目录
在矿物数据分析与建模任务中,缺失值是数据预处理阶段无法回避的问题。缺失值会导致模型训练偏差、特征信息丢失,甚至直接影响最终分类 / 预测效果。本文基于实际矿物数据集,实现了完整行保留、均值、中位数、众数、线性回归、随机森林六种缺失值填充方法,并详细讲解各方法的实现逻辑与适用场景,为矿物数据预处理提供可复用的解决方案。
一、先对数据进行基础预处理
创建一个数据集六种方法填充.py文件:
python
import pandas as pd
import fill_data
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import os
# 1. 数据读取与预处理
data = pd.read_excel("矿物数据.xls")
data = data[data['矿物类型'] != 'E'] # 数据筛选:删除矿物类型为'E'的行
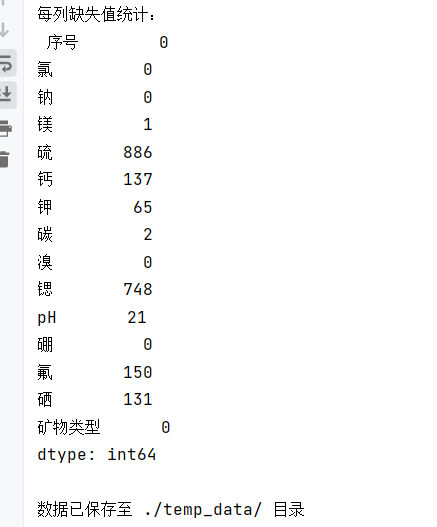
# 2. 检查缺失值
null_num = data.isnull() # 每列缺失值的布尔矩阵
null_total = null_num.sum() # 每列缺失值的总数
print("每列缺失值统计:\n", null_total)
# 3. 分离特征和标签
X_whole = data.drop('矿物类型', axis=1).drop('序号', axis=1) # 获取全部特征数据
y_whole = data.矿物类型 # 获取全部标签数据
# 4. 标签编码(将中文标签转换为数字)
label_dict = {"A": 0, "B": 1, "C": 2, "D": 3}
encoded_labels = [label_dict[label] for label in y_whole]
y_whole = pd.Series(encoded_labels, name='矿物类型') # 将列表转换为Pandas Series
# 5. 数据类型转换:处理异常值(将字符串、空格转为NaN)
# 数据中存在大量字符串数值、|、空格等异常数据,字符串数值直接转换为float,空格转换为nan
for column_name in X_whole.columns:
X_whole[column_name] = pd.to_numeric(X_whole[column_name], errors='coerce')
# 6. 数据标准化:Z标准化
scaler = StandardScaler()
X_whole_Z = scaler.fit_transform(X_whole)
X_whole = pd.DataFrame(X_whole_Z, columns=X_whole.columns)
# 7. 数据切分(先切分,后填充:测试集不能参与训练,避免数据泄露)
x_train_w, x_test_w, y_train_w, y_test_w = train_test_split(
X_whole, y_whole, test_size=0.3, random_state=50000)二、六种缺失值方法的实现
1.完整行保留(CCA)
直接删除包含缺失值的行,仅保留完整数据。优点是简单无偏差,缺点是会丢失大量数据(尤其缺失率高时),仅适用于缺失值极少的场景。
数据集六种方法填充.py文件中的代码:
python
# 方法1: 只保留完整行的数据集(CCA填充)
x_train_fill,y_train_fill = fill_data.cca_train_fill(x_train_w,y_train_w)
x_test_fill,y_test_fill=fill_data.cca_test_fill(x_train_w,y_train_w,x_test_w,y_test_w)
if not os.path.exists('./temp_data'):
os.makedirs('./temp_data')
# 合并特征与标签并保存
data_train = pd.concat([y_train_fill, x_train_fill], axis=1)
data_test = pd.concat([y_test_fill, x_test_fill], axis=1)
data_train.to_excel(r'./temp_data/训练数据集[只保留完整数据行].xlsx', index=False)
data_test.to_excel(r'./temp_data/测试数据集[只保留完整数据行].xlsx', index=False)
print("\n数据已保存至 ./temp_data/ 目录")fill_data.py中的代码:
python
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression
#-----------------------------考虑包含完整行的数据--------------------------------------#
def cca_train_fill(train_data,train_label):
'''CCA(Complete Case Anglysis)只考虑包含完整数据的行'''
data = pd.concat([train_data,train_label],axis=1)
data = data.reset_index(drop=True)#用于重置泰州的。当你对数据进行了排序、选或其他操作后素州川能会变得不连续或混乱
df_filled=data.dropna()#用于删除(或过滤掉)包含缺失值(NaN)的行或列。pandas里面有大量和数据洁洗相关的函数
return df_filled.drop('矿物类型',axis=1),df_filled.矿物类型
