上篇博客中讲到,系统调用接口中找到指定文件的方式是通过文件按描述符,那什么是文件描述符?
我们通过下面的程序来看看:
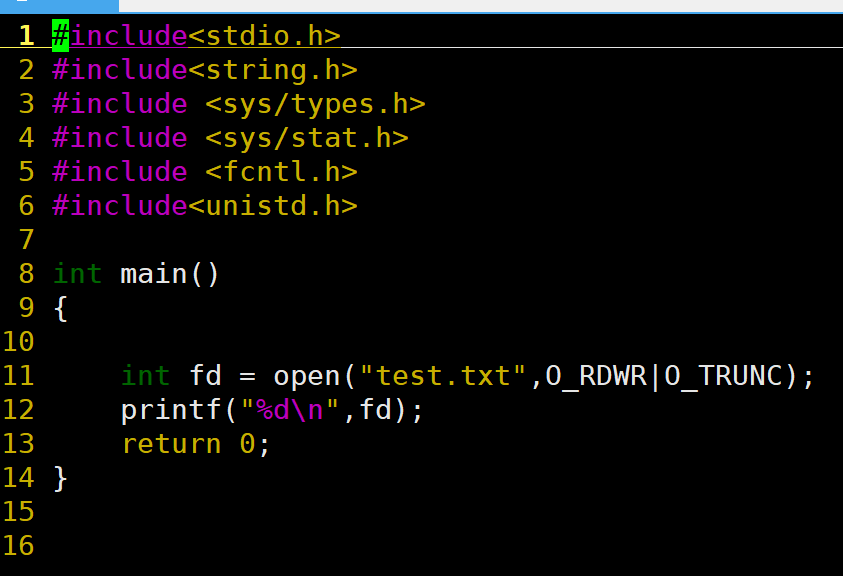

可以看到执行的结果是3,不难想到,管理流的结构是类似于数组的。3下标代表第4个流,那前三个流是什么?
标准输入流 ------0,键盘
标准输出流------1,显示器
标准错误流 ------2,显示器
这些是系统默认帮我们打开的,这就是我们后续打开的文件的文件描符都是按照3,4,5,...这样的顺序来的。
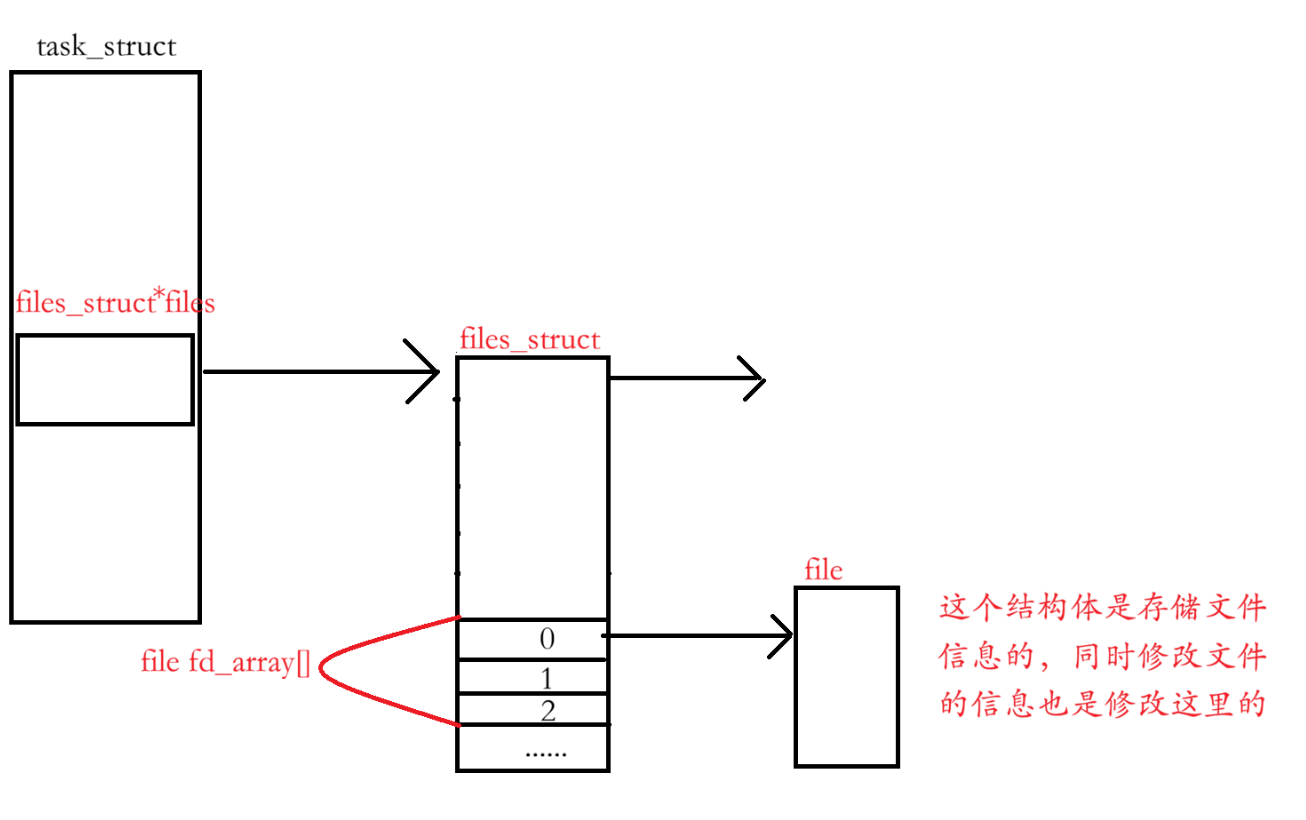
那不妨推测一下,这个数组存储的内容是什么?
Linux中存在一个结构体,专门来管理文件信息,files_struct
前面讲过close接口,如果close(1) 会发生什么?在这基础上添加一个新流会发生什么?
