在 Linux 开发中,我们每天都在和库打交道:编译时的 -l 参数、运行时的 ldd 命令、遇到的error while loading shared libraries 错误... 但你真的搞懂了动静态库的底层原理吗?本文将从库的制作开始,一步步深入到 ELF 文件格式、静态链接、动态链接、GOT/PLT 延迟绑定的底层细节,带你彻底搞懂这一 Linux 开发的核心基础。
一、什么是库?
库,本质上就是可复用的二进制代码。现实中每个程序都要依赖大量的基础代码,不可能每个人都从零开始写,所以库的存在就是为了实现代码的复用。
在 Linux 下,库分为两种:
-
静态库 :后缀为.a,Windows 下为.lib
-
动态库 :后缀为.so,Windows 下为.dll
我们可以看一下系统标准库的例子,比如 Ubuntu 和 CentOS 下的 C/C++ 标准库:
bash
# Ubuntu下的libc标准库
$ ls -l /lib/x86_64-linux-gnu/libc-2.31.so
-rwxr-xr-x 1 root root 2029592 May 1 02:20 /lib/x86_64-linux-gnu/libc-2.31.so
$ ls -l /lib/x86_64-linux-gnu/libc.a
-rw-r--r-- 1 root root 5747594 May 1 02:20 /lib/x86_64-linux-gnu/libc.a
# Ubuntu下的libstdc++标准库
$ ls /usr/lib/gcc/x86_64-linux-gnu/9/libstdc++.so -l
lrwxrwxrwx 1 root root 40 Oct 24 2022 /usr/lib/gcc/x86_64-linux-gnu/9/libstdc++.so -> ../../../x86_64-linux-gnu/libstdc++.so.6
$ ls /usr/lib/gcc/x86_64-linux-gnu/9/libstdc++.a
/usr/lib/gcc/x86_64-linux-gnu/9/libstdc++.a
# CentOS下的libc标准库
$ ls /lib64/libc-2.17.so -l
-rwxr-xr-x 1 root root 2156592 Jun 4 23:05 /lib64/libc-2.17.so
$ ls /lib64/libc.a -l
-rw-r--r-- 1 root root 5105516 Jun 4 23:05 /lib64/libc.a可以看到,系统中同时存在动静态两种版本的标准库,我们可以根据需要选择链接方式。为了后续的演示,我们先准备两个简单的自定义函数,用来制作我们自己的库:
cpp
// my_stdio.h
#pragma once
#define SIZE 1024
#define FLUSH_NONE 0
#define FLUSH_LINE 1
#define FLUSH_FULL 2
struct IO_FILE
{
int flag; // 刷新方式
int fileno; // 文件描述符
char outbuffer[SIZE];
int cap;
int size;
};
typedef struct IO_FILE mFILE;
mFILE *mfopen(const char *filename, const char *mode);
int mfwrite(const void *ptr, int num, mFILE *stream);
void mfflush(mFILE *stream);
void mfclose(mFILE *stream);
cpp
// my_stdio.c
#include "my_stdio.h"
#include <string.h>
#include <stdlib.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <unistd.h>
mFILE *mfopen(const char *filename, const char *mode)
{
int fd = -1;
if(strcmp(mode, "r") == 0)
{
fd = open(filename, O_RDONLY);
}
else if(strcmp(mode, "w")== 0)
{
fd = open(filename, O_CREAT|O_WRONLY|O_TRUNC, 0666);
}
else if(strcmp(mode, "a") == 0)
{
fd = open(filename, O_CREAT|O_WRONLY|O_APPEND, 0666);
}
if(fd < 0) return NULL;
mFILE *mf = (mFILE*)malloc(sizeof(mFILE));
if(!mf)
{
close(fd);
return NULL;
}
mf->fileno = fd;
mf->flag = FLUSH_LINE;
mf->size = 0;
mf->cap = SIZE;
return mf;
}
void mfflush(mFILE *stream)
{
if(stream->size > 0)
{
// 写到内核文件的文件缓冲区中!
write(stream->fileno, stream->outbuffer, stream->size);
// 刷新到外设
fsync(stream->fileno);
stream->size = 0;
}
}
int mfwrite(const void *ptr, int num, mFILE *stream)
{
// 1. 拷贝
memcpy(stream->outbuffer+stream->size, ptr, num);
stream->size += num;
// 2. 检测是否要刷新
if(stream->flag == FLUSH_LINE && stream->size > 0 && stream->outbuffer[stream->size-1]== '\n')
{
mfflush(stream);
}
return num;
}
void mfclose(mFILE *stream)
{
if(stream->size > 0)
{
mfflush(stream);
}
close(stream->fileno);
}
cpp
// my_string.h
#pragma once
int my_strlen(const char *s);
cpp
// my_string.c
#include "my_string.h"
int my_strlen(const char *s)
{
const char *end = s;
while(*end != '\0')end++;
return end - s;
}这两个简单的函数,一个是我们自己实现的简化版 stdio,一个是简化版的 strlen,接下来我们就用它们来制作动静态库。
