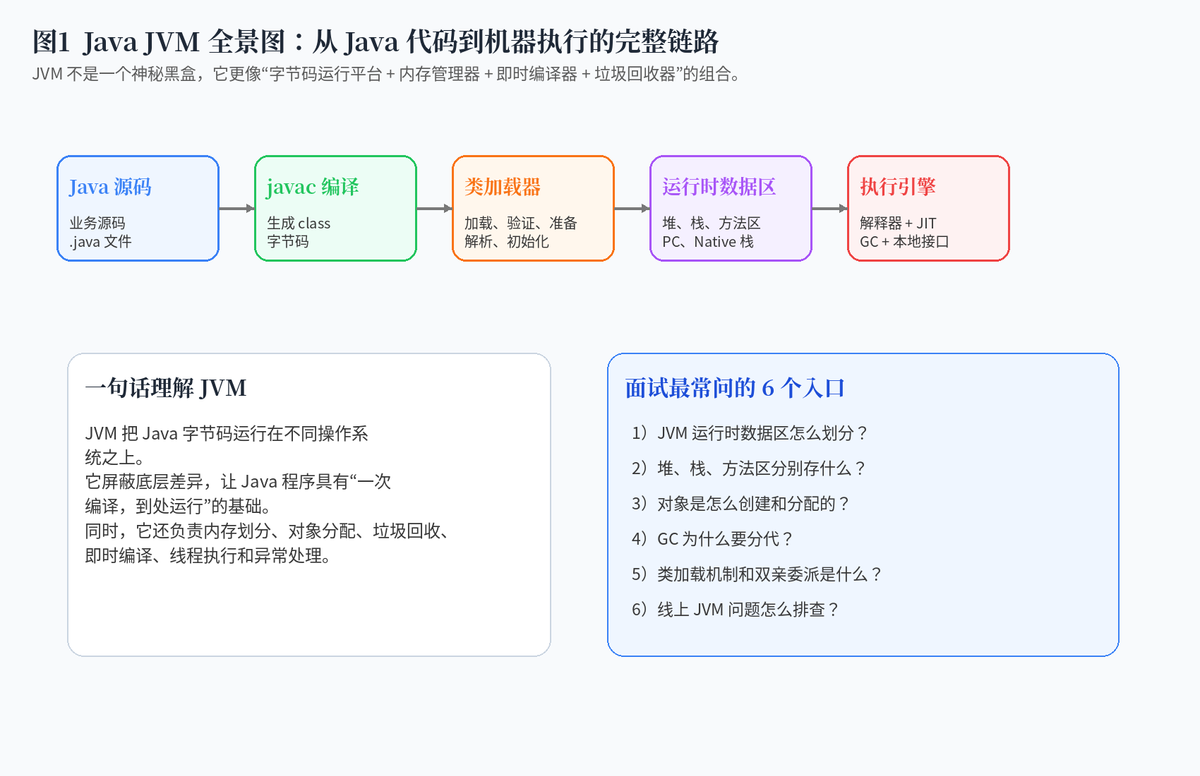
1. JVM 到底是什么?为什么 Java 程序离不开它?
JVM,全称 Java Virtual Machine,可以理解为 Java 字节码的运行平台。Java 代码先被 javac 编译成 class 字节码,再由 JVM 负责加载、解释、编译、执行和管理内存。这样 Java 程序不需要直接面对不同操作系统和 CPU 的差异,只要目标机器有对应的 JVM,就可以运行同一份字节码。
面试中讲 JVM,不要一开始就钻进 GC 参数。更好的结构是:类加载器把 class 送进来,运行时数据区提供内存,执行引擎执行字节码,垃圾回收器回收无用对象,本地接口负责和底层 native 能力打交道。
