引言
在Java服务的生产环境中,90%以上的性能问题、系统卡顿、OOM崩溃都与JVM内存管理和GC相关。很多开发者面对问题时,只会盲目调整-Xmx/-Xms参数,调优全靠试错,本质是没有吃透JVM分代回收的底层逻辑。本文基于JDK 17 ,从核心理论、分代配比、晋升机制,到架构级调优、可落地实战、避坑指南,全链路拆解JVM内存调优的核心方法论,兼顾底层深度与落地实用性。
一、JVM分代回收的底层本质与内存架构
1.1 分代回收的核心理论基石
分代回收的设计不是凭空而来,而是基于两个经过业界几十年验证的弱分代假说,这是所有调优动作的底层逻辑:
-
绝大多数对象都是朝生夕死的:超过90%的对象在创建后很快就会变成不可达状态,不会熬过第一次GC;
-
熬过越多次垃圾收集的对象,越难消亡:经过多次GC依然存活的对象,大概率会长期存活,后续被回收的概率极低。
基于这两个假说,JVM将堆内存划分为不同的区域,针对不同生命周期的对象采用不同的回收策略,从而兼顾吞吐量与停顿时间,这就是分代回收的核心意义。
1.2 JDK 17 内存架构全解析
JDK 17默认采用G1垃圾收集器,内存结构分为线程共享内存 与线程私有内存,其中分代回收的核心是堆内存区域,架构图如下:
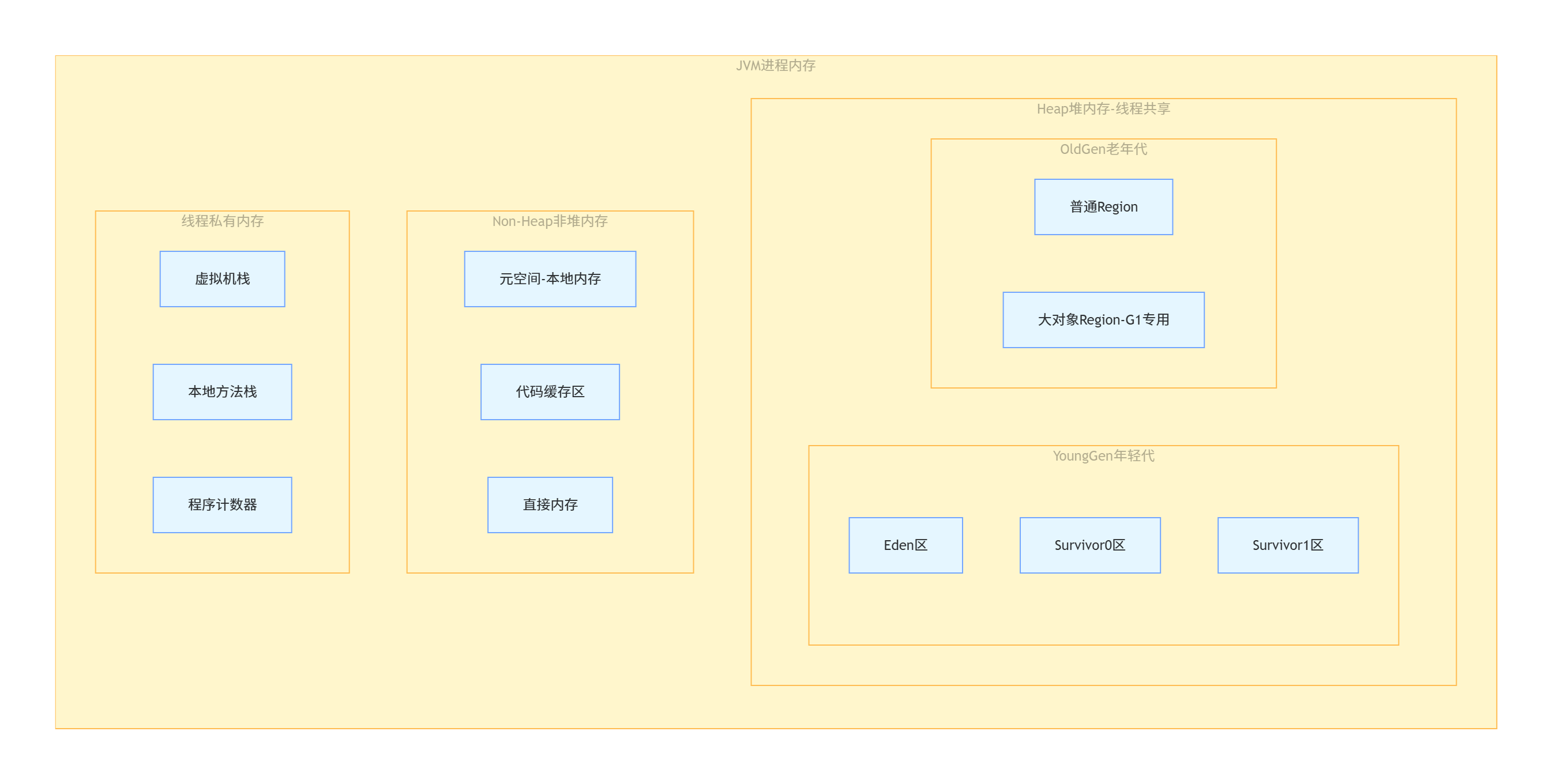
核心区域核心说明(100%符合JDK 17规范)
-
堆内存 :JVM内存管理的核心,所有对象实例与数组都在此分配,是GC的主要战场,受
-Xmx(最大堆内存)、-Xms(初始堆内存)控制; -
年轻代:存放新创建的对象,分为1个Eden区和2个大小完全相等的Survivor区(S0/S1,也叫From/To区),90%以上的对象在此创建并回收;
-
老年代 :存放长期存活的对象、大对象,GC频率低但单次耗时更长,G1的大对象专属区域
Humongous Region也属于老年代范畴; -
元空间 :JDK 8之后替代永久代,存放类元数据、方法信息,直接使用本地内存,默认不受堆内存限制,仅受本地物理内存约束,通过
-XX:MaxMetaspaceSize设置上限; -
线程私有内存:不存在GC问题,随线程创建而创建,随线程销毁而释放,OOM场景极少出现。
1.3 对象分配的完整生命周期流程
对象从创建到销毁的完整流程,是理解分代回收与晋升机制的基础,流程图如下:
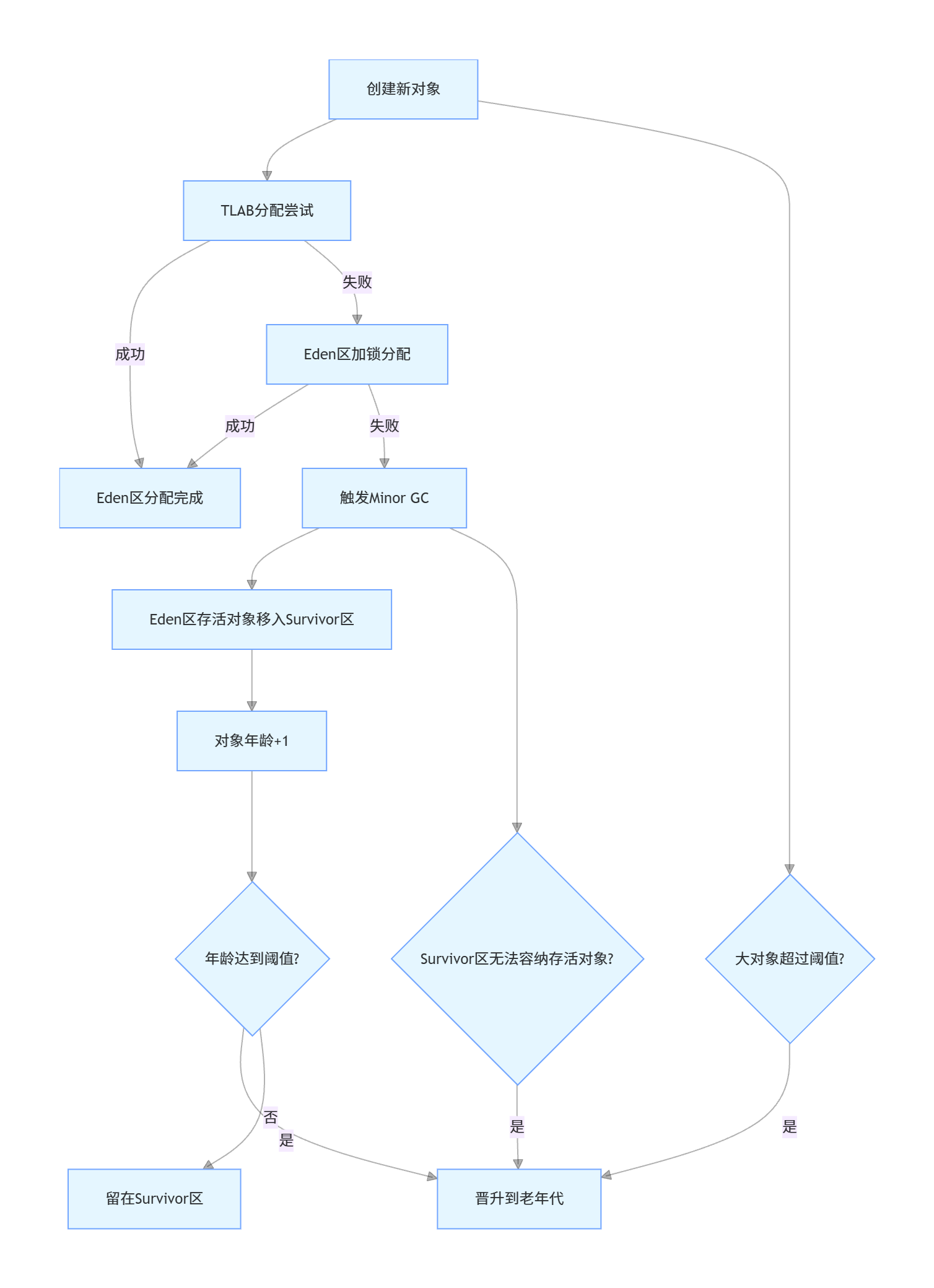
核心细节说明:
-
TLAB(线程本地分配缓冲区):每个线程在Eden区的私有分配缓冲区,避免多线程分配对象时的加锁竞争,是对象分配的第一站,大幅提升对象分配效率;
-
Minor GC:年轻代专属GC,采用复制算法,速度极快,STW(Stop The World)停顿时间短,当Eden区满时自动触发;
-
复制算法:年轻代GC的核心算法,每次GC时,将Eden区和其中一个Survivor区的存活对象,复制到另一个空的Survivor区,然后清空原区域,解决内存碎片问题,这也是两个Survivor区必须大小相等的核心原因。
二、分代内存配比的核心规则与调优实践
分代配比是JVM内存调优的核心入口,不合理的配比会直接导致GC频繁、内存浪费、OOM等问题,本章节基于JDK 17规范,拆解不同收集器的配比规则、调优原则与可落地实践。
2.1 分代配比的默认规则(JDK 17 官方默认值)
JVM的分代配比分为物理分代 (Parallel/Serial/CMS收集器)和逻辑分代(G1收集器),两者的配比规则完全不同,这是最容易混淆的核心知识点,必须严格区分。
| 收集器类型 | 年轻代/老年代默认配比 | Eden/Survivor默认配比 | 核心配比参数 |
|---|---|---|---|
| Parallel(吞吐量优先) | 1:2(年轻代占堆1/3) | 8:1:1(-XX:SurvivorRatio=8) | -Xmn、-XX:NewRatio、-XX:SurvivorRatio |
| G1(JDK 17默认,停顿时间优先) | 动态自适应,年轻代占比5%~60% | 动态调整,不推荐手动设置 | -XX:G1NewSizePercent、-XX:G1MaxNewSizePercent、-XX:MaxGCPauseMillis |
核心参数说明
-
-XX:NewRatio=N :设置老年代与年轻代的比例为N:1,例如
-XX:NewRatio=2代表老年代:年轻代=2:1,与默认值一致; -
-XX:SurvivorRatio=N :设置Eden区与单个Survivor区的比例为N:1,例如
-XX:SurvivorRatio=8代表Eden:S0:S1=8:1:1,单个Survivor区占年轻代的1/10; -