def cca_test_fill(train_data,train_label,test_data,test_label):
'''cca('''
data = pd.concat([test_data,test_label],axis=1)
data = data.reset_index(drop=True)
df_filled=data.dropna()
return df_filled.drop('矿物类型',axis=1),df_filled.矿物类型最后运行的结果是在路径D:\software\Pycharm\矿物项目\temp_data中生成训练数据集只保留完整数据行.xlsx和测试数据集只保留完整数据行.xlsx两个文件
2.均值填充
按矿物类别分别计算特征均值,用类别内均值填充该类别下的缺失值,训练集用自身均值填充,测试集用训练集对应类别均值填充。
数据集六种方法填充.py文件中的代码:
python
# 方法2: 平均值填充
x_train_fill,y_train_fill = fill_data.mean_train_fill(x_train_w,y_train_w)
x_test_fill,y_test_fill = fill_data.mean_test_fill(x_train_w,y_train_w,x_test_w,y_test_w)
if not os.path.exists('./temp_data'):
os.makedirs('./temp_data')
# 合并特征与标签并保存
data_train = pd.concat([y_train_fill, x_train_fill], axis=1)
data_test = pd.concat([y_test_fill, x_test_fill], axis=1)
data_train.to_excel(r'./temp_data/训练数据集[线性回归].xlsx', index=False)
data_test.to_excel(r'./temp_data/测试数据集[线性回归].xlsx', index=False)
print("\n数据已保存至 ./temp_data/ 目录")fill_data.py中的代码:
python
def mean_train_method(data):
'''平均值计算方法'''
fill_values =data.mean()
return data.fillna(fill_values)#使用均值填充缺失值,pandas读取表格数据,
def mean_train_fill(train_data,train_label):
'''使用平均值的方法对数据进行填充'''
data = pd.concat([train_data,train_label],axis=1)
data = data.reset_index(drop=True)
A=data[data['矿物类型']==0]
B=data[data['矿物类型']==1]
C=data[data['矿物类型']==2]
D=data[data['矿物类型']==3]
A=mean_train_method(A)
B=mean_train_method(B)
C=mean_train_method(C)
D=mean_train_method(D)
df_filled=pd.concat([A,B,C,D])
df_filled=df_filled.reset_index(drop=True)
return df_filled.drop('矿物类型',axis=1),df_filled.矿物类型
# ----------------------测试集均值填充----------------------
def mean_test_method(train_data, test_data):
'''使用训练集均值填充测试集缺失值'''
fill_values = train_data.mean()
return test_data.fillna(fill_values)
def mean_test_fill(train_data,train_label,test_data,test_label):
train_data_all=pd.concat([train_data,train_label],axis=1)
train_data_all=train_data_all.reset_index(drop=True)
test_data_all=pd.concat([test_data,test_label],axis=1)
test_data_all=test_data_all.reset_index(drop=True)
A_train=train_data_all[train_data_all['矿物类型']==0]
B_train=train_data_all[train_data_all['矿物类型']==1]
C_train=train_data_all[train_data_all['矿物类型']==2]
D_train=train_data_all[train_data_all['矿物类型']==3]
A_test=test_data_all[test_data_all['矿物类型']==0]
B_test=test_data_all[test_data_all['矿物类型']==1]
C_test=test_data_all[test_data_all['矿物类型']==2]
D_test=test_data_all[test_data_all['矿物类型']==3]
A=mean_test_method(A_train,A_test)
B=mean_test_method(B_train,B_test)
C=mean_test_method(C_train,C_test)
D=mean_test_method(D_train,D_test)
#填充测试集
