LLM基础入门
- AI
- [LLM - 大语言模型](#LLM - 大语言模型)
- 上下文窗口
- 模型能力增强
- AI工程的增强
- [创建一个ChatBot:通过 OpenAI+模型供应商提供的调用api的接口建立自己的模型调用](#创建一个ChatBot:通过 OpenAI+模型供应商提供的调用api的接口建立自己的模型调用)
- [Function call(tools)](#Function call(tools))
- 知识库和rag
目的:做一个端到端的生成式UI前端界面Agent
围绕AI工程化都是在去弥补大语言模型先天的不足,以及通过工程能力提升大语言模型完成任务的表现
AI
AI进入人们生活的原因:
- 核心技术的突破
Transformer架构 -> 提升模型预测准确度与完成任务表现,降低了模型的训练成本 - 硬件的发展和适配
与GPU并行计算适配 - 互联网数据的沉淀
LLM - 大语言模型
large language model 大语言模型
基于海量的文本/语料训练出来的超大型神经网络
给一个输入,模型来预测下一个出现的文本是什么
由于是概率的,因此可能会出错,出错 -> 幻觉;需要尽可能少出现幻觉
模型规模大到一定程度的话,会出现涌现 ,是无法解释的
模型可以拥有:多步推理能力,指令遵从能力,注意力集中/转移的能力
一般来说,模型规格越大,具备的推理、复杂任务处理等能力越强
代价:处理的时长越久
上下文窗口
上下文:今天天气
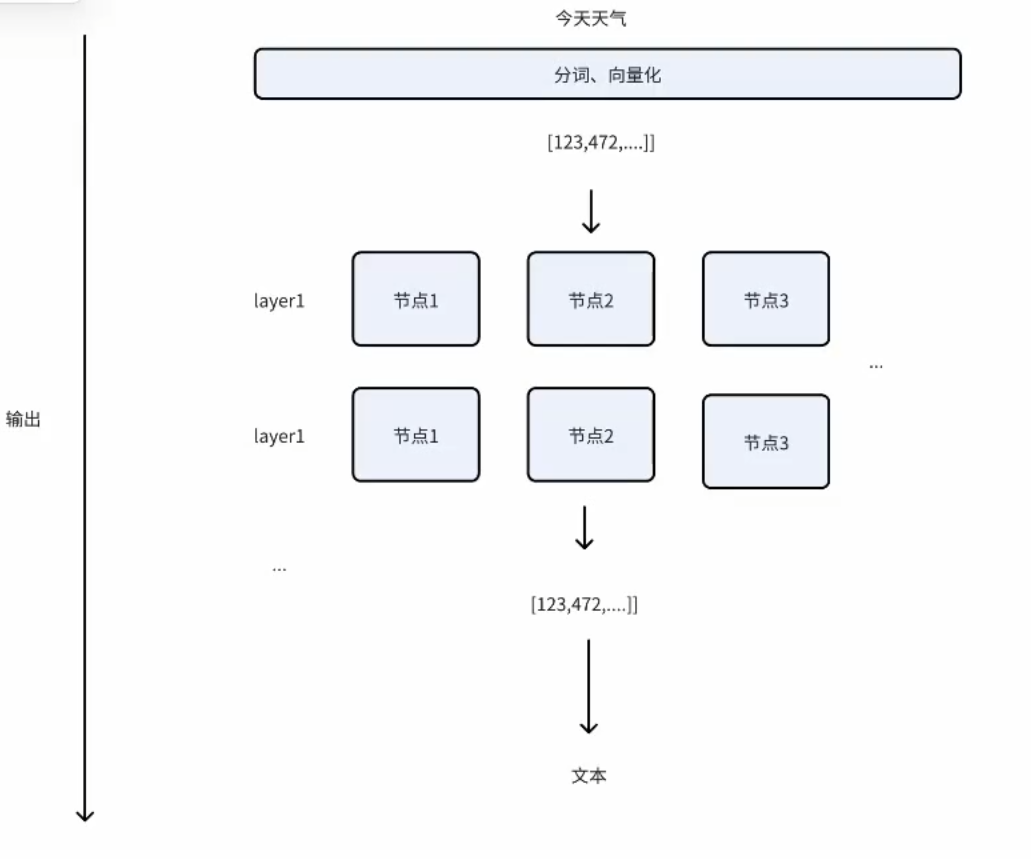
LLM -> 宽带/光信号
上下文窗口 -> 带宽,单次处理的大小
模型调用,是 无状态调用
模型能力增强
模型知识:模型所掌握的所有文本信息的汇总,常见的通用(基座模型)的只是来源大部分是互联网上的资料(公域知识)
私域知识:不在互联网上,无法被检索,自然也不会被基座模型训练
模型增强分为两大类:
- 第一大类,从模型的本身去增强
(1)微调:专业的算法团队去处理,将私域知识放到已有模型中再训练 -> 微调
(2)模型蒸馏:大模型在特定任务上提取一个较小的模型
(3)剪枝和拼接 - 减少模型的参数规格和模型层数
成本非常高 - 模型团队长达数周数月的训练增强评测,并且还会有微调税,灾难性遗忘 - 第二大类,AI工程的增强
AI工程的增强
提示词 - Prompt
模型供应商
国外:Claude, opanai ChatGPT, Gemini
兼容 OpenAI 格式的 模型供应商提供的模型;还没有采购自己模型的,在百炼上注册自己的账号,会有免费的千问3.5plus的活动,去做生成式AI的话,效果是不错的,并且支持多模态(图片等),以及根据设计图生成代码的能力也是不错的。
免费额度:一百万token
字节的方舟等都可以
Coding Plan是模型的组合
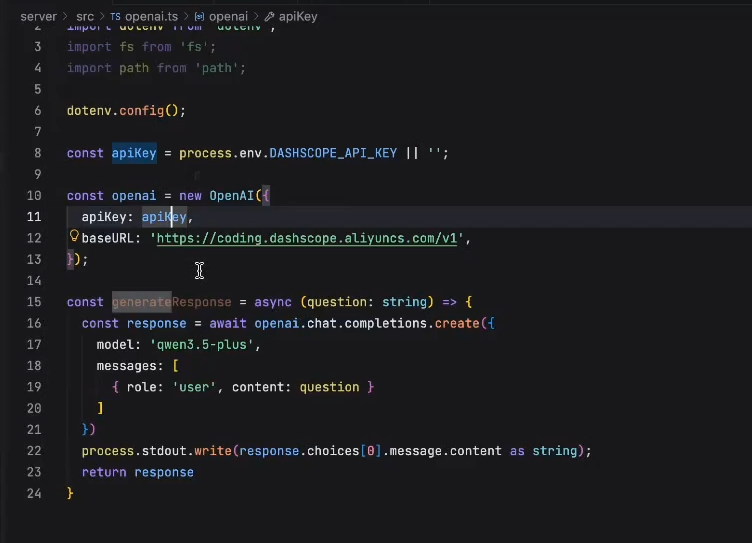
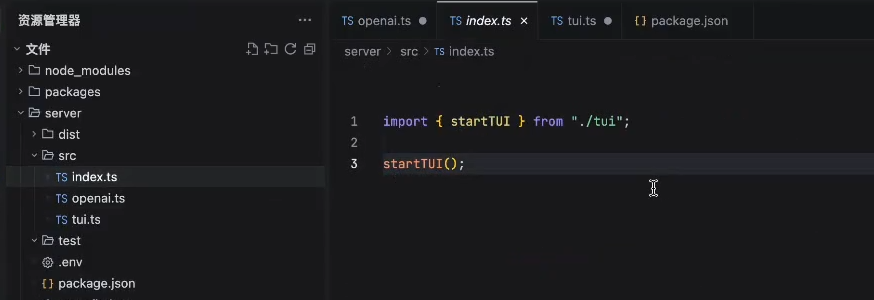
创建一个ChatBot:通过 OpenAI+模型供应商提供的调用api的接口建立自己的模型调用
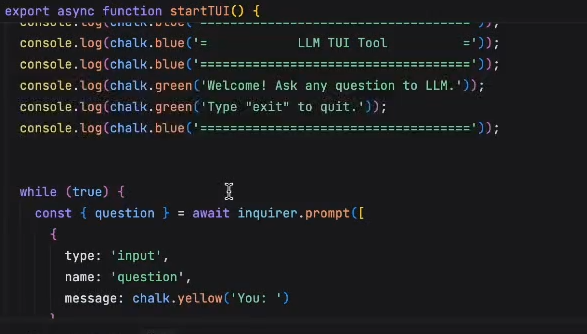
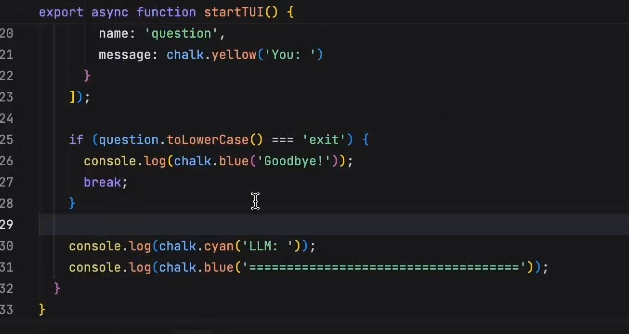
基于openAI SDK实现一个LLM TUI交互MVP
基本实现交互
ts-node src/index.js
执行
在IDE中怎么开debugger呢?