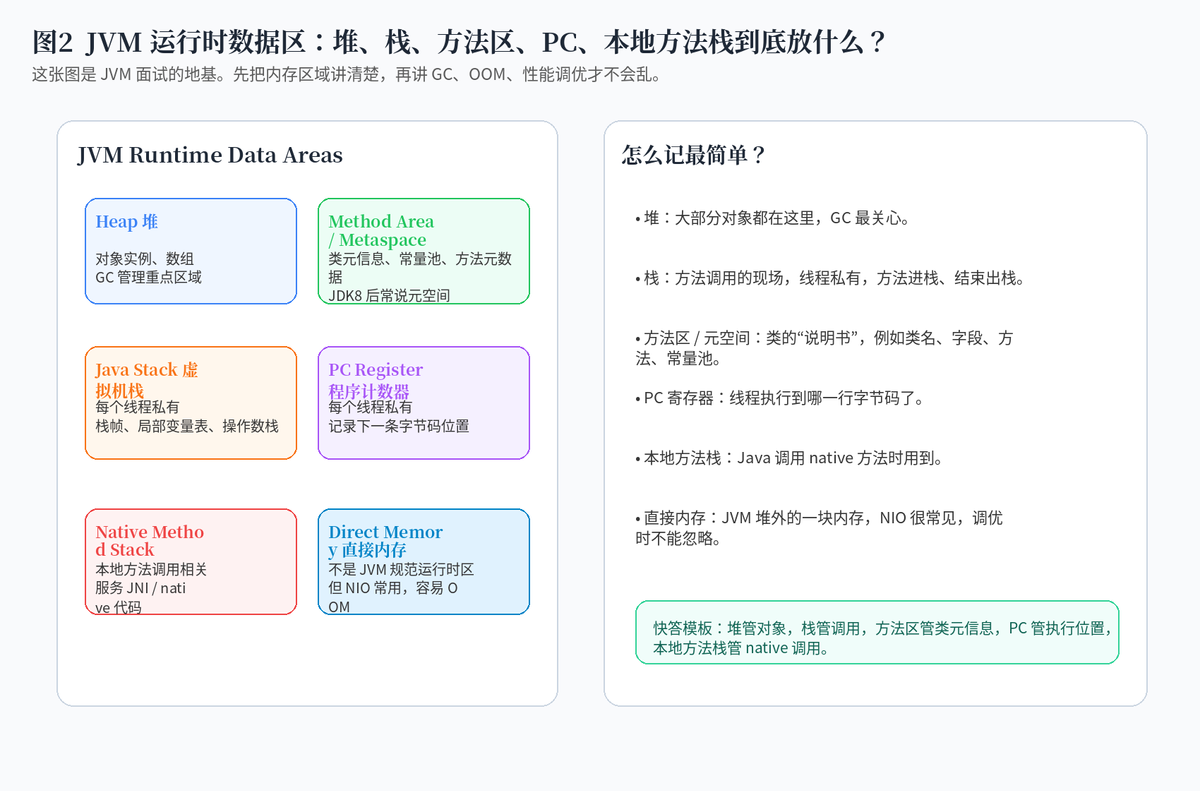
2. JVM 运行时数据区怎么划分?
JVM 运行时数据区是面试高频中的高频。最常见的划分包括:堆、Java 虚拟机栈、方法区或元空间、程序计数器、本地方法栈。除此之外,工程实践里还要关注直接内存,因为 NIO、Netty 等框架经常使用堆外内存。
堆主要存放对象实例和数组,是 GC 管理的重点区域。栈是线程私有的,用来保存方法调用的栈帧。方法区或元空间保存类元信息、常量池、方法元数据等。程序计数器记录当前线程执行到哪一条字节码指令。本地方法栈则和 native 方法调用相关。
3. 堆、栈、方法区最容易混淆,怎么讲最清楚?
