目录
- 一、进程间通信
-
- [1.1 为什么要进行进程间通信?](#1.1 为什么要进行进程间通信?)
- [1.2 如何进行进程间通信?](#1.2 如何进行进程间通信?)
- [1.3 管道](#1.3 管道)
-
- [1.3.1 什么是管道?](#1.3.1 什么是管道?)
- [1.3.2 匿名管道](#1.3.2 匿名管道)
- [1.4 深入理解管道](#1.4 深入理解管道)
- [1.5 系统调用 pipe](#1.5 系统调用 pipe)
- [1.6 代码验证](#1.6 代码验证)
- [1.7 一个进程控制一批进程](#1.7 一个进程控制一批进程)
个人主页:矢望
个人专栏:C++、Linux、C语言、数据结构、Coze-AI
一、进程间通信
我们之前学习进程的时候,知道进程之间的独立性很强,各自运行在隔离的内存空间中。那么如果进程之间要进行协同工作时该怎么办呢? 这时候就需要进行进程间通信来完成。
之前我们知道父子进程的数据是可以共享的,父进程的数据,子进程是可以看到的,那么为什么还要有进程间通信呢? 因为父子进程之间存在写时拷贝,所以父子进程之间是无法进行相互传递数据的。
1.1 为什么要进行进程间通信?
简单来说,进程间通信是为了让独立的进程能够安全、可控地交换数据和协同工作。
数据传输 :一个进程需要将它的数据发送给另一个进程。
资源共享 :多个进程之间共享同样的资源。
通知事件 :一个进程需要向另一个或一组进程发送消息,通知它们发生了某种事件,比如进程终止时要通知父进程。
进程控制 :有些进程希望完全控制另一个进程的执行,如Debug进程,此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
数据传输解决了物质交换;资源共享解决了空间利用;通知事件解决了行动协调;进程控制解决了集中管理。
1.2 如何进行进程间通信?
进程进程间通信的本质是要让不同的进程看到同一份资源,也就是不同的进程要看到同一份内存块 。
进程之间是具有独立性的,进程A中,进程B中自己的资源它们相互看不到。所以这个资源,这个内存块只能有操作系统来提供,而进程是不能直接从操作系统中获取数据的,所以要进行进程间通信,肯定有对应的系统调用。
所以在精确一点:进程间通信的本质,就是通过操作系统提供的系统调用,让隔离的进程能够安全地访问同一份由内核管理的资源,从而打破独立性带来的壁垒,实现数据交换和协同工作。
1.3 管道
1.3.1 什么是管道?
管道是类Unix中最古老的进程间通信的形式。我们把从一个进程连接到另一个进程的一个数据流称为一个管道。