tip:在这个模式下执行代码,才能在断点处停止操作呢
然后在调试控制台打印response查看
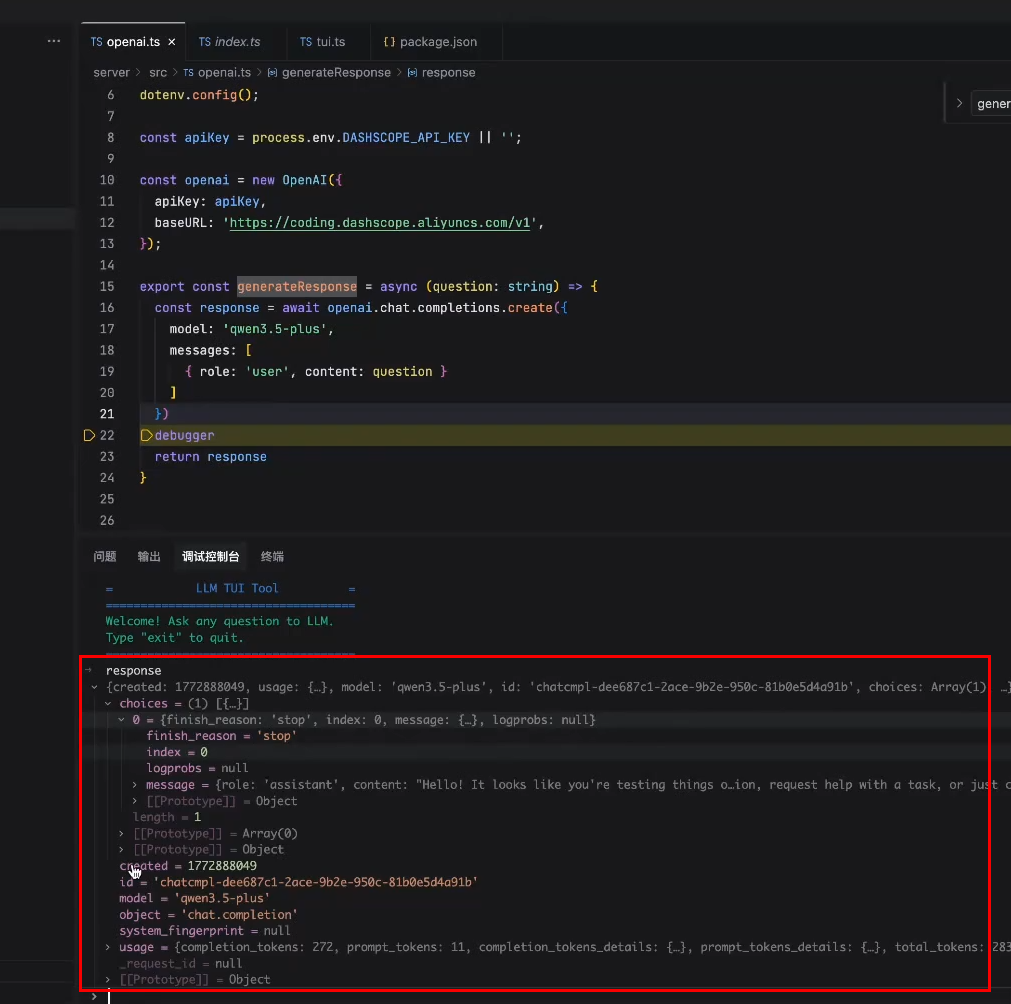
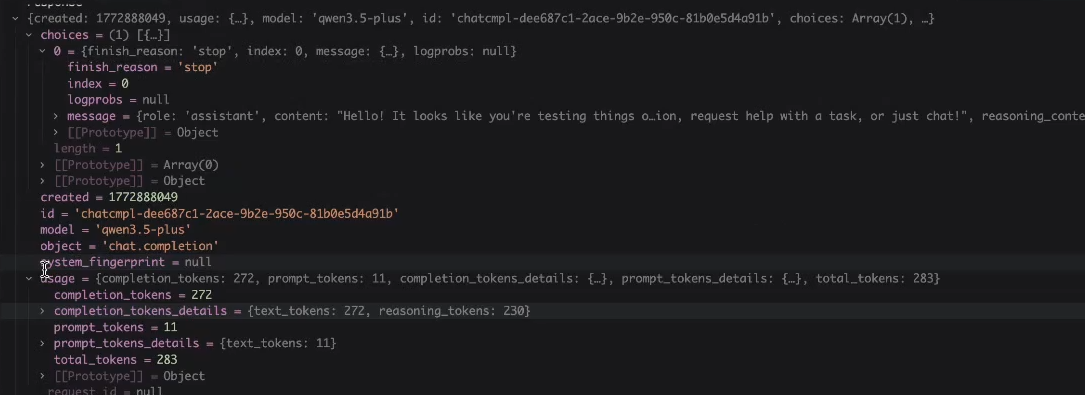
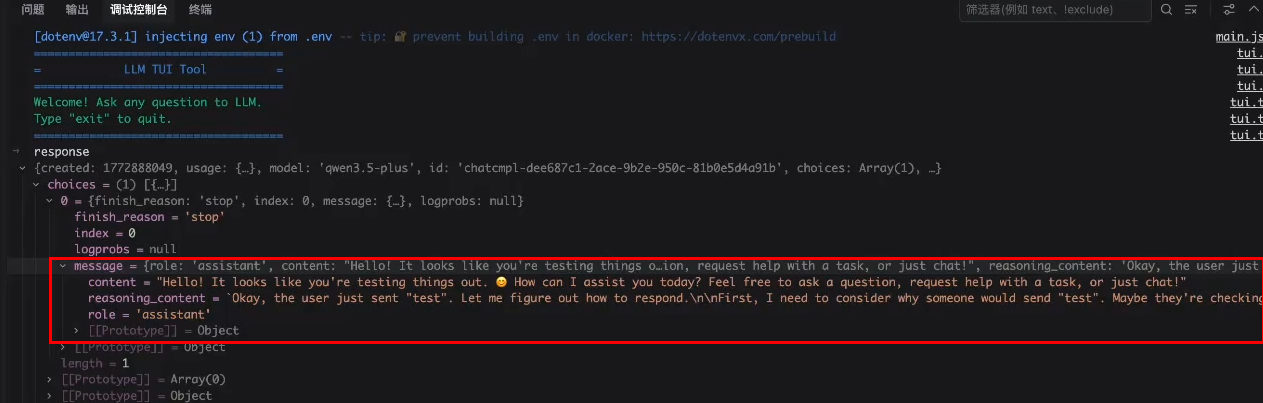
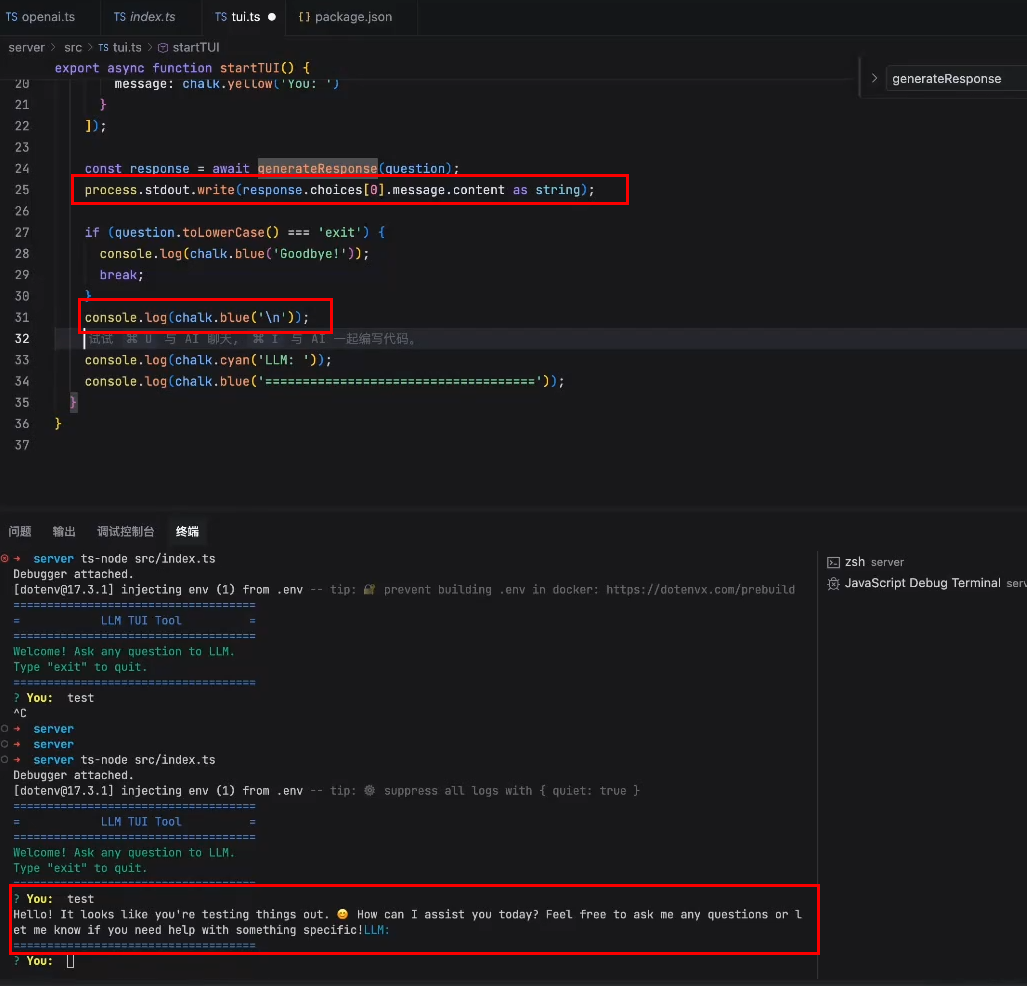