-Xmn :直接设置年轻代的固定大小,优先级高于
-XX:NewRatio,生产环境不推荐G1收集器使用此参数; -
-XX:G1NewSizePercent/N:G1收集器年轻代最小占比,默认5%;
-
-XX:G1MaxNewSizePercent=N:G1收集器年轻代最大占比,默认60%;
-
-XX:MaxGCPauseMillis=N:G1收集器的核心参数,设置GC最大停顿时间目标,默认200ms,G1会基于此目标动态调整年轻代大小与GC频率,这是G1调优的核心,而非手动固定分代比例。
2.2 分代配比的核心调优原则
调优的核心不是记住参数,而是理解场景,所有配比调整都必须基于业务场景,以下是经过生产环境验证的核心原则:
-
生产环境必须固定堆内存大小 :
-Xms与-Xmx必须设置为相同值,避免堆内存动态扩容/缩容带来的性能损耗与额外GC压力,这是所有调优的基础; -
年轻代调优核心原则:朝生夕死的对象越多,年轻代应该越大,减少Minor GC的频率,避免对象过早晋升到老年代;
-
老年代调优核心原则:长生命周期对象越多、大对象越多,老年代应该预留足够的空间,避免频繁Full GC与分配担保失败;
-
G1收集器调优优先级 :优先调整
-XX:MaxGCPauseMillis设置合理的停顿目标,而非手动固定年轻代大小,手动固定年轻代会破坏G1的自适应停顿机制,导致停顿时间超标; -
Survivor区调优原则:必须保证Survivor区能容纳Minor GC后的存活对象,避免存活对象直接晋升到老年代,默认8:1:1的比例适用于绝大多数场景,无明确监控数据不建议修改。
2.3 不同业务场景的配比最佳实践
以下是JDK 17环境下,生产环境高频场景的配比方案:
场景1:高并发Web服务(电商、支付、接口网关)
-
业务特征:对象生命周期短,请求级对象占比90%以上,朝生夕死,对响应时间敏感
-
服务器配置:4核8G
-
推荐JVM参数:
-Xms4G -Xmx4G
-XX:+UseG1GC
-XX:MaxGCPauseMillis=100
-XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=512M
-Xlog:gc*:file=/var/log/gc-%t.log:time,uptime,level,tags:filecount=10,filesize=100M
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/var/log/heapdump.hprof -
配比说明:不手动固定年轻代大小,让G1基于100ms的停顿目标自适应调整,最大化年轻代空间,减少对象晋升,适配高并发场景的短生命周期对象。
场景2:大数据计算/离线任务服务
-
业务特征:长生命周期对象多,大对象多,对吞吐量要求高,对单次停顿时间不敏感
-
服务器配置:8核16G
-
推荐JVM参数:
-Xms12G -Xmx12G
-Xmn4G
-XX:+UseParallelGC
-XX:SurvivorRatio=8
-XX:MaxTenuringThreshold=15
-XX:MetaspaceSize=512M -XX:MaxMetaspaceSize=1G
-Xlog:gc*:file=/var/log/gc-%t.log:time,uptime,level,tags:filecount=10,filesize=100M
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/var/log/heapdump.hprof -
配比说明:固定年轻代4G,老年代8G,采用Parallel收集器追求吞吐量最大化,Survivor区比例8:1:1,最大化Eden区空间,减少Minor GC频率。
场景3:微服务小实例场景
-
业务特征:堆内存较小(2G以内),服务数量多,对内存占用与GC停顿都有要求
-
服务器配置:2核4G
-
推荐JVM参数:
-Xms2G -Xmx2G
-XX:+UseG1GC
-XX:MaxGCPauseMillis=50
-XX:G1NewSizePercent=20
-XX:G1MaxNewSizePercent=50
-XX:MetaspaceSize=128M -XX:MaxMetaspaceSize=256M
-Xlog:gc*:file=/var/log/gc-%t.log:time,uptime,level,tags:filecount=5,filesize=50M
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/var/log/heapdump.hprof -
