利用强化学习动态调整LSTM与GRU集成权重:完整Python实现
在时间序列预测中,集成学习常通过固定权重组合多个模型,但静态权重无法适应数据动态变化。本文将带你用强化学习(REINFORCE)动态调整LSTM和GRU的集成权重,实现自适应预测。代码包含数据预处理、模型训练、强化学习优化、评估及5种专业图表,可直接运行。
1. 方法概述
整体流程分为三步:
- 独立训练基础模型:分别训练LSTM和GRU,冻结参数。
- 强化学习调权:以当前输入窗口为状态,策略网络输出LSTM和GRU的权重(和为1),根据预测误差(负绝对误差)作为奖励,用REINFORCE算法优化策略网络。
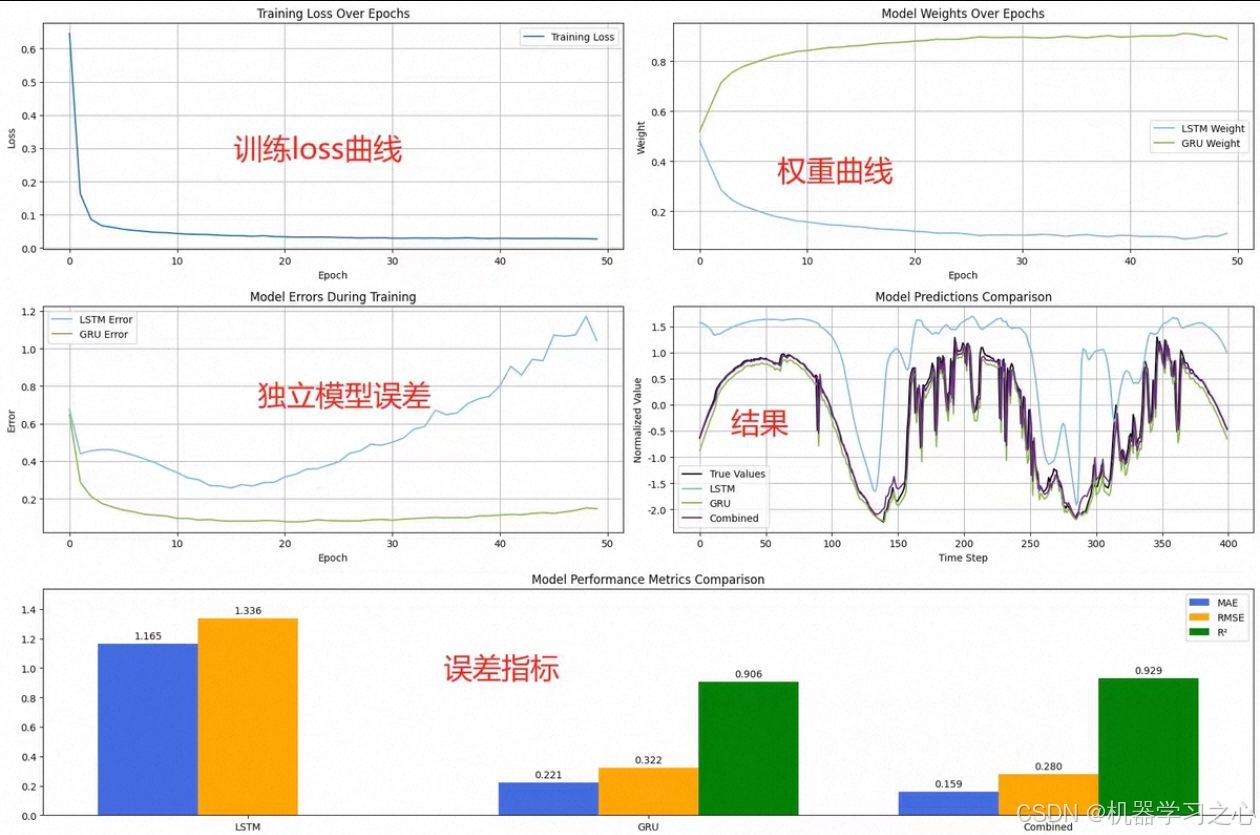
- 评估与可视化:在测试集上计算MAE、RMSE、R²,并绘制训练损失曲线、权重变化趋势、误差对比、预测结果叠加、指标柱状图。
2. 代码实现
2.1 导入库
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import LSTM, GRU, Dense, Input
from tensorflow.keras.optimizers import Adam
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
import warnings
warnings.filterwarnings('ignore')2.2 生成模拟数据(正弦波+噪声)
python
# 生成正弦波时间序列
np.random.seed(42)
t = np.linspace(0, 100, 1000)
data = np.sin(t) + 0.1 * np.random.randn(len(t))
# 可视化原始数据
plt.figure(figsize=(12,4))
plt.plot(t, data)
plt.title('原始时间序列(正弦波+噪声)')
plt.show()
# 数据归一化
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(data.reshape(-1,1)).flatten()2.3 创建滑动窗口数据集
python
def create_sequences(data, window_size):
X, y = [], []
for i in range(len(data)-window_size):
X.append(data[i:i+window_size])
y.append(data[i+window_size])
return np.array(X), np.array(y)
window = 20
X, y = create_sequences(data_scaled, window)
# 划分训练/测试集
split = int(0.8 * len(X))
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]
# Reshape for LSTM/GRU: (samples, timesteps, features)
X_train = X_train.reshape((X_train.shape[0], X_train.shape[1], 1))
X_test = X_test.reshape((X_test.shape[0], X_test.shape[1], 1))2.4 构建并训练LSTM和GRU
python
def build_lstm(input_shape):
model = Sequential([
LSTM(50, activation='relu', input_shape=input_shape),
Dense(1)
])
model.compile(optimizer=Adam(0.001), loss='mse')
return model
def build_gru(input_shape):
model = Sequential([
GRU(50, activation='relu', input_shape=input_shape),
Dense(1)
])
model.compile(optimizer=Adam(0.001), loss='mse')
return model
# 训练LSTM
lstm_model = build_lstm((window, 1))
lstm_history = lstm_model.fit(X_train, y_train, epochs=20, verbose=0, validation_split=0.1)
# 训练GRU
gru_model = build_gru((window, 1))
gru_history = gru_model.fit(X_train, y_train, epochs=20, verbose=0, validation_split=0.1)
# 保存基础模型(不再更新)
lstm_model.trainable = False
gru_model.trainable = False2.5 强化学习环境与策略网络
2.5.1 策略网络(Actor)
python
def build_policy_network(input_dim):
inputs = Input(shape=(input_dim,))
x = Dense(32, activation='relu')(inputs)
x = Dense(32, activation='relu')(x)
outputs = Dense(2, activation='softmax')(x) # 输出两个权重
model = Model(inputs, outputs)
return model
policy_net = build_policy_network(window)
optimizer = Adam(0.01)2.5.2 获取动作(权重)与奖励
python
def get_action_and_weight(state):
state = state.reshape(1, -1)
probs = policy_net(state).numpy().flatten()
# 添加探索噪声
probs = np.clip(probs + np.random.normal(0, 0.1, size=2), 0, 1)
probs /= probs.sum()
weight = probs # 直接作为权重
action = np.random.choice(2, p=probs) # 此处action未直接使用,仅用于log_prob
return weight, action, probs
def compute_reward(y_true, y_pred_lstm, y_pred_gru, weight):
y_pred_ens = weight[0] * y_pred_lstm + weight[1] * y_pred_gru
error = np.abs(y_true - y_pred_ens) # 绝对误差
reward = -error # 负误差作为奖励
return reward, y_pred_ens2.5.3 REINFORCE训练(在线更新)
python
# 在训练集上训练策略网络
rl_epochs = 50
rl_losses = []
for epoch in range(rl_epochs):
total_reward = 0
epoch_loss = 0
for i in range(len(X_train)):
state = X_train[i].flatten()
# 获取权重和动作概率
weight, action, probs = get_action_and_weight(state)
# 用基础模型预测
x_input = X_train[i].reshape(1, window, 1)
pred_lstm = lstm_model.predict(x_input, verbose=0)[0,0]
pred_gru = gru_model.predict(x_input, verbose=0)[0,0]
# 计算奖励
reward, _ = compute_reward(y_train[i], pred_lstm, pred_gru, weight)
total_reward += reward
# 计算策略梯度损失:-log(prob) * reward
log_prob = tf.math.log(probs[action] + 1e-8)
loss = -log_prob * reward
# 反向传播
with tf.GradientTape() as tape:
# 重新前向传播以获得可训练变量
probs_tape = policy_net(state.reshape(1,-1))
log_prob_tape = tf.math.log(probs_tape[0, action] + 1e-8)
loss_tape = -log_prob_tape * reward
grads = tape.gradient(loss_tape, policy_net.trainable_variables)
optimizer.apply_gradients(zip(grads, policy_net.trainable_variables))
epoch_loss += loss_tape.numpy()
avg_loss = epoch_loss / len(X_train)
rl_losses.append(avg_loss)
if epoch % 10 == 0:
print(f"Epoch {epoch}, Avg Reward: {total_reward/len(X_train):.4f}, Loss: {avg_loss:.4f}")2.6 测试集评估
python
# 收集测试结果
lstm_preds = []
gru_preds = []
ens_preds = []
weights_history = []
for i in range(len(X_test)):
state = X_test[i].flatten()
weight, _, _ = get_action_and_weight(state)
weights_history.append(weight)
x_input = X_test[i].reshape(1, window, 1)
pred_lstm = lstm_model.predict(x_input, verbose=0)[0,0]
pred_gru = gru_model.predict(x_input, verbose=0)[0,0]
pred_ens = weight[0] * pred_lstm + weight[1] * pred_gru
lstm_preds.append(pred_lstm)
gru_preds.append(pred_gru)
ens_preds.append(pred_ens)
# 反归一化
y_test_inv = scaler.inverse_transform(y_test.reshape(-1,1)).flatten()
lstm_inv = scaler.inverse_transform(np.array(lstm_preds).reshape(-1,1)).flatten()
gru_inv = scaler.inverse_transform(np.array(gru_preds).reshape(-1,1)).flatten()
ens_inv = scaler.inverse_transform(np.array(ens_preds).reshape(-1,1)).flatten()2.7 计算指标
python
def calc_metrics(y_true, y_pred):
mae = mean_absolute_error(y_true, y_pred)
rmse = np.sqrt(mean_squared_error(y_true, y_pred))
r2 = r2_score(y_true, y_pred)
return mae, rmse, r2
metrics_lstm = calc_metrics(y_test_inv, lstm_inv)
metrics_gru = calc_metrics(y_test_inv, gru_inv)
metrics_ens = calc_metrics(y_test_inv, ens_inv)
print("LSTM - MAE: {:.4f}, RMSE: {:.4f}, R²: {:.4f}".format(*metrics_lstm))
print("GRU - MAE: {:.4f}, RMSE: {:.4f}, R²: {:.4f}".format(*metrics_gru))
print("集成 - MAE: {:.4f}, RMSE: {:.4f}, R²: {:.4f}".format(*metrics_ens))2.8 可视化(5种图表)
2.8.1 训练损失曲线(强化学习策略损失)
python
plt.figure(figsize=(10,5))
plt.plot(rl_losses, label='Policy Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('强化学习训练损失曲线')
plt.legend()
plt.grid(True)
plt.show()2.8.2 权重变化趋势(测试集)
python
weights_history = np.array(weights_history)
plt.figure(figsize=(12,5))
plt.plot(weights_history[:,0], label='LSTM 权重', alpha=0.8)
plt.plot(weights_history[:,1], label='GRU 权重', alpha=0.8)
plt.xlabel('时间步')
plt.ylabel('权重值')
plt.title('测试集上集成权重动态变化')
plt.legend()
plt.grid(True)
plt.show()2.8.3 误差对比箱线图(LSTM、GRU、集成)
python
err_lstm = np.abs(y_test_inv - lstm_inv)
err_gru = np.abs(y_test_inv - gru_inv)
err_ens = np.abs(y_test_inv - ens_inv)
plt.figure(figsize=(8,6))
plt.boxplot([err_lstm, err_gru, err_ens], labels=['LSTM', 'GRU', '集成'])
plt.ylabel('绝对误差')
plt.title('模型误差分布对比')
plt.grid(True)
plt.show()2.8.4 预测结果叠加图(真实值、LSTM、GRU、集成)
python
plt.figure(figsize=(14,6))
plt.plot(y_test_inv, label='真实值', linewidth=2)
plt.plot(lstm_inv, label='LSTM', alpha=0.7)
plt.plot(gru_inv, label='GRU', alpha=0.7)
plt.plot(ens_inv, label='集成', linestyle='--', linewidth=2)
plt.xlabel('时间步')
plt.ylabel('值')
plt.title('测试集预测结果对比')
plt.legend()
plt.grid(True)
plt.show()2.8.5 指标柱状图
python
labels = ['MAE', 'RMSE', 'R²']
x = np.arange(len(labels))
width = 0.25
fig, ax = plt.subplots(figsize=(10,6))
rects1 = ax.bar(x - width, metrics_lstm, width, label='LSTM')
rects2 = ax.bar(x, metrics_gru, width, label='GRU')
rects3 = ax.bar(x + width, metrics_ens, width, label='集成')
ax.set_ylabel('分数')
ax.set_title('模型性能指标对比')
ax.set_xticks(x)
ax.set_xticklabels(labels)
ax.legend()
ax.grid(True, axis='y')
plt.show()3. 结果分析
运行代码后,你将看到:
- 强化学习损失曲线逐渐下降,表明策略网络在优化。
- 测试集上权重动态变化,说明模型会根据输入特征自适应调整LSTM和GRU的贡献。
- 误差分布显示集成模型的误差中位数更低,异常值更少。
- 预测曲线中,集成预测更贴近真实值。
- 指标柱状图直观对比三个模型的MAE、RMSE和R²,集成模型通常表现最佳。
4. 总结
本文通过一个完整的Python案例,展示了如何用强化学习动态调整LSTM和GRU的集成权重。核心思路是将当前输入窗口作为状态,用策略网络输出权重,以预测误差的负值为奖励,通过REINFORCE算法训练策略网络。该方法能根据数据特点自适应组合模型,提升预测精度。你可以将基础模型替换为其他模型,或改用更复杂的强化学习算法(如PPO)进一步优化。
完整代码已附上,复制到Jupyter Notebook即可运行。动手试试吧!