说明 :本文介绍的是 Voicebox(GitHub: jamiepine/voicebox)------一款本地优先的开源桌面应用。不是 Meta 于 2023 年发布的学术研究项目 Voicebox。
信息来源:官方文档 docs.voicebox.sh、GitHub README;版本与 Star 数以 2026 年初 为参考。
voicebox支持模型
---
目录
- 前言:为什么需要本地语音栈
- [Voicebox 是什么](#Voicebox 是什么)
- 核心功能详解
- 安装与系统要求
- 快速上手教程
- [GPU 与性能](#GPU 与性能)
- 典型使用场景
- 局限与注意事项
- 总结与资源
前言:为什么需要本地语音栈
过去两年,语音 AI 被两家「云原生」产品分别占领了一半用户旅程:
| 维度 | ElevenLabs(典型云 TTS) | WisprFlow(典型云听写) | Voicebox(本地一体化) |
|---|---|---|---|
| 核心能力 | 克隆音色、高质量 TTS | 全局听写、快速 STT | TTS + STT + 本地 LLM 一体 |
| 数据位置 | 上传云端处理 | 通常云端转写 | 默认全部在本机 |
| 费用模式 | 订阅 / 按量计费 | 订阅 | 免费开源(MIT) |
| Agent 集成 | API 为主 | 偏人类输入 | 内置 MCP + REST |
| 账号依赖 | 需要 | 需要 | 无需账号 |
对以下人群而言,「本地语音栈」不再是极客玩具,而是刚需:
- 隐私敏感用户:声纹、口述内容、商业旁白不愿上传第三方。
- 高频创作者:长视频、播客、有声书需要批量生成,云 API 成本随用量线性上升。
- 开发者 / Agent 用户 :希望 Cursor、Claude Code 等工具不仅能打字回复,还能用固定声线播报状态。
- 无障碍与替代沟通:需要 STT 输入与 TTS 输出在同一套工具链里闭环。
Voicebox 的定位很明确:在单机上闭合「人说 → 字 → Agent/人说 → 声」整条语音 I/O 回路,作为 ElevenLabs 与 WisprFlow 的开源、本地替代方案。
Voicebox 是什么
Voicebox 是一款 local-first(本地优先) 的 AI 语音工作室桌面应用。你可以:
- 用几秒参考音频 零样本克隆 音色并生成语音;
- 用 全局热键 在任意应用中听写(STT);
- 通过 MCP / REST API 让 AI Agent 用指定克隆声线「开口说话」;
- 在 Stories 多轨编辑器里制作多角色对话或播客时间线。
项目由 Jamie Pine 等人维护,MIT 协议开源;截至 2026 年初 GitHub Star 约 2.5 万+,最新稳定版可参考 Releases(如 v0.5.0)。
架构概览
Python FastAPI 后端
Tauri 桌面壳 Rust
本地 HTTP
React + TypeScript + Tailwind
7 款 TTS 引擎
Whisper STT
Qwen3 本地 LLM
SQLite
MCP Server
REST + WebSocket
MLX Apple Silicon
PyTorch CUDA/ROCm/DirectML/CPU
Cursor Claude Code 等
设计要点:
- Tauri(Rust) 做桌面壳,而非 Electron,原生性能更好、资源占用更低。
- FastAPI(Python) 承载推理与 API;首次启动时后端自动拉起。
- 推理双栈 :Apple Silicon 走 MLX + Metal ;Windows / Linux NVIDIA 走 PyTorch CUDA;另支持 ROCm、DirectML、Intel Arc、纯 CPU。
- SQLite 存储音色档案、生成版本、Captures 元数据等。
- 无云回退:文档明确「Local is the product」------不需要自备 OpenAI / ElevenLabs API Key。
技术栈一览
| 层级 | 技术 |
|---|---|
| 桌面应用 | Tauri (Rust) |