配比说明:限制年轻代占比20%~50%,避免年轻代过大导致老年代空间不足,设置50ms的低停顿目标,适配微服务的轻量调用场景。
2.4 分代配比验证代码示例
以下代码基于JDK 17编写,用于验证不同分代配比下的GC表现:
package com.jam.demo.jvm;
import lombok.extern.slf4j.Slf4j;
import org.springframework.util.StopWatch;
import com.google.common.collect.Lists;
import java.util.List;
/**
* 分代配比验证测试类,用于测试不同年轻代/老年代配比下的GC表现
* JVM启动参数示例:-Xms2G -Xmx2G -Xmn500M -XX:SurvivorRatio=8 -XX:+UseParallelGC -Xlog:gc*:file=gc-ratio.log:time,uptime
* @author ken
* @date 2026-03-13
*/
@Slf4j
public class GenerationRatioTest {
/**
* 1MB字节数组常量
*/
private static final int _1MB = 1024 * 1024;
/**
* 单次循环创建的对象数量
*/
private static final int OBJECT_COUNT_PER_LOOP = 100;
/**
* 测试循环次数
*/
private static final int LOOP_COUNT = 1000;
/**
* 主方法,执行分代配比测试
* @param args 启动参数
*/
public static void main(String[] args) {
StopWatch stopWatch = new StopWatch("分代配比测试");
stopWatch.start("对象分配循环测试");
// 持有长生命周期对象,模拟老年代占用
List<byte[]> longLivedObjects = Lists.newArrayListWithCapacity(100);
for (int i = 0; i < 50; i++) {
longLivedObjects.add(new byte[10 * _1MB]);
}
log.info("长生命周期对象初始化完成,总大小:{}MB", 50 * 10);
// 循环创建短生命周期对象,模拟高并发请求场景
for (int i = 0; i < LOOP_COUNT; i++) {
List<byte[]> shortLivedObjects = Lists.newArrayListWithCapacity(OBJECT_COUNT_PER_LOOP);
for (int j = 0; j < OBJECT_COUNT_PER_LOOP; j++) {
shortLivedObjects.add(new byte[_1MB]);
}
// 每100次循环打印一次进度
if (i % 100 == 0) {
log.info("当前循环次数:{}", i);
}
}
stopWatch.stop();
log.info("测试执行完成,总耗时:{}ms", stopWatch.getTotalTimeMillis());
log.info("请查看gc-ratio.log日志,分析不同配比下的Minor GC频率与晋升情况");
}
}代码使用说明
-
调整JVM启动参数中的
-Xmn(年轻代大小)、-XX:SurvivorRatio参数,对比不同配比下的GC日志; -
核心观察指标:Minor GC的频率、每次GC的晋升到老年代的对象大小、Full GC的频率;
-
验证结论:年轻代设置过小时,Minor GC频率会显著提升,对象晋升到老年代的数量会大幅增加,最终触发频繁Full GC。
三、对象晋升机制的底层原理与坑点规避
对象从年轻代晋升到老年代的机制,是分代回收的核心环节,绝大多数的Full GC频繁问题,都是晋升机制异常导致的。本章节讲透晋升的4个核心条件、底层实现与生产环境高频坑点。
3.1 对象头与分代年龄的底层实现
对象的晋升核心是分代年龄,而分代年龄存储在对象的Mark Word(对象头)中,这是理解晋升机制的底层基础。
-
JVM中,每个对象的对象头都包含一个4bit的分代年龄字段,4bit的二进制最大值是15,因此对象的最大分代年龄只能是15,这就是
-XX:MaxTenuringThreshold参数的最大值只能是15的根本原因,不存在任何例外; -
