一、引言
SQL 是关系数据库操作的标准语言,函数依赖与规范化是数据库设计的核心理论,二者共同构成软考软件设计师数据库模块的核心考点,相关知识点在选择题中每年占比8-12 分,案例分析题中几乎每年都会出现数据库设计优化类题目,是必须熟练掌握的核心内容。
本文将系统讲解 SQL 高级查询、数据定义与更新语句的核心语法与应用规则,深入解析函数依赖的定义与分类,完整梳理 1NF 到 BCNF 的范式判定方法与优化路径,覆盖所有考试要求的核心知识点。
二、SQL 高级查询
2.1 连接查询
连接查询是跨多表数据检索的核心机制,本质是通过关联条件将多个关系的元组进行拼接,实现分散存储数据的关联查询。
连接查询分为等值连接、非等值连接、自连接、外连接四类,其中等值连接是最常用的类型,关联条件使用等于运算符匹配两个表的公共属性。非等值连接使用大于、小于、范围等运算符作为关联条件,常用于区间匹配类场景,如根据成绩区间匹配等级。自连接是将同一个表与自身进行连接,常用于层级数据查询,如查询员工及其上级的信息。外连接包括左外连接、右外连接和全外连接,可保留连接条件不满足的一侧的元组,解决常规等值连接中数据丢失的问题。
连接查询的性能与关联字段的索引设计直接相关,关联字段如果没有建立索引,在大表场景下会产生全表扫描的性能瓶颈,实际应用中需要确保连接条件涉及的字段都已创建合适的索引。
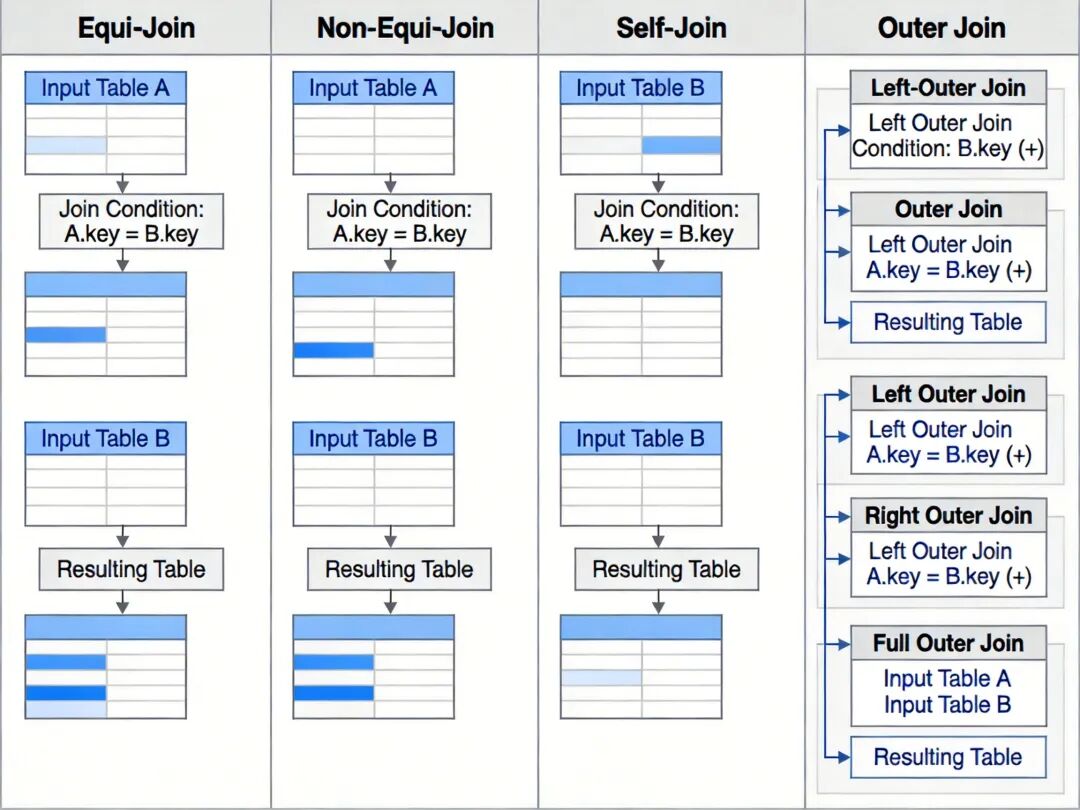
四种连接查询的结果集对比示意图
2.2 聚集函数与分组查询
聚集函数 用于对一组数据进行聚合计算,返回单个统计结果,常用的聚集函数包括 COUNT ()、SUM ()、AVG ()、MAX ()、MIN ()。COUNT () 统计元组数量,参数使用 * 时统计所有元组,使用具体列名时忽略 NULL 值;SUM () 和 AVG () 仅适用于数值类型字段,MAX () 和 MIN () 可适用于数值、字符串、日期类型字段。
