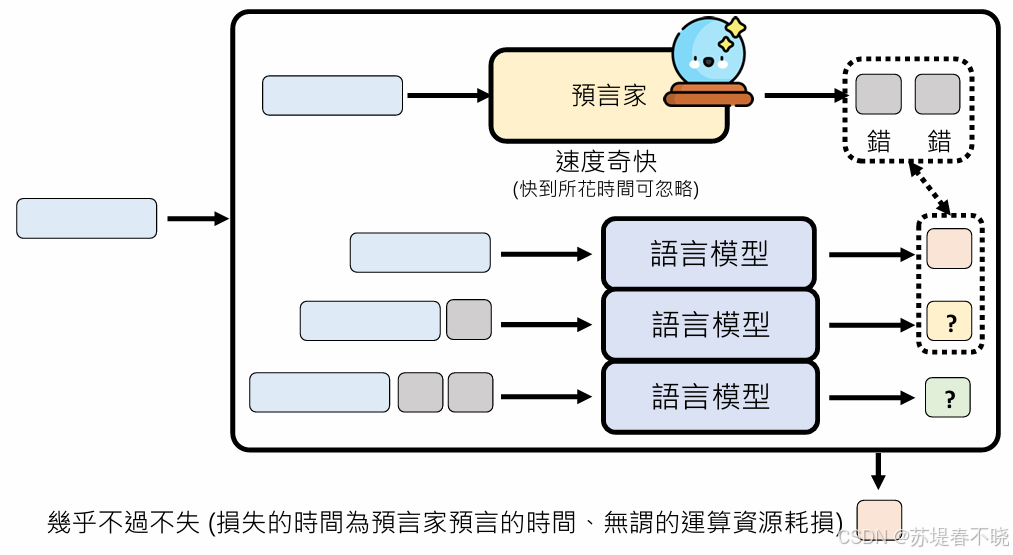
即使预言3个,错了2个,也仅仅损失预言家的时间,运算资源无谓的耗损
用运算资源换取运算时间
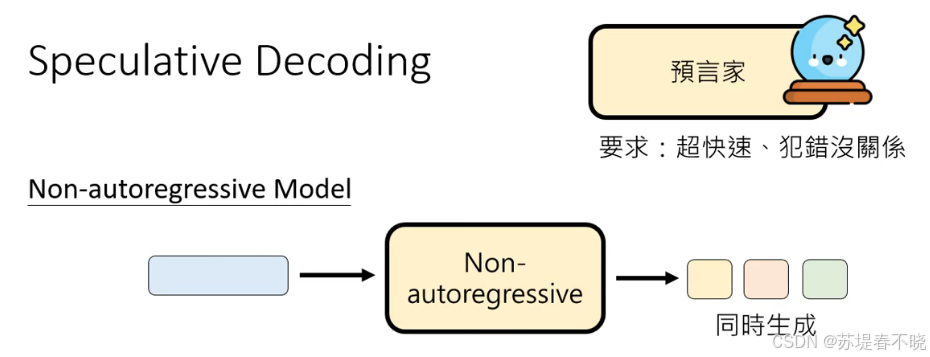
可以让 non-autoregressive model 当预言家,这样 speculative decoding 就是 AR 和 NAR 的结合
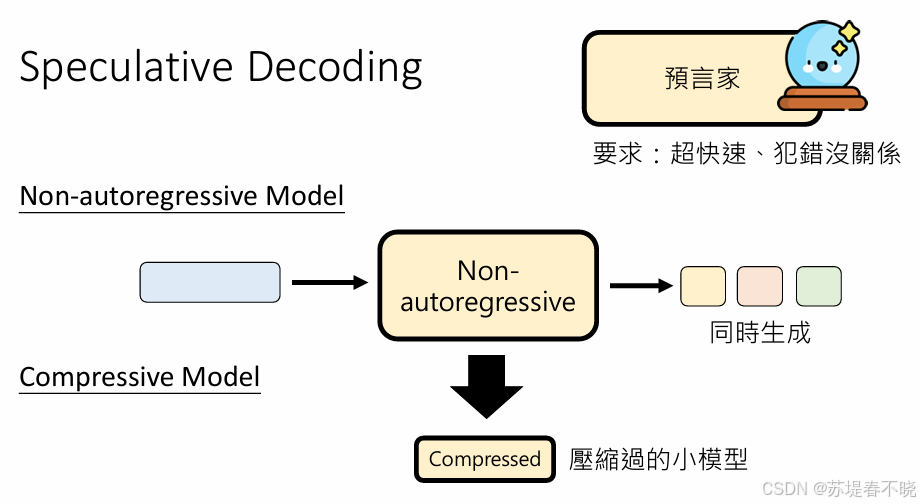
还可以用大模型压缩后的小模型来当预言家
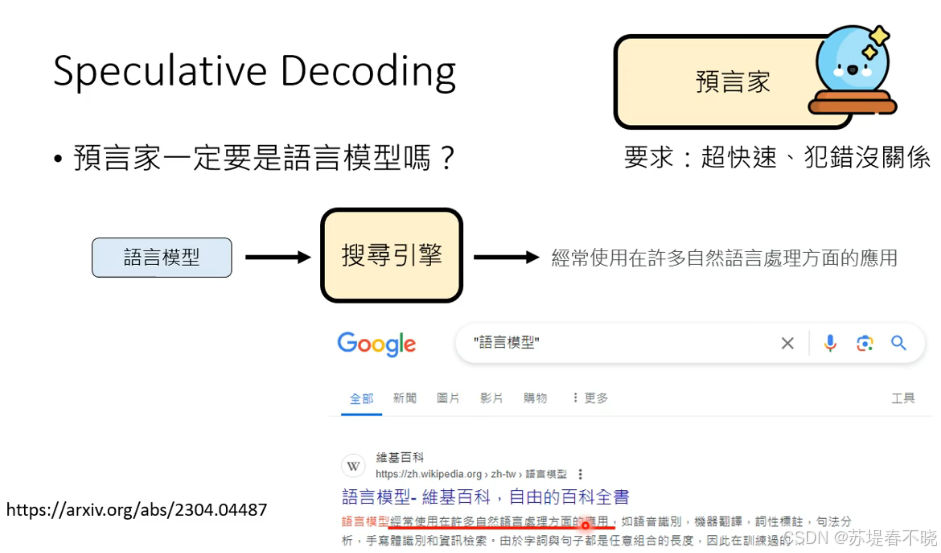
预言家一定要是语言模型吗?搜索引擎也可以是预言家
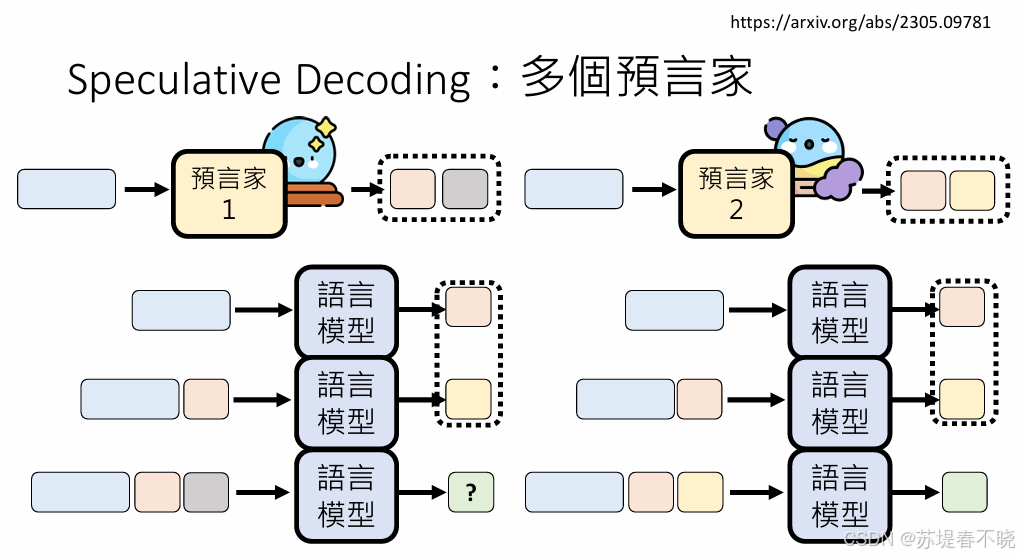
也可以有多个预言家
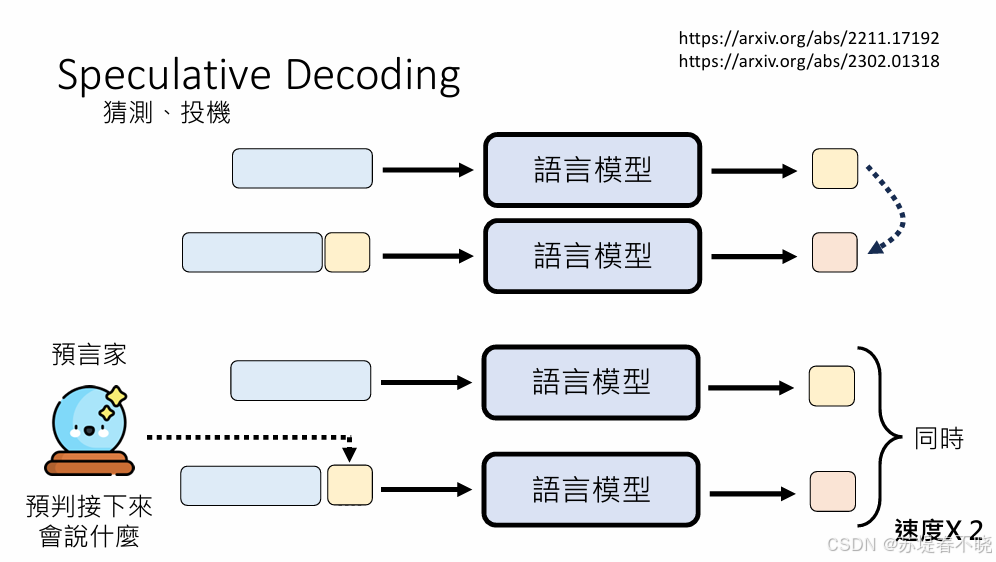
2、Speculative Decoding
👉 Speculative Decoding(猜测解码) 就是:
🤖 让一个"小模型先帮你猜答案",
🧠 再让"大模型快速检查对不对",
👉 对的就直接用,错的再重算
👉 这样就能更快!
🍔 用生活例子理解
想象你在写作业:
- 👶 小朋友(小模型)先快速写一版答案(猜)
