这篇文章用通俗直白的语言,轻松讲解自注意力、编码器‑解码器注意力、注意力分数与掩码的内部原理。
这是我 Transformer 系列教程的第三篇 。我们将采用自上而下 的方式讲解它的工作原理。在前几篇文章中,我们已经了解了 Transformer 是什么、它的整体架构以及运行流程。通俗易懂的 Transformer 入门文章(第一部分):功能概述通俗易懂的 Transformer 入门文章(第二部分):工作原理分步拆解
在本文中,我们将更进一步,深入剖析多头注意力机制 ------ 它正是 Transformer 的核心与精髓。
下面快速回顾本系列的已发布文章 与后续计划 。我的目标始终是:不仅弄懂**"它是如何运行的"** ,更要理解**"它为什么要这样设计"**。
- 功能概览(Transformer 的用途、为何优于 RNN;架构组成,以及训练与推理阶段的行为)
- 运行原理(端到端内部流程:数据如何流动、执行哪些计算,包括矩阵表示)
- 多头注意力------ 即本文(Transformer 中注意力模块的内部原理)
- 注意力为何能提升性能(不只看注意力做了什么,而是它为何效果如此出色;注意力如何捕捉句子中单词之间的关系)
如果你对深度学习应用感兴趣,这里还有一些我其他的文章,你可能会喜欢:3D Gaussian Splatting高斯泼溅技术简单介绍解读 PointNet:使用 Python 和 PyTorch 进行 3D 分割的实用指南语义分割:基于 TensorFlow 对 FCN 与迁移学习的探究解读openAI的文本图像模型-CLIP
Transformer 中注意力的使用位置
正如我们在第 2 部分 中所讲,Transformer 中的注意力机制主要用在三个地方:
- 编码器中的自注意力------ 输入序列关注自身
- 解码器中的自注意力------ 目标序列关注自身
- 解码器中的编码器‑解码器注意力------ 目标序列关注输入序列
注意力输入参数 ------ 查询(Query)、键(Key)与值(Value)
注意力层接收三个形式为参数的输入,分别称为查询(Query)、键(Key)和值(Value)。
这三个参数结构相似,序列中的每个单词都由一个向量来表示。
