目录
-
- [使用 PyQt5 + Pandas 打造全能的表格(Excel/CSV)读取与处理工具](#使用 PyQt5 + Pandas 打造全能的表格(Excel/CSV)读取与处理工具)
- [🎯 核心功能一览](#🎯 核心功能一览)
- [🛠️ 技术栈与依赖](#🛠️ 技术栈与依赖)
- [💻 核心代码解析](#💻 核心代码解析)
-
- [1. 拖拽文件与目录加载功能](#1. 拖拽文件与目录加载功能)
- [2. Pandas 与 QTableView 联动 (数据预览)](#2. Pandas 与 QTableView 联动 (数据预览))
- [3. 数据处理:拆分、去重与透视](#3. 数据处理:拆分、去重与透视)
- [4. 字符串的精细批量修改](#4. 字符串的精细批量修改)
- [🚀 总结](#🚀 总结)
专栏导读
🌸 欢迎来到Python办公自动化专栏---Python处理办公问题,解放您的双手
🏳️🌈 个人博客主页:请点击------> 个人的博客主页 求收藏
🏳️🌈 Github主页:请点击------> Github主页 求Star⭐
🏳️🌈 知乎主页:请点击------> 知乎主页 求关注
🏳️🌈 CSDN博客主页:请点击------> CSDN的博客主页 求关注
👍 该系列文章专栏:请点击------>Python办公自动化专栏 求订阅
🕷 此外还有爬虫专栏:请点击------>Python爬虫基础专栏 求订阅
📕 此外还有python基础专栏:请点击------>Python基础学习专栏 求订阅
文章作者技术和水平有限,如果文中出现错误,希望大家能指正🙏
❤️ 欢迎各位佬关注! ❤️
使用 PyQt5 + Pandas 打造全能的表格(Excel/CSV)读取与处理工具
在日常办公和数据分析中,我们经常需要处理各种 Excel 和 CSV 文件。无论是进行简单的数据累加、去重,还是复杂的数据透视、批量拆分,传统的操作往往需要使用 Excel 的复杂函数,或者编写重复的 Python 脚本。
为了提高工作效率,今天我们将手把手教大家使用 PyQt5 和 Pandas 开发一款图形化的表格读取与处理工具。这款工具不仅支持直接拖拽文件加载,还能实时预览,并内置了多种常用的数据处理功能,非常适合零基础办公人员和数据分析师使用!
- 完整代码:
- 点我直达
🎯 核心功能一览
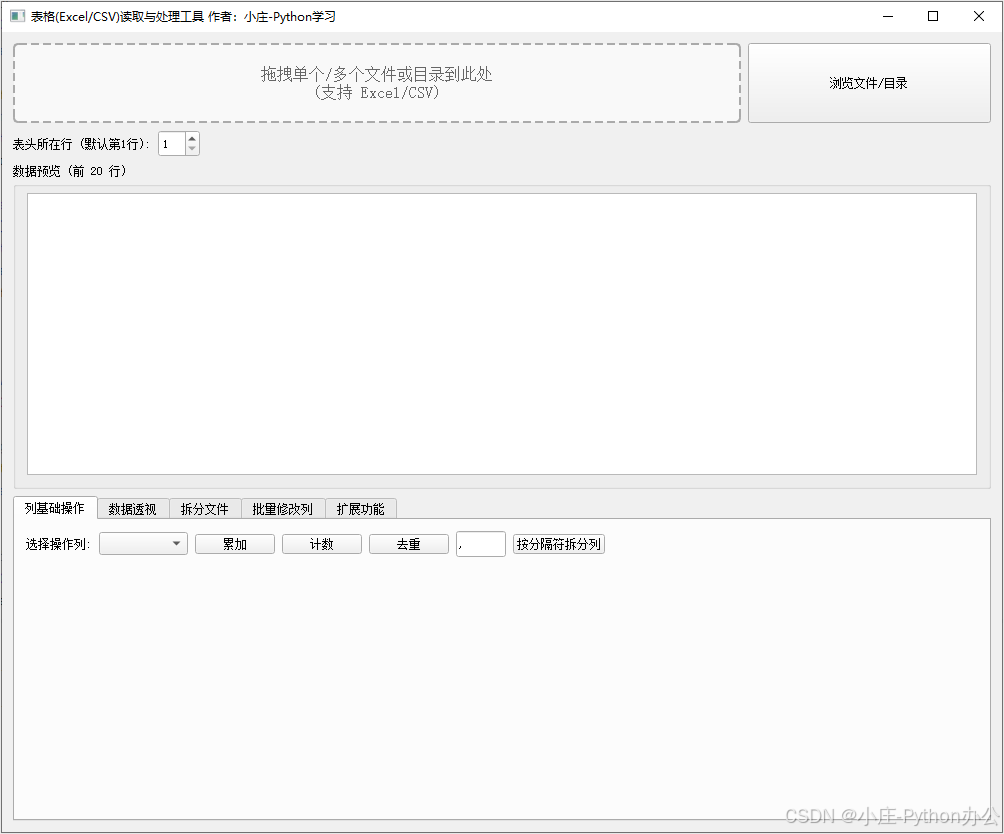
我们这款工具内置了以下实用功能:
- 智能文件加载 :支持点击按钮选择,或直接拖拽单个/多个文件、甚至整个目录 到软件中,自动识别并合并 Excel (
.xls,.xlsx) 和.csv文件。 - 实时数据预览:加载文件后,主界面会实时显示数据的前 20 行,方便确认数据是否正确。
- 自定义表头:遇到表头不在第一行的数据怎么办?用户可以自定义表头所在的行数,工具会自动重新解析数据。
- 丰富的列操作 :
- 快速对指定列进行 累加 、计数
- 对指定列进行数据 去重
- 按照自定义分隔符将一列 拆分 为多列
- 一键数据透视:图形化选择透视的索引(Index)、列(Columns)和值(Values),自动执行求和透视并支持一键导出结果。
- 大文件按行拆分:遇到几十万行的大文件处理卡顿?设置"每文件行数",一键将大文件拆分为多个小文件保存。
- 强大的批量修改列功能 :
- 全部修改为固定值
- 在数据头部/尾部添加特定字符
- 在第 X 个字符后插入特定字符
- 扩展功能:一键处理缺失值(如填充0、填充空字符串或直接删除缺失行),以及一键导出当前处理完毕的所有数据。
🛠️ 技术栈与依赖
本项目基于 Python 开发,主要用到了以下三个强大的库:
- PyQt5:负责构建整个图形化用户界面 (GUI),提供了丰富的控件和交互能力。
- Pandas:负责底层的数据读取、处理和分析,是数据处理的"核武器"。
- openpyxl :Pandas 读写新版 Excel (
.xlsx) 文件的必备引擎。
安装依赖
可以通过以下命令一键安装所有所需库:
bash
pip install PyQt5 pandas openpyxl💻 核心代码解析
下面我们来拆解一下这个工具的几个核心实现点。
1. 拖拽文件与目录加载功能
为了让用户体验更好,我们继承 QLabel 自定义了一个 DragDropWidget,用于接收拖拽事件:
python
class DragDropWidget(QLabel):
def __init__(self, parent=None):
super().__init__(parent)
self.setText("拖拽单个/多个文件或目录到此处\n(支持 Excel/CSV)")