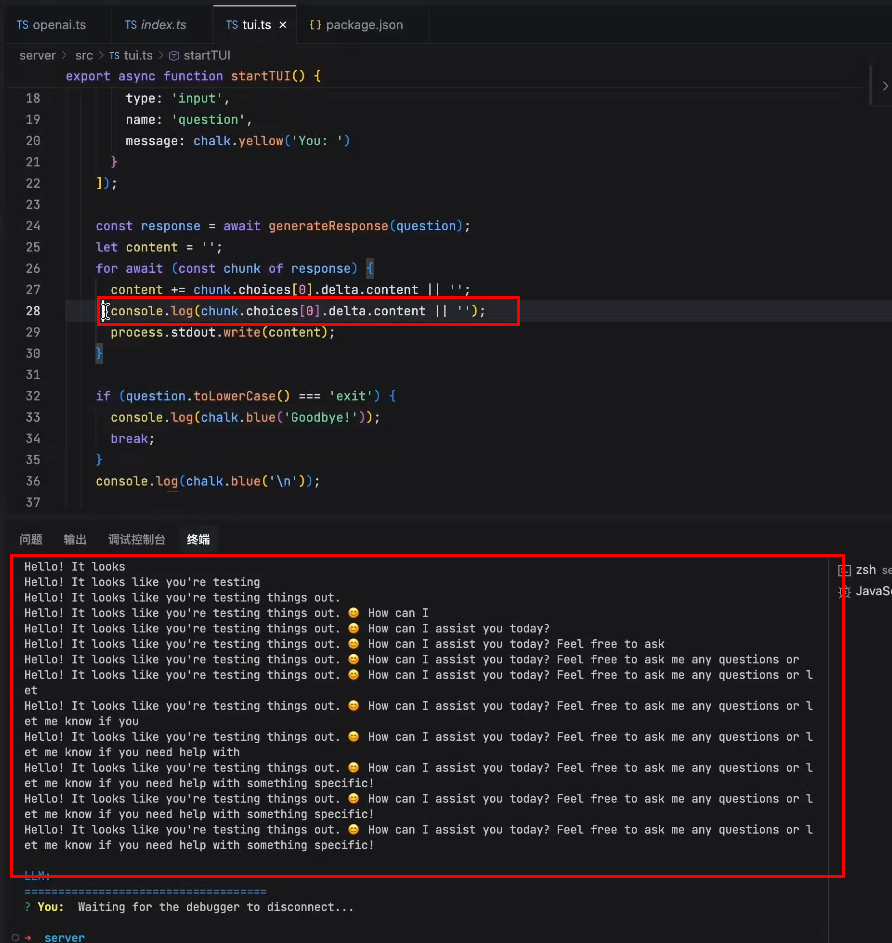
将模型返回的内容放到终端中:
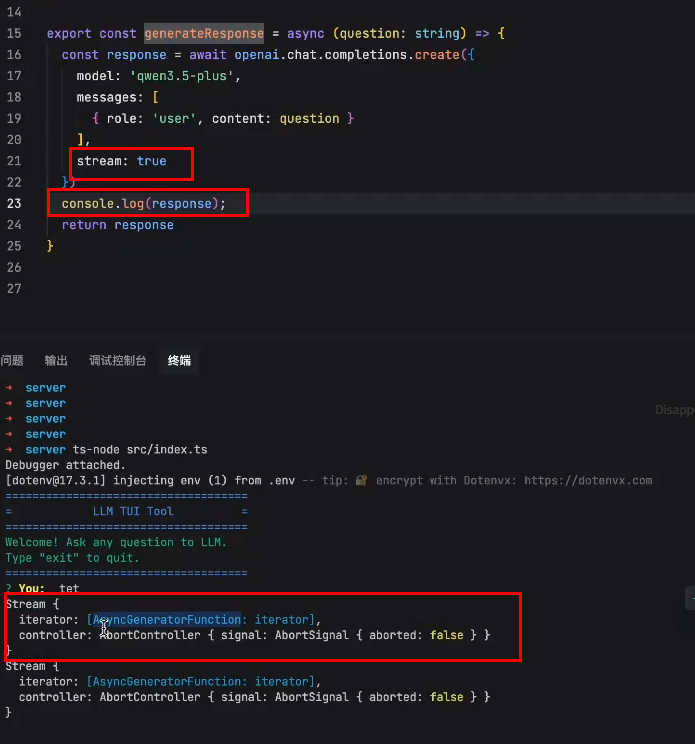
stream为true,使用http stream长链接传输协议去做的,请求直到某一个终止信号时,才会中断掉
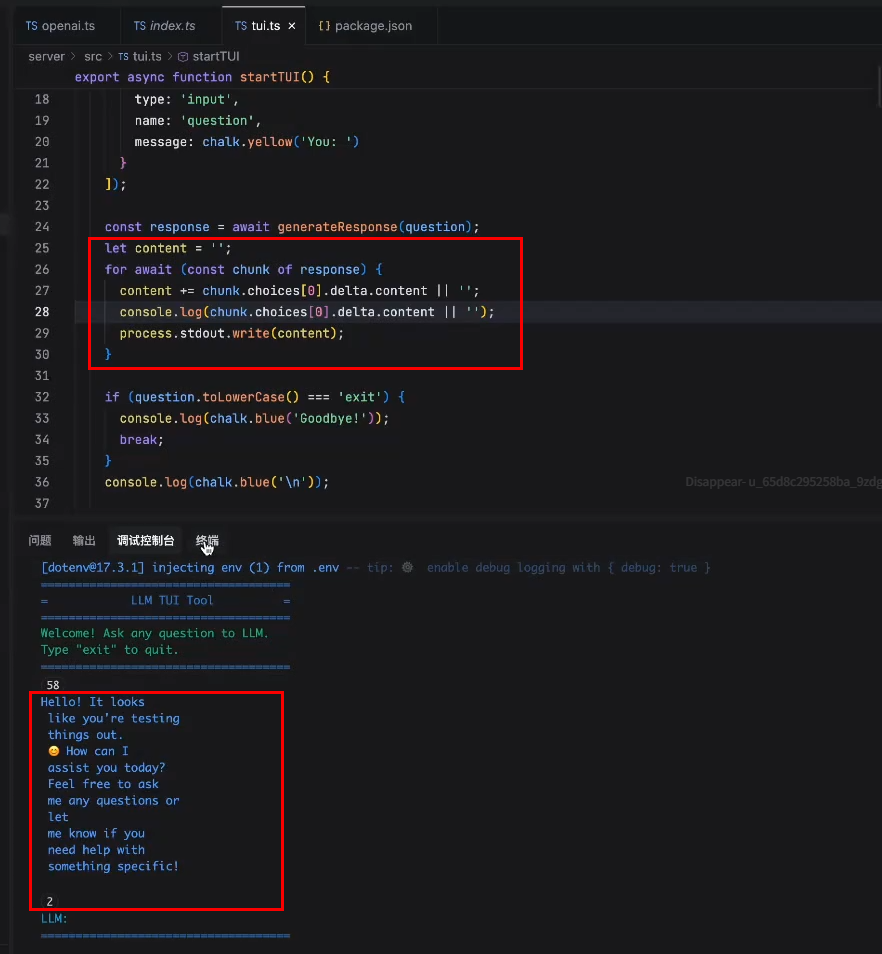
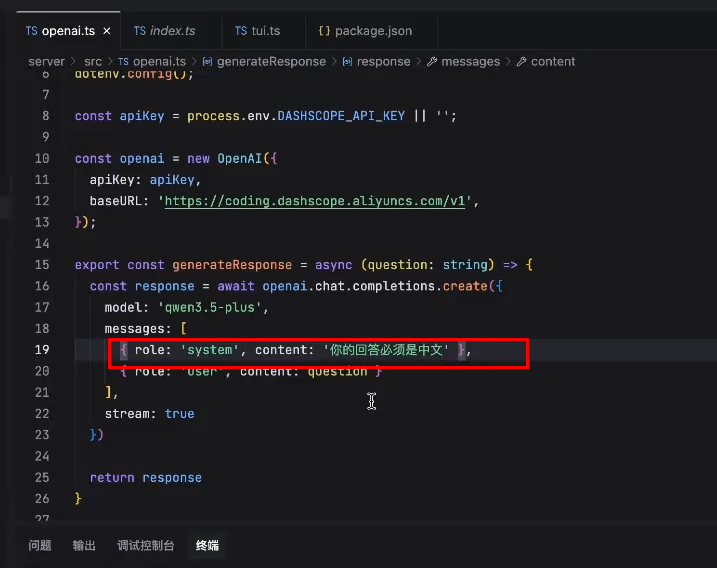