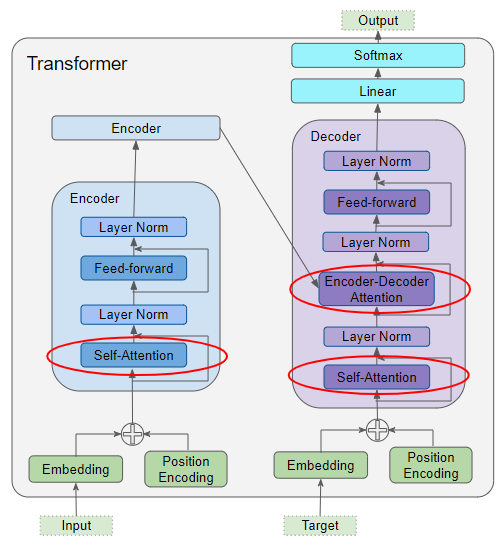
编码器自注意力(Encoder Self-Attention)
输入序列被送入输入嵌入层 与位置编码层 ,它们为输入序列中的每个单词生成编码表示,捕捉每个单词的含义与位置信息。该结果会被同时传入第一个编码器中自注意力层的 Query、Key、Value 三个参数。随后,该层同样为输入序列的每个单词生成编码表示,此时的表示中已经融入了每个单词对应的注意力分数。
当数据流经编码器栈中的所有编码器时,每个自注意力模块都会将自身计算出的注意力分数,进一步加入到每个单词的表示中。
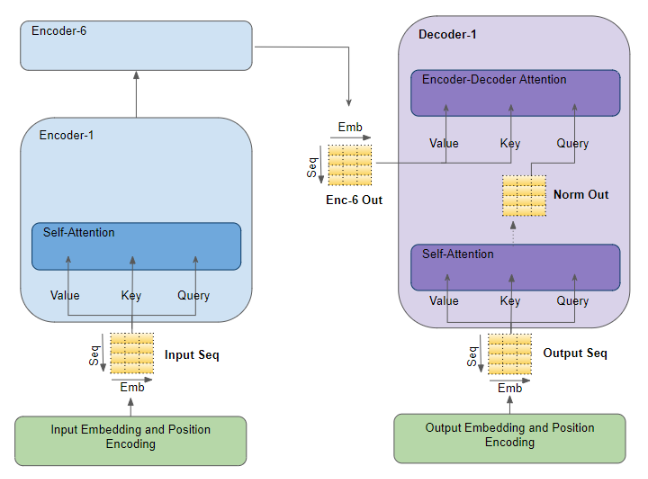
解码器自注意力
来到解码器栈,目标序列被送入输出嵌入层 与位置编码层 ,它们为目标序列中的每个单词生成编码表示,捕捉每个单词的含义与位置信息。该结果会被同时传入第一个解码器中自注意力层的 Query、Key、Value 三个参数。随后,该层同样为目标序列的每个单词生成编码表示,此时的表示中也已经融入了每个单词对应的注意力分数。
经过层归一化之后,该结果被送入第一个解码器中编码器‑解码器注意力层 的 Query 参数。
编码器‑解码器注意力
与此同时,编码器栈中最后一个编码器 的输出,被送入编码器‑解码器注意力层的 Value 和 Key 参数。
因此,编码器‑解码器注意力层同时得到了目标序列的表示 (来自解码器自注意力)和输入序列的表示(来自编码器栈)。它会为目标序列的每个单词生成包含注意力分数的表示,同时也捕捉到输入序列注意力分数带来的影响。
当数据流经解码器栈中的所有解码器时,每一层自注意力和每一层编码器‑解码器注意力,都会将各自计算出的注意力分数进一步加入到每个单词的表示中。
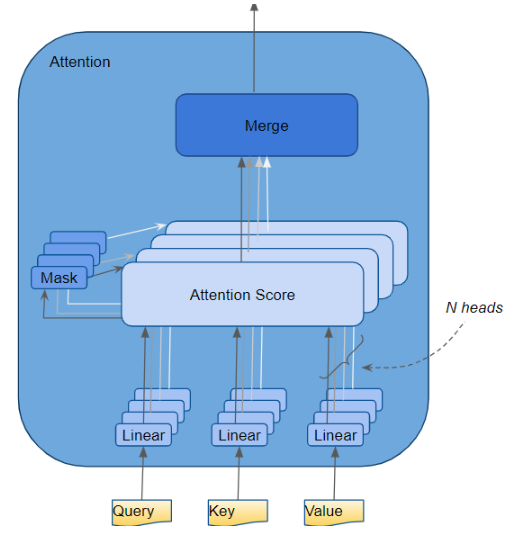
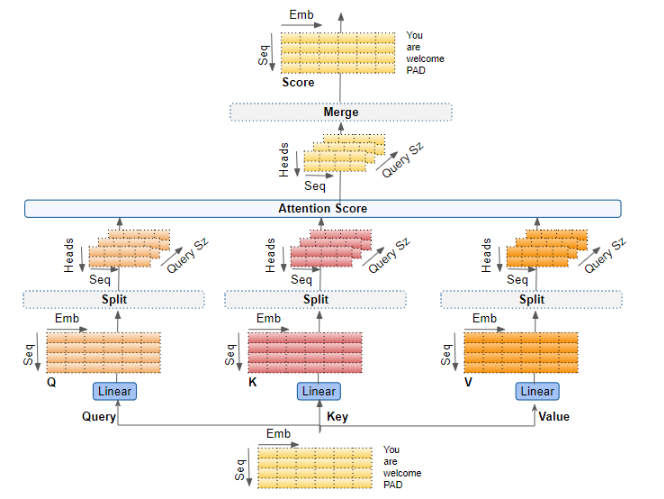
多头注意力
在 Transformer 中,注意力模块会并行重复执行多次计算 。每一次独立计算称为一个注意力头 。注意力模块将 Query、Key、Value 参数分成 N 份,每份分别独立送入不同的注意力头。所有这些相似的注意力计算结果会被合并,生成最终的注意力分数。这一结构被称为多头注意力,它让 Transformer 具备更强的能力,为每个单词编码多种语义关系与细节特征。