- 👨🏫 老师(大模型)来检查
两种情况:
✅ 猜对了
老师看了一眼:
👉 "对的!"
✔ 不用重新写
✔ 直接通过
👉 省时间!
❌ 猜错了
老师说:
👉 "不对,重写"
✔ 只改错的地方
👉 比从头写快很多
⚡ 为什么能加速?
正常大模型是这样工作的:
text
一个字一个字慢慢生成👉 很慢 ❗
用了 Speculative Decoding:
text
小模型:一次猜 5 个字
大模型:一次检查 5 个字👉 就变成:
✔ 少调用大模型
✔ 一次处理更多内容
👉 速度直接提升 2~5 倍(甚至更多)
原来:
text
N tokens = N 次 forward现在:
text
N tokens ≈ N/K 次 forward👉 如果 K=4:
👉 理论加速 ≈ 4 倍(实际 2~3 倍)
🔥 autoregressive 不是一次只能出一个 token 吗?
❓ autoregressive 不是一次只能出一个 token 吗?
👉 对,但只对"生成"成立,不对"验证"成立
🟢 1. 生成(必须一步一步)
text
P(x1)
P(x2 | x1)
P(x3 | x1,x2)👉 必须按顺序
👉 因为不知道下一个 token
🔵 2. 验证(可以并行!)
现在我们已经有小模型给的:
text
y1, y2, y3, y4👉 注意:
👉 这些 token 已经"已知"了!
