📃 论文题目 :GeoFormer: Learning Point Cloud Completion with Tri-Plane Integrated Transformer
🏫 论文来源 :ACM MM 2024 (ACM International Conference on Multimedia, CCF-A)
🧑🔬 论文作者:Jinpeng Yu, Binbin Huang, Yuxuan Zhang, Huaxia Li, Xu Tang, Shenghua Gao
一、引言:三维视觉的"盲人摸象"困境与降维打击
在三维计算机视觉领域,点云(Point Cloud)是最基础且最直观的数据表征形式。然而,在自动驾驶、机器人导航以及真实场景的三维重建中,由于激光雷达(LiDAR)的扫描线束限制、深度相机(ToF/RGB-D)的视角遮挡(Self-occlusion)以及物体表面的材质反射等物理限制,我们通过传感器获取的点云往往是极度稀疏且严重残缺的"2.5D表面" 。这就好比盲人摸象,机器只能"看"到物体的正面,却需要推断出被遮挡的背面。
图片:
点云补全(Point Cloud Completion) 任务的核心目标,就是根据这部分残缺的输入,预测出具有完整几何拓扑结构和高保真局部细节的三维点云。这是一个典型的病态(Ill-posed)逆问题,因为缺失区域的解空间极其庞大。
回顾点云补全的发展史,现有的主流方法在探索过程中遇到了难以逾越的理论瓶颈:
- 纯三维路径的计算与表征灾难 :早期的工作(如 PCN, FoldingNet)尝试直接在 3D 坐标空间进行回归,使用基于多层感知机(MLP)或 PointNet 架构的网络。近年来的 SOTA 方法(如 PoinTr, SnowflakeNet)引入了 3D Transformer。虽然自注意力机制(Self-Attention)极大地提升了全局感受野,但由于点云的无序性(Unordered)和不规则性(Irregular),纯 3D Transformer 的计算复杂度随着点数呈平方级增长。更致命的是,置换不变性(Permutation-invariant)网络往往过于关注全局的粗粒度拓扑,而极其容易抹杀诸如飞机尾翼、椅子横梁等细粒度的局部几何特征。
- 传统 2D 降维路径的"几何失真" :为了解决 3D 处理的低效问题,部分研究(如 ViPC)尝试将 3D 点云投影为 2D 视角下的灰度深度图(Depth Maps) ,然后利用成熟的 2D CNN 进行特征提取。然而,深度图仅仅记录了相机坐标系下的单轴距离(Z轴),丢失了绝对的 X 和 Y 坐标映射。当从多个视角投影时,这些深度图之间无法建立严密的"多视角几何一致性(Multi-view Consistency)"。网络无法通过多张灰度图精确还原出三维空间中的同一点,最终导致补全的点云表面充满噪点和拓扑断裂。
站在前人的肩膀上,ACM MM 2024 的这篇 《GeoFormer: Learning Point Cloud Completion with Tri-Plane Integrated Transformer》 提出了一个极其优雅且硬核的破局思路。
作者敏锐地察觉到了近期在 NeRF(神经辐射场)和 3D AIGC 领域大放异彩的 "三平面(Tri-Plane)" 隐式表征,并创新性地提出将残缺点云转化为 规范坐标图(Canonical Coordinate Map, CCM) ,随后通过 Tri-Plane 投影与 Transformer 结合,形成了一套全局几何增强与局部多尺度特征交织的全新补全范式。这不仅解决了 3D 处理的高昂代价,更从根本上保证了 2D 投影的多视角严格一致性。
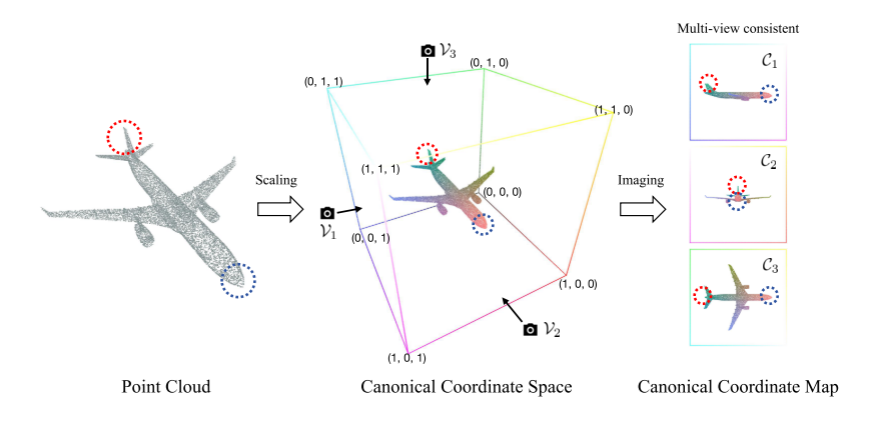
图1:GeoFormer 将 3D 转换到 2D 的核心物理过程
二、GeoFormer 模型架构深度剖析
