先问一句:线上出问题的时候,是你们先发现,还是用户先发现?
如果答案是后者,这篇就是写给你的。
一、我们曾经面对的窘境
业务越做越大,监控却各搞各的。没有统一标准,没有统一平台,一个团队N套监控,结果就是:
- 告警要么不来,要么半夜乱炸
- 阈值全靠人拍脑袋,流量一波动就误报
- 人工配置繁琐,维护成本居高不下
- 没有监控标准,想起来就加,想不起来就裸奔。用户都投诉到客服了,技术才反应过来
发现滞后,响应更滞后。
我们给自己定了一条线:出现问题,30分钟内必须解决!
要做到这一点,靠零散的监控远远不够。我们需要一套面向业务场景、能分钟级感知异常的智能监控与告警体系。
于是有了「星盾」。
二、星盾是什么?一句话说清
面向业务场景的智能监控报警系统。
- 对业务全链路做分钟级监控 + 即时告警
- 覆盖前端页面、服务端功能:前端用「lego」采集用户行为数据,服务端用 Prometheus 和 k=s 看接口与性能
- 目标只有一个:异常早发现、早响应、早定位、早解决
核心逻辑只有十个字:监控 → 告警 → 响应 → 定位 → 解决,形成闭环。
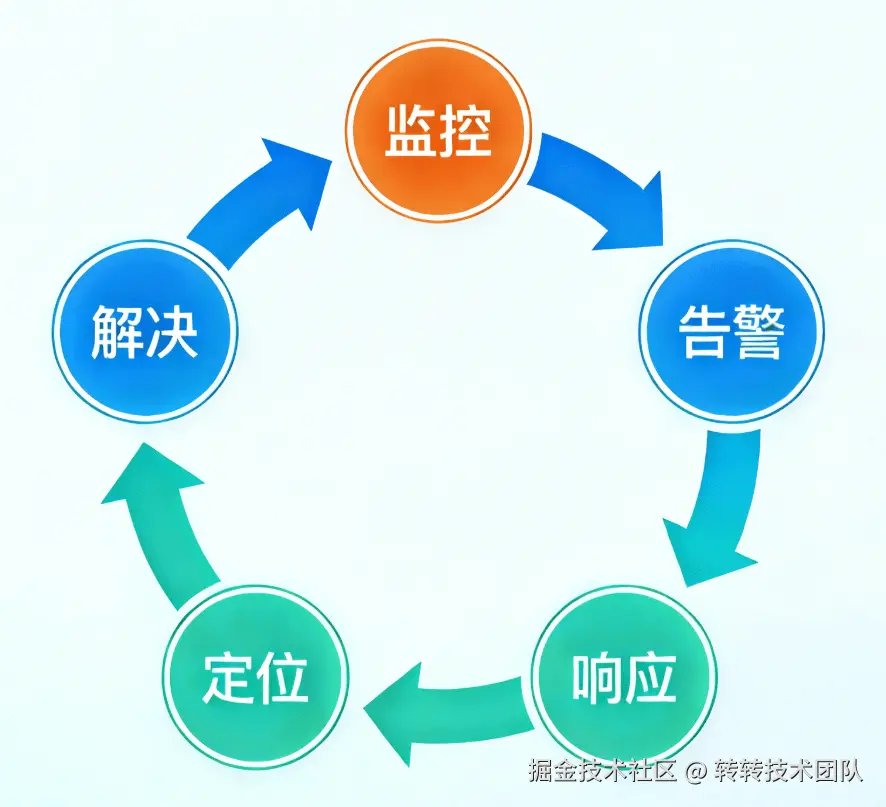
三、凭什么能「分钟级」?架构与能力撑腰
整体架构
从数据采集到展示运营,星盾采用清晰的四层架构:
数据采集 → 数据处理 → 监控告警 → 展示运营 ,各司其职,统一收口。 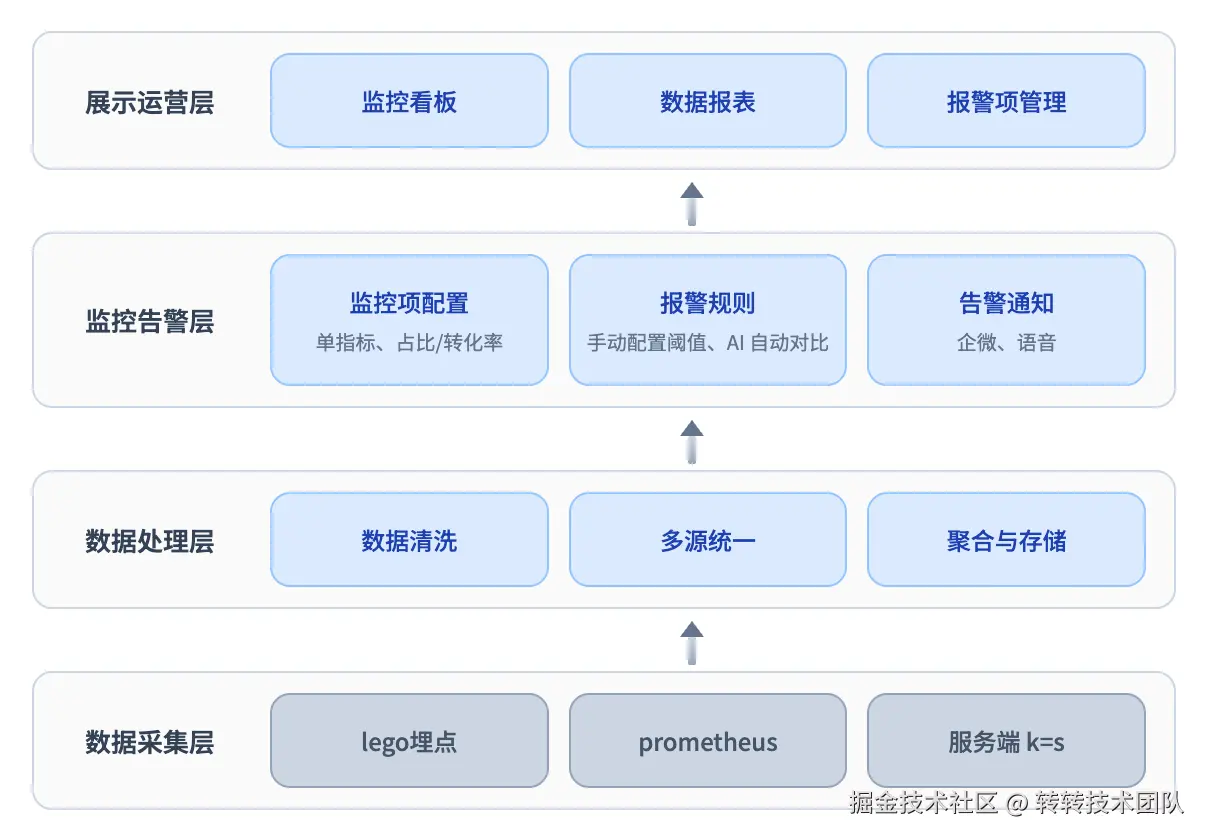
配置有多简单?三步搞定
一句话:先告诉系统「要盯哪块业务」(监控项),再配个「能看趋势的图」(看板),最后定「啥情况算异常、通知谁」(报警项)。配完就自动跑,有问题就分钟级提醒。 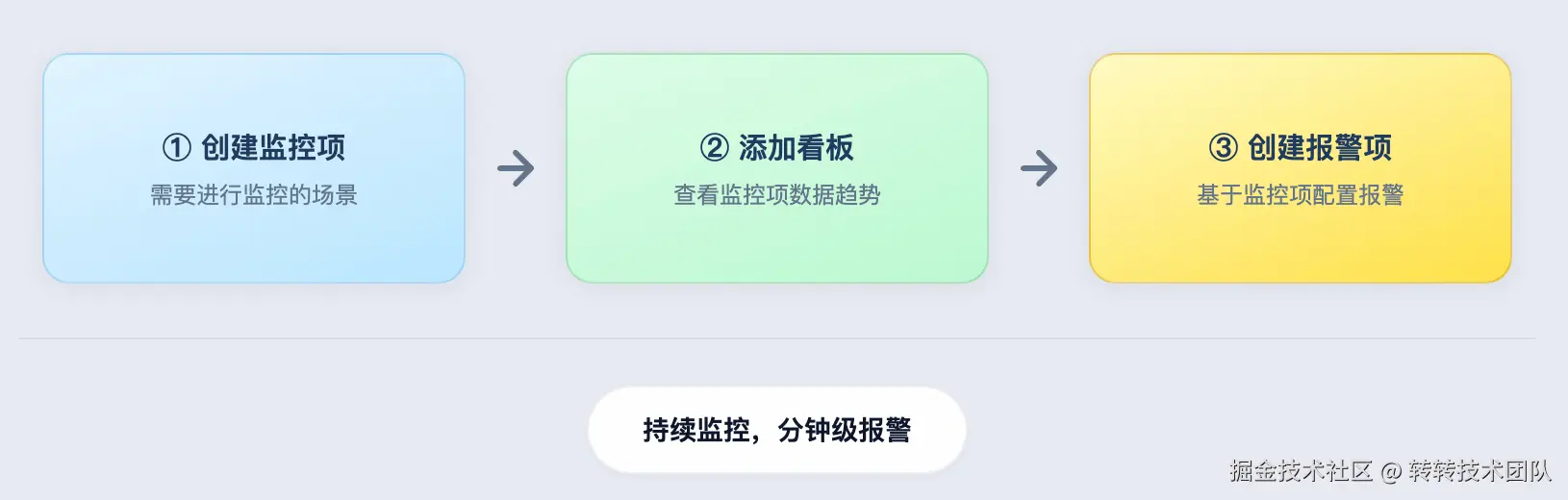
PS: 开启「AI通用分析」后,前两步配完即可,第三步可跳过。
下面分别说明每一步要做什么、怎么配。
第一步:创建监控项
如图所示: 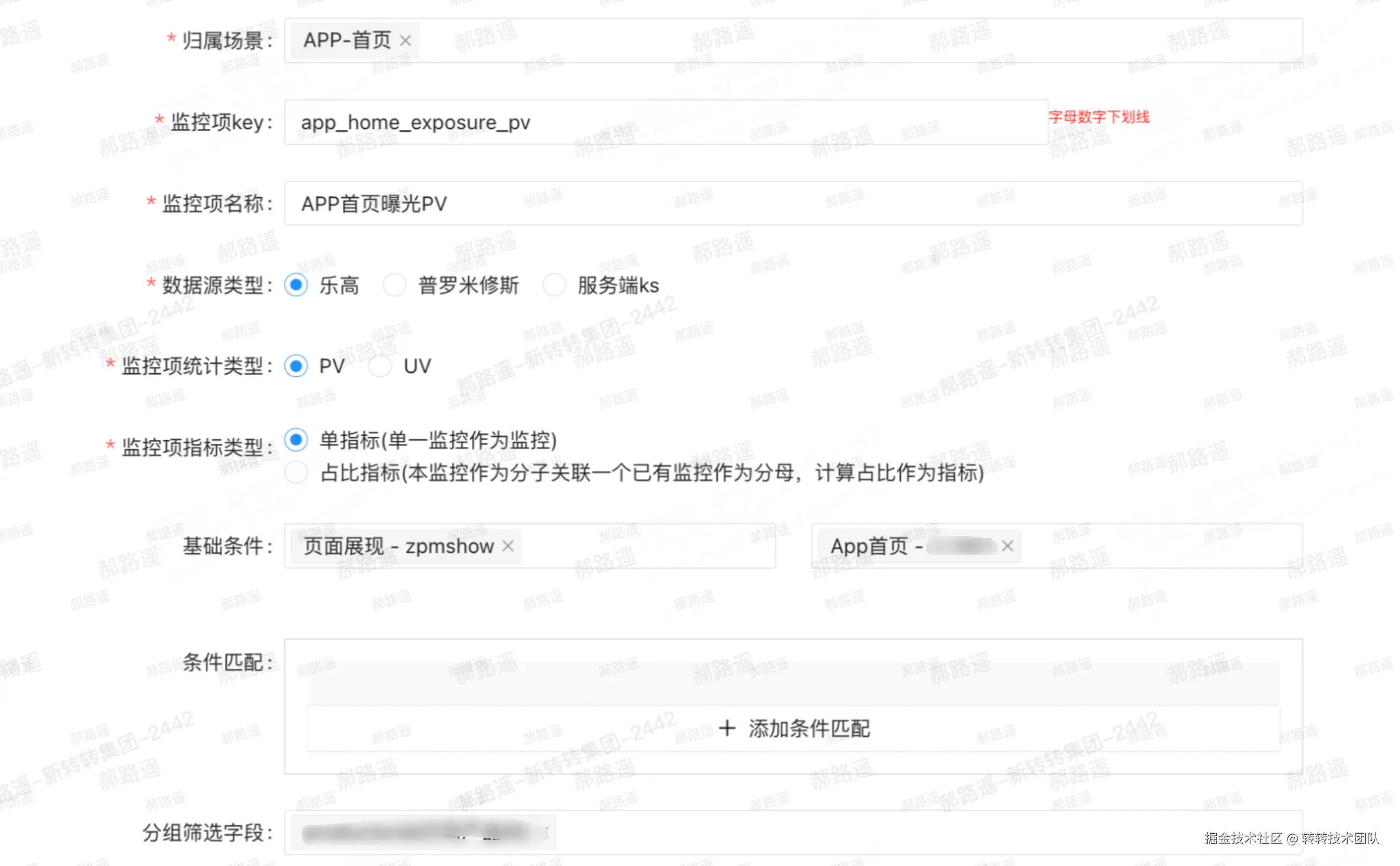
把「看什么」说清楚------要监控哪个业务场景、看哪些指标、怎么算这部分数据。
1. 先把数据收全
覆盖前端、服务端等多端数据,在同一平台内统一配置与告警。