1.3.2 匿名管道
现在呢,我们有一个进程,它在内存中打开了一个磁盘上的文件,操作系统将它加载到了内存中,这个文件有自己的struct file结构体,有自己的文件描述符。后来这个进程fork()创建了子进程,所以这个子进程就需要以父进程为模版,进行子进程PCB的创建工作,将task_struct和文件描述符表都复制过去了,那么struct file结构体要不要复制呢? 它是要的,只不过struct file结构体指向的文件内容(如inode,操作表,文件内核级缓冲区),不需要给子进程拷贝。如下图所示。
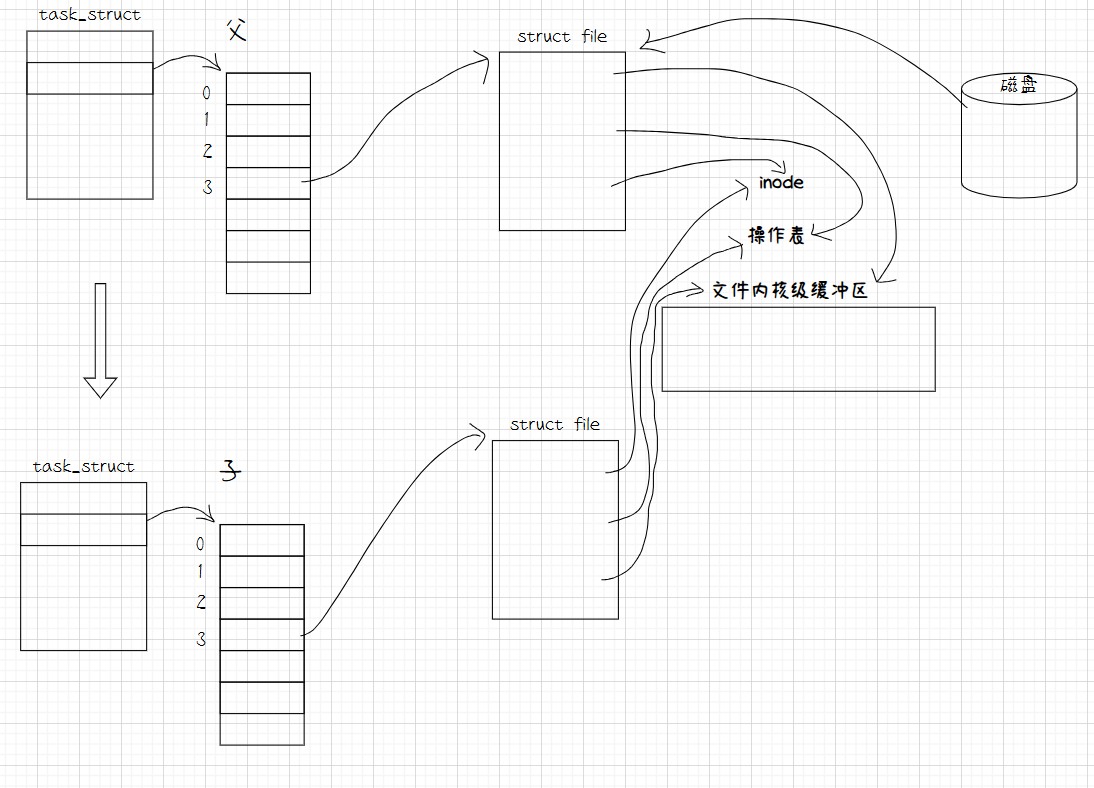
所以父子进程现在同时指向了同一个资源,那么将来子进程向这个文件的内核级缓冲区写数据,父进程就可以看到了。这就满足了形成进程间通信的基本条件。
所以管道是基于文件进行内核级进程间通信。
当然两个进程之间进行通信,它们的通信内容能够传输即可,不需要向磁盘进行写入,也不需要磁盘这个角色,同时也不需要文件的多余结构的出现,它只是需要一块内核级缓冲区。
所以真实的情况是这样的。
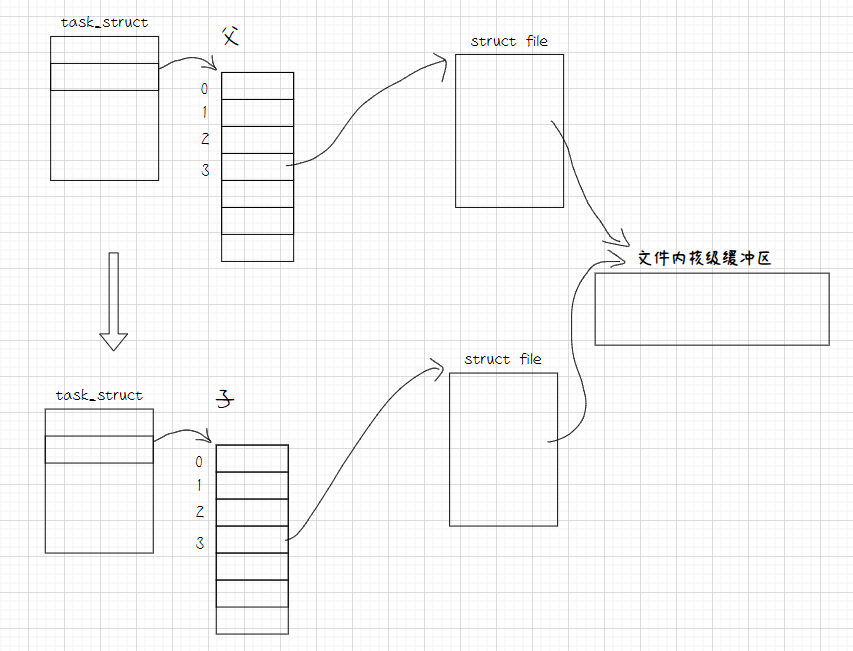
实际上,上面子进程的struct file结构体也不需要复制,父进程fork()后不需要复制 struct file 结构体本身。内核的做法是:将父进程的文件描述符表整张复制给子进程,这使得子进程的描述符指向了内核中同一个 struct file 对象。同时,内核会将这个 struct file 的引用计数增加1。这样,只有当所有指向它的文件描述符都关闭时,这个内核对象才会被回收。
需要我们注意的是,管道是单向通信的,也叫做单工通信 。补充 :单工通信 是一方讲,另一方听,例如看视频;全双工通信 是两方同时在讲,同时在听,例如吵架的时候;半双工通信是一方讲的时候另一方在听,两方的角色可以互换,是人类的正常沟通模式。
由于只能进行单向通信,所以我们把这种通信模式叫做管道。由于不需要磁盘文件,也就不需要路径+文件名找文件,所以我们才把这种管道叫做匿名管道。
所以管道是一个内存级的文件,不需要打开磁盘文件之类的,没有路径,也不需要路径名,所以它是匿名管道。
1.4 深入理解管道
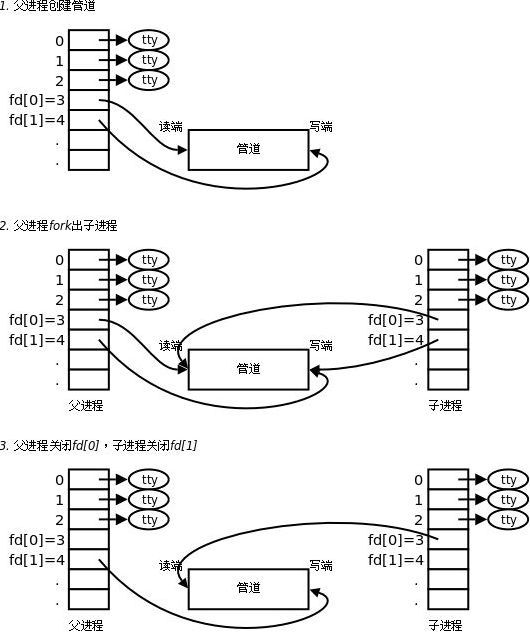
如上就是管道的创建部分,很容易看懂。首先,父进程以同时读写的方式打开匿名管道,然后父进程fork()创建子进程,子进程也就以同时读写的方式同时看到文件了,这样在依据读写的场景,让父子进程合理的关掉读或写端,这样就形成了单向信道,能够进行通信了。
