目录
[三、为什么 insert 函数是 "不可重入函数"?](#三、为什么 insert 函数是 “不可重入函数”?)
总结
[Linux 线程的概念](#Linux 线程的概念)[四、Linux 下线程的实现:复用 task_struct 模拟线程](#四、Linux 下线程的实现:复用 task_struct 模拟线程)
重谈虚拟地址空间与页表[一、页表的本质与 32 位虚拟地址的映射结构](#一、页表的本质与 32 位虚拟地址的映射结构)
thread.cc1(线程接口函数pthread_create)
[一、thread.cc1 代码的核心执行逻辑](#一、thread.cc1 代码的核心执行逻辑)
[二、pthread_create 函数的原型与参数解析](#二、pthread_create 函数的原型与参数解析)
[三、进程 pid 与线程 tid 的关系](#三、进程 pid 与线程 tid 的关系)
thread.cc2(线程接口函数pthread_join)
[一、thread.cc2 中线程退出的相关操作](#一、thread.cc2 中线程退出的相关操作)
[二、pthread_join 函数详解](#二、pthread_join 函数详解)
[三、pthread_exit 函数详解](#三、pthread_exit 函数详解)
[四、pthread_cancel 函数详解](#四、pthread_cancel 函数详解)
[重谈 pthread_create 函数的参数和返回值](#重谈 pthread_create 函数的参数和返回值)[thread.cc3(pthread_create 函数参数和返回值的实际使用)](#thread.cc3(pthread_create 函数参数和返回值的实际使用))
[一、pthread_create 函数返回值的实际使用](#一、pthread_create 函数返回值的实际使用)
[二、pthread_create 函数参数的实际使用](#二、pthread_create 函数参数的实际使用)
[重谈 pthread_create 函数的第一个参数](#重谈 pthread_create 函数的第一个参数)[thread.cc4(POSIX 用户级线程 ID)](#thread.cc4(POSIX 用户级线程 ID))
[一、thread.cc4 代码整体逻辑](#一、thread.cc4 代码整体逻辑)
[二、pthread_self () 函数](#二、pthread_self () 函数)
[三、重谈 pthread_create 函数的第一个参数](#三、重谈 pthread_create 函数的第一个参数)
[四、syscall (SYS_gettid) 与 pthread_self () 的区别](#四、syscall (SYS_gettid) 与 pthread_self () 的区别)
[五、用户级 TCB 与新线程栈的位置](#五、用户级 TCB 与新线程栈的位置)
创建多个线程[thread.cc5(线程栈 / 全局变量 / 线程局部存储特性验证)](#thread.cc5(线程栈 / 全局变量 / 线程局部存储特性验证))
[二、测试 1:testData 栈变量 → 验证每个线程有独立的栈结构](#二、测试 1:testData 栈变量 → 验证每个线程有独立的栈结构)
[三、测试 2:全局指针 p 访问线程 1 的 testData → 验证线程栈数据可跨线程访问 / 修改](#三、测试 2:全局指针 p 访问线程 1 的 testData → 验证线程栈数据可跨线程访问 / 修改)
[四、测试 3:全局变量 g_val → 验证全局变量是进程级共享资源](#四、测试 3:全局变量 g_val → 验证全局变量是进程级共享资源)
[五、测试 4:__thread 修饰的 g_val2 → 验证线程局部存储(TLS)](#五、测试 4:__thread 修饰的 g_val2 → 验证线程局部存储(TLS))
[二、pthread_detach 函数详解](#二、pthread_detach 函数详解)
[四、分离线程的核心特性验证(无法调用 pthread_join)](#四、分离线程的核心特性验证(无法调用 pthread_join))
[一、thread.cc7 代码解析与多线程抢票的并发问题](#一、thread.cc7 代码解析与多线程抢票的并发问题)
[二、thread.cc8 代码解析与互斥锁解决并发问题](#二、thread.cc8 代码解析与互斥锁解决并发问题)
[二、pthread_mutex_lock () 底层原理(伪代码 + 线程调度示例)](#二、pthread_mutex_lock () 底层原理(伪代码 + 线程调度示例))
[三、pthread_mutex_unlock () 底层原理(伪代码 + 设计逻辑)](#三、pthread_mutex_unlock () 底层原理(伪代码 + 设计逻辑))
[二、pthread_cond_wait 必须在加锁后调用的原因及自动释放锁机制](#二、pthread_cond_wait 必须在加锁后调用的原因及自动释放锁机制)
[三、全局 mutex 和 cond 的静态初始化特性](#三、全局 mutex 和 cond 的静态初始化特性)
[二、BlockQueue 类中 pop 函数(消费逻辑)解析](#二、BlockQueue 类中 pop 函数(消费逻辑)解析)
[三、BlockQueue 类中 push 函数(生产逻辑)解析](#三、BlockQueue 类中 push 函数(生产逻辑)解析)
总结
[基于 POSIX 信号量实现环形队列的生产消费模型](#基于 POSIX 信号量实现环形队列的生产消费模型)[thread.cc11(基于 POSIX 信号量的多生产多消费环形队列)](#thread.cc11(基于 POSIX 信号量的多生产多消费环形队列))
[一、POSIX 信号量的核心本质](#一、POSIX 信号量的核心本质)
[三、thread.cc11 代码整体逻辑](#三、thread.cc11 代码整体逻辑)
[四、RingQueue 类中 push 函数(生产者入队)解析](#四、RingQueue 类中 push 函数(生产者入队)解析)
[五、RingQueue 类中 pop 函数(消费者出队)解析](#五、RingQueue 类中 pop 函数(消费者出队)解析)
[六、加锁 / 解锁放在 P/V 操作之间的核心原因](#六、加锁 / 解锁放在 P/V 操作之间的核心原因)
[三、thread.cc12 中自旋锁的核心接口解析](#三、thread.cc12 中自旋锁的核心接口解析)
[四、thread.cc12 代码整体逻辑解析](#四、thread.cc12 代码整体逻辑解析)
[一、读者写者模型的 "321 原则"](#一、读者写者模型的 “321 原则”)
可重入函数的概念
一、可重入函数与不可重入函数的核心概念
1. 可重入函数
可重入函数是指可以被多个执行流(如主控制流、信号处理函数、多线程)同时或交叉调用,且不会出现数据错误、逻辑混乱的函数。核心特征:
- 不依赖全局变量、静态变量(或对全局 / 静态变量的访问是原子的、可保护的);
- 仅使用栈上的局部变量、参数传递数据;
- 不调用其他不可重入的函数。
2. 不可重入函数
不可重入函数是指若被多个执行流同时或交叉调用,会导致数据不一致、逻辑错误(如内存泄漏、节点丢失、程序崩溃)的函数。核心诱因:
- 函数内部访问了全局变量、静态变量,且对这些变量的操作不是 "原子的"(即操作分多步完成,中间可被打断);
- 函数内部调用了其他不可重入的函数。
二、结合伪代码的执行流程分析(节点丢失与内存泄漏的原因)
1. 伪代码的核心结构
-
main 函数:
// 全局变量:所有执行流共享
struct Node* hand; // 全局链表头指针
struct Node node1; // 全局节点1
struct Node node2; // 全局节点2// main主控制流
int main()
{
insert(&node1); // 主流程调用insert插入node1
} -
insert 函数:
// 插入函数(不可重入的核心)
void insert(struct Node* node)
{
node->next = hand; // 步骤1:将新节点的next指向当前头// 【关键中断点】假设此处收到信号,主流程被打断,跳转到信号处理函数 hand = node; // 步骤2:将头指针指向新节点}
-
sighandler 函数:
// 信号处理函数(另一个执行流)
void sighandler(int signo)
{
insert(&node2); // 信号处理流也调用insert插入node2
}
2. 具体执行流程拆解(按时间线)
假设初始状态:hand = NULL(全局头指针为空)。
| 时间线 | 执行流 | 执行的代码 | 关键变量变化 |
|---|---|---|---|
| 1 | main 主流程 | 调用insert(&node1),进入函数 |
- |
| 2 | main 主流程 | 执行node1->next = hand |
node1->next = NULL(因为 hand 初始为 NULL) |
| 3 | (中断发生) | 进程收到信号,暂停 main 主流程,切换到信号处理流 | - |
| 4 | 信号处理流 | 调用insert(&node2),进入函数 |
- |
| 5 | 信号处理流 | 执行node2->next = hand |
node2->next = NULL(此时 hand 仍为 NULL) |
| 6 | 信号处理流 | 执行hand = node2 |
hand = &node2(全局头指针指向 node2) |
| 7 | 信号处理流 | 执行完毕,返回 main 主流程,从之前的中断处继续 | - |
| 8 | main 主流程 | 继续执行insert(&node1)的剩余代码:hand = node1 |
hand = &node1(全局头指针从 node2 改为指向 node1) |
| 9 | main 主流程 | insert 执行完毕 | - |
3. 最终结果:节点丢失与逻辑错误
执行完成后:
hand最终指向node1;node1->next = NULL;node2->next = NULL,但没有任何指针指向node2(hand 已经被 main 主流程的后续代码修改为指向 node1)。
这就导致node2节点从链表中 "丢失":
- 如果节点是动态分配的(
malloc/new),会直接造成内存泄漏; - 即使是全局节点(如本例),也会导致链表逻辑错误,node2 永远无法被访问到。
三、为什么 insert 函数是 "不可重入函数"?
核心原因有两个:
- 访问了全局变量
hand:hand是所有执行流共享的全局变量,多个执行流(main 和 sighandler)都能修改它,没有任何保护机制。 - 对全局变量的操作不是 "原子的" :
insert函数对hand的修改分两步(先改node->next,再改hand),中间可以被信号打断,导致两个执行流的操作 "交叉",最终覆盖了正确的结果。
总结
- 可重入函数:多个执行流调用不会出错,核心是 "不依赖全局 / 静态变量,或操作是原子的";
- 不可重入函数:多个执行流调用会出错,核心是 "访问了全局 / 静态变量,且操作非原子";
- 本例中
insert函数因访问全局hand且操作分两步,被 main 和信号处理流交叉调用后,导致node2丢失,是典型的不可重入函数案例。
Linux 线程的概念
一、线程的基础概念:进程内的执行分支
1. 线程与进程的资源对比
创建进程时,进程会拥有独立的内核数据结构(task_struct)、虚拟地址空间、页表、代码段、数据段、文件描述符表等完整资源。创建线程时,线程仅拥有独立的 task_struct 内核数据结构,不具备独立的虚拟地址空间、页表等资源,而是与所属进程共享虚拟地址空间、页表、代码段、数据段、文件描述符等。
2. 线程执行颗粒度更细的原因
进程的 0GB-3GB 用户空间原本由进程独享,引入线程后,该空间被所属进程的一个或多个线程共享。共享的用户空间使得代码、数据等资源可以被多个执行流更细粒度地划分、访问和执行,因此线程的执行颗粒度比进程更细。
二、进程与线程的重新定义
1. 进程:资源分配的基本实体
从内核观点看,进程是承担分配系统资源的基本实体,是操作系统为执行流创建的 "资源容器",负责分配虚拟地址空间、页表、文件描述符、信号处理配置等核心资源。
2. 线程:CPU 调度的基本单位
线程是操作系统的基本调度单位,是进程内的独立执行流。从 CPU 角度,进行调度时不区分进程和线程,将两者统一视为 "执行流"。
3. 单执行流进程的本质
早期学习的进程,内部仅包含一个执行流,是进程的特殊情况 ------ 此时进程既是资源分配实体,也是唯一的执行流。
三、进程与线程的数量关系及组织需求
1. 数量关系
进程与线程的关系至少为一对一(单执行流进程)或一对多(多线程进程):一个进程可以包含一个或多个线程,一个线程必须从属于一个进程。
2. 线程的描述与组织需求
由于存在多个执行流,必须对线程进行 "先描述、再组织":
- 描述:需要记录线程的执行状态、栈空间、寄存器上下文、调度优先级等信息;
- 组织:需要实现线程的调度、阻塞、唤醒、挂起等管理逻辑。
3. 不同系统的设计差异
Windows 为线程设计独立的 TCB(线程控制块)结构,配备独立的调度算法、阻塞机制、挂起机制,将线程与进程作为两个独立的概念管理;Linux 未采用该设计。
四、Linux 下线程的实现:复用 task_struct 模拟线程
1. 轻量级进程(LWP)的概念
Linux 通过 "轻量级进程(LWP)" 模拟线程,每个线程对应一个独立的 task_struct 结构,无需为线程设计新的内核数据结构。
2. 资源的共享与独立
- 共享资源:同一进程内的所有轻量级进程共享虚拟地址空间、页表、代码段、数据段、文件描述符表、信号处理方式、当前工作目录等;
- 独立资源:每个轻量级进程拥有独立的栈空间、寄存器上下文、task_struct 中的调度相关字段(如优先级、时间片)、信号屏蔽字等。
3. 调度与管理的复用
Linux 直接复用进程的调度算法和管理逻辑,无需为线程设计独立的调度器。通过 task_struct 的复用,实现线程的调度、阻塞、唤醒等操作,以 "轻量级进程" 的形式模拟线程的功能。
重谈虚拟地址空间与页表
一、页表的本质与 32 位虚拟地址的映射结构
1. 页表的本质:虚拟地址到物理地址的映射表
页表是操作系统内核维护的核心数据结构,本质是建立 "虚拟地址" 到 "物理地址" 的映射关系,解决进程虚拟地址空间独立与物理内存全局共享的矛盾,同时实现内存保护、权限控制等功能。
2. 32 位虚拟地址的三级划分(10+10+12)
32 位 Linux 系统中,虚拟地址被硬件划分为三部分,用于二级页表的映射:
- 最高 10 位(位 31 - 位 22):一级页表索引(页目录索引);
- 中间 10 位(位 21 - 位 12):二级页表索引(页表表项索引);
- 最低 12 位(位 11 - 位 0):页内偏移量。
3. 一级页表(页目录)的作用
一级页表又称页目录,是一个包含 1024 个表项的数组(2^10 = 1024),数组下标对应虚拟地址的最高 10 位(范围 0, 1023)。每个表项存储的是对应二级页表的物理起始地址,以及该二级页表的权限位(如读 / 写、用户态 / 内核态等)。
4. 二级页表(页表表项)的作用
二级页表又称页表表项,每个二级页表同样是包含 1024 个表项的数组,数组下标对应虚拟地址的中间 10 位(范围 0, 1023)。每个表项存储的是物理内存中 "页框" 的起始地址,以及该页框的权限位(如存在位、脏位、访问位等)。
5. 页框与物理内存的基本单位
物理内存被操作系统划分为固定大小的 "页框"(Page Frame),常规大小为 4KB(2^12 = 4096 字节),是物理内存分配与管理的基本单位。虚拟地址的最低 12 位(页内偏移量)范围为 0, 4095,刚好对应一个页框内的所有字节位置。
6. 虚拟地址到物理地址的完整映射过程
- CPU 通过 CR3 寄存器获取当前进程的一级页表(页目录)的物理起始地址;
- 提取虚拟地址的最高 10 位,作为下标访问一级页表,获取对应二级页表的物理起始地址;
- 提取虚拟地址的中间 10 位,作为下标访问二级页表,获取对应页框的物理起始地址;
- 提取虚拟地址的最低 12 位(页内偏移量),与页框的物理起始地址相加,得到最终的物理地址;
- CPU 通过最终物理地址访问物理内存中的数据。
7. 二级页表的稀疏性与缺页中断
二级页表通常是 "稀疏的"------ 并非所有 1024 个表项都有效。当进程访问的虚拟地址对应的二级页表表项 "存在位" 为 0 时,CPU 会触发 "缺页中断",陷入内核态,由操作系统的缺页中断处理程序分配物理页框、填充二级页表表项,之后恢复进程执行。
8. CR3 寄存器与变量访问的大小控制
CR3 寄存器是 CPU 的控制寄存器,存储当前进程一级页表(页目录)的物理起始地址,是虚拟地址映射的起点。变量的类型(如 int 占 4 字节)决定了访问数据的字节长度,CPU 在访问物理内存时,会根据变量类型从起始物理地址开始,连续读取对应长度的字节。
9. 变量地址的本质:起始地址 + 类型(偏移量)
对变量取地址(&a)得到的是变量的 "起始虚拟地址"。从 CPU 角度,变量的访问等价于 "起始虚拟地址 + 类型长度"------ 类型长度相当于 "偏移量",确定了从起始地址开始需要访问的字节范围。
二、虚拟地址的普遍性与多线程的地址空间共享
1. 虚拟地址的普遍性:变量、代码、函数均有虚拟地址
虚拟地址空间覆盖进程的所有资源:
- 全局变量、局部变量(栈上)、动态分配变量(堆上)均有对应的虚拟地址;
- 代码段中的指令、函数入口均有对应的虚拟地址,函数的虚拟地址即函数第一条指令的起始虚拟地址。
2. 多线程的地址空间共享规则
同一进程内的所有线程共享 0GB-3GB 的用户空间:
- 共享资源:代码段、数据段、堆、文件描述符表、信号处理方式、当前工作目录等;
- 独立资源:每个线程拥有独立的栈空间、寄存器上下文、信号屏蔽字、errno 变量等。
3. 函数虚拟地址的独立性与线程执行流的分离
函数的虚拟地址是全局唯一的(在进程的虚拟地址空间内),与线程无关。通过让不同线程执行不同的函数(将不同函数的虚拟地址作为线程入口),可天然实现 "线程执行流" 与 "代码逻辑" 的分离 ------ 每个线程根据入口函数的虚拟地址,执行对应的代码逻辑。
4. 线程分配资源的本质:分配地址空间的范围
线程的资源分配本质是在共享的虚拟地址空间内,划分独立的地址范围:
- 栈空间:为每个线程在用户空间划分独立的栈地址范围,存储线程的局部变量、函数调用帧;
- 其他资源:若需线程私有数据,可通过线程局部存储(TLS)在共享地址空间内划分独立范围。
线程的创建
thread.cc1(线程接口函数pthread_create)
#include <iostream> // 标准输入输出流头文件,用于向终端打印文本
#include <unistd.h> // Linux系统调用头文件,用于调用getpid、sleep等系统函数
#include <pthread.h> // POSIX线程库头文件,用于创建、管理线程
#include <string> // C++字符串头文件,本例未直接使用,仅做预留
#include <sys/syscall.h> // Linux系统调用号头文件,用于通过syscall间接调用SYS_gettid
using namespace std;
// 线程入口函数:返回值和参数均为void*类型,这是POSIX线程库对线程函数的强制要求
void* threadRoutine(void* args)
{
// 将传入的void*类型参数强制转换为const char*类型,用于后续打印线程标识
const char* s = (const char*)args;
// 进入无限循环,模拟线程持续运行
while(true)
{
sleep(1); // 休眠1秒,降低CPU占用率
// 向终端打印线程标识、进程ID、线程ID
// getpid获取的是整个进程的ID,同一进程内的所有线程共享同一个进程ID
// syscall(SYS_gettid)通过系统调用间接获取线程的内核级ID,这是Linux特有的获取真实线程ID的方式
cout << s << ", My pid is : " << getpid() << ", My tid is : " << syscall(SYS_gettid) << endl;
}
}
int main()
{
// 定义POSIX线程库的线程标识符变量,用于后续标识和管理新创建的线程
pthread_t tid;
// 定义const char*类型的字符串变量,作为参数传递给新线程的入口函数
const char* s = "I am new thread";
// 调用pthread_create创建一个新的线程
// 第一个参数&tid:将新创建的线程标识符存储到tid变量中
// 第二个参数nullptr:使用线程的默认属性(如栈大小、调度策略等)
// 第三个参数threadRoutine:指定新线程的入口函数,新线程启动后会立即执行该函数
// 第四个参数(void*)s:将字符串变量s强制转换为void*类型,传递给新线程的入口函数
pthread_create(&tid, nullptr, threadRoutine, (void*)s);
// 进入无限循环,模拟主线程持续运行
while(true)
{
// 向终端打印主线程标识、进程ID、线程ID
cout << "I am main thread, My pid is : " << getpid() << ", My tid is : " << syscall(SYS_gettid) << endl;
sleep(1); // 休眠1秒,降低CPU占用率
}
// 主函数的返回语句,由于前面是无限循环,该语句永远不会被执行
return 0;
}一、thread.cc1 代码的核心执行逻辑
1. 代码的整体结构
代码分为两部分:线程入口函数threadRoutine和主函数main。主函数调用pthread_create创建新线程,主线程与新线程分别进入独立的死循环,每秒打印自身标识、进程 ID(pid)、线程 ID(tid),模拟多线程持续运行的场景。
二、pthread_create 函数的原型与参数解析
1. pthread_create 函数的原型
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine)(void*), void *arg);- 返回值:成功返回
0,失败返回错误码(非 0)。
2. pthread_create 函数的参数含义(结合代码)
- 参数 1:
pthread_t *thread指向pthread_t类型变量的指针,用于存储新创建线程的 "用户级线程标识符",后续可通过该标识符管理线程(如等待、分离)。代码中传入&tid,将新线程的标识符存入tid变量。 - 参数 2:
const pthread_attr_t *attr指向线程属性结构体的指针,用于指定线程的特殊属性(如栈大小、调度策略、分离状态等)。代码中传入nullptr,表示使用线程的默认属性。 - 参数 3:
void *(*start_routine)(void*)函数指针,指向新线程的 "入口函数"。新线程启动后,会立即执行该函数,函数的返回值和参数均为void*类型,这是 POSIX 线程库对线程入口函数的强制要求。代码中传入threadRoutine,指定新线程的入口为该函数。 - 参数 4:
void *arg传递给新线程入口函数的参数,类型为void*,需由用户自行定义参数的实际类型并在入口函数中强制转换。代码中传入(void*)s,将字符串s传递给threadRoutine。
三、进程 pid 与线程 tid 的关系
1. 主线程与新线程 pid 相同的原因
所有线程从属于同一个进程,共享进程的虚拟地址空间、页表、文件描述符表等核心资源,属于同一个 "资源容器"。getpid函数返回的是进程的唯一标识符,因此同一进程内的所有线程调用getpid时,得到的 pid 完全相同。
2. 各个线程 tid 不同的原因
Linux 下通过 "轻量级进程(LWP)" 模拟线程,每个线程对应一个独立的task_struct内核数据结构。内核会为每个轻量级进程分配唯一的 "内核级线程标识符(tid)",作为 CPU 调度的独立标识,因此不同线程的 tid 必然不同。
3. 主线程的 tid 等于进程 pid 的规则
Linux 系统中,进程的第一个线程(即执行main函数的线程,称为主线程)的内核级 tid,与进程的 pid 完全相同;后续通过pthread_create创建的新线程,tid 为其他唯一数值,可通过该规则快速识别主线程。
4. 查看线程 tid 与 pid 的命令使
用ps -aL命令可查看系统中线程的详细信息:
-a:显示所有终端的进程;-L:显示轻量级进程(线程)的信息,包括进程 pid(PID 列)和线程 tid(LWP 列)。
四、线程的健壮性与天然通信能力
1. kill -9 任意线程 tid 导致整个进程退出的原因
Linux 下线程是轻量级进程,共享进程的所有资源,信号的作用对象是 "进程" 而非单个线程。kill -9发送的 9 号信号(SIGKILL)是强制终止信号,会终止整个进程的所有执行流,而非仅终止目标线程,体现出线程的健壮性较差 ------ 单个线程的异常可能导致整个进程崩溃。
2. 线程间天然具备通信能力的原因
同一进程的所有线程共享 0GB-3GB 的用户空间(包括代码段、数据段、堆、全局变量等)。一个线程修改全局变量、堆上的数据或文件内容,其他线程能直接读取到修改后的结果,无需额外的进程间通信机制(如匿名管道、共享内存、消息队列等),通信成本远低于进程间通信。
线程的等待
thread.cc2(线程接口函数pthread_join)
#include <iostream> // 标准输入输出流头文件,用于向终端打印文本
#include <unistd.h> // Linux系统调用头文件,用于调用getpid、sleep等系统函数
#include <pthread.h> // POSIX线程库头文件,用于创建、管理、取消、等待线程
#include <string> // C++字符串头文件,本例未直接使用,仅做冗余预留
#include <sys/syscall.h> // Linux系统调用号头文件,用于通过syscall间接调用SYS_gettid
using namespace std;
// 线程入口函数:返回值和参数均为void*类型,这是POSIX线程库对线程函数的强制要求
void* threadRoutine(void* args)
{
// 将传入的void*类型参数强制转换为const char*类型,用于后续打印线程标识
const char* s = (const char*)args;
// 定义循环计数器,初始值为5,控制线程打印5次后退出
int count = 5;
// 进入无限循环,模拟线程持续运行
while(true)
{
sleep(1); // 休眠1秒,降低CPU占用率
// 向终端打印线程标识、进程ID、线程ID
// getpid获取的是整个进程的ID,同一进程内的所有线程共享同一个进程ID
// syscall(SYS_gettid)通过系统调用间接获取线程的内核级ID,这是Linux特有的获取真实线程标识的方式
cout << s << ", My pid is : " << getpid() << ", My tid is : " << syscall(SYS_gettid) << endl;
// 计数器自减,若减至0则跳出循环
if(--count == 0)
break;
}
// ============线程的第一种退出方式(直接return退出)============
// 返回值为void*类型,可被pthread_join的第二个参数接收
// 注意:此处return之后,后续代码永远不会执行
return (void*)1;
// ============线程的第二种退出方式(通过POSIX线程库专用函数退出)============
// 功能与return类似,返回值为void*类型,可被pthread_join的第二个参数接收
// 适用于无法直接return的场景(如在嵌套函数中退出线程)
pthread_exit((void*)1);
// ============error:线程的错误退出方式============
// exit是进程级别的退出函数,调用后会直接终止整个进程,包括所有线程
exit(1);
}
int main()
{
// 定义POSIX线程库的线程标识符变量,用于后续标识和管理新创建的线程
pthread_t tid;
// 定义const char*类型的字符串变量,作为参数传递给新线程的入口函数
const char* s = "I am new thread";
// 调用pthread_create创建一个新的线程
// 第一个参数&tid:将新创建的线程标识符存储到tid变量中
// 第二个参数nullptr:使用线程的默认属性(如栈大小、调度策略等)
// 第三个参数threadRoutine:指定新线程的入口函数,新线程启动后会立即执行该函数
// 第四个参数(void*)s:将字符串变量s强制转换为void*类型,传递给新线程的入口函数
// 返回值ret:0表示创建成功,非0表示创建失败
int ret = pthread_create(&tid, nullptr, threadRoutine, (void*)s);
// 主线程休眠3秒,模拟新线程先运行一段时间
sleep(3);
// ============线程的第三种退出方式(申请取消指定线程继续执行)============
// 若线程被成功取消,pthread_join的第二个参数会接收到PTHREAD_CANCELED(值为-1)
// 仅当pthread_create返回0(创建成功)时,才执行取消操作
if(ret == 0)
{
pthread_cancel(tid);
}
// 进入无限循环,模拟主线程持续运行
while(true)
{
// 向终端打印主线程标识、进程ID、线程ID
cout << "I am main thread, My pid is : " << getpid() << ", My tid is : " << syscall(SYS_gettid) << endl;
sleep(1); // 休眠1秒,降低CPU占用率
// 注意:此处break会导致循环只执行一次,属于逻辑冗余/错误
break;
}
// 定义void*类型的指针变量,用于接收新线程的退出返回值
void* retval;
// ============*pthread_join默认是阻塞等待============
// 第一个参数tid:指定要等待的线程标识符
// 第二个参数&retval:将新线程的退出返回值存储到retval变量中
// 作用:回收新线程的资源,避免新线程变成僵尸线程
pthread_join(tid, &retval);
// **因为Linux是64位机器,所以指针是8字节,所以要把retval强转为long long int**
// 若强转为int(4字节),会导致数据截断
cout << "new thread quit, get a retval is : " << (long long int)retval << endl;
return 0;
}一、thread.cc2 中线程退出的相关操作
1. 线程的第一种退出方式:入口函数 return
在线程入口函数中直接执行return语句,是线程主动退出的常见方式。返回值类型为void*,可被pthread_join的第二个参数接收。return执行后,线程入口函数的后续代码永远不会执行。
2. 线程的第二种退出方式:pthread_exit 函数
pthread_exit是 POSIX 线程库提供的专用线程退出函数,功能与入口函数return类似,返回值类型为void*,可被pthread_join的第二个参数接收。该函数适用于无法直接return的场景(如在嵌套的子函数中退出线程)。
3. 线程的第三种退出方式:被其他线程 pthread_cancel 取消
pthread_cancel是由其他线程调用的接口,用于向目标线程发送取消请求。若目标线程被成功取消,pthread_join的第二个参数会接收到PTHREAD_CANCELED(值为 - 1)。目标线程是否立即取消,取决于线程的取消状态与取消类型(默认是延迟取消,在取消点才会退出)。
4. 线程的错误退出方式:调用 exit 函数
exit是进程级别的退出函数,调用后会直接终止整个进程,包括所有线程,因此不能用于单个线程的退出。
二、pthread_join 函数详解
1. pthread_join 函数的原型
int pthread_join(pthread_t thread, void **retval);- 返回值:成功返回
0,失败返回错误码(非 0)。
2. pthread_join 函数的参数含义(结合代码)
- 参数 1:
pthread_t thread目标线程的标识符(pthread_t类型),指定需要等待的线程。代码中传入tid,即之前通过pthread_create创建的新线程的标识符。 - 参数 2:
void **retval二级指针,用于接收目标线程的退出返回值。该返回值可以是线程入口函数return的返回值,也可以是pthread_exit的参数,还可以是线程被取消后的PTHREAD_CANCELED。代码中传入&retval,将新线程的退出返回值存入retval变量。
3. pthread_join 的默认阻塞等待特性
pthread_join默认是阻塞等待的:调用该函数后,当前线程会暂停执行,直到目标线程退出后才会继续向下执行。其核心作用是回收目标线程的资源,避免目标线程变成 "僵尸线程"。
4. 不考虑线程异常情况的原因
线程共享进程的所有核心资源(虚拟地址空间、页表、文件描述符等),若某个线程出现异常(如段错误、除零错误),会触发整个进程崩溃,所有线程都会终止。因此无法像子进程那样,通过信号单独处理单个线程的异常 ------ 进程崩溃后,主线程也会终止,无法执行pthread_join或其他异常处理逻辑。
三、pthread_exit 函数详解
1. pthread_exit 函数的原型
void pthread_exit(void *retval);2. pthread_exit 函数的参数与作用
- 参数:
void *retval线程的退出返回值,类型为void*,会被pthread_join的第二个参数接收。 - 作用 主动退出当前线程,不会影响同一进程内的其他线程。该函数适合在嵌套的子函数中退出线程(例如在某个子函数中需要终止线程,但无法直接
return到线程入口函数的场景)。
四、pthread_cancel 函数详解
1. pthread_cancel 函数的原型
int pthread_cancel(pthread_t thread);- 返回值:成功返回
0,失败返回错误码(非 0)。
2. pthread_cancel 函数的参数与作用
- 参数:
pthread_t thread目标线程的标识符(pthread_t类型),指定需要发送取消请求的线程。 - 作用 向目标线程发送取消请求。目标线程的取消行为取决于其取消状态与取消类型(默认是延迟取消,仅在遇到取消点时才会退出)。被成功取消的线程,其退出返回值为
PTHREAD_CANCELED,可被pthread_join的第二个参数接收。
重谈 pthread_create 函数的参数和返回值
thread.cc3(pthread_create函数参数和返回值的实际使用)
#include <iostream> // 标准输入输出流头文件,用于向终端打印文本
#include <unistd.h> // Linux系统调用头文件,本例未直接使用,仅做冗余预留
#include <pthread.h> // POSIX线程库头文件,用于创建、等待线程
#include <string> // C++字符串头文件,用于Request类中的线程名称存储
#include <sys/syscall.h> // Linux系统调用号头文件,本例未直接使用,仅做冗余预留
using namespace std;
// 请求类:封装线程需要处理的计算参数(起始值、结束值、线程名称)
class Request
{
public:
// 构造函数:初始化计算参数和线程名称
Request(int start, int end, const string& threadName)
: _start(start)
, _end(end)
, _threadName(threadName)
{}
// 计算方法:计算从_start到_end的累加和
int Sum()
{
int sum = 0;
for(int i = _start; i <= _end; i++)
{
sum = sum + i;
}
return sum;
}
public:
int _start; // 累加起始值
int _end; // 累加结束值
string _threadName; // 线程名称(本例未实际使用,仅做封装演示)
};
// 响应类:封装线程的计算结果和退出码
class Response
{
public:
// 构造函数:初始化计算结果和退出码(默认值均为0)
Response(int result = 0, int exitCode = 0)
: _result(result)
, _exitCode(exitCode)
{}
public:
int _result; // 累加计算结果
int _exitCode; // 线程退出码(本例未实际使用,仅做封装演示)
};
// 线程入口函数:接收Request参数,执行累加计算,返回Response结果
void* sumCount(void* args)
{
// 将传入的void*类型参数强制转换为Request*类型,获取计算参数
Request* rq = (Request*)args;
// 动态创建Response对象,用于存储计算结果
Response* rsp = new Response;
// 调用Request的Sum方法执行累加计算,将结果存入Response
rsp->_result = rq->Sum();
// 返回Response对象的指针,可被pthread_join的第二个参数接收
return rsp;
}
int main()
{
// 动态创建Request对象,初始化累加参数(1到100)和线程名称
Request* rq = new Request(1, 100, "thread 1");
// 定义POSIX线程库的线程标识符变量,用于后续标识和管理新创建的线程
pthread_t tid;
// ==================== pthread_create函数参数和返回值的实际使用(重点) ====================
// 调用pthread_create创建一个新的线程,参数和返回值的具体含义如下:
//
// **返回值(int类型)**:
// - 0:线程创建成功
// - 非0:线程创建失败(如资源不足、参数错误等),本例未对返回值做错误处理
//
// **参数1(pthread_t* tid)**:
// - 传入&tid:将新创建的线程的**用户级标识符**存储到tid变量中
// - 后续可通过tid变量对该线程进行操作(如pthread_join、pthread_cancel等)
//
// **参数2(const pthread_attr_t* attr)**:
// - 传入nullptr:使用线程的**默认属性**(如栈大小为8MB、调度策略为SCHED_OTHER、分离状态为非分离等)
// - 若需自定义属性(如修改栈大小、设置分离状态),需先调用pthread_attr_init初始化属性对象,再传入属性指针
//
// **参数3(void* (*start_routine)(void*))**:
// - 传入sumCount:指定新线程的**入口函数**
// - 新线程启动后会立即执行该函数,函数的返回值和参数均为void*类型(POSIX线程库的强制要求)
//
// **参数4(void* arg)**:
// - 传入rq:将Request对象的指针**强制转换为void*类型**,传递给新线程的入口函数sumCount
// - 该参数是线程间传递数据的常用方式,可传递任意类型的指针(如类对象、结构体、基本类型等)
pthread_create(&tid, nullptr, sumCount, rq);
// 定义void*类型的指针变量,用于接收新线程的退出返回值
void* ret;
// pthread_join默认是阻塞等待,回收新线程的资源,避免新线程变成僵尸线程
// 第一个参数tid:指定要等待的线程标识符
// 第二个参数&ret:将新线程入口函数的返回值(rsp指针)存储到ret变量中
pthread_join(tid, &ret);
// 将接收到的void*类型返回值强制转换为Response*类型,获取计算结果
Response* rsp = (Response*)ret;
// 打印累加计算结果和线程退出码
cout << "sum is : " << rsp->_result << ", exit code is : " << rsp->_exitCode << endl;
// 释放动态创建的Request和Response对象
delete rq;
delete rsp;
return 0;
}一、pthread_create 函数返回值的实际使用
代码中定义int ret变量接收 pthread_create 的返回值:
- 返回值为
0:表示线程创建成功,代码中未对该情况做额外处理,直接继续执行后续逻辑; - 返回值为非
0:表示线程创建失败(如系统资源不足、参数配置错误等),代码中未对返回值做错误处理,实际工程中需根据返回值判断是否成功创建线程。
二、pthread_create 函数参数的实际使用
*参数 1:pthread_t thread 代码中传入&tid:
- 将新创建线程的用户级线程标识符 存储到
tid变量中; - 后续可通过
tid变量对该线程进行管理操作,代码中后续调用pthread_join(tid, &ret)等待该线程并回收资源。
*参数 2:const pthread_attr_t attr 代码中传入nullptr:
- 指定线程的属性配置(如栈大小、调度策略、分离状态等);
- 传入
nullptr表示使用线程的默认属性:默认栈大小为 8MB、调度策略为 SCHED_OTHER(普通调度)、分离状态为非分离(需通过 pthread_join 回收资源)。
*参数 3:void (start_routine)(void) 代码中传入sumCount:
- 指定新线程的入口函数,新线程启动后会立即执行该函数;
- 该函数的返回值和参数均为
void*类型,是 POSIX 线程库对线程入口函数的强制要求; - 代码中
sumCount函数接收Request*类型的参数,调用Request::Sum()执行 1 到 100 的累加计算,动态创建Response对象存储结果并返回。
*参数 4:void arg 代码中传入rq(动态创建的Request对象指针):
- 向新线程的入口函数传递数据,需强制转换为
void*类型; - 可传递任意类型的指针(如类对象、结构体、基本类型等),是线程间传递数据的常用方式;
- 代码中
rq通过Request构造函数初始化累加起始值 1、结束值 100 和线程名称,新线程入口函数sumCount中将arg强制转换回Request*类型,获取计算参数。
重谈 pthread_create 函数的第一个参数
thread.cc4(POSIX 用户级线程 ID)
#include <iostream> // 标准输入输出流头文件,用于向终端打印文本
#include <unistd.h> // Linux系统调用头文件,用于调用sleep函数
#include <pthread.h> // POSIX线程库头文件,用于创建、等待、获取线程ID
#include <string> // C++字符串头文件,用于存储和返回转换后的十六进制线程ID
#include <sys/syscall.h> // Linux系统调用号头文件,本例未直接使用,仅做冗余预留
using namespace std;
// 自定义函数:将POSIX线程库的用户级线程ID转换为十六进制字符串
string toHex(pthread_t tid)
{
char hex[64]; // 定义字符数组,用于存储转换后的十六进制字符串
// **snprintf函数**:格式化输出到字符数组,第三个参数sizeof(hex)防止缓冲区溢出
// **%p格式符**:将指针类型(pthread_t在Linux下本质是结构体指针或无符号长整型,可兼容%p)转换为十六进制字符串
snprintf(hex, sizeof(hex), "%p", tid);
return hex; // 返回转换后的十六进制字符串
}
// 线程入口函数:返回值和参数均为void*类型,这是POSIX线程库对线程函数的强制要求
void* threadFunc(void* args)
{
// 进入无限循环,模拟线程持续运行
while(true)
{
// **pthread_self()函数**:获取当前执行线程的POSIX用户级线程ID
cout << "I am new thread, id is : " << toHex(pthread_self()) << endl;
sleep(1); // 休眠1秒,降低CPU占用率
}
}
int main()
{
// 定义POSIX线程库的线程标识符变量,用于后续标识和管理新创建的线程
pthread_t tid;
// **pthread_create函数参数4传nullptr**:表示不向新线程的入口函数传递任何数据
pthread_create(&tid, nullptr, threadFunc, nullptr);
// 打印主线程标识和新创建线程的POSIX用户级线程ID
cout << "I am main thread, new thread id is : " << toHex(tid) << endl;
// **pthread_join函数参数2传nullptr**:表示不关心新线程的退出返回值,仅回收新线程的资源
pthread_join(tid, nullptr);
return 0;
}一、thread.cc4 代码整体逻辑
代码的核心是演示 POSIX 线程库的用户级线程 ID 的获取与使用:
- 定义
toHex函数,将pthread_t类型的用户级线程 ID 转换为十六进制字符串打印; - 新线程入口函数
threadFunc中,通过pthread_self()获取自身的用户级线程 ID 并每秒打印; - 主线程通过
pthread_create创建新线程,获取并打印新线程的用户级 ID; - 主线程通过
pthread_join等待并回收新线程资源。
二、pthread_self () 函数
函数原型:
pthread_t pthread_self(void);作用 :获取当前执行线程 的 POSIX 用户级线程 ID,返回值类型为 pthread_t。
- 该 ID 由 POSIX 线程库(
pthread库)在用户态维护,仅用于线程库内部的线程标识与管理(如pthread_join、pthread_cancel等接口均使用该 ID)。
三、重谈 pthread_create 函数的第一个参数
参数类型:
pthread_t *thread作用 :将新创建线程的用户级线程 ID 存储到传入的 pthread_t 变量中。
- 代码中传入
&tid,pthread_create执行成功后,tid变量中就存储了新线程的用户级 ID。 - 该 ID 用
%p格式打印时看起来像一个地址,因为在 Linux 的pthread库实现中,pthread_t的本质是用户级线程控制块(TCB)的起始地址。
四、syscall (SYS_gettid) 与 pthread_self () 的区别
| 维度 | syscall(SYS_gettid) | pthread_self() |
|---|---|---|
| ID 类型 | 内核级轻量级进程(LWP)ID | POSIX 用户级线程 ID |
| 维护者 | Linux 内核 | 用户态 pthread 线程库 |
| 用途 | 内核调度线程的唯一标识,全局唯一整数 | 线程库内部管理线程的标识,仅在进程内有效 |
| 表现形式 | 整数(如 12345) |
在 Linux 下本质是指针 / 地址(用 %p 打印为十六进制地址) |
| 使用场景 | 调试、查看内核线程信息(如 ps -L) |
pthread 库的所有线程管理接口(pthread_join、pthread_detach 等) |
五、用户级 TCB 与新线程栈的位置
-
用户级 TCB 的本质
pthread_create第一个参数和pthread_self()获取的pthread_t,本质是线程库在用户态维护的线程控制块(TCB)的起始地址 。这个 TCB 位于进程的共享地址空间 (如堆或共享库映射区),由pthread库分配和管理,存储了线程的用户态上下文、属性等信息。 -
新线程独立栈的位置 除了主线程的栈位于进程地址空间的固有栈区,其他通过
pthread_create创建的新线程,其独立栈 也位于进程的共享地址空间中,具体就分配在pthread_t指向的用户级 TCB 附近。这块内存用于存放线程的临时变量、函数调用栈帧、返回值等数据。
创建多个线程
thread.cc5(线程栈 / 全局变量 / 线程局部存储特性验证)
#include <iostream> // 标准输入输出流,用于打印测试信息
#include <unistd.h> // Linux系统调用头文件,用于sleep函数
#include <pthread.h> // POSIX线程库头文件,用于创建/等待线程
#include <string> // C++字符串头文件,用于线程名称封装
#include <vector> // C++容器,用于存储多个线程的tid
#include <sys/syscall.h> // 本例未使用,仅冗余包含
using namespace std;
#define NUM 3 // 定义要创建的线程数量为3
// 测试2:全局指针,用于主线程获取线程1栈上的testData地址
int* p = nullptr;
// 测试3:全局变量(进程级共享资源),验证多线程共享全局数据
int g_val = 100;
// 测试4:__thread修饰的线程局部存储变量(TLS),每个线程拥有独立副本
// __thread是GCC扩展,编译时需保证编译器支持(如GCC/Clang)
__thread int g_val2 = 100;
// 线程入口函数:核心逻辑是验证4个测试点的特性
void* threadFunc(void* args)
{
// 将传入的void*参数强转为string*,获取线程名称
string* ps = (string*)args;
// 测试1:栈变量testData → 证明每个线程有独立的栈空间
// 栈变量的生命周期随线程栈,每个线程的testData在各自栈上,地址不同
int testData = 0;
// 测试2:将线程1的testData地址赋值给全局指针p,让主线程尝试访问
if(*ps == "thread_1")
{
p = &testData; // 主线程通过p访问线程1的栈变量(存在内存访问风险)
}
// 循环10次打印测试数据,直观展示各变量特性
for(int i = 0; i < 10; i++)
{
// 打印线程名称和POSIX用户级线程ID
cout << "new thread name is : " << ps->c_str() << ",tid is : " << pthread_self() << endl;
// 测试1/2:打印当前线程的testData值和地址 → 验证栈独立
cout << "I have a testData, val is : " << testData << ", &testData is : " << &testData << endl;
testData++; // 仅修改当前线程栈上的testData
// 测试3:打印全局变量g_val的值和地址 → 验证全局变量共享
cout << "We have a g_val, val is : " << g_val << ", &g_val is : " << &g_val << endl;
g_val++; // 所有线程修改同一个全局变量
// 测试4:打印__thread变量g_val2的值和地址 → 验证线程局部存储
cout << "g_val2 is : " << g_val2 << ", &g_val2 is : " << &g_val2 << endl;
g_val2++; // 仅修改当前线程的g_val2副本
cout << "================================================================================" << endl << endl;
sleep(1); // 休眠1秒,便于观察输出顺序
}
delete ps; // 释放主线程传入的动态字符串(避免内存泄漏)
return nullptr; // 线程正常退出,无返回值
}
int main()
{
vector<pthread_t> tids; // 容器存储所有新线程的tid,便于后续join
for(int i = 0; i < NUM; i++)
{
// 动态创建线程名称字符串(避免栈变量生命周期问题)
string* threadName = new string("thread_" + to_string(i));
pthread_t tid;
// 创建线程:参数4传递线程名称指针,每个线程拿到独立的名称
pthread_create(&tid, nullptr, threadFunc, threadName);
tids.push_back(tid); // 保存tid到容器
sleep(1); // 间隔1秒创建线程,避免输出混乱
}
// 测试2:主线程尝试访问线程1的testData
sleep(1); // 等待线程1完成p = &testData的赋值
if(p != nullptr)
{
// 注意:此处存在**未定义行为**!
// 线程1的testData是栈变量,主线程访问时可能已被覆盖/销毁
cout << "get thread_1 testData, val is " << *p << ", &testData is : " << p << endl;
}
// 主线程阻塞等待所有子线程退出,回收资源
for(int i = 0; i < NUM; i++)
{
pthread_join(tids[i], nullptr);
}
return 0;
}一、代码整体逻辑概述
代码通过pthread_create创建 3 个线程,设计 4 个核心测试点,结合栈变量 、全局指针 、全局变量 、__thread修饰变量的操作,验证多线程环境下不同数据存储类型的核心特性,核心代码围绕threadFunc线程入口函数和main函数中的线程创建、资源回收逻辑展开。
二、测试 1:testData 栈变量 → 验证每个线程有独立的栈结构
代码逻辑 :线程入口函数threadFunc中定义局部变量testData,该变量存储在线程栈中,每个线程循环打印该变量的值和地址,并执行自增操作,核心代码片段如下:
// 线程入口函数内
int testData = 0; // 栈上局部变量
for(int i = 0; i < 10; i++)
{
cout << "I have a testData, val is : " << testData << ", &testData is : " << &testData << endl;
testData++; // 仅修改当前线程栈上的testData
sleep(1);
}核心现象与结论:
- 地址层面:3 个线程打印的
&testData(栈变量地址)完全不同,证明每个线程拥有独立的栈空间; - 值层面:每个线程的
testData从 0 独立递增到 9,互不干扰(如 thread_1 的 testData 为 1 时,thread_2 的 testData 仍为 0); - 本质原因:新线程的栈分配在进程的共享区,栈上的局部变量是线程私有的,仅在当前线程栈内生效,无跨线程共享特性。
三、测试 2:全局指针 p 访问线程 1 的 testData → 验证线程栈数据可跨线程访问 / 修改
代码逻辑 :定义全局指针p,线程 1 将自身栈上testData的地址赋值给p,主线程通过p访问该地址对应的栈数据,核心代码片段如下:
// 全局作用域
int* p = nullptr;
// 线程入口函数内
if(*ps == "thread_1")
{
p = &testData; // 线程1将栈变量地址赋值给全局指针
}
// main函数内
sleep(1); // 等待线程1完成地址赋值
if(p != nullptr)
{
cout << "get thread_1 testData, val is " << *p << ", &testData is : " << p << endl;
}核心现象与结论:
- 语法可行性:主线程可通过全局指针
p读取线程 1 栈上testData的地址和值,说明线程栈数据的地址对同进程内所有线程可见; - 风险提示:该访问存在未定义行为 (若线程 1 的栈帧被销毁 / 覆盖,主线程访问
*p会触发内存错误); - 核心总结:线程栈的 "私有性" 是逻辑层面 的(每个线程有独立栈区),而非地址 / 权限层面的隔离 ------ 同进程的线程之间,只要获取到栈变量的地址,即可访问 / 修改对方栈上的数据,无 "访问密码" 限制。
四、测试 3:全局变量 g_val → 验证全局变量是进程级共享资源
代码逻辑 :定义全局变量g_val,所有线程循环打印该变量的值和地址,并执行自增操作,核心代码片段如下:
// 全局作用域
int g_val = 100; // 进程级全局变量
// 线程入口函数内
for(int i = 0; i < 10; i++)
{
cout << "We have a g_val, val is : " << g_val << ", &g_val is : " << &g_val << endl;
g_val++; // 所有线程修改同一个全局变量
sleep(1);
}核心现象与结论:
- 地址层面:3 个线程打印的
&g_val完全相同,因为全局变量存储在进程的数据段,地址全局唯一; - 值层面:
g_val的值持续递增(thread_1 第一次打印 100→自增为 101,thread_2 第一次打印 101→自增为 102,以此类推); - 本质原因:全局变量是进程级共享资源,被同进程内所有线程共享,一个线程修改后,其他线程可立即读取到修改结果,是多线程共享数据的核心载体(需注意线程安全问题)。
五、测试 4:__thread 修饰的 g_val2 → 验证线程局部存储(TLS)
代码逻辑 :使用__thread修饰全局变量g_val2,所有线程循环打印该变量的值和地址,并执行自增操作,核心代码片段如下:
// 全局作用域
__thread int g_val2 = 100; // 线程局部存储变量
// 线程入口函数内
for(int i = 0; i < 10; i++)
{
cout << "g_val2 is : " << g_val2 << ", &g_val2 is : " << &g_val2 << endl;
g_val2++; // 仅修改当前线程的g_val2副本
sleep(1);
}核心现象与结论:
__thread特性:该关键字是 GCC 编译器扩展,属于编译期选项 ,仅支持修饰内置类型(int、char 等),无法修饰自定义类型(如 string);- 地址层面:3 个线程打印的
&g_val2完全不同,证明每个线程拥有独立的g_val2副本; - 值层面:每个线程的
g_val2从 0 独立递增到 9,互不干扰; - 底层实现:
__thread变量由pthread 库 维护,存储在进程虚拟地址空间的共享区 中,且位于pthread_create第一个参数(用户级 TCB 地址)对应的线程私有区域附近,逻辑上是 "线程私有全局变量",既保留全局变量的可见性,又实现线程级私有性。
总结
- 线程栈特性:每个线程拥有独立栈空间,栈变量逻辑私有,但地址对同进程线程可见,可被跨线程访问 / 修改;
- 全局变量特性:进程级共享资源,地址唯一,所有线程可访问 / 修改,是多线程共享数据的基础;
- 线程局部存储(__thread):编译期扩展特性,将全局变量转为线程私有副本,存储在共享区的线程私有区域,兼顾全局可见性和线程私有性;
- 核心边界:线程的 "私有 / 共享" 是逻辑层面设计,而非地址隔离 ------ 同进程线程共享整个虚拟地址空间,仅通过栈分区、TLS 等机制实现数据逻辑私有。
线程分离(非阻塞等待分支线程的释放)
thread.cc6(线程分离函数接口及特性)
#include <iostream> // 标准输入输出流,用于打印错误信息
#include <pthread.h> // POSIX线程库头文件(核心:pthread_detach/pthread_create/pthread_self)
#include <unistd.h> // 用于sleep函数(可选,演示主线程退出时机)
#include <string.h> // 用于strerror函数,解析错误码
using namespace std;
// 线程入口函数:演示"分支线程自行分离"的方式
void* threadFunc(void* args)
{
// 线程分离第二种方式:分支线程主动分离自身
// pthread_self():获取当前线程的POSIX用户级ID
// 作用:线程运行后,主动将自己设置为"分离状态"
pthread_detach(pthread_self());
// 模拟线程执行耗时任务(可选,便于观察主线程退出的影响)
for(int i = 0; i < 5; i++)
{
cout << "分支线程运行中,tid: " << pthread_self() << endl;
sleep(1);
}
// 分离线程的返回值无意义(无法通过pthread_join获取)
return nullptr;
}
int main()
{
pthread_t tid;
// 创建分支线程:参数均为默认(属性nullptr,无参数传递)
int create_ret = pthread_create(&tid, nullptr, threadFunc, nullptr);
if(create_ret != 0)
{
cout << "线程创建失败:" << strerror(create_ret) << endl;
return -1;
}
// 线程分离第一种方式:主线程主动分离分支线程(与分支线程自分离二选一)
// 注意:两种分离方式只需选一种,重复调用不会报错,但无意义
// int detach_ret = pthread_detach(tid);
// if(detach_ret != 0)
// {
// cout << "线程分离失败:" << strerror(detach_ret) << endl;
// return -1;
// }
// ==================== 分离线程的核心特性验证 ====================
// 尝试join已分离的线程:会返回22号错误码(EINVAL:无效参数)
void* retval;
int join_ret = pthread_join(tid, &retval);
if(join_ret != 0)
{
cout << "pthread_join失败,错误码:" << join_ret << ",错误信息:" << strerror(join_ret) << endl;
}
// 主线程休眠1秒(若注释此行,主线程会直接退出,分支线程也会被终止)
// sleep(1);
// 主线程退出:若未休眠,即使分支线程还在运行,也会被内核终止
cout << "主线程退出" << endl;
return 0;
}一、代码整体逻辑概述
代码核心演示pthread_detach线程分离函数的使用方式及分离线程的核心特性:
- 实现两种线程分离方式(主线程主动分离分支线程、分支线程自分离);
- 验证 "已分离线程无法被
pthread_join等待" 的核心特性; - 演示主线程退出对分离线程生命周期的影响,整体围绕
pthread_detach和pthread_join的交互逻辑展开。
二、pthread_detach 函数详解
函数原型:
int pthread_detach(pthread_t thread);参数 :thread为需要设置分离状态的线程的 POSIX 用户级 ID(pthread_t类型);返回值 :成功返回0,失败返回非 0 错误码(可通过strerror解析错误信息);核心作用 :将指定线程设置为分离状态(detached) ,本质是修改该线程对应的用户级 TCB(线程控制块) 中的 "分离标记位":
- 标记位为
0:线程处于可连接状态(joinable) ,可通过pthread_join等待并回收资源; - 标记位为
1:线程处于分离状态(detached) ,系统会在线程退出时自动回收其资源,无需调用pthread_join。
三、代码中的两种线程分离方式
1. 主线程主动分离分支线程核心代码片段(注释中演示):
// main函数内,创建线程后执行
int detach_ret = pthread_detach(tid);
if(detach_ret != 0)
{
cout << "线程分离失败:" << strerror(detach_ret) << endl;
return -1;
}逻辑说明 :主线程通过pthread_create获取分支线程的tid后,主动调用pthread_detach将分支线程设置为分离状态,该方式需在分支线程退出前执行。
2. 分支线程自分离核心代码片段:
// 线程入口函数threadFunc内
pthread_detach(pthread_self()); // pthread_self()获取当前线程的POSIX ID逻辑说明 :分支线程启动后,通过pthread_self()获取自身的 POSIX 用户级 ID,主动调用pthread_detach将自己设置为分离状态;两种分离方式只需选择一种,重复调用不会报错,但无实际意义。
四、分离线程的核心特性验证(无法调用 pthread_join)
代码逻辑 :主线程尝试对已分离的分支线程调用pthread_join,验证是否能等待成功,核心代码片段:
// main函数内
void* retval;
int join_ret = pthread_join(tid, &retval);
if(join_ret != 0)
{
cout << "pthread_join失败,错误码:" << join_ret << ",错误信息:" << strerror(join_ret) << endl;
}核心现象与本质原因:
- 执行结果:
pthread_join返回22号错误码(EINVAL,无效参数),错误信息为Invalid argument; - 本质原因:线程被
pthread_detach设置为分离状态后,其 TCB 中的分离标记位被置为 1 ,内核 / 线程库会判定该线程不支持pthread_join操作 ------pthread_join的核心逻辑是检测目标线程的分离标记位,若为 1 则直接返回参数无效错误,无法完成等待和资源回收。
五、主线程退出对分离线程的影响
代码逻辑:
// main函数末尾(可选休眠逻辑)
// sleep(1); // 注释此行,主线程直接退出
cout << "主线程退出" << endl;
return 0;核心现象与结论:
- 若注释
sleep(1):主线程创建分支线程后立即退出,即使分支线程已设置为分离状态,也会随进程终止而被内核强制终止; - 若保留
sleep(1):主线程休眠期间,分支线程可正常执行完 5 次循环,体现 "分离线程仅无需 join 回收资源,但仍依赖进程存活" 的特性。
总结
pthread_detach核心作用:修改线程 TCB 中的分离标记位,将线程从可连接状态转为分离状态;- 分离线程核心特性:标记位为 1 时,无法调用
pthread_join(返回 EINVAL 错误),线程退出时系统自动回收资源; - 分离方式:主线程主动分离、分支线程自分离二选一,重复分离无意义;
- 生命周期边界:分离线程仍依赖进程存活,进程退出(主线程退出)会终止所有分离线程。
线程并发导致的数据不一致问题与互斥锁
thread.cc7(多线程抢票的竞态条件与并发问题)
#include <iostream> // 标准输入输出流,用于打印抢票信息
#include <unistd.h> // Linux系统调用头文件,用于usleep函数(模拟耗时操作)
#include <pthread.h> // POSIX线程库头文件,用于创建/管理线程
#include <string> // C++字符串头文件,用于线程名称封装
#include <vector> // C++容器,用于存储线程tid
using namespace std;
#define NUM 4 // 定义抢票线程的数量为4
int ticket = 1000; // 全局共享资源:总票数,所有线程共享同一块内存
// 线程管理类:用于存储线程tid,并在析构时自动join所有线程,回收资源
class Thread
{
public:
Thread()
{}
// 存储新创建线程的tid到容器中
void getTid(pthread_t tid)
{
_tids.push_back(tid);
}
// 析构函数:自动调用pthread_join回收所有线程资源,避免僵尸线程
~Thread()
{
for(int i = 0; i < _tids.size(); i++)
{
pthread_join(_tids[i], nullptr);
}
}
private:
vector<pthread_t> _tids; // 存储所有抢票线程的tid
};
// 线程入口函数:核心抢票逻辑,参数为线程名称的字符串指针
void* getTicket(void* args)
{
string* ps = (string*)args; // 强转参数为线程名称
while(true) // 循环抢票,直到票售罄
{
// 【关键问题点1】:检查票是否还有剩余(非原子操作)
if(ticket > 0)
{
// 【关键问题点2】:模拟抢票的耗时操作(如网络请求、数据库查询)
// usleep会让线程主动让出CPU,放大并发问题,让多个线程同时进入if块
usleep(1000);
// 【关键问题点3】:修改共享资源ticket(非原子操作)
ticket--;
// 打印抢票结果:线程名称 + 剩余票数
cout << ps->c_str() << " get a ticket, ticket emaining : " << ticket << endl;
}
else
{
break; // 票售罄,退出循环
}
}
delete ps; // 释放主线程传入的动态字符串(避免内存泄漏)
return nullptr;
}
int main()
{
Thread ts; // 创建线程管理对象
// 创建NUM个抢票线程
for(int i = 1; i <= NUM; i++)
{
pthread_t tid;
// 动态创建线程名称字符串(避免栈变量生命周期问题)
string* ps = new string("thread_" + to_string(i));
// 创建线程:参数4传递线程名称指针
pthread_create(&tid, nullptr, getTicket, ps);
// 将新线程的tid存入管理对象,便于后续回收
ts.getTid(tid);
}
// main函数返回时,Thread对象析构,自动join所有线程,回收资源
return 0;
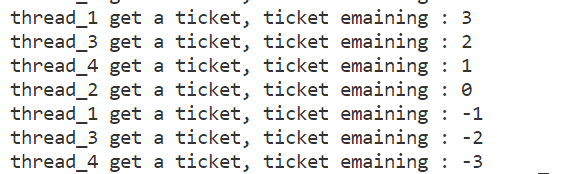
}多次验证运行代码后出现的并发问题:
thread.cc8(互斥锁解决抢票并发问题)
#include <iostream> // 标准输入输出流,打印抢票信息
#include <unistd.h> // Linux系统调用,usleep/sleep函数
#include <pthread.h> // POSIX线程库,线程/互斥锁相关函数
#include <string> // C++字符串,封装线程名称
#include <vector> // 存储线程tid,便于批量join
#include <sys/syscall.h> // 本例未使用,仅冗余包含
using namespace std;
#define NUM 4 // 抢票线程数量
int ticket = 1000; // 全局共享资源:总票数(所有线程共享)
// 线程管理类:存储线程tid,析构时自动join所有线程,回收资源
class Thread
{
public:
Thread()
{}
// 存储新创建线程的tid到容器
void getTid(pthread_t tid)
{
_tids.push_back(tid);
}
// 析构函数:自动join所有线程,避免僵尸线程
~Thread()
{
for(int i = 0; i < _tids.size(); i++)
{
pthread_join(_tids[i], nullptr);
}
}
private:
vector<pthread_t> _tids; // 存储所有抢票线程的tid
};
// 线程数据封装类:传递线程名称和互斥锁指针(避免多个独立参数传递)
class ThreadData
{
public:
// 构造函数:初始化线程名称和互斥锁指针
ThreadData(int threadNumber, pthread_mutex_t* lock)
: _lock(lock)
{
_threadName = "thread_" + to_string(threadNumber);
}
// 获取线程名称的C风格字符串(适配cout打印)
const char* getThreadName()
{
return _threadName.c_str();
}
// 获取互斥锁指针(用于加锁/解锁)
pthread_mutex_t* getThreadLock()
{
return _lock;
}
private:
string _threadName; // 线程名称
pthread_mutex_t* _lock; // 互斥锁指针(共享同一个锁,保证全局唯一)
};
// 互斥锁管理类:RAII机制自动初始化/销毁互斥锁,避免手动管理遗漏
class Lock
{
public:
// 构造函数:初始化互斥锁
Lock(pthread_mutex_t* lock)
: _lock(lock)
{
// pthread_mutex_init:初始化互斥锁
// 参数1:待初始化的互斥锁指针;参数2:互斥锁属性(nullptr=默认属性)
// 默认属性为"普通互斥锁",同一线程重复加锁会死锁,解锁必须由加锁线程执行
pthread_mutex_init(_lock, nullptr);
}
// 析构函数:销毁互斥锁(释放内核资源)
~Lock()
{
// pthread_mutex_destroy:销毁已初始化的互斥锁
// 注意:必须确保所有线程已释放该锁,否则会导致未定义行为
pthread_mutex_destroy(_lock);
}
private:
pthread_mutex_t* _lock; // 互斥锁指针
};
// 线程入口函数:核心抢票逻辑(加互斥锁保护共享资源)
void* getTicket(void* args)
{
// 强转参数为ThreadData指针,获取线程名称和互斥锁
ThreadData* ps = (ThreadData*)args;
while(true) // 循环抢票,直到票售罄
{
// ==================== pthread_mutex_lock:加锁 ====================
// 作用:申请获取互斥锁,若锁已被其他线程持有,则阻塞等待
// 注意:同一线程重复调用会死锁;必须由加锁线程解锁
pthread_mutex_lock(ps->getThreadLock());
if(ticket > 0) // 检查是否有剩余票(加锁后,仅一个线程能执行此判断)
{
usleep(1000); // 模拟抢票的耗时操作(如数据库写入、网络请求)
ticket--; // 修改共享资源(加锁后,仅一个线程能修改,避免竞态)
cout << ps->getThreadName() << " get a ticket, ticket emaining : " << ticket << endl;
// ==================== 解锁分支1:抢票成功后解锁 ====================
// pthread_mutex_unlock:释放互斥锁,让其他线程有机会获取锁
// 注意:必须与pthread_mutex_lock成对调用,且由加锁线程执行
pthread_mutex_unlock(ps->getThreadLock());
}
else // 票已售罄
{
// ==================== 解锁分支2:无票时解锁 ====================
// 【核心原因】:若此处不解锁,线程会持有锁退出循环,其他线程永远阻塞在pthread_mutex_lock,导致死锁!
// 加锁后,无论if/else分支,都必须解锁,确保锁资源被释放
pthread_mutex_unlock(ps->getThreadLock());
break; // 退出抢票循环
}
usleep(10); // 抢票成功后让出CPU,避免单个线程长期霸占锁,提升并发公平性
}
delete ps; // 释放主线程传入的ThreadData对象,避免内存泄漏
return nullptr;
}
int main()
{
pthread_mutex_t lock; // 定义互斥锁变量(全局/局部均可,只要所有线程共享)
Lock threadLock(&lock); // RAII管理互斥锁,自动初始化/销毁
Thread ts; // 线程管理对象,析构时自动join所有线程
// 创建NUM个抢票线程
for(int i = 1; i <= NUM; i++)
{
pthread_t tid;
// 动态创建ThreadData对象,传递线程编号和互斥锁指针
ThreadData* td = new ThreadData(i, &lock);
// 创建线程:参数4传递ThreadData指针,所有线程共享同一个互斥锁
pthread_create(&tid, nullptr, getTicket, td);
ts.getTid(tid); // 存储线程tid,便于后续join
}
// main函数返回时,Thread对象析构,自动join所有线程;Lock对象析构,自动销毁互斥锁
return 0;
}一、thread.cc7 代码解析与多线程抢票的并发问题
整体逻辑 :代码创建 4 个线程争抢全局共享资源ticket(初始值 1000),模拟多线程抢票场景;通过Thread类管理线程 tid,析构时自动调用pthread_join回收资源;抢票逻辑中加入usleep模拟耗时操作,放大并发问题,最终出现票数为负数的异常。
核心代码片段(抢票逻辑):
void* getTicket(void* args)
{
string* ps = (string*)args;
while(true)
{
if(ticket > 0) // 非原子的检查操作
{
usleep(1000); // 模拟耗时操作,放大并发问题
ticket--; // 非原子的修改操作
cout << ps->c_str() << " get a ticket, ticket emaining : " << ticket << endl;
}
else
{
break;
}
}
delete ps;
return nullptr;
}1. 共享数据不一致与票数负数的核心原因
ticket操作非原子性 :ticket--看似是一条 C++ 代码,实际会被编译为 3 条核心汇编指令:① 读取ticket的值到寄存器;② 寄存器值减 1;③ 将寄存器值写回ticket内存。这三步操作可被操作系统调度打断,无法保证 "一次性执行完",即不具备原子性。- 多线程同时进入
if判断 :当ticket=1时,多个线程(如线程 1、线程 2)同时通过if(ticket>0)的判断(usleep让线程让出 CPU,操作系统调度其他线程执行),都进入抢票逻辑;线程 1 执行ticket--后ticket=0,线程 2 仍会执行ticket--,最终导致ticket=-1。 - 操作系统调度算法的影响 :Linux 采用时间片轮转调度,线程执行到
usleep时主动让出 CPU,或时间片用完被强制切换,导致多个线程同时操作ticket,破坏数据一致性。
2. 多次运行的一致性异常每次运行代码都会出现票数负数,因为上述非原子操作和调度问题是多线程并发的固有问题,只要无同步机制保护共享资源,竞态条件就必然导致数据不一致。
二、thread.cc8 代码解析与互斥锁解决并发问题
整体逻辑 :代码基于 thread.cc7 的抢票场景,引入POSIX 互斥锁(pthread_mutex_t) 保护共享资源ticket;通过Lock类(RAII 机制)自动初始化 / 销毁锁,ThreadData类封装线程名称和锁指针,确保所有线程共享同一把锁;在抢票逻辑的临界区加锁 / 解锁,解决数据不一致问题。
核心代码模块解析:
1. 互斥锁管理类(Lock)------ RAII 自动管理锁生命周期
class Lock
{
public:
Lock(pthread_mutex_t* lock) : _lock(lock)
{
pthread_mutex_init(_lock, nullptr); // 初始化锁(默认属性)
}
~Lock()
{
pthread_mutex_destroy(_lock); // 销毁锁
}
private:
pthread_mutex_t* _lock;
};2. 加锁 / 解锁保护的抢票逻辑
void* getTicket(void* args)
{
ThreadData* ps = (ThreadData*)args;
while(true)
{
pthread_mutex_lock(ps->getThreadLock()); // 加锁
if(ticket > 0)
{
usleep(1000);
ticket--;
cout << ps->getThreadName() << " get a ticket, ticket emaining : " << ticket << endl;
pthread_mutex_unlock(ps->getThreadLock()); // 抢票成功解锁
}
else
{
pthread_mutex_unlock(ps->getThreadLock()); // 无票时必须解锁
break;
}
usleep(10); // 避免线程饥饿
}
delete ps;
return nullptr;
}3. 临界资源与临界区
- 临界资源 :加锁和解锁之间被保护的共享数据(此处为
ticket变量),是多线程竞争的核心资源; - 临界区 :加锁(
pthread_mutex_lock)和解锁(pthread_mutex_unlock)之间的代码块,包含对临界资源的检查、修改操作;只有申请锁成功的线程能执行临界区代码,其他线程会阻塞等待。
4. 阻塞等待的本质 当线程调用pthread_mutex_lock申请已被持有的锁时,操作系统会将该线程的PCB(进程控制块) 从R(运行)状态切换为非R(如等待)状态,并将 PCB 加入该锁的等待队列 ;当持有锁的线程解锁后,操作系统会从等待队列中唤醒一个线程,将其 PCB 切回R状态,使其有机会获取锁并执行临界区代码。
5. 代码中的潜在风险(对象构造 / 析构顺序)
- 错误顺序:若
Thread ts;定义在Lock threadLock(&lock);之前,根据 C++ 栈对象 "先构造、后析构" 的规则:ts先构造,threadLock后构造;- 程序退出时,
threadLock先析构(销毁互斥锁),而ts析构时还在pthread_join等待线程,此时线程可能仍在使用已销毁的锁,导致未定义行为(如崩溃、死锁)。
- 正确顺序:先定义
Lock threadLock(&lock);,后定义Thread ts;,确保ts先析构(join 回收所有线程),threadLock后析构(销毁锁),避免锁被提前销毁。
6. 加锁的本质与原则
- 加锁本质 :用 "时间" 换 "安全"------ 互斥锁让多线程对临界区的执行由并行 变为串行,牺牲了并发效率,但保证了共享数据的一致性;
- 加锁原则:临界区代码越少越好,仅将 "必须串行执行的共享资源操作" 放入临界区,减少线程阻塞时间,尽可能保留并发效率。
7. 纯互斥环境下的线程饥饿问题 若删除抢票成功后的usleep(10),某个线程解锁后可能立即再次获取锁(操作系统调度优先级 / 时间片分配),导致该线程长期霸占锁,其他线程无法抢到锁执行抢票逻辑,即线程饥饿 ;usleep(10)让抢票成功的线程主动让出 CPU,提升并发公平性,避免饥饿。
8. 同步的概念 同步是指多线程按照预定的顺序获取 / 操作资源,解决 "并发执行的无序性" 问题;互斥是同步的一种特例(保证临界区串行执行),核心是让线程按规则访问资源,避免竞态条件。
9. 锁的原子性保障
- 锁本身是所有线程共享的资源,但
pthread_mutex_lock和pthread_mutex_unlock的实现被操作系统设计为原子操作; - 原子性定义:一条 C/C++ 代码若对应多条汇编指令,且这些指令能 "一次性执行完,不被打断",则具备原子性;反之(如
ticket--)则不具备; - 锁的申请 / 释放操作被封装为原子指令(如 CPU 的 CAS 指令),确保多个线程竞争锁时,只有一个线程能成功获取锁,无需担心锁本身的安全问题。
总结
- thread.cc7 核心问题:共享资源
ticket的检查 / 修改非原子,多线程调度导致竞态条件,出现票数负数; - thread.cc8 解决方案:互斥锁将临界区串行化,通过 RAII 管理锁生命周期,避免手动操作遗漏;
- 加锁关键:临界区最小化、锁对象析构晚于线程回收、加解锁成对执行;
- 核心概念:原子性(操作不可打断)、临界资源 / 临界区(需保护的资源 / 代码)、同步(有序访问)、饥饿(线程长期无资源)。
互斥锁的底层原理
一、互斥锁的底层核心原理
互斥锁的底层依赖CPU 原子指令(如 xchgb 交换指令) 和操作系统的线程调度 / 等待队列机制 ,核心是通过内存中的mutex变量(本质是一个整数标记)实现 "唯一占有":
mutex=1:锁处于未持有状态,线程可申请获取;mutex=0:锁处于已持有状态,线程需挂起等待;- 申请 / 释放锁的核心操作被设计为原子性,避免锁本身成为竞态资源。
二、pthread_mutex_lock () 底层原理(伪代码 + 线程调度示例)
伪代码:
lock:
movb $0, %al ; 将0存入al寄存器
xchgb %al, mutex ; 原子交换al寄存器和mutex变量的值
if(al寄存器的内容 > 0)
{
return 0; ; 申请锁成功,进入临界区
}
else
{
挂起等待; ; 申请锁失败,线程进入锁的等待队列
}
goto lock; ; 被唤醒后重新尝试申请锁核心指令解析:
movb $0, %al:字节级赋值指令,将常量 0 写入 CPU 的 al 通用寄存器,为后续交换操作做准备;xchgb %al, mutex:原子交换指令,核心是 "交换 al 寄存器值和内存中 mutex 变量值",该操作由 CPU 硬件保证原子性(执行过程中不可被中断),是锁能保证互斥的关键。
线程 1、线程 2 竞争锁的完整调度过程 :前提:初始状态mutex=1(锁未被持有),系统采用时间片轮转调度。
- 线程 1 执行
movb $0, %al:al 寄存器被赋值为 0,此时线程 1 时间片耗尽,操作系统保存线程 1 的上下文(al=0、执行到xchgb %al, mutex前),切换至线程 2; - 线程 2 执行
movb $0, %al:al 寄存器被赋值为 0,继续执行xchgb %al, mutex;- 原子交换后:al 寄存器值变为 1(原 mutex 的值),内存中
mutex=0(原 al 的值); - 此时线程 2 时间片耗尽,操作系统保存线程 2 的上下文(al=1、mutex=0、执行到
if(al>0)前),切换回线程 1;
- 原子交换后:al 寄存器值变为 1(原 mutex 的值),内存中
- 线程 1 恢复上下文:al 寄存器恢复为 0,执行
xchgb %al, mutex;- 此时 mutex 已被线程 2 改为 0,交换后 al=0、mutex=0(无变化);
- 线程 1 执行
if(al>0):al=0 不满足条件,进入else分支,线程 1 的 PCB 被置为非 R 状态,加入锁的等待队列;
- 操作系统切换至线程 2,恢复其上下文:al=1、mutex=0;
- 线程 2 执行
if(al>0):al=1 满足条件,执行return 0,成功获取锁,进入临界区执行;
- 线程 2 执行
- 其他线程(若有)执行
goto lock:重复申请锁的逻辑,直到线程 2 解锁后被唤醒。
三、pthread_mutex_unlock () 底层原理(伪代码 + 设计逻辑)
伪代码:
unlock:
movb $1, mutex; ; 将mutex变量的值重置为1(锁回到未持有状态)
唤醒等待的Mutex的线程; ; 从锁的等待队列中唤醒一个线程
return 0; ; 解锁成功核心逻辑解析:
movb $1, mutex:直接将内存中 mutex 变量的值修改为 1,让锁回到 "可被申请" 的状态;唤醒等待的Mutex的线程:操作系统从该锁的等待队列中选取一个线程(如线程 1),将其 PCB 从非 R 状态切换为 R 状态,使其重新参与 CPU 调度,有机会再次执行lock逻辑申请锁。
解锁的设计考量:
- 常规场景:由持有锁的线程执行解锁操作,保证锁的 "申请 - 释放" 成对性;
- 特殊设计原因:解锁逻辑未限制 "必须由加锁线程执行",是为了应对异常场景:
- 若持有锁的线程因死锁、崩溃、异常挂起等原因无法解锁,可由其他线程(如监控线程)强制解锁,避免所有线程永久阻塞在等待队列中;
- 该设计是对 "锁异常" 的容错,而非常规用法,实际开发中仍需保证加解锁由同一线程执行,避免逻辑混乱。
总结
- 互斥锁底层核心:依赖 CPU 原子交换指令保证锁申请的原子性,结合操作系统线程调度 / 等待队列实现阻塞等待;
- pthread_mutex_lock:通过原子交换检测锁状态,失败则挂起,成功则进入临界区,被唤醒后重试;
- pthread_mutex_unlock:重置锁状态为未持有,唤醒等待线程,设计上支持非加锁线程解锁以容错异常。
线程的同步与条件变量
thread9.cc(条件变量实现线程的有序唤醒控制)
#include <iostream> // 标准输入输出流,打印线程执行信息
#include <unistd.h> // Linux系统调用,sleep/usleep函数
#include <pthread.h> // POSIX线程库,线程/互斥锁/条件变量相关函数
#include <cstdint> // 包含uint64_t类型定义
using namespace std;
int count = 0; // 全局共享计数器,所有线程竞争修改
#define NUM 5 // 要创建的线程数量
// 静态初始化互斥锁(PTHREAD_MUTEX_INITIALIZER):无需手动调用pthread_mutex_init/destroy
// 适用于全局/静态变量,系统自动完成初始化和资源释放,简化代码
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
// 静态初始化条件变量(PTHREAD_COND_INITIALIZER):无需手动调用pthread_cond_init/destroy
// 与互斥锁配合使用,实现线程的"等待-唤醒"机制
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
// 线程入口函数:等待条件变量信号,被唤醒后修改并打印count
void* threadFunc(void* args)
{
// 线程分离:分离后无需主线程pthread_join,线程退出时内核自动回收资源
pthread_detach(pthread_self());
// 将void*参数强转为uint64_t,获取线程编号(主线程传递的i)
uint64_t number = (uint64_t)args;
while(true) // 线程无限循环,持续等待条件变量信号
{
// 1. 先加互斥锁:pthread_cond_wait必须在加锁后调用(核心要求)
pthread_mutex_lock(&mutex);
// ==================== 条件变量等待核心逻辑 ====================
// pthread_cond_wait:让当前线程进入条件变量的等待队列,核心机制:
// - 第一步:自动释放已持有的互斥锁(避免其他线程永远拿不到锁,导致死锁);
// - 第二步:线程进入休眠状态,等待被pthread_cond_signal/broadcast唤醒;
// - 第三步:被唤醒后,线程会重新竞争获取互斥锁,拿到锁后才会继续执行后续代码;
// 必须传入互斥锁的原因:保证"等待条件"和"唤醒后执行"的原子性,避免竞态
pthread_cond_wait(&cond, &mutex);
// 被唤醒后执行:修改共享变量count并打印(加锁状态下,保证count修改的原子性)
cout << "thread_" << number << ", count : " << count++ << endl;
// 释放互斥锁:让其他线程有机会竞争锁/等待条件变量
pthread_mutex_unlock(&mutex);
}
return nullptr; // 无限循环,此语句永远不会执行
}
int main()
{
// 创建NUM个线程,每个线程传入唯一的编号i
for(uint64_t i = 0; i < NUM; i++)
{
pthread_t tid;
// 创建线程:参数4传递线程编号i(强转为void*)
pthread_create(&tid, nullptr, threadFunc, (void*)i);
usleep(1000); // 间隔1ms创建线程,避免线程编号传递的竞态(可选)
}
// 主线程:作为"控制器",每隔1秒唤醒一个等待条件变量的线程
while(true)
{
sleep(1); // 主线程休眠1秒,控制唤醒频率
// pthread_cond_signal:唤醒条件变量等待队列中的**一个**线程
// 注意:signal仅"通知"线程可以竞争锁,线程需重新拿到锁后才能执行后续逻辑
pthread_cond_signal(&cond);
// 或者可替换为 pthread_cond_broadcast(&cond);
// 表示一次性唤醒所有线程
}
return 0; // 无限循环,此语句永远不会执行
}一、线程同步的核心概念
线程同步是指在保证共享数据安全 (通过互斥锁等机制避免竞态条件)的前提下,让多个线程访问资源时遵循预定的顺序性 ,而非无序抢占资源。thread9.cc 中,多个子线程竞争修改全局变量count(临界资源),主线程通过条件变量cond控制子线程的唤醒时机,让子线程按 "每 1 秒唤醒一个" 的顺序有序修改count,既保证了count修改的原子性(互斥锁保护),又实现了线程执行的顺序性,是典型的同步场景。
二、pthread_cond_wait 必须在加锁后调用的原因及自动释放锁机制
核心代码片段:
pthread_mutex_lock(&mutex); // 先加锁
pthread_cond_wait(&cond, &mutex); // 等待条件变量,自动释放锁1. 加锁后调用的核心原因
- 保证 "检查条件" 和 "进入等待" 的原子性:若不加锁直接调用
pthread_cond_wait,可能出现线程在 "判断是否需要等待" 和 "进入等待队列" 之间被打断,导致条件信号丢失(如主线程提前发送 signal,子线程还未进入等待,最终子线程永久阻塞); - 保护条件相关的共享资源:
pthread_cond_wait的等待逻辑与共享资源(如代码中的count)的状态强相关,加锁可避免等待过程中共享资源被其他线程修改,破坏等待逻辑。
2. pthread_cond_wait 自动释放锁的机制
pthread_cond_wait执行时包含两个核心原子操作:
- 第一步:自动释放已持有的
mutex锁(避免其他线程因锁被持有而永久阻塞,保证主线程能正常加锁修改条件 / 发送信号); - 第二步:将当前线程的 PCB 置为非 R 状态,加入条件变量
cond的等待队列,进入休眠;该机制是为了平衡 "等待条件" 和 "锁的可用性",既让等待线程不占用锁资源,又保证等待逻辑的原子性。
三、全局 mutex 和 cond 的静态初始化特性
核心代码片段:
// 静态初始化互斥锁:PTHREAD_MUTEX_INITIALIZER是POSIX定义的初始化宏
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
// 静态初始化条件变量:PTHREAD_COND_INITIALIZER同理
pthread_cond_t cond = PTHREAD_COND_INITIALIZER; - 初始化特性:全局 / 静态变量使用上述宏初始化时,无需手动调用
pthread_mutex_init/pthread_cond_init,系统会在程序启动时自动完成互斥锁、条件变量的初始化; - 释放特性:程序退出时,系统会自动调用
pthread_mutex_destroy/pthread_cond_destroy释放内核资源,无需手动管理,简化代码且避免资源泄漏。
四、主线程控制子线程的唤醒逻辑
核心代码片段(主线程):
while(true)
{
sleep(1); // 控制唤醒频率,每1秒唤醒一个线程
pthread_cond_signal(&cond); // 唤醒cond等待队列中的一个线程
// pthread_cond_broadcast(&cond); // 可选:唤醒等待队列中的所有线程
}- 主线程角色:作为 "同步控制器",通过
pthread_cond_signal主动触发条件变量的唤醒信号,控制子线程的执行节奏; pthread_cond_signal作用:仅向条件变量cond的等待队列发送 "唤醒通知",选择一个等待线程将其 PCB 置为 R 状态,使其重新参与 CPU 调度;pthread_cond_broadcast区别:一次性唤醒等待队列中的所有线程,适用于需要所有线程同时响应条件的场景(如 "任务开始" 的广播通知)。
五、线程被唤醒后重新持有锁的逻辑及解锁要求
核心代码片段(子线程):
pthread_cond_wait(&cond, &mutex); // 被唤醒后,重新竞争mutex锁
cout << "thread_" << number << ", count : " << count++ << endl;
pthread_mutex_unlock(&mutex); // 必须释放锁,保证其他线程可竞争- 唤醒后的锁竞争:子线程被
pthread_cond_signal唤醒后,不会立即执行后续代码,而是先重新竞争mutex锁 ------ 只有成功获取锁的线程,才能执行count的修改操作,未获取到锁的线程会继续阻塞在锁的等待队列; - 解锁的必要性:子线程执行完临界区代码(修改
count)后,必须调用pthread_mutex_unlock释放锁,否则该线程会永久持有锁,导致其他线程(包括后续被唤醒的线程)无法获取锁,最终引发死锁。
总结
- 线程同步核心:在互斥保证数据安全的基础上,通过条件变量实现线程访问资源的顺序性;
pthread_cond_wait关键特性:加锁后调用,执行时自动释放锁,唤醒后重新竞争锁;- 静态初始化优势:全局互斥锁 / 条件变量无需手动初始化 / 销毁,系统自动管理;
- 唤醒逻辑:主线程通过
signal/broadcast控制子线程唤醒,子线程唤醒后需重新加锁,执行完必须解锁。
生产者消费模型问题
thread.cc10(基于阻塞队列的生产者消费者模型)
#include <iostream>
#include <queue>
#include <string>
#include <unistd.h>
#include <pthread.h>
#include <cstdlib>
#include <ctime>
using namespace std;
// --------------------------- 全局常量/枚举:任务运算相关 ---------------------------
// 支持的运算符号集合:加、减、乘、除、取模
string ops = "+-*/%";
// 任务执行错误码枚举(标识运算异常类型)
enum
{
DivZero = 1, // 除法分母为0
ModZero, // 取模分母为0
Unknown // 未知运算符
};
// --------------------------- 任务类:封装运算任务的参数、执行、结果 ---------------------------
class Task
{
public:
// 构造函数:初始化运算参数(两个操作数+运算符),结果和错误码默认初始化为0
Task(int data1, int data2, char op)
: _data1(data1) // 第一个运算数
, _data2(data2) // 第二个运算数
, _op(op) // 运算符(+、-、*、/、%)
, _result(0) // 运算结果(默认0)
, _exitcode(0) // 退出码(0=正常,非0=异常)
{}
// 核心方法:执行运算逻辑,处理异常并设置错误码
void run()
{
switch (_op)
{
case '+': // 加法运算
_result = _data1 + _data2;
break;
case '-': // 减法运算
_result = _data1 - _data2;
break;
case '*': // 乘法运算
_result = _data1 * _data2;
break;
case '/': // 除法运算(需处理分母为0)
{
if(_data2 == 0) // 分母为0,设置除法错误码
{
_exitcode = DivZero;
}
else // 分母合法,执行除法
{
_result = _data1 / _data2;
}
}
break;
case '%': // 取模运算(需处理分母为0)
{
if(_data2 == 0) // 分母为0,设置取模错误码
{
_exitcode = ModZero;
}
else // 分母合法,执行取模
{
_result = _data1 % _data2;
}
}
break;
default: // 未知运算符,设置未知错误码
_exitcode = Unknown;
break;
}
}
// 获取任务执行结果的字符串(格式:操作数1+运算符+操作数2=结果 [exit:错误码])
string getResult()
{
string s = to_string(_data1) + _op + to_string(_data2) + "=" + to_string(_result) + " [exit:" + to_string(_exitcode) + "]";
return s;
}
// 获取任务描述的字符串(格式:操作数1+运算符+操作数2= ?)
string getTask()
{
string s = to_string(_data1) + _op + to_string(_data2) + "= ?";
return s;
}
// 析构函数:默认空实现(无动态资源需要释放)
~Task()
{}
private:
int _data1; // 运算数1
int _data2; // 运算数2
char _op; // 运算符
int _result; // 运算结果
int _exitcode; // 退出码(0=正常,1=除零,2=模零,3=未知运算符)
};
// --------------------------- 阻塞队列类:封装线程安全的队列,实现生产/消费阻塞 ---------------------------
template<class T>
class BlockQueue
{
// 静态常量:队列默认最大容量(20)
static const int defalutnum = 20;
public:
// 构造函数:初始化队列容量、水位线,初始化互斥锁和条件变量
BlockQueue(int maxCap = defalutnum)
: _maxCap(maxCap) // 队列最大容量(默认20)
, _minCap(0) // 队列最小容量(空,0)
, _lowWater(defalutnum/4) // 低水位线(5):本例未实际使用
, _highWater(defalutnum/4*3)// 高水位线(15):本例未实际使用
{
// 初始化互斥锁(保护队列操作的原子性)
pthread_mutex_init(&_mutex, nullptr);
// 初始化消费者条件变量(队列有数据时唤醒消费者)
pthread_cond_init(&_Ccond, nullptr);
// 初始化生产者条件变量(队列有空位时唤醒生产者)
pthread_cond_init(&_Pcond, nullptr);
}
// 消费方法:从队列头部取出数据,队空时阻塞等待
T pop()
{
// 加锁:保证队列操作的线程安全(同一时间仅一个线程操作队列)
pthread_mutex_lock(&_mutex);
// 队空时,消费者阻塞等待(必须等生产者生产数据)
while(_q.size() == _minCap) //防止被伪唤醒,要让唤醒的进程再次判断
{
// 等待时自动释放锁,被唤醒后重新竞争获取锁
pthread_cond_wait(&_Ccond, &_mutex);
}
// 取出队列头部的任务(消费数据)
T out = _q.front();
_q.pop();
// 消费后唤醒生产者:告知生产者"队列有空位,可以继续生产"
pthread_cond_signal(&_Pcond);
// 解锁:释放队列的独占权,让其他线程(生产者/消费者)可以操作队列
pthread_mutex_unlock(&_mutex);
return out;
}
// 生产方法:向队列尾部插入数据,队满时阻塞等待
void push(const T& in)
{
// 加锁:保证队列操作的线程安全
pthread_mutex_lock(&_mutex);
// 队满时,生产者阻塞等待(必须等消费者消费数据)
while(_q.size() == _maxCap) //防止被伪唤醒
{
// 等待时自动释放锁,被唤醒后重新竞争获取锁
pthread_cond_wait(&_Pcond, &_mutex);
}
// 插入任务到队列尾部(生产数据)
_q.push(in);
// 生产后唤醒消费者:告知消费者"队列有数据,可以继续消费"
pthread_cond_signal(&_Ccond);
// 解锁:释放队列的独占权
pthread_mutex_unlock(&_mutex);
}
// 析构函数:销毁互斥锁和条件变量,释放内核资源
~BlockQueue()
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_Ccond);
pthread_cond_destroy(&_Pcond);
}
private:
queue<T> _q; // 存储任务的队列(核心数据结构)
int _maxCap; // 队列最大容量(防止队列溢出)
int _minCap; // 队列最小容量(空队列)
pthread_mutex_t _mutex; // 互斥锁:保护队列的push/pop操作
pthread_cond_t _Ccond; // 消费者条件变量:通知消费者"队列有数据"
pthread_cond_t _Pcond; // 生产者条件变量:通知生产者"队列有空位"
};
// --------------------------- 线程入口函数:生产者/消费者逻辑 ---------------------------
// 生产者线程:无限循环生成随机运算任务,推入阻塞队列
void* Producer(void* args)
{
// 将void*参数强转为阻塞队列指针(接收主线程传递的队列对象)
BlockQueue<Task>* bq = static_cast<BlockQueue<Task>*>(args);
while(true) // 无限循环生产任务
{
// 模拟生成随机运算参数
int data1 = rand() % 10 + 1; // 随机数范围:[1,10](避免运算数为0,仅为演示)
int data2 = rand() % 10 + 1;
char op = ops[rand() % ops.size()]; // 随机选择运算符(+、-、*、/、%)
// 创建任务对象
Task t(data1, data2, op);
usleep(10); // 轻微延迟,模拟生产耗时(避免生产速度过快)
// 将任务推入阻塞队列
bq->push(t);
// 打印生产的任务信息
cout << "生产了一个任务 : " << t.getTask() << endl;
}
}
// 消费者线程:无限循环从阻塞队列取出任务,执行并打印结果
void* Consumer(void* args)
{
// 将void*参数强转为阻塞队列指针
BlockQueue<Task>* bq = static_cast<BlockQueue<Task>*>(args);
while(true) // 无限循环消费任务
{
// 从队列取出任务(队空时阻塞等待)
Task t = bq->pop();
// 执行任务运算逻辑
t.run();
// 打印任务执行结果
cout << "处理了一个任务 : " << t.getResult() << endl;
}
}
// --------------------------- 主函数:初始化并启动生产者/消费者线程 ---------------------------
int main()
{
// 设置随机数种子(基于当前时间),保证每次运行生成的随机数不同
srand((unsigned int)time(nullptr));
// 创建阻塞队列对象(存储Task类型,默认最大容量20)
BlockQueue<Task>* bq = new BlockQueue<Task>();
// 定义生产者/消费者线程tid
pthread_t p; // 生产者线程标识符
pthread_t c; // 消费者线程标识符
// 创建生产者线程:参数4传递阻塞队列指针,让生产者能访问队列
pthread_create(&p, nullptr, Producer, bq);
// 创建消费者线程:参数4传递阻塞队列指针,让消费者能访问队列
pthread_create(&c, nullptr, Consumer, bq);
// 阻塞等待线程退出(无限循环,实际不会执行到此处)
pthread_join(p, nullptr);
pthread_join(c, nullptr);
// 释放阻塞队列内存(实际不会执行到此处)
delete bq;
return 0;
}一、生产者消费者模型的核心概念
生产者消费者模型是多线程同步的经典应用模型,核心是通过中间缓存区解耦生产和消费行为,平衡生产 / 消费速度的差异,解决 "忙闲不均" 问题。以现实场景类比:
- 生产者:对应供货商,职责是生成数据(生产商品);
- 消费者:对应购买商品的用户,职责是处理数据(消费商品);
- 交易场所(共享资源):对应超市,是存储数据的特定结构内存空间(队列、栈、链表等),作为生产者和消费者的交互媒介。
超市(中间缓存区)的核心意义
- 缓存作用:生产者生产的 "商品(数据)" 先存入超市,消费者从超市获取,避免生产者直接对接消费者;
- 解耦作用:生产者无需关注消费者的消费节奏,消费者无需关注生产者的生产节奏,两者仅与超市交互;
- 平衡忙闲:生产者生产速度快时,超市可缓存多余商品;消费者消费速度快时,可从超市获取存量商品,避免一方闲置等待。
多生产者 / 多消费者场景的三种关系超市作为共享资源,多生产者、多消费者访问时存在三类核心关系:
- 生产者 vs 消费者:互斥 + 同步------ 互斥保证同一时间仅一方操作超市;同步保证超市空时消费者等待,超市满时生产者等待;
- 生产者 vs 生产者:互斥------ 多个供货商不能同时向超市的同一位置存放商品,避免数据混乱;
- 消费者 vs 消费者:互斥------ 多个用户不能同时取超市的同一商品,避免数据重复消费。
生产者消费者模型的 "321 原则"
- 三种关系:
生产者与消费者(互斥 + 同步);
生产者与生产者(互斥);
消费者与消费者(互斥)。 - 两种角色:生产者(生成数据)、消费者(处理数据);
- 一个交易场所:存储数据的特定结构内存空间(如本例的阻塞队列)。
二、BlockQueue 类中 pop 函数(消费逻辑)解析
核心功能:从阻塞队列头部取出数据,队列为空时阻塞等待生产者生产数据,保证线程安全,核心代码如下:
T pop()
{
pthread_mutex_lock(&_mutex); // 加锁,保证队列操作原子性
while(_q.size() == _minCap) // 队空(_minCap=0),消费者阻塞
{
pthread_cond_wait(&_Ccond, &_mutex); // 等待消费者条件变量,自动释放锁
}
T out = _q.front(); // 取出队列头部数据
_q.pop(); // 移除队列头部数据
pthread_cond_signal(&_Pcond); // 唤醒生产者:队列有空位,可生产
pthread_mutex_unlock(&_mutex); // 解锁,释放队列独占权
return out;
}关键逻辑拆解:
- 加锁(pthread_mutex_lock) :获取互斥锁
_mutex,保证同一时间仅一个线程(生产者 / 消费者)操作队列,避免并发问题; - 队空判断与阻塞 :若队列大小等于
_minCap(0,空队列),调用pthread_cond_wait(&_Ccond, &_mutex):- 自动释放已持有的
_mutex锁,避免生产者因锁被占用无法生产; - 当前消费者线程进入
_Ccond(消费者条件变量)的等待队列,休眠等待生产者唤醒;
- 自动释放已持有的
- 消费数据 :被生产者唤醒并重新获取锁后,取出队列头部的
T类型数据,执行队列pop操作移除该数据; - 唤醒生产者 :调用
pthread_cond_signal(&_Pcond),向生产者条件变量_Pcond发送信号,唤醒阻塞的生产者线程(告知队列有空位,可继续生产); - 解锁(pthread_mutex_unlock):释放互斥锁,让其他线程(生产者 / 消费者)有机会操作队列。
三、BlockQueue 类中 push 函数(生产逻辑)解析
核心功能:向阻塞队列尾部插入数据,队列满时阻塞等待消费者消费数据,保证线程安全,核心代码如下:
void push(const T& in)
{
pthread_mutex_lock(&_mutex); // 加锁,保证队列操作原子性
while(_q.size() == _maxCap) // 队满(_maxCap=20),生产者阻塞
{
pthread_cond_wait(&_Pcond, &_mutex); // 等待生产者条件变量,自动释放锁
}
_q.push(in); // 向队列尾部插入数据
pthread_cond_signal(&_Ccond); // 唤醒消费者:队列有数据,可消费
pthread_mutex_unlock(&_mutex); // 解锁,释放队列独占权
}关键逻辑拆解:
- 加锁(pthread_mutex_lock) :获取互斥锁
_mutex,独占队列操作权,避免并发修改; - 队满判断与阻塞 :若队列大小等于
_maxCap(20,满队列),调用pthread_cond_wait(&_Pcond, &_mutex):- 自动释放
_mutex锁,避免消费者因锁被占用无法消费; - 当前生产者线程进入
_Pcond(生产者条件变量)的等待队列,休眠等待消费者唤醒;
- 自动释放
- 生产数据 :被消费者唤醒并重新获取锁后,执行队列
push操作,将in(待生产的T类型数据)插入队列尾部; - 唤醒消费者 :调用
pthread_cond_signal(&_Ccond),向消费者条件变量_Ccond发送信号,唤醒阻塞的消费者线程(告知队列有数据,可继续消费); - 解锁(pthread_mutex_unlock):释放互斥锁,让其他线程有机会操作队列。
总结
- 生产者消费者模型核心:通过中间缓存区(阻塞队列)解耦生产 / 消费,平衡速度差异,解决忙闲不均;
- BlockQueue::pop:消费数据,队空时阻塞,消费后唤醒生产者,全程互斥锁保证线程安全;
- BlockQueue::push:生产数据,队满时阻塞,生产后唤醒消费者,全程互斥锁保证线程安全;
- 核心同步逻辑:消费者条件变量(_Ccond)控制 "有数据可消费",生产者条件变量(_Pcond)控制 "有空位可生产"。
基于 POSIX 信号量实现环形队列的生产消费模型
thread.cc11(基于 POSIX 信号量的多生产多消费环形队列)
// 补充编译所需的头文件(必须)
#include <iostream> // cout 控制台输出
#include <vector> // vector 容器存储环形队列数据
#include <semaphore.h>// POSIX信号量(sem_t/sem_init/sem_wait/sem_post)
#include <pthread.h> // POSIX线程(pthread_create/pthread_join/互斥锁)
#include <cstdlib> // rand() 生成随机数
#include <ctime> // time() 设置随机数种子
#include <unistd.h> // usleep() 延迟(可选,优化输出体验)
using namespace std; // 简化std::前缀,新手更易阅读
// 环形队列默认容量:20个槽位
const int defaultcap = 20;
// 模板类:环形队列(支持任意类型数据),实现多生产者多消费者模型
template<class T>
class RingQueue
{
private:
// P操作:申请信号量(sem减1,无可用资源则阻塞等待)
// 封装sem_wait,简化代码调用
void P(sem_t& sem)
{
sem_wait(&sem);
}
// V操作:释放信号量(sem加1,唤醒等待该信号量的线程)
// 封装sem_post,简化代码调用
void V(sem_t& sem)
{
sem_post(&sem);
}
// 加锁操作:封装pthread_mutex_lock,简化调用
void Lock(pthread_mutex_t& mutex)
{
pthread_mutex_lock(&mutex);
}
// 解锁操作:封装pthread_mutex_unlock,简化调用
void Unlock(pthread_mutex_t& mutex)
{
pthread_mutex_unlock(&mutex);
}
public:
// 构造函数:初始化环形队列核心资源
// maxCap:队列最大容量(默认20)
RingQueue(int maxCap = defaultcap)
: _maxCap(maxCap) // 初始化队列最大容量
, _cStep(0) // 消费者读取下标(初始0)
, _pStep(0) // 生产者写入下标(初始0)
{
// 初始化vector容量为maxCap:提前分配固定槽位,避免下标越界
// 环形队列核心:固定容量,循环复用槽位,而非无限扩容
_ringqueue.resize(maxCap);
// 初始化信号量(第二个参数0:线程间共享,非进程间)
// 1. _cDataSem:消费者关注的"数据资源量",初始0(无数据可消费)
sem_init(&_cDataSem, 0, 0);
// 2. _pSpaceSem:生产者关注的"空间资源量",初始maxCap(有20个空位可生产)
sem_init(&_pSpaceSem, 0, maxCap);
// 初始化互斥锁:保护临界区(下标修改、数据读写)
// 1. _cMutex:消费者专属锁(保护_cStep修改)
pthread_mutex_init(&_cMutex, nullptr);
// 2. _pMutex:生产者专属锁(保护_pStep修改)
pthread_mutex_init(&_pMutex, nullptr);
}
// 生产者入队:将数据写入环形队列(多生产者安全)
// in:待生产的数据(const& 避免拷贝,提高效率)
void push(const T& in)
{
// 第一步:P操作申请"空间资源"
// 若队列已满(_pSpaceSem=0),生产者阻塞,直到消费者消费出空位
P(_pSpaceSem);
// 第二步:加生产者锁 → 进入临界区(必须在P后)
// 临界区:_pStep下标修改、数据写入_ringqueue[_pStep]
// 多生产者同时修改_pStep会导致下标错乱,必须加锁保护
Lock(_pMutex);
// 核心逻辑:数据写入当前生产者下标位置
_ringqueue[_pStep] = in;
// 生产者下标后移
_pStep++;
// 环形下标:超过最大容量则重置为0(循环复用槽位)
_pStep = _pStep % _maxCap;
// 第三步:解锁 → 退出临界区(临界区代码尽可能短,减少锁竞争)
Unlock(_pMutex);
// 第四步:V操作释放"数据资源"(必须在解锁后)
// 通知消费者:队列中有新数据可消费(_cDataSem+1)
V(_cDataSem);
// 可选:生产后轻微延迟,避免输出刷屏,便于观察多生产多消费效果
usleep(100000); // 100ms
}
// 消费者出队:从环形队列读取数据(多消费者安全)
// out:输出参数(传引用),返回消费到的数据
void pop(T& out)
{
// 第一步:P操作申请"数据资源"
// 若队列为空(_cDataSem=0),消费者阻塞,直到生产者生产数据
P(_cDataSem);
// 第二步:加消费者锁 → 进入临界区(必须在P后)
// 临界区:_cStep下标修改、数据读取_ringqueue[_cStep]
// 多消费者同时修改_cStep会导致下标错乱,必须加锁保护
Lock(_cMutex);
// 核心逻辑:从当前消费者下标位置读取数据
out = _ringqueue[_cStep];
// 消费者下标后移
_cStep++;
// 环形下标:超过最大容量则重置为0
_cStep = _cStep % _maxCap;
// 第三步:解锁 → 退出临界区
Unlock(_cMutex);
// 第四步:V操作释放"空间资源"(必须在解锁后)
// 通知生产者:队列中有新空位可生产(_pSpaceSem+1)
V(_pSpaceSem);
// 可选:消费后轻微延迟,优化输出体验
usleep(100000); // 100ms
}
// 析构函数:释放内核资源(信号量、互斥锁)
~RingQueue()
{
// 销毁信号量
sem_destroy(&_cDataSem);
sem_destroy(&_pSpaceSem);
// 补充:销毁互斥锁(原代码遗漏,必须加,避免资源泄漏)
pthread_mutex_destroy(&_cMutex);
pthread_mutex_destroy(&_pMutex);
}
private:
vector<T> _ringqueue; // 环形队列存储容器(固定容量)
int _maxCap; // 队列最大容量(槽位数)
int _cStep; // 消费者读取位置下标(多消费者共享)
int _pStep; // 生产者写入位置下标(多生产者共享)
pthread_mutex_t _cMutex; // 消费者互斥锁:保护_cStep的原子修改
pthread_mutex_t _pMutex; // 生产者互斥锁:保护_pStep的原子修改
sem_t _cDataSem; // 消费者信号量:表示"可消费的数据数量"
sem_t _pSpaceSem; // 生产者信号量:表示"可生产的空间数量"
};
// ------------------------- 线程入口函数 -------------------------
// 生产者线程:无限循环生产随机数据(0-9),写入环形队列
void* Producer(void* args)
{
// 将void*参数强转为环形队列指针(接收main函数传递的队列对象)
RingQueue<int>* prq = static_cast<RingQueue<int>*>(args);
while(true) // 无限循环生产
{
// 模拟生产:生成0-9的随机整数
int data = rand() % 10;
// 数据入队(多生产者安全)
prq->push(data);
// 打印生产日志(多线程下cout可能乱序,工业级需加锁,新手可忽略)
cout << "生产者[" << pthread_self() << "]生产了数据 : " << data << endl;
}
return nullptr; // 无限循环,此语句不会执行
}
// 消费者线程:无限循环从环形队列读取数据,模拟消费
void* Consumer(void* args)
{
// 将void*参数强转为环形队列指针
RingQueue<int>* crq = static_cast<RingQueue<int>*>(args);
while(true) // 无限循环消费
{
// 模拟消费:定义变量接收数据
int data;
// 数据出队(多消费者安全)
crq->pop(data);
// 打印消费日志
cout << "消费者[" << pthread_self() << "]消费了数据 : " << data << endl;
}
return nullptr; // 无限循环,此语句不会执行
}
// 主函数:创建多生产者、多消费者线程,启动环形队列模型
int main()
{
// 设置随机数种子(基于当前时间),保证每次运行随机数不同
srand((unsigned int)time(nullptr));
// 创建环形队列对象(默认容量20)
RingQueue<int>* rq = new RingQueue<int>();
// 定义5个消费者线程ID、5个生产者线程ID(多生产多消费)
pthread_t c[5]; // 消费者线程数组
pthread_t p[5]; // 生产者线程数组
// 第一步:创建5个消费者线程
for(int i = 0; i < 5; i++)
{
// 参数说明:&c[i](线程ID)、nullptr(默认属性)、Consumer(线程入口)、rq(传递给线程的参数)
pthread_create(c + i, nullptr, Consumer, rq);
}
// 第二步:创建5个生产者线程
for(int i = 0; i < 5; i++)
{
pthread_create(p + i, nullptr, Producer, rq);
}
// 第三步:等待线程退出(无限循环,需手动Ctrl+C终止程序)
// 等待所有消费者线程
for(int i = 0; i < 5; i++)
{
pthread_join(c[i], nullptr);
}
// 等待所有生产者线程(实际不会执行到此处)
for(int i = 0; i < 5; i++)
{
pthread_join(p[i], nullptr);
}
// 释放环形队列内存(实际不会执行到此处)
delete rq;
return 0;
}一、POSIX 信号量的核心本质
POSIX 信号量的本质是原子性的计数器,该计数器的核心作用是描述 "可用资源的数目"(如可生产的空间数、可消费的数据数)。信号量的核心优势是将 "资源是否就绪" 的判断逻辑剥离到临界区之外,无需像条件变量那样在加锁后再判断资源状态,核心伪代码逻辑:
P(sem); // 申请资源:信号量值减1,无可用资源则阻塞等待
// 临界区:访问共享资源(仅资源申请成功后执行)
V(sem); // 释放资源:信号量值加1,唤醒等待该信号量的线程- P 操作(sem_wait):原子性地将信号量值减 1,若减后值≥0,说明资源申请成功,继续执行;若 < 0,当前线程进入信号量的等待队列阻塞,直到有其他线程执行 V 操作释放资源。
- V 操作(sem_post):原子性地将信号量值加 1,若加后值≤0,说明有线程在等待该信号量,唤醒等待队列中的一个线程。
- 原子性保障:P/V 操作由操作系统内核实现为原子指令,即使多线程并发调用,也能保证信号量计数的准确性,无需额外加锁保护信号量本身。
- 对比条件变量:条件变量需在加锁后判断资源状态(如队列是否为空 / 满),而信号量通过 P 操作直接在临界区外完成资源申请,减少临界区代码量,提升并发效率。
二、环形队列生产者消费者模型的核心原则与信号量设计
以 "线程 1(生产者放苹果)、线程 2(消费者拿苹果)" 为例,环形队列需遵循三大核心原则:
- 空 / 满判断原则 :
- 空状态:生产者、消费者指向同一位置且无资源时,仅生产者可操作(消费者资源未就绪);
- 满状态:生产者、消费者指向同一位置且有资源时,仅消费者可操作(生产者若操作会覆盖数据)。
- 消费不超前原则:消费者下标不能超过生产者下标(消费者不能拿未生产的苹果)。
- 生产不套圈原则:生产者下标不能超出消费者下标一整圈(避免覆盖未消费的苹果)。
信号量设计逻辑
环形队列的核心是将共享资源(队列槽位)拆分为 "空间资源" 和 "数据资源",分别用两个信号量描述:
- SpaceSem(生产者信号量):初始值为环形队列容量 N,描述 "可生产的空槽位数量";
- DataSem(消费者信号量):初始值为 0,描述 "可消费的有效数据数量"。
核心执行流程
- 生产者放苹果:
- 执行
P(SpaceSem):申请 1 个空槽位,SpaceSem 值减 1; - 向当前下标位置放入苹果(生产数据);
- 执行
V(DataSem):释放 1 个数据资源,DataSem 值加 1,告知消费者有新数据可消费。
- 执行
- 消费者拿苹果:
- 执行
P(DataSem):申请 1 个数据资源,DataSem 值减 1; - 从当前下标位置拿走苹果(消费数据);
- 执行
V(SpaceSem):释放 1 个空间资源,SpaceSem 值加 1,告知生产者有新空位可生产。
- 执行
- 非空 / 非满状态:生产者、消费者指向不同槽位,可并发操作不同槽位,无需互相等待,提升并发效率。
三、thread.cc11 代码整体逻辑
代码实现多生产者多消费者环形队列模型,核心结构与逻辑如下:
- 模板类 RingQueue :封装环形队列核心逻辑,通过
SpaceSem(空间资源)、DataSem(数据资源)实现同步,通过_pMutex(生产者锁)、_cMutex(消费者锁)实现互斥; - 线程入口函数 :
Producer:无限循环生成 0-9 的随机数,调用push方法将数据写入环形队列;Consumer:无限循环调用pop方法从环形队列读取数据,模拟消费;
- main 函数:初始化环形队列,创建 5 个生产者线程、5 个消费者线程,阻塞等待线程退出(需手动终止)。
四、RingQueue 类中 push 函数(生产者入队)解析
核心功能:多生产者安全写入数据,申请空间资源后写入,释放数据资源,核心代码及解析:
void push(const T& in)
{
P(_pSpaceSem); // 1. P操作:申请空间资源(空槽位),无资源则阻塞
Lock(_pMutex); // 2. 加生产者锁:保护_pStep下标修改(临界区开始)
_ringqueue[_pStep] = in; // 写入数据到当前生产者下标位置
_pStep++; // 生产者下标后移
_pStep = _pStep % _maxCap;// 环形下标:超出容量则重置为0
Unlock(_pMutex); // 3. 解锁:退出临界区(临界区结束)
V(_cDataSem); // 4. V操作:释放数据资源,告知消费者有新数据
usleep(100000);
}- P(_pSpaceSem):申请可生产的空槽位,若队列已满(_pSpaceSem=0),生产者阻塞,直到消费者消费出空位;
- Lock(_pMutex) :加生产者专属锁,保护
_pStep(生产者下标)的原子修改,避免多生产者同时修改下标导致数据覆盖; - V(_cDataSem):生产数据后,将数据资源数加 1,唤醒阻塞的消费者线程。
五、RingQueue 类中 pop 函数(消费者出队)解析
核心功能:多消费者安全读取数据,申请数据资源后读取,释放空间资源,核心代码及解析:
void pop(T& out)
{
P(_cDataSem); // 1. P操作:申请数据资源,无数据则阻塞
Lock(_cMutex); // 2. 加消费者锁:保护_cStep下标修改(临界区开始)
out = _ringqueue[_cStep]; // 从当前消费者下标读取数据
_cStep++; // 消费者下标后移
_cStep = _cStep % _maxCap; // 环形下标:超出容量则重置为0
Unlock(_cMutex); // 3. 解锁:退出临界区(临界区结束)
V(_pSpaceSem); // 4. V操作:释放空间资源,告知生产者有新空位
usleep(100000);
}- P(_cDataSem):申请可消费的数据资源,若队列为空(_cDataSem=0),消费者阻塞,直到生产者生产数据;
- Lock(_cMutex) :加消费者专属锁,保护
_cStep(消费者下标)的原子修改,避免多消费者同时读取同一数据; - V(_pSpaceSem):消费数据后,将空间资源数加 1,唤醒阻塞的生产者线程。
六、加锁 / 解锁放在 P/V 操作之间的核心原因
1. 提升并发度
- 信号量 P 操作已完成 "资源是否就绪" 的判断,仅资源就绪的线程会进入临界区,减少锁竞争的概率;
- 临界区仅包含 "下标修改 + 数据读写" 的核心逻辑,代码量极小,线程持有锁的时间极短,其他线程等待锁的时间减少,整体并发效率提升;
- 若将加锁放在 P 操作前,所有线程(包括资源未就绪的线程)都会竞争锁,导致大量无意义的锁等待,降低并发度。
2. 保证代码逻辑正确性
- P 操作在前:确保只有拿到资源的线程才会进入临界区操作共享资源,避免 "无资源却操作队列" 的逻辑错误(如生产者无空位却写入数据、消费者无数据却读取);
- 解锁在后:确保下标修改、数据读写完成后再释放锁,避免多线程并发修改下标导致的错乱;
- V 操作在解锁后:V 操作仅负责唤醒等待线程,无需在临界区内执行,进一步缩短临界区长度,提升并发效率。
总结
- POSIX 信号量本质是原子计数器,描述资源数目,P/V 操作实现资源的申请 / 释放,将资源判断剥离到临界区外;
- 环形队列生产消费模型遵循空 / 满判断、消费不超前、生产不套圈三大原则,通过 SpaceSem(空间资源)、DataSem(数据资源)实现同步;
- push/pop 函数核心逻辑:P 操作申请资源→加锁修改下标 / 读写数据→解锁→V 操作释放资源;
- 加锁 / 解锁放在 P/V 之间的核心:减少锁竞争提升并发度,保证资源就绪后才操作共享资源,确保逻辑正确。
自旋锁
thread.cc12(自旋锁实现抢票逻辑)
// 补充编译所需的头文件(必须)
#include <iostream> // cout 控制台输出
#include <pthread.h> // POSIX线程 + 自旋锁相关接口(pthread_spin_*)
#include <string> // string 字符串类型
#include <unistd.h> // usleep 微秒级延迟(模拟抢票耗时)
using namespace std; // 简化std::前缀,新手更易阅读
// 全局自旋锁变量:保护共享资源ticket的原子操作
pthread_spinlock_t slock;
// 共享资源:100张票(多线程竞争的核心资源)
int ticket = 100;
// 线程入口函数:模拟多线程抢票逻辑
// args:传递给线程的参数(字符串指针,标识线程名称)
void *threadFunc(void *args)
{
// 将void*参数强转为string*,获取线程名称
string *s = static_cast<string *>(args);
// 无限循环抢票,直到票抢完退出
while (true)
{
// ========== 自旋锁核心接口1:加锁(阻塞式自旋) ==========
// 功能:尝试获取自旋锁,若锁已被占用,当前线程不放弃CPU,持续循环(自旋)尝试申请
// 特点:忙等(Busy Waiting),适合锁持有时间极短的场景(如抢票仅修改一个int)
// 对比互斥锁:互斥锁获取失败会让线程休眠(放弃CPU),自旋锁则一直占用CPU重试
pthread_spin_lock(&slock);
// 【补充说明】非阻塞式自旋锁接口:pthread_spin_trylock(&slock)
// 功能:尝试获取锁,成功返回0,失败直接返回错误码(不会自旋等待)
// 若用trylock实现抢票,需手动加循环判断,示例逻辑:
// while (pthread_spin_trylock(&slock) != 0) { /* 自旋等待,空循环 */ }
// 临界区:操作共享资源ticket(必须加锁保护,避免多线程竞态)
if (ticket > 0)
{
// 打印当前线程抢到的票号
cout << s->c_str() << " get a ticket : " << ticket << endl;
// 票号减1(原子操作,需锁保护)
ticket--;
// ========== 自旋锁核心接口2:解锁(分支1) ==========
// 功能:释放自旋锁,让其他自旋等待的线程可以获取锁
// 注意:解锁必须与加锁一一对应,且只能由持有锁的线程解锁
pthread_spin_unlock(&slock);
}
else
{
// 票已抢完,解锁后退出循环
pthread_spin_unlock(&slock); // 解锁分支2(必须解锁,否则死锁)
break; // 退出抢票循环
}
// 微秒级延迟:模拟抢票后的耗时操作(释放CPU,让其他线程有机会抢票)
usleep(10);
}
// 释放线程名称的内存(避免内存泄漏)
delete s;
return nullptr;
}
int main()
{
// ========== 自旋锁核心接口3:初始化 ==========
// 函数原型:int pthread_spin_init(pthread_spinlock_t *lock, int pshared);
// 参数1:自旋锁变量地址;参数2:共享属性(0=线程内共享,PTHREAD_PROCESS_SHARED=进程间共享)
// 作用:初始化自旋锁,必须先初始化才能使用
pthread_spin_init(&slock, 0);
// 定义3个线程ID:模拟3个抢票线程
pthread_t p[3];
// 创建3个抢票线程
for (int i = 0; i < 3; i++)
{
// 为每个线程创建唯一名称(thread_1/thread_2/thread_3)
string *s = new string("thread_" + to_string(i + 1));
// 创建线程:参数分别为线程ID、默认属性、线程入口函数、线程名称参数
pthread_create(p + i, nullptr, threadFunc, s);
}
// 等待所有线程执行完毕(阻塞主线程)
for (int i = 0; i < 3; i++)
{
pthread_join(p[i], nullptr);
}
// ========== 自旋锁核心接口4:销毁 ==========
// 功能:释放自旋锁占用的内核资源,初始化后必须销毁,避免资源泄漏
// 注意:销毁前必须确保所有线程都已释放该锁
pthread_spin_destroy(&slock);
cout << "所有票已抢完!" << endl;
return 0;
}一、自旋锁的核心定义
自旋锁(Spin Lock)是一种忙等(Busy Waiting) 型的同步锁机制,核心逻辑是:当线程尝试获取自旋锁时,若锁已被其他线程持有,该线程不会放弃 CPU 执行权,也不会被操作系统挂起,而是在一个无限循环中持续 "自旋"(重复检测锁的状态),直到锁被释放并成功获取。
自旋锁的设计初衷是针对临界区执行时间极短的场景(如仅修改一个整数变量),避免线程 "挂起 - 唤醒" 的内核态切换开销,从而提升并发效率。
二、自旋锁与互斥锁的核心区别
| 特性 | 互斥锁(pthread_mutex_t) | 自旋锁(pthread_spinlock_t) |
|---|---|---|
| 等待机制 | 申请失败时,线程被操作系统挂起(PCB 从 R 态转为非 R 态),加入锁的阻塞队列,放弃 CPU | 申请失败时,线程不挂起,持续循环检测锁状态(忙等),占用 CPU 不释放 |
| 核心开销 | 线程挂起 / 唤醒的内核态切换开销(较大) | 自旋循环的 CPU 占用开销(较小,仅消耗 CPU 时间片) |
| 适用场景 | 临界区执行时间较长(如包含 IO、sleep、复杂计算) | 临界区执行时间极短(如仅修改单个变量) |
| 资源占用 | 等待时不占用 CPU,释放 CPU 给其他线程 | 等待时持续占用 CPU,可能导致 CPU 利用率飙升 |
关键补充说明
互斥锁的执行逻辑:
- 线程调用
pthread_mutex_lock申请锁,若锁被占用,线程立即被挂起,进入阻塞队列; - 持有锁的线程调用
pthread_mutex_unlock释放锁时,操作系统从阻塞队列中唤醒一个线程,使其重新竞争锁; - 线程 "挂起 - 唤醒" 需要内核态切换,耗时约几十微秒,若临界区执行时间比这个开销短,互斥锁的效率反而更低。
自旋锁的优势与局限:
- 优势:无 "挂起 - 唤醒" 开销,临界区极短时效率远高于互斥锁;
- 局限:若临界区执行时间长,自旋线程会持续占用 CPU,导致其他线程无法执行,甚至 CPU 利用率 100%,反而降低整体性能。
三、thread.cc12 中自旋锁的核心接口解析
自旋锁的函数接口设计与互斥锁高度相似(便于开发者迁移使用),核心区别仅在于 "等待机制",以下是代码中关键接口的解析:
1. 自旋锁初始化:pthread_spin_init
pthread_spin_init(&slock, 0);- 函数原型 :
int pthread_spin_init(pthread_spinlock_t *lock, int pshared); - 参数说明 :
lock:待初始化的自旋锁变量地址(全局变量slock);pshared:共享属性,0表示仅当前进程内的线程共享(最常用),PTHREAD_PROCESS_SHARED表示跨进程共享;
- 核心作用:初始化自旋锁的内核资源,必须在使用自旋锁前调用,否则会导致未定义行为。
2. 自旋锁加锁:pthread_spin_lock
pthread_spin_lock(&slock);- 核心功能 :阻塞式自旋加锁 ------ 尝试获取自旋锁,若锁已被占用,当前线程进入无限自旋循环,持续检测锁状态,直到成功获取锁;
- 与互斥锁的核心区别:不会将线程放入阻塞队列,也不会放弃 CPU,而是一直 "忙等",直到锁可用。
3. 非阻塞式自旋加锁:pthread_spin_trylock
// 代码中注释的非阻塞接口,需手动循环模拟阻塞自旋
while (pthread_spin_trylock(&slock) != 0) { /* 空循环,自旋等待 */ }- 核心功能 :尝试获取自旋锁,成功返回
0,失败(锁被占用)直接返回非 0 错误码(如EBUSY),不会自旋等待; - 模拟
pthread_spin_lock的逻辑 :需手动加循环,让线程在循环中持续调用pthread_spin_trylock,直到返回 0(获取锁成功),等价于阻塞式自旋。
4. 自旋锁解锁:pthread_spin_unlock
pthread_spin_unlock(&slock);- 核心功能:释放自旋锁,让其他自旋等待的线程有机会获取锁;
- 注意事项 :
- 解锁必须与加锁一一对应,且只能由持有锁的线程解锁;
- 代码中抢票逻辑的
if/else分支都必须解锁,否则会导致死锁(自旋等待的线程永远无法获取锁)。
5. 自旋锁销毁:pthread_spin_destroy
pthread_spin_destroy(&slock);- 核心功能:释放自旋锁占用的内核资源,避免资源泄漏;
- 注意事项:必须在所有线程都已释放锁后调用,否则会导致未定义行为(如崩溃)。
四、thread.cc12 代码整体逻辑解析
- 全局资源定义 :
pthread_spinlock_t slock:全局自旋锁,保护共享资源ticket的原子操作;int ticket = 100:共享资源(100 张票),多线程竞争修改。
- 线程入口函数
threadFunc:- 接收线程名称参数,无限循环抢票;
- 调用
pthread_spin_lock加锁,进入临界区判断ticket > 0:- 有票则打印抢票信息,
ticket--,然后解锁; - 无票则解锁并退出循环;
- 有票则打印抢票信息,
usleep(10):模拟抢票后的耗时操作,释放 CPU,让其他线程有机会抢票。
- 主函数逻辑 :
- 初始化自旋锁
slock; - 创建 3 个抢票线程,每个线程传递唯一名称;
- 调用
pthread_join等待所有线程结束; - 销毁自旋锁,释放内核资源。
- 初始化自旋锁
总结
- 自旋锁核心是 "忙等":申请锁失败时不挂起线程,持续循环检测锁状态,适合临界区执行时间极短的场景;
- 自旋锁与互斥锁的核心区别:等待机制(忙等 vs 挂起 - 唤醒)、开销(CPU 占用 vs 内核态切换)、适用场景(短临界区 vs 长临界区);
- 自旋锁核心接口:
pthread_spin_init:初始化锁;pthread_spin_lock:阻塞式自旋加锁(忙等);pthread_spin_trylock:非阻塞加锁,需手动循环模拟阻塞自旋;pthread_spin_unlock:解锁;pthread_spin_destroy:销毁锁。
读者写者模型
一、读者写者模型的 "321 原则"
1. 1 个交易场所
指共享的内存空间 / 资源(如共享变量、缓冲区、文件等),是所有读者、写者线程操作的核心对象,所有线程通过访问该空间完成读写操作。
2. 2 个角色
- 读者线程 :仅读取共享数据,不修改数据;
- 写者线程:修改 / 写入共享数据,会改变数据状态。在操作系统中,这两个角色均由线程承担。
3. 3 种核心关系
| 关系 | 类型 | 核心原因 |
|---|---|---|
| 写者 vs 写者 | 互斥竞争 | 写者会修改共享数据,多个写者同时写入会导致数据错乱、覆盖,必须保证同一时间仅一个写者操作 |
| 写者 vs 读者 | 互斥 + 同步 | 互斥:写者修改数据时,读者不能读取(否则读到中间状态的脏数据);读者读取时,写者不能写入(否则破坏数据一致性);同步:写者写完后读者才能读,读者读完后写者才能写,保证数据安全 |
| 读者 vs 读者 | 共享并发 | 读者仅读取数据,不修改数据,多个读者同时读取同一数据不会导致数据不一致,因此可以并发读取,无需互斥 |
与生产者消费者模型的区别
生产者消费者模型中,消费者 vs 消费者是互斥关系 ------ 消费者会 "拿走 / 消耗" 数据(如从队列弹出数据,属于修改共享资源),必须互斥避免重复消费;读者写者模型中,读者 vs 读者是共享关系------ 读者仅读取数据,不修改,因此可以并发读取,这是两者的本质区别。
二、读者优先的场景与设计逻辑
实际业务场景中,读者数量远多于写者 (如新闻网站:浏览新闻的读者远多于编辑新闻的写者),因此设计为读者优先:让读者可以并发读取,尽量减少读者的等待时间,写者仅在无读者时才能写入。
三、读者优先伪代码设计
全局变量定义:
int reader_count = 0; // 记录当前活跃的读者数量
mutex_t rlock, wlock; // rlock:保护reader_count的互斥锁;wlock:写锁,控制写操作与读者互斥读者加锁 & 解锁伪代码
// 读者加锁
lock(&rlock); // 加rlock,保护reader_count的原子修改
reader_count++; // 读者计数+1
if(reader_count == 1) // 若为第一个读者,加wlock(阻止写者写入)
lock(&wlock);
unlock(&rlock); // 释放rlock,允许其他读者修改reader_count
// 并发读取操作(多个读者可同时执行)
// 读者解锁
lock(&rlock); // 加rlock,保护reader_count的原子修改
reader_count--; // 读者计数-1
if(reader_count == 0) // 若为最后一个读者,释放wlock(允许写者写入)
unlock(&wlock);
unlock(&rlock); // 释放rlock写者加锁 & 解锁伪代码
// 写者加锁
lock(&wlock); // 加wlock,阻止所有读者和其他写者
// 写入操作(仅一个写者可执行)
// 写者解锁
unlock(&wlock); // 释放wlock读者优先的核心逻辑:
- 第一个读者会获取
wlock,之后的读者仅需修改reader_count(通过rlock保护),即可并发读取,无需等待写者; - 写者必须等待所有读者都读完(
reader_count=0)才能获取wlock写入,因此读者的优先级更高。
四、写者优先的伪代码实现
写者优先的核心是:当有写者等待时,阻止新读者进入,让写者可以尽快获取锁写入。
新增全局变量
int reader_count = 0;
int writer_waiting = 0; // 记录等待的写者数量
mutex_t rlock, wlock, rqlock; // rqlock:阻止新读者的读请求锁读者加锁 & 解锁伪代码(写者优先)
// 读者加锁
lock(&rqlock); // 先获取读请求锁,检查是否有写者等待
lock(&rlock);
reader_count++;
if(reader_count == 1)
lock(&wlock);
unlock(&rlock);
unlock(&rqlock); // 释放读请求锁
// 并发读取操作
// 读者解锁
lock(&rlock);
reader_count--;
if(reader_count == 0)
unlock(&wlock);
unlock(&rlock);写者加锁 & 解锁伪代码(写者优先)
// 写者加锁
lock(&rqlock); // 先获取读请求锁,阻止新读者进入
writer_waiting++;
if(writer_waiting == 1) // 第一个写者加wlock
lock(&wlock);
unlock(&rqlock); // 释放读请求锁
lock(&wlock); // 加写锁,执行写入
// 写入操作
unlock(&wlock); // 释放写锁
// 写者解锁
lock(&rqlock);
writer_waiting--;
if(writer_waiting == 0) // 最后一个写者释放wlock
unlock(&wlock);
unlock(&rqlock);写者优先的核心逻辑:
- 写者先获取
rqlock,阻止新读者进入,保证写者可以优先获取wlock; - 已有读者在读取时,写者会等待,但新读者会被
rqlock阻塞,直到写者完成写入; - 写者完成后,才允许新读者继续读取,实现 "写者优先" 的调度逻辑。
总结
- 读者写者模型遵循 "321 原则",核心是读者共享、写者互斥、读写互斥 + 同步;
- 读者优先通过
reader_count和wlock实现,让读者并发读取,写者等待所有读者完成; - 写者优先通过新增
rqlock和writer_waiting,阻止新读者,让写者优先获取锁写入。