| 前端 | React, TypeScript, Tailwind CSS, Zustand, React Query |
| 后端 | FastAPI (Python) |
| TTS | Qwen3-TTS, Qwen CustomVoice, LuxTTS, Chatterbox, Chatterbox Turbo, TADA, Kokoro |
| STT | Whisper / Whisper Turbo (PyTorch 或 MLX) |
| 本地 LLM | Qwen3 0.6B / 1.7B / 4B |
| 音频效果 | Pedalboard (Spotify) |
| 音频可视化 | WaveSurfer.js, librosa |
| 数据库 | SQLite |
核心功能详解
1. 语音克隆(Voice Cloning)
Voicebox 支持 零样本克隆 :上传或录制参考样本,创建 Voice Profile,即可用多款引擎合成该音色的新语音。档案支持多样本、导入导出、按语言与描述组织。
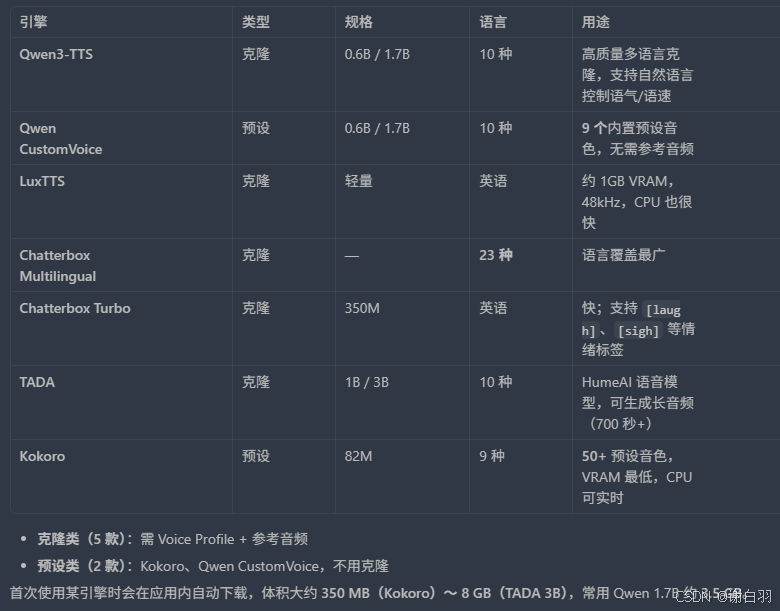
克隆向引擎(5 款):
| 引擎 | 参数量级 | 语言 | 特点 |
|---|---|---|---|
| Qwen3-TTS (0.6B / 1.7B) | 中小 | 10 | 高质量多语言克隆;支持自然语言 delivery 指令(如「慢一点」「耳语」) |
| LuxTTS | 轻量 | 英语 | 约 1GB VRAM,48kHz 输出,CPU 上可达约 150× 实时 |
| Chatterbox Multilingual | --- | 23 | 语言覆盖最广(含阿拉伯语、印地语、希伯来语、斯瓦希里语等) |
| Chatterbox Turbo | 350M | 英语 | 速度快;支持副语言 情绪/音效标签(见下文) |
| TADA (1B / 3B) | 大 | 10 | HumeAI 语音-语言模型;可生成长达 700 秒以上 连贯音频 |
预设向引擎(无需克隆样本):
| 引擎 | 说明 |
|---|---|
| Qwen CustomVoice (0.6B / 1.7B) | 9 款精选预设 + 自然语言控制语气、情绪、语速 |
| Kokoro | 82M 极小模型,50+ 预设音色,CPU 实时,VRAM 占用最低 |
生成时可 按次切换引擎,不必全局锁定单一模型。
2. 表现力:情绪标签与自然语言控制
Chatterbox Turbo 能解析副语言标签,在文本中插入即可生效,例如:
[laugh] [chuckle] [gasp] [cough] [sigh] [groan] [sniff] [shush] [clear throat]在输入框输入 / 可打开标签插入器。注意:Qwen3-TTS、LuxTTS、Chatterbox Multilingual、TADA 会把标签当普通文字读出来,仅 Turbo 真正演绎。
Qwen CustomVoice / Qwen3-TTS 则通过自然语言描述 delivery(tone、emotion、pace),适合「用一句话指挥怎么说」而非记标签语法。
3. 后期处理(Post-Processing)
生成后可链式应用 8 种 基于 Spotify Pedalboard 的效果,并支持实时预览与自定义预设:
| 效果 | 说明 |
|---|---|
| Pitch Shift | 升降调,最高 ±12 半音 |
| Reverb | 可调房间大小、阻尼、干湿比 |
| Delay | 回声:时间、反馈、混合 |
| Chorus / Flanger | 调制延迟纹理 |
| Compressor | 动态范围压缩 |
| Gain | -40 ~ +40 dB |
| High-Pass / Low-Pass Filter | 高低频滤波 |
内置预设包括 Robotic、Radio、Echo Chamber、Deep Voice 等;可为每个 Profile 绑定默认效果链。
生成版本体系:每次生成保留 Original;可基于任意版本叠加 Effects、用新 seed 做 Takes、标星收藏,并追踪版本血缘。