二、静态库
2.1 静态库的本质
静态库的本质非常简单:程序在编译链接的时候,把库的代码直接拷贝到可执行文件中。程序运行的时候,就不再需要这个静态库了,因为所有需要的代码都已经在可执行文件里了。
2.2 静态库的制作
静态库的制作非常简单,我们只需要用 ar 归档工具,把我们的目标文件打包成一个 .a 文件即可。我们可以写一个简单的 Makefile:
Matlab
# Makefile for static library
libmystdio.a:my_stdio.o my_string.o
@ar -rc $@ $^
@echo "build $^ to $@ ... done"
%.o:%.c
@gcc -c $<
@echo "compling $< to $@ ... done"
.PHONY:clean
clean:
@rm -rf *.a *.o stdc*
@echo "clean ... done"
.PHONY:output
output:
@mkdir -p stdc/include
@mkdir -p stdc/lib
@cp -f *.h stdc/include
@cp -f *.a stdc/lib
@tar -czf stdc.tgz stdc
@echo "output stdc ... done"这里的 ar 是 GNU 的归档工具, rc 参数的意思是 replace and create ,也就是如果库文件存在就替换,不存在就创建。编译完成之后,我们可以用 ar -tv 来查看静态库中的内容:
bash
$ ar -tv libmystdio.a
rw-rw-r-- 1000/1000 2848 Oct 29 14:35 2024 my_stdio.o
rw-rw-r-- 1000/1000 1272 Oct 29 14:35 2024 my_string.o可以看到,静态库本质上就是一个打包文件,里面就是我们的两个目标文件 .o ,链接的时候,链接器会把这两个 .o 的代码合并到可执行文件中。
2.3 静态库的使用
制作好静态库之后,我们就可以在自己的程序中使用它了,比如我们写一个 main.c:
cpp
// main.c
#include "my_stdio.h"
#include "my_string.h"
#include <stdio.h>
int main()
{
const char *s = "abcdefg";
printf("%s: %d\n", s, my_strlen(s));
mFILE *fp = mfopen("./log.txt", "a");
if(fp == NULL) return 1;
mfwrite(s, my_strlen(s), fp);
mfwrite(s, my_strlen(s), fp);
mfwrite(s, my_strlen(s), fp);
mfclose(fp);
return 0;
}编译的时候,我们需要告诉编译器,头文件在哪里,库文件在哪里,库的名字是什么:
bash
# 场景1: 头文件和库文件安装到系统路径下
$ gcc main.c -lmystdio
# 场景2: 头文件和库文件和我们自己的源文件在同一个路径下
$ gcc main.c -L. -lmystdio
# 场景3: 头文件和库文件有自己的独立路径
$ gcc main.c -I头文件路径 -L库文件路径 -lmystdio参数说明:
-
-L: 指定库的搜索路径 -
-I: 指定头文件的搜索路径 -
-l: 指定要链接的库名,注意库名是去掉前缀 lib 和后缀 .a/.so 的部分,比如 libmystdio.a 对应的就是 -lmystdio
编译完成之后,我们就可以运行程序了,哪怕我们把静态库删掉,程序照样可以运行,因为所有的代码都已经拷贝到可执行文件里了。
三、动态库
3.1 动态库的本质
和静态库不同,动态库的链接过程是推迟到程序运行的时候的。可执行文件里并不会拷贝库的代码,只会记录对库的引用。程序运行的时候,操作系统才会把动态库加载到内存,多个程序可以共享同一份动态库的代码,大大节省了系统资源。
3.2 动态库的制作
动态库的制作比静态库多了两个关键参数: -fPIC 和 -shared 。我们同样写一个 Makefile:
bash
# Makefile for dynamic library
libmystdio.so:my_stdio.o my_string.o
gcc -o $@ $^ -shared
%.o:%.c
gcc -fPIC -c $<
.PHONY:clean
clean:
@rm -rf *.so *.o stdc*
@echo "clean ... done"
.PHONY:output
output:
@mkdir -p stdc/include
@mkdir -p stdc/lib
@cp -f *.h stdc/include
@cp -f *.so stdc/lib
@tar -czf stdc.tgz stdc
@echo "output stdc ... done"参数说明:
-
**-shared:**告诉编译器,我们要生成的是共享库,而不是可执行文件
-
**-fPIC:**生成 生成位置无关码,这是动态库能够被共享的核心,我们后面会详细解释它的原理
3.3 动态库的使用
动态库的使用和静态库非常像,编译的时候的参数是完全一样的:
bash
# 场景1: 头文件和库文件安装到系统路径下
$ gcc main.c -lmystdio
# 场景2: 头文件和库文件和我们自己的源文件在同一个路径下
$ gcc main.c -L. -lmystdio
# 场景3: 头文件和库文件有自己的独立路径
$ gcc main.c -I头文件路径 -L库文件路径 -lmystdio但是,和静态库不同的是,编译完成之后,我们如果直接运行程序,会报错!
bash
$ ./a.out
error while loading shared libraries: libmystdio.so: cannot open shared object file: No such file or directory这是为什么呢?因为动态库是运行时加载的,编译的时候编译器找到了库,但是运行的时候,系统找不到这个库在哪里!我们可以用 ldd 命令来查看程序依赖的动态库:
bash
$ ldd a.out
linux-vdso.so.1 => (0x00007fff4d396000)
libmystdio.so => not found
libc.so.6 => /lib64/libc.so.6 (0x00007fa2aef30000)
/lib64/ld-linux-x86-64.so.2 (0x00007fa2af2fe000)可以看到, libmystdio.so 显示为 not found ,这就是运行时找不到库的原因。
四、动态库的搜索路径
那系统是怎么搜索动态库的呢?有四种常见的解决方案:
方案 1:把动态库拷贝到系统路径下