df_filled=pd.concat([A,B,C,D])
df_filled=df_filled.reset_index(drop=True)
return df_filled.drop('矿物类型',axis=1),df_filled.矿物类型最后运行的结果是在路径D:\software\Pycharm\矿物项目\temp_data中生成训练数据集线性回归.xlsx和测试数据集线性回归.xlsx两个文件
3:中位数填充
与均值填充逻辑一致,仅将填充值从 "均值" 改为 "中位数"。中位数对异常值更鲁棒,适合特征存在极端值的矿物数据。
数据集六种方法填充.py文件中的代码:
python
方法3: 中位数填充
x_train_fill,y_train_fill = fill_data.median_train_fill(x_train_w,y_train_w)
x_test_fill,y_test_fill = fill_data.median_test_fill(x_train_w,y_train_w,x_test_w,y_test_w)
if not os.path.exists('./temp_data'):
os.makedirs('./temp_data')
# 合并特征与标签并保存
data_train = pd.concat([y_train_fill, x_train_fill], axis=1)
data_test = pd.concat([y_test_fill, x_test_fill], axis=1)
data_train.to_excel(r'./temp_data/训练数据集[中位数].xlsx', index=False)
data_test.to_excel(r'./temp_data/测试数据集[中位数].xlsx', index=False)
print("\n数据已保存至 ./temp_data/ 目录")fill_data.py中的代码:
python
# ----------------------中位数填充方法----------------------
def median_method(data):
'''数据集中的空值使用每列的中位数替代'''
fill_values = data.median()
return data.fillna(fill_values) # 使用中位数填充缺失值
def median_train_fill(train_data, train_label):
'''使用中位数的方法对数据进行填充'''
data = pd.concat([train_data, train_label], axis=1)
data = data.reset_index(drop=True)
A = data[data['矿物类型'] == 0]
B = data[data['矿物类型'] == 1]
C = data[data['矿物类型'] == 2]
D = data[data['矿物类型'] == 3]
A = median_method(A) # 按照每个类别的数据进行填充
B = median_method(B)
C = median_method(C)
D = median_method(D)
df_filled = pd.concat([A, B, C, D])
df_filled = df_filled.reset_index(drop=True)
return df_filled.drop('矿物类型', axis=1), df_filled.矿物类型
# ----------------------测试集中位数填充----------------------
def median_test_method(train_data, test_data):
'''使用训练集中位数填充测试集缺失值'''
fill_values = train_data.median()
return test_data.fillna(fill_values)
def median_test_fill(train_data, train_label, test_data, test_label):
'''使用中位数的方法对数据进行填充'''
train_data_all = pd.concat([train_data, train_label], axis=1)
train_data_all = train_data_all.reset_index(drop=True)
test_data_all = pd.concat([test_data, test_label], axis=1)
test_data_all = test_data_all.reset_index(drop=True)
A_train = train_data_all[train_data_all['矿物类型'] == 0]
B_train = train_data_all[train_data_all['矿物类型'] == 1]
C_train = train_data_all[train_data_all['矿物类型'] == 2]
D_train = train_data_all[train_data_all['矿物类型'] == 3]
A_test = test_data_all[test_data_all['矿物类型'] == 0]
B_test = test_data_all[test_data_all['矿物类型'] == 1]
C_test = test_data_all[test_data_all['矿物类型'] == 2]
D_test = test_data_all[test_data_all['矿物类型'] == 3]
A = median_test_method(A_train, A_test)
B = median_test_method(B_train, B_test)