4. 无限长文本生成
长文稿不会一次性塞进模型,而是:
- 在 句边界 智能分块(尊重缩写、CJK 标点、
[tags]); - 分块独立生成后 交叉淡化(crossfade) 拼接;
- 可配置分块上限(100--5000 字符)、交叉淡化 0--200ms;
- 最大文本长度 50,000 字符。
适合旁白、章节朗读、课程解说等场景。
5. Stories 编辑器
面向 多角色对话、播客、叙事 的多轨时间线:
- 多轨拖拽编排;
- 轨内裁剪、分割;
- 同步播放头自动回放;
- 每个片段可固定特定生成版本。
6. 听写、STT 与 Captures
全局听写:
- 可配置 按住说话(push-to-talk) 与 点按切换(toggle) 组合键;
- macOS 上经验证的 无障碍注入,将转写结果粘贴到当前焦点输入框,并尽量保持剪贴板原子恢复;
- 应用内任意文本框均有 麦克风按钮;
- 可选 本地 LLM 润色:去口头禅、口吃、自我纠正等再粘贴;
- 屏幕 浮动 Pill 显示
recording/transcribing/refining/speaking状态。
Whisper STT 档位:Base / Small / Medium / Large / Turbo(Turbo 约为 Large 的 8× 速度,质量损失很小)。
Captures 标签页:每次听写、应用内录音、上传的音频都会与转写配对归档,支持:
- 重放、用不同 Whisper 尺寸 重新转写;
- 用不同 LLM 标志 精炼 转写;
- 内联编辑保存;
- 一键用克隆音色播放 该段文字;
- 提升为 Voice Profile 参考样本。
7. Voice Personalities(音色人设)
为 Profile 附加自由文本 人格描述 后,可启用:
- Compose:本地 Qwen3 LLM 生成符合人设的新台词,填入文本框再 TTS;
- Speak in character :将你输入的原文先经人设 LLM 改写 再朗读。
同一套本地 LLM 也用于听写润色,共享模型缓存与 GPU 显存。Agent 通过 MCP 传 personality: true 可走相同改写管线。
可选模型:Qwen3 0.6B / 1.7B / 4B(MLX 或 PyTorch)。
8. Agent 集成:MCP 与 REST API
Voicebox 默认在 http://127.0.0.1:17493 暴露 REST API 与 内置 MCP Server。
生成语音:
bash
curl -X POST http://127.0.0.1:17493/generate \
-H "Content-Type: application/json" \
-d '{"text": "Hello world", "profile_id": "abc123", "language": "en"}'Agent 播报(任意 HTTP 客户端):
bash
curl -X POST http://127.0.0.1:17493/speak \
-H "Content-Type: application/json" \
-H "X-Voicebox-Client-Id: my-script" \
-d '{"text": "Deploy complete.", "profile": "Morgan"}'转写音频文件:
bash
curl -X POST http://127.0.0.1:17493/transcribe \
-F "audio=@recording.wav" \
-F "model=whisper-turbo"MCP 工具调用示例(TypeScript 语义):
typescript
await voicebox.speak({
text: "Deploy complete.",
profile: "Morgan",
});在 Claude Code 中一键添加 MCP:
bash
claude mcp add voicebox \
--transport http \
--url http://127.0.0.1:17493/mcp \
