1. mutex互斥锁
1.1 mutex锁引入的背景
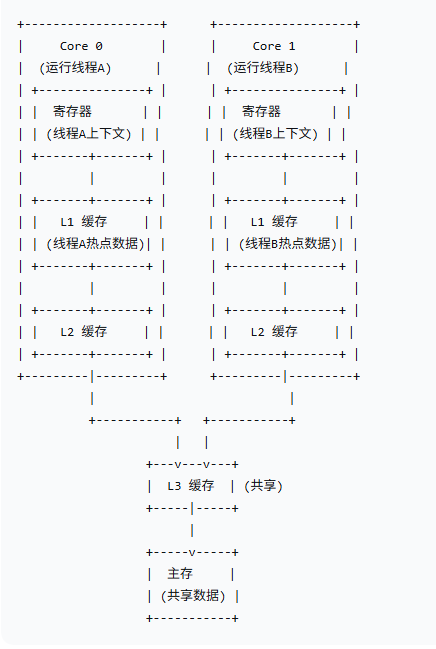
在多线程条件下,多个线程要执行某段代码去操作共享资源(可以理解为主存中的变量),但是由于硬件层面 寄存器运行效率远高于内存,所以衍生出来的缓存会导致各个线程之间数据不一致问题。因此为了保证数据一致性问题,同一时间只允许一个线程去操作临界区,所以锁的概念由此而来。
1.2 mutex锁的使用方式
以线程池中的阻塞队列pop()任务为例:
- 红框: 加锁和解锁
- 蓝框: 临界区

1.3 mutex锁的实现思路
1.3.1 占有标记
锁是一个独占的资源,需要内存标记,所有的线程都可以访问
因此设计一个lock : 0表示为锁未被占有;1表示锁被占有。
1.3.2 持有者
锁需要被谁占用对应的就需要被谁释放,即:需要占有锁线程释放
因此需要一个owner : 表示占用锁的线程id
1.3.3 线程等待标记
当出现锁竞争的时候,如果另外线程自旋之后获取不到锁,则会引入一个标记
因此需要一个std::atomic<int> futex : 用来和系统调用futex交互
1.3.4 加锁
- 获取当前线程id
- 自旋检查是否能够修改lock = 1
- 失败调用futex,进入内核态阻塞
- 否则成功修改修改owner为当前线程id
cpp
// 加锁操作
void lock() {
int spins = 100; // 自旋次数
// 第一阶段:自旋尝试获取锁
while (spins--) {
// 尝试原子交换 lock 的值:如果原来为0(未锁定),则交换为1并返回0,表示成功获取锁
if (!lock.exchange(1, std::memory_order_acquire)) {
// 记录当前线程为锁的持有者(使用 relaxed 顺序,因为 lock 已保证同步)
owner.store(std::this_thread::get_id(), std::memory_order_relaxed);
return; // 获取锁成功,返回
}
// 可在此处插入 CPU pause 指令,减少自旋功耗(但非必须)
}
// 第二阶段:自旋失败,进入基于 futex 的等待
while (true) {
// 标记有线程即将进入等待状态
futex.store(1, std::memory_order_relaxed);
// 再次检查锁状态,避免在设置标志后锁被释放却仍然去等待
if (lock.load(std::memory_order_relaxed) != 0) {
// 锁仍被持有,调用 futex_wait 进入睡眠
// 当 futex 的值等于期望值 1 时,线程被挂起;否则立即返回
futex_wait(reinterpret_cast<int*>(&futex), 1);
// 被唤醒后,重新尝试获取锁(循环继续)
}
// 如果锁已经空闲(lock.load() == 0),则直接尝试获取锁
// 尝试通过原子交换获取锁
if (!lock.exchange(1, std::memory_order_acquire)) {
// 成功获取锁,记录持有者并返回
owner.store(std::this_thread::get_id(), std::memory_order_relaxed);
return;
}
// 若获取失败(其他线程抢先获得锁),则继续循环,再次设置 futex 并等待
}
}1.3.5 解锁
- 检查是否持有锁
- 若持有则释放: futex置0 , owner置0
cpp
// 解锁操作
void unlock() {
// 检查当前线程是否持有锁(非必须,但有助于调试;这里简单返回,实际可能抛出异常)
if (std::this_thread::get_id() != owner.load(std::memory_order_relaxed)) {
// 未持有锁却调用 unlock,通常为未定义行为,这里直接返回
return;
}
// 释放锁:将 lock 置为 0,并使用 release 语义确保临界区操作在此之前完成
lock.store(0, std::memory_order_release);
// 清除锁持有者记录
