本文利用llama.cpp在高通芯片安卓系统部署Qwen3.5 2B模型的全流程,全套代码由豆包辅助生成,豆包最成功的一点是可以不断修正,就错误发给豆包,一步步改进,最终完成。
1、将模型转化为gguf格式
Qwen3.5 2B模型,从阿里魔塔下载,存放在Qwen3.5-2B目录下。
python convert_hf_to_gguf.py /home/**/work/models/Qwen3.5-2B --outfile qwen3.5-2b-f16.gguf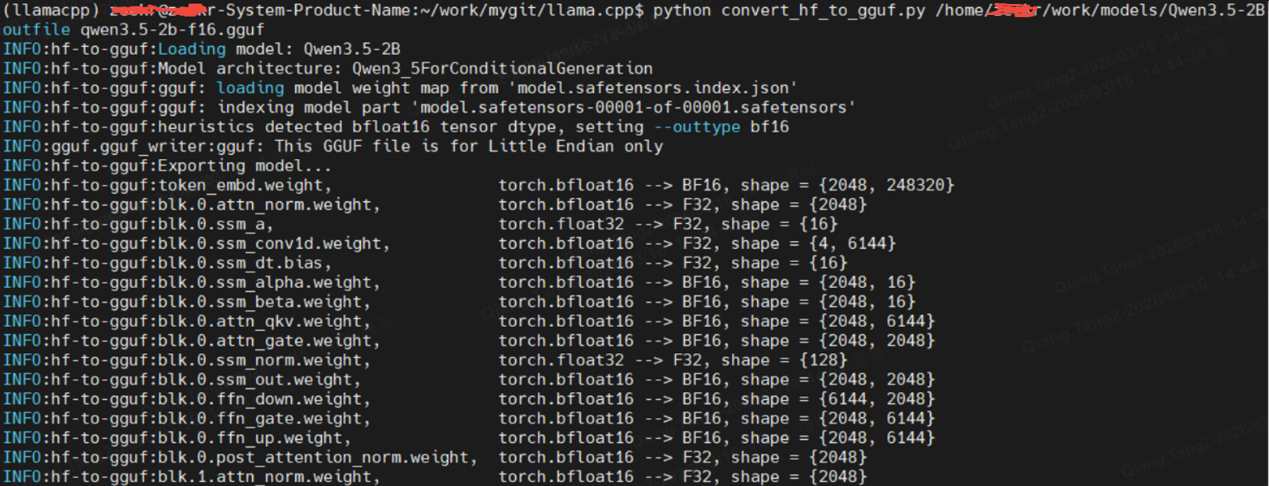

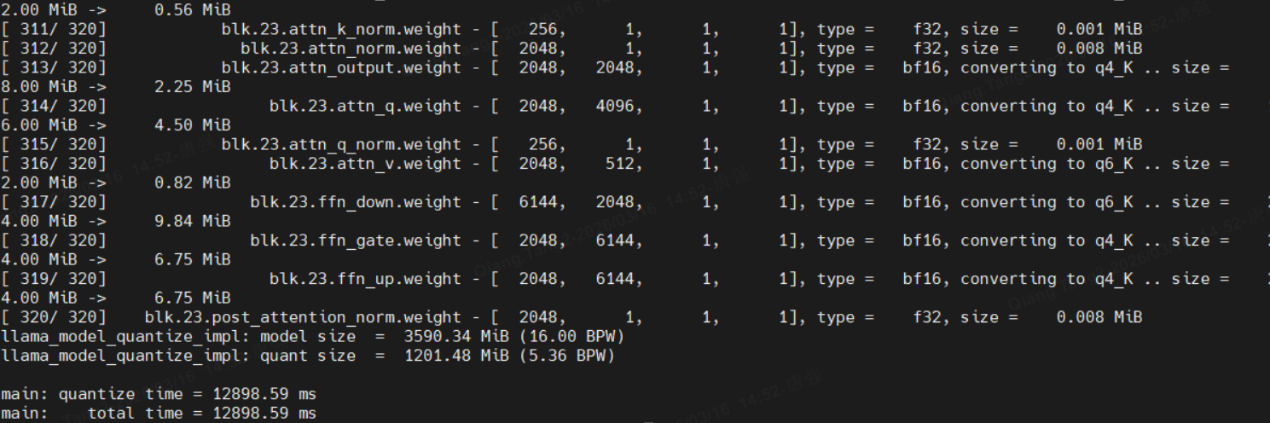
2、量化,生成qwen3.5-2b-q4km.gguf文件
/home/**/work/mycharm/llama.cpp/build/bin/llama-quantize qwen3.5-2b-f16.gguf qwen3.5-2b-q4km.gguf q4_k_m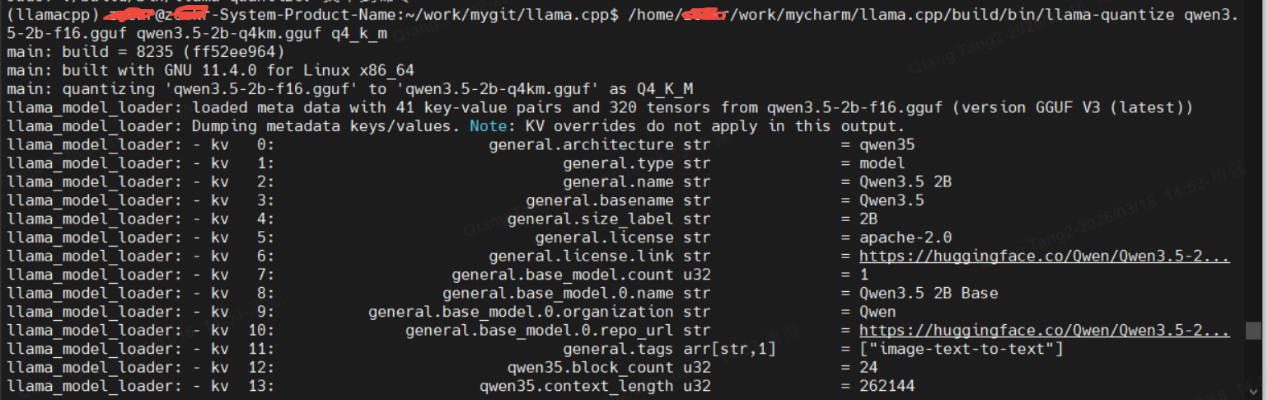