最简单的说法是:堆放对象,栈放方法调用现场,方法区放类的说明书。比如一个 User 对象通常在堆上,main 方法调用 service 方法时,相关的局部变量、操作数栈、返回地址等在栈帧里,而 User 类有哪些字段、哪些方法、常量池信息,则在方法区或元空间对应的类元数据中。
为什么栈不用 GC?因为栈帧随着方法调用自动入栈、出栈,生命周期很明确。堆上的对象生命周期则不一定,可能跨方法、跨线程、被多个对象引用,所以需要 GC 判断哪些对象还活着。
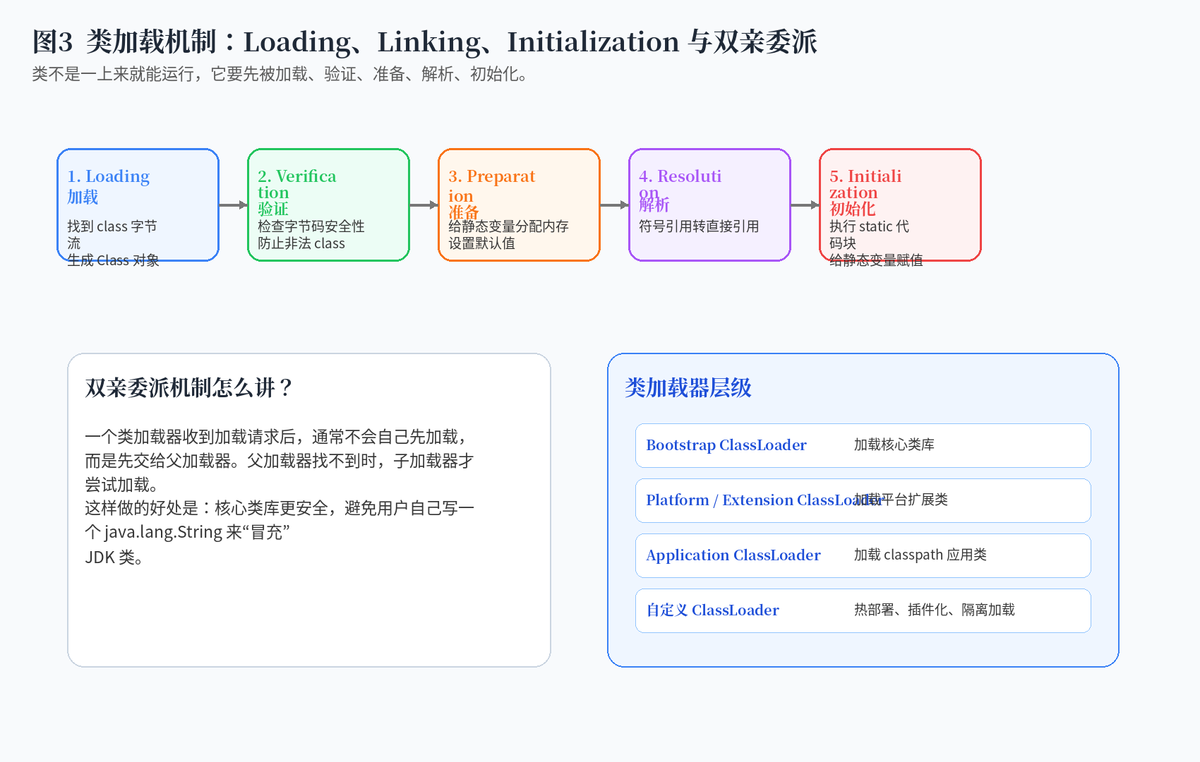
4. 类加载机制:Loading、Linking、Initialization 到底是什么?