那么父进程为什么要以同时读写的方式打开一个文件呢?以只读或者只写不行吗? 如果是只读或只写,那么之后子进程也和父进程拥有的读写端一样,都是只读或只写,那这样是无法进行通信的呀,所以同时也读写的方式打开一个文件是为了方便让子进程也能同时看到读写。
为什么最后要关掉对应的读写端呢? 其实不关闭也可以的,只不过它容易进行误操作另一个你不适用的一端,所以建议关闭掉对应的读写端。
所以,看待管道,就像看待文件一样,管道的使用和文件一致,这也迎合了Linux下一切皆文件的思想。
1.5 系统调用 pipe
那么上面说的操作具体要怎么做呢? 那就需要用到系统调用pipe了。
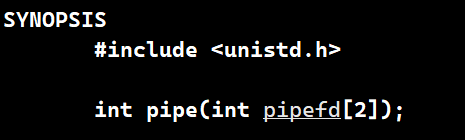
这个系统调用的参数是输出型参数,当你调用系统调用打开一个文件的时候,它的读写端会被返回,其中fd[0]一般存储的是读端r的文件描述符,fd[1]一般存储的是写端w的文件描述符。

关于它的返回值:

成功返回0,失败返回-1,并设置错误码。
1.6 代码验证
我们要实现的是子进程执行的是写入工作w,父进程执行的是读取工作r。
说明一下,接下来,写代码的平台是VSCode+云服务器。
要进行代码验证首先要执行的工作就是创建管道文件。
先完成一下Makefile。

c
#include <stdio.h>
#include <unistd.h>
int main()
{
int pipefd[2] = { 0 }; // 创建一个数组接收读写端的文件描述符
int r = pipe(pipefd);
if(r < 0) // 如果执行失败
{
perror("pipe");
return 1;
}
// 打印输出两个文件描述符
printf("pipefd[0]: %d, pipefd[1]: %d\n", pipefd[0], pipefd[1]);
return 0;
}如上,上面的代码,简单使用pipe系统调用创建出了管道文件,接下来,我们编译运行,看看文件的读写端的文件描述符。
编译运行 :
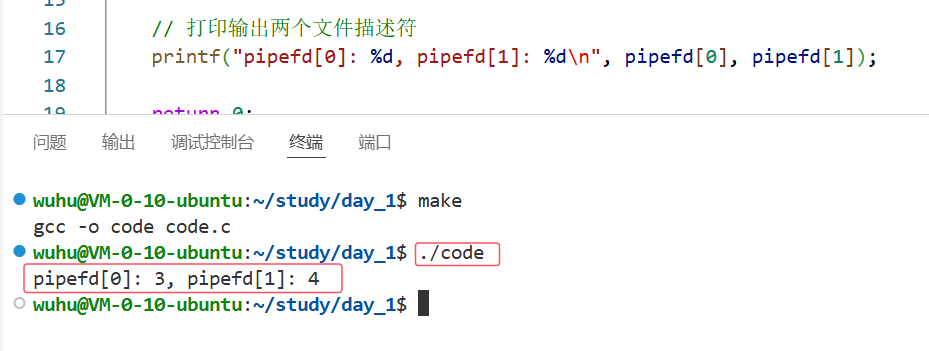
如上,文件描述符0、1、2被占用,我们形成的管道文件占用3、4符合预期。
形成匿名管道之后,接下来就是fork创建子进程,让子进程执行写工作,父进程进行读工作。也就是子进程需要关闭pipefd[0],而父进程需要关闭pipefd[1]。
这里我们要将需要给父进程发送的消息写入到一个数组中然后再将信息写入到管道文件中,让父进程时刻进行读取。所以我们需要用到snprintf、write、read。