owner.store(std::thread::id(), std::memory_order_relaxed);
// 原子地将 futex 从 1 交换为 0,并获取旧值
int old = futex.exchange(0, std::memory_order_relaxed);
// 如果旧值为 1,说明有线程在等待,唤醒一个等待者
if (old == 1) {
futex_wake(reinterpret_cast<int*>(&futex), 1);
}
}1.4 mutex简易版整体代码(包含测试案例)
cpp
#include <atomic>
#include <thread>
#include <iostream>
#include <vector>
#include <unistd.h>
#include <sys/syscall.h>
#include <linux/futex.h> // 提供 FUTEX_WAIT 和 FUTEX_WAKE 宏
class Mutex {
private:
std::atomic<int> lock; // 锁状态:0-未锁定,1-已锁定
std::atomic<std::thread::id> owner; // 记录当前持有锁的线程id
std::atomic<int> futex; // 用于futex系统调用的标志:0-无等待者,1-有等待者
// 封装futex系统调用:等待条件成立(*addr == expected)时挂起线程
static int futex_wait(int* addr, int expected) {
return syscall(SYS_futex, addr, FUTEX_WAIT, expected, nullptr, nullptr, 0);
}
// 封装futex系统调用:唤醒最多 wake_count 个等待在 addr 上的线程
static int futex_wake(int* addr, int wake_count) {
return syscall(SYS_futex, addr, FUTEX_WAKE, wake_count, nullptr, nullptr, 0);
}
public:
Mutex() : lock(0), owner(std::thread::id()), futex(0) {}
// 加锁操作
void lock() {
int spins = 100; // 自旋次数
// 第一阶段:自旋尝试获取锁
while (spins--) {
// 尝试原子交换 lock 的值:如果原来为0(未锁定),则交换为1并返回0,表示成功获取锁
if (!lock.exchange(1, std::memory_order_acquire)) {
// 记录当前线程为锁的持有者(使用 relaxed 顺序,因为 lock 已保证同步)
owner.store(std::this_thread::get_id(), std::memory_order_relaxed);
return; // 获取锁成功,返回
}
// 可在此处插入 CPU pause 指令,减少自旋功耗(但非必须)
}
// 第二阶段:自旋失败,进入基于 futex 的等待
while (true) {
// 标记有线程即将进入等待状态
futex.store(1, std::memory_order_relaxed);
// 再次检查锁状态,避免在设置标志后锁被释放却仍然去等待
if (lock.load(std::memory_order_relaxed) != 0) {
// 锁仍被持有,调用 futex_wait 进入睡眠
// 当 futex 的值等于期望值 1 时,线程被挂起;否则立即返回
futex_wait(reinterpret_cast<int*>(&futex), 1);
// 被唤醒后,重新尝试获取锁(循环继续)
}
// 如果锁已经空闲(lock.load() == 0),则直接尝试获取锁
// 尝试通过原子交换获取锁
if (!lock.exchange(1, std::memory_order_acquire)) {
// 成功获取锁,记录持有者并返回
owner.store(std::this_thread::get_id(), std::memory_order_relaxed);