每熬过一次Minor GC,对象的分代年龄就会+1,当年龄达到晋升阈值时,对象就会从年轻代晋升到老年代。
3.2 对象晋升的4个核心条件
JVM中,对象晋升到老年代只有4个触发条件,所有的晋升行为都符合以下规则,无任何例外:
条件1:分代年龄达到晋升阈值
这是最基础的晋升条件,由-XX:MaxTenuringThreshold参数设置最大阈值,不同收集器的默认值不同:
-
Serial/Parallel收集器默认值:15
-
CMS收集器默认值:6
-
G1收集器:自适应调整阈值,最大值不超过15
核心注意点 :-XX:MaxTenuringThreshold设置的是最大阈值,而非固定阈值,JVM会根据动态年龄判定规则,动态调整实际的晋升阈值,实际阈值永远不会超过该参数的设置值。
条件2:动态年龄判定规则
这是最容易被忽略的晋升条件,也是很多年轻代对象提前晋升的核心原因,规则如下:
❝
在Survivor区中,相同年龄的所有对象大小总和,超过Survivor区容量的50%时,年龄大于等于该年龄的所有对象,会直接晋升到老年代,无需等到
MaxTenuringThreshold设置的阈值。
这个规则的设计目的,是为了避免Survivor区内存浪费,提前将大概率长期存活的对象晋升到老年代,但是如果配置不合理,会导致大量短生命周期对象提前晋升,触发频繁Full GC。
条件3:大对象直接进入老年代
大对象指的是需要大量连续内存空间的对象,最典型的就是大数组、长字符串,这类对象会直接跳过年轻代,直接分配到老年代,避免在年轻代的Survivor区之间来回复制,带来大量的内存拷贝开销。
不同收集器的大对象判定规则不同,必须严格区分:
-
Serial/ParNew收集器 :通过
-XX:PretenureSizeThreshold参数设置大对象阈值,单位为字节,超过该阈值的对象直接进入老年代,该参数仅对Serial和ParNew收集器生效,对G1收集器无效; -
G1收集器 :大对象判定规则为「对象大小超过单个Region容量的50%」,这类对象会直接分配到老年代的Humongous Region中,无需设置任何参数,Region的大小通过
-XX:G1HeapRegionSize设置,取值范围为1M~32M,且必须是2的幂。
核心坑点:G1的Humongous Region只能在Full GC时回收,频繁创建大对象会导致老年代空间快速占满,触发频繁Full GC,这是高并发场景下最常见的GC问题之一。
条件4:Minor GC后的存活对象超过Survivor区容量(分配担保机制)
当Minor GC执行后,存活对象的总大小超过了Survivor区的容量,这些对象无法放入Survivor区,会通过分配担保机制直接进入老年代。
分配担保机制的完整流程如下:
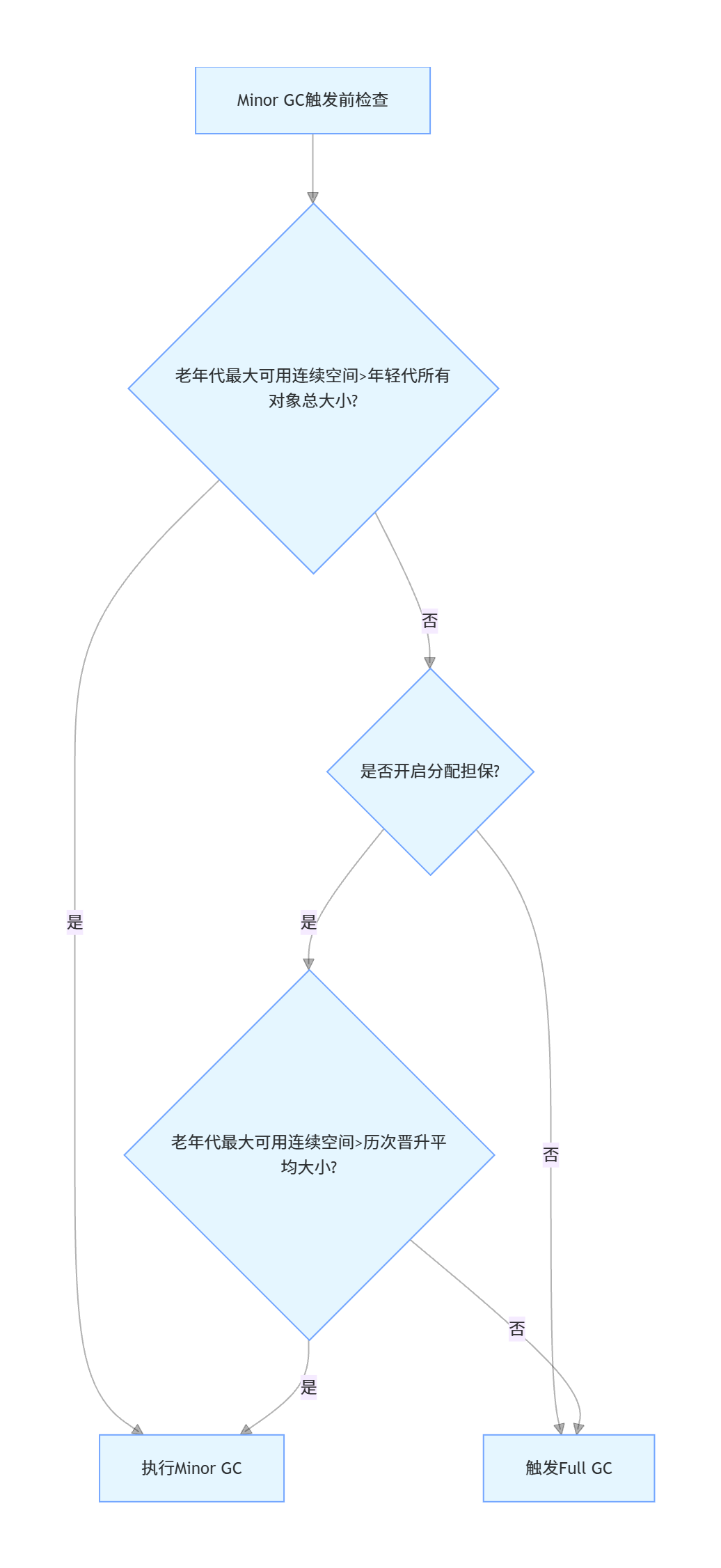
核心说明:
-
分配担保的本质,是用老年代的空间为年轻代的GC做担保,避免Survivor区无法容纳存活对象导致的GC失败;
-
如果老年代空间不足,无法完成担保,会直接触发Full GC,这就是很多时候Minor GC之前会先触发Full GC的核心原因;
-
JDK 17中,分配担保机制默认开启,无需手动设置参数。
3.3 晋升机制验证代码示例
以下代码分别验证动态年龄判定、大对象直接晋升、分配担保3个核心晋升条件:
示例1:动态年龄判定验证
package com.jam.demo.jvm;
import lombok.extern.slf4j.Slf4j;
import org.springframework.util.StopWatch;
import com.google.common.collect.Lists;
import java.util.List;
/**
* 动态年龄判定规则验证测试类
* JVM启动参数:-Xms200M -Xmx200M -Xmn100M -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=15 -XX:+UseSerialGC -Xlog:gc*:file=gc-dynamic-age.log:time,uptime
* 配置说明:Eden区80M,S0/S1各10M,最大年龄阈值15,验证动态年龄判定规则
* @author ken
* @date 2026-03-13
*/
@Slf4j
public class DynamicAgeJudgeTest {
/**
* 1MB字节数组常量
*/
private static final int _1MB = 1024 * 1024;
/**
* 主方法,执行动态年龄判定测试
* @param args 启动参数