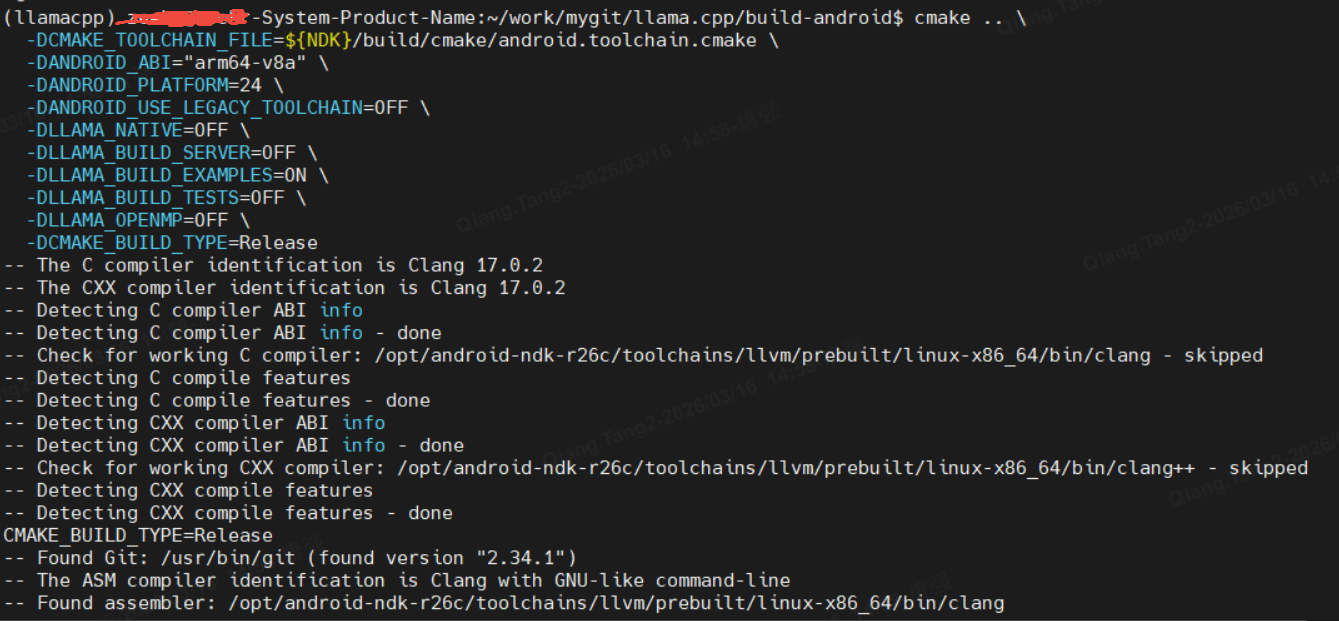
构建目录进行交叉编译
注意要下载NDK并设置环境变量
安卓NDK存放目录,/opt/android-ndk-r26c
export NDK=/opt/android-ndk-r26c
mkdir build-android
cd build-android
cmake .. \
-DCMAKE_TOOLCHAIN_FILE=${NDK}/build/cmake/android.toolchain.cmake \
-DANDROID_ABI="arm64-v8a" \
-DANDROID_PLATFORM=24 \
-DANDROID_USE_LEGACY_TOOLCHAIN=OFF \
-DLLAMA_NATIVE=OFF \
-DLLAMA_BUILD_SERVER=OFF \