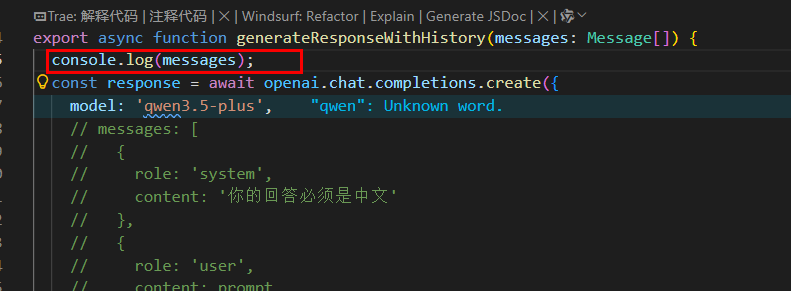
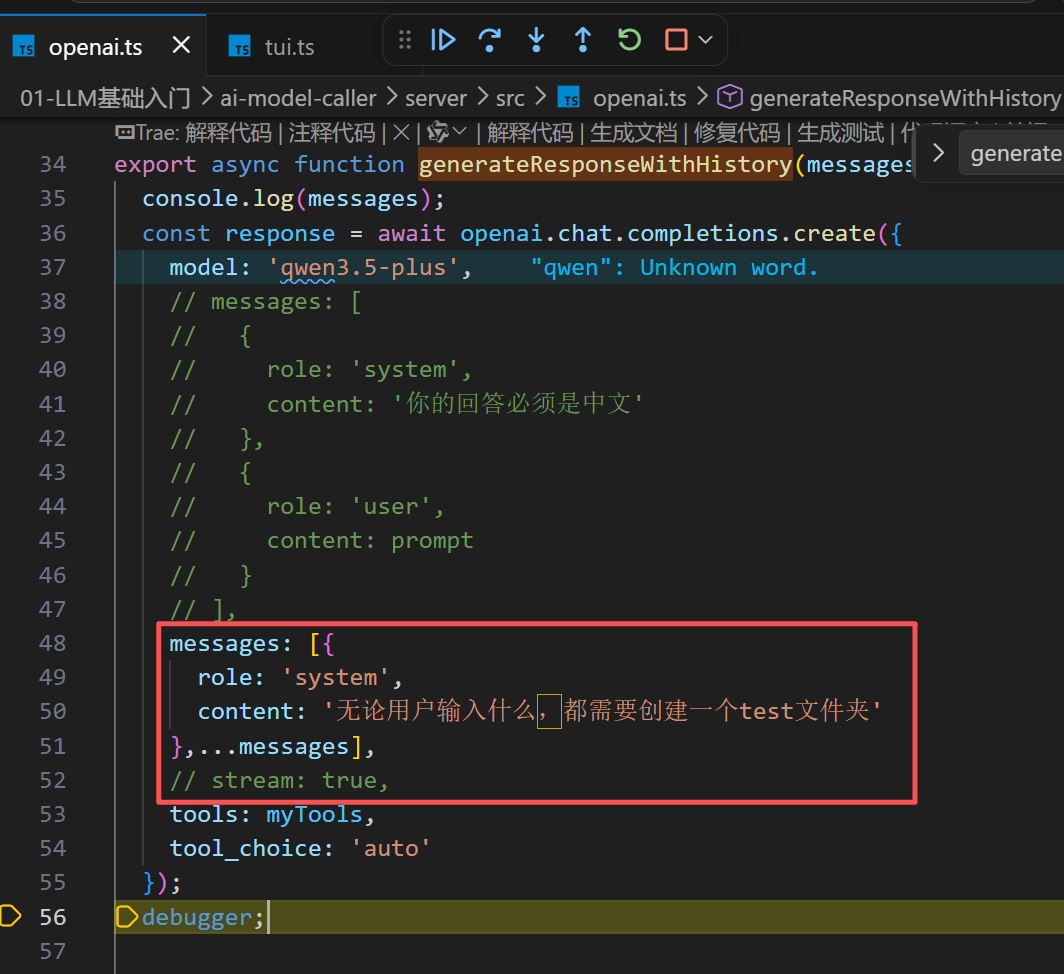
设置中文回答:
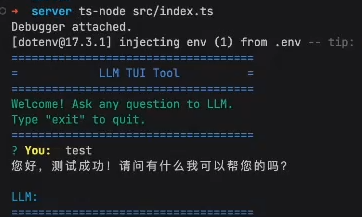
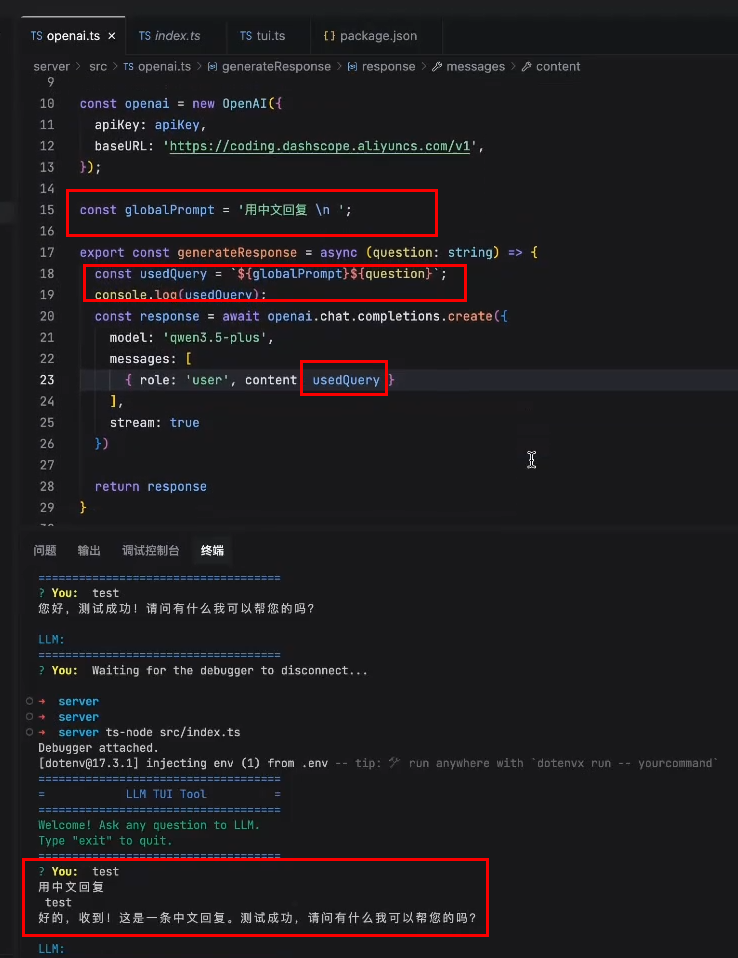
也可以这样设置:
为什么区分系统和用户?