🎯 关键点来了!
大模型可以这样做:
👉 把整段一起喂进去:
text
[x0, y1, y2, y3]👉 一次 forward 输出:
text
P(y1 | x0)
P(y2 | x0,y1)
P(y3 | x0,y1,y2)
P(y4 | x0,y1,y2,y3)⚡ 为什么可以"一次算出来"?
因为 Transformer 本质是:
👉 并行计算所有位置的概率(teacher forcing)
🧠 Transformer 的秘密(核心理解)
在训练时,模型就是这样算的:
text
输入:我 爱 吃 苹果
输出:
P(爱 | 我)
P(吃 | 我爱)
P(苹果 | 我爱吃)👉 一次 forward 全算出来!
🧠 一个"最关键理解"(很多人卡这里)
👉 autoregressive 的限制在"未知 token",一旦 token 已知,就可以并行算概率
🔧 实际中怎么用?
在 AI 系统里一般这样做:
🟢 Step 1:小模型先生成
比如:
text
输入:今天天气很好,我想去
小模型:公园散步玩耍🟡 Step 2:大模型验证
大模型会:
👉 一个字一个字检查:
text
公 ✔
园 ✔
散 ✔
步 ✔
玩 ✔
耍 ❌(不太合适)🔴 Step 3:修正
👉 前面正确的直接用
👉 错的地方重新生成
🎯 怎么判断"预言家(小模型)靠不靠谱"?