GeoFormer 的网络架构打破了以往"编码器-解码器(Encoder-Decoder)"的线性思维,而是构建了一个**"2D-3D双流特征对齐 + 由粗到精(Coarse-to-Fine)多尺度重建"**的庞大系统。整个架构可以拆解为三个极其关键的硬核组件。
1. 核心杀手锏:规范坐标图(CCM)与 Tri-Plane 特征对齐
这是 GeoFormer 区别于所有传统方法的灵魂所在。为什么传统的深度图不行?因为深度图不仅受相机内外参影响,且颜色(灰度值)只代表相对距离。GeoFormer 巧妙地引入了 CCM(Canonical Coordinate Map),彻底改变了 3D 到 2D 的降维规则。
1.1 CCM 的数学定义与物理直觉
所谓 CCM,是将 3D 点云放置在一个归一化的绝对坐标系(规范空间,通常是 −1,13-1, 1^3−1,13 或是 0,130, 1^30,13)中。
对于空间中的任意一点 Pi=(Xi,Yi,Zi)P_i = (X_i, Y_i, Z_i)Pi=(Xi,Yi,Zi),将其坐标值线性映射到 0,2550, 2550,255 的 RGB 颜色空间:
R=Xi,G=Yi,B=Zi R = X_i, \quad G = Y_i, \quad B = Z_i R=Xi,G=Yi,B=Zi
这里的物理直觉极其强大 :在 CCM 图像中,每一个像素的颜色(RGB)不再代表外观纹理,而是严格绑定了该点在三维空间中的绝对坐标!
1.2 Tri-Plane(三平面)正交投影机制
NeRF 领域的前沿研究(如 EG3D)证明了,三维空间可以被极高效率地压缩到三个正交的 2D 平面上。GeoFormer 借用这一思想:
- 它将带有 (R,G,B)(R, G, B)(R,G,B) 颜色属性的残缺点云,分别向 XYXYXY 面(俯视图)、XZXZXZ 面(正视图)和 YZYZYZ 面(侧视图)进行正交投影。
- 生成了三幅 CCM 图像:Ixy,Ixz,IyzI_{xy}, I_{xz}, I_{yz}Ixy,Ixz,Iyz。
- 多视角一致性的数学保证 :由于这三幅图中的颜色都直接对应着同一个规范坐标系下的 (X,Y,Z)(X,Y,Z)(X,Y,Z),网络在提取 IxyI_{xy}Ixy 中的某一块红色区域时,能够与 IxzI_{xz}Ixz 中的同色区域进行绝对的物理对齐。这种约束是传统深度图完全无法企及的。
1.3 2D 与 3D 模态的 Transformer 深度融合
拿到三张 CCM 图像后,GeoFormer 并没有抛弃纯 3D 点云,而是采用了一条**双流融合(Dual-stream Fusion)**路径:
- 2D 视觉分支 :使用预训练的 ResNet(如 ResNet-18)对三幅 CCM 图像进行特征提取,得到具有高分辨率空间感知能力的 2D 几何特征图,随后将其展平(Flatten)为一维的 Token 序列 F2DF_{2D}F2D。
- 3D 点云分支 :使用轻量级的 3D 提取器(如简化版 PointNet)直接从输入的残缺点云中提取纯 3D 特征 F3DF_{3D}F3D。
- Transformer 编码器聚合 :将 F2DF_{2D}F2D 和 F3DF_{3D}F3D 进行级联(Concatenation),送入标准的 Transformer Encoder。在 Self-Attention 机制的计算下,网络将 2D 视角下学到的"全局拓扑轮廓"与 3D 学到的"稀疏空间分布"进行信息交换,最终解码输出一组全局粗粒度特征(Global Shape Proxy)。
基于这个强大的特征,生成器首先吐出一个粗粒度的初始完整点云 PcoarseP_{coarse}Pcoarse 。这个点云具备了完美的全局对称性和轮廓,但在微小的局部结构上还显得粗糙。
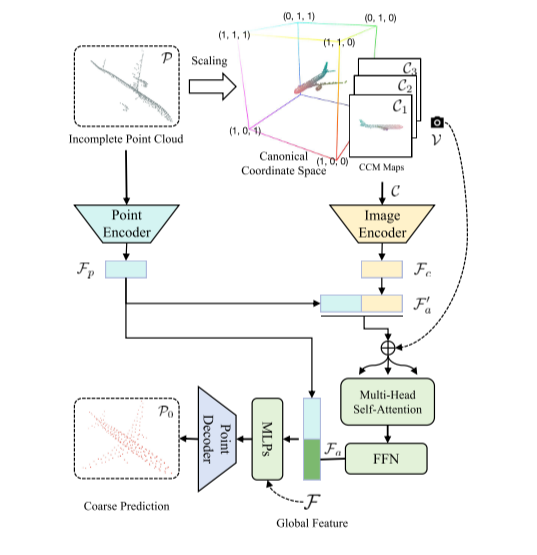
图2:CCM特征增强点生成器的详细结构
2. 细节修复大师:多尺度几何感知上采样器