--header "X-Voicebox-Client-Id: claude-code"Cursor / VS Code 等可在 MCP 配置中使用:
json
{
"mcpServers": {
"voicebox": {
"url": "http://127.0.0.1:17493/mcp",
"headers": {
"X-Voicebox-Client-Id": "cursor"
}
}
}
}在 Settings → MCP 中可为不同 Agent 绑定不同默认声线(例如 Claude 用 Morgan、Cursor 用 Scarlett),便于「听声辨 Agent」。
此外提供 WebSocket、异步生成队列(SSE 状态流)、失败重试与崩溃后 stale 任务恢复。
9. 异步生成队列
生成任务 非阻塞:提交后可继续编辑下一条。内部串行队列避免 GPU 争抢;支持多版本 Takes、收藏与失败重试。
安装与系统要求
下载渠道
| 平台 | 安装方式 |
|---|---|
| macOS (Apple Silicon) | DMG / tar.gz |
| macOS (Intel) | DMG / tar.gz |
| Windows | MSI 或 Setup 可执行文件 |
| Docker | docker compose up(无头服务 + Web UI,见文档 Docker 章节) |
| Linux | 预编译包仍在推进;可参考 linux-install 源码构建 |
所有二进制见 GitHub Releases。
系统要求
最低配置:
- 系统:macOS 11+、Windows 10+ 或 Linux
- 内存:8 GB
- 磁盘:5 GB 可用(模型 + 数据)
- CPU:现代多核处理器
推荐配置:
- 内存:16 GB+
- GPU:NVIDIA CUDA(Windows / Linux)或 Apple Silicon(MLX)
- 磁盘:10 GB+
纯 CPU 可用,但生成速度明显慢于 GPU;实时工作流强烈建议独显或 Apple Silicon。
首次启动
- 模型自动下载:首次使用某 TTS 引擎时会拉取对应模型(约 350 MB 的 Kokoro 到约 8 GB 的 TADA 3B;常用 Qwen 1.7B 约 3.5 GB)。
- 数据目录 :
- macOS:
~/Library/Application Support/sh.voicebox.app/ - Windows:
%APPDATA%/sh.voicebox.app/ - Linux:
~/.config/sh.voicebox.app/
- macOS:
- 后端服务 :捆绑的 Python 服务自动启动;左下角状态指示应为 绿色。
可通过环境变量 VOICEBOX_MODELS_DIR 自定义模型存储路径。
安装验证清单
- 启动 Voicebox,确认左下角服务状态为绿;
- 进入 Profiles,创建测试档案;
- 输入短句生成音频,确认能听到输出。
若失败,参阅官方 Troubleshooting(安装、GPU、模型下载等常见问题)。
快速上手教程
步骤一:创建 Voice Profile
- 打开 Profiles → New Profile;
- 上传 一段 5--30 秒清晰干声,或 应用内录制;
- 可选添加多个样本以提升克隆稳定性;
- 填写描述、默认语言标签。
伦理提示:仅使用你有权克隆的声音(本人、已授权演员、合同范围内素材)。
步骤二:生成第一段语音
- 在主界面选择刚创建的 Profile;
- 在引擎下拉框选择起始引擎(新手可试 Qwen3-TTS 1.7B 或轻量 Kokoro 预设);
- 输入英文或目标语言文本;
- 点击生成,等待队列完成(首次会包含模型下载时间);
- 试听 Original,必要时切换 Chatterbox Turbo 并加入
[laugh]等标签对比效果。
步骤三:体验听写(可选)
- 在设置中配置全局听写组合键;
- macOS 需授予 Accessibility 与 Input Monitoring(应用内有引导);
- 在任意文本框聚焦后按住热键说话,松手查看转写是否粘贴;