类加载一般可以拆成加载、验证、准备、解析、初始化几个阶段。加载阶段把 class 字节流读进来,并生成对应的 Class 对象;验证阶段检查字节码是否合法、安全;准备阶段给静态变量分配内存并设置默认值;解析阶段把符号引用转换成直接引用;初始化阶段才真正执行 static 代码块和静态变量赋值。
双亲委派机制可以理解为:一个类加载器收到加载请求后,先让父加载器尝试加载,父加载器加载不了,自己才动手。这能保证核心类库的安全性和稳定性,避免用户自定义类冒充 JDK 核心类。
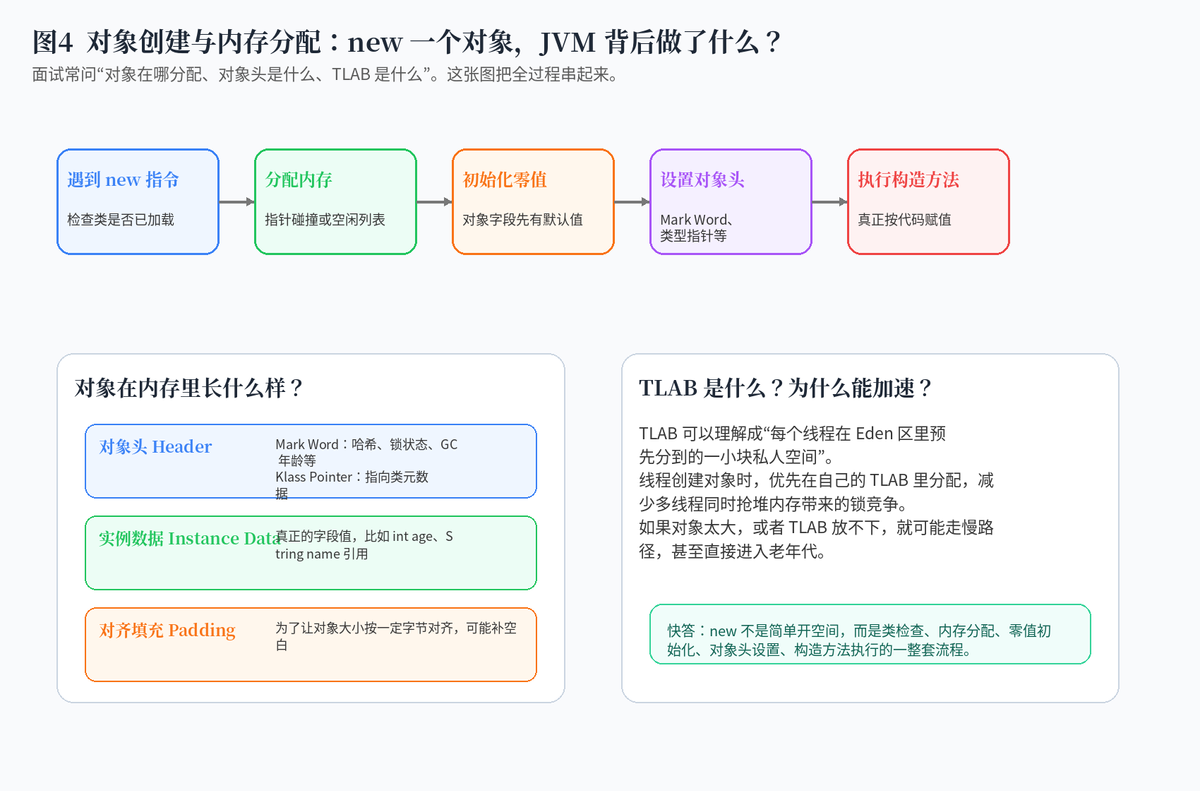
5. 一个对象 new 出来,JVM 背后做了什么?
new 一个对象,并不是简单地"开一块内存"。JVM 会先检查类是否已经加载,然后给对象分配内存,把对象字段初始化为默认零值,再设置对象头,最后执行构造方法。
对象在内存里通常可以分成对象头、实例数据和对齐填充三部分。对象头里有 Mark Word 和类型指针等信息,Mark Word 里可能存放哈希、锁状态、GC 年龄等;实例数据才是业务字段;对齐填充只是为了满足内存对齐。
6. TLAB 是什么?为什么它能提升对象分配效率?
TLAB 可以理解为每个线程在 Eden 区里提前分到的一小块私人空间。线程创建小对象时,优先在自己的 TLAB 里分配,这样就不需要每次都和其他线程抢同一块堆空间,减少锁竞争。
如果对象很大,或者 TLAB 空间不够,就可能走慢路径,甚至直接进入老年代。线上如果对象创建特别频繁,TLAB、Eden、Minor GC 这些关键词就会经常一起出现。
类加载机制
对象创建与内存分配
7. Java 堆为什么要分代?
分代 GC 的核心假设是:大多数对象很快就会死亡,少数对象会活很久。新对象通常先分配到 Eden,Eden 满了触发 Minor GC,存活对象进入 Survivor 区,多次存活后才晋升老年代。