为了准确理解数据在内部是如何被处理的,我们以翻译任务 为例,一步步走一遍 Transformer 在训练过程中注意力模块 的工作流程。我们将使用训练数据中的一个样本:
-
输入序列:英文
You are welcome -
目标序列:西班牙语
De nada
注意力超参数
有三个超参数决定了数据的维度:
-
嵌入维度(Embedding Size) 嵌入向量的宽度(本例中我们使用宽度为 6)。这个维度会贯穿整个 Transformer 模型,因此有时也被称为模型维度等。
-
查询维度(Query Size)(与 Key、Value 维度相等)三个线性层分别用来生成 Query、Key、Value 矩阵的权重维度(本例中我们使用 3)。
-
注意力头数量(Number of Attention heads) 本例中我们使用 2 个头。
此外,还有批次大小(Batch size),对应样本数量这一维度。
输入层
输入嵌入层(Input Embedding)和位置编码层(Position Encoding)会生成一个形状为**(样本数,序列长度,嵌入维度)** 的矩阵,并将其送入编码器栈中第一个编码器的 Query、Key、Value。
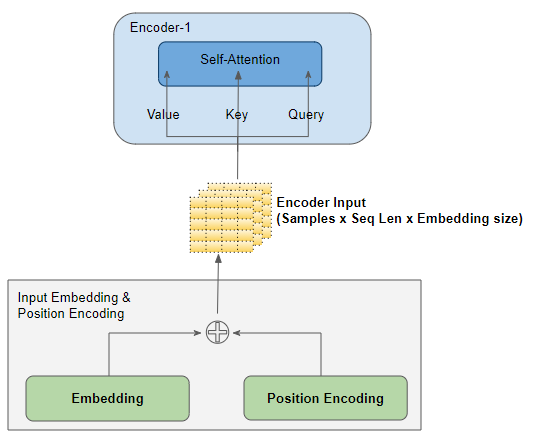
为了方便可视化理解,我们将在示意图中去掉批次维度,只关注剩下的维度。
线性层
针对查询(Query)、键(Key)、值(Value) ,分别有三个独立的线性层 ,每个线性层都有各自的权重。输入数据经过这些线性层后,会分别生成 Q、K、V 三个矩阵。
将数据分配到多个注意力头
现在,数据会被分配到多个注意力头中,以便每个头都能独立处理数据。
但需要重点理解的是:这只是一种逻辑上的划分 。Query、Key、Value 并不会在物理上被拆分成多个独立矩阵(每个头一个)。Query、Key、Value 各自仍然使用单一的数据矩阵 ,只是矩阵中不同的区域在逻辑上 分别对应不同的注意力头。同样,也不会为每个注意力头单独设置线性层。所有注意力头共享同一个线性层 ,只是在数据矩阵中各自负责自己的逻辑区域。
线性层权重按头进行逻辑划分
这种逻辑划分,是通过将输入数据 和线性层权重均匀分配给各个注意力头来实现的。我们可以通过下面的公式设置查询维度(Query Size)来达到这一目的:
查询维度(Query Size) = 嵌入维度(Embedding Size) ÷ 注意力头数量(Number of heads)
在我们的例子中,这就是查询维度 = 6/2 = 3 的原因。尽管层权重(以及输入数据)是单个矩阵 ,我们仍可以把它看作是把每个头各自独立的层权重 "堆叠在一起"。
因此,所有注意力头的计算都可以通过单次矩阵运算完成,而不需要执行 N 次独立操作。这使得计算更加高效,同时让模型保持简洁 ------ 所需的线性层更少,却依然能获得独立注意力头带来的强大能力。
对 Q、K、V 矩阵进行形状重塑
由线性层输出的 Q、K、V 矩阵会被重塑形状 ,以显式加入头维度(Head dimension)。此时,矩阵中的每一个 "切片" 都对应一个注意力头的子矩阵。
随后通过交换头维度与序列维度 ,再次对矩阵进行形状调整。虽然图中没有画出批次维度,但此时 Q 的维度变为:(批次,头数,序列长度,查询维度)。
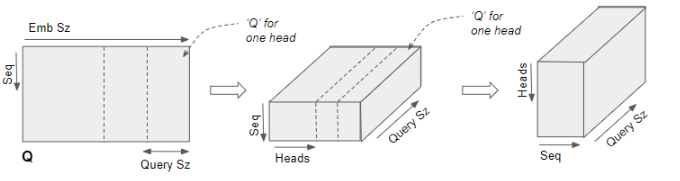
Q 矩阵被重塑形状以加入头维度(Head dimension),然后再次重塑,交换头维度与序列维度。
在下图中,我们可以看到示例中的 Q 矩阵从线性层输出后,完整的切分过程。
最后一步仅用于可视化理解 ------ 尽管 Q 矩阵是一个整体矩阵,但我们可以把它看作每个注意力头在逻辑上独立的 Q 矩阵。
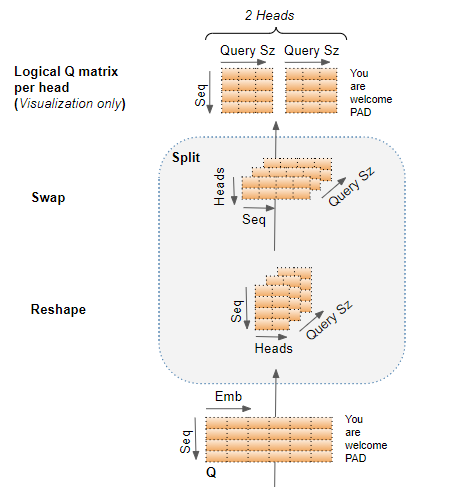
现在我们可以开始计算注意力分数了。
为每个注意力头计算注意力分数
我们现在已经得到了按头划分好的 Q、K、V 三个矩阵,并用它们来计算注意力分数。
我们将只使用最后两个维度(序列维度和查询维度)来展示单个头 的计算过程,并忽略前两个维度(批次和头数)。本质上,你可以把我们看到的计算过程,想象成在每个头 和批次中的每个样本 上都 "重复执行"(尽管显然它们是通过单次矩阵运算完成的,而不是循环)。
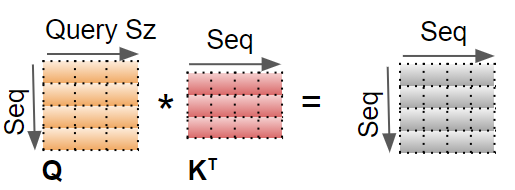
第一步:对 Q 和 K 执行矩阵乘法。
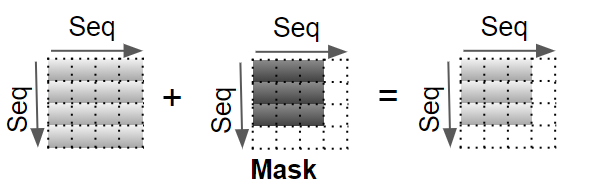
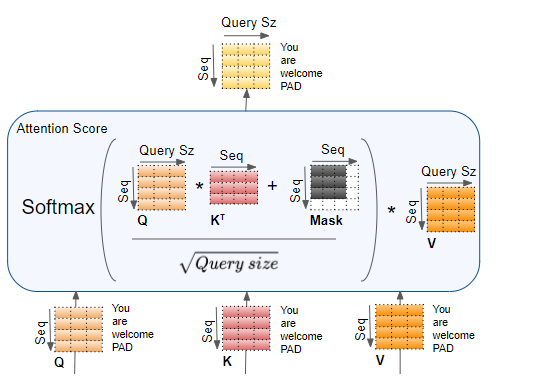
现在向计算结果中加入掩码值 。在编码器自注意力 中,掩码用于屏蔽填充(Padding)位置,使它们不参与注意力分数的计算。
在解码器自注意力 和解码器中的编码器‑解码器注意力 中会使用不同的掩码,我们将在后续流程中讲到。
现在将结果除以查询维度的平方根 进行缩放,然后对其应用 Softmax 函数。
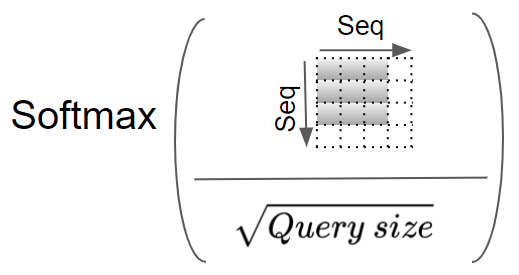
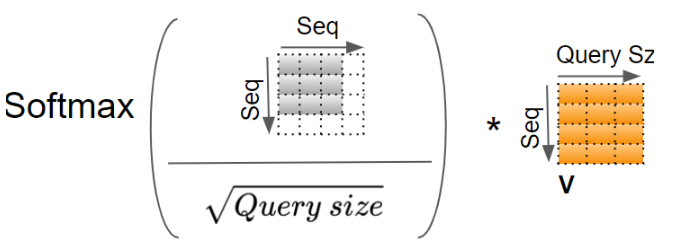
将 Softmax 的输出与 V 矩阵再进行一次矩阵乘法。
编码器自注意力中完整的注意力分数计算过程如下:
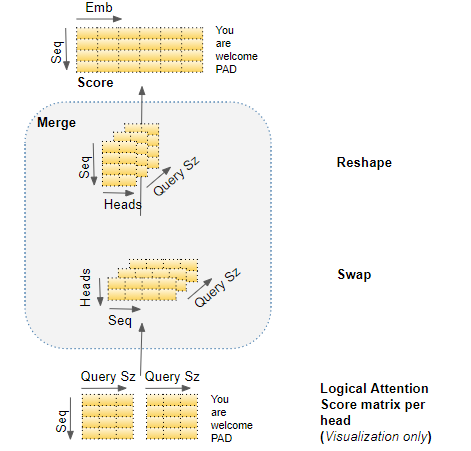
合并每个注意力头的注意力分数
现在我们得到了每个头独立的注意力分数,需要将它们合并为一个分数 。这个合并操作 本质上是切分操作的逆过程。
只需通过重塑结果矩阵来消除头维度即可完成合并。具体步骤:
-
交换头维度 与序列维度 ,重塑注意力分数矩阵。换句话说,矩阵形状从 (批次,头数,序列长度,查询维度) 变为 (批次,序列长度,头数,查询维度)。
-
再次重塑,将头维度合并,形状变为 (批次,序列长度,头数 × 查询维度) 。这实际上是把每个注意力头的分数向量拼接在一起,形成一个合并后的注意力分数。
由于嵌入维度 = 头数 × 查询维度 ,合并后的分数形状为 (批次,序列长度,嵌入维度)。在下图中,你可以看到示例分数矩阵完整的合并过程。
端到端多头注意力
将所有步骤整合到一起,这就是多头注意力的端到端流程。
多头切分能够捕捉更丰富的语义信息
嵌入向量用于表示一个单词的含义。正如我们所见,在多头注意力 中,输入序列(和目标序列)的嵌入向量会被逻辑划分到多个注意力头中。这一操作的意义是什么?
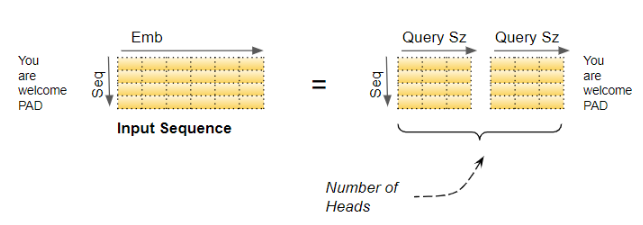
这意味着嵌入向量的不同部分 可以学习每个单词含义的不同侧面 ,以及它与序列中其他单词的关联方式 。这让 Transformer 能够对序列进行更丰富、更多维度的理解。
下面这个例子未必完全真实,但能帮你建立直观感受:比如,其中一部分可以学习名词的**"性别属性"** (阳性、阴性、中性),另一部分则可以学习名词的**"单复数"**。这些信息在翻译中非常重要,因为在很多语言里,动词的形式必须根据这些属性来变化。
解码器自注意力与掩码
解码器自注意力 的工作方式与编码器自注意力 几乎完全一样,唯一的区别是:它作用于目标序列的每个单词。
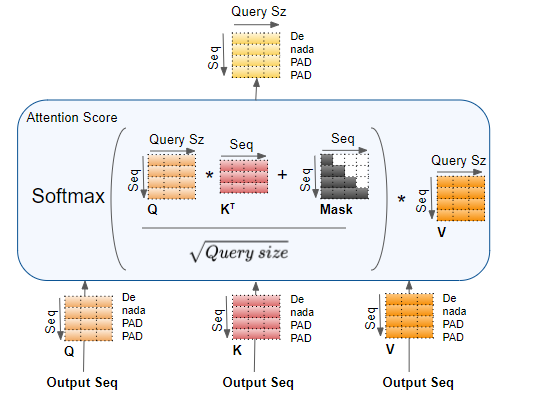
同样地,掩码(Masking)会屏蔽掉目标序列中的填充词(Padding words)。
解码器中的编码器‑解码器注意力与掩码
编码器‑解码器注意力的输入来自两个来源。因此,与以下两种注意力不同:
-
编码器自注意力:计算输入序列中每个词 与其他输入词之间的关联
-
解码器自注意力:计算目标序列中每个词 与其他目标词之间的关联
编码器‑解码器注意力 计算的是:目标序列中的每个词 与输入序列中的每个词之间的关联。
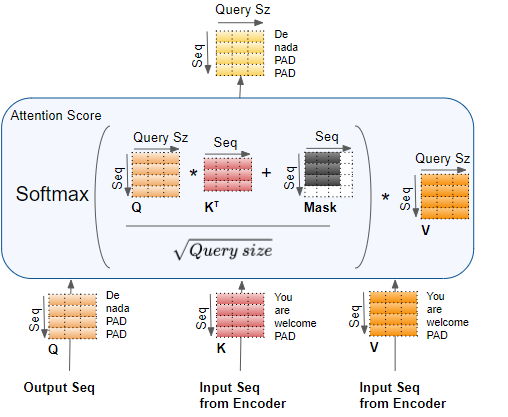
因此,最终注意力分数中的每个单元 ,都对应着一个查询 Q(即目标序列中的单词)与所有键 K(即输入序列中的单词)、** 所有值 V(即输入序列中的单词)** 之间的关联关系。
同样,掩码会屏蔽掉目标输出中当前位置之后的单词,这一点在本系列的第二篇文章中已有详细说明。
总结
希望这篇文章能让你清楚理解 Transformer 中注意力模块 的作用。结合我们在第二篇中讲解的 Transformer 整体端到端流程 ,现在我们已经完整覆盖了整个 Transformer 架构的详细运行过程。
我们现在已经确切知道 Transformer 做了什么 。但还没有完全回答一个核心问题:为什么 Transformer 的注意力机制要这样计算 ?为什么它要使用 Query、Key、Value 的概念?为什么要执行我们刚才看到的这些矩阵乘法?
我们只有一个模糊的直观感受:它 "捕捉了每个单词与其他单词之间的关系",但这具体意味着什么?它究竟如何让 Transformer 的注意力机制具备理解序列中每个单词细微含义的能力?
这是一个很有意思的问题,也将是本系列最后一篇文章的主题。一旦弄懂这一点,我们就能真正理解 Transformer 架构的精妙之处。