下面是创建子进程并进行通信的核心代码。
cpp
// 创建子进程
pid_t id = fork();
if (id == 0)
{
// 子进程
close(pipefd[0]);
char outbuffer[1024];
const char *c = "hello world!";
int cnt = 9;
while (cnt)
{
// 将消息写到数组中再写入管道中
snprintf(outbuffer, sizeof(outbuffer), "子->父:%s, cnt: %d, pid: %d\n", c, cnt--, getpid());
write(pipefd[1], outbuffer, strlen(outbuffer));
sleep(1);
}
exit(0);
}
// 父进程
close(pipefd[1]);
while (1)
{
char inbuffer[1024];
ssize_t n = read(pipefd[0], inbuffer, sizeof(inbuffer) - 1); // 给 '\0' 留出一个位置
if (n > 0)
{
inbuffer[n] = '\0';
printf("%s", inbuffer);
}
else if(n == 0) // 读到文件结尾
{
printf("read pipe end of file!\n");
break;
}
else
{
perror("read");
break;
}
}如上,当读端读完管道的数据后,再读就会读到空,表明读到结尾,返回值n就是0了。
编译运行:
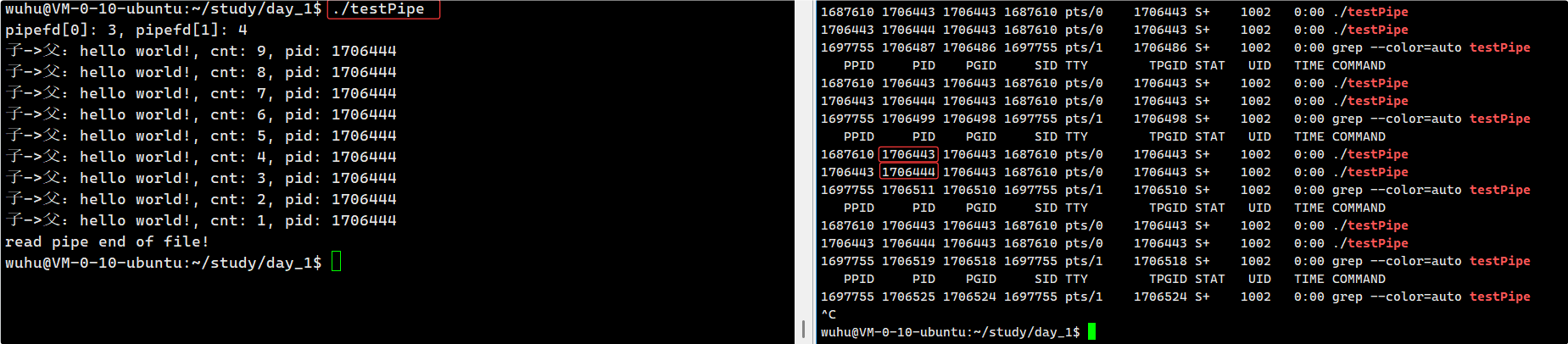
如上图,父子进程通过匿名管道通信成功了,父进程读到了来自子进程发送的数据。
总结 :匿名管道只能用来单向通信(单工通信)。
我们看到一个进程fork创建出子进程,和这个进程有血缘关系的进程都能看到同一个文件描述符表,也就是都能看到同一份匿名管道,所以匿名管道只能用来进行具有血缘关系的进程之间的通信。
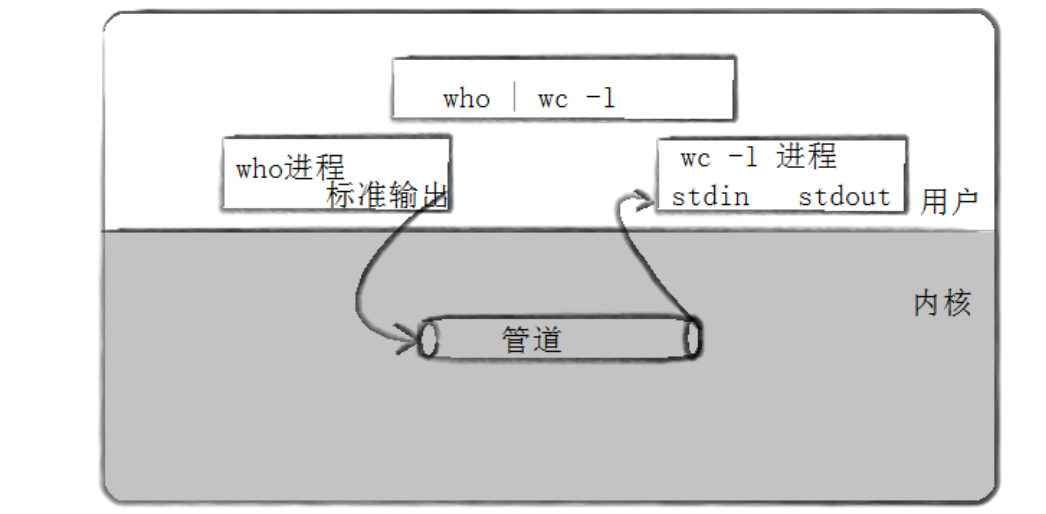
我们在Linux下运行的一条条指令,最终都会变成进程,指令使用|连接本质就是具有血缘关系的进程通过匿名管道进行通信 。如下。

三个指令最后就变成了三个具有血缘关系(兄弟关系)的进程通过匿名管道进行通信,它们的父进程都是bash进程。
管道是面向字节流的 。管道不管你写的是什么数据,字符串也好,图片也好,它都可以,所以管道是面向字节的。面向字节流最核心的含义是:写入和读取的次数没有必然联系,数据之间没有天然的间隔或边界。