这样做的好处是,JVM 可以把新生代作为"高频清理区",因为这里垃圾最多;把老年代作为"低频清理区",因为能活到老年代的对象通常比较稳定。
8. Minor GC、Major GC、Full GC 有什么区别?
Minor GC 通常指新生代回收,频率较高,速度相对较快。Major GC 常被用来描述老年代回收,但不同 JVM、不同日志语境里含义可能略有差异。Full GC 则通常表示一次影响范围更大的停顿式回收,可能涉及整个堆甚至元空间,线上要重点关注。
面试时可以这样回答:不要死抠名词,而要看 GC 日志里的回收区域、触发原因、停顿时间和回收效果。
9. 常见 GC 算法与收集器怎么记?
基础算法有标记-清除、复制、标记-整理。标记-清除简单但容易有碎片;复制算法适合新生代,因为新生代存活对象少;标记-整理解决碎片,但对象移动成本更高。
收集器方面,Serial 简单,Parallel 偏吞吐,G1 是服务端常见选择,ZGC 和 Shenandoah 更偏低延迟场景。真正选型时,要结合堆大小、停顿目标、吞吐要求、JDK 版本和业务类型。

堆内存与分代 GC

垃圾回收算法与常见收集器
10. 什么是 GC Roots?可达性分析怎么理解?
JVM 判断对象是否可回收,常用的是可达性分析。它从一组根对象出发,沿着引用链往下找,能被找到的对象就是"还活着",找不到的对象就可能被回收。
常见 GC Roots 包括栈帧中的局部变量引用、静态变量引用、常量引用、JNI 引用等。用人话说,只要一个对象还能从正在运行的线程、类静态变量或底层引用里绕着找到,它就不能随便回收。
