本篇分享、介绍的是:
👉 把模型转成 GGUF → 丢进 LM Studio → 直接聊天 or 当 API 用
一、先搞清楚:为什么一定是 GGUF
如果你用过 llama.cpp 或本地推理工具,大概率已经见过这个格式。
GGUF 本质上就是:
- 专门为本地推理优化的模型格式
- 支持量化(大幅降低显存 / 内存占用)
- LM Studio、Ollama、llama.cpp 都能吃
也就是说:👉 想在本地跑模型,GGUF 基本就是通行证
二、把微调的模型导出成 GGUF
如果是用 Unsloth 微调的,直接一行代码搞定:
ini
model.save_pretrained_gguf(
"my_model_gguf",
tokenizer,
quantization_method="q4_k_m"
)常见几个选择你可以这么理解:
q4_k_m:默认推荐,体积小、速度快,本地跑最舒服q8_0:质量更好,体积也更大f16:接近原始精度,但又大又慢
一般来说,直接用 q4_k_m 就够了。如果还想分享模型,也可以直接推到 Hugging Face:
ini
model.push_to_hub_gguf(
"hf_username/my_model_gguf",
tokenizer,
quantization_method="q4_k_m"
)三、把 GGUF 丢进 LM Studio
这里有三种方式,但最稳的是 CLI。
方式1:一行命令导入(就这句)
arduino
lms import /path/to/model.gguf如果你不想移动原文件:
css
lms import /path/to/model.gguf --copy导入完成后,打开 LM Studio:👉 "我的模型"里就能看到它了