| 数据源 | 典型用途 |
|---|---|
| lego | 前端/客户端页面曝光、按钮点击、关键行为(PV/UV、曝光、点击等) |
| Prometheus | 服务端指标:QPS、延迟、错误率等,接口、服务、中间件可用性与性能 |
| 服务端 k=s | 业务服务端自定义指标/上报,与 Prometheus 互补 |
2. 用户行为指标:规模、转化、占比
先把「用户行为」本身看清楚:有多少人来(UV)、做了多少次行为(PV)、其中有多少转化(占比)。
| 维度 | 含义 | 典型用法 |
|---|---|---|
| PV(次数) | 按次数统计 | 看规模与总量:接口调用次数、页面曝光次数、点击次数 |
| UV(人数) | 按人数/设备去重 | 看覆盖与体验面:多少用户受影响、多少人完成某行为 |
| 单指标 | 当前监控项自身的统计值(可以是 PV 或 UV) | 看某一行为的绝对值:首页曝光 PV、某接口 QPS |
| 占比指标 | 本监控项 ÷ 关联监控项,得到占比 | 看比例与转化:区域曝光占比、成功率;流量波动时更稳,减少误报 |
做转化率类报警(如区域曝光 PV / 页面曝光 UV)时,分子分母会分别用到 PV、UV,两种都要支持;占比指标需要在配置时关联一个已有监控项作为分母,系统自动计算占比并报警。
3. 精确到终端/页面/模块:基础条件 + 条件匹配 + 分组筛选
- 基础条件: 先圈出「哪一类事件、哪一块页面/模块」(如商品曝光、App 首页_推荐),对应埋点中的事件类型 + 模块/页面,是最粗的一层场景圈选。
- 条件匹配: 在基础条件上再做精细过滤,如 sectionId=108、firsttab=精选、终端类型等,实现同一模块下不同 tab、不同区域、不同终端分别监控。
- 分组筛选字段: 指定按哪一维度分组(如渠道、终端),方便在看板和告警里对比不同终端/页面/模块,并按具体实体下钻。
第二步:添加看板
如图所示: 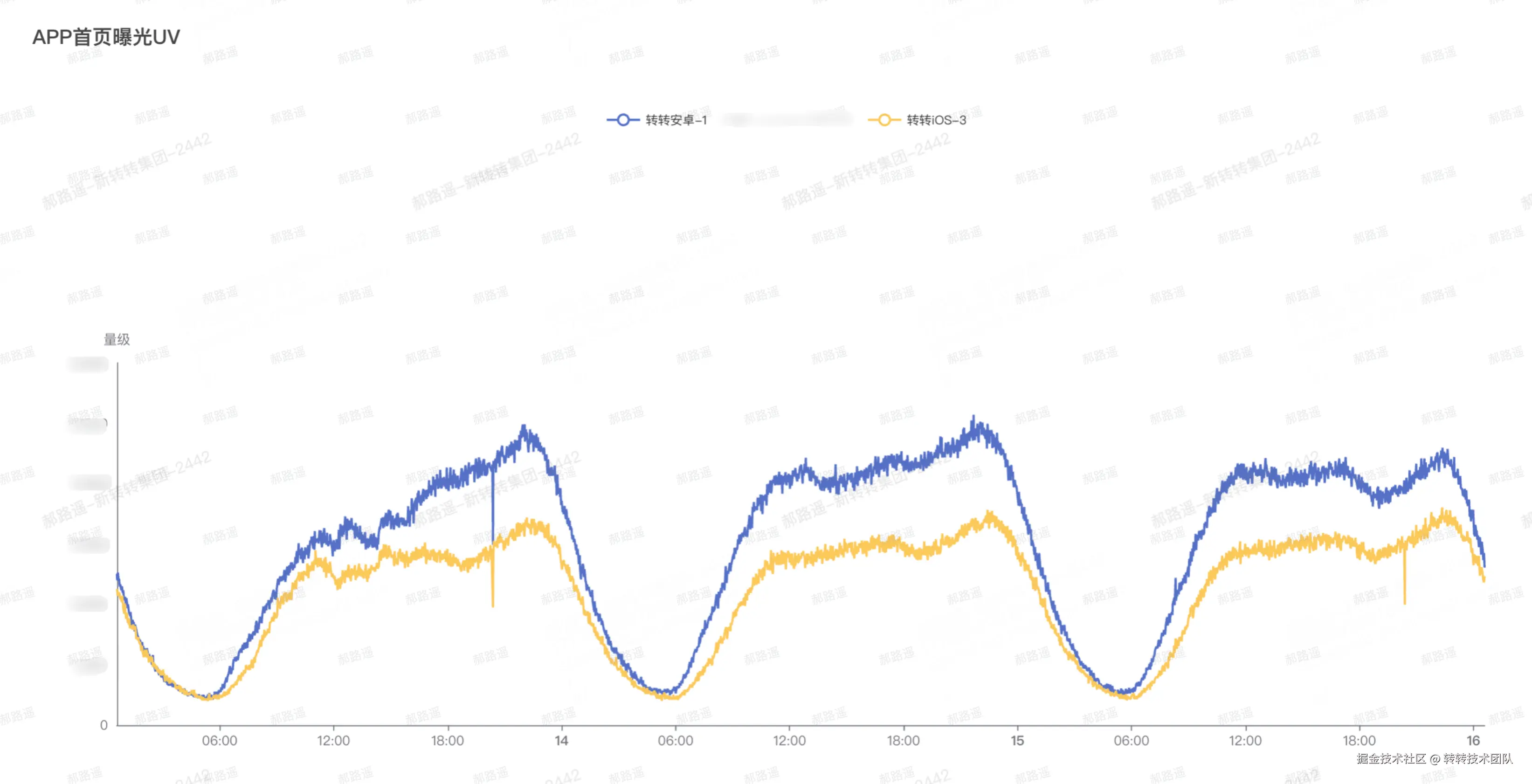
为监控项配置可视化看板,用于查看该监控项的数据趋势。
看板主要有两个作用:
- 配置报警阈值时参考实际值: 创建报警项、设定手动阈值时,需先在看板查看该监控项的历史曲线与量级,再根据实际数据设定,避免阈值过松或过紧。
- 日常出问题时帮助定位: 线上出现问题后,可查看看板看趋势、发生时间等,辅助判断异常时段与影响范围,便于定位问题。
第三步:创建报警项
如图所示: 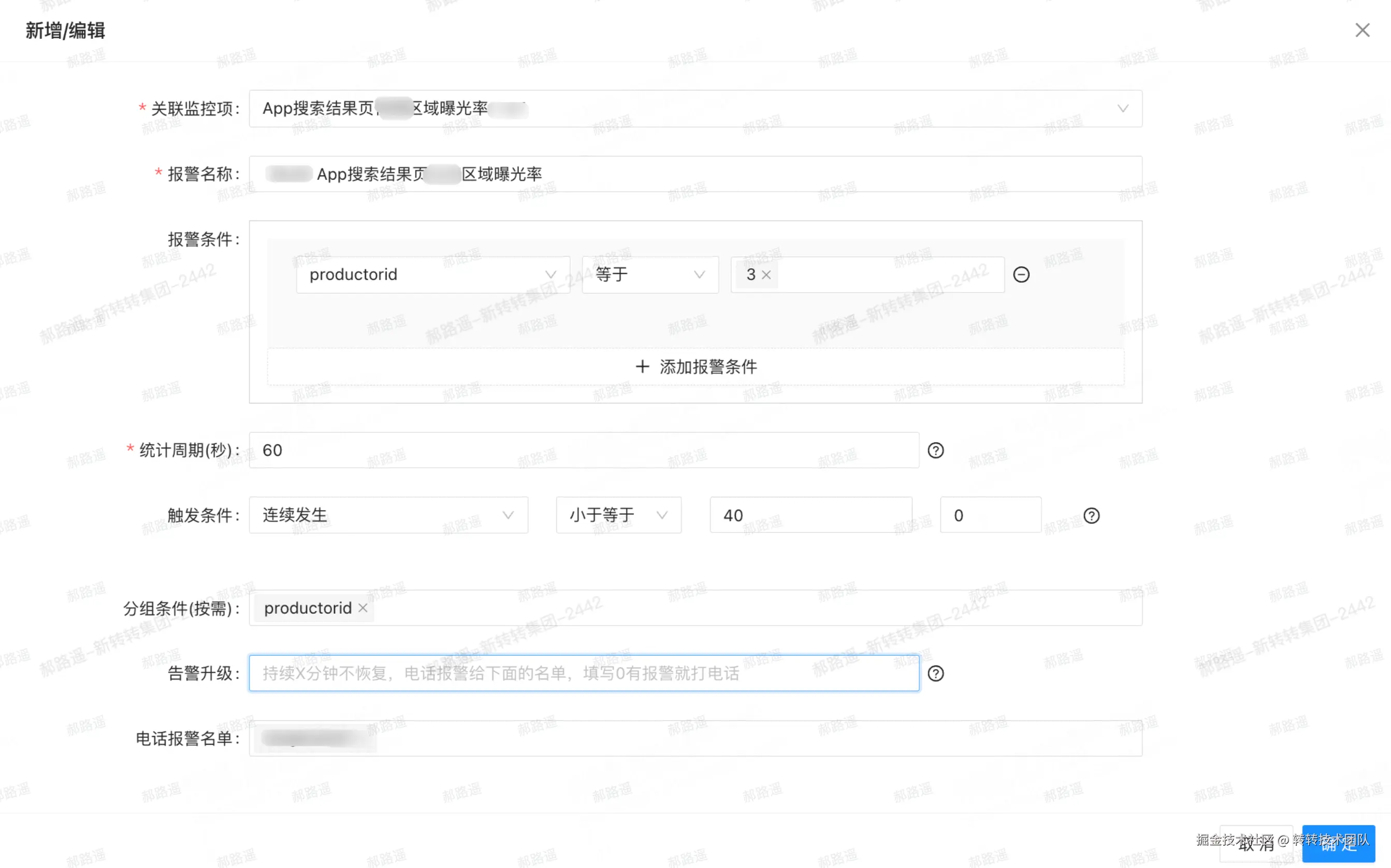
在监控项与看板的基础上,定义「什么情况下算异常、如何通知到人」,把观测能力转化为可执行的告警策略,实现「监控 --- 告警 --- 响应」闭环。
| 配置项 | 含义 / 用途 |
|---|---|
| 关联监控项 | 告警绑定到具体监控项(曝光率、接口 QPS 等) |
| 报警条件 | 按维度过滤,只对符合条件的数据做统计与触发(如 t值终端类型) |
| 统计周期(秒) | 按多少秒聚合再判断(如 60 秒),减少瞬时抖动 |
| 触发条件 | 最大值/最小值/平均值/求和、连续发生、环比变化率等,适配不同场景 |
| 分组条件 | 告警触发时按某维度展示(如按 t值),便于定位 |
| 告警方式 | 企微通知、语音报警等,重要告警多通道触达 |