propmt融入到用户中去,里面带的prompt当作用户输入返回给我,因此要做区分。
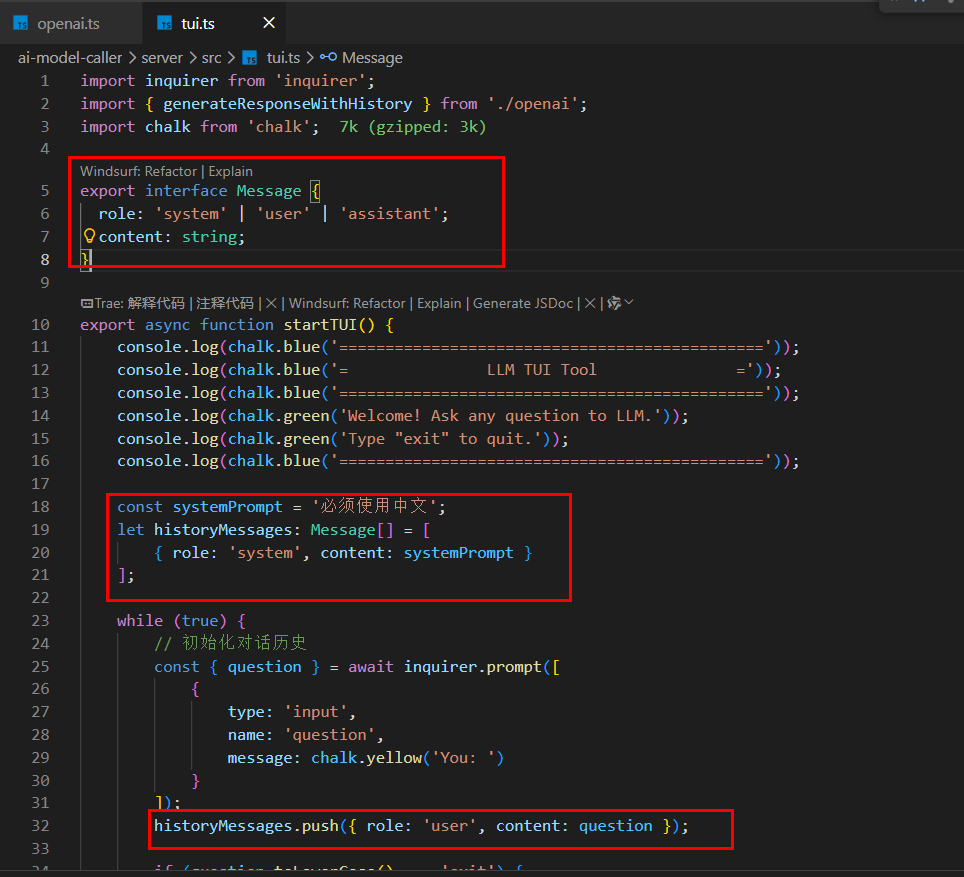
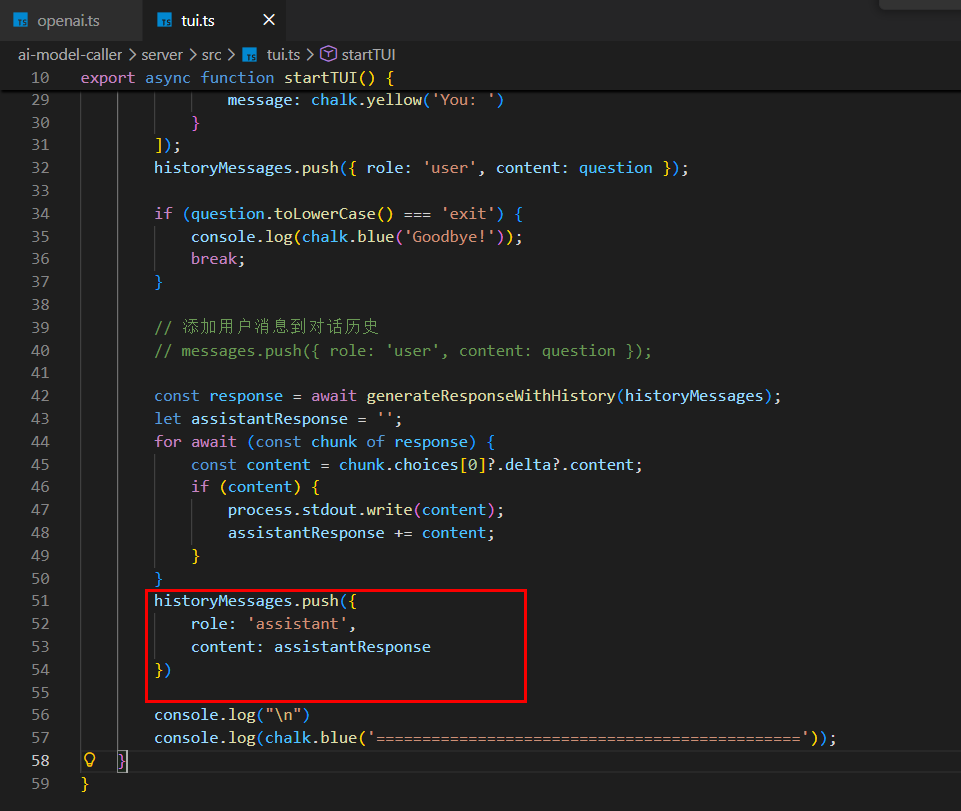
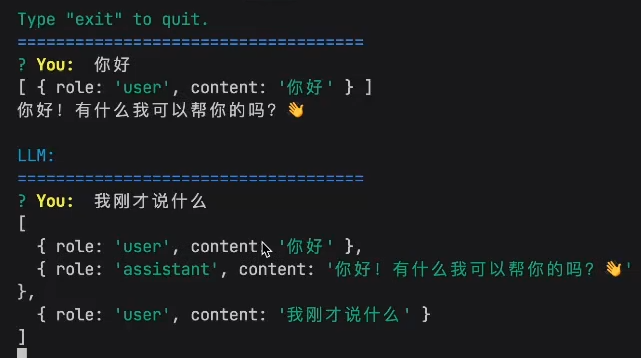
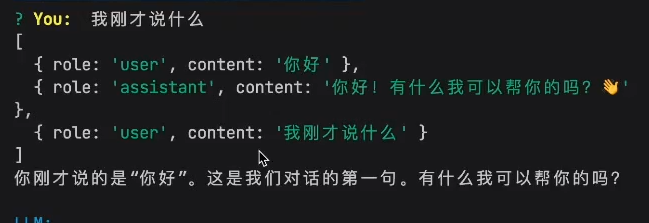
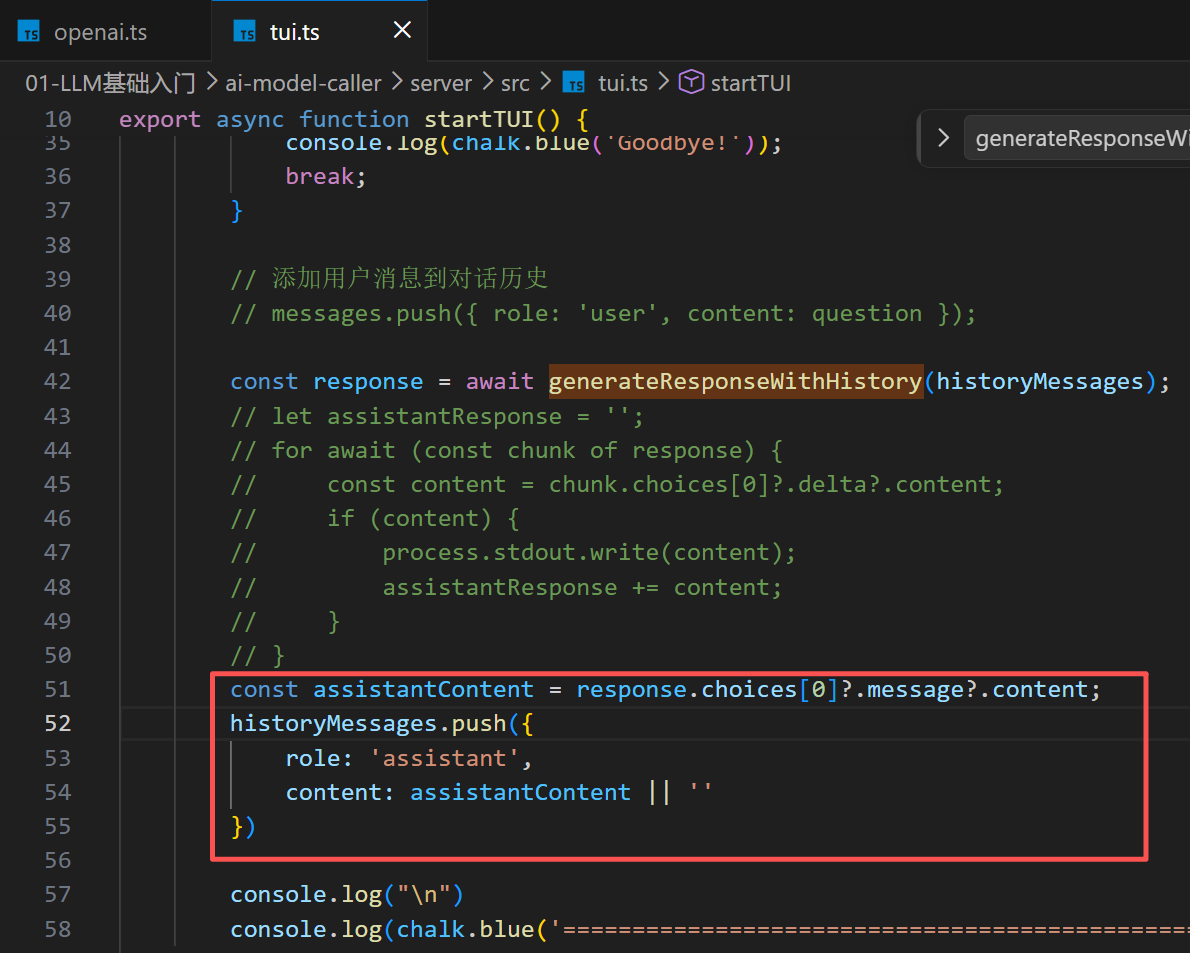
让LLM有状态
让各种工程能力使得大模型有记忆能力
=> 将之前模型的回复包括我的问题一并都发给模型
Function call(tools)
Chat bot 应用的 deepseek、豆包(早期)、chatGPT早期都是问答的形式
MCP skills rules agent multiagent agentteam => 原理都是 prompt 和 function call
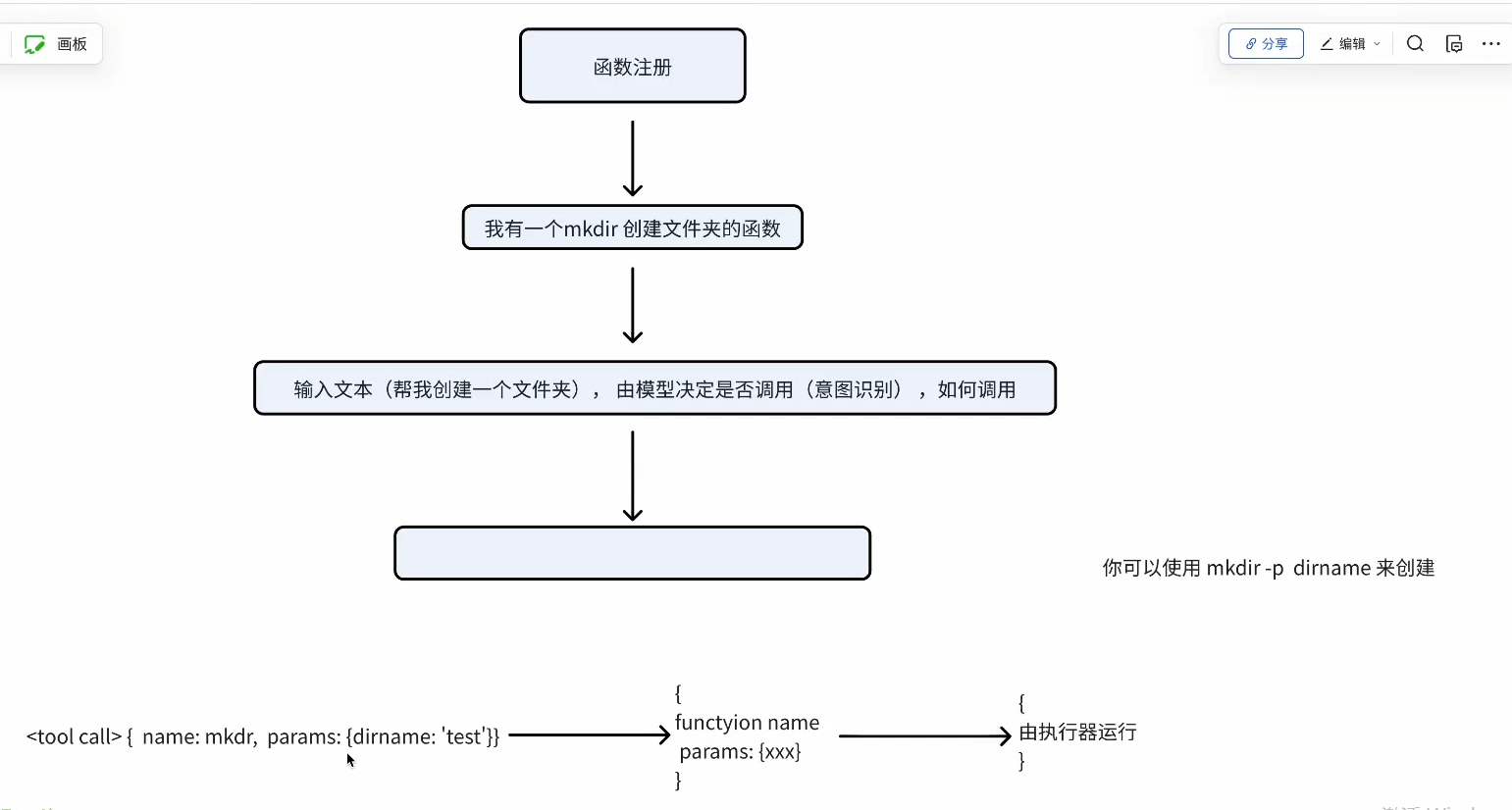