C = median_test_method(C_train, C_test)
D = median_test_method(D_train, D_test)
df_filled = pd.concat([A, B, C, D])
df_filled = df_filled.reset_index(drop=True)
return df_filled.drop('矿物类型', axis=1), df_filled.矿物类型最后运行的结果是在路径D:\software\Pycharm\矿物项目\temp_data中生成训练数据集中位数.xlsx和测试数据集中位数.xlsx两个文件
4.众数填充
众数是特征中出现频率最高的值,适合离散型特征,同样按类别计算众数,避免跨类别偏差。
数据集六种方法填充.py文件中的代码:
python
# 方法4: 众数填充
x_train_fill,y_train_fill = fill_data.mode_train_fill(x_train_w,y_train_w)
x_test_fill,y_test_fill = fill_data.mode_test_fill(x_train_w,y_train_w,x_test_w,y_test_w)
if not os.path.exists('./temp_data'):
os.makedirs('./temp_data')
# 合并特征与标签并保存
data_train = pd.concat([y_train_fill, x_train_fill], axis=1)
data_test = pd.concat([y_test_fill, x_test_fill], axis=1)
data_train.to_excel(r'./temp_data/训练数据集[众数].xlsx', index=False)
data_test.to_excel(r'./temp_data/测试数据集[众数].xlsx', index=False)
print("\n数据已保存至 ./temp_data/ 目录")fill_data.py中的代码:
python
# ----------------------众填充方法----------------------
def mode_method(data):
'''数据集中的空值使用每列的中位数替代'''
fill_values = data.apply(lambda x: x.mode().iloc[e] if len(x.mode())> 0 else None)
a = data.mode()
return data.fillna(fill_values) # 使用中位数填充缺失值
def mode_train_fill(train_data, train_label):
'''使用中位数的方法对数据进行填充'''
data = pd.concat([train_data, train_label], axis=1)
data = data.reset_index(drop=True)
A = data[data['矿物类型'] == 0]
B = data[data['矿物类型'] == 1]
C = data[data['矿物类型'] == 2]
D = data[data['矿物类型'] == 3]
A = median_method(A) # 按照每个类别的数据进行填充
B = median_method(B)
C = median_method(C)
D = median_method(D)
df_filled = pd.concat([A, B, C, D])
df_filled = df_filled.reset_index(drop=True)
return df_filled.drop('矿物类型', axis=1), df_filled.矿物类型
# ----------------------测试集众数填充----------------------
def mode_test_method(train_data, test_data):
'''数据集中的空值使用每列的众数替代'''
fill_values = train_data.apply(lambda x: x.mode().iloc[0] if len(x.mode()) > 0 else None)
return test_data.fillna(fill_values) # 使用众数填充缺失值
def mode_test_fill(train_data, train_label, test_data, test_label):
'''使用众数方法对数据进行填充'''
train_data_all = pd.concat([train_data, train_label], axis=1)
train_data_all = train_data_all.reset_index(drop=True)
test_data_all = pd.concat([test_data, test_label], axis=1)
test_data_all = test_data_all.reset_index(drop=True)
A_train = train_data_all[train_data_all['矿物类型'] == 0]
B_train = train_data_all[train_data_all['矿物类型'] == 1]
C_train = train_data_all[train_data_all['矿物类型'] == 2]
D_train = train_data_all[train_data_all['矿物类型'] == 3]
A_test = test_data_all[test_data_all['矿物类型'] == 0]
B_test = test_data_all[test_data_all['矿物类型'] == 1]