主要看 3 件事:
🧩 1. 看通过率(命中率)
👉 小模型猜的内容:
- 90%都被接受 ✅ → 很靠谱
- 50%被打回 ❌ → 不靠谱
🧩 2. 看概率(置信度)
大模型会算:
text
这个词出现的概率高不高?👉 如果:
- 概率高 → 接受
- 概率低 → 拒绝
🧩 3. 连续接受长度
👉 一次能连续通过多少个 token:
- 连续通过很多 👉 小模型很强
- 经常被打断 👉 小模型很弱
🎯 什么时候效果最好?
👉 Speculative Decoding 最适合:
- 📚 自然语言(连续性强)
- 🧠 小模型和大模型"风格接近"
- 🔁 长文本生成
👉 效果差的情况:
- 🧮 数学推理(容易分歧)
- 🎯 精确生成(代码、符号)
- 🤯 小模型太弱
⚙️ 工程里的关键优化点
🟢 1. 一次验证多个 token(核心加速点)
👉 不是一个一个算,而是:
text
一次 forward = 验证 K 个 token👉 这就是为什么快
🟡 2. KV Cache 复用
👉 大模型不会重复计算历史:
text
只算新增 token👉 极大降低计算量
🔵 3. 动态调整 K(很关键)
👉 如果小模型很准:
text
K = 8 / 16👉 如果不准:
text
K = 2 / 4👉 自动平衡速度和浪费
🔴 4. 提前终止(Early Stop)
一旦发现错误:
text
立即停止验证后面的 token👉 避免浪费计算
🚀 GPU 上真实执行时间线(工程版)
先看没有 Speculative Decoding时:
text
时间 →
┌────────┬────────┬────────┬────────┐
│ forward│ forward│ forward│ forward│
│ token1 │ token2 │ token3 │ token4 │
└────────┴────────┴────────┴────────┘👉 每次 forward(大模型推理)
👉 只生成 1 个 token
❗ GPU 利用率其实不高(很多等待)
🚀 加了 Speculative Decoding 后
text
时间 →
┌──────────────────────┬──────────────────────┐
│ 小模型:生成 K=4 tokens │ 小模型:再生成 K=4 │
└──────────┬───────────┴──────────┬───────────┘
↓ ↓
┌────────────────────────────────────┐
│ 大模型:一次 forward 验证 4 个 token │
└────────────────────────────────────┘👉 关键变化:
- ❌ 原来:1 次 forward = 1 token
- ✅ 现在:1 次 forward = 验证 K 个 token
👉 GPU 一次干更多活 → 吞吐提升
🧠 核心总结(超简单版)
🎯 所以 Speculative 利用了什么?
👉 把"生成问题"变成"打分问题"
text
生成(慢) → 验证(快)👉 Speculative Decoding 就是:
text
先猜 → 再检查 → 对的直接用 → 错的再改👉 加速原因:
text
少用大模型,多用小模型👉 判断小模型好不好:
text
看猜对的比例高不高
text
小模型先猜一串
大模型逐个来审判
通过直接往前走
不对立刻重新算👉 核心本质:
加速的是"计算路径",不是"概率结果"
text
生成:必须串行(因为未知)
验证:可以并行(因为已知)👉 Speculative 做的就是:
text
用小模型把"未知 → 变已知"
再让大模型并行处理3、举个例子
用一个极小的模型先去"猜"后面几个字,再让大模型来一键"批改"。
1. 实际中如何应用(工作流)
在实际部署中,它通常包含两个角色:
- Draft Model(草稿模型/预言家):一个小模型(比如几亿参数),速度极快,但逻辑一般。
- Target Model(目标模型/主官):你想真正使用的大模型(比如几百亿参数),逻辑极强,但速度慢。
具体步骤:
- 小模型连猜 K K K 步 :小模型以 AR(自回归)方式快速吐出 K K K 个词(比如 4 个词)。
- 主模型一键审核 :主模型拿到这 K K K 个词,进行一次并行推理。
- 结果对比 :主模型判断小模型猜的前 N N N 个词是否符合自己的概率分布。
2. 加速的原理:从 AR 变回并行
还记得我们聊过的 AR(自回归) 为什么慢吗?因为它必须一个词一个词地蹦。
Speculative Decoding 的本质是利用了 GPU 的"算力闲置":
- 算力 vs 带宽:大模型推理通常受限于"显存带宽"而不是"计算算力"。在处理一个词时,GPU 大部分算力其实在"等"显存里的权重数据加载。
- 并行验证 :主模型验证小模型猜出来的 K K K 个词,在底层计算上只需要 一次 Forward 过程。
- 数学账单 :
- 没有投机:生成 4 个词需要主模型跑 4 次。
- 有投机:如果小模型全猜对了,主模型只跑了 1 次就生成了 4 个词。
- 即便小模型猜得全错,主模型也就跑了 1 次,并不亏多少(因为反正都要跑 1 次)。
3. 如何确定预言家(小模型)是否可靠?
