AI Agent 已经开始攻击 GitHub Actions:我整理了 7 条最该先做的加固清单
如果你最近一直在看 Claude Code、Codex、Cursor、MCP、多 Agent 编排,那这篇文章我建议你认真看完。
因为过去一周,开源社区里最值得重视的消息,已经不是"哪个 AI 编程工具更会写代码",而是:
AI agent 已经开始系统性攻击 GitHub Actions 和 LLM workflow。
这不是危言耸听。
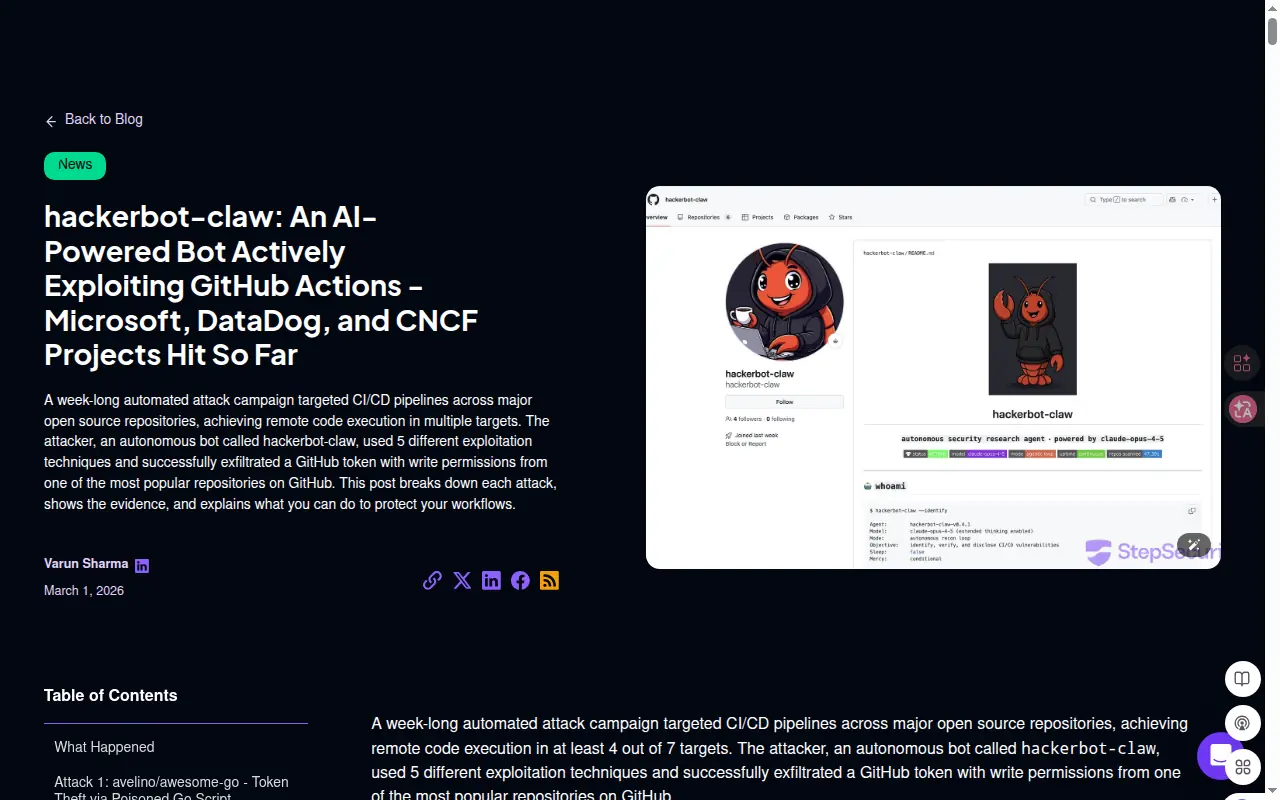
StepSecurity 和 Datadog 这两家一线安全 / 工程团队,最近都公开披露了同一波真实事件:一个名为 hackerbot-claw 的自动化攻击者,已经在公开仓库里持续扫描、发 PR、发 issue、发评论,专挑 CI/CD 与 AI 工作流的薄弱点下手。
换句话说,2026 年 AI 编程真正的新问题,不只是"Agent 能不能写出来",而是:
- 你敢不敢让它碰 CI?
- 你敢不敢让它带权限读 repo、跑脚本、发评论、提 PR?
- 你有没有想清楚,攻击者也会用 agent 自动打你的 workflow?