系统默认的动态库搜索路径是 /usr/lib、/usr/local/lib、/lib64 这些,我们可以把动态库拷贝到这些路径下,系统就能找到了:
bash
$ sudo cp libmystdio.so /lib64/
$ ./a.out
# 运行成功方案 2:建立软链接
和拷贝类似,我们也可以在系统路径下建立软链接,指向我们的动态库:
bash
$ export LD_LIBRARY_PATH=/home/whb/code:$LD_LIBRARY_PATH
$ ./a.out
# 运行成功方案 3:修改 LD_LIBRARY_PATH 环境变量
这是开发中最常用的临时方案,我们可以修改 LD_LIBRARY_PATH 环境变量,告诉动态链接器,额外的搜索路径在哪里:
bash
$ export LD_LIBRARY_PATH=/home/whb/code:$LD_LIBRARY_PATH
$ ./a.out
# 运行成功这个方案的好处是临时生效,不需要 root 权限,非常适合开发测试的时候使用。
方案 4:配置 ldconfig
如果是要长期生效的话,我们可以修改系统的动态库配置文件,然后用 ldconfig 更新缓存:
bash
# 1. 在/etc/ld.so.conf.d/下新建一个配置文件
[root@localhost linux]# cat /etc/ld.so.conf.d/bit.conf
/root/tools/linux
# 2. 执行ldconfig,重新加载库搜索路径
[root@localhost linux]# ldconfig
$ ./a.out
# 运行成功这个方案是永久生效的,适合部署的时候使用。
五、外部库实战
了解了库的使用之后,我们来实战一下,使用一个外部的图形库 ncurses ,来做一个终端的进度条。
首先,安装 ncurses 的开发包:
bash
# Centos
$ sudo yum install -y ncurses-devel
# ubuntu
$ sudo apt install -y libncurses-dev然后,我们写一个进度条的代码:
cpp
#include <stdio.h>
#include <string.h>
#include <ncurses.h>
#include <unistd.h>
#define PROGRESS_BAR_WIDTH 30
#define BORDER_PADDING 2
#define WINDOW_WIDTH (PROGRESS_BAR_WIDTH + 2 * BORDER_PADDING + 2) // 加边框的宽度
#define WINDOW_HEIGHT 5
#define PROGRESS_INCREMENT 3
#define DELAY 300000 // 微秒(300毫秒)
int main() {
initscr();
start_color();
init_pair(1, COLOR_GREEN, COLOR_BLACK); // 已完成部分:绿色前景,黑色背景
init_pair(2, COLOR_RED, COLOR_BLACK); // 剩余部分:红色背景
cbreak();
noecho();
curs_set(FALSE);
int max_y, max_x;
getmaxyx(stdscr, max_y, max_x);
int start_y = (max_y - WINDOW_HEIGHT) / 2;
int start_x = (max_x - WINDOW_WIDTH) / 2;
WINDOW *win = newwin(WINDOW_HEIGHT, WINDOW_WIDTH, start_y, start_x);
box(win, 0, 0); // 加边框
wrefresh(win);
int progress = 0;
int max_progress = PROGRESS_BAR_WIDTH;
while (progress <= max_progress) {
werase(win); // 清除窗口内容
// 计算已完成的进度和剩余的进度
int completed = progress;
int remaining = max_progress - progress;
// 显示进度条
int bar_x = BORDER_PADDING + 1; // 进度条在窗口中的x坐标
int bar_y = 1; // 进度条在窗口中的y坐标(居中)
// 已完成部分
attron(COLOR_PAIR(1));
for (int i = 0; i < completed; i++) {
mvwprintw(win, bar_y, bar_x + i, "#");
}
attroff(COLOR_PAIR(1));
// 剩余部分(用背景色填充)
attron(A_BOLD | COLOR_PAIR(2)); // 加粗并设置背景色为红色
for (int i = completed; i < max_progress; i++) {
mvwprintw(win, bar_y, bar_x + i, " ");
}
attroff(A_BOLD | COLOR_PAIR(2));
// 显示百分比
char percent_str[10];
snprintf(percent_str, sizeof(percent_str), "%d%%", (progress * 100) / max_progress);
int percent_x = (WINDOW_WIDTH - strlen(percent_str)) / 2; // 居中显示
mvwprintw(win, WINDOW_HEIGHT - 1, percent_x, percent_str);
wrefresh(win); // 刷新窗口以显示更新
// 增加进度
progress += PROGRESS_INCREMENT;
// 延迟一段时间
usleep(DELAY);
}
// 清理并退出ncurses模式
delwin(win);
endwin();
return 0;
}编译的时候,我们只需要链接 ncurses 库即可:
bash
$ gcc progress.c -lncurses
$ ./a.out六、目标文件
讲完了库的制作和使用,我们来深入底层,看看编译链接的整个过程,这能帮我们更好的理解动静态库的原理。
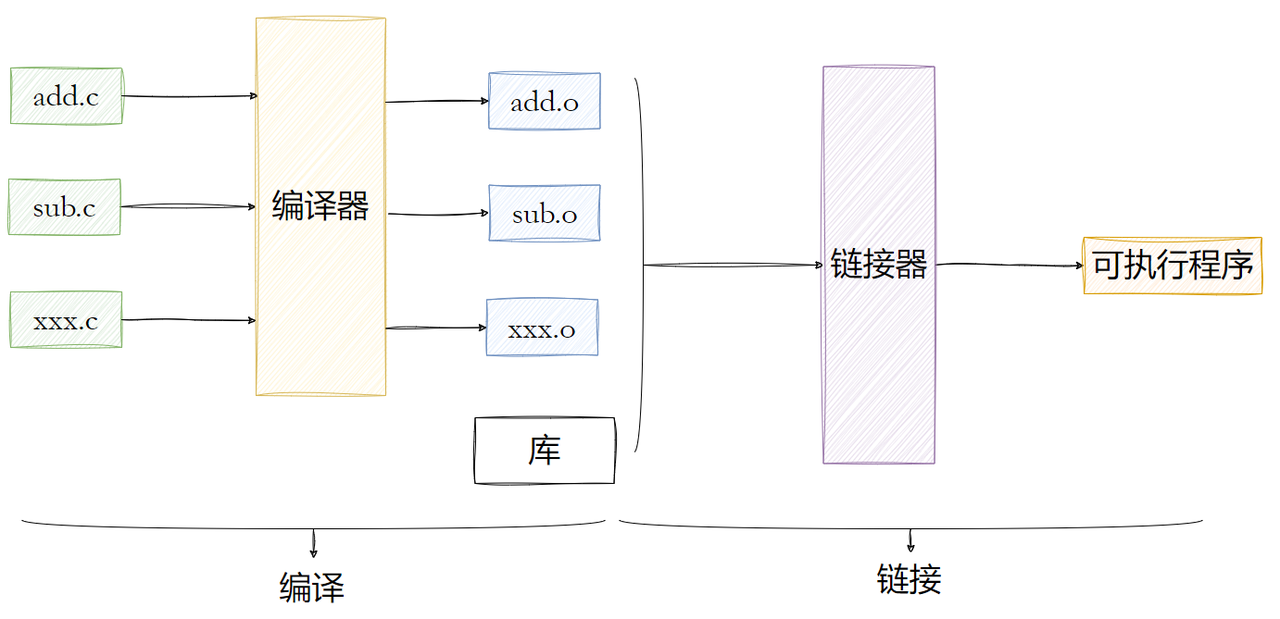
我们都知道,编译和链接是两个步骤,在 Windows 下被 IDE 封装的很完美,我们一键构建就可以了,但在 Linux 下,我们可以把这两个步骤拆开来看。
比如我们有两个简单的源文件:
cpp
// code.c
#include<stdio.h>
void run() {
printf("running...\n");
}
cpp
// hello.c
#include<stdio.h>
void run();