return;
}
// 若获取失败(其他线程抢先获得锁),则继续循环,再次设置 futex 并等待
}
}
// 解锁操作
void unlock() {
// 检查当前线程是否持有锁(非必须,但有助于调试;这里简单返回,实际可能抛出异常)
if (std::this_thread::get_id() != owner.load(std::memory_order_relaxed)) {
// 未持有锁却调用 unlock,通常为未定义行为,这里直接返回
return;
}
// 释放锁:将 lock 置为 0,并使用 release 语义确保临界区操作在此之前完成
lock.store(0, std::memory_order_release);
// 清除锁持有者记录
owner.store(std::thread::id(), std::memory_order_relaxed);
// 原子地将 futex 从 1 交换为 0,并获取旧值
int old = futex.exchange(0, std::memory_order_relaxed);
// 如果旧值为 1,说明有线程在等待,唤醒一个等待者
if (old == 1) {
futex_wake(reinterpret_cast<int*>(&futex), 1);
}
}
};
// 测试案例:多线程递增共享计数器
const int NUM_THREADS = 4;
const int NUM_ITER = 1000000;
int shared_counter = 0;
Mutex mutex;
void increment() {
for (int i = 0; i < NUM_ITER; ++i) {
mutex.lock();
++shared_counter;
mutex.unlock();
}
}
int main() {
std::vector<std::thread> threads;
for (int i = 0; i < NUM_THREADS; ++i) {
threads.emplace_back(increment);
}
for (auto& t : threads) {
t.join();
}
std::cout << "Counter: " << shared_counter
<< " (expected " << NUM_THREADS * NUM_ITER << ")" << std::endl;
return 0;
}1.5 深入 futex
1.5.1 所谓进入内核态等待
futex 真正将线程陷入内核态进行等待和的系统调用
- 线程的休眠状态是由内核维护的,因此需要在内核态权限下操作
- 线程的休眠是指被标记为"睡眠"或"暂不执行"
- 所谓的陷入内核态并不是说将线程整个搬迁到内核空间,而是说将代表该线程的fd存入到内核空间中维护着的一个睡眠状态散列表中
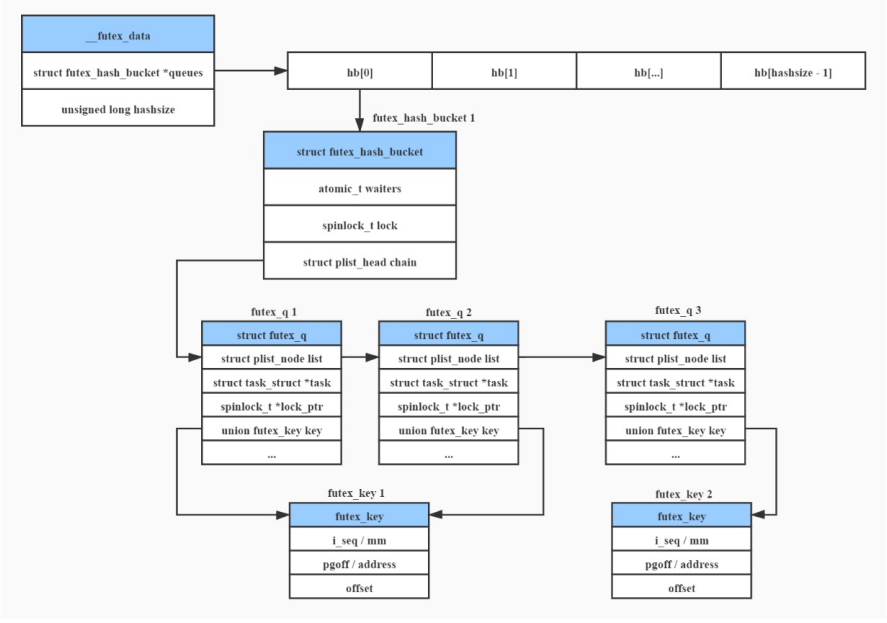
1.5.2 系统调用 futex_wait 和 futex_wake
futex_wait
① 插入等待队列,挂起当前线程
② 如果设置了超时参数,创建定时任务,定时唤醒线程
futex_wake
遍历等待队列,唤醒等待线程
该系统调用向上封装了一层syscall,可以通过传入阻塞还是唤醒的状态的参数。


2. 自旋锁
所谓自旋锁 ,在上面代码中已经体现了其思想,就是让线程在用户态持续自旋(CPU 空转),不会进入内核睡眠,适用于锁持有时间极短的场景。
2.1 真中的自旋锁 spinlock
cpp
class Spinlock {
std::atomic_flag flag = ATOMIC_FLAG_INIT;
public:
void lock() {
while (flag.test_and_set(std::memory_order_acquire)) {
// 自旋等待,可以加 pause 指令优化
#if defined(__x86_64__)
__builtin_ia32_pause(); // 降低功耗,避免流水线惩罚
#endif
}
}
void unlock() {
flag.clear(std::memory_order_release);