触发条件怎么用?常见几种:连续发生 (连续 N 个周期才告警,减少误报)、统计周期内最大/最小值 、环比变化率(发现相对基线的突然变差)。
而触发条件里最核心的是阈值------什么算异常、多少才报?两种配置方式,告别「拍脑袋」:
| 阈值配置方式 | 说明 |
|---|---|
| 手动配置(自己设阈值) | 单指标: 对单一指标(如首页曝光 PV、某接口 QPS)直接设阈值,超过或低于即告警,适合量级、绝对值类监控。转化率: 用组合指标(如区域曝光 PV / 页面曝光 UV)算转化率再报警,流量高峰、低谷波动再大,也能更稳地判断是不是真异常,减少误报。 |
| 自动对比(AI) | 基于历史数据自动学习业务规律,对异常波动做智能识别 + 实时告警。该设多少阈值、什么时候报,系统自己学,人工配置和维护成本都降下来。 |
四、手动阈值的两个坑,我们用 AI 填上了
前面说到可以通过手动配置或 AI 自动对比来设阈值。如果只靠手动设阈值,很容易踩两个坑:
- 报警配置滞后: 阈值要参考看板历史曲线与量级,往往得先收集一周左右数据,才能配出合适阈值。
- 无法应对流量持续变化: 业务调整后数值持续升高或下降并稳定在新范围,若不及时改阈值,就会误报或该报不报。
举例: 大促期间某核心转化率从平时的 5% 提升到 8% 并稳定下来。若阈值仍按 5% 设「低于 4% 报警」,大促后回落到 6% 本属正常,却可能被误报;反之若按 8% 设,平时 5% 时又可能该报不报。人工改阈值总存在时间差。
为此我们接入了 AI 通用分析能力。
接下来用大白话讲清楚:系统怎么知道「出问题了」并发出告警。 
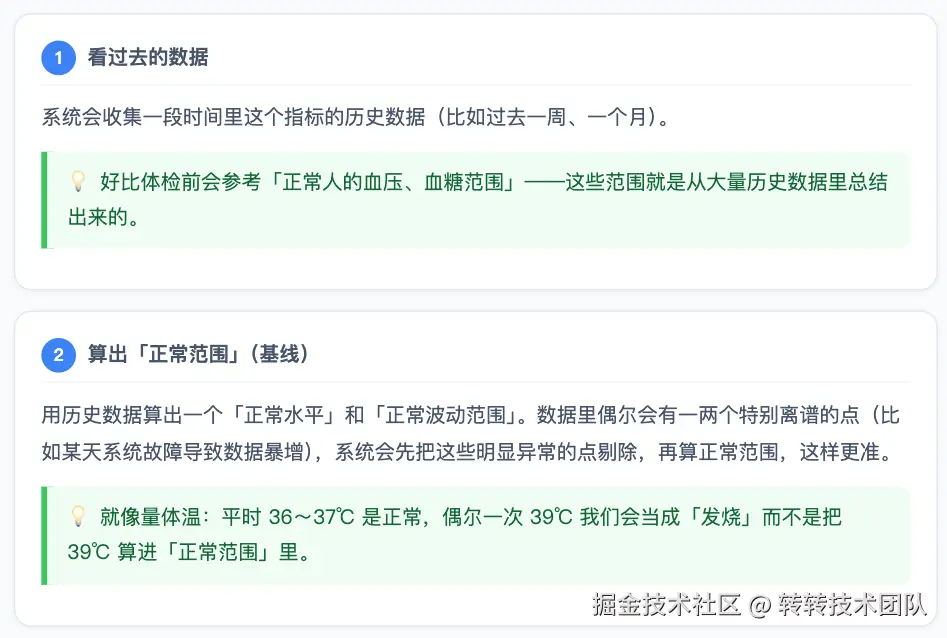


判定为异常之后,还要明确一点:往哪边偏才需要告警? 有的指标我们只关心「掉下去了」(如转化率、曝光量),有的只关心「飙上去了」(如错误率、延迟)。星盾支持按业务诉求配置指标方向,避免双向波动都报、噪音过多。 
一句话总结: 星盾先用历史数据算出「正常范围」,再拿当前数据和它比;只有偏离够大、持续够久才判定为异常,并根据严重程度给出正常 / 警告 / 严重,从而减少误报、又能及时发现问题。
真实例子:报警长什么样?