C_test = test_data_all[test_data_all['矿物类型'] == 2]
D_test = test_data_all[test_data_all['矿物类型'] == 3]
A = mode_test_method(A_train, A_test) # 按照每个类别的数据进行填充
B = mode_test_method(B_train, B_test)
C = mode_test_method(C_train, C_test)
D = mode_test_method(D_train, D_test)
df_filled = pd.concat([A, B, C, D])
df_filled = df_filled.reset_index(drop=True)
return df_filled.drop('矿物类型', axis=1), df_filled.矿物类型最后运行的结果是在路径D:\software\Pycharm\矿物项目\temp_data中生成训练数据集众数.xlsx和测试数据集众数.xlsx两个文件
5.线性回归填充
基于特征间的线性相关性,用 "无缺失特征" 预测 "缺失特征" 的值。按缺失值数量升序填充(先填缺失少的特征,再用填充后的特征预测缺失多的特征),最大化利用已有数据。
数据集六种方法填充.py文件中的代码:
python
# 方法5: 线性回归算法填充(训练集+测试集)
# 核心修正1:接收3个返回值,变量名与返回值对应(填充后特征、训练标签、模型)
# 核心修正2:修正变量名错误(原y_train_w改为y_train_fill,避免混淆)
x_train_fill, y_train_fill= fill_data.lr_train_fill(x_train_w, y_train_w)
# 测试集填充(按函数参数顺序传参,修正注释笔误)
x_test_fill, y_test_fill = fill_data.lr_test_fill(x_train_fill,y_train_fill,x_test_w,y_test_w)
if not os.path.exists('./temp_data'):
os.makedirs('./temp_data')
# 合并特征与标签并保存
data_train = pd.concat([y_train_fill, x_train_fill], axis=1)
data_test = pd.concat([y_test_fill, x_test_fill], axis=1)
data_train.to_excel(r'./temp_data/训练数据集[线性回归].xlsx', index=False)
data_test.to_excel(r'./temp_data/测试数据集[线性回归].xlsx', index=False)
print("\n数据已保存至 ./temp_data/ 目录")fill_data.py中的代码:
python
# ===================== 5. 线性回归填充 =====================
def lr_train_fill(train_data, train_label):
# 1. 合并特征与标签,并重置索引
train_data_all = pd.concat([train_data,train_label],axis=1)
train_data_all = train_data_all.reset_index(drop=True)
# 分离出纯特征部分(不含标签列'矿物类型')
train_data_X = train_data_all.drop('矿物类型',axis=1)
# 2. 统计每列缺失值数量,并按缺失值升序排序
null_num = train_data_X.isnull().sum() # 査看每个特种中存在空数据的个数
null_num_sorted = null_num.sort_values(ascending=True)# 将字数据的类别从小到大进行排序
filling_feature = []#用来存储需要传入模型的特征名称
for i in null_num_sorted.index:
filling_feature.append(i)# 将当前特征加入待填充列表
if null_num_sorted[i]!=0:#当前特征是否有空缺的内容。用来判断是否开始训练模型
# 构建训练集:用已填充/无缺失的特征预测当前特征i
X = train_data_X[filling_feature].drop(i,axis=1)#构建训练集
y=train_data_X[i]# # 当前特征i作为预测目标
# 获取当前特征i中缺失行的索引
row_numbers_mg_null = train_data_X[train_data_X[i].isnull()].index.tolist()
# 非空数据作为训练集
X_train = X.drop(row_numbers_mg_null)
y_train = y.drop(row_numbers_mg_null)
#空数据作为测试集(需要测试填充 )
X_test = x.iloc[row_numbers_mg_null]
# 4. 训练线性回归模型并预测填充
regr = LinearRegression()#创建线性回归模型
regr.fit(X_train,y_train) #用非空数据训练模型
y_pred = regr.predict(X_test)# 用模型预测缺失值
train_data_X.loc[row_numbers_mg_null,i] = y_pred# 将预测值回填到原数据
print('完成训练数据集中的\'{}\'列数据的填充'.format(i))