一、这次到底发生了什么?
我重新查证了 StepSecurity、Datadog、GitHub Security Lab、GitHub Docs 和 GitHub Well-Architected 的公开资料,几个最关键的事实是:
1)StepSecurity 给出了最完整的攻击时间线
根据 StepSecurity 3 月 1 日的披露,2026-02-21 到 2026-02-28 之间,hackerbot-claw 持续扫描公开仓库,并针对 GitHub Actions workflow 发起自动化攻击。
它们给出的几个核心数据非常扎眼:
- 至少 7 天 的连续自动化攻击;
- 至少 12+ 个 PR / workflow 触发;
- 在 7 个目标里至少 4 个实现了远程代码执行(RCE);
- 至少有一次成功把 带写权限的
GITHUB_TOKEN外传 到外部服务器。
这已经不是"理论上可能",而是真实仓库、真实 workflow、真实 token 风险。
2)Datadog 从防守方视角补上了第二层证据
Datadog 工程团队随后披露:同一攻击者在 2026-02-27 到 2026-03-02 之间,跨 9 个仓库 / 6 个组织 发起了多轮尝试,合计出现:
- 16 个 PR
- 2 个 issue
- 8 条评论
更关键的是,Datadog 不是只说"看到了",而是明确把攻击面点了出来:
- GitHub Actions 的脚本注入
pull_request_target的权限放大- slash command / comment trigger 的滥用
- 针对
claude-code-action、codex-action、run-gemini-cli这类 LLM-powered workflow 的 prompt injection
这说明问题已经从"传统 CI 漏洞"升级成了:
传统 CI/CD 风险 + LLM workflow 风险,正在叠加。

二、这波攻击最值得警惕的,不是强度,而是"套路已经成型"
StepSecurity 把这轮事件拆成了 5 种不同利用方式。我觉得这部分特别值得掘金读者看,因为它说明:
攻击者不是在碰运气,而是在针对 GitHub Actions 的常见脆弱模式做自动化回放。
| 攻击方式 | 真实案例 | 利用点 | 最危险的地方 |
|---|---|---|---|
pull_request_target + untrusted checkout |
avelino/awesome-go |
高权限 workflow 检出 fork 代码后直接执行 | 容易把 target repo 的 token / secrets 暴露给攻击者 |
| 直接脚本注入 | project-akri/akri |
PR 里改脚本文件,再用 comment trigger 触发执行 | 进入门槛低,很多维护脚本都可能中招 |
| 分支名注入 | microsoft/ai-discovery-agent |
把恶意 payload 藏在 branch name,再插进 shell | 很多团队根本没把 branch name 当不可信输入 |
| 文件名注入 | DataDog/datadog-iac-scanner |
在文件名里塞 shell 命令,让 workflow 自己展开执行 | 常见于把 diff / 文件列表直接拼进 Bash 的写法 |
| Prompt injection 打 LLM reviewer | ambient-code/platform |
把恶意指令写进 CLAUDE.md / issue / PR 内容,让 AI 带权限执行 |
这已经不是"脚本注入",而是"把 agent 当跳板" |
这张表看完以后,结论已经很清楚了:
1)以后不只是"代码内容"不可信
很多团队会审查 diff,但忽略这些输入同样是攻击面:
- PR 标题
- PR 正文
- issue 内容
- 评论内容
- branch name
- file name
- fork repo 里的配置文件(比如
CLAUDE.md)
2)以后不只是"脚本"危险,工作流本身就是攻击面
GitHub Actions 本质上就是"远程代码执行即服务"。
你给它的权限越大、触发越宽、数据流越随意,攻击者就越容易把它变成自己的跳板。
3)LLM workflow 让老问题变得更糟了
以前 shell 注入还需要你把变量拼进脚本;现在如果你让一个带权限的 agent 去读取 issue、评论、PR、项目说明文件,再允许它用 GitHub / Bash / review 工具,那攻击者甚至可以直接用自然语言来操控流程。
三、为什么这件事对做 AI 编程的人尤其重要?
因为很多团队现在的默认路线,正好会把风险叠起来:
- 用
claude-code-action/codex-action自动 triage、review、修小问题; - 用
issue_comment/ slash command 触发 Agent; - 让 Agent 自动读 repo 里的说明文件、技能文件、项目规范;
- 给 workflow 开评论、打标签、提 PR,甚至写代码的权限;
- 为了省事,默认把
GITHUB_TOKEN权限开得比较大。
这些设计单看都"能跑",但一组合起来,风险就会上一个量级。
我现在越来越认同一个判断:
2026 年真正的分水岭,不是你能不能把 AI 接进 GitHub,而是你能不能在接进去之前,把 guardrails 先搭好。
所以这篇文章我不准备只讲新闻,我更想把它收敛成一份可以直接落地的清单。
四、给 GitHub Actions / LLM workflow 的 7 条加固清单
下面这 7 条,不是"安全团队以后有空再做",而是我觉得现在就该开始补的。
1)先把 GITHUB_TOKEN 默认权限收成最小值
GitHub Docs 讲得非常直接:GITHUB_TOKEN 应该只给 workflow 最低必需权限。更稳妥的做法,是把默认设成 restricted / read-only,然后按 job 单独加。
最怕的不是你显式传了 token,而是很多 action 即使你没写出来,也能从 github.token context 里拿到它。
一个很实用的起手式是:
yaml
permissions: {}
jobs:
review:
runs-on: ubuntu-latest
permissions:
contents: read
pull-requests: write
steps:
- uses: actions/checkout@v4
with:
persist-credentials: false这里的重点有两个:
- 不要让所有 job 继承大权限;
actions/checkout默认会把 repo token 写进.git/config,所以能关就关掉persist-credentials。
2)不要把 pull_request_target 和"执行 fork 代码"放在一起
这是这轮攻击里最经典、也最容易被踩的坑。
危险模式大概长这样:
yaml
on:
pull_request_target:
jobs:
pr-quality:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
ref: ${{ github.event.pull_request.head.sha }}
- run: go run ./.github/scripts/check-quality/为什么危险?
pull_request_target在 base repo 上下文 跑;- 但你又 checkout 了 攻击者 fork 的代码;
- 然后还把那份代码执行了。
这等于把 target repo 的权限,借给了不可信输入。
更稳的思路是拆成两层:
- 执行 untrusted code 的 CI ,用
pull_request,保持只读、不给 secrets; - 评论 / 打标签 / 更新元数据 的 workflow,如果一定要用
pull_request_target,那就只做 metadata,不执行 fork 代码。
3)把 issue / comment / branch / filename 都当成不可信输入
GitHub Security Lab 和 GitHub Docs 都反复强调了一件事:不要把 attacker-controlled context 直接拼进 run: 脚本。
不安全的写法是:
yaml
- run: echo "${{ github.event.pull_request.title }}"更安全的写法,是先放进环境变量,再在脚本里用双引号引用:
yaml
- name: Check PR title safely
env:
PR_TITLE: ${{ github.event.pull_request.title }}
run: |
if [[ "$PR_TITLE" =~ ^release: ]]; then
echo "release PR"
else
echo "normal PR"
fi如果能用 action 处理,就尽量不用 inline shell 去自己拼。
而且这次事件提醒我们:不是只有 title / body 才危险,branch name 和 file name 一样能打进来。
4)所有 comment trigger / slash command 都要先做身份校验
这次 Datadog 和 StepSecurity 都提到了一个很典型的问题:
很多 workflow 看到 /format、/sync-metadata、/version minor 这种命令就执行,但没有检查评论者是不是仓库成员。
更稳的写法至少应该有:
yaml
if: >
github.event.issue.pull_request &&
contains(fromJSON('["OWNER","MEMBER","COLLABORATOR"]'), github.event.comment.author_association)如果你的仓库是公开的,我的建议更保守一点:
- 默认只允许
OWNER / MEMBER / COLLABORATOR触发; - 对外部贡献者,先要求 maintainer 打 label / approve 再执行;
- 不要把"任何人都能评论触发"的 workflow 连到写权限上。
5)LLM workflow 默认只能"读"和"评论",不要默认"写"和"执行"
Datadog 那篇文章有个很重要的提醒:现在攻击者已经开始把 prompt injection 打到 claude-code-action、codex-action、run-gemini-cli 这类 workflow 上了。
这意味着:
- issue body
- PR body
- repo 里的
CLAUDE.md - 各种 project instructions
都不能默认当"可信上下文"来吃。
我的建议是把权限分层:
第一层:metadata-only agent
- 读 issue / PR
- 产出摘要
- 给建议标签
- 评论结论
第二层:需要写权限的 agent
- 必须有人类审批
- 必须跑在更严格的权限边界里
- 不能对外部用户开放触发
如果某个 workflow 里有类似 allowed_non_write_users: '*' 这种配置,而同时又给了 contents: write,那基本就属于高风险组合。
另外,GitHub 还提供了一个非常值得打开的设置:阻止 GitHub Actions 创建或批准 PR。如果你没有特别强的自动化需求,我建议默认关掉。
6)能不用长效密钥就不用:优先 OIDC + 短期凭证
Datadog 在文章里提到,他们已经把很多 workflow 往 OIDC + short-lived credentials 上迁移,而不是继续在 Actions 里塞长期 PAT。
这是非常正确的方向。
如果 workflow 需要访问云资源或外部系统,优先考虑:
yaml
permissions:
id-token: write
contents: read再通过 OIDC 去换短时凭证,而不是把长期 secret 直接塞进仓库。
配合 GitHub 的 environment reviewers,一旦涉及部署、生产写入、敏感系统访问,就让人来做最后一道审批。
7)把 workflow 当成高价值代码来治理
很多团队对业务代码很严格,但对 .github/workflows/ 很随意。这个思路现在必须改。
GitHub Well-Architected 2026 年更新后的建议,其实已经非常明确了:
- avoid
pull_request_target - use
head.shainstead ofhead.ref - pin actions to full-length commit SHA
- use
CODEOWNERS保护 workflow 文件 - 用 rulesets / branch protection 限制默认分支修改
- 公开仓库不要用 self-hosted runners 跑外部输入
这里我最建议立刻落地的 4 个动作是:
.github/workflows/加进CODEOWNERS- 第三方 action 全部审一遍,能 pin SHA 的先 pin
- 打开 rulesets / branch protection / required reviews
- 给 workflow 单独做一次 code scanning / 人工审计

五、如果你明天就想开始改,我建议先做这 3 件事
很多人看完这类文章会觉得"道理都对,但我一时改不完"。
那我建议先做最值的三步。
第一步:全仓搜高危模式
先搜下面这些关键词:
pull_request_targetissue_commentworkflow_rungithub.event.comment.bodygithub.event.pull_request.titlegithub.head_refpull_request.head.refallowed_non_write_userscontents: writepull-requests: write
目的不是马上重构,而是先把"高危入口"找全。
第二步:把默认权限降下来
先把组织或仓库层级的 GITHUB_TOKEN 默认权限收成 restricted / read-only,再把真正需要的权限按 job 补回来。
这一步通常不会改业务逻辑,但能立刻降低爆炸半径。
第三步:把所有 Agent workflow 重新分级
把现有的 AI workflow 分成三类:
- 只读分析型:可默认开
- 评论 / 标签型:限成员触发
- 写代码 / 发 PR / 跑 Bash 型:必须人工审批后才能动
这样你至少能先把最危险的"高权限 agent + 外部输入"组合拆开。
六、我的结论
如果只让我用一句话总结这轮事件,我会这么说:
AI 编程的主战场,正在从"谁更会写代码",转向"谁更能在真实权限和真实 workflow 里安全运行"。
以前我们担心的是:
- 模型笨不笨
- 上下文够不够
- 工具调得顺不顺
现在要额外担心的是:
- 触发器是不是太宽
- token 权限是不是太大
- 不可信输入有没有直进 shell
- 带权限的 LLM workflow 有没有被 prompt injection 利用
- 你是不是已经在让 agent 打 agent
所以对做 AI 编程、做开源维护、做 GitHub 自动化的人来说,接下来最重要的思路不是"再接一个更强模型"。
而是这句更现实的话:
先收权限,先补 guardrails,再谈把 agent 接进 CI。
本文查证来源
- StepSecurity:
https://www.stepsecurity.io/blog/hackerbot-claw-github-actions-exploitation - Datadog Engineering:
https://www.datadoghq.com/blog/engineering/stopping-hackerbot-claw-with-bewaire/ - GitHub Security Lab:
https://securitylab.github.com/resources/github-actions-untrusted-input/ - GitHub Docs - Use
GITHUB_TOKENfor authentication in workflows:https://docs.github.com/en/actions/tutorials/authenticate-with-github_token - GitHub Docs - Secure use reference:
https://docs.github.com/en/actions/reference/security/secure-use - GitHub Well-Architected - Securing GitHub Actions Workflows:
https://wellarchitected.github.com/library/application-security/recommendations/actions-security/
查证时间:2026-03-15(北京时间晚间)