这是这项技术最优雅的部分:拒绝采样(Rejection Sampling) 机制。
我们不需要在生成前判断它可不可靠,而是在生成的瞬间通过概率比对来验证:
- 接受概率 :设小模型预测下一个词的概率为 p ( x ) p(x) p(x),主模型的概率为 q ( x ) q(x) q(x)。
- 验证标准 :
- 如果 q ( x ) ≥ p ( x ) q(x) \ge p(x) q(x)≥p(x),主模型觉得"你猜的比我想的还要稳",直接接受。
- 如果 q ( x ) < p ( x ) q(x) < p(x) q(x)<p(x),主模型会以 q ( x ) p ( x ) \frac{q(x)}{p(x)} p(x)q(x) 的概率有条件接受。
- 截断机制:一旦某个词被主模型"毙掉"(判定为不可靠),它后面的词即便全对也会被扔掉,主模型会根据自己的概率分布重新纠正这一个词,然后开始下一轮投机。
4、推测解码验证流程图
推测解码(Speculative Decoding)的核心在于:"小模型(Draft Model)低成本试错,大模型(Target Model)高效率审核"。
eg:当小模型预测出"我"、"爱"、"吃"、"苹果"这四个词后,大模型会通过一次前向传播(Forward Pass)同时算出这四个位置的概率分布。
以下是其验证逻辑的流程图:
T1:我 (匹配)
T2:爱 (匹配)
T3:吃 (不匹配)
全部匹配
开始验证: 输入序列
小模型生成的推测序列:
T1:我, T2:爱, T3:吃, T4:苹果
大模型并行推理:
一次性输入 T1~T4
逐个位置对比概率
接受 T1
接受 T2
拒绝 T3及后续所有词
大模型采样修正:
根据 T1, T2 的 context 产出正确的 T3'
更新 KV Cache 并开始下一轮推测
接受 T1, T2, T3, T4
大模型额外产出下一个词 T5
1. 并行采样(Parallel Scoring)
大模型不会像小模型那样一个词一个词地蹦。它会将小模型给出的序列 x 1 , x 2 , x 3 , x 4 x_1, x_2, x_3, x_4 x1,x2,x3,x4 拼接到已知前缀后,作为一个 Batch 输入。
- 输入 :
[Prefix, 我, 爱, 吃, 苹果] - 大模型输出(Logits) :
- 在"我"的位置,预测下一个词的分布 P 1 P_1 P1
- 在"爱"的位置,预测下一个词的分布 P 2 P_2 P2
- 在"吃"的位置,预测下一个词的分布 P 3 P_3 P3
- 在"苹果"的位置,预测下一个词的分布 P 4 P_4 P4
2. 逐位验证(Token Validation)
大模型会拿自己的 P i P_i Pi 去看小模型选的词是否合理。通常使用拒绝采样(Rejection Sampling):
- 验证 T1 ("我") :看 P 1 P_1 P1 中"我"的概率。如果通过,继续;
- 验证 T2 ("爱") :看 P 2 P_2 P2 中"爱"的概率。如果通过,继续;
- 验证 T3 ("吃") :假设大模型认为这里应该是"喝",则 P 3 P_3 P3 指向"喝"的概率远高于"吃"。此时验证失败。
3. 截断与修正(Truncation & Correction)
一旦某个位置(如 T3)验证失败:
- 立即截断:即便 T4 ("苹果") 在语义上没错,但因为它建立在错误的 T3 基础上,大模型也会直接丢弃 T4。
- 修正输出 :大模型会直接给出它在 P 3 P_3 P3 位置采样出的正确词(比如"喝")。
4. 奖励步(The Bonus Token)
如果小模型预测的 k k k 个词全中了,大模型在验证完最后一个词 T k T_k Tk 的同时,其实已经算出了 T k + 1 T_{k+1} Tk+1 的分布。因此,大模型会额外多给一个词 。这意味着如果推测全对,一轮可以产出 k + 1 k+1 k+1 个词。