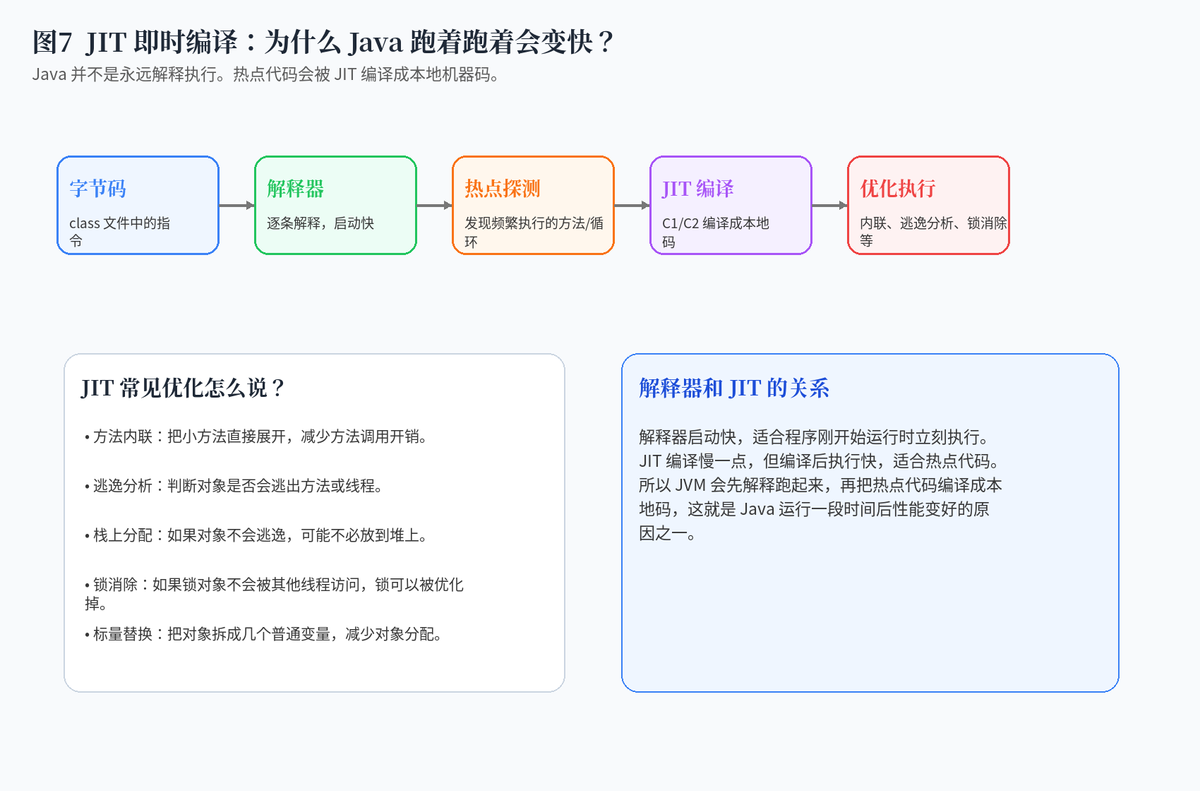
11. JIT 即时编译:为什么 Java 跑着跑着会变快?
Java 程序刚开始运行时,很多字节码会先由解释器执行,启动快但执行效率一般。随着程序运行,JVM 会发现哪些方法或循环被频繁执行,这些就是热点代码。JIT 编译器会把热点代码编译成本地机器码,并做方法内联、逃逸分析、锁消除等优化。
所以 Java 不是永远解释执行,而是解释器和 JIT 配合:解释器保证启动速度,JIT 保证热点性能。
12. JVM 调优到底调什么?
JVM 调优不是上来就改一堆参数,而是先明确目标:是要降低延迟、提高吞吐、减少 Full GC、降低内存占用,还是解决 OOM?然后通过 GC 日志、线程栈、堆 dump、JFR 等数据定位瓶颈。
常见参数包括 -Xms、-Xmx、-Xss、-XX:+UseG1GC、-XX:MaxGCPauseMillis、GC 日志参数等。但参数只是工具,不能替代对业务分配速率、对象生命周期、并发规模的理解。
13. 线上 CPU 飙高、内存泄漏、频繁 Full GC 怎么查?
CPU 飙高时,先用 top 找到 Java 进程和占用高的线程,再把线程 ID 转成十六进制,到 jstack 里找对应线程栈,看它在执行什么。内存持续上涨时,用 jstat 看 GC 变化,再用 jmap 导出 heap dump,用 MAT 或类似工具分析对象占用和引用链。
频繁 Full GC 时,要看 GC 日志:是老年代满了、元空间满了、大对象太多、晋升失败,还是参数不合理。排查 JVM 问题的关键不是背命令,而是把现象和数据对上。
14. 常见 OOM 类型怎么理解?