*/
public static void main(String[] args) {
StopWatch stopWatch = new StopWatch("动态年龄判定测试");
stopWatch.start("测试对象分配");
// 持有对象,避免被GC回收,总大小5MB,刚好达到Survivor区10M的50%
List<byte[]> objectHolder = Lists.newArrayListWithCapacity(5);
for (int i = 0; i < 5; i++) {
objectHolder.add(new byte[_1MB]);
}
log.info("5MB固定对象分配完成,达到Survivor区容量的50%");
// 分配70MB对象,填满Eden区,触发第一次Minor GC
byte[] tempObject = new byte[70 * _1MB];
stopWatch.stop();
log.info("Eden区填满,触发Minor GC完成,总耗时:{}ms", stopWatch.getTotalTimeMillis());
log.info("请查看gc-dynamic-age.log日志,验证对象年龄是否提前达到晋升阈值");
}
}验证结论:执行后查看GC日志,会发现5个1MB的对象,在第一次Minor GC后,年龄直接被设置为晋升阈值,无需等到15次GC就会晋升到老年代,完美验证动态年龄判定规则。
示例2:大对象直接晋升验证
package com.jam.demo.jvm;
import lombok.extern.slf4j.Slf4j;
import org.springframework.util.StopWatch;
/**
* 大对象直接晋升老年代验证测试类
* JVM启动参数:-Xms2G -Xmx2G -Xmn1G -XX:SurvivorRatio=8 -XX:PretenureSizeThreshold=10485760 -XX:+UseSerialGC -Xlog:gc*:file=gc-big-object.log:time,uptime
* 配置说明:PretenureSizeThreshold=10M,超过10M的对象直接进入老年代
* @author ken
* @date 2026-03-13
*/
@Slf4j
public class BigObjectPromotionTest {
/**
* 10MB字节数组常量,对应PretenureSizeThreshold阈值
*/
private static final int _10MB = 10 * 1024 * 1024;
/**
* 主方法,执行大对象分配测试
* @param args 启动参数
*/
public static void main(String[] args) {
StopWatch stopWatch = new StopWatch("大对象晋升测试");
stopWatch.start("分配10MB大对象");
// 分配10MB大对象,超过阈值,直接进入老年代
byte[] bigObject = new byte[_10MB];
stopWatch.stop();
log.info("10MB大对象分配完成,耗时:{}ms", stopWatch.getTotalTimeMillis());
log.info("请查看gc-big-object.log日志,验证对象是否直接分配到老年代,无Minor GC触发");
}
}3.4 晋升机制高频坑点与规避方案
| 坑点场景 | 根因分析 | 规避方案 |
|---|---|---|
| 动态年龄判定导致短生命周期对象提前晋升 | Survivor区设置过小,相同年龄对象总和超过Survivor区50%,触发提前晋升 | 1. 不盲目调小Survivor区比例,默认8:1:1优先;2. 保证Survivor区能容纳Minor GC后的存活对象;3. 监控每次GC的晋升对象大小 |
| 大对象导致频繁Full GC | G1收集器中,大对象放入Humongous Region,只能在Full GC时回收,频繁创建大对象导致老年代快速占满 | 1. 避免一次性创建大数组/大集合,采用分页/分片处理;2. 避免大字符串拼接,使用StringBuilder;3. 合理设置G1的Region大小,让大对象不超过Region的50% |
| 分配担保失败导致频繁Full GC | 老年代空间预留不足,Minor GC前检查不通过,直接触发Full GC | 1. 保证老年代有足够的预留空间,不盲目加大年轻代占比;2. 监控历次晋升的平均大小,保证老年代可用空间大于该值 |