- 在 Captures 中查看归档,尝试 Play as voice profile。
步骤四:为 Cursor 配置 MCP(可选)
- 确保 Voicebox 正在运行且 API 可访问;
- 在 Cursor MCP 设置中加入上文 JSON 配置;
- 在 Settings → MCP 绑定默认 Profile;
- 让 Agent 在任务完成时调用
speak,观察浮动 Pill 与音频输出。
更细的图文流程见官方 Quick Start。
GPU 与性能
| 平台 | 推理后端 | 说明 |
|---|---|---|
| macOS (Apple Silicon) | MLX (Metal) | Neural Engine 加速,文档称约 4--5× 于纯 CPU |
| Windows / Linux (NVIDIA) | PyTorch CUDA | 应用内可自动下载 CUDA 构建 |
| Linux (AMD) | PyTorch ROCm | 自动配置 HSA_OVERRIDE_GFX_VERSION 等 |
| Windows (通用 GPU) | DirectML | 覆盖更多 Windows 显卡 |
| Intel Arc | IPEX / XPU | 独显加速 |
| 任意 | CPU | 全平台兜底,速度最慢 |
可在模型管理中 卸载 未用模型以释放 VRAM,而不删除已下载文件。
典型使用场景
视频与播客配音
- 用克隆或 Kokoro 预设批量生成旁白;
- 长稿启用自动分块 + crossfade;
- Stories 编排主持人与嘉宾对谈轨。
游戏与互动叙事
- 为 NPC 建立 Profile,通过 REST API 动态拉台词;
- Chatterbox Turbo 标签增强喜剧或紧张氛围。
无障碍与辅助沟通
- STT 填入任意应用输入框;
- TTS 用本人或定制音色「说回去」。
Agent 开发闭环
典型循环:听写提问 → Agent 推理 → voicebox.speak 用克隆声线播报结果。与 Cursor、Claude Code、Windsurf、Cline 等 MCP 客户端兼容。
生产管线自动化
CI、脚本、自定义 harness 通过 POST /generate、POST /speak、POST /transcribe 接入,无需 GUI 操作(Docker 部署更适合服务器场景)。
局限与注意事项
技术局限
- Linux 桌面安装包:预编译二进制仍在解决 CI 磁盘等问题;Linux 用户可能需要源码或 Docker。
- 模型体积:多引擎意味着多份权重;请预留足够 SSD 空间。
- CPU-only:LuxTTS、Kokoro 相对友好,大模型(TADA 3B、Qwen 1.7B)在 CPU 上延迟明显。
- 语言与引擎匹配 :并非每个引擎都支持 23 语言;跨语言克隆需选对 Chatterbox Multilingual 等。
伦理与合规
语音克隆技术极易被滥用。请务必:
- 获得声音主体的 明示同意;
- 不得用于诈骗、深度伪造诽谤、未授权冒充公众人物;
- 在商业项目中核对当地法律法规与平台政策。
Voicebox 作为工具本身中立,责任在使用者。
与商业产品的差距(诚实评价)
- 云服务的 延迟稳定性、运维负担 由厂商承担;本地方案需自行管理 GPU、驱动、模型更新。
- 极端拟真度与韵律控制在部分语种上,可能仍不及顶尖商业 API 的最新专有模型------但 Voicebox 的优势在于 隐私、成本、可编排、Agent 原生,而非单一指标碾压。
总结与资源
Voicebox 是目前少有的、将 语音克隆 / TTS、Whisper STT、本地 LLM 润色与人设、MCP Agent 发声、多轨 Stories 集成在同一开源桌面中的项目。它用 Tauri 保证原生体验,用 7 款可切换引擎覆盖从极简 CPU 到高质量 GPU 的谱系,并明确以 本地、无账号、无云回退 为产品哲学。
若你正在评估 ElevenLabs + WisprFlow 的替代方案,或希望 Cursor 里的 Agent 「用你的声音说话」,值得花一个下午安装试用。
官方资源
本文基于公开文档整理,功能随版本迭代可能变化,请以官方文档为准。