# 5. 返回填充后的特征和标签
return train_data_X, train_data_all.矿物类型
# ===================== 线性回归测试集填充 =====================
def lr_test_fill(train_data,train_label,test_data,test_label):
train_data_all= pd.concat([train_data, train_label], axis=1)
train_data_all= train_data_all.reset_index(drop=True)
test_data_all = pd.concat([test_data, test_label], axis = 1)
test_data_all = test_data_all.reset_index(drop=True)
train_data_X=train_data_all.drop('矿物类型',axis=1)
test_data_X=test_data_all.drop('矿物类型',axis=1)
# 2. 复用训练集的缺失值排序(保证填充顺序和训练集一致)
null_num= test_data_X.isnull().sum()
null_num_sorted= null_num.sort_values(ascending=True)
filling_feature= [] # 同步训练集的特征填充顺序
for i in null_num_sorted.index:
filling_feature.append(i)
# 仅处理训练集有模型的特征(即训练集有缺失的特征)
if null_num_sorted[i]!=0:
X_train=train_data_X[filling_feature].drop(i,axis=1)
y_train=train_data_X[i]
X_test=test_data_X[filling_feature].drop(i,axis=1)
row_numbers_mg_null=test_data_X[test_data_X[i].isnull()].index.tolist()
X_test=X_test.iloc[row_numbers_mg_null]
# 用训练集的模型预测测试集缺失值
regr= LinearRegression()#创建随森林回归模型
regr.fit(X_train,y_train)#训练模型
y_pred= regr.predict(X_test)
# 回填预测值到测试集
test_data_X.loc[row_numbers_mg_null, i] =y_pred
print(f'完成测试数据集中的\'{i}\'列数据的填充')
# 返回填充后的测试集特征和标签
return test_data_X, test_data_all.矿物类型最后运行的结果是在路径D:\software\Pycharm\矿物项目\temp_data中生成训练数据集线性回归.xlsx和测试数据集线性回归.xlsx两个文件
6.随机森林填充
线性回归仅能捕捉线性关系,随机森林可捕捉特征间的非线性关系,更适合矿物数据。填充逻辑与线性回归一致,仅替换为随机森林回归模型。
fill_data.py中的代码:
python
'''随机森林填充'''
# ---------------------- 训练集缺失值填充 ----------------------
def rf_train_fill(train_data, train_label):
"""
使用随机森林回归算法填充训练集中的缺失值
:param train_data: 训练集特征 DataFrame
:param train_label: 训练集标签 Series (矿物类型)
:return: 填充完成的训练集特征和标签
"""
# 合并特征与标签,方便后续处理
train_data_all = pd.concat([train_data, train_label], axis=1)
train_data_all = train_data_all.reset_index(drop=True)
# 分离特征和标签
train_data_X = train_data_all.drop('矿物类型', axis=1)
# 统计各特征缺失值数量并按升序排序(先补缺失少的特征)
null_num = train_data_X.isnull().sum()
null_num_sorted = null_num.sort_values(ascending=True)
filling_feature = [] # 已填充特征列表,用于构建模型输入
for i in null_num_sorted.index:
filling_feature.append(i)
if null_num_sorted[i] != 0: # 仅对有缺失的特征进行填充
# 构建训练集:使用已填充特征 + 当前特征的非空行
X = train_data_X[filling_feature]
row_numbers_mg_null = train_data_X[train_data_X[i].isnull()].index.tolist()
X_train = X.drop(row_numbers_mg_null) # 非空数据作为训练集
y_train = train_data_X[i].drop(row_numbers_mg_null) # 对应标签
X_test = X.iloc[row_numbers_mg_null] # 空数据作为待预测集
# 训练随机森林回归模型
regr = RandomForestRegressor(n_estimators=100, random_state=42)
regr.fit(X_train, y_train)
# 预测并填充缺失值
y_pred = regr.predict(X_test)