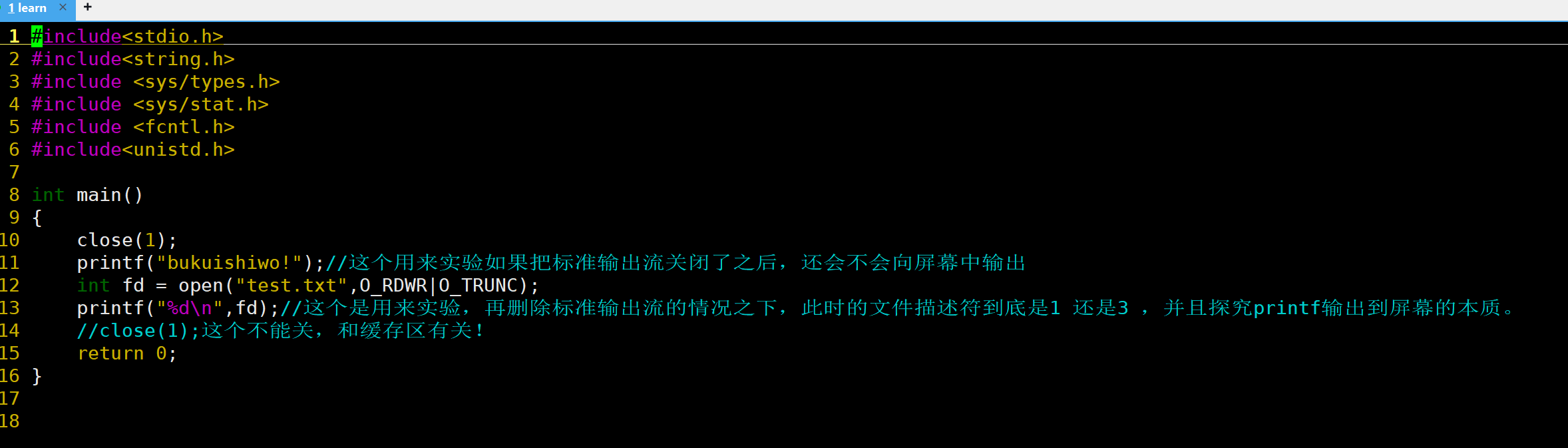

说明了,如果你把标准输出流删除了,再使用printf的话就不会向屏幕输出。
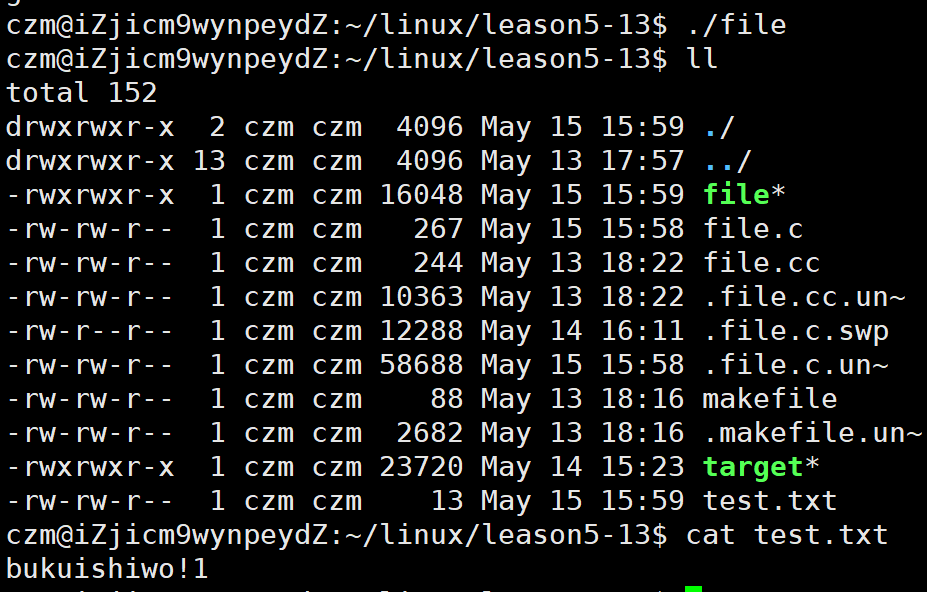
从上面看到,files_struct 中的 fd_arr 存储下标的从0 - n,哪个没有了,就放在哪个下标。
而printf是输出到fd_arr中下标为1的流中。
那假设现在我想修改fd_arr中某个流的下标,比如我想把标准错误流(下标为2) 和标准输出流换位置怎么办。
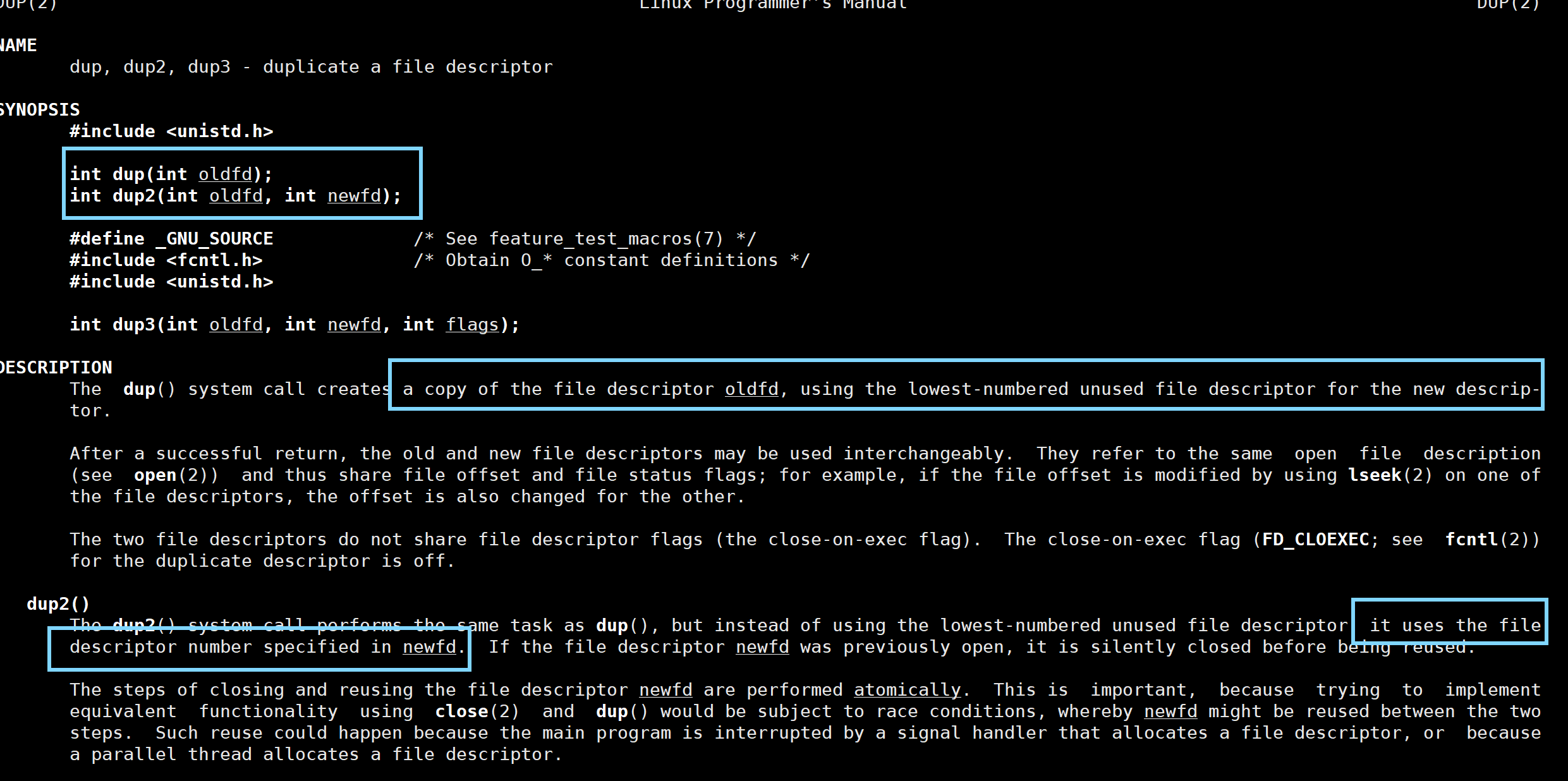
先用dup备份一下,再用dup2进行覆盖,dup2(int oldfd,int newefd) 这里是第一个参数覆盖第二个参数的流,比如dup2( 2,1) 那么下标为1的流就会被覆盖成下标为2的流,同时你可以把下标为2的哪个备份给close,如果你觉得有必要的话!
重定向:
很早的时候我们就讲过重定向的使用:
重定向分为 > 和 >>
>:相当于在open中flag或上了O_TRUNC,这个在每次写入之前都会清除文件内容
>>:相当于在open中flag没有或上O_TRUNC,这个是追加写入,在上次的基础上写入
重定向的本质(下面以 > 为例):
ls > 目标处,这个实际上就是 先把这个目标添加到fd_arr中,再dup(目标的fd,1),就是将这个覆盖标准输出流,是这个目标成为输入的对象文件!
所以这个写法的格式是:
commad newfd>oldfd ------对单个流进行重定向,相当于执行了 dup2(oldfd,newfd)
command newfd>oldfd1 oldfd1>oldfd2 这个操作就相当于把newfd 弄成oldfd2 ,这里举这个操作目的是想说明可以多次重定向,格式是 command newfd1>oldfd1 newfd1>oldfd2 ......
上面的操作可以转换成其他形式
command newfd1>oldfd newfd2>&newfd1 这个操作相当于dup2(oldfd,newfd1) dup(oldfd,newfd2)
这里&newfd1的意思是下标为newfd1指向的流!
流的刷新
全缓冲:
刷新条件:
只有当缓存区满了,才会刷新到内存中
行缓冲:
刷新条件:
遇到 '\n' 就刷新一次
无缓冲
刷新条件:
一旦数据到缓存区中,就直接刷新到内存中
手动刷新 flush(int fd)
这个的具体操作不妨留到下一篇博客 缓存区 中进行详细讲解
现在重新审视一下系统调用,显示通过open,在files_struct中存储这个file,并返回下标,接着我们通过这个下标来寻址file,接着进行wirte等操作。
那这些文件操作又是如何执行的?
很容易观察的一点,往屏幕上write和往文件中write的操作不相同,那这个不就说明了根据不同的file流,文件操作也不相同!!!
那系统如何知道要执行哪一种操作?