}
};核心
flag.test_and_set(std::memory_order_acquire):不断获取锁,循环忙等待__builtin_ia32_pause();降低功耗
2.2 自旋锁思想
cpp
spin = 100;
while (spins--) { //不断的使用原子操作改变lock的值,不进入内核态,自旋思想
if (!lock.exchange(1, std::memory_order_acquire)) {
owner.store(std::this_thread::get_id(), std::memory_order_relaxed);
}
// 可在此处插入 CPU pause 指令,减少自旋功耗(但非必须)
}3 读写锁
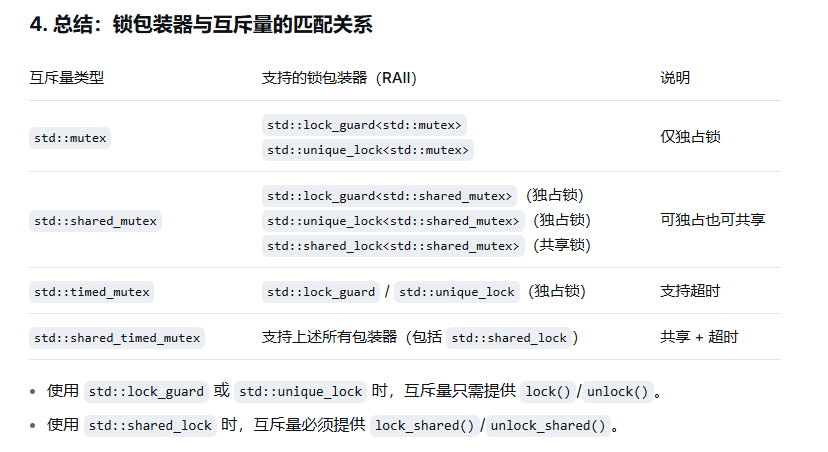
核心思想: 读写锁,读锁可以多个共享,写锁只能独占!
- 读锁使用
shared_lock包装器 - 写锁使用
unique_lock包装器
std::shared_mutex一般用于读多写少的情况,相对来说 std::mutex效率低
cpp
#include <iostream>
#include <shared_mutex>
#include <thread>
#include <vector>
#include <map>
#include <chrono>
// 模拟共享缓存(键值对)
std::map<int, std::string> cache;
std::shared_mutex rw_mutex; // 读写锁
// 读者:查询缓存
void reader(int id) {
for (int i = 0; i < 5; ++i) {
{
std::shared_lock<std::shared_mutex> lock(rw_mutex); // 获取读锁(共享)
// 读取操作:例如打印缓存内容(这里简单打印第一个元素)
if (!cache.empty()) {
auto it = cache.begin();
std::cout << "Reader " << id << " sees: [" << it->first << "] = " << it->second << std::endl;
} else {
std::cout << "Reader " << id << " sees empty cache" << std::endl;
}
} // 读锁自动释放
std::this_thread::sleep_for(std::chrono::milliseconds(100)); // 模拟间隔
}
}
// 写者:更新缓存
void writer(int id) {
for (int i = 0; i < 3; ++i) {
{
std::unique_lock<std::shared_mutex> lock(rw_mutex); // 获取写锁(独占)
// 修改缓存:添加或更新条目
cache[i] = "value" + std::to_string(i);
std::cout << "Writer " << id << " updated cache: [" << i << "] = value" << i << std::endl;
} // 写锁自动释放
std::this_thread::sleep_for(std::chrono::milliseconds(300)); // 模拟写间隔
}
}
int main() {
std::vector<std::thread> threads;
// 启动两个读者线程
for (int i = 0; i < 2; ++i) {
threads.emplace_back(reader, i);
}
// 启动一个写者线程
threads.emplace_back(writer, 0);
// 等待所有线程结束
for (auto& t : threads) {
t.join();
}
return 0;
}
4. 信号量 Semaphore
4.1 简单的异步思想
在工作线程中优先准备好主线程需要的数据后直接调用 release(),通知主线程主要数据已加载完毕,后续工作线程继续完成初始化工作,同时主线程开始工作!