function call:让LLM装上了四肢,让LLM不仅可以思考、输出内容,还可以具体执行
Function call本身不能完成任何事情,是由执行器来完成的
执行器,接收的就是 模型输出的 需要调用的函数名称,入参
 为模型输出的特殊文本
为模型输出的特殊文本
Fucntion call实现原理:
- 模型侧: 通过训练和模型能力增强,让模型可以输出特定规格的文本结构
- 工程侧:处理模型返回,提取需要执行的函数信息,并最终代替模型执行(手和脚)
相对于直接输出JSON的方式,模型生成特殊的字符串,损耗的token是最小的
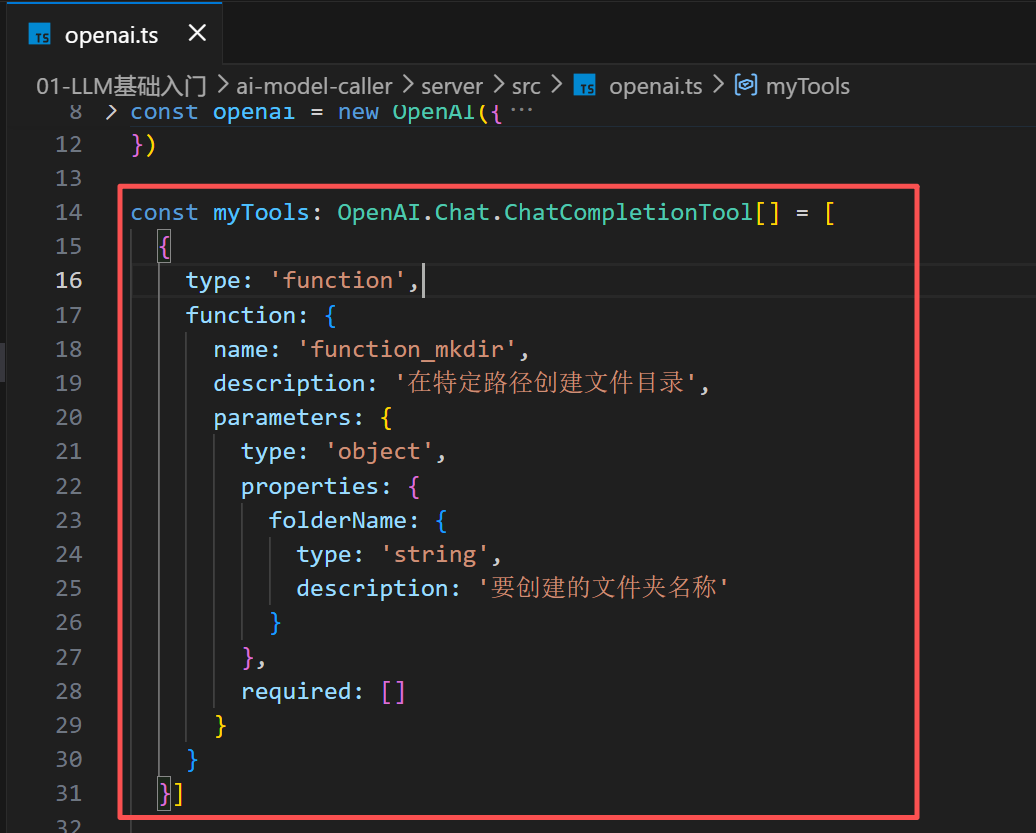
tools使用
description: 模型根据上下文做最佳的回复策略,告诉大模型这个工具是做什么事情的,后面用户输入的时候,模型会决定调用哪个函数
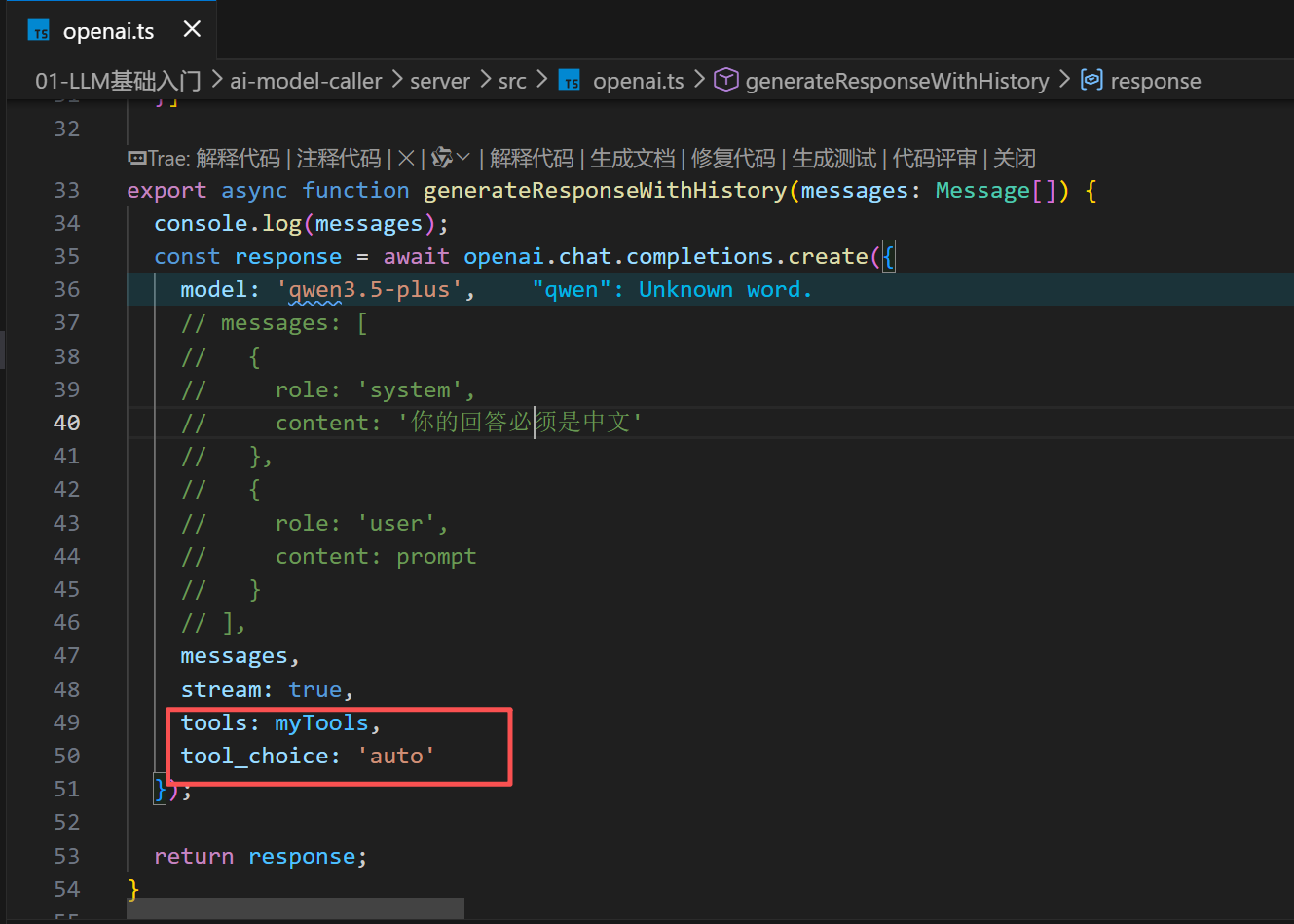
这里必须要将流式关闭才能得到如下的结果:
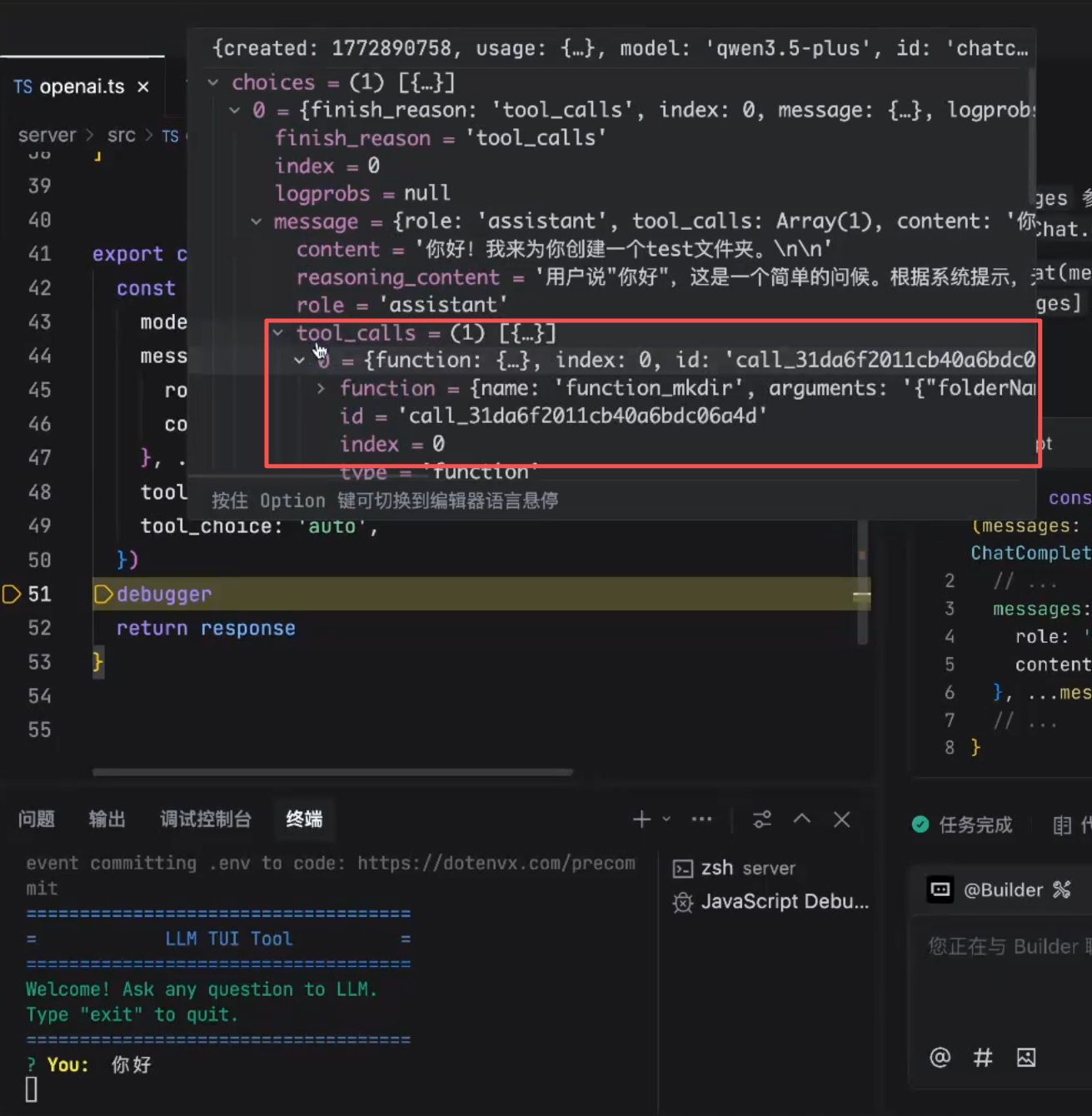