train_data_X.loc[row_numbers_mg_null, i] = y_pred
print("完成训练数据集中的'{}'列数据的填充".format(i))
train_data_X= train_data_X.fillna(train_data_X.mean())
# 合并填充后的特征与标签(return 移到循环外部,确保所有列填充完成后再返回)
train_data_all = pd.concat([train_data_X, train_label], axis=1)
return train_data_X, train_data_all.矿物类型 # 用引号包裹列名更规范
# ---------------------- 测试集缺失值填充 ----------------------
def rf_test_fill(train_data, train_label, test_data, test_label):
# 合并训练集特征与标签
train_data_all = pd.concat([train_data, train_label], axis=1)
train_data_all = train_data_all.reset_index(drop=True)
# 合并测试集特征与标签
test_data_all = pd.concat([test_data, test_label], axis=1)
test_data_all = test_data_all.reset_index(drop=True)
# 分离特征和标签
train_data_X = train_data_all.drop('矿物类型', axis=1)
test_data_X = test_data_all.drop('矿物类型', axis=1)
# 统计测试集各特征缺失值数量并按升序排序
null_num = test_data_X.isnull().sum()
null_num_sorted = null_num.sort_values(ascending=True)
filling_feature = [] # 已填充特征列表
for i in null_num_sorted.index:
filling_feature.append(i)
if null_num_sorted[i] != 0: # 仅对有缺失的特征进行填充
# 构建训练集:使用训练集的已填充特征 + 当前特征
X_train = train_data_X[filling_feature].drop(i, axis=1)
y_train = train_data_X[i]
y_train = y_train.fillna(y_train.mean())
# 构建测试集:使用测试集的已填充特征 + 当前特征的空行
X_test = test_data_X[filling_feature].drop(i, axis=1)
row_numbers_mg_null = test_data_X[test_data_X[i].isnull()].index.tolist()
X_test = X_test.iloc[row_numbers_mg_null]
# 训练随机森林回归模型
regr = RandomForestRegressor(n_estimators=100, random_state=42)
regr.fit(X_train, y_train)
# 预测并填充测试集缺失值
y_pred = regr.predict(X_test)
test_data_X.loc[row_numbers_mg_null, i] = y_pred
print("完成测试数据集中的'{}'列数的填充".format(i))
# 合并填充后的测试集特征与标签
test_data_all = pd.concat([test_data_X, test_label], axis=1)
return test_data_X, test_data_all.矿物类型数据集六种方法填充.py文件中的代码:
python
#6、随机森林算法实现训练数据集、测试数据集的填充
x_train_fill,y_train_fill = fill_data.rf_train_fill(x_train_w,y_train_w)
# 测试集的填充
x_test_fill,y_test_fill = fill_data.rf_test_fill(x_train_fill, y_train_fill,x_test_w, y_test_w)#调用户己写的impt
# 8. 保存填充后的数据
if not os.path.exists('./temp_data'):
os.makedirs('./temp_data')
# 合并特征与标签并保存
data_train = pd.concat([y_train_fill, x_train_fill], axis=1)
data_test = pd.concat([y_test_fill, x_test_fill], axis=1)
data_train.to_excel(r'./temp_data/训练数据集[随机森林].xlsx', index=False)
data_test.to_excel(r'./temp_data/测试数据集[随机森林].xlsx', index=False)
print("\n数据已保存至 ./temp_data/ 目录")运行结果在路径D:\software\Pycharm\矿物项目\temp_data中生成训练数据集随机森林.xlsx和测试数据集随机森林.xlsx两个文件
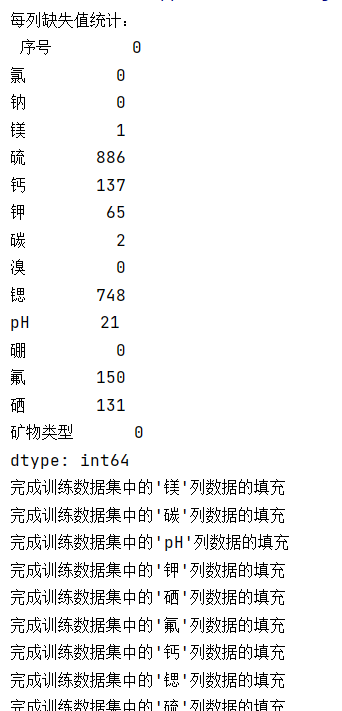

最终在D:\software\Pycharm\矿物项目\temp_data中生成12个文件,包括6个训练集填充数据和6个测试集填充数据: