导读
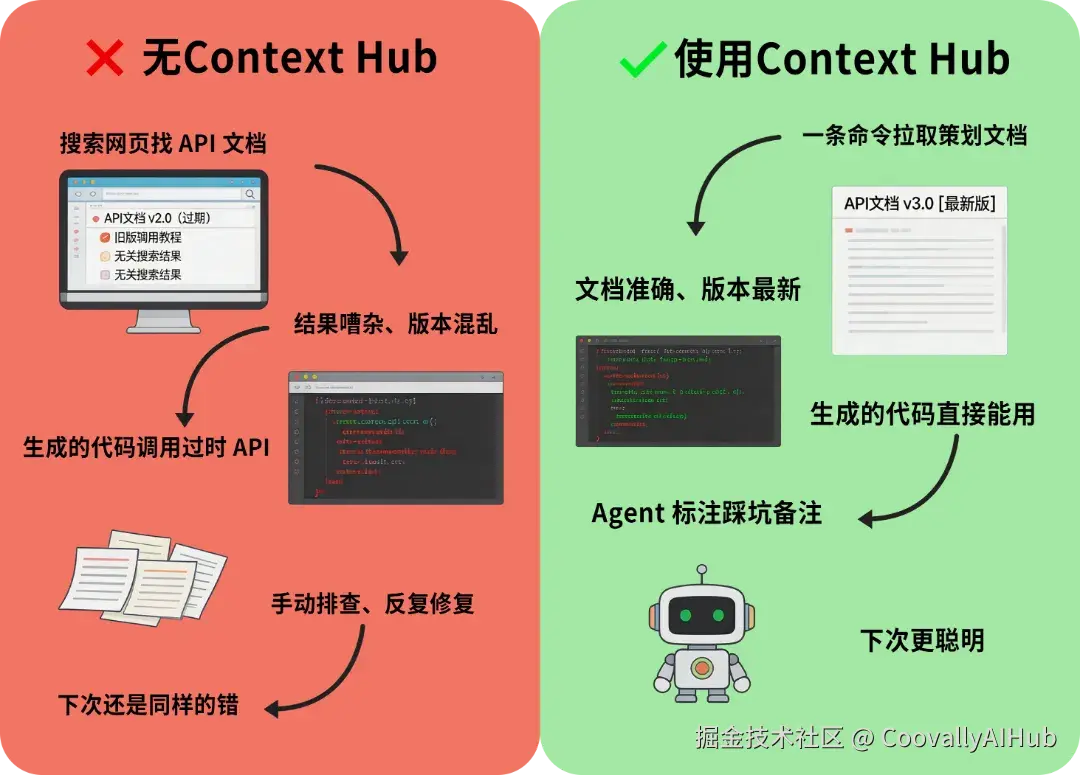
使用 AI Agent 编写代码时,您大概遇到过情况:Agent 生成的代码调用了一个已经废弃的 API 版本,或者用了最新版本中的一个参数名称已经修改了。您花时间,发现 Agent 接下来修改还是犯同样的错误。
这不是模型"笨",而是一个结构性问题------大语言模型的训练数据有相当日期,但 API 在持续迭代。模型学习的可能是 6 个月前的 API 文档,而库已经更新了 3 个版本。这种现象被开发者社区称为****API 相互(APIdrift)** **。
2026年3月9日,Andrew Ng团队开源了Context Hub ,一个专门解决这个问题的CLI工具。它的思路很直接:给Agent提供一个可搜索、可版本管理的API文档知识库,让Agent在生成代码时能拉取最新的、经过策划的文档,而不是依赖训练时的记忆。
发布时收录了68个API 的文档,GitHub获得6,300+颗星,MIT协议开源。

图片来源于GitHub社区
一、为什么值得关注?
Context Hub背后指向的是一个更大的话题------**上下文工程(Context Engineering) **。当Agent的能力越来越强,给Agent提供什么上下文 比Agent本身更聪明能决定最终的质量输出。因为Andrew Ng在发布时也明确提到:Agent经常使用过时的API,不是因为模型不够好,而是它没有得到正确的上下文。Context Hub就是这个方向上的一个具体工具实现。
二、API到底是什么问题?为什么RAG不够用?
问题的本质
AI编码Agent(Claude Code、Cursor、Aider等)在生成代码时依赖两类知识:
- 模型内化知识:训练阶段学习的API用法、代码模式
- 上下文提供的知识:通过系统提示或文档注入的即时信息
第一类知识的问题是过时 ------训练数据有预先日期。第二类知识的问题是不系统------每次都靠用户手动复制文档到提示里,效率低且不完整。
API造成的具体后果:
- 使用已废弃的函数签名
- 确定已不再支持的参数
- 遗漏新版本引入的必填字段
- 使用旧版本的认证方式
这些错误的麻烦所在是:代码"看起来对",甚至能通过部分测试,但在生产环境中会失败。
为什么简单的RAG还不够?
一个自然的想法是"用 RAG 检索最新文档"。但 API 文档中通用的 RAG 方案场景有几个:
- API文档的信噪比很少:一个SDK的完整文档可能有几万行,但代理现在只需要一个函数的签名和参数说明
- 版本管理复杂:需要确保检索到文档的当前版本,而不是旧版本
- 跨语言差异:Python 和 JavaScript SDK 中的同一个 API 的用法可能不同
Context Hub 的做法是:不做通用的文档搜索,而是提供人工策划(curated)、版本管理、按语言区分的 API 文档片段。
三、Context Hub的架构和易用性
核心设计
Context Hub 的架构非常简洁:
| 组件 | 说明 |
|---|---|
| 内容层 | Markdown 文件 + YAML 前置信息,存储在 GitHub 仓库的/content目录 |
| 命令行工具 | Node.js 编写,通过 npm 分发(@aisuite/chub),需要 Node.js ≥ 18 |
| 文档库 | 目前收录了 68 个 API 的策划文档 |
安装:
bash
npm install -g @aisuite/chub四个核心命令
| 命令 | 用途 | 效果 | |
|---|---|---|---|
chub search [query] |
搜索可用文档 | chub search "openai" |
|
chub get <id> |
获取特定的 API 文档 | chub get openai/chat --lang py |
|
chub annotate <id> <note> |
给文档添加持久化注释 | 代理在使用中发现的注意事项 | |
| `chub feedback <up | down>` | 对文档质量投票 | 帮助维护者改进内容 |
关键特性
按语言区分 :同一个 API,Python 和 JavaScript 的文档是独立的。chub get openai/chat --lang py并--lang js返回不同的内容。
增量获取:可以只拉取一些参考文件或摘要,而不是完整文档。这对于令牌使用敏感的场景很重要------代理不需要每次都加载全量文档。
Agent自学习 :annotate命令让Agent可以在使用文档过程中留下备注,这些备注在后续会话中仍然可用。比如Agent发现某些参数有隐含的格式要求,可以标注下来,接下来直接读到。
社区反馈循环 :feedback命令收集的评分数据会汇总给文档维护者,帮助持续改进内容质量。
四、实际使用场景:Agent如何调用Context Hub
Context Hub 设计为被代理"主动调用"的工具,而不是被动的文档库。典型的使用流程:
场景:Agent需要调用OpenAI Chat API
- 代理在系统提示中获知"使用
chub获取API文档" - 代理执行
chub search "openai chat",找到文档ID - 代理执行
chub get openai/chat --lang py,获取最新的Python SDK文档 - Agent根据文档生成代码,是使用当前版本的参数和函数签名
- 如果代理在过程中发现文档中没有提及的注意事项,请执行
chub annotate留下备注
与直接把文档复制到提示相比,这种方式的优点:
- 代理获取:不是全部大脑加载所有文档,而是根据当前搜索任务并获取
- 版本始终最新:文档在 GitHub 仓库中维护,更新后代理即可立即获取到
- 跨会话积累:注释功能让代理的经验可以跨会话保留
五、68个API:覆盖了什么?
Context Hub 发布时收录了 68 个 API 的策划文档,此后社区持续贡献,数量持续增长。虽然仓库没有公开完整的 API 列表,但从社区讨论和 DEV 社区的文章概览,覆盖的范围包括主流的 AI/ML API、云服务 API 和开发工具 API。
仓库采用社区贡献模式:任何人都可以通过 PR 向/content目录添加新的 API 文档。每个份文档遵循统一的 Markdown + YAML 前置信息格式,确保 CLI 工具能够正确解析和索引。
仓库数据(截至2026年3月)
| 维度 | 数据 |
|---|---|
| 星星 | 6300+ |
| 叉子 | 597 |
| 贡献者 | 11 |
| 提交 | 132 |
| 语言 | JavaScript(100%) |
| 许可 | 麻省理工学院 |
| npm 包名 | @aisuite/chub |
597 个 fork 和 11 个贡献者,说明社区参与程度不低。但 68 个 API 相对于开发者日常使用的 API 接口来说仍然只是启动阶段,参与的社区贡献是这个项目能否真正实用的关键。
六、总结:Context Hub适合什么场景?
Context Hub 解决的核心问题:AI 编码代理依赖过时的 API 知识,导致生成的代码使用了废弃的接口或错误的参数。
它的方法:提供一个CLI工具,让Agent能够在生成代码之前继续获取经过策划的、最新的API文档。
适合的场景:
- 使用 Claude Code、Aider 等终端型 Agent 编写代码的开发者
- 间隔使用快速迭代的API(如AI/ML平台API)的项目
- 团队内部想统一Agent使用的API文档版本
需要注意的咳嗽:
- 68个API的覆盖面仍然有限,你用的API可能还没有记录
- 依赖社区贡献扩展和更新文档,响应速度取决于社区活跃度
- 目前只是 CLI 工具,没有与主流编码 Agent 的集成(需要通过提示引导 Agent 使用)
- 与 MCP(Model Context Protocol)的值得关注的关系------未来如果有 Context Hub 的 MCP Server,Agent 的调用会更自然
相关链接
- GitHub仓库 :andrewyng/context-hub
- npm包 : @aisuite/chub
- 吴恩达 发布推文 :Twitter/X 发布(2026.3.9)
Coovally 平台提供算法开发 API,同时在探索用 Agent 驱动 CV 算法开发的工作流程。如果您对 Agent+CV 的结合方向感兴趣,欢迎联系我们交流或在评论区留言讨论~