cpp
#include <semaphore>
#include <thread>
#include <iostream>
std::binary_semaphore init_done(0);
void worker() {
std::cout << "Worker: initializing..." << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "Worker: init done, signaling main." << std::endl;
init_done.release(); // 通知主线程
// 继续做其他工作...
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "Worker: finished." << std::endl;
}
int main() {
std::thread t(worker);
init_done.acquire(); // 等待 worker 初始化完成
std::cout << "Main: worker is ready, proceeding." << std::endl;
t.join();
}4.2 数据库连接池
可以限流,假设数据连接池最大数量为10,当10个连接全部用完的时候就会阻塞在semaphore_.acquire()这一行,等待有semaphore_.release(),具体如下:

cpp
class ConnectionPool {
public:
ConnectionPool(size_t max_conn)
: semaphore_(max_conn) // 信号量初始值 = 最大连接数
{
for (size_t i = 0; i < max_conn; ++i) {
// 预先创建连接对象,放入队列
connections_.push(createConnection());
}
}
std::unique_ptr<Connection> get() {
semaphore_.acquire(); // 等待可用连接(计数减1)
std::unique_lock lock(mutex_); // 保护队列
auto conn = std::move(connections_.front());
connections_.pop();
return conn;
}
void put(std::unique_ptr<Connection> conn) {
{
std::unique_lock lock(mutex_);
connections_.push(std::move(conn));
}
semaphore_.release(); // 释放一个可用连接(计数加1)
}
private:
std::counting_semaphore<> semaphore_; // 动态可用资源
std::queue<std::unique_ptr<Connection>> connections_;
std::mutex mutex_; // 保护队列(因为信号量不保护队列本身)
};当然抛开信号量,也可以使用条件变量 + 互斥锁的方式实现
cpp
class ConnectionPoolCV {
public:
ConnectionPoolCV(size_t max_conn) : available_connections_(max_conn) {
for (size_t i = 0; i < max_conn; ++i) {
connections_.push(createConnection());
}
}
std::unique_ptr<Connection> get() {
std::unique_lock lock(mutex_);
// 等待直到有可用连接
cv_.wait(lock, [this] { return available_connections_ > 0; });
--available_connections_; // 占用一个连接
auto conn = std::move(connections_.front());
connections_.pop();
return conn;
}
void put(std::unique_ptr<Connection> conn) {
std::unique_lock lock(mutex_);
connections_.push(std::move(conn));
++available_connections_;
cv_.notify_one(); // 唤醒一个等待的线程
}
private:
std::queue<std::unique_ptr<Connection>> connections_;
size_t available_connections_; // 可用连接计数
std::mutex mutex_;
std::condition_variable cv_;
};- 执行情况: 当available_connections_=0时,所有调用get()的线程都会阻塞在cv_.wait()处,直到有线程归还连接并调用notify_one(),才会唤醒其中一个线程继续执行。
- wait/notify机制:wait会自动释放锁,并将线程加入条件变量的等待队列,线程进入睡眠状态(内核态)。notify_one会从等待队列中取出一个线程,将其状态改为就绪,由调度器调度执行。这涉及内核空间的操作(如futex)。