GROUP BY 子句按指定的一个或多个列对结果集进行分组,分组后聚集函数会针对每个分组独立计算结果。分组操作的核心规则是:SELECT 子句中出现的非聚集函数字段,必须全部出现在 GROUP BY 子句中,否则会产生语法错误或逻辑错误。
HAVING 子句用于对分组后的聚合结果进行筛选,必须与 GROUP BY 子句联用。HAVING 与 WHERE 的区别在于作用阶段不同:WHERE 作用于分组前,过滤原始元组,不能使用聚集函数;HAVING 作用于分组后,过滤聚合结果,可以使用聚集函数。
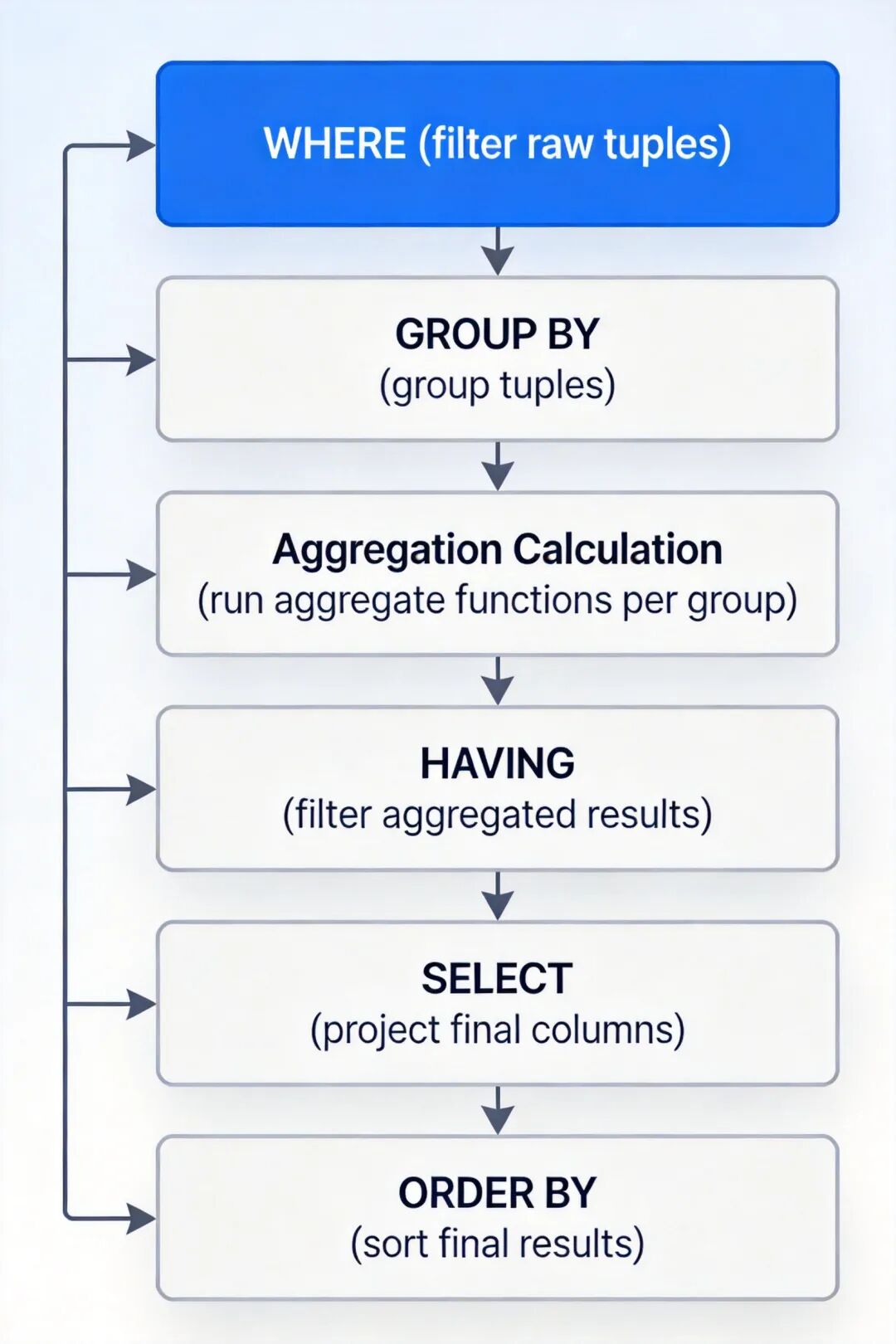
分组查询执行流程图(WHERE→GROUP BY→聚集计算→HAVING→SELECT→ORDER BY)
2.3 子查询
子查询 是指嵌套在其他查询语句中的查询块,也称为嵌套查询,外层查询称为父查询。子查询按返回结果可分为单行子查询、多行子查询和多列子查询:单行子查询返回单个值,可使用 =、>、< 等比较运算符与父查询关联;多行子查询返回多个值,需要使用 IN、ANY、ALL 等运算符关联;多列子查询返回多个列,通常用于组合条件匹配。
子查询按执行方式可分为相关子查询 和非相关子查询:非相关子查询的执行不依赖于父查询的属性,可以独立执行,执行效率较高;相关子查询的执行依赖于父查询的属性,需要为父查询的每个元组重复执行子查询,执行效率较低,大数据量场景下建议使用连接查询替代相关子查询。
EXISTS 是子查询的特殊运算符,用于判断子查询是否有返回结果,不关心返回的具体内容,只要存在匹配的元组就返回真,常用于存在性判断类场景。
三、SQL 数据定义与更新
3.1 数据定义语言(DDL)
数据定义语言用于创建、修改、删除数据库对象,核心操作对象包括表、视图、索引、约束等。
CREATE TABLE 用于创建基本表,定义时需要指定每个字段的名称、数据类型、约束条件。常见的约束包括 PRIMARY KEY(主键约束,保证实体完整性,非空且唯一)、FOREIGN KEY(外键约束,保证参照完整性)、NOT NULL(非空约束)、UNIQUE(唯一约束)、CHECK(自定义检查约束)。软考中需要重点掌握主键、外键的定义规则,以及数据类型的选择原则,如固定长度字符串使用 CHAR,可变长度字符串使用 VARCHAR,日期类型使用 DATE 或 DATETIME。
CREATE VIEW 用于创建视图 ,视图是从一个或多个基本表导出的虚表,本身不存储数据,仅存储查询定义。视图的作用包括简化复杂查询、提供数据逻辑独立性、实现数据安全访问控制,用户可以通过视图访问部分字段,无需直接接触完整的基本表。
CREATE INDEX 用于创建索引 ,索引是提高查询性能的核心机制,分为聚集索引和非聚集索引:聚集索引决定表中数据的物理存储顺序,一个表只能有一个聚集索引;非聚集索引存储索引键值和指向元组的指针,一个表可以创建多个非聚集索引。索引的创建需要权衡查询性能和更新性能,索引可以加快查询速度,但会降低 INSERT、UPDATE、DELETE 操作的性能,因为更新数据时需要同步维护索引结构。
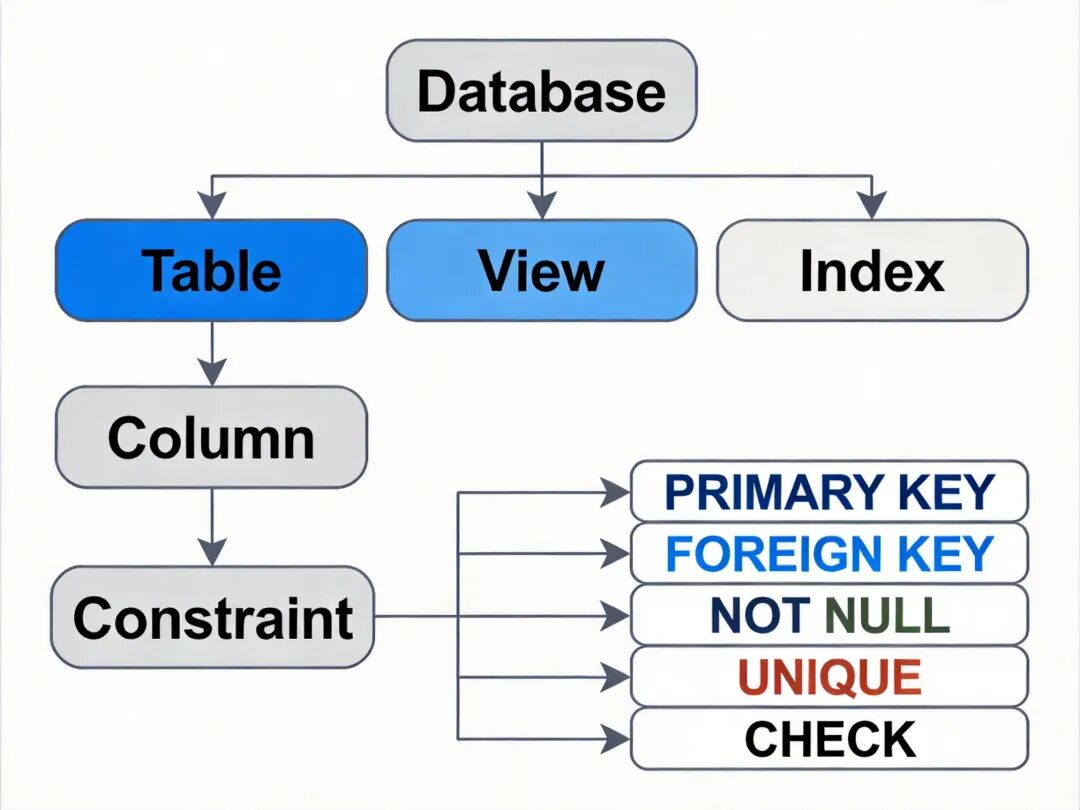
数据库对象层级关系图(数据库→表 / 视图 / 索引→字段 / 约束)
3.2 数据操纵语言(DML)
数据操纵语言用于对表中的数据进行增、删、改操作,核心语句包括 INSERT、UPDATE、DELETE。
INSERT 语句 用于插入新的元组,两种常用语法:一种是指定字段列表和对应的值列表,未指定的字段使用默认值或 NULL;另一种是不指定字段列表,按表定义的字段顺序提供所有字段的值。批量插入时可以在 VALUES 子句后提供多组值,或使用 SELECT 子句将查询结果直接插入目标表。
UPDATE 语句 用于更新已有元组的字段值,可以使用 WHERE 子句指定需要更新的元组范围,不写 WHERE 子句时会更新表中所有元组。更新操作可以基于其他表的数据,通过子查询或关联更新实现跨表的批量更新。
DELETE 语句 用于删除表中的元组,可以使用 WHERE 子句指定删除范围,不写 WHERE 子句时会删除表中所有元组。DELETE 操作删除的是数据,不会删除表结构,与 DROP TABLE(删除表结构和数据)、TRUNCATE TABLE(清空表数据,不可回滚)有本质区别。
DML 操作默认处于事务控制中,执行后需要提交事务才能永久生效,回滚事务可以撤销未提交的 DML 操作。
四、函数依赖理论
函数依赖是规范化理论的核心基础,用于描述关系模式中属性之间的约束关系,定义为:在关系模式 R (U) 中,X 和 Y 是属性集 U 的子集,若对于 R (U) 的任意一个合法关系 r,r 中不存在两个元组在 X 上的属性值相等,而在 Y 上的属性值不等,则称 X 函数决定 Y,或 Y 函数依赖于 X,记作 X→Y。X 称为决定因素,Y 称为依赖因素。
函数依赖是语义层面的约束,需要根据业务规则判断,而不是根据某个时刻的具体数据判断。例如,学生表中如果业务规则规定学号唯一,则 Sno→Sname 成立,即使当前表中没有重名的学生,也不能得出 Sname→Sno 的结论,因为未来可能出现重名学生。
4.1 函数依赖的分类
完全函数依赖 :若 X→Y,且对于 X 的任意真子集 X',都有 X' 不能决定 Y,则称 Y 对 X 完全函数依赖,记作 X→F Y。例如,在选课关系 SC (Sno, Cno, Grade) 中,(Sno, Cno)→Grade,单独的 Sno 或 Cno 都不能决定 Grade,因此 Grade 对 (Sno, Cno) 是完全函数依赖。
部分函数依赖 :若 X→Y,但 Y 不完全依赖于 X,即存在 X 的真子集 X',使得 X'→Y,则称 Y 对 X 部分函数依赖,记作 X→P Y。例如,在关系 S (Sno, Cno, Sname, Credit) 中,(Sno, Cno)→Sname,而单独的 Sno 就可以决定 Sname,因此 Sname 对 (Sno, Cno) 是部分函数依赖。
传递函数依赖 :若 X→Y,Y→Z,且 Y 不包含于 X,Y 不能决定 X,则称 Z 对 X 传递函数依赖,记作 X→T Z。例如,在关系 Student (Sno, Dno, Dname, Dhead) 中,Sno→Dno,Dno→Dname,且 Dno 不能决定 Sno,因此 Dname 对 Sno 是传递函数依赖。
4.2 候选键的求解
候选键是关系模式中能够唯一标识一个元组的最小属性集,满足两个条件:能够函数决定关系中的所有属性,且不存在真子集可以决定所有属性。一个关系模式可以有多个候选键,选定其中一个作为主键。
候选键的常用求解方法是属性分类法:首先将属性分为四类,L 类(仅出现在函数依赖左部的属性)、R 类(仅出现在函数依赖右部的属性)、N 类(在函数依赖左右部都没有出现的属性)、LR 类(在函数依赖左右部都出现的属性)。L 类和 N 类属性一定属于候选键,R 类属性一定不属于候选键,LR 类属性需要判断是否能和 L、N 类属性组合推导出所有属性。
例如,关系模式 R (A,B,C,D,E),函数依赖集 F={A→C, BC→D, D→B, C→E},L 类属性是 A,N 类属性没有,A 可以推出 C,C 可以推出 E,A 和 B 可以推出 D,A 和 D 也可以推出 B,因此候选键是 AB 和 AD。
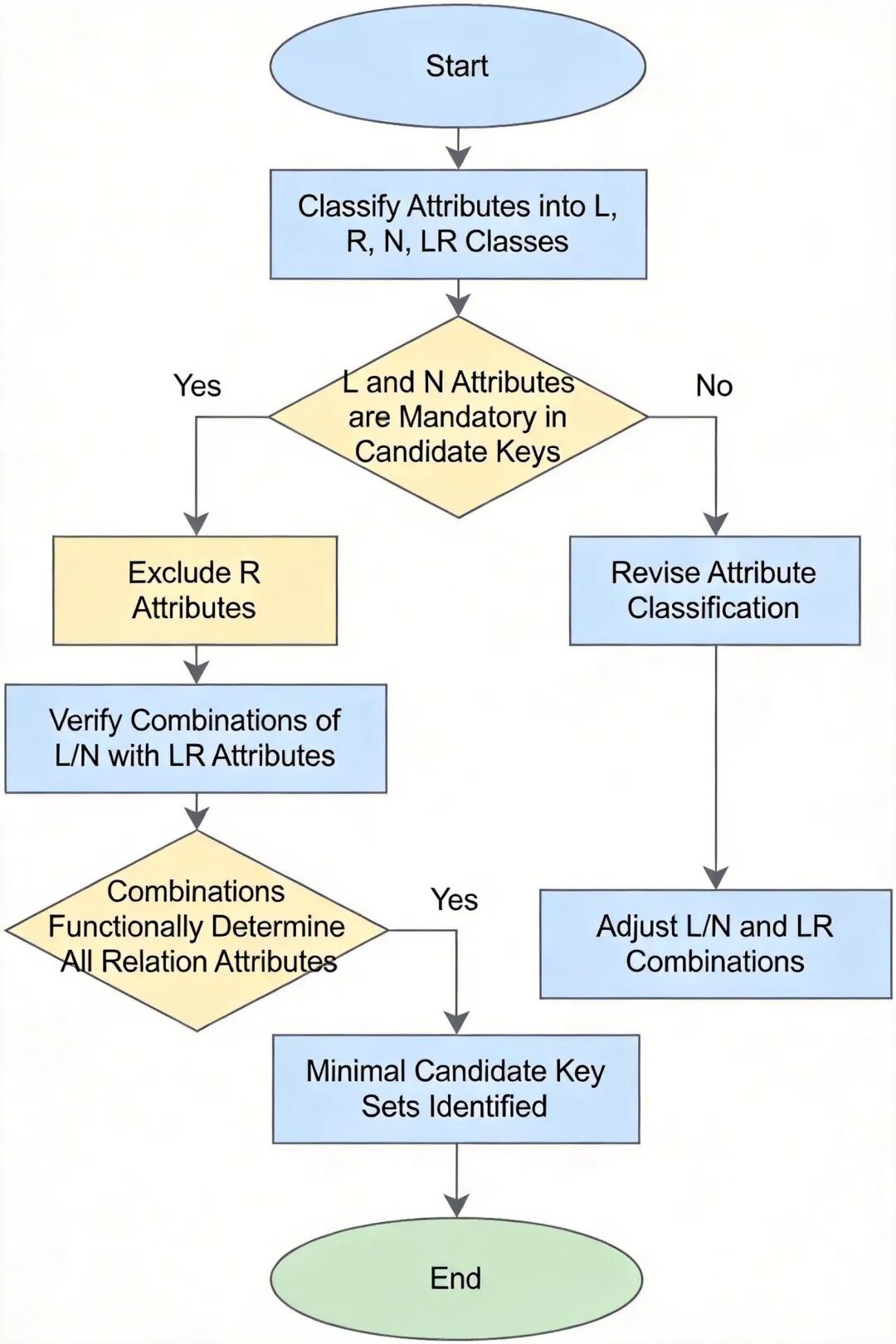
候选键求解流程图
五、关系模式规范化
规范化是将存在数据冗余、插入异常、删除异常、更新异常的关系模式,分解为更优的关系模式的过程,核心目标是消除不合适的函数依赖,减少数据冗余,提高数据一致性。范式是衡量关系模式规范化程度的标准,从低到高依次为 1NF、2NF、3NF、BCNF、4NF、5NF,软考要求掌握到 BCNF。
5.1 各级范式的定义与判定
第一范式(1NF) :关系模式的所有属性都是不可再分的原子值,不存在组合属性或多值属性。1NF 是关系模式的最低要求,不满足 1NF 的设计不能称为关系数据库。常见的违反 1NF 的情况包括:一个字段存储多个值,如联系电话字段同时存储手机号和固定电话;字段包含嵌套结构,如地址字段包含省、市、街道三个子属性。
第二范式(2NF) :在 1NF 的基础上,消除非主属性对候选键的部分函数依赖,即所有非主属性都完全函数依赖于候选键。主属性是指包含在任意一个候选键中的属性,非主属性是指不包含在任何候选键中的属性。如果关系模式的候选键是单属性,那么天然满足 2NF,因为单属性不存在真子集,不可能产生部分依赖。
第三范式(3NF) :在 2NF 的基础上,消除非主属性对候选键的传递函数依赖,即所有非主属性都直接依赖于候选键,不依赖于其他非主属性。3NF 可以解决大部分数据冗余和操作异常问题,是实际项目中最常用的规范化级别。
BC 范式(BCNF) :在 3NF 的基础上,消除主属性对候选键的部分函数依赖和传递函数依赖,即所有函数依赖的决定因素都包含候选键。BCNF 是修正的第三范式,比 3NF 更严格,满足 BCNF 的关系模式在函数依赖范围内已经消除了所有的插入、删除、更新异常,数据冗余度最低。
5.2 规范化的实施方法
规范化的核心方法是模式分解,将一个大的关系模式拆分为多个小的关系模式,分解需要满足两个准则:无损连接性 ,即分解后的关系通过自然连接可以恢复到原来的关系,不丢失数据;保持函数依赖性,即分解后的关系集合能够保持原来的所有函数依赖,不丢失业务约束。
分解为 2NF 的方法:将部分函数依赖的决定因素和对应的依赖属性提取出来,单独构成一个新的关系,原关系中保留候选键和完全依赖的属性。
分解为 3NF 的方法:在 2NF 的基础上,将传递函数依赖的中间属性和对应的依赖属性提取出来,单独构成新的关系,原关系中保留候选键和直接依赖的属性。
实际应用中不需要盲目追求最高范式,需要根据业务场景在规范化和查询性能之间做权衡。对于查询为主、更新较少的系统,可以适当降低规范化级别,通过引入少量冗余减少连接查询,提高查询性能;对于更新频繁、数据一致性要求高的系统,需要达到 3NF 或 BCNF,减少数据冗余导致的一致性问题。
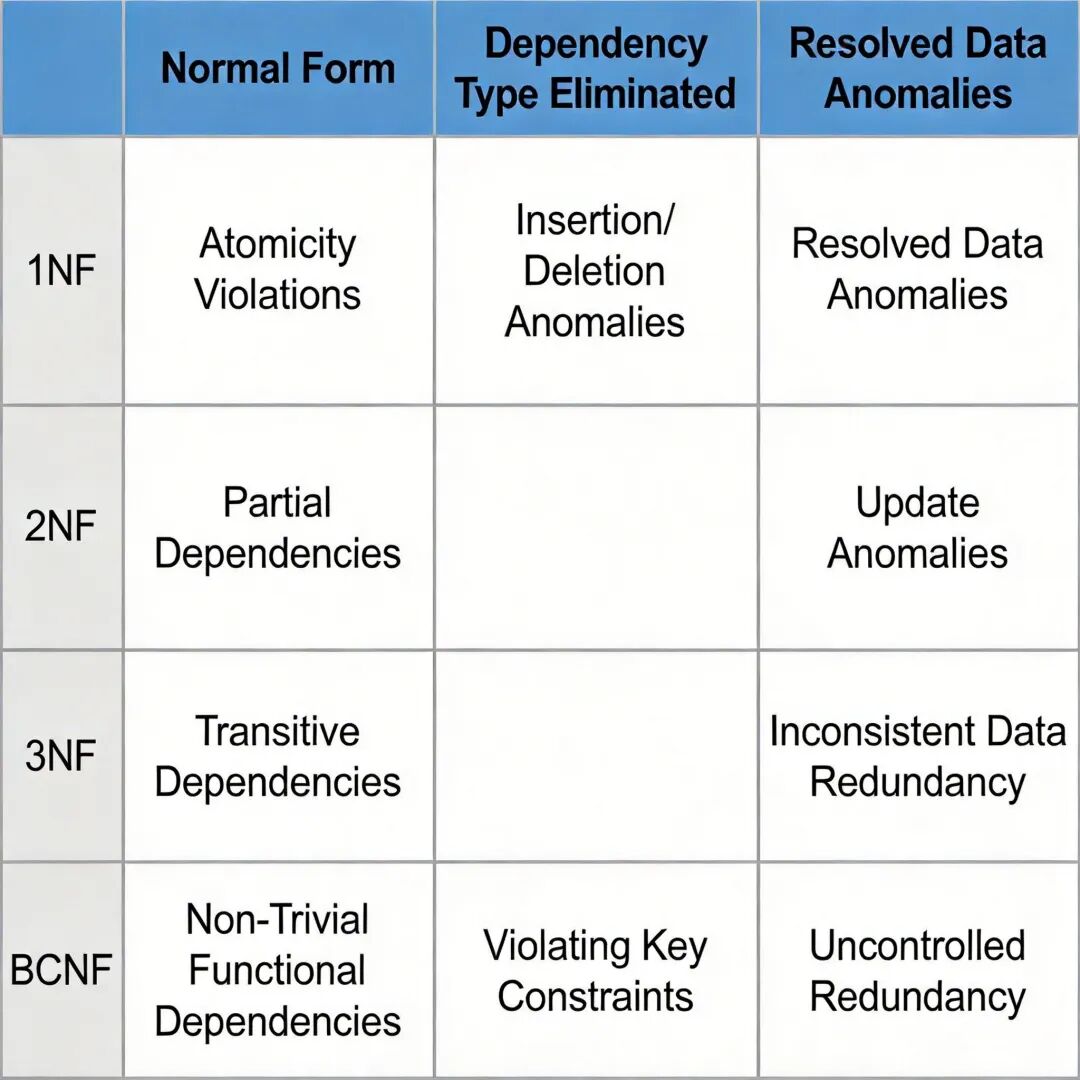
各级范式对应消除的依赖类型和存在的问题对比表
六、总结与建议
6.1 核心知识点提炼
SQL 高级查询部分核心要点 :连接查询的分类与适用场景,GROUP BY 与 HAVING 的执行逻辑和与 WHERE 的区别,子查询的分类和性能特点。
SQL 数据定义与更新部分核心要点 :表约束的类型与作用,视图的本质与作用,索引的分类与性能权衡,DML 操作的事务特性。
函数依赖部分核心要点 :函数依赖的定义,完全、部分、传递函数依赖的判定,候选键的求解方法。
规范化部分核心要点 :1NF 到 BCNF 的各级范式定义与判定规则,模式分解的准则,规范化的权衡策略。
6.2 软考考试重点提示
选择题高频考点包括:HAVING 与 WHERE 的区别,视图的特性,候选键的求解,各级范式的判定,函数依赖类型判断。其中范式判定每年必考,通常给出一个关系模式和函数依赖集,要求判断当前属于第几范式,以及分解到更高范式的方法。
案例分析题常考题型包括:根据业务场景补充 SQL 查询语句,找出关系模式中的主键和外键,判断现有设计存在的异常,将不符合范式的关系模式优化到 3NF。答题时需要注意区分主属性和非主属性,逐一检查是否存在部分依赖和传递依赖,确保分解后的关系满足无损连接和保持函数依赖。
6.3 学习与实践建议
学习 SQL 部分时要结合实际练习,通过编写不同场景的 SQL 语句加深语法理解,重点掌握多表连接、分组统计、子查询的写法,注意区分容易混淆的语法点。
学习规范化理论时,首先熟练掌握函数依赖的分类和候选键的求解方法,这是范式判定的基础。可以通过多做练习题熟悉各级范式的判定步骤,从简单的关系模式开始,逐步过渡到复杂的多依赖场景。
实际项目设计中,优先保证核心业务表达到 3NF,对于报表类、统计类的非核心表,可以根据查询需求适当冗余字段,减少跨表连接。设计完成后要反向验证是否存在插入、删除、更新异常,确保数据一致性。
数据库规范化理论经过多年发展已经非常成熟,随着分布式数据库的广泛应用,适度去规范化已经成为常见的设计策略,但规范化的核心思想依然是保证数据质量的基础,需要在理解核心原理的基础上灵活应用。