模型已经有了工具了
这里模型已经判断出来了,需要调用这样一个tools,现在还需要做一个函数执行器,给模型装配上他的手和脚
调用方法:
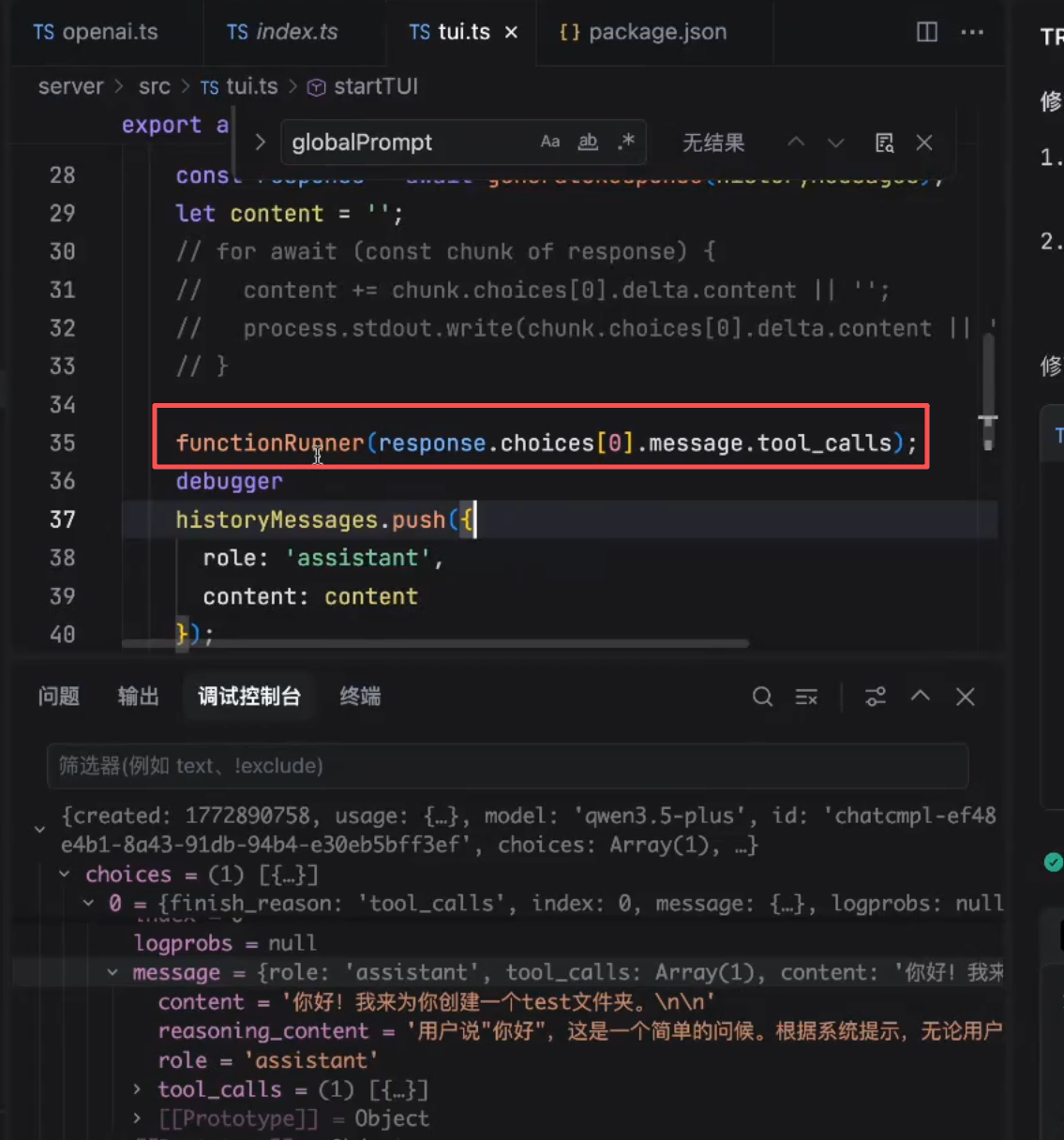
函数定义:
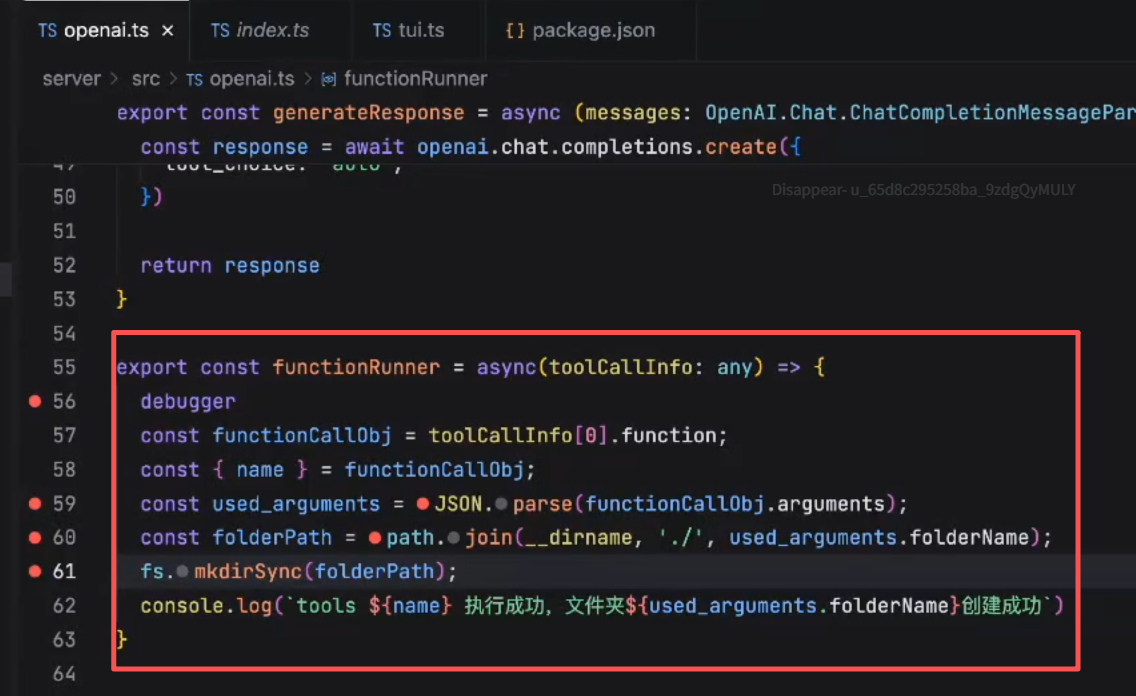
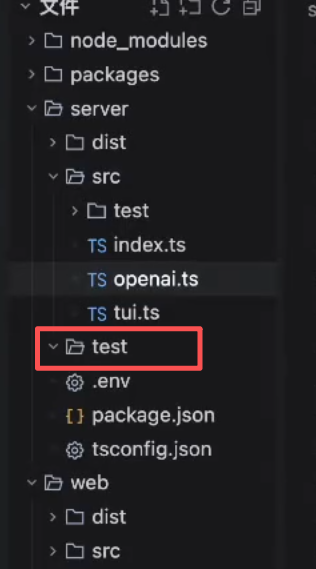
执行完后:在当前目录下创建了一个test文件夹
function_call 在流式返回中,返回的是每个参数,也就是说,function_call的参数是会逐渐在每一个chunk中返回的,当支持stream的function_call实现的时候,需要从chunk中读取当前的参数,当所有参数都返回完毕后,再统一的执行function_render去调用最终的东西即可
Function_call和tools的区别
tools是function_call的升级版
- tools支持并行,function_call是串行
- 语义:tools代表llm agent工具(不仅限于函数调用),function_call只代表函数调用
- 跨执行器环境的能力
tools中有type:bash,browser_fetch
实现一个支持stream的tools(function_call),尝试将参数解析出来
知识库和rag
知识库指的就是,全部私域知识语料的数据库(里面就是 html, text, excel, markdown)
内容巨大,因此只能:
动态检索和匹配内容(召回)

通过向量数据库召回拼到prompt中去
检索召回:通过 function_call
注入通过 prompt
不建议看算法向的内容,这是由于:
现在的AI应用,大语言模型的瓶颈短时间内靠算法(可见视野范围内)是没办法解决的
通过工程能力,能极大的提升整个AI,LLM落地的能力
大语言核心:文本预测
极端:假如说能将全世界所有应用程序的二进制码给到AI,并且让他能够学会,掌握二进制语言的话,未来则根本不需要编译器,翻译器;可以直接让AI生成二进制文件。
AI的能力局限于自然语言的
AI写代码,学习代码仓库,能力非常差的原因:
AI理解的是变量,命名是自然语言
搭建小龙虾