上面我们的子进程写入和父进程的读取都是很有规律的,所以我们感知不出来,现在我们变动一下。
cpp
// 创建子进程
pid_t id = fork();
if (id == 0)
{
// 子进程
close(pipefd[0]);
char outbuffer[1024];
char *c = "hello world!";
int cnt = 20;
while (cnt)
{
// 将消息写到数组中再写入管道中
snprintf(outbuffer, sizeof(outbuffer), "子->父:%s, cnt: %d, pid: %d\n", c, cnt--, getpid());
write(pipefd[1], outbuffer, strlen(outbuffer));
if(cnt % 3 == 0) // 打乱子进程的输入速率
sleep(1);
}
exit(0);
}
// 父进程
close(pipefd[1]);
char inbuffer[1024];
int sum = 0;
while (1)
{
// 打乱父进程的读取速率
sum++;
if(sum % 3 != 0)
{
sleep(1);
continue;
}
ssize_t n = read(pipefd[0], inbuffer, sizeof(inbuffer) - 1); // 给 '\0' 留出一个位置
if (n > 0)
{
inbuffer[n] = '\0';
printf("%s\n", inbuffer); // 添加换行符,区分每次的读取
}
else if(n == 0) // 读到文件结尾
{
printf("read pipe end of file!\n");
break;
}
else
{
perror("read");
break;
}
}如上,我们将它们的写入和读取的速率都变一下看看是什么结果。
编译运行 :
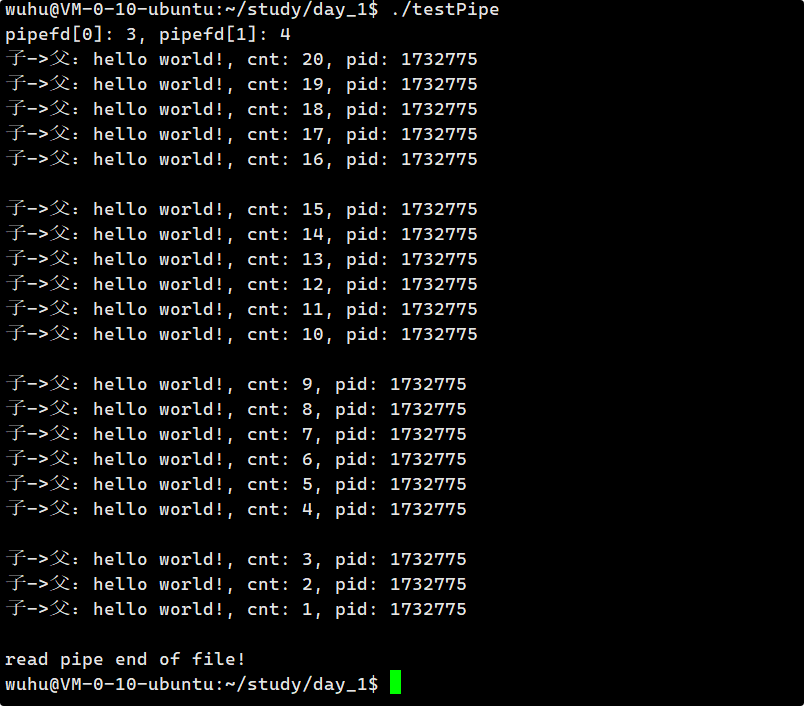
如上,并不是说子进程写一条消息,父进程就要读一条。写十次不一定非要读十次。
简而言之,管道就像一根水管,数据像水流一样在里面连续流动。发送方可以一杯一杯地倒水,接收方可以一桶一桶地接水。只要保证数据的先后顺序不变,双方完全不需要协调倒水和接水的节奏与分量。这正是它被称为流的原因,它像水流一样连续、无边界、有序,且读写完全异步。
所以管道是面向字节流的。
那么当父进程不再从匿名管道中读数据,子进程不再向匿名管道中写数据,这个匿名管道会释放吗?