粗粒度点云 PcoarseP_{coarse}Pcoarse 的生成只是第一步。由于 CCM 投影不可避免地会导致离散点在连续网格上的量化误差(Quantization Error),原始残缺点云中保留的那些珍贵的高频细节(如桌子的尖角、飞机的引擎引擎舱)可能会在粗略重建中被平滑掉。
为了找回这些细节,GeoFormer 设计了一个基于 Cross-Attention(交叉注意力) 的多尺度上采样模块。其运作原理堪称点云特征工程的教科书:
2.1 局部几何的精细提权 (EdgeConv 机制)
首先,对原始的残缺输入点云 PinP_{in}Pin 使用类似 DGCNN 中的 EdgeConv 操作。EdgeConv 通过 K-NN(K近邻)算法在局部构建动态图(Dynamic Graph),不仅提取中心点的特征,还提取中心点与其邻居节点之间的相对边缘向量(Edge Vector) 。
GeoFormer 通过多层 EdgeConv,构建了一个特征金字塔(Feature Pyramid),从局部到更大范围,提取出多尺度(Multi-scale)的残缺几何特征集 Flocal={f1,f2,f3}\mathcal{F}_{local} = \{f_1, f_2, f_3\}Flocal={f1,f2,f3}。
2.2 跨维度的交叉注意力 (Cross-Attention 借用机制)
接下来是整个网络最精彩的特征注入环节。为了让粗粒度的点 PcoarseP_{coarse}Pcoarse 变得"锋利",网络采用了 Transformer 的 Cross-Attention 机制:
- Query (Q) :由当前正在生成的、需要细化的粗点云特征(即 PcoarseP_{coarse}Pcoarse 映射出的高维特征)作为查询向量。
- Key (K) / Value (V) :由上一步提取出的、带有原始精准局部信息的残缺多尺度特征 Flocal\mathcal{F}_{local}Flocal 作为键和值。
数学计算与物理意义 :
Attention(Q,K,V)=Softmax(QKTd)V \text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T}{\sqrt{d}}\right)V Attention(Q,K,V)=Softmax(d QKT)V
在这个公式中,QKTQK^TQKT 计算的是"正在生成的粗糙点"与"原始输入点"在特征空间中的相似度。如果粗点云中某个点位于机翼边缘,它会通过相似度矩阵自动"向原始残缺输入中真正的机翼边缘点"投去极高的注意力权重,从而精准地从 VVV 中"借用"真正的高频几何特征 。
这种多尺度的特征借用,让模型在放大点云密度(上采样)时,绝不是简单地做几何插值,而是有理有据地根据局部几何曲率生成新的点。
3. 残差学习:坐标偏移预测与形状整合
经过 Cross-Attention 的特征赋能后,每个生成的点都拥有了融合全局拓扑(来自 CCM)与局部高频(来自多尺度 EdgeConv)的"终极特征向量"。
GeoFormer 并没有让网络直接回归输出每一个点最终的绝对三维坐标 (xfinal,yfinal,zfinal)(x_{final}, y_{final}, z_{final})(xfinal,yfinal,zfinal),而是采取了更易于优化的残差学习(Residual Learning)策略。网络最终的预测输出是 坐标偏移量(Point Offsets ΔP\Delta PΔP)。
Pfine=Pcoarse+MLP(Fultimate_feature)→Pcoarse+ΔP P_{fine} = P_{coarse} + \text{MLP}(F_{ultimate\feature}) \rightarrow P{coarse} + \Delta P Pfine=Pcoarse+MLP(Fultimate_feature)→Pcoarse+ΔP
为什么要预测偏移量?
因为直接回归绝对坐标会导致解空间剧烈震荡,网络难以收敛。而预测微小的 ΔP\Delta PΔP,相当于在 PcoarseP_{coarse}Pcoarse(已经给出了大致正确的空间位置)的基础上,进行局部的"微调"和"雕刻"。这种 Coarse-to-Fine(由粗到精)的范式,极大地降低了优化难度,确保最终生成的 PfineP_{fine}Pfine 在空间分布上既均匀(Uniform),又紧贴物体的真实物理表面(Surface-aligned)。
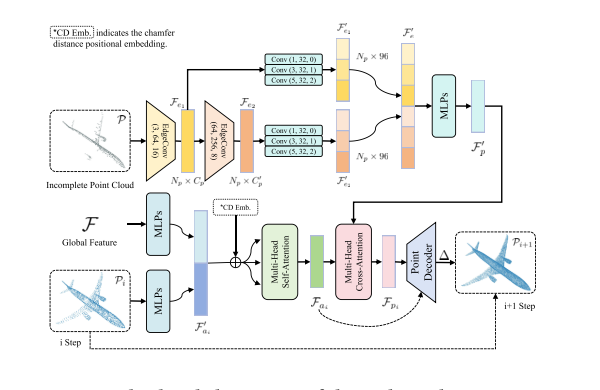
图3::多尺度几何感知上采样器的详细结构
三、实验结果与深度解析:全方位的降维打击
为了证明 Tri-Plane 与 CCM 架构的优越性,GeoFormer 在三大业界最具挑战性的基准数据集上进行了残酷的对比实验。评价指标采用了点云处理的"黄金准则"------**倒角距离(Chamfer Distance, CD)**和 F1-Score。
1. PCN 数据集:复杂拓扑的统治力 (定量分析)
PCN (Point Cloud Network) 数据集包含了 8 个常见类别的海量数据,且遮挡情况极为严重。
在与近年来的顶尖模型(如基于 3D Transformer 的 PoinTr、SnowflakeNet,以及基于显式种子的 SeedFormer)的横向对决中,GeoFormer 在 CD-L1 指标上实现了显著的超越 。
特别是在 Cabinet (橱柜) 和 Lamp (台灯) 这种拓扑结构极其复杂、内部存在大量镂空和不规则支撑件的类别中,GeoFormer 的优势被无限放大。这直接证明了:纯 3D Transformer 处理镂空结构容易产生"拓扑糊化",而 GeoFormer 通过三平面的正交约束,像 X 光扫描一样死死锁定了物体的内部骨架,防止了结构的坍塌。
2. ShapeNet-55/34:零样本与长尾泛化能力
ShapeNet-55 包含了多达 55 个大类、几万个精细模型。GeoFormer 在这里不仅测试了已知类别的补全,更重要的是测试了模型对长尾类别(样本极少)的泛化能力 。
由于 CCM 将复杂的 3D 分布转换为了 2D 视角的彩色图,使得模型能够复用在 2D 卷积中沉淀的"平移不变性"和"边缘检测"等通用几何先验。因此,即便面对训练集中极其罕见的类别,GeoFormer 也能凭借三张投影图勾勒出合理的全局结构,展现出了惊人的泛化鲁棒性。
3. 视觉保真度对比:拒绝"离群点"与"马赛克" (定性分析)
实验部分的定性可视化(Qualitative Results)更是令人震撼。从论文提供的对比图可以清晰地观察到不同流派算法的致命缺陷:
- 传统基于 MLP 的方法(如 PCN):倾向于输出模糊、圆滑的"团状物(Blobs)",毫无细节可言。
- 纯 3D Transformer 方法(如 PoinTr):虽然能大致恢复结构,但在点云拼接的断层面容易出现密集的噪点(Outliers),且点云分布极不均匀,像马赛克一样粗糙。
- GeoFormer 的表现 :补全后的物体表面如丝般顺滑。由于最后一步 Offset 偏移预测的引入,GeoFormer 补全出的汽车表面平整、飞机的机翼边缘锐利,且新生成的点与输入残缺点在边界处的融合实现了真正的"无缝衔接"。
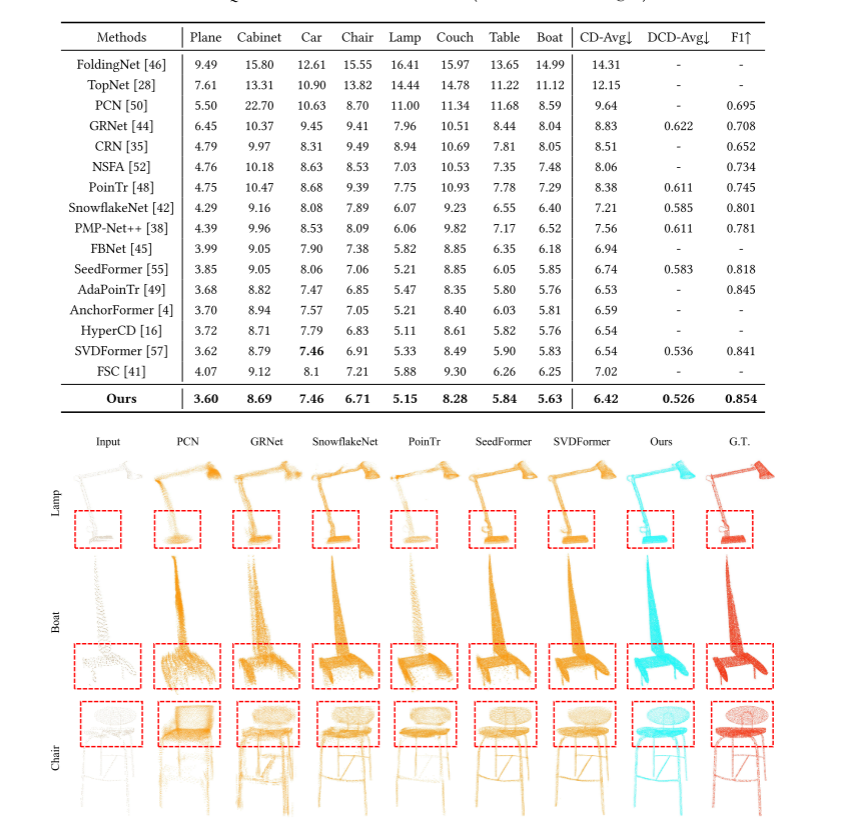 图4::PCN数据集对比
图4::PCN数据集对比
4. KITTI 真实场景试金石:跨越 Sim-to-Real 鸿沟
实验室的仿真数据再好,如果不落地也只是空中楼阁。GeoFormer 在著名的真实自动驾驶数据集 KITTI 上进行了测试。KITTI 的点云是通过真实的车载 LiDAR 扫描得到的,不仅稀疏度极其夸张(只有几百个点),且伴随着严重的传感器噪声和环境遮挡。
在如此恶劣的域偏移(Domain Gap)下,GeoFormer 依然能够稳定地根据几根稀疏的扫描线,利用多尺度特征交叉注意力,推理出汽车的完整外轮廓。这为其在自动驾驶感知下游任务(如 3D 目标检测)中的应用打下了坚实基础。
)

图5::kitti数据集对比
5. 消融实验的终极证明 (Ablation Studies)
论文最硬核的自证环节在于消融实验:
- CCM vs. Depth Map (深度图):当作者把具有物理绝对坐标意义的 CCM 替换为普通的灰度深度图时,网络性能出现了断崖式的下跌。这在数学上验证了"多视角一致性"对于 3D 几何重建的决定性作用。
- Multi-view vs. Single-view :如果只投影到一个平面(比如只看俯视图),模型就会在 Z 轴方向上产生严重的"幻觉",导致模型纵向结构拉伸失真。Tri-Plane 的三向正交约束是缺一不可的"铁三角"。
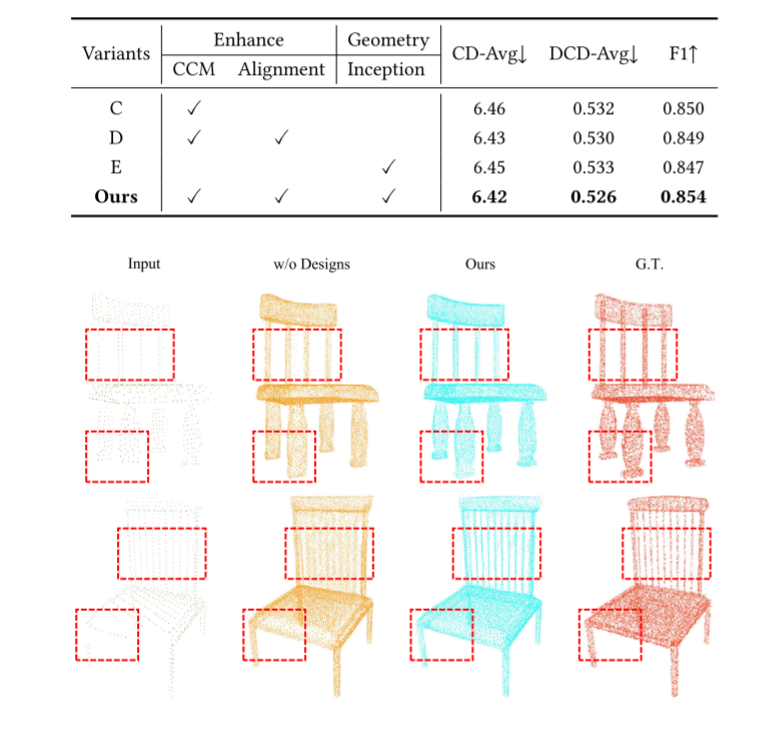
图6::消融实验 ---
四、结论与三维视觉的未来展望
《GeoFormer》这篇 ACM MM 2024 的高水平论文,绝对不是简单的"模块拼接(Stacking modules)",而是代表了三维视觉领域一种深刻的哲学级方法论转变。
它的核心贡献可以总结为:首次将 NeRF/3D AIGC 领域成熟的 Tri-Plane(三平面)隐式表征与 CCM 结合,作为一种降维打击的武器,引入到了判别式的点云补全任务中。
它告诉我们一个深刻的道理:面对复杂的 3D 无序数据,我们不一定要硬着头皮在三维坐标系里死磕计算复杂度。通过将 3D 物理坐标巧妙地映射为多视角下具有严格一致性的 2D 颜色特征(CCM),我们完全可以借用强大的 2D 视觉先验,对 3D 几何的残缺形成降维打击。
当然,技术的发展总是螺旋上升的,GeoFormer 依然为我们留下了值得探讨的局限与挑战:
- 计算开销的权衡:尽管降维到了 2D,但前向推理时,点云到规范坐标系的映射、三个视角的投影渲染以及 ResNet 的特征提取,不可避免地增加了系统的整体计算和显存开销。相较于纯点云端到端网络,其推理延迟(Latency)可能需要进一步的工程优化(如 TensorRT 加速或自定义 CUDA 算子)。
- 动态点云与场景级补全:目前的 GeoFormer 依然聚焦于单一物体级别(Object-level)的补全。在未来,如何将这种 Tri-Plane 思想扩展到大规模、无边界的真实场景级别补全(Scene-level Completion),甚至引入时间维度处理 4D 动态点云,将是一片广阔的无人区。
- 与 Diffusion 扩散模型的强强联手:考虑到如今 2D 扩散模型的强大概率推断能力,未来若能将 GeoFormer 的 CCM 投影作为条件引导(Condition Guidance),接入预训练的 Stable Diffusion 进行零样本(Zero-shot)的细节生成,三维几何补全或许将迎来下一个性能奇点。
总而言之,GeoFormer 以其扎实的数学推导、优雅的架构设计和惊艳的实验数据,为点云处理领域注入了新鲜的血液。对于所有从事 3D 视觉、自动驾驶感知和神经渲染的研究者来说,这篇论文的源码和思想,绝对值得反复研读与借鉴。