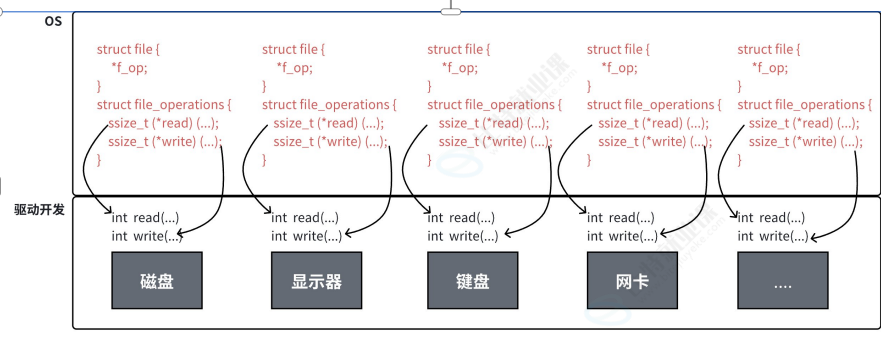
根据file中的人不同,此时我们就要了解一下file的内容了
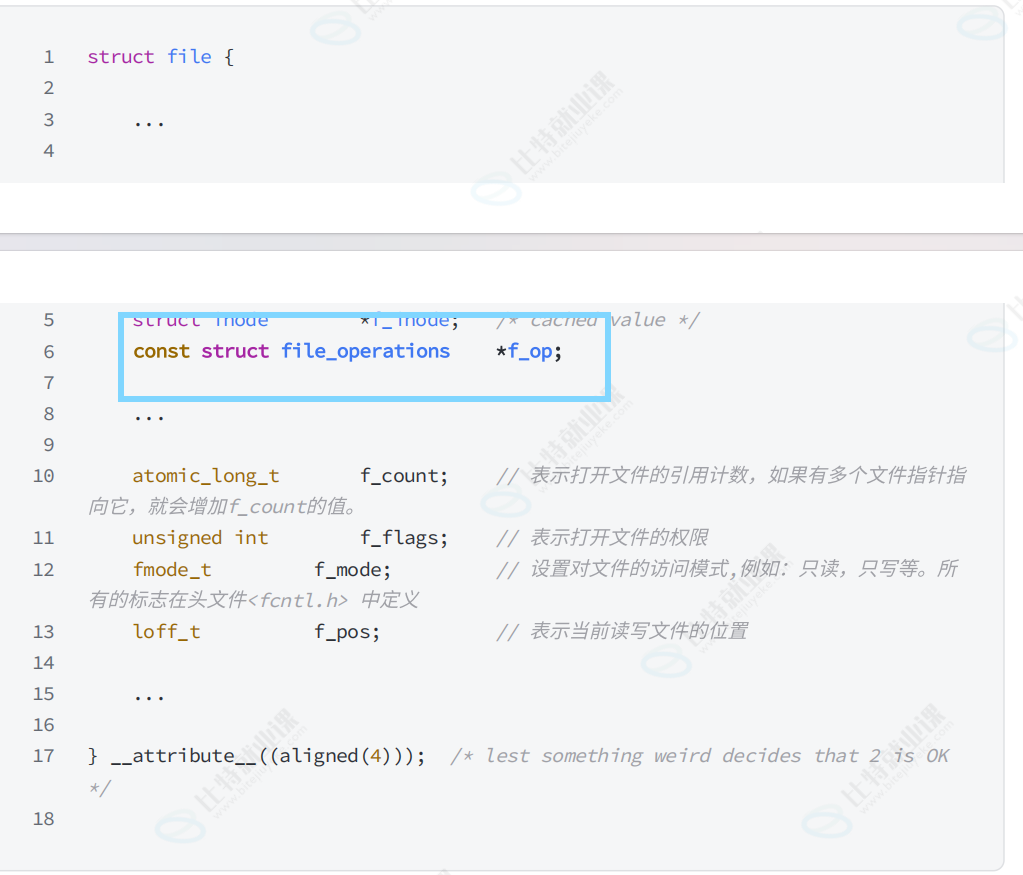
file结构体中又存在一个结构体 file_operation* f_op;从类型中就可以读出这个是具体的文件操作的指针

这里面几乎都是函数指针!所以我们就得出了一个结论,每个file中都存储了具体如何进行文件操作。
往深处想一想流和硬件是有强相关的
标准输入流 ------键盘
标准输出流 ------屏幕
标准错误流 ------屏幕
文件流 ------ 硬盘
所以这里就把我们对硬件的操作转换成了对文件的操作!这就是一切皆文件在硬件上的理解