对于文件而言,它的inode属性中有一个引用计数的东西,当有一个进程指向它,它的引用计数就要加一,当它的引用计数降到零时,它就要被释放掉了,所以打开的文件的生命周期随进程 。而管道也是文件,所以管道的生命周期随进程。
如果子进程写的慢,那么父进程会如何呢?
cpp
// 创建子进程
pid_t id = fork();
if (id == 0)
{
// 子进程
close(pipefd[0]);
char outbuffer[1024];
char *c = "hello world!";
int cnt = 20;
while (cnt)
{
sleep(10);
// 将消息写到数组中再写入管道中
snprintf(outbuffer, sizeof(outbuffer), "子->父:%s, cnt: %d, pid: %d\n", c, cnt--, getpid());
write(pipefd[1], outbuffer, strlen(outbuffer));
}
exit(0);
}
// 父进程
close(pipefd[1]);
char inbuffer[1024];
int sum = 0;
while (1)
{
ssize_t n = read(pipefd[0], inbuffer, sizeof(inbuffer) - 1); // 给 '\0' 留出一个位置
if (n > 0)
{
inbuffer[n] = '\0';
printf("%s\n", inbuffer); // 添加换行符,区分每次的读取
}
else if(n == 0) // 读到文件结尾
{
printf("read pipe end of file!\n");
break;
}
else
{
perror("read");
break;
}
}如上,子进程每隔十秒向管道写一条数据。
编译运行:
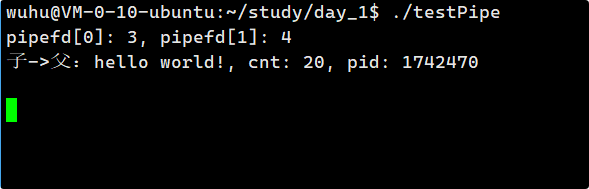
如上,运行结果显示,父进程等了十秒,获取了子进程写的一条数据,也就是父进程在等待子进程,也就是父进程阻塞住了,那么为什么呢?
管道通信,对于多进程而言是带有互斥与同步机制的。
管道通信的前提是让不同的进程看到同一份资源(内存块),如果子进程在向管道中写数据,它才写了一半,父进程就瞬间将这一半数据读走了,那么此时就出现问题了,这叫做由于并发访问所导致的问题。
而什么是互斥呢? 就是任何时刻只允许一个人访问资源。同步是访问数据具有一定的顺序性,而不是它们同时去争夺一份资源。
如何证明带有互斥和同步机制呢?