Java heap space 通常表示堆内存不够,可能是对象太多、缓存无限增长、集合未清理。Metaspace OOM 可能和大量动态类、代理类、类加载器泄漏有关。Direct buffer memory 可能来自 NIO 或 Netty 堆外内存使用不当。Unable to create new native thread 则往往与线程数过多或系统资源限制有关。
面试里可以补一句:OOM 不是简单把 Xmx 调大就解决,必须先判断是正常业务需要更多内存,还是代码存在泄漏。
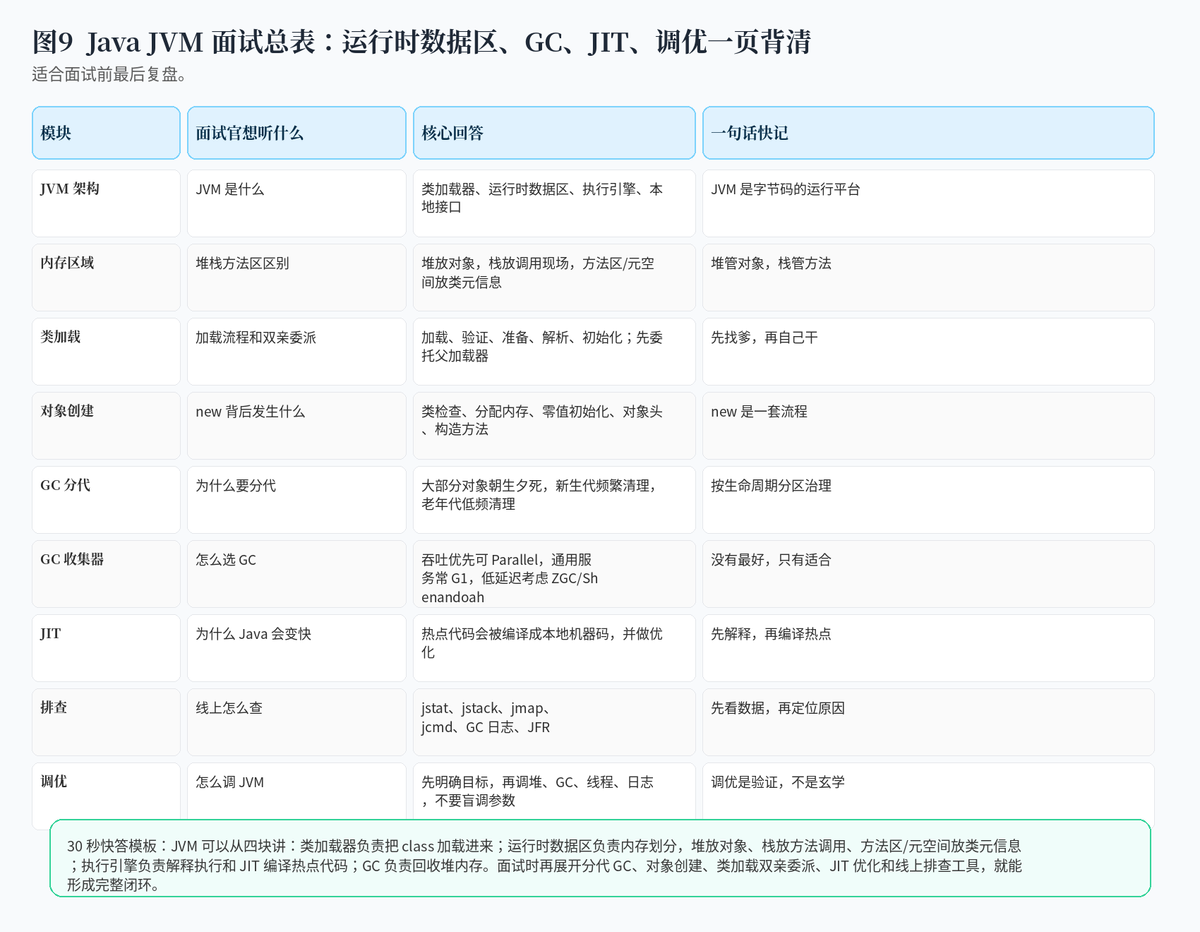
15. Java JVM 面试如何组织答案最稳?
最稳的结构是从 JVM 总架构开始讲:类加载器、运行时数据区、执行引擎、GC、本地接口。然后展开运行时数据区:堆、栈、方法区、PC、本地方法栈。再讲对象创建和分代 GC,最后补 JIT、类加载双亲委派、线上排查工具和调优思路。
这样回答的好处是层层递进,既有理论,也有工程落地,不会显得只会背八股。

JVM 线上问题排查路线
Java JVM 面试总表
16. 总结:JVM 的核心不是"背参数",而是理解 Java 程序如何运行
JVM 是 Java 后端绕不开的基础。它负责把 class 字节码加载进来,划分运行时内存,解释或编译执行字节码,并通过 GC 管理对象生命周期。理解 JVM,不是为了死背一堆名词,而是为了在写代码、排查线上问题、优化性能时知道问题到底可能出在哪。
如果你能把类加载、内存区域、对象创建、分代 GC、JIT 编译、GC 日志和线上排查串成一条完整链路,JVM 相关面试题基本就能回答得比较稳。
附:30 秒快答模板
"JVM 可以从四块讲:类加载器负责把 class 字节码加载进来;运行时数据区负责内存划分,堆存对象,栈存方法调用现场,方法区或元空间存类元信息;执行引擎负责解释执行和 JIT 编译热点代码;GC 负责回收堆里的无用对象。面试里再展开对象创建流程、类加载双亲委派、分代 GC、常见收集器和线上排查工具,就能形成完整闭环。"