-DLLAMA_BUILD_EXAMPLES=ON \
-DLLAMA_BUILD_TESTS=OFF \
-DLLAMA_OPENMP=OFF \
-DCMAKE_BUILD_TYPE=Release最后输出以下内容表示成功
-- Build files have been written to: /home/**/work/mygit/llama.cpp/build-android
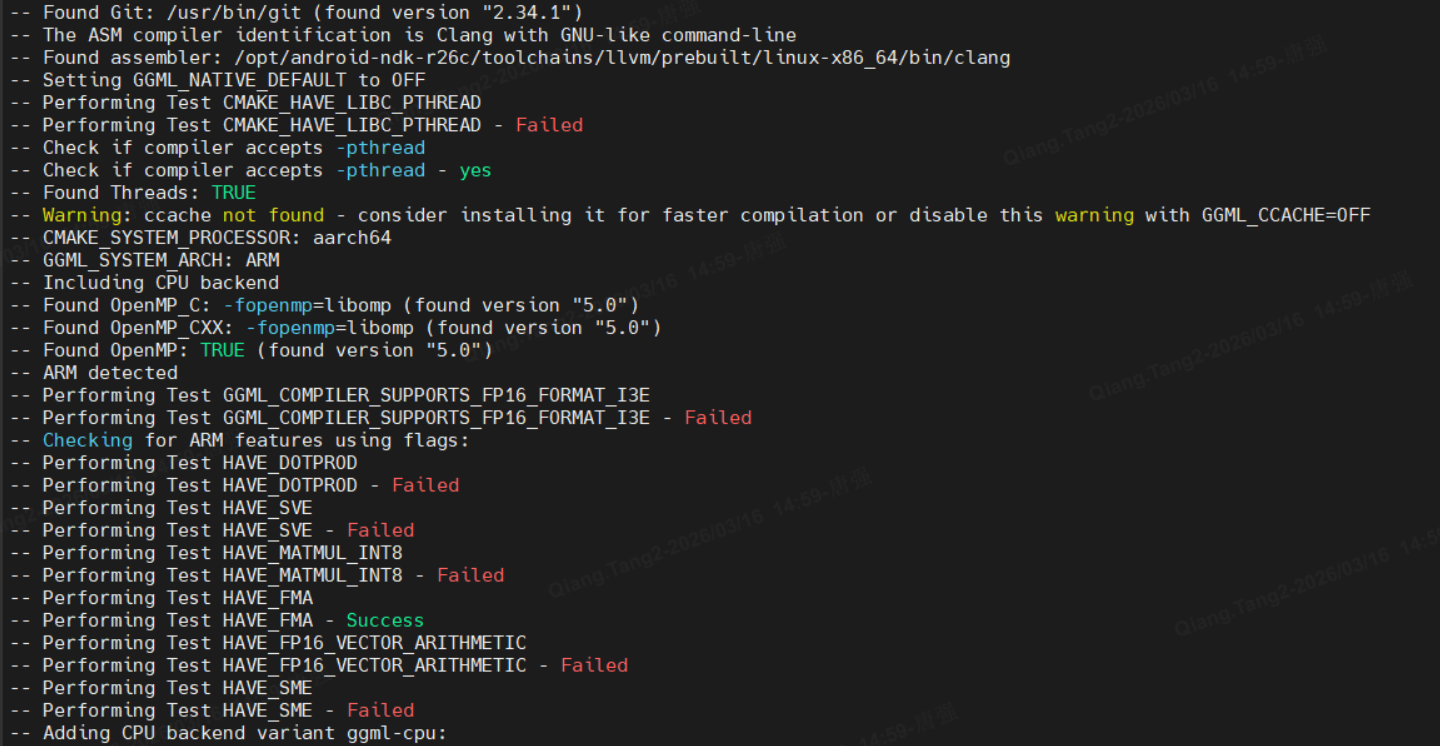
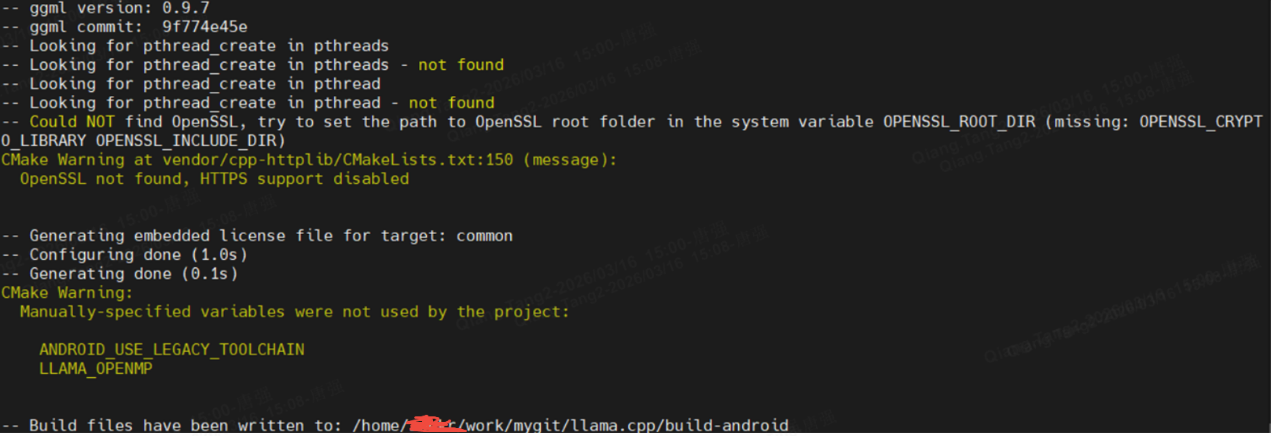
然后执行
make -j$(nproc)
生成的内容在bin目录下
adb push bin/* /data/local/tmp/qwen35/bin
3、推送文件到安卓车机
推送bin目录下文件到车机
另外需要把libomp.so这个库也推送车机bin目录