self.setAcceptDrops(True)
self.main_window = parent
def dragEnterEvent(self, event: QDragEnterEvent):
# 允许接收包含路径的文件拖拽
if event.mimeData().hasUrls():
event.acceptProposedAction()
def dropEvent(self, event: QDropEvent):
urls = event.mimeData().urls()
paths = [url.toLocalFile() for url in urls]
# 将获取到的路径交给主窗口处理
self.main_window.handle_dropped_files(paths)2. Pandas 与 QTableView 联动 (数据预览)
要在 PyQt 的 QTableView 中展示 Pandas 数据框,我们需要自定义一个 QAbstractTableModel,重写其行数、列数和数据返回方法:
python
class PandasModel(QAbstractTableModel):
def __init__(self, data):
super().__init__()
self._data = data
def rowCount(self, parent=None):
return self._data.shape[0]
def columnCount(self, parent=None):
return self._data.shape[1]
def data(self, index, role=Qt.DisplayRole):
if index.isValid():
if role == Qt.DisplayRole:
val = self._data.iloc[index.row(), index.column()]
return str(val) if not pd.isna(val) else ""
return None
def headerData(self, col, orientation, role):
if orientation == Qt.Horizontal and role == Qt.DisplayRole:
return str(self._data.columns[col])
return None在工具中,我们通过 self.df.head(20) 获取前 20 行数据并传入该 Model,实现了轻量级的数据预览。
3. 数据处理:拆分、去重与透视
基于 Pandas 的强大功能,我们可以仅用几行代码实现复杂的逻辑:
- 去重 :
self.df = self.df.drop_duplicates(subset=[col]) - 拆分列 :
new_cols = self.df[col].astype(str).str.split(sep, expand=True) - 数据透视:
python
pivot_df = pd.pivot_table(
self.df,
values=val,
index=idx,
columns=col,
aggfunc='sum',
fill_value=0
)4. 字符串的精细批量修改
对于"在第 X 个字符后插入内容"这种需求,我们可以利用 Pandas 的 apply 方法搭配自定义函数实现:
python
def insert_str(s):
s_str = str(s)
if len(s_str) >= pos:
return s_str[:pos] + val + s_str[pos:]
return s_str + val
self.df[col] = self.df[col].apply(insert_str)🚀 总结
通过将 PyQt5 和 Pandas 结合,我们打造出了一个功能完备、界面友好的本地数据处理利器。这个工具不仅能极大提升我们处理零碎 Excel 文件的效率,更提供了一个很好的学习范例------你可以根据自己的实际业务需求,在 main.py 的选项卡中继续添加更多自定义的数据清洗和分析功能!
快把这份代码运行起来,让你的数据处理工作从此告别加班吧!
结尾
希望对初学者有帮助;致力于办公自动化的小小程序员一枚
希望能得到大家的【❤️一个免费关注❤️】感谢!
求个 🤞 关注 🤞 +❤️ 喜欢 ❤️ +👍 收藏 👍
此外还有办公自动化专栏,欢迎大家订阅:Python办公自动化专栏
此外还有爬虫专栏,欢迎大家订阅:Python爬虫基础专栏
此外还有Python基础专栏,欢迎大家订阅:Python基础学习专栏