对于互斥,我们可以同时创建三个进程,让它们同时向一个管道文件写数据,观察父进程读出的数据是不是乱的。如果完整且有序说明每条消息内部的数据是连续的,不会被其他进程的数据打断。这就是互斥机制。
cpp
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
#include <string.h>
int main()
{
int pipefd[2];
pipe(pipefd);
// 创建3个子进程同时写入
for (int i = 0; i < 3; i++)
{
if (fork() == 0)
{
close(pipefd[0]); // 子进程关闭读端
char msg[100];
// 每个子进程写50次,每次写入固定格式的字符串
for (int j = 0; j < 50; j++)
{
snprintf(msg, sizeof(msg), "进程%d的第%d条消息\n", i, j);
write(pipefd[1], msg, strlen(msg));
// 故意不加延时,让它们疯狂写入
}
exit(0);
}
}
// 父进程关闭写端,开始读取
close(pipefd[1]);
char buffer[1024];
ssize_t n;
while ((n = read(pipefd[0], buffer, sizeof(buffer) - 1)) > 0)
{
buffer[n] = '\0';
// 直接打印,观察消息是否完整
printf("%s", buffer);
}
// 等待所有子进程结束
while (wait(NULL) > 0);
return 0;
}编译运行 :
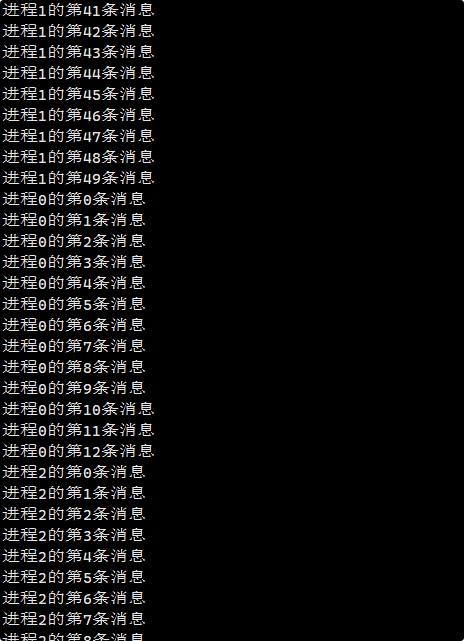
如上,父进程读到的数据是完整且有序的,证明了互斥机制。
证明同步机制,让子进程一直写,父进程不读。
匿名管道是有大小的,如下可以通过man 7 pipe查看。
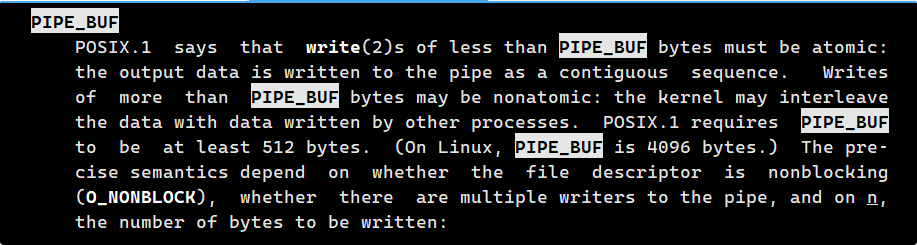
上面主要说了
原子性边界 :PIPE_BUF 是内核保证单次 write 操作原子性的最大尺寸。在你的代码中,每次写入的消息长度远小于 4096 字节,所以内核保证每次写入都是一次性完整完成的,这正是管道互斥机制的体现。
非原子情况 :如果一次写入超过 4096 字节,内核可能会将其拆分成多个数据块进行传输。这时如果有多个进程同时写入,这些数据块就可能相互交织,导致接收方读到乱序或交错的数据。
多种影响因素:最终行为还取决于是否设置了非阻塞标志、并发写入的进程数量以及具体的数据量。
上面说的我们先不管,它说了管道的大小是65536字节也就是64KB。
接下来,我们让父进程休眠一段时间,子进程疯狂写,并把写的字节数打印出来。
cpp
// 创建子进程
pid_t id = fork();
if (id == 0)
{
// 子进程
close(pipefd[0]);
char ch = 'c';
int size = 0;
while(1)
{
write(pipefd[1], &ch, 1);
size++;
printf("%d\n", size);
}
exit(0);
}
// 父进程
close(pipefd[1]);
char inbuffer[1024];
int sum = 0;
while (1)
{
sleep(100);
ssize_t n = read(pipefd[0], inbuffer, sizeof(inbuffer) - 1); // 给 '\0' 留出一个位置
if (n > 0)
{
inbuffer[n] = '\0';
printf("%s\n", inbuffer); // 添加换行符,区分每次的读取
}
else if(n == 0) // 读到文件结尾
{
printf("read pipe end of file!\n");
break;
}
else
{
perror("read");
break;
}
}编译运行 :

如上子进程,写满匿名管道之后就停下来了,子进程阻塞了。并且我们看到管道的大小的确是65536字节也就是64KB。
管道为空,读端阻塞,给写机会;管道写满,写端阻塞,给读机会。这就是同步。
如果写端一直写,但读端不读,并且读端还把相关读的文件描述符关闭了,那么写端会怎样?
cpp
// 创建子进程
pid_t id = fork();
if (id == 0)
{
// 子进程
close(pipefd[0]);
char outbuffer[1024];
char *c = "hello world!";
int cnt = 20;
while (cnt)
{
sleep(10);
// 将消息写到数组中再写入管道中
snprintf(outbuffer, sizeof(outbuffer), "子->父:%s, cnt: %d, pid: %d\n", c, cnt--, getpid());
write(pipefd[1], outbuffer, strlen(outbuffer));
}
exit(0);
}
// 父进程
close(pipefd[1]);
close(pipefd[0]);
sleep(10);
int status = 0;
pid_t rid = waitpid(id, &status, 0);
if(rid > 0)
{
printf("quit_code: %d, signal: %d\n", (status >> 7) & 0xFF, status & 0x7F);
}上面代码,我们获取了子进程的退出信息,包括退出码和退出信号。
编译运行 :
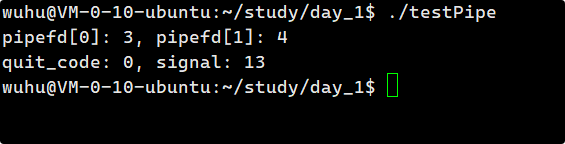
如上,退出信号是13,它是什么呢?
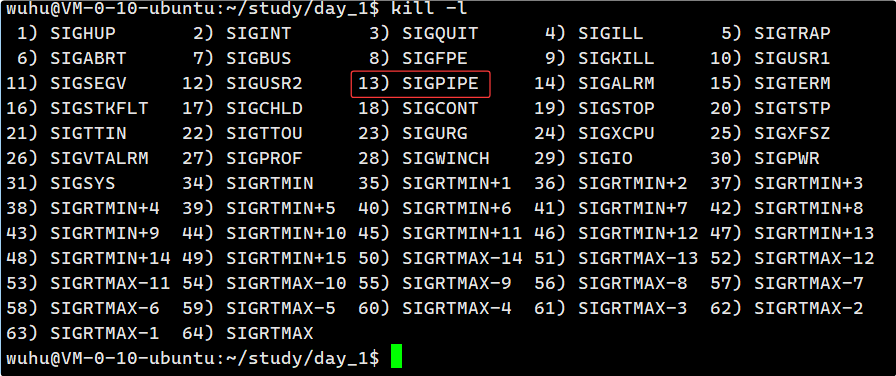
当一个进程试图向一个读端已经被关闭的管道写入数据时,内核会向该写入进程发送 SIGPIPE 信号。也就是管道破裂,没有读端,写端继续写,OS终止进程。
1.7 一个进程控制一批进程
那么将来一个进程可以提前fork创建出一批子进程,由父进程担任各个管道的写端,由子进程担任各个管道的读端,当父进程没有写入数据时,由上面的互斥规则,所以子进程就会阻塞在那里。当父进程向管道中写入数据时,子进程就会被唤醒,读取父进程发送的内容。
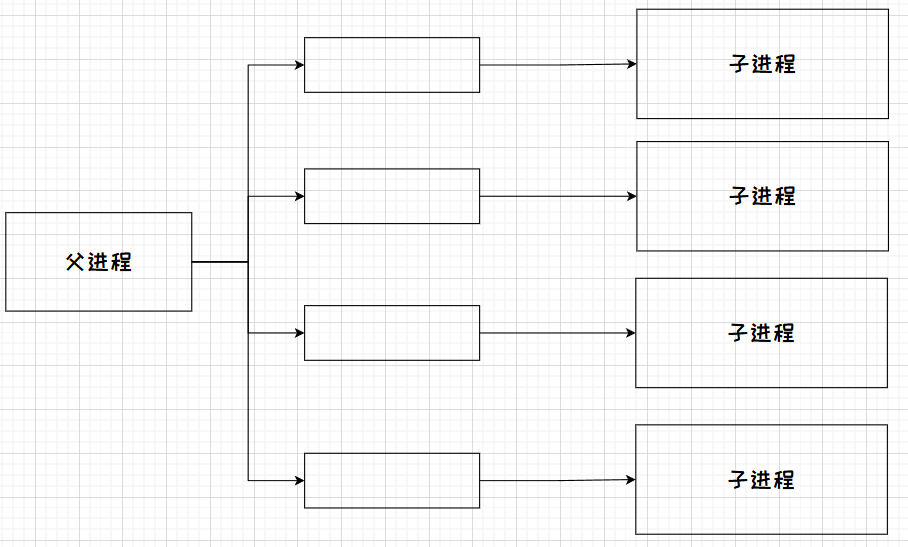
如上图,父进程不写时,子进程都在待命。将来父进程可以通过管道向子进程派发一个个任务,让子进程去执行,这种模式叫做Master Slaver主从模式 。
这就是主从模式的进程池 ,所有的池化技术都是为了提高效率,父进程提前创建出一批子进程,然后当有任务要执行时,就立刻交给子进程执行,而不是有任务时再fork创建出子进程让子进程去执行,这就提高了效率。
总结:
以上就是本期博客分享的全部内容啦!如果觉得文章还不错的话可以三连支持一下,你的支持就是我前进最大的动力!
技术的探索永无止境! 道阻且长,行则将至!后续我会给大家带来更多优质博客内容,欢迎关注我的CSDN账号,我们一同成长!
(~ ̄▽ ̄)~