adb push /opt/android-ndk-r26c/toolchains/llvm/prebuilt/linux-x86_64/lib/clang/17/lib/linux/aarch64/libomp.so /data/local/tmp/qwen35/bin推送模型到车机目录
adb push qwen3.5-2b-q4km.gguf /data/local/tmp/qwen35/models进入车机
adb shell
cd /data/local/tmp/qwen35/
export LD_LIBRARY_PATH=/data/local/tmp/qwen35/bin:$LD_LIBRARY_PATH
/data/local/tmp/qwen35/bin模型文件目录
4、模型启动
执行以下命令启动模型
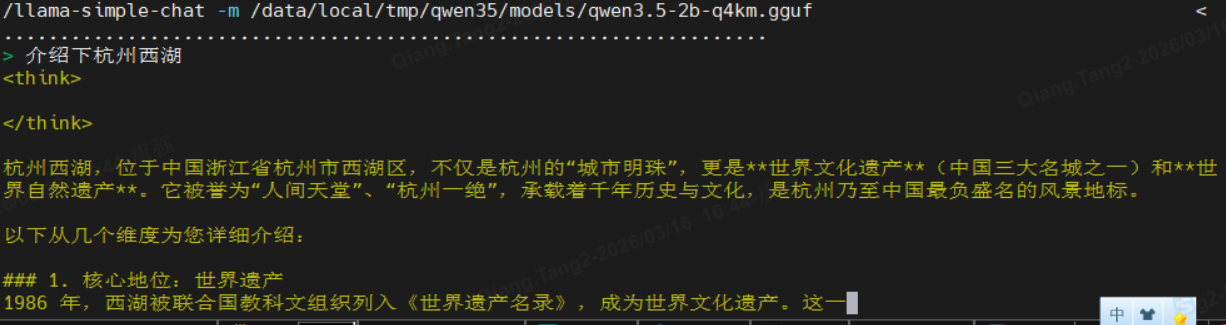
./llama-simple-chat -m /data/local/tmp/qwen35/models/qwen3.5-2b-q4km.gguf