App 搜索结果页短暂进不去时,从图中可以清晰看出 17:10--17:18 左右出现问题并触发告警,方便快速定位与恢复。 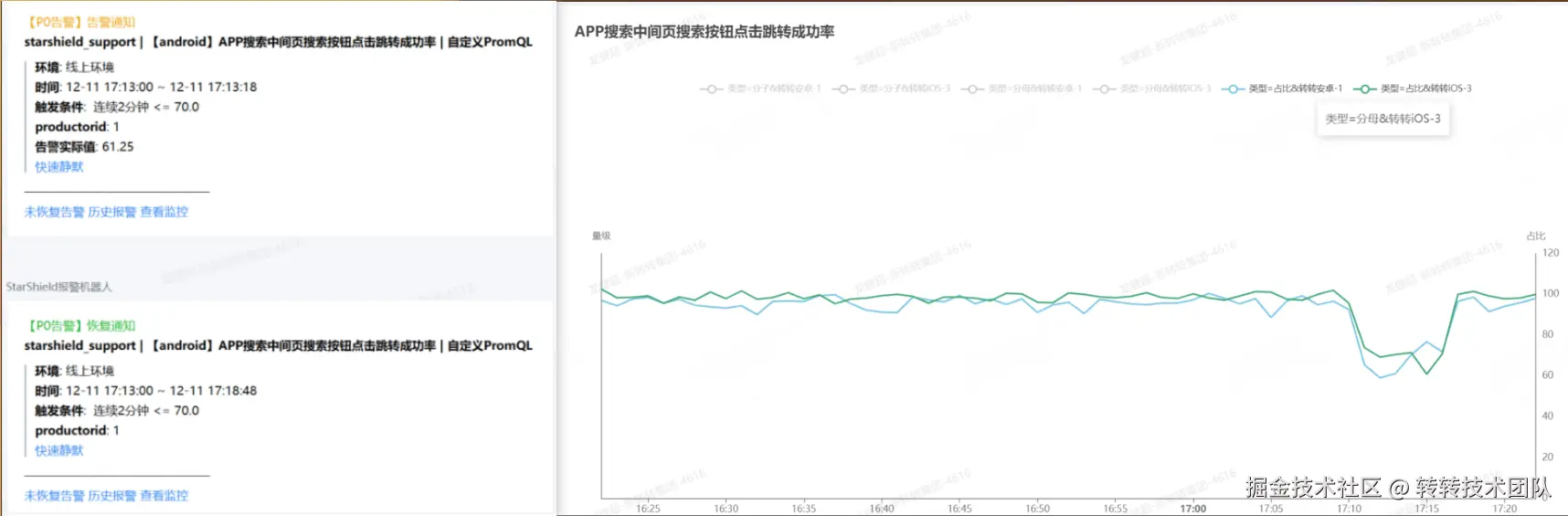
五、监控从哪来?创建与补充机制
配好了报警,还要问一句:监控数据从哪来?
历史功能怎么补、新需求怎么跟上?下面就是我们的补充机制。
1.历史功能补充(先覆盖哪些已有场景):
- 按公司链路等级优先覆盖核心链路(APP 首页、商品发布、浏览、下单支付等)
- 访问量:PV/UV topN页面、曝光 topN功能模块
2.新增功能补充(新需求怎么跟上):
- 需求阶段评估是否需增加监控;开发或上线后及时补充
- 按周统计新上线业务需求,通知 QA 负责人,评估本周是否有需补充的监控报警
这样历史场景不遗漏、新需求能跟上,监控和业务一起迭代。
六、上线之后,数字会说话
1.APP平台内部:
- 50+ 条报警已接入,App 核心场景 100% 覆盖
- 自 2025 年 4 月底上线至今,累计发现线上问题 20 个(运营配置问题 5 个,内部 bug 3 个,外部 bug 7 个,业务规则调整 1 个,业务正常波动 4 个)
- 避免 2 次三级事故
2.其他业务方:
- 过期页面: 累计发现 2 个线上投放问题,分钟级感知 + 自动下架,有效阻止持续曝光
- 魔方专题构建失败: 成功预警并推动处理 10 余起故障,保障运营活动稳定上线
用户还没发现,我们先知道了;该下架的下架,该修的被修。这就是「星盾」要达成的效果。
写在最后
线上质量监控,从来都不是一个团队中某个职能的事,而是整个业务维度的事,关注用户真实业务感受。
星盾要做的,就是把这件「业务维度」的事,用统一平台、统一标准、分钟级感知串起来,让各职能都能在同一套体系里看问题、响应问题、定位问题。
如果你也经历过「线上崩了,用户先知道」的尴尬,不妨试试!
转转研发中心及业界小伙伴们的技术学习交流平台,定期分享一线的实战经验及业界前沿的技术话题。 关注公众号「转转技术」(综合性)、「大转转FE」(专注于FE)、「转转QA」(专注于QA),更多干货实践,欢迎交流分享~