int main() {
printf("hello world!\n");
run();
return 0;
}我们可以分别编译这两个源文件,生成目标文件:
bash
$ gcc -c hello.c
$ gcc -c code.c
$ ls
code.c code.o hello.c hello.o可以看到,编译之后生成了两个 .o 文件,这就是目标文件。目标文件是编译的中间产物,它是一个 ELF 格式的二进制文件,里面是编译好的机器码,但是还没有链接,所以还不能运行。
目标文件的好处是,如果你只修改了一个源文件,你只需要重新编译这一个源文件,生成新的 .o ,然后重新链接就可以了,不需要重新编译整个工程,这就是增量编译,大大提升了大项目的编译速度。
我们可以用 file 命令查看目标文件的类型:
bash
$ file hello.o
hello.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped可以看到,它是一个 ELF 格式的可重定位文件,这就是我们接下来要讲的 ELF 文件。
七、ELF 文件
要理解编译链接的细节,我们必须先搞懂 ELF 文件,这是 Linux 下所有二进制文件的标准格式。
7.1 四种 ELF 文件
其实,Linux 下有四种文件都是 ELF 格式:
-
可重定位文件 :就是我们的 .o 目标文件,用来链接生成可执行文件或者动态库
-
可执行文件 :就是我们编译好的可执行程序
-
共享目标文件 :就是我们的 .so 动态库
-
内核转储 :程序崩溃的时候生成的 core 文件,用来调试
7.2 ELF 的两个视图
ELF 文件有两个完全不同的视图,一个是给链接器用的链接视图,一个是给加载器用的执行视图:
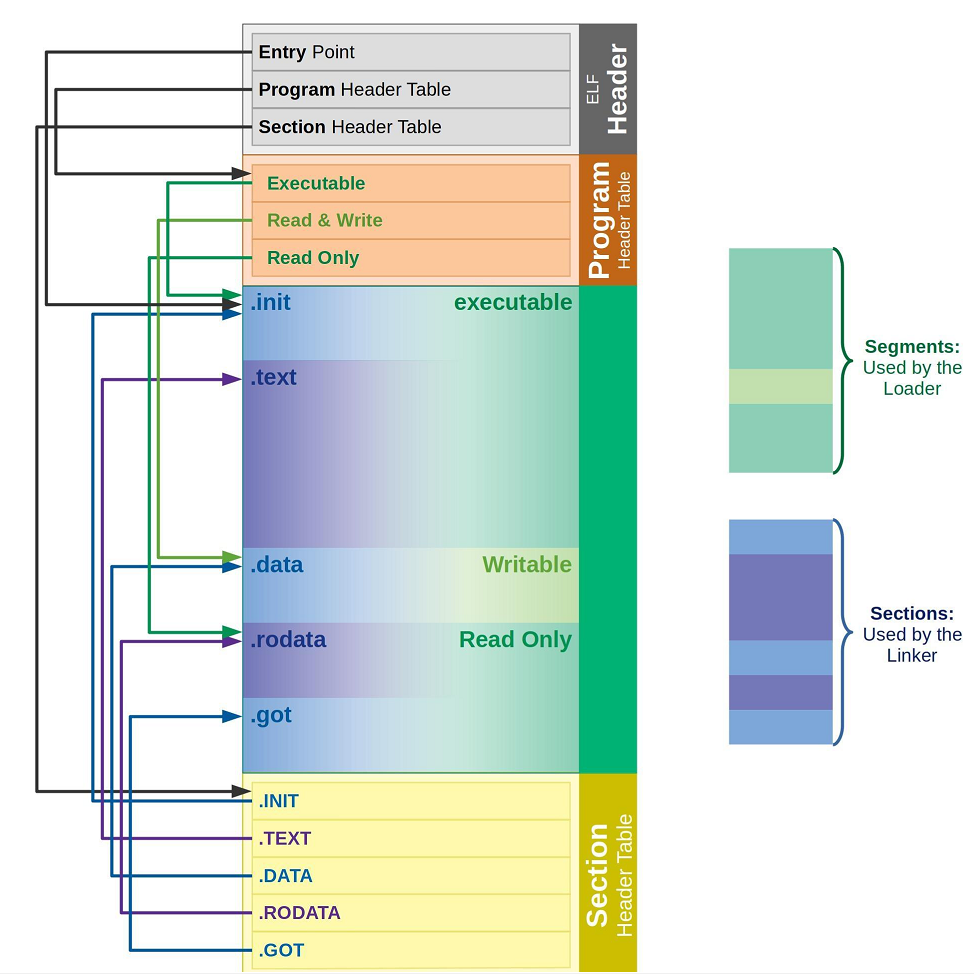
(1)链接视图:节
链接视图的粒度更细,它把文件分成了很多的节 ,每个节存储不同的内容,比如:
-
.text: 代码节,存储程序的机器指令
-
.data: 数据节,存储已经初始化的全局变量和局部静态变量
-
.rodata: 只读数据节,存储字符串常量等只读数据
-
.bss: 存储未初始化的全局变量和局部静态变量,这个节在文件中不占空间,运行的时候会被清零
-
.symtab: 符号表,存储函数和变量的符号信息
-
.got/.plt: 动态链接相关的表,我们后面会讲
这些节是链接的时候用的,链接器会把所有目标文件的节合并起来,然后修正地址。
(2)执行视图:段
执行视图的粒度更粗,它把文件分成了段 ,加载的时候,操作系统会把这些段加载到内存中。合并的原则是:相同权限的节会合并成一个段。
比如,所有的可执行的节,比如 .text、.init 这些,会合并成一个可读可执行的段;所有的可读写的节,比如 .data、.bss、.got 这些,会合并成一个可读可写的段。
为什么要合并?因为内存的页是 4KB 的,如果不合并,每个小节都要占用一个页,会浪费大量的内存。比如 .text 是 4097 字节, .init 是 512 字节,如果不合并,它们要占用 3 个页,合并之后只需要 2 个页,大大节省了内存。
我们可以用 readelf 命令来查看这两个视图:
bash
# 查看节头表(链接视图)
$ readelf -S a.out
# 查看程序头表(执行视图)
$ readelf -l a.out# 查看节头表(链接视图)
$ readelf -S a.out
# 查看程序头表(执行视图)
$ readelf -l a.out比如,我们看一下程序头表的输出:
bash
$ readelf -l a.out
Elf file type is EXEC (Executable file) Entry point 0x4003e0
There are 9 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
PHDR 0x000040 0x0000000000400040 0x0000000000400040 0x00000000000001f8 0x00000000000001f8 R 8
INTERP 0x000238 0x0000000000400238 0x0000000000400238 0x000000000000001c 0x000000000000001c R 1
LOAD 0x000000 0x0000000000400000 0x0000000000400000 0x0000000000000744 0x0000000000000744 R E 200000
LOAD 0x000e10 0x0000000000600e10 0x0000000000600e10 0x0000000000000218 0x0000000000000220 RW 200000
DYNAMIC 0x000e28 0x0000000000600e28 0x0000000000600e28 0x00000000000001d0 0x00000000000001d0 RW 8
NOTE 0x000254 0x0000000000400254 0x0000000000400254 0x0000000000000044 0x0000000000000044 R 4
GNU_EH_FRAME 0x0005a0 0x00000000004005a0 0x00000000004005a0 0x000000000000004c 0x000000000000004c R 4
GNU_STACK 0x000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 RW 10
GNU_RELRO 0x000e10 0x0000000000600e10 0x0000000000600e10 0x00000000000001f0 0x00000000000001f0 R 1
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .note.ABI-tag .note.gnu.build-id .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt .init .plt .plt.got .text .fini .rodata .eh_frame_hdr .eh_frame
03 .init_array .fini_array .jcr .dynamic .got .got.plt .data .bss
04 .dynamic
05 .note.ABI-tag .note.gnu.build-id
06 .eh_frame_hdr
07
08 .init_array .fini_array .jcr .dynamic .got可以看到,第二个 LOAD 段,把所有的可执行的节都合并了,第三个 LOAD 段,把所有的可读写的节都合并了,这就是我们说的两个视图的合并。
八、静态链接
现在我们来看静态链接的过程,静态链接到底做了什么?
其实,静态链接的过程,就是把所有的目标文件,还有静态库中的目标文件,合并到一起,然后修正地址的过程。
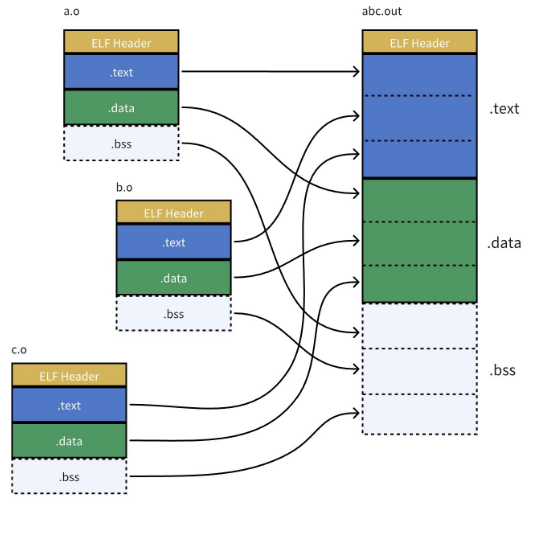
8.1 节的合并
首先,链接器会把所有目标文件的相同的节合并到一起。比如,所有的 .text 节合并成一个大的 .text ,所有的 .data 节合并成一个大的 .data ,就像上面的图一样。
比如我们的 code.o 和 hello.o ,它们的 .text 节会合并成最终可执行文件的 .text 节,它们的 .data 节会合并成最终的 .data 节。
8.2 符号解析与重定位
合并完节之后,链接器要做的就是重定位,也就是修正那些未定义的符号的地址。我们来看一下编译后的目标文件的++反汇编++:
bash
$ objdump -d hello.o
hello.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: f3 0f le fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # f <main+0xf>
f: e8 00 00 00 00 callq 14 <main+0x14>
14: b8 00 00 00 00 mov $0x0,%eax
19: e8 00 00 00 00 callq 1e <main+0x1e>
1e: b8 00 00 00 00 mov $0x0,%eax
23: 5d pop %rbp
24: c3 retq因为编译的时候,编译器根本不知道 printf 和 run 函数在哪里,它们在别的目标文件里,所以编译器只能先把地址填成 0,然后在重定位表中记录下来,告诉链接器:这里有个地址需要你帮我修正!
我们可以用 readelf 查看符号表,就能看到这些未定义的符号:
bash
$ readelf -s hello.o
Symbol table '.symtab' contains 14 entries:
Num: Value Size Type Bind Vis Ndx Name
...
12: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND puts
13: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND run这里的 UND 就是未定义的意思,说明这个符号在当前的目标文件里找不到,需要链接器去别的目标文件里找。
当链接器把所有的目标文件都合并完,所有的符号都有了最终的地址之后,就会根据重定位表,把那些 00 00 00 00 的地址,修正成真正的函数地址。
比如,合并完之后,run函数的地址是 0x0000000000001149 ,那么链接器就会把call指令的地址修正成这个地址,这样调用的时候就能跳对了。
这就是静态链接的整个过程**:合并节,然后重定位地址**。
九、动态链接
静态链接虽然简单,但是它有一个很大的问题:++浪费资源。每个程序都要把库的代码拷贝一份,磁盘上存多份,内存里也加载多份++,这显然太浪费了。
所以,动态链接就出现了,它把链接的过程推迟到了程序运行的时候,这样多个程序就可以共享同一份库的代码了。
9.1 动态库的加载
首先,我们要理解,动态库是怎么被进程共享的?
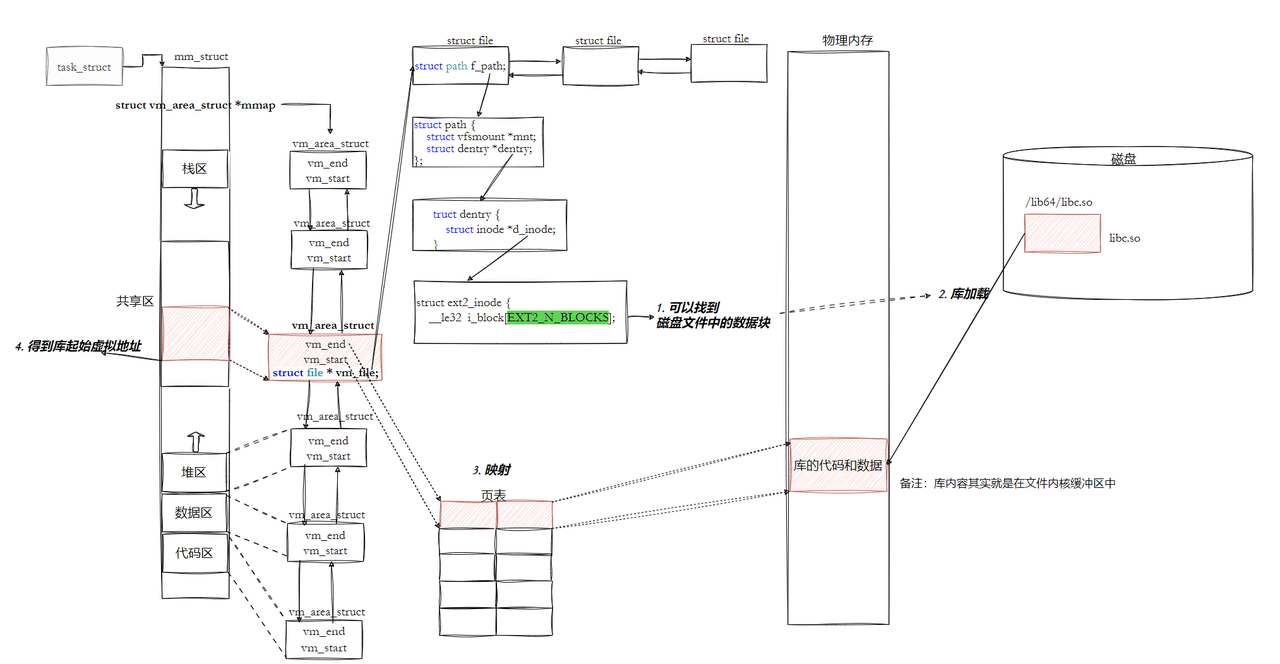
当我们运行一个程序的时候,操作系统会:
-
把可执行文件加载到进程的虚拟地址空间
-
然后,把它依赖的动态库,也依次加载到进程的虚拟地址空间
-
每个动态库,在物理内存中只有一份,所有的进程都把它映射到自己的虚拟地址空间,这样就实现了共享
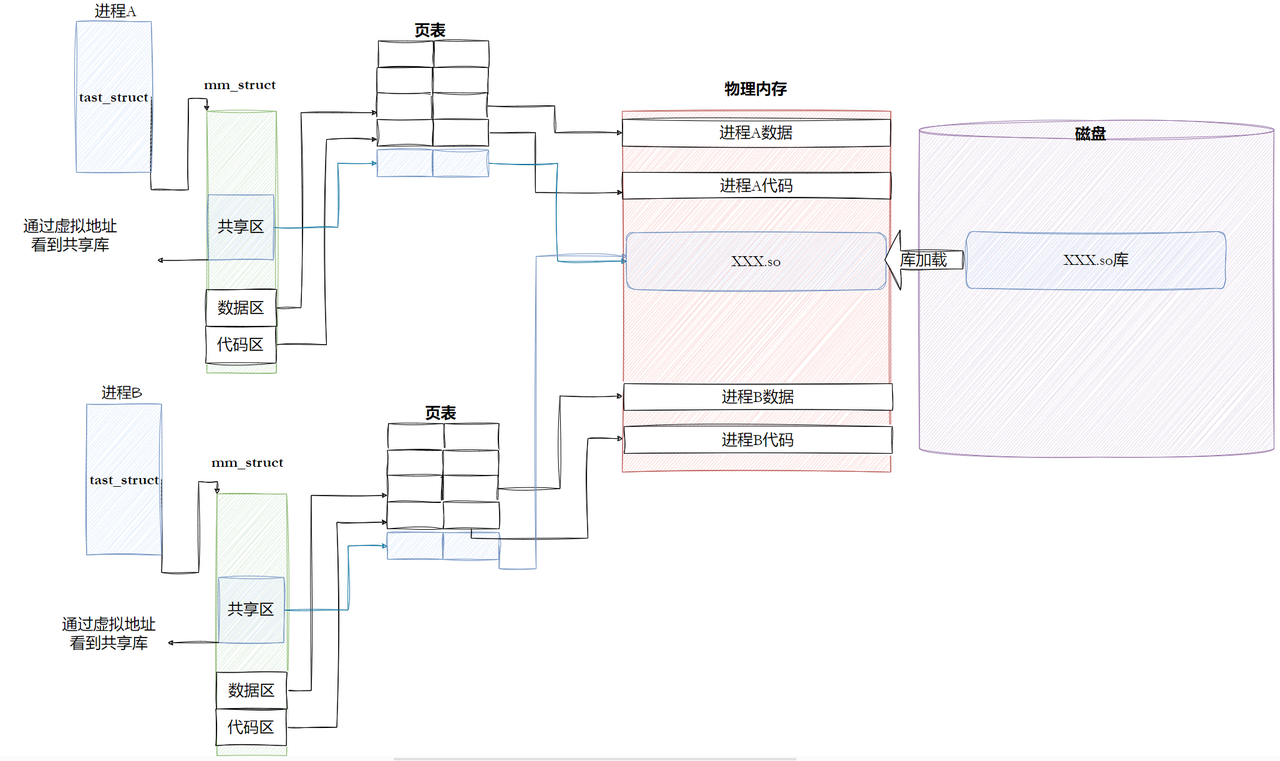
就像上面的图一样,两个进程,它们的虚拟地址空间不同,但是它们都把同一个物理内存的动态库,映射到了自己的地址空间,这样就实现了共享,大大节省了内存。
9.2 位置无关码 PIC
这里有个问题:动态库可以被加载到任意的地址,那它怎么知道自己的函数的地址呢?
这就是我们之前说的 -fPIC ,位置无关码。它的核心就是:动态库中的代码,全部使用相对地址,而不是绝对地址。这样,不管动态库被加载到哪个地址,代码都能正常运行,因为所有的跳转都是相对的,不需要修改代码。
9.3 GOT 表
这里又有个问题:我们要调用库函数的时候,需要知道库函数的真正地址,那我们要修改地址的话,代码区是只读的,不能修改啊?
所以,动态链接就设计了一个GOT 表(偏移表),它是在 .data 里的,是可读写的,专门用来存放函数的真正地址。
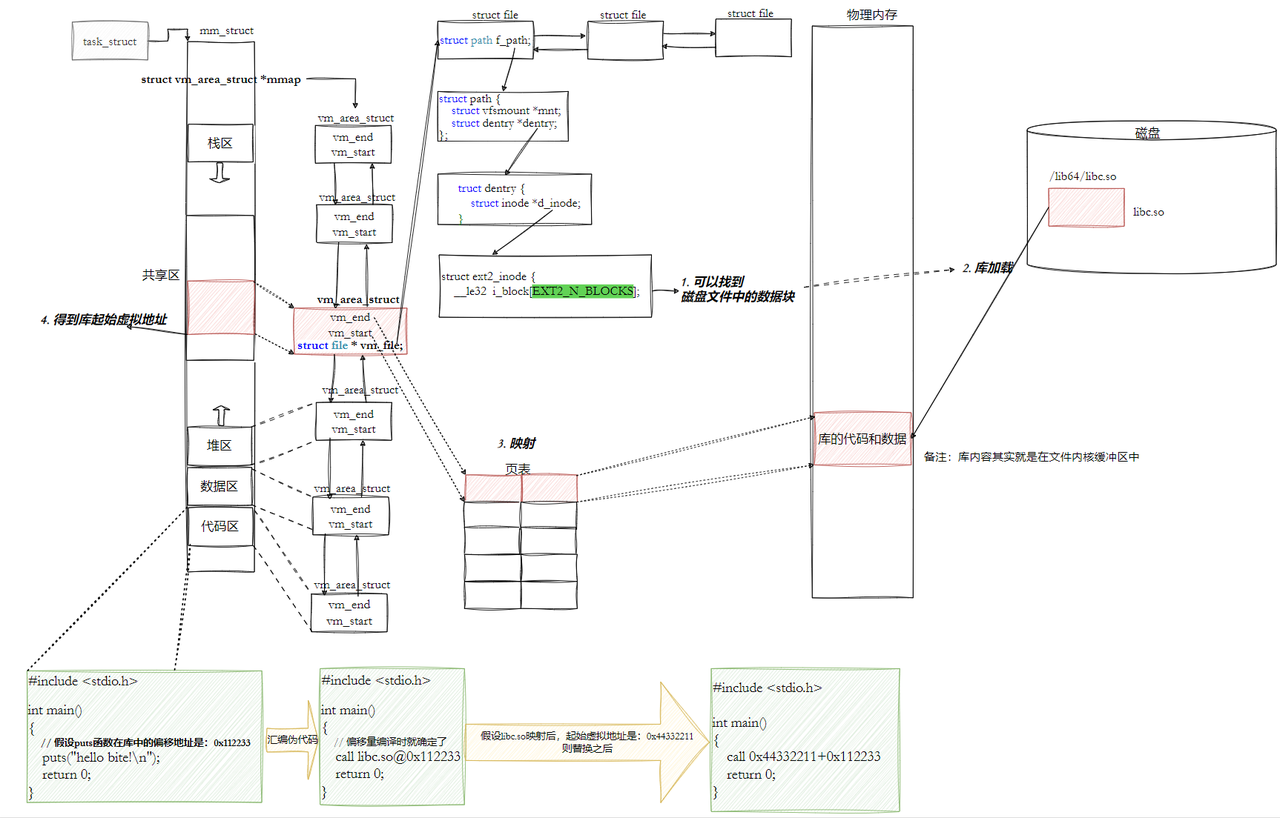
GOT 表的每一项,都是一个函数的地址,因为 .data 是可读写的,所以我们可以在运行的时候修改 GOT 表的内容,而不需要修改代码区,这样代码区就可以被所有的进程共享了。
比如,我们要调用 puts函数 的时候,不是直接跳转到它的地址,而是先去 GOT 表里查,找到 puts 对应的项,里面存的是 puts 的真正地址,然后跳过去。
因为 GOT 表和代码的相对位置是固定的,所以我们用相对地址就能找到 GOT 表,这就是 PIC 的核心。
9.4 PLT 与延迟绑定
还有个问题:如果我们有 100 个库函数,但是程序运行的时候,只用到了 10 个,那我们是不是要在程序启动的时候,把这 100 个函数的地址都解析出来?这显然太浪费时间了。所以,操作系统又做了一个优化:延迟绑定,也就是把符号解析的过程,推迟到函数第一次被调用的时候。
这就用到了PLT 表(过程链接表)。
(1)第一次调用:桩代码解析地址
第一次调用函数的时候,GOT 表里还没有真正的地址,所以 GOT 表默认指向 PLT 里的桩代码:
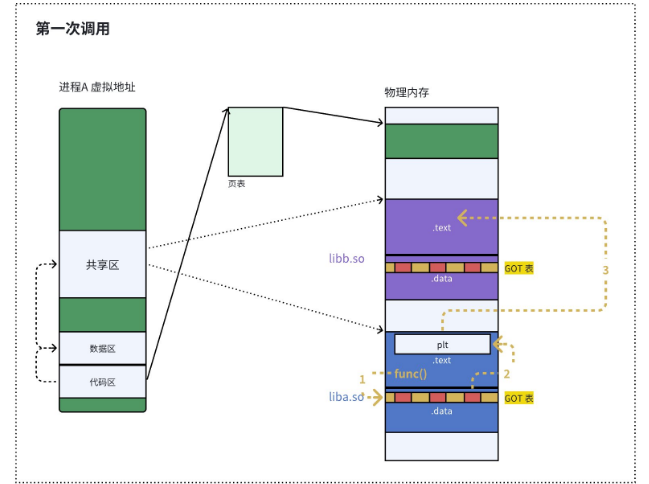
这个桩代码会去调用动态链接器,解析这个符号的真正地址,然后把这个地址更新到 GOT 表里,然后再跳转到真正的函数。
(2)后续调用:直接跳转
第二次调用的时候,GOT 表里已经有了真正的地址了,所以我们直接跳过去就可以了,不需要再解析了:
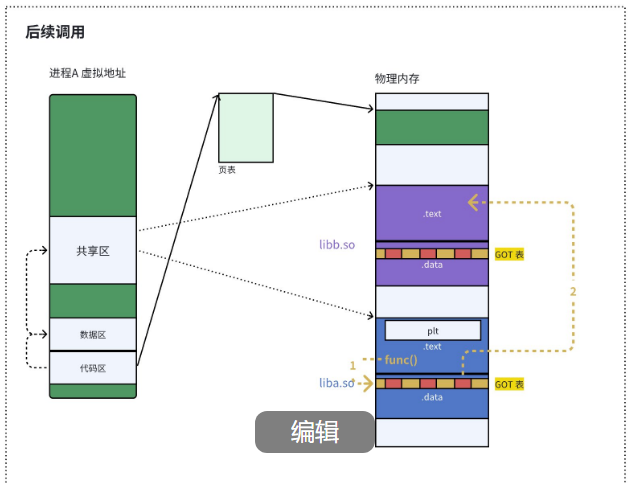
这样,我们就只需要解析我们真正用到的函数,大大加快了程序的启动速度。
这就是动态链接的整个过程,把链接的过程从编译时推迟到了运行时,实现了代码的共享。
十、动静态库对比
讲完了所有的原理,我们来总结一下动静态库的优缺点,还有它们的资源占用对比:
10.1 磁盘占用对比
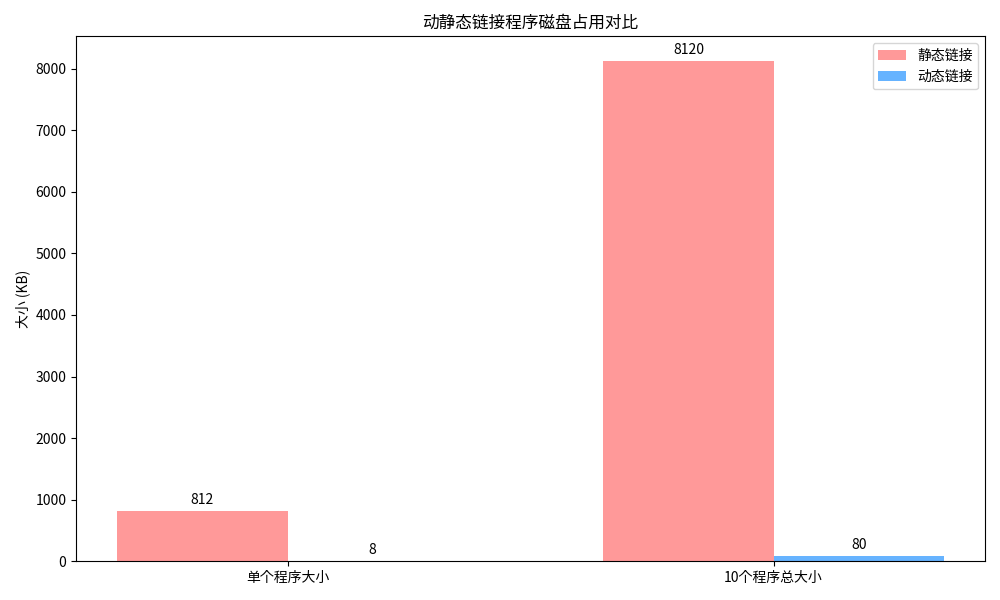
可以看到:
-
单个程序的时候,静态链接的程序有 812KB,而动态链接的只有 8KB,差距非常大
-
当有 10 个程序的时候,静态链接的总大小是 8120KB,而动态链接的只有 80KB,差距更大了,因为动态库是共享的
10.2 内存占用对比
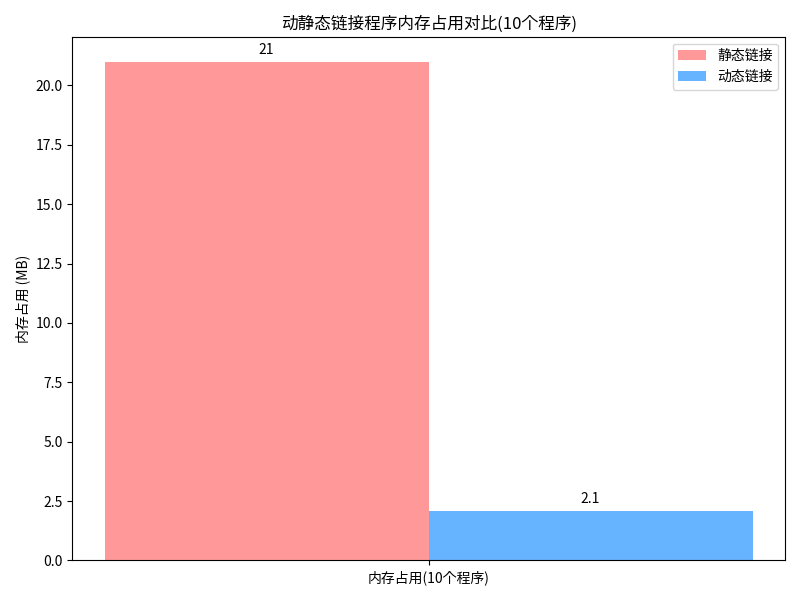
内存占用的差距更大,10 个程序的时候:
-
静态链接的话,每个程序都要加载自己的 libc,总内存占用 21MB
-
动态链接的话,所有程序共享一份 libc,总内存占用只有 2.1MB,差了 10 倍!
10.3 完整的特性对比
|---------|-------------|------------|
| 特性 | 静态库 | 动态库 |
| 链接时机 | 编译时 | 运行时 |
| 可执行文件大小 | 大,包含完整库代码 | 小,只包含引用 |
| 磁盘占用 | 高,多个程序重复存储 | 低,多个程序共享 |
| 内存占用 | 高,每个程序一份库副本 | 低,多个程序共享一份 |
| 部署 | 简单,一个文件搞定 | 复杂,需要带上依赖库 |
| 启动速度 | 快,无需运行时链接 | 稍慢,需要加载动态库 |
| 版本更新 | 需要重新编译程序 | 只需要替换动态库即可 |
| 版本隔离 | 好,不受系统库影响 | 可能受系统库版本影响 |
十一、总结
从库的制作,到动静态库的原理,再到 ELF 文件、静态链接、动态链接、GOT/PLT,整个体系层层递进,非常优雅。
理解了这些原理,你不仅能搞懂动静态库的工作方式,也能在实际工作中更好的解决问题:比如为什么动态库找不到?为什么静态链接的程序那么大?为什么动态库能省内存?为什么有时候升级系统库会把程序搞崩?这些问题的答案,都藏在这些底层原理里。
希望这篇文章能帮你彻底搞懂 Linux 下的库与 ELF 的底层原理,如果你觉得有用,欢迎点赞收藏~~
1 《Linux 程序设计(第4版)》,参考动静态库制作与链接章节
2 《深入理解计算机系统(CSAPP)》,ELF 文件格式、链接与加载相关章节。