| 年龄阈值设置不合理导致GC效率低下 | 阈值设置过小,对象过早晋升;阈值设置过大,对象在Survivor区多次复制,增加GC开销 | 1. 无明确监控数据不修改默认阈值;2. 长生命周期对象多的场景,适当调小阈值;3. 短生命周期对象多的场景,适当调大阈值 |
四、架构级JVM内存调优策略
很多时候,JVM的内存问题根本不是参数配置的问题,而是代码与架构设计的问题。真正的顶级调优,是从架构与代码层面,从根源上减少GC压力,而非单纯调整JVM参数。本章节讲解生产环境验证过的架构级调优策略,从根源上解决JVM内存问题。
4.1 代码级调优:从根源减少对象创建与回收
代码层面的优化,是JVM调优的第一道防线,也是性价比最高的优化,核心原则是减少不必要的对象创建,避免短生命周期对象长期持有,减少大对象的生成。
核心优化实践
-
避免循环内创建对象:循环内创建的对象会快速填满Eden区,触发频繁Minor GC,应将对象创建移到循环外,复用对象;
-
字符串拼接优化 :避免循环内使用
+进行字符串拼接,+会生成大量临时String对象,应使用StringBuilder; -
避免不必要的装箱拆箱:高频场景下,基本数据类型优先于包装类型,避免自动装箱拆箱生成大量包装类对象;
-
对象复用优化:高频创建的轻量级对象,可采用对象池复用,但是必须注意:池化对象会长期存活在老年代,仅适用于创建开销极高的对象,避免过度池化;
-
集合初始化优化:创建集合时,指定初始容量,避免集合扩容时生成新的数组对象,带来大量的临时对象与内存拷贝;
-
避免内存泄漏:及时释放对象引用,尤其是静态集合、ThreadLocal、本地缓存等场景,避免对象无法被GC回收,导致老年代内存持续上涨,最终OOM。
4.2 架构级调优:从设计层面降低JVM内存压力
架构层面的优化,能从根本上解决大堆、高GC压力的问题,核心原则是拆分大内存占用的服务,避免单个服务堆内存过大,减少长生命周期对象的持有,控制大对象的生成。
核心优化实践
-
微服务拆分:将大单体服务拆分为多个微服务,避免单个服务堆内存过大(超过16G),大堆会导致Full GC停顿时间过长,拆分后每个服务的堆内存控制在4G~8G,GC停顿时间更容易控制;
-
缓存架构优化:避免使用本地缓存(如HashMap、Caffeine)存储大量数据,本地缓存的对象会长期存活在老年代,导致老年代空间占满,应采用分布式缓存(Redis)替代本地缓存,仅在本地缓存热点小数据;
-
大对象处理优化:大文件上传、大数据查询、批量导入等场景,采用分片/分页处理,避免一次性加载全量数据到内存,生成大对象;
-
异步化与池化优化:合理使用线程池、数据库连接池、Redis连接池,避免频繁创建销毁线程/连接对象,同时控制池的最大大小,避免池化对象过多占用老年代内存;
-
无状态化设计:服务尽量设计为无状态,避免在服务内持有会话级、业务级的长生命周期对象,减少老年代的内存占用。
4.3 生产环境调优的正确步骤与最佳实践
JVM调优不是盲目调整参数,而是有标准的流程,以下是经过互联网大厂生产环境验证的标准调优步骤,严格遵循可避免90%的调优误区:
-
明确性能目标:调优前必须明确核心目标,吞吐量、延迟、内存占用三者只能选两个作为核心目标,不可能同时三者最优。例如高并发Web服务,核心目标是低延迟,优先保证GC停顿时间;离线计算服务,核心目标是高吞吐量,优先保证CPU利用率。
-
全面监控与数据采集:开启GC日志,使用JDK自带工具采集堆内存、GC、线程数据,核心采集指标包括:Minor GC/Full GC的频率与停顿时间、年轻代/老年代的内存占用率、每次GC的晋升对象大小、元空间占用情况。
-
定位瓶颈与根因分析:基于采集的数据,定位核心问题,例如:是Minor GC频繁?还是Full GC频繁?是对象提前晋升?还是大对象过多?是内存泄漏?还是分代配比不合理?必须找到根因,再进行优化,禁止盲目调整参数。
-
先优化代码与架构,再调整JVM参数:80%以上的JVM内存问题,都可以通过代码与架构优化解决,参数调优只是辅助手段,永远不要用参数调优来掩盖代码与架构的缺陷。
-
小步迭代,基准测试:每次只调整一个参数,调整后必须进行压测,对比调整前后的核心指标,验证优化效果,禁止一次调整多个参数,导致无法定位优化效果。
-
上线验证与持续监控:优化后的参数上线后,持续监控GC指标与服务性能,验证优化效果是否符合预期,若不符合,回滚参数,重新分析。
五、生产环境实战案例:频繁Full GC问题排查与调优
5.1 案例背景
某电商订单服务,基于JDK 17 + Spring Boot 3.x开发,部署在4核8G服务器,JVM堆内存设置4G,上线后出现以下问题:
-
每10分钟触发一次Full GC,单次Full GC停顿时间超过500ms;
-
系统响应时间从正常的100ms以内,上涨到500ms以上,频繁出现超时;
-
高峰期TPS无法提升,CPU使用率居高不下,大部分CPU时间消耗在GC上。
5.2 排查过程与根因分析
-
GC日志分析:通过GCEasy工具分析GC日志,发现Full GC频繁的核心原因是老年代内存占用率快速上涨,每次Full GC只能回收不到10%的内存,说明有大量对象长期被引用,无法回收,同时发现大量大对象直接进入老年代的Humongous Region。
-
堆内存分析 :使用
jcmd命令生成堆转储文件,通过MAT工具分析,发现两个核心根因:-
根因1:本地缓存使用
HashMap存储订单明细数据,没有设置过期时间与容量上限,缓存的订单对象数量超过100万,占用2.2G老年代内存,导致内存泄漏; -
根因2:订单明细查询接口,一次性加载全量订单明细数据,生成超过20M的大对象,频繁进入G1的Humongous Region,导致老年代空间快速占满。
-
-
代码验证:查看代码,发现本地缓存是静态变量,订单完成后没有从缓存中移除,同时订单查询接口没有分页,一次性查询全量数据,完全符合分析的根因。
5.3 调优方案与落地
1. 代码与架构优化(核心优化)
-
本地缓存优化:替换
HashMap为Caffeine缓存,设置最大容量1万条,过期时间5分钟,避免内存泄漏; -
大对象优化:订单明细查询接口新增分页功能,单次查询最大条数1000条,避免一次性加载全量数据,消除20M以上的大对象;
-
集合初始化优化:所有业务集合创建时指定初始容量,避免扩容带来的临时对象。
2. JVM参数优化(辅助优化)
基于JDK 17的G1收集器,优化后的参数如下:
-Xms4G -Xmx4G
-XX:+UseG1GC
-XX:MaxGCPauseMillis=100
-XX:G1HeapRegionSize=16M
-XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=512M
-Xlog:gc*:file=/var/log/gc-%t.log:time,uptime,level,tags:filecount=10,filesize=100M
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/var/log/heapdump.hprof- 优化说明:设置Region大小为16M,让10M以内的对象不会被判定为大对象,避免进入Humongous Region;设置100ms的最大停顿目标,让G1自适应调整分代比例,保证响应时间。
5.4 优化效果验证
-
Full GC频率:从每10分钟一次,降到每天2次以内,仅在夜间低峰期触发;
-
GC停顿时间:Full GC停顿时间从500ms降到100ms以内,Minor GC停顿时间稳定在10ms以内;
-
系统性能:接口平均响应时间从500ms降到80ms以内,高峰期TPS提升3倍,CPU使用率从80%以上降到30%左右;
-
内存占用:老年代内存占用稳定在800M以内,无内存泄漏,Humongous Region无新增大对象。
六、JDK 17 调优工具与高频误区避坑指南
6.1 JDK 17 核心调优工具(官方自带,无需额外安装)
JDK 17自带了完善的调优工具,其中jcmd是官方推荐的全能工具,替代了传统的jps、jstat、jmap、jstack等工具,核心工具与常用命令如下:
| 工具 | 核心功能 | 常用命令 |
|---|---|---|
| jcmd | JVM全能工具,可执行堆转储、GC触发、线程打印、内存信息查看等所有操作 | 1. jcmd -l:查看所有Java进程PID 2. jcmd <pid> GC.heap_info:查看堆内存分代信息 3. jcmd <pid> GC.heap_dump <file-path>:生成堆转储文件 4. jcmd <pid> Thread.print:打印线程栈信息 5. jcmd <pid> VM.command_line:查看JVM启动参数 |
| jstat | 实时监控GC与内存统计信息,适合线上实时排查 | jstat -gc <pid> 1000 10:每1秒打印一次GC信息,共打印10次,核心观察年轻代/老年代占用、GC次数与时间 |
| jconsole | 可视化监控工具,图形化展示堆内存、GC、线程、CPU使用率,适合本地调试 | 直接命令行输入jconsole启动,选择对应Java进程即可 |
| jhat | 堆转储文件分析工具,适合离线分析堆内存泄漏问题 | jhat <heap-dump-file>:解析堆转储文件,启动HTTP服务,通过浏览器查看分析结果 |
6.2 高频调优误区避坑指南
-
误区1:堆内存设置越大越好
- 真相:堆内存越大,Full GC的停顿时间越长,尤其是Parallel/CMS收集器,大堆会导致单次Full GC停顿时间达到数秒,严重影响服务可用性。正确的做法是:在满足业务内存需求的前提下,尽量控制堆内存大小,优先通过代码与架构优化减少内存占用。
-
误区2:用G1收集器时,手动固定年轻代大小
- 真相:G1收集器的核心优势是基于
-XX:MaxGCPauseMillis的停顿时间目标,自适应调整年轻代大小,手动固定年轻代会破坏G1的自适应机制,导致停顿时间无法达到目标,甚至出现更长的停顿。正确的做法是:优先设置合理的停顿目标,无特殊情况不手动固定年轻代大小。
- 真相:G1收集器的核心优势是基于
-
误区3:盲目调整
-XX:MaxTenuringThreshold参数- 真相:很多开发者认为将该参数调大就能减少对象晋升,但是如果Survivor区空间不足,动态年龄判定规则会提前触发晋升,调大该参数毫无意义,反而会导致对象在Survivor区多次复制,增加Minor GC的开销。正确的做法是:无明确监控数据,不修改默认值。
-
误区4:不开启GC日志,出问题无法排查
- 真相:GC日志是排查JVM问题的核心依据,很多生产环境服务不开启GC日志,出现GC问题时无法回溯分析,只能重启服务,错过最佳排查时机。正确的做法是:生产环境必须开启GC日志,配置日志滚动策略,避免日志文件占满磁盘。
-
误区5:调优不做基准测试,凭感觉调整参数
- 真相:很多开发者调优时,一次调整多个参数,上线后不知道哪个参数起了作用,甚至越调越差。正确的做法是:小步迭代,每次只调整一个参数,调整后做压测,对比核心指标,验证优化效果。
-
误区6:用JDK 8的GC日志参数配置JDK 17
- 真相:JDK 9之后引入了统一日志框架(JEP 158),废弃了JDK 8的
-XX:+PrintGCDetails、-XX:+PrintGCDateStamps等参数,JDK 17中使用这些参数会启动失败。正确的做法是:使用-Xlog参数配置GC日志,本文所有示例中的GC日志参数均符合JDK 17规范,可直接使用。
- 真相:JDK 9之后引入了统一日志框架(JEP 158),废弃了JDK 8的
七、总结
JVM内存调优的核心,从来不是记住多少参数,而是吃透分代回收的底层逻辑,理解对象从创建、分配、GC到晋升的完整生命周期,从业务场景出发,先解决代码与架构的核心问题,再通过参数调优做辅助优化。
记住:最好的调优,是从根源上减少GC的压力,而不是在问题出现后,盲目调整参数去掩盖问题。
附录:项目依赖pom.xml(JDK 17)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.4</version>
<relativePath/>
</parent>
<groupId>com.jam.demo</groupId>
<artifactId>jvm-tuning-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>jvm-tuning-demo</name>
<description>JVM调优示例项目</description>
<properties>
<java.version>17</java.version>
<guava.version>33.1.0-jre</guava.version>
<fastjson2.version>2.0.52</fastjson2.version>
<mybatis-plus.version>3.5.6</mybatis-plus.version>
<springdoc.version>2.5.0</springdoc.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-webmvc-ui</artifactId>
<version>${springdoc.version}</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>${guava.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>${fastjson2.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.34</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>