方式2:手动放文件(容易踩坑)
路径要对:
javascript
~/.lmstudio/models/publisher/model/model.gguf就是要注意版本:
但这个方式很容易结构写错,优先用 lms import。
四、直接在 LM Studio 里跑起来
打开 LM Studio → Chat 页面:
-
打开模型加载器
-
选择你的模型
-
调整参数(可选)
- GPU offload
- context length
-
开始聊天
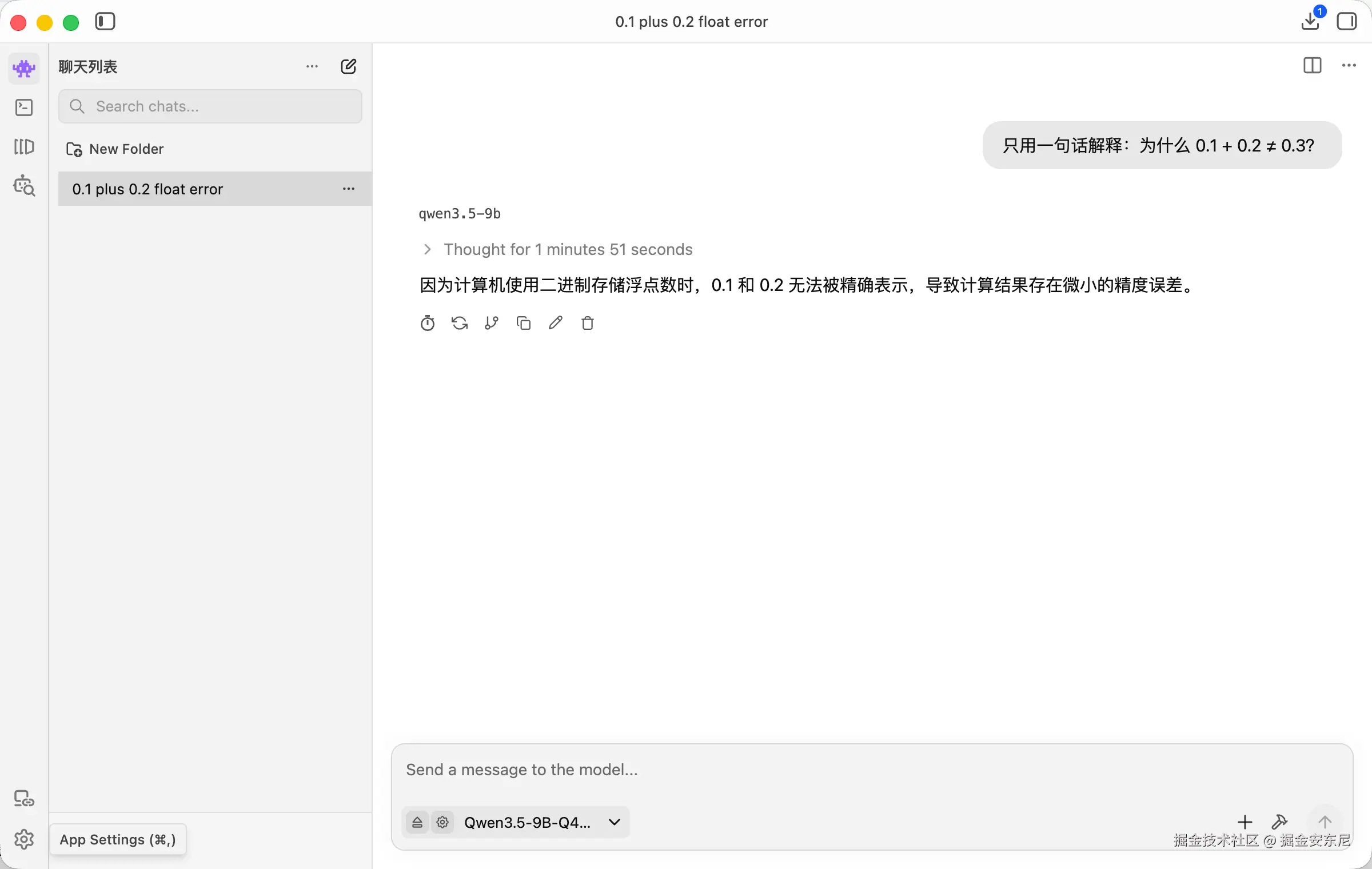
到这里,其实已经能用了。
五、进阶玩法:把模型当本地 API
这一步才是很多人真正想要的。
LM Studio 可以直接变成一个 OpenAI 兼容接口。
打开:👉 Developer(开发者)面板 → 启动本地服务
默认地址:
bash
http://localhost:1234/v1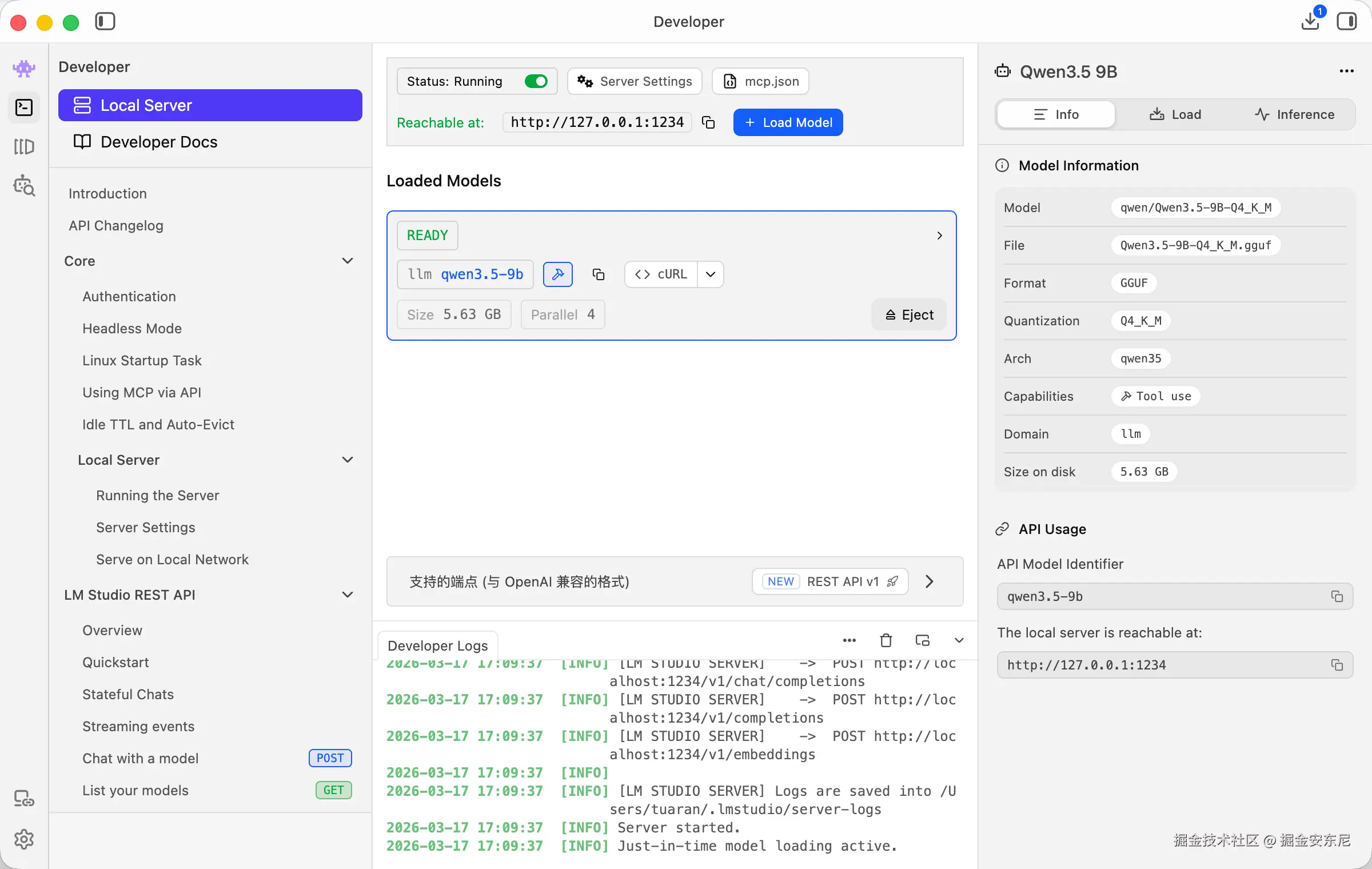
1、先测一下模型有没有起来
bash
curl http://localhost:1234/v1/models2、用 Python 调用(直接当 OpenAI 用)
ini
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:1234/v1",
api_key="lm-studio",
)
resp = client.chat.completions.create(
model="your-model-id",
messages=[
{"role": "user", "content": "来一句测试"}
],
temperature=0.7,
)
print(resp.choices[0].message.content)3、CURL 也能直接打
arduino
curl http://localhost:1234/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "your-model-id",
"messages": [
{"role": "user", "content": "Say this is a test!"}
]
}'六、几个最常见的坑
这部分很关键,基本 80% 的问题都在这里。
1、输出乱码 / 一直重复
核心原因:提示模板不匹配
解决方式:
- 打开模型设置 ⚙️
- 手动设置 Prompt Template
- 或在聊天侧边栏强制启用模板
2、模型导入了但看不到
优先用:
arduino
lms import不要手动乱放路径。
3、跑不动 / 很卡
可以这样调:
- 换更小量化(Q4)
- 减小 context length
- 调整 GPU offload
七、一整套流程,本质
其实你可以把它抽象成一个标准链路:
微调模型
↓
导出 GGUF
↓
本地加载(LM Studio)
↓
对话 or API 服务这条链路一旦打通,你手里的模型就不再是"文件",而是一个可以被调用、被集成、被产品化的能力。
很多人卡在"模型很强", 真正拉开差距的是:
👉 谁能把模型变成接口,再变成产品,再塞进流程里跑起来
LM Studio 这一层,其实就是把模型接入现实世界的第一步。
以上就是本次分享。我是安东尼(github: TUARAN),持续关注大模型应用、AI工程化与自动化系统。欢迎一起交流 OpenClaw、Agent、数字员工 等实践,也欢迎共创 《前端周刊》 、加入 博主联盟 。加我或进